Audio Caption: Listen and Tell
Increasing amount of research has shed light on machine perception of audio events, most of which concerns detection and classification tasks. However, human-like perception of audio scenes involves not only detecting and classifying audio sounds, bu…
Authors: Mengyue Wu, Heinrich Dinkel, Kai Yu
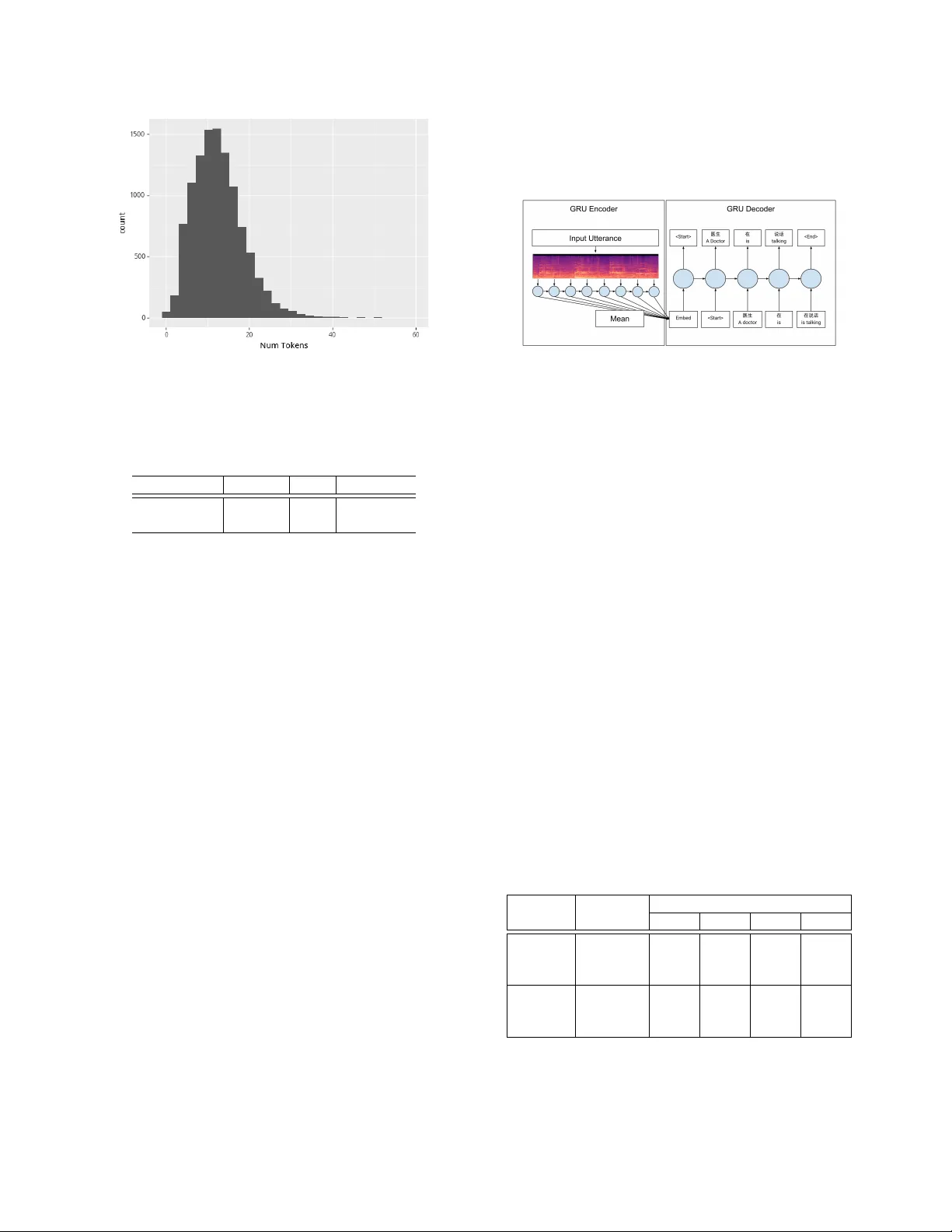
A UDIO CAPTION: LISTEN AND TELL Mengyue W u, Heinrich Dink el and Kai Y u MoE K ey Lab of Artificial Intelligence SpeechLab, Department of Computer Science and Engineering Shanghai Jiao T ong Uni versity , Shanghai, China { mengyuewu, richman, kai.yu } @sjtu.edu.cn ABSTRA CT Increasing amount of research has shed light on machine perception of audio ev ents, most of which concerns detection and classifica- tion tasks. Howe ver , human-like perception of audio scenes in volves not only detecting and classifying audio sounds, but also summa- rizing the relationship between different audio ev ents. Comparable research such as image caption has been conducted, yet the audio field is still quite barren. This paper introduces a manually-annotated dataset for audio caption. The purpose is to automatically generate natural sentences for audio scene description and to bridge the gap between machine perception of audio and image. The whole dataset is labelled in Mandarin and we also include translated English an- notations. A baseline encoder-decoder model is provided for both English and Mandarin. Similar BLEU scores are deri ved for both languages: our model can generate understandable and data-related captions based on the dataset. Index T erms — Audio Caption, Audio Databases, Natural Lan- guage Generation, Recurrent Neural Networks 1. INTR ODUCTION Current audio databases for audio perception (e.g. AudioSet [1], TUT Acoustic Scenes database [2], UrbanSound dataset [3]) are mainly segmented and annotated with indi vidual labels, either free of choice or fixed. These datasets provide a systematic paradigm of sound taxonomy and generate relativ ely great results for both clas- sification [4] and detection tasks [5]. Howe ver , audio scenes in real world usually consist of multiple o verlapped sound events. When humans percei ve and describe an audio scene, we not only detect and classify audio sounds, but more importantly , we figure out the inner relationship between individual sounds and summarize in nat- ural language. This is a superior ability and consequently more chal- lenging for machine perception. Similar phenomenon is present with images, that to describe an image requires more than classification and object recognition. T o achiev e human-like perception, using natural language to de- scribe images([6, 7, 8]) and videos has attracted much attention([9, 10, 11]). Y et only little research has been made regarding audio scenes[12], which we think is due to the difference between visual Heinrich Dinkel is the co-first author . Kai Y u and Mengyue W u are the corresponding authors. This work has been supported by the Major Program of National Social Science Foundation of China (No.18ZDA293). Experi- ments have been carried out on the PI supercomputer at Shanghai Jiao T ong Univ ersity . and auditory perception. For visual perception, spatial information is processed and and we could describe the visual object by its shape, colour , size, and its position to other object. Howe ver for audio sounds, the traits are to be established. Auditory perception mainly in volves temporal information processing and the overlap of multi- ple sound ev ents is the norm. T o describe an audio scene therefore requires a large amount of cogniti ve computation. A preliminary step is to discriminate the fore ground and background sound e vents, and to process the relationship of dif ferent sounds in temporal order . Secondly , we need to acquire our common knowledge to fully under - stand each sound event. For instance, a 3-year-old child might not entirely understand the meaning of a siren - the y could not infer that an ambulance/fire engine is coming. Our common knowledge accu- mulates as we age. Lastly , for most audio scenes inv olving speech, we need access to the semantic information behind speech signals to fully understand the whole audio scene. Sometimes further reason- ing based on the speech information is also needed. For example, through a conv ersation concerning treatment option, we could spec- ulate this might be between a doctor and a patient. Nev ertheless, current machine perception tasks are mostly clas- sification and detection. In order to help machine understand audio ev ents in a more human-like way , we are in need of a dataset that en- ables automatic audio caption. Its aim is to automatically generate natural language to describe an audio scene. Broad application can be expected: hearing-impaired people can understand the content of an audio scene and detailed audio surveillance will be possible. Just as humans need both audio and visual information for comprehen- siv e understanding, the combination of these two channels for ma- chine perception is inevitable. It is therefore practical and essential to have a tool to help process audio information. Further , English is quite a dominant language in captioning field. Among the limited attempts to caption images in other languages, a translation method is usually used (e.g. [13]) and to our knowledge, there is no audio dataset specifically set up for Mandarin caption. Section 2 will introduce the Audio Caption Dataset and detailed data analysis can be found in Section 3. Baseline model description is provided in Section 4. W e present human ev aluation results of the model generated sentences in Section 5. 2. THE A UDIOCAPTION D A T ASET Previous datasets (e.g. AudioSet [1]) mostly concentrate on indi vid- ual sound class with single-word labels like music, speech, vehicle etc.. Howe ver these labels are insufficient to probe the relationship between sound classes. For instance, provided with labels ‘speech’ and ‘music’ for one sound clip, the exact content of an audio re- mains unclear . Further , although AudioSet contains as many as 527 sound labels, it still cannot include all sound classes, especially some scene-specific sounds. This database departs itself from pre vious audio datasets in four aspects 1)the composition of more complicated sound e vents in one audio clip; 2) a new annotation method to enable audio caption; 3) the se gmentation of specific scenes for scene-specific audio process- ing; 4) the use of Mandarin Chinese as the natural language. W e also include translated English annotations for broader use of this dataset. W e identify fiv e scenes that might be in most interest of audio cap- tion - hospital, banking A TMs, car , home and conference room. W e firstly rev eal our 10h labelled dataset on hospital scene and will keep publishing other scenes. Source As audio-only information is not sufficient for determin- ing a sound e vent, we included video clips with sound. All video data were extracted from Y ouku, Iqiyi and T encent movies which are video websites equiv alent to Y outube. They also hav e exclu- siv e authorization of TV shows, thus some of the video clips were from TV shows and interviews. When sampling the data, we limited background music and maximized real-life similarity . Each video was 10s in length, with no segmentation of sound classes. Thus our sound clips contain richer information than current mainstream datasets. The hospital scene consists 3710 video clips (about 10h duration in total, see T able 3). Annotation W e think of four traits to describe the sound ev etns in an audio clip: its definition (what sound is it), its owner (what’ s making the sound), its attrib ute (how does it sound like), its location (where is the sound happening). Almost e very ev ent scene can be un- derstood via these four traits, e.g. “T wo dogs are barking acutely”,“ A bunch of firemen are putting out fire and there are people scream- ing”. Each video was labelled by three raters to ensure some variance of the dataset. All human raters received undergraduate education and were instructed to focus on the sound of the video while la- belling. They were asked to label in two steps: 1. Answer the following four questions: 1) list all the sounds you’ ve heard; 2) who/what is making these sounds; 3) how are these sounds lik e; 4) where is the sound happening. 2. Use natural language to describe the audio ev ents; The questions in Step 1 are to help generate a sentence like the description in Step 2, which are the references in our current task. All the labelling language was chosen freely as there is great subjec- tiv e variability in human perception of the audio scene. 3. D A T A ANAL YSIS Our raters used free Mandarin Chinese to label the dataset, a character-based language in which sev eral characters can signify the same meaning. For instance, ‘ 声 音 ’ ‘ 声 ’ ‘ 声 响 ’ all mean sound. ‘ 音 乐 ’ means music, and ‘ 音 乐 声 ’ ‘ 音 乐 声 音 ‘ mean the sound of music. Consequently , we firstly need to merge those labels with the same meaning. T able 1 is a showcase of the most frequent 15 sound Rank T ags Instances 1 People speaking/talking 24.70% 2 People having con versation 7.42% 3 Footsteps/W alking 5.65% 4 Post production sound 5.34% 5 Medical machine sound 3.96% 6 Noisy background sound 2.68% 7 Music 1.23% 8 Monologue 0.95% 9 Crying 0.69% 10 Door opening/closing 0.54% 11 Medical instrument sound 0.43% 12 Laughing 0.43% 13 Friction 0.28% 14 Coughing 0.26% 15 Collision 0.24% T able 1: T op 15 Sound T ags Rank Sound Belonging Scene 1 Doctors Hospital 2 Patients W ard 3 Patient’ s family Operation room 4 Humans Hospital corridor 5 Nurses Hospital hall T able 2: T op 5 Sound Belongings and Scenes Metric Train Dev Combined # Utterances 3337 371 3707 6 ◦ # token 11.14 11.19 11.14 max # token 48 54 54 min # token 1 1 1 duration(h) 9.3 1 10.3 T able 3: Data metrics between training and dev elopment sets. T oken metrics were calculated using the Chinese dataset. labels in our dataset after merging, collected from the answers to Question 1. Most frequent sound belongings and scenes can be seen in T able 2. All labelling results were then translated into English by Baidu T ranslation to increase the accessibility of the dataset. The collected dataset was divided into a training and de velop- ment subset such that the av erage number of tokens (words) within each subset was roughly equal (see T able 3 and Figure 1). 4. EXPERIMENTS The baseline with instructions on how to obtain the proposed dataset and how to run e xperiments can be found online 1 . Data prepr ocessing Since this paper lays foundation for a new task, different feature types were in vestigated. Similar features used for tasks such as automatic speech recognition (ASR) and audio ev ent detection (AED) were extracted. W e adopted standard log- 1 www .github.com/richermans/AudioCaption Fig. 1: Distribution of sentence length by number of tok ens melspectrogram (AED), as well as filterbank (ASR) features as our baseline (as seen in T able 4). Featurename W indow Shift Dimension Lms128 40 20 128 Fbank64 25 10 64 T able 4: Detailed information on feature extraction parameters. Lms128 stands for logmelspectrogram, fbank64 for filterbank fea- tures. W indow and Shift v alues are given in milliseconds (ms). Regarding the AED features, 128 dimensional logmelspectra [14, 15, 16, 17] were e xtracted. Here, a single frame is extracted ev ery 20ms with a window size of 40ms (T able 4). Moreover stan- dard 64 dimensional ASR filterbank features were extracted every 10ms with a window size of 20ms. The feature value range is nor- malized by the mean and standard deviation of the training dataset. The dataset was labelled in written Mandarin Chinese, a language in which words are not separated by white spaces. Therefore, a tokenizer is needed to split a gi ven sentence into its semantic com- ponents (tokens). The Stanfords NLP toolkit [18] was utilized to extract tokens (here we opted for words) for each sentence. Commas, dots and other Chinese specific calligraphy symbols were removed. Regarding the translated English sentences, the same preprocessing pipeline was utilized. The resulting token length distribution can be seen in T able 3 and Figure 1. Model The objectiv e of this task is to generate reasonable sen- tences from fed-in audio utterances.The baseline model proposed for this task adopts an encoder -decoder approach, similar to that of end- to-end automatic speech recognition [19, 20] and image captioning [6, 7] tasks. The encoder outputs a single fixed dimensional vector u for each utterance. This fixed dimensional vector is then concate- nated with the source sentence and fed to the decoder (see Figure 2). The decoder produces an output word for each input word. The encoder model consists of a single layer gated recurrent unit (GR U) model. W e fix ed the embedding size to be a 256 dimensional vector and the hidden size to be 512. The mean of all timestep out- puts is used as the utterance representation (denoted as u ) (see Fig- ure 2). Furthermore, the decoder model also uses a single layer GR U structure, but applies its dropout in addition to the word embedding output. Fig. 2: Proposed GRU Encoder-Decoder Model. Circles represent the hidden state of the recurrent model. An embedding u for a input utterance is extracted by using mean reduction o ver all time steps. L ( S | u ; θ ) = − T X t =1 log p t ( S t | u ; θ ) (1) The training loss is the negativ e log likelihood of the correct word ( S t ) at each timestep t [see Equation (1)] given the model pa- rameters θ as well as the embedding vector u . T raining is run for at most 20 epochs, whereas the epoch gener- ating the lo west perplexity on the training set is chosen for sampling. Sampling is done greedily , by inserting the most likely output as the input of the next timestep and done up until 50 words are generated or an end token is seen. Evaluation Since this dataset uses Chinese labels, the choice of ev aluation metrics is limited to language agnostic methods such as BLEU [21]. BLEU can be regarded as a weighted N -gram. In this work, we provide scores up to 4-gram. As seen in T able 3, some utterances contain less than four tokens, which leads to an unstable BLEU score. In cases the system generates a hypothesis < N , we use method 1 of chancherry smoothing [22]. The results in T able 5 are ev aluated on the held out development set. Feature Language BLEU N 1 2 3 4 Human English 0.376 0.196 0.121 0.086 Fbank64 0.375 0.188 0.097 0.060 Lms128 0.367 0.198 0.109 0.069 Human Chinese 0.369 0.201 0.122 0.088 Fbank64 0.339 0.161 0.088 0.058 Lms128 0.369 0.192 0.113 0.076 T able 5: Evaluation results on the development set. BLEU N refers to the BLEU score up until N grams. Each hypothesis sentence is ev aluated against two references. The average of all 3 references being treated as hypothesis is displayed as the human score. humanscore ( N ) = 1 D D X d =1 1 R R X r =1 X q 6 = r BLEU N ( Ref r , Ref q ) modelscore ( N ) = 1 D D X d =1 1 R R X r =1 X q 6 = r BLEU N ( Hyp , Ref q ) (2) In order to compute the human score, we treat one sentence (Ref r ) as hypothesis and the other two (Ref q ) as being references. Then we average the scores generated by treating each sentence as hypothesis (as seen in Equation (2)). This procedure is unfortunately biased towards model generated sentence, since its output has three corresponding references. For adequate comparisons between both outputs, we only compare the model hypothesis with Q = R − 1 references, where R = 3 and D is the number of utterances in the dataset. The final BLEU score is then computed as the av erage of all per utterance BLEU scores. The performance in T able 5 indi- cates that AED features are more suitable for the audio caption task across both languages. Our baseline model exhibits close to human performance, in both Chinese and English. Therefore, we further in- vestigated the BLEU score reliability by reev aluating the generated sentences by human raters. Human Evaluation W e in vited eight native Mandarin speakers to e valuate our Chinese hypothesis by scoring the four captions (one hypothesis from our best model and three human references) from 1 to 4 by its extent of usefulness: 1 stands for the least and 4 indicates the most. Our model averaged 1.89 and humans’ captions achieved a score of 2.88, with a two-tailed t -test yielding p < .001. Fleiss’ Kappa score [23] was calculated for the eight human ev aluators and results indicated that for Hypothesis, almost perfect agreement ( κ = 0.82) was achieved on ‘1’. It is quite agreeable that the generated captions are not useful compared to human captions. Howe ver , little agreement on the three references was found (average κ = 0.28), meaning that ev en raters agree the human captions are more useful, the extent is subject to preference. This contradictory result to the BLEU score shows that humans are still more reliable and accurate in captioning audio e vents, thus more attempts are encouraged on this task. 5. DISCUSSION Surprisingly , the baseline results sho wn in this work achieve scores nearly equal to human scores with BLEU as our criteria, regardless of the language adopted (English or Chinese). W e provide a few pos- sible explanations for this behaviour . First, since the dataset is rela- tiv ely small and domain-specific, many labels can describe multiple utterances. As an example, since the word sound ( 声 ) appears fre- quently , generated sentences are likely to include this word. Second, because of the large variety of words used in Chinese to describe mundane things (e.g., the English word talk can be one of 交 谈 , 说话 , 聊 天 , 聊 , 讲 , 谈 论 , 讨 论 , 商 量 ), the human captions hav e great variance thus the computed BLEU score is relativ ely low with humans. Additionally , we found that the captions generated by our base- line are consistently more repetitive compared to humans. For human references, there are 1236 unique words (averaged while for our hypothesis, only 193 unique words occurred), indicating that humans can generate sentences with a v ariety of le xicon, while more repetitiv e words were generated by our model. Statistics on unique sentences mirrored this observation: 1060 unique sentences from human raters while merely 106 from our model. The overlapping unigrams between hypothesis and reference (80 percent overlap for top 10 unigrams and 83 percent for top 30) showed that the model tends to produce the most possible words. As the current scene is limited to hospital, the model has a bigger chance in modelling relev ant captions. Howe ver under further e valuation by humans, our model re veals its defect. A few instances can be seen in the box below . Hyp (Score 4 Most Useful): 医 医 医 生 生 生 在 在 在 病 病 病 房 房 房 里 里 里 医 医 医 生 生 生 和 和 和 病 病 病 人 人 人 的 的 的 对 对 对 话 话 话 声 声 声 The doctor’ s conv ersation with the patient in the ward. Ref 1: 病 人 和 医 生 对 话 (Score 2) Dialogue between patients and doctors Ref 2: 在 病 房 里 , 有 说话 声 (Score 1) In the ward, there was a v oice. Ref 3: 病 人 和 护 士 的 对 话 (Score 3) Dialogue between patients and nurses Hyp (Score 3 Medium Useful): 医 医 医 生 生 生 和 和 和 病 病 病 人 人 人 家 家 家 属 属 属 在 在 在 说 说 说话 话 话 有 有 有 人 人 人 的 的 的 对 对 对 话 话 话 声 声 声 The doctor and the patient’ s family are talking. Ref 1: 一 位 医 生 与一 位 女 士 交 谈 (Score 2) A doctor talked to a lady . Ref 2: 病 患 询 问 医 生 派 出 所 的 位 置 (Score 1) The patient inquired about the location of the doctor’ s police station. Ref 3: 大 厅 广 播 声 , 脚 步 声 , 医 生 和 病 人 对 话 声 , 大 厅 嘈 杂 声 (Score 4) The hall was broadcasted, footsteps, doctors and patients chatting, the hall was noisy . Hyp (Score 1 Not Useful) 医 医 医 生 生 生 和 和 和 病 病 病 人 人 人 的 的 的 对 对 对 话 话 话 声 声 声 Dialogue between doctors and patients Ref 1: 一个 医 生 和 另 一 个 正 在 打 电 话 的 医 生 交 谈 , 说话 声 , 走路 声 , 吵 杂 声 (Score 4) A doctor talked to another doctor on the phone, speaking, walking, and noisy . Ref 2: 两个 医 生 在 医 院 对 话 , 但 并 不 是 说 同 一件事 情 (Score 3) The two doctors talked in the hospital, b ut not the same thing. Ref 3: 男 医 生 说话 , 另 一 名 男 医 生电 话 交 流 (Score 2) Male doctor speaks, another male doctor exchanges by telephone. 6. CONCLUSION In this paper we endeav ored to enhance machine perception of audio ev ents, and to minimize the gap between audio and image research. The aim is to automatically generate captions for audio ev ents. W e collected 3710 video clips on hospital scene, with each clip contain- ing more than one sound classes. W e established a new way of sub- jectiv e labelling to enable automatic audio caption. Each 10s clip is entitled to three human-labelled captions. An encoder-decoder model was conducted as our baseline and experiment results show that the best results were achieved with logmelspectrogram input features. T o our surprise, this model‘s BLEU score is slightly lower than the human one. Howe ver , this might not be the best way to ev aluate Chinese captions: human e valuation showed that our model is still not very accurate. W e could generate grammatically-correct and data-related captions but the model tends to produce repetitive words and sentences. This behaviour is likely a result of the limited data diversity . In future work we would like to extend the dataset to all fiv e provided scenes. 7. REFERENCES [1] Jort F . Gemmeke, Daniel P . W . Ellis, Dylan Freedman, Aren Jansen, W ade La wrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter, “ Audio set: An ontology and human-labeled dataset for audio ev ents, ” in Pr oc. IEEE ICASSP 2017 , New Orleans, LA, 2017. [2] Annamaria Mesaros, T oni Heittola, and T uomas V irtanen, “T ut database for acoustic scene classification and sound ev ent de- tection, ” 2016 24th European Signal Pr ocessing Conference (EUSIPCO) , pp. 1128–1132, 2016. [3] Justin Salamon, Christopher Jacoby , and Juan Pablo Bello, “ A dataset and taxonomy for urban sound research, ” in A CM Mul- timedia , 2014. [4] Y ong Xu, Qiuqiang Kong, W enwu W ang, and Mark D Plumb- ley , “Large-scale weakly supervised audio classification using gated con volutional neural network, ” in 2018 IEEE Interna- tional Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 121–125. [5] Brian McFee, Justin Salamon, and Juan Pablo Bello, “ Adaptiv e pooling operators for weakly labeled sound e vent detection, ” IEEE/A CM T ransactions on Audio, Speech and Language Pr o- cessing (T ASLP) , vol. 26, no. 11, pp. 2180–2193, 2018. [6] Oriol V inyals, Alexander T oshev , Samy Bengio, and Dumitru Erhan, “Show and tell: A neural image caption genera- tor , ” 2015 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , Jun 2015. [7] Andrej Karpathy and Li Fei-Fei, “Deep visual-semantic align- ments for generating image descriptions, ” IEEE T rans. P attern Anal. Mach. Intell. , vol. 39, no. 4, pp. 664–676, Apr . 2017. [8] Kelvin Xu, Jimmy Ba, Ryan Kiros, K yunghyun Cho, Aaron Courville, Ruslan Salakhudinov , Rich Zemel, and Y oshua Ben- gio, “Show , attend and tell: Neural image caption generation with visual attention, ” in International confer ence on machine learning , 2015. [9] Zhiqiang Shen, Jianguo Li, Zhou Su, Minjun Li, Y urong Chen, Y u-Gang Jiang, and Xiangyang Xue, “W eakly supervised dense video captioning, ” 2017 IEEE Conference on Computer V ision and P attern Recognition (CVPR) , Jul 2017. [10] Ramakanth Pasunuru and Mohit Bansal, “Multi-task video captioning with video and entailment generation, ” Proceed- ings of the 55th Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , 2017. [11] Y ingwei Pan, T ao Mei, Ting Y ao, Houqiang Li, and Y ong Rui, “Jointly modeling embedding and translation to bridge video and language, ” 2016 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , Jun 2016. [12] K. Drossos, S. Adav anne, and T . V irtanen, “ Automated au- dio captioning with recurrent neural networks, ” in 2017 IEEE W orkshop on Applications of Signal Pr ocessing to Audio and Acoustics (W ASP AA) , Oct 2017, pp. 374–378. [13] Xirong Li, W eiyu Lan, Jianfeng Dong, and Hailong Liu, “Adding Chinese Captions to Images, ” in Pr oceedings of the 2016 ACM on International Conference on Multimedia Re- trieval , 2016. [14] Keunw oo Choi, George Fazekas, and Mark Sandler, “ Au- tomatic tagging using deep conv olutional neural networks, ” arXiv pr eprint arXiv:1606.00298 , 2016. [15] Shawn Hershey , Sourish Chaudhuri, Daniel PW Ellis, Jort F Gemmeke, Aren Jansen, R Channing Moore, Manoj Plakal, Devin Platt, Rif A Saurous, Bryan Seybold, et al., “Cnn architectures for large-scale audio classification, ” Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE Interna- tional Confer ence on , pp. 131–135, 2017. [16] Y ong Xu, Qiuqiang Kong, W enwu W ang, and Mark D Plumb- ley , “Large-scale weakly supervised audio classification us- ing gated con volutional neural network, ” arXiv pr eprint arXiv:1710.00343 , 2017. [17] Qiuqiang K ong, Y ong Xu, Iwona Sobieraj, W enwu W ang, and Mark D Plumbley , “Sound event detection and time- frequency segmentation from weakly labelled data, ” arXiv pr eprint arXiv:1804.04715 , 2018. [18] Christopher D Manning, Mihai Surdeanu, John Bauer , Jenn y Finkel, Ste ven J Bethard, and Da vid McClosky , “The Stanford CoreNLP Natural Language Processing T oolkit, ” in Associa- tion for Computational Linguistics (A CL) System Demonstra- tions , 2014, pp. 55–60. [19] Zhehuai Chen, Maha veer Jain, Y ongqiang W ang, Michael Seltzer , and Christian Fuegen, “End-to-end contextual speech recognition using class language models and a tok en passing decoder , ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing(ICASSP) , Brighton, UK, May 2019. [20] Zhehuai Chen, Qi Liu, Hao Li, and Kai Y u, “On modular train- ing of neural acoustics-to-word model for lvcsr, ” in IEEE In- ternational Conference on Acoustics, Speech and Signal Pr o- cessing(ICASSP) , Calgary , Canada, April 2018. [21] Kishore Papineni, Salim Roukos, T odd W ard, and W ei-Jing Zhu, “Bleu: A method for automatic e valuation of machine translation, ” in Pr oceedings of the 40th Annual Meeting on Association for Computational Linguistics , Stroudsburg, P A, USA, 2002, A CL ’02, pp. 311–318, Association for Computa- tional Linguistics. [22] Boxing Chen and Colin Cherry , “ A systematic comparison of smoothing techniques for sentence-level bleu, ” in Pr oceed- ings of the Ninth W orkshop on Statistical Machine T ranslation , 2014, pp. 362–367. [23] Joseph L Fleiss, “Measuring nominal scale agreement among many raters., ” Psychological bulletin , vol. 76, no. 5, pp. 378, 1971.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment