Informative Scene Decomposition for Crowd Analysis, Comparison and Simulation Guidance
Crowd simulation is a central topic in several fields including graphics. To achieve high-fidelity simulations, data has been increasingly relied upon for analysis and simulation guidance. However, the information in real-world data is often noisy, mixed and unstructured, making it difficult for effective analysis, therefore has not been fully utilized. With the fast-growing volume of crowd data, such a bottleneck needs to be addressed. In this paper, we propose a new framework which comprehensively tackles this problem. It centers at an unsupervised method for analysis. The method takes as input raw and noisy data with highly mixed multi-dimensional (space, time and dynamics) information, and automatically structure it by learning the correlations among these dimensions. The dimensions together with their correlations fully describe the scene semantics which consists of recurring activity patterns in a scene, manifested as space flows with temporal and dynamics profiles. The effectiveness and robustness of the analysis have been tested on datasets with great variations in volume, duration, environment and crowd dynamics. Based on the analysis, new methods for data visualization, simulation evaluation and simulation guidance are also proposed. Together, our framework establishes a highly automated pipeline from raw data to crowd analysis, comparison and simulation guidance. Extensive experiments and evaluations have been conducted to show the flexibility, versatility and intuitiveness of our framework.
💡 Research Summary
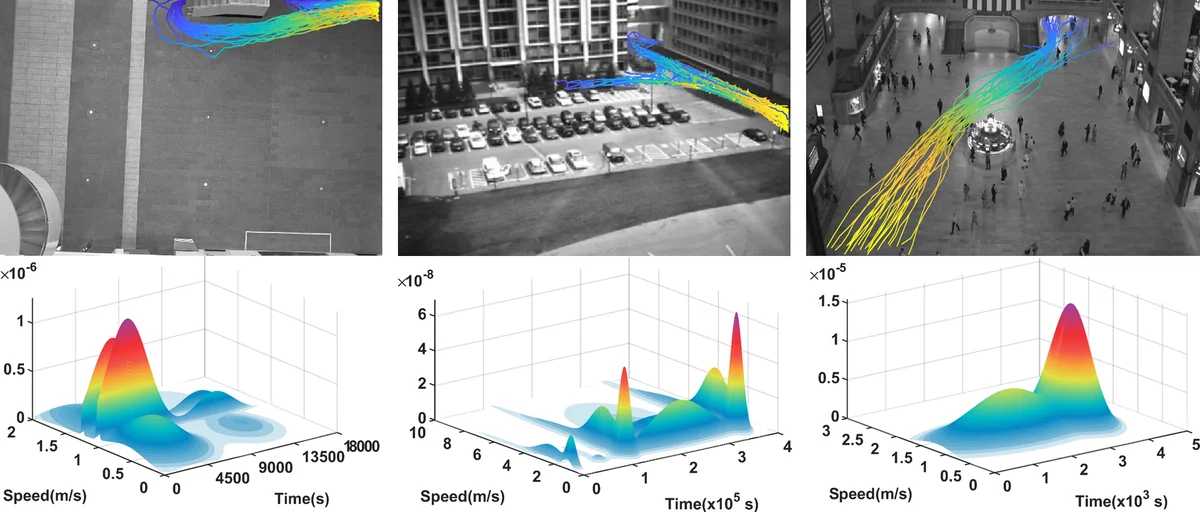
The paper addresses a fundamental bottleneck in crowd simulation: the under‑exploitation of noisy, mixed, and unstructured real‑world trajectory data. To bridge the gap between raw data and high‑fidelity simulation, the authors propose a fully automated, unsupervised framework that extracts semantically meaningful “modes” from large‑scale crowd recordings. Each mode jointly encodes three correlated dimensions—spatial flow (a recurrent path through the environment), temporal profile (when the flow appears, peaks, and fades), and dynamics (the speed distribution of agents following the flow).
The methodological core is a novel non‑parametric Bayesian model called Triplet Hierarchical Dirichlet Processes (THDP). THDP consists of three intertwined Hierarchical Dirichlet Processes, one for each dimension, allowing the number of modes to be inferred automatically from the data. To perform inference on this complex structure, the authors introduce a new Markov Chain Monte Carlo scheme named Chinese Restaurant Franchise League (CRFL), which generalizes the classic Chinese Restaurant Process and Franchise used for HDP inference. CRFL samples global topics (the modes) and local topic assignments for space, time, and dynamics simultaneously, achieving efficient convergence even on datasets containing tens of thousands of trajectories with substantial noise.
Extensive experiments on diverse real‑world datasets—train stations, historic buildings, large public events—demonstrate that THDP/CRFL outperforms traditional clustering approaches (K‑means, GMM, spectral clustering) and earlier single‑dimensional HDP models. The model reliably discovers meaningful flow patterns, distinguishes temporal variations of the same spatial route, and captures heterogeneous speed profiles, all without any prior knowledge of the number of patterns.
Beyond analysis, the paper leverages the extracted modes for three practical applications. First, a visualization tool renders each mode as a colored flow on a map, animates its temporal evolution, and displays its speed histogram, giving users an intuitive overview of complex crowd behavior. Second, a suite of quantitative metrics is defined for simulation evaluation: spatial overlap scores compare geometric paths, temporal alignment measures assess timing similarity, and dynamic divergence (e.g., KL‑divergence) quantifies speed distribution differences. These metrics can be applied holistically or to individual modes, enabling fine‑grained comparison between simulated and real crowds. Third, the framework provides automated simulation guidance. By treating the mode weights and distributions as target objectives, the authors formulate an optimization problem that tunes simulation parameters so that synthetic agents reproduce the same spatial, temporal, and dynamic characteristics observed in the data. Importantly, the method incorporates heterogeneous motion randomness by sampling agent speeds from the learned dynamic distributions rather than applying a uniform noise model.
The contributions can be summarized as follows: (1) introduction of the first non‑parametric Bayesian model that jointly models space, time, and dynamics for crowd analysis; (2) development of the CRFL inference algorithm that makes such a model tractable on large, noisy datasets; (3) creation of an end‑to‑end pipeline that transforms raw trajectories into interpretable modes, supports intuitive visualization, provides rigorous multi‑dimensional evaluation metrics, and enables data‑driven simulation parameter tuning. This work thus offers a comprehensive solution that not only deepens our understanding of crowd semantics but also directly improves the realism and reliability of crowd simulations in graphics, architecture, and crowd management applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment