Learning Dialog Policies from Weak Demonstrations
💡 Research Summary
The paper tackles the challenge of training a dialog manager (DM) for multi‑domain task‑oriented systems using reinforcement learning (RL) despite the large state/action spaces and sparse rewards that typically hinder RL in this setting. Building on Deep Q‑learning from Demonstrations (DQfD), the authors propose to replace costly, rule‑based or fully‑labeled expert demonstrations with progressively weaker, cheaper “weak demonstrations”. Three expert models are introduced:
-
Full Label Expert (FLE) – a conventional supervised classifier trained on a fully annotated in‑domain dialog corpus to predict the exact next system action. It uses the original DQfD large‑margin auxiliary loss.
-
Reduced Label Expert (RLE) – a multi‑label classifier that only predicts high‑level dialog act categories (inform, request, other) which are common across many datasets. The RLE is trained on datasets stripped to these coarse labels. During DQfD training, an action is sampled uniformly from the set of environment actions that belong to the predicted reduced label, and the auxiliary loss is adapted to penalize actions outside this set.
-
No Label Expert (NLE) – a binary relevance model that requires no annotations. It is trained on pairs of user utterances and system responses extracted from unannotated human‑to‑human dialogs. Positive examples are the original pairs; negatives are generated by randomly pairing a user utterance with an unrelated system response. At inference time, the NLE scores candidate system utterances for the current user turn; actions whose verbalizations exceed a threshold form a candidate set from which a demonstration action is sampled. The same reduced‑label‑style margin loss is applied.
All three experts are used to pre‑populate the DQfD replay buffer, providing the agent with useful guidance early in training.
To address the domain gap between the offline dialog corpora (used to train the experts) and the RL environment (which includes a user simulator and a database), the authors introduce Reinforced Fine‑tune Learning (RoFL). While the agent interacts with the environment, any transition whose reward exceeds a threshold is stored as “in‑domain” data. Every k steps the expert network is fine‑tuned on the accumulated in‑domain set, gradually adapting its parameters to the dynamics of the RL setting. After a pre‑training phase, the fine‑tuned expert is frozen and used to generate the final demonstration buffer for the main DQfD training phase. RoFL is agnostic to the expert type and can be applied to FLE, RLE, or NLE.
Experimental setup: Experiments are conducted in ConvLab, a multi‑domain dialog framework built on the MultiWOZ dataset. The task is to assist a user in planning a city trip, covering domains such as hotels, taxis, and attractions. Evaluation metrics include task success rate, average dialogue length, and cumulative reward.
Results:
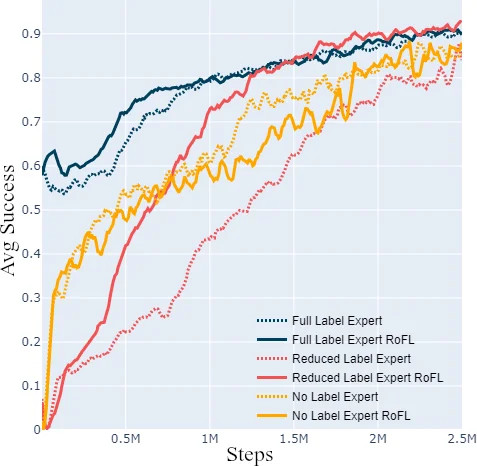
- FLE achieves high success rates comparable to prior work; RoFL further speeds up convergence by ~20 %.
- RLE, despite using only coarse labels, reaches performance close to FLE, and with RoFL it essentially matches FLE’s results, demonstrating that expensive fine‑grained annotation is unnecessary.
- NLE, the weakest expert, still yields a respectable success rate; RoFL improves it by over 15 % absolute, showing that even unlabeled data can be turned into effective demonstrations after adaptation.
Overall, the study shows that weak demonstrations, when combined with DQfD and the RoFL adaptation loop, can train a high‑performing multi‑domain dialog policy while dramatically reducing annotation costs.
Discussion and limitations: The quality of weak demonstrations depends on the construction of negative samples for NLE and the definition of reduced label sets for RLE. NLE may struggle with complex dialog phenomena that require fine‑grained act distinctions. RoFL introduces additional hyper‑parameters (reward threshold, fine‑tune interval) that need careful tuning. Experiments are conducted with a user simulator; real‑user evaluations are left for future work.
Conclusion: The paper contributes (i) a hierarchy of low‑cost expert models, (ii) a seamless integration of these experts into DQfD via modified auxiliary losses, and (iii) the RoFL algorithm for domain adaptation. Together they provide a practical, scalable pathway to train dialog managers with reinforcement learning without the prohibitive cost of fully annotated, in‑domain expert data. Future research may explore extending the approach to other RL domains and validating it with live users.
Comments & Academic Discussion
Loading comments...
Leave a Comment