Generative Adversarial Networks are Special Cases of Artificial Curiosity (1990) and also Closely Related to Predictability Minimization (1991)
I review unsupervised or self-supervised neural networks playing minimax games in game-theoretic settings: (i) Artificial Curiosity (AC, 1990) is based on two such networks. One network learns to generate a probability distribution over outputs, the other learns to predict effects of the outputs. Each network minimizes the objective function maximized by the other. (ii) Generative Adversarial Networks (GANs, 2010-2014) are an application of AC where the effect of an output is 1 if the output is in a given set, and 0 otherwise. (iii) Predictability Minimization (PM, 1990s) models data distributions through a neural encoder that maximizes the objective function minimized by a neural predictor of the code components. I correct a previously published claim that PM is not based on a minimax game.
💡 Research Summary
**
The paper provides a historical‑theoretical synthesis showing that three seemingly distinct lines of research—Artificial Curiosity (AC) introduced in 1990, Generative Adversarial Networks (GANs) popularized between 2014 and 2019, and Predictability Minimization (PM) from the early 1990s—are in fact instances of the same underlying minimax game.
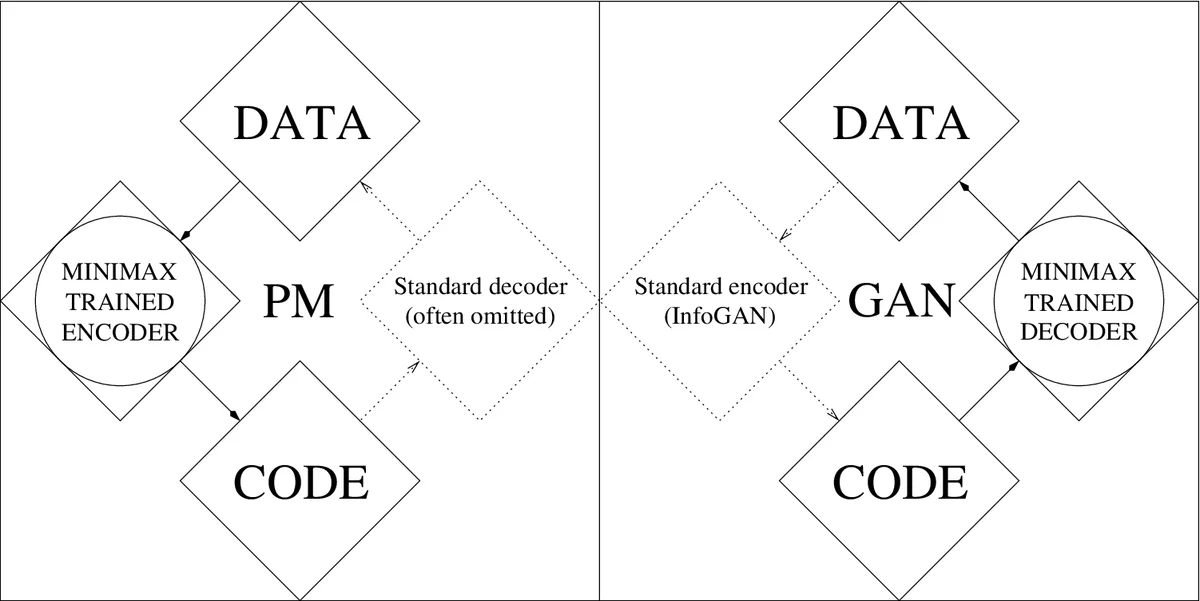
In the original AC‑1990 framework a single agent contains two neural networks: a controller C that generates actions (or output vectors) and a world model M that predicts the consequences of those actions. M is trained by gradient descent to minimize its prediction error; C, lacking any external reward, receives as intrinsic reward the error of M and therefore learns to maximize that error. The result is a self‑motivated exploration strategy: C deliberately produces data that are still surprising to M, driving continual learning without a teacher.
The authors argue that a GAN is exactly a special case of AC‑1990. In a GAN the generator G (identical to C) receives random noise and produces a sample x. The discriminator D (identical to M) receives x and outputs a binary decision y = 1 if x belongs to the real data set X, otherwise y = 0. D is trained to minimize a binary cross‑entropy loss, while G is trained to maximize the same loss (i.e., to make D’s predictions as wrong as possible). This mirrors the AC‑1990 objective where C maximizes the loss minimized by M. The paper further shows that conditional GANs (cGANs, 2010) correspond to AC‑1990 with additional environmental inputs to C, and StyleGANs (2019) correspond to AC‑1990 with noise injected not only at the input layer but also in deeper hidden layers—both already present in the original mean‑and‑variance Gaussian units of the 1990 controller.
Predictability Minimization (PM) is similarly recast as a minimax game. PM consists of an encoder E that maps data to a code vector z and a set of predictors P_i, each trying to predict a component of z from the remaining components. Each predictor minimizes its own prediction error, while the encoder maximizes the sum of those errors, thereby encouraging a representation in which components are statistically independent. This is precisely the same adversarial relationship as in AC‑1990, contrary to a previously published claim that PM does not involve a minimax formulation.
The paper also surveys extensions of the original AC idea. In stochastic environments the raw prediction error can be misleading (e.g., an agent stuck in front of a TV showing white noise would receive high error but no learning progress). A 1991 improvement proposes using the change in prediction error (the learning progress) as the intrinsic reward, which discourages the agent from exploiting stochastic but uninformative regions. This idea later appears as Bayesian surprise or information‑gain‑based curiosity.
A more sophisticated variant, AC‑1997, introduces two competing policies (left and right “brains”) that generate programs (experiments) whose binary outcomes are bet upon. After execution, the winning brain receives a reward proportional to its bet, the loser receives an equal negative reward. Each brain therefore tries to produce experiments that surprise the other, extending the AC principle to meta‑learning over program space.
Finally, the authors discuss convergence and stability, noting that all three frameworks inherit the classic instability of minimax games. Techniques developed for GAN training—learning‑rate scheduling, experience replay, gradient penalties, and regularization—are suggested as ways to stabilize AC and PM training as well.
In conclusion, the paper demonstrates that the 1990s artificial curiosity framework anticipated the core adversarial learning principle that underlies modern GANs and PM. Recognizing this common foundation not only clarifies the historical lineage but also provides a unified perspective for designing future self‑supervised, intrinsically motivated learning systems and for addressing their stability challenges.
Comments & Academic Discussion
Loading comments...
Leave a Comment