A Dataset of Enterprise-Driven Open Source Software
We present a dataset of open source software developed mainly by enterprises rather than volunteers. This can be used to address known generalizability concerns, and, also, to perform research on open source business software development. Based on the premise that an enterprise’s employees are likely to contribute to a project developed by their organization using the email account provided by it, we mine domain names associated with enterprises from open data sources as well as through white- and blacklisting, and use them through three heuristics to identify 17,264 enterprise GitHub projects. We provide these as a dataset detailing their provenance and properties. A manual evaluation of a dataset sample shows an identification accuracy of 89%. Through an exploratory data analysis we found that projects are staffed by a plurality of enterprise insiders, who appear to be pulling more than their weight, and that in a small percentage of relatively large projects development happens exclusively through enterprise insiders.
💡 Research Summary
The paper addresses a notable gap in software‑engineering research: the overwhelming focus on volunteer‑driven open‑source projects hosted on GitHub, which limits the generalizability of findings to the corporate world where a large share of modern software development occurs. To remedy this, the authors construct a curated dataset of “enterprise‑driven” open‑source projects—repositories in which the majority of contributions are made by employees of a business, identified via corporate email domains.
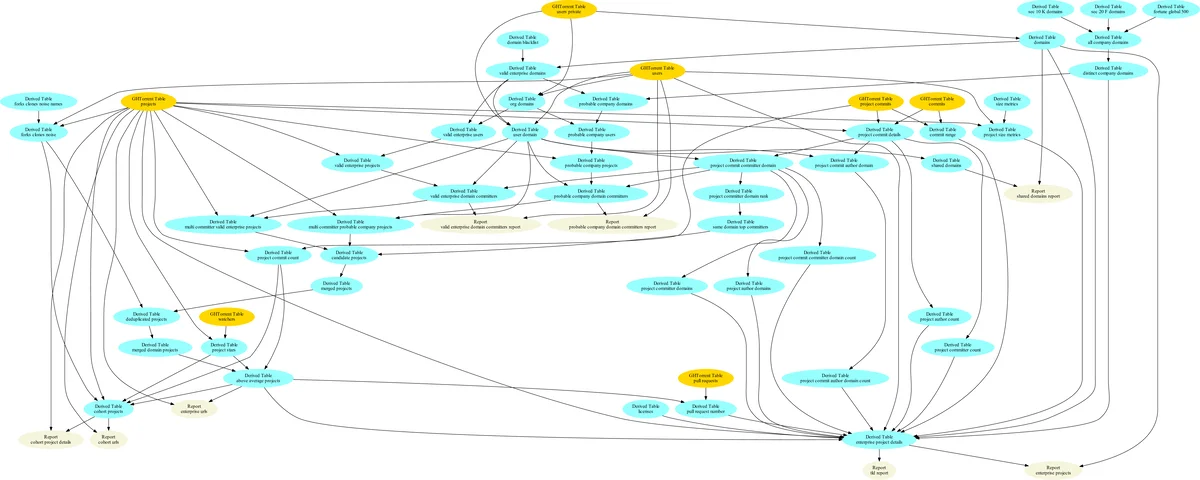
The methodology proceeds in several stages. First, the authors start from the GitHub Torent snapshot (June 2019) and extract every commit’s author email address. They then build two complementary domain lists: (1) a “valid enterprise” list obtained by filtering out domains associated with free email providers, universities, open‑source hubs, and other non‑commercial entities (blacklist), and (2) a “probable company” list derived from publicly available corporate data sources, namely the Fortune Global 500 list and the U.S. SEC filings (Forms 10‑K and 20‑F). The latter are parsed for XBRL files, from which the company’s internet domain is inferred (e.g., intel.com). These lists are merged with domains registered for GitHub organizations, yielding tables that map user email domains to the corresponding corporate organization.
Next, three heuristics are applied to select projects:
- Same‑Domain Top Committers (SDTC) – a project is kept if the three most prolific committers share the same corporate domain.
- Multiple Committers – Valid Enterprise (MCVE) – a project is retained when at least ten distinct committers use a domain from the valid‑enterprise list.
- Multiple Committers – Probable Company (MCP C) – analogous to MCVE but with a lower threshold (five committers) and using the probable‑company list.
Projects that are clones of other repositories are removed, and only those exceeding the dataset’s average star count (14) and commit count (29) are retained, ensuring a baseline of visibility and activity. The resulting candidate set (17,264 projects) is enriched with a rich set of 29 attributes: URL, GitHub ID, star and commit counts, file and line metrics, pull‑request statistics, timestamps for first and latest commits, numbers of distinct committers and authors, dominant email domain, domain‑specific contribution breakdowns, Fortune 500/SEC flags, company name, owner organization, and SPDX license identifier.
To evaluate precision, the authors randomly sampled 378 projects and had two independent raters label each as “enterprise” or “non‑enterprise” according to the paper’s definition, without revealing the underlying heuristics. Inter‑rater agreement was 78 % (Cohen’s κ = 0.29). After resolving disagreements by majority vote, 89 % of the sampled projects were confirmed as enterprise‑driven. Bootstrapping (1,000 iterations) produced a 95 % confidence interval of 87–93 % for the proportion of true enterprise projects, implying that roughly 15,354 (CI 15,009–16,044) of the 17,264 entries are genuinely corporate‑originated.
Exploratory analysis yields several insights. Across the dataset, 33 % of authors and 24 % of committers belong to the project’s dominant domain; however, they generate 45 % of all commits, indicating a “heavy‑weight” effect of corporate insiders. The most common top‑level domains are .com (13,494 projects), .io (763), .de (383), .gov (339), etc. The leading corporate owners are Microsoft (855 projects), Azure (328), Google (123), Twitter (93), and others. Projects where all commits come from enterprise committers or authors are rare (0.5 % and 1.3 % respectively) but are not small; they average 45 k and 97 k lines of code, respectively. Pull‑request activity is pervasive: 95 % of projects have at least one PR, with an average of 161 PRs per project. Licensing is dominated by permissive licenses—MIT (4,340 projects) and Apache 2.0 (3,771 projects)—while GPL appears in only 780 projects, suggesting limited reliance on copyleft business models. Notably, 3,535 projects lack a detectable license, and another 3,374 have licenses that do not map to an SPDX identifier.
The authors argue that this dataset enables researchers to mitigate the “volunteer bias” that plagues many empirical software‑engineering studies. By providing a vetted set of corporate‑centric repositories, scholars can conduct stratified sampling, cohort analyses, or case studies that more accurately reflect the practices of professional development teams, including code review processes, CI/CD pipelines, and business‑driven release strategies. The authors acknowledge that the construction deliberately favors precision over recall; consequently, many smaller or less active enterprise projects are omitted. Future work could expand coverage by relaxing thresholds or incorporating additional signals (e.g., issue‑tracker activity, corporate CI logs).
In summary, the paper delivers a high‑quality, openly available dataset of 17,264 enterprise‑driven open‑source projects, validated at 89 % precision, and accompanied by extensive metadata. It demonstrates that corporate contributions constitute a substantial and distinct segment of the open‑source ecosystem, with characteristic patterns of dominance, licensing, and pull‑request usage. The dataset is positioned as a valuable resource for the software‑engineering community to explore the intersection of open source and commercial software development.
Comments & Academic Discussion
Loading comments...
Leave a Comment