Multilingual and Unsupervised Subword Modeling for Zero-Resource Languages
Subword modeling for zero-resource languages aims to learn low-level representations of speech audio without using transcriptions or other resources from the target language (such as text corpora or pronunciation dictionaries). A good representation …
Authors: Enno Hermann, Herman Kamper, Sharon Goldwater
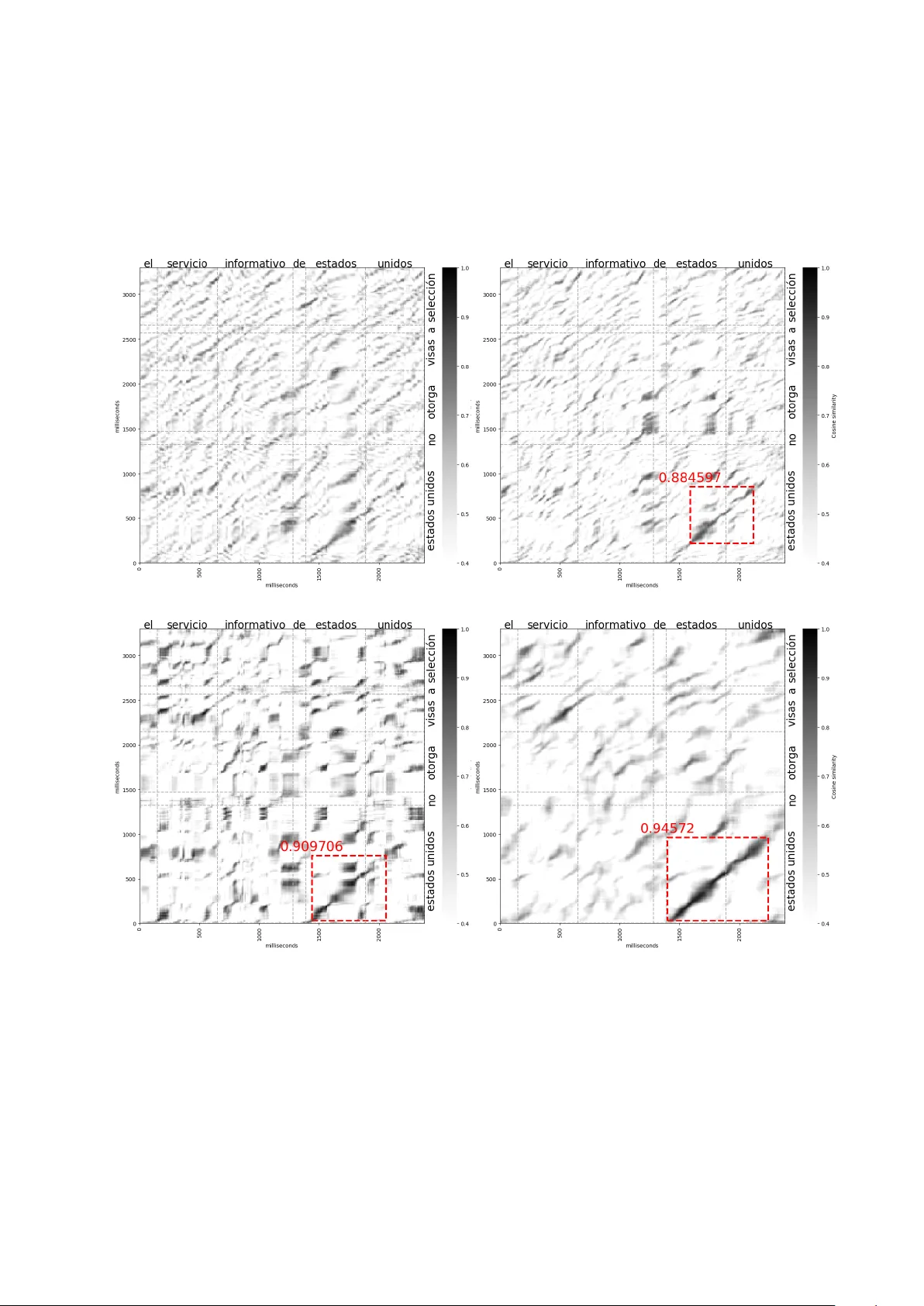
http://cr e ative c ommons.or g/lic enses/by-nc-nd/4.0/ This manuscript version is made available under the CC-BY-NC-ND 4.0 lic ense: c 2020. A c c epte d for public ation in Computer Sp e e ch and L anguage. Multilingual and Unsup ervised Sub w ord Mo deling for Zero-Resource Languages Enno Hermann a, ∗ , Herman Kamp er b , Sharon Goldw ater a a Scho ol of Informatics, University of Edinbur gh, Edinbur gh EH8 9AB, U.K. b Dep artment of E&E Engine ering, Stel lenb osch University, Stel lenb osch 7600, South Afric a Abstract Sub word mo deling for zero-resource languages aims to learn low-lev el representations of sp eech audio without using transcriptions or other resources from the target language (suc h as text corp ora or pronunciation dictionaries). A go o d representation should capture phonetic con tent and abstract a wa y from other types of v ariabilit y , such as sp eaker differences and channel noise. Previous work in this area has primarily fo cused unsup ervised learning from target language data only , and has b een ev aluated only intrinsically . Here we directly compare m ultiple metho ds, including some that use only target language sp eec h data and some that use transcrib ed sp eec h from other (non-target) languages, and we ev aluate using tw o intrinsic measures as well as on a do wnstream unsup ervised word segmentation and clustering task. W e find that combining t wo existing target-language-only metho ds yields b etter features than either metho d alone. Nev ertheless, ev en b etter results are obtained by extracting target language b ottleneck features using a mo del trained on other languages. Cross-lingual training using just one other language is enough to provide this b enefit, but m ultilingual training helps even more. In addition to these results, which hold across b oth in trinsic measures and the extrinsic task, we discuss the qualitativ e differences b etw een the different types of learned features. Keywor ds: Multilingual b ottlenec k features, subw ord mo deling, unsup ervised feature extraction, zero-resource sp eec h technology . 1. In tro duction Recen t y ears hav e seen increasing interest in sp eec h technology for “zero-resource” languages, where systems must b e developed for a target language without using transcrib ed data or other hand-curated resources from that language. Such systems could p oten tially b e applied to tasks such as endangered language do cumen tation or query-by-example search for languages without a written form. One challenge for these systems, highlighted by the Zero Resource Sp eec h Challenge (ZRSC) shared tasks of 2015 (V ersteegh et al., 2015) and 2017 (Dunbar et al., 2017), is to improv e sub word mo deling, i.e., to extract or learn sp eec h features from the target language audio. Go od features should b e more effective at discriminating b etw een linguistic units, e.g. w ords or subw ords, while abstracting aw a y from factors such as sp eak er identit y and channel noise. The ZRSCs were motiv ated largely b y questions in artificial intelligence and human p erceptual learning, and fo cused on approaches where no transcrib ed data from any language is used. Y et from an engineering p erspective it also makes sense to explore how training data from higher-resource languages can b e used to impro ve sp eec h features in a zero-resource language. This pap er explores several metho ds for improvin g subw ord mo deling in zero-resource languages, either with or without the use of lab eled data from other languages. Although the individual methods are not new, our work provides a muc h more thorough empirical ev aluation of these metho ds compared to the existing ∗ Corresponding author. Present address: Idiap Research Institute, Rue Marconi 19, Martigny 1920, Switzerland. Email addr esses: enno.hermann@idiap.ch (Enno Hermann), kamperh@sun.ac.za (Herman Kamper), sgwater@inf.ed.ac.uk (Sharon Goldwater) literature. W e exp eriment with each metho d b oth alone and in comb inations not tried b efore, and provide results across a range of target languages, ev aluation measures, and tasks. W e start by ev aluating tw o metho ds for feature extraction that are trained using (untranscribed) target language data only: traditional vocal tract length normalization (VTLN) and the corresp ondence autoenco der (cAE) prop osed more recently by Kamp er et al. (2015). The cAE learns to abstract aw ay from signal noise and v ariability b y training on pairs of sp eec h segments extracted using an unsup ervised term discov ery (UTD) system—i.e., pairs that are likely to b e instances of the same word or phrase. W e confirm previous work sho wing that cAE features outp erform Mel-frequency cepstral co efficien ts (MFCCs) on a w ord discriminability task, although we also show that this b enefit is not consistently b etter than that of simply applying VTLN. More interestingly , how ev er, we find that applying VTLN to the input of the cAE system improv es the learned features considerably , leading to b etter p erformance than either metho d alone. These impro vemen ts indicate that cAE and VTLN abstract ov er different aspects of the signal, and suggest that VTLN might also b e a useful prepro cessing step in other recent neural-net work-based unsup ervised feature-learning metho ds. Next, we explore how multilingual annotated data can b e used to improv e feature extraction for a zero- resource target language. W e train multilingual b ottlenec k features (BNFs) on b etw e en one and ten languages from the GlobalPhone collection and ev aluate on six other languages (simulating differen t zero-resource targets). W e show that training on more languages consistently impro v es p erformance on w ord discrimination, and that the impro vemen t is not simply due to more training data: an equiv alen t amount of data from one language fails to give the same b enefit. In fact, we observe the largest gain in p erformance when adding the second training language, which is already b etter than adding three times as m uch data from the same language. Moreo v er, when compared to our best results from training unsup ervised on target language data only , w e find that BNFs trained on just a single other language already outp erform the target-language-only training, with m ultilingual BNFs doing b etter by a wide margin. Although m ultilingual training outp erforms unsup ervised target-language training, it could still be possible to impro ve on the multilingual BNFs by using them as inputs for further target-language training. T o test this hypothesis, we passed the multilingual BNFs as input to the cAE. When trained with UTD word pairs, w e found no b enefit to this metho d. How ever, training with manually lab eled word pairs did yield b enefits, suggesting that this type of sup ervision can help improv e on the BNFs if the w ord pairs are sufficiently high-qualit y . The results ab o ve were presented as part of an earlier conference v ersion of this pap er (Hermann and Goldw ater, 2018). Here, we expand up on that work in several wa ys. First, we include new results on the corp ora and ev aluation measures used in the ZRSC, to allow more direct comparisons with other work. In doing so, we also provide the first set of results on identical systems ev aluated using b oth the same-different and ABX ev aluation measures. This p ermits the tw o measures themselves to b e b etter compared. Finally , w e provide b oth a qualitative analysis of the differences b etw een the differen t features we extract, and a quantitativ e ev aluation on the do wnstream target-language task of unsup ervised full-cov erage sp eech segmen tation and clustering using the system of Kamp er et al. (2017). This is the first time that multilingual features are used in suc h a system, which p erforms a complete segmentation of input sp eech in to h yp othesized w ords. As in our intrinsic ev aluations, we find that the multilingual BNFs consistently outp erform the b est unsup ervised cAE features, which in turn outp erform or do similarly to MF CCs. 2. Unsup ervised T raining, T arget Language Only W e start by in vestigating how unlab eled data from the target language alone can b e used for unsup ervised sub word mo deling and how sp eak er normalisation with VTLN can improv e such systems. Below we first review related work and provide a brief in tro duction to the cAE and VTLN metho ds. W e then describ e our exp erimen ts directly comparing these metho ds, b oth alone and in combination. 2.1. Backgr ound and Motivation V arious approac hes hav e b een applied to the problem of unsup ervised subw ord mo deling. Some metho ds w ork in a strictly b ottom-up fashion, for example by extracting p osteriorgrams from a (finite or infinite) 2 y Align word pair frames Correspondence autoencoder cAE features Unsupervised term discovery (or forced alignment) x' x Figure 1: Corresp ondence auto enco der training procedure (see section 2.1). Gaussian mixture model trained on the unlab eled data (Zhang and Glass, 2009; Huijbregts et al., 2011; Chen et al., 2015), or by using neural netw orks to learn representations using auto enco ding (Zeiler et al., 2013; Badino et al., 2014, 2015) or other loss functions (Synnaeve and Dupoux, 2016). Other metho ds incorp orate weak top-down sup ervision by first extracting pairs of similar word- or phrase-like units using unsup ervised term detection, and using these to constrain the representation learning. Examples include the corresp ondence auto encoder (cAE) (Kamp er et al., 2015) and ABNet (Synnaeve et al., 2014). Both aim to learn represen tations that make similar pairs even more similar; the ABNet additionally tries to make differen t pairs more different. In this w ork w e use the cAE in our exp erimen ts on unsupervised represen tation learning, since it performed w ell in the 2015 ZRSC, achiev ed some of the b est-reported results on the same-different task (which we also consider), and has readily av ailable co de. As noted ab o v e, the cAE attempts to normalize out non-linguistic factors such as sp eak er, c hannel, gender, etc., by using top-down information from pairs of similar sp eech segmen ts. Extracting cAE features requires three steps, as illustrated in Figure 1. First, an unsup ervised term discov ery (UTD) system is applied to the target language to extract pairs of sp eec h segments that are lik ely to b e instances of the same word or phrase. Eac h pair is then aligned at the frame level using dynamic time w arping (DTW), and pairs of aligned frames are presented as the input x and target output x 0 of a deep neural net work (DNN). After training, a middle lay er y is used as the learned feature representation. The cAE and other unsup ervised metho ds describ ed ab o ve implicitly aim to abstract a wa y from sp eak er v ariability , and indeed they succeed to some extent in doing so (Kamp er et al., 2017). Nev ertheless, they provide less explicit sp eak er adaptation than standard metho ds used in sup ervised automatic sp eech recognition (ASR), such as feature-space maximum lik eliho o d linear regression (fMLLR) (Gales, 1998), learning hidden unit contributions (LHUC) (Swieto janski et al., 2016) or i-vectors (Saon et al., 2013). Explicit sp eaker adaptation seems to hav e attracted little attention until recen tly (Zeghidour et al., 2016; Hec k et al., 2016; Tsuc hiya et al., 2018) in the zero-resource communit y , p erhaps b ecause most of the standard metho ds assume transcrib ed data is av ailable. Nev ertheless, recent work suggests that at least some of these metho ds may b e applied effectively even in an unsup ervised setting. In particular, Heck et al. (2017, 2018b) won the ZRSC 2017 using a typical ASR pip eline with sp eak er adaptiv e fMLLR and other feature transforms. They adapted these metho ds to the unsup ervised setting by first obtaining phone-like units with the Dirichlet Pro cess Gaussian mixture mo del (DPGMM), an unsup ervised clustering technique, and then using the cluster assignments as unsup ervised phone lab els during ASR training. In this work we instead consider a very simple feature-space adaptation metho d, v o cal tract length normalization (VTLN), which normalizes a sp eaker’s sp eec h by warping the frequency-axis of the sp ectra. VTLN mo dels are trained using maximum likelihoo d estimation under a given acoustic mo del—here, an unsup ervised Gaussian mixture mo del (GMM). W arp factors can then b e extracted for b oth the training data and for unseen data. Although VTLN has recently b een used by a few zero-resource sp eech systems (Chen et al., 2015; Heck 3 et al., 2017, 2018b), its impact in thes e systems is unclear because there is no comparison to a baseline without VTLN. Chen et al. (2017) did precisely suc h a comparison and sho wed that applying VTLN to the input of their unsup ervised feature learning metho d improv ed its results in a phoneme discrimination task, esp ecially in the cross-sp eak er case. Ho w ever, we don’t know whether other feature learning metho ds are similarly b enefited by VTLN, nor even ho w VTLN on its own p erforms in comparison to more recent metho ds. Thus, our first set of exp eriments is designed to answer these questions by ev aluating the b enefits of using VTLN and cAE learning, b oth on their own and in combination. 2.2. Exp erimental Setup W e use the GlobalPhone corpus of sp eec h read from news articles (Sch ultz et al., 2013). W e chose 6 languages from different language families as zero-resource languages on which we ev aluate the new feature representations. That means our mo dels do not hav e any access to the transcriptions of the training data, although transcriptions still need to b e av ailable to run the ev aluation. The selected languages and dataset sizes are shown in T able 1. Each GlobalPhone language has recordings from around 100 sp eak ers, with 80% of these in the training sets and no sp eak er ov erlap b etw een training, developmen t, and test sets. T able 1: Zero-resource languages, dataset sizes in hours. Language T rain Dev T est Glob alPhone Croatian (HR) 12.1 2.0 1.8 Hausa (HA) 6.6 1.0 1.1 Mandarin (ZH) 26.6 2.0 2.4 Spanish (ES) 17.6 2.1 1.7 Sw edish (SV) 17.4 2.1 2.2 T urkish (TR) 13.3 2.0 1.9 ZRSC 2015 Buc key e English (EN-B) 5 Xitsonga (TS) 2.5 F or baseline features, we use Kaldi (Po v ey et al., 2011) to extract MFCCs+∆+∆∆ and p erceptual linear prediction co efficien ts (PLPs)+∆+∆∆ with a window size of 25 ms and a shift of 10 ms, and we apply p er-speaker cepstral mean normalization. W e also ev aluated MFCCs and PLPs with VTLN. The acoustic mo del used to extract the warp factors was a diagonal-cov ariance GMM with 1024 comp onen ts. A single GMM w as trained unsup ervised on each language’s training data. T o train the cAE, we obtained UTD pairs using a freely av ailable UTD system 1 (Jansen and V an Durme, 2011) and extracted 36k word pairs for each target language. Published results with this system use PLP features as input, and indeed our preliminary exp eriments confirmed that MFCCs did not work as well. W e therefore rep ort results using only PLP or PLP+VTLN features as input to UTD. F ollowing Rensha w et al. (2015) and Kamp er et al. (2015), w e train the cAE mo del 2 b y first pre-training an auto encoder with eight 100-dimensional la yers and a final lay er of size 39 la yer-wise on the entire training data for 5 ep o c hs with a learning rate of 2 . 5 × 10 − 4 . W e then fine-tune the netw ork with same-word pairs as weak sup ervision for 60 ep o c hs with a learning rate of 2 . 5 × 10 − 5 . F rame pairs are presented to the cAE using either MF CC, MF CC+VTLN, or BNF represen tation, dep ending on the exp erimen t (preliminary exp erimen ts indicated that PLPs p erformed worse than MFCCs, so MFCCs are used as the stronger baseline). F eatures are extracted from the final hidden la yer of the cAE as shown in Figure 1. T o provide an upp er b ound on cAE p erformance, we also rep ort results using gold standar d same-word pairs for cAE training. As in Kamp er et al. (2015); Jansen et al. (2013); Y uan et al. (2017b), we force-align 1 https://gith ub.com/arenjansen/ZR T o ols 2 https://gith ub.com/k amperh/sp eech corresp ondence 4 the target language data and extract all the same-word pairs that are at least 5 characters and 0.5 seconds long (b et ween 89k and 102k pairs for each language). 2.3. Evaluation All exp eriments in this section are ev aluated using the same-different task (Carlin et al., 2011), which tests whether a given sp eec h representation can correctly class ify tw o sp eech segmen ts as having the same w ord type or not. F or each word pair in a pre-defined set S the DTW cost betw een the acoustic feature v ectors under a given representation is computed. Tw o segments are then considered a match if the cost is b elo w a threshold. Precision and recall at a given threshold τ are defined as P ( τ ) = M SW ( τ ) M all ( τ ) , R ( τ ) = M SWDP ( τ ) | S SWDP | where M is the num ber of same-w ord (SW), same-w ord different-speaker (SWDP) or all discov ered matches at that threshold and | S SWDP | is the num b er of actual SWDP pairs in S . W e can compute a precision-recall curv e by v arying τ . The final ev aluation metric is the av erage precision (AP) or the area under that curve. W e generate ev aluation sets of word pairs for the GlobalPhone developmen t and test sets from all words that are at least 5 c haracters and 0.5 seconds long, except that we now also include different-w ord pairs. Previous work (Carlin et al., 2011; Kamp er et al., 2015) calculated recall with all SW pairs for easier computation b ecause their test sets included a negligible num b er of same-word same-sp eak er (SWSP) pairs. In our case the smaller num b er of sp eak ers in the GlobalPhone corp ora results in up to 60% of SW pairs b eing from the same sp eaker. W e therefore alwa ys explicitly compute the recall only for SWDP pairs to fo cus the ev aluation of features on their sp eak er inv ariance. 2.4. R esults and Discussion T able 2 shows AP results on all target languages for cAE features learned using raw features as input (as in previous work) and for cAE features learned using VTLN-adapted features as input to either the UTD system, the cAE, or b oth. Baselines are raw MFCCs, or MFCCs with VTLN. MFCCs with VTLN hav e not previously b een c ompared to more recen t unsup ervised subw ord mo deling metho ds, but as our results show, they are a muc h stronger baseline than MFCCs alone. Indeed, they are nearly as go o d as cAE features (as trained in previous work). How ev er, we obtain muc h b etter results by applying VTLN to b oth the cAE and UTD input features (MFCCs and PLPs, resp ectiv ely). Individually these changes each result in substantial impro vemen ts that are consistent across all 6 languages, and applying VTLN at b oth stages helps further. Indeed, applying VTLN is b eneficial even when using gold pairs as cAE input, although to a lesser degree. So, although previous studies hav e indicated that cAE training and VTLN are helpful individually , our exp erimen ts provide further evidence and quantification of those results. In addition, we ha ve shown that com bining the tw o metho ds leads to further improv emen ts, suggesting that cAE training and VTLN abstract o ver different asp ects of the sp eech signal and should b e used together. The large gains we found with VTLN, and the fact that it was part of the winning system in the 2017 ZRSC, suggest that it is also likely to help in com bination with other unsup ervised subw ord mo deling metho ds. 3. Sup ervision from High-Resource Languages Next w e inv estigate how lab eled data from high-resource languages can b e used to obtain impro ved features on a target zero-resource language for which no lab eled data is av ailable. F urthermore, are there b enefits in deriving this weak sup ervision from m ultiple languages? 5 T able 2: Average precision scores on the same-different task (dev sets), showing the effects of applying VTLN to the input features for the UTD and/or cAE systems. cAE input is either MFCC or MF CC+VTLN. T opline results (rows 5-6) train cAE on gold standard pairs, rather than UTD output. Baseline results (final ro ws) directly ev aluate acoustic features without UTD/cAE training. Best unsupervised result in b old. UTD input cAE input ES HA HR SV TR ZH cAE systems: PLP MF CC 28.6 39.9 26.9 22.2 25.2 20.4 PLP MF CC+VTLN 46.2 48.2 36.3 37.9 31.4 35.7 PLP+VTLN MF CC 40.4 45.7 35.8 25.8 25.9 26.9 PLP+VTLN MF CC+VTLN 51.5 52.9 39.6 42.9 33.4 44.4 Gold p airs MF CC 65.3 65.2 55.6 52.9 50.6 60.5 Gold p airs MF CC+VTLN 68.9 70.1 57.8 56.9 56.3 69.5 Baseline: MFCC 18.3 19.6 17.6 12.3 16.8 18.3 Baseline: MFCC+VTLN 27.4 28.4 23.2 20.4 21.3 27.7 3.1. Backgr ound and Motivation There is considerable evidence that BNFs extracted using a m ultilingually trained DNN can improv e ASR for target languages with just a few hours of transcrib ed data (V esel´ y et al., 2012; V u et al., 2012; Thomas et al., 2012; Cui et al., 2015; Alum¨ ae et al., 2016). How ev er, there has b een little work so far exploring sup ervised multilingual BNFs for target languages with no transcrib ed data at all. Y uan et al. (2016) and Rensha w et al. (2015) trained monolingual BNF extractors and show ed that applying them cross-lingually impro ves word disc rimination in a zero-resource setting. Y uan et al. (2017a) and Chen et al. (2017) trained a m ultilingual DNN to extract BNFs for a zero-resource task, but the DNN itself was trained on untranscribed sp eec h: an unsup ervised clustering metho d w as applied to each language to obtain phone-like units, and the DNN w as trained on these unsup ervised phone lab els. W e kno w of only t wo previous studies of sup ervised multilingual BNFs for zero-resource sp eech tasks. In the first, Y uan et al. (2017b) trained BNFs on either Mandarin, Spanish or b oth, and used the trained DNNs to extract features from English (simulating a zero-resource language). On a query-by-example task, they sho wed that BNFs alwa ys p erformed b etter than MF CCs, and that bilingual BNFs p erformed as w ell or b etter than monolingual ones. F urther impro vemen ts were ac hieved b y applying weak sup ervision in the target language using a cAE trained on English word pairs. Ho w ever, the authors did not exp erimen t with more than t wo training languages, and only ev aluated on English. In the second study , Shibata et al. (2017) built multilingual systems using either seven or ten high- resource languages, and ev aluated on the three “developmen t” and tw o “surprise” languages of the ZRSC 2017. How ev er, they included transcrib ed training data from four out of the five ev aluation languages, so only one language’s results (W olof ) were truly zero-resource. Our exp erimen ts therefore aim to ev aluate on a wider range of target languages, and to explore the effects of b oth the amount of lab eled data, and the numb er of languages from which it is obtained. 3.2. Exp erimental Setup W e pick ed another 10 languages (different from the target languages describ ed in Section 2.2) with a combined 198.3 hours of sp eec h from the GlobalPhone corpus. W e consider these as high-resource languages, for which transcriptions are av ailable to train a sup ervised ASR system. The languages and dataset sizes are listed in T able 3. W e also use the English W all Street Journal (WSJ) corpus (Paul and Bak er, 1992) whic h is comparable to the GlobalPhone corpus. It contains a total of 81 hours of sp eech, which w e either use in its entiret y or from which we use a 15 hour subset; this allows us to compare the effect of increasing the amount of data for one language with training on similar amounts of data but from differen t languages. 6 T able 3: High-resource languages, dataset sizes in hours. Language T rain Bulgarian (BG) 17.1 Czec h (CS) 26.8 F rench (FR) 22.8 German (DE) 14.9 Korean (K O) 16.6 P olish (PL) 19.4 P ortuguese (PT) 22.8 Russian (R U) 19.8 Thai (TH) 21.2 Vietnamese (VI) 16.9 English81 WSJ (EN) 81.3 English15 WSJ 15.1 MF CC + i-vecto r Hidden lay ers BNF lay er Ko rean F rench German Figure 2: Multilingual acoustic model training architecture. All la yers are shared b et ween languages except for the language- specific output lay ers at the top. Sup ervised mo dels trained on these high-resource languages are ev aluated on the same set of zero-resource languages as in Section 2. T ranscriptions of the latter are still never used during training. F or initial monolingual training of ASR systems for the high-resource languages, we follow the Kaldi recip es for the GlobalPhone and WSJ corp ora and train a subspace GMM (SGMM) system for eac h language to get initial con text-dep endent state alignments; these states serve as targets for DNN training. F or multilingual training, we closely follow the existing Kaldi recip e for the Bab el corpus (T rmal et al., 2017). W e train a time-delay neural net work (TDNN) (W aib el et al., 1989; Lang et al., 1990; Peddin ti et al., 2015) with blo c k softmax (Gr´ ezl et al., 2014), i.e. all hidden lay ers are shared b etw een languages, but there is a separate output lay er for eac h language. F or each training instance only the error at the corresp onding language’s output lay er is used to up date the w eights. This arc hitecture is illustrated in Figure 2. The TDNN has six 625-dimensional hidden lay ers 3 follo wed by a 39-dimensional b ottlenec k lay er with ReLU activ ations and batc h normalization. Eac h language then has its own 625-dimensional affine and a softmax lay er. The inputs to the netw ork are 40-dimensional MFCCs with all cepstral co efficien ts to which we app end i-vectors for sp eak er adaptation. The netw ork is trained with sto chastic gradient descent for 2 ep o c hs with an initial learning rate of 10 − 3 and a final learning rate of 10 − 4 . 3 The splicing indexes are -1,0,1 -1,0,1 -1,0,1 -3,0,3 -3,0,3 -6,-3,0 0 . 7 35 45 55 65 75 Average precision (%) ES HA HR 0 40 80 120 160 200 35 45 55 65 75 Hours of data Average precision (%) SV 0 40 80 120 160 200 Hours of data TR 0 40 80 120 160 200 Hours of data ZH BNF 1 BNF 2 EN cAE UTD cAE gold Figure 3: Same-differen t task ev aluation on the developmen t sets for BNFs trained on different amounts of data. W e compare training on up to 10 different languages with additional data in one language (English). F or m ultilingual training, languages were added in tw o different orders: FR-PT-DE-TH-PL-KO-CS-BG-R U-VI (BNFs 1) and RU-CZ-VI-PL-KO-TH-BG-PT-DE-FR (BNFs 2). Each datapoint shows the result of adding an additional language. As baselines we include the b est unsup ervised cAE and the cAE trained on gold standard pairs from rows 4 and 6 of T able 2. In preliminary exp erimen ts we trained a separate i-vector extractor for each different sized subset of training languages. Ho wev er, results were similar to training on the p o oled set of all 10 high-resource languages, so for exp edience w e used the 100-dimensional i-v ectors from this p o oled training for all rep orted exp erimen ts. The i-v ectors for the zero-resource languages are obtained from the same extractor. This allows us to also apply sp eaker adaptation in the zero-resource scenario and to draw a fair comparison with our b est cAE results that made use of sp eaker normalisation in the form of VTLN. The results will only show the effect of increasing the num b er of training languages b ecause the acoustic mo dels are alw ays trained with i-vectors. Including i-vectors yielded a small p erformance gain ov er not doing so; w e also tried applying VTLN to the MF CCs for TDNN training, but found no additional b enefit. 3.3. R esults and Discussion As a sanity chec k w e include word error rates (WER) for the acoustic mo dels trained on the high-resource languages. T able 4 compares the WER of the monolingual SGMM systems that provide the targets for TDNN training to the WER of the final mo del trained on all 10 high-resource languages. The multilingual mo del shows small but consistent improv ements for all languages except Vietnamese. Ultimately though, w e are not so muc h in terested in the p erformance on typical ASR tasks, but in whether BNFs from this mo del also generalize to zero-resource applications on unseen languages. T able 4: W ord error rates of monolingual SGMM and 10-lingual TDNN ASR system evaluated on the developmen t sets. Language Mono Multi Language Mono Multi BG 17.5 16.9 PL 16.5 15.1 CS 17.1 15.7 PT 20.5 19.9 DE 9.6 9.3 R U 27.5 26.9 FR 24.5 24.0 TH 34.3 33.3 K O 20.3 19.3 VI 11.3 11.6 8 Figure 3 shows AP on the same-different task of multilingual BNFs trained from scratch on an increasing n umber of languages in tw o randomly chosen orders. W e provide tw o baselines for comparison, drawn from our results in T able 2. Firstly , our b est cAE features trained with UTD pairs (row 4, T able 2) are a reference for a fully unsup ervised system. Secondly , the b est cAE features trained with gold standard pairs (row 6, T able 2) give an upp er b ound on the cAE p erformance. In all 6 languages, even BNFs from a monolingual TDNN already considerably outp erform the cAE trained with UTD pairs. Adding another language usually leads to an increas e in AP, with the BNFs trained on 8–10 high-resource languages p erforming the b est, also alwa ys b eating the gold cAE. The biggest p erformance gain is obtained from adding a second training language—further increases are mostly smaller. The order of languages has only a small effect, although for example adding other Sla vic languages is generally asso ciated with an increase in AP on Croatian. This suggests that it may b e b eneficial to train on languages related to the zero-resource language if p ossible, but further exp eriments need to b e conducted to quantify this effect. T o determine whether these gains come from the div ersity of training languages or just the larger amount of training data, w e trained mo dels on the 15 hour subset and the full 81 hours of the English WSJ corpus, whic h corresponds to the amount of data of four GlobalPhone languages. More data do es help to some degree, as Figure 3 shows. But, except for Mandarin, training on just tw o languages (46 hours) already w orks b etter. 4. Ev aluation using ZRSC Data and Measures Do the results from the previous exp eriments generalise to other corp ora and how do they compare to other works? So far we used data from GlobalPhone, whic h provides corpora collected and formatted similarly for a wide range of languages. How ever, GlobalPhone is not freely av ailable and no previous zero-resource studies hav e used these corp ora, so in this section we also pro vide results on the Zero Resource Speech Challenge (ZRSC) 2015 (V ersteegh et al., 2015) data sets, which hav e b een widely used in other work. The target languages that we treat as zero-resource are English (from the Buck eye corpus (Pitt et al., 2007)) and Xitsonga (NCHL T corpus (De V ries et al., 2014)). T able 1 includes the statistics of the subsets of these corp ora that were used in the ZRSC 2015 and in this work. These corp ora are not split into train/dev/test; since training is unsup ervised, the system is simply trained directly on the unlab eled test set (which could also b e done in deploymen t). Imp ortantly , no hyperparameter tuning is done on the Buck eye or Xitsonga data, so these results still provide a useful test of generalization. Notably , the Buck eye English corpus con tains conv ersational sp eec h and is therefore different in style from the rest of our data. F or training the cAE on the B uc k eye English and Xitsonga corp ora, we use the same sets of UTD pairs as Rensha w et al. (2015), which were discov ered from frequency-domain linear prediction (FDLP) features. W e ev aluate using b oth the same-different measures from ab ov e, as well as the ABX phone discriminability task (Schatz et al., 2013) used in the ZRSC and other recen t work (V ersteegh et al., 2015; Dunbar et al., 2017). The ABX task ev aluates phoneme discriminabilit y using minimal pairs: sequences of three phonemes where the central phoneme differs b et w een the t wo sequences A and B in the pair, such as b ih n and b eh n . F eature representations are then ev aluated on how well they can identify a third triplet X as ha ving the same phoneme sequence as either A or B . See V ersteegh et al. (2015) and Dunbar et al. (2017) for details on ho w the scores are computed and av eraged ov er sp eakers and phonemes to obtain the final ABX error rate. One usually distinguishes b et ween the within-sp e aker error rate where all three triplets b elong to the same sp eak er, and the cr oss-sp e aker error rate where A and B are from the same and X from a different sp eak er. The ABX ev aluation includes all such minimal pair phoneme triplets of the ev aluation corpus. These pairs therefore rarely corresp ond to full words, making it a somewhat abstract task whose results may b e difficult to interpret when summarizing it as a single final metric. ABX can how ever b e very suitable for more fine-grained analysis of sp eec h phenomena by including only sp ecific phonetic contrasts in the ev aluation (Schatz et al., 2018). In contrast, the same-different task alwa ys compares whole words and directly ev aluates ho w go o d feature representations are at telling whether tw o utterances are the same w ord or not. Th us it has an immediate link to applications lik e sp ok en term detection and it allows easier error analysis. It is also faster to prepare the same-different ev aluation set and run the ev aluation. W e wish to 9 T able 5: Comparison of AP on the same-different task (higher is b etter) and ABX cross-/within-sp eaker error rates (low er is better) for the Buck eye English and Xitsonga corp ora. English Xitsonga F eatures Dimensions ABX Same-diff ABX Same-diff Unsup ervise d MF CC 39 28.4 / 15.5 19.14 33.4 / 20.9 10.46 MF CC+VTLN 39 26.5 / 15.4 24.19 31.9 / 21.4 13.33 cAE 39 24.0 / 14.5 31.97 23.8 / 14.8 22.79 cAE+VTLN 39 22.9 / 14.3 37.85 22.6 / 14.5 47.41 We ak multilingual sup ervision BNF 39 18.0 / 12.4 60.19 17.0 / 12.3 63.44 ZRSC T opline (V ersteegh et al., 2015) 49 16.0 / 12.1 - 4.5 / 3.5 - Hec k et al. (2018b) 139–156 14.9 / 10.0 - 11.7 / 8.1 - Riad et al. (2018) 100 17.2 / 10.4 - 15.2 / 9.4 - v erify that the ABX and same-different measures correlate w ell, to b etter compare studies that use only one of them and to allo w choosing the task that is more appropriate for the situation at hand. T able 5 shows results on the Xitsonga and Buck eye English corp ora. Here we compare ABX error rates computed with the ZRSC 2015 (V ersteegh et al., 2015) ev aluation scripts with AP on the same-different task. T o the b est of our knowledge, this is the first time such a comparison has b een made. The results on b oth tasks correlate well, esp ecially when looking at the ABX cross-sp eaker error rate b ecause the same-different ev aluation as describ ed in Section 2.3 also fo cuses on cross-sp eak er pairs. As migh t b e exp ected VTLN only impro ves cross-sp eak er, but not within-sp eaker ABX error rates. F or comparison we also include ABX results of the official ZRSC 2015 topline (V ersteegh et al., 2015), whic h are p osteriorgrams obtained from a supervised speech recognition system, the current state-of-the-art system 4 (Hec k et al., 2018b) which ev en outp erforms the topline for English, and the system of Riad et al. (2018) which is the most recent form of the ABNet (Synnaeve et al., 2014), an architecture that is similar to our cAE. These systems score b etter than all of our features, but are not directly comparable for several reasons. Firstly , it is unclear how these systems w ere optimized, since there was no separate developmen t set in ZRSC 2015. Secondly , our features are all 39-dimensional to b e directly comparable with MF CCs, whereas the other t wo systems hav e higher dimensionality—indeed, the dimensionality of the winning DPGMM system from the ZRSC 2017 was even greater, with more than 1000 dimensions (Heck et al., 2017)—and we don’t know whether the comp eting systems would work as w ell with few er dimensions. Suc h higher dimensional features ma y b e useful in some circumstances, but require more memory and pro cessing p o wer to use, whic h could b e undesirable or even prohibitive for some downstream applications (such as the unsup ervised segmentation and clustering system used in Section 6. Hec k et al. (2018a) prop ose a more complex sampling approach to reduce the p oten tially very high dimensionality of the features obtained with the DPGMMs in their previous w ork. Ho wev er, the resulting dimensionality is still around 90–120 and cannot be con trolled precisely , which migh t b e required for down-stream applications. This complexity of ev aluating zero-resource subw ord mo deling systems was addressed in the ZRSC 2019, where the bitrate of the features w as added as another ev aluation metric alongside the ABX p erfor- mance (Dun bar et al., 2019). This means that systems are now compared on tw o dimensions and researchers ma y choose to trade off b et ween the tw o, while ultimately the goal is to find a representation that p erforms w ell on b oth measures, like phonemes. 4 The ZRSC website maintains a list of results: https://zerospeech.com/2015/results.h tml 10 The BNFs are in any case comp etitive with the higher dimensional features, and hav e the adv antage that they can b e built using standard Kaldi scripts and do not require any training on the target language, so can easily b e deploy ed to new languages. The comp etitiv e result of Riad et al. (2018) also sho ws that in general a system trained on w ord pairs discov ered from a UTD system can p erform very well. 5. Can W e Improv e the Multilingual BNFs? So far we hav e shown that multilingual BNFs that are completely agnostic to the target language work b etter than an y of the features trained using only the target language data. Ho w ever, in principle it could b e p ossible to improv e p erformance further by passing the BNFs as inputs to mo dels that train on the target language data in an unsup ervised fashion. W e explored this possibility by simply training a cAE using BNFs as input rather than MFCCs. That is, we trained the cAE with the same word pairs as b efore, but replaced VTLN-adapted MFCCs with the 10-lingual BNFs as input features, without any other changes in the training pro cedure. T able 6 (p enultimate ro w) shows that the cAE trained with UTD pairs is able to sligh tly improv e on the BNFs in some cases, but this is not consistent across all languages and for Croatian the cAE features are muc h worse. On the other hand, when trained using gold standard pairs (final row), the resulting cAE features ar e consistently b etter than the input BNFs. This indicates that BNFs can in principle b e improv ed by further unsup ervised target-language training, but the top-down sup ervision needs to b e of higher quality than the current UTD system provides. This observ ation leads to a further question: could we improv e the UTD pairs themselves by using our impro ved features (either BNFs or cAE features) as input to the UTD system? If the output is a b etter set of UTD pairs than the original set, these could p oten tially b e used to further improv e the features, and p erhaps the pro cess could b e iterated as illustrated in Figure 4. As far as we know, no previously published w ork has combined unsup ervised subw ord mo deling with a UTD system. 5 Unfortunately , after considerable effort to mak e this work w e found that the ZR T o ols UTD system seems to b e to o finely tuned to wards features that resemble PLPs to get go o d results from our new features. Examining the similarit y plots for several pairs of utterances helps explain the issue, and also reveals in teresting qualitative differences b etw een our learned features and the PLPs, as shown in Figures 6 and 5. Darker areas in these plots indicate higher acoustic similarity , so diagonal line segments p oin t to similar sequences, as in Figure 6 where b oth utterances contain the words estados unidos . The ZR T o ols UTD to olkit iden tifies these diagonal lines with fast computer vision techniques (Jansen and V an Durme, 2011) and then runs a segmen tal-DTW algorithm only in the candidate regions for efficient discov ery of matches. PLPs are designed to con tain fine-grained acoustic information ab out the sp eec h signal and can therefore v ary a lot throughout the duration of a phoneme. Accordingly , the diagonal lines in Figure 6 (a) are very T able 6: AP on the same-different task when training cAE on the 10-lingual BNFs from ab o ve (cAE-BNF) with UTD and gold standard word pairs (test set results). Baselines are MF CC+VTLN and the cAE models from rows 4 and 6 of T able 2 that use MFCC+VTLN as input features. Best result without target language sup ervision in b old. F eatures ES HA HR SV TR ZH MF CC+VTLN 44.1 22.3 25.0 34.3 17.9 33.4 cAE UTD 72.1 41.6 41.6 53.2 29.3 52.8 cAE gold 85.1 66.3 58.9 67.1 47.9 70.8 10-lingual BNFs 85.3 71.0 56.8 72.0 65.3 77.5 cAE-BNF UTD 85.0 67.4 40.3 74.3 64.6 78.8 cAE-BNF gold 89.2 79.0 60.8 79.9 69.5 81.6 5 While some other work, such as Lee et al. (2015) and W alter et al. (2013), has fo cused on join t phonological and lexical discov ery , these do not p erform representation learning on the low-lev el features. 11 UTD PLP features cAE T raining BNFs cAE F eatures BNFs x (1) x 0 (1) UTD cAE features cAE T raining BNFs cAE F eatures BNFs x (2) x 0 (2) Figure 4: Cycling cAE and UTD systems: Iteration 1) UTD is run on PLP features to obtain word pairs. Pairs ( x , x’ ) are then represented using m ultilingual BNFs and used to train the cAE. Iteration 2) F eatures from the last hidden cAE la yer are passed to the UTD system, which discovers new word pairs that can b e used in the next iteration of cAE training. (a) PLP (b) PLP-VTLN (c) cAE UTD (d) BNF Figure 5: F rame-wise cosine similarity matrices for tw o Spanish utterances from differen t speakers, comparing differen t feature representations. Dark regions corresp ond to high cosine similarity and v alues b elo w 0.4 are clipp ed. Red rectangles mark matches discov ered by the UTD system and include their DTW similarity scores. The discov ered matches are incorrect—although phonetically similar—and found only for cAE features and BNFs. thin and there is a lot of spurious noise that do es not necessarily corresp ond to phonetically similar units. This pattern is similar for VTLN-adapted PLPs in (b), but with less noise. On the other hand, cAE features and BNFs are trained to ignore such lo cal v ariation within phonemes. This results in significantly different app earance of frame-wise cosine sim ilarit y plots of tw o utterances. The trained features remain more constant throughout the duration of a phoneme, resulting in wider diagonal lines in the similarity plots. Esp ecially cAE features are very go od at learning phoneme-level information, indicated by the large rectangular blocks in Figure 6 (c) where phonemes of the tw o utterances match or are v ery similar. W e also found the b oundaries of these blo c ks to align well with actual phoneme b oundaries pro vided by forced alignmen t. This is despite the cAE not ha ving any information ab out phoneme identities or b oundaries during training. P arameters in the segmental DTW algorithm of ZR T o ols, which searc hes for exact matches within the iden tified diagonal line segments where matches are likely to o ccur, include the maximum deviation of the path from the diagonal and similarity budgets and thresholds that determine how far the path should extend at each end (Jansen and V an Durme, 2011). While ZR T o ols still finds the diagonal lines in cAE features and BNFs, the DTW algorithm then finds to o many exact matches bec ause the lines are muc h wider and similarit y v alues ov erall higher than for PLPs. F or example Figure 5 sho ws a t ypical example of phonetically similar, but incorrect matc hes that are only discov ered in cAE features and BNFs. While this b ehaviour can b e comp ensated for to some degree by changing ZR T o ols’ parameters, we could not iden tify metrics that can reliably predict whether a given set of discov ered UTD pairs will result in b etter cAE p erformance. Th us tuning these parameters is very time-consuming b ecause it requires running b oth 12 (a) PLP (b) PLP-VTLN (c) cAE UTD (d) BNF Figure 6: F rame-wise cosine similarity matrices for tw o Spanish utterances from differen t speakers, comparing differen t feature representations. Dark regions corresp ond to high cosine similarity and v alues b elo w 0.4 are clipp ed. Red rectangles mark matches discov ered by the UTD system and include their DTW similarit y scores. In this case the match is not found with PLPs as input features. 13 UTD and cAE training for each step. Although it might b e p ossible to even tually identify a set of DTW parameters that can work with features that are relatively stable within phones, it could b e more productive to consider differen t approaches for these types of features. 6. Do wnstream Application: Segmentation and Clustering Our exp erimen t with the UTD system was disapp ointing, suggesting that although cAE features and BNFs impro ve intrinsic discriminability measures, they may not work with some do wnstream zero-resource to ols. Ho wev er, ZR T o ols is a single example. T o further inv estigate the downstream effects of the learned features, we now consider the task of full-cov erage sp eec h segmentation and clustering. The aim here is to tok enize the en tire sp eech input into hypothesized categories, p otentially corresp onding to words, and to do so without any form of sup ervision—essen tially a form of unsup ervised sp eech recognition. Suc h systems could prov e useful from a sp eec h technology p erspective in lo w-resource settings, and could b e useful in studying ho w human infants acquire language from unlab eled sp eec h input. Here w e sp ecifically inv estigate whether our BNFs improv e the Bay esian embedded segmental Gaussian mixture mo del (BES-GMM), first prop osed by Kamp er et al. (2016). This approac h relies on a mapping where p oten tial word segments (of arbitrary length) are embedded in a fixed-dimensional acoustic v ector space. The mo del, implemen ted as a Gibbs sampler, builds a whole-w ord acoustic mo del in this acoustic em b edding space, while jointly p erforming segmentation. Sev eral acoustic word em b edding metho ds hav e b een considered, but here we use the very simple approach also used Kamp er et al. (2017): an y segment is uniformly downsampled so that it is represented by the same fixed n umber of frame-lev el features, whic h are then flattened to obtain the fixed-dimensional em b edding (Levin et al., 2013). 6.1. Exp erimental Setup and Evaluation W e retrained the cAE and BNF mo dels to return 13-dimensional features with all other parameters unc hanged to be consisten t with the exp eriments of Kamp er et al. (2017) and for computational reasons. W e also did not tune any hyperparameters of the BES-GMM for our new input features. Nonetheless, our baseline cAE results do not exactly corresp ond to the ones of Kamp er et al. (2017) be cause for example the MF CC input features hav e b een extracted with a different to olkit and we used a slightly different training pro cedure. W e use several metrics to compare the resulting segmented word tokens to ground truth forced alignments of the data. By mapping every discov ered word token to the ground truth w ord with which it o verlaps most, av erage cluster purity can b e calculated as the total prop ortion of correctly mapp ed tokens in all clusters. More than one cluster may b e mapp ed to the same ground truth word type. In a similar wa y , we can calculate unsup ervised word error rate (WER) , which uses the same cluster-to-w ord mapping but also takes insertions and deletions into account. Here we consider tw o wa ys to p erform the cluster mapping: man y-to-one, where m ore than one cluster can b e assigned the s ame word lab el (as in purity), or one-to-one, where at most one cluster is mapp ed to a ground truth word type (accomplished in a greedy fashion). W e also compute the gender and sp eaker purit y of the clusters, where we wan t to see clusters that are as div erse as p ossible on these measures, i.e., low purity . T o explicitly ev aluate how accurate the mo del p erforms segmen tation, we compare the prop osed w ord b oundary p ositions to those from forced alignments of the data (falling within a single true phoneme from the b oundary). W e calculate b oundary precision and recall, and rep ort the resulting w ord b oundary F-scores . W e also calculate w ord token F-score , which requires that b oth b oundaries from a ground truth word tok en b e correctly predicted. 6.2. R esults T able 7 compares MFCCs, cAE features (with and without VTLN) and BNFs as input to the system of Kamp er et al. (2017). It shows that both VTLN and BNFs help on all metrics, with im pro v ements ranging from small to more substantial and BNFs clearly giving the most b enefit. The effects of VTLN are mostly confined to reducing b oth gender and sp eak er purity of the identified clusters (whic h is desirable) while 14 T able 7: Segmentation and clustering results (low er scores are b etter, except for token and b oundary F-score, and cluster purit y). WER F-score Purit y F eatures one-to-one ↓ many-to-one ↓ T oken ↑ Boundary ↑ Cluster ↑ Gender ↓ Sp eak er ↓ English MF CC 93.7 82.0 29.0 42.4 29.9 87.6 55.9 cAE 93.7 82.4 28.9 42.3 29.3 83.1 49.9 cAE+VTLN 93.6 82.1 29.0 42.3 29.9 75.8 44.8 BNF 92.0 77.9 29.4 42.9 36.6 67.6 35.5 Xitsonga MF CC 102.4 89.8 19.4 43.6 24.5 87.1 43.0 cAE 101.8 89.7 19.5 43.2 24.5 82.5 37.6 cAE+VTLN 100.7 84.7 20.1 44.5 31.0 74.7 32.7 BNF 96.4 76.9 20.6 44.6 38.8 65.6 27.5 main taining the p erformance on other metrics. 6 This means that the learned representations hav e b ecome more inv ariant to v ariation in sp eak er and gender, which is exactly what VTLN aims to do. How ever, this app ears to b e insufficient to also help other metrics, aligning with the exp eriments by Kamp er et al. (2017) that indicate that impro vemen ts on the other metrics are hard to obtain. On the other hand, BNFs result in b etter performance across all metrics. While some of these impro v ements are small, they are very consistent across all metrics. In particular, we observe a muc h higher cluster purity and low er w ord error rates, whic h b oth indicate that more tok ens are correctly identified. Gender and sp eaker purit y hav e decreased further, which means that the BNFs are even more agnostic to gender and sp eak er v ariations than the cAE features with VTLN. This shows that the BNFs are also useful for down-stream tasks in zero-resource settings. It esp ecially demonstrates that such BNFs which are trained on high-resource languages without seeing any target language sp eech at all are a strong alternative to fully unsup ervised features for practical scenarios or could in turn b e used to impro ve unsup ervised systems trained on the target language sp eec h data. 7. Conclusions In this work we inv estigated different representations obtained using data from the target language alone (i.e., fully unsup ervised) and from multilingual sup ervised systems trained on lab eled data from non-target languages. W e found that the corresp ondence auto enco der (cAE), a recen t neural approach to unsupervised sub word mo deling, learns complemen tary information to the more traditional approach of VTLN. This suggests that VTLN should also b e considered by other researchers using neural approaches. On the other hand, our b est results were achiev ed using multilingual b ottlenec k features (BNFs). Although these results do not completely match the state-of-the-art features learned from target language data only (Hec k et al., 2017, 2018b), they still p erform well and hav e the adv an tage of only requiring a single mo del from which features can b e immediately extracted for new target languages. Our BNFs show ed robust p erformance across the 8 languages we ev aluated without language-sp ecific parameter-tuning. In addition, it is easy to con trol the dimensionality of the BNFs, unlik e in the nonparametric mo dels of Heck et al. (2017, 2018b), and this allow ed us to use them in the downstream task of word segmentation and clustering. W e observed consisten t improv ements from BNFs across all metrics in this downstream task, and other work demonstrates that these features are also useful for downstream keyw ord sp otting in settings with very small amounts of lab eled data (Menon et al., 2018). W e also show ed that it is theoretically p ossible to further improv e BNFs 6 Perfectly balanced clusters would hav e a speaker purity of 8.3% for English and 4.2% for Xitsonga, and a gender purity of 50% for b oth corp ora. 15 with language-sp ecific unsup ervised training, and we hop e to explore mo dels that can do this more reliably than the cAE in the future. Finally , our qualitative analysis show ed that b oth cAE features and BNFs tend to v ary muc h less ov er time than traditional PLPs, supp orting the idea that they are b etter at capturing phonetic information rather than small v ariations in the acoustics. Although this prop ert y helps explain the b etter p erformance on in trinsic measures and the segmentation task, it harms p erformance for unsup ervised term discov ery (UTD), where the system seems heavily tuned tow ards PLPs. Therefore, our w ork also p oin ts to the need for term disco very systems that are more robust to different types of input features. Ac knowledgemen ts This researc h was funded in part by a James S. McDonnell F oundation Scholar Award. References Alum¨ ae, T., Tsak alidis, S., Sch wartz, R.M., 2016. Impro ved Multilingual T raining of Stack ed Neural Netw ork Acoustic Mo dels for Low Resource Languages, in: Pro c. Interspeech, pp. 3883–3887. Badino, L., Canev ari, C., F adiga, L., Metta, G., 2014. An Auto-encoder Based Approach to Unsup ervised Learning of Subw ord Units, in: Pro c. ICASSP , pp. 7634–7638. Badino, L., Mereta, A., Rosasco, L., 2015. Discovering Discrete Subw ord Units with Binarized Auto encoders and Hidden- Marko v-Model Encoders, in: Pro c. Interspeech. Carlin, M.A., Thomas, S., Jansen, A., Hermansky , H., 2011. Rapid Evaluation of Sp eec h Represen tations for Sp ok en T erm Discov ery, in: Pro c. Interspeech, pp. 828–831. Chen, H., Leung, C.C., Xie, L., Ma, B., Li, H., 2015. P arallel Inference of Dirichlet Process Gaussian Mixture Mo dels for Unsupervised Acoustic Mo deling: A F easibilit y Study, in: Pro c. Interspeech, pp. 3189–3193. Chen, H., Leung, C.C., Xie, L., Ma, B., Li, H., 2017. Multilingual Bottle-Nec k F eature Learning from Untranscribed Speech, in: Proc. ASRU, pp. 727–733. Cui, J., Kingsbury , B., Ramabhadran, B., Sethy , A., Audhkhasi, K., et al., 2015. Multilingual Representations for Low Resource Speech Recognition and Keyw ord Searc h, in: Pro c. ASR U, pp. 259–266. De V ries, N.J., Dav el, M.H., Badenhorst, J., Basson, W.D., De W et, F., Barnard, E., De W aal, A., 2014. A Smartphone-based ASR Data Collection T o ol for Under-resourced Languages. Sp eec h Communication 56, 119–131. Dunbar, E., Alga yres, R., Karadayi, J., Bernard, M., Benjumea, J., Cao, X.N., Miskic, L., Dugrain, C., Ondel, L., Black, A.W., Besacier, L., Sakti, S., Dup oux, E., 2019. The Zero Resource Speech Challenge 2019: TTS without T, in: Pro c. Interspeech, pp. 1088–1092. Dunbar, E., Cao, X.N., Benjumea, J., Karadayi, J., Bernard, M., Besacier, L., Anguera, X., Dupoux, E., 2017. The Zero Resource Sp eec h Challenge 2017, in: Proc. ASR U, pp. 323–330. Gales, M.J., 1998. Maximum Likelihood Linear T ransformations for HMM-based Sp eec h Recognition. Computer Sp eec h & Language 12, 75–98. Gr´ ezl, F., Karafi´ at, M., V esel ´ y, K., 2014. Adaptation of Multilingual Stack ed Bottle-neck Neural Netw ork Structure for New Language, in: Pro c. ICASSP , pp. 7704–7708. Heck, M., Sakti, S., Nak amura, S., 2016. Sup ervised Learning of Acoustic Models in a Zero Resource Setting to Improv e DPGMM Clustering, in: Pro c. Interspeech, pp. 1310–1314. Heck, M., Sakti, S., Nak amura, S., 2017. F eature Optimized DPGMM Clustering for Unsup ervised Sub word Mo deling: A Contribution to Zerospeech 2017, in: Pro c. ASR U, pp. 740–746. Heck, M., Sakti, S., Nak am ura, S., 2018a. Dirichlet Pro cess Mixture of Mixtures Model for Unsup ervised Subw ord Modeling 14, 1–16. Heck, M., Sakti, S., Nak amura, S., 2018b. Learning Supervised F eature T ransformations on Zero Resources for Improv ed Acoustic Unit Discov ery. IEICE T ransactions on Information and Systems 101, 205–214. doi: 10.1587/transinf.2017EDP7175 . Hermann, E., Goldwater, S., 2018. Multilingual Bottleneck F eatures for Subw ord Mo deling in Zero-resource Languages, in: Proc. Interspeech, pp. 2668–2672. Huijbregts, M., McLaren, M., V an Leeuwen, D., 2011. Unsup ervised Acoustic Sub-word Unit Detection for Query-b y-example Spoken T erm Detection, in: Pro c. ICASSP , pp. 4436–4439. Jansen, A., Thomas, S., Hermansky , H., 2013. W eak T op-down Constraints for Unsupervised Acoustic Model T raining, in: Proc. ICASSP , pp. 8091–8095. Jansen, A., V an Durme, B., 2011. Efficient Sp ok en T erm Discov ery Using Randomized Algorithms, in: Pro c. ASRU, pp. 401–406. doi: 10.1109/ASRU.2011.6163965 . Kamper, H., Elsner, M., Jansen, A., Goldwater, S., 2015. Unsupervised Neural Netw ork Based F eature Extraction Using W eak T op-Down Constraints, in: Pro c. ICASSP , pp. 5818–5822. Kamper, H., Jansen, A., Goldw ater, S., 2016. Unsup ervised W ord Segmentation and Lexicon Disco very Using Acoustic W ord Embeddings. IEEE/ACM T ransactions on Audio, Sp eec h and Language Pro cessing 24, 669–679. 16 Kamper, H., Jansen, A., Goldwater, S., 2017. A Segmental F ramework for F ully-unsup ervised Large-v o cabulary Speech Recognition. Computer Sp eech & Language 46, 154–174. Lang, K.J., W aib el, A.H., Hinton, G.E., 1990. A Time-Delay Neural Network Architecture for Isolated W ord Recognition. Neural Netw orks 3, 23–43. Lee, C.y ., O’Donnell, T.J., Glass, J., 2015. Unsup ervised Lexicon Discov ery from Acoustic Input 3, 389–403. Levin, K., Henry , K., Jansen, A., Livescu, K., 2013. Fixed-dimensional Acoustic Embeddings of V ariable-length Segments in Low-resource Settings, in: Pro c. ASRU, pp. 410–415. Menon, R., Kamp er, H., Yilmaz, E., Quinn, J., Niesler, T., 2018. ASR-free CNN-DTW Keyword Sp otting Using Multilingual Bottleneck F eatures for Almost Zero-resource Languages, in: Proc. SL TU, pp. 20–24. Paul, D.B., Baker, J.M., 1992. The Design for the W all Street Journal-based CSR Corpus, in: Proc. HL T, pp. 357–362. Peddin ti, V., Po vey , D., Khudanpur, S., 2015. A Time Delay Neural Netw ork Architecture for Efficient Mo deling of Long T emp oral Contexts, in: Proc. Interspeech, pp. 3214–3218. Pitt, M.A., Dilley , L., Johnson, K., Kiesling, S., Raymond, W., Hume, E., F osler-Lussier, E., 2007. Buc key e Corpus of Conv ersational Sp eec h (Second Release). Department of Psychology , Ohio State Universit y . URL: www.buckeyecorpus.osu. edu . Po v ey , D., Ghoshal, A., Boulianne, G., Burget, L., Glembek, O., Go el, N., Hannemann, M., Motl ´ ıˇ cek, P ., Qian, Y., Sch w arz, P ., Silovsk´ y, J., Stemmer, G., V esel ´ y, K., 2011. The Kaldi Sp eec h Recognition T o olkit, in: Pro c. ASRU. Renshaw, D., Kamp er, H., Jansen, A., Goldwater, S., 2015. A Comparison of Neural Netw ork Metho ds for Unsup ervised Representation Learning on the Zero Resource Sp eec h Challenge, in: Pro c. Interspeech, pp. 3199–3203. Riad, R., Dancette, C., Karadayi, J., Zeghidour, N., Schatz, T., Dupoux, E., 2018. Sampling Strategies in Siamese Netw orks for Unsupervised Speech Representation Learning, in: Pro c. Interspeech, pp. 2658–2662. Saon, G., Soltau, H., Nahamo o, D., Pichen y , M., 2013. Sp eaker Adaptation of Neural Netw ork Acoustic Models Using I-V ectors, in: Pro c. ASRU, pp. 55–59. Schatz, T., Bac h, F., Dup oux, E., 2018. Ev aluating Automatic Sp eech Recognition Systems as Quantitativ e Mo dels of Cross-lingual Phonetic Category P erception. The Journal of the Acoustical So ciety of America 143, 372–378. Schatz, T., Peddin ti, V., Bach, F., Jansen, A., Dupoux, E., Schatz, T., Peddin ti, V., Bach, F., Jansen, A., Hermansky , H., Schatz, T., P eddinti, V., Bach, F., 2013. Ev aluating Sp eech F eatures with the Minimal-P air ABX T ask : Analysis of the Classical MFC / PLP Pip eline, in: Proc. In tersp eech, pp. 1781–1785. Sch ultz, T., V u, N.T., Sc hlipp e, T., 2013. GlobalPhone: A Multilingual T ext & Speech Database in 20 Languages, in: Proc. ICASSP , pp. 8126–8130. Shibata, H., Kato, T., Shinozaki, T., W atanab e, S., 2017. Comp osite Embedding Systems for Zerosp eec h 2017 T rack 1, in: Pro c. ASRU, pp. 747–753. Swieto janski, P ., Li, J., Renals, S., 2016. Learning Hidden Unit Contributions for Unsup ervised Acoustic Mo del Adaptation. IEEE/ACM T ransactions on Audio, Speech, and Language Processing 24, 1450–1463. Synnaeve, G., Dup oux, E., 2016. A T emp oral Coherence Loss F unction for Learning Unsup ervised Acoustic Embeddings. Procedia Computer Science 81, 95–100. Synnaeve, G., Schatz, T., Dup oux, E., 2014. Phonetics Em b edding Learning with Side Information, in: Proc. SL T, pp. 106–111. Thomas, S., Ganapathy , S., Hermansky , H., 2012. Multilingual MLP features for Low-resource L VCSR Systems, in: Proc. ICASSP , pp. 4269–4272. T rmal, J., Wiesner, M., Peddin ti, V., Zhang, X., Ghahremani, P ., W ang, Y., Manohar, V., Xu, H., Po vey , D., Khudanpur, S., 2017. The Kaldi OpenKWS System: Improving Low Resource Keyword Search, in: Pro c. Interspeech, pp. 3597–3601. Tsuchiy a, T., T a wara, N., Ogawa, T., Koba yashi, T., 2018. Sp eak er In v ariant F eature Extraction for Zero-Resource Languages with Adversarial Learning, in: Pro c. ICASSP, pp. 2381–2385. V ersteegh, M., Thiolliere, R., Sc hatz, T., Cao, X.N., Anguera, X., Jansen, A., Dupoux, E., 2015. The Zero Resource Sp eech Challenge 2015, in: Pro c. Interspeech, pp. 3169–3173. V esel´ y, K., Karafi´ at, M., Gr´ ezl, F., Janda, M., Egorov a, E., 2012. The Language-indep endent Bottleneck F eatures, in: Pro c. SL T, pp. 336–341. doi: 10.1109/SLT.2012.6424246 . V u, N.T., Breiter, W., Metze, F., Sch ultz, T., 2012. An Inv estigation on Initialization Schemes for Multilayer P erceptron T raining Using Multilingual Data and their Effect on ASR Performance, in: Pro c. Interspeech, pp. 2586–2589. W aib el, A., Hanaza wa, T., Hinton, G., Shik ano, K., Lang, K.J., 1989. Phoneme Recognition Using Time-Delay Neural Netw orks. IEEE T ransactions on Acoustics, Sp eech, and Signal Pro cessing 37, 328–339. W alter, O., Korthals, T., Haeb-Um bach, R., Ra j, B., 2013. A hierarc hical system for word discov ery exploiting DTW-based initialization, in: 2013 IEEE W orkshop on Automatic Sp eech Recognition and Understanding, IEEE. pp. 386–391. Y uan, Y., Leung, C.C., Xie, L., Chen, H., Ma, B., Li, H., 2017a. Extracting Bottleneck F eatures and W ord-Like Pairs from Untranscribed Sp eec h for F eature Representation, in: Pro c. ASRU, pp. 734–739. Y uan, Y., Leung, C.c., Xie, L., Chen, H., Ma, B., Li, H., 2017b. Pairwise Learning Using Multi-lingual Bottlenec k F eatures for Low-Resource Query-by-Example Sp ok en T erm Detection, in: Pro c. ICASSP , pp. 5645–5649. Y uan, Y., Leung, C.C., Xie, L., Ma, B., Li, H., 2016. Learning Neural Netw ork Representations Using Cross-Lingual Bottleneck F eatures with W ord-Pair Information, in: Pro c. Interspeech, pp. 788–792. Zeghidour, N., Synnaev e, G., Usunier, N. , Dupoux, E., 2016. Joint Learning of Sp eaker and Phonetic Similarities with Siamese Netw orks, in: Pro c. Interspeech 2016, pp. 1295–1299. Zeiler, M.D., Ranzato, M., Monga, R., Mao, M., Y ang, K., Le, Q.V., Nguyen, P ., Senior, A., V anhoucke, V., Dean, J., et al., 2013. On Rectified Linear Units for Speech Pro cessing, in: Pro c. ICASSP , pp. 3517–3521. Zhang, Y., Glass, J.R., 2009. Unsupervised Spoken Keyw ord Sp otting via Segmental DTW on Gaussian Posteriorgrams, in: Proc. ASRU, pp. 398–403. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment