Parallel/distributed implementation of cellular training for generative adversarial neural networks
Generative adversarial networks (GANs) are widely used to learn generative models. GANs consist of two networks, a generator and a discriminator, that apply adversarial learning to optimize their parameters. This article presents a parallel/distributed implementation of a cellular competitive coevolutionary method to train two populations of GANs. A distributed memory parallel implementation is proposed for execution in high performance/supercomputing centers. Efficient results are reported on addressing the generation of handwritten digits (MNIST dataset samples). Moreover, the proposed implementation is able to reduce the training times and scale properly when considering different grid sizes for training.
💡 Research Summary
**
The paper addresses the well‑known instability of Generative Adversarial Networks (GANs), which often suffer from gradient explosion, mode collapse, and discriminator collapse during training. To mitigate these pathologies, the authors adopt a spatial co‑evolutionary approach that maintains two populations—one of generators and one of discriminators—and lets them evolve competitively. This idea builds on the Mustangs and Lipizzaner frameworks, which already demonstrated that multiple generators and discriminators can improve robustness, but their original implementations were limited to single‑node execution and suffered from quadratic scaling as the population size grew.
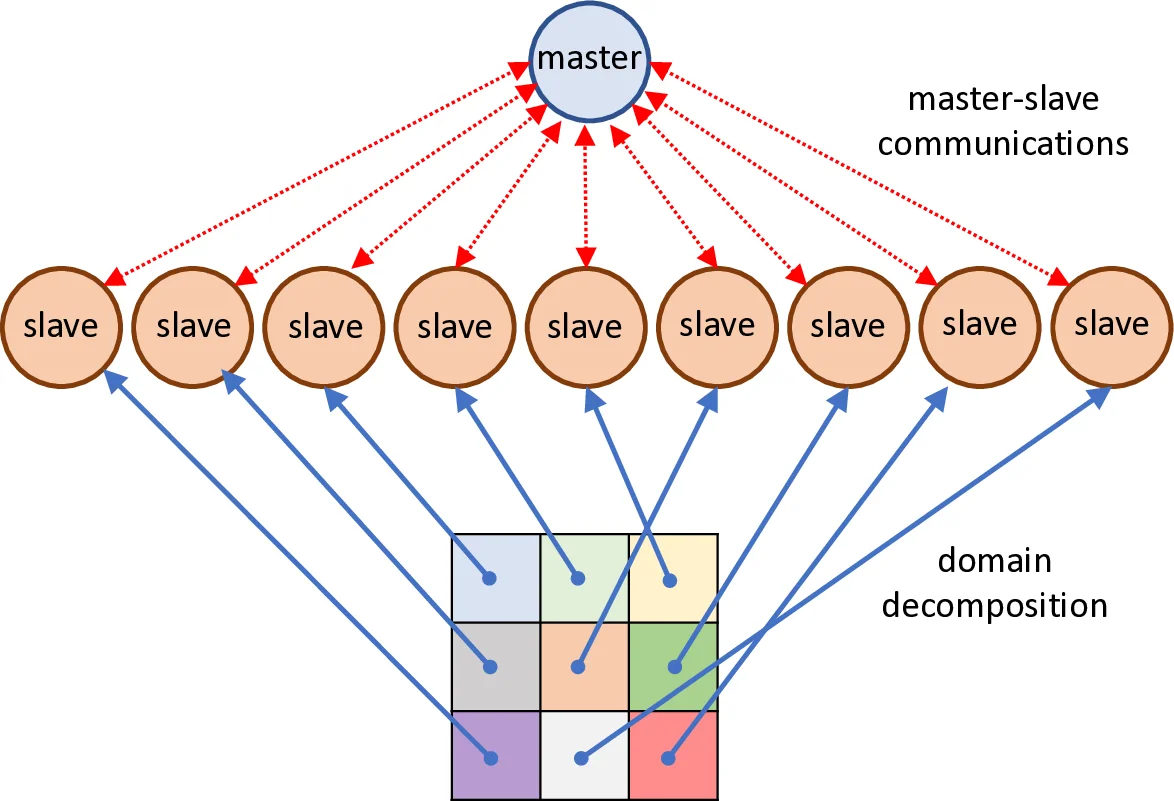
The core contribution of this work is a high‑performance, distributed‑memory implementation of the Mustangs/Lipizzaner algorithm, designed for execution on modern supercomputing clusters. The authors model the training environment as a toroidal grid (sizes ranging from 2 × 2 to 4 × 4 cells). Each cell hosts a single GAN pair (generator and discriminator) and interacts with a five‑cell Moore neighborhood (the cell itself plus its north, south, east, and west neighbors). Within a cell, a local sub‑population of size s = 5 is evolved asynchronously; after each training epoch the central GAN is exchanged with neighboring cells, thereby propagating high‑quality solutions while keeping the computational load per cell constant.
To map this spatial model onto a cluster, the authors employ a classic master‑slave paradigm augmented with multithreading. The master process is responsible for (i) discovering the available compute resources, (ii) assigning each grid cell to a distinct MPI rank (slave), (iii) distributing configuration parameters, (iv) monitoring progress through a dedicated heartbeat thread, and (v) aggregating final results. Each slave runs two threads: a main thread that handles all MPI communication with the master, and a training thread that performs the actual GAN updates, neighbor exchanges, and local evolutionary operations. This separation ensures that communication does not stall the compute‑intensive training loop.
Communication is abstracted in a new comm-manager class that wraps MPI primitives. Three MPI communicators are defined: (1) WORLD, used for global initialization, start/stop commands, and status checks; (2) LOCAL, which contains only the active slaves belonging to a given grid and enables collective operations (e.g., gather of neighbor fitness) without involving the master; and (3) GLOBAL, which includes all slaves plus the master for final reduction of results. By limiting collective operations to the smallest necessary communicator, the implementation reduces network contention and scales efficiently as the number of cells grows.
The experimental evaluation focuses on the MNIST handwritten‑digit dataset. The neural architecture is a simple multilayer perceptron: a 64‑dimensional latent vector, two hidden layers of 256 tanh units each, and a 784‑dimensional output representing the flattened image. Training uses Adam (learning rate 0.0002), a mutation scale of 0.01, mutation probability 0.5, and a tournament size of 2. The authors run 200 evolutionary iterations for each grid size. Results show that larger grids achieve near‑linear speed‑up: the 4 × 4 configuration reduces epoch time by roughly a factor of six compared with the sequential baseline, while maintaining an efficiency above 85 %. Moreover, the quality of generated samples, measured by the Inception Score and visual inspection, improves with the co‑evolutionary scheme, indicating that the neighborhood exchanges help prevent mode collapse and encourage diversity.
Although the current implementation runs exclusively on CPUs, the training thread contains a placeholder for GPU kernels, suggesting an obvious path for future acceleration. Additionally, the grid class supports dynamic reconfiguration of neighborhoods at runtime, opening the door to adaptive topologies that could balance exploration and exploitation more effectively during training.
In summary, the paper delivers a practical, scalable solution for training populations of GANs on large‑scale HPC resources. By combining a spatial co‑evolutionary algorithm with a carefully engineered MPI‑based master‑slave framework, the authors demonstrate both substantial reductions in training time and improvements in generative performance. The work paves the way for further research on GPU‑enabled co‑evolution, adaptive grid structures, and application to more complex data domains beyond MNIST.
Comments & Academic Discussion
Loading comments...
Leave a Comment