A Survey of Autonomous Driving: Common Practices and Emerging Technologies
Automated driving systems (ADSs) promise a safe, comfortable and efficient driving experience. However, fatalities involving vehicles equipped with ADSs are on the rise. The full potential of ADSs cannot be realized unless the robustness of state-of-…
Authors: Ekim Yurtsever, Jacob Lambert, Alex
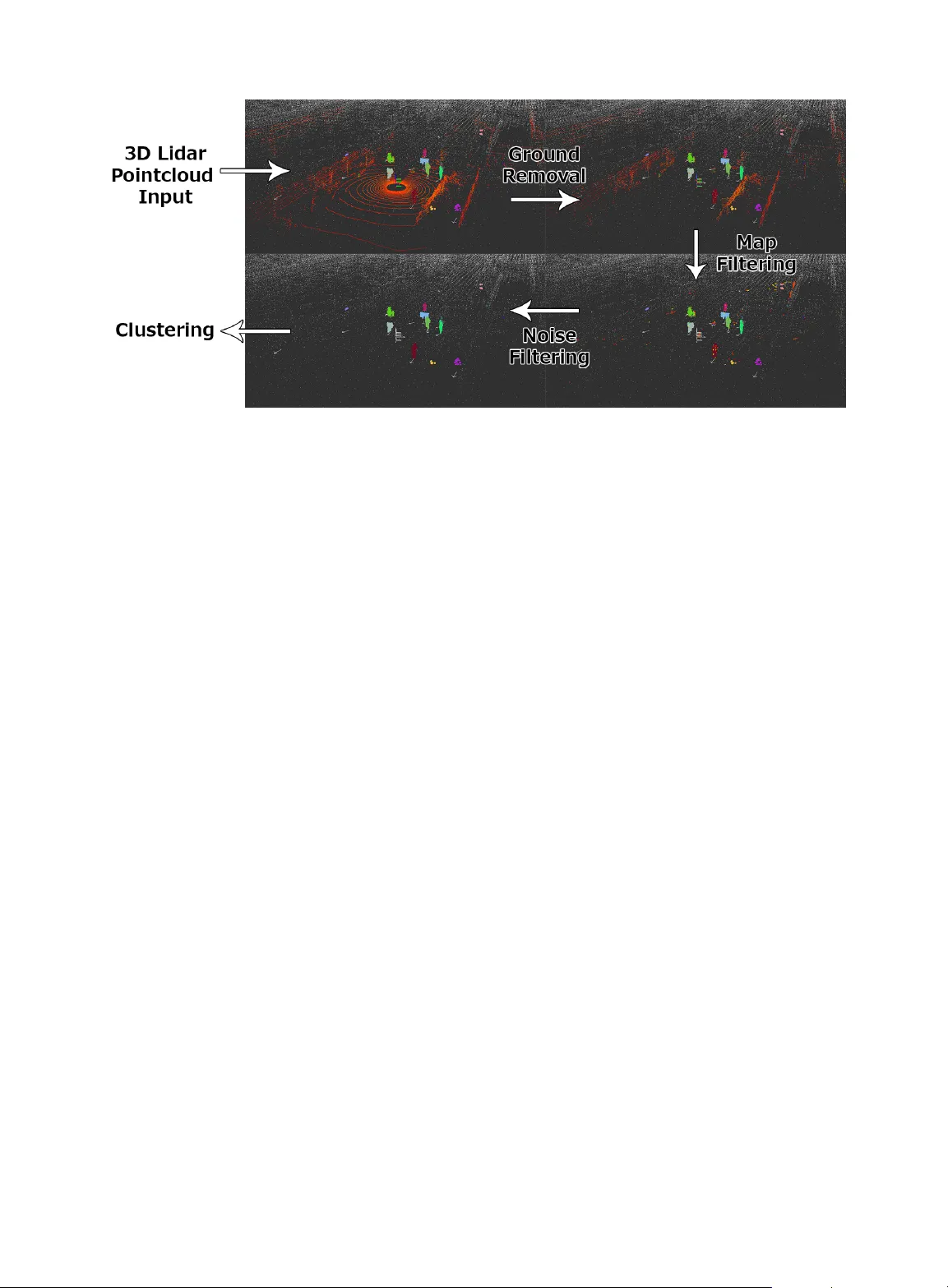
Accepted March 22, 2020 Digital Object Identifier 10.1109/ACCESS.2020.2983149 A Survey of A utonomous Driving: Common Pr actices and Emer ging T ec hnologies EKIM YURTSEVER 1 , (Member , IEEE), JA COB LAMBER T 1 , ALEXANDER CARB ALLO 1 , (Member , IEEE), AND KAZUY A T AKED A 1, 2 , (Senior Member , IEEE) 1 Nagoya Univ ersity , Furo-cho, Nagoya, 464-8603, Japan 2 Tier4 Inc. Nago ya, Japan Corresponding author: Ekim Y urtsever (e-mail: ekimyurtse ver@gmail.com). ABSTRA CT Automated dri ving systems (ADSs) promise a safe, comfortable and ef ficient driving experience. Ho we ver , fatalities in v olving vehicles equipped with ADSs are on the rise. The full potential of ADSs cannot be realized unless the robustness of state-of-the-art is impro ved further . This paper discusses unsolved problems and surveys the technical aspect of automated driving. Studies re garding present challenges, high- lev el system architectures, emerging methodologies and core functions including localization, mapping, perception, planning, and human machine interfaces, were thoroughly revie wed. Furthermore, many state- of-the-art algorithms were implemented and compared on our own platform in a real-world driving setting. The paper concludes with an ov erview of a v ailable datasets and tools for ADS de velopment. INDEX TERMS Autonomous V ehicles, Control, Robotics, Automation, Intelligent V ehicles, Intelligent T ransportation Systems I. INTR ODUCTION A CCORDING to a recent technical report by the National Highway T raf fic Safety Administration (NHTSA), 94% of road accidents are caused by human errors [1]. Against this backdrop, Automated Driving Sys- tems (ADSs) are being dev eloped with the promise of prev enting accidents, reducing emissions, transporting the mobility-impaired and reducing driving related stress [2]. If widespread deployment can be realized, annual social benefits of ADSs are projected to reach nearly $800 billion by 2050 through congestion mitigation, road casualty reduction, decreased energy consumption and increased producti vity caused by the reallocation of driving time [3]. The accumulated kno wledge in vehicle dynamics, break- throughs in computer vision caused by the advent of deep learning [4] and availability of ne w sensor modalities, such as lidar [5], catalyzed ADS research and industrial implementa- tion. Furthermore, an increase in public interest and market potential precipitated the emergence of ADSs with varying degrees of automation. Howe ver , rob ust automated dri ving in urban en vironments has not been achiev ed yet [6]. Accidents caused by immature systems [7]–[10] undermine trust, and furthermore, cost li ves. As such, a thorough in vestigation of unsolved challenges and the state-of-the-art is deemed necessary here. Eureka Project PROMETHEUS [11] was carried out in Europe between 1987-1995, and it was one of the earliest major automated dri ving studies. The project led to the dev elopment of VIT A II by Daimler-Benz, which succeeded in automatically dri ving on highways [12]. D ARP A Grand Challenge, org anized by the US Department of Defense in 2004, was the first major automated dri ving competition where all of the attendees failed to finish the 150-mile off- road parkour . The difficulty of the challenge was in the rule that no human intervention at any lev el was allowed during the finals. Another similar D ARP A Grand Challenge was held in 2005. This time five teams managed to complete the off-road track without an y human interference [13]. Fully automated driving in urban scenes was seen as the biggest challenge of the field since the earliest attempts. Dur - ing D ARP A Urban Challenge [26], held in 2007, many differ - ent research groups around the globe tried their ADSs in a test en vironment that was modeled after a typical urban scene. Six teams managed to complete the ev ent. Even though this competition was the biggest and most significant ev ent up to that time, the test en vironment lacked certain aspects of a real-world urban driving scene such as pedestrians and cyclists. Nevertheless, the fact that six teams managed to VOLUME 8, 2020 1 T ABLE 1: Comparison of ADS related survey papers Related work Survey coverage Connected systems End-to-end Localization Perception Assessment Planning Control HMI Datasets & software Implementation [14] - - - X - - - - - - [15] - - X X - X X - - X [16] - - X X - X - - - - [17] - - X - - - - - - - [18] - - - - - X X - - - [19] - - - - - X - - - - [20] X X X X - - - - - - [21] X - X - - - - - X - [22] X - - - - - - - - - [23] - - X X - X X - - X [24] - X - - X X X - - - [25] - - - - X X - - - - Ours X X X X X X - X X X complete the challenge attracted significant attention. After D ARP A Urban Challenge, several more automated dri ving competitions such as [27]–[30] were held in different coun- tries. Common practices in system architecture ha ve been estab- lished over the years. Most of the ADSs divide the massive task of automated driving into subcategories and employ an array of sensors and algorithms on various modules. More re- cently , end-to-end driving started to emerge as an alternativ e to modular approaches. Deep learning models hav e become dominant in many of these tasks [31]. The Society of Automotiv e Engineers (SAE) refers to hardware-software systems that can ex ecute dynamic driving tasks (DDT) on a sustainable basis as ADS [32]. There are also vernacular alternati ve terms such as "autonomous driving" and "self-driving car" in use. Nonetheless, despite being commonly used, SAE advices not to use them as these terms are unclear and misleading. In this paper we follo w SAE’ s conv ention. The present paper attempts to provide a structured and comprehensiv e ov erview of state-of-the-art automated driv- ing related hardware-software practices. Moreov er , emerging trends such as end-to-end driving and connected systems are discussed in detail. There are ov erview papers on the subject, which cov ered sev eral core functions [15], [16], and which concentrated only on the motion planning aspect [18], [19]. Howe v er , a survey that covers: present challenges, available and emerging high-lev el system architectures, individual core functions such as localization, mapping, perception, plan- ning, vehicle control, and human-machine interface alto- gether does not exist. The aim of this paper is to fill this gap in the literature with a thorough surve y . In addition, a detailed summary of av ailable datasets, software stacks, and simulation tools is presented here. Another contribution of this paper is the detailed comparison and analysis of alter- nativ e approaches through implementation. W e implemented some state-of-the-art algorithms in our platform using open- source software. Comparison of existing overvie w papers and our work is sho wn in T able 1. The remainder of this paper is written in eight sections. Section II is an overvie w of present challenges. Details of automated driving system components and architectures are giv en in Section III. Section IV presents a summary of state- of-the-art localization techniques followed by Section V, an in-depth revie w of perception models. Assessment of the driving situation and planning are discussed in Section VI and VII respectiv ely . In Section VIII, current trends and shortcomings of human machine interface are introduced. Datasets and av ailable tools for developing automated dri v- ing systems are giv en in Section IX. II. PR OSPECTS AND CHALLENGES A. SOCIAL IMP A CT W idespread usage of ADSs is not imminent. Y et it is still possible to foresee its potential impact and benefits to a certain degree: 1) Problems that can be solved : pre venting traffic acci- dents, mitigating traffic congestions, reducing emis- sions 2) Arising opportunities : reallocation of dri ving time, transporting the mobility impaired 3) New tr ends : consuming Mobility as a Service (MaaS), logistics rev olution W idespread deployment of ADSs can reduce the societal loss caused by erroneous human beha vior such as distraction, driving under influence and speeding [3]. Globally , the elder group (ov er 60 years old) is growing faster than the younger groups [33]. Increasing the mobility of elderly with ADSs can have a huge impact on the quality of life and productivity of a lar ge portion of the population. A shift from personal vehicle-o wnership tow ards consum- ing Mobility as a Service (MaaS) is an emerging trend. Currently , ride-sharing has lower costs compared to vehicle- ownership under 1000 km annual mileage [34]. The ratio of owned to shared vehicles is expected to be 50:50 by 2030 [35]. Large scale deployment of ADSs can accelerate this trend. B. CHALLENGES ADSs are complicated robotic systems that operate in inde- terministic en vironments. As such, there are myriad scenarios with unsolved issues. This section discusses the high le vel challenges of driving automation in general. More minute, task-specific details are discussed in corresponding sections. The Society of Automoti ve Engineers (SAE) defined fiv e lev els of driving automation in [32]. In this taxonomy , level zero stands for no automation at all. Primitiv e driv er as- sistance systems such as adaptiv e cruise control, anti-lock braking systems and stability control start with level one [36]. Lev el two is partial automation to which advanced assistance systems such as emergency braking or collision av oidance [37], [38] are integrated. With the accumulated kno wledge in the vehicle control field and the experience of the industry , lev el two automation became a feasible technology . The real challenge starts abov e this lev el. Lev el three is conditional automation; the driv er could focus on tasks other than driving during normal operation, howe v er , s/he has to quickly respond to an emergenc y alert from the vehicle and be ready to take ov er . In addition, lev el three ADS operate only in limited operational de- sign domains (ODDs) such as highways. Audi claims to be the first production car to achiev e lev el 3 automation in limited highway conditions [39]. Howe ver , taking ov er the control manually from the automated mode by the driver raises another issue. Recent studies [40], [41] inv estigated this problem and found that the takeover situation increases the collision risk with surrounding vehicles. The increased likelihood of an accident during a takeover is a problem that is yet to be solved. Human attention is not needed in any degree at level four and fiv e. Howe ver , lev el four can only operate in limited ODDs where special infrastructure or detailed maps exist. In the case of departure from these areas, the vehicle must stop the trip by automatically parking itself. The fully automated system, level five, can operate in an y road network and any weather condition. No production vehicle is capable of level four or le vel five driving automation yet. Moreo ver , T oyota Research Institute stated that no one in the industry is ev en close to attaining lev el fi ve automation [42]. Lev el four and above dri ving automation in urban road networks is an open and challenging problem. The environ- mental variables, from weather conditions to surrounding human behavior , are highly indeterministic and difficult to predict. Furthermore, system failures lead to accidents: in the Hyundai competition one of the ADSs crashed because of rain [7], Google’ s ADS hit a bus while lane changing because it failed to estimate the speed of a bus [8], and T esla’ s Autopilot failed to recognize a white truck and collided with it, killing the driv er [9]. Fatalities [9], [10] caused by immature technology under- mine public acceptance of ADSs. According to a recent sur- ve y [34], the majority of consumers question the safety of the technology , and want a significant amount of control over the dev elopment and use of ADS. On the other hand, extremely cautious ADSs are also making a negati v e impression [43]. Ethical dilemmas pose another set of challenges. In an inevitable accident situation, how should the system beha ve [44]? Experimental ethics were proposed regarding this issue FIGURE 1: A high level classification of automated driving system architectures [45]. Risk and reliability certification is another task yet to be solved. Like in aircraft, ADSs need to be designed with high redundancies that will minimize the chance of a catastrophic failure. Even though there is promising projects in this regard such as DeepT est [46], the design-simulation-test-redesign- certification procedure is still not established by the industry nor the rule-makers. Finally , various optimization goals such as time to reach the destination, fuel ef ficiency , comfort, and ride-sharing optimization increases the complexity of an already difficult to solve problem. As such, carrying all of the dynamic driving tasks safely under strict conditions outside a well defined, geofenced area remains as an open problem. III. SYSTEM COMPONENTS AND ARCHITECTURE A. SYSTEM ARCHITECTURE Classification of system architectures is sho wn in Figure 1. ADSs are designed either as standalone, ego-only systems [15], [47] or connected multi-agent systems [48]–[50]. Fur- thermore, these design philosophies are realized with two alternativ e approaches: modular [15], [47], [51]–[58] or end- to-end driving [59]–[67]. 1) Ego-only systems The ego-only approach is to carry all of the necessary auto- mated driving operations on a single self-sufficient vehicle at all times, whereas a connected ADS may or may not de- pend on other vehicles and infrastructure elements given the situation. Ego-only is the most common approach amongst the state-of-the-art ADSs [15], [47], [51]–[56], [56]–[58]. W e believ e this is due to the practicality of having a self-sufficient platform for development and the additional challenges of connected systems. 2) Modular systems Modular systems, referred as the mediated approach in some works [59], are structured as a pipeline of separate components linking sensory inputs to actuator outputs [31]. FIGURE 2: Information flow diagrams of: (a) a generic modular system, and (b) an end-to-end dri ving system. Core functions of a modular ADS can be summarized as: localization and mapping, perception, assessment, planning and decision making, vehicle control, and human-machine interface. T ypical pipelines [15], [47], [51]–[56], [56]–[58] start with feeding raw sensor inputs to localization and object detection modules, followed by scene prediction and decision making. Finally , motor commands are generated at the end of the stream by the control module [31], [68]. Dev eloping indi vidual modules separately divides the challenging task of automated driving into an easier-to-solv e set of problems [69]. These sub-tasks hav e their correspond- ing literature in robotics [70], computer vision [71] and v ehi- cle dynamics [36], which makes the accumulated know-ho w and expertise directly transferable. This is a major adv antage of modular systems. In addition, functions and algorithms can be integrated or built upon each other in a modular design. E.g, a safety constraint [72] can be implemented on top of a sophisticated planning module to force some hard- coded emergenc y rules without modifying the inner workings of the planner . This enables designing redundant but reliable architectures. The major disadvantages of modular systems are being prone to error propagation [31] and over -complexity . In the unfortunate T esla accident, an error in the perception module in the form of a misclassification of a white trailer as sky , propagated do wn the pipeline until failure, causing the first ADS related fatality [46]. 3) End-to-end driving End-to-end driving, referred as direct perception in some studies [59], generate ego-motion directly from sensory in- puts. Ego-motion can be either the continuous operation of steering wheel and pedals or a discrete set of actions, e.g, ac- celeration and turning left. There are three main approaches for end-to-end dri ving: direct supervised deep learning [59]– [63], neuroev olution [66], [67] and the more recent deep reinforcement learning [64], [65]. The flow diagram of a generic end-to-end driving system is shown in Figure 2 and comparison of the approaches is giv en in T able 2. The earliest end-to-end dri ving attempt dates back to T ABLE 2: Common end-to-end driving approaches Related works Learning/training strategy Pros/cons [59]–[63] Direct supervised deep learning Imitates the target data: usually a human driv er . Can be trained offline. Poor generalization performance. [64], [65] Deep reinforcement learning Learns the optimum way of driving. Requires online interaction. Urban driving has not been achiev ed yet [66], [67] Neuroev olution No backpropagation. Requires online interaction. Real world driving has not been achie ved yet. AL VINN [60], where a 3-layer fully connected network was trained to output the direction that the vehicle should follow . An end-to-end driving system for of f-road driving w as intro- duced in [61]. W ith the advances in artificial neural network research, deep conv olutional and temporal networks became feasible for automated dri ving tasks. A deep con v olutional neural netw ork that takes image as input and outputs steering was proposed in [62]. A spatiotemporal network, an FCN- LSTM architecture, was dev eloped for predicting ego-v ehicle motion in [63]. DeepDriving is another con volutional model that tries to learn a set of discrete perception indicators from the image input [59]. This approach is not entirely end-to-end though, the proper driving actions in the perception indicators hav e to be generated by another module. All of the mentioned methods follow direct supervised training strategies. As such, ground truth is required for training. Usually , the ground truth is the ego-action sequence of an expert human dri v er and the network learns to imitate the driv er . This raises an import design question: should the ADS driv e like a human? A nov el deep reinforcement learning model, Deep Q Net- works (DQN), combined reinforcement learning with deep learning [73]. In summary , the goal of the network is to select a set of actions that maximize cumulati ve future rewards. A deep con volutional neural network was used to approximate the optimal action reward function. Actions are generated first with random initialization. Then, the network adjust its parameters with experience instead of direct supervised learning. An automated driving framework using DQN was introduced in [64], where the network was tested in a simu- lation en vironment. The first real world run with DQN was achiev ed in a countryside road without traffic [65]. DQN based systems do not imitate the human driver , instead, they learn the optimum way of dri ving. Neuroev olution refers to using ev olutionary algorithms to train artificial neural networks [74]. End-to-end driving with neuroev olution is not popular as DQN and direct supervised learning. T o the best of our kno wledge, real w orld end-to-end driving with neuroev olution is not achieved yet. Howe ver , some promising simulation results were obtained [66], [67]. AL VINN was trained with neuroev olution and outperformed the direct supervised learning version [66]. A RNN was trained with neuroev olution in [67] using a driving simulator . The biggest advantage of neuroev olution is the remov al of backpropagation, hence, the need for direct supervision. End-to-end driving is promising, howe v er it has not been implemented in real-world urban scenes yet, except lim- ited demonstrations. The biggest shortcomings of end-to-end driving in general are the lack of hard coded safety measures and interpretability [69]. In addition, DQN and neuroev o- lution has one major disadvantage over direct supervised learning: these networks must interact with the en vironment online and fail repeatedly to learn the desired behavior . On the contrary , direct supervised networks can be trained offline with human driving data, and once the training is done, the system is not expected to fail during operation. 4) Connected systems There is no operational connected ADS in use yet, howe ver , some researchers believe this emer ging technology will be the future of dri ving automation [48]–[50]. With the use of V ehicular Ad hoc NET work (V ANETs), the basic operations of automated driving can be distributed amongst agents. V2X is a term that stands for “vehicle to e v erything." From mobile devices of pedestrians to stationary sensors on a traffic light, an immense amount of data can be accessed by the vehicle with V2X [22]. By sharing detailed information of the traf fic network amongst peers [75], shortcomings of the ego-only platforms such as sensing range, blind spots, and compu- tational limits may be eliminated. More V2X applications that will increase safety and traf fic efficiency are expected to emerge in the foreseeable future [76]. V ANETs can be realized in two different ways: con ven- tional IP based networking and Information-Centric Net- working (ICN) [48]. For vehicular applications, lots of data hav e to be distributed amongst agents with intermittent and in less than ideal connections while maintaining high mobility [50]. Conv entional IP-host based Internet protocol cannot function properly under these conditions. On the other hand, in information-centric netw orking, vehicles stream query messages to an area instead of a direct address and they accept corresponding responses from any sender [49]. Since vehicles are highly mobile and dispersed on the road network, the identity of the information source becomes less relev ant. In addition, local data often carries more crucial information for immediate dri ving tasks such as av oiding a rapidly ap- proaching vehicle on a blind spot. Early works, such as the CarSpeak system [82], proved that vehicles can utilize each other’ s sensors and use the shared information to ex ecute some dynamic driving tasks. Howe v er , without reducing huge amounts of continuous driv- ing data, sharing information between hundreds of thousand vehicles in a city could not become feasible. A semiotic framew ork that integrates different sources of information and con verts raw sensor data into meaningful descriptions was introduced in [83] for this purpose. In [84], the term V ehicular Cloud Computing (VCC) was coined and the main advantages of it o ver conv entional Internet cloud applications was introduced. Sensors are the primary cause of the differ- ence. In VCC, sensor information is kept on the vehicle and only shared if there is a local query from another vehicle. This potentially sav es the cost of uploading/downloading a constant stream of sensor data to the web . Besides, the high rele vance of local data increases the feasibility of VCC. Regular cloud computing was compared to vehicular cloud computing and it was reported that VCC is technologically feasible [85]. The term ”Internet of V ehicles" (IoV) was proposed for describing a connected ADS [48] and the term ”vehicular fog" was introduced in [49]. Establishing an ef ficient V ANET with thousands of vehi- cles in a city is a huge challenge. For an ICN based V ANET , some of the challenging topics are security , mobility , rout- ing, naming, caching, reliability and multi-access computing [86]. In summary , ev en though the potential benefits of a connected system is huge, the additional challenges increase the complexity of the problem to a significant degree. As such, there is no operational connected system yet. B. SENSORS AND HARDW ARE State-of-the-art ADSs employ a wide selection of onboard sensors. High sensor redundancy is needed in most of the tasks for robustness and reliability . Hardware units can be categorized into fiv e: exterocepti ve sensors for perception, proprioceptiv e sensors for internal vehicle state monitoring tasks, communication arrays, actuators, and computational units. Exteroceptiv e sensors are mainly used for percei ving the en vironment, which includes dynamic and static objects, e.g., driv able areas, buildings, pedestrian crossings. Camera, lidar , radar and ultrasonic sensors are the most commonly used modalities for this task. A detailed comparison of exterocep- tiv e sensors is gi ven in T able 3. 1) Monocular Cameras Cameras can sense color and are passiv e, i.e. they do not emit any signal for measurements. Sensing color is extremely important for tasks such as traffic light recognition. Further- more, 2D computer vision is an established field with remark- able state-of-the-art algorithms. Moreov er , a passive sensor T ABLE 3: Exteroceptiv e sensors Modality Affected by Illumination Affected by weather Color Depth Range Accuracy Size Cost Lidar - X - X medium ( < 200 m) high large* high* Radar - - - X high medium small medium Ultrasonic - - - X short low small low Camera X X X - - - smallest lowest Stereo Camera X X X X medium ( < 100 m) low medium low Flash Camera [77] X X X X medium ( < 100 m) low medium low Event Camera [78] limited X - - - - smallest low Thermal Camera [79], [80] - X - - - - smallest low * Cost, size and weight of lidars started to decrease recently [81] FIGURE 3: Ricoh T etha V panoramic images collected using our data collection platform, in Nagoya Univ ersity campus. Note some distortion still remains on the periphery of the image. does not interfere with other systems since it does not emit any signals. Howe ver , cameras have certain shortcomings. Illumination conditions affect their performance drastically , and depth information is difficult to obtain from a single cam- era. There are promising studies [87] to improve monocular camera based depth perception, but modalities that are not negati v ely affected by illumination and weather conditions are still necessary for dynamic dri ving tasks. Other camera types gaining interest for ADS include flash cameras [77], thermal cameras [79], [80], and ev ent cameras [78]. 2) Omnidirectional Camera For 360 ◦ 2D vision, omnidirectional cameras are used as an alternativ e to camera arrays. The y ha ve seen widespread use, with increasingly compact and high performance hardware being constantly released. Panoramic vie w is particularly desirable for applications such as navigation, localization and mapping [88]. An example panoramic image is shown in Figure 3. 3) Event Cameras Event cameras are among the newer sensing modalities that hav e seen use in ADS [89]. Event cameras record data asynchronously for individual pixels with respect to visual FIGURE 4: D A VIS240 ev ents, overlayed on the image (left) and corresponding RBG image from a dif ferent camera (right), collected by our data collection platform, at a road crossing near Nagoya University . The motion of the cyclist and vehicle causes brightness changes which trigger e vents. stimulus. The output is therefore an irregular sequence of data points, or events triggered by changes in brightness. The response time is in the order of microseconds [90]. The main limitation of current e vent cameras is pixel size and image resolution. For example, the D A VIS40 image shown in Figure 4 has a pixel size of 18 . 5 × 18 . 5 µ m and a resolution of 240 × 180 . Recently , a driving dataset with event camera data has been published [89]. 4) Radar Radar , lidar and ultrasonic sensors are very useful in cov- ering the shortcomings of cameras. Depth information, i.e. distance to objects, can be measured ef fectiv ely to retrieve 3D information with these sensors, and they are not affected by illumination conditions. Ho wev er , the y are acti v e sensors. Radars emit radio waves that bounce back from objects and measure the time of each bounce. Emissions from acti ve sensors can interfere with other systems. Radar is a well- established technology that is both lightweight and cost- effecti v e. For example, radars can fit inside side-mirrors. Radars are cheaper and can detect objects at longer distances than lidars, but the latter are more accurate. FIGURE 5: The ADS equipped Prius of Nagoya Univ ersity . W e have used this vehicle to perform core automated dri ving operations. 5) Lidar Lidar operates with a similar principle that of radar but it emits infrared light wav es instead of radio wav es. It has much higher accuracy than radar under 200 meters. W eather conditions such as fog or sno w have a negati v e impact on the performance of lidar . Another aspect is the sensor size: smaller sensors are preferred on the vehicle because of lim- ited space and aerodynamic restraints and lidars are generally larger than radars. In [91], human sensing performance is compared to ADS. One of the key findings of this study is that even though human driv ers are still better at reasoning in general, the perception capability of ADSs with sensor -fusion can exceed humans, especially in degraded conditions such as insuf fi- cient illumination. 6) Propr ioceptive sensors Proprioceptiv e sensing is another crucial category . V ehicle states such as speed, acceleration and yaw must be con- tinuously measured in order to operate the platform safely with feedback. Almost all of the modern production cars are equipped with proprioceptiv e sensors. Wheel encoders are mainly used for odometry , Inertial Measurement Units (IMU) are emplo yed for monitoring the v elocity and position changes, tachometers are utilized for measuring speed and altimeters for altitude. These signals can be accessed through the CAN protocol of modern cars. Besides sensors, an ADS needs actuators to manipulate the vehicle and adv anced computational units for processing and storing sensor data. 7) Full size cars There are numerous instrumented vehicles introduced by different research groups, such as Stanford’ s Junior [15], which employs an array of sensors with different modalities for perceiving external and internal v ariables. Boss won the D ARP A Urban Challenge with an abundance of sensors [47]. RobotCar [53] is a cheaper research platform aimed for data collection. In addition, different lev els of driving T ABLE 4: Onboard sensor setup of ADS equipped vehicles Platform # 360 ◦ rotating lidars # stationary lidars # Radars # Cameras Ours 1 - - 4 Boss [47] 1 9 5 2 Junior [15] 1 2 6 4 BRAiVE [52] - 5 1 10 RobotCar [53] - 3 - 4 Google car (prius) [55] 1 - 4 1 Uber car (XC90) [56] 1 - 10 7 Uber car (Fusion) [56] 1 7 7 20 Bertha [57] - - 6 3 Apollo Auto [58] 1 3 2 2 automation have been introduced by the industry; T esla’ s Autopilot [92] and Google’ s self driving car [93] are some examples. Bertha [57] is dev eloped by Daimler and has 4 120 ◦ short-range radars, two long-range range radar on the sides, stereo camera, wide angle-monocular color camera on the dashboard, another wide-angle camera for the back. Our vehicle is sho wn in Figure 5. A detailed comparison of sensor setups of 10 different full-size ADSs is gi v en in T able 4. 8) Large vehicles and trailers Earliest intelligent trucks were developed for the P A TH pro- gram in California [102], which utilized magnetic markers on the road. Fuel economy is an essential topic in freight trans- portation and methods such as platooning has been dev eloped for this purpose. Platooning is a well-studied phenomenon; it reduces drag and therefore fuel consumption [103]. In semi- autonomous truck platooning, the lead truck is driv en by a human driv er , and se veral automated trucks follow it; form- ing a semi-autonomous road-train as defined in [104]. Sartre European Union project [105] introduced such a system that satisfies three core conditions: using the already existing public road network, sharing the traf fic with non-automated vehicles and not modifying the road infrastructure. A platoon consisting of three automated trucks was formed in [103] and significant fuel savings were reported. T ractor-trailer setup poses an additional challenge for au- tomated freight transport. Con ventional control methods such as feedback linearization [106] and fuzzy control [107] were used for path tracking without considering the jackknifing constraint. The possibility of jackknifing, the collision of the truck and the trailer with each other , increases the difficulty of the task [108]. A control safety governor design was proposed in [108] to prev ent jackknifing while re versing. IV . LOCALIZA TION AND MAPPING Localization is the task of finding ego-position relativ e to a reference frame in an en vironment [17], and it is fundamental to any mobile robot. It is especially crucial for ADSs [21]; the vehicle must use the correct lane and position itself in it accurately . Furthermore, localization is an elemental requirement for global navigation. The reminder of this section details the three most common approaches that use solely on-board sensors: Global Posi- T ABLE 5: Localization techniques Methods Robustness Cost Accuracy Size Computational requirements Related works Absolute positioning sensors low lo w low small lowest [94] Odometry/dead reckoning low lo w low smallest low [95] GPS-IMU fusion medium medium low small low [96] SLAM medium-high medium high large very high [97] A priori Map-based Landmark search high medium high large medium [98], [99] Point cloud matching highest highest highest largest high [100], [101] tioning System and Inertial Measurement Unit (GPS-IMU) fusion, Simultaneous Localization And Mapping (SLAM), and state-of-the-art a priori map-based localization. Readers are referred to [17] for a broader localization ov ervie w . A comparison of localization methods is giv en in T able 5. A. GPS-IMU FUSION The main principle of GPS-IMU fusion is correcting accu- mulated errors of dead reckoning in intervals with absolute position readings [109]. In a GPS-IMU system, changes in position and orientation are measured by IMU, and this information is processed for localizing the vehicle with dead reckoning. There is a significant drawback of IMU, and in general dead reckoning: errors accumulate with time and they often lead to failure in long-term operations [110]. With the integration of GPS readings, the accumulated errors of the IMU can be corrected in intervals. GPS-IMU systems by themselves cannot be used for v ehi- cle localization as they do not meet the performance criteria [111]. In the 2004 D ARP A Grand Challenge, the red team from Carnegie Mellon Uni versity [96] failed the race because of a GPS error . The accuracy required for urban automated driving is too high for the current GPS-IMU systems used in production cars. Moreov er , in dense urban en vironments, the accuracy drops further, and the GPS stops functioning from time to time because of tunnels [109] and high buildings. Even though GPS-IMU systems by themselves do not meet the performance requirements and can only be utilized for high-lev el route planning, they are used for initial pose estimation in tandem with lidar and other sensors in state-of- the-art localization systems [111]. B. SIMUL T ANEOUS LOCALIZA TION AND MAPPING Simultaneous localization and mapping (SLAM) is the act of online map making and localizing the vehicle in it at the same time. A priori information about the environment is not required in SLAM. It is a common practice in robotics, especially in indoor environments. Howe v er , due to the high computational requirements and en vironmental challenges, running SLAM algorithms outdoors, which is the operational domain of ADSs, is less efficient than localization with a pre- built map [112]. T eam MIT used a SLAM approach in D ARP A urban challenge [113] and finished it in the 4th place. Whereas, the winner, Carnegie Mellon‘s Boss [47] and the runner-up, Stanford‘s Junior [15], both utilized a priori information. In spite of not ha ving the same lev el of accuracy and ef ficiency , SLAM techniques hav e one major adv antage ov er a priori methods: they can work an ywhere. SLAM based methods hav e the potential to replace a priori techniques if their performances can be increased further [20]. W e refer the readers to [21] for a detailed SLAM surve y in the intelligent vehicle domain. C. A PRIORI MAP-BASED LOCALIZA TION The core idea of a priori map-based localization techniques is matching: localization is achiev ed through the comparison of online readings to the information on a detailed pre-b uilt map and finding the location of the best possible match [111]. Often an initial pose estimation, for example with a GPS, is used at the beginning of the matching process. There are various approaches to map b uilding and preferred modalities. Changes in the en vironment affect the performance of map-based methods negati v ely . This effect is pre valent es- pecially in rural areas where past information of the map can deviate from the actual en vironment because of changes in roadside v egetation and constructions [114]. Moreo ver , this method requires an additional step of map making. There are two different map-based approaches; landmark search and matching. 1) Landmar k search Landmark search is computationally less expensiv e in com- parison to point cloud matching. It is a robust localization technique as long as a sufficient amount of landmarks exists. In an urban en vironment, poles, curbs, signs and road mark- ers can be used as landmarks. A road marking detection method using lidar and Monte Carlo Localization (MCL) was used in [98]. In this method, road markers and curbs were matched to a 3D map to find the location of the vehicle. A vision based road marking detec- tion method was introduced in [115]. Road markings detected by a single front camera were compared and matched to a lo w-volume digital marker map with global coordinates. Then, a particle filter was employed to update the position and heading of the vehicle with the detected road markings and GPS-IMU output. A road marking detection based lo- calization technique using; tw o cameras directed to wards the ground, GPS-IMU dead reckoning, odometry , and a precise marker location map was proposed in [116]. Another vision based method with a single camera and geo-referenced traffic signs was presented in [117]. FIGURE 6: W e used NDT matching [101], [118] to localize our vehicle in the Nagoya Univ ersity campus. White points belong to the offline pre-built map and the colored ones were obtained from online scans. The objectiv e is to find the best match between colored points and white points, thus localizing the vehicle. This approach has one major disadvantage; landmark de- pendency makes the system prone to fail where landmark amount is insufficient. 2) P oint cloud matching The state-of-the-art localization systems use multi-modal point cloud matching based approaches. In summary , the online-scanned point cloud, which covers a smaller area, is translated and rotated around its center iteratively to be compared against the larger a priori point cloud map. The position and orientation that gives the best match between the two point clouds giv e the localized position of the sensor relativ e to the map. For initial pose estimation, GPS is used commonly along dead reckoning. W e used this approach to localize our vehicle. The matching process is shown in Figure 6 and the map-making in Figure 7. In the seminal work of [111], a point cloud map collected with lidar was used to augment inertial navigation and lo- calization. A particle filter maintained a three-dimensional vector of 2D coordinates and the yaw angle. A multi-modal approach with probabilistic maps was utilized in [100] to achiev e localization in urban en vironments with less than 10 cm RMS error . Instead of comparing two point clouds point by point and discarding the mismatched reads, the v ariance of all observed data was modeled and used for the matching task. A matching algorithm for lidar scans using multi- resolution Gaussian Mixture Maps (GMM) was proposed in [119]. Iterative Closest Point (ICP) was compared against Normal Distribution Transform (NDT) in [118], [120]. In NDT , accumulated sensor readings are transformed into a grid that is represented by the mean and cov ariance obtained from the scanned points that fall into its’ cells/v oxels. NDT prov ed to be more rob ust than point-to-point ICP matching. An improv ed version of 3D NDT matching was proposed in [101], and [114] augmented NDT with road marker matching. An NDT -based Monte Carlo Localization (MCL) method that utilizes an offline static map and a constantly FIGURE 7: Creating a 3D pointcloud map with congregation of scans. W e used Autoware [122] for mapping. updated short-term map was developed by [121]. In this method, NDT occupancy grid was used for the short-term map and it was utilized only when and where the static map failed to gi ve suf ficient explanations. Map-making and maintaining is time and resource con- suming. Therefore some researchers such as [99] ar gue that methods with a priori maps are not feasible given the size of road networks and rapid changes. 3) 2D to 3D matching Matching online 2D readings to a 3D a priori map is an emerging technology . This approach requires only a camera on the ADS equipped vehicle instead of the more expensiv e lidar . The a priori map still needs to be created with a lidar . A monocular camera was used to localize the vehicle in a point cloud map in [123]. With an initial pose estimation, 2D synthetic images were created from the offline 3D point cloud map and they were compared with normalized mutual information to the online images received from the camera. This method increases the computational load of the localiza- tion task. Another vision matching algorithm was introduced in [124] where a stereo camera setup was utilized to compare online readings to synthetic depth images generated from 3D prior . Camera based localization approaches could become pop- ular in the future as the hardware requirement is cheaper than lidar based systems. V . PERCEPTION Perceiving the surrounding environment and e xtracting infor- mation which may be critical for safe navigation is a critical objectiv e for ADS. A variety of tasks, using different sensing modalities, fall under the category of perception. Building on decades of computer vision research, cameras are the most commonly used sensor for perception, with 3D vision becoming a strong alternativ e/supplement. The reminder of this section is divided into core per- ception tasks. W e discuss image-based object detection in Section V -A1, semantic segmentation in Section V -A2, 3D object detection in Section V -A3, road and lane detection in Section V -C and object tracking in Section V -B. T ABLE 6: Comparison of 2D bounding box estimation ar- chitectures on the test set of ImageNet1K, ordered by T op 5% error . Number of parameters (Num. P arams) and number of layers (Num. Layers), hints at the computational cost of the algorithm. Architecture Num. Params Num. ImageNet1K ( × 10 6 ) Layers T op 5 Error % Incept.ResNet v2 [125] 30 95 4.9 Inception v4 [125] 41 75 5 ResNet101 [126] 45 100 6.05 DenseNet201 [127] 18 200 6.34 YOLOv3-608 [128] 63 53+1 6.2 ResNet50 [126] 26 49 6.7 GoogLeNet [129] 6 22 6.7 VGGNet16 [130] 134 13+2 6.8 AlexNet [4] 57 5+2 15.3 A. DETECTION 1) Image-based Object Detection Object detection refers to identifying the location and size of objects of interest. Both static objects, from traffic lights and signs to road crossings, and dynamic objects such as other vehicles, pedestrians or cyclists are of concern to ADSs. Generalized object detection has a long-standing history as a central problem in computer vision, where the goal is to determine if objects of specific classes are present in an image, then to determine their size via a rectangular bounding box. This section mainly discusses state-of-the-art object detection methods, as they represent the starting point of sev eral other tasks in an ADS pipe, such as object tracking and scene understanding. Object recognition research started more than 50 years ago, but only recently , in the late 1990s and early 2000s, has algorithm performance reached a level of relev ance for driving automation. In 2012, the deep con v olutional neural network (DCNN) Ale xNet [4] shattered the ImageNet image recognition challenge [131]. This resulted in a near complete shift of focus to supervised learning and in particular deep learning for object detection. There exists a number of exten- siv e surveys on general image-based object detection [132]– [134]. Here, the focus is on the state-of-the-art methods that could be applied to ADS. While state-of-the-art methods all rely on DCNNs, there currently exist a clear distinction between them: 1) Single stage detection framew orks use a single network to produce object detection locations and class predic- tion simultaneously . 2) Region proposal detection frame works use tw o distinct stages, where general regions of interest are first pro- posed, then categorized by separate classifier networks. Region proposal methods are currently leading detection benchmarks, but at the cost requiring high computation power , and generally being dif ficult to implement, train and fine-tune. Meanwhile, single stage detection algorithms tend to hav e fast inference time and low memory cost, which is well-suited for real-time driving automation. YOLO (Y ou Only Look Once) [135] is a popular single stage detector, which has been improved continuously [128], [136]. Their network uses a DCNN to extract image features on a coarse grid, significantly reducing the resolution of the input image. A fully-connected neural network then predicts class proba- bilities and bounding box parameters for each grid cell and class. This design makes YOLO very fast, the full model operating at 45 FPS and a smaller model operating at 155 FPS for a small accuracy trade-off. More recent versions of this method, YOLOv2, YOLO9000 [136] and YOLOv3 [128] briefly took over the P ASCAL VOC and MS COCO benchmarks while maintaining low computation and memory cost. Another widely used algorithm, e v en faster than Y OLO, is the Single Shot Detector (SSD) [137], which uses standard DCNN architectures such as VGG [130] to achie v e competi- tiv e results on public benchmarks. SSD performs detection on a coarse grid similar to YOLO, but also uses higher resolution features obtained early in the DCNN to improve detection and localization of small objects. Considering both accuracy and computational cost is es- sential for detection in ADS; the detection needs to be reli- able, but also operate better than real-time, to allow as much time as possible for the planning and control modules to react to those objects. As such, single stage detectors are often the detection algorithms of choice for ADSs. Ho wev er , as sho wn in T able 6, region proposal networks (RPN), used in two- stage detection frame works, hav e prov en to be unmatched in terms of object recognition and localization accuracy , and computational cost has improved greatly in recent years. They are also better suited for other tasks related to detection, such as semantic segmentation as discussed in Section V -A2. Through transfer learning, RPNs achieving multiple percep- tion tasks simultaneously are become increasingly feasible for online applications [138]. RPNs can replace single stage detection networks for ADS applications in the near future. Omnidirectional and event camera-based per ception: 360 degree vision, or at least panoramic vision, is necessary for higher le vels of automation. This can be achie ved through camera arrays, though precise extrinsic calibration between each camera is then necessary to make image stitching pos- sible. Alternativ ely , omnidirectional cameras can be used, or a smaller array of cameras with very wide angle fisheye lenses. These are ho we ver difficult to intrinsically calibrate; the spherical images are highly distorted and the camera model used must account for mirror reflections or fisheye lens distortions, depending on the camera model producing the panoramic images [141], [142]. The accuracy of the model and calibration dictates the quality of undistorted images pro- duced, on which the aforementioned 2D vision algorithms are used. An example of fisheye lenses producing two spherical images then combined into one panoramic image is shown in Figure 3. Some distortions ine vitably remain, but despite these challenges in calibration, omnidirectional cameras hav e been used for man y applications such as SLAM [143] and 3D reconstruction [144]. FIGURE 8: An urban scene near Nagoya University , with camera and lidar data collected by our experimental vehicle and object detection outputs from state-of-the-art perception algorithms. (a) A front facing camera’ s vie w , with bounding box results from Y OLOv3 [128] and (b) instance segmentation results from MaskRCNN [138]. (c) Semantic segmentation masks produced by DeepLabv3 [139]. (d) The 3D Lidar data with object detection results from SECOND [140]. Amongst the four , only the 3D perception algorithm outputs range to detected objects. Event cameras are a fairly new modality which output asynchronous ev ents usually caused by movement in the observed scene, as sho wn in Figure 4. This makes the sensing modality interesting for dynamic object detection. The other appealing factor is their response time on the order of mi- croseconds [90], as frame rate is a significant limitation for high-speed dri ving. The sensor resolution remains an issue, but ne w models are rapidly improving. They hav e been used for a variety of applications closely related to ADS. A re- cent survey outlines progress in pose estimation and SLAM, visual-inertial odometry and 3D reconstruction, as well as other applications [145]. Most notably , a dataset for end-to- end driving with ev ent cameras was recently published, with preliminary experiments showing that the output of an event camera can, to some extent, be used to predict car steering angle [89]. Poor Illumination and Changing Appearance: The main drawback with using camera is that changes in lighting conditions can significantly affect their performance. Low light conditions are inherently difficult to deal with, while changes in illumination due to shifting shado ws, intemperate weather , or seasonal changes, can cause algorithms to fail, in particular supervised learning methods. For example, snow drastically alters the appearance of scenes and hides poten- tially ke y features such as lane markings. An easy alternati ve is to use an alternate sensing modalities for perception, but lidar also has difficulties with some weather conditions like fog and snow [146], and radars lack the necessary resolution for many perception tasks [51]. A sensor fusion strategy is often employed to a void an y single point of failure [147]. Thermal imaging through infrared sensors are also used for object detection in lo w light conditions, which is particularly effecti v e for pedestrian detection [148]. Camera-only meth- ods which attempt to deal with dynamic lighting conditions directly ha ve also been de veloped. Both attempting to extract lighting inv ariant features [149] and assessing the quality of features [150] hav e been proposed. Pre-processed, illumina- tion inv ariant images hav e applied to ADS [151] and were shown to improv e localization, mapping and scene classifica- tion capabilities o ver long periods of time. Still, dealing with the unpredictable conditions brought forth by inadequate or changing illumination remains a central challenge pre v enting the widespread implementation of ADS. 2) Semantic Segmentation Beyond image classification and object detection, computer vision research has also tackled the task of image segmen- tation. This consists of classifying each pixel of an image with a class label. This task is of particular importance to driving automation as some objects of interest are poorly defined by bounding boxes, in particular roads, traffic lines, sidew alks and buildings. A segmented scene in an urban area can be seen in Figure 8. As opposed to semantic seg- mentation, which labels pixels based on a class, instance segmentation algorithms further separates instances of the same class, which is important in the context of driving automation. In other words, objects which may ha ve different trajectories and behaviors must be differentiated from each FIGURE 9: Outline of a traditional method for object detection from 3D pointcloud data. V arious filtering and data reduction methods are used first, followed by clustering. The resulting clusters are shown by the different colored points in the 3D lidar data of pedestrians collected by our data collection platform. other . W e used the COCO dataset [152] to train the instance segmentation algorithm Mask R-CNN [138] with the sample result shown in Figure 8. Segmentation has recently become feasible for real-time applications. Generally , dev elopments in this field progress in parallel with image-based object detection. The afore- mentioned Mask R-CNN [138] is a generalization of Faster R-CNN [153]. The multi-task R-CNN network can achie ve accurate bounding box estimation and instance segmentation simultaneously and can also be generalized to other tasks like pedestrian pose estimation with minimal domain kno wledge. Running at 5 fps means it is approaching the area of real-time use for ADS. Unlike Mask-RCNN’ s architecture which is more akin to those used for object detection through its use of region proposal networks, segmentation networks usually employ a combination of con volutions for feature extraction. Those are followed by decon volutions, also called transposed con volu- tions, to obtain pixel resolution labels [154], [155]. Feature pyramid networks are also commonly used, for example in PSPNet [156], which also introduced dilated conv olutions for segmentation. This idea of sparse con v olutions was then used to de velop DeepLab [157], with the most recent version being the current state-of-the-art for object segmentation [139]. W e employed DeepLab with our ADS and a segmented frame is shown in Figure 8. While most segmentation networks are as of yet too slow and computationally expensi v e to be used in ADS, it is im- portant to notice that many of these segmentations networks are initially trained for different tasks, such as bounding box estimation, then generalized to segmentation networks. Furthermore, these networks were shown to learn uni versal feature representations of images, and can be generalized for many tasks. This suggests the possibility that single, generalized perception networks may be able to tackle all perception tasks required for an ADS. 3) 3D Object Detection Giv en their affordability , av ailability and widespread re- search, cameras are used by nearly all algorithms presented so far as the primary perception modality . Howe v er , cam- eras hav e limitations that are critical to ADS. Aside from illumination which was previously discussed, camera-based object detection occurs in the projected image space and therefore the scale of the scene is unknown. T o make use of this information for dynamic driving tasks like obstacle av oidance, it is necessary to bridge the gap from 2D image- based detection to the 3D, metric space. Depth estimation is therefore necessary , which is in fact possible with a single camera [158] though stereo or multi-vie w systems are more robust [159]. These algorithms necessarily need to solve an expensi ve image matching problem, which adds a significant amount of processing cost to an already complex perception pipeline. A relatively new sensing modality , the 3D lidar, offers an alternativ e for 3D perception. The 3D data collected inherently solv es the scale problem, and since they ha v e their own emission source, they are far less dependable on lighting condition, and less susceptible to intemperate weather . The sensing modality collects sparse 3D points representing the surfaces of the scene, as sho wn in Figure 9, which are challenging to use for object detection and classification. The appearance of objects change with range, and after some distance, very fe w data points per objects are av ailable to detect an object. This poses some challenges for detection, but since the data is a direct representation of the world, it is more easily separable. Traditional methods often use euclidean clustering [160] or region-growing methods [161] for grouping points into objects. This approach has been made much more robust through v arious filtering techniques, FIGURE 10: A depth image produced from synthetic lidar data, generated in the CARLA [164] simulator . such as ground filtering [162] and map-based filtering [163]. W e implemented a 3D object detection pipeline to get clus- tered objects from raw point cloud input. An example of this process is shown in Figure 9. As with image-based methods, machine learning has also recently taken over 3D detection methods. These methods hav e also notably been applied to RGB-D [165], which produce similar, but colored, point clouds; with their limited range and unreliability outdoors, RGB-D hav e not been used for ADS applications. A 3D representation of point data, through a 3D occupancy grid called vox el grids, was first applied for object detection in RGB-D data [165]. Shortly thereafter , a similar approach was used on point clouds created by lidars [166]. Inspired by image-based methods, 3D CNNs are used, despite being computationally very ex- pensiv e. The first convincing results for point cloud-only 3D bound- ing box estimation were produced by V oxelNet [167]. Instead of hand-crafting input features computed during the dis- cretization process, V oxelNet learned an encoding from raw point cloud data to vox el grid. Their voxel feature encoder (VFE) uses a fully connected neural network to con v ert the variable number of points in each occupied voxel to a feature vector of fixed size. The voxel grid encoded with feature vectors was then used as input to an aforementioned RPN for multi-class object detection. This work was then improved both in terms of accuracy and computational efficiency by SECOND [140] by exploiting the natural sparsity of lidar data. W e employed SECOND and a sample result is sho wn in Figure 8. Sev eral algorithms hav e been produced recently , with accuracy constantly improving as shown in T able 7, yet the computational comple xity of 3D conv olutions remains an issue for real-time use. Another option for lidar-based perception is 2D projection of point cloud data. There are two main representations of point cloud data in 2D, the first being a so-called depth image shown in Figure 10, largely inspired by camera-based methods that perform 3D object detection through depth esti- mation [168] and methods that operate on RGB-D data [169]. The V eloFCN network [170] proposed to use single-channel depth image as input to a shallow , single-stage conv olutional neural network which produced 3D vehicle proposals, with many other algorithms adopting this approach. Another use FIGURE 11: Bird’ s eye view perspective of 3D lidar data, a sample from the KITTI dataset [177]. T ABLE 7: A verage Precision (AP) in % on the KITTI 3D object detection test set car class, ordered based on moderate category accuracy . These algorithms only use pointcloud data. Algorithm T [s] Easy Moderate Hard PointRCNN [179] 0.10 85.9 75.8 68.3 PointPillars [180] 0.02 79.1 75.0 68.3 SECOND [140] 0.04 83.1 73.7 66.2 IPOD [181] 0.20 82.1 72.6 66.3 F-PointNet [182] 0.17 81.2 70.4 62.2 V oxelNet (Lidar) [167] 0.23 77.5 65.1 57.7 MV3D (Lidar) [172] 0.24 66.8 52.8 51.3 of depth image w as sho wn for semantic classification of lidar points [171]. The other 2D projection that has seen increasing popular- ity , in part due to the ne w KITTI benchmark, is projection to bird’ s eye view (BV) image. This is a top-view image of point clouds as shown in Figure 11. Bird’ s eye view images discretize space purely in 2D, so lidar points which v ary in height alone occlude each other . The MV3D algorithm [172] used camera images, depth images, as well as multi-channel BV images; each channel corresponding to a different range of heights, so as to minimize these occlusions. Several other works have reused camera-based algorithms and trained ef- ficient networks for 3D object detection on 2D BV images [173]–[176]. State-of-the-art algorithms are currently being ev aluated on the KITTI dataset [177] and nuScenes dataset [178] as they offer labeled 3D scenes. T able 7 shows the lead- ing methods on the KITTI benchmark, alongside detection times. 2D methods are far less computationally expensi ve, but recent methods that take point sparsity into account [140] are real-time viable and rapidly approaching the accuracy necessary for integration in ADSs. Radar Radar sensors hav e already been used for various perception applications, in various types of vehicles, with different models operating at complementary ranges. While not as accurate as the lidar , it can detect at object at high range and estimate their v elocity [113]. The lack of precision for estimating shape of objects is a major drawback when it is used in perception systems [51], the resolution is simply too low . As such, it can be used for range estimation to large objects like vehicles, but it is challenging for pedestrians or FIGURE 12: A scene with sev eral tracked pedestrians and cy- clist with a basic particle filter on an urban road intersection. Past trajectories are sho wn in white with current heading and speed shown by the direction and magnitude of the arrow , sample collected by our data collection platform. static objects. Another issue is the very limited field of view of most radars, forcing a complicated array of radar sensors to cover the full field of view . Nevertheless, radar hav e seen widespread use as an AD AS component, for applications including proximity warning and adaptive cruise control [146]. While radar and lidar are often seen as competing sensing modalities, they will likely be used in tandem in fully automated dri ving systems. Radars are very long range, hav e low cost and are robust to poor weather, while lidar offer precise object localization capabilities, as discussed in Section IV. Another similar sensor to the radar are sonar devices, though their e xtremely short range of < 2 m and poor angular resolution makes their use limited to very near obstacle detection [146]. B. OBJECT TRACKING Object tracking is also often referred to as multiple object tracking (MO T) [183] and detection and tracking of multiple objects (D A TMO) [184]. For fully automated driving in complex and high speed scenarios, estimating location alone is insufficient. It is necessary to estimate dynamic objects’ heading and velocity so that a motion model can be applied to track the object o ver time and predict future trajectory to av oid collisions. These trajectories must be estimated in the vehicle frame to be used by planning, so range information must be obtained through multiple camera systems, lidars or radar sensors. 3D lidars are often used for their precise range information and large field of view , allowing tracking ov er longer periods of time. T o better cope with the limitations and uncertainties of different sensing modalities, a sensor fusion strategy is often use for tracking [47]. Commonly used object trackers rely on simple data as- sociation techniques followed by traditional filtering meth- ods. When objects are tracked in 3D space at high frame rate, nearest neighbor methods are often sufficient for estab- lishing associations between objects. Image-based methods, howe v er , need to establish some appearance model, which may consider the use of color histograms, gradients and other features such as KL T to ev aluate the similarity [185]. Point cloud based methods may also use similarity metrics such as point density and Hausdorf f distance [163], [186]. Since association errors are always a possibility , multiple hypothesis tracking algorithms [187] are often employed, which ensures tracking algorithms can recover from poor data association at any single time step. Using occupancy maps as a frame for all sensors to contribute to and then doing data association in that frame is common, especially when using multiple sensors [188]. T o obtain smooth dynamics, the detection results are filtered by traditional Bayes filters. Kalman filtering is sufficient for simple linear models, while the extended and and unscented Kalman filters [189] are used to handle nonlinear dynamic models [190]. W e implemented a basic particle filter based object-tracking algorithm, and an example of tracked pedestrians in contrasting camera and 3D lidar perspectiv e is sho wn in Figure 12. Physical models for the object being tracked are also often used for more robust tracking. In that case, non-parametric methods such as particle filters are used, and physical pa- rameters such as the size of the object are tracked alongside dynamics [191]. More inv olved filtering methods such as Rao-Blackwellized particle filters hav e also been used to keep track of both dynamic variables and vehicle geometry variables for an L-shape v ehicle model [192]. V arious models hav e been proposed for vehicles and pedestrians, while some models generalize to any dynamic object [193]. Finally , deep learning has also been applied to the problem of tracking, particularly for images. Tracking in monocular images was achiev ed in real-time through a CNN-based method [194], [195]. Multi-task network which estimate ob- ject dynamics are also emer ging [196] which further suggests that generalized networks tackling multiple perception tasks may be the future of ADS perception. C. RO AD AND LANE DETECTION Bounding box estimation methods previously covered are useful for defining some objects of interest but are inadequate for continuous surfaces like roads. Determining the driv able surface is critical for ADSs and has been specifically re- searched as a subset of the detection problem. While driv able surfaces can be determined through semantic segmentation, automated vehicles need to understand road semantics to properly negotiate the road. An understanding of lanes, and how they are connected through merges and intersections remains a challenge from the perspective of perception. In this section, we pro vide an overvie w of current methods used for road and lane detection, and refer the reader to in-depth surve ys of traditional methods [198] and the state-of-the-art methods [199], [200]. This problem is usually subdivided in se veral tasks, each unlocking some level of automation. The simplest is deter- mining the driv able area from the perspectiv e of the ego- vehicle. The road can then be divided into lanes, and the FIGURE 13: Annotating a 3D point cloud map with topological information. A large number of annotators were employed to build the map sho wn on the right-hand side. The point-cloud and annotated maps are a vailable on [197]. vehicles’ host lane can be determined. Host lane estimation ov er a reasonable distance allows AD AS technology such as lane departure warning, lane keeping and adaptiv e cruise con- trol [198], [201]. Even more challenging is determining other lanes and their direction [202], and finally understanding complex semantics, as in their current and future direction, or merging and turning lanes [47]. These ADAS or ADS technologies have different criteria both in terms of task, detection distance and reliability rates, but fully automated driving will require a complete, semantic understanding of road structures and the ability to detect sev eral lanes at long ranges [199]. Annotated maps as shown in Figure 13 are extremely useful for understanding lane semantics. Current methods on road understanding typically first rely on exteroceptiv e data preprocessing. When cameras are used, this usually means performing image color corrections to normalize lighting conditions [203]. For lidar , several fil- tering methods can be used to reduce clutter in the data such as ground extraction [162] or map-based filtering [163]. For any sensing modality , identifying dynamic objects which conflicts with the static road scene is an important pre- processing step. Then, road and lane feature extraction is performed on the corrected data. Color statistics and intensity information [204], gradient information [205], and various other filters hav e been used to detect lane markings. Similar methods ha ve been used for road estimation, where the usual uniformity of roads and elev ation gap at the edge allows for region growing methods to be applied [206]. Stereo camera systems [207], as well as 3D lidars [204], have been used determine the 3D structure of roads directly . More recently , machine learning-based methods which either fuse maps with vision [200] or use fully appearance-based segmentation [208] hav e been used. Once surfaces are estimated, model fitting is used to es- tablish the continuity of the road and lanes. Geometric fitting through parametric models such as lines [209] and splines [204] have been used, as well as non-parametric continuous models [210]. Models that assume parallel lanes hav e been used [201], and more recently models integrating topological elements such as lane splitting and merging were proposed [204]. T emporal inte gration completes the road and lane se gmen- tation pipeline. Here, vehicle dynamics are used in combina- tion with a road tracking system to achie ve smooth results. Dynamic information can also be used alongside Kalman filtering [201] or particle filtering [207] to achieve smoother results. Road and lane estimation is a well-researched field and many methods have already been integrated successfully for lane keeping assistance systems. Howe ver , most methods remain riddled with assumptions and limitations, and truly general systems which can handle complex road topologies hav e yet to be developed. Through standardized road maps which encode topology and emerging machine learning- based road and lane classification methods, robust systems for driving automation are slo wly taking shape. VI. ASSESSMENT A robust ADS should constantly evaluate the overall risk lev el of the situation and predict the intentions of surrounding human driv ers and pedestrians. A lack of acute assessment mechanism can lead to accidents. This section discusses assessment under three subcategories: overall risk and uncer- tainty assessment, human driving behavior assessment, and driving style recognition. A. RISK AND UNCERT AINTY ASSESSMENT Overall assessment can be summarized as quantifying the uncertainties and the risk level of the driving scene. It is a promising methodology that can increase the safety of ADS pipelines [31]. Using Bayesian methods to quantify and measure uncer- tainties of deep neural networks was proposed in [212]. A Bayesian deep learning architecture was designed for prop- agating uncertainty throughout an ADS pipeline, and the advantage of it over conv entional approaches was shown in a hypothetical scenario [31]. In summary , each module con ve ys and accepts probability distrib utions instead of exact outcomes throughout the pipeline, which increases the over - all robustness of the system. An alternative approach is to assess the o verall risk level of the dri ving scene separately , i.e outside the pipeline. Sensory inputs were fed into a risk inference frame work in [83], [213] to detect unsafe lane change events using Hidden Markov Models (HMMs) and language models. Recently , a deep FIGURE 14: Assessing the ov erall risk le vel of dri ving scenes. W e employed an open-source 1 deep spatiotemporal video-based risk detection framew ork [211] to assess the image sequences sho wn in this figure. spatiotemporal network that infers the overall risk lev el of a driving scene was introduced in [211]. Implementation of this method is av ailable open-source 1 . W e employed this method to assess the risk le vel of a lane change as shown in Figure 14. B. SURROUNDING DRIVING BEHA VIOR ASSESSMENT Understanding surrounding human driv er intention is most relev ant to medium to long term prediction and decision making. In order to increase the prediction horizon of sur- rounding object behavior , human traits should be considered and incorporated into the prediction and ev aluation steps. Un- derstanding surrounding driv er intention from the perspectiv e of an ADS is not a common practice in the field, as such, state-of-the-art is not established yet. In [214], a target vehicle’ s future behavior was predicted with a hidden Markov model (HMM) and the prediction time horizon was extended 56% by learning human driving traits. The proposed system tagged observations with predefined maneuvers. Then, the features of each type were learned in a data-centric manner with HMMs. Another learning based approach was proposed in [215], where a Bayesian network classifier w as used to predict maneuvers of individual dri v ers on highways. A framework for long term driv er behavior prediction using a combination of a hybrid state system and HMM was introduced in [216]. Surrounding vehicle information was integrated with ego-behavior through a sym- bolization frame w ork in [83], [213]. Detecting dangerous cut in maneuvers was achiev ed with an HMM frame work that was trained on safe and dangerous data in [217]. Lane change ev ents were predicted 1.3 seconds in advance with support vector machines (SVM) and Bayesian filters [218]. The main challenges are the short observation windo w for understanding the intention of humans and real-time high- frequency computation requirements. ADSs can typically only observe a surrounding vehicle only for seconds. Compli- 1 https://github .com/Ekim-Y urtsever/DeepTL-Lane-Change- Classification cated driving behavior models that require longer observation periods cannot be utilized under these circumstances. C. DRIVING STYLE RECOGNITION In 2016, Google’ s self-driving car collided with an oncoming bus [8] during a lane change where it assumed that the b us driv er was going to yield. Howe ver , the bus driver accelerated instead. This accident may ha ve been pre vented if the ADS understood the bus driv er’ s indi vidual, unique driving style and predicted his behavior . Driving style is a broad term without an established com- mon definition. Furthermore, recognizing the surrounding human driving styles is a sev erely understudied topic. How- ev er , thorough revie ws of driving style categorization of human-driven ego vehicles can be found in [220] and in [221]. Readers are referred to these papers for a complete re- view . The remainder of this subsection giv es a brief overvie w of human-driven ego vehicle-based dri ving style recognition. T ypically , driving style is defined with respect to either ag- gressiv eness [222]–[226] or fuel consumption [227]–[231]. For example, [232] introduced a rule-based model that clas- sified driving styles with respect to jerk. This model decides whether a maneuver is aggressiv e or calm by a set of rules and jerk thresholds. Driv ers were categorized with respect to their average speed in [233]. In con ventional methods, total number and meaning of driving style classes are predefined beforehand. The vast majority of driving style recognition literature uses two [83], [213], [222], [223], [227] or three [234]–[236] classes. Representing driving style in a con- tinuous domain is uncommon, but there are some studies. In [237], driving style was depicted as a continuous value between -1 and +1, which stands for mild and active respec- tiv ely . Details of classification methods are giv en in T able 8. More recently , machine learning based approaches hav e been utilized for driving style recognition. Principal com- ponent analysis was used and fiv e distinct driving classes were detected in an unsupervised manner in [238] and a GMM based driv er model was used to identify individ- ual drivers with success in [241]. Car-following and pedal FIGURE 15: Global plan and the local paths. The annotated vector map shown in Figure 13 was utilized by the planner . W e employed OpenPlanner [219], which is a graph-based planner , to illustrate a typical planning approach. T ABLE 8: Driving style categorization of human-driv en ego vehicles Related work # Classes Methodology Class details [238] 5 PCA non-aggressive to v ery aggressiv e [239] 3 NN, SVM, DT expert/typical/lo w-skill [234] 3 FL sporty/normal/comfortable [235] 3 PCMLP aggressiv e/moderate/calm [240] 3 SAE & K-means unidentified clusters [83] 2 non-param. Bayesian risky/safe [222] 2 DTW aggressiv e/non- aggressiv e [223] 2 RB sudden/safe [237] Continuous [ − 1 , 1] NN mild to acti ve operation behavior was in vestigated separately in the lat- ter study . Another GMM based dri ving style recognition model was proposed for electric vehicle range prediction in [242]. In [222], aggressi ve ev ent detection with dynamic time warping was presented where the authors reported a high success score. Bayesian approaches were utilized in [243] for modeling dri ving style on roundabouts and in [244] to asses critical braking situations. Bag-of-words and K-means clustering was used to represent individual driving features in [245]. A stacked autoencoder was used to extract unique driving signatures from different drivers, and then macro driving style centroids were found with clustering [240]. Another autoencoder network was used to extract road-type specific driving features [246]. Similarly , driving beha vior was encoded in a 3-channel RGB space with a deep sparse autoencoder to visualize individual dri ving styles [247]. A successful integration of driving style recognition into a real world ADS pipeline is not reported yet. Howe v er , these studies are promising and point to a possible ne w direction in ADS dev elopment. VII. PLANNING AND DECISION MAKING Planning can be divided into two sub-tasks: global route planning and local path planning. Figure 15 illustrates a typical planning approach in detail. The remainder of this section gi ves a brief overvie w of the subject. For more information studies such as [18], [23], [248] can be referred. A. GLOBAL PLANNING The global planner is responsible for finding the route on the road network from origin to the final destination. The user usually defines the final destination. Global navigation is a well-studied subject, and high performance has become an industry standard for more than a decade. Almost all modern production cars are equipped with navig ation systems that utilize GPS and offline maps to plan a global route. Route planning is formulated as finding the point-to-point shortest path in a directed graph, and conv entional methods are examined under four categories in [248]. These are; goal-directed, separator-based, hierarchical and bounded-hop techniques. A* search [249] is a standard goal-directed path planning algorithm and used extensi vely in various fields for almost 50 years. The main idea of separator-based techniques is to remove a subset of vertices [250] or arcs from the graph and com- pute an ov erlay graph over it. Using the overlayed graph to calculate the shortest path results in faster queries. Hierarchical techniques take advantage of the road hier- archy . For example, the road hierarchy in the US can be listed from top to bottom as freew ays, arterials, collectors and local roads respectiv ely . For a route query , the importance of hierarchy increases as the distance between origin and destination gets longer . The shortest path may not be the fastest nor the most desirable route anymore. Getting away from the destination thus making the route a bit longer to take the closest highway ramp may result in f aster tra vel time in comparison to follo wing the shortest path of local roads. Contraction Hierarchies (CH) method was proposed in [251] for exploiting road hierarchy . T ABLE 9: Local planning techniques Approach Methods Pros and cons Graph search Dijkstra [254], A* [249], State lattice [255] Slow and jerk y Sampling based RPP [256], RR T [257], RR T* [258], PRM [259] Fast solution b ut jerky Curve interpolation clothoids [260], polynomials [261], Bezier [262], splines [104] Smooth but slo w Numerical optimization num. non-linear opt. [263], Newton’ s method [264] increases computational cost but impro ves quality Deep learning FCN [265], segmentation network [266] high imitation performance, but no hard coded safety measures Precomputing distances between selected vertex es and utilizing them on the query time is the basis of bounded-hop techniques. Precomputed shortcuts can be utilized partly or exclusi vely for navigation. Howe v er , the nai ve approach of precomputing all possible routes from ev ery pair of vertices is impractical in most cases with large networks. One possible solution to this is to use hub labeling (HL) [252]. This approach requires preprocessing also. A label associated with a vertex consists of nearby hub vertices and the distance to them. These labels satisfy the condition that at least one shared hub vertex must e xist between the labels of any giv en two vertices. HL is the f astest query time algorithm for route planning [248], in the expense of high storage usage. A combination of the abov e algorithms are popular in state-of-the-art systems. F or example, [253] combined a sep- arator with a bounded-hop method and created the T ransit Node Routing with Arc Flags (TNR+AF) algorithm. Modern route planners can make a query in milliseconds. B. LOCAL PLANNING The objectiv e of the local planner is to ex ecute a global plan without failing . In other words, in order to complete its trip, the ADS must find trajectories to av oid obstacles and satisfy optimization criteria in the configuration space (C- space), giv en a starting and destination point. A detailed local planning revie w is presented in [19] where the taxonomy of motion planning was divided into four groups; graph- based planners, sampling-based planners, interpolating curve planners and numerical optimization approaches. After a summary of these conv entional planners, the emerging deep learning-based planners are introduced at the end of this section. T able 9 giv es a brief summary of local planning methods. Graph-based local planners use the same techniques as graph-based global planners such as Dijkstra [254] and A* [249], which output discrete paths rather than continuous ones. This can lead to jerky trajectories [19]. A more ad- vanced graph-based planner is the state lattice algorithm. As all graph-based methods, state lattice discretizes the decision space. High dimensional lattice nodes, which typically en- code 2D position, heading and curvature [255], are used to create a grid first. Then, the connections between the nodes are precomputed with an inv erse path generator to build the state lattice. During the planning phase, a cost function, which usually considers proximity to obstacles and de viation from the goal, is utilized for finding the best path with the precomputed path primitiv es. State lattices can handle high dimensions and is good for local planning in dynamical en- vironments, howe ver , the computational load is high and the discretization resolution limits the planners’ capacity [19]. A detailed ov erview of Sampling Based Planning (SBP) methods can be found in [267]. In summary , SBP tries to build the connectivity of the C-space by randomly sampling paths in it. Randomized Potential Planner (RPP) [256] is one of the earliest SBP approaches, where random walks are generated for escaping local minimums. Probabilistic roadmap method (PRM) [259] and rapidly-e xploring random tree (RR T) [257] are the most commonly used SBP algo- rithms. PRM first samples the C-space during its learning phase and then makes a query with the predefined origin and destination points on the roadmap. RR T , on the other hand, is a single query planner . The path between start and goal configuration is incrementally built with random tree-like branches. RR T is faster than PRM and both are probabilis- tically complete [257], which means a path that satisfies the giv en conditions will be guaranteed to be found with enough runtime. RR T* [258], an extension of the RR T , provides more optimal paths instead of completely random ones while sacrificing computational efficienc y . The main disadv antage of SBP in general is, again, the jerky trajectories [19]. Interpolating curve planners fit a curve to a known set of points [19], e.g. way-points generated from the global plan or a discrete set of future points from another local planner . The main obstacle av oidance strategy is to inter- polate ne w collision-free paths that first deviate from, and then re-enter back to the initial planned trajectory . The new path is generated by fitting a curve to a new set of points: an exit point from the currently traversed trajectory , newly sampled collision free points, and a re-entry point on the initial trajectory . The resultant trajectory is smooth, howe v er , the computational load is usually higher compared to other methods. There are v arious curv e families that are used com- monly such as clothoids [260], polynomials [261], Bezier curves [262] and splines [104]. Optimization based motion planners improv e the quality of already existing paths with optimization functions. A* trajectories were optimized with numeric non-linear func- tions in [263]. Potential Field Method (PFM) was improved by solving the inherent oscillation problem using Newton’ s method with obtaining C 1 continuity in [264]. Recently , Deep Learning (DL) and reinforcement learning based local planners started to emerge as an alternativ e. Fully con v olutional 3D neural networks can generate future paths from sensory input such as lidar point clouds [265]. An interesting take on the subject is to segment image data with path proposals using a deep segmentation network [266]. Planning a safe path in occluded intersections was achiev ed in a simulation en vironment using deep reinforcement learn- ing in [268]. The main difference between end-to-end driving and deep learning based local planners is the output: the former outputs direct vehicle control signals such as steering and pedal operation, whereas the latter generates a trajectory . This enables DL planners to be integrated into conv entional pipelines [24]. Deep learning based planners are promising, b ut they are not widely used in real-world systems yet. Lack of hard- coded safety measures, generalization issues, need for la- beled data are some of the issues that need to be addressed. VIII. HUMAN MACHINE INTERA CTION V ehicles communicate with their driv ers/passengers through their HMI module. The nature of this communication greatly depends on the objecti ve, which can be divided into two: primary driving tasks and secondary tasks. The interaction in- tensity of these tasks depend on the automation lev el. Where a manually operated, lev el zero con ventional car requires constant user input for operation, a lev el fiv e ADS may need user input only at the beginning of the trip. Furthermore, the purpose of interaction may affect intensity . A shift from ex ecuting primary driving tasks to monitoring the automation process raises new HMI design requirements. There are se veral in vestigations such as [269], [270] about automotiv e HMI technologies, mostly from the distraction point of vie w . Manual user interfaces for secondary tasks are more desired than their visual counterparts [269]. The main reason is vision is absolutely necessary and has no alterna- tiv e for primary driving tasks. V isual interface interactions require glances with durations between 0.6 and 1.6 seconds with a mean of 1.2 seconds [269]. As such, secondary task interfaces that require vision is distracting and detrimental for driving. Auditory User Interfaces (A UI) are good alternativ es to visually taxing HMI designs. A UIs are omni-directional: ev en if the user is not attending, the auditory cues are hard to miss [271]. The main challenge of audio interaction is auto- matic speech recognition (ASR). ASR is a very mature field. Howe v er , in vehicle domain there are additional challenges; low performance caused by uncontrollable cabin conditions such as wind and road noise [272]. Beyond simple voice commands, conv ersational natural language interaction with an ADS is still an unrealized concept with many unsolved challenges [273]. The biggest HMI challenge is at automation le vel three and four . The user and the ADS need to have a mutual understanding, otherwise, they will not be able to grasp each other’ s intentions [270]. The transition from manual to automated driving and vice versa is prone to fail in the state- of-the-art. Recent research showed that dri vers exhibit low cognitiv e load when monitoring automated driving compared to doing a secondary task [288]. Even though some exper - imental systems can recognize driv er-acti vity with a driv er facing camera based on head and eye-tracking [289], and prepare the dri ver for handover with visual and auditory cues [290] in simulation en vironments, a real world system with an ef ficient handov er interaction module does not exist at the moment. This is an open problem [291] and future research should focus on delivering better methods to inform/prepare the driv er for easing the transition [41]. IX. DA T ASETS AND A V AILABLE TOOLS A. DA T ASETS AND BENCHMARKS Datasets are crucial for researchers and de velopers because most of the algorithms and tools have to be tested and trained before going on road. T ypically , sensory inputs are fed into a stack of algorithms with v arious objectiv es. A common practice is to test and validate these functions separately on annotated datasets. F or example, the output of cameras, 2D vision, can be fed into an object detection algorithm to detect surrounding vehicles and pedestrians. Then, this information can be used in an- other algorithm for planning purposes. Even though these two algorithms are connected in the stack of this example, the object detection part can be worked on and validated separately during the development process. Since computer vision is a well-studied field, there are annotated datasets for object detection and tracking specifically . The existence of these datasets increases the development process and enables interdisciplinary research teams to work with each other much more efficiently . For end-to-end driving, the dataset has to include additional ego-vehicle signals, chiefly steering and longitudinal control signals. As learning approaches emer ged, so did training datasets to support them. The P ASCAL V OC dataset [292], which grew from 2005 to 2012, was one of the first dataset fea- turing a large amount of data with relev ant classes for ADS. Howe v er , the images often featured single objects, in scenes and scales that are not representativ e of what is encountered in driving scenarios. In 2012, the KITTI V ision Benchmark [177] remedied this situation by pro viding a relatively large amount of labeled driving scenes. It remains as one of the most widely used datasets for applications related to driving automation. Y et in terms of quantity of data and number of labeled classes, it is far inferior to generic image databases such as ImageNet [131] and COCO [152]. While no doubt useful for training, these generic image databases lack the adequate context to test the capabilities of ADS. UC Berkeley DeepDriv e [275] is a recent dataset with annotated image data. The Oxford RobotCar [53] was used to collect over 1000 km of driving data with six cameras, lidar , GPS and INS in the UK but is not annotated. ApolloScape is a very recent dataset that is not fully public yet [278]. Cityscapes [274] is commonly used for computer vision algorithms as a benchmark set. Mapillary V istas is a big image dataset with annotations [276]. T orontoCity benchmark [286] is a very detailed dataset; ho wev er it is not public yet. The nuScenes dataset is the most recent urban driving dataset with lidar and image sensors [178]. Comma.ai has released a part of their dataset [293] which includes 7.25 hours of driving. In T ABLE 10: Driving datasets Dataset Image LID AR 2D annotation* 3D annotation* ego signals Naturalistic PO V Multi trip all weathers day & night Cityscapes [274] X - X - - - V ehicle - - - Berkley DeepDri ve [275] X - X - - - V ehicle - X X Mapillary [276] X - X - - - V ehicle - X X Oxford RobotCar [53] X X - - - - V ehicle X X X KITTI [177] X X X X - - V ehicle - - - H3D [277] X X - X - - V ehicle - - - ApolloScape [278] X X X X - - V ehicle - - - nuScenes [178] X X X X - - V ehicle - X X Udacity [279] X X X X - - V ehicle - - - DDD17 [89] X - X - X - V ehicle - X X Comma2k19 [280] X - - - X - V ehicle - - X LiV i-Set [281] X X - - X - V ehicle - - - NU-driv e [282] X - - - X Semi V ehicle X - - SHRP2 [283] X - - - X X V ehicle - - - 100-Car [284] X - - - X X V ehicle - X X euroFO T [285] X - - - X X V ehicle - - - T orontoCity [286] X X X X - - Aerial, panorama, vehicle - - - KAIST multi-spectral [287] X X X - - - V ehicle - - X *2D and 3D annotation can vary from bounding box es to segmentation masks. Readers are referred to sources for details of the datasets. DDD17 [89] around 12 hours of dri ving data is recorded. The LiV i-Set [281] is a new dataset that has lidar, image and driving behavior . CommonRoad [294] is a new benchmark for motion-planning. Naturalistic driving data is another type of dataset that con- centrates on the individual element of the driving: the driv er . SHRP2 [283] includes over 3000 volunteer participants’ driv- ing data ov er a 3-year collection period. Other naturalistic driving datasets are the 100-Car study [284], euroFOT [285] and NUDriv e [282]. T able 10 shows the comparison of these datasets. B. OPEN-SOURCE FRAMEWORKS AND SIMULA T ORS Open source frame works are very useful for both researchers and the industry . These frameworks can “democratize" ADS dev elopment. Auto ware [122], Apollo [295], Nvidia Dri ve- W orks [296] and openpilot [297] are amongst the most used software-stacks capable of running an ADS platform in real world. W e utilized Autow are [122] to realize core automated driving functions in this study . Simulations also have an important place for ADS devel- opment. Since the instrumentation of an experimental vehicle still has a high cost and conducting experiments on public road networks are highly regulated, a simulation en viron- ment is beneficial for de veloping certain algorithms/modules before road tests. Furthermore, highly dangerous scenarios such as a collision with pedestrian can be tested in simula- tions with ease. CARLA [164] is an urban driving simulator dev eloped for this purpose. TORCS [298] was de v eloped for race track simulation. Some researchers ev en used computer games such as Grand Theft Auto V [299]. Gazebo [300] is a common simulation en vironment for robotics. For traffic simulations, SUMO [301] is a widely used open-source plat- form. [302] proposed different concepts of integrating real- world measurements into the simulation en vironment. X. CONCLUSIONS In this surve y on automated driving systems, we outlined some of the key innov ations as well as existing systems. While the promise of automated dri ving is enticing and already marketed to consumers, this survey has shown there remains clear gaps in the research. Se veral architecture mod- els have been proposed, from fully modular to completely end-to-end, each with their o wn shortcomings. The optimal sensing modality for localization, mapping and perception is still disagreed upon, algorithms still lack accuracy and efficienc y , and the need for a proper online assessment has become apparent. Less than ideal road conditions are still an open problem, as well as dealing with intemperate weather . V ehicle-to-vehicle communication is still in its inf ancy , while centralized, cloud-based information management has yet to be implemented due to the comple x infrastructure required. Human-machine interaction is an under-researched field with many open problems. The dev elopment of automated dri ving systems relies on the advancements of both scientific disciplines and new technologies. As such, we discussed the recent research dev elopments which are likely to hav e a significant impact on automated dri ving technology , either by ov ercoming the weakness of pre vious methods or by proposing an alterna- tiv e. This surve y has shown that through inter-disciplinary academic collaboration and support from industries and the general public, the remaining challenges can be addressed. W ith directed ef forts tow ards ensuring rob ustness at all levels of automated driving systems, safe and efficient roads are just beyond the horizon. REFERENCES [1] S. Singh, “Critical reasons for crashes inv estigated in the national motor vehicle crash causation surve y , ” T ech. Rep., 2015. [2] T . J. Crayton and B. M. Meier , “ Autonomous vehicles: Developing a public health research agenda to frame the future of transportation policy , ” Journal of T ransport & Health, vol. 6, pp. 245–252, 2017. [3] W . D. Montgomery , R. Mudge, E. L. Groshen, S. Helper, J. P . MacDuf fie, and C. Carson, “ America’ s workforce and the self-driving future: Realiz- ing productivity gains and spurring economic gro wth, ” 2018. [4] A. Krizhevsky , I. Sutskever , and G. E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neural infor- mation processing systems, 2012, pp. 1097–1105. [5] B. Schwarz, “Lidar: Mapping the world in 3d, ” Nature Photonics, vol. 4, no. 7, p. 429, 2010. [6] S. Hecker, D. Dai, and L. V an Gool, “End-to-end learning of dri ving models with surround-view cameras and route planners, ” in Proceedings of the European Conference on Computer V ision (ECCV), 2018, pp. 435–453. [7] D. Lavrinc. This is ho w bad self-driving cars suck in rain. https://jalopnik.com/this- is- how- bad- self- driving- cars- suck- in- the- rain- 1666268433. [Retrieved December 16, 2018]. [8] A. Davies. Google’s self-driving car caused its first crash. https://www .wired.com/2016/02/googles- self- driving- car- may- caused- first- crash/. [Retrieved December 16, 2018]. [9] M. McFarland. Who’ s responsible when an autonomous car crashes? https://money .cnn.com/2016/07/07/technology/tesla- liability- risk/index.html. [Retrie ved June 4, 2019]. [10] T . B. Lee. Autopilot was active when a tesla crashed into a truck, killing driv er . https://arstechnica.com/cars/2019/05/feds- autopilot- was- activ e- during- deadly- march- tesla- crash/. [Retrieved May 19, 2019]. [11] Eureka. E! 45: Programme for a european traffic system with high- est efficiency and unprecedented safety . https://www .eurekanetwork.org/ project/id/45. [Retriev ed May 19, 2019]. [12] B. Ulmer, “V ita ii-activ e collision av oidance in real traf fic, ” in Intelligent V ehicles’ 94 Symposium, Proceedings of the. IEEE, 1994, pp. 1–6. [13] M. Buehler , K. Iagnemma, and S. Singh, The 2005 DARP A grand challenge: the great robot race. Springer , 2007. [14] D. Feng, C. Haase-Schuetz, L. Rosenbaum, H. Hertlein, F . Duffhauss, C. Glaeser, W . W iesbeck, and K. Dietmayer, “Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges, ” arXiv preprint arXiv:1902.07830, 2019. [15] J. Levinson, J. Askeland, J. Becker, J. Dolson, D. Held, S. Kammel, J. Z. K olter, D. Langer, O. Pink, V . Pratt, et al., “T o wards fully autonomous driving: Systems and algorithms, ” in Intelligent V ehicles Symposium (IV), 2011 IEEE. IEEE, 2011, pp. 163–168. [16] M. Campbell, M. Egerstedt, J. P . How , and R. M. Murray , “ Autonomous driving in urban environments: approaches, lessons and challenges, ” Philosophical Transactions of the Royal Society of London A: Mathemat- ical, Physical and Engineering Sciences, vol. 368, no. 1928, pp. 4649– 4672, 2010. [17] S. Kuutti, S. Fallah, K. Katsaros, M. Dianati, F . Mccullough, and A. Mouzakitis, “ A survey of the state-of-the-art localization techniques and their potentials for autonomous vehicle applications, ” IEEE Internet of Things Journal, vol. 5, no. 2, pp. 829–846, 2018. [18] B. Paden, M. ˇ Cáp, S. Z. Y ong, D. Y ershov , and E. Frazzoli, “ A survey of motion planning and control techniques for self-driving urban vehicles, ” IEEE T ransactions on intelligent vehicles, vol. 1, no. 1, pp. 33–55, 2016. [19] D. González, J. Pérez, V . Milanés, and F . Nashashibi, “ A revie w of motion planning techniques for automated vehicles, ” IEEE T ransactions on Intelligent T ransportation Systems, vol. 17, no. 4, pp. 1135–1145, 2016. [20] J. V an Brummelen, M. O’Brien, D. Gruyer , and H. Najjaran, “ Au- tonomous vehicle perception: The technology of today and tomorrow , ” T ransportation research part C: emerging technologies, vol. 89, pp. 384– 406, 2018. [21] G. Bresson, Z. Alsayed, L. Y u, and S. Glaser , “Simultaneous localization and mapping: A survey of current trends in autonomous driving, ” IEEE T ransactions on Intelligent V ehicles, vol. 20, pp. 1–1, 2017. [22] K. Abboud, H. A. Omar , and W . Zhuang, “Interworking of dsrc and cellular network technologies for v2x communications: A surve y , ” IEEE transactions on vehicular technology , vol. 65, no. 12, pp. 9457–9470, 2016. [23] C. Badue, R. Guidolini, R. V . Carneiro, P . Azev edo, V . B. Cardoso, A. Forechi, L. F . R. Jesus, R. F . Berriel, T . M. Paixão, F . Mutz, et al., “Self-driving cars: A surv ey , ” arXiv preprint arXi v:1901.04407, 2019. [24] W . Schwarting, J. Alonso-Mora, and D. Rus, “Planning and decision- making for autonomous vehicles, ” Annual Review of Control, Robotics, and Autonomous Systems, vol. 1, pp. 187–210, 2018. [25] S. Lefèvre, D. V asquez, and C. Laugier, “ A survey on motion predic- tion and risk assessment for intelligent vehicles, ” ROBOMECH journal, vol. 1, no. 1, p. 1, 2014. [26] M. Buehler, K. Iagnemma, and S. Singh, The DARP A urban challenge: autonomous vehicles in city traf fic. Springer , 2009. [27] A. Broggi, P . Cerri, M. Felisa, M. C. Laghi, L. Mazzei, and P . P . Porta, “The vislab intercontinental autonomous challenge: an extensive test for a platoon of intelligent vehicles, ” International Journal of V ehicle Autonomous Systems, vol. 10, no. 3, pp. 147–164, 2012. [28] A. Broggi, P . Cerri, S. Debattisti, M. C. Laghi, P . Medici, D. Molinari, M. Panciroli, and A. Prioletti, “Proud-public road urban driverless-car test, ” IEEE Transactions on Intelligent T ransportation Systems, vol. 16, no. 6, pp. 3508–3519, 2015. [29] P . Cerri, G. Soprani, P . Zani, J. Choi, J. Lee, D. Kim, K. Y i, and A. Broggi, “Computer vision at the hyundai autonomous challenge, ” in 14th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2011, pp. 777–783. [30] C. Englund, L. Chen, J. Ploeg, E. Semsar-Kazerooni, A. V oronov , H. H. Bengtsson, and J. Didoff, “The grand cooperative driving challenge 2016: boosting the introduction of cooperati ve automated vehicles, ” IEEE W ireless Communications, vol. 23, no. 4, pp. 146–152, 2016. [31] R. McAllister , Y . Gal, A. Kendall, M. V an Der Wilk, A. Shah, R. Cipolla, and A. V . W eller , “Concrete problems for autonomous vehicle safety: advantages of bayesian deep learning. ” International Joint Conferences on Artificial Intelligence, Inc., 2017. [32] SAE, “T axonomy and definitions for terms related to driving automation systems for on-road motor vehicles, ” SAE J3016, 2016, T ech. Rep. [33] Department of Economic and Social Affairs (DESA), Population Divi- sion, “The 2017 revision, key findings and advance tables, ” in W orld Population Prospects. United Nations, 2017, no. ESA/P/WP/248. [34] Deloitte. 2019 deloitte global automoti ve consumer study – advanced vehicle technologies and multimodal transportation, global focus coun- tries. https://www2.deloitte.com/content/dam/Deloitte/us/Documents/ manufacturing/us- global- automoti ve- consumer- study- 2019.pdf. [Retriev ed May 19, 2019]. [35] Federatione Internationale de l’Automobile (FiA) Region 1. The auto- motiv e digital transformation and the economic impacts of existing data access models. https://www.fiare gion1.com/wp- content/uploads/2019/ 03/The- Automotive- Digital- T ransformation_Full- study .pdf. [Retrieved May 19, 2019]. [36] R. Rajamani, V ehicle dynamics and control. Springer Science & Business Media, 2011. [37] M. R. Hafner, D. Cunningham, L. Caminiti, and D. Del V ecchio, “Coop- erativ e collision avoidance at intersections: Algorithms and experiments, ” IEEE Transactions on Intelligent T ransportation Systems, vol. 14, no. 3, pp. 1162–1175, 2013. [38] A. Colombo and D. Del V ecchio, “Efficient algorithms for collision av oidance at intersections, ” in Proceedings of the 15th A CM international conference on Hybrid Systems: Computation and Control. ACM, 2012, pp. 145–154. [39] P . E. Ross, “The audi a8: the world’ s first production car to achieve lev el 3 autonomy , ” IEEE Spectrum, 2017. [40] C. Gold, M. Körber, D. Lechner, and K. Bengler , “T aking over control from highly automated vehicles in complex traffic situations: the role of traffic density , ” Human factors, v ol. 58, no. 4, pp. 642–652, 2016. [41] N. Merat, A. H. Jamson, F . C. Lai, M. Daly , and O. M. Carsten, “Transi- tion to manual: Driver behaviour when resuming control from a highly automated vehicle, ” T ransportation research part F: traffic psychology and behaviour , v ol. 27, pp. 274–282, 2014. [42] E. Ackerman, “T oyota’ s gill pratt on self-driving cars and the reality of full autonomy , ” IEEE Spectrum, 2017. [43] J. D’Onfro. ‘I hate them’: Locals reportedly are frustrated with alphabet’ s self-driving cars. https://www .cnbc.com/2018/08/28/locals- reportedly- frustrated- with- alphabets- waymo- self- driving- cars.html. [Retrieved May 19, 2019]. [44] J.-F . Bonnefon, A. Shariff, and I. Rahwan, “The social dilemma of autonomous vehicles, ” Science, v ol. 352, no. 6293, pp. 1573–1576, 2016. [45] ——, “ Autonomous v ehicles need experimental ethics: Are we ready for utilitarian cars?” arXiv preprint arXi v:1510.03346, 2015. [46] Y . Tian, K. Pei, S. Jana, and B. Ray , “Deeptest: Automated testing of deep-neural-network-driven autonomous cars, ” in Proceedings of the 40th International Conference on Software Engineering. ACM, 2018, pp. 303–314. [47] C. Urmson, J. Anhalt, D. Bagnell, C. Baker , R. Bittner, M. Clark, J. Dolan, D. Duggins, T . Galatali, C. Geyer , et al., “ Autonomous driving in urban environments: Boss and the urban challenge, ” Journal of Field Robotics, vol. 25, no. 8, pp. 425–466, 2008. [48] M. Gerla, E.-K. Lee, G. Pau, and U. Lee, “Internet of vehicles: From intelligent grid to autonomous cars and vehicular clouds, ” in IEEE W orld Forum on Internet of Things (WF-IoT). IEEE, 2014, pp. 241–246. [49] E.-K. Lee, M. Gerla, G. Pau, U. Lee, and J.-H. Lim, “Internet of vehicles: From intelligent grid to autonomous cars and vehicular fogs, ” Interna- tional Journal of Distributed Sensor Networks, v ol. 12, no. 9, 2016. [50] M. Amadeo, C. Campolo, and A. Molinaro, “Information-centric net- working for connected vehicles: a survey and future perspectives, ” IEEE Communications Magazine, vol. 54, no. 2, pp. 98–104, 2016. [51] J. W ei, J. M. Snider , J. Kim, J. M. Dolan, R. Rajkumar, and B. Litkouhi, “T owards a viable autonomous driving research platform, ” in Intelligent V ehicles Symposium (IV), 2013 IEEE. IEEE, 2013, pp. 763–770. [52] A. Broggi, M. Buzzoni, S. Debattisti, P . Grisleri, M. C. Laghi, P . Medici, and P . V ersari, “Extensiv e tests of autonomous dri ving technologies, ” IEEE Transactions on Intelligent T ransportation Systems, vol. 14, no. 3, pp. 1403–1415, 2013. [53] W . Maddern, G. Pascoe, C. Linegar , and P . Newman, “1 year , 1000 km: The oxford robotcar dataset, ” The International Journal of Robotics Research, vol. 36, no. 1, pp. 3–15, 2017. [54] N. Akai, L. Y . Morales, T . Y amaguchi, E. T akeuchi, Y . Y oshihara, H. Okuda, T . Suzuki, and Y . Ninomiya, “ Autonomous driving based on accurate localization using multilayer lidar and dead reckoning, ” in IEEE 20th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2017, pp. 1–6. [55] E. Guizzo, “How google’s self-driving car works, ” IEEE Spectrum On- line, vol. 18, no. 7, pp. 1132–1141, 2011. [56] H. Somerville, P . Lienert, and A. Sage. Uber’ s use of fe wer safety sensors prompts questions after arizona crash. Business news, Reuters, March 2018. [Retriev ed December 16, 2018]. [57] J. Ziegler , P . Bender, M. Schreiber, H. Lategahn, T . Strauss, C. Stiller, T . Dang, U. Franke, N. Appenrodt, C. G. Keller , et al., “Making Bertha driv e – an autonomous journey on a historic route, ” IEEE Intelligent T ransportation Systems Magazine, vol. 6, no. 2, pp. 8–20, 2014. [58] Baidu. Apollo auto. https://github.com/ApolloAuto/apollo. [Retrieved May 1, 2019]. [59] C. Chen, A. Seff, A. Kornhauser , and J. Xiao, “Deepdriving: Learning affordance for direct perception in autonomous driving, ” in Proceedings of the IEEE International Conference on Computer V ision, 2015, pp. 2722–2730. [60] D. A. Pomerleau, “ Alvinn: An autonomous land vehicle in a neural network, ” in Advances in neural information processing systems, 1989, pp. 305–313. [61] U. Muller, J. Ben, E. Cosatto, B. Flepp, and Y . L. Cun, “Off-road obstacle avoidance through end-to-end learning, ” in Advances in neural information processing systems, 2006, pp. 739–746. [62] M. Bojarski, D. Del T esta, D. Dworakowski, B. Firner , B. Flepp, P . Goyal, L. D. Jackel, M. Monfort, U. Muller , J. Zhang, et al., “End to end learning for self-driving cars, ” arXiv preprint arXi v:1604.07316, 2016. [63] H. Xu, Y . Gao, F . Y u, and T . Darrell, “End-to-end learning of driving models from large-scale video datasets, ” arXiv preprint, 2017. [64] A. E. Sallab, M. Abdou, E. Perot, and S. Y ogamani, “Deep reinforcement learning framework for autonomous driving, ” Electronic Imaging, vol. 2017, no. 19, pp. 70–76, 2017. [65] A. Kendall, J. Hawke, D. Janz, P . Mazur , D. Reda, J.-M. Allen, V .-D. Lam, A. Be wley , and A. Shah, “Learning to dri ve in a day , ” arXiv preprint arXiv:1807.00412, 2018. [66] S. Baluja, “Evolution of an artificial neural network based autonomous land vehicle controller, ” IEEE Transactions on Systems, Man, and Cybernetics-Part B: Cybernetics, v ol. 26, no. 3, pp. 450–463, 1996. [67] J. Koutník, G. Cuccu, J. Schmidhuber, and F . Gomez, “Evolving large- scale neural networks for vision-based reinforcement learning, ” in Pro- ceedings of the 15th annual conference on Genetic and ev olutionary computation. A CM, 2013, pp. 1061–1068. [68] S. Behere and M. T orngren, “ A functional architecture for autonomous driving, ” in First International W orkshop on Automotive Software Archi- tecture (W ASA). IEEE, 2015, pp. 3–10. [69] L. Chi and Y . Mu, “Deep steering: Learning end-to-end driving model from spatial and temporal visual cues, ” arXi v preprint 2017. [70] J.-P . Laumond et al., Robot motion planning and control. Springer, 1998, vol. 229. [71] R. Jain, R. Kasturi, and B. G. Schunck, Machine vision. McGra w-Hill New Y ork, 1995, vol. 5. [72] S. J. Anderson, S. B. Karumanchi, and K. Iagnemma, “Constraint-based planning and control for safe, semi-autonomous operation of vehicles, ” in IEEE intelligent vehicles symposium. IEEE, 2012, pp. 383–388. [73] V . Mnih, K. Kavukcuoglu, D. Silv er , A. A. Rusu, J. V eness, M. G. Belle- mare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-lev el control through deep reinforcement learning, ” Nature, vol. 518, no. 7540, p. 529, 2015. [74] D. Floreano, P . Dürr, and C. Mattiussi, “Neuroev olution: from architec- tures to learning, ” Evolutionary Intelligence, vol. 1, no. 1, pp. 47–62, 2008. [75] H. T . Cheng, H. Shan, and W . Zhuang, “Infotainment and road safety service support in vehicular networking: From a communication per- spectiv e, ” Mechanical Systems and Signal Processing, vol. 25, no. 6, pp. 2020–2038, 2011. [76] J. W ang, Y . Shao, Y . Ge, and R. Y u, “ A survey of vehicle to everything (v2x) testing, ” Sensors, vol. 19, no. 2, p. 334, 2019. [77] C. Jang, C. Kim, K. Jo, and M. Sunwoo, “Design factor optimization of 3d flash lidar sensor based on geometrical model for automated vehicle and advanced driv er assistance system applications, ” International Jour- nal of Automotiv e T echnology , vol. 18, no. 1, pp. 147–156, 2017. [78] A. I. Maqueda, A. Loquercio, G. Galle go, N. García, and D. Scaramuzza, “Event-based vision meets deep learning on steering prediction for self- driving cars, ” in Proceedings of the IEEE Conference on Computer V ision and Pattern Recognition (CVPR), 2018, pp. 5419–5427. [79] C. Fries and H.-J. W uensche, “ Autonomous conv oy driving by night: The vehicle tracking system, ” in Proceedings of the IEEE International Conference on T echnologies for Practical Robot Applications (T ePRA). IEEE, 2015, pp. 1–6. [80] Q. Ha, K. W atanabe, T . Karasawa, Y . Ushiku, and T . Harada, “Mfnet: T owards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes, ” in Proceedings of the 2017 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 5108–5115. [81] T . B. Lee. How 10 leading companies are trying to make powerful, low- cost lidar . https://arstechnica.com/cars/2019/02/the- ars- technica- guide- to- the- lidar- industry/. [Retriev ed May 19, 2019]. [82] S. Kumar , L. Shi, N. Ahmed, S. Gil, D. Katabi, and D. Rus, “Carspeak: a content-centric network for autonomous driving, ” in Proceedings of the ACM SIGCOMM conference on Applications, technologies, archi- tectures, and protocols for computer communication. ACM, 2012, pp. 259–270. [83] E. Y urtsever , S. Y amazaki, C. Miyajima, K. T akeda, M. Mori, K. Hitomi, and M. Egawa, “Integrating driving behavior and traffic context through signal symbolization for data reduction and risky lane change detection, ” IEEE Transactions on Intelligent V ehicles, vol. 3, no. 3, pp. 242–253, 2018. [84] M. Gerla, “V ehicular cloud computing, ” in Ad Hoc Networking W ork- shop (Med-Hoc-Net), 2012 The 11th Annual Mediterranean. IEEE, 2012, pp. 152–155. [85] M. Whaiduzzaman, M. Sookhak, A. Gani, and R. Buyya, “ A survey on vehicular cloud computing, ” Journal of Network and Computer applica- tions, vol. 40, pp. 325–344, 2014. [86] I. Din, B.-S. Kim, S. Hassan, M. Guizani, M. Atiquzzaman, and J. Ro- drigues, “Information-centric network-based vehicular communications: overvie w and research opportunities, ” Sensors, vol. 18, no. 11, p. 3957, 2018. [87] A. Saxena, S. H. Chung, and A. Y . Ng, “Learning depth from single monocular images, ” in Advances in neural information processing sys- tems, 2006, pp. 1161–1168. [88] J. Janai, F . Güney , A. Behl, and A. Geiger, “Computer vision for au- tonomous vehicles: Problems, datasets and State-of-the-Art, ” pre-print, Apr . 2017. [89] J. Binas, D. Neil, S.-C. Liu, and T . Delbruck, “Ddd17: End-to-end davis driving dataset, ” arXiv preprint arXi v:1711.01458, 2017. [90] P . Lichtsteiner, C. Posch, and T . Delbruck, “ A 128 × 128 120 db 15 µ s latency asynchronous temporal contrast vision sensor , ” IEEE J. Solid- State Circuits, vol. 43, no. 2, pp. 566–576, Feb . 2008. [91] B. Schoettle, “Sensor fusion: A comparison of sensing capabilities of human drivers and highly automated vehicles, ” University of Michigan, Sustainable W orldwide Transportation, T ech. Rep. SWT -2017-12, Au- gust 2017. [92] T esla Motors. Autopilot press kit. https://www .tesla.com/presskit/ autopilot#autopilot. [Retriev ed December 16, 2018]. [93] SXSW Interactiv e 2016. Chris Urmson explains google self-driving car project. https://www .sxsw .com/interactive/2016/chris- urmson- explain- googles- self- driving- car- project/. [Retriev ed December 16, 2018]. [94] M. A. Al-Khedher, “Hybrid GPS-GSM localization of automobile track- ing system, ” arXiv preprint arXiv:1201.2630, 2012. [95] K. S. Chong and L. Kleeman, “ Accurate odometry and error modelling for a mobile robot, ” in IEEE International Conference on Robotics and Automation (ICRA), vol. 4. IEEE, 1997, pp. 2783–2788. [96] C. Urmson, J. Anhalt, M. Clark, T . Galatali, J. P . Gonzalez, J. Gowdy , A. Gutierrez, S. Harbaugh, M. Johnson-Roberson, H. Kato, et al., “High speed navigation of unrehearsed terrain: Red team technology for grand challenge 2004, ” Robotics Institute, Carnegie Mellon University , Pitts- bur gh, P A, T ech. Rep. CMU-RI-TR-04-37, 2004. [97] T . Bailey and H. Durrant-Whyte, “Simultaneous localization and map- ping (slam): Part ii, ” IEEE Robotics & Automation Magazine, vol. 13, no. 3, pp. 108–117, 2006. [98] A. Hata and D. W olf, “Road marking detection using lidar reflecti ve intensity data and its application to v ehicle localization, ” in 17th Interna- tional Conference on Intelligent Transportation Systems (ITSC). IEEE, 2014, pp. 584–589. [99] T . Ort, L. Paull, and D. Rus, “ Autonomous vehicle navigation in rural en vironments without detailed prior maps, ” in International Conference on Robotics and Automation, 2018. [100] J. Levinson and S. Thrun, “Robust vehicle localization in urban en viron- ments using probabilistic maps, ” in IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2010, pp. 4372–4378. [101] E. T akeuchi and T . Tsubouchi, “ A 3-d scan matching using improv ed 3-d normal distributions transform for mobile robotic mapping, ” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2006, pp. 3068–3073. [102] S. E. Shladover , “Path at 20-history and major milestones, ” IEEE Trans- actions on intelligent transportation systems, vol. 8, no. 4, pp. 584–592, 2007. [103] A. Alam, B. Besselink, V . T urri, J. Martensson, and K. H. Johansson, “Heavy-duty vehicle platooning for sustainable freight transportation: A cooperative method to enhance safety and efficiency , ” IEEE Control Systems, vol. 35, no. 6, pp. 34–56, 2015. [104] C. Bergenhem, S. Shladover , E. Coelingh, C. Englund, and S. Tsugawa, “Overvie w of platooning systems, ” in Proceedings of the 19th ITS W orld Congress, Oct 22-26, V ienna, Austria (2012), 2012. [105] E. Chan, “Sartre automated platooning vehicles, ” T owards Inno vati ve Freight and Logistics, vol. 2, pp. 137–150, 2016. [106] A. K. Khalaji and S. A. A. Moosavian, “Robust adaptive controller for a tractor–trailer mobile robot, ” IEEE/ASME Transactions on Mechatron- ics, vol. 19, no. 3, pp. 943–953, 2014. [107] J. Cheng, B. W ang, and Y . Xu, “Backward path tracking control for mobile robot with three trailers, ” in International Conference on Neural Information Processing. Springer , 2017, pp. 32–41. [108] M. Hejase, J. Jing, J. M. Maroli, Y . B. Salamah, L. Fiorentini, and Ü. Özgüner, “Constrained backward path tracking control using a plug- in jackknife prevention system for autonomous tractor-trailers, ” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018, pp. 2012–2017. [109] F . Zhang, H. Stähle, G. Chen, C. C. C. Simon, C. Buckl, and A. Knoll, “ A sensor fusion approach for localization with cumulati ve error elimina- tion, ” in 2012 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI). IEEE, 2012, pp. 1–6. [110] W .-W . Kao, “Integration of gps and dead-reckoning navigation systems, ” in V ehicle Na vigation and Information Systems Conference, 1991, vol. 2. IEEE, 1991, pp. 635–643. [111] J. Levinson, M. Montemerlo, and S. Thrun, “Map-based precision vehicle localization in urban en vironments, ” in Robotics: Science and Systems III, W . Burgard, O. Brock, and C. Stachniss, Eds. MIT Press, 2007, ch. 16, pp. 4372–4378. [112] A. Ranganathan, D. Ilstrup, and T . W u, “Light-weight localization for vehicles using road markings, ” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS). IEEE, 2013, pp. 921–927. [113] J. Leonard, J. How , S. T eller , M. Berger , S. Campbell, G. Fiore, L. Fletcher, E. Frazzoli, A. Huang, S. Karaman, et al., “ A perception- driv en autonomous urban vehicle, ” Journal of Field Robotics, vol. 25, no. 10, pp. 727–774, 2008. [114] N. Akai, L. Y . Morales, E. T akeuchi, Y . Y oshihara, and Y . Ninomiya, “Robust localization using 3d ndt scan matching with experimentally de- termined uncertainty and road marker matching, ” in Intelligent V ehicles Symposium (IV), 2017 IEEE. IEEE, 2017, pp. 1356–1363. [115] J. K. Suhr, J. Jang, D. Min, and H. G. Jung, “Sensor fusion-based low- cost vehicle localization system for complex urban environments, ” IEEE T ransactions on Intelligent T ransportation Systems, vol. 18, no. 5, pp. 1078–1086, 2017. [116] D. Gruyer , R. Belaroussi, and M. Revilloud, “ Accurate lateral positioning from map data and road marking detection, ” Expert Systems with Appli- cations, vol. 43, pp. 1–8, 2016. [117] X. Qu, B. Soheilian, and N. Paparoditis, “V ehicle localization using mono-camera and geo-referenced traffic signs, ” in Intelligent V ehicles Symposium (IV), 2015 IEEE. IEEE, 2015, pp. 605–610. [118] M. Magnusson, “The three-dimensional normal-distributions transform: an efficient representation for registration, surface analysis, and loop detection, ” PhD dissertation, Örebro Universitet, 2009. [119] R. W . W olcott and R. M. Eustice, “Fast lidar localization using mul- tiresolution gaussian mixture maps, ” in IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 2814–2821. [120] M. Magnusson, A. Nuchter, C. Lorken, A. J. Lilienthal, and J. Hertzberg, “Evaluation of 3d registration reliability and speed-a comparison of icp and ndt, ” in IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2009, pp. 3907–3912. [121] R. V alencia, J. Saarinen, H. Andreasson, J. V allvé, J. Andrade-Cetto, and A. J. Lilienthal, “Localization in highly dynamic en vironments using dual-timescale ndt-mcl, ” in IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 3956–3962. [122] S. Kato, E. T ak euchi, Y . Ishiguro, Y . Ninomiya, K. T akeda, and T . Hamada, “ An open approach to autonomous vehicles, ” IEEE Micro, vol. 35, no. 6, pp. 60–68, 2015. [123] R. W . W olcott and R. M. Eustice, “V isual localization within lidar maps for automated urban driving, ” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS). IEEE, 2014, pp. 176–183. [124] C. McManus, W . Churchill, A. Napier, B. Davis, and P . Newman, “Distraction suppression for vision-based pose estimation at city scales, ” in IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2013, pp. 3762–3769. [125] C. Szegedy , S. Ioffe, V . V anhoucke, and A. Alemi, “Inception-v4, Inception-ResNet and the impact of residual connections on learning, ” Feb . 2016. [126] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in 2016 IEEE Conference on Computer V ision and Pattern Recognition (CVPR). IEEE, June 2016, pp. 770–778. [127] G. Huang, Z. Liu, L. van der Maaten, and K. Q. W einberger , “Densely connected con volutional networks, ” Aug. 2016. [128] J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement, ” Apr . 2018. [129] C. Szegedy , W . Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . V anhoucke, and A. Rabinovich, “Going deeper with con volutions, ” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9. [130] K. Simonyan and A. Zisserman, “V ery deep con volutional networks for Large-Scale image recognition, ” Computing Research Repository CoRR, vol. abs/1409.1556, 2015. [131] J. Deng, W . Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-fei, “Imagenet: A large-scale hierarchical image database, ” in In CVPR, 2009. [132] A. Andreopoulos and J. K. Tsotsos, “50 years of object recognition: Directions forward, ” Comput. V is. Image Underst., vol. 117, no. 8, pp. 827–891, Aug. 2013. [133] Z.-Q. Zhao, P . Zheng, S.-T . Xu, and X. W u, “Object detection with deep learning: A revie w , ” July 2018. [134] L. Liu, W . Ouyang, X. W ang, P . Fieguth, J. Chen, X. Liu, and M. Pietikäi- nen, “Deep learning for generic object detection: A survey , ” Sept. 2018. [135] J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi, “Y ou only look once: Unified, real-time object detection, ” 2016 IEEE Conference on Computer V ision and Pattern Recognition (CVPR), pp. 779–788, 2016. [136] J. Redmon and A. Farhadi, “Y olo9000: Better , faster , stronger, ” 2017 IEEE Conference on Computer V ision and Pattern Recognition (CVPR), pp. 6517–6525, 2017. [137] W . Liu, D. Anguelov , D. Erhan, C. Szegedy , S. Reed, C.-Y . Fu, and A. C. Berg, “SSD: Single shot MultiBox detector , ” Dec. 2015. [138] K. He, G. Gkioxari, P . Dollár , and R. Girshick, “Mask R-CNN, ” in 2017 IEEE International Conference on Computer V ision (ICCV), Oct. 2017, pp. 2980–2988. [139] L.-C. Chen, Y . Zhu, G. Papandreou, F . Schroff, and H. Adam, “Encoder- Decoder with atrous separable con volution for semantic image segmen- tation, ” Feb. 2018. [140] Y . Y an, Y . Mao, and B. Li, “SECOND: Sparsely embedded conv olutional detection, ” Sensors, vol. 18, no. 10, Oct. 2018. [141] C. Geyer and K. Daniilidis, “ A unifying theory for central panoramic systems and practical implications, ” in Computer V ision — ECCV 2000. Springer Berlin Heidelberg, 2000, pp. 445–461. [142] D. Scaramuzza, A. Martinelli, and R. Siegwart, “ A toolbox for easily calibrating omnidirectional cameras, ” in 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Oct. 2006, pp. 5695– 5701. [143] D. Scaramuzza and R. Siegwart, “Appearance-Guided monocular omni- directional visual odometry for outdoor ground vehicles, ” IEEE T rans. Rob ., vol. 24, no. 5, pp. 1015–1026, Oct. 2008. [144] M. Schönbein and A. Geiger, “Omnidirectional 3D reconstruction in aug- mented manhattan worlds, ” in 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Sept. 2014, pp. 716–723. [145] G. Gallego, T . Delbruck, G. Orchard, C. Bartolozzi, B. T aba, A. Censi, S. Leutenegger, A. Davison, J. Conradt, K. Daniilidis, and D. Scara- muzza, “Event-based vision: A surve y , ” pre-print, Apr . 2019. [146] R. H. Rasshofer and K. Gresser , “ Automotive radar and lidar systems for next generation driver assistance functions, ” Adv . Radio Sci., vol. 3, no. B.4, pp. 205–209, May 2005. [147] P . Radecki, M. Campbell, and K. Matzen, “ All weather perception: Joint data association, tracking, and classification for autonomous ground vehicles, ” pre-print, May 2016. [148] P . Hurney , P . W aldron, F . Morgan, E. Jones, and M. Glavin, “Revie w of pedestrian detection techniques in automotive far-infrared video, ” IET Intel. T ransport Syst., vol. 9, no. 8, pp. 824–832, 2015. [149] N. Carlevaris-Bianco and R. M. Eustice, “Learning visual feature descrip- tors for dynamic lighting conditions, ” in 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Sept. 2014, pp. 2769– 2776. [150] V . Peretroukhin, W . V ega-Brown, N. Roy , and J. Kelly , “PR OBE-GK: Predictiv e robust estimation using generalized kernels, ” pre-print, Aug. 2017. [151] W . Maddern, A. Stewart, C. McManus, B. Upcroft, W . Churchill, and P . Newman, “Illumination in variant imaging: Applications in robust vision-based localisation, mapping and classification for autonomous vehicles, ” in Proceedings of the V isual Place Recognition in Changing En vironments W orkshop, IEEE International Conference on Robotics and Automation (ICRA), Hong K ong, China, vol. 2, 2014, p. 3. [152] T .-Y . Lin, M. Maire, S. Belongie, L. Bourdev , R. Girshick, J. Hays, P . Perona, D. Ramanan, C. Lawrence Zitnick, and P . Dollár, “Microsoft COCO: Common objects in context, ” May 2014. [153] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: T owards Real- T ime object detection with region proposal networks, ” June 2015. [154] H. Noh, S. Hong, and B. Han, “Learning deconv olution network for semantic segmentation, ” in Proceedings of the 2015 IEEE International Conference on Computer V ision (ICCV), ser. ICCV ’15. W ashington, DC, USA: IEEE Computer Society , 2015, pp. 1520–1528. [Online]. A vailable: http://dx.doi.org/10.1109/ICCV .2015.178 [155] O. Ronneber ger , P . Fischer , and T . Brox, “U-Net: Con v olutional networks for biomedical image segmentation, ” May 2015. [156] H. Zhao, J. Shi, X. Qi, X. W ang, and J. Jia, “Pyramid scene parsing network, ” Dec. 2016. [157] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy , and A. L. Y uille, “DeepLab: Semantic image segmentation with deep con volutional nets, atrous con volution, and fully connected CRFs, ” pre-print, June 2016. [158] X. Ma, Z. W ang, H. Li, W . Ouyang, and P . Zhang, “ Accurate monoc- ular 3D object detection via Color-Embedded 3D reconstruction for autonomous driving, ” Mar . 2019. [159] X. Cheng, P . W ang, and R. Y ang, “Learning depth with conv olutional spatial propagation network, ” 2018. [160] R. B. Rusu, “Semantic 3d object maps for everyday manipulation in human living en vironments, ” October 2009. [161] W . W ang, K. Sakurada, and N. Kawaguchi, “Incremental and enhanced Scanline-Based segmentation method for surface reconstruction of sparse LiD AR data, ” Remote Sensing, v ol. 8, no. 11, p. 967, Nov . 2016. [162] P . Narksri, E. T akeuchi, Y . Ninomiya, Y . Morales, and N. Kawaguchi, “ A slope-robust cascaded ground segmentation in 3D point cloud for autonomous vehicles, ” in 2018 IEEE International Conference on Intelli- gent T ransportation Systems (ITSC), Nov . 2018, pp. 497–504. [163] J. Lambert, L. Liang, Y . Morales, N. Akai, A. Carballo, E. T akeuchi, P . Narksri, S. Seiya, and K. T akeda, “Tsukuba challenge 2017 dy- namic object tracks dataset for pedestrian behavior analysis, ” Journal of Robotics and Mechatronics (JRM), vol. 30, no. 4, Aug. 2018. [164] A. Dosovitskiy , G. Ros, F . Code villa, A. Lopez, and V . K oltun, “Carla: An open urban driving simulator , ” arXiv preprint arXi v:1711.03938, 2017. [165] S. Song and J. Xiao, “Sliding shapes for 3D object detection in depth images, ” in Proceedings of the European Conference on Computer V ision ECCV 2014. Springer International Publishing, 2014, pp. 634–651. [166] D. Z. W ang and I. Posner , “V oting for voting in online point cloud object detection, ” in Proceedings of Robotics: Science and Systems, July 2015. [167] Y . Zhou and O. Tuzel, “V oxelNet: End-to-End learning for point cloud based 3D object detection, ” Nov . 2017. [168] X. Chen, K. Kundu, Y . Zhu, A. G. Berneshawi, H. Ma, S. Fidler, and R. Urtasun, “3D object proposals for accurate object class detection, ” in Advances in Neural Information Processing Systems 28, C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, Eds. Curran Associates, Inc., 2015, pp. 424–432. [169] D. Lin, S. Fidler, and R. Urtasun, “Holistic scene understanding for 3D object detection with RGBD cameras, ” in 2013 IEEE International Conference on Computer V ision, Dec. 2013, pp. 1417–1424. [170] B. Li, T . Zhang, and T . Xia, “V ehicle detection from 3D lidar using fully conv olutional network, ” in Proceedings of Robotics: Science and Systems, June 2016. [171] L. Liu, Z. Pan, and B. Lei, “Learning a rotation inv ariant detector with rotatable bounding box, ” Nov . 2017. [172] X. Chen, H. Ma, J. W an, B. Li, and T . Xia, “Multi-view 3D object detection netw ork for autonomous driving, ” in 2017 IEEE Conference on Computer V ision and Pattern Recognition (CVPR), July 2017, pp. 6526– 6534. [173] M. Ren, A. Pokrovsky , B. Y ang, and R. Urtasun, “SBNet: Sparse blocks network for fast inference, ” in Proceedings of the IEEE Conference on Computer V ision and Pattern Recognition, 2018, pp. 8711–8720. [174] W . Ali, S. Abdelkarim, M. Zahran, M. Zidan, and A. El Sallab, “YOLO3D: End-to-end real-time 3D oriented object bounding box de- tection from LiD AR point cloud, ” Aug. 2018. [175] B. Y ang, W . Luo, and R. Urtasun, “PIXOR: Real-time 3D object detection from point clouds, ” in 2018 IEEE/CVF Conference on Computer V ision and Pattern Recognition (CVPR), June 2018, pp. 7652–7660. [176] D. Feng, L. Rosenbaum, and K. Dietmayer, “T owards safe autonomous driving: Capture uncertainty in the deep neural network for lidar 3D vehicle detection, ” Apr . 2018. [177] A. Geiger, P . Lenz, and R. Urtasun, “ Are we ready for autonomous driv- ing? the kitti vision benchmark suite, ” in IEEE Conference on Computer V ision and Pattern Recognition (CVPR). IEEE, 2012, pp. 3354–3361. [178] H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Kr- ishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuScenes: A multimodal dataset for autonomous dri ving, ” arXiv preprint arXi v:1903.11027, 2019. [179] S. Shi, X. W ang, and H. Li, “PointRCNN: 3D object proposal generation and detection from point cloud, ” Dec. 2018. [180] A. H. Lang, S. V ora, H. Caesar , L. Zhou, J. Y ang, and O. Beijbom, “PointPillars: Fast encoders for object detection from point clouds, ” Dec. 2018. [181] Z. Y ang, Y . Sun, S. Liu, X. Shen, and J. Jia, “IPOD: Intensi ve point-based object detector for point cloud, ” Dec. 2018. [182] C. R. Qi, W . Liu, C. W u, H. Su, and L. J. Guibas, “Frustum PointNets for 3D object detection from RGB-D data, ” Nov . 2017. [183] W . Luo, J. Xing, A. Milan, X. Zhang, W . Liu, X. Zhao, and T .-K. Kim, “Multiple object tracking: A literature revie w , ” Sept. 2014. [184] A. Azim and O. A ycard, “Detection, classification and tracking of moving objects in a 3D environment, ” in 2012 IEEE Intelligent V ehicles Sympo- sium, June 2012, pp. 802–807. [185] T . S. Shi, “Good features to track, ” in 1994 Proceedings of IEEE Confer - ence on Computer V ision and Pattern Recognition, June 1994, pp. 593– 600. [186] M. . Dub uisson and A. K. Jain, “ A modified hausdorff distance for object matching, ” in Proceedings of 12th International Conference on Pattern Recognition, vol. 1, Oct. 1994, pp. 566–568 v ol.1. [187] S. Hwang, N. Kim, Y . Choi, S. Lee, and I. S. Kweon, “Fast multiple objects detection and tracking fusing color camera and 3D LID AR for in- telligent vehicles, ” in 2016 13th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Aug. 2016, pp. 234–239. [188] T . Nguyen, B. Michaelis, A. Al-Hamadi, M. T ornow , and M. Meinecke, “Stereo-Camera-Based urban en vironment perception using occupancy grid and object tracking, ” IEEE Trans. Intell. T ransp. Syst., vol. 13, no. 1, pp. 154–165, Mar . 2012. [189] J. Ziegler, P . Bender, T . Dang, and C. Stiller, “Trajectory planning for bertha — a local, continuous method, ” in 2014 IEEE Intelligent V ehicles Symposium Proceedings, June 2014, pp. 450–457. [190] A. Ess, K. Schindler, B. Leibe, and L. V an Gool, “Object detection and tracking for autonomous navigation in dynamic en vironments, ” Int. J. Rob . Res., vol. 29, no. 14, pp. 1707–1725, Dec. 2010. [191] A. Petrovskaya and S. Thrun, “Model based vehicle detection and track- ing for autonomous urban driving, ” Auton. Robots, vol. 26, no. 2-3, pp. 123–139, Apr . 2009. [192] M. He, E. T akeuchi, Y . Ninomiya, and S. Kato, “Precise and efficient model-based vehicle tracking method using Rao-Blackwellized and scal- ing series particle filters, ” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS), Oct. 2016, pp. 117–124. [193] D. Z. W ang, I. Posner , and P . Newman, “Model-free detection and tracking of dynamic objects with 2D lidar , ” Int. J. Rob. Res., vol. 34, no. 7, pp. 1039–1063, June 2015. [194] B. Huval, T . W ang, S. T andon, J. Kiske, W . Song, J. Pazhayampallil, M. Andriluka, P . Rajpurkar , T . Migimatsu, R. Cheng-Y ue, F . Mujica, A. Coates, and A. Y . Ng, “ An empirical evaluation of deep learning on highway dri ving, ” pre-print, Apr . 2015. [195] D. Held, S. Thrun, and S. Savarese, “Learning to track at 100 FPS with deep regression networks, ” pre-print, Apr . 2016. [196] S. Chowdhuri, T . Pankaj, and K. Zipser, “MultiNet: Multi-Modal Multi- T ask learning for autonomous driving, ” pre-print, Sept. 2017. [197] Autoware. https://github.com/auto warefoundation/auto ware. [Retriev ed June 12, 2019]. [198] J. C. McCall and M. M. Tri vedi, “Video-based lane estimation and tracking for driver assistance: survey , system, and ev aluation, ” IEEE T rans. Intell. Transp. Syst., v ol. 7, no. 1, pp. 20–37, Mar . 2006. [199] A. B. Hillel, R. Lerner , D. Le vi, and G. Raz, “Recent progress in road and lane detection: a survey , ” Machine vision and applications, v ol. 25, no. 3, pp. 727–745, 2014. [200] C. Fernández, D. Fernández-Llorca, and M. A. Sotelo, “A hybrid Vision- Map method for urban road detection, ” Journal of Advanced T ransporta- tion, vol. 2017, Oct. 2017. [201] R. Labayrade, J. Douret, J. Laneurit, and R. Chapuis, “ A reliable and robust lane detection system based on the parallel use of three algorithms for driving safety assistance, ” IEICE T rans. Inf. Syst., vol. 89, no. 7, pp. 2092–2100, 2006. [202] Y an Jiang, Feng Gao, and Guoyan Xu, “Computer vision-based multiple- lane detection on straight road and in a curve, ” in 2010 International Conference on Image Analysis and Signal Processing, Apr. 2010, pp. 114–117. [203] M. Paton, K. MacT avish, C. J. Ostafew , and T . D. Barfoot, “It’s not easy seeing green: Lighting-resistant stereo visual teach & repeat using color- constant images, ” in 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 1519–1526. [204] A. S. Huang, D. Moore, M. Antone, E. Olson, and S. T eller , “Finding multiple lanes in urban road networks with vision and lidar , ” Auton. Robots, vol. 26, no. 2, pp. 103–122, Apr . 2009. [205] H. Cheng, B. Jeng, P . Tseng, and K. Fan, “Lane detection with moving vehicles in the traffic scenes, ” IEEE T rans. Intell. Transp. Syst., vol. 7, no. 4, pp. 571–582, Dec. 2006. [206] J. M. Álvarez, A. M. López, and R. Baldrich, “Shadow resistant road segmentation from a mobile monocular system, ” in Pattern Recognition and Image Analysis. Springer Berlin Heidelber g, 2007, pp. 9–16. [207] R. Danescu and S. Nede vschi, “Probabilistic lane tracking in difficult road scenarios using stereovision, ” IEEE Trans. Intell. Transp. Syst., vol. 10, no. 2, pp. 272–282, June 2009. [208] J. Long, E. Shelhamer, and T . Darrell, “Fully conv olutional networks for semantic segmentation, ” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440. [209] A. Borkar , M. Hayes, and M. T . Smith, “Robust lane detection and tracking with ransac and kalman filter , ” in 2009 16th IEEE International Conference on Image Processing (ICIP), Nov . 2009, pp. 3261–3264. [210] A. V . Nefian and G. R. Bradski, “Detection of driv able corridors for Off-Road autonomous navigation, ” in 2006 International Conference on Image Processing, Oct. 2006, pp. 3025–3028. [211] E. Y urtsev er, Y . Liu, J. Lambert, C. Miyajima, E. T akeuchi, K. T akeda, and J. H. L. Hansen, “Risky action recognition in lane change video clips using deep spatiotemporal networks with se gmentation mask transfer, ” in 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Oct 2019, pp. 3100–3107. [212] Y . Gal, “Uncertainty in deep learning, ” Ph.D. dissertation, PhD thesis, Univ ersity of Cambridge, 2016. [213] S. Y amazaki, C. Miyajima, E. Y urtsever , K. T akeda, M. Mori, K. Hitomi, and M. Egawa, “Integrating driving behavior and traffic context through signal symbolization, ” in Intelligent V ehicles Symposium (IV), 2016 IEEE. IEEE, 2016, pp. 642–647. [214] X. Geng, H. Liang, B. Y u, P . Zhao, L. He, and R. Huang, “ A scenario- adaptiv e driving behavior prediction approach to urban autonomous driving, ” Applied Sciences, vol. 7, no. 4, p. 426, 2017. [215] M. Bahram, C. Hubmann, A. Lawitzky , M. Aeberhard, and D. W ollherr, “ A combined model-and learning-based framework for interaction-aware maneuver prediction, ” IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 6, pp. 1538–1550, 2016. [216] V . Gadepally , A. Krishnamurthy , and Ü. Özgüner , “ A framework for estimating long term driver beha vior , ” Journal of advanced transportation, vol. 2017, 2017. [217] P . Liu, A. Kurt, K. Redmill, and U. Ozguner, “Classification of highway lane change behavior to detect dangerous cut-in maneuvers, ” in The T ransportation Research Board (TRB) 95th Annual Meeting, v ol. 2, 2015. [218] P . Kumar , M. Perrollaz, S. Lefevre, and C. Laugier, “Learning-based approach for online lane change intention prediction, ” in 2013 IEEE Intelligent V ehicles Symposium (IV). IEEE, 2013, pp. 797–802. [219] H. Darweesh, E. T akeuchi, K. T akeda, Y . Ninomiya, A. Sujiwo, L. Y . Morales, N. Akai, T . T omizaw a, and S. Kato, “Open source integrated planner for autonomous navigation in highly dynamic en vironments, ” Journal of Robotics and Mechatronics, vol. 29, no. 4, pp. 668–684, 2017. [220] F . Sagberg, Selpi, G. F . Bianchi Piccinini, and J. Engström, “ A re view of research on driving styles and road safety , ” Human factors, v ol. 57, no. 7, pp. 1248–1275, 2015. [221] C. M. Martinez, M. Heucke, F .-Y . W ang, B. Gao, and D. Cao, “Driving style recognition for intelligent vehicle control and advanced driver assistance: A survey , ” IEEE Transactions on Intelligent Transportation Systems, vol. 19, no. 3, pp. 666–676, 2018. [222] D. A. Johnson and M. M. Triv edi, “Driving style recognition using a smartphone as a sensor platform, ” in 14th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2011, pp. 1609–1615. [223] M. Fazeen, B. Gozick, R. Dantu, M. Bhukhiya, and M. C. González, “Safe driving using mobile phones, ” IEEE T ransactions on Intelligent T ransportation Systems, vol. 13, no. 3, pp. 1462–1468, 2012. [224] N. Karginov a, S. Byttner, and M. Svensson, “Data-driven methods for classification of driving styles in buses, ” SAE T echnical Paper , T ech. Rep., 2012. [225] A. Doshi and M. M. Triv edi, “Examining the impact of driving style on the predictability and responsiv eness of the driver: Real-world and simulator analysis, ” in Intelligent V ehicles Symposium (IV), 2010 IEEE. IEEE, 2010, pp. 232–237. [226] V . V aitkus, P . Lengvenis, and G. Žylius, “Driving style classification using long-term accelerometer information, ” in 19th International Con- ference On Methods and Models in Automation and Robotics (MMAR). IEEE, 2014, pp. 641–644. [227] F . Syed, S. Nallapa, A. Dobryden, C. Grand, R. McGee, and D. Filev , “Design and analysis of an adaptive real-time advisory system for im- proving real world fuel economy in a hybrid electric vehicle, ” SAE T echnical Paper, T ech. Rep., 2010. [228] A. Corti, C. Ongini, M. T anelli, and S. M. Savaresi, “Quantitative driv- ing style estimation for energy-oriented applications in road vehicles, ” in IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2013, pp. 3710–3715. [229] E. Ericsson, “Independent driving pattern factors and their influence on fuel-use and exhaust emission factors, ” Transportation Research Part D: T ransport and Environment, v ol. 6, no. 5, pp. 325–345, 2001. [230] V . Manzoni, A. Corti, P . De Luca, and S. M. Savaresi, “Driving style estimation via inertial measurements, ” in 13th International Conference on Intelligent T ransportation Systems (ITSC), 2010, pp. 777–782. [231] J. S. Neubauer and E. W ood, “ Accounting for the variation of driv er aggression in the simulation of conventional and advanced v ehicles, ” SAE T echnical Paper, T ech. Rep., 2013. [232] Y . L. Murphey , R. Milton, and L. Kiliaris, “Driv er’ s style classification using jerk analysis, ” in IEEE W orkshop on Computational Intelligence in V ehicles and V ehicular Systems (CIVVS). IEEE, 2009, pp. 23–28. [233] E. Y urtsever , K. T akeda, and C. Miyajima, “Traf fic trajectory history and driv e path generation using gps data cloud, ” in Intelligent V ehicles Symposium (IV), 2015 IEEE. IEEE, 2015, pp. 229–234. [234] D. Dörr, D. Grabengiesser, and F . Gauterin, “Online driving style recog- nition using fuzzy logic, ” in 17th International Conference on Intelligent T ransportation Systems (ITSC). IEEE, 2014, pp. 1021–1026. [235] L. Xu, J. Hu, H. Jiang, and W . Meng, “Establishing style-oriented driv er models by imitating human dri ving behaviors, ” IEEE Transactions on Intelligent T ransportation Systems, vol. 16, no. 5, pp. 2522–2530, 2015. [236] B. V . P . Rajan, A. McGordon, and P . A. Jennings, “ An inv estigation on the ef fect of dri ver style and driving events on energy demand of a phev , ” W orld Electric V ehicle Journal, vol. 5, no. 1, pp. 173–181, 2012. [237] A. Augustynowicz, “Preliminary classification of driving style with ob- jectiv e rank method, ” International journal of automotive technology , vol. 10, no. 5, pp. 607–610, 2009. [238] Z. Constantinescu, C. Marinoiu, and M. Vladoiu, “Driving style analysis using data mining techniques, ” International Journal of Computers Com- munications & Control, vol. 5, no. 5, pp. 654–663, 2010. [239] Y . Zhang, W . C. Lin, and Y .-K. S. Chin, “ A pattern-recognition approach for driving skill characterization, ” IEEE transactions on intelligent trans- portation systems, vol. 11, no. 4, pp. 905–916, 2010. [240] E. Y urtsever , C. Miyajima, and K. T akeda, “ A traffic flow simulation framew ork for learning dri ver heterogeneity from naturalistic driving data using autoencoders, ” International Journal of Automotive Engineering, vol. 10, no. 1, pp. 86–93, 2019. [241] C. Miyajima, Y . Nishiwaki, K. Ozaw a, T . W akita, K. Itou, K. T akeda, and F . Itakura, “Dri ver modeling based on dri ving behavior and its e valuation in dri ver identification, ” Proceedings of the IEEE, v ol. 95, no. 2, pp. 427– 437, 2007. [242] A. Bolovinou, I. Bakas, A. Amditis, F . Mastrandrea, and W . V inciotti, “Online prediction of an electric vehicle remaining range based on regression analysis, ” in Electric V ehicle Conference (IEVC), 2014 IEEE International. IEEE, 2014, pp. 1–8. [243] A. Mudgal, S. Hallmark, A. Carriquiry , and K. Gkritza, “Driving behavior at a roundabout: A hierarchical bayesian re gression analysis, ” T ransporta- tion research part D: transport and en vironment, vol. 26, pp. 20–26, 2014. [244] J. C. McCall and M. M. Tri vedi, “Driver behavior and situation aware brake assistance for intelligent vehicles, ” Proceedings of the IEEE, vol. 95, no. 2, pp. 374–387, 2007. [245] E. Y urtsever , C. Miyajima, S. Selpi, and K. T akeda, “Driving signature extraction, ” in F AST -zero’15: 3rd International Symposium on Future Activ e Safety T echnology T oward zero traffic accidents, 2015, 2015. [246] K. Sama, Y . Morales, N. Akai, H. Liu, E. T akeuchi, and K. T akeda, “Driv- ing feature extraction and behavior classification using an autoencoder to reproduce the velocity styles of experts, ” in 2018 21st International Conference on Intelligent T ransportation Systems (ITSC). IEEE, 2018, pp. 1337–1343. [247] H. Liu, T . T aniguchi, Y . T anaka, K. T akenaka, and T . Bando, “V isual- ization of driving behavior based on hidden feature extraction by using deep learning, ” IEEE T ransactions on Intelligent Transportation Systems, vol. 18, no. 9, pp. 2477–2489, 2017. [248] H. Bast, D. Delling, A. Goldberg, M. Müller-Hannemann, T . Pajor , P . Sanders, D. W agner, and R. F . W erneck, “Route planning in transporta- tion networks, ” in Algorithm engineering. Springer , 2016, pp. 19–80. [249] P . E. Hart, N. J. Nilsson, and B. Raphael, “ A formal basis for the heuristic determination of minimum cost paths, ” IEEE transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968. [250] D. V an Vliet, “Impro ved shortest path algorithms for transport networks, ” T ransportation Research, vol. 12, no. 1, pp. 7–20, 1978. [251] R. Geisberger , P . Sanders, D. Schultes, and C. V etter, “Exact routing in large road networks using contraction hierarchies, ” T ransportation Science, vol. 46, no. 3, pp. 388–404, 2012. [252] E. Cohen, E. Halperin, H. Kaplan, and U. Zwick, “Reachability and distance queries via 2-hop labels, ” SIAM Journal on Computing, v ol. 32, no. 5, pp. 1338–1355, 2003. [253] R. Bauer, D. Delling, P . Sanders, D. Schieferdecker, D. Schultes, and D. W agner, “Combining hierarchical and goal-directed speed-up tech- niques for dijkstra’ s algorithm, ” Journal of Experimental Algorithmics (JEA), vol. 15, pp. 2–3, 2010. [254] D. Delling, A. V . Goldberg, A. Nowatzyk, and R. F . W erneck, “Phast: Hardware-accelerated shortest path trees, ” Journal of Parallel and Dis- tributed Computing, v ol. 73, no. 7, pp. 940–952, 2013. [255] M. Pivtoraiko and A. Kelly , “Efficient constrained path planning via search in state lattices, ” in International Symposium on Artificial Intel- ligence, Robotics, and Automation in Space, 2005, pp. 1–7. [256] J. Barraquand and J.-C. Latombe, “Robot motion planning: A distrib uted representation approach, ” The International Journal of Robotics Re- search, vol. 10, no. 6, pp. 628–649, 1991. [257] S. M. LaV alle and J. J. K uffner Jr, “Randomized kinodynamic planning, ” The international journal of robotics research, vol. 20, no. 5, pp. 378–400, 2001. [258] S. Karaman and E. Frazzoli, “Sampling-based algorithms for optimal motion planning, ” The international journal of robotics research, vol. 30, no. 7, pp. 846–894, 2011. [259] L. Kavraki, P . Svestka, and M. H. Overmars, “Probabilistic roadmaps for path planning in high-dimensional configuration spaces, ” vol. 1994, 1994. [260] H. Fuji, J. Xiang, Y . T azaki, B. Lev edahl, and T . Suzuki, “Trajectory planning for automated parking using multi-resolution state roadmap considering non-holonomic constraints, ” in Intelligent V ehicles Sympo- sium Proceedings, 2014 IEEE. IEEE, 2014, pp. 407–413. [261] P . Petrov and F . Nashashibi, “Modeling and nonlinear adaptive control for autonomous vehicle overtaking. ” IEEE Transactions on Intelligent T ransportation Systems, vol. 15, no. 4, pp. 1643–1656, 2014. [262] J. P . Rastelli, R. Lattarulo, and F . Nashashibi, “Dynamic traj ectory gener - ation using continuous-curvature algorithms for door to door assistance vehicles, ” in Intelligent V ehicles Symposium Proceedings, 2014 IEEE. IEEE, 2014, pp. 510–515. [263] D. Dolgov , S. Thrun, M. Montemerlo, and J. Diebel, “Path planning for autonomous vehicles in unknown semi-structured environments, ” The International Journal of Robotics Research, vol. 29, no. 5, pp. 485–501, 2010. [264] J. Ren, K. A. McIsaac, and R. V . Patel, “Modified ne wton’ s method applied to potential field-based navigation for mobile robots, ” IEEE T ransactions on Robotics, vol. 22, no. 2, pp. 384–391, 2006. [265] L. Caltagirone, M. Bellone, L. Svensson, and M. W ahde, “Lidar-based driving path generation using fully con v olutional neural networks, ” in 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2017, pp. 1–6. [266] D. Barnes, W . Maddern, and I. Posner , “Find your own way: W eakly- supervised segmentation of path proposals for urban autonomy , ” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 203–210. [267] M. Elbanhawi and M. Simic, “Sampling-based robot motion planning: A revie w , ” Ieee access, vol. 2, pp. 56–77, 2014. [268] D. Isele, R. Rahimi, A. Cosgun, K. Subramanian, and K. Fujimura, “Navigating occluded intersections with autonomous vehicles using deep reinforcement learning, ” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 2034–2039. [269] C. A. Pickering, K. J. Burnham, and M. J. Richardson, “ A review of automotiv e human machine interface technologies and techniques to re- duce driv er distraction, ” in 2nd Institution of Engineering and T echnology international conference on system safety. IET , 2007, pp. 223–228. [270] O. Carsten and M. H. Martens, “How can humans understand their automated cars? hmi principles, problems and solutions, ” Cognition, T echnology & W ork, vol. 21, no. 1, pp. 3–20, 2019. [271] P . Bazilinskyy and J. de W inter , “ Auditory interfaces in automated driving: an international surv ey , ” PeerJ Computer Science, vol. 1, p. e13, 2015. [272] M. Peden, R. Scurfield, D. Sleet, D. Mohan, A. A. Hyder , E. Jarawan, and C. D. Mathers, “W orld report on road traffic injury prevention. ” W orld Health Organization Gene va, 2004. [273] D. R. Large, L. Clark, A. Quandt, G. Burnett, and L. Skrypchuk, “Steering the conv ersation: a linguistic exploration of natural language interactions with a digital assistant during simulated driving, ” Applied ergonomics, v ol. 63, pp. 53–61, 2017. [274] M. Cordts, M. Omran, S. Ramos, T . Rehfeld, M. Enzweiler , R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding, ” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223. [275] F . Y u, W . Xian, Y . Chen, F . Liu, M. Liao, V . Madhavan, and T . Darrell, “Bdd100k: A div erse driving video database with scalable annotation tooling, ” arXiv preprint arXiv:1805.04687, 2018. [276] G. Neuhold, T . Ollmann, S. R. Bulò, and P . K ontschieder , “The mapillary vistas dataset for semantic understanding of street scenes, ” in ICCV, 2017, pp. 5000–5009. [277] A. Patil, S. Malla, H. Gang, and Y .-T . Chen, “The h3d dataset for full-surround 3d multi-object detection and tracking in crowded urban scenes, ” arXiv preprint arXiv:1903.01568, 2019. [278] X. Huang, X. Cheng, Q. Geng, B. Cao, D. Zhou, P . W ang, Y . Lin, and R. Y ang, “The apolloscape dataset for autonomous driving, ” arXiv preprint arXiv:1803.06184, 2018. [279] Udacity . Udacity dataset. https://github.com/udacity/self- driving- car/ tree/master/datasets. [Retriev ed April 30, 2019]. [280] H. Schafer , E. Santana, A. Haden, and R. Biasini. (2018) A commute in data: The comma2k19 dataset. [281] Y . Chen, J. W ang, J. Li, C. Lu, Z. Luo, H. Xue, and C. W ang, “Lidar -video driving dataset: Learning driving policies effecti vely , ” in Proceedings of the IEEE Conference on Computer V ision and Pattern Recognition, 2018, pp. 5870–5878. [282] K. T akeda, J. H. Hansen, P . Boyraz, L. Malta, C. Miyajima, and H. Abut, “International large-scale v ehicle corpora for research on driver beha vior on the road, ” IEEE Transactions on Intelligent Transportation Systems, vol. 12, no. 4, pp. 1609–1623, 2011. [283] A. Blatt, J. Piero wicz, M. Flanigan, P .-S. Lin, A. K ourtellis, C. Lee, P . Jov anis, J. Jenness, M. Wilaby , J. Campbell, et al., “Naturalistic driving study: Field data collection. ” Transportation Research Board, National Academy of Sciences, 2015. [284] S. G. Klauer , F . Guo, J. Sudweeks, and T . A. Dingus, “ An analysis of driver inattention using a case-crossover approach on 100-car data. ” National Highway T raffic Safety Administration (NHTSA), 2010. [285] M. Benmimoun, A. Pütz, A. Zlocki, and L. Eckstein, “euroFOT : Field operational test and impact assessment of advanced dri ver assistance systems: Final results, ” in Proceedings of the FISIT A 2012 W orld Au- tomotiv e Congress. Springer , 2013, pp. 537–547. [286] S. W ang, M. Bai, G. Mattyus, H. Chu, W . Luo, B. Y ang, J. Liang, J. Cheverie, S. Fidler, and R. Urtasun, “T orontocity: Seeing the world with a million eyes, ” in IEEE International Conference on Computer V ision (ICCV). IEEE, 2017, pp. 3028–3036. [287] Y . Choi, N. Kim, S. Hwang, K. Park, J. S. Y oon, K. An, and I. S. Kweon, “KAIST multi-spectral day/night data set for autonomous and assisted driving, ” IEEE T ransactions on Intelligent Transportation Sys- tems, vol. 19, no. 3, pp. 934–948, 2018. [288] S. Sibi, H. A yaz, D. P . Kuhns, D. M. Sirkin, and W . Ju, “Monitoring driv er cognitiv e load using functional near infrared spectroscopy in partially autonomous cars, ” in 2016 IEEE Intelligent V ehicles Symposium (IV). IEEE, 2016, pp. 419–425. [289] C. Braunagel, E. Kasneci, W . Stolzmann, and W . Rosenstiel, “Driver - activity recognition in the context of conditionally autonomous driving, ” in 2015 IEEE 18th International Conference on Intelligent T ransportation Systems. IEEE, 2015, pp. 1652–1657. [290] M. W alch, K. Lange, M. Baumann, and M. W eber, “ Autonomous driv- ing: investig ating the feasibility of car-dri ver handover assistance, ” in Proceedings of the 7th International Conference on Automotive User Interfaces and Interactiv e V ehicular Applications. ACM, 2015, pp. 11– 18. [291] J. H. Hansen, C. Busso, Y . Zheng, and A. Sathyanarayana, “Driver modeling for detection and assessment of driv er distraction: Examples from the utdriv e test bed, ” IEEE Signal Processing Magazine, vol. 34, no. 4, pp. 130–142, 2017. [292] M. Everingham, A. Zisserman, C. K. Williams, L. V an Gool, M. Allan, C. M. Bishop, O. Chapelle, N. Dalal, T . Deselaers, G. Dorkó, et al., “The 2005 pascal visual object classes challenge, ” in Machine Learning Challenges W orkshop. Springer , 2005, pp. 117–176. [293] E. Santana and G. Hotz, “Learning a driving simulator, ” arXiv preprint arXiv:1608.01230, 2016. [294] M. Althoff, M. Koschi, and S. Manzinger, “Commonroad: Composable benchmarks for motion planning on roads, ” in 2017 IEEE Intelligent V ehicles Symposium (IV). IEEE, 2017, pp. 719–726. [295] H. Fan, F . Zhu, C. Liu, L. Zhang, L. Zhuang, D. Li, W . Zhu, J. Hu, H. Li, and Q. Kong, “Baidu apollo em motion planner, ” arXiv preprint arXiv:1807.08048, 2018. [296] NVIDIA. Driv eworks sdk. https://dev eloper .n vidia.com/driv ew orks. [Re- triev ed December 9, 2018]. [297] CommaAI. OpenPilot. https://github .com/commaai/openpilot. [Retrie ved December 9, 2018]. [298] B. W ymann, C. Dimitrakakis, A. Sumner, E. Espié, and C. Guionneau. (2015) TORCS: the open racing car simulator. http://www .cse.chalmers. se/~chrdimi/papers/torcs.pdf. [Retriev ed May 2, 2019]. [299] S. R. Richter, Z. Hayder, and V . Koltun, “Playing for benchmarks, ” in International Conference on Computer V ision (ICCV), v ol. 2, 2017. [300] N. P . Koenig and A. Howard, “Design and use paradigms for gazebo, an open-source multi-robot simulator, ” in IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS), vol. 4. IEEE, 2004, pp. 2149–2154. [301] D. Krajzewicz, G. Hertkorn, C. Rössel, and P . W agner , “Sumo (simula- tion of urban mobility)-an open-source traffic simulation, ” in Proceed- ings of the 4th middle East Symposium on Simulation and Modelling (MESM20002), 2002, pp. 183–187. [302] J. E. Stellet, M. R. Zofka, J. Schumacher, T . Schamm, F . Niewels, and J. M. Zöllner, “T esting of advanced driver assistance towards automated driving: A survey and taxonomy on existing approaches and open ques- tions, ” in 18th International Conference on Intelligent T ransportation Systems (ITSC). IEEE, 2015, pp. 1455–1462. EKIM YURTSEVER (Member, IEEE) receiv ed his B.S. and M.S. degrees from Istanbul T echni- cal University in 2012 and 2014 respectively . He receiv ed his Ph.D. in Information Science in 2019 from Nagoya Uni versity , Japan and is working as a postdoctoral researcher at the Department of Electrical and Computer Engineering, Ohio State Univ ersity since 2019. His research interests include artificial intel- ligence, machine learning, and computer vision. Currently , he is working on machine learning and computer vision tasks in the intelligent vehicle domain. JA COB LAMBERT (Student Member, IEEE) re- ceiv ed his B.S. in Honours Physics in 2014 at McGill Univ ersity in Montreal, Canada. He re- ceiv ed his M.A.Sc. in 2017 at the University of T oronto, Canada, and is currently a PhD candidate in Nagoya Uni versity , Japan. His current research focuses on 3D perception through lidar sensors for autonomous robotics. ALEXANDER CARBALLO (Member, IEEE) re- ceiv ed his Dr .Eng. degree from the Intelligent Robot Laboratory , University of Tsukuba, Japan. From 1996 to 2006, he worked as lecturer at School of Computer Engineering, Costa Rica In- stitute of T echnology . From 2011 to 2017, work ed in Research and De velopment at Hokuyo Auto- matic Co., Ltd. Since 2017, he is a Designated Assistant Professor at Institutes of Innov ation for Future Society , Nagoya University , Japan. His main research interests are lidar sensors, robotic perception and autonomous driving. KAZUY A T AKEDA (Senior Member , IEEE) re- ceiv ed his B.E.E., M.E.E., and Ph.D. from Nagoya Univ ersity , Japan. Since 1985 he had been work- ing at Advanced T elecommunication Research Laboratories and at KDD R&D Laboratories, Japan. In 1995, he started a research group for signal processing applications at Nagoya Univ er- sity . He is currently a Professor at the Institutes of Innov ation for Future Society , Nagoya Univ ersity and with T ier IV inc. He is also serving as a member of the Board of Governors of the IEEE ITS society . His main focus is investig ating driving behavior using data centric ap- proaches, utilizing signal corpora of real driving beha vior .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment