Data Centers Job Scheduling with Deep Reinforcement Learning
Efficient job scheduling on data centers under heterogeneous complexity is crucial but challenging since it involves the allocation of multi-dimensional resources over time and space. To adapt the complex computing environment in data centers, we pro…
Authors: Sisheng Liang, Zhou Yang, Fang Jin
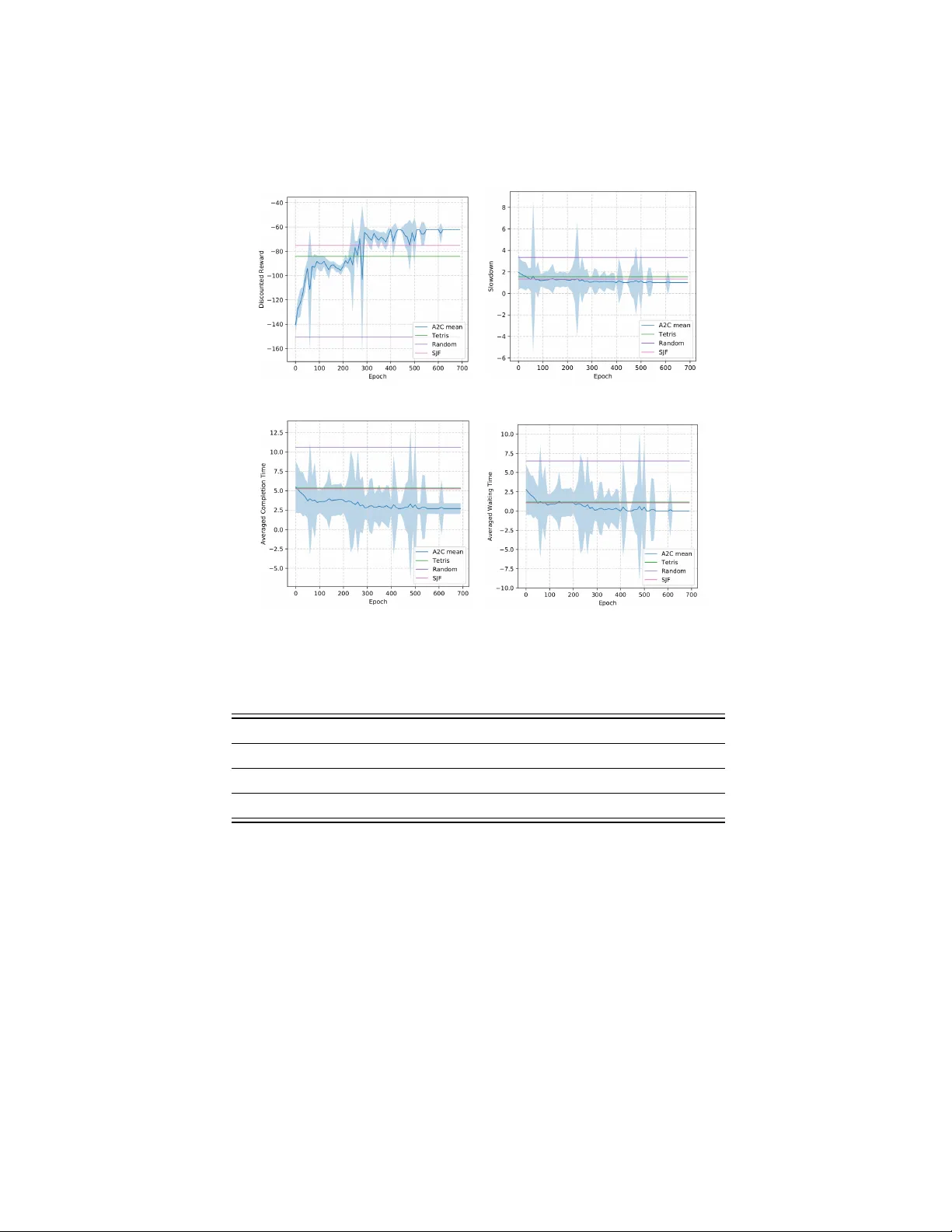
Data Cen ters Job Sc heduling with Deep Reinforcemen t Learning Sisheng Liang, Zhou Y ang, F ang Jin, and Y ong Chen Departmen t of Computer Science T exas T ech Univ ersity { sisheng.liang, zhou.yang, fang.jin, yong.chen } @ttu.edu Abstract. Efficien t job scheduling on data centers under heterogeneous complexit y is crucial but challenging since it in v olves the allo cation of m ulti-dimensional resources o ver time and space. T o adapt the com- plex computing en vironment in data centers, we proposed an inno v ative Adv an tage Actor-Critic (A2C) deep reinforcement learning based ap- proac h called A2cSc heduler for job scheduling. A2cScheduler consists of t wo agents, one of whic h, dubb ed the actor, is resp onsible for learning the scheduling p olicy automatically and the other one, the critic, re- duces the estimation error. Unlike previous p olicy gradient approaches, A2cSc heduler is designed to reduce the gradient estimation v ariance and to update parameters efficiently . W e show that the A2cSc heduler can ac hieve competitive sc heduling p erformance using both simulated work- loads and real data collected from an academic data center. Keyw ords: Job scheduling · Cluster sc heduling · Deep reinforcemen t learning · Actor critic. 1 In tro duction Job scheduling is a critical and challenging task for computer systems since it in volv es a complex allo cation of limited resources such as CPU/GPU, memory and IO among numerous jobs. It is one of the ma jor tasks of the scheduler in a computer system’s Resource Managemen t System (RMS), esp ecially in high- p erformance computing (HPC) and cloud computing systems, where inefficient job scheduling ma y result in a significant w aste of v aluable computing resources. Data centers, including HPC systems and cloud computing systems, hav e b e- come progressively more complex in their architecture [15], configuration(e.g., sp ecial visualization no des in a cluster) [6] and the size of w ork and workloads receiv ed [3], all of which increase the job scheduling complexities sharply . The undoubted imp ortance of job sc heduling has fueled interest in the sc hedul- ing algorithms on data centers. At presen t, the fundamental sc heduling metho d- ologies [18], suc h as F CFS (first-come-first-serve), bac kfilling, and priorit y queues that are commonly deplo yed in data cen ters are extremely hard and time- consuming to configure, sev erely compromising system p erformance, flexibility and usability . T o address this problem, several researchers hav e prop osed data- driv en machine learning metho ds that are capable of automatically learning the 2 Sisheng Liang, Zhou Y ang, F ang Jin, and Y ong Chen sc heduling policies, th us reducing h uman interference to a minimum. Sp ecifically , a series of p olicy based deep reinforcement learning approaches hav e b een pro- p osed to manage CPU and memory for incoming jobs [10], sc hedule time-critical w orkloads [8], handle jobs with dep endency [9], and sc hedule data centers w ith h undreds of no des [2]. Despite the extensiv e research in to job scheduling, how ev er, the increasing heterogeneit y of the data b eing handled remains a challenge. These difficulties arise from multiple issues. First, p olicy gradient DRL metho d based scheduling metho d suffers from a high v ariance problem, whic h can lead to low accuracy when computing the gradient. Second, previous work has relied on used Mon te Carlo (MC) metho d to up date the parameters, which in volv ed massive calcula- tions, esp ecially when there are large num b ers of jobs in the tra jectory . T o solv e the ab ov e-men tioned challenges, we propose a p olicy-v alue based deep reinforcement learning scheduling metho d called A2cScheduler, which can satisfy the heterogeneous requiremen ts from diverse users, impro ve the space ex- ploration efficiency , and reduce the v ariance of the p olicy . A2cScheduler consists of t w o agen ts named actor and critic resp ectively , the actor is responsible for learning the scheduling p olicy and the critic reduces the estimation error. The appro ximate v alue function of the critic is incorp orated as a baseline to reduce the v ariance of the actor, th us reducing the estimation v ariance considerably [14]. A2cSc heduler up dates parameters via the multi-step T emp oral-difference (TD) metho d, which speeds up the training pro cess markedly compared to con ven- tional MC metho d due to the w ay TD metho d up dates parameters. The main con tributions are summarized as b elow: 1. This represen ts the first time that A2C deep reinforcemen t has been suc- cessfully applied to a data cen ter resource management, to the b est of the authors’ kno wledge. 2. A2cSc heduler up dates parameters via m ulti-step T emp oral-difference (TD) metho d which speeds up the training pro cess comparing to MC metho d due to the w ay TD metho d up dates parameters. This is critical for the real w orld data center sc heduling application since jobs arrive in real time and lo w latency is undeniably imp ortant. 3. W e tested the prop osed approac h on b oth real-w orld and sim ulated datasets, and results demonstrate that our prop osed mo del outp erformed man y exist- ing widely used metho ds. 2 Related W ork Job sche duling with de ep r einfor c ement le arning Recen tly , researc hers ha ve tried to apply deep reinforcement learning on cluster resources manage- men t. A resource manager DeepRM was prop osed in [10] to manage CPU and memory for incoming jobs. The results show that p olicy based deep reinforce- men t learning outp erforms the conv entional job scheduling algorithms such as Short Job First and T etris [4]. [8] improv es the exploration efficiency by adding Data Centers Job Sc heduling with Deep Reinforcemen t Learning 3 Fig. 1. A2cScheduler job sc heduling framework. baseline guided actions for time-critical workload job scheduling. [17] discussed heuristic based metho d to co ordinate disaster resp onse. Mao prop osed Decima in [9] whic h could handle jobs with dependency when graph embedding technique is utilized. [2] prov ed that p olicy gradient based deep reinforcement learning can b e implemented to sc hedule data centers with hundreds of no des. A ctor-critic r einfor c ement le arning Actor-critic algorithm is the most p op- ular algorithm applied in the reinforcemen t learning framework [5] which falls in to three categories: actor-only , critic-only and actor-critic metho ds [7]. Actor- critic methods com bine the adv antages of actor-only and critic-only metho ds. Actor-critic metho ds usually hav e go o d conv ergence prop erties, in contrast to critic-only [5]. A t the core of several recent state-of-the-art Deep RL algorithms is the adv an tage actor-critic (A2C) algorithm [11]. In addition to learning a p olicy (actor) π ( a | s ; θ ), A2C learns a parameterized critic: an estimate of v alue function v π ( s ), whic h then uses b oth to estimate the remaining return after k steps, and as a con trol v ariate (i.e. baseline) that reduces the v ariance of the return estimates [13]. 3 Metho d and Problem F orm ulation In this section, we first review the framework of A2C deep reinforcement learning, and then explain how the prop osed A2C based A2cScheduler w orks in the job sc heduling on data cen ters. The rest part of this section cov ers the essen tial details ab out mo del training. 3.1 A2C in Job Scheduling The Adv antage Actor-critic (A2C), whic h com bines policy based method and v alue based method, can o vercome the high v ariance problem from pure p olicy gradien t approach. The A2C algorithm is comp osed of a p olicy π ( a t | s t ; θ ) and a v alue function V ( s t ; w ), where p olicy is generated b y p olicy net work and v alue is estimated by critic net work. The prop osed the A2cSc heduler framew ork is 4 Sisheng Liang, Zhou Y ang, F ang Jin, and Y ong Chen sho wn in figure 1, which consists of an actor net work, a critic net work and the cluster environmen t. The cluster environmen t includes a global queue, a backlog and the sim ulated machines. The queue is the place holding the w aiting jobs. The bac klog is an extension of the queue when there is not enough space for w aiting jobs. Only jobs in the queue will b e allo cated in each state. The setting of A2C – Actor : The p olicy π is an actor whic h generates probability for eac h possible action. π is a mapping from state s t to action a t . Actor can choose a job from the queue based on the action probability generated by the p olicy π . F or instance, given the action probability P = { p 1 , . . . , p N } for N actions, p i denotes the probability that action a i will b e selected. If the action is chosen according to the maxim um probabilit y ( action = arg max i ∈ [0 ,N ] ,i ∈ N + p i ), the actor acts greedily whic h limits the exploration of the agent. Exploration is allow ed in this researc h. The p olicy is estimated by a neural net work π ( a | s, θ ), where a is an action, s is the state of the system and θ is the w eights of the p olicy netw ork. – Critic : A state-v alue function v ( s ) used to ev aluate the p erformance of the actor. It is estimated by a neural net work ˆ v ( s, w ) in this researc h where s is the state and w is the weigh ts of the v alue neural net work. – State s t ∈ S : A state s t is defined as the resources allo cation status of the data center including the status of the cluster and the status of the queue at time t . The states S is a finite set. Figure 2 sho ws an example of the state in one time step. The state includes three parts: status of the resources allo cated and the av ailable resources in the cluster, resources requested by jobs in the queue, and status of the jobs waiting in the bac klog. The scheduler will only sc hedules jobs in the queue. – Action a t ∈ A : An action a t = { a t } N 1 denotes the allo cation strategy of jobs w aiting in the queue at time t , where N is the n umber of slots for w aiting jobs in the queue. The action space A of an actor sp ecifies all the p ossible allo cations of jobs in the queue for the next iteration, which gives a set of N + 1 discrete actions represented b y {∅ , 1 , 2 , . . . , N } where a t = i ( ∀ i ∈ { 1 , . . . , N } ) means the allo cation of the i th job in the queue and a t = ∅ denotes a v oid action where no job is allo cated. – En vironment : The sim ulated data center con tains resources suc h as CPUs, RAM and I/O. It also includes resource management queue system in which jobs are w aiting to b e allo cated. – Discoun t F actor γ : A discount factor γ is b etw een 0 and 1, and is used to quan tify the difference in importance betw een immediate rew ards and future rew ards. The smaller of γ , the less imp ortance of future rewards. – T ransition function P : S × A → [0 , 1]: T ransition function describ es the probabilities of moving b et ween current state to the next state. The state transition probability p ( s t +1 | s t , a t ) represents the probability of transiting to s t +1 ∈ S given a join t action a t ∈ A is tak en in the current state s t ∈ S . – Rew ard function r ∈ R = S × A → ( −∞ , + ∞ ): A rew ard in the data cen ter scheduling problem is defined as the feedbac k from the en vironment Data Centers Job Scheduling with Deep Reinforcemen t Learning 5 Fig. 2. An example of the tensor representation of a state. At each iteration, the deci- sion combination of num b er of jobs will b e scheduled is 2 T otal j obs , which has exp onen- tial growth rate. W e simplify the case by selecting a decision from decision domain = { 0 , 1 , . . . , N } , where N is a fixed hyper-parameter, decision = i denotes select i th job, and decision = 0 denotes no job will b e selected. when the actor takes an action at a state. The actor attempts to maximize its exp ected discoun ted reward: R t = E ( r i t + γ r i t +1 + ... ) = E ( ∞ P k =0 γ k r i t + k ) = E ( r i t + γ R t +1 ). The agent rew ard at time t is defined as r t = − 1 T j , where T j is the run time for job j . The goal of data cen ter job scheduling is to find the optimal policy π ∗ (a sequence of actions for agents) that maximizes the total reward. The state v alue function Q π ( s, a ) is in tro duced to ev aluate the p erformance of differen t p olicies. Q π ( s, a ) stands for the exp ected total reward with discoun t from current state s on-w ards with the p olicy π , which is equal to: Q π ( s t , a t ) = E π ( R t | s t , a t ) = E π ( r t + γ Q π ( s 0 , a 0 )) = r t + γ X s 0 ∈ S P π ( s 0 | s ) Q π ( s 0 , a 0 ) (1) , where s 0 is the next state, and a 0 is the action for the next time step. F unction approximation is a w ay for generalization when the state and/or action spaces are large or con tinuous. Sev eral reinforcemen t learning algorithms ha ve b een prop osed to estimate the v alue of an action in v arious contexts suc h as the Q-learning [16] and SARSA [12]. Among them, the mo del-free Q-learning algorithm stands out for its simplicit y [1]. In Q-learning, the algorithm uses a Q-function to calculate the total rew ard, defined as Q : S × A → R . Q-learning 6 Sisheng Liang, Zhou Y ang, F ang Jin, and Y ong Chen iterativ ely ev aluates the optimal Q-v alue function using bac kups: Q ( s, a ) = Q ( s, a ) + α [ r + γ max a 0 Q ( s 0 , a 0 ) − Q ( s, a )] (2) , where α ∈ [0 , 1) is the learning rate and the term in the brack ets is the temp oral- difference (TD) error. Conv ergence to Q π ∗ is guaran teed in the tabular case pro vided there is sufficient state/action space exploration. The loss function for critic Loss function of the critic is utilized to up date the critic net work parameters. L ( w i ) = E ( r + γ max a 0 Q ( s 0 , a 0 ; w i − 1 ) − Q ( s, a ; w i )) 2 , (3) where s 0 is the state encountered after state s . Critic up date the parameters of the v alue netw ork by minimizing critic loss in equation 3. A dvantage actor-critic The critic up dates state-action v alue function pa- rameters, and the actor up dates p olicy parameters, in the direction suggested b y the critic. A2C up dates b oth the policy and v alue-function net works with the m ulti-step returns as described in [11]. Critic is up dated by minimizing the loss function of equation 3. Actor netw ork is up dated by minimizing the actor loss function in equation L ( θ 0 i ) = ∇ θ 0 log π ( a t | s t ; θ 0 ) A ( s t , a t ; θ , w i ) (4) , where θ i is the parameters of the actor neural net work and w i is the parameters of the critic neural netw ork. Note that the parameters θ i of policy and w i of v alue are distinct for generality . Algorithm 1 presents the calculation and up date of parameters p er episo de. 3.2 T raining algorithm The A2C consists of an actor and a critic, and we implemen t b oth of them using deep con volutional neural netw ork. F or the Actor neural netw ork, it takes the afore-men tioned tensor representation of resource requests and mac hine status as the input, and outputs the probability distribution ov er all p ossible actions, represen ting the jobs to b e scheduled. F or the Critic neural net work, it takes as input the combination of action and the state of the system, and outputs the a single v alue, indicating the ev aluation for actor’s action. 4 Exp erimen ts 4.1 Exp erimen t Setup The experiments are executed on a desktop computer with t wo R TX-2080 GPUs and one i7-9700k 8-core CPU. A2cScheduler is implemented using T ensorflo w framew ork. Simulated jobs arriv e online in Bernouli pro cess. A piece of job trace Data Centers Job Scheduling with Deep Reinforcemen t Learning 7 Algorithm 1 A2C reinforcement learning scheduling algorithm Input: a p olicy parameterization π ( a | s, θ ) Input: a state-v alue function parameterization ˆ v ( s, w ) P arameters: step sizes α θ > 0 , α w > 0 Initialization: p olicy parameter θ ∈ R d 0 and state-v alue function weigh ts w ∈ R d ( e.g. , to 0 . 001 ) Output: The scheduled sequence of jobs[1..n] Lo op forever (for each episo de): Initialize S (state of episo de) Lo op while S is not terminal (for each time step of episo de): A ∼ π ( ·| S, θ ) T ake action A , observe state S 0 , r ew ard R δ ← R + γ ˆ v ( S 0 , w ) − ˆ v ( S, w ) ( If S 0 is terminal, then ˆ v ( S 0 , w ) . = 0) w ← w + α w δ ∇ ˆ v ( S, w ) θ ← θ + α θ δ ∇ ln π ( A | S, θ ) S ← S 0 T able 1. Performance comparison when mo del conv erged. Job Rate 0.9 0.8 Type Random T etris SJF A2cScheduler Random T etris SJF A2cScheduler Slowdo wn 5.50 ± 0.00 2.90 ± 0.00 1.81 ± 0.00 2.03 ± 0.01 6.2 ± 0.00 3.25 ± 0.00 2.52 ± 0.00 2.30 ± 0.05 Complete time 12.51 ± 0.00 8.61 ± 0.00 7.42 ± 0.00 7.20 ± 0.01 14.21 ± 0.00 8.50 ± 0.00 6.50 ± 0.00 6.20 ± 0.04 W aiting time 8.22 ± 0.00 3.32 ± 0.00 2.21 ± 0.00 2.20 ± 0.01 9.15 ± 0.00 2.10 ± 0.00 1.93 ± 0.00 2.12 ± 0.005 from a real data center is also tested. CPU and Memory are the tw o kinds of resources considered in this researc h. The training pro cess b egins with an initial state of the data cen ter. At each time step, a state is passed in to the p olicy net w ork π . An action is generated under p olicy π . A v oid action is made or a job is chosen from the global queue and put into the cluster for execution. Then a new state is generated and some reward is collecte d. The states, actions, p olicy and rewards are collected as tra jectories. Mean while, the state is also passed into the v alue netw ork to estimate the v alue, whic h used to ev aluate the p erformance of the action. Actor in A2cScheduler learns to pro duce resource allocation strategies from exp eriences after ep o chs. T able 2. Performance comparison when mo del conv erged. Job Rate 0.7 0.6 Type Random T etris SJF A2cScheduler Random T etris SJF A2cScheduler Slowdo wn 5.05 ± 0.00 3.32 ± 0.00 2.14 ± 0.00 1.91 ± 0.02 3.22 ± 0.00 1.82 ± 0.00 1.56 ± 0.00 1.36 ± 0.04 Complete time 13.15 ± 0.00 10.02 ± 0.00 7.66 ± 0.00 6.10 ± 0.03 10.0 ± 0.00 5.50 ± 0.00 5.50 ± 0.00 5.50 ± 0.04 W aiting time 8.32 ± 0.00 4.51 ± 0.00 2.53 ± 0.00 1.82 ± 0.03 8.32 ± 0.00 1.48 ± 0.00 1.48 ± 0.00 1.50 ± 0.003 8 Sisheng Liang, Zhou Y ang, F ang Jin, and Y ong Chen 4.2 Ev aluation Metrics Reinforcemen t learning algorithms, including A2C, hav e b een mostly ev aluated b y conv erging speed. Ho wev er, these metrics are not v ery informative in domain- sp ecific applications suc h as scheduling. Therefore, w e present sev eral ev aluation metrics that are helpful for access the p erformance of the prop osed mo del. Giv en a set of jobs J = { j 1 , . . . , j N } , where i th job is asso ciated with arriv al time t a i , finish time t f i , and execution time t e i . A ver age job slowdown The slowdo wn for i th job is defined as s i = t f i − t a i t e i = c i t i , where c i = t f i − t a i is the completion time of the job and t i is the duration of the job. The a verage job slowdo wn is defined as s av g = 1 N n P i =1 t f i − t a i t e i = 1 n N P i =1 c i t i . The slo wdown metric is imp ortant b ecause it helps to ev aluate normalized waiting time of a system. A ver age job waiting time F or the i th job, the w aiting time t wi is the time b etw een arriv al and start of execution, which is formally defined as t wi = t s i − t a i . 4.3 A2cSc heduler with CNN W e simulated the data center cluster con taining N no des with tw o resources: CPU and Memory . W e trained the A2cScheduler with different neural net works including a fully connected la y er and Conv olutional Neural Net works (CNN). In order to design the b est p erformance neural netw orks, we explore different CNN architectures and compare whether it conv erges and how is the conv erge sp eed with different settings. As sho wn in table 3, fully connected lay er (FC la yer) with a flatten lay er in front did not conv erge. This is because the state of the en vironment is a matrix with lo cation information while some lo cation information lost in the flatten la yer when the state is processed. T o k eep the lo cation information, w e utilize CNN la yers (16 3*3-filters CNN lay er and 32 3*3-filters CNN lay er) and they show b etter results. Then, we explored CNN with max-p o oling and CNN with flattening lay er behind. Results sho w b oth of them could con verge but CNN with max-po oling gets p o orer results. This is due to some of the state information also get lost when it passes max-p o oling la yer. According to the exp erimen t results, we decide to choose the CNN with a flattening lay er b ehind architecture as it con verges fast and giv es the best p erformance. 4.4 Baselines The p erformance of the prop osed metho d is compared with some of the main- stream baselines such as Shortest Job First (SJF), T etris [4], and random p olicy . SJF sorts jobs according to their execution time and sc hedules jobs with the Data Centers Job Scheduling with Deep Reinforcemen t Learning 9 (a) Discoun ted reward. (b) Slo wdown. (c) Av erage completion time. (d) Av erage waiting time. Fig. 3. A2C p erformance with a job arrival r ate=0.7 T able 3. Performances of different netw ork architectures. Arc hitecture Con verge Con verging Con verging Sp eed Ep ochs F C lay er No N.A. N.A. Con v3-16 Y es F ast 500 Con v3-32 Y es Slo w 1100 Con v3-16 + p ooling Y es F ast 700 Con v3-32 + p ooling Y es F ast 900 shortest execution time first; T etris schedules job by a combined score of pref- erences for the short jobs and resource packing; random p olicy schedules jobs randomly . All of these baselines w ork in a greedy wa y that allo cates as many jobs as allow ed by the resources, and share the same resource constraints and tak e the same input as the prop osed mo del. 10 Sisheng Liang, Zhou Y ang, F ang Jin, and Y ong Chen (a) Discoun ted reward. (b) Slo wdown. (c) Av erage completion time. (d) Av erage waiting time. Fig. 4. A2C p erformance with real world log data T able 4. Results of Job T races. T yp e Random T etris SJF A2cSc heduler Slo wdown 3.52 ± 0.00 1.82 ± 0.00 1.61 ± 0.00 1.01 ± 0.02 C T ∗ 10.2 ± 0.00 5.55 ± 0.00 5.51 ± 0.00 2.58 ± 0.01 W T ∗ 6.32 ± 0.00 1.25 ± 0.00 1.21 ± 0.00 0.01 ± 0.02 4.5 P erformance Comparison Performanc e on Synthetic Dataset In our exp eriment, the A2cScheduler utilized an A2C reinforcement learning metho d. It is worth to men tion that the mo del includes the option to ha ve m ultiple episo des in order to allow us to measure the a verage p erformance achiev ed and the capacity to learn for each sc heduling policy . Algorithm 1 presen ts the calculation and up date of parameters p er episo de. Figure 3 shows exp erimental results with syn thetic job distribution as input. Data Centers Job Scheduling with Deep Reinforcemen t Learning 11 Figure 3(a) and Figure 3(b) presen t the rewards and av eraged slowdo wn when the new job rate is 0.7. Cum ulative rewards and a veraged slo wdown conv erge around 500 episo des. A2cScheduler has low er a veraged slo wdown than random, T etris and SJF after 500 episo des. Figure 3(c) and Figure 3(d) show the av erage completion time and av erage w aiting time of the A2cScheduler algorithm versus baselines. As w e can see, the p erformance of A2cScheduler is the best comparing to all the baselines. T able 1, 2 present the steady state simulation results at different job rates. W e can see the A2cScheduler algorithm gets the b est or close to the b est p erfor- mance regrading slowdo wn, av erage completion time and av erage waiting time at differen t job rates ranging from 0.6 to 0.9. Performanc e on R e al-world Dataset W e ran experiments with a piece of job trace from an academic data center. The results w ere shown in figure 4. The job traces were prepro cessed before they are trained with the A2cScheduler. There w as some fluctuation at the first 500 episo des in 4(a), then it started to con verge. Figure 4(b) sho ws the av erage slo wdown w as b etter than all the baselines and close to optimal v alue 1, which means the av erage w aiting time w as almost 0 as shown in figure 4(d). This happ ens b ecause there were only 60 jobs in this case study and jobs runtime are small. This was an case where almost no job w as w aiting for the allocation when it was optimally sc heduled. A2cScheduler also gains the shortest completion time among different metho ds from figure 4(c). T able 4 sho ws the steady state results from a real-world job distribution running on an academic cluster. A2cSc heduler gets optimal sc heduling results since there is near 0 a v erage waiting time for this jobs distribution. Again, this experimental results pro v es A2cSc heduler effectiv ely finds the prop er sc heduling policies b y itself giv en adequate training, both on simulation dataset and real-world dataset. There were no rules predefined for the scheduler in adv ance, instead, there was only a rew ard defined with the system optimization target included. This pro v en our defined reward function was effective in helping the scheduler to learn the optimal strategy automatically after adequate training. 5 Conclusion Job scheduling with resource constrain ts is a long-standing but critically im- p ortan t problem for computer systems. In this pap er, we prop osed an A2C deep reinforcemen t learning algorithm to address the customized job sc heduling prob- lem in data centers W e defined a reward function related to av eraged job w ait- ing time whic h leads A2cScheduler to find scheduling policy by itself. Without the need for any predefined rules, this scheduler is able to automatically learn strategies directly from exp erience and th us improv e scheduling p olicies. Our exp erimen ts on both simulated data and real job traces for a data center show that our prop osed metho d p erforms b etter than widely used SJF and T etris for m ulti-resource cluster scheduling algorithms, offering a real alternative to cur- ren t conv entional approaches. The exp erimental results reported in this paper 12 Sisheng Liang, Zhou Y ang, F ang Jin, and Y ong Chen are based on t wo-resource (CPU/Memory) restrictions, but this approac h can also b e easily adapted for more complex multi-resource restriction sc heduling scenarios. 6 Ac kno wledgement W e are thankful to the anonymous reviewers for their v aluable feedback. This researc h is supp orted in part by the National Science F oundation under grant CCF-1718336 and CNS-1817094. References 1. Al-T amimi, A., et al.: Mo del-free q-learning designs for linear discrete-time zero- sum games with application to h-infinity control. Automatica 43 (3), 473–481 (2007) 2. Domeniconi, G., Lee, E.K., Morari, A.: Cush: Cognitive scheduler for heterogeneous high p erformance computing system (2019) 3. Garg, S.K., Gopalaiy engar, S.K., Buyya, R.: Sla-based resource provisioning for heterogeneous wo rkloads in a virtualized cloud datacenter. In: Pro c. ICA3PP . pp. 371–384 (2011) 4. Grandl, R., et al.: Multi-resource packing for cluster sc hedulers. Computer Com- m unication Review 44 (4), 455–466 (2015) 5. Grondman, I., et al.: A survey of actor-critic reinforcement learning: Standard and natural policy gradients. IEEE T ransactions on Systems, Man, and Cyb ernetics 42 (6), 1291–1307 (2012) 6. Ho vestadt, M., Kao, O., Keller, A., Streit, A.: Scheduling in hp c resource manage- men t systems: Queuing vs. planning. In: W orkshop on JSSPP . pp. 1–20. Springer (2003) 7. Konda, V.R., et al.: Actor-critic algorithms. In: Pro c. NIPS. pp. 1008–1014 (2000) 8. Liu, Z., Zhang, H., Rao, B., W ang, L.: A reinforcement learning based resource managemen t approach for time-critical workloads in distributed computing envi- ronmen t. In: Pro c. Big Data. pp. 252–261. IEEE (2018) 9. Mao, H., et al.: Learning scheduling algorithms for data pro cessing clusters. arXiv preprin t arXiv:1810.01963 (2018) 10. Mao, H., Alizadeh, M., Menache, I., Kandula, S.: Resource managemen t with deep reinforcemen t learning. In: HotNets ’16. pp. 50–56. ACM, New Y ork. h ttps://doi.org/10.1145/3005745.3005750 11. Mnih, V., et al.: Asynchronous metho ds for deep reinforcement learning. In: Pro c. ICML. pp. 1928–1937 (2016) 12. Sprague, N., Ballard, D.: Multiple-goal reinforcement learning with mo dular sarsa (0) (2003) 13. Sriniv asan, S., et al.: Actor-critic p olicy optimization in partially observ able m ul- tiagen t environmen ts. In: Proc. NIPS. pp. 3422–3435 (2018) 14. Sutton, R.S., Barto, A.G., et al.: Introduction to reinforcement learning, vol. 135. MIT press Cambridge (1998) 15. V an Craeynest, K., et al.: Scheduling heterogeneous multi-cores through p erfor- mance impact estimation (pie). In: Computer Architecture News. vol. 40, pp. 213– 224 Data Centers Job Scheduling with Deep Reinforcemen t Learning 13 16. W atkins, C.J., Day an, P .: Q-learning. Mac hine learning 8 (3-4), 279–292 (1992) 17. Y ang, Z., Nguyen, L., Jin, F.: Co ordinating disaster emergency resp onse with heuristic reinforcement learning 18. Zhou, X., Chen, H., W ang, K., Lang, M., Raicu, I.: Exploring distributed re- source allo cation techniques in the slurm job management system. T echnical Re- p ort (2013)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment