A Fixed point view: A Model-Based Clustering Framework
With the inflation of the data, clustering analysis, as a branch of unsupervised learning, lacks unified understanding and application of its mathematical law. Based on the view of fixed point, this paper restates the model-based clustering and propo…
Authors: Jianhao Ding, Lansheng Han
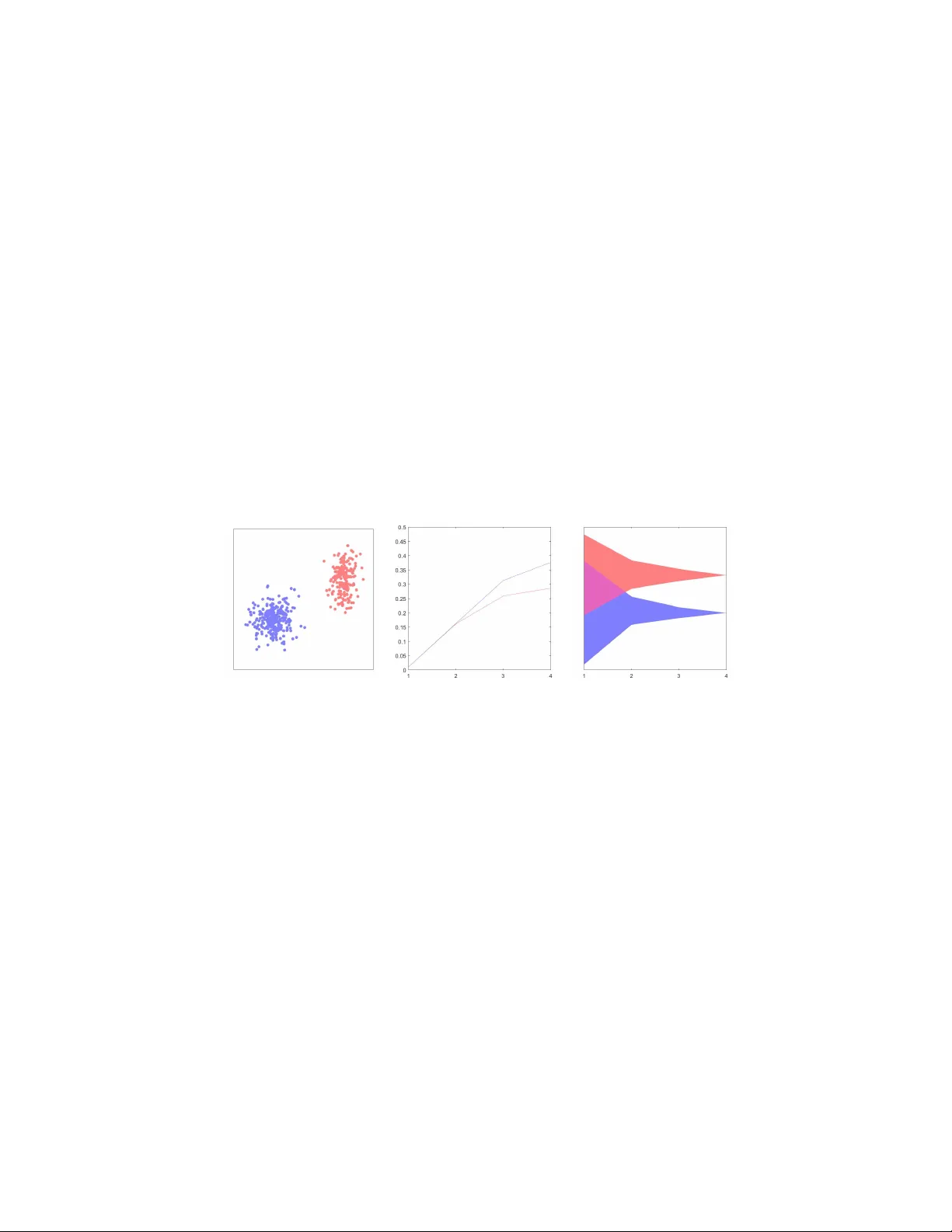
A Fixed p oin t view: A Mo del-Based Clustering F ramew ork Jianhao Ding a,1 , Lansheng Han a, ∗ a Scho ol of Computer Scienc e and T e chnolo gy, Huazhong University of Scienc e and T e chnology, Wuhan 430074, China Abstract With the inflation of the data, clustering analysis, as a branch of unsup ervised learning, lac ks unified understanding and application of its mathematical law. Based on the view of fixed p oint, this pap er restates the mo del-based cluster- ing and prop oses a unified clustering framework. In order to find fixed p oin ts as cluster cen ters, the framew ork iterativ ely constructs the contraction map, whic h strongly rev eals the con vergence mechanism and in terconnections among algorithms. By sp ecifying a contraction map, Gaussian mixture mo del (GMM) can b e mapped to the framew ork as an application. W e hope the fixed point framew ork will help the design of future clustering algorithms. Keywor ds: Fixed P oint, Mo del-based Clustering, Unsup ervised Learning 1. Introduction No wada ys, w e are in the Big Data Era, human so ciety can pro duce tens of thousands of unstructured or semi-structured data in a second. Ho wev er, not all of the data are representativ e and meaningful, so the analysis and disp osal of large-scale data o ccupies an increasingly imp ortan t p osition in scientific re- searc h and so cial life [1]. Cluster analysis is an imp ortan t unsup ervised learning metho d in machine learning. Its basic idea is grouping a set of ob jects into clusters, in a wa y that ob jects in the same cluster share more similarity than those from separated clusters, in terms of distances of a certain space. In the ev olution of clustering, due to the differences of data t yp es and cluster- ing strategies, cluster analysis can b e divided into tw o main branc hes, namely , traditional clustering algorithms and mo dern clustering algorithms. T raditional clustering algorithms include clustering algorithm based on partition, densit y , mo del, fuzzy theory and so on [2, 3]. In con trast, mo dern clustering algorithms ∗ Lansheng Han, Professor of Information Security , School of Computer Science and T ec h- nology , Huazhong Universit y of Science and T echnology . Email: 1998010309@hust.edu.cn. Academic Areas: Information Securit y , Security of Net work, Security of Big Data. 1 Jianhao Ding, Undergraduate of School of Computer Science and T ec hnology , Huazhong Universit y of Science and T echnology . Email: ding jh1998@hust.edu.cn. Pr eprint submitte d to Elsevier F ebruary 20, 2020 are mainly presen ted from the p erspective of modern scien tific researc h or sw arm in telligence. With resp ect of representativ eness and inclusiveness of mo del-based cluster- ing [4], this paper focuses on the uniform char acteristics of model-based clus- tering algorithms. Such algorithms require a priori. Thus, the iterativ e scheme v aries with the priori. Probabilistic clustering mo del, for example, Exp ectation Maximization Algorithm (EM) and Gaussian mixture mo del algorithm (GMM), use maximum lik eliho o d estimation to obtain the mo del parameters [5, 6]; algo- rithms based on neural netw ork get the clusters by adjusting weigh ts of neurons in neural netw ork. Typical algorithms are self-organizing feature map (SOM), Neural-Gas algorithm and AR T [7, 8, 9]. F or the same dataset, different priori mo dels lead to differen t clustering results. As mo del-based clustering algorithms need to figure out the mo del parameters, they usually hav e a high time complex- it y . But the adv antage is that the con vergen t model can explain the distribution features of the data. 1.1. Motivation and Contributions There are a v ariety of mo del- based clustering algorithms. The hypothesis of similarity and the metho dology of parameter up dating are not necessarily in terconnected. Sometimes, the iterativ e metho d can b e used as an independent mo dule. F or example, the GMM algorithm and the EM algorithm share the same iterative metho d to maximize parameters b efore conv ergence. The goal of con vergence is to obtain explicit mo del parameters, which also applies to the neural net work mo del. By studying the conv ergen t mo del and visualizing the membership degree of each p oin t on the data space R n , the visualization illustrates the p oin t that most of the data can b e represented by a lo cal model, and the distribution of mem b ership degree exists con v ex structure. In other w ords, there may b e more than one extremum in the conv ex hull of any cluster. This inspires us to reexamine the problem from the view of fixed p oin t. The existing framew ork to date has tended to focus on data distribution or partition. Extensive research has rarely b een carried out on whic h frame- w ork to apply in order to achiev e b etter clustering and how to discriminate the con vergence of algorithm [10, 11]. The conv ergence of a clustering algorithm corresp onds to the finite time to complete the iterative process. Different clus- tering models need a framework to b etter unify the workflo w of model-based clustering algorithms. Besides, a working mo del can b e regarded as a contrac- tion map in nature, which may reveal common features of the similarit y and the dissimilarity of the data. The up dating of contraction map compresses the image space in the iteration of clustering, and thus completes the algorithm. The clustering algorithm is generally more dep enden t on cluster shap e. The c hoice of model and also fixed the shape of the cluster. Gaussian mixture mo del, for example, is a clustering mo del based on Gaussian distribution, so the shap e of clusters is typically a hyper ellipsoid. The Gaussian distribution h yp othesis is often appropriate for some datasets, but it is inv alid for datasets without Gaussian distribution feature. While in hierarchical clustering, the data distribution h yp othesis is w eakened, so the algorithm can iden tify more complex 2 cluster shapes. By emphasizing the similarit y or relations with neigh b oring data, there exists a unified framework, which is less sensitive to the cluster shap e and satisfies the requiremen ts of v arious cluster. Besides, a typical algorithm can only b e classified into one category of clus- tering. Considering the global or lo cal linear prop erties, the strong generaliza- tion of neural netw orks can supp ort a clustering framework. Now adays, neural net works p erform w ell in supervised learning using their forward and back prop- agation features [12]. Self-organizing feature map and its deriv ations are rep- resen tative of unsupervised learning metho ds in neural netw orks [8, 9]. These algorithms discuss and study the lateral propagation of neural netw orks. But the order of the neurons in physical implementation is not well em b o died, whic h con tributes to a low er efficiency . In this paper, w e presen t a unified clustering framework based on fixed point. The framework constructs the contraction map by compressing space, and de- termine the num b er of clusters by the fixed p oint. The new framework not only unifies the clustering in theory , but also giv es another reasonable explanation for the conv ergence of clustering algorithm. And this may rev eals the inherent la ws of itself, rather than simply clustering under sp ecific purp oses. Th us, the framew ork provides a theoretical basis for the construction of new clustering metho ds. The pap er contributes in the following w ays: 1) W e restate the mo del-based clustering mo del. 2) W e prop ose a unified framework from the view of fixed p oint. 3) W e map the GMM algorithm to the prop osed framework by sp ecifying a con traction map. 1.2. Or ganization The rest of the pap er is organized as follows. In Section 2, axiomatic cluster- ing and some relev ant unified clustering framework are reviewed. In Section 3, a unified clustering framew ork from the view of fixed point is presented. Section 4 discussed the relation betw een the proposed framew ork and GMM. Finally , Section 5 summarizes the pap er and discusses the future work. 2. Related W orks Man y researc hers ha ve expressed their p ersp ectiv e on the issue of unified clustering framework. Jon Klein b erg prop osed axiomatic clustering in 2003. He summarized the cluster as three axioms , namely Scale-In v ariance , Ric h- ness and Consistency . Scale-Inv ariance requires the partitions are inv ariant to linear transformations [13]. Richness requires guaran tee of surjection b etw een distance d and partition Γ. Consistency ensures the inv ariance of clusters after the measure is reconstructed in term of the similarity b et ween the clusters. In 2009, Zadeh et al. considered to replace the prior three axioms with three w eaker axioms, namely Scale-In v ariance, Order Consistency and k-Richness [14]. The concept of axiomatic clustering has strong theoretical bac kground, but it is very 3 limited in practical application. On the one hand, algorithms which fully sat- isfy three axioms are difficult to construct. Zadeh [14], Bandyopadh ya y [15] and other researc hers hav e tried to construct the algorithm satisfying axioms. On the other hand, Klop otek in [16] analyzed the association b etw een K-means and Klein b erg’s axioms, and pointed out that the absence of cluster shap e during the construction of axioms will result in the loss of the v alidit y of the axiomatic clustering. Axiomatic clustering is the cornerstone of unified clustering framework. More researc hers hav e devoted to studying the framework for some clustering metho ds. Zhong et al. developed a unified framew ork for mo del-based clus- tering. The framework studied the similarity of data from the persp ective of bipartite graph, where data space χ and cluster mo del M constitute surjection. The clustering model is further separated into partitional clustering and hier- arc hical clustering due to the data organization [10]. How ev er, this framework ignores the similarit y b et ween the data, whic h will result in merely the c harac- terization of relationship betw een the comp onents. Based on the optimization theory in conv ex analysis, T eb oulle utilized supp ort and asymptotic functions to construct a contin uous framework for clustering in [11]. Li and Vidal for- malized an optimization framework to unified the subspace clustering metho ds. In their framework, affinity matrix is learned. Subspace structured norm and structured sparse subspace L 1 norm is brought up. Based on the new norm, the sp ectral clustering is combined to improv e the clustering accuracy [17]. In view of information deficiency in sp ectral clustering, Y ang and Shen et al. put forw ard a unified framework. It is the basis of normal mode that distinguish sp ectral clustering with other clustering algorithms. Y ang et al. replaced the L 2 F rob enius norm loss with the L 2 ,p norm loss for clustering to impro ve the generalization abilit y of the mo del [18]. Eac h cluster framework men tioned ab o ve tends to fo cus on some specified structural features of the data, with the conv ergence feature weak ened. No wa- da ys, conditions for a qualitative change in big data is approac hing, due to the complexit y and v olume of big data. Corresp ondingly , with the clarity of data hierarc hy and the increasing time complexity of algorithms, a new framew ork needs to complement the adv an tages of different types of clustering. In other w ords, the research of clustering algorithms should not merely fo cus on mate- rialization. And the internal relations and rules, instead, need to b e extracted, whic h is the main motiv ation of this article. 3. A Unified F ramework for Mo del-based Clustering In this section, we propose a new unified framework for model-based cluster- ing from the view of fixed p oin t. The existing framework has many theoretical pro ofs, but there is no consensus on the structure of the cluster. The framew ork presen ted in this pap er giv es a constructive opinion. 4 3.1. Mo del-b ase d Clustering With the inten t of eliciting the framework, we restate the mo del-based clus- tering. Let X = ( X 1 , X 2 , X 3 , · · · , X N ) b e a set of N random observed vectors, and the v ector is of L dimensions. The universal set U = C onv ( X ) ∈ R L is the con vex hull of the N observ ed vectors. In other words, for all observed v ectors x , y in the univ ersal set U , with α ∈ [0 , 1], αx + (1 − α ) y ∈ U . In general, the mo del-based clustering has finite mixture mo dels. So the densit y of x in the mo del f ( x | π , θ ) is given as: f ( x | π , θ ) = G X g =1 π g φ g ( x | θ g ) . (1) In Equation 1, G is the num b er of mixed mo dels, and π g is the mixture co efficien t, which satisfies π g > 0 and P G g =1 π g = 1. φ g ( x | θ g ) represen ts the densit y of x in the g th mo del comp onent. θ g is the parameter of the g th com- p onen t. θ = [ θ 1 , θ 2 , · · · , θ G ], π = [ π 1 , π 2 , · · · , π G ]. More detailed research on mo del-based clustering is given in [19]. The data observ ation v alues are correlated with the clusters by the proba- bilit y . The maxim um v alue of the probabilities can imply the interpretation of the whole mo del. T o facilitate discussions in Section 3.2, we dra w a definition of the in terpretation degree in the mo del. Definition 3.1. Define φ ( x | M ) as the interpr etation de gr e e of observation x in the G-c omp onents mixtur e mo del, which also r epr esents the maximum density of x in a single mo del c omp onent. φ ( x | M ) c an b e given by: φ ( x | M ) = max { φ 1 ( x | θ 1 ) , φ 2 ( x | θ 2 ) , · · · , φ G ( x | θ G ) } . (2) 3.2. A Fixe d Point View Mo del-based clustering algorithm mainly relies on the contin uous reuse of the data and the iterative up dating of the model parameters until conv ergence. A clas sical iterative scheme for model-based clustering is the EM algorithm. By iterating, the data observ ation X can matc h one or more comp onen ts in the mixed mo del, whic h corresp onds to the iterativ e c hanges of φ ( x | M ) v alues. T ypically , as the n umber of iterations increases, φ ( x | M ) of data observ ation tends to b ecome 1. F or example, in the Gaussian mixture model algorithm, the µ parameter in the mo del indicates the center of the mo del comp onent. A more general condition has b een taken into consideration in this article that, the parameters do not indicate the the clustering cen ters. Instead, it is the fixed p oin ts that suggest the clustering cen ter, whic h are formalized by the contraction map. In order to ensure the compressing characteristic of the con traction map, the follo wing tw o definitions are prop osed first. 5 Definition 3.2. Define α -se quenc e as an incr emental se quenc e with time serial t satisfying: ∃ C ∈ (0 , 1] and C is c onstant, so that: α ( t ) < α ( t +1) < C , ∀ t ≥ 0 α (0) = 0 lim t →∞ α ( t ) = C . (3) Definition 3.3. Define α -critic al sp ac e as a subsp ac e S in R L . S is the c onvex hul l of data observation satisfying φ ( x | M ) ≥ α . This c an b e interpr ete d as: S ( α ) = C onv { x | φ ( x | M ) ≥ α } . (4) In p articular, if S is an α -critic al sp ac e in sp ac e D , then we have: S D ( α ) = C onv { x | φ ( x | M ) ≥ α, x ∈ D } . When the mo del-based clustering algorithm iterates to the t th time, there alw ays exists t and α ( t ) so that S U ( α ( t ) ) 6 = ∅ . T o simplify the notation, S U ( α ( t ) ) is denoted as S ( t ) . The current nonempty S ( t ) can b e regarded as the universal set for constructing α -critical space, if and only if there exist x 0 and > 0 so that B or el ( x 0 , ) ⊂ S ( t ) . F rom the ab o v e analysis, it is worth y of note that a spatial mapping can alw ays b e constructed, due to the adjustmen t of parameters b efore and after the iteration. W e clarify the compression of the space as a mapping for b etter explaining and analyzing the mechanism. Definition 3.4. F or a given mo del c omp onent g , b efor e the iter ation, the nonempty universal set is S ( i − 1) , which is gener ate d after the ( i − 1) th iter ation. F or the i th iter ation: 1) If ther e exist x 0 and > 0 so that B orel ( x 0 , ) ⊂ S ( i − 1) , then find an ade quate α ( i ) so that S ( i ) ⊂ S ( i − 1) . Define a surje ction H i g for the g th mo del c omp onent at the i th iter ation as H i g : S ( i − 1) → S ( i ) . In this article, the surje ction is c al le d the c ontr action map, which also c al le d the H -map in the fol lowing discussions. 2) If the c ondition in 1) is not satisfie d, the mo del c omp onent c onver ges. Note that for the i th iteration, by finding an adequate α ( i ) , we construct a compressed space S ( i ) in S ( i − 1) . The con traction of S ( i ) guaran tee the existence of fix p oints for the H -map, which ensures the conv erge of algorithm in finite time. When S ( i ) is compressed to a single observ ation p oint, that is, diameter diam ( S ( i ) ) = 0, the H -map discov ers the only fixed p oin t. And when all the H -maps in the algorithm find the unique fixed p oint, the algorithm complete. Th us, the clusters of the mo del can b e discriminated by the num b er of fixed p oin ts and the structure of the mo del. In actual fact, almost all the conv ergence and discriminant pro cess of clus- tering algorithms can b e explained by the fixed p oin ts of the H -map. Although they represen t different meanings in different algorithms, fixed p oin ts can b e 6 Figure 1: The construction of the H-map from the iteration of the algorithm generally interpreted as the cluster centers. In common clustering algorithms suc h as K-means and GMM, fixed p oin ts are usually the center of their data distribution. It is b ecause of the utilization of central iterativ e sc hemes, as the parameters of the mo del priori are also centric. But for other algorithms, suc h as DBSCAN [20, 21], OPTICS [22], DENCLUE [23], they are v ariants from densit y-based clustering. These algorithms are identical in idea, whic h is iden tifying a high-density region as a cluster and a density center as a cluster cen ter. Owing to the difference b etw een densit y-based feature and distance- based feature, their fixed p oin ts are rarely consistent with the distance-based cen ter. Notice that the H -map does not guaran tee the uniqueness of the fixed point. In other words, more than one fixed p oin t may exist in the compressed space, whic h constitutes the structure of tree. In the prop osed unified framework, the iteration ob jectiv ely ensures the existence of α ( t ) less than the constant C to ac hieve the compression b efore con vergence. The growth of the α -sequence can assess the suitability of the mo del. Note that eac h contraction map can only b e mapp ed to a simply-connected α -critical space. The segmentation of space should be conducted for a more complex space suc h as m ultiply-connected space or a closed manifold. The most imp ortan t idea of the prop osed framew ork is that, during the iteration of the clustering, the cluster cen ter is given by abstracting the map and determining the feasible subspace, rather than directly c haracterized b y the parameters. With the iteration of the model, the feasible subspace for fixed p oin ts shrinks with the growth of α -sequence. In other words, the conv ergence of clustering is a necessary condition of satisfying the framework in this pap er. By this p oin t, the basic form of the unified clustering framew ork has b een in tro duced. The metho dology of framework is shown in Algorithm 1. 4. Relation with GMM GMM is a typical Model-Based Clustering Algorithm. Its parameter up date relies on the EM estimation or the Maxim um A P osteriori (MAP) method. Supp ose that there are G 0 predicted comp onents, then components will conv erge 7 Algorithm 1 A Unified F ramework for mo del-based clustering Input: Data observ ation X , Mixture mo dels M ( G 0 comp onen ts) Input: Initial parameter θ 0 , Initial mixture co efficien t π 0 Input: Step size ∆ α Initialize: First term of α -sequence α (0) = 0, Con vex hull S (0) = C onv ( X ) Initialize: G (0) = G 0 , θ (0) = θ 0 , π (0) = π 0 , i = 0 1: while not conv erged do 2: Adjust θ ( i ) , π ( i ) using estimation of observ ation 3: Adjust φ ( x | M ) ← max { φ 1 ( x | θ 1 ) , φ 2 ( x | θ 2 ) , · · · , φ G ( x | θ G ) } 4: Adjust α ( i +1) ← ∆ α + α ( i ) 5: Adjust all S ( i +1) g ← H ( S i g )( g = 1 , 2 , · · · , G (0) ) 6: Adjust G ( i +1) in accordance with the n umber of S ( i +1) g 7: if diam ( S ( i +1) g ) = diam ( S ( i ) g ) then 8: The algorithm con verges 9: else 10: i ← i + 1 11: end if 12: end while 13: Output: Mixture mo dels M indep enden tly to G 0 fixed p oin ts of the corresp onding space. Therefore, GMM is mapp ed to the framew ork with the EM estimation method to discuss the application of framew ork. Giv en an L -dimensional observ ation set X , and assume that the data distri- bution is sub jected to the Gaussian distribution and each comp onen t is indepen- den t. The estimation steps get the similarity betw een the Gaussian distribution and the data b y the maximum likelihoo d metho d. The p osterior probabilities for the comp onen ts is calculated based on the initial or previous parameters. Denote φ g ( X i | θ g ) as the p osterior probability . The p osterior probability of X i in the g th mo del comp onent is given by [6]: φ g ( X i | θ ( t ) g ) = π ( t ) g N ( X i | µ ( t ) g , Σ ( t ) g ) P G k =1 π ( t ) k N ( X i | µ ( t ) k , Σ ( t ) k ) . (5) Then, the mixture co efficien t π ( t +1) , the cov ariance matrix Σ ( t +1) , and the mo del cen ters µ ( t +1) in step t + 1 are updated based on the posterior probability 8 in the previous step: π ( t +1) g = P N i =1 φ g ( X i | θ ( t ) g ) N ; Σ ( t +1) = P N i =1 φ g ( X i | θ ( t ) g )( X i − µ ( t ) g )( X i − µ ( t ) g ) T P N i =1 φ g ( X i | θ ( t ) g ) ; µ ( t +1) = P N i =1 φ g ( X i | θ ( t ) g ) X i P N i =1 φ g ( X i | θ ( t ) g ) Select one dimension (denoted as e ) of the observ ation v ector for further study . Due to the features of the Gaussian distribution, the distribution in the observ ational dimension reduce from the multi-dimensional Gaussian dis- tribution to one-dimensional Gaussian distribution f e ( x | π , θ ) ( σ ( t ) e,g and µ ( t ) e,g are parameters in observ ational dimension for the g th comp onen t): f e ( x | π , θ ) = G 0 X g =1 π g √ 2 π σ ( t ) e,g exp ( − | x − µ ( t ) e,g | 2 2 σ ( t ) e,g 2 ) (6) The conv ex hull C onv ( X ) is also pro jected in to closed in terv al P r oj [ C onv ( X )] in observ ational dimension, which satisfies P r oj [ C onv ( X )] ⊂ Γ e . Γ e is the α - critical space in observ ational dimension. F or the g th mo del comp onent: Γ ( t ) e,g = { x | µ ( t ) e,g − σ ( t ) e,g q − 2 ln ( √ 2 π α ( t ) σ ( t ) e,g ) ≤ x ≤ µ ( t ) e,g + σ ( t ) e,g q − 2 ln ( √ 2 π α ( t ) σ ( t ) e,g ) } T o ensure the result of q − 2 ln ( √ 2 π α ( t ) σ ( t ) e,g ) is real num b er, α ( t ) < 1 / √ 2 π α ( t ) σ ( t ) e,g should b e satisfied. Let the length of interv al b e l e,g = 2 σ ( t ) e,g q − 2 ln ( √ 2 π α ( t ) σ ( t ) e,g ) and obtain the partial deriv ative of l g with regard to α : ∂ l e,g ∂ α = − 4 σ ( t ) e,g 2 αl e,g . As l e,g > 0 and σ ( t ) e,g > 0, ∂ l e,g /∂ α is negative constantly , so the interv al Γ ( t ) e,g shrinks as α increases. Considering Γ ( t ) e,g and Γ ( t +1) e,g , if Γ ( t ) e,g ∩ Γ ( t +1) e,g 6 = ∅ , let K b e sup (Γ ( t ) e,g ∩ Γ ( t +1) e,g ) − inf (Γ ( t ) e,g ∩ Γ ( t +1) e,g ) sup (Γ ( t ) e,g ) − inf (Γ ( t ) e,g ) , from the ab ov e analyses, it is apparen t that K ∈ [0 , 1). The contracting map H g in observ ational dimension H e,g : Γ ( t ) e,g → Γ ( t +1) e,g can b e constructed as: y = K ( x − inf (Γ ( t ) e,g )) . (7) Then for all x 1 , x 2 ∈ Γ ( t ) e,g , k H e,g ( x 1 ) − H e,g ( x 2 ) k ≤ K k x 1 − x 2 k , K ∈ [0 , 1), whic h satisfies the Lipsc hitz condition. By the Banac h fixed p oint theorem, H e,g map is pro ved to hav e only one fixed p oin t. 9 As a result, the framework guarantees the con v ergence under certain con- ditions. Under the domination of the n umber of clusters, the nonempt y inter- section of the previous and the latter α -critical space ma y b e ac hiev ed and a linear contraction map can b e constructed b et ween the previous and the latter α -critical space. If the ab o ve conditions are met, the framew ork can ensure that, for eac h comp onen t, no extra fixed p oint will b e generated. This, hence, main- tain the priori not to b e changed by iteration. The reasonable explanation for the ab o ve conclusion is that, the iterativ e metho d has absolute or logarithmic linear characteristic, which makes it reasonable to construct the linear mapping to satisfy the Lipschitiz condition. Similar analyses can also b e applied to the distance-based clustering metho d for further discussion. An experiment is carried out. By em b edding the GMM algorithm, we adjust the α -sequence, for the purp ose of compressing the α -critical space of the differ- en t comp onen ts. The upp er bound of the α -sequence is related to the v ariance of the component. According to the abov e analysis, a smaller v ariance is related to a greater upper b ound. Figure 2 presen ts the visualization of the experiment. (a) (b) (c) Figure 2: The scatter diagram of a Gaussian mixture mo del with tw o components (a) and the visualization of the α -sequence (b) and the contraction map (c) of tw o comp onents in one dimension during the iteration. 5. Conclusion and F uture W ork In this pap er, after the analysis on the mo del-based clustering, a unified framew ork for mo del-based clustering is prop osed from the view of fixed p oin t. It iterativ ely constructs the con traction map to find fixed points as cluster cen ters. Through sp ecifying a contraction map, the GMM algorithm is mapp ed to the prop osed framew ork as an application. The framework can inspire us to develop future mo dular clustering algorithm. It can be applied in represen tative learning and ac hieve unsup ervised recognition and reasoning. 10 Reference References [1] S. R, S. K. R, Data mining with big data, in: 2017 11th International Conference on Intelligen t Systems and Control (ISCO), 2017, pp. 246–250. doi:10.1109/ISCO.2017.7855990 . [2] D. Xu, Y. Tian, A comprehensive survey of clustering algorithms, Annals of Data Science 2 (2) (2015) 165–193. doi:10.1007/s40745- 015- 0040- 1 . URL https://doi.org/10.1007/s40745- 015- 0040- 1 [3] P . Nerurk ar, A. Shirke, M. Chandane, S. Bhirud, Empirical analysis of data clustering algorithms, Pro cedia Computer Science 125 (2018) 770 – 779, the 6th In ternational Conference on Smart Computing and Commu- nications. doi:https://doi.org/10.1016/j.procs.2017.12.099 . URL http://www.sciencedirect.com/science/article/pii/ S1877050917328673 [4] P . D. McNicholas, Mo del-based clustering, Journal of Classification 33 (3) (2016) 331–373. [5] X. Jin, J. Han, Exp ectation Maximization Clustering, Springer US, Boston, MA, 2017, pp. 480 – 482. doi:10.1007/978- 1- 4899- 7687- 1_344 . URL https://doi.org/10.1007/978- 1- 4899- 7687- 1_344 [6] D. Reynolds, Gaussian Mixture Mo dels, Springer US, Boston, MA, 2009, pp. 659–663. doi:10.1007/978- 0- 387- 73003- 5_196 . URL https://doi.org/10.1007/978- 0- 387- 73003- 5_196 [7] G. A. Carp enter, S. Grossberg, Art 3: Hierarc hical searc h using c hemical transmitters in self-organizing pattern recognition arc hi- tectures, Neural Netw orks 3 (2) (1990) 129 – 152. doi:https: //doi.org/10.1016/0893- 6080(90)90085- Y . URL http://www.sciencedirect.com/science/article/pii/ 089360809090085Y [8] G. A. Carp en ter, S. Grossb erg, Art 2: Stable self-organization of pattern recognition codes for analog input patterns 26 (1987) 4919–30. doi:10. 1364/AO.26.004919 . [9] G. A. Carpenter, S. Grossb erg, A massiv ely parallel architecture for a self-organizing neural pattern recognition machine, Computer Vision, Graphics, and Image Pro cessing 37 (1) (1987) 54 – 115. doi:10.1016/S0734- 189X(87)80014- 2 . URL http://www.sciencedirect.com/science/article/pii/ S0734189X87800142 11 [10] S. Zhong, J. Ghosh, A unified framew ork for model-based clustering, J. Mac h. Learn. Res. 4 (2003) 1001–1037. doi:10.1162/1532443041827943 . URL http://dl.acm.org/citation.cfm?id=945365.964287 [11] M. T eb oulle, A unified con tinuous optimization framew ork for cen ter-based clustering metho ds, Journal of Machine Learning Researc h 8 (2007) 65–102. URL http://dl.acm.org/citation.cfm?id=1248659.1248662 [12] B. Scellier, Y. Bengio, Equilibrium propagation: Bridging the gap b etw een energy-based mo dels and bac kpropagation, F rontiers in computational neu- roscience 11 (2017) 24. doi:10.3389/fncom.2017.00024 . URL http://europepmc.org/articles/PMC5415673 [13] J. Kleinberg, An imp ossibilit y theorem for clustering 15 (2003) 446–453. doi:10.1103/PhysRevE.90.062813 . [14] R. B. Zadeh, S. Ben-David, A uniqueness theorem for clustering, in: Pro- ceedings of the Twen ty-Fifth Conference on Uncertain t y in Artificial In- telligence, UAI ’09, AUAI Press, Arlington, Virginia, United States, 2009, pp. 639–646. URL http://dl.acm.org/citation.cfm?id=1795114.1795189 [15] S. Bandy opadhy ay , M. N. Murty , Axioms to characterize efficien t incremen- tal clustering, in: 2016 23rd International Conference on P attern Recogni- tion (ICPR), 2016, pp. 450–455. doi:10.1109/ICPR.2016.7899675 . [16] R. A. Klop otek, M. A. Klop otek, On the discrepancy b et w een klein- b erg’s clustering axioms and k-means clustering algorithm b eha vior, CoRR abs/1702.04577. . URL [17] C.-G. Li, R. Vidal, Structured sparse subspace clustering: A unified opti- mization framew ork, in: 2015 IEEE Conference on Computer Vision and P attern Recognition (CVPR), 2015, pp. 277–286. doi:10.1109/CVPR. 2015.7298624 . [18] Y. Y ang, F. Shen, Z. Huang, H. T. Shen, A unified framew ork for dis- crete sp ectral clustering, in: Pro ceedings of the Twen ty-Fifth In ternational Join t Conference on Artificial In telligence, IJCAI’16, AAAI Press, 2016, pp. 2273–2279. URL http://dl.acm.org/citation.cfm?id=3060832.3060939 [19] P . D. McNicholas, Mo del-based clustering, Journal of Classification 33 (3) (2016) 331–373. doi:10.1007/s00357- 016- 9211- 9 . URL https://doi.org/10.1007/s00357- 016- 9211- 9 [20] K. M. Kumar, A. R. M. Reddy , A fast dbscan clustering algorithm b y accelerating neighbor searching using groups metho d, P attern Recognition 58 (2016) 39 – 48. doi:10.1016/j.patcog.2016.03.008 . 12 URL http://www.sciencedirect.com/science/article/pii/ S0031320316001035 [21] M. Ester, H. Kriegel, J. Sander, X. Xiaow ei, A density-based algorithm for disco vering clusters in large spatial databases with noise (1996) 226–231. [22] M. Ank erst, M. M. Breunig, H.-P . Kriegel, J. Sander, Optics: Ordering p oin ts to identify the clustering structure, SIGMOD Rec. 28 (2) (1999) 49–60. doi:10.1145/304181.304187 . URL http://doi.acm.org/10.1145/304181.304187 [23] A. Hinnebu rg, D. A. Keim, An efficient approach to clustering in large m ul- timedia databases with noise, in: Pro ceedings of the F ourth International Conference on Knowledge Disco very and Data Mining, KDD’98, AAAI Press, 1998, pp. 58–65. URL http://dl.acm.org/citation.cfm?id=3000292.3000302 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment