Learning to Remember from a Multi-Task Teacher
Recent studies on catastrophic forgetting during sequential learning typically focus on fixing the accuracy of the predictions for a previously learned task. In this paper we argue that the outputs of neural networks are subject to rapid changes when…
Authors: Yuwen Xiong, Mengye Ren, Raquel Urtasun
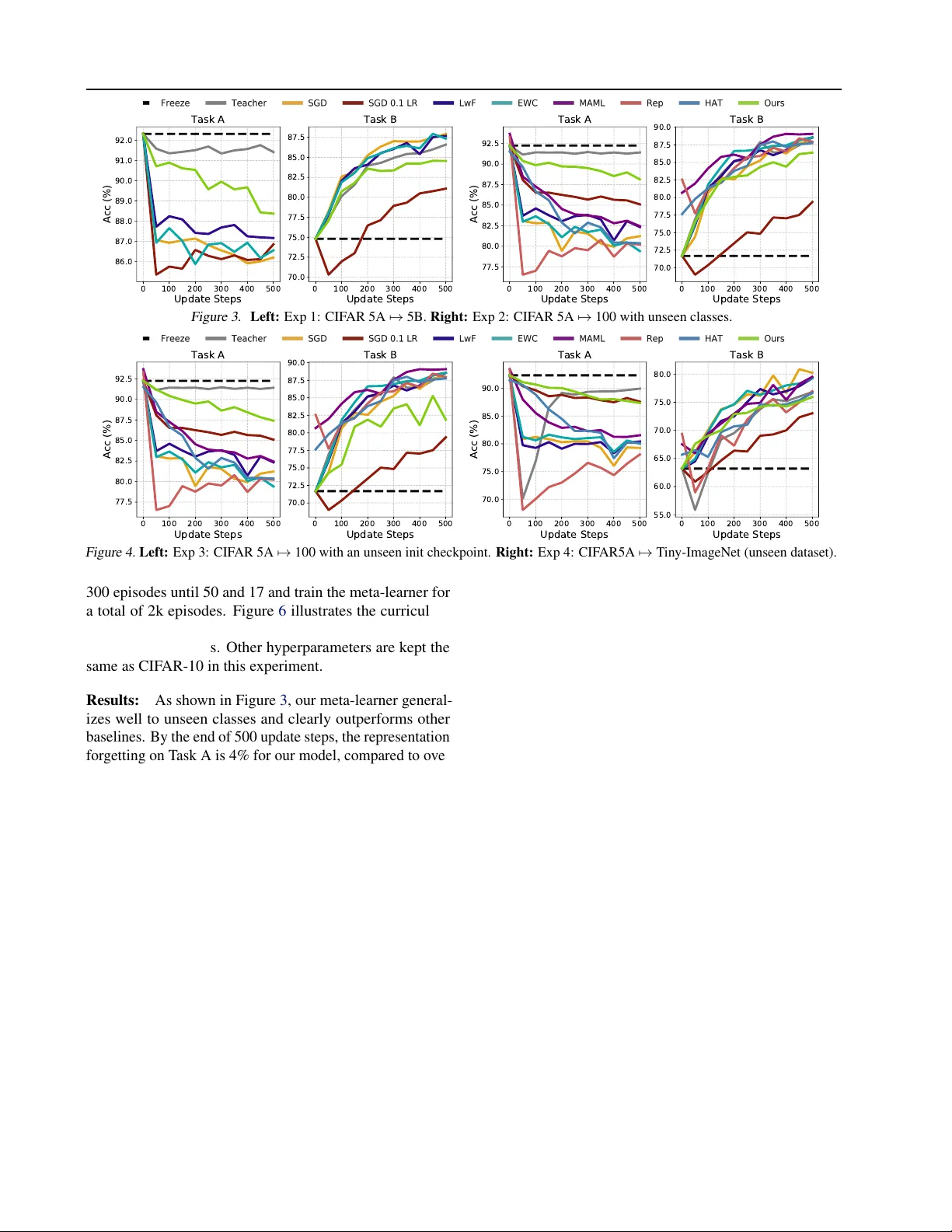
Learning to Remember fr om a Multi-T ask T eacher Y uwen Xiong * Mengye Ren * Raquel Urtasun Abstract Recent studies on catastrophic forgetting dur - ing sequential learning typically focus on fixing the accuracy of the predictions for a pre viously learned task. In this paper we argue that the outputs of neural networks are subject to rapid changes when learning a new data distribution, and networks that appear to “forget” e verything still contain useful representation to wards pre vi- ous tasks. Instead of enforcing the output accu- racy to stay the same, we propose to reduce the ef fect of catastrophic for getting on the representa- tion lev el, as the output layer can be quickly recov- ered later with a small number of e xamples. T o- wards this goal, we propose an e xperimental setup that measures the amount of representational for - getting, and de velop a nov el meta-learning algo- rithm to ov ercome this issue. The proposed meta- learner produces weight updates of a sequential learning network, mimicking a multi-task teacher network’ s representation. W e show that our meta- learner can improv e its learned representations on new tasks, while maintaining a good representa- tion for old tasks. 1. Introduction An intelligent agent needs to deal with a dynamic world and is typically presented with sequential tasks that are highly correlated in time yet constantly changing. New- borns learn to build generic representations from video and audio streaming input. Kids can learn highly skilled tasks such as skiing and swimming sequentially without w orrying about for getting one another . Humans seem to ha ve a rob ust way of learning representations from sequential inputs (and tasks), yet state-of-the-art machine learning algorithms rely heavily on uniformly sampled training examples from the same distribution. One of the major challenges in sequential learning of neural networks is the issue of catastr ophic for getting ( McClosk ey * Equal contribution . Uber Advanced T echnologies Group and Univ ersity of T oronto. Correspondence to: Y uwen Xiong < yuwen@uber .com > , Mengye Ren < mren3@uber .com > , Raquel Urtasun < urtasun@uber .com > . & Cohen , 1989 )–after a neural network is trained on a ne w task, its performance on old tasks drops significantly . De- spite se veral attempts, this problem remains unsolved. Ex- plicit weight regularization methods ( Evgeniou & Pontil , 2004 ; Kirkpatrick et al. , 2016 ; Lee et al. , 2017 ) often rely on simplistic assumptions on the shape of the weight poste- rior distribution. Model compression methods ( Serr ` a et al. , 2018 ; Fernando et al. , 2017 ; Mallya & Lazebnik , 2018 ) seem promising on existing benchmarks, howe ver the un- derlying mechanism is to train small individual networks that may lack global cooperation, a limiting factor when learning a large number of classes to wards a generic repre- sentation. Generativ e models ( Shin et al. , 2017 ; Kemk er & Kanan , 2018 ; V enkatesan et al. , 2017 ) seem to be a natural choice; howe ver , training a high quality generative model is far from tri vial, oftentimes more complex than training the original network itself. Despite the variety of models that ha ve been proposed, there seems to be a lack of general understanding on what kind of knowledge is being forgotten and to what extent it can be recovered. Recent research places much of its focus on maintaining the output performance of previous tasks. In this paper we argue that this can be misleading since the output layer of a network is very sensitive to changes in the output distribution. Instead, here we would like to understand how much of the performance drop is related to the lack of training on pre vious output layers v ersus the loss of information in the newly learned representation. T o wards this goal, we exploit a linear decoding layer to measure the amount of catastrophic for getting on the representation lev el. This gi ves us insights on whether the drop in performance is likely to be reco vered by re-learning the output layer from very fe w examples. Motiv ated by recent progress on meta-learning ( Jaderberg et al. , 2017 ; Andrycho wicz et al. , 2016 ; Metz et al. , 2018 ), in this paper we propose to learn a weight update rule to ov ercome representational forgetting. our meta-learning algorithm learn such a rule by rolling out many sequen- tial learning experiences during training. In human lan- guage acquisition, it is found that children who lost their first language maintain similar brain acti vation to bilingual speakers ( Pierce et al. , 2014 ). Inspired by this fact, we pro- pose a nov el meta-learning algorithm that tries to mimic a multi-task teacher network’ s representation, an offline oracle Learning to Remember fr om a Multi-T ask T eacher in our sequential learning setup, since multi-task learning has simultaneous access to all tasks whereas our sequential learning algorithm only has access to one task at a time. In summary , the contributions of our paper are two-fold. First, we propose a measure of catastrophic forgetting at the representation lev el, which provides more insight on the amount of previous knowledge forgotten in the new task. Second, we dev elop a new meta-learning algorithm that can predict weight updates that are less prone to catastrophic forgetting than standard backpropag ation. W e demonstrate the effecti veness of our approach on the CIF AR-10, CIF AR- 100 ( Krizhe vsky , 2009 ) and T iny-ImageNet 1 datasets, and find that our meta-learner is able to generalize to unseen object classes from meta-training. The rest of the paper is org anized as follows: we first surve y existing literature in Section 2 ; Section 3 describes rep- resentational forgetting in deep neural networks, and our experimental setup to measure it; Section 4 details our pro- posed meta-learning algorithm, followed by experimental results in Section 5 . 2. Related W ork Catastrophic forgetting in sequential learning has been stud- ied in the early literature of neural networks ( McCloskey & Cohen , 1989 ; Ratcliff , 1990 ; French , 1991 ; Mcrae & Het- herington , 1993 ; French , 1999 ). The degree of forgetting is usually measured in terms of the amount of time, typi- cally the number of iterations, sav ed to relearn the old task. This metric has sev eral drawbacks as the number of itera- tions can be fairly sensitiv e to the choice of optimization hyper-parameters and network architecture. Furthermore, the network may nev er recover fully the original perfor- mance. W ith the recent success of deep learning, the issue of catas- trophic forgetting has regained attention in the research community . Unlike classical methods, recent papers mea- sure the old task performance immediately after training on the new task ( Kirkpatrick et al. , 2016 ; Goodfellow et al. , 2013 ; Li & Hoiem , 2018 ). In this setting, networks that are trained in a sequential manner over tasks suf fer dramatically , due to the fact that the previous output classifier branches are no longer tuned to the newly learned representations. In this paper we follo w the early literature, and allow the network to relearn on old tasks, as we belie ve it is natural to revie w the old task before testing on it again. But instead of counting the number of iterations to recov er the old task performance, we propose to train on top of the newly learned representation using a small decoding model to perform the old task. W e belie ve this measure well captures the amount of representational forgetting. T o this end, we exploit a 1 https://tiny- imagenet.herokuapp.com/ simple linear readout layer, as it is relatively fast to train and is more rob ust than measuring the number of reco vering steps. One way to address catastrophic forgetting is through ex- plicit regularization. Evgeniou & Pontil ( 2004 ) add an L2 regularizer to ensure that the new weights do not “drift” away from the old weights. Elastic weight consolida- tion ( Kirkpatrick et al. , 2016 ) computes the strength of the regularizer on each weight dimension using a diagonal ap- proximation of the Fisher information matrix. Zenke et al. ( 2017 ) propose to directly approximate the regularization strength online. Benyahia et al. ( 2019 ) uses similar regular- ization function to counter interference in multi-task learn- ing. Lee et al. ( 2017 ) incrementally match the moments of posterior Gaussian distributions of new tasks. These meth- ods are often motiv ated from a simple quadratic loss surf ace, and can be potentially limiting their ability to deal with more complex learning dynamics. Regularization can also be imposed on the activ ation le vel: Learning without F orget- ting ( Li & Hoiem , 2018 ) re gularizes the network such that the logits of the ne w examples on the old classifier remain similar . While this frame work is more flexible, using the old activ ations to distill new tasks can be less informativ e if the network has not seen enough classes. In contrast to continuous regularization, model compression based approaches ( Mallya & Lazebnik , 2018 ; Fernando et al. , 2017 ; Rusu et al. , 2016 ; Y oon et al. , 2018 ) discretely allocate certain capacity of a network towards learning ne w tasks. PackNet ( Mallya & Lazebnik , 2018 ) applies network pruning in between sequential tasks, so that the pruned neu- rons can be re-allocated. P athNet ( Fernando et al. , 2017 ) uses genetic algorithms to select pathways of the network for reuse. HA T ( Serr ` a et al. , 2018 ) learns a different task- oriented hard binary mask for each hidden unit. Rusu et al. ( 2016 ) add connections from old frozen modules towards newly allocated modules, at the price of learning more inter - mediate layers, thus scaling quadratically with the number of tasks. Y oon et al. ( 2018 ) propose to dynamically prune and allocate neurons at the same time. In comparison, our meta-learner can also be interpreted as implicitly learning to perform dynamic capacity re-allocation without increasing the network size; howe ver , our approach does not choose a discrete set of neurons or synapses to update, but try to mimic the acti vation responses from a multi-task network. This allows the algorithm to learn to implicitly allocate weight subspaces for learning the new tasks. Another class of methods store a subset of the old data, so that the old task can be jointly trained. iCaRL Rebuf fi et al. ( 2017 ) propose to choose representativ e exemplars of old tasks. Gradient episodic memory ( Lopez-Paz & Ranzato , 2017 ) stores old examples and mak es sure that the new e x- ample only updates in the direction that agrees with the gra- Learning to Remember fr om a Multi-T ask T eacher Task A Task B Readout Task A Test Images CIFAR - 5A CIFAR - 5B A B C 92 .3 % Acc. Original Readout Figure 1. Using a readout layer to measure catastrophic forgetting on representations. A) A network is first pre-trained on T ask A. B) Then it is finetuned on T ask B. C) T ask A training data is then fed to the network, and the representation prior to the classification layer is recorded. W e re-train a readout layer to recover T ask A output. T est accuracy on T ask A is “Readout”, and original classification layer accuracy is “Original”. Chance is 20%. dient directions of old examples. Sprechmann et al. ( 2018 ) explore a learnable memory architecture to dynamically store and retriev e examples facilitating sequential learning. Though effecti ve, storing raw data points costs additional storage and it may also lack biological plausibility . T o ad- dress the issue of data storage, generativ e models have also been used to avoid storing old raw data ( Shin et al. , 2017 ; V enkatesan et al. , 2017 ; Kemk er & Kanan , 2018 ; van der V en & T olias , 2018 ). Although generativ e models enjoy the benefits of data storage based models, the final perfor- mance heavily depends on the quality of the generated data, because training a competitiv e generativ e model itself may be more complex and take more capacity than the original network. Our proposed model is inspired from prior work in meta- learning: using a learned parameterized weight update rule ( Bengio et al. , 1990 ) instead of standard optimization methods. Synthetic gradient ( Jaderberg et al. , 2017 ) uses an MLP to predict the gradient direction when performing for- ward passes, allo wing asynchronous weight updates across layers. Andrychowicz et al. ( 2016 ); Ravi & Larochelle ( 2017 ) use a recurrent network to predict updates. Metz et al. ( 2018 ) propose to learn an unsupervised learning rule based solely on activ ations. Miconi et al. ( 2018 ; 2019 ) com- bine a learned Hebbian plasticity rule with learned weights. The largest difference between our proposed model and prior work is the fact that instead of predicting the gradients or improv e the task performance at the end of the training episode, our meta-learner is trained with a teacher network’ s activ ation as supervision. 3. Representational F orgetting in Sequential Learning Sequential learning is the process of learning tasks sequen- tially without revisiting pre vious tasks. At each incremental learning stage, the network has learned a set of source tasks and then is presented with a no vel tar get task. For simplicity , we refer the union of all source tasks as T ask A , and the nov el task as T ask B . The exposure to T ask A can bring positiv e benefits tow ards learning T ask B if the two tasks are similar . This is a prop- erty often studied in the transfer learning literature. Unfortu- nately , it is challenging to maintain the initial performance of the model learned on T ask A (when updating it to perform well on task B), especially when the old task en vironment is not av ailable to the agent. F or example, a commercial robot needs to adapt and learn in new en vironments while the original training data cannot be shipped together with the learning algorithm. Catastrophic forgetting ( McClosk ey & Cohen , 1989 ) occurs when a learning agent forgets the old task after adapting to the new task. While recent literature solely focuses on the output performance of an agent on the previous tasks, it is unclear whether the agent “truly for gets” the prior expe- riences, or only the output layers are miscalibrated due to learning the ne w task. The latter issue has an easy solution as simply training the output classifier on the old task for a few iterations can recover most of the performance loss. This is similar to human revisiting pre viously learned skills. In this paper we study ho w much forgetting occurs at the representation lev el. T owards this goal, we propose the experiment setup illustrated in Figure 1 where a network is first trained on T ask A, and it learns the representation of the inputs, referred to as the final layer prior to the classification head. Next, a different task, T ask B is introduced. In the second stage of training, the model no longer has access to T ask A. It then fine-tunes all its layers on T ask B, since learning a better representation will be useful for the new task. T o test the amount of forgetting on T ask A, we train a linear readout layer on the newly learned representations, using the training e xamples from T ask A, and ev aluate the test performance. W e repeatedly do this readout training throughout the learn- ing of task B. In the beginning, the readout performance is close to the original T ask A performance, and later, the features become less selectiv e towards T ask A. As shown in Figure 1 , we indeed observe that the readout accuracy of T ask A is constantly decreasing as the learning process goes on. In contrast to measuring the output performance directly (“Readout” vs. “Original” in Figure 1 ), as was done in prior catastrophic for getting literature, the le vel of forgetting here is not as dramatic, suggesting a portion of forgetting happens due to the miscalibration of the output layer . Representational forgetting is still significant–for the binary classification problem illustrated in Figure 1 , readout accuracy on T ask A drops ov er 15% after 300 iterations of training on T ask B. Learning to Remember fr om a Multi-T ask T eacher ! " # $ % # " ! $ % ! " # " Teacher (multi -task) Student (sequential) Meta - learner & ' ( ) & ' ( * & ' (+* ) & ' (+* * ' ( ) ' ( * ' (+* ) ' (+* * ! $ % ! " ! $ % ! " Legend , - . - -/ 0 1 2 0 3 0 4 0 3 0 52 0 x Meta - learner 6 - 7 -/ 0 2 0 Before update 3 0 Weights Gradients Pre - acts Post- act Weight Update LSTM LSTM 6 ) 6 * SGD SGD -/ 0 2 0 8 52 0 After update - 7 Figure 2. Left: Overvie w of our purposed method during one training step: 1) the teacher network is updated using SGD on multi-task data; 2) the student network is updated using the meta-learner on T ask B data only; 3) the multi-task data are fed into both networks and we record the representations as h and ˆ h ; 4) the meta module is then updated to minimize the dif ference between h and ˆ h . At meta-test time, the teacher network is no longer present, and we update the student network solely with the trained meta-learner for the entire training sequence. Right: Our meta-learner module is a stacked LSTM network. For a giv en output neuron h 0 j , the meta-network takes in its activ ation, its pre-activ ations, current weights and gradients, and output the weight updates associated with h 0 j . W eights in the same layer will be shared a single meta-network, while dif ferent layers will have dif ferent meta-networks. Meta-learning is a general tool for us to learn a ne w learn- ing algorithm with desired properties. In the next section, we propose a novel meta-learning algorithm that directly addresses the issue of representational forgetting. 4. Learning fr om a Multi-T ask T eacher As the learning process goes on in T ask B, each gradient descent step can potentially erase useful features for the old task. Continuous regularization ( Evgeniou & Pontil , 2004 ; Kirkpatrick et al. , 2016 ; Zenke et al. , 2017 ) or dis- crete model pruning based methods ( Mallya & Lazebnik , 2018 ; Fernando et al. , 2017 ; Rusu et al. , 2016 ; Y oon et al. , 2018 ), as discussed in Section 2 , can hurt the capacity of learning new tasks and limit the sharing of a distributed representation. Manually designing a sophisticated learning objectiv e is not obvious, thus we are interested in learning a learning rule that can predict dynamic weight updates alongside the training of T ask B. For simplicity , we describe the setting of a fully connected layer , shown in Figure 2 , where i index es pre-activ ations and j post-activ ations. A weight synapse w i,j connects to its pre-acti vation h i and post-activ ation h 0 j . Let g i,j be the gradient of the connection obtained through regular backpropagation. Our meta-learner f is implemented as a long short-term memory (LSTM) network that takes as inputs the weight connection, gradients, inputs and outputs, similar to what has been done by ( Metz et al. , 2018 ). The network intuiti vely predicts a dynamic gating that modulates the plasticity of synapses: δ · ,j = f ( w · ,j , g · ,j , h · , h 0 j ; θ ) , which is then multiplied with the original gradients to form the updates of the synapse: ∆ w · ,j = δ · ,j · g · ,j . Finally , the weights are updated in a similar w ay to SGD, ˆ w · ,j = w · ,j − α ∆ w · ,j , where α is the learning rate. W e can generalize this setup to con volutional layers as well by considering all filter locations together , with more details in Section 5.1 . Learning this meta-learner , is howe ver a non-trivial task. In ( Metz et al. , 2018 ), the learning process is unrolled just like a recurrent neural network for a lar ge number of steps, and meta-learning is done using backpropagation through time, which is inef ficient since each meta-update can only be done in the outer loop. A key insight of our paper is that, we can actually learn from a multi-task teacher network as if it is an oracle to our sequential learner . Similar to knowledge distillation ( Hinton et al. , 2015 ), where a student network learns acti vation patterns from a teacher network, here, we would like to train the meta-learner such that the student network has a similar activ ation pattern compared to the teacher network. This avoids using the final accuracy of an episode as the supervision signal, which can be very inef ficient. The idea of using a multi-task network as a teacher is in- spired by the human language acquisition literature. It was found that adopted children who were separated from the Chinese language (their birth language) at around one year old on av erage, still maintain activ ations in their left superior temporal gyrus similar to French/Chinese bilingual speakers at the age of 9 to 17, ev en though they hav e no exposure to Chinese for 13 years on average ( Pierce et al. , 2014 ). W e draw a parallel in our sequential learning frame work here: whereas the network is allowed to for get the old task on the output lev el, the learned representation should resemble the one learned by a multi-task network. The ov erall algorithm has two nested loops, like many other meta-learning algorithms. The inner loop simulates the ex- perience of doing a single learning process, and the outer loop rolls the network back to its initial point and re-starts the learning again. Different from standard hyper-parameter optimization, in our proposed algorithm, the meta-learner is updated ev ery step in the inner loop, which makes the train- Learning to Remember fr om a Multi-T ask T eacher ing more effi cient. The meta-training procedure is detailed in Algorithm 1 . In the beginning of each inner loop, the teacher network and the student network share the same initialization that is pre-trained on T ask A. For e very step in the inner loop, as illustrated in Figure 2 , the teacher network performs a regu- lar SGD update using data from both the old and new tasks. The student network, who does not have access to the old task, computes the gradients on the ne w task and sends them to the meta-learner network, which then predicts a multi- plicativ e gating. Now using the newly updated weights, we compare the representation dif ference between the teacher and student networks, and update the meta-learner to mini- mize this difference. Algorithm 1 Learning to Remember Require: w 0 , D 1 ...K Ensure: θ (Meta-parameters) 1: f or i = 1 ... N do 2: w ← w 0 // Reinitialize teacher and student networks 3: ˆ w ← w 0 4: Meta-learner resets hidden state; 5: // Reinitialize T -BPTT step s to zero 6: s ← 0 7: for k = 2 ...K do 8: D A ← D 1 ...k − 1 ; 9: D B ← D k // New T ask ; 10: for t = 1 ... T ( i ) do 11: x a , y a ← Sample ( D A ) ; x b , y b ← Sample ( D B ) ; 12: g ← T eacherNetBackward ( x a ∪ x b , y a ∪ y b ; w ) ; 13: ˆ g ← StudentNetBackward ( x b , y b ; ˆ w ) ; 14: // T eacher update 15: w ← w − αg ; 16: // Student update with meta-learner f 17: ∆ ˆ w ← ˆ g · f ( ˆ w , ˆ g , ˆ h ; θ ) ; 18: ˆ w ← ˆ w − α ∆ ˆ w ; 19: h ← T eacherNet ( x a ∪ x b ; w ) ; 20: ˆ h ← StudentNet ( x a ∪ x b ; ˆ w ) ; 21: L ← HuberLoss ( h, ˆ h ) ; 22: s ← s + 1 ; 23: // Meta-learner update, backprop thru time s steps 24: θ ← θ − η T -BPTT ( L, θ , s ) ; 25: if L > LossThreshold( i ) then 26: Restart inner-loop learning 27: end if 28: if s ≥ T -BPTTSteps( i ) then 29: s ← 0 ; // Reset T -BPTT steps 30: end if 31: end for 32: end for 33: end f or W e use Huber loss multiplied with a scalar hyperparameter as the objecti ve for minimizing the representational dif fer- ences. T o help the meta-learner gradually make progress, we set up a curriculum such that whene ver the loss is greater than certain threshold, we will reinitialize the learn- ing process to prev ent the meta-learner deviating too far (see Line 25 of Algorithm 1 ). T o speed up learning, we perform truncated backpropagation through time on the meta-learner LSTM. Gradient accumulation is reset whene ver the num- ber of unrolled steps is longer than the truncation steps (see Line 28 of Algorithm 1 ). 5. Experiments In this section, we first gi ve implementation details of our algorithm, and then report experimental results on fi ve sets of experiments, detailed in T able 1 . In the first set, we test a setting where meta-testing samples the same task distribution as meta-training. In the second and third sets of experiments, we verify the generalization ability of our meta- learner , by using unseen classes and unseen initialization checkpoints for ev aluation. In the fourth sets, we verify whether the algorithm can generalize to a ne w dataset; and lastly , we try longer sequences with three sequential tasks. For all results in the figures, we report an av erage of 5 runs. 5.1. Implementation details A separate three-layer stacked LSTM meta-learner is learned for each layer of the student network (except the classification layer). The meta-learner uses ReLU acti vation functions in the hidden layers and tanh in the output layer . The weights and biases of the output layer are initialized to 0 and 1 respectiv ely , to produce a reasonable value at the starting time. A learnable scaling coefficient is then applied to the output to adjust the range. For the classification layer , we apply standard SGD without a meta-learner . Meta-learner specification: For conv olutional layers, we take the a verage ov er the spatial window of the pre- and post- acti vations. The con volutional kernel of size k H × k W × C in is flattened to a v ector as the input to the meta-learner, which outputs the weight updates of size k H × k W × C in . For example, for a 3 × 3 × 10 con volutional layer , the input dimension of the meta-learner is 3 × 3 × 10 (weights) +3 × 3 × 10 (gradients) +10 (pre-act) + 1 (post-act) = 191 , and the output dimension is 3 × 3 × 10 = 90 . For other layers, k H × k W is not applicable, and the input is C in × 3 (weight, gradient, pre-act) +1 (post-act) and the output is C in . Baselines: W e compare our proposed method to several baselines: • SGD performs standard SGD on new tasks with the same learning rate as T ask A. • SGD × 0.1 is standard SGD with 0.1 × learning rate. This is to see whether forgetting on T ask A can be traded off with learning progress on T ask B. • Learning without Forgetting (LwF) ( Li & Hoiem , 2018 ) distills new data on the old classification branch as additional regularization. W e v alidate the regularization coefficient and set it to 1.0. Learning to Remember fr om a Multi-T ask T eacher No. Experiment # T asks # Cls # Steps Unseen Cls Unseen Network Unseen Domain Source Meta-Train Meta-T est 1 Seq. Transfer 2 10 500 CIF AR-5A CIF AR-5B CIF AR-5B 2 New Classes 2 10 500 X CIF AR-5A CIF AR-50A CIF AR-50B 3 New Ckpt 2 10 500 X X CIF AR-5A CIF AR-50A CIF AR-50B 4 New Dataset 2 10 500 X X CIF AR-5A CIF AR-50A Tin y-ImageNet 5 Three T ask 3 30 300 × 2 X CIF AR-10 CIF AR-50A × 2 CIF AR-50B × 2 T able 1. Experimental setup: Our experiments mainly focus on the sequential transfer between two tasks, with various conditions at meta-testing time, such as unseen image classes, unseen pretrained network and unseen data domain. W e also studied sequential transfer of three tasks in Experiment 5. • Elastic W eight Consolidation (EWC) ( Kirkpatrick et al. , 2016 ) adds a quadratic regularizer on the weights, where the regularization strength is computed as a diago- nal approximation of the Fisher information matrix. W e validate the re gularization coefficient and set it to 1.0. • Hard Attention to T ask (HA T) ( Serr ` a et al. , 2018 ) pro- duces a task-specific hard attention on the hidden units of each layer , which helps allocate a fixed portion of the network to wards each task. W e tune the hyperparameters and set s max to 3.0 and λ to 0.75. • Model-Agnostic Meta-Learning (MAML) ( Finn et al. , 2017 ) unrolls the readout SGD steps for 10 steps on T ask B, and backprop through SGD from the “query” set to learn a good representation of the backbone. During meta- test we follo w the same protocol as SGD and use linear readout to get accuracy of old/ne w task. Note that this is an attempt to replicate the MAML method proposed in ( Jav ed & White , 2019 ) in our experimental settings. • Representation Learning (Rep) is a representation learning baseline on the meta-training set. W e use the meta-training 50 classes plus data from T ask A to per- train a representation backbone using cross entropy clas- sification objectiv e. During meta-test we follow the same protocol as SGD . 5.2. Experiment 1: Sequential learning on two tasks W e first conduct experiments on CIF AR-10 to verify the effecti veness of our meta-learner . T o ensure that the meta- learner does not overfit to the training examples, we split the data of T ask B into two parts ev enly , denoted as D B 1 and D B 2 respecti vely . At meta-training time, only D B 1 will be used; at meta-test time, only D B 2 will be used. CIF AR-10: W e split the CIF AR-10 dataset into two sub- sets, the first subset (CIF AR-5A) consists of the first 5 classes (“airplane”, “automobile”, “bird”, “cat”, “deer”) and the second subset (CIF AR-5B) consists of the remain- ing 5 classes (“dog”, “frog”, “horse”, “ship”, “truck”). A ResNet-32 ( He et al. , 2016 ) netw ork is first pre-trained on CIF AR-5A, with all BatchNorm ( Ioffe & Szegedy , 2015 ) layers replaced by GroupNorm ( W u & He , 2018 ), using a learning rate of 0.1 and momentum of 0.9. During meta- learning, we use learning rate 0.1 without momentum. For pre-training we use 128 examples as a mini-batch, and for meta-learning we use 128 for the teacher and 64 for the student (T ask B only). The meta-learner is a 3-layer LSTM with 64 hidden units for the conv olutional kernels and 32 hidden units for γ or β of the GroupNorm layers. W e set the curriculum threshold to 20 and T -BPTT step to 5 initially and increase them by 5 and 2 every 300 episodes until 30 and 9, respecti vely . The loss scaling coef ficient is set to 300. W e train the meta-learner using the Adam optimizer with learning rate 1e-3 for a total of 900 episodes. At meta-test time, we take the acti vations before the last layer and train a linear readout network using 500 Adam optimizer steps with a learning rate of 1e-1. Results: Figure 3 sho ws results on CIF AR-10. The accu- racy is the mean of 5 runs. All entries in the table use the proposed readout measure. W e found that reducing learning rate cannot help pre vent from catastrophic for getting. Our meta-learner outperforms other methods by a large mar gin on T ask A. On T ask B, our meta-learner has very similar performance to the teacher network, which matches our expectation. 5.3. Experiment 2: Generalizing to unseen classes In Experiment 1, T ask B is the same for both training and testing. T o verify the generalization ability of our model to unseen classes, we utilize the CIF AR-100 dataset, to construct two dif ferent tasks, B 1 and B 2 from disjoint subset of data. W e start from an initial model trained on CIF AR-5A, at meta-training time we train a meta-learner on T ask B 1 , while at meta-test time we e valuate meta-learner on T ask B 2 . Unlike the previous experiment, the class definition changes from meta-training to meta-testing. This is a more practical setting since in reality we do not know a priori which ne w task the model needs to adapt to. CIF AR-100: W e split CIF AR-100 dataset into two sub- sets. The first subset consists of the first 50 classes, the second subset consists of the remaining 50 classes. At meta-training time we randomly sample 5 classes from the first subset to constitute T ask B 1 at the be ginning of ev ery episode. And at meta-test time, we randomly sample 5 classes from the second subset to constitute T ask B 2 , and we repeat it for 5 times to take the av erage performance. T ask B 1 and T ask B 2 hav e no ov erlap for both images and classes. W e set the curriculum threshold to 20 and the T - BPTT step to 5 initially and increase them by 5 and 2 every Learning to Remember fr om a Multi-T ask T eacher 0 100 200 300 400 500 Update Steps 86.0 87.0 88.0 89.0 90.0 91.0 92.0 Acc (%) Task A 0 100 200 300 400 500 Update Steps 70.0 72.5 75.0 77.5 80.0 82.5 85.0 87.5 Task B 0 100 200 300 400 500 Update Steps 77.5 80.0 82.5 85.0 87.5 90.0 92.5 Acc (%) Task A 0 100 200 300 400 500 Update Steps 70.0 72.5 75.0 77.5 80.0 82.5 85.0 87.5 90.0 Task B Figure 3. Left: Exp 1: CIF AR 5A 7→ 5B. Right: Exp 2: CIF AR 5A 7→ 100 with unseen classes. 0 100 200 300 400 500 Update Steps 77.5 80.0 82.5 85.0 87.5 90.0 92.5 Acc (%) Task A 0 100 200 300 400 500 Update Steps 70.0 72.5 75.0 77.5 80.0 82.5 85.0 87.5 90.0 Task B 0 100 200 300 400 500 Update Steps 70.0 75.0 80.0 85.0 90.0 Acc (%) Task A 0 100 200 300 400 500 Update Steps 55.0 60.0 65.0 70.0 75.0 80.0 Task B Figure 4. Left: Exp 3: CIF AR 5A 7→ 100 with an unseen init checkpoint. Right: Exp 4: CIF AR5A 7→ T iny-ImageNet (unseen dataset). 300 episodes until 50 and 17 and train the meta-learner for a total of 2k episodes. Figure 6 illustrates the curriculum threshold schedule and number of unrolled steps to indicate the training progress. Other hyperparameters are kept the same as CIF AR-10 in this experiment. Results: As shown in Figure 3 , our meta-learner general- izes well to unseen classes and clearly outperforms other baselines. By the end of 500 update steps, the representation forgetting on T ask A is 4% for our model, compared to ov er 10% for SGD, EWC, and LwF; meanwhile on T ask B our model performs much better than SGD × 0.1, only ≈ 2% behind other baselines. 5.4. Experiment 3: Generalizing to unseen initialization In Experiment 3, we remove the assumption on a fixed initialization checkpoint. In order for the meta-learner to generalize to different initialization state, during training time we provide 100 different pretrained checkpoints and each training episode uses a dif ferent checkpoint. At test time, an unseen checkpoint is provided. Results: As shown in Figure 4 , our meta-learner general- izes well to unseen initialization (as well as unseen classes) and still outperforms other baselines. The performance drops a little as expected, since the meta-learner model has to learn to adapt dif ferent initializations during meta train- ing/test. 5.5. Experiment 4: Generalizing to unseen domain In Experiment 1, 2, and 3. All tasks are inducted from CIF AR-10/100 datasets which hav e similar domain. T o ver- ify the generalization ability of our model to unseen domain, we further utilize T iny-ImageNet as an unseen ne w dataset. It has dif ferent image resolution/data distrib ution comparing to CIF AR, while they both contain natural images thus the learned representation can be shared. Tiny-ImageNet: T iny-ImageNet has 200 classes in total. At meta-training time we use the same protocol as men- tioned in Experiment 2 and keep Tin y-ImageNet data intact. At meta-test time, 5 classes from Tin yImageNet are ran- domly sampled to serv e as T ask B 2 , and we repeat it for 5 times to take the a verage performance. As shown in Figure 4 , our meta-learner can generalize well to unseen domain, by the end of 500 update steps it outper- forms other baselines by a large margin on T ask A except SGD × 0.1; meanwhile it is close to other baselines on T ask B and performs better than SGD × 0.1. 5.6. Experiment 5: Sequential learning on more than two tasks W e further extend our meta-learner to perform sequential learning on three tasks (T ask 1, 2, 3). For training efficienc y , ResNet-14 is utilized as the backbone network. CIF AR-10 is used as T ask 1; In meta-training, for each rollout we sample two 10-way classification tasks from the first 50 classes of Learning to Remember fr om a Multi-T ask T eacher 65.0 70.0 75.0 80.0 85.0 90.0 Task 1 0 50 100 150 200 250 300 Update Steps 62.0 65.0 68.0 71.0 74.0 77.0 Task 2 300 350 400 450 500 550 600 Update Steps 57.0 61.0 65.0 69.0 73.0 77.0 Figure 5. Exp5: CIF AR-10 7→ 100. Three sequential tasks. Col- umn 1 sho ws T ask 1-2 accuracy while learning on T ask 2 only; Column 2 shows T ask 1-3 accuracy while learning on T ask 3 only . CIF AR-100; and in meta-testing we sample from the last 50 classes. TBPTT step is set to 2 initially and the loss scaling coef ficient is set to 200. W e train the meta-learner for 2k episode. All other hyperparameters are kept the same as Experiment 2. At each episode, we first start from T ask 2, when the loss reaches the corresponding curriculum threshold, we keep the hidden state of meta-learner and student network weights, increase the curriculum threshold by 5 temporarily and shift to T ask 3 when the loss reaches the threshold again, we reset meta-learner states, network weights and threshold, and start a new episode. At meta-test time, we unroll all models on T ask 2 with fixed 300 steps, then we switch to T ask 3 for another 300 steps. W e record read-out accuracies for all three tasks. Results: From Figure 5 we can see that our meta-learner can generalize well when training on more than two tasks. At 600 steps it is very close to the T eacher while other baselines may drop up to 20% on T ask 1. On T ask 2 it performs no worse than other baseline and on T ask 3 the gap is very close, only only ≈ 2% behind the T eacher . Since T ask 2 has not been trained till con ver gence, the reduction in forgetting is not as significant as T ask 1. 0 500 1000 1500 2000 training episode 0 200 400 600 800 1000 1200 1400 unroll step 20 25 30 35 40 45 50 55 curriculum threshold Figure 6. T raining curve on Experiment 2 0.5 0.0 0.5 conv1 1 0 3 1 0 1 res2a_1 1 0 4 2 0 2 res2a_2 1 0 4 2 0 2 res2b_1 1 0 3 2.5 0.0 2.5 res2b_2 1 0 3 1 0 1 res3a_1 1 0 4 Figure 7. V isualization of the meta-learner outputs 5.7. V isualization of meta-learner outputs T o further understanding the behavior of our meta-learner , we visualize the distribution of the output of the meta-learner (i.e. the gradient multiplier δ ) in Figure 7 . Our meta-learner produces non-trivial outputs that are not simply a global scaling of the learning rate. Sometimes the multiplier can be negativ e, which means the final update direction is op- posite to the gradient descent direction. It shows that the meta-learner can learn to dynamically modify the gradient direction to prev ent catastrophic forgetting. 6. Conclusion and Future W ork Catastrophic forgetting handicaps state-of-the-art deep neu- ral networks from learning online tasks in the wild. This paper studies the effect of representational forgetting in a sequential learning framework. In particular, we propose to add a linear readout layer to test the amount of forget- ting at the representation le vel, where a significant drop in performance on old tasks is still observ ed, consistent with prior literature. W e then propose to train a meta-learner to predict the weight updates, with supervision from a multi- task teacher network. Our meta-learner is able to overcome catastrophic forgetting while impro ving its performance on new tasks. W e further verify that our meta-learner has the ability to generalize to unseen classes, unseen checkpoint initializations, and unseen datasets. Currently we hav e made the meta-learner successful at predicting weight updates for up to 600 steps, but we still find it challenging to let it gen- eralize to even longer sequences. In the future, we expect these issues can be addressed by training the meta-learner with longer sequences and more sequential tasks with more computational resources. Learning to Remember fr om a Multi-T ask T eacher References Andrychowicz , M., Denil, M., Colmenarejo, S. G., Hoffman, M. W ., Pfau, D., Schaul, T ., and de Freitas, N. Learn- ing to learn by gradient descent by gradient descent. In Advances in Neural Information Pr ocessing Systems 29, NIPS , 2016. Bengio, Y ., Bengio, S., and Cloutier , J. Learning a synap- tic learning rule . Univ ersit ´ e de Montr ´ eal, D ´ epartement d’informatique et de recherche , 1990. Benyahia, Y ., Y u, K., Bennani-Smires, K., Jaggi, M., Davi- son, A. C., Salzmann, M., and Musat, C. Overcoming multi-model forgetting. In Proceedings of the 36th Inter- national Conference on Machine Learning, ICML , 2019. Evgeniou, T . and Pontil, M. Regularized multi–task learning. In Pr oceedings of the tenth A CM SIGKDD international confer ence on Knowledge discovery and data mining . A CM, 2004. Fernando, C., Banarse, D., Blundell, C., Zwols, Y ., Ha, D., Rusu, A. A., Pritzel, A., and W ierstra, D. Pathnet: Evolu- tion channels gradient descent in super neural networks. CoRR , abs/1701.08734, 2017. Finn, C., Abbeel, P ., and Levine, S. Model-agnostic meta- learning for f ast adaptation of deep networks. In Pr oceed- ings of the 34th International Conference on Machine Learning, ICML , 2017. French, R. M. Using semi-distributed representations to ov ercome catastrophic forgetting in connectionist net- works. 1991. French, R. M. Catastrophic forgetting in connectionist net- works. T r ends in cognitive sciences , 3(4):128–135, 1999. Goodfellow , I. J., Mirza, M., Xiao, D., Courville, A., and Bengio, Y . An empirical inv estigation of catas- trophic forgetting in gradient-based neural networks. arXiv:1312.6211 , 2013. He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer V ision and P attern Recognition, CVPR , 2016. Hinton, G. E., V inyals, O., and Dean, J. Distilling the knowledge in a neural network. CoRR , abs/1503.02531, 2015. Ioffe, S. and Szegedy , C. Batch normalization: Accelerating deep network training by reducing internal cov ariate shift. In Pr oceedings of the 32nd International Confer ence on Machine Learning, ICML , 2015. Jaderberg, M., Czarnecki, W . M., Osindero, S., V in yals, O., Grav es, A., Silver , D., and Kavukcuoglu, K. Decoupled neural interfaces using synthetic gradients. In Pr oceed- ings of the 34th International Conference on Machine Learning, ICML , 2017. Jav ed, K. and White, M. Meta-learning representations for continual learning. In Advances in Neural Information Pr ocessing Systems 32, NeurIPS , 2019. Kemk er , R. and Kanan, C. Fearnet: Brain-inspired model for incremental learning. In 6th International Confer ence on Learning Repr esentations, ICLR , 2018. Kirkpatrick, J., Pascanu, R., Rabino witz, N. C., V eness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T ., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., and Hadsell, R. Overcom- ing catastrophic forgetting in neural networks. CoRR , abs/1612.00796, 2016. Krizhevsk y , A. Learning multiple layers of features from tiny images. T echnical report, Uni versity of T oronto, 2009. Lee, S., Kim, J., Jun, J., Ha, J., and Zhang, B. Overcoming catastrophic forgetting by incremental moment matching. In Advances in Neural Information Pr ocessing Systems 30, NIPS , 2017. Li, Z. and Hoiem, D. Learning without forgetting. IEEE T rans. P attern Anal. Mach. Intell. , 40(12):2935–2947, 2018. Lopez-Paz, D. and Ranzato, M. Gradient episodic memory for continual learning. In Advances in Neural Information Pr ocessing Systems 30, NIPS , 2017. Mallya, A. and Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In IEEE Confer ence on Computer V ision and P attern Recognition, CVPR , 2018. McCloskey , M. and Cohen, N. J. Catastrophic interfer- ence in connectionist networks: The sequential learning problem. In Psychology of learning and motivation , vol- ume 24, pp. 109–165. Elsevier , 1989. Mcrae, K. and Hetherington, P . A. Catastrophic interference is eliminated in pretrained netw orks. In In Proceedings of the 15h Annual Confer ence of the Cognitive Science Society . Erlbaum, 1993. Metz, L., Maheswaranathan, N., Cheung, B., and Sohl- Dickstein, J. Learning unsupervised learning rules. CoRR , abs/1804.00222, 2018. Learning to Remember fr om a Multi-T ask T eacher Miconi, T ., Stanley , K. O., and Clune, J. Differentiable plasticity: training plastic neural networks with back- propagation. In Pr oceedings of the 35th International Confer ence on Machine Learning, ICML , 2018. Miconi, T ., Rawal, A., Clune, J., and Stanley , K. O. Back- propamine: training self-modifying neural networks with differentiable neuromodulated plasticity . In 7th Interna- tional Confer ence on Learning Repr esentations, ICLR , 2019. Pierce, L. J., Klein, D., Chen, J.-K., Delcenserie, A., and Genesee, F . Mapping the unconscious maintenance of a lost first language. Proceedings of the National Academy of Sciences , 111(48):17314–17319, 2014. ISSN 0027- 8424. doi: 10.1073/pnas.1409411111. Ratcliff, R. Connectionist models of recognition memory: constraints imposed by learning and forgetting functions. Psychological re view , 97(2):285, 1990. Ravi, S. and Larochelle, H. Optimization as a model for few-shot learning. In 5th International Confer ence on Learning Representations, ICLR , 2017. Rebuf fi, S., Kolesniko v , A., Sperl, G., and Lampert, C. H. icarl: Incremental classifier and representation learning. In 2017 IEEE Confer ence on Computer V ision and P at- tern Recognition, CVPR , 2017. Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer , H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., and Hadsell, R. Progressi ve neural networks. CoRR , abs/1606.04671, 2016. Serr ` a, J., Suris, D., Miron, M., and Karatzoglou, A. Over- coming catastrophic forgetting with hard attention to the task. In Pr oceedings of the 35th International Conference on Machine Learning, ICML , 2018. Shin, H., Lee, J. K., Kim, J., and Kim, J. Continual learn- ing with deep generati ve replay . In Advances in Neural Information Pr ocessing Systems 30, NIPS , 2017. Sprechmann, P ., Jayakumar , S. M., Rae, J. W ., Pritzel, A., Badia, A. P ., Uria, B., V in yals, O., Hassabis, D., Pas- canu, R., and Blundell, C. Memory-based parameter adaptation. In 6th International Conference on Learning Repr esentations, ICLR , 2018. van der V en, G. M. and T olias, A. S. Generativ e replay with feedback connections as a general strate gy for continual learning. CoRR , abs/1809.10635, 2018. V enkatesan, R., V enkateswara, H., Panchanathan, S., and Li, B. A strategy for an uncompromising incremental learner . CoRR , abs/1705.00744, 2017. W u, Y . and He, K. Group normalization. In 15th European Confer ence on Computer V ision, ECCV , 2018. Y oon, J., Y ang, E., Lee, J., and Hwang, S. J. Lifelong learning with dynamically e xpandable networks. In 6th International Confer ence on Learning Repr esentations, ICLR , 2018. Zenke, F ., Poole, B., and Ganguli, S. Continual learning through synaptic intelligence. In Proceedings of the 34th International Confer ence on Machine Learning, ICML , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment