Data Vision: Learning to See Through Algorithmic Abstraction
Learning to see through data is central to contemporary forms of algorithmic knowledge production. While often represented as a mechanical application of rules, making algorithms work with data requires a great deal of situated work. This paper exami…
Authors: Samir Passi, Steven J. Jackson
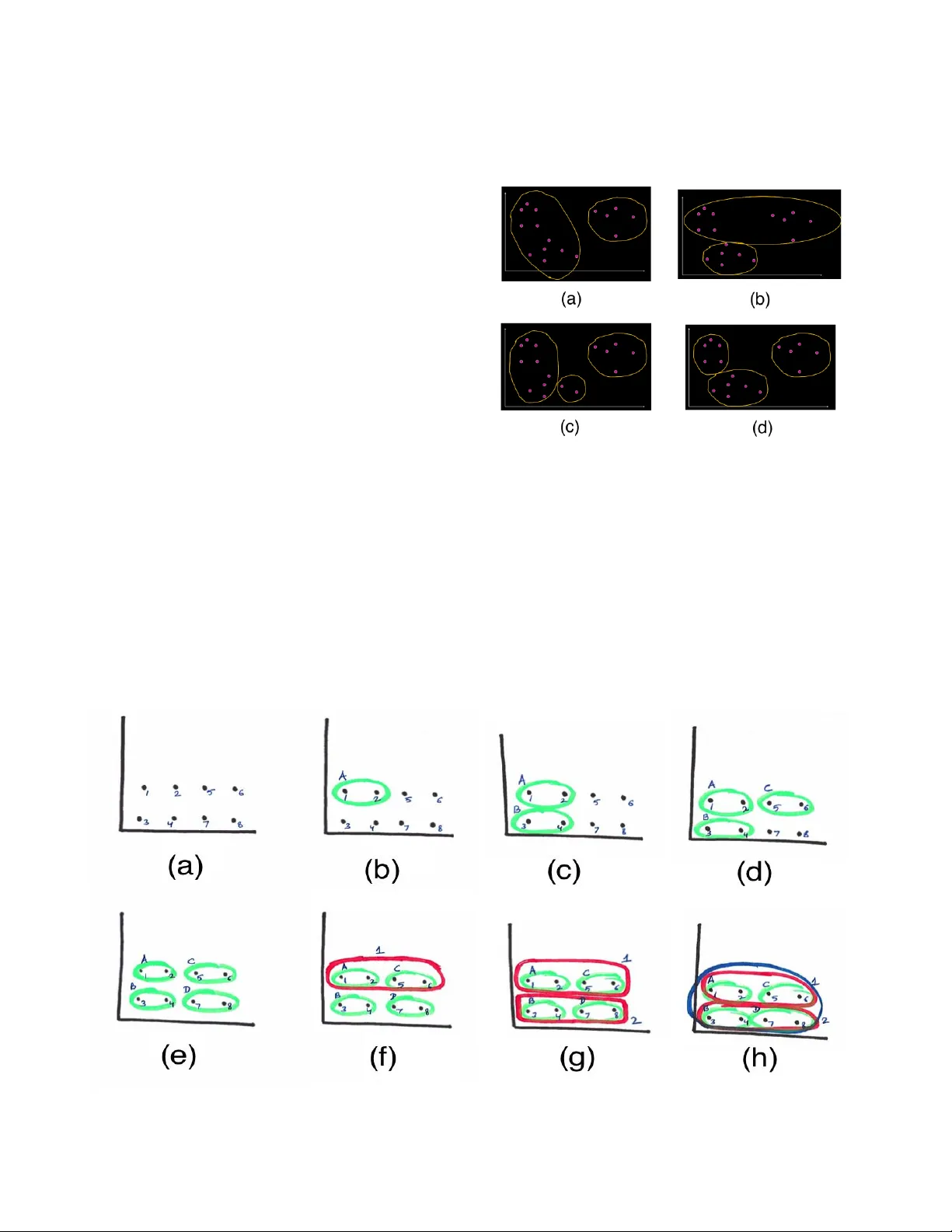
Data V ision: Learning to See Through Algorithmic Abstraction Samir Passi Dept. of Information Science Cornell University sp966@cornell.edu Steven J. Jackson Dept. of Information Science Co rnell University sjj54@cornell.edu ABSTRACT Learning to see thro ugh data is central to contemporar y forms of algorithm ic knowledge production. While often represented as a mechanical application of rules , making algorithms work with data requires a great deal of situated work. This paper examines how the often-divergen t demand s of mec hanization and discretion manifest in data analytic learning environments. Drawing on research in CSCW and the social scien ces, and ethnographic fieldwork in two data learning environments , we show how an algorithm’s app lication is seen sometimes as a mechanical sequence of ru les and at other times as an array of situated decisions. Casting data an alytics as a rule - based (rather than rule- bound ) practice, we show that effective data vision requires wo uld-be analysts to straddle th e comp eting demands of formal ab straction and empirical contingency . We conclud e by discussing how the notion of data vision can help better leverage the role of human work in data analytic lear ning, research, and practice. Author Keywords Data Vision; Data Analysis; Pro fessional Vision; Ma chine Learning; Digital Humanities; Pro fessionalization ACM Classification Keywords H.m. [Info rmation Systems] : Miscellaneous INTRODUCTION Algorithmic d ata analysis has come to en able new w ay s of producing and v alidating knowledge [15 , 25 ]. Algorithms are in tegral to many contemporary knowled ge practices, especially ones that rely on the analys is of large -scale datasets [15 , 20, 21 , 34]. At the same tim e, we know th at algorithms can be selectiv e [34], subjective [7], and biased [3]; that th ey work on multiple assumptions about the world and how it functions [ 5, 1 5, 34, 35]; and that th ey simultaneously enable and constrain possibilities of hu man action and knowledge [5, 6]. Algorithmic knowledge production is a deeply social and collaborative practice with sociocultural, economic, and po litical gr oundings and consequen ces. In all these ways, data analysis emb odies a distinct and powerful way of seeing the world . Data analysts learn to represent and organize the wo rld through computational forms such as graphs, matrices, and a h ost o f standardized formats, en abling them to make knowledg e claim s based on algorithmic an alyses. But this is just one half of the story. The wo rld doesn’ t always nea tly fit into spreadsheets, matrices, and tables. While data analysis is often understood as th e wo rk of faceless and unbiased numbers and algorithms, a large amount of situated and discretionary work is req uired to organize an d manipulate the world algorithmically . Effective algorithmic analysis also demands mastery of the way s that worlds and tools are put together , and which worlds an d tools are so combined (across th e wide range of m ethods, tools, and objects amenable to representation) . Taken tog ether, these two seemingly contradictory features constitute what we call data vision: the ab ility to o rganize and man ipulate the world with data and algorithms , while simultaneou s ly mastering forms of d iscretion aro und why , how , and wh en to ap ply and improvise around established meth ods and tools in the wak e of empirical diversity. Integrated, often seamlessly, in th e practice of expert practitioners, these co ntradictory demands stand out with particular clarity in the moments o f learning and professionalizatio n through which novices learn to master and balance the intricacies of data vision. Ho w do students learn to “ see ” the world through data and algorithms? How do they learn to man euver and improvise around forms and formalization s in th e face o f empirical contingen cy? This paper addresses such qu estions in the con text o f d ata analytic learn ing enviro nments such as classroom s and workshop s. While distinct from oth er contexts o f profession al practice (e.g., industry settings or research centers) , learning environments provide p artial b ut meanin gful sites to understand some of the ways in which would-be practitioners are immersed and ac cultur at ed into professional discourse and practice. [On the relatio n and relevance of learning environmen ts for ‘mature’ professional practice, see inter alia 8 , 16 , an d 24 ]. The explicit focus in learning environments on d emonstrating established methods and theories to wou ld-be professionals Pre - pr int version. allows us to see how par ticular ped agogic demon strations and analytic examples enable specific algorithmic norms and heuristics. Mor e im portantly, a study of classroo ms and workshop s draws attention to the social aspects of learning – a p rocess of participation and mem bersh ip in a d iscourse, instead of just a set of ind ividual exper iences. In learning environments, aspects of professionalization are accomplished th rough guided interaction s b etween instructors, students, teaching assistants, edu cational materials, assignments, and exams. Lea rning environments thus function as important sites in which would-be data analysts learn to see the world through an d as data – a crucial rite of passage on their way to becoming full- fledged member s in the data analytic “co mmunit y of practice.” [2 4] This paper describes two separate sequences of events – one from a machine-learning classroom , and another f rom a series of digital human ities workshops – to show how learning to see through data requir es students to m aintain a balance between viewing the wo rld through abstract constructs, while simultaneous ly adap ting to empirical contingen cy. We advance a rule- ba sed (as opposed to a rule- boun d ) understand ing of d ata analy tic practice, highlighting the situated inter play between formal abstraction and mechanical routin ization on th e one hand , and discretionary action and empirical con tingency on the other. We sho w how it is th e mastery of this inter play – an d not just the practice of data analy tic techniques in their formal dimension – that is central to the gro wing skill and efficacy of would-be data analysts. We argue that better understand ing o f data vision in its more com prehensive an d discretionary forms can h elp researchers and instructors better en gage and leverage the hum an dimensions and limits of data analytic learning and practice. The sections that follow begin by rev iewing CSCW, HCI, and social science literatures on profession al v ision, situated knowledge , and discretio nary practice . We then describe our research sites , b efore m oving to the empirical examples . We conclude by discussing th e im plications of the no tion and practice of data vision, an d the distinction between a rule-bound and rule-based understanding of data analysis, for data analytic learning and practice , and for CSCW research an d practice more broadly. PROFESSIONAL VISION, SI TUATED KNOWLEDGE, AND DISCRETIONARY PRACTICE Our work on data vision builds on a classic and growing body of wor k in th e social s cien ces that has exp lored fo rms of id entity, p ractice, an d perception u nderpinning and constituting f orms o f professional knowledge. G ood win ’s work on pro fessional vision [16] analyzes two profession al activities (arch aeological field ex cavation and leg al argumen tation) to show how professionals learn to “ see ” relevant objects of p rofessional knowledge with and through pra ctice : the exposure to and exercise of theo ries, methods, and tools to produce artifacts and kn owledge in line with professional g oals. Learn ing professional practice , he argue s, help professionals make salient specific aspects of phenomena, transforming them into o bjects of knowledg e amenable to pro fessional analysis. Lea rning to see the world professionally, h owever, is not red ucible to the mastery of g eneric rules and f ormal techn iques. Instead, professional vision is slowly and carefully built through training, socializatio n, and immersion into professional discourse [16, 24 , 30 , 32]. Professional vision, thus, is a substantive and collaborative sociocultural acco mplishment – a way of seeing th e world constructed an d shaped by a “commun ity of practice.” [2 4 ] A key aspect of professional vision, as Abbo tt [1] argues, is the way in which pr actitioners situate given prob lems within existing reper toires of professional k nowledge, methods, and expertise. Acc ording to Abbott, the proce ss of situating given problems – of “ seeing ” professionally – must be clear en ough for professionals to create relation s between a given problem and existing knowledg e (e.g., what can I say about this specific da taset?) , yet abstract, even ambiguous, enough to en able prof essionals to create such r elations fo r a wide v ariety of problems (e.g., what a re the d ifferent kinds o f datasets about which I can say something? ) . A similar interplay between abstrac tion, clarity, and discretion ex ists within data analytic practices . Algorithms, developed in co mputational domains such as machine - learning, information retrieval, and natural language processing, provide means of an alyzing data . It is often argued that a specific algorithm ca n work on m ultiple datasets as long as the d atasets are mod eled in particular ways. However , data analysis requires much mo re work than simp ly applying an algorithm to a dataset . As Mackenzie argues: certain data analy tic practices such as vectorization , approximation , and modeling o ften mask the inherent subjectiv ity of dataset and algorithms, imbuing them with a sense of inher ent “generaliza tion.” [ 26 ] F ro m choice of analytic method , to ch oices co ncerning data formatting, to d ecisions about h ow best to re presen t and communicate data an alytic results to ‘outside’ audien ces , a large amount of situated an d discretio nary work – e.g ., in the fo rm of data collect ion, data clean ing, data modeling, and o ther forms of p re- an d post-proce ssing – is required to make datasets work with cho sen algorithms. Data analysts not just learn to see and organize the world th rough data and algorithm s, but also learn and discern meaningful and effective co mbinations of data and alg orithms . As Gitelman et al. [15 ] argue: “raw data” – at least as a workable entity – is an oxymoro n. It takes work to make d ata work. Abbott’s [1 ] example of chess is instru ctive in evoking the situated and discretionary work ch aracteristic of all forms of prac tice. T he opening and closing m oves in a game o f chess, Abbott argues , often appear methodic al and rigorous . However, in between the se two moves , he argued, is the game itself in which knowledge, ex pertise, and experience intermingle as the g ame progresses. On one hand, we can summarize a nd t each chess as a co llection of formal rules and techniques (e.g., how a pawn moves, how the rook moves, ways to minimize saf e moves f or your opponent , etc.). On the o ther hand, however, we have to acknowledge that any and all application o f such rules is situated – contingen t to the specif ic layout o f the game at hand. In this way , chess (an d p rofessional v ision) is rule - based but not rule- boun d – a distinction we return to in the discussion . These insights are backed in turn by a long line of pragmatist social science d ealing with the natur e of ‘ routines ’ and ‘routinizab le tasks’ in organizatio nal and other contexts . Build ing on Dewey ’s [1 2 ] f oundational work, Cohen [9] argues against the common understand ing of routinized task s as collec tions of rig id and mundane actions , guided by “ min dless ” rules and mechanized actions; instead, th e per formance of a routine is both skilled and un ique: “For an established routin e, the na tural fluctua tion of its surroun ding environment guara ntees that e ach performance is different, and yet, it is th e ‘same. ’ Somehow there is a pattern in the action, su fficient to allow us to say the pattern is recurring, even though there is substantial va riety to the action .” [9 : 782] Klemp et al. [ 22] also draw on Deweyan ro ots to add ress these “similar , y et diff erent” application s of routines through the vocabulary o f plan s, takes, and mis - takes . There might be a p lan (a method, an alg orithm, a script), and there migh t be known mistakes (incom patibility, inefficiency , misfit), but ev ery application of the p lan is a tak e ripe for mis- ta kes . M is - ta kes occu r when profession als are faced with something unexpec ted durin g the ex ecution of formal an d estab lished routines . Drawing on the example of a Thelon ious Mo nk jazz performance , t he au thors explore the co mplex discretionar y processes by wh ich a musician d eals with mis- takes : “When we listen to mu sic, we hear neither plan s nor mistakes, bu t takes in which expectations and difficulties get worked on in the mediu m o f notes, tones and rhythms. Notes live in connec tion with ea ch other. They ma ke dema nds on each other, and, if o ne n ote sticks ou t, th e lo gic of their conn ections demands tha t they be reset an d realigned.” [22 : 10 ] Mis- takes , then, mark elements of “contingency, surprise, and repair [f ound] in all hu man activities. ” [22 : 4] Signifying the lived differences between theor etical reality and empirical richness, mis- takes necessitate situated, o ften creative, improvisatio ns on the part of professionals and other social acto rs. Like Abbott’s descrip tion of chess, Klemp et al.’s analysis draws o ut the situated nature of professional knowledg e and practice, even in apparently straightforward and routinized procedures. This p oint is further elaborated by Feldm an & Pentland [ 14], who show how routin es are ostensive (th e structural ru le-like elemen ts of a ro utine) as well as performative ( the situated and contingent execution of a routine) . It is the interplay between the two aspects that allows f or the discernable but shifting reality of routinized work and p rofessional practice . Along similar lines, Wylie ’s study o f p aleontology laboratories [3 7] shows how adapting situated routines and p ractices to dea l with new problems - at -hand is considered an integral aspect of learning by doing. “ Problem-solving in ways ac ceptable to a field [...] can be an indicator o f skill, knowled ge, and membership in that particular field.” [3 7: 43] However, the situatedness of a practice is no t always visible. Ingold [17 : 98 ], using the example of a c arpenter sawing planks, describes how to an observer, “it may look as though [ …a] carpenter is merely reproducin g th e same gesture, over and over again.” Such a description, he reminds us , is incomplete: “For the carpen ter, [...] who is ob liged to follow the material a nd respo nd to its singularities, sawing is a matter of enga ging ‘in a continuous variation o f variables …” [1 7 : 98 ] To improvise on seemingly routine tasks then is to “ follow the way s of the world, as they open up , rather than to recover a ch ain o f connections, from an end-point to a starting-po int, on a route already travelled. ” [17 : 97 ] Such social science insigh ts on pr ofessional vision and discretionar y practice have translated into im portant CSC W and HCI research programs. For instance, Suchman and Trigg [ 32] demonstrate the role an d significan ce of representation al dev ices fo r ways in which Artificial Intelligence (AI) researchers see an d produce profession al objects and knowled ge. Mentis, Chellali, & Sch waitzberg [27 ] show how laparoscopic surgeons demonstrate ways of “ seeing ” the body through imag ing techniques to students: “ seeing ” the body in a medical imag e is not a given, bu t a process requiring discussion and interpretation. Mentis & Taylor [28] similarly argue that “work requ ired to see medical images is hig hly co nstructed and embod ied with the action o f m anipulating the bod y.” Situatin g objects or phenomena in representations, they argue, is a situated act: representation s don’ t just reveal thin gs, but al so produce them , turning the “blooming, buzzin g conf usion” of the world [19 ] into stable and tractable “ objects ” amenable to analytic and other forms of action . Performing analytical and other forms of action on the world, howev er, require s people to deal directly with empirical contingency. Suchman [33] argu es that “ plans ” are theoretica l, often formulaic, representatio ns of human actions and practices . “Situated action , ” howev er, require s people to work with co ntinuous variation and uncertainty in th e wo rld. Human action, she ar gues , is a form of iterative problem solving in an attempt to accomplish a task. Creativity often em erges with in such situated and discretionary forms of problem solvin g. As Jackson & Kang ’s [18] study o f interactive artists shows, d ealing with material mess and contingency (in this case, attached to the breakdown of techno logical systems and object s) may necessitate and drive forms of improvisation and creativity at the margins of formal order. Crea tivity – understood not as an ab stract and free-standing act o f cogn ition bu t rath er as a situated sociomaterial a ccomplishment – emerges through the interplay between r outines and applications, between plans, takes, and mis -take s , and between empirical mess and theo retical clarity . Such situated and discretion ary acts are n o less central to forms of data analy sis and algorith mic k nowledge studied and p racticed by CSCW and HCI research ers. Clarke [11] , for instan ce, an alyzes the human collabo rative work in d ata analytics that is o ften overlo oked in the face o f the gro wing “ popular ity of automation and statistics. ” He analyzes the processes used by online ad vertising p rofessionals to cr eate user mo dels, bring ing to light ways in wh ich we can design better software to acco mmodate the mu ndane, assump tive, and interp retive deliberation work that g oes into producing such “social - culturally co nstituted” mo dels. Pine & Liboiron [ 30 ] study the use of p ublic health data, showing how data collection practices are actu ally social in nature. One does not simply collect “ raw data. ” Data collection practices are shap ed by values and ju dgments ab out “what is counted and what is not, what is considered the best unit of measurement, and h ow different th ings are g rouped together and ‘made’ into a measurable entity.” [ 30 : 3147] Along similar lines, Ver tesi & Dourish [36 ] show how the use and sharing of data in scientific collabor ation dep ends on the contex ts of production and acquisition from wh ich such data arise. Tay lor et al. [35 ] show how data materializes di fferently in dif ferent places by and for different actors. In deed, it is precisely the erasure of these kinds of work that produces the trou bling effects of neutrality, “ opacity ” , and self-efficacy that all too often clouds public understand ing o f “big d ata,” and mak es algorithms appea r ‘ m agical ’ in learning, b ut also ‘real - world’ enviro nments [8]. These bodies of CS CW and HCI research call attentio n to aspects of f ormalism, co ntingen cy , and discretion at the heart of algorithmic knowledge and data analytic practices. An algorithm is a collection of f or mal r ules – indeed, a routinizable plan of action – that or ganizes data in predictable and actionable ways. Yet each dataset p oses unique challenges (and opportunities) for the data analy st , necessitating ways to accommodate the var iations in the seemingly ro utine acts of “ applying ” algorithm s . To learn data vision then is to learn to s ee similarities as well as differences in th e way s in wh ich d ata, algo rithms, and worlds are put togeth er. To see with data is to see the unknown, the d ifferent, and the singular within th e space of the mundane and pr edictable. Advancing an understanding of data analytics as a rule - based (as opposed to a rule - bound ) practice, t his paper argues that data vision is not merely a collection of formal and mechanical rules , but a situated an d discretio nary pr ocess requir ing data analysts to continuously straddle the competing demands of formal abstraction an d empirical contingen cy . METHODS AND FINDINGS Th e arguments that follow build on ethnographic fieldwork conducted at a major U.S. East Coast Univ ersity. W e conducted a four month long participant -observation study in a graduate level machine-lear ning class taught at the university in fall 2014 . One of the authors was enrolled as a student in one section o f the cour se with ~80 studen ts. We also con ducted a participant-observatio n study of a ser ies of three digital humanities workshops organized at the same university during spring 2 015. The workshop s’ purpose was to expo se students to computation al techniques for text analyses. Each workshop lasted two hours , and the nu mber of participan ts in each workshop rang ed from n ine to thirteen. CASE 1: MACHINE-LEARNING CLASSROOM Our first case follows an instance of data analysis and learning revealed du ring a machine- learning class. At the point we p ick up the story, t he instructor is about to introduce a type of algorithm that classifies things into groups (called clusters) such that th ings within a clu ster are sufficiently similar to each other, and thing s ac r oss cluster s are sufficiently different from each oth er. Figure 1. Class exercise to introduce the notion of clusters. The instructo r starts by showing an imag e to the stud ents (figure 1) and inquiring : how many clusters d o yo u see? Most students g ive the same answer: “three clusters.” Figure 2. The three clusters that the students initially saw. Having an ticipated this respon se, th e instructor sho ws another image with three clearly mar ked clusters (f igure 2) . The instructor informs the students that the n umber o f clusters present in the image is actu ally unclea r: How ma ny clusters? I don’t know. I ha ven’t even to ld you what the similarity mea sure is [i.e., how do you even know which two dots are similar to each o ther in this gr aph.] But, yo u all somehow a ssumed E uclidean Distance [i.e., the closer two dots are, the more similar they are.] He now shows other types of clusters that could have been “seen” (figure 3 ). As is clear from these imag es, the re coul d have been two or thr ee clusters. Mo reover, there could have been different k inds of two clusters (figure 3a /3b) and different kinds of three clusters (fig ure 3c/3d ). After the students have had a ch ance to digest thi s lesson, the instructor g oes on to introduce the conce pt of a cluster ing algorithm: A clu stering algorithm does partitioning. Closer points are similar, and further away points a re dissimilar. We haven’t yet defined what we mean exactly by similarity, but it ’ s intuitive, right? Having made this point, t he instructo r move s on to a more specific algorithm. The instructor explains that th is algorithm works o n a simple prin ciple: the similarity of two clusters is eq ual to the similarity of th e most similar members of the two clu sters . Having made this point, t he instructo r move s on to a more specific algorithm. The instructor explains that th is algorithm works o n a simple prin ciple: the similarity of two clusters is eq ual to the similarity of th e most similar members o f the t wo clu sters . The idea is to take a clu ster (say, X), f ind the cluster that is most similar to it (say, Y), and then mer ge X and Y t o make a new cluster. It is important to note th at knowin g th e pr emise on which this algorithm functio ns is diff erent from kn o wing h ow to apply it to data. How do we find a cluster most similar to a given cluster? What does it mean when we say “ most simila r members o f the two clusters ” ? Such q uestions, as we will see, are key to this a lgorithm ’s application. The instructor now demonstrat es the application of this algorithm by dr awin g a 2 -dimensional graph marked with eight dots (figure 4a). The closer the two dots are, he explains, th e more similar th ey are f or the purpose of this algorithm . At the start (figure 4a), there are no clu sters but only a set o f eight dots. The instructo r tells the stu dents th at Figure 4. In -class exercise to learn a particular clustering algorithm. Figure 3. Different kinds of clusters that could have been seen. each dot will be treated initially as a cluster. He then starts to apply the alg or ithm beginning with d ot -1. On visual inspection, the instructor and student s infer that dot-1 is closer to d ot-2, d ot-3, and d ot-4, t ha n it is to the other dots. The in structor and the students then look again, and determine that of the three remaining poin ts, dot - 2 is the one closest to do t-1. Thus, based o n th e chosen similarit y metric of physical distance, dot- 1 and dot- 2 a re merged to form cluster -A (figure 4b). The instructor n ow moves on to dot-3. Following the same logic, the instru ctor and students infer that dot-3 is closer to cluster-A and do t-4 than it is to the other do ts. Th e instructor reminds the students that for this algorithm, two clusters ar e compar ed based on their most similar mem bers (i.e. two dots – one in each cluster – that ar e closest to each other). T hus, compar ing dot-3 and cluster-A, he says, means comparing dot -3 and dot- 1 (as dot-1 is the dot in cluster-A that is closest to dot-3) . Looking at dot-3, dot-1, and dot-4, the instructor and students infer that dot -4 is the one closest to dot-3; d ot -3 and dot- 4 ar e then merged to form cluster -B (figure 4c) . In the next two steps, the instructor and students go o n to dot -3 and do t-4 , forming cluster-C (figu re 4d) and clu ster-D (figure 4e ) respectively. At this point, eight do ts have b een lost, and f our clusters (with two dots each ) gained (figure 4e) . After reminding the students that comparing two clu sters requires finding two dots – on e in each cluster – that ar e closest to each other, the instructor moves on to cluster-A . A few students point out that the similar ity between cluster -A an d cluster- B is equivalent to th e similarity between dot -1 and do t-3 . Other students argue that it is equ ivalent to the distance between dot -2 and dot-4, as the distances between t hem lo ok the same. The in structor agrees with the students, an d info rms them that these distances represen t the similarity b etween cluster-A and cluster- B. The students g o on to perform the same analysis to co mpare cluster -A, -C, and – D. With regard to clu ster-A, the compa rison is now down to three sets of distances: between a) d ot -2 an d dot-4, b) dot - 2 and dot-5, and c) d ot -2 and dot-7. O n visual inspection, the students observe that dot-2 is closest to d ot-5 . Cluster- A and clu ster- C a re t heref ore merged to for m cluster- 1 (figure 4f). A similar operation merges cluster -B an d cluster- D to form clu ster-2 (figure 4g ). In the last step, cluster -1 and - 2 are merged to form a single clu ster co ntaining all eigh t d ots (figure 4h). With this, the instru ctor t ells the students, they have reached the en d of the exercise, hav ing successfully “appl ied ” the clustering algorithm . There are three striking features abou t the in -class exercises described in this section . The first is th e step- by -step mechanical natu re of the instructor’s d emonstration of th e algorithm . Explicit in the algorithm ’s demonstration is a collection of formal rules specifying h ow to treat individu al dots, how to compare two dots, how to compar e a dot and a cluster, etc. Aspects of data vision , as we see in this case, are b uilt sequen tially with students learning an algorithm’s application as a set of mechan ical and ro utine steps throu gh which data – r epresented as dots – are manipulated , enabling th e formation of similarity clusters. A second and related feature is the abstract nature of the represented and an alyzed d ata. T he se ex ercises do not have a specific “ real-wor ld ” context supplemen ting them. The students were n ever told, and they never inquired , what the dots and the graph r epresented. The d ots wer e presented and analyzed simply as label-less d ots o n a nameless graph , generic rep resentations of any and all kinds of d ata that this algorithm ca n work on. A third and final poin t concerns the reliance on v isuals to demonstrate the o peration of the algorithm. We see how visual fo rms such as dots, circles, an d graphs h elp ed students learn to “ see ” data in way s amenable to formal representation and organization. This allo ws the students to learn to manipulate the wo rld as a set of data points ar rayed in 2-dim ensional space . The algorithm , it appears , “ work s ” as long as data is in the form of d ots in n-dimen sions. While seeing and organizing the world through mechanical rules and abstract rep resentations is key to data vision, students also need to learn to see the app lication of an abstract, generic method as a situated and discretio nary activity. An instance of this appears in th e case below. CASE 2: DIGITAL HUMANITIES WORKSHOPS Our second case f ollows the constructio n of data v ision as revealed during a series of d igital human ities workshops . Digital humanities, broadly put, is a research area in w hich humanists and information scientists use comp utational as well as interpretive methods to analyze data in domains such as history and literature. The vignette that follows describes how workshop conv eners and students decide what dataset to work on and what happ en s when they begin to analyze the chosen dataset. It has n’ t been straightforward for the work shop conveners to decid e what tex ts (i.e. , data) the students sho uld work on as a group not only b ecause students have different resear ch interests but also because not all texts are digitally available. In the f irst work shop session, there is a lo ng discussion on h ow to get dig itized version of texts (e. g., from Project Gutenberg, Hath iTrust, etc.), what form at to use (e.g ., XML, HTML, or plain -tex t files), how to work with specific elemen ts of a file (e.g., h eaders, tags, etc.), and how to clean the files (e.g., fixing formatting issues, removing stop -words, etc.). The students can, of course, simply down load a novel, an d start read ing it righ t away, but the point of the d iscussion is to find ways in which the students can make algorithms do the work of “read ing. ” While d escribing ways to co nvert files from one format to another, something catches the conven er’s eyes as he shows the students an online n ovel’s source cod e. There is a vertical bar ( |) in certain wor ds such as ‘over|whelmin g’ and ‘dis|tance.’ At first, students suspect the d igitized version has no t been properly proof read . Howev er, after noticing more and more words with the vertical bar symbol, the convener returns to the non-sou rce-code version of the novel to discover that these ar e actu ally wo rds th at cu t across lines with a hyphen (-). The computer has b een joining the two parts of these words with a vertical b ar. At this po int, a student asks a bo ut ways in which she ca n recognize such errors, separatin g “g ood” from “bad” data. A discussion ensues about ready- to -use scripts and packages. Several stu den ts observe that manual read ing can help spo t such error s, b ut the whole point of using algorithms is to allow work with much more text than can be read an d check ed in this way . The discussion end s with no clear an swers in sight. A second q uestion concern s the dataset to be used for purposes of the common class exer cises. Th is decision is reached only by the e nd of the second session: English Gothic novels. Th is choice is arrived at on the basis of conven ience rather th an common interest – only o ne student has a research interest in Go thic literature. But a complete set of English Gothic novels in digital form is perceived to be ea sier to obtain than oth er candidates suggested by the group. “The allur e of th e av ailable,” as the co nvener remark s , “is a powerfu l thing.” But this rai ses another is sue: what actually q ualifies as a Gothic novel? So mething with the word Go thic in the title? On e tagged as Go thic by the library? Or one acknowledged as Go thic by the wider literary commu nity? After some discussion, the convener s and studen ts agree to ask one of the librar y’s d igital curators to select a set o f Gothic no vels , and at the start of th e third wo rkshop session students are presen ted with plain-text f iles of 131 English Gothic nov els. While discussing ways in wh ich this dataset c an be used, a student inquires whether it is possible to create a separate file fo r each novel contain ing only d irect quotes from characters in the no vel. The worksho p conven er and students d ecide to try this ou t for themselves and immediately en counter a question: how can an algorithm know what is a nd isn’t a character quote? After some discussion, the students d ecide to write a scrip t that parses the text, inserting a section break e ach time a quotation mark is enco untered. They surm ise that this proced ure will thereby capture all quo tes as the text falling between sequential p airs of quotes. The total of such pairs w ill also indicate the n umber of quotes in each novel. Based on th is understand ing, the studen ts create the below algorithm (in Python) to perform this work: import sys text = “” for line in op en(sys.argv[1]): text += line.rstrip() + “ ” quote_segm ents = text.split(“ \ ””) is_quote = Fa lse for segment in q uote_segments: print “{0} \t{1} \{2}\ n”.format (“Q” if i s_quote else “N”, len(segment), seg ment) ## every oth er segment is a quote is_quote = n ot is_quote When tested again st one of the novels in the set ho wever the r esults are surprising : the script has p roduced just o ne section break . Most stud ents fe el that this result is “wr ong.” “Oh wow! That’s it?” “I think it didn’t even go th rough the file.” “Just one quotation mark?” To see what wen t wrong , students scroll through the chosen novel, glancing through the first twenty paragraphs or so. Upon i nspection , they conclude that there is n othing wrong with their scr ipt. It i s just that this particular n ov el actually d oes not have any quotes in it. (The single quotation mark that the script encounter ed was the result of an optical character recognition error.) This leads to a d iscussion of differences in writin g styles between a uthors. A couple of students mention how some au thors don’t use quotation marks, but instead a series o f hyphens (-) to mark the beginning and end of charac ter quotes. This raises a new p roblem. Is it safe to use quotation marks as proxies for ch aracter quotes, or should the script also look for hyphens? Are there still other v ariations that studen ts w ill need to account f or? Out of curiosity, the students randomly open a few files to manually search for hyphens. Some authors are indeed using them in place of quotation marks: ------ Except dimity, ------ rep lied my father. Others, howev er, are using them to mark incom plete sentences: But ‘tis impossible, ---- In some cases, hyphens h ave resulted becau se em-dash es ( — ) or e n -dash es ( – ) were converted to hyphens by the optical charac ter recognition system : Postscript -- I did n ot tell you that Blandly… It is no w clear to th e students that if hyphens sometimes mark speech , they are less robust than quotatio n marks as proxies for charac ter quotes. They decide to u se only quotation marks for the remainder o f th e exercise to keep things “ relativ ely simple. ” It is now time to choose another novel to test the script. This time , the choice is n ot so ran dom, as students wan t a novel that has many character quo tes as a “good ” sam ple or test case. The script is changed such that it now parses th e text of all the novels, returning a list of novels along with the nu mber of section s p roduced in each novel. These range from 0 to ~600 . Since there are no pr e-defined ex pectations for number of quotes in a novel, th ere is no way to just lo ok at these numbers and know if th ey are accurate. However, some students still fe el that s omething has g one “wro ng.” They argue th at becau se every quo te needs two quo tation marks, the total numb er of “correct” quo tation marks in a novel should be an even number. By the same logic, the number of sections p roduced o n this basis should also be even. But the resu lt r eturned show s odd number s for almost half the novels . Students open some of these “wrong” novels to manually search for q uotation marks. Af ter trying this out on five d ifferent novels, the y are puzzled. The novels do have an ev en number of quotation marks in them. Why then is the script returning o dd number s? It does not take long to identify th e problem. The students are right in pointing out that the n umber of quotation mar ks in a novel should be even. However, they ha ve misconstrued how the script creates sections in a novel . A student ex plains this by reference to one o f the novel’ s in the set : An n Radcliffe’s The Mysteries o f Udo lpho. In the passage b elow, th e pyth on scr ipt will g o thr ough the text inserting four secti on breaks: She discovered in her early years a taste fo r works of genius; and it was St. Aubert's principle, as well as h is inclination, to pro mote every innocent mea ns of happines s. <>“ A well-informed mind, <>” he wo uld say, <>“ is the best security again st th e contagion of folly and of vice. ”<> The vaca nt mind is ever on the watch for relief, and ready to plunge into error, to escape from the languor of idleness. Th is example sh ows the stu dents that th ey had b een confusing sections with section-breaks . Although the script creates four section -breaks in the novel, the number of sections created by the script is actually five. The stu dents realize that th e number of sections will thus be on e more than the count of qu otation marks. Since these will always be even, th e number of sections created by the script must always be odd. The p roblem has now reversed itself. Wher eas earlier the participants b elieved that an odd numb er of sections wa s “wrong”, they now ag ree th at having an odd number of sections is actually “righ t”. W hy then, they p uzzle, do some novels have an ev en number of sections? The participants manually check out a few “even” novels to search fo r quotation marks. T hey discover another set of optical character recogn ition errors, formatting issues, and variance in authors’ writing styles that is producing the “wrong” or unexpected result . At the conclu sion of th e workshop session shortly thereafter , the studen ts still do not have a script that can reliably extract all character quotes in an automated way . There are many ways to explain wh at has happen ed here . One is to say that the nov els wer e not i n the “ right ” format – they had formatting issues, exhibite d style inconsistencies, and contained typographical errors. This, however, is true for most, if not all, kinds of data that analysts hav e to deal with on a d aily basis. Clean, complete, and consistent datasets – as e very data analyst knows – are a theoretica l fantasy. Outside of theory, data is o ften inconsistent and incomplete. Th e requ irement of prim and proper datasets, we argue, does not do justice either to th e reality of the data world or to the explanation of this workshop exercise. Another explanation is that the studen ts simply lacked skill and experience, and were making what some would call “ rookie mistakes ” . After all, these students were here to learn these methods, and were not expected to know them beforehand. However, the ability to identify and avoid “ rookie mistakes ” is in itself an important artifact of the training and professionalization of would- be professionals. In lar ge part, what mak es a ro okie a rookie is his/her inability to rec ognize and avoid th ese kind s of errors. A s sites for learning and training, classro oms an d w orkshop s thus provide avenues for s eein g how would-be professionals learn to “ see ” and avo id “rookie mistakes.” Similar if less stark examples of such mistakes appeared in the mach ine-learning class (using part of training data as a test case, confu sing correlation f or causation, etc. ). Our workshop case bring s together prior kno wledge, human decisions, and empirical c ontingen cy . The ch oice of the dataset is not a giv en, bu t a co mpromise between themat ic alignment and practical accessibility. Mo reover, as seen in the case of vertical bars, hyphens, and quotation marks, data is o ften idiosyncratic in its own ways, necessitating situated and discretionary forms o f pre -processing. Even clearly articulated computation al routines (e. g., search for quotation marks, label text b etween marks as a section, count sections, pu t sections in a separate file) often require a host o f situated decisions (e.g ., what novels to look at, what stylistic elements to account f or, how to alleviate formattin g errors, how to infer and man age empirical contingen cy, etc.). In all these ways, a lgorithm ically identifyin g and extracting character q uotes is a situated activity that r equires practitioners to find t heir way around specificities of th e data at hand. DISCUSSION The cases above provide i mpor tant insight into the practice and profession alization o f would-b e data analysts. In case one, w e saw h ow mac hine learn ing students learn to see data in form s am enable to algorithmic manipulation, and an algorithm ’s application as a co llection of formal rule-lik e steps. The rules to be followed appear m ethodical , rigoro us, and mechanical , and the algorithm is demon strated usin g an abstract represen tational f orm : label-less dots on a n ame- less graph. Whether it is d iscerning the similarity between two dots or k nowing ways to com pare and merge clu sters of dots, studen ts learn to work with an d organize the world through a fix ed set of rules. Such a demon stration privileges an abstract understanding of data analytics, allowing students to learn to man ipulate the world in p redictable and actionable ways. This, we argu e, is a great sou rce o f algorithmic strength: if the hallmark of real-world empiric s is its richness and unpredictability, the hallmark of data analysis is its ability to organize and eng age the world via abstract ca tegorization an d computation ally actio nable manipulation . I n ca se two, b y co ntrast, we saw how process es of learning and practicing data analysis are also situated, reflexive, and discretionary , in ways that ab stract rep resentation s and mechanical demonstrations significantly understate . Multiple decisions were required to effectively combine the script with the given dataset ranging fr om id entifying ho w to isolate character quotes, d iscerning ways in which q uotes appear in data, to figuring out h ow to test the scrip t . Unique datasets necess itate differ ent f ixes and workarounds, requiring a co nstant adjustment betwe en prior kno wledge, empirical co ntingencies, and formal methodologies. Making prior knowledge and abstrac t m ethods work with data is indee d hard work. Data may be hard to find , un available, o r incomplete . Under such cir cumstances, practitioners have to make do with what they can get, in ways that go against the ab stracted ap plication story u sually shared in data analytic research pap ers and presen tations. Recognizing the inco mplete natur e of the abstracted data story helps situate an algorithm’s application as a site no t only f or abstract categorization and formal manipulation but also for discretion and creativity. Lear ning to app ly an algorithm, as we saw, involv es a ser ies o f situated deci sions to iteratively , often creatively, ad apt prior knowledge, data analytic routines , and empirical data to each other. Elements of creativity manif est themselves as professional acts of discretio n in the use of abstract , seemingly mechanical m ethods. While cer tain d atasets may sh are similarities that support mechanical ap plications of rules across co ntexts, mastery of operation s in their mechan ical form con stitutes only one p art of the professionalization of data analysts. Eac h dataset is inco mplete and inconsistent in its own way, requiring situated strategies, wo rkarounds, an d fixes to make it ready and usable for data analysis. Data analysts are much like Suchman’s [ 33 ] problem solvers , Klemp et al.’s [ 2 2 ] musicians, and I ngold’s [ 17] carpenters: constantly negotiating with and work ing around established routines in the face of emer gent empirical diversity. Viewing data analysis as an ongoing neg otiation between rules and empirics help s mark a clear distinction b etween two ways of describing the professionalization and practice of data analytics that ar e relevant fo r CSCW and HCI researchers. One of these approaches data analytics as a rule -boun d prac tice, in which data is organized and analyzed through the application o f abstract and mech anical methods. Casting data analytics as a rule - bound practice helps m ake visible sp ecific aspects of data an alytic learning and pr actice. First, it allows data analy sts to better understand th e abstract nature of data analytic th eories , facilitating novel ways of computationally organizing an d manipulating the world . Second , it enables research ers to focus on constraints and limits of algorithmic analyses, providing a detailed look at some of the cr itical assumptions un derlying data analyses. Finally, it allows students to learn not only how to work with basic, yet foundational, data an alytic ideas, but also how to organize and manipulate the world in predictable and ac tionable ways. Howev er, the same properties that make these aspec ts visible, tend to render in - visible the em pirical challenges confronting efforts to make algorithm s work with data , making it d ifficult to account f or the situated, often creative, decisions made by data an alysts to co nform empirical contingency t o effective (and often innovative) abstraction. What’s left is a stripped down notion of data analytics – analytics as rules and tools – that only tells half the da ta an alytic story , understating the breadth and depth of hum an work r equired to make data speak to algorithms . Significantly underappreciating the craftsmanship of data analysts, the rule-bo und perspective paints a d ry pictur e of data analysis – a p rocess that often comprises of artfu l and innovative ways to produce novel forms of kno wledge. A more fruitful way t o understand data analytics , we ar gue, is to see it not as r ule - bound but rather as rule -based : structured but not fully deter mined by mechan ical implementation s of formal method s . In a rule-b ound understand ing, an algor ithm ’s applicatio n req uires organizatio n and man ipulation of the world through abstract constructs and mechanical rules . In a rule- based understand ing, however, emergent empir ical conting encies and practical issues come to t he fore, reminding u s that the world requ ires a large amount of work for it to conform to high-lev el data analytic l earn ing, expectations, an d analyses. Following Feldman & Pentland’s [1 4 ] view of routines, a rule-b ased u nderstanding of data analysis casts algorithms as ostensive as well as performative objects , highlighting how the performances of algorithms draw on and feed in to their ostensive natur e, and vice v ersa. Seeing data analy tics as a rule - based practice focu ses our attention on the situated, d iscretionary, and improvisational nature of data analytics. It helps make salient not only the partial and contin gent nature of the data world (i.e., data is often incomplete and inconsistent), but also the role of human decisions in aligning the wo rld with formal assumptions and abstract representations of order as stipulated under abstract algorithmic methods and theories. Data analy sis is a craf t, an d like every o ther fo rm of c raf t it is never fully bo und by rules, but only based on them. A rule-based u nderstanding of data analysis acknowledges and celebrates the lived differen ces between theoretical reality, empirical richness, and situated improvisatio ns on the part of d ata analysts. It is in and through these lived d ifferences that d ata analy sts gain data vision. As with Dewey’s [ 1 2] , Cohen’s [ 9], and Feldman & Pentland’s [ 14] descriptions o f ro utines and routinized tasks, we see in data vision the always -ongoing negotiation between ab stract alg orithmic “ routines ” an d th e situated and ref lexive “applications” o f such “ routines. ” Data vision is mu ch like an array of plans, takes, and mis - takes [ 22 ] – a constant reminder o f the situated an d discretionary nature of the professionalization and practice of data an alysis. Such an u nderstanding of data vision can inform data analytic learning, research, collabo ration, and practice in three basic ways. First , it helps focus attention on the r ole of hum an work in the p rofessionalization and prac tice of data analy tics; while mod els, algorithms, and statistics clearly matter , focusing o n situated and discretionary judgment helps contex tualize algo rithmic k nowledge , facilitating a better understanding of the mechanics, exactness, an d limits of such kn owledge. Algo rithms and data don’t p roduce knowledge by themselves. We pro duce knowledg e with and through them. The notion of data vision put s humans back in the algorithm. Second , data vision can help us better attend to the way s in which algo rithmic results are documented, presen ted, and written up. Although algorithmic and statistical choices constitute a significant part o f data analytic publications, also providing an explicit description of key dec isions that data analy sts take can not only help communicate a nuanced understand ing of technical ch oices and algor ithmic results, bu t also enab le students as well as practitio ners to think through aspects of their work that though m ay seem “ non -technical, ” g reatly impact their knowledge claims . This helps to not only reduce the “opacity” [8 ] of data analytic p ractices, but also better teach and commun icate, what some call, the “black art” or “f olk knowledge” [13 ] of data analysis, contributing to the develo pment of a complete an d “reflective practitioner” [ 31 ]. Thi rd , better under standing of data vision ca n h elp inform both professional training and community conv ersations around data analysis . I n data analytics, and in many other forms of research (including our own!) , we often present research setup, pro cess, and results in a dry and straightforwar d manner . We had a q uestion, we collected this data, we did this analysis, and here is the ans wer . Open and effective conversatio ns about the messy and c ontin gent aspects of research work – data analytic or other wise – tend to escap e th e for mal description s of meth ods sections and grant applications, reserved instead for water cooler and hallway conv ersations by which workarounds, ‘tricks of th e trade’, and ‘good enough’ so lutions are shared. Th e result is an exce ssively “ neat ” pictu re that fails to communicate the real practices an d contingencies b y which d ata analytic work proceeds. This becomes even more dif ficult outside the classroo m. In industry, research centers, and other contexts of algorithmic knowledge production, d ata analysts often work with huge volumes of data in multiple teams, simultaneously interfac ing with a host o f other actors such as off-site developers, marketer s, managers, and clients. Wher e the r esults of data analy tics meet other kind s of public cho ices and d ecisions (think co ntemporary debates over online tracking and surveillance , or the charismatic p ower o f New York Times inf ographic s) these complication s – an d their importance – only multiply . Data analy tic results o ften trav el far beyond the ir immediate contexts of production, taking on forms of certainty and objectivity (ev en magic!) that may or may not b e warranted, in ligh t of the real -world conditions and operation s from which they spring. Here as in other wo rlds of exp ert knowledg e, “distance lend s enchantment” [10 ]. More broadly , an u nderstanding of data vision helps support the div erse forms of oft-inv isible collaborative d ata analytic work. Data analysis n ot only warrants algo rithmic techniques and computation al fo rms, but also comprises answers to cr ucial questions suc h as what is the relation between data and question, what can actually be answered through data , what are some of the underlying assumptions concerning d ata, meth ods, etc. By brin ging such questions – and, indeed, other forms of human work – to the fore, data vision directs our attention to forms of situated discretionary work en abling and facilitating data analysis. Data are never “raw” [ 15], and a large amount o f work goes into making data speak for themselves. The notion of data vision can help us to identify and build ac knowledgment and supp ort mechanisms for sharin g such fo lk knowledge that, though immen sely u seful, is often lost. Data v ision is not merely ab out perceiving the wo rld, but a highly consequen tial way of seeing that turns per ception into action. Data often s peak specific forms of knowledge to power. Like all forms of ex planation, data analysis has its own set o f biases [3 , 15], assumption s [4, 7, 34 ], and consequen ces [4, 5, 6 ]. Understanding d ata vision allows us to b etter delin eate an d co mmunicate the strengths as well as the limitation of such collaborative knowledge – indeed, o f seeing the wo rld with and through data. CONCLUSION Given our g rowing use of and relian ce on algorithm ic data analysis, an understan ding of data vision is now integral to contemporary knowledg e production practices, in CSCW and indeed many other fields . In this pap er we presented two distinct, y et complem entary, way s of learning and pr acticing data an alysis. We a rgu ed in favor of a rule-based , as o pposed to a r ule -bound , understanding o f data analytics to introd uce the conce pt of data vision – a notion that we find integral, if not foundational, to the p rofessionalization and practice of data analysts. We described how a better understand ing of d ata vision allow s us to better grasp an d value th e intimate co nnection b etween methodological abstraction, empirical contingency, and situated discretio n in data analytic practice . Shedding light on the diverse forms of data analytic work, data vision produce s a more open and acco untable understan ding of algorithmic work in data analytic learning and p ractice. Studying lear ning en vironments helps showcase basic, yet formative, aspects in the training and pr ofessionalization of data analysts. In this paper, using empirical ex amples from classrooms an d wo rkshops , we hav e describ ed not only a rule-based view of data analysis, bu t also the outline of the notion and pr actice of data vision. Studying learnin g environments , howev er, has its limitation s. Classroom s are but one step in the professionalization of data analysts. Data analysis, like all practices, is a constant lear ning en deavor. To better u nderstand data analytic pr actice, we then n eed t o also study oth er contexts of algorithmic knowledge production such as those in industry, r esearch centers, startups, and even hackathons. Acting as avenues for future research, diverse contexts of data an alyses p rovide opportunities to furth er and strengthen our understan ding of data vision . In different contexts, data analysis is shaped by a diver se set of professional expec tations and o rganizational imperatives, rem inding us that the prac tice of data an alysis remains a deep ly social and collabo rative ac complishment . This p aper has suggested early steps in definin g an d understand ing data vision. Future work will seek to extend and deepen this holistic ap proach. ACKNOWLEDGMENT Support fo r this research was provided by U.S. National Science Fou ndation Gran t #1526 155, and the Intel Science and Technolo gy Center (ISTC) for Social Co mputing. REFERENCES 1. Andrew Abbott. 2014. The System of Professions: An essay on the d ivision of expert labo r. Univ ersity of Chicago Press. 2. Chris Anderson. 2008. The End of Theory: The Data Deluge Makes th e Scientific Method Ob solete. Retrieved Aug ust 21, 2015 from http://archive.wir ed.com/science/discov eries/mag azine/ 16 -07/pb_theory/ 3. Solon Barocas. Data Mining and the Discourse on Discrimination. I n Proceed ings of Data Ethics Workshop at ACM Con ference on Kno wledge Discovery and Da ta-Mining (KDD), 1- 4. 4. Tom Boellstorff. 2013. Making b ig data, in theory. First Monday, 18, 10. 5. Geoffrey C. Bowker. 2013. Data Flakes: An Afterword to “Raw Data” Is an Oxymoron. In Raw Data Is an Oxymoron, Lisa Gitelman (ed.). MI T Press, Cambridge, 167 - 171. 6. Geoffrey C. Bowker. 2014. The Theory/Data Thin g. Internationa l Journal of Communicatio n, 8: 1 795- 1799. 7. danah boyd and Kate Crawf ord. 2012. Critical Questions for Big Data: Provocations fo r a cultural, technolog ical, and scholarly phenom enon. I nformation, Communication & Society, 1 5, 5: 662-679 . 8. Jenna Burrell. 2016. Ho w the machine ‘thinks’: Understandin g opacity in machine learn ing algorithms. Big Data & Society , 3(1). 9. Michael D. Cohen. 2007 . Reading Dewey: Reflection s on the study o f routine. Orga nization Stud ies, 28, 5: 773 - 786. 10. Harry Collins. 1985. Changing Order: Replica tion and Induction in S cientific Practice . University of Chicago Press. 11. Michael F. Clarke. 2015. T he Work of Mad Men that Makes the Metho ds of Math Men Work: Prac tically Occasioned Segm ent Design. In Proceedings o f the SIGCHI Conference on Human Facto rs in Computing Systems (CHI ’15) , 3275 -32 84. 12. John Dewey. 1922. Human nature and conduct: An introduction to social psychology. H. Holt & Company. 13. Peter Domingos. 2012. A few useful thing s to know about machine learning. Co mmunications of the ACM 55, 10 (Octob er 12), 78-87. 14. Martha S. Feldman and Brian T. Pentland. 2003. Reconceptualizin g Organizational Rou tines as a Source of Flexibility an d Change. Administrative Science Quarterly, 48, 1: 94 - 118. 15. Lisa Gitelman. 2006 . Raw Data Is an Oxymo ron. MIT Press. 16. Charles Goodwin. 1994 . Professional Vision. American Anthropologist, 96, 3: 606-6 33. 17. Tim Ingold. 2010. The Textility of Making. Cambridg e Journal o f Economics, 34, 1 : 91- 10 2. 18. Steven J. Jackson and Laewoo Kang. 2014. Breakdown, obsolescence and reuse: HCI and the art of repair. In P roceedings of the SIGCHI Con ference on Human Fa ctors in Computing Systems (CHI ’14), 4 49 - 458. 19. James Joyce . 1 922 . Ulysses. Project Gu tenberg. 20. Rob Kitchin. 2014. Big Data , new epistemologies an d paradigm shifts. Big Data & Society, 1, 1: 1- 12. 21. Rob Kitchin. 2014. The Data Revolution: Big Data, Open Data, Data Infrastructures and Their Consequences. Sage Publicatio ns. 22. Nathaniel Klemp, Ray McDermott, Jason Raley, Matthew Thibeau lt, Kimberly Powell, and Dan iel J. Levitin. 2008. Plans, Takes, and Mis -takes. Outlines. Critical Practice Studies, 10, 1: 4 -21. 23. Bruno Latour. 1986. The powers of association. In Power, Action, a nd Belief, John L aw (ed.). Routledg e, London, 264 - 280. 24. Jean Lave and Etienne Wen ger. 1991. Situated learning: Leg itimate peripheral participa tion. Cambridge Un iversity Press. 25. Sabina Leonelli. 201 4. What differences does quan tity make? On th e epistemology of Big Data in b iology. Big Data & Society , 1, 1, 1- 11. 26. Adrian Mackenzie . 2015. The production of prediction: What does mach ine learning want? Europea n Journal of Cultural Stud ies, 18, 4- 5: 4 29 -445. 27. Helena M. Mentis, Amine Ch ellali, and Steven Schwaitzberg. 2014. Learning to see the body : supporting instru ctional practices in lapar oscopic surgical pro cedures. In Proce edings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’1 4) , 2113-2122. 28. Helena M. Mentis and Alex S. Taylor. 2013. Imaging the body: embod ied vision in minimally in vasive surgery. In Proceedings of the SIGCHI Conference on Human Fa ctors in Computing Systems (CHI ’13), 1479 -1488. 29. Alex Pentland. 2009. Reality Mining o f Mobile Communication : Towards a New Deal on Data. In The Global Info rmation Technology Report 2 008 -2010: Mobility in a Networked World, Sumatra Du tta and Irene Mia (eds.). Wo rld Economic Forum, 75 -80. 30. Kathleen H. Pine and Max Liboiron. 2015. The Poli tics of Measuremen t and Action. In Proceedings o f the SIGCHI Conference on Human Facto rs in Computing Systems (CHI ’15) , 3147 -31 56. 31. Donald A. Schön. 1983 . The Reflective Practitioner: How Professionals Think in Action. Basic Books. 32. Lucy Suchman and Randall H. Trigg. 1993. Artificial intelligence as craf twork. In Understanding practice: Perspectives on activity and context, Seth Chaiklin and Jean Lave (ed s.). Cambridg e University Press, Cambridge, 144 - 178. 33. Lucy Suchman. 2007. Human-mach ine reconfiguration s: Plans and situated actions. Cambridge Un iversity Press. 34. Tarleton Gillespie. 2014. T he Relevance of Algorithms. In Media Techno logies: Essays on Communicatio n, Materiality, and Society, Tarleton Gillespie, Pablo J. Bo czkowski and Kirsten A. Foot (eds.). MIT Press, Cambridge, 167 -194. 35. Alex S. Taylor, Siân L indley, Tim Regan, David Sweeney, Vasillis Vlacho kyriakos, L ille Grainger, and Jessica Lingel. 201 5. Data- in -place: Thinking through the Relations Between Data and Com munity. In Pr oceedin gs of the SIGCHI Conference on Human Factors in Compu ting Systems (CHI ’15), 2863 - 2872. 36. Janet Vertesi and Paul Dou rish. 2011. The v alue of data: consider ing the context of pr oduction in d ata economies. In Proceedings of the ACM Conferen ce on Computer Sup ported Cooperative Work (CSCW ’11), 533 - 542. 37. Caitlin D. Wylie. 2014. ‘The artist’s piece is already in the stone’: Con structing creativity in p aleontology laboratories. Social Studies of Science, 45, 1: 31 -55.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment