A Recurrent Variational Autoencoder for Speech Enhancement
This paper presents a generative approach to speech enhancement based on a recurrent variational autoencoder (RVAE). The deep generative speech model is trained using clean speech signals only, and it is combined with a nonnegative matrix factorizati…
Authors: Simon Leglaive (IETR), Xavier Alameda-Pineda (PERCEPTION), Laurent Girin (GIPSA-CRISSP
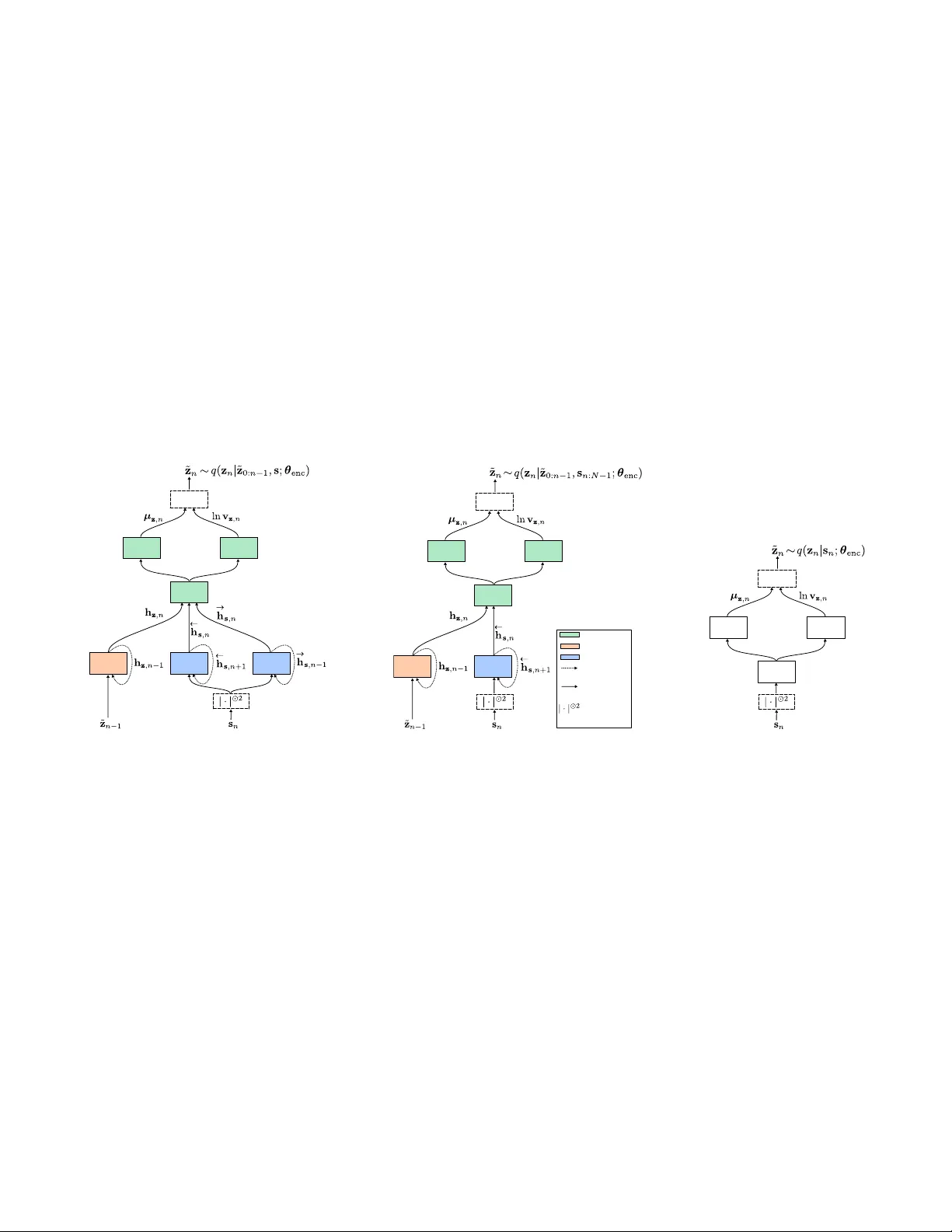
A RECURRENT V ARIA TIONAL A UTOENCODER FOR SPEECH ENHANCEMENT Simon Le glaive 1,2 Xavier Alameda-Pineda 2 Laur ent Girin 2,3 Radu Horaud 2 1 CentraleSupélec, IETR, France 2 Inria Grenoble Rhône-Alpes, France 3 Uni v . Grenoble Alpes, Grenoble INP , GIPSA-lab, France ABSTRA CT This paper presents a generativ e approach to speech enhancement based on a recurrent variational autoencoder (R V AE). The deep gen- erativ e speech model is trained using clean speech signals only , and it is combined with a nonnegativ e matrix factorization noise model for speech enhancement. W e propose a v ariational expectation- maximization algorithm where the encoder of the R V AE is fine- tuned at test time, to approximate the distribution of the latent vari- ables given the noisy speech observations. Compared with previous approaches based on feed-forward fully-connected architectures, the proposed recurrent deep generative speech model induces a poste- rior temporal dynamic over the latent variables, which is shown to improv e the speech enhancement results. Index T erms — Speech enhancement, recurrent v ariational au- toencoders, nonnegati ve matrix factorization, v ariational inference. 1. INTR ODUCTION Speech enhancement is an important problem in audio signal pro- cessing [1]. The objectiv e is to recover a clean speech signal from a noisy mixture signal. In this work, we focus on single-channel (i.e. single-microphone) speech enhancement. Discriminativ e approaches based on deep neural networks have been extensi vely used for speech enhancement. They try to estimate a clean speech spectrogram or a time-frequency mask from a noisy speech spectrogram, see e.g. [2, 3, 4, 5, 6]. Recently , deep gener- ativ e speech models based on variational autoencoders (V AEs) [7] hav e been in vestigated for single-channel [8, 9, 10, 11] and multi- channel speech enhancement [12, 13, 14]. A pre-trained deep gen- erativ e speech model is combined with a nonnegativ e matrix fac- torization (NMF) [15] noise model whose parameters are estimated at test time, from the observation of the noisy mixture signal only . Compared with discriminati ve approaches, these generativ e methods do not require pairs of clean and noisy speech signal for training. This setting was referred to as “semi-supervised source separation” in pre vious works [16, 17, 18], which should not be confused with the supervised/unsupervised terminology of machine learning. T o the best of our knowledge, the aforementioned works on V AE-based deep generativ e models for speech enhancement have only considered an independent modeling of the speech time frames, through the use of feed-forward and fully connected architectures. In this work, we propose a recurrent V AE (R V AE) for modeling the speech signal. The generative model is a special case of the one proposed in [19], but the inference model for training is dif ferent. At test time, we develop a v ariational expectation-maximization al- gorithm (VEM) [20] to perform speech enhancement. The encoder Xavier Alameda-Pineda acknowledges the French National Research Agency (ANR) for funding the ML3RI project. This w ork has been partially supported by MIAI @ Grenoble Alpes, (ANR-19-P3IA-0003). of the R V AE is fine-tuned to approximate the posterior distribution of the latent v ariables, given the noisy speech observations. This model induces a posterior temporal dynamic over the latent v ari- ables, which is further propagated to the speech estimate. Experi- mental results show that this approach outperforms its feed-forward and fully-connected counterpart. 2. DEEP GENERA TIVE SPEECH MODEL 2.1. Definition Let s = { s n ∈ C F } N − 1 n = 0 denote a sequence of short-time Fourier transform (STFT) speech time frames, and z = { z n ∈ R L } N − 1 n = 0 a corresponding sequence of latent random v ectors. W e define the fol- lowing hierarchical generative speech model independently for all time frames n ∈ { 0 , ..., N − 1 } : s n z ∼ N c ( 0 , diag { v s ,n ( z )}) , with z n i.i.d ∼ N ( 0 , I ) , (1) and where v s ,n ( z ) ∈ R F + will be defined by means of a decoder neu- ral network. N denotes the multivariate Gaussian distribution for a real-valued random vector and N c denotes the multi variate complex proper Gaussian distribution [21]. Multiple choices are possible to define the neural network corresponding to v s ,n ( z ) , which will lead to different probabilistic graphical models represented in Fig. 1. FFNN generative speech model v s ,n ( z ) = ϕ FFNN dec ( z n ; θ dec ) where ϕ FFNN dec ( ⋅ ; θ dec ) ∶ R L ↦ R F + denotes a feed-forward fully- connected neural network (FFNN) of parameters θ dec . Such an architecture was used in [8, 9, 10, 11, 12, 13, 14]. As represented in Fig. 1a, this model results in the following factorization of the complete-data likelihood: p ( s , z ; θ dec ) = N − 1 n = 0 p ( s n z n ; θ dec ) p ( z n ) . (2) Note that in this case, the speech STFT time frames are not only conditionally independent, b ut also marginally independent, i.e. p ( s ; θ dec ) = ∏ N − 1 n = 0 p ( s n ; θ dec ) . RNN generative speech model v s ,n ( z ) = ϕ RNN dec ,n ( z 0 ∶ n ; θ dec ) where ϕ RNN dec ,n ( ⋅ ; θ dec ) ∶ R L × ( n + 1 ) ↦ R F + denotes the output at time frame n of a recurrent neural network (RNN), taking as input the sequence of latent random vectors z 0 ∶ n = { z n ′ ∈ R L } n n ′ = 0 . As represented in Fig. 1b, we ha ve the following factorization of the complete-data likelihood: p ( s , z ; θ dec ) = N − 1 n = 0 p ( s n z 0 ∶ n ; θ dec ) p ( z n ) . (3) Note that for this RNN-based model, the speech STFT time frames are still conditionally independent, but not mar ginally independent . BRNN generative speech model v s ,n ( z ) = ϕ BRNN dec ,n ( z ; θ dec ) where ϕ BRNN dec ,n ( ⋅ ; θ dec ) ∶ R L × N ↦ R F + denotes the output at time frame n of s 0 z 0 s 1 z 1 s 2 z 2 (a) FFNN s 0 z 0 s 1 z 1 s 2 z 2 (b) RNN s 0 z 0 s 1 z 1 s 2 z 2 (c) BRNN Fig. 1 : Probabilistic graphical models for N = 3 . a bidirectional RNN (BRNN) taking as input the complete sequence of latent random vectors z . As represented in Fig. 1c, we end up with the following f actorization of the complete-data likelihood: p ( s , z ; θ dec ) = N − 1 n = 0 p ( s n z ; θ dec ) p ( z n ) . (4) As for the RNN-based model, the speech STFT time frames are con- ditionally independent but not mar ginally . Note that for avoiding cluttered notations, the variance v s ,n ( z ) in the generativ e speech model (1) is not made explicitly dependent on the decoder network parameters θ dec , but it clearly is. 2.2. T raining W e would like to estimate the decoder parameters θ dec in the max- imum likelihood sense, i.e. by maximizing ∑ I i = 1 ln p s ( i ) ; θ dec , where { s ( i ) ∈ C F × N } I i = 1 is a training dataset consisting of I i.i.d sequences of N STFT speech time frames. In the follo wing, be- cause it simplifies the presentation, we simply omit the sum ov er the I sequences and the associated subscript ( i ) . Due to the non-linear relationship between s and z , the mar ginal likelihood p ( s ; θ dec ) = ∫ p ( s z ; θ dec ) p ( z ) d z is analytically in- tractable, and it cannot be straightforwardly optimized. W e therefore resort to the framework of variational autoencoders [7] for parame- ters estimation, which builds upon stochastic fixed-form variational inference [22, 23, 24, 25, 26]. This latter methodology first introduces a variational distribu- tion q ( z s ; θ enc ) (or inference model) parametrized by θ enc , which is an approximation of the true intractable posterior distribution p ( z s ; θ dec ) . For any variational distribution, we hav e the following decomposition of log-marginal lik elihood: ln p ( s ; θ dec ) = L s ( θ enc , θ dec ) + D KL q ( z s ; θ enc ) ∥ p ( z s ; θ dec ) , (5) where L s ( θ enc , θ dec ) is the variational free ener gy (VFE) (also re- ferred to as the evidence lo wer bound) defined by: L s ( θ enc , θ dec ) = E q ( z ∣ s ; θ enc ) [ ln p ( s , z ; θ dec ) − ln q ( z s ; θ enc )] = E q ( z ∣ s ; θ enc ) [ ln p ( s z ; θ dec )] − D KL q ( z s ; θ enc ) ∥ p ( z ) , (6) and D KL ( q ∥ p ) = E q [ ln q − ln p ] is the Kullback-Leibler (KL) div ergence. As the latter is always non-negati ve, we see from (5) that the VFE is a lower bound of the intractable log-marginal likeli- hood. Moreov er, we see that it is tight if and only if q ( z s ; θ enc ) = p ( z s ; θ dec ) . Therefore, our objective is now to maximize the VFE with respect to (w .r .t) both θ enc and θ dec . But in order to fully de- fine the VFE in (6), we have to define the form of the v ariational distribution q ( z s ; θ enc ) . Using the chain rule for joint distributions, the posterior distri- bution of the latent v ectors can be exactly expressed as follo ws: p ( z s ; θ dec ) = N − 1 n = 0 p ( z n z 0 ∶ n − 1 , s ; θ dec ) , (7) where we considered p ( z 0 z − 1 , s ; θ dec ) = p ( z 0 s ; θ dec ) . The v aria- tional distribution q ( z s ; θ enc ) is naturally also expressed as: q ( z s ; θ enc ) = N − 1 n = 0 q ( z n z 0 ∶ n − 1 , s ; θ enc ) . (8) In this work, q ( z n z 0 ∶ n − 1 , s ; θ enc ) denotes to the probability density function (pdf) of the following Gaussian infer ence model : z n z 0 ∶ n − 1 , s ∼ N µ z ,n ( z 0 ∶ n − 1 , s ) , diag v z ,n ( z 0 ∶ n − 1 , s ) , (9) where { µ z ,n , v z ,n }( z 0 ∶ n − 1 , s ) ∈ R L × R L + will be defined by means of an encoder neural network. Inference model f or the BRNN generative speech model For the BRNN generati ve speech model, the parameters of the variational distribution in (9) are defined by { µ z ,n , v z ,n }( z 0 ∶ n − 1 , s ) = ϕ BRNN enc ,n ( z 0 ∶ n − 1 , s ; θ enc ) , (10) where ϕ BRNN enc ,n ( ⋅ , ⋅ ; θ enc ) ∶ R L × n × C F × N ↦ R L × R L + denotes the output at time frame n of a neural network whose parameters are denoted by θ enc . It is composed of: 1. “Prediction bloc k” : a causal recurrent block processing z 0 ∶ n − 1 ; 2. “Observation block” : a bidirectional recurrent block processing the complete sequence of STFT speech time frames s ; 3. “Update block” : a feed-forward fully-connected block process- ing the outputs at time-frame n of the two previous blocks. If we want to sample from q ( z s ; θ enc ) in (8), we have to sample recursiv ely each z n , starting from n = 0 up to N − 1 . Interestingly , the posterior is formed by running forwar d over the latent vectors, and both forward and backwar d over the input sequence of STFT speech time-frames. In other words, the latent vector at a giv en time frame is inferred by taking into account not only the latent vectors at the previous time steps, but also all the speech STFT frames at the current, past and future time steps. The anti-causal relationships were not taken into account in the R V AE model [19]. Inference model for the RNN generative speech model Using the fact that z n is conditionally independent of all other nodes in Fig. 1b giv en its Markov blanket (defined as the set of parents, children and co-parents of that node) [27], (7) can be simplified as: p ( z n z 0 ∶ n − 1 , s ; θ dec ) = p ( z n z 0 ∶ n − 1 , s n ∶ N − 1 ; θ dec ) , (11) where s n ∶ N − 1 = { s n ′ ∈ C F } N − 1 n ′ = n . This conditional independence also applies to the variational distribution in (9), whose parameters are now gi ven by: { µ z ,n , v z ,n }( z 0 ∶ n − 1 , s ) = ϕ RNN enc ,n ( z 0 ∶ n − 1 , s n ∶ N − 1 ; θ enc ) , (12) where ϕ RNN enc ,n ( ⋅ , ⋅ ; θ enc ) ∶ R L × n × C F × ( N − n ) ↦ R L × R L + denotes the same neural network as for the BRNN-based model, except that the observation block is not a bidirectional recurrent block anymore, but an anti-causal recurrent one. The full approximate posterior is now formed by running forward over the latent v ectors, and backwar d ov er the input sequence of STFT speech time-frames. Inference model f or the FFNN generative speech model For the same reason as before, by studying the Mark ov blanket of z n in Fig. 1a, the dependencies in (7) can be simplified as follows: p ( z n z 0 ∶ n − 1 , s ; θ dec ) = p ( z n s n ; θ dec ) . (13) This simplification also applies to the variational distribution in (9), whose parameters are now gi ven by: { µ z ,n , v z ,n }( z 0 ∶ n − 1 , s ) = ϕ FFNN enc ( s n ; θ enc ) , (14) where ϕ FFNN enc ( ⋅ ; θ enc ) ∶ C F ↦ R L × R L + denotes the output of an FFNN. Such an architecture was used in [8, 9, 10, 11, 12, 13, 14]. This is the only case where, from the approximate posterior, we can sample all latent vectors in parallel for all time frames, without fur- ther approximation. Here also, the mean and variance v ectors in the inference model (9) are not made explicitly dependent on the encoder network pa- rameters θ enc , but the y clearly are. V ariational free energy Giv en the generative model (1) and the general inference model (9), we can dev elop the VFE defined in (6) as follows (deri vation details are pro vided in Appendix A.1): L s ( θ enc , θ dec ) c = − F − 1 f = 0 N − 1 n = 0 E q ( z ∣ s ; θ enc ) d IS s f n 2 , v s ,f n ( z ) + 1 2 L − 1 l = 0 N − 1 n = 0 E q ( z 0 ∶ n − 1 ∣ s ; θ enc ) ln v z ,ln ( z 0 ∶ n − 1 , s ) − µ 2 z ,ln ( z 0 ∶ n − 1 , s ) − v z ,ln ( z 0 ∶ n − 1 , s ) , (15) where c = denotes equality up to an additiv e constant w .r .t θ enc and θ dec , d IS ( a, b ) = a b − ln ( a b ) − 1 is the Itakura-Saito (IS) di- ver gence [15], s f n ∈ C and v s ,f n ( z ) ∈ R + denote respectively the f -th entries of s n and v s ,n ( z ) , and µ z ,ln ( z 0 ∶ n − 1 , s ) ∈ R and v z ,ln ( z 0 ∶ n − 1 , s ) ∈ R + denote respectiv ely the l -th entry of µ z ,n ( z 0 ∶ n − 1 , s ) and v z ,n ( z 0 ∶ n − 1 , s ) . The e xpectations in (15) are analytically intractable, so we com- pute unbiased Monte Carlo estimates using a set { z ( r ) } R r = 1 of i.i.d. realizations drawn from q ( z s ; θ enc ) . For that purpose, we use the “reparametrization trick” introduced in [7]. The obtained objectiv e function is dif ferentiable w .r .t to both θ dec and θ enc , and it can be optimized using gradient-ascent-based algorithms. Finally , we re- call that in the final expression of the VFE, there should actually be an additional sum ov er the I i.i.d. sequences in the training dataset { s ( i ) } I i = 1 . For stochastic or mini-batch optimization algorithms, we would only consider a subset of these training sequences for each update of the model parameters. 3. SPEECH ENHANCEMENT : MODEL AND ALGORITHM 3.1. Speech, noise and mixture model The deep generativ e clean speech model along with its parameters learning procedure were defined in the previous section. For speech enhancement, we now consider a Gaussian noise model based on an NMF parametrization of the variance [15]. Independently for all time frames n ∈ { 0 , ..., N − 1 } , we have: b n ∼ N c ( 0 , diag { v b ,n }) , (16) where v b ,n = ( W b H b ) ∶ ,n with W b ∈ R F × K + and H b ∈ R K × N + . The noisy mixture signal is modeled as x n = √ g n s n + b n , where g n ∈ R + is a gain parameter scaling the lev el of the speech signal at each time frame [9]. W e further consider the independence of the speech and noise signals so that the likelihood is defined by: x n z ∼ N c ( 0 , diag { v x ,n ( z )}) , (17) where v x ,n ( z ) = g n v s ,n ( z ) + v b ,n . 3.2. Speech enhancement algorithm W e consider that the speech model parameters θ dec which ha ve been learned during the training stage are fixed, so we omit them in the rest of this section. W e now need to estimate the remaining model parameters φ = g = [ g 0 , ..., g N − 1 ] ⊺ , W b , H b from the observa- tion of the noisy mixture signal x = { x n ∈ C F } N − 1 n = 0 . Howe ver , very similarly as for the training stage (see Section 2.2), the marginal likelihood p ( x ; φ ) is intractable, and we resort again to v ariational inference. The VFE at test time is defined by: L x ( θ enc , φ ) = E q ( z ∣ x ; θ enc ) [ ln p ( x z ; φ ) ] − D KL q ( z x ; θ enc ) ∥ p ( z ) . (18) Follo wing a VEM algorithm [20], we will maximize this criterion alternativ ely w .r .t θ enc at the E-step, and φ at the M-step. Note that here also, we have L x ( θ enc , φ ) ≤ ln p ( x ; φ ) with equality if and only if q ( z x ; θ enc ) = p ( z x ; φ ) . V ariational E-Step with fine-tuned encoder W e consider a fixed- form variational inference strategy , reusing the inference model learned during the training stage. More precisely , the variational distribution q ( z x ; θ enc ) is defined exactly as q ( z s ; θ enc ) in (9) and (8) except that s is replaced with x . Remember that the mean and variance vectors µ z ,n ( ⋅ , ⋅ ) and v z ,n ( ⋅ , ⋅ ) in (9) correspond to the V AE encoder network, whose parameters θ enc were estimated along with the parameters θ dec of the generati ve speech model. During the training stage, this encoder network took clean speech signals as input. It is now fine-tuned with a noisy speech signal as input. For that purpose, we maximize L x ( θ enc , φ ) w .r .t θ enc only , with fix ed φ . This criterion takes the e xact same form as (15) except that s f n 2 is replaced with x f n 2 where x f n ∈ C denotes the f -th entry of x n , s is replaced with x , and v s ,f n ( z ) is replaced with v x ,f n ( z ) , the f -th entry of v x ,n ( z ) which was defined along with (17). Exactly as in Section 2.2, intractable expectations are replaced with a Monte Carlo estimate and the VFE is maximized w .r .t. θ enc by means of gradient-based optimization techniques. In summary , we use the framew ork of V AEs [7] both at training for estimating θ dec and θ enc from clean speech signals, and at testing for fine-tuning θ enc from the noisy speech signal, and with θ dec fixed. The idea of refitting the encoder was also proposed in [28] in a dif ferent context. Point-estimate E-Step In the experiments, we will compare this variational E-step with an alternativ e proposed in [29], which con- sists in relying only on a point estimate of the latent variables. In our frame work, this approach can be understood as assuming that the approximate posterior q ( z x ; θ enc ) is a dirac delta function cen- tered at the maximum a posteriori estimate z ⋆ . Maximization of p ( z x ; φ ) ∝ p ( x z ; φ ) p ( z ) w .r .t z can be achiev ed by means of gradient-based techniques, where backpropagation is used to com- pute the gradient w .r .t. the input of the generative decoder netw ork. M-Step For both the VEM algorithm and the point-estimate al- ternativ e, the M-Step consists in maximizing L x ( θ enc , φ ) w .r .t. φ under a non-negati vity constraint and with θ enc fixed. Replacing in- tractable expectations with Monte Carlo estimates, the M-step can be recast as minimizing the following criterion [9]: C ( φ ) = R r = 1 F − 1 f = 0 N − 1 n = 0 d IS x f n 2 , v x ,f n z ( r ) , (19) where v x ,f n ( z ( r ) ) implicitly depends on φ . For the VEM algo- rithm, { z ( r ) } R r = 1 is a set of i.i.d. sequences drawn from q ( z x ; θ enc ) using the current value of the parameters θ enc . For the point esti- mate approach, R = 1 and z ( 1 ) corresponds to the maximum a pos- teriori estimate. This optimization problem can be tackled using a majorize-minimize approach [30], which leads to the multiplicative update rules derived in [9] using the methodology proposed in [31] (these updates are recalled in Appendix A.2). Speech r econstruction Gi ven the estimated model parameters, we want to compute the posterior mean of the speech coef ficients: ˆ s f n = E p ( s f n ∣ x f n ; φ ) [ s f n ] = E p ( z ∣ x ; φ ) √ g n v s ,f n ( z ) v x ,f n ( z ) x f n . (20) In practice, the speech estimate is actually gi ven by the scaled co- efficients √ g n ˆ s f n . Note that (20) corresponds to a W iener-like fil- tering, averaged over all possible realizations of the latent variables according to their posterior distribution. As before, this expectation is intractable, but we approximate it by a Monte Carlo estimate us- ing samples drawn from q ( z x ; θ enc ) for the VEM algorithm. For the point-estimate approach, p ( z x ; φ ) is approximated by a dirac delta function centered at the maximum a posteriori. In the case of the RNN- and BRNN-based generati ve speech models (see Section 2.1), it is important to remember that sam- pling from q ( z x ; θ enc ) is actually done recursively , by sampling q ( z n z 0 ∶ n − 1 , x ; θ enc ) from n = 0 to N − 1 (see Section 2.2). There- fore, there is a posterior temporal dynamic that will be propagated from the latent vectors to the estimated speech signal, through the ex- pectation in the W iener-like filtering of (20). This temporal dynamic is expected to be beneficial compared with the FFNN generativ e speech model, where the speech estimate is built independently for all time frames. 4. EXPERIMENTS Dataset The deep generativ e speech models are trained using around 25 hours of clean speech data, from the "si_tr_s" subset of the W all Street Journal (WSJ0) dataset [32]. Early stopping with a patience of 20 epochs is performed using the subset "si_dt_05" (around 2 hours of speech). W e removed the trailing and leading silences for each utterance. For testing, we used around 1.5 hours of noisy speech, corresponding to 651 synthetic mixtures. The clean speech signals are taken from the "si_et_05" subset of WSJ0 (unseen speakers), and the noise signals from the "verification" subset of the QUT -NOISE dataset [33]. Each mixture is created by uniformly sampling a noise type among {"café", "home", "street", "car"} and a signal-to-noise ratio (SNR) among {-5, 0, 5} dB. The intensity of each signal for creating a mixture at a giv en SNR is computed using the ITU-R BS.1770-4 protocol [34]. Note that an SNR computed with this protocol is here 2.5 dB lower (in av erage) than with a simple sum of the squared signal coefficients. Finally , all signals hav e a 16 kHz-sampling rate, and the STFT is computed using a 64-ms sine window (i.e. F = 513 ) with 75%-overlap. Network architectur e and training parameters All details re- garding the encoder and decoder network architectures and their training procedure are provided in Appendix A.3. Speech enhancement parameters The dimension of the latent space for the deep generativ e speech model is fixed to L = 16 . The rank of the NMF-based noise model is fixed to K = 8 . W b and H b are randomly initialized (with a fixed seed to ensure fair com- parisons), and g is initialized with an all-ones v ector . For computing (19), we fix the number of samples to R = 1 , which is also the case for building the Monte Carlo estimate of (20). The VEM algorithm and its "point estimate" alternativ e (referred to as PEEM) are run for 500 iterations. W e used Adam [35] with a step size of 10 − 2 for Algorithm Model SI-SDR (dB) PESQ ESTOI MCEM [9] FFNN 5.4 ± 0.4 2.22 ± 0.04 0.60 ± 0.01 PEEM FFNN 4.4 ± 0.4 2.21 ± 0.04 0.58 ± 0.01 RNN 5.8 ± 0.5 2.33 ± 0.04 0.63 ± 0.01 BRNN 5.4 ± 0.5 2.30 ± 0.04 0.62 ± 0.01 VEM FFNN 4.4 ± 0.4 1.93 ± 0.05 0.53 ± 0.01 RNN 6.8 ± 0.4 2.33 ± 0.04 0.67 ± 0.01 BRNN 6.9 ± 0.5 2.35 ± 0.04 0.67 ± 0.01 noisy mixture -2.6 ± 0.5 1.82 ± 0.03 0.49 ± 0.01 oracle W iener filtering 12.1 ± 0.3 3.13 ± 0.02 0.88 ± 0.01 T able 1 : Median results and confidence interv als. the gradient-based iterati ve optimization technique in volved at the E-step. For the FFNN deep generativ e speech model, it was found that an insuf ficient number of gradient steps had a strong negati ve impact on the results, so it was fixed to 10. F or the (B)RNN model, this choice had a much lesser impact so it was fixed to 1, thus limit- ing the computational burden. Results W e compare the performance of the VEM and PEEM al- gorithms for the three types of deep generative speech model. For the FFNN model only , we also compare with the Monte Carlo EM (MCEM) algorithm proposed in [9] (which cannot be straightfor- wardly adapted to the (B)RNN model). The enhanced speech quality is ev aluated in terms of scale-inv ariant signal-to-distortion ratio (SI- SDR) in dB [36], perceptual e valuation of speech quality (PESQ) measure (between -0.5 and 4.5) [37] and extended short-time objec- tiv e intelligibility (ESTOI) measure (between 0 and 1) [38]. For all measures, the higher the better . The median results for all SNRs along with their confidence interval are presented in T able 1. Best results are in black-color-bold font, while gray-color-bold font indi- cates results that are not significantly different. As a reference, we also pro vide the results obtained with the noisy mixture signal as the speech estimate, and with oracle W iener filtering. Note that oracle results are here particularly lo w , which shows the difficulty of the dataset. Oracle SI-SDR is for instance 7 dB lo wer than the one in [9]. Therefore, the VEM and PEEM results should not be directly compared with the MCEM results provided in [9], but only with the ones provided here. From T able 1, we can draw the following conclusions: First, we observe that for the FFNN model, the VEM algorithm performs poorly . In this setting, the performance measures actually strongly decrease after the first 50-to-100 iterations of the algorithm. W e did not observe this behavior for the (B)RNN model. W e argue that the posterior temporal dynamic over the latent variables helps the VEM algorithm finding a satisfactory estimate of the overparametrized posterior model q ( z x ; θ enc ) . Second, the superiority of the RNN model o ver the FFNN one is confirmed for all algorithms in this comparison. Howe ver , the bidirectional model (BRNN) does not perform significantly better than the unidirectional one. Third, the VEM algorithm outperforms the PEEM one, which shows the inter- est of using the full (approximate) posterior distrib ution of the latent variables and not only the maximum-a-posteriori point estimate for estimating the noise and mixture model parameters. Audio e xamples and code are av ailable online [39]. 5. CONCLUSION In this work, we proposed a recurrent deep generati ve speech model and a variational EM algorithm for speech enhancement. W e sho wed that introducing a temporal dynamic is clearly beneficial in terms of speech enhancement. Future works include dev eloping a Marko v chain EM algorithm to measure the quality of the proposed v aria- tional approximation of the intractable true posterior distribution. 6. REFERENCES [1] P . C. Loizou, Speech enhancement: theory and practice , CRC press, 2007. [2] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “ A regression approach to speech enhancement based on deep neural networks, ” IEEE T rans. Audio, Speec h, Language Pr ocess. , vol. 23, no. 1, pp. 7–19, 2015. [3] F . W eninger, H. Erdogan, S. W atanabe, E. Vincent, J. Le Roux, J. R. Hershey , and B. Schuller , “Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR, ” in Pr oc. Int. Conf. Latent V ariable Analysis and Signal Separation (L V A/ICA) , 2015, pp. 91–99. [4] D. W ang and J. Chen, “Supervised speech separation based on deep learning: An overvie w , ” IEEE Tr ans. Audio, Speech, Language Pr o- cess. , vol. 26, no. 10, pp. 1702–1726, 2018. [5] X. Li, S. Leglai ve, L. Girin, and R. Horaud, “ Audio-noise power spec- tral density estimation using long short-term memory , ” IEEE Signal Pr ocess. Letters , vol. 26, no. 6, pp. 918–922, 2019. [6] X. Li and R. Horaud, “Multichannel speech enhancement based on time-frequency masking using subband long short-term memory , ” in Pr oc. IEEE W orkshop Applicat. Signal Process. Audio Acoust. (W AS- P AA) , 2019. [7] D. P . Kingma and M. W elling, “ Auto-encoding variational Bayes, ” in Pr oc. Int. Conf. Learning Repr esentations (ICLR) , 2014. [8] Y . Bando, M. Mimura, K. Itoyama, K. Y oshii, and T . Kawahara, “Sta- tistical speech enhancement based on probabilistic integration of vari- ational autoencoder and non-negativ e matrix factorization, ” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 2018, pp. 716–720. [9] S. Le glaive, L. Girin, and R. Horaud, “ A v ariance modeling framew ork based on variational autoencoders for speech enhancement, ” in Pr oc. IEEE Int. W orkshop Mac hine Learning Signal Process. (MLSP) , 2018, pp. 1–6. [10] S. Le glaive, U. ¸ Sim¸ sekli, A. Liutkus, L. Girin, and R. Horaud, “Speech enhancement with v ariational autoencoders and alpha-stable distribu- tions, ” in Pr oc. IEEE Int. Conf. Acoust., Speech, Signal Pr ocess. (ICASSP) , 2019, pp. 541–545. [11] M. Pariente, A. Deleforge, and E. Vincent, “ A statistically principled and computationally efficient approach to speech enhancement using variational autoencoders, ” in Pr oc. Interspeech , 2019. [12] K. Sekiguchi, Y . Bando, K. Y oshii, and T . Ka wahara, “Bayesian multi- channel speech enhancement with a deep speech prior , ” in Pr oc. Asia- P acific Signal and Information Pr ocessing Association Annual Summit and Confer ence (APSIP A ASC) , 2018, pp. 1233–1239. [13] S. Leglaive, L. Girin, and R. Horaud, “Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization, ” in Pr oc. IEEE Int. Conf. Acoust., Speech, Signal Pr ocess. (ICASSP) , 2019, pp. 101–105. [14] M. Fontaine, A. A. Nugraha, R. Badeau, K. Y oshii, and A. Liutkus, “Cauchy multichannel speech enhancement with a deep speech prior, ” in Pr oc. European Signal Pr ocessing Conference (EUSIPCO) , 2019. [15] C. Févotte, N. Bertin, and J.-L. Durrieu, “Nonnegativ e matrix factor- ization with the Itakura-Saito div ergence: With application to music analysis, ” Neural Computation , v ol. 21, no. 3, pp. 793–830, 2009. [16] P . Smaragdis, B. Raj, and M. Shashanka, “Supervised and semi- supervised separation of sounds from single-channel mixtures, ” in Pr oc. Int. Conf. Indep. Component Analysis and Signal Separation , 2007, pp. 414–421. [17] G. J. Mysore and P . Smaragdis, “ A non-negati ve approach to semi- supervised separation of speech from noise with the use of temporal dynamics, ” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Pr ocess. (ICASSP) , 2011, pp. 17–20. [18] N. Mohammadiha, P . Smaragdis, and A. Leijon, “Supervised and unsu- pervised speech enhancement using nonnegati ve matrix factorization, ” IEEE T rans. Audio, Speech, Language Process. , vol. 21, no. 10, pp. 2140–2151, 2013. [19] J. Chung, K. Kastner , L. Dinh, K. Goel, A. C. Courville, and Y . Bengio, “ A recurrent latent variable model for sequential data, ” in Pr oc. Adv . Neural Information Pr ocess. Syst. (NIPS) , 2015, pp. 2980–2988. [20] R. M. Neal and G. E. Hinton, “ A view of the EM algorithm that justi- fies incremental, sparse, and other variants, ” in Learning in Graphical Models , M. I. Jordan, Ed., pp. 355–368. MIT Press, 1999. [21] F . D. Neeser and J. L. Massey , “Proper complex random processes with applications to information theory , ” IEEE T rans. Information Theory , vol. 39, no. 4, pp. 1293–1302, 1993. [22] M. I. Jordan, Z. Ghahramani, T . S. Jaakkola, and L. K. Saul, “ An introduction to variational methods for graphical models, ” Machine Learning , vol. 37, no. 2, pp. 183–233, 1999. [23] A. Honkela, T . Raiko, M. Kuusela, M. T ornio, and J. Karhunen, “ Ap- proximate Riemannian conjugate gradient learning for fixed-form vari- ational Bayes, ” Journal of Machine Learning Resear ch , vol. 11, no. Nov ., pp. 3235–3268, 2010. [24] T . Salimans and D. A. Knowles, “Fixed-form v ariational posterior ap- proximation through stochastic linear regression, ” Bayesian Analysis , vol. 8, no. 4, pp. 837–882, 2013. [25] M. D. Hoffman, D. M. Blei, C. W ang, and J. Paisley , “Stochastic variational inference, ” Journal of Machine Learning Researc h , vol. 14, no. 1, pp. 1303–1347, 2013. [26] D. M. Blei, A. Kucukelbir , and J. D. McAulif fe, “V ariational infer - ence: A revie w for statisticians, ” Journal of the American Statistical Association , vol. 112, no. 518, pp. 859–877, 2017. [27] C. M. Bishop, P attern Recognition and Machine Learning , Springer, 2006. [28] P .-A. Mattei and J. Frellsen, “Refit your encoder when new data comes by , ” in 3rd NeurIPS workshop on Bayesian Deep Learning , 2018. [29] H. Kameoka, L. Li, S. Inoue, and S. Makino, “Supervised determined source separation with multichannel variational autoencoder, ” Neural Computation , vol. 31, no. 9, pp. 1–24, 2019. [30] D. R. Hunter and K. Lange, “ A tutorial on MM algorithms, ” The American Statistician , vol. 58, no. 1, pp. 30–37, 2004. [31] C. Févotte and J. Idier, “ Algorithms for nonnegati ve matrix factoriza- tion with the β -divergence, ” Neural Computation , vol. 23, no. 9, pp. 2421–2456, 2011. [32] J. S. Garofalo, D. Graff, D. Paul, and D. Pallett, “CSR- I (WSJ0) Sennheiser LDC93S6B, ” https://catalog.ldc. upenn.edu/LDC93S6B , 1993, Philadelphia: Linguistic Data Con- sortium. [33] D. B. Dean, A. Kanag asundaram, H. Ghaemmaghami, M. H. Rahman, and S. Sridharan, “The QUT -NOISE-SRE protocol for the ev aluation of noisy speaker recognition, ” in Proc. Interspeech , 2015, pp. 3456– 3460. [34] “ Algorithms to measure audio programme loudness and true-peak au- dio level, ” Recommendation BS.1770-4, International T elecommuni- cation Union (ITU), Oct. 2015. [35] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimiza- tion, ” in Pr oc. Int. Conf. Learning Repr esentations (ICLR) , 2015. [36] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR – Half- baked or W ell Done?, ” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Pr ocess. (ICASSP) , 2019, pp. 626–630. [37] A. W . Rix, J. G. Beerends, M. P . Hollier, and A. P . Hekstra, “Perceptual ev aluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, ” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Pr ocess. (ICASSP) , 2001, pp. 749–752. [38] C. H. T aal, R. C. Hendriks, R. Heusdens, and J. Jensen, “ An algorithm for intelligibility prediction of time–frequency weighted noisy speech, ” IEEE Tr ans. Audio, Speech, Language Process. , vol. 19, no. 7, pp. 2125–2136, 2011. [39] “Companion website, ” https://sleglaive.github.io/ demo- icassp2020.html . [40] S. Hochreiter and J. Schmidhuber , “Long short-term memory , ” Neural Computation , vol. 9, no. 8, pp. 1735–1780, 1997. A. APPENDIX A.1. V ariational free energy deri vation details In this section we gi ve deri vation details for obtaining the e xpression of the v ariational free energy in (15). W e will develop the two terms in volved in the definition of the v ariational free energy in (6). Data-fidelity term From the generati ve model defined in (1) we hav e: E q ( z ∣ s ; θ enc ) [ ln p ( s z ; θ dec )] = N − 1 n = 0 E q ( z ∣ s ; θ enc ) [ ln p ( s n z ; θ dec )] = − F − 1 f = 0 N − 1 n = 0 E q ( z ∣ s ; θ enc ) ln v s ,f n ( z ) + s f n 2 v s ,f n ( z ) − F N ln ( π ) (21) Regularization term From the inference model defined in (9) and (8) we hav e: D KL q ( z s ; θ enc ) ∥ p ( z ) = E q ( z ∣ s ; θ enc ) [ ln q ( z s ; θ enc ) − ln p ( z )] = N − 1 n = 0 E q ( z ∣ s ; θ enc ) [ ln q ( z n z 0 ∶ n − 1 , s ; θ enc ) − ln p ( z n )] = N − 1 n = 0 E q ( z 0 ∶ n ∣ s ; θ enc ) [ ln q ( z n z 0 ∶ n − 1 , s ; θ enc ) − ln p ( z n )] = N − 1 n = 0 E q ( z 0 ∶ n − 1 ∣ s ; θ enc ) E q ( z n ∣ z 0 ∶ n − 1 , s ; θ enc ) ln q ( z n z 0 ∶ n − 1 , s ; θ enc ) − ln p ( z n ) = N − 1 n = 0 E q ( z 0 ∶ n − 1 ∣ s ; θ enc ) D KL q ( z n z 0 ∶ n − 1 , s ; θ enc ) ∥ p ( z n ) = − 1 2 L − 1 l = 0 N − 1 n = 0 E q ( z 0 ∶ n − 1 ∣ s ; θ enc ) ln v z ,ln ( z 0 ∶ n − 1 , s ) − µ 2 z ,ln ( z 0 ∶ n − 1 , s ) − v z ,ln ( z 0 ∶ n − 1 , s ) − N L 2 . (22) Summing up (21) and (22) and recognizing the IS di vergence we end up with the expression of the v ariational free energy in (15). A.2. Update rules for the M-step The multiplicative update rules for minimizing (19) using a majorize- minimize technique [30, 31] are given by (see [9] for deriv ation details): H b ← H b ⊙ W ⊺ b X ⊙ 2 ⊙ R ∑ r = 1 V ( r ) x ⊙− 2 W ⊺ b R ∑ r = 1 V ( r ) x ⊙− 1 ⊙ 1 / 2 ; (23) W b ← W b ⊙ X ⊙ 2 ⊙ R ∑ r = 1 V ( r ) x ⊙− 2 H ⊺ b R ∑ r = 1 V ( r ) x ⊙− 1 H ⊺ b ⊙ 1 / 2 ; (24) g ⊺ ← g ⊺ ⊙ 1 ⊺ X ⊙ 2 ⊙ R ∑ r = 1 V ( r ) s ⊙ V ( r ) x ⊙− 2 1 ⊺ R ∑ r = 1 V ( r ) s ⊙ V ( r ) x ⊙− 1 ⊙ 1 / 2 , (25) where ⊙ denotes element-wise multiplication and e xponentiation, matrix division is also element-wise, V ( r ) s , V ( r ) x ∈ R F × N + are the matrices of entries v s ,f n z ( r ) and v x ,f n z ( r ) respectiv ely , X ∈ C F × N is the matrix of entries x f n and 1 is an all-ones column vec- tor of dimension F . Note that non-negati vity of H b , W b and g is ensured provided that the y are initialized with non-negativ e values. A.3. Neural network ar chitectures and training The decoder and encoder network architectures are represented in Fig. 2 and Fig. 3 respectiv ely . The "dense" (i.e. feed-forward fully- connected) output layers are of dimension L = 16 and F = 513 for the encoder and decoder , respectively . The dimension of all other layers was arbitrarily fixed to 128. RNN layers correspond to long short-term memory (LSTM) ones [40]. For the FFNN generative model, a batch is made of 128 time frames of clean speech power spectrogram. For the (B)RNN generativ e model, a batch is made 32 sequences of 50 time frames. Given an input sequence, all LSTM hidden states for the encoder and decoder networks are initialized to zero. For training, we use the Adam optimizer [35] with a step size of 10 − 3 , exponential decay rates of 0 . 9 and 0 . 999 for the first and second moment estimates, respectively , and an epsilon of 10 − 8 for prev enting division by zero. Dense (linear) Dense (tanh) (a) FFNN Dense (linear) RNN (b) RNN RNN RNN Dense (linear) Recurrent connection Feed-f or ward connection (c) BRNN Fig. 2 : Decoder network architectures corresponding to the speech generativ e models in Fig. 1. RNN RNN RNN Dense (linear) Dense (linear) Sampling Dense (tanh) (a) BRNN RNN RNN Dense (linear) Dense (linear) Dense (tanh) Prediction Observation Update Recurrent connection Feed-f or ward connection Element-wise squared modulus Sampling (b) RNN Dense (linear) Dense (linear) Dense (tanh) Sampling (c) FFNN Fig. 3 : Encoder network architectures associated with the decoder network architectures of Fig. 2.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment