A Machine-Learning Approach for Earthquake Magnitude Estimation
In this study we develop a single-station deep-learning approach for fast and reliable estimation of earthquake magnitude directly from raw waveforms. We design a regressor composed of convolutional and recurrent neural networks that is not sensitive…
Authors: S.Mostafa Mousavi, Gregory C. Beroza
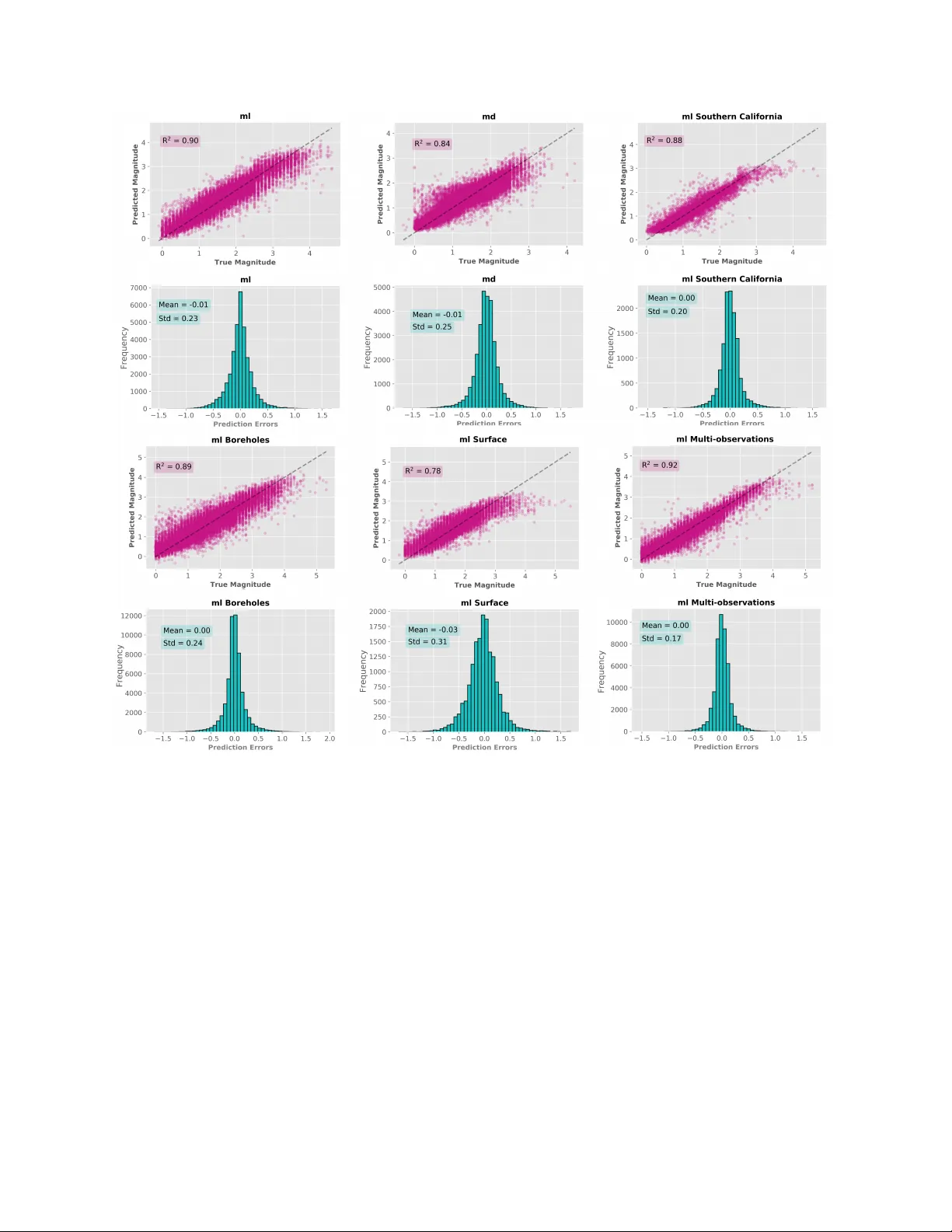
A Machine-Learning Appr oach f or Ear thquake Magnitude Estimation S. Mostafa Mousa vi 1 * † & Gregory C. Beroza 1 Geophysics Department, Stanford Univ ersity, Stanford, California, USA In this study we dev elop a single-station deep-lear ning appr oach for fast and r eliable estima- tion of earthquake magnitude dir ectly fr om raw wavef orms. W e design a regressor composed of con volutional and recurr ent neural networks that is not sensitive to the data normalization, hence wa vef orm amplitude information can be utilized during the training . Our netw ork can predict earthquake magnitudes with an a verage error close to zero and standard deviation of ~ 0.2 based on single-station wavef orms without instrument response correction. W e test the network f or both local and duration magnitude scales and show a station-based learn- ing can be an effective approach f or improving the performance. The proposed approach has a variety of potential applications from routine earthquak e monitoring to early warning systems. Plain Language Summary The size of an earthquake at its source is measured from the amplitude (or sometimes the duration) of the ground motion r ecorded on seismic instruments, and is expressed in terms of magnitude. Magnitude is a logarithmic measure and usually is measured based on data recorded by multiple stations after applying some pr e-proccessing and corrections to the raw * Corresponding author . † E-mail: mmousavi@stanford.edu 1 signals. Here, we introduce the first successful deep-learning approach to estimate directly the magnitude from raw seismic signals r ecorded on a single station. 1 K ey Points: A deep-learning approach is presented for earthquake magnitude estimation. Network consists of both con volutional and recurrent neural networks. It can estimate both M L and M d directly from ra w seismograms recorded on a single station. 2 Introduction Earthquake magnitude is one of the fundamental parameters for earthquake characterization. It is a logarithmic measure that represents the strength of the earthquake source. Magnitude provides the public with quick information on earthquakes and is used in scientific research as well. Since Charles F . Richter introduced the earthquake magnitude scale, the so-called local ( M L ) or Richter scale, in 1935 ( 1 ), there hav e been many studies proposing various types of magnitude scales. These magnitude scales measure different properties of the seismic wav es (e.g., low-frequenc y energy vs. high-frequency energy , surface wa ves vs. body wa ves) and although they may represent fundamentally different characteristics of the source, they are suitable for dif ferent earthquake sizes and different epicentral distance ranges. Most magnitude scales are empirical. Usually a magnitude M is determined from the amplitude A and the period T of a certain type of seismic 2 wa ve through a formula that contains sev eral constants. These constants are determined in such a way that the magnitudes for a new scale agree with those of an existing one at least ov er a certain magnitude range. In some cases, the duration of shaking seismogram is used to determine magnitude 2 . Hence, the various magnitude-types may have values that differ by more than a magnitude-unit for very lar ge and very small earthquakes as well as for some specific classes of seismic source. This is because the physical process underlying an earthquake is complex 3 . A typical magnitude estimation procedure includes: 1) con verting the raw seismograms into displacement after correcting them for the instrument response. 2) estimating magnitudes at each station after correcting for propagation effect, for the station-epicenter distance. 3) a veraging the single-station estimates to compensate for possible site effects. In earthquake and tsunami early warning systems (e.g. 4 ), howe ver , where time is of the essence to broadcast a warning, rapid and reliable estimation of a preliminary magnitude with what data is immediatly av ailable has specific importance 3 . In this study , we present a fast and reliable method for end-to-end estimation of earthquake magnitude from raw seismograms observed at single stations. Although there hav e been attempts to estimate earthquake magnitude using deep neural networks (e.g. 5 ), to the best of our kno wledge, this is the first successful study to do so. 3 Method Neural networks hav e been sho wn to be a po werful tool for earthquake signal processing and characterization (e.g. 6–10 ). Among different types of neural networks, con volutional networks 3 recently gained popularity for seismological applications because of their ability for automatic feature extraction and scaling to long input vectors, which are usually the case for earthquake sig- nals; ho wev er , their sensiti vity to un-normalized input data, makes their application for magnitude estimation challenging because amplitude information plays a key role (at least for scales like local magnitude). T o ov ercome this problem, we designed a network that mainly consisted of con volu- tional and recurrent layers where the con volutional layers do not hav e an y activ ation function b ut are used only for dimensionality reduction and feature extraction (Figure 1). The learning is mainly done in the Long-Short T erm-Memory (LSTM) units and their follo w- ing fully connected layers. Long-Short T erm-Memory (LSTM) ( 11 ) are specific types of recurrent neural networks capable of retaining the temporal dependencies among the input elements during the training process. Hence, they are commonly used for modeling of sequential data similar to earthquake signals. A detailed description of LSTMs and their applications to earthquake data can be found in 12 . The adv antage of using LSTM units for magnitude estimation lies in their insensiti vity to un-normalized inputs due to their gated mechanism. The input to the network are three-channel seismograms each 30 second (3000 smaples) long. Our network (Figure 1) consists of two con volutional layers (with 64 and 32 kernels of size 3 respecti vely) at its fore front, each followed by a dropout ( 13 ) and maxpooling ( 14 ) layer . Dropout layers are used for regularization. Each maxpooling layer reduces the dimension of the input data by a factor of 4 to facilitate the training speed at the bidirectional LSTM layer (with 100 units). At the end, the output of the LSTM layer is passed to a fully connected layer with one neuron and a 4 linear acti va tion to estimate the magnitude. Here, we trained the model with dropout rate of 0.2 by minimizing the mean square error . 4 Results W e use a selected portion of ST anford EArthquak e Dataset (STEAD) 15 for training of the network. STEAD is a global dataset of labeled seismograms including local earthquake and seismic noise wa veforms. Here, we only used ~ 300,000 earthquake wa veforms recorded at epicentral distances of less than 1 degree, for which their full wa veforms (from 1 second before P until the end of the S coda) are equal or less than 30 seconds. The magnitude distribution of the e vents is shown in Figure 2. All wa veforms were band-passed filtered between 1.0-40.0 Hz and have signal-to- noise ration of greater than 20 db. T o in vestigate the potential ef fects of v arious factors such as magnitude type, site effects, regional ef fects (using data in a specific geographical location), and site-dependent learning (using a limited number of stations) we divide the data into smaller subsets, each from 60K to 140K, and used 70% of each subset for the training and 10% and 20% for the validation and testing respecti vely . W e train the network using Adam optimizer ( 16 ) and automatically stop the training when validation loss doesn’t decrease for 5 consecuti ve epochs to av oid ov erfitting. Results are presented in Figure 3. Overall the network is able to predict earthquake magni- tudes with a mean error close to zero and standard deviation of ~ 0.2. The regression performance is worst at upper and lower bounds where fewer training/test samples are a vailable for lar ger and 5 smaller magnitudes size respecti vely . The network can predict both local and duration magnitudes with a reasonable accuracy which indicates its ability to learn both attenuation (interpreting the amplitudes with regards to the e vent-station distance) and duration, directly from the input wa ve- form from a single station. W e note that these estimates for local magnitude are based on global data recorded and reported by 98 monitoring networks around the world where dif ferent attenua- tion or calibration corrections might have been applied. T o see if regional based models perform better , we build a model using only ev ents in southern California. Although the coefficient of de- termination decreases slightly , due to relati vely smaller size of the training set, we see only a small improv ement in standard deviation of prediction error . In single-station estimates of the earthquake magnitudes, site amplification can play an im- portant role. T o check for a potential ef fect of this factor on our network’ s estimates, we b uild two separate models based on surface and borehole station data. Although performance deterio- rates in the case of the surface stations, it is hard to associate this to the site amplification alone because surface data hav e higher noise le vels which, as we will see later , has a direct impact on the magnitude estimates. W e test whether a station-based model performs better by building a model using only sta- tions (globally distrib uted) that ha ve more than 1000 observ ations each. The best result is obtained by this model, suggesting a stronger ef fect of sites than regions on the learning performance. The cataloged magnitudes used for training are basically averaged values ov er multiple sta- tions for each e vent. T o see how close our single-station estimates are to each other and the multi- 6 station av eraged estimations, we look at 311 e vents in our M L dataset where 4 or more observ ations (stations) are a vailable for each ev ent. V ariation of single-station observ ations for each e vent are very small and in most cases within the ground truth range (Figure 4). For each e vent, the predicted v alues for each station, av eraged prediction, and ground truth are provided in the supplementary materials. W e found that the signal-to-noise ratio has the grater impact on the performance of our re- gressor network (Figure 5). Building a deeper network can be an effecti ve solution to make the network less sensiti ve to the noise le vel; ho wev er , this requires more training data to prev ent over - fitting. 5 Conclusions W e showed that neural networks can learn general relations for estimating earthquake magnitudes directly from raw single-station wa veforms. These estimates can be based on different magnitude types pro vided enough training data are a vailable. Our results suggest site-specific learning can be an ef fectiv e strategy for improving the performance, while re gion-based training might not be that important. Although we obtained better results using borehole stations compared with the surface stations, it is hard to conclude that site amplification effects alone are responsible for these results because a strong ef fect of noise level is also observ able. The proposed method can provide a fast estimation of earthquake magnitude from raw seismograms observ ed at single stations. This has a v ariety of potential applications from routine earthquake monitoring to early warning systems. 7 1. Richter , C. F . An instrumental earthquake magnitude scale. Bulletin of the Seismological Society of America 25 , 1–32 (1935). 2. Kanamori, H. Magnitude scale and quantification of earthquak es. T ectonophysics 93 , 185–199 (1983). 3. Kanamori, H. Quantification of earthquakes. Natur e 271 , 411 (1978). 4. Minson, S. E. et al. Crowdsourced earthquake early warning. Science advances 1 , e1500036 (2015). 5. Lomax, A., Michelini, A. & Jozinovi ´ c, D. An in vestigation of rapid earthquake character- ization using single-station wa veforms and a con volutional neural network. Seismological Resear ch Letters 90 , 517–529 (2019). 6. Chen, Y ., Zhang, M., Bai, M. & Chen, W . Improving the Signal-to-Noise Ratio of Seismolog- ical Datasets by Unsupervised Machine Learning. Seismological Resear ch Letters (2019). 7. Zhu, W ., Mousavi, S. M. & Beroza, G. C. Seismic signal denoising and decomposition using deep neural networks. IEEE T ransactions on Geoscience and Remote Sensing (2019). 8. Mousavi, S. M., Zhu, W ., Ellsworth, W . & Beroza, G. Unsupervised Clustering of Seismic Signals Using Deep Con volutional Autoencoders. IEEE Geoscience and Remote Sensing Let- ters (2019). 8 9. Ross, Z. E., Meier , M.-A. & Hauksson, E. P wa ve arriv al picking and first-motion polarity determination with deep learning. J ournal of Geophysical Resear ch: Solid Earth 123 , 5120– 5129 (2018). 10. Mousavi, S. M., Horton, S. P ., Langston, C. A. & Samei, B. Seismic features and automatic discrimination of deep and shallo w induced-microearthquakes using neural network and lo- gistic regression. Geophysical J ournal International 207 , 29–46 (2016). 11. Hochreiter , S. & Schmidhuber , J. Long short-term memory. Neural computation 9 , 1735–1780 (1997). 12. Mousavi, S. M., Zhu, W ., Sheng, Y . & Beroza, G. C. CRED: A deep residual network of con volutional and recurrent units for earthquake signal detection. Scientific r eports 9 , 10267 (2019). 13. Sriv astav a, N., Hinton, G., Krizhevsky , A., Sutskev er , I. & Salakhutdinov , R. Dropout: a simple way to prev ent neural networks from ov erfitting. The journal of machine learning r esear ch 15 , 1929–1958 (2014). 14. Nagi, J. et al. Max-pooling con volutional neural networks for vision-based hand gesture recog- nition. In 2011 IEEE International Conference on Signal and Image Pr ocessing Applications (ICSIP A) , 342–347 (2011). 15. Mousavi, S. M., Sheng, Y ., Zhu, W ., Beroza, G. et al. ST anford EArthquake Dataset (STEAD): A Global Data Set of Seismic Signals for AI. IEEE Access (2019). URL 10.1109/A CCESS. 2019.2947848. 9 16. Bergen, K. J., Chen, T . & Li, Z. Preface to the focus section on machine learning in seismol- ogy . Seismological Resear ch Letters 90 , 477–480 (2019). Acknowledgements SMM was partially support by Stanford Center for Induced and T riggered Seismicity during this project. GCB was supported by AFRL under contract number F A9453-19-C-0073. Seismic wa ve- form data are av ailable from Incorporated Research Institutions for Seismology (IRIS) at http://ds .iris.edu/ds/. 10 Figure 1: Network architecture. 11 Figure 2: Magnitude distribution of e vents used for training and tests. 12 Figure 3: Prediction results on test sets for local magnitude (ml), duration magnitude (md), ev ents occured in the Southern California, borehole stations, surface stations, and in a case where only stations with more than 1000 observ ations are used. 13 Figure 4: a) circles are a veraged v alues o ver multiple station predictions where the error bar repre- sents the standard deviation for single-station predictions of the e vent’ s magnitude. b) distribution of standard de viations of single-station estimations. 14 Figure 5: Prediction errors as a function of signal-to-noise ratio. For local magnitude estimates. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment