Capacity Approaching Coding for Low Noise Interactive Quantum Communication, Part I: Large Alphabets
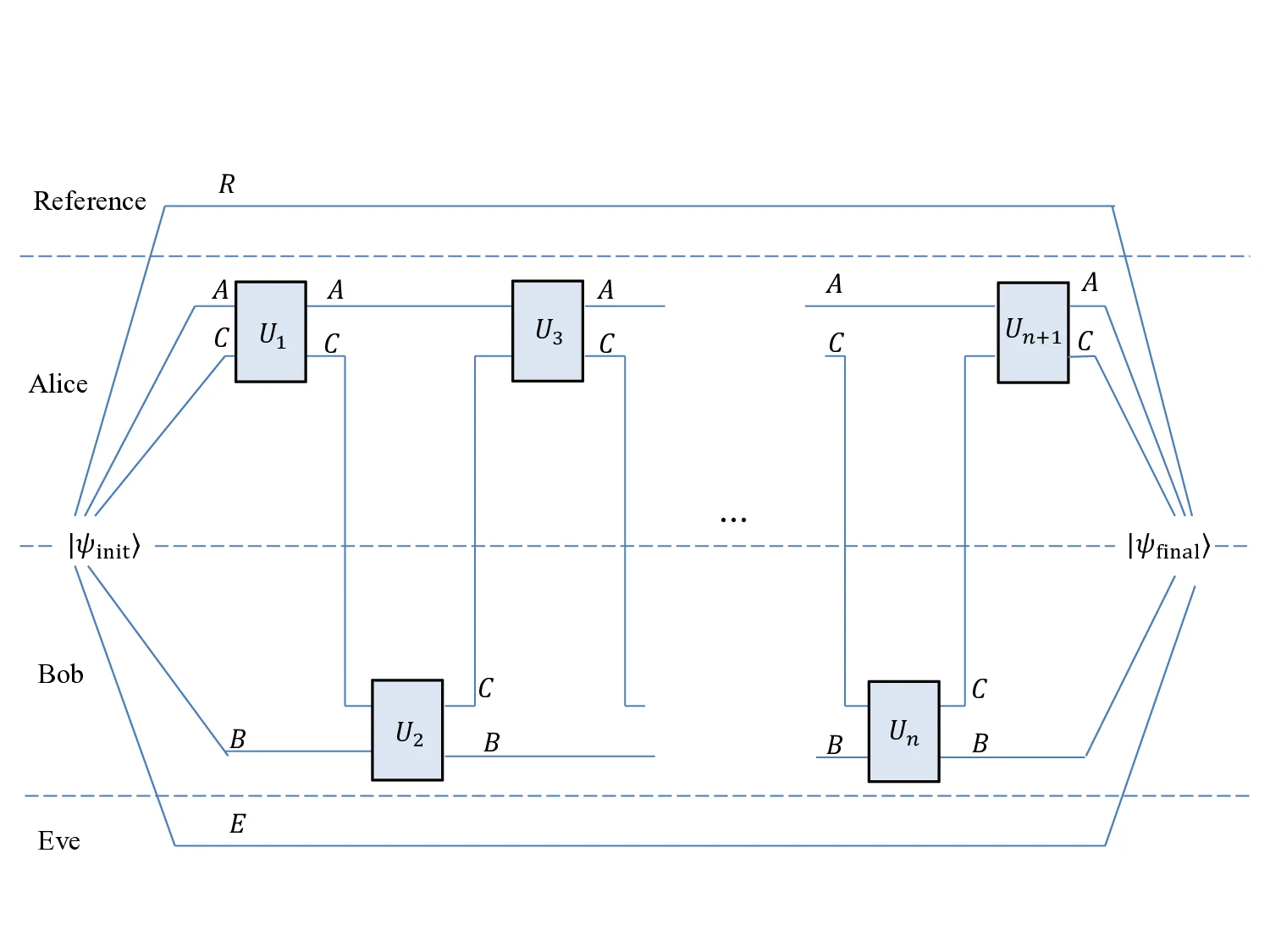
We consider the problem of implementing two-party interactive quantum communication over noisy channels, a necessary endeavor if we wish to fully reap quantum advantages for communication. For an arbitrary protocol with $n$ messages, designed for a noiseless qudit channel over a $\mathrm{poly}(n)$ size alphabet, our main result is a simulation method that fails with probability less than $2^{-\Theta(n\epsilon)}$ and uses a qudit channel over the same alphabet $n\left(1+\Theta \left(\sqrt{\epsilon}\right)\right)$ times, of which an $\epsilon$ fraction can be corrupted adversarially. The simulation is thus capacity achieving to leading order, and we conjecture that it is optimal up to a constant factor in the $\sqrt{\epsilon}$ term. Furthermore, the simulation is in a model that does not require pre-shared resources such as randomness or entanglement between the communicating parties. Our work improves over the best previously known quantum result where the overhead is a non-explicit large constant [Brassard et al., FOCS'14] for low $\epsilon$.
💡 Research Summary
The paper addresses the fundamental problem of executing arbitrary two‑party interactive quantum communication protocols over noisy channels while preserving the quantum advantage. For any protocol consisting of n messages that originally assumes a noiseless qudit channel with a polynomial‑size alphabet, the authors present a simulation technique that succeeds with probability at least 1 – 2^{‑Θ(n ε)} and uses the same alphabet qudit channel only n · (1 + Θ(√ε)) times, where an adversary may corrupt an ε fraction of the channel uses. This overhead is asymptotically optimal to leading order, and the authors conjecture that the Θ(√ε) term cannot be improved by more than a constant factor.
The work is divided into two main constructions. The first (Section 3) builds a teleportation‑based protocol that runs over a large‑alphabet classical channel. The original quantum protocol is decomposed into three components for each round: metadata (which tracks the current teleportation step and the number of maximally entangled states, MES, consumed), the count of MES used, and Pauli correction data. By encoding these components into the classical channel and using hash‑based verification, the parties can collectively detect and correct errors without needing to backtrack—a crucial advantage because backtracking is impossible in the quantum setting due to the no‑cloning theorem. A major technical obstacle is “out‑of‑sync teleportation,” where the parties’ views of the entanglement resource diverge because of errors. The authors resolve this by maintaining two representations of the quantum registers (pre‑ and post‑correction) and dynamically switching between them, while a pseudo‑random generator synchronizes the hash functions without any pre‑shared randomness.
The second construction (Section 4) handles scenarios where teleportation is not applicable. It combines the Quantum Vernam Cipher (QVC) with entanglement recycling. QVC works like a one‑time pad for quantum data, but the key is a shared entangled state that can be reused after appropriate correction. The protocol again faces out‑of‑sync issues, now in the context of the QVC key. The authors introduce quantum hashing and the same two‑representation technique to keep the joint state coherent. By recycling the MES after each round, the total number of channel uses stays within the same n · (1 + Θ(√ε)) bound.
Both constructions are analyzed under an adversarial error model where up to an ε fraction of the transmitted symbols may be arbitrarily corrupted. The analysis shows that the failure probability decays exponentially in n ε, and that the communication overhead scales as Θ(√ε) relative to the noiseless protocol. This improves dramatically over the previous best quantum result (Brassard et al., FOCS 2014), which achieved only a non‑explicit large constant overhead for low ε. Moreover, the protocols require no pre‑shared randomness or entanglement, making them suitable for practical deployment where such resources are costly or unavailable.
The authors also discuss the fundamental limits of interactive quantum coding. Standard error‑correcting codes cannot be applied directly because each message is dynamically generated and must be protected collectively; a single corrupted message could otherwise destroy the entire computation. The no‑cloning principle further prevents the usual “backtrack‑and‑replay” strategy used in classical interactive coding. By designing coding schemes that operate over many rounds simultaneously and by carefully managing entanglement resources, the paper demonstrates that interactive quantum communication can be made robust with a rate that approaches the channel capacity as the noise level goes to zero.
In conclusion, the paper provides the first explicit, near‑capacity‑achieving coding scheme for low‑noise interactive quantum communication over large alphabets, with provable exponential reliability, polynomial‑time encoding/decoding, and without any pre‑shared resources. It opens the door to robust quantum distributed algorithms, quantum communication‑complexity results, and practical quantum network protocols that retain their quantum advantage even in the presence of realistic noise.
Comments & Academic Discussion
Loading comments...
Leave a Comment