An Introduction to Probabilistic Spiking Neural Networks: Probabilistic Models, Learning Rules, and Applications
Spiking neural networks (SNNs) are distributed trainable systems whose computing elements, or neurons, are characterized by internal analog dynamics and by digital and sparse synaptic communications. The sparsity of the synaptic spiking inputs and th…
Authors: Hyeryung Jang, Osvaldo Simeone, Brian Gardner
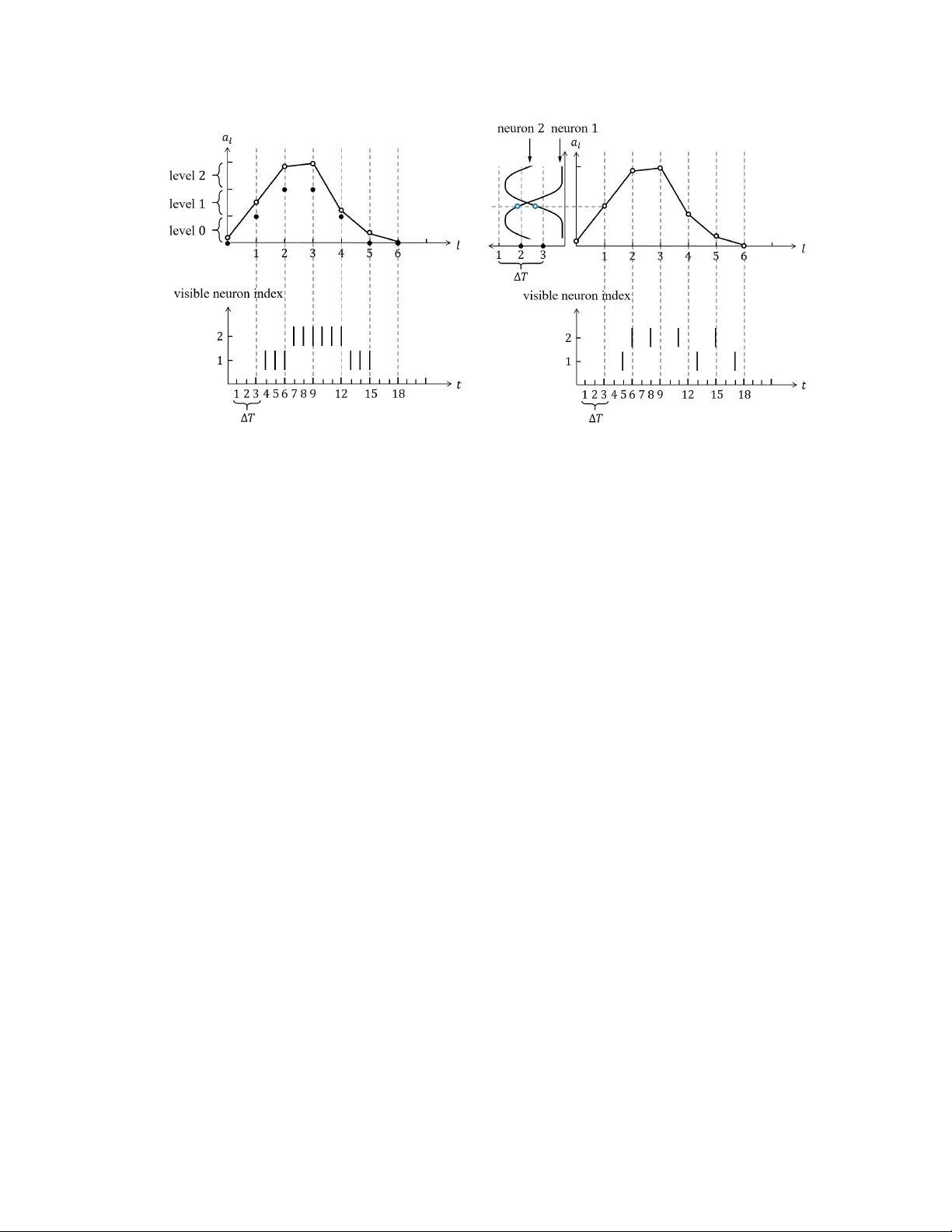
1 An Introduction to Probabilistic Spiking Neural Networks Hyeryung Jang, Osv aldo Simeone, Brian Gardner , and Andr ´ e Gr ¨ uning Abstract Spiking neural networks (SNNs) are distributed trainable systems whose computing elements, or neurons, are characterized by internal analog dynamics and by digital and sparse synaptic communica- tions. The sparsity of the synaptic spiking inputs and the corresponding e vent-dri ven nature of neural processing can be lev eraged by energy-ef ficient hardware implementations, which can of fer significant energy reductions as compared to con ventional artificial neural networks (ANNs). The design of training algorithms lags behind the hardware implementations. Most existing training algorithms for SNNs ha ve been designed either for biological plausibility or through con version from pretrained ANNs via rate encoding. This article provides an introduction to SNNs by focusing on a probabilistic signal processing methodology that enables the direct deriv ation of learning rules by le veraging the unique time-encoding capabilities of SNNs. W e adopt discrete-time probabilistic models for networked spiking neurons and deriv e supervised and unsupervised learning rules from first principles via variational inference. Examples and open research problems are also pro vided. I N T RO D U C T I O N ANNs have become the de facto standard tool to carry out supervised, unsupervised, and reinforcement learning tasks. Their recent successes range from image classifiers that outperform human experts in medical diagnosis to machines that defeat professional players at complex games such as Go. These breakthroughs ha ve built upon various algorithmic adv ances b ut have also heavily relied on the unprece- dented av ailability of computing power and memory in data centers and cloud computing platforms. The resulting considerable energy requirements run counter to the constraints imposed by implementations on lo w-po wer mobile or embedded devices for such applications as personal health monitoring or neural prosthetics [1]. ANNs versus SNNs. V arious new hardware solutions hav e recently emer ged that attempt to improve the energy efficienc y of ANNs as inference machines by trading complexity for accuracy in the imple- mentation of matrix operations. A dif ferent line of research, which is the subject of this article, seeks an alternati ve frame work that enables ef ficient online infer ence and learning by taking inspiration from the working of the human brain. 2 (a) (b) Fig. 1: Illustration of NNs: (a) an ANN, where each neuron i processes real numbers s 1 , . . . , s n to output and communicates a real number s i as a static nonlinearity and (b) an SNN, where dynamic spiking neurons process and communicate sparse spiking signals over time t in a causal manner to output and communicate a binary spiking signal s i,t . The human brain is capable of performing general and complex tasks via continuous adaptation at a minute fraction of the power required by state-of-the-art supercomputers and ANN-based models [2]. Neurons in the human brain are qualitati vely different from those in an ANN. They are dynamic devices featuring recurrent behavior , rather than static nonlinearities, and they process and communicate using sparse spiking signals over time, rather than real numbers. Inspired by this observation, as illustrated in Fig. 1, SNNs have been introduced in the theoretical neuroscience literature as networks of dynamic spiking neurons [3]. SNNs hav e the unique capability to process information encoded in the timing of e vents, or spikes. Spikes are also used for synaptic communications, with synapses delaying and filtering signals before they reach the postsynaptic neuron. Because of the presence of synaptic delays, neurons in an SNN can be naturally connected via arbitrary recurrent topologies, unlike standard multilayer ANNs or chain-like recurrent neural networks. Proof-of-concept and commercial hardware implementations of SNNs have demonstrated orders-of- magnitude improvements in terms of energy efficienc y ov er ANNs [4]. Gi ven the extremely low idle energy consumption, the energy spent by SNNs for learning and inference is essentially proportional to the number of spikes processed and communicated by the neurons, with the energy per spike being as lo w as a fe w picojoules [5]. Deterministic versus probabilistic SNN models. The most common SNN model consists of a network of neurons with deterministic dynamics whereby a spike is emitted as soon as an internal state variable, kno wn as the membrane potential , crosses a given threshold value. A typical example is the leaky integrate-and-fire model, in which the membrane potential increases with each spike recorded in the incoming synapses, while decreasing in the absence of inputs. When information is encoded in the rate of spiking of the neurons, an SNN can approximate the behavior of a con ventional ANN with the same 3 topology . This has motiv ated a popular line of work that aims at con verting a pretrained ANN into a potentially more efficient SNN implementation (see [6] and the “Models” section for further details). T o make full use of the temporal processing capabilities of SNNs, learning problems should be formulated as the minimization of a loss function that directly accounts for the timing of the spikes emitted by the neurons. As for ANNs, this minimization can, in principle, be done using stochastic gradient descent (SGD). Unlike ANNs, howe ver , this con ventional approach is made challenging by the nondif ferentiability of the output of the SNN with respect to the synaptic weights due to the threshold crossing-triggered behavior of spiking neurons. The potentially complex recurrent topology of SNNs also mak es it difficult to implement the standard backpropagation procedure used in multilayer ANNs to compute gradients. T o obviate this problem, a number of existing learning rules approximate the deri v ati ve by smoothing out the membrane potential as a function of the weights [7]–[9]. In contrast to deterministic models for SNNs, a probabilistic model defines the outputs of all spiking neurons as jointly distributed binary random processes. The joint distribution is differentiable in the synaptic weights, and, as a result, so are principled learning criteria from statistics and information theory , such as likelihood function and mutual information. The maximization of such criteria can apply to arbitrary topologies and does not require the implementation of backpropagation mechanisms. Hence, a stochastic viewpoint has significant analytic advantages, which translate into the deriv ation of flexible learning rules from first principles. These rules recov er as special cases many known algorithms proposed for SNNs in the theoretical neuroscience literature as biologically plausible algorithms [10]. Scope and overview . This article aims to provide a revie w on the topic of probabilistic SNNs with a specific focus on the most commonly used generalized linear models (GLMs). W e cover models, learning rules, and applications, highlighting principles and tools. The main goal is to make key ideas in this emerging field accessible to researchers in signal processing, who may otherwise find it difficult to navig ate the theoretical neuroscience literature on the subject, giv en its focus on biological plausibility rather than theoretical and algorithmic principles [10]. At the end of the article, we also revie w alternati ve probabilistic formulations of SNNs, extensions, and open problems. L E A R N I N G T A S K S An SNN is a network of spiking neurons. As seen in Fig. 2, the input and output interfaces of an SNN typically transfer spiking signals. Input spiking signals can either be recorded directly from neuromorphic sensors, such as silicon cochleas and retinas [Fig. 2(a)], or be con verted from a natural signal to a set of spiking signals [Fig. 2(b)]. Conv ersion can be done by following different rules, including r ate encoding , whereby amplitudes are con verted into the (instantaneous) spiking rate of a neuron; time encoding , 4 (a) (b) Fig. 2: Depictions of the input/output interfaces of an SNN: (a) a direct interface with a neuromorphic sensor and actuator and (b) an indirect interface through encoding and decoding. whereby amplitudes are translated into spike timings; and population encoding , whereby amplitudes are encoded into the (instantaneous) firing rates [11] or relati ve firing times of a subset of neurons (see [10] for a revie w). In a similar manner, output spiking signals can either be fed directly to a neuromorphic actuator , such as neuromorphic controllers or prosthetic systems [Fig. 2(a)], or be con verted from spiking signals to natural signals [Fig. 2(b)]. This can be done by following rate, time, or population decoding principles. The SNN generally acts as a dynamic mapping between inputs and outputs that is defined by the model parameters, including, most notably , the interneuron synaptic weights. This mapping can be designed or trained to carry out infer ence or contr ol tasks. When training is enabled, the model parameters are automatically adapted based on data fed to the network, with the goal of maximizing a giv en performance criterion. T raining can be carried out in a supervised, unsupervised, or reinforcement learning manner , depending on the av ailability of data and feedback signals, as further discussed subsequently . For both inference/control and training, data can be presented to the SNN in a batch mode (also known as frame- based mode) or in an online mode (see the “Training SNNs” section). W ith supervised learning , the training data specify both input and desired output. Input and output pairs are either in the form of a number of separate examples, in the case of batch learning, or presented ov er time in a streaming fashion for online learning. As an example, the training set may include a number of spike-encoded images and corresponding correct labels, or a single time sequence to be used to e xtrapolate predictions (see also the “Batch Learning Examples” and “Online Learning Examples” sections). Under unsupervised learning , the training data only specify only the desired input or output to the SNN, which can again be presented in a batch or online fashion. Examples of applications include representation learning, which aims to translate the input into a more compact, interpretable, or useful representation, and generati ve modeling, which seeks to generate outputs with statistics akin to the training data (see, e.g., [12]). Finally , with r einforcement learning , the SNN is used to control an agent on the basis of input observations from the environment to accomplish a gi ven goal. T o this end, the SNN is 5 (a) (b) Fig. 3: (a) An architecture of an SNN with N = 4 spiking neurons. The directed links between tw o neurons represent causal feedforward, or synaptic, dependencies, while the self-loop links represent feedback dependencies. The directed graph may ha ve loops, including self-loops, indicating recurrent behavior . (b) A time-expanded view of the temporal dependencies implied by (a) with synaptic and feedback memories equal to one time step. provided with feedback on the selected outputs that guides the SNN in updating its parameters in a batch or online manner [13]. M O D E L S Here, we describe the standard discrete-time GLM for SNNs, also known as the spike r esponse model with escape noise (see, e.g., [14] and [15]). Discrete-time models reflect the operation of a number of neuromorphic chips, including Intel’ s Loihi [4], while continuous-time models are more commonly encountered in the computer neuroscience literature [10]. Graphical repr esentation. As illustrated in Fig. 3, an SNN consists of a network of N spiking neurons. At any time t = 0 , 1 , 2 , . . . , each neuron i outputs a binary signal s i,t ∈ { 0 , 1 } , with value s i,t = 1 corresponding to a spike emitted at time t . W e collect in vector s t = ( s i,t : i ∈ V ) the binary signals emitted by all neurons at time t , where V is the set of all neurons. Each neuron i ∈ V recei ves the signals emitted by a subset P i of neurons through directed links, known as synapses . Neurons in set P i are referred to as presynaptic for postsynaptic neuron i . Membrane potential and filtered traces. The internal, analog state of each spiking neuron i ∈ V at time t is defined by its membrane potential u i,t (and possibly by other secondary variables to be discussed) [15]. The value of the membrane potential indicates the probability of neuron i to spike. As illustrated in Fig. 4, the membrane potential is the sum of contributions from the incoming spikes of the presynaptic neurons and from the past spiking behavior of the neuron itself, where both contributions are filtered by the respectiv e kernels a t and b t . T o elaborate, we denote as s i, ≤ t = ( s i, 0 , . . . , s i,t ) the spike signal emitted by neuron i up to time t . Giv en past input spike signals from the presynaptic neurons P i , 6 Fig. 4: An illustration of the membrane potential model, with exponential feedforward and feedback kernels (see also Fig. 5). denoted as s P i , ≤ t − 1 = { s j, ≤ t − 1 } j ∈P i , and the local spiking history s i, ≤ t − 1 , the membrane potential of postsynaptic neuron i at time t can be written as [15] u i,t = X j ∈P i w j,i − → s j,t − 1 + w i ← − s i,t − 1 + γ i , (1) where the quantities w j,i for j ∈ P i are synaptic (feedforward) weights, w i is a feedback weight, γ i is a bias parameter , and the quantities − → s i,t = a t ∗ s i,t and ← − s i,t = b t ∗ s i,t (2) are known as filter ed feedforward and feedback tr aces of neuron i , respectiv ely , where ∗ denotes the con volution operator f t ∗ g t = P δ ≥ 0 f δ g t − δ . K ernels and model weights. In (1)-(2), the filter a t defines the synaptic response to a spike from a presynaptic neuron at the postsynaptic neuron. This filter is known as the feedforwar d , or synaptic , kernel . The filtered contribution of a spike from the presynaptic neuron j ∈ P i is multiplied by a learnable weight w j,i for the synapse from neuron j to neuron i ∈ V . When the filter is of finite duration τ , computing the feedforward trace − → s i,t requires keeping track of the window { s i,t , s i,t − 1 , . . . , s i,t − ( τ − 1) } of prior synaptic inputs as part of the neuron’ s state [16]. An example is giv en by the function a t = exp( − t/τ 1 ) − exp( − t/τ 2 ) for t = 0 , ..., τ − 1 and zero otherwise, with time constants τ 1 and τ 2 and duration τ , as illustrated in Fig. 5(a). When the kernel is chosen as an infinitely long decaying exponential, i.e., as a t = exp( − t/τ 1 ) , the feedforward trace − → s i,t can be directly computed using an autoregressi ve update that requires the storage of only a single scalar variable in the neuron’ s state [16], i.e., − → s i,t = exp( − 1 /τ 1 )( − → s i,t − 1 + s i,t ) . In general, the time constants and kernel shapes determine the synaptic memory and synaptic delays. 7 (a) (b) (c) (d) Fig. 5: Examples of feedforward/feedback kernels: (a) an exponentially decaying feedforward kernel a t , (b) an exponentially decaying feedback kernel b t , (c) raised cosine basis functions a k,t in [14], and (d) spike-timing-dependent plasticity basis functions a k,t for long-term potentiation (L TP) and long-term depression (L TD), where the synaptic conduction delay equals d [16]. The filter b t describes the response of a neuron to a local output spike and is kno wn as a feedback kernel . A negati ve feedback kernel, such as b t = − exp( − t/τ m ) , with time constant τ m (see Fig. 5(b)), models the refractory period upon the emission of a spik e, with the time constant of the feedback kernel determining the duration of the refractory period. As per (1), the filtered contribution of a local output spike is weighted by a learnable parameter w i . Similar considerations as for the feedforward traces apply regarding the computation of the feedback trace. Generalizing the model described previously , a synapse can be associated with K a learnable synaptic weights { w j,i,k } K a k =1 . In this case, the contribution from presynaptic neuron j in (1) can be written as [14] K a X k =1 w j,i.k a k,t ∗ s j,t , (3) where we have defined K a fixed basis functions { a k,t } K a k =1 , with learnable weights { w j,i,k } K a k =1 . The feedback kernel can be similarly parameterized as the weighted sum of fixed K b basis functions. Pa- rameterization (3) makes it possible to adapt the shape of the filter applied by the synapse by learning the weights { w j,i,k } K a k =1 . T ypical examples of basis functions are the raised cosine functions shown in Fig. 5(c). W ith this choice, the system can learn the sensiti vity of each synapse to dif ferent synaptic delays, each corresponding to a dif ferent basis function, by adapting the weights { w j,i,k } K a k =1 . In the rest of this article, with the exception of the “Batch Learning Examples” and “Online Learning Examples” sections, we focus on the simpler model of (1)-(2). Practical implementations of the membrane potential model (1) can leverage the fact that linear filtering of binary spiking signals requires only carrying out sums while doing aw ay with the need to compute expensi ve floating-point multiplications [5]. GLM. As discussed, a probabilistic model defines the joint probability distribution of the spik e signals 8 emitted by all neurons. In general, with the notation s ≤ t = ( s 0 , . . . , s t ) using the chain rule, the log- probability of the spike signals s ≤ T = ( s 0 , . . . , s T ) emitted by all neurons in the SNN up to time T can be written as log p θ ( s ≤ T ) = T X t =0 log p θ ( s t | s ≤ t − 1 ) = T X t =0 X i ∈V log p θ i ( s i,t | s P i ∪{ i } , ≤ t − 1 ) , (4) where θ = { θ i } i ∈V is the learnable parameter vector , with θ i being the local parameters of neuron i . The decomposition (4) is in terms of the conditional probabilities p θ i ( s i,t | s P i ∪{ i } , ≤ t − 1 ) , which represent the spiking probability of neuron i at time t , gi ven its past spike timings and the past behaviors of its presynaptic neurons P i . Under the GLM, the dependency of the spiking behavior of neuron i ∈ V on the history s P i ∪{ i } , ≤ t − 1 is mediated by the neuron’ s membrane potential u i,t . Specifically , the instantaneous firing probability of neuron i at time t is equal to p θ i ( s i,t = 1 | s P i ∪{ i } , ≤ t − 1 ) = p ( s i,t = 1 | u i,t ) = σ ( u i,t ) , (5) with σ ( · ) being the sigmoid function, i.e., σ ( x ) = 1 / (1 + exp( − x )) . According to (5), a larger potential u i,t increases the probability that neuron i spik es. The model (5) is parameterized by the local learnable vector θ i = { γ i , { w j,i } j ∈P i , w i } of neuron i . SNNs modeled according to the described GLM framework can be thought of as a generalization of dynamic models of belief networks [17], and they can also be interpreted as a discrete-time version of Hawkes processes [18]. In a variant of this model, probability (5) can be written as σ ( u i,t / ∆ u ) , where ∆ u is a bandwidth parameter that dictates the smoothness of the firing rate about the threshold. When taking the limit ∆ u → 0 , we obtain the deterministic leaky integrate-and-fire model [19]. Relationship with ANNs. Under rate encoding, as long as the duration T is large enough, the deterministic inte grate-and-fire model can mimic the operation of a con ventional feedforward ANN with a nonnegati ve acti v ation function. T o this end, consider an ANN with an arbitrary topology defined by an acyclic directed graph. The corresponding SNN has the same topology , a feedforward kernel defined by a single basis function implementing a perfect integrator (i.e., a filter with a constant impulse response), the same synaptic weights of the ANN, and no feedback kernel. In this way , the value of the filtered feedforward trace for each synapse approximates the spiking rate of the presynaptic neuron as T increases. The challenge in enabling a con version from ANN to SNN is to choose the thresholds γ i and possibly a renormalization of the weights, so that the spiking rates of all neurons in the SNN approximate the outputs of the neurons in the ANN [6]. When including loops, deterministic SNNs can also implement 9 recurrent neural networks (RNNs) [20]. Gradient of the log-likelihood. The gradient of the log probability , or log-likelihood , L s ≤ T ( θ ) = log p θ ( s ≤ T ) in (4), with respect to the learnable parameters θ , plays a ke y role in the problem of training a probabilistic SNN. Focusing on any neuron i ∈ V , from (1) to (5), the gradient of the log-likelihood with respect to the local parameters θ i for neuron i is giv en as ∇ θ i L s ≤ T ( θ ) = T X t =0 ∇ θ i log p θ i ( s i,t | s P i ∪{ i } , ≤ t − 1 ) , (6) where the individual entries of the gradient of time t can be obtained as ∇ γ i log p θ i ( s i,t | s P i ∪{ i } , ≤ t − 1 ) = s i,t − σ ( u i,t ) , (7a) ∇ w j,i log p θ i ( s i,t | s P i ∪{ i } , ≤ t − 1 ) = − → s j,t − 1 s i,t − σ ( u i,t ) , (7b) and ∇ w i log p θ i ( s i,t | s P i ∪{ i } , ≤ t − 1 ) = ← − s i,t − 1 s i,t − σ ( u i,t ) . (7c) The gradients (7) depend on the difference between the desired spiking behavior and its average behavior under the model distribution (5). The implications of this result for learning will be discussed in the next sections. T R A I N I N G S N N S SNNs can be trained using supervised, unsupervised, and reinforcement learning. T o this end, the network follo ws a learning rule , which defines how the model parameters θ are updated on the basis of the av ailable observ ations. As we will detail, learning rules can be applied in a batch mode at the end of a full period T of use of the SNN, based on multiple observations of duration T , or in an online fashion, i.e., after each time instant t , based on an arbitrarily long observation. Locality . A learning rule is local if its operation can be decomposed into atomic steps that can be carried out in parallel at distributed processors based only on locally av ailable information and limited communication on the connectivity graph (see Fig. 3). Local information at a neuron includes the membrane potential, the feedforward filtered traces for the incoming synapses, the local feedback filtered trace, and the local model parameters. The processors will be considered here to be con ventionally implemented at the lev el of individual neurons. Beside local signals, learning rules may also require global feedback signals, as discussed next. Three-factor rule. While the details differ for each learning rule and task, a general form of the learning rule for the synaptic weights follows the three-factor rule [21], [22]. Accordingly , the synaptic 10 weight w j,i from presynaptic neuron j ∈ P i to a postsynaptic neuron i ∈ V is updated as w j,i ← w j,i + η × ` × pre j × post i , (8) where η is a learning rate, ` is a scalar global learning signal that determines the sign and magnitude of the update, pre j is a function of the activity of the presynaptic neuron j ∈ P i , and post i depends on the acti vity of the postsynaptic neuron i ∈ V . For most learning rules, pre- and postsynaptic terms are local to each neuron, while the learning signal ` , if present, plays the role of a global feedback signal. As a special case, the rule (8) can implement Hebb’ s hypothesis that “neurons that spike together wire together”. This is indeed the case if the product of pre j and post i terms is large when the two neurons spike at nearly the same time, resulting in a large change of the synaptic weight w j,i [10]. In the next two sections, we will see ho w learning rules of the form (8) can be deri ved in a principled manner as SGD updates obtained under the described probabilistic SNN models. T R A I N I N G S N N S : F U L LY O B S E RV E D M O D E L S Fully observed vs partially observed models. Neurons in an SNN can be divided into the subset of visible , or observed , neurons, which encode inputs and outputs, and hidden , or latent , neurons, whose role is to facilitate the desired behavior of the SNN. During training, the behavior of visible neurons is specified by the training data. F or example, under supervised learning, input neurons are clamped to the input data, while the spiking signals of output neurons are determined by the desired output. Another related example is a reinforcement learning task in which the SNN models a policy , with input neurons encoding the state and output neurons encoding the action previously taken by the learner in response to the giv en input [23]. In the case of fully observed models , the SNN contains only visible neurons while, in the case of partially observed models , the SNN also includes hidden neurons. W e first consider the simpler former case and then extend the discussion to partially observed models. Maximum likelihood learning via SGD The standard training criterion for probabilistic models for both supervised and unsupervised learning is maximum likelihood (ML). ML selects model parameters that maximize the probability of the observed data and, hence, of the desired input/output beha vior under the model. T o elaborate, we consider an example x ≤ T consisting of fully observed spik e signals for all neurons in the SNN, including both input and output neurons. Using the notation in the “Models” section, we hence have s ≤ T = x ≤ T . During training, the spike signals for all neurons are thus clamped to the v alues assumed in the data point x ≤ T , 11 and the log-likelihood is giv en as L x ≤ T ( θ ) = log p θ ( x ≤ T ) in (4), with s ≤ T = x ≤ T . As we will see ne xt, for batch learning, there are multiple such examples x ≤ T in the training set while, for online learning, we have a single arbitrary long example x ≤ T for large T . Batch SGD. In the batch training mode, a training set D = { x m ≤ T } M m =1 of M fully observed e xamples is av ailable to enable the learning of the model parameters. The batch SGD-based rule proceeds iterativ ely by selecting an example x ≤ T from the training set D at each iteration (see, e.g., [24]). The model parameters θ are then updated in the direction of the gradient (6) and (7), with s ≤ T = x ≤ T , as θ ← θ + η ∇ θ L x ≤ T ( θ ) , (9) where the learning rate η is assumed to be fixed here for simplicity of notation. Note that the update (9) is applied at the end of the observat ion period T . The batch algorithm can be generalized by summing ov er a minibatch of examples at each iteration [24]. Online SGD. In the online training mode, an arbitrary long e xample x ≤ T is av ailable, and the model parameters θ are updated at each time t (or , more generally , periodically every fe w time instants). This can be done by introducing an eligibility trace e i,t for each neuron i [19], [22]. As summarized in Algorithm 1, the eligibility trace e i,t in (A1), with κ < 1 , computes a weighted av erage of current and past gradient updates. In this update, the current gradient ∇ θ log p θ ( x t | x ≤ t − 1 ) is weighted by a factor (1 − κ ) , and the gradient that is e valuated l steps in the past is multiplied by the exponentially decaying coef ficient (1 − κ ) · κ l . The eligibility trace captures the impact of past updates on the current spiking behavior , and it can help stabilize online training by reducing the variance of the updates (for sufficiently large κ ) [13]. Interpr etation. The online gradient update for any synaptic weight w j,i can be interpreted in light of the general form of rule (8). In fact, the gradient (7b) has a two-factor form, whereby the global learning signal is absent; the presynaptic term is given by the filtered feedforward trace − → x j,t − 1 of the presynaptic neuron j ∈ P i , and the postsynaptic term is giv en by the error term x i,t − σ ( u i,t ) . This error measures the difference between the desired spiking behavior of the postsynaptic neuron i at any time t and its av erage behavior under the model distribution (5). This update can be related to the standard spike-timing-dependent plasticity (STDP) rule [10], [16], [25]. In fact, STDP stipulates that the long-term potentiation (L TP) of a synapse occurs when the presynaptic neuron spikes right before a postsynaptic neuron, while long-term depression (L TD) of a synapse takes place when the presynaptic neuron spikes right after a postsynaptic neuron. W ith the basis functions depicted in Fig. 5(d), if a presynaptic spike occurs more than d steps prior to the postsynaptic spike at 12 Algorithm 1: ML T raining via online SGD Input: Training example x ≤ T and learning rates η and κ Output: Learned model parameters θ 1 initialize parameters θ 2 repeat 3 for each t = 0 , 1 , . . . , T 4 f or each neuron i ∈ V do 5 compute the gradient ∇ θ i log p θ i ( x i,t | x P i ∪{ i } , ≤ t − 1 ) with respect to the local parameters θ i from (7) 6 compute the eligibility trace e i,t e i,t = κ e i,t − 1 + (1 − κ ) ∇ θ i log p θ i ( x i,t | x P i ∪{ i } , ≤ t − 1 ) (A1) 7 update the local model parameters θ i ← θ i + η e i,t (A2) 8 end 9 until stopping criterion is satisfied time t , an increase in the synaptic weight, or L TP , occurs, while a decrease in the synaptic weight, or L TD, takes place otherwise [16]. The parameter d can hence be interpreted as synaptic delay . As for the synaptic weights, all other gradients (7) also depend on an error signal measuring the gap between the desired and average model behavior . In (7a)-(7c), the desired behavior is giv en by samples s i,t = x i,t in the training example. The contribution of this error signal can be interpreted as a form of (task-specific) homeostatic plasticity , in that it regulates the neuronal firing rates around desirable set-point values [10], [26]. Locality and implementation. Gi ven the absence of a global learning signal, the online SGD rule in Algorithm 1 and the batch SGD rule can be implemented locally , so that each neuron i updates its own local parameters θ i . Each neuron i uses information about the local spike signal x i,t , the feedforward filtered traces − → x j,t − 1 for all presynaptic neurons j ∈ P i , and the local feedback filtered trace ← − x i,t − 1 to compute the first terms in (7a)-(7c), while the second terms in (7a)-(7c) are obtained from (5) by using the neuron’ s membrane potential u i,t . T R A I N I N G S N N S : P A RT I A L L Y O B S E RV E D M O D E L S Latent neurons. As mentioned previously , the set V of neurons can be partitioned into the disjoint subsets of observed (input and output) and hidden neurons. The N X neurons in the subset X are observed, and the N H neurons in the subset H are hidden, or latent, and we have V = X ∪ H . W e write as x t = ( x i,t : i ∈ X ) and h t = ( h i,t : i ∈ H ) the binary signals emitted by the observed and hidden 13 neurons at time t , respectively . Therefore, using the notation in the “Models” section, we ha ve s i,t = x i,t for any observed neuron i ∈ X and s i,t = h i,t for any latent neuron i ∈ H as well as s t = ( x t , h t ) for the o verall set of spike signals at time t . During training, the spik e signals x ≤ T of the observed neurons are clamped to the examples in the training set while the probability distribution of the signals h ≤ T of the hidden neurons can be adapted to ensure the desired input/output behavior . Mathematically , the probabilistic model is defined as in (4) and (5), with s ≤ T = ( x ≤ T , h ≤ T ) . ML via SGD and variational learning Here, we revie w a standard learning rule that tackles the ML problem by using SGD. Unlike in the fully observed case, as we will see, variational infer ence is needed to cope with the complexity of computing the gradient of the log-likelihood of the observed spike signals in the presence of hidden neurons [12]. Log-likelihood. The log-likelihood of an example of observed spike signals x ≤ T is obtained via marginalization by summing ov er all possible values of the latent spike signals h ≤ T as L x ≤ T ( θ ) = log p θ ( x ≤ T ) = log P h ≤ T p θ ( x ≤ T , h ≤ T ) . Let us denote as h·i p the expectation ov er a distribution p , as in h f ( x ) i p ( x ) = P x f ( x ) p ( x ) , for some function f ( x ) . The gradient of the log-likelihood with respect to the model parameters θ can be expressed as (see, e.g., [12, Ch. 6]) ∇ θ L x ≤ T ( θ ) = D ∇ θ log p θ ( x ≤ T , h ≤ T ) E p θ ( h ≤ T | x ≤ T ) , (10) where the expectation is with respect to the posterior distribution p θ ( h ≤ T | x ≤ T ) of the latent variables h ≤ T , giv en the observation x ≤ T . Note that the gradient ∇ θ log p θ ( x ≤ T , h ≤ T ) = T X t =0 ∇ θ log p θ ( x t , h t | x ≤ t − 1 , h ≤ t − 1 ) is obtained from (7), with s ≤ T = ( x ≤ T , h ≤ T ) . Computing the posterior p θ ( h ≤ T | x ≤ T ) amounts to the Bayesian inference of the hidden spike signals for the observed v alues x ≤ T . Given that we hav e the equality p θ ( h ≤ T | x ≤ T ) = p θ ( x ≤ T , h ≤ T ) /p θ ( x ≤ T ) , this task requires the e v aluation of the marginal dis- tribution p θ ( x ≤ T ) = P h ≤ T p θ ( x ≤ T , h ≤ T ) . For problems of practical size, this computation is intractable and, hence, so is ev aluating the gradient (10). V ariational learning . V ariational inference, or variational Bayes, approximates the true posterior distribution p θ ( h ≤ T | x ≤ T ) by means of any arbitrary variational posterior distribution q φ ( h ≤ T | x ≤ T ) parameterized by a vector φ of learnable parameters. For any v ariational distribution q φ ( h ≤ T | x ≤ T ) , using Jensen’ s inequality , the log-likelihood L x ≤ T ( θ ) can be lower bounded as (see, e.g., [12, Ch. 6 and 14 Ch. 8]) L x ≤ T ( θ ) = log X h ≤ T p θ ( x ≤ T , h ≤ T ) ≥ X h ≤ T q φ ( h ≤ T | x ≤ T ) log p θ ( x ≤ T , h ≤ T ) q φ ( h ≤ T | x ≤ T ) = D ` θ , φ x ≤ T , h ≤ T E q φ ( h ≤ T | x ≤ T ) := L x ≤ T ( θ , φ ) , (11) where we hav e defined the learning signal as ` θ , φ ( x ≤ T , h ≤ T ) := log p θ ( x ≤ T , h ≤ T ) − log q φ ( h ≤ T | x ≤ T ) . (12) A baseline variational learning rule, also kno wn as the variational expectation maximization algorithm, is based on the maximization of the evidence lower bound (ELBO) L x ≤ T ( θ , φ ) in (11) with respect to both the model parameters θ and the variational parameters φ . Accordingly , for a gi ven observed example x ≤ T ∈ D , the learning rule is gi ven by gradient ascent updates, where the gradients can be computed as ∇ θ L x ≤ T ( θ , φ ) = D ∇ θ log p θ ( x ≤ T , h ≤ T ) E q φ ( h ≤ T | x ≤ T ) , and (13a) ∇ φ L x ≤ T ( θ , φ ) = D ` θ , φ ( x ≤ T , h ≤ T ) · ∇ φ log q φ ( h ≤ T | x ≤ T ) E q φ ( h ≤ T | x ≤ T ) , (13b) respecti vely . The gradient (13a) is deriv ed in a manner analogous to (10), and the gradient (13b) is obtained from the standard REINFORCE, or score function, gradient [12, Ch. 8], [27]. Importantly , the gradients (13) require e xpectations with respect to the kno wn v ariational posterior q φ ( h ≤ T | x ≤ T ) ev aluated at the current v alue of variational parameters φ rather than with respect to the hard-to-compute posterior p θ ( h ≤ T | x ≤ T ) . An alternati ve to the computation of the gradient o ver the variational parameters φ as in (13b) is giv en by the so-called reparameterization trick [28], as briefly discussed in the “Conclusions and Open Problems” section. In practice, computing the av erages in (13) is still intractable because of the large domain of the hidden v ariables h ≤ T . Therefore, the expectations over the variational posterior are typically approximated by means of Monte Carlo empirical av erages. This is possible as long as sampling from the v ariational posterior q φ ( h ≤ T | x ≤ T ) is feasible. As an example, if a single spike signal h ≤ T is sampled from q φ ( h ≤ T | x ≤ T ) , we obtain the Monte Carlo approximations of (13) as ∇ θ ˆ L x ≤ T ( θ , φ ) = ∇ θ log p θ ( x ≤ T , h ≤ T ) , and (14a) ∇ φ ˆ L x ≤ T ( θ , φ ) = ` θ , φ ( x ≤ T , h ≤ T ) · ∇ φ log q φ ( h ≤ T | x ≤ T ) . (14b) Batch doubly SGD. In a batch training formulation, at each iteration, an example x ≤ T is selected 15 from the training set D . At the end of the observation period T , both model and variational parameters can be updated in the direction of the gradients ∇ θ ˆ L x ≤ T ( θ , φ ) and ∇ φ ˆ L x ≤ T ( θ , φ ) in (14) as θ ← θ + η θ ∇ θ ˆ L x ≤ T ( θ , φ ) , and (15a) φ ← φ + η φ ∇ φ ˆ L x ≤ T ( θ , φ ) , (15b) respecti vely , where the learning rates η θ and η φ are assumed to be fixed for simplicity . Rule (15) is kno wn as doubly SGD since sampling is carried out ov er both the observed examples x ≤ T in the training set and the hidden spike signals h ≤ T . The doubly stochastic gradient estimator (14b) typically e xhibits a high v ariance. T o reduce the v ariance, a common approach is to subtract a baseline contr ol variate from the learning signal. This can be done by replacing the learning signal in (14b) with the centered learning signal ` θ , φ ( x ≤ T , h ≤ T ) − ¯ ` , where the baseline ¯ ` is calculated as a moving av erage of learning signals computed at pre vious iterations [22], [27], [29]. Online doubly SGD. The batch doubly SGD rule (15) applies with any choice of v ariational distrib ution q φ ( h ≤ T | x ≤ T ) , as long as it is feasible to sample from it and to compute the gradient in (14b). Howe ver , the locality properties and complexity of the learning rule are strongly dependent on the choice of the v ariational distribution. W e now discuss a specific choice considered in [16], [22], and [29]–[31] that yields an online rule, summarized in Algorithm 2. The approach approximates the true posterior p θ ( h ≤ T | x ≤ T ) with a feedforward distrib ution that ignores the stochastic dependence of the hidden spike signals h t at time t on the future v alues of the observed spike signals x ≤ T . The corresponding variational distribution can be written as q θ H ( h ≤ T | x ≤ T ) = T Y t =0 p θ H ( h t | x ≤ t − 1 , h ≤ t − 1 ) = T Y t =0 Y i ∈H p ( h i,t | u i,t ) , (16) where we denote as θ H = { θ i } i ∈H the collection of the model parameters for hidden neurons, and p ( h i,t = 1 | u i,t ) = σ ( u i,t ) by (5), with s i,t = h i,t . W e note that (16) is an approximation of the true posterior p θ ( h ≤ T | x ≤ T ) = Q T t =0 p θ ( h t | x ≤ T , h ≤ t − 1 ) since it neglects the correlation between variables h t and the future observed samples x ≥ t . In (16), we ha ve emphasized that the variational parameters φ are tied to a subset of the model parameters, as per the equality φ = θ H . As a result, this choice of v ariational distribution does not include additional learnable parameters apart from the model parameters θ . The learning signal (12) with the feedforward distribution (16) reads ` θ X ( x ≤ T , h ≤ T ) = T X t =0 log p θ X ( x t | x ≤ t − 1 , h ≤ t − 1 ) = T X t =0 X i ∈X log p ( x i,t | u i,t ) , (17) 16 Algorithm 2: ML T raining via online Doubly SGD Input: Training data x ≤ T and learning rates η and κ Output: Learned model parameters θ 1 initialize parameters θ 2 repeat 3 feedforw ard sampling: 4 f or each hidden neuron i ∈ H do 5 emit a spike h i,t = 1 with probability σ ( u i,t ) 6 end 7 global feedback: 8 a central processor collects the log probabilities p ( x i,t | u i,t ) in (5) from all observed neurons i ∈ X , computes a time-av eraged learning signal (17) as ` t = κ` t − 1 + (1 − κ ) X i ∈X log p ( x i,t | u i,t ) , (A3) and feeds back the global learning signal ` t to all latent neurons 9 parameter update: 10 f or each neuron i ∈ V do 11 e valuate the eligibility trace e i,t as e i,t = κ e i,t − 1 + (1 − κ ) ∇ θ i log p θ i ( s i,t | x ≤ t − 1 h ≤ t − 1 ) , (A4) with s i,t = x i,t if i ∈ X and s i,t = h i,t if i ∈ H 12 update the local model parameters as θ i ← θ i + η · ( e i,t , if i ∈ X ` t e i,t , if i ∈ H (A5) 13 end 14 until stopping criterion is satisfied where θ X = { θ i } i ∈X is the collection of the model parameters for observed neurons. W ith the choice (16) for the variational posterior , the batch doubly SGD update rule (15) can be turned into an online rule by generalizing Algorithm 1, as detailed in Algorithm 2. At each step of the online procedure, each hidden neuron i ∈ H emits a spike, i.e., h i,t = 1 , at any time t by following the current model distribution (16), i.e., with probability σ ( u i,t ) . Note that the membrane potential u i,t of any neuron i at time t is obtained from (1), with observed neurons clamped to the training example x ≤ t − 1 and hidden neurons clamped to the samples h ≤ t − 1 . Then, a central processor collects the log probabilities p ( x i,t | u i,t ) under the current model from all observed neurons i ∈ X to compute the time-av eraged learning signal ` t , as in (A3) and feeds back the global learning signal to all latent neurons. Intuiti vely , this learning signal indicates to the hidden neurons ho w effecti ve their current signaling is in ensuring the desired input/output beha vior with high probability . Finally , each observed and hidden 17 neuron i computes the eligibility trace e i,t of the gradient, i.e., ∇ θ i log p θ i ( x i,t | x ≤ t − 1 , h ≤ t − 1 ) and ∇ θ i log p θ i ( h i,t | x ≤ t − 1 , h ≤ t − 1 ) , respecti vely , as in (A4). The local parameters θ i of each observed neuron i ∈ X are updated in the direction of the eligibility trace e i,t , while each hidden neuron i ∈ H updates the parameter using e i,t and the learning signal ` t in (A3). Sparsity and regularization. As discussed, the energy consumption of SNNs depends on the number of spikes emitted by the neurons. Since the ML criterion does not enforce any sparsity constraint, an SNN trained using the methods discussed so far may present dense spiking signals [18]. This is especially the case for the hidden neurons, whose behavior is not tied to the training data. T o obviate this problem, it is possible to add a regularization term − α · KL ( q φ ( h ≤ T | x ≤ T ) || r ( h ≤ T )) to the learning objectiv e L x ≤ T ( θ , φ ) in (11), where KL ( p k q ) = P x p ( x ) log( p ( x ) /q ( x )) is the Kullback-Leibler di vergence between distrib utions p and q , r ( h ≤ T ) represents a baseline distrib ution with the desired lev el of sparsity , and α > 0 is a parameter adjusting the amount of regularization. This regularizing term, which penalizes v ariational distributions far from the baseline distribution, can also act as a regularizer to minimize ov erfitting by enforcing a bounded rationality constraint [32]. The learning rule in Algorithm 2 can be modified accordingly . Interpr etation. The update (A5) for the synaptic weight w j,i of any observed neuron i ∈ X follows the local two-factor rule, as described in the “Interpretation” section for fully observed models. In contrast, for any hidden neuron i ∈ H , the update applies a three-factor nonlocal learning rule (8). Accordingly , the postsynaptic error signal of hidden neuron i and the filtered feedforw ard trace of presynaptic neuron j are multiplied by the global learning signal (17). As anticipated previously , the global learning signal can be interpreted as an internal reward signal. T o see this more generally , we can re write (17) as ` θ X ( x ≤ T , h ≤ T ) = log p θ ( x ≤ T | h ≤ T ) − log q θ H ( h ≤ T | x ≤ T ) p θ ( h ≤ T ) . (18) According to (18), the learning signal rew ards hidden spike signals h ≤ T , producing observations x ≤ T that yield a large likelihood log p θ ( x ≤ T | h ≤ T ) for the desired behavior . Furthermore, it penalizes v alues of hidden spike signals h ≤ T that hav e large variational probability q θ H ( h ≤ T | x ≤ T ) while having a low prior probability p θ ( h ≤ T ) under the model. As discussed in the “Learning T asks” section, SNNs can be trained in a batch or online mode. In the next sections, we provide a representati ve, simple, and reproducible example for each case. B AT C H L E A R N I N G E X A M P L E S As an example of batch learning, we consider the standard handwritten digit classification task on the USPS data set [35]. W e adopt an SNN with two layers, the first encoding the input and the second 18 Fig. 6: A performance of classification based on a two-layer SNN trained via batch ML learning in terms of accuracy versus the duration T of the operation of the SNN. The performance of an ANN with the same topology is also shown as a baseline (see [33] and [34] for details). the output, with directed synaptic links existing from all neurons in the input layer to all neurons in the output layer . No hidden neurons exist, and, hence, training can be done as described in the section “T raining SNNs: Fully Observed Models”. Each 16 × 16 input image, representing either a “ 1 ” or a “ 7 ” handwritten digit, is encoded in the spike domain by using rate encoding. Each gray pixel is conv erted into an input spiking signal by generating an independent identically distributed (i.i.d.) Bernoulli vector of T samples, with the spiking probability proportional to the pixel intensity and limited to between zero and 0 . 5 . As a result, we hav e 256 input neurons, with one per pixel of the input image. The digit labels { 1 , 7 } are also rate encoded using each one of the two output neurons. The neuron corresponding to the correct label index emits spikes with a frequency of one ev ery three sample, while the other output neurons are silent. W e refer the reader to [33] and the supplementary material [34] for further details on the numerical setup. Fig. 6 shows the classification accuracy in the test set versus the duration T of the operation of the SNN after the con ver gence of the training process. The classification accuracy of a con ventional ANN with the same topology and a soft-max output layer is added for comparison. Note that, unlike the SNN, the ANN outputs real v alues, namely , the logits for each class processed by the soft-max layer . From the figure, the SNN is seen to provide a graceful tradeof f between accuracy and complexity of learning: as T increases, the number of spikes that are processed and the output by the SNN gro ws larger , entailing a larger inference complexity but also an improved accuracy that tends to that of the baseline ANN. O N L I N E L E A R N I N G E X A M P L E S W e now consider an online prediction task in which the SNN sequentially observes a time sequence { a l } and the SNN is trained to predict, in an online manner , the next value of sequence a l , giv en the observ ation of the previous values a ≤ l − 1 . The time sequence { a l } is encoded in the spike domain, producing a spike signal { x t } , consisting of N X spiking signals x t = ( x 1 ,t , . . . , x N X ,t ) with ∆ T ≥ 1 19 (a) (b) Fig. 7: An online prediction task based on an SNN with N X = 9 visible neurons and N H = 2 hidden neurons trained via Algorithm 2. (a) A real, analog time signal and a predicted, decoded signal (top) and the total number of spikes emitted by the SNN (bottom). (b) A spike raster plot of visible neurons (top) and a spike raster plot of hidden neurons (bottom). samples for each sample a l . W e refer to ∆ T as a time expansion factor . Each of the spiking signals x i,t is associated with one of N X visible neurons. W e adopt a fully connected SNN topology that also includes N H hidden neurons. In this online prediction task, we trained the SNN using Algorithm 2, with the addition of a sparsity regularization term. This is obtained by assuming an i.i.d. reference Bernoulli distribution with a desired spiking rate r ∈ [0 , 1] , i.e., log r ( h ≤ T ) = P T t =0 P i ∈H h i,t log r + (1 − h i,t ) log(1 − r ) (see the supplementary material [34] for details). The source sequence is randomly generated as follows: at ev ery T s = 25 time steps, one of three possible sequences of duration T s is selected, namely , an all-zero sequence with probability 0 . 7 , a sequence of class 1 from the SwedishLeaf data set of the UCR archiv e [36], or a sequence of class 6 from the same archiv e, with equal probability [see Fig. 7(a) for an illustration]. Encoding and decoding. Each value a l of the time sequence is con verted into ∆ T samples x l ∆ T +1 , x l ∆ T +2 , . . . , x ( l +1)∆ T of the N X spike signals { x t } via rate or time coding, as illustrated in Fig. 8. W ith rate coding , the value a l is first discretized into N X + 1 uniform quantization levels using rounding to the largest lower value. The lowest, “silent”, lev el is con verted to all-zero signals x l ∆ T +1 , x l ∆ T +2 , . . . , x ( l +1)∆ T . Each of the other N X le vels is assigned to a visible neuron, so that the neuron associated with the quantization lev el corresponding to v alue a l emits ∆ T consecutiv e spikes while the other neurons are silent. Rate decoding predicts value a l +1 by generating the samples x ( l +1)∆ T +1 , . . . , x ( l +2)∆ T from the trained model and then selecting the neuron with the largest number of spikes in this window . For time coding , each of the N X visible neurons is associated with a dif ferent shifted, truncated Gaussian recepti ve field [37]. Accordingly , as seen in Fig. 8(b), for each value a l , each visible neuron i emits a 20 (a) (b) Fig. 8: Examples of coding schemes with N X = 2 visible neurons and time expansion factor ∆ T = 3 . (a) W ith rate coding, each value a l is discretized into N X + 1 = 3 le vels (top), and ∆ T = 3 consecutive spikes are assigned to input neuron i for lev el i = 1 , 2 , and no spikes are assigned otherwise (bottom). (b) With time coding, value a l is encoded for each visible neuron into zero or one spike, whose timing is giv en by the v alue of the corresponding Gaussian receptiv e field [37]. signal x i,l ∆ T +1 , x i,l ∆ T +2 , . . . , x i, ( l +1)∆ T that contains no spike if the v alue a l is outside the receptiv e field and, otherwise, contains one spike, with the timing determined by the value of the corresponding truncated Gaussian receptive field quantized to values { 1 , . . . , ∆ T } using rounding to the nearest v alue. T ime decoding considers the first spike timing of the samples x i, ( l +1)∆ T +1 , . . . , x i, ( l +2)∆ T for each visible neuron i and predicts a value a l +1 using a least-squares criterion on the values of the receptiv e fields (see [11] and [37]). W e refer to the supplementary material [34] for further details on the numerical setup. Rate coding. First, assuming rate encoding with ∆ T = 5 , we train an SNN with N X = 9 visible neurons and N H = 2 hidden neurons using Algorithm 2. In the top portion of Fig. 7(a), we see a segment of the signal and of the prediction for a time windo w after the observation of the 23 , 700 plus training samples of the sequence. The corresponding spikes emitted by the SNN [Fig. 7(b)] are also shown, along with the total number of spikes per time instant [Fig. 7(a), bottom]. The SNN is seen to be able to provide an accurate prediction. Furthermore, the number of spikes, and, hence, the operating ener gy , depends on the lev el of acti vity of the input signal. This demonstrates the potential of SNNs for alw ays-on ev ent- dri ven applications. As a final note, in this particular example, the hidden neurons are observed to act as a detector of activity versus silence, which facilitates the correct behavior of the visible neurons. The role of the number N H of hidden neurons is further in vestigated in Fig. 9, which sho ws the 21 Fig. 9: The prediction error versus training time for SNNs with N X = 9 visible neurons and N H = 1 , 2 , and 5 hidden neurons trained via ML learning using Algorithm 2. The dashed line indicates the performance of a baseline persistent predictor that outputs the previous sample (quantized to N X le vels, as described in the text). prediction error as a function of the number of observed training samples for different values of N H . Increasing the number of hidden neurons is seen to improve the prediction accuracy as long as training is carried out for a sufficiently long time. The prediction error is measured in terms of av erage mean absolute error (MAE). For reference, we also compare the prediction performance with a persistent baseline (dashed line) that outputs the previous sample, upon quantization to N X le vels for fairness. Rate vs time encoding. we now discuss the impact of the coding schemes on the online prediction task. W e train an SNN with N X = 2 visible neurons and N H = 5 hidden neurons. Fig. 7(a) shows the prediction error and Fig. 7(b) the number of spikes in a windo w of 2 , 500 samples of the input sequence, after the observ ation of the 17 , 500 training samples, versus the time expansion factor ∆ T . From the figure, rate encoding is seen to be preferable for smaller v alues of ∆ T , while time encoding achieves better prediction error for larger ∆ T , with fewer spikes and, hence, energy consumption. This result is a consequence of the different use that the two schemes make of the time expansion ∆ T . W ith rate encoding, a lar ger ∆ T entails a large number of spikes for the neuron encoding the correct quantization le vel, which provides increased robustness to noise. In contrast, with time encoding, the v alue ∆ T controls the resolution of the mapping between input v alue a l and the spiking times of the visible neurons. This demonstrates the ef ficiency benefits of SNNs that may arise from their unique time encoding capabilities. C O N C L U S I O N S A N D O P E N P R O B L E M S As illustrated by the examples in the previous section, SNNs provide a promising alternativ e solution to con ventional ANNs for the implementation of lo w-po wer learning and inference. When using rate encoding, they can approximate the performance of any ANN, while also providing a graceful tradeoff between accuracy , on the one hand, and energy consumption and delay , on the other . Most importantly , 22 (a) (b) Fig. 10: An online prediction task based on an SNN consisting of N X = 2 visible neurons and N H = 5 hidden neurons, with rate and time coding schemes: (a) the prediction error and (b) the number of spik es emitted by the SNN versus the time expansion factor ∆ T . they ha ve the unique capacity to process time-encoded information, yielding sparse, e vent-dri ve, and lo w-complexity inference and learning solutions. The recent advances in hardware design revie wed in [5] are motiv ating renewed efforts to tackle the current lack of well-established direct training algorithms that are able to harness the potential ef ficiency gains of SNNs. This article has argued that this gap is, at least in part, a consequence of the insistence on the use of deterministic models, which is in turn due to their dominance in the context of ANNs. As discussed, not only can probabilistic models allow the recov ery of learning rules that are well kno wn in theoretical neuroscience, b ut they can also provide a principled framework for the deri vation of more general training algorithms. Notably , these algorithms dif fer significantly from the standard backpropagation approach used for ANNs, owing to their locality coupled with global feedback signaling. W ith the main aim of inspiring more research on the topic, this article has presented a revie w of models and training methods for probabilistic SNNs with a probabilistic signal processing framew ork. W e focused on GLM spiking neuron models, given their flexibility and tractability , and on ML-based training methods. W e conclude this article with some discussion on extensions in terms of models and algorithms as well as on open problem. The SNN models and algorithms we hav e considered can be extended and modified along various directions. In terms of models, while randomness is defined here at the lev el of neurons’ outputs, alternati ve models introduce randomness at the lev el of synapses or thresholds [38], [39]. Furthermore, while the models studied in this article encode information in the temporal behavior of the network within a giv en interval of time, information can also be retrie ved from the asymptotic steady-state spiking rates, which define a joint probability distribution [4], [40], [41]. Specifically , when the GLM (4)-(5) has 23 symmetric synaptic weights [ - ] i.e., w j,i = w i,j , the memory of the synaptic filter is τ = 1 , and there is no feedback filter , the conditional probabilities (5) for all neurons define a Gibbs sampling procedure for a Boltzmann machine that can be used for this purpose. As another extension, more general connections among neurons can be defined, including instantaneous firing correlations, and more information, such as a sign, can be encoded in a spike [33]. Finally , while here we focus on signal processing aspects, at a semantic lev el, SNNs can process logical information by following different principles [11]. In terms of algorithms, the doubly stochastic SGD approach re viewed here for ML training can be extended and improv ed by lev eraging an alternati ve estimator of the ELBO and its gradients with respect to the v ariational parameters that is kno wn as the r eparameterization tric k [28]. Furthermore, similar techniques can be dev eloped to tackle other training criteria, such as Bayesian optimal inference [31], rew ard maximization in reinforcement learning (see [12] for a discussion in the context of general probabilistic models). Interesting open problems include the dev elopment of meta-learning algorithms, whereby the goal is learning how to train or adapt a network to a new task (see, e.g., [41]); the design of distributed learning techniques; and the definition of clear use cases and applications with the quantification of advantages in terms of power efficiency [42]. Another important problem is the design of ef ficient input/ output interfaces between information sources and the SNN, at one end, and between the SNN and actuators or end users, on the other . In the absence of such efficient mechanisms, SNNs risk replacing the so-called memory wall of standard computing architectures with an input/output wall. A C K N O W L E D G M E N T S This work was supported in part by the European Research Council under the European Union’ s Horizon 2020 research and innov ation program under grant 725731 and by the U.S. National Science Foundation under grant ECCS 1710009. A.G (partly) and B.G (fully) are supported by the European Union’ s Horizon 2020 Frame work Programme for Research and Innov ation under the Specific Grant Agreement No. 785907 (Human Brain Project SGA2). R E F E R E N C E S [1] M. W elling, “Intelligence per kilowatt-hour , ” https://youtu.be/7QhkvG4MUbk, 2018. [2] H. Paugam-Moisy and S. Bohte, “Computing with spiking neuron netw orks, ” in Handbook of Natur al Computing . Springer , 2012, pp. 335–376. [3] W . Maass, “Networks of spiking neurons: the third generation of neural network models, ” Neural networks , vol. 10, no. 9, pp. 1659–1671, 1997. [4] M. Davies et al., “Loihi: A neuromorphic manycore processor with on-chip learning, ” IEEE Micr o , vol. 38, no. 1, pp. 82–99, 2018. 24 [5] B. Rajendran, A. Sebastian, M. Schmuker , N. Srinivasa, and E. Eleftheriou, “Lo w-po wer neuromorphic hardware for signal processing applications, ” arXiv pr eprint arXiv:1901.03690 , 2019. [6] B. Rueckauer and S.-C. Liu, “Con version of analog to spiking neural networks using sparse temporal coding, ” in Pr oc. IEEE International Symposium on Cir cuits and Systems (ISCAS) , Florence, Italy , May 2018, pp. 1–5. [7] J. H. Lee, T . Delbruck, and M. Pfeiffer , “T raining deep spiking neural networks using backpropagation, ” F r ontiers in Neur oscience , vol. 10, p. 508, 2016. [8] P . O’Connor and M. W elling, “Deep spiking networks, ” arXiv pr eprint arXiv:1602.08323 , 2016. [9] Y . W u, L. Deng, G. Li, J. Zhu, and L. Shi, “Spatio-temporal backpropagation for training high-performance spiking neural networks, ” F rontiers in Neur oscience , vol. 12, 2018. [10] P . Dayan and L. Abbott, Theoretical Neur oscience: Computational and Mathematical Modeling of Neural Systems . MIT Press, 2001. [11] C. Eliasmith and C. H. Anderson, Neural engineering: Computation, repr esentation, and dynamics in neur obiological systems . MIT press, 2004. [12] O. Simeone, “ A brief introduction to machine learning for engineers, ” F oundations and T rends R in Signal Pr ocessing , vol. 12, no. 3-4, pp. 200–431, 2018. [13] R. S. Sutton and A. G. Barto, Reinforcement learning: An intr oduction . MIT press, 2018. [14] J. W . Pillow et al., “Spatio-temporal correlations and visual signalling in a complete neuronal population, ” Nature , vol. 454, no. 7207, p. 995, 2008. [15] W . Gerstner and W . M. Kistler, Spiking neuron models: Single neur ons, populations, plasticity . Cambridge Uni versity Press, 2002. [16] T . Osogami, “Boltzmann machines for time-series, ” arXiv pr eprint arXiv:1708.06004 , 2017. [17] R. M. Neal, “Connectionist learning of belief networks, ” Artificial Intelligence , vol. 56, no. 1, pp. 71–113, 1992. [18] F . Gerhard, M. Deger , and W . Truccolo, “On the stability and dynamics of stochastic spiking neuron models: Nonlinear hawkes process and point process glms, ” PLoS computational biology , vol. 13, no. 2, p. e1005390, 2017. [19] B. Gardner , I. Sporea, and A. Gr ¨ uning, “Learning spatiotemporally encoded pattern transformations in structured spiking neural networks, ” Neural Computation , vol. 27, no. 12, pp. 2548–2586, 2015. [20] E. O. Neftci, H. Mostafa, and F . Zenke, “Surrogate gradient learning in spiking neural networks, ” arXiv preprint arXiv:1901.09948 , 2019. [21] N. Fr ´ emaux and W . Gerstner , “Neuromodulated spike-timing-dependent plasticity , and theory of three-factor learning rules, ” F r ontiers in Neural Circuits , vol. 9, p. 85, 2016. [22] J. Brea, W . Senn, and J.-P . Pfister, “Matching recall and storage in sequence learning with spiking neural networks, ” Journal of Neur oscience , vol. 33, no. 23, pp. 9565–9575, 2013. [23] B. Rosenfeld, O. Simeone, and B. Rajendran, “Learning first-to-spike policies for neuromorphic control using policy gradients, ” in Pr oc. IEEE International W orkshop on Signal Processing Advances in W ireless Communications (SP A WC) , Cannes, France, July 2019. [24] I. Goodfello w , Y . Bengio, and A. Courville, Deep learning . MIT press, 2016. [25] E. L. Bienenstock, L. N. Cooper , and P . W . Munro, “Theory for the development of neuron selecti vity: orientation specificity and binocular interaction in visual cortex, ” Journal of Neur oscience , vol. 2, no. 1, pp. 32–48, 1982. [26] A. J. W att and N. S. Desai, “Homeostatic plasticity and STDP: keeping a neuron’ s cool in a fluctuating world, ” F r ontiers in Synaptic Neuroscience , vol. 2, p. 5, 2010. 25 [27] A. Mnih and K. Gregor , “Neural v ariational inference and learning in belief networks, ” in Pr oc. International Conference on Machine Learning (ICML) , Beijing, China, June 2014, pp. 1791–1799. [28] D. P . Kingma and M. W elling, “ Auto-encoding variational bayes, ” in Pr oc. International Conference on Learning Repr esentations (ICLR) , Banff, Canada, Apr . 2014. [29] D. J. Rezende and W . Gerstner, “Stochastic v ariational learning in recurrent spiking networks, ” F r ontiers in Computational Neur oscience , vol. 8, p. 38, 2014. [30] G. E. Hinton and A. D. Brown, “Spiking boltzmann machines, ” in Pr oc. Advances in Neural Information Processing Systems (NIPS) , Denv er , US, Nov . 2000, pp. 122–128. [31] D. Kappel, S. Habenschuss, R. Legenstein, and W . Maass, “Network plasticity as Bayesian inference, ” PLoS Computational Biology , vol. 11, no. 11, p. e1004485, 2015. [32] F . Leibfried and D. A. Braun, “ A rew ard-maximizing spiking neuron as a bounded rational decision maker , ” Neural Computation , v ol. 27, no. 8, pp. 1686–1720, 2015. [33] H. Jang and O. Simeone, “Training dynamic exponential family models with causal and lateral dependencies for generalized neuromorphic computing, ” in Pr oc. IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , Brighton, UK, May 2019, pp. 3382–3386. [34] H. Jang, O. Simeone, B. Gardner , and A. Gr ¨ uning, “ An introduction to spiking neural networks: Probabilistic models, learning rules, and applications [supplementary material], ” https://nms.kcl.ac.uk/osvaldo.simeone/spm- supp.pdf, 2019. [35] J. J. Hull, “ A database for handwritten text recognition research, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 16, no. 5, pp. 550–554, 1994. [36] H. A. Dau, E. Keogh, K. Kamgar, C.-C. M. Y eh, Y . Zhu, S. Gharghabi, C. A. Ratanamahatana, Y anping, B. Hu, N. Begum, A. Bagnall, A. Mueen, and G. Batista, “The ucr time series classification archive, ” https://www .cs.ucr .edu/ ∼ eamonn/time { } series { } data { } 2018/, 2018. [37] S. M. Bohte, H. La Poutr ´ e, and J. N. K ok, “Unsupervised clustering with spiking neurons by sparse temporal coding and multilayer rbf networks, ” IEEE T ransactions on Neural Networks , vol. 13, no. 2, pp. 426–435, 2002. [38] N. Kasabov , “T o spike or not to spike: A probabilistic spiking neuron model, ” Neural Networks , vol. 23, no. 1, pp. 16–19, 2010. [39] H. Mostafa and G. Cauwenberghs, “ A learning framework for winner-take-all networks with stochastic synapses, ” Neural Computation , v ol. 30, no. 6, pp. 1542–1572, 2018. [40] W . Maass, “Noise as a resource for computation and learning in networks of spiking neurons, ” Pr oceedings of the IEEE , vol. 102, no. 5, pp. 860–880, 2014. [41] G. Bellec, D. Salaj, A. Subramoney , R. Legenstein, and W . Maass, “Long short-term memory and learning-to-learn in networks of spiking neurons, ” in Pr oc. Advances in Neural Information Pr ocessing Systems (NIPS) , Montreal, Canada, Dec. 2018, pp. 787–797. [42] P . Blouw , X. Choo, E. Hunsberger , and C. Eliasmith, “Benchmarking keyw ord spotting ef ficiency on neuromorphic hardware, ” arXiv pr eprint arXiv:1812.01739 , 2018. 26 Hyeryung Jang (hyeryung.jang@kcl.ac.uk) received her B.S., M.S., and Ph.D. degrees in electrical engineering from the K orea Advanced Institute of Science and T echnology , in 2010, 2012, and 2017, respecti vely . She is currently a research associate in the Department of Informatics, King’ s College London, United Kingdom. Her recent research interests lie in the mathematical modeling, learning, and inference of probabilistic graphical models, with a specific focus on spiking neural networks and communication systems. Her past research works also include network economics, game theory , and distributed algorithms in communication networks. Osvaldo Simeone (osvaldo.simeone@kcl.ac.uk) received his M.Sc. degree (with honors) and Ph.D. degree in information engineering from Politecnico di Milano, Italy , in 2001 and 2005, respectively . He is a professor of information engineering with the Centre for T elecommunications Research, Department of Informatics, King’ s College London, United Kingdom. He is a corecipient of the 2019 IEEE Communication Society Best T utorial P aper A ward, the 2018 IEEE Signal Processing Society Best Paper A ward, the 2017 Beest Paper by J ournal of Communications and Networks , the 2015 IEEE Communication Society Best Tutorial Paper A ward, and the IEEE International W orkshop on Signal Processing Advances in W ireless Communications 2007 and IEEE W ireless Rural and Emergency Communications Conference 2007 Best Paper A wards. He currently serves on the editorial board of IEEE Signal Pr ocessing Magazine and is a Distinguished Lecturer of the IEEE Information Theorey Society . He is a Fellow of the Institution of Engineering and T echnology and of the IEEE. Brian Gardner (b .gardner@surrey .ac.uk) recieved his M.Phys. degree from the University of Exeter , United Kingdom, in 2011 and his Ph.D. degree in computational neuroscience from the University of Surrey , Guildford, United Kingdom, in 2016. He is a research fellow in the Department of Computer Science, University of Surrey . Currently , his research focuses on the theoretical aspects of learning in spiking neural networks. He is also working as a part of the Human Brain Project and is in volv ed with the implementation of spike-based learning algorithms in neuromorphic systems for embedded applications. Andr ´ e Gr ¨ uning (andre.gruening@hochschule-stralsund.de) recei ved his U.G. degree in Theoretical Physics from the Uni versity of G ´ ’ottingen and his Ph.D. degree in Computer Science from the University of Leipzig. He is a professor of mathematics and computational intelligence at the University of Applied Sciences, Stralsund, Germany . He is a visiting member of the European Institute for Theoretical Neuroscience, Paris, France. Previously , he was a senior lecturer (associate professor) in the Department of Computer Science, Uni versity of Surrey , Guildford, United Kingdom. He held research posts in computational neuroscience at the Scuola Internazionale Superiore di Studi A vanzati, T rieste, Italy , and in cognitive neuroscience at the Univ ersity of W arwick, Coventry , United Kingdom. His research concentrates on computational and cognitiv e neuroscience, especially learning algorithms for spiking neural networks. He is a partner in the Human Brain Project, a European Union Horizon 2020 Flagship Project.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment