Are skip connections necessary for biologically plausible learning rules?
Backpropagation is the workhorse of deep learning, however, several other biologically-motivated learning rules have been introduced, such as random feedback alignment and difference target propagation. None of these methods have produced a competiti…
Authors: Daniel Jiwoong Im, Rutuja Patil, Kristin Branson
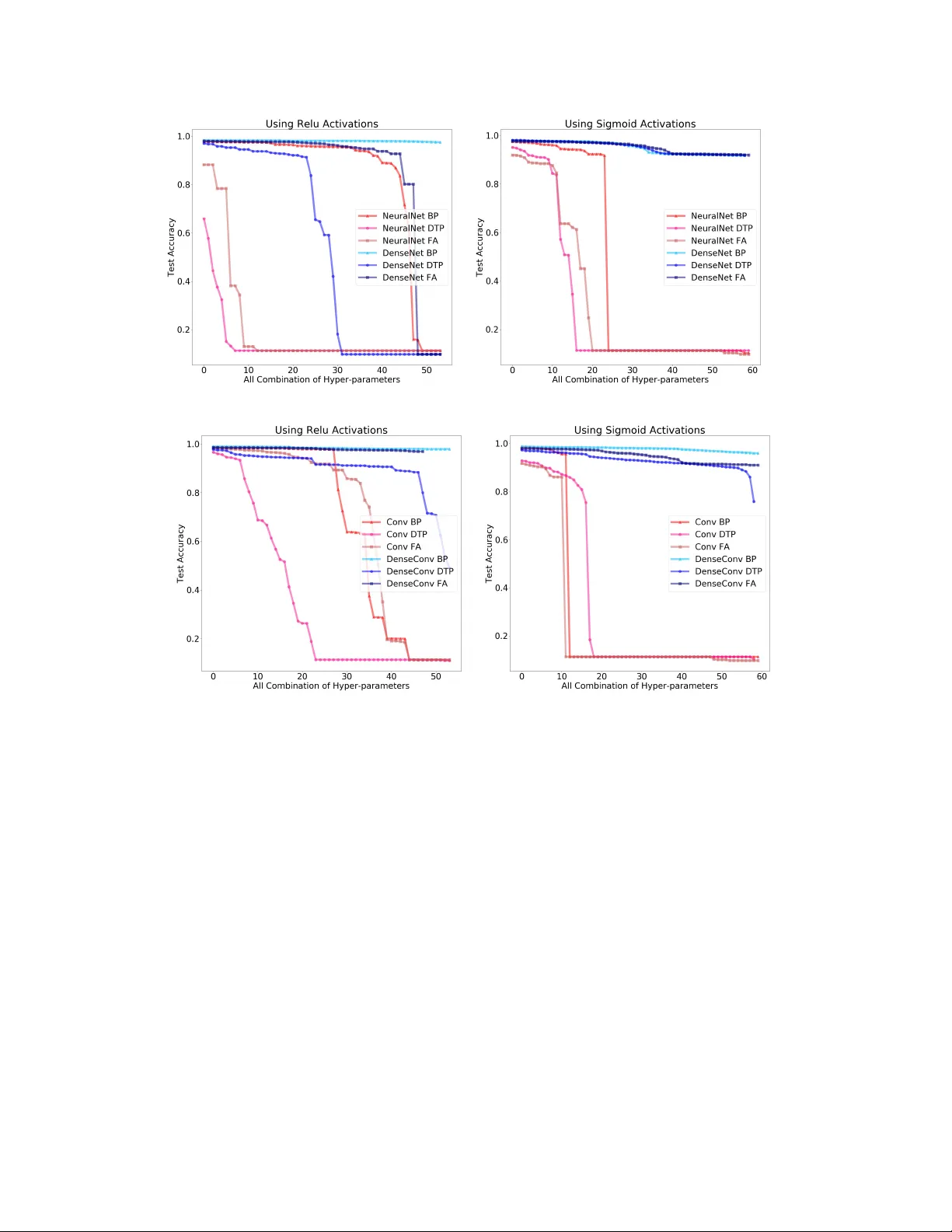
Ar e skip connections necessary f or biologically plausible lear ning rules? Daniel Jiwoong Im, Rutuja Patil, Kristin Branson Janelia Research Campus, HHMI { imd,patilr,bransonk } @janelia.hhmi.org Abstract Backpropagation is the workhorse of deep learning, howe v er sev eral other biologically-motiv ated learning rules hav e been introduced, such as random feed- back alignment and dif ference target propagation. None of these methods hav e produced competitiv e performance against backpropagation. In this paper , we show that biologically-moti v ated learning rules with skip connections between intermediate layers can perform as well as backpropagation on the MNIST dataset and are robust to v arious sets of hyper -parameters. 1 Introduction The backpropagation (BP) of global error [ 11 ] has been tremendously successful in solving hard AI tasks using deep learning. All deep learning models, such as deep feed forward neural networks, recurrent neural networks, and deep reinforcement learning, use BP as the main credit assignment tool to update their weights (model parameters) [ 6 ]. Ho we ver , BP for the brain is widely considered to be biologically implausible because BP requires symmetric backward connecti vity patterns (weight transpose) and it does not deli v er the error signals through a distinct pathw ay . Such concerns have inspired researchers to develop biologically-motiv ated learning rules 1 while trying to attain the performance of artificial neural networks. The two most popular learning rules are random feedback alignment (F A) [ 8 ] and difference tar get propagation (DTP) [ 7 ]. Instead of ha ving symmetric weight connections, F A uses random feedback weights as a backward pathway to propagate the error information. DTP trains separate feedback neural network that produces the target activities and then minimizes the error between tar get acti vities and forward propag ated activities. Sev eral other methods were inspired by F A and DTP , such as directed feedback alignment [ 9 ] and simplified difference target propag ation (SDTP) [ 1 ]. Howe ver , Bartunov et. al. demonstrate that not only are these methods non scalable to problems like the ImageNet dataset, but also that performance decays as more biologically plausible constraints are added [ 1 ]. W e sho w in addition that performance is not robust with respect to hyper -parameters for variants of DTP methods. The concept of skip and dense connections in deep learning was first introduced from residual neural networks[ 4 ] and densely connected conv olutional networks [ 5 ], wherein skip implies later layers receiv e signal from the earlier layers with intermediate skips, whereas dense implies each layer is connected to each other . The brain contains of many e xamples of both skip and dense connections. For e xample, the neocortex has a similar structure to residual nets; where cortical layer VI neurons get input from layer I, which skips intermediate layers [ 12 ]. Similar skip connection structure e xist in multiple other layers [ 3 ]. Oh et. al. [ 10 ] laid out the adult mouse brain mesoscale connectome and showed skip connections between inter-re gions. The whole-brain and corticocortical connections can be fit by one-component lognormal distributions. In general, the log-normal distribution connecti vity implies that sparse long-range connections e xist in the brain, which may act as skip connections in our context [2, 10]. 1 W e refer to credit assignment methods as learning rules. Sigmoid Relu Learning Rate Early Stop Depth Learning Rate Early Stop Depth BP (0.1-0.001) (200k-800k) (3-7) (0.001-0.00001) (100k-300k) (5-10) F A (0.01-0.0001) (200k-800k) (3-7) (0.001-0.00001) (600k-1000k) (5-10) DTP (0.01-0.0001) (200k-800k) (3-7) (0.001-0.00001) (50k-150k) 2 (5-10) T able 1: The table provides a range of hyper -parameters explored for v arious learning rules. Through- out the hyper -parameter search, we explored three sets of learning rates and fiv e sets of the early stopping starting points. W e tried 0.001, 1e-3, and 1e-4 learning rates and 0.01, 0.001, and 1e- 03 learning rates for the architectures with ReLU and sigmoid activ ations respecti vely . W e tried 200k,400k,600k,800k, 1,000k early stop starting point for NN and DN. W e tried three different range of early stop starting points that are uniformly spaced out for Con vNet and DenseCon vNet. The performance of computer vision and natural language processing methods has improv ed ov er the last fiv e years by increasing the depth of deep neural networks. With the introduction of skip and dense connections from residual neural networks [ 4 ] and densely connected con volutional netw orks [ 5 ], training with hundreds e ven thousands of layers has became possible. The core idea behind the performance gain with skip and dense connections is that a shorter path from earlier layers to later layers is created, and information as gradients gets propagated more ef ficiently through more layers. In our experiments, we demonstrate that such type of skip connections help ev en more for biologically motiv ated learning rules. T aking inspiration from the connecti vity in the brain and taking the performance adv ancement in deep skip and dense networks as e xemplars, we sho w that skip and dense connections allow biologically- plausible learning rules to perform as well as backpropagation. W e show that F A and DTP with densely connected deep neural networks perform comparable to BP e ven with an increase in depth, and sho w that the y are much more robust against dif ferent hyper -parameters compared to non-densely connected networks. 2 Methods W e use fully connected neural network and con volutional network architectures with dense con- nectivity . Dense connecti vity refers to direct connections from any layer to all subsequent layers. More formally , we define densely connected neural network to be h l = f l ([ h 1 ; · · · ; h l − 1 ]; θ l ) = σ ( W l, 1 h 1 + · · · W l,l − 1 h l − 1 + b l ) , where θ l = { W l, 1 , · · · , W l,l − 1 , b l } are the parameters of neural network with weights W l,l − 1 connecting from layer l − 1 to l , and h 0 = x . [ · ; · ] refers to the concatenation between vectors. W e can use standard BP on dense network to learn the weights. The gradient of hidden layer l and parameter θ l can be deri ved using chain rule: d L dh i = P L i =1 dh i dh l T d L dh i and d L dθ l = dh l dθ l T d L dh l . Similarly for F A, we can replace the transpose weight matrices with fixed random connections. For DTP , the decoder network is defined as ˆ h l = g ( h l +1 ; λ l +1 ) which is learned to act as an in verse transformation f − 1 ( h l +1 ; θ l +1 ) . Then, the target activ ation l , ˆ h l , becomes h l ← h l − P L j = l +1 ( g j ( h j ) − g j ( ˆ h j )) . W e can minimize the standard dif ference target loss and reconstruction loss for θ and λ [7]. Note that all the abov e can be easily extended to con volutional neural network. 3 Experiment W e conducted our experiments on dif ferent learning methods with dif ferent network architectures on the MNIST dataset. W e compared the performance of feedfow ard neural network (NN) against dense neural network (DN) and con volution netw ork (Con vNet) against dense con volutional netw ork (DenseCon vNet) for BP , F A and DTP . It is well known that BP without batch normalization suff ers from vanishing gradients as the feedfow ard neural network depth increases, especially with sigmoid 2 Early stopping range between 200k-600k explored for multi-lyer perceptron (NN and DN) and 50k-150k explored for con volutional neural networks (ConNet and DenseCon vNet) 2 (a) NN vs DN (b) Con vNet vs DenseCon v Figure 1: The performance o ver BP , F A, DTP with respect to different network depths. acti vation function. The same holds for F A and DTP as well. W e want to ev aluate the performance of F A and DTP as we increase network depth for densely connected networks. Furthermore, we want to know whether the y are more rob ust to different sets of h yper-parameters. In our experiments, the dataset w as di vided into 50,000 training, 10,000 v alidation, and 10,000 test. W e trained each network with a batch size of 128 and a 0.00001 L2 weight decay coefficient. T able 1 presents the set of hyper-parameters we tested. W e explored learning rates between 0.00001 and 0.1 and explored early stopping criterion starting points between 20,000 and 1,000,000. W e used 128 hidden units for each fully connected hidden layer . W e used a con v olutional filter size of three and channel size (depth x 16) for con volutional neural networks. W e explored both sigmoid and ReLu activ ation functions for multi-layer perceptron and con volutional neural networks. W e measured the performance of the model with network depth from three to se ven layers for sigmoid acti v ation and fiv e to ten layers for ReLu acti v ation. Figure 1 presents the test accuracy over BP , F A, and DTP with respect to network depth. The results of BP , F A, DTP are paired with NN and DN in Figure 1a, and paired with ConvNet, and DenseCon vNet in Figure 1b. The best hyper-parameters for each model is chosen across 10 folds. W e observe that test accuracy for all three methods drop for NN and Con vNet with network depths, whereas the test accurac y maintains for DN and DenseCon vNet. This illustrates that the network did not suffer from propagating error signals all the way to bottom layers when having dense connections. It is well-known that BP suffers from vanishing gradients with deep neural networks, and yet the 3 (a) NN vs DN (b) Con vNet vs DenseCon v Figure 2: The sensiti vity of test accuracy ov er multiple hyper -parameter for BP , F A, DTP . X-axis are all combination of hyper-parameter settings for learning rates, epochs, and network depth (sorted based on accuracy rate). dense connectivi ty allows short pathw ay from the top layers to bottom layers. W e suspect that F A benefits from the dense connecti vity the same way as BP . Even though DTP is a local learning rule, the acti vities in the top layers need to be informati ve in order for the local weight updates to mak e sense, otherwise, the local updates are based on random signals from the adjacent layers for the fully connected neural network. Howev er , the dense connecti vity will enable transfer of information from the top layers to bottom, since ev ery hidden layer are adjacent layers from each other . Figure 2 presents the sensiti vity of test accuracy over multiple hyper -parameters. W e explored combinations of learning rates, epochs, and depth, which are ordered based on sorted test accuracy . W e can see that the performance of F A and DTP for NN and Con vNet (red lines) v aries across a wide range. In fact, there are big accurac y discrepanc y for depth 3, 4, and 5 for NN and Con vNet. Howe ver , the performance of all three learning rules for DN and DenseConvNet (blue lines) remain nearly constant. This illustrates that having dense connections makes the model more robust to different hyper-parameters. 4 4 Discussion Building an intelligent system may require an appropriate objectiv e/rew ard function, credit assignment method, specific architecture types, or some combination of all of the abo ve. The nervous systems of animals illustrate some of the b uilding blocks necessary for b uilding intelligent systems, such as dopamine-based rew ard signals, distinct error signal pathways and neuronal architectures capable of performing computations. Ho wev er , the error rates for the ImageNet classification challenge using AlexNet are in the range of 93 ∼ 98% for all biologically motiv ated learning rules, whereas the BP error rate is 63.9% [1]. BP is therefore more effecti ve than biologically moti v ated learning rules. Howe ver , BP cannot be employed in biologically plausible architectures because it requires symmetric backward connecti vity and does not hav e a distinct error signal propagation pathway . Why are biologically-plausible learning rules so inef fecti ve in the context of deep learning? W e believ e it is because biologically-inspired learning rules hav e been studied in isolation, rather than considering them in the context of biologically-constrained architectures. Thus, re-examining the other key biological conditions that induce better learning performance is required. In this paper , we posit that the skip connections in nervous systems could be one of the k ey architectural components that are required to enhance existing and still unexplored credit assignment methods. Through this experiment, we sho w that biologically-moti v ated learning rules like F A and DTP are more effecti ve when combined with dense and skip connections. Furthermore, it is possible that having lognormal- distributed skip connections, as observ ed in the mouse brain, could be the computationally ef ficient way to propagate information. W e leave this to future work. References [1] Serge y Bartunov , Adam Santoro, Blake A. Richards, Luke Marris, Geoffre y E. Hinton, and T imothy Lillicrap. Assessing the scalability of biologically-moti v ated deep learning algorithms and architectures. Neur al Information Pr ocessing Systems , 2018. [2] György Buzsáki and K enji Mizuseki. The log-dynamic brain: ho w ske wed distrib utions affect network operations. In Nature Reviews Neur oscience , pages 264—-278. 2014. [3] David Fitzpatrick. The Functional Org anization of Local Circuits in V isual Cortex: Insights from the Study of T ree Shre w Striate Cortex. Cerebr al Cortex , 1996. [4] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. Computer V ision and P attern Recognition (CVPR) , 2015. [5] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. W einberger . Densely connected con v olutional networks. Computer V ision and P attern Recognition (CVPR) , 2017. [6] Y ann LeCun, Y oshua Bengio, and Geoffre y E Hinton. Deep learning. In Natur e , pages 436—-444. 2015. [7] Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Y oshua Bengio. Difference tar get propaga- tion. Eur opean confer ence of machine learning , 2015. [8] T imothy P . Lillicrap, Daniel Cownden, Douglas B. T weed, and Colin J. Akerman. Random synaptic feedback weights support error backpropagation for deep learning. In Natur e Commu- nication , pages 207—-214. 2016. [9] Arild Nøkland. Direct feedback alignment provides learning in deep neural networks. Neural Information Pr ocessing Systems , 2016. [10] Seung W ook Oh, Julie A. Harris, and Hongkui Zeng. A mesoscale connectome of the mouse brain. In Natur e , pages 207—-214. 2014. [11] David E Rumelhard, Geof frey E. Hinton, and Ronald J. W illiams. Learning representations by back-propagation errors. Natur e , 1986. [12] Alex M. Thomson. Neocortical layer 6, a re view. F ront. Neur oanat , 2010. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment