How Personal is Machine Learning Personalization?
Though used extensively, the concept and process of machine learning (ML) personalization have generally received little attention from academics, practitioners, and the general public. We describe the ML approach as relying on the metaphor of the pe…
Authors: Travis Greene, Galit Shmueli
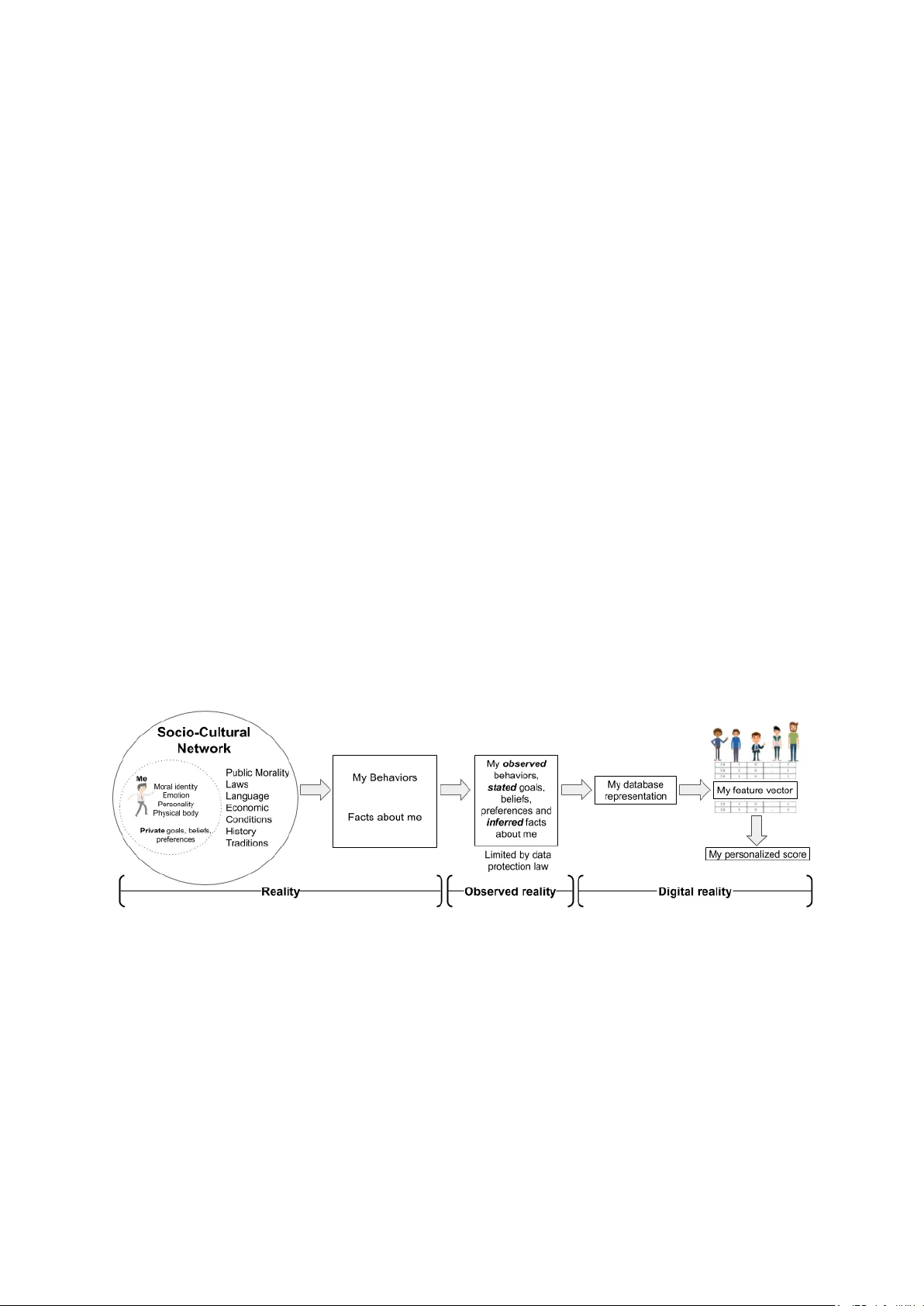
H O W P E R S O N A L I S M AC H I N E L E A R N I N G P E R S O N A L I Z A T I O N ? T ra vis Greene Institute of Service Science National Tsing Hua Univ ersity Hsinchu, T aiwan travis.greene@iss.nthu.edu.tw Galit Shmueli Institute of Service Science National Tsing Hua Univ ersity Hsinchu, T aiwan galit.shmueli@iss.nthu.edu.tw December 25, 2019 A B S T R AC T Though used extensi v ely , the concept and process of machine learning (ML) personalization hav e generally recei ved little attention from academics, practitioners, and the general public. W e describe the ML approach as relying on the metaphor of the person as a featur e vector and contrast this with humanistic vie ws of the person. In light of the recent calls by the IEEE to consider the effects of ML on human well-being, we ask whether ML personalization can be reconciled with these humanistic views of the person, which highlight the importance of moral and social identity . As human beha vior increasingly becomes digitized, analyzed, and predicted, to what extent do our subsequent decisions about what to choose, buy , or do, made both by us and others, reflect who we are as persons? This paper first explicates the term per sonalization by considering ML personalization and highlights its relation to humanistic conceptions of the person , then proposes sev eral dimensions for e valuating the degree of personalization of ML personalized scores. By doing so, we hope to contribute to current debate on the issues of algorithmic bias, transparency , and fairness in machine learning. keywords: Person, feature vector , user embedding, GDPR, moral identity , digital identity , humanistic vie w , AI 1 Introduction Explication is elimination: W e start with a concept the e xpr ession for which is somehow tr ouble- some; but it serves certain ends that cannot be given up. - John Rawls Personalized products and services are an inescapable fact of modern life. From personalized predictions (Uber ET A, recidivism risk scores, credit scores), to personalized recommendations (Netflix, Spotify , Amazon, T inder), personalized treatments (medicine and psychiatry), personalized ads, of fers, prices, and more, we are inundated with personalized scores 1 based on data about our physical condition, genetic mak eup, location, measurable beha viors and interactions. Ideally , personalization reduces information ov erload and search costs, thereby improving decision making and user experience. The decision maker and scored individual can be the same (self-directed) as in recommender systems, or different (other -directed) as in decision support systems used in law , medicine, b usiness, and finance. In both cases, personalization relies on machine learning (ML). Nev ertheless, ML personalization remains an ambiguous and under-examined concept. A literature search reveals a surprising lack of consensus on its essential characteristics. It is either not explicitly defined, explained circularly , or used in relation to or interchangeably with customization , tailoring , or pr ecision marketing . Cremonesi et al. (2010) say what personalization is not : giving "any user a pre-defined, fixed list of items, regardless of his/her preferences." Like wise, in the paper "What Is Personalization?" Fan and Poole (2006) classify v arious approaches to personalization. Despite offering a useful taxonomy of ideal personalization types, the authors overlook ed a simple, but fundamental point: the user is a person . Thus, critical questions arise: Does merely assigning a unique score to each user constitute a personalized score? Is a score personalized when it is based (wholly or in part) on the behavior of other persons? Does it matter who these "others" are? Does personalization require personal data ? Such questions are critical because lawmakers, journalists, social scientists, managers, and the general public encounter ML personalization ev erywhere, yet each group may hav e a very dif ferent understanding of the process. These dif ferences can lead to confusion about the origin and accuracy of so-called "personalized" scores. This is 1 W e refer to recommendations, predictions, and treatments more generally as "scores." especially relev ant in light of recent regulations, such as the General Data Protection Regulation’ s (GDPR) right to explanation for cases of automated profiling and its inclusion of a right to be for gotten . This paper contrasts the process of ML personalization with the humanistic concept of a person and of fers some normativ e criteria for e v aluating the le v el of personalization. A clearer understanding of ML personalization will also contribute to current debates on algorithmic bias, transparenc y , and fairness in machine learning. 2 The Machine Learning Personalization Perspectiv e: The P erson as a Featur e V ector Most commercial personalization engines (e.g. recommender systems) rely on a combination of explicitly-gi ven preferences, demographic data, and observed behavior assumed to reflect one’ s underlying preferences, (i.e., "implicit ratings") such as purchases, repeated use, sa ve/print, delete, reply , mark, glimpse, query (Nichols, 1998). Such data are derived only from what is actually observed when using an application or device and are a small subset of our possibly observed behaviors. Further, this narrow subset of recorded behaviors must be con v erted into a digital (database) representation supporting ML algorithms. Information is lost during the transformation of unstructured data (text, pictures, images, videos) into structured data which can be represented in matrix form. Lastly , the database representation is projected into featur e space . Figure 1 illustrates the ML pipeline resulting in the operationalization of a person as a feature vector . A ke y idea in ML personalization rests on the metaphor of the per son as a featur e vector . A feature vector (also known as a user embedding ) is an array of numbers–each representing some descriptiv e feature or aspect of an object–which can be thought of as the axes of a coordinate system (Kelleher et al., 2015). A 10-dimensional feature vector of a person, for instance, represents a person as an array of 10 numbers, deri ved from measurements of their observed beha vior , and replaces the "person" with a single point in 10-dimensional feature space. Once con verted to a point in feature space, the "similarity" of this person to others can be computed by measuring the distance between this point and others in the feature space. Points closer to each other are deemed more similar . Depending on one’ s modeling and predictiv e goals, this can indeed be a useful approach. But like any good metaphor , the feature vector approach emphasizes certain similarities at the expense of certain dissimilarities. When we represent a person as a feature vector , we tend to for get the long abstraction process that preceded it. As just one example of a potential problem in this process, Barocas et al. (2017) remark, "[numeric] features incorporate normative and subjecti ve . . . assumptions about measurements, but all features are treated as numerical truth by ML systems." In short, three key characteristics of ML personalization arise from the abov e process: ML personalization 1) is highly behaviorist in its assumptions, 2) is extremely narro w in predictive scope, and 3) often relies on data of a "community" whose selection is based on predictiv e goals. Figure 1: From humanistic concepts of the person to personalized scores: ML operationalization requires narrowing a person embedded in social and cultural space to a feature vector embedded in feature space. Three Characteristics of ML Personalization: Behaviorism, Predictiv e Scope, and Community First, ML personalization is str ongly behaviorist . In the behaviorist worldview , "reality" is only what can be observed (V an Otterlo, 2013). Behaviorism seeks to eliminate the messy theoretical causal mechanisms of human behavior (beliefs, intentions, goals, etc.) and focus instead on what can be measured and recorded (Skinner, 1965). ML personalization takes this idea one step further by focusing on predictive accurac y rather than on causal factors leading to the observed beha vior (Rudin, 2019). In the representation of the person as a feature v ector , "important" attrib utes are only those that contrib ute to the algorithm’ s predictiv e accuracy . The predicti ve goal of ML personalization leads to valuing certain aspects of human behavior more than others; for example, behaviors most amenable to measurement tend to be recorded. This leads to a form of selection bias in the representation of the person. Unpredictable behavior is deemed noise, and measured behaviors which do not add to predicti ve accurac y are deemed redundant. Extraneous features can 2 lead to the "curse of dimensionality" and are removed in order to preserve model parsimony , storage space, and computational efficienc y . One example of how ML personalization fa vors parsimon y is the use of unsupervised dimension reduction techniques, such as Singular V alue Decomposition (SVD). These techniques rely on the discov ery that many of our measured beha viors are simply linear combinations of other beha viors and can thus be discarded with little information loss. W e will see how issues of parsimony , scale, and computational efficiency constrain the degree of personalization when we e xamine Instagram’ s Explore, which must select rele vant content for a focal user from hundreds of millions of other potential users’ contributions. As we discuss in Section 4, the ML approach is at odds with a humanistic view of the person concei ved as having an inner and outer self. As persons, our self-conceptions are highly bound up with our reasons for action, and these reasons may stem from our identity . If the reasons we giv e for our actions are indeed causes of our action, as many philosophers believ e (see, e.g., Davidson, 1963), then we lose an important aspect of the human experience by focusing solely on prediction. The representation of a person as a feature vector abstracts a "person" aw ay from her socio-cultural network of meanings, identities, and v alues and represents her as a precisely-defined digital object in order to predict a very specific behavior , limited to a specific application (see Figure 1). Human societies ev olve over time and v ary in their interpretations of codes of conduct regulating behavior (i.e., morality); yet, due to their abstract generality , mathematical objects and numbers do not. Further , the definitions and properties of mathematical objects remain fixed as a formal public system of rules, whereas human morality is an informal public system of rules of conduct in which the meaning of behavior is often unclear and ev olving (Gert, 1998). This is one possible source of the disconnect in the feature vector representation of the person used in ML personalization. Second, ML personalization focuses on pr edicting a very narr ow set of possible behaviors, often limited by the context of the application . This can make it seem more powerful and accurate than it really is, especially when predictiv e performance is e v aluated. For example, Y eomans et al. (2019) compared the predictions by friends and spouses to those from a simple collaborativ e filtering (CF) system for predicting a focal user’ s ratings of jokes. The study found the basic CF system w as able to predict more accurately than a friend or spouse. Y et, the experiment included a set of 12 jokes pr e-selected by the researchers. The much more difficult problem of selecting 12 jokes from a nearly infinite set of possible jokes in all cultures and languages was left to the humans. In essence, the researchers had already personalized a list of jok es to each subject in the study , gi ven their linguistic background, country of origin, and current location. Once narrowed to such a small recommendation space, the algorithm’ s performance appears quite impressive, b ut nev ertheless hides the fact the hardest task had already been done by humans. A similar argument can be made for personalization on e-commerce sites: by going to a website, a person has already self-selected into a group who would be interested in products of fered by the website. Lastly , recidivism prediction in the judicial setting provides another example of the narrow predictive goal of ML personalization. Small changes in the definition of recidivism and its time-horizon– Is it one, two, or three years in the future? Does it include misdemeanors or only felonies?–will drastically affect the algorithm’ s predicted scores and performance. Third, ML personalization uses data not only fr om the focal user , but also fr om other users . This is clear in the case of recommendation systems using social network data, where the interests and preferences of a focal user can be inferred from their direct and indirect connections to other users and groups. But this point is less obvious when when the data are from measured behaviors on an application or device. Though recommendations based on data from other users could lead one to believe that one’ s personalized scores are not, in fact, "personal," in the sense of stemming from one and the same person, the real issue is whether the "community" chosen reflects one’ s chosen social identity . In other words, personalization can still occur when the personalized scores are based on the behavior of others sharing the same social identity as the focal user . Howe ver , this is unlikely to occur in many ML contexts because "nearest neighbor" threshold v alues are chosen in order to optimize a gi ven error metric, such as RMSE or precision/recall/top-N, not on the basis of any shared social identity (Cremonesi et al., 2010). Recommendations based on the beha vior of others who do not share a similar social and moral identity with the focal user are less personalized under our conception of personalization–all things equal. This principle also implies that when dimension reduction techniques are used, such as PCA and SVD (which rely on calculations of total v ariance across the entire user-item matrix), the selection of a "community" of users making up the user-item matrix is important. Personalized scores using latent factors deriv ed from users who do not share a similar social or moral identity are less personalized in our view . Of course, determining who is truly "similar" to us is a difficult question, but it is one where the methods and concepts of the humanities and social sciences may play an important role. ML Personalization Case Study: Instagram’s Explore The personalization system of the popular social network Instagram shapes the desires, preferences, and self- conceptions of millions of people every day . By determining which content is displayed to which users, social media personalization systems may play an important role in the formation and maintenance of one’ s online and offline identity (Helmond, 2010). When scaled to hundreds of millions of users, ML personalization can ev en hav e society-wide ef fects, shifting opinions tow ards political issues and candidates, as in the 2016 US presidential election. For this reason, we believ e it is important to see ho w ML personalization relates to the "person" and its tacit assumptions reg arding observed beha vior . W e therefore briefly describe Instagram’ s Explore to illustrate the person as a feature vector approach and the implications discussed in the pre vious section. 3 The complicated set of algorithms used for Instagram’ s Explore recommendations essentially work by creating "account embeddings" in order to infer topical similarity . 2 Roughly put, a feature vector (FV) representation of an Instagram user is deri ved from the sequence of account IDs a user has visited. Next, the FV is used to determine a "community" of similar accounts. Similarity in this space implies topical similarity , assuming users do not randomly explore dif ferent topics, but instead tend to view multiple accounts offering similar content. Once the candidate accounts (the nearest neighbors) hav e been found, a random sample of 500 pieces of eligible content (videos, stories, pictures, etc.) is taken and a "first-pass" ranking is made to select the 150 "most rele vant" pieces of content for a focal user . Then a neural network narro ws the 150 to the top 50 most rele v ant. Notice that at each stage, possible content is narro wed-down and that computational ef ficiency is a high priority . Finally , a deep neural network is used to predict specific actions (narro wed only to those possible on the Instagram app) for 25 pieces of content, such as "like," "sa ve," or "see fe wer posts like this." Content is then ranked based on a weighted sum of these very specific behaviors permitted in the app and their associated predicted probabilities. W eights are not determined by users; they are determined by the system engineers and reflect their assumptions about the users’ intentions. Assuming a user wishes to discov er new topics and a v oid seeing content from the same users, a simple heuristic rule is used to downrank certain content and di versify the results. After applying the do wnranking procedure, the content with the highest weighted sum in the "value model" is displayed in decreasing order on the focal user’ s Explore page. 3 The Person, Personal Data, and the Legal Issues of Personalized Scores As described and illustrated in Section 2, personalized scores are generated by combining information about your observed beha vior with certain assumptions about you and your goals, beliefs, and preferences to predict a very constrained set of future actions. But which information should constitute me as a person, and from whose viewpoint ? These are difficult philosophical questions. T o answer we might first ask, "What is a person?" But this question is problematic because "person" is often defined in such a way as to justify a particular w orld-vie w . It can variously mean "human animal, ” "moral agent, ” "rational, self-conscious subject”, "possessor of particular rights, ” and "being with a defined personality or character" (Schechtman, 2018). Nevertheless, W estern thought has focused on two general aspects to the person, one of which is rev ealed through the etymology of the word itself. "Person" comes from the Latin per sona , which deri ves from the Ancient Greek word for a type of mask worn by dramatic actors. For the Ancient Greeks, the idea of a person was inherently connected to context and role. One’ s persona was a specific kind of self-identity that was public, socially defined, and varied depending on context. In time, the outw ard-facing Greek conception was complemented by a Christian emphasis on self-reflection and awareness, resulting in a focus on the human capacity for rational introspection (Douglas and Ney, 1998). Later thinkers e xpanded the idea of the person into tw o main parts: an outer personnage of public roles and masks, and an inner conscience, identity , and consciousness. In short, W estern thought has generally viewed the person as consisting in two co-existing inner and outer domains. W e note that the word personalization contains the adjecti ve per sonal , implying that personalized scores should, at least in part, be based on personal data . For example, Liang et al. (2006) write that personalization is "a process of collecting and using personal information to uniquely tailor products, content and services to an individual." Y et, researchers in ML have lar gely ov erlooked the crucial connection between personalized scores and legal definitions of personal data. A source of complexity is that dif ferent le gal regimes define personal data differently . For instance, the most influential data protection law at the moment, the EU’ s GDPR, defines personal data as "any information relating to an identified or identifiable natural person (‘data subject’)" (Article 4). Such a broad definition means personal data could constitute anything from browser cookies, to location data, to ev en a combination of non- sensitiv e measurements, if there are sufficiently fe w or unique observ ations to single out individuals. Ultimately , context determines whether data are personal data (Greene et al., 2019). Consent is another legal issue in the generation of personalized scores, especially when sensitive data such as race, gender , or political affiliation are inv olv ed. The GDPR’ s reliance on explicit consent has important moral implications. Consent implies choice in how one represents oneself publicly and also which inferences data processors can draw about one’ s identity (see, e.g., K osinski et al., 2013). The GDPR’ s right to rectification and erasure (the so-called "right to be forgotten") further entrenches the importance of autonomy in deciding the factual basis on which one will be judged, classified, and potentially discriminated against, and the extent to which our identities as persons are reflected in observations of our public beha vior . This notion has been called informational privacy (Moreau, 2010; Shoemaker, 2010). In short, the existing literature on ML personalization o verlooks two key points: first, that it depends on dif fering legal definitions of personal data; and second, informational pri v acy concerns are generally not considered in the design of personalized systems. 2 Example taken from ai.facebook.com/blog/powered-by-ai-instagrams-explore-recommender-system/ 4 4 Identity , Self, and Data Regulation ML researchers and practitioners normally deal with issues of “practical identity , ” while philosophers and social scientists deal with issues of "moral" and "social" identity (De Vries, 2010; Manders-Huits, 2010). Recently , humanistic scholars hav e focused on a ne w , third kind of identity arising from the difficulties in the formation of a single, unitary digital identity in light of rapidly ev olving technology . The nature of distrib uted storage and collection of observ able behavioral data related to li ving persons further complicates the process of identity formation (see "Digital reality" in Figure 1). These distributed digital representations of our practical, moral, and social identities hav e been v ariously termed data citizens , data doubles , data shadows and digital subjects (Goriunov a, 2019). The narrowing from reality , to observed reality , to digital reality (Fig 1) raises questions about the relation between persons, personal data, and personalized scores. While many of today’ s ML algorithms generate dif ferent scores giv en dif ferent contextual input data, these scores can fail to reflect our moral identities . For example, scores based on categorical features may not reflect one’ s social or personal identity . Similarly , explanations for personalized scores at the algorithm or model le vel (e.g., v ariable importance scores) may fail to reflect the salience of beliefs, motiv ations, and intentions we hav e when explaining our behavior to others. An explanation of a personalized score that leav es out these important aspects of one’ s moral identity surely cannot be said to relate to one as a person . Though we cannot control how society sees us, we can choose to (partly) accept or reject society’ s categorization of us. This latter aspect of human experience remains largely unaccounted for in ML personalization. As Manders-Huits (2010) argues, "The challenge [of] justice to data subjects as moral persons is to take into account the self-informativ e perspecti ve that is part of ‘identity management. ’" W e no w provide a brief overvie w of identity theories and humanistic perspectives dra wing mainly from social and personality psychology , consumer behavior , sociology , philosophy , economics, information systems, and recent data protection law . W e hope exposure to these ideas can influence future thinking on and design of ML systems generating personalized scores. T able 1 summarizes ke y concepts related to the person from these disciplines. Identity from a Social Science Perspective Theories and concepts of self and identity are fundamental topics in psychology , despite being difficult to precisely define. Personality psychologists Larsen and Buss (2009) define personality as a an organized set of relatively enduring psychological traits that guide a person’ s interactions with her "intrapsychic, physical, and social en viron- ments." These traits can be e xpressed as the "Big Fi ve" dimensions of personality: Openness to New Experience, Conscientiousness, Extrav ersion, Agreeableness, and Neuroticism (also kno wn as OCEAN), and hav e been shown to hav e varying le vels of predictive po wer . 3 Personality psychology has also begun to study the formation of moral identity . For e xample, Aquino et al. (2002) sho w how highly important moral identities–the collection of certain beliefs, attitudes, and behaviors relating to what is right or wrong–can provide a basis for the construction of one’ s "self-definition." Finally , social psychologists define the self as an interface between the biological processes of the body and the larger social and cultural context. Further , they highlight the power of the cultural context in defining identity: "W ithout society , the self would not e xist in full" (Baumeister and Bushman, 2014, p. 74). As the summaries abov e illustrate, understanding the person requires description at multiple lev els. McAdams (1995) presents an influential multi-dimensional theory of the person, focusing on traits, personal concerns, and life stories. According to identity theorists in sociology and psychology , the self is fluid and occupies multiple social roles (identity theory) or group identities (social identity theory) that coe xist and v ary ov er time. The dynamism of the self-concept is reflected in its numerous sub-components or self-representations: the past, present, and future self; the ideal, "ought," actual, possible, and undesired self (Markus and W urf, 1987). Identity theorists highlight ho w a unified self-conception arises from the v ariety of meanings gi ven to v arious social roles the self occupies (Stryker and Burke, 2000). Common types of social identities relate to one’ s ethnicity , religion, political af filiation, job, and relationships. People may also identify strongly with their gender , se xual orientation, and v arious other "stigmatized" identities, such as being homeless, an alcoholic, or overweight (Deux 2001). In short, social psychologists generally agree one’ s self-concept is one of the most important regulators of one’ s behavior . The self-concept has also influenced postmodernist consumer beha vior research. Consumers now take for granted their sometimes paradoxical identities, beliefs, and behaviors in ev eryday life (Fuat Firat et al., 1995). In the postmodern condition one "listens to reggae, watches a W estern, eats McDonald’ s food for lunch and local cuisine for dinner , wears P aris perfume in T okyo and retro clothes in Hong K ong" (L yotard, 1984). Identity , the Self, and Morality from a Philosophical Perspective How do philosophers understand the link between the identity and the self? For some, the self arises from an identification of structural sameness over time, e xperienced as a kind of narrativ e (Ricoeur, 1994). Though indi vidual cells of our bodies are constantly renewed, a person’ s essential structure nevertheless remains similar enough to be identified as the "same" over time. For others, such as T aylor (1989), social and communal life link the two concepts. T aylor (1989) argues that one’ s identity is tied to one’ s moral values and a defining social community . He 3 Mischel et al. (2007) show that kno wing an individual’ s Big Fiv e trait profile allows for only weak prediction of a particular behavior in a particular conte xt 5 T able 1: Perspectives and K e y Concepts on the Person and Personal Identity Philosophy & Humanities Psychology , Sociology & Con- sumer Behavior Economics & Information Systems Data Regulation & Profes- sional Codes of Conduct Moral identity Personality: Big 5 Identity explains irrational Right to be forgotten Community-defined identity Socially-defined identity behavior Right to rectification Pursuit of the good life Culturally-influenced narrativ es Digital identity Automated profiling The Postmodern experience Emotions and moods Online identity affects Informational priv acy Narrativ e identity Hermeneutic interpretation behavior Agency o ver digital identity Inner and outer-f acing self Meaning of symbols, texts, images Identity as economic choice Ethically-aligned design writes, "I define who I am by defining where I speak from, in the family tree, in social space, in the geography of social statuses and functions, in my intimate relations to the ones I love, and also crucially in the space of moral and spiritual orientation within which my most important defining relations are li ved out." Our identities therefore rest on the constant interplay between ho w others vie w us and ho w we vie w ourselv es. These "community" identities further entail various moral oblig ations to others that influence and moti vate our beha vior . Atkins (2010) draws on work by Ricoeur and K orsgaard to explain the connection between morality and identity . She claims that "one’ s identity is the source of one’ s moral agency , e xpressed in one’ s normativ e reasons." One’ s identity constitutes "the condition of the possibility for having a perspectiv e from which to perceiv e, deliberate, and act . . . it is a condition of the possibility of morality ." For both T aylor and Atkins, the de velopment of a self-identity provides a moral scaffolding upon which possible actions can be ev aluated; our identities are critical for embedding us both in the physical and social worlds, and adding a moral dimension to our actions as persons. In Schechtman (2018)’ s influential narrati ve self-constitution vie w , personhood and personal identity are fleshed out in terms of a unified and "unfolding dev elopmental structure, ” analogous to a complex musical sonata. Echoing the ideas of Ricoeur , she writes that human life "is a structural whole that has, by its very nature, attrib utes that apply to it as a whole which do not necessarily apply to each indi vidual portion." Through the unity of e xperience–which takes the form of a narrati ve–the same person can be an inf ant at one time and later in life suf fer from dementia. Her notion of personal identity is similar to McAdams’ psychological vie w in that it explains via a diachronic process how identity can e volve o ver time. These views highlight the processual, dynamic, and emergent nature of the self. Identity in Information Systems (IS) and Economics As the W orld W ide W eb grew in popularity , scholars in the field of IS began to examine its impact not just on the organization, but on the individual. Some were influenced by postmodern arguments and pushed for a reconsideration of such fundamental concepts as space, time, the world, and the self (Introna and Whitley, 1996). Erickson (1996), for example, foreshado wed the rise of social media when he e xamined the "portrayal management" of online identities afforded by personal webpages. The anonymity of the Internet meant that individuals could selectiv ely represent themselv es to others without the comple xities of physical contact. Nearly two decades later , the study of online communities and identity formation has entered into the mainstream, leading to novel methods of data collection and analysis. A gro wing stream of research in IS now draws on the constructs of identity and socio-cultural norms to explain online beha vior . Burtch et al. (2016), for example, explored ho w contrib uting to the same cro wdfunding campaign could foster a common identity in users and influence a campaign’ s fundraising success. Finally , in the more traditional domain of economics, Akerlof and Kranton (2000) presented one of the first and most influential economic analyses of the role of social and group identity on beha vior . Their work illustrates how decisions about identity can be used to explain apparently irrational behavior , the creation of behavioral externalities in others, and preference e v olution. Digital Identity in Data Regulation and Professional Codes of Conduct Around the world, the passage of new data protection laws reflects growing social concern over the process of turning a person into a feature vector . The GDPR and the California Consumer Pri v acy Act (CCP A) both seek to giv e citizens more control ov er their personal data and their digital identities. The GDPR giv es data subjects rights to opt out of "automated profiling" with "legal" or other "significant" ef fects. The GDPR’ s right to be for gotten can be vie wed as a potential le gal remedy to the issue of one’ s practical and moral identity div er ging ov er time. Data subjects hav e the right to destroy and recreate aspects of their digital identities when they no longer represent them as persons. At the same time, important ML societies, such as the IEEE and A CM, ha ve also v oiced concern about the effects of ML on human well-being. For e xample, recent IEEE guidelines state that autonomous and intelligent systems should gi ve people access and control ov er their personal data and allo w them "agency over their digital identity ." 4 The following section thus lays out a basic conceptual framework for use by regulators, professional groups, and practitioners to assess lev els of personalization. 4 The IEEE Global Initiative on Ethics of Autonomous and Intelligent Systems. Ethically Aligned Design: A V ision for Prioritizing Human W ell-being with Autonomous and Intellig ent Systems , 1st ed, 2019 https://ethicsinaction.ieee.org 6 5 Evaluating ML Personalization In order to better align ML personalization with a humanistic vie w of the person and current trends in data protection law , we propose six criteria to guide future discussions. W e consider the degree of personalization to be on a continuum and to depend on objectiv e (outer-f acing) and subjectiv e (inner-f acing) dimensions. As shown earlier in Figure 1, the inner aspects of the person are inaccessible through observational methods. First-person, subjectiv e input from the person herself is therefore crucial in measuring the lev el of personalization. The social sciences and humanities are especially well-positioned to contribute to the interdisciplinary dev elopment of such measures using quantitativ e and qualitati ve data collection and analysis methods. Lastly , legal experts will also be needed to relate these measures to data subjects’ rights under current data protection laws, such as the GDPR. Objective dimensions include (1) a per sonal data component - the extent to which le gally-defined personal data are used, and (2) a uniqueness component - the percent of other users sharing the same input data, personalized score, or discretized recommendation. The personal data component implies that le gally-allo wable de grees of personalization may v ary by country and leg al regime. Regarding the uniqueness component, it is not clear ho w to weight these three aspects in determining the degree of personalization. Numeric measurements may uniquely identify you more so than categorical measurements, but these cate gories may more closely reflect your personal identity and community . Similarly , it is not obvious how to reconcile dimension reduction techniques with personalization. For example, when highly morally-salient measurements are correlated to other measures, should the y be remov ed? Another objecti ve dimension w orth examining is (3) an accur acy component - the accuracy of predicted scores. It seems reasonable to assume personalized predictions should be more accurate than non-personalized predictions. But how should accurac y be measured? As we noted above, the very narro w predicti ve goal of ML personalization can obscure the interpretation of some accuracy metrics. An easy way to improv e accuracy is simply to narro w the size of the "recommendation set." Howe v er , in some cases, accuracy may not be desired; some persons may prefer to trade off predicti ve accuracy (in the narro w sense above) for informational pri vacy . As noted earlier , data subjects hav e basic rights to informational pri v acy under the GDPR. Subjective dimensions include (4) a self-determination component - the extent to which personalized scores respect the data subject’ s right to determine his public self, captured in the notion of informational priv acy . This subjectiv e component is rele vant to debates on fair and transparent ML (F A TML). Current legal and ML approaches to fairness operate on the lev el of the "database representation" of the person (i.e., practical identity), overlooking the person’ s moral identity . Thus we propose a (5) right reasons component - fair decisions should capture the person’ s intended public self and associated goals, attitudes, meanings and motiv ations in that context. The relev ance of reasons giv en in algorithmic explanations can be assessed, for example, using rele vance feedback techniques already in use in information retriev al. Lastly , another subjective dimension is (6) a moral importance component - the moral importance of the personalization conte xt. For example, ho w should the dif ferent subjective and objectiv e components be weighted when assessing a system that recommends a movie v ersus a bail amount? Finally , our proposed list of ev aluation components is by no means e xhaustiv e. In fact, some of these components might interact with or ev en contradict other aspects of personalization. For example, serendipitous recommendations 5 (Ge et al., 2010) can stimulate e volution in one’ s moral identity , yet might conflict with the accur acy component . Allowing users to decide for themselv es ho w they w ould like to weight these aspects may be one solution. 6 Future W ork and Conclusion Going forward, we believ e that as ML personalization becomes increasingly rooted in daily life, we should consider new approaches to data collection, such as those used in qualitati ve social science (e.g., hermeneutics, discourse analysis, fuzzy-set theory). By incorporating more div erse forms of personal data into personalized scores, we may be able to reduce the gap between one’ s identity as a person embedded in social and cultural space and as a featur e vector embedded in feature space. As we emphasize, howe ver , the ML personalization process will nev er be perfect. Our presentation of the ML pipeline can also be expanded to consider further ML operations, such as how and which data are used for training algorithms. For example, personalized scores for a gi v en person are computed using models that were trained on data from other persons, typically excluding that person’ s o wn data. Chronology of the training set is also important when considering the dynamism of a person’ s self-concept. Lastly , these ev aluation dimensions are merely an entry point into an interdisciplinary discussion about personaliza- tion. W e hope to initiate and contribute to such a discussion by describing what the process of ML personalization typically looks like, particularly its defining metaphor of the person as feature vector . W e ar gued that this conception is radically dif ferent from that found in the humanities, social sciences, and l aw . As the long-term effects of ML personalization on personal identity , politics, la w and society are still unclear , it is important to critically examine the process of ML personalization. Perhaps it cannot be precisely defined, but an examination of its ke y characteristics and assumptions may help foster new insights on the issues of algorithmic bias, transparenc y , and fairness. 5 Serendipity is used in Instagram’ s "downranking" procedure, under the assumption that one’ s preferences should not remain static and so new topics should be presented in order to pro vide di verse personalized content. 7 Acknowledgements W e thank Ching-Fu Lin, Jack Buchanan, Mariangela Guidolin, Kellan Nguyen, and Boaz Shmueli for their helpful comments on an earlier draft of this paper . References Akerlof, G. A. and Kranton, R. E. (2000). Economics and identity . Quarterly J ournal of Economics , 115(3):715–753. Aquino, K., Reed, I., et al. (2002). The self-importance of moral identity . J of per sonality and soc psych , 83(6):1423. Atkins, K. (2010). Narrative identity and mor al identity . T aylor & Francis. Barocas, S., Hardt, M., and Narayanan, A. (2017). Fairness in machine learning. NIPS T utorial . Baumeister , R. F . and Bushman, B. (2014). Social psychology and human natur e . Belmont, CA: Cengage Learning. Burtch, G., Ghose, A., and W attal, S. (2016). Secret admirers: An empirical examination of information hiding and contribution dynamics in online cro wdfunding. Information Systems Researc h , 27(3):478–496. Cremonesi, P ., K oren, Y ., and T urrin, R. (2010). Performance of recommender algorithms on top-n recommendation tasks. In Pr oceedings of the fourth A CM conference on Recommender systems . A CM. Davidson, D. (1963). Actions, reasons, and causes. The journal of philosophy , 60(23):685–700. De Vries, K. (2010). Identity , profiling algorithms and a world of ambient intelligence. Ethics and information technology , 12(1):71–85. Douglas, M. and Ney , S. (1998). Missing persons: A critique of the personhood in the social sciences , volume 1. Univ of California Press. Erickson, T . (1996). The world-wide-web as social hypertext. Communications of the ACM , 39(1):15–17. Fan, H. and Poole, M. S. (2006). What is personalization? perspectiv es on the design and implementation of personalization in information systems. Journal of Or g. Comp. and Elec. Comm. , 16(3-4):179–202. Fuat Firat, A., Dholakia, N., and V enkatesh, A. (1995). Mark eting in a postmodern world. Eur opean journal of marketing , 29(1):40–56. Ge, M., Delgado-Battenfeld, C., and Jannach, D. (2010). Beyond accurac y: ev aluating recommender systems by cov erage and serendipity . In Pr oceedings of the fourth A CM confer ence on Recommender systems . ACM. Gert, B. (1998). Morality: Its nature and justification . Oxford Univ ersity Press on Demand. Goriunov a, O. (2019). The digital subject: People as data as persons. Theory , Cultur e & Society , 36(6):125–145. Greene, T ., Shmueli, G., Ray , S., and Fell, J. (2019). Adjusting to the gdpr: The impact on data scientists and behavioral researchers. Big data , 7. Helmond, A. (2010). Identity 2.0: Constructing identity with cultural software. In Pr oceeding of Mini-confer ence initiative, University of Amster dam (Amsterdam, ND–J an 20-22 2010) . Citeseer . Introna, L. D. and Whitley , E. A. (1996). Information systems as a social science? the individual perspective. Information Systems , 8:16–1996. Kelleher , J. D., Mac Namee, B., and D’arcy , A. (2015). Fundamentals of machine learning for predictive data analytics: algorithms, worked e xamples, and case studies . MIT Press. K osinski, M., Stillwell, D., and Graepel, T . (2013). Priv ate traits and attributes are predictable from digital records of human behavior . Proceedings of the National Academy of Sciences , 110(15):5802–5805. Larsen, R. and Buss, D. M. (2009). P ersonality psyc hology . McGraw-Hill Publishing. Liang, T .-P ., Lai, H.-J., and Ku, Y .-C. (2006). Personalized content recommendation and user satisfaction: Theoreti- cal synthesis and empirical findings. Journal of Mana gement Information Systems , 23(3):45–70. L yotard, J.-F . (1984). The postmodern condition: A r eport on knowledge , v olume 10. U of Minnesota Press. Manders-Huits, N. (2010). Practical versus moral identities in identity management. Ethics and information technology , 12(1):43–55. Markus, H. and W urf, E. (1987). The dynamic self-concept: A social psychological perspectiv e. Annual r evie w of psychology , 38(1):299–337. McAdams, D. P . (1995). What do we know when we kno w a person? J ournal of personality , 63(3):365–396. Mischel, W ., Shoda, Y ., and A yduk, O. (2007). Intr oduction to per sonality: T oward an inte grative science of the person . John Wile y & Sons. Moreau, S. (2010). What is discrimination? Philosophy & Public Affairs , 38(2):143–179. Nichols, D. (1998). Implicit rating and filtering. In Pr oc of 5th DELOS W orkshop on F iltering and Collab F iltering . Ricoeur , P . (1994). Oneself as another . University of Chicago Press. Rudin, C. (2019). Stop e xplaining black box machine learning models for high stakes decisions and use interpretable models instead. Natur e Machine Intellig ence , 1(5):206. Schechtman, M. (2018). The constitution of selves . Cornell univ ersity press. Shoemaker , D. W . (2010). Self-exposure and exposure of the self: informational priv acy and the presentation of identity . Ethics and Information T ec hnology , 12(1):3–15. Skinner , B. F . (1965). Science and human behavior . Simon and Schuster . Stryker , S. and Burke, P . J. (2000). The past, present, and future of an identity theory . Social Psychology Quarterly , 63(4):284–297. T aylor , C. (1989). Sources of the self: The making of the modern identity . Harvard Uni versity Press. 8 V an Otterlo, M. (2013). A machine learning view on profiling. Privacy , Due Pr ocess and the Computational T urn-Philosophers of Law Meet Philosophers of T echnology . Abingdon: Routledge . Y eomans, M., Shah, A., Mullainathan, S., and Kleinberg, J. (2019). Making sense of recommendations. Journal of Behavioral Decision Making , 32(4):403–414. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment