The Expressivity and Training of Deep Neural Networks: toward the Edge of Chaos?
Expressivity is one of the most significant issues in assessing neural networks. In this paper, we provide a quantitative analysis of the expressivity for the deep neural network (DNN) from its dynamic model, where the Hilbert space is employed to an…
Authors: Gege Zhang, Gangwei Li, Ningwei Shen
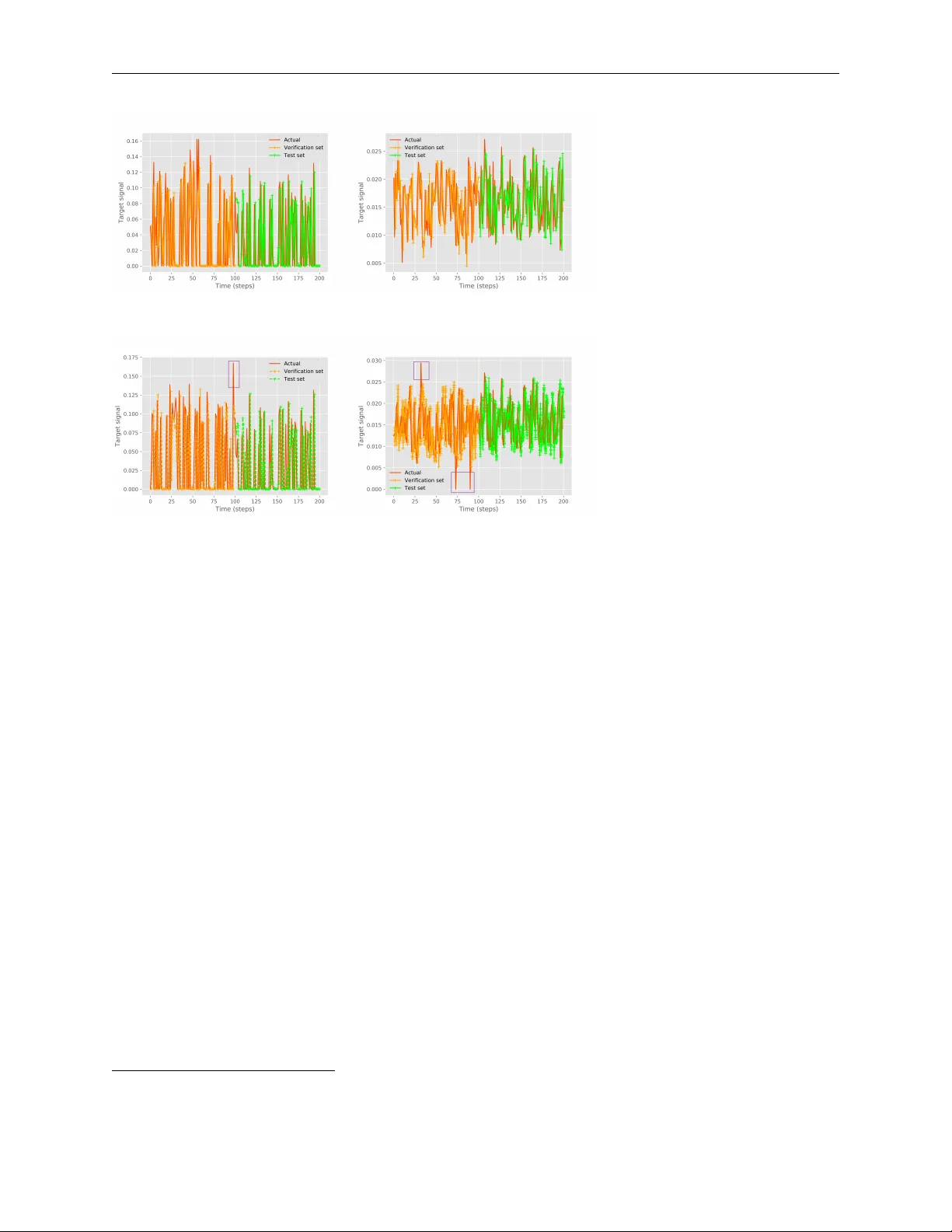
T H E E X P R E S S I V I T Y A N D T R A I N I N G O F D E E P N E U R A L N E T W O R K S : T O W A R D T H E E D G E O F C H A O S ? A P R E P R I N T Gege Zhang Department of Automation Shanghai Jiao T ong University Shanghai 200240, PR China ggzhang@sjtu.edu.cn Gangwei Li NVIDIA Corporation Building 2 No. 26 Qiuyue Road Shanghai PRC, Shanghai 201210, PR China vili@nvidia.com W eining Shen Information and Computer Sciences Univ ersity of California Irvine, CA 92697, USA weinings@uci.edu W eidong Zhang Department of Automation Shanghai Jiao T ong University Shanghai 200240, PR China. wdzhang@sjtu.edu.cn December 24, 2019 A B S T R A C T Expressivity is one of the most significant issues in assessing neural networks. In this paper , we pro- vide a quantitati ve analysis of the expressi vity for the deep neural network (DNN) from its dynamic model, where the Hilbert space is employed to analyze the con vergence and criticality . W e study the feature mapping of se veral widely used acti vation functions obtained by Hermite polynomials, and find sharp declines or e ven saddle points in the feature space, which stagnate the information transfer in DNNs. W e then present a ne w acti vation function design based on the Hermite polynomi- als for better utilization of spatial representation. Moreover , we analyze the information transfer of DNNs, emphasizing the con vergence problem caused by the mismatch between input and topologi- cal structure. W e also study the effects of input perturbations and re gularization operators on critical expressi vity . Our theoretical analysis rev eals that DNNs use spatial domains for information repre- sentation and ev olve to the edge of chaos as depth increases. In actual training, whether a particular network can ultimately arrive the edge of chaos depends on its ability to overcome con vergence and pass information to the required netw ork depth. Finally , we demonstrate the empirical performance of the proposed hypothesis via multiv ariate time series prediction and image classification examples. K eywords Deep neural networks; expressi vity; criticality theory; con vergence; acti vation function; Hilbert transform 1 Introduction Deep neural networks (DNNs) ha ve achiev ed outstanding performance in many fields, from the automatic translation to speech and image recognition [1, 2]. It is no w understood that a ke y ingredient of its success is the so-called high expr essivity property . For example, Bianchini, Scarselli and Zhang et al. [3, 4] showed by numerical analysis that DNN had an exponential expressi vity as depth increased. Similar results were obtained using a topological measure in [5]. Ef forts hav e also been made to explore the black box structure of DNNs from a theoretical perspectiv e. This starts with the in vestigation of the dynamics (e.g., depth and width) of DNNs; and it was found that the dynamics of DNNs were very dif ferent from those of shallow networks [6]. Subsequently , mathematical analysis, e.g., wavelet and function approximation frame works, were applied towards a better understanding of DNNs, although most of the works were limited to two-layer networks only [7, 8]. Further , due to the non-linear functional mappings of the input-to-output acti vation functions, the con vergence and expressivity with respect to activ ation functions hav e been The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T in vestigated [9, 10, 11, 12, 13]. Although these studies provide significant adv ances in understanding DNNs, their excellent representation performance is still largely not well understood. Moreo ver , as noted by many previous works, training DNNs remains very challenging, where the major difficulties include the existence of local minimums, lo w curvature re gions, and exponential growth or fading of backpropag ation gradients [14]. T o solve the aforementioned challenges in interpreting and implementing DNNs, the current dev elopment of com- plexity theory prompts people to understand DNNs from a general theoretical perspecti ve. It has been pointed out that DNNs could be thought of as a type of complex network that possesses an exponential expressi vity in their depth, where the information capacity reaches maximum in an order-disorder phase transition [5, 10, 15]. All fea- tures of interest can be represented by a medium-sized network, similar to today’ s DNNs, etc. This motiv ates the relev ant literature on in vestigating DNNs from a complexity theory perspective. For example, Hanna et al. [16] estab- lished a natural connection between the autoencoder and the energy function, and then provided a classifier based on class-specific autoencoder . Morningstar et al. [17] showed that shallow networks were more effecti ve than DNNs in representing probability distrib ution. Del et al. [18] inv estigated the critical characteristics of self-organizing recurrent neural network (RNN), and showed that a neural plasticity mechanism was necessary to reach a critical state, but not to maintain it. Moreover , field theories such as Mean-field, Symmetry Breaking, and Renormalization Group have been postulated to explain the criticality of DNNs [5, 19, 20, 21, 22]. Some network structures such as small-world networks and scale-free networks hav e been utilized for the topology design of DNNs; and the results indicate that they can achieve faster con vergence than that of random networks [23, 24]. Although the pre vious work pro vides some profound insights into DNNs, a quantitativ e analysis of the rich dynamics in DNNs remains elusive. The goal of this paper is to (i) examine the expressi vity and training of DNN through quantifying its vanilla version, as well as analyze its conv ergence and criticality based on its dynamics; and (ii) study the factors influencing the con vergence of DNNs such as activ ation functions, inputs, and model training. These results will provide more insights on how to impro ve the empirical performance of DNNs. W e summarize our major contributions as follo ws: • In theory , we sho w that DNN uses spatial domains for information representation and approaches the edge of chaos as depth increases. In actual training, whether a network can ultimately arri ve at the edge of chaos or not depends on its ability to ov ercome con ver gence and pass information to the desired network depth. • By analyzing the feature mapping of commonly used activ ation functions under Hermite polynomials, we find that there are significant drops or even saddle points in the feature space that slow down the message passing in DNNs. W e propose an activ ation function design based on the Hermite polynomials to accelerate con vergence. • W e also analyze the information transfer in DNNs with an emphasis on model matching between inputs and topological structures. The results suggest that the appropriate network size is crucial to reach the chaotic edge. The rest of the paper is organized as follows. Sec. 2 analyzes the dynamic model of a vanilla DNN. Sec. 3 studies the feature mapping of sev eral commonly used activ ation functions under Hermite polynomials and proposes a new activ ation function to use. Sec. 4 examines information transfer in model training, focusing on the model matching between inputs and topological structures. Sec. 5 studies the impact of input perturbation and re gularization on critical representation. Sec. 6 verifies the provided perspectiv e by multi variate time series prediction and image classification. W e discuss some relev ant work in Sec. 7 and conclude with a few remarks in Sec. 8. 2 Dynamics of a vanilla deep neural network In this section, we study the conv ergence and criticality properties of DNN based on its dynamic model. First consider a vanilla DNN with an L -layer weight matrix W 1 , . . . , W L and ( L + 1) -layer neural activity v ectors x 0 , . . . , x L , assuming N l neurons in the layer l , so that x l ∈ R and W l is a N l × N l − 1 weight matrix. The feedforward dynamics from the input x 0 is giv en by x l = σ ( W l x l − 1 + b l ) , for l = 1 , . . . , L, (1) where b l is a bias vector , and σ is an activ ation function that transforms inputs to nonlinear outputs. W ithout loss of generality , we assume that the weight matries W l all follo w a normal distribution and denote W l as W for simplicity . Criticality plays a significant role in the theory of phase transitions. It appears in a variety of complex networks, e.g., water freezing and iron magnetizing [15]. As a network approaches a critical point, it exhibits some interesting phenomena, such as fantastic expressi vity and self-organization, etc. DNNs maximize entropy between inputs and outputs through information transfer between neurons, which are analogous to complex networks. Below we analyze the criticality of a vanilla DNN from dynamics by utilizing its L yapunov function (the eigenv alues of the system’ s 2 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T Jacobian matrix). According to the chain rule, the Jacobian matrix of Eq. (1) can be expressed as J ( x ) = σ 0 ( W x + b ) W , (2) where σ 0 is the deri vati ve of acti vation function σ . Then the netw ork status can be calculated as the eigenv alues of the Jacobian matrix at time n : λ = max l =1 ,...,L 1 N N X n =1 log ( | σ l ( n ) | ) , (3) where σ l ( n ) denotes the eigen values of J ( x ) at time n . There may be many equilibrium points for general DNNs. T o determine whether an equilibrium point is stable, we can check the local approximation at the equilibrium point. For instance, by linearing (1) at the equilibrium point x 0 , we obtain x ( n ) = J ( x 0 ) ( W x ( n − 1)) , (4) which is a homogeneous differential equation whose solution can be determined by the roots of its characteristic polynomial. When all roots have negati ve real parts, the system is considered stable; it is assumed chaotic when any root posses a positiv e real part; and it is on the edge of chaos when any root owns zero real part. Fortunately , the roots (eigen values) of commonly used acti vation functions are in general constrained within [0 , 1) , thus avoiding the tendency tow ard a chaotic state. Moreo ver , early advances in designing activ ation function mainly focus on the existence of global asymptotic/exponential stability of critical points (along with the lines, concerning the existence, uniqueness, completeness, sparsity , con ver gence, and accuracy of such a function [25]). Howe ver , it is in general difficult to determine the eigenv alues for an arbitrary dynamic equation. Therefore, to date, there is still a lack of clear guidelines for designing activ ation functions. Therefore, an adaptiv e activ ation function called Swish activ ation has been dev eloped recently and shown to hav e significantly outperformed the ReLU activ ation [26]. 3 F eature mapping using Hilbert space Suitable and univ ersal activ ation function design can greatly improve the performance of DNNs. Hilbert space, as a natural infinite-dimensional generalization of Euclidean space, and as such, enjoys the essential features of complete- ness and orthogonality . In this section, we present the feature mapping using Hilbert space and then give an appropriate activ ation function design based on the analysis. The proofs of all the theorems can be found in Chapters 2 and 5 of [27]. Consider an inner product space with a norm defined by k x k = h x, x i 1 / 2 . If space H is complete with respect to this norm, it is called a Hilbert space. A complete normed vector space is called a Banach space, hence a Hilbert space is a closed subset of a Banach space. The following Contraction-Mapping Theorem, also kno wn as the Banach’ s Fixed Point Theorem, is a useful tool for guaranteeing the existence and uniqueness of solutions for a dif ferential equation. Theorem 1 ( The Contraction-Mapping Theorem ) Given a function T : X → X for any set X , if an x ∈ X makes T ( x ) = x , then x is called a fixed point. If the fixed point is unique,then the only solution can be obtained by the limit of x ( n ) defined by x ( n ) = T x ( n − 1) , n = 1 , 2 , . . . , expr essed as: x = lim n →∞ T n x 0 , (5) wher e x 0 is an arbitrary initial element. Theorem 1 also provides a useful way to find the solutions to the dif ferential equation through an iterativ e process. The following is a natural e xtension of the theorem. Lemma 1 If T is a self-adjoint operator , then ther e exists B ≥ A > 0 satisfying: ∀ f ∈ H , A k f k 2 ≤ h T f , f i ≤ B k f k 2 . (6) If T is invertible , then we have: ∀ f ∈ H , 1 B k f k ≤ h T − 1 f , f i ≤ 1 A k f k 2 . (7) Inequality (6) shows that the eigen values of T are between A and B . In a finite dimension, it is diagonal on an orthogonal basis since T is self-adjoint. It is therefore in vertible with eigen values between B − 1 and A − 1 , which prov es inequality (7). From the Theorem 1 and the Lemma 1, we know that Hilbert space can conv ert the dynamics of DNN into a linear model, and the unique solution can be found by increasing depth. Specifically , the eigen values of the current DNNs 3 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T (a) MNIST data sets (b) CIF AR10 data sets Fig. 1. Comparison of the con vergence for differ ent activation functions . The experiment adopted the default settings in the conv olutional neural network, including con volution, nonlinearity , and pooling. The stochastic gradient descent is used as the optimization method. The same experimental setup is used for Fig. 2 and 3. are within [ − 1 , 1) , which make them con ver ge to 0 by iteration, so that 0 is a critical point of the system. From the dynamics in Sec. 2, if an y of the roots of (4) is 0 , then the system is on the edge of chaos. Therefore, DNN approaches the edge of chaos at an exponential speed as depth increases. According to the definition of information entropy , that is a property that identifies system’ s tendency to mo ve toward a completely random or disordered state [28]. A system of high entropy is more disordered or chaotic than that of lo w entropy , therefore, information entropy can be used to the expressivity of DNNs. From this viewpoint, we also see that the so-called fantastic expressi vity in complexity theory will show up when in vestigating the high-dimensional presentation of DNN. From the feature mapping perspective, Hilbert space can be employed to understand the beha vior of existing activ ation functions. Due to the space limit, we postpone a detailed analysis of the activ ation functions under Hermite polyno- mials to A. In Fig. 1, we provide a numerical comparison of their con vergence based on the MNIST and CIF AR10 data sets. It can be seen that the Sigmoid activ ation attenuates coefficients with higher amplitude and saturates near the output zero, making it unsuitable for DNNs. The T anh activ ation function saturates at the output − 1 and +1 and has a well-defined gradient at output 0 , which suggests that the vanishing eigen values around output 0 can be avoided by employing the T anh activ ation function. The ReLU activ ation achieves fast con vergence, and requires cheap com- putation in implementation. Howe ver , there are many zero elements in the ReLU activ ation, which correspond to the saddle points in training neural networks. The Swish activ ation avoids this issue, and it achieves the best results in terms of the fast conv ergence to the global optima. The Swish activ ation largely replaces the Sigmoid activ ation and the soft T anh activ ation because of its easiness in training DNNs. The abov e analysis indicates that Hermite polynomials can be used to design useful activ ation functions, similarly with the use of wavelet for acti vation function designs [7]. T o get close to the edge of chaos, the Hermite coefficients of activ ation functions should be within (0 , 1) . In practice, to allow information to transfer in an iterativ e process, the coefficients should be around 0 . 5 (the middle of the interval). Also, based on the dynamics, the maximum and the minimum Hermite coefficients should also have an impact on the con ver gence. T o demonstrate their impact, we plot the con vergence error of DNNs on the MNIST and CIF AR10 data sets using dif ferent maximum and minimum Hermite coefficient values in Figures 2 and 3. The results show that for both data sets, when the maximum Hermite coefficient is 0.6–0.65, and the minimum is around 0 . 4 , the system is optimal. In addition to the maximum and minimum Hermite coefficients, the spacing between the eigenv alues may also af fect the performance of the Hermite polynomial (HP) activ ation function. Fig. 4 shows the influence of the interval of Hermite coefficients on con vergence, indicating that the optimal interval is 0.12–0.14. Through the above analysis, we find that, similarly with complex networks, there is an interesting spatiotemporal in- formation representation and propagation in DNNs, where information capability becomes more and more abundant by increasing spatial representation and the ev olution tow ards the edge of chaos as depth grows [29]. The spatiotem- poral structures can also be modeled by feature selection. For example, instead of taking features only from current regions, elements from adjacent areas can be stacked together to form a larger feature space. In the context of image processing, this idea was generalized to conv olutional neural networks (CNNs) to calculate the adjacent properties of images [30]. RNNs provide another useful way to model the temporal dependency , rendering the network to extract the specific time-dependent length of information [31]. 4 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T (a) MNIST data sets (b) CIF AR10 data sets (10 Monte Carlo ex- periments) Fig. 2. The maximum Hermite coefficients . (a) MNIST data sets (b) CIF AR10 data sets (10 Monte Carlo ex- periments) Fig. 3. The minimum Hermite coefficients . (a) MNIST data sets (b) CIF AR10 data sets (10 Monte Carlo ex- periments) Fig. 4. The intervals of hermite coefficients . 5 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T 4 Inf ormation transfer in deep neural networks: T raining network models So far our discussion is mainly focused on the expressivity of DNNs. In this section, we discuss another crucial step, the training process. It is well known that different learning problems require different network models, and the training process plays a crucial-yet-challenging role [32]. The training can be viewed as a complex matching process [33]. T o date, many works inv olving model matching hav e focused on graph neural netw orks, since graphs can vividly capture the relationship between nodes [34]. Xu et al. [35] pointed out that the expressi vity of GNNs w as equiv alent to the W eisfeiler-Lehman graph isomorphism test. Howe ver , for general non-conv ex problems, solving the exact model matching is very dif ficult due to its NP complexity and a lack of guarantee for global optimality [36, 37]. Furthermore, current neural networks are in variably static networks, i.e., the network structures are pre-set before training. Dauphin and other researchers have suggested that the number of saddle points (not local minimums) increases exponentially likely with the network depth [38]. In other words, a local minimum in a low dimension space may be a saddle point in a high dimension space. This phenomenon is also called by the proliferation of saddle points hypothesis, which can be easily verified by the dynamics. From Sec. 2, we kno w that DNNs with an activ ation function whose declining eigen values are within (0 , 1) at the output of the previous layer will result in unstable equilibrium points in the later layers. Therefore exact model matching is rarely used in practical applications. Instead, an inexact matching is commonly used to relax the requirements with an error-tolerant measure. For example, backpropagation is an inexact matching method by passing the information from a loss function to inputs based on calculating the deri vati ve of the loss function. Below we discuss more details on ho w the information transfers in backpropagation. Backpropagation e xploits a chain rule of information transfer using gradient-based optimization techniques. The orig- inal gradient descent method provides an approximate linear con ver gence, that is, the error between weights and loss function asymptotically con ver ges in the form of a geometric series. The con vergence rate on the quadratic error sur- face is in versely proportional to the condition number of a Hessian matrix, i.e., the ratio between the maximum and the minimum eigenv alues λ max /λ min . The corresponding eigenv ectors represent different directions of curvature. When the Hessian matrix has a high condition number, the eigen values attenuate at a high amplitude, and the corresponding deriv ative decreases rapidly in some directions, while declines gently in other directions. Furthermore, when there is a saddle point (then the Hessian matrix is called an ill-conditioned matrix), it typically forms a long plateau with a gradient close to zero, which makes it difficult to escape from the area (we ha ve verified a similar point in the acti vation function analysis of Sec. 3). This issue, howe ver , becomes more complicated when there is a proliferation of saddle points in high dimensional DNNs. Next, we discuss the latest de velopment that may help alle viate this issue. From the dynamics in (4), the eigen values of gradient optimization are dependent on hidden weight matrices and inputs, besides the acti vation functions. For arbitrary inputs, se veral methods such as principal component analysis can be adopted to ensure the input is conv ex (for graph data, the primary method is graph kernels [39, 40]). For con ve x networks, the first-order stochastic gradient descent method and its variants may break saddle points if the saddle points are along with other directions [11, 41]. Some previous work has attempted to utilize second-order methods such as the Hessian matrix to adjust the direction obtained by first-order methods. But these methods only av oid local minimums, not saddle points [38]. Therefore, second-order methods are not always preferable to first-order methods. Real-world practitioners often prefer a combinational algorithm that incorporates first-order methods and second-order methods, such as Adam. In addition to the optimization methods, there is some ef fort dedicated to building the con ve x topological structures [42]. For example, Amos et al. [43] de veloped a con vex structure with a non-ne gativ e constraint on the hidden weight matrices. Rodriguez et al. [44] proposed a regularization of CNNs through a decorrelated network structure. Most recently , Zhang et al. [45] confirmed via experiments that the success of recently proposed neural network architectures (e.g., ResNet, Inception, Xception, SqueezeNet, and W ide ResNet) was attributed to a multi-branch design that reduced the non-conv ex structure of DNNs. Ho wev er , most of these methods still focus on the local minimums; little is known for the saddle points that slo w down the con vergence. In addition to optimization techniques, heuristic optimization techniques based on swarm intelligence are also explored to tackle the conv ergence of DNNs [46]. The most popular method was designed to pre-train the hyperparameters (e.g., network depth, width, etc.) for later stage network setting [47]. Erskine et al. [48] prov ed the con ver gence of particle swarm optimization corresponding to self-or ganized criticality . Moreo ver , Hoffmann et al. [49] demonstrated that criticality could be determined by the system’ s primary parameters. One intuitive explanation is that if one can determine a moderate network model through prior training, then the saddle points caused by ov er-parameterization can be av oided. Evolved topology also provides an exciting opportunity to address these challenges [4]. Howe ver , they start with a small-scale network that takes a long time to achieve global optimality [46]. In conclusion, it is so far still unclear the “best” algorithm that can be employed to reliably analyze the conv ergence of DNNs, especially with a small computation budget. Later we will discuss how an ev olutionary algorithm can help DNN arriv e at the edge of chaos through numerical examples. 6 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T 5 Experiment: input perturbation and the regularization This section studies the impact of input perturbation and regularization operator on expressi vity . According to the criticality theory , gi ven a perturbation on the constant v ariance, e.g., Gaussian white noise v ariance, DNN can ev entu- ally con ver ge to a criticality via multilayer learning. When there is an input abnormality after training, there will be a deviation to the critical point. The of fset, on the other hand, provides an indicator of whether an exception occurred or not [50]. The offset created by the regularizations hinders the trend tow ard criticality and finally degrades the sys- tem’ s representation. Fig. 5 shows the variation of the L 2 -regularization coefficients under dif ferent network sizes. The result indicates that L 2 -regularization may not be necessary since the error increases as the coefficients increase. Similar findings were also reported in [44]. Fig. 5. V ariation of L 2 -regularization coefficients under different network sizes . The results are for multiv ariate time series prediction based on the Mackey-Glass time series. The ideal network size is in 400–500. As can be seen, the error increases as the regularization coefficient increases. This suggests that L 2 -regularization is not completely necessary for performance improv ement. 6 Experiment: Expressi vity and model training validity This section examines the proposed expressivity and model training theory through the multiv ariate time series pre- diction and image classification examples. First, we consider the evolution of time series prediction. 6.1 The evolution of deep echo state netw orks for time series pr ediction W e consider two data sets for multiv ariate time series prediction purpose. The first data set is called Solar-Ener gy 1 , where the solar po wer production in 2006 were obtained from 137 PV plants, and recorded e very 10 minutes in Alabama, USA. The second data set is called T raffic 2 , which is a collection of 48-month (2015-2016) hourly trans- portation data from California that describes the road occupancy rates measured by dif ferent sensors on San Francisco Bay Area freew ays. All data sets were chronologically di vided into training sets, validation sets, and test sets. The ratios of the training set and test set represent relativ ely short-term and long-term predictions, and the rate of validation set is fixed at 0 . 1 . Fig. 6 presents the multiv ariate time series prediction results via an improved DeepESN [51], in which activ ation is the HP acti vation, and the hyperparameters (i.e., network depth and width) are optimized by an e volutionary algorithm called population-based algorithm (MPSOGSA) as proposed in [52]. The optimized network layers for both data sets are 3 and 6 , respectively . The results sho w that the predictiv e accuracy of the test set is comparable to that of the vali- dation set. Besides, in subfigures (c) and (d), the proposed method is able to identify the potential anomalies/outliers (marked with purple boxes) since the prediction error e xceeds a certain threshold. Next, we examine the relationship between expressi vity and training. The hidden state of DNNs enables us to store information ef ficiently from the past, commonly referred to as the “memory” of DNNs [53]. One w ay to visualize this characteristic is the recurrence plot, which is a tool that displays recurrent states in phase space via a two dimensional plot [54]. Consider R i,j = Θ( ε i − | ~ x i − ~ x j | ) , ~ x i , ~ x j ∈ R m i, j = 1 , . . . , N , (8) where Θ( · ) is the Heaviside step function, N is the number of states, and ε i is the distance threshold. When | ~ x i − ~ x j | < ε i , the value of the recurrence matrix R ij is one; otherwise zero. From an information transfer perspectiv e, when the 1 http://www.nrel.gov/grid/solar- power- data.html 2 http://pems.dot.ca.gov 7 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T (a) Solar energy data set (0.7:0.1:0.2) (b) T raffic data set (0.7:0.1:0.2) (c) Solar energy data set (0.5:0.1:0‘.4) (d) T raffic data set (0.5:0.1:0.4) Fig. 6. Short-term prediction and long-term prediction resutls dynamics satisfy x ( n ) = f ( W x ( n − 1)) , a strong time dependency appears and the system is on the edge of chaos. Therefore, the closeness of the chaotic edge can be identified by the presence of a large number of black points in the recurrence plot. Fig. 7 shows the hidden state change from initial ev olution to the final stage. Indeed we see that as the hyperparameters of DeepESN ev olve, considerable time dependencies appear 3 . Otherwise, if the network size and input do not match, there is no apparent time dependency . This result verifies that suitable network size is essential for reaching the chaotic edge. Based on the analysis in Sec. 4, we can say that the training process is close to a chaotic edge, b ut whether it can ultimately arri ve that edge depends on its ability to overcome conv ergence and to pass information to the required network depth. The above analysis also shows that the time depends on the training process, which is closely relev ant to the long- term time series prediction 4 . Next, we compare the performance of the given method with that of two benchmark methods (LSTNet [55] and DeepESN [51]) to check if they can improve predicti ve performance, especially for long- term series prediction. T ab . 1 shows a comparison result of different multiv ariate time series prediction in terms of mean absolute error (MAE), root mean squared error (RMSE), and mean absolute predictiv e error (MAPE) for different training/testing/v alidation proportions. W e observe that LSTNet achie ves better results than DeepESN for short-term prediction of (0 . 7 : 0 . 1 : 0 . 2) , while DeepESN is slightly better than LSTNet for long-term prediction of (0 . 5 : 0 . 1 : 0 . 4) . Besides, the two baseline algorithms hav e a considerable improvement when the HP activ ation is utilized to capture spatial features. The optimized HP-DeepESN, in general, has the best performance as it can ov ercome con ver gence issues. 6.2 The impact of batch size on the con vergence for image classification Next, we analyze the impact of batch size on information transfer for image classification. Fig. 8 shows the ef fect of batch size on conv ergence based on the MNIST and CIF AR10 data sets. As the batch size increases, the loss con verges. Meanwhile, as shown in Fig. 9, the hidden state is gradually disappearing, which means the information transfer becomes weak. Therefore this example gives an illustration that an appropriate batch size should be selected to balance the trade-off between the con ver gence of loss and the information transfer strength. 3 Sometimes there might be a con ver gence issue for the current e volutionary algorithm. As a result, we did not always observe the darkening ef fect over time in e volution, but the o verall trend is quite obvious 4 A common issue in the long-term prediction is that time dependencies may be extremely long, for more details, refer to [55]. 8 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T (a) i Solar energy data set (b) T raffic data set Fig. 7. Evolution of the time dependence of hidden state . Predictiv e methods 0.7:0.1:0.3 0.6:0.1:0.2 0.5:0.1:0.4 MAE RMSE MAPE MAE RMSE MAPE MAE RMSE MAPE LSTNet [55] 16.2569 0.1338 1.3332 17.043 0.1459 1.4788 19.9066 0.1659 1.2265 DeepESN [51] 16.9215 0.1403 1.4170 17.1019 0.1586 1.5026 19.0810 0.1600 1.0485 HP-LSTNet 14.0910 0.1173 1.2750 15.4805 0.1278 1.2592 17.7437 0.1574 1.0128 HP-DeepESN 14.4248 0.1257 1.3480 15.8189 0.1264 1.3560 17.1191 0.1621 1.1890 Optimized-HP-DeepESN 13.4751 0.1143 1.1825 14.1346 0.1148 1.2883 15.7616 0.1392 0.8683 (a) Solar-Ener gy data set Predictiv e methods 0.7:0.1:0.2 0.6:0.1:0.3 0.5:0.1:0.4 MAE RMSE MAPE MAE RMSE MAPE MAE RMSE MAPE LSTNet [55] 26.2603 0.0638 0.4561 26.7099 0.0645 0.4498 27.6093 0.0677 0.4856 DeepESN [51] 26.0551 0.0641 0.4519 27.1709 0.0695 0.5212 27.6028 0.0657 0.4772 HP-LSTNet 25.6275 0.0597 0.4143 25.804 0.0610 0.4846 27.1432 0.0613 0.4646 HP-DeepESN 25.6869 0.0617 0.4202 25.6190 0.0654 0.4886 27.1368 0.0607 0.4613 Optimized-HP-DeepESN 24.7516 0.0442 0.3043 24.0963 0.04252 0.4063 25.04305 0.0424 0.2588 (b) T raffic data set iT ab . 1. Performance comparison of different multi variate time series prediction methods. (a) MNIST data set (10 Monte Carlo experiments) (b) CIF AR10 data set (20 Monte Carlo experiments) Fig. 8. The impacts of batch size on the conver gence of image classification . 9 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T (a) MNIST data set (b) CIF AR10 data set Fig. 9. Evolution of the time dependence of hidden state . 7 Related work In the literature, the mean-field theory has been widely used to describe the expressi vity of neural networks [5, 22, 56, 57, 58]. For example, several groundbreaking studies using statistical physics have shown that DNNs exhibit exponential expressi vity as network depth increases. These works highlighted the importance of orthogonal weights initialization [5, 56, 57], and sho wed that the gating mechanism could help RNNs avoid local minimums [22]. Besides, Schoenhiolz and Y ang et al. have found that dropout or batch normalization is also a cause of gradient explosion [56, 58]. Compared to those previous work based on mean-field theory , our work manages to obtain similar results in terms of expressivity without the need of certain assumptions in statistical physics theory , Moreover , our work highlights the connection between the actual training and expressi vity , which has not been covered by field theory . 8 Concluding remarks This paper discusses the expressi vity and training issues of DNN based on its conv ergence and criticality . A dynamic model in Hilbert space is employed to analyze the feature mapping of a vanilla DNN. By studying the feature mapping of several significant activ ation functions, we find that the eigen values in the feature space hav e sharp decay or even saddle points, hence slowing do wn the information transfer in DNNs. An acti vation function design based on Hermite polynomials is then proposed to make better use of the spatial representation. Training issues, especially the con ver- gence problem caused by dimensional mismatching between inputs and network models, inv olving backpropagation are analyzed. The impact of input perturbation and regularization operators on expressivity is also inv estigated. The analysis sho ws that in theory , DNN uses spatial domains for information representation and evolv es to the edge of chaos as depth increases, where (shannon) entropy reach a maximum. In actual training, whether a network can arriv e or not depends on its ability to ov ercome con ver gence and pass information to the required network depth. Model matching between input and output topological structure is critical to facilitate fast con ver gence. For DNNs, this is achiev ed by adding or removing neuron connections. Through the formation of saddle points, the network structure needs to hav e desired contraction characteristics to a void saddle points in high dimensional representation [7]. Therefore, it will be of interest to explore the ef ficient dynamic topology ev olution in future work to help provide guidelines for designing networks with faster con ver gence. A Hermite polynomials This part includes the definition of the Hermite polynomial and the properties we used. Supposing the probabilists’ s weight function p ( x ) = e − x 2 / 2 , apply Lemma 1 it follows that the Hermite polynomials are orthogonal with respect to the weight function in the interval ( −∞ , ∞ ) , then we have the follo wing important results, Z ∞ −∞ H m ( x ) H n ( x ) e − x 2 / 2 d x = ( 2 n n ! √ π , for m = n 0 , otherwise . (9) 10 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T W e use the following facts about the Hermite polynomials (see Chapter 11 in [59]): H n +1 ( x ) = x √ n + 1 H n ( x ) − r n n + 1 H n − 1 ( x ) , (10) H 0 n ( x ) = √ nH n − 1 ( x ) , (11) H n (0) = ( 0 , if n is odd ; 1 √ n ! ( − 1) n 2 ( n − 1)!! if n is even . (12) Next, we analyze the eigen values of several commonly used acti vation functions under Hermite polynomials and their impacts on the con vergence and criticality of DNNs. A.0.1 Radial basis function activation If the acti vation used is RBF , the corresponding feature space is a Hilbert space of infinite dimension, whose value depends on the distance from the fixed point c . f ( x ) = exp( − k x − c k 2 2 σ 2 ) . (13) where σ is a scale parameter . Since H 0 ( x ) = 1 , H 1 ( x ) = x, and H 2 ( x ) = x 2 − 1 √ 2 , Substitute Eq. (13) into Eq. (9) , and get the corresponding Hermite coefficients: a 0 = √ 2 π σ ce − c 2 / (2 σ 2 +2) √ σ 2 + 1 , (14) a 1 = √ 2 π ce − c 2 / (2 σ 2 +2) σ ( σ 2 + 1) 3 / 2 , (15) a 2 = √ 2 π ce − c 2 / (2 σ 2 +2) σ ( σ 2 + 1) 5 / 2 . (16) Therefore, the Hermite coefficients of RBF can be e xpressed as: a n = √ 2 π ce − c 2 / (2 σ 2 +2) σ ( σ 2 + 1) ( n +1 / 2) , n = 0 , 1 , . . . . (17) W e see all eigen values a n > 0 , n = 0 , 1 , . . . , indicating that RBF activ ation limits quadratic error surfaces that con verges to the global minimum (or maximum). Besides, the coefficients attenuates at the speed of a n a n − 1 = 1 σ 2 +1 . If σ 2 ≤ 1 , the coef ficients attenuate slo wly; otherwise, the coef ficients decay rapidly . It is, therefore, that small σ should be chosen as activ ation, and Shi et al. have made the RBF as acti vation function [60]. A.1 Step activation According to the literature [61], the Hermite polynomials of Step activ ation are: a n = ( n − 2)!! √ 2 π n ! if n is odd ; 1 √ 2 if n = 0; 0 if n is odd ≥ 2 . (18) A.2 ReLU activation The Hermite coefficients of ReLU acti vation are [61]: a n = ( n − 3)!! √ π n ! if n is ev en ; 1 √ 2 if n = 1; 0 if n is odd ≥ 3 . (19) The maximum eigenv alue is 1 √ 2 , then gradually decay to the critical point 0 . W e also see that there are 0 values with an interval of 1 , which may result in information that can not be efficiently passed from inputs to outputs, nor is backpropagation, it is unfa vorable from the perspecti ve of information transfer [11]. 11 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T A.3 Sigmoid activation Consider the Sigmoid function σ ( x ) = 1 e − x +1 , substitute it into Eq. (9), and get: a 0 = E x ∼ N (0 , 1) [ σ ( x )] = 1 2 , (20) a 1 = E x ∼ N (0 , 1) [ σ ( x ) x ] = 0 . 206621 , (21) a 2 = 1 √ 2 E x ∼ N (1 , 1) [ σ ( x )( x 2 − 1)] = 0 (22) According to the symmetry of integral operator , when n is ev en, the Hermite polynomial is 0 . W e kno w that Sigmoid activ ation attenuates the values with a higher magnitude. Since the first Hermite coefficients of sigmoid activ ation is much smaller than 1 and saturate quickly , when it is used as an acti vation function in DNNs, the chance of the gradient fading to 0 is very high. A.4 Swish activation function Consider the activ ation f ( x ) = x sigmoid ( x ) . Substitute it into Eq. (9), and get: a 0 = E x ∼ N (0 , 1) [ σ ( x )] = 0 . 292206 (23) a 1 = E x ∼ N (0 , 1) [ σ ( x ) x ] = 1 √ 2 (24) a 2 = 1 √ 2 E x ∼ N (0 , 1) [ σ ( x )( x 2 − 1)] = 0 . 350845 (25) Calculation from Mathematical [62], we conclude that there is no 0 value in the Swish activ ation, forming a con vex function, and the coefficients decay slowly , so it can effecti vely pass information in DNNs, which can be used as an activ ation function. References [1] Y ann LeCun, Y oshua Bengio, and Geof frey Hinton. Deep learning. Nature , 521(7553):436, 2015. [2] Da vid Silver , Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driess che, Julian Schrittwieser , Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Natur e , 529(7587):484, 2016. [3] M Bianchini and F Scarselli. On the complexity of neural network classifiers: a comparison between shallo w and deep architectures. IEEE T ransactions on Neur al Networks & Learning Systems , 25(8):1553–1565, 2014. [4] Saizheng Zhang, Y uhuai W u, T ong Che, Zhouhan Lin, Roland Memisevic, Ruslan Salakhutdinov , and Y oshua Bengio. Architectural complexity measures of recurrent neural networks. In Advances in Neural Information Pr ocessing Systems 29: Annual Confer ence on Neural Information Pr ocessing Systems , pages 1822–1830, De- cember 5-10, 2016. [5] Ben Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl-Dickstein, and Surya Ganguli. Exponential expres- sivity in deep neural networks through transient chaos. In Advances in Neural Information Pr ocessing Systems 29: Annual Conference on Neur al Information Pr ocessing Systems 2016 , pages 3368–3376, Barcelona, Spain, December 5-10, 2016. Neural Information Processing Systems Foundation. [6] Peter L. Bartlett, V italy Maiorov , and Ron Meir . Almost linear vc-dimension bounds for piecewise polynomial networks. Neural Computation , 10(8):2159–2159, 1998. [7] St ´ ephane Mallat. Understanding deep con volutional networks. Philosophical T ransactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , 374(2065):20150203, 2016. [8] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol V inyals. Understanding deep learning requires rethinking generalization. In 5th International Confer ence on Learning Repr esentations, ICLR , April 24-26, 2017. [9] F orest Agostinelli, Matthew D. Hof fman, Peter J. Sadowski, and Pierre Baldi. Learning activ ation functions to improv e deep neural networks. In 3r d International Confer ence on Learning Repr esentations, ICLR , May 7-9, 2015. 12 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T [10] Maithra Raghu, Ben Poole, Jon M. Kleinberg, Surya Ganguli, and Jascha Sohl-Dickstein. On the expressiv e power of deep neural networks. In Pr oceedings of the 34th International Confer ence on Machine Learning, ICML , pages 2847–2854, August 6-11, 2017. [11] Y uanzhi Li andi Y ang Y uan. Con ver gence analysis of two-layer neural networks with relu activ ation. In Advances in Neural Information Pr ocessing Systems 30: Annual Conference on Neural Information Pr ocessing Systems , pages 597–607, December 4-9, 2017. [12] Y uandong T ian. An analytical formula of population gradient for two-layered relu network and its applications in conv ergence and critical point analysis. In Pr oceedings of the 34th International Confer ence on Machine Learning ICML , pages 3404–3413, August 6-11, 2017. [13] Chulhee Y un, Suvrit Sra, and Ali Jadbabaie. Small nonlinearities in activ ation functions create bad local minima in neural networks. In 7th International Confer ence on Learning Repr esentations, ICLR , May 6-9, 2019. [14] Hao Shen. T o wards a mathematical understanding of the dif ficulty in learning with feedforward neural networks. In 2018 IEEE Confer ence on Computer V ision and P attern Recognition, CVPR , pages 811–820, June 18-22, 2018. [15] Stanle y and H. Eugene (Harry Eugene. Introduction to phase transitions and critical phenomena. Physics T oday , 26(1):71–72, 1973. [16] Kamyshanska Hanna and Memise vic Roland. The potential energy of an autoencoder . IEEE T ransactions on P attern Analysis and Machine Intelligence , 37(6):1261–1273, 2015. [17] Alan Morningstar and Roger G. Melko. Deep learning the ising model near criticality . Journal of Machine Learning Resear ch , 18(1):5975–5991, 2017. [18] P apa B Del, V Priesemann, and J Triesch. Criticality meets learning: Criticality signatures in a self-organizing recurrent neural network. Plos One , 12(5):e0178683, 2017. [19] Ge Y ang and Samuel Schoenholz. Mean field residual networks: on the edge of chaos. In Advances in Neural Information Pr ocessing Systems , pages 7103–7114, December 4-9, 2017. [20] Ga vin S Hartnett, Edward Parker , and Edward Geist. Replica symmetry breaking in bipartite spin glasses and neural networks. Physical Review E , 98(2):022116, 2018. [21] Maciej Kochjanusz and Zohar Ringel. Mutual information, neural networks and the renormalization group. Natur e Physics , 2017. [22] Minmin Chen, Jeffre y Pennington, and Samuel S. Schoenholz. Dynamical isometry and a mean field theory of rnns: Gating enables signal propagation in recurrent neural networks. In Proceedings of the 35th International Confer ence on Machine Learning, ICML, Stoc kholmsm ¨ assan , pages 872–881, July 10-15, 2018. [23] Shuang-Xin W ang, Meng Li, Long Zhao, and Chen Jin. Short-term wind power prediction based on improved small-world neural network. Neural Computing and Applications , 31(7):3173–3185, 2019. [24] Roberto LS Monteiro, T ereza Kelly G Carneiro, Jos ´ e Roberto A Fontoura, V al ´ eria L da Silv a, Marcelo A Moret, and Hernane Borges de Barros Pereira. A model for improving the learning curves of artificial neural networks. PloS one , 11(2):e0149874, 2016. [25] Huaguang Zhang, Zhanshan W ang, and Derong Liu. A comprehensi ve revie w of stability analysis of continuous- time recurrent neural networks. IEEE T ransactions on Neural Networks and Learning Systems , 25(7):1229–1262, 2014. [26] Stef an Elfwing, Eiji Uchibe, and K enji Doya. Sigmoid-weighted linear units for neural netw ork function approx- imation in reinforcement learning. Neural Networks , 107:3–11, 2018. [27] Erwin Kre yszig. Intr oductory Functional Analysis with Applications . Wile y Ne w Y ork, 1978. [28] V ito Latora, Michel Baranger , Andrea Rapisarda, and Constantino Tsallis. The rate of entropy increase at the edge of chaos. Physics Letters A , 273(1-2):97–103, 2000. [29] Chittaranjan Hens, Uzi Harush, Simi Haber , Reuven Cohen, and Baruch Barzel. Spatiotemporal signal propaga- tion in complex networks. Natur e Physics , 15(4):403, 2019. [30] Ale x Krizhe vsky , Ilya Sutskev er , and Geof frey E. Hinton. Imagenet classification with deep con volutional neural networks. Commun. ACM , 60(6):84–90, 2017. [31] Ale x Graves, Abdel-rahman Mohamed, and Geoffre y E. Hinton. Speech recognition with deep recurrent neural networks. In IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing, ICASSP , pages 6645– 6649, May 26-31, 2013. 13 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T [32] Jaehoon Lee, Y asaman Bahri, Roman Nov ak, Samuel S. Schoenholz, Jeffrey Pennington, and Jascha Sohl- Dickstein. Deep neural networks as gaussian processes. In 6th International Confer ence on Learning Repr e- sentations, ICLR , April 30 - May 3, 2018. [33] Ja vad Usefie Mafahim, David Lambert, Marzieh Zare, and Paolo Grigolini. Complexity matching in neural networks. New J ournal of Physics , 17(1):1–18, 2015. [34] W illiam L. Hamilton, Rex Y ing, and Jure Leskov ec. Representation learning on graphs: Methods and applica- tions. IEEE Data Eng. Bull. , 40(3):52–74, 2017. [35] K eyulu Xu, W eihua Hu, Jure Leskovec, and Stefanie Jegelka. How po werful are graph neural networks? In 7th International Confer ence on Learning Repr esentations, ICLR , May 6-9, 2019. [36] Y onathan Aflalo, Ale xander Bronstein, and Ron Kimmel. On con ve x relaxation of graph isomorphism. Pr oceed- ings of the National Academy of Sciences , 112(10):2942–2947, 2015. [37] Francis Bach. Breaking the curse of dimensionality with conv ex neural networks. The Journal of Machine Learning Resear ch , 18(1):629–681, 2017. [38] Y ann N Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyungh yun Cho, Surya Ganguli, and Y oshua Bengio. Identifying and attacking the saddle point problem in high-dimensional non-con vex optimization. In Advances in Neural Information Pr ocessing Systems 27: Annual Conference on Neural Information Pr ocessing Systems , pages 2933–2941, December 8-13 2014. [39] T ao Lei, W engong Jin, Regina Barzilay , and T ommi Jaakkola. Deriving neural architectures from sequence and graph kernels. In Pr oceedings of the 34th International Confer ence on Machine Learning, ICML , pages 2024–2033. JMLR. org, August 6-11, 2017. [40] Luca Oneto, Nicol ` o Na varin, Michele Donini, Alessandro Sperduti, Fabio Aiolli, and Davide Anguita. Measuring the expressi vity of graph kernels through statistical learning theory . Neur ocomputing , 268:4–16, 2017. [41] T ao Gao, Zhen Zhang, Qin Chang, Xuetao Xie, Peng Ren, and Jian W ang. Conjugate gradient-based takagi- sugeno fuzzy neural network parameter identification and its conv ergence analysis. Neur ocomputing , 364:168– 181, 2019. [42] Xian ye Bu, Hongli Dong, Fei Han, Nan Hou, and Gongfa Li. Distributed filtering for time-varying systems ov er sensor networks with randomly switching topologies under the round-robin protocol. Neur ocomputing , 346:58–64, 2019. [43] Brandon Amos, Lei Xu, and J Zico Kolter . Input con vex neural networks. In Pr oceedings of the 34th International Confer ence on Machine Learning, ICML , pages 146–155, August 6-11, 2017. [44] P au Rodr ´ ıguez, Jordi Gonz ` alez, Guillem Cucurull, Josep M. Gonfaus, and F . Xavier Roca. Regularizing cnns with locally constrained decorrelations. In 5th International Confer ence on Learning Repr esentations, ICLR , April 24-26, 2017. [45] Hongyang Zhang, Junru Shao, and Ruslan Salakhutdino v . Deep neural networks with multi-branch architectures are intrinsically less non-con vex. In The 22nd International Conference on Artificial Intelligence and Statistics, AIST ATS , pages 1099–1109, April 16-18, 2019. [46] K enneth O Stanley , Jeff Clune, Joel Lehman, and Risto Miikkulainen. Designing neural networks through neuroev olution. Nature Mac hine Intelligence , 1(1):24–35, 2019. [47] Lin W ang, Y i Zeng, and T ao Chen. Back propagation neural network with adiaptiv e differential e volution algo- rithm for time series forecasting. Expert Systems with Applications , 42(2):855–863, 2015. [48] Adam Erskine and J. Michael Herrmann. Crips: Critical particle swarm optimisation. In Proceedings of the Thirteenth Eur opean Conference Artificial Life , ECAL 2015, Y ork, UK, July 20-24, 2015 , pages 207–214, 2015. [49] Heik o Hoffmann and David W Payton. Optimization by self-organized criticality . Scientific r eports , 8(1):2358, 2018. [50] Sebastian Bathiany , Henk Dijkstra, Michel Crucifix, V asilis Dakos, V ictor Brovkin, Mark S. Wil liamson, Tim- othy M. Lenton, and Marten Scheffer . Beyond bifurcation: using complex models to understand and predict abrupt climate change. Dynamics and Statistics of the Climate System , 1(1), 11 2016. [51] Claudio Gallicchio, Alessio Micheli, and Luca Pedrelli. Deep reservoir computing: a critical experimental analysis. Neurocomputing , 268:87–99, 2017. [52] Ge ge Zhang, Chao, Zheqing Li, and W eidong Zhang. A ne w PSOGSA inspired con volutional echo state network for long-term health status prediction. In IEEE International Conference on Robotics and Biomimetics, R OBIO , pages 1298–1303, December 12-15, 2018. 14 The Expressivity and T raining of Deep Neural Networks: tow ard the Edge of Chaos? A P R E P R I N T [53] F an Y ang, Hongli Dong, Zidong W ang, W eijian Ren, and Fuad E Alsaadi. A new approach to non-fragile state estimation for continuous neural networks with time-delays. Neur ocomputing , 197:205–211, 2016. [54] Filippo Maria Bianchi, Lorenzo Livi, and Cesare Alippi. Inv estigating echo-state networks dynamics by means of recurrence analysis. IEEE T ransactions on Neur al Networks and Learning Systems , 29(2):427–439, 2018. [55] Guokun Lai, W ei-Cheng Chang, Y iming Y ang, and Hanxiao Liu. Modeling long- and short-term temporal pat- terns with deep neural networks. In The 41st International ACM SIGIR Conference on Resear ch & Development in Information Retrieval, S IGIR , pages 95–104, July 08-12, 2018. [56] Samuel S. Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein. Deep information propagation. In 5th International Confer ence on Learning Repr esentations, ICLR , April 24-26, 2017. [57] Lechao Xiao, Y asaman Bahri, Jascha Sohl-Dickstein, Samuel S. Schoenholz, and Jeffre y Pennington. Dynamical isometry and a mean field theory of cnns: How to train 10, 000-layer vanilla con volutional neural networks. In Pr oceedings of the 35th Initernational Conference on Machine Learning, ICML , pages 5389–5398, July 10-15, 2018. [58] Gre g Y ang, Jeffrey Pennington, V inay Rao, Jascha Sohl-Dickstein, and Samuel S. Schoenholz. A mean field theory of batch normalization. In 7th International Conference on Learning Repr esentations, ICLR , May 6-9, 2019. [59] Ryan ODonnell. Analysis of Boolean Functions , volume 9781107038325. Cambridge Univ ersity Press, 2013. [60] Y uge Shi andi Basura Fernando and Richard Hartley . Action anticipation with RBF kernelized feature mapping RNN. In 15th European Confer ence Computer V isionECCV , pages 305–322, September 8-14, 2018. [61] Amit Daniely , Roy Frostig, and Y oram Singer . T oward deeper understanding of neural networks: The power of initialization and a dual vie w on expressi vity . In Advances in Neur al Information Pr ocessing Systems 29: Annual Confer ence on Neural Information Pr ocessing Systems , pages 2253–2261, December 5-10, 2016. [62] W olfram Research, Inc. Mathematica, Version 11.3. Champaign, IL, 2018. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment