Deep 2FBSDEs For Systems With Control Multiplicative Noise
We present a deep recurrent neural network architecture to solve a class of stochastic optimal control problems described by fully nonlinear Hamilton Jacobi Bellmanpartial differential equations. Such PDEs arise when one considers stochastic dynamics…
Authors: Marcus A Pereira, Ziyi Wang, Tianrong Chen
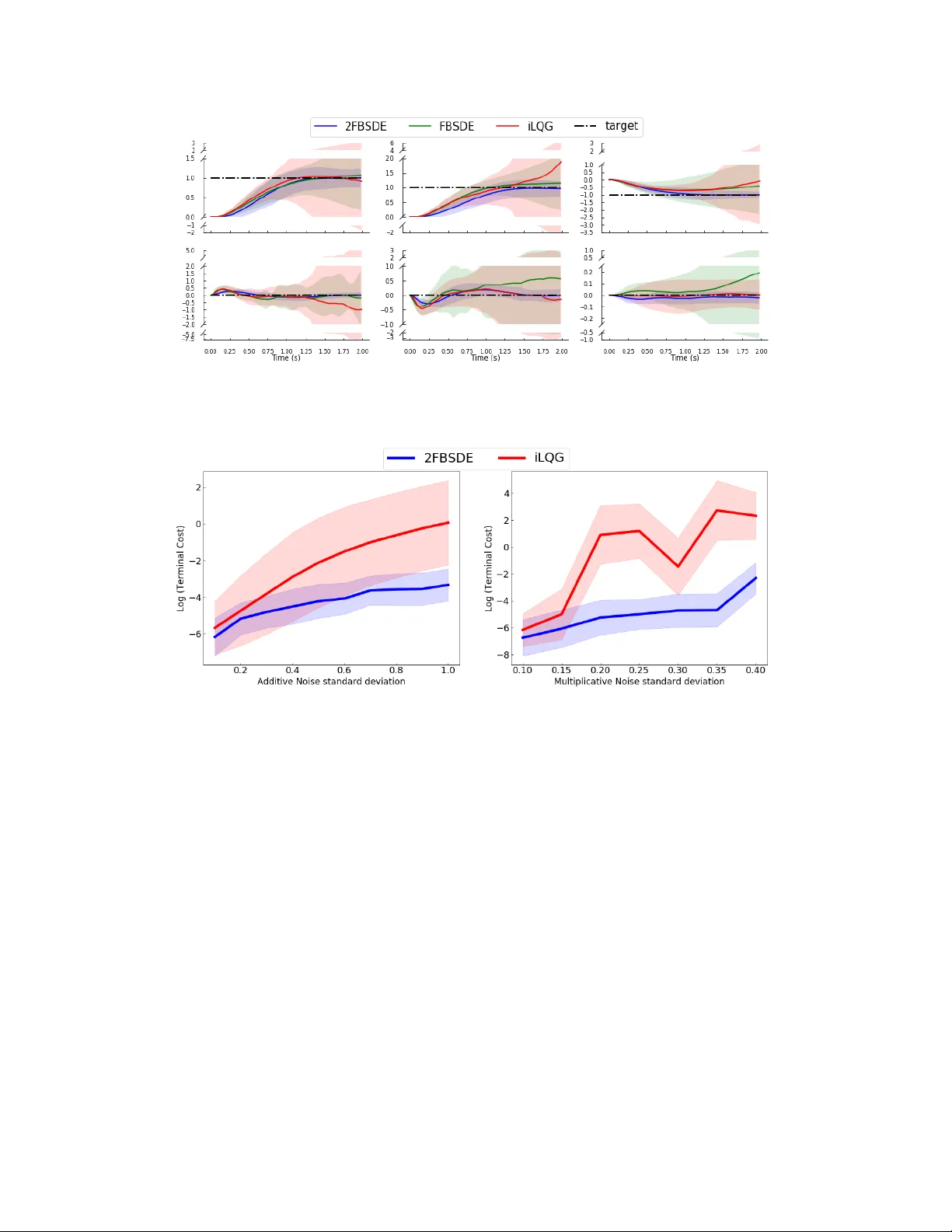
D E E P 2 F B S D E S F O R S Y S T E M S W I T H C O N T R O L M U L T I P L I C A T I V E N O I S E A P R E P R I N T Ziyi W ang ∗ , Marcus A. P ereira ∗ , Tianr ong Chen ∗ , Evangelos A. Theodor ou Autonomous Control and Decision Systems Laboratory (A CDS Lab) School of Aerospace Engineering Georgia Institute of T echnology , Atlanta GA 30313, USA ziyiwang@gatech.edu , mpereira30@gatech.edu Emily A.Reed Department of Electrical Engineering, Univ ersity of Southern California, Los Angeles, CA 90089-2905, USA December 24, 2019 A B S T R AC T W e present a deep recurrent neural network architecture to solve a class of stochastic optimal control problems described by fully nonlinear Hamilton Jacobi Bellman partial differential equations. Such PDEs arise when one considers stochastic dynamics characterized by uncertainties that are additive, state dependent and control multiplicative. Stochastic models with the aforementioned characteristics hav e been used in computational neuroscience, biology , finance and aerospace systems and provide a more accurate representation of actuation than models with only additiv e uncertainty . Previous literature has established the inadequac y of the linear HJB theory and instead relies on a non-linear Feynman-Kac lemma resulting in a second order F orward-Backward Stochastic Differential Equations representation. Howe ver , the proposed solutions that use this representation suffer from compounding errors and computational complexity resulting in lack of scalability . In this paper , we propose a deep learning based algorithm that lev erages the second order Forward-Backward SDE representation and LSTM based recurrent neural networks to not only solve such Stochastic Optimal Control problems but also ov ercome the problems faced by traditional approaches and shows promising scalability . The resulting control algorithm is tested on nonlinear systems from robotics and biomechanics in simulation to demonstrate feasibility and out-performance against pre vious methods. K eywords Deep Learning, Stochastic Optimal Control, Nonlinear Feynman-Kac, Forw ard-Backward Stochastic Differential Equations, LSTM 1 Introduction Stochastic Optimal Control ( SOC ) is the center of decision making under uncertainty with a long history and e xtensiv e prior work both in terms of theory as well as algorithms [ 36 , 13 ]. One of the most celebrated formulations of stochastic optimal control is for linear dynamics and additi ve noise, kno wn as the Linear Quadratic Gaussian (LQG) case [ 36 ]. For stochastic systems that are nonlinear in the state and af fine in control, the stochastic optimal control formulation results in the Hamilton-Jacobi-Bellman ( HJB ) equation, which is a backw ard nonlinear Partial Dif ferential Equation ( PDE ). Solving the HJB PDE for high dimensional systems is generally a challenging task and suffers from the curse of dimensionality . ∗ Equal contribution A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Different algorithms have been deri ved to address stochastic optimal control problems and solve the HJB equation. These algorithms can be mostly classified into two groups: (i) algorithms that rely on linearization and (ii) algorithms that rely on sampling. Linearization-based algorithms rely on first order T aylor’ s approximation of dynamics (iterativ e LQG or iLQG) or quadratic approximation of dynamics (Stochastic Differential Dynamic Programming), and quadratic approximation of the cost function [ 44 , 39 ]. Application of the aforementioned algorithms is not straightforward and requires very small time discretization or special linearization schemes especially for the cases of control and/or state dependent noise. It is also w orth mentioning that the con ver gence properties of these algorithms ha ve not been in vestigated and remain open questions. Sampling-based methods include the Marko v-Chain Monte Carlo (MCMC) approximation of the HJB equation [ 25 , 19 ]. MCMC-based algorithms rely on backward propag ation of the value function on a pre-specified grid. Recently researchers hav e incorporated tensor-train decomposition techniques to scale these methods [ 15 ]. Howe ver , these techniques have been applied to special classes of systems and stochastic control problem formulations and have demonstrated limited applicability so far . Other methods include transforming the SOC problem into a deterministic one by working with the F okker -Planck PDE representation of the system dynamics [ 2 , 3 ]. This approach requires solving the problem on a grid as well and therefore doesn’t scale to high dimensional systems due to the aforementioned curse of dimensionality . Alternativ e sampling-based methodologies rely on the probabilistic representation of the backward PDE s and gen- eralization of the so-called linear Feynman-Kac lemma [ 22 ] to its nonlinear version [ 31 ]. Application of the linear Feynman-Kac lemma requires the e xponential transformation of the value function and certain assumptions related to the control cost matrix and the variance of the noise. Controls are then computed using forward sampling of stochastic dif ferential equations [ 21 , 41 , 42 , 38 ]. The nonlinear version of the Feynman-Kac lemma overcomes the aforementioned limitations. Howe ver it requires a more sophisticated numerical scheme than just forward sampling, which relies on the theory of Forward-Backward Stochastic Dif ferential Equations ( FBSDE s) and their connection to backw ard PDE s. The FBSDE formulation is very general and has been utilized in many problem formulations such as L 2 and L 1 stochastic control [ 10 , 9 , 11 ], min-max and risk-sensitiv e control [ 12 ] and control of systems with control multiplicativ e noise [ 4 ]. The major limitation of the algorithms that rely on FBSDE s, is the compounding of errors from Least Squares approximation used at ev ery timestep of the Backward Stochastic Dif ferential Equation (BSDE). Recent ef forts in the area of Deep Learning for solving nonlinear PDE s hav e demonstrated encouraging results in terms of scalability and numerical ef ficiency . A Deep Learning-based algorithm was introduced by Han et al. [16] to approximate the solution of non-linear parabolic PDE s through their connection to first order FBSDE s. Howe ver , the algorithm was tested on a simple high-dimensional linear system for which an analytical solution already exists. A more recent approach by Pereira et al. [32] extended this work with a more efficient deep learning architecture and successfully applied the algorithm for control tasks on non-linear systems. Howe ver , similar to Han et al. [17] , the approach is only applicable to stochastic systems wherein noise is either additiv e or state dependent. In this paper , we dev elop a nov el Deep Neural Network ( DNN ) architecture for HJB PDE s that correspond to SOC problems in which noise is not only additive or state-dependent but control multiplicativ e as well. Such problem formulations are important in biomechanics and computational neuroscience, autonomous systems, and finance [ 43 , 29 , 34 , 28 , 33 ]. Prior work on stochastic optimal control of such systems considers linear dynamics and quadratic cost functions. Attempts to generalize these linear methods to the case of stochastic nonlinear dynamics with control multiplicativ e noise are only primitiv e and require special treatment in terms of methods to forw ard propagate and linearize the underlying stochastic dynamics [ 45 ]. Aforementioned probabilistic methods relying on the linear Fe ynman- Kac lemmma cannot be deriv ed in case of control multiplicativ e noise. Below we summarize the contrib utions of our work: • W e design a nov el DNN architecture tailored to solve second-order FBSDEs ( 2FBSDE s). The neural network architecture consists of Fully Connected ( FC ) feed-forward and Long-Short T erm Memory ( LSTM ) recurrent layers. The resulting Deep 2FBSDE network can be used to solve fully nonlinear PDEs for nonlinear systems with control multiplicativ e noise. • W e demonstrate the applicability and correctness of the proposed algorithm in four examples ranging from, traditionally used linear and nonlinear systems in control theory , to robotics and biomechanics. The proposed algorithm reco vers analytical controls in the case of linear dynamics while it is also able to successfully control nonlinear dynamics with control-multiplicativ e and additiv e sources of uncertainty . Our simulations show the robustness of the Deep 2FBSDE algorithm and prove the importance of considering the nature of the stochastic disturbances in the problem formulation as well as in neural network architecture. The rest of the paper is org anized as follows: in Section 2 we first introduce notation, some preliminaries and discuss the problem formulation. Next, in Section 3 we provide the 2FBSDE formulation. The Deep 2FBSDE algorithm is introduced in Section 4. Then we demonstrate and discuss results from our simulation experiments in Section 5. Finally we conclude the paper in Section 6 with discussion and future directions. 2 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 2 Stochastic Optimal Control In this section we provide notations and stochastic optimal control concepts essential for the dev elopment of our proposed algorithm and then present the problem formulation. Note that the bold f aced notation will be abused for both vectors and matrices, while non-bold faced will be used for scalars. 2.1 Preliminaries W e first introduce stochastic dynamical systems which hav e a drift component (i.e. the non-stochastic component of the dynamics) that is a nonlinear function of the state b ut affine with respect to the controls. The stochastic component is comprised of nonlinear functions of the state and affine control multiplicati ve matrix coef ficients. Let x ∈ R n x be the vector of state v ariables, and u ∈ R n u be the vector of control v ariables taking values in the set of all admissible controls U ([0 , T ]) , for a fixed finite time horizon T ∈ [0 , ∞ ) . Let [ v ( t ) T w ( t ) T ] T t ∈ [0 ,T ] be a Brownian motion in R n w +1 , where v ( t ) ∈ R , w ( t ) ∈ R n w and the components of w ( t ) are mutually independent one dimensional standard Brownian motions. W e now assume that functions f : [0 , T ] × R n x → R n x , G : [0 , T ] × R n x → R n x × n u , Σ : [0 , T ] × R n x → R n x × n w and σ ∈ R + satisfy certain Lipschitz and gro wth conditions (see supplementary materials (SM) A). Giv en this assumption, it is known that for e very initial condition ξ ∈ R n x , there exists a unique solution x ( t ) t ∈ [0 ,T ] to the Forward Stochastic Dif ferential Equation (FSDE), d x ( t ) = f ( t, x ( t )) + G ( t, x ( t )) u ( t ) | {z } drift vector d t + σ G ( t, x ( t )) u ( t ) d v ( t ) | {z } contr ol multiplicative noise + Σ ( t, x ( t )) d w ( t ) | {z } only state-dependent noise = f ( t, x ( t )) + G ( t, x ( t )) u ( t ) d t + C t, x ( t ) , u ( t ) d ( t ) x (0) = ξ , (1) where C ( t, x ( t ) , u ( t )) = σ G ( t, x ( t )) u ( t ) , Σ ( t, x ( t )) and ( t ) = v ( t ) w ( t ) . 2.2 Problem Statement and HJB PDE For the controlled stochastic dynamical system abo ve, we formulate the SOC problem as minimizing the follo wing expected cost quadratic in control J t, x ( t ); u ( t ) = E Q " T Z t q ( s, x ( s )) + 1 2 u ( s ) T Ru ( s ) d s + φ x ( T ) # (2) where q : R n x → R + is the running state-dependent cost function, R (control cost coefficients) is a symmetric positi ve definite matrix of size n u × n u and φ : R n x → R + is the terminal state cost. q and φ are differentiable with continuous deriv atives up to the second order . The expectation is taken with respect to the probability measure Q ov er the space of trajectories induced by the controlled stochastic dynamics in (1). W e can define the value function as ( V t, x ( t ) = inf u ( t ) ∈ U ([ t,T ]) J t, x ( t ); u ( t ) V T , x ( T ) = φ x ( T ) . (3) Under the condition that the value function is once dif ferentialble in t and twice differentiable in x with continuous deri vati ves, we can follow the standard stochastic optimal control deriv ation to obtain the HJB PDE (written without all the functional dependencies for simplicity) V t + q + V T x f − 1 2 V T x G ˆ R − 1 G T V x + 1 2 tr( V xx ΣΣ T ) = 0 V ( T , x ( T )) = φ ( x ( T )) , (4) with the optimal control of the form, u ∗ ( t, x ) = − ˆ R − 1 G ( t, x ) T V x ( t, x ) . (5) where, ˆ R , ( R + σ 2 G T V xx G ) . The deriv ation for both equations 4 and 5 can be found in SM B. 3 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 3 A FBSDE Solution to the HJB PDE The theory of BSDE s establishes a connection between the solution of a parabolic PDE and a set of FBSDE s [ 30 , 7 ]. This connection has been used to solv e the HJB PDE in the context of SOC problems. Exarchos and Theodorou [10] solved the HJB PDE in the absence of control multiplicativ e noise d v with a set of first order FBSDE s. Bakshi et al. [4] utilized the second order FBSDE s or 2FBSDE s to solv e the fully nonlinear HJB PDE in the presence of control multiplicativ e noise, but did not consider any control in the FSDE . Lack of control leads to insuf ficient exploration and for highly nonlinear systems renders it impossible to find an optimal solution to complete the task. In light of this, we introduce a new set of 2FBSDEs d x = f d t + Gu ∗ d t + C d ( FSDE ) d V = H ( V ) d t + V T x Gu ∗ d t + V T x C d ( BSDE 1 ) d V x = H ( V x ) d t + V xx Gu ∗ d t + V xx C d ( BSDE 2 ) x (0) = ξ , V ( T ) = φ ( x ( T )) , V x ( T ) = φ x ( x ( T )) , (6) where u ∗ is the optimal control giv en by (5) and the operator H is defined as H ( · ) , ∂ t ( · ) + ∂ x ( · ) T f + 1 2 tr( ∂ xx ( · ) CC T ) . (7) Note that the functional dependencies are dropped in this and the follo wing section for simplicity . W e can obtain this particular set of 2FBSDE s by substituting for the optimal control ( (5) ) in the forward process ( (1) ). The backward processes are obtained by applying Ito’ s lemma [ 20 ], which is essentially the second order T aylor series e xpansion, to the v alue function V and its gradient V x . Additionally , we substitute the expression for V t from (4) into BSDE 1 and obtain the final form of the 2FBSDEs (detailed deriv ation is included in SM C) as d x = f d t + G ( u ∗ d t + σ u ∗ d v ) + Σ d w d V = − q − 1 2 V T x G ˆ R − T ( R + 2 σ 2 G T V xx G ) ˆ R − 1 G T V x d t + V T x G ( u ∗ d t + σ u ∗ d v ) + V T x Σ d w d V x = ( A + V xx f ) d t + V xx G ( u ∗ d t + σ u ∗ d v ) + V xx Σ d w x (0) = ξ , V ( T ) = φ ( x ( T )) , V x ( T ) = φ x ( x ( T )) , (8) with A = ∂ t ( V x ) + 1 2 tr( ∂ xx ( V x ) CC T ) . Using (8) , we can forward sample the FSDE . The second-order BSDEs ( 2BSDE s), on the other hand, need to satisfy a terminal condition and therefore hav e to be propagated backwards in time. Ho wev er , since the uncertainty that enters the dynamics ev olves forward in time, only the conditional expectations of the 2BSDE s can be back-propagated. For more details please refer to Shre ve [35 , Chapter 2 ] . Bakshi et al. [4] back-propagate approximate conditional expectations, computed using regression, of the tw o processes. This method howe ver , suf fers from compounding errors introduced by least squares estimation at e very time step. In contrast a Deep Learning ( DL ) based approach, first introduced by Han et al. [16] , mitigates this problem by using the terminal condition as the prediction target for a forward propagated BSDE . This is enabled by randomly initializing the value function and its gradient at the start time and treating them as trainable parameters of a self-supervised deep learning problem. In addition, the approximation errors at each time step are compensated for by backpropagation during training of the DNN . This allowed using FBSDE s to solve the HJB PDE for high-dimensional linear systems. A more recent approach, the Deep FBSDE controller [ 32 ], futher extends the work successfully to nonlinear systems, with and without control constraints, in simulation that correspond to first order FBSDE s. It also introduced a LSTM -based netw ork architecture, in contrast to using separate feed-forward neural networks at e very timestep as in Han et al. [17] , that resulted in superior performance, memory and time complexity . Extending this work, we propose a ne w framework for solving SOC problems of systems with control multiplicati ve noise, for which the value function solutions correspond to 2FBSDEs. 4 Deep 2FBSDE Controller In this section, we introduce a ne w deep network architecture called the Deep 2 FBSDE Contr oller and present a training algorithm to solve SOC problems with control multiplicati ve noise. Time discr etization: In order to approximate numerical solutions of the Stochastic Differential Equations ( SDE s) we choose the explicit Euler-Maruyama time-discretization scheme [ 24 , Chapter 9] similar to [ 32 , 16 ]. Here we ov erload t as both the continuous-time v ariable and discrete time index and discretize the task horizon 0 < t < T as t = { 0 , 1 , · · · , N } , where T = N ∆ t . This is also used to discretize all v ariables as step functions if their discrete time 4 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Figure 1: Deep 2FBSDE neural network architectur e. The blocks F C 1 , 2 are fully connected layers with linear acti vations while the LS T M block represents recurrent layers of stack ed LSTM cells with standard nonlinear activ ations. These layers are parameterized by θ and shared temporally . Additionally , V ( x 0 , t 0 ) and V x ( x , t 0 ) are parameterized by ψ and ζ respecti vely . The self-supervised tar gets V ∗ N , V ∗ x ,N are the terminal conditions from (8) and V ∗ xx ,N = φ xx ( x N ) . Algorithm 1: Finite T ime Horizon Deep 2FBSDE Controller Given: ξ , f , G , Σ , σ : Initial state, drift, actuation dynamics, state dependent noise matrix and control multiplicative noise std. deviation; φ, q , R : Cost function parameters; N : T ask horizon, K : Number of iterations, M : Batch size; ∆ t : T ime discretization; λ : regularization parameter; Parameters: V 0 = V ( x 0 ; ψ ) : V alue function at t = 0 parameterized by trainable weight ψ ; V x , 0 = V x ( x ; ζ ) : Gradient of value function at t = 0 parameterized by trainable weights ζ ; θ : W eights and biases of all fully-connected and LSTM layers; Initialize all trainable paramters and states: θ 0 , ψ 0 , ζ 0 , x 0 = ξ for k = 1 to K do for i = 1 to M do for t = 0 to N − 1 do Compute G matrix: G i t = G x i t , t ; Network prediction: V i xx ,t , A i t = f F C 1 f LS T M ( x ; θ k − 1 ) , f F C 2 f LS T M ( x ; θ k − 1 ) Compute optimal control: u i ∗ t = − ( R + σ 2 G i T t V i xx ,t G i t ) − 1 G i T t V i x ,t ; Sample Brownian noise: ∆ w i t ∼ N (0 , I ∆ t ); ∆ v i t ∼ N (0 , ∆ t ) Compute control: K i t = K ( t, x i t ) = G i t ( u i ∗ t ∆ t + σ u i ∗ t ∆ v i t ) Forward propag ate the SDEs: x i t +1 , V i t +1 , V i x ,t +1 = f 2 F B S D E ( x i t , V i t , V i x ,t , V i xx ,t , K i t ) ← time discretized (8) end for end for Compute mini-batch loss: L = f Loss ( V N , V ∗ N , V x ,N , V ∗ x ,N , V xx ,N , V ∗ xx ,N , θ k − 1 ) Gradient update: θ k , ψ k , ζ k ← Adam.step( L , θ k − 1 , ψ k − 1 , ζ k − 1 ) end for retur n θ K , ψ K , ζ K index t lies in the interval [ t ∆ t, ( t + 1)∆ t ) . W e use subscript t to denote the discretized v ariables in our proposed algorithm Alg. 1. Network architecture: Inspired by the LSTM -based recurrent neural network architecture introduced by Pereira et al. [32] for solving first order FBSDE s, we propose the network in fig.1 adapted to the uncertainties in 2FBSDE s giv en by (8) . Instead of predicting the gradient of the v alue function V x at e very time step, the output of the LSTM is used to predict the Hessian of the v alue function V xx and A = ∂ t ( V x ) + 1 2 tr( ∂ xx ( V x ) CC T ) using two separate FC layers with linear acti vations. Notice that ∂ xx ( V x ) is a rank 3 tensor and using neural networks to predict this term explicitly w ould render this method unscalable. W e, howe ver , bypass this problem by instead predicting the trace of the tensor product which is a vector allo wing linear growth in output size with state dimensionality . Of these, V xx is used to compute the control term K = G ( u ∗ d t + σ u ∗ d v ) . This in turn is used to propagate the stochastic dynamics in (8) . Both V xx and A are used to propagate V x which is then used to propag ate V . This is repeated until the end of the time horizon as sho wn 5 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 in fig.1. Finally , the predicted v alues of V , V x and V xx are compared with their targets computed using x at the end of the horizon, to compute a loss function for backpropagation. Algorithm: Algorithm 1 details the training procedure of the Deep 2FBSDE Controller . Note that superscripts indicate batch index for v ariables and iteration number for trainable parameters. The value function V 0 and its gradient V x , 0 (at time index t = 0 ), are randomly initialized and trainable. Functions f LS T M , f F C 1 and f F C 2 denote the forward propagation equations of standard LSTM layers [ 18 ] and FC layers with tanh and linear acti v ations respectiv ely , and f 2 F B S D E represents a discretized v ersion of (8) using the explicit Euler-Maruyama time discretization scheme. The loss function ( L ) is computed using the giv en terminal conditions as tar gets, the propagated v alue function ( V ), its gradient ( V x ) and Hessian ( V xx ) at the final time index as well as an L 2 regularization term as follo ws L = c 1 || V ∗ − V N || 2 2 + c 2 || V ∗ x − V x ,N || 2 2 + c 3 || V ∗ xx − V xx ,N || 2 2 + c 4 || V ∗ || 2 2 + λ || θ || 2 2 . (9) A detailed justification of each loss term is included in SM D. The netw ork is trained using any v ariant of Stochastic Gradient Descent ( SGD ) such as Adam [ 23 ] until conv ergence. The algorithm returns a trained netw ork capable of computing an optimal feedback control at ev ery timestep starting from the giv en initial state. 5 Simulation Results In this section we demonstrate the capability of the Deep 2FBSDE Controller on 4 different systems in simulation. W e first compare the solution of the Deep 2FBSDE Controller to the analytical solution for a scalar linear system to v alidate the correctness of our proposed algorithm. W e then consider a cart-pole swing-up task and a reaching task for a 12-state quadcopter . Finally , we tested on a 2-link 6-muscle (10-state) human arm model for a planar reaching task. The results were compared against the Deep FBSDE Controller in Pereira et al. [32] , where in the ef fect of control multiplicativ e noise was ignored by only considering additi ve noise models resulting in first order FBSDE s, and the iLQG controller in Li and T odorov [27] . Hereon we use 2FBSDE , FBSDE and iLQG to denote the Deep 2FBSDE , Deep FBSDE and iLQG controllers respectiv ely . The system dynamics can be found in SM F and the simulation parameters can be found in SM G. Figure 2: The 2FBSDE solution is very similar to the ana- lytical solution for a scalar linear system. All the comparison plots contain statistics gathered ov er 128 test trials. F or 2FBSDE and FBSDE, we used time discretization ∆ t = 0 . 004 seconds for the linear system problem, ∆ t = 0 . 02 seconds for the cart-pole and quad- copter simulations and ∆ t = 0 . 02 seconds for the human arm simulation. For the iLQG simulations, ∆ t = 0 . 01 seconds for cartpole and quadcopter and ∆ t = 0 . 001 seconds for the human arm were used to av oid numeri- cal instability . These v alues were hand-tuned until rea- sonable performance was observed from iLQG. In all plots, the solid lines represent mean trajectories, and the shaded regions represent the 68% confidence re gion (mean ± standard de viation). Scalar Linear System: W e consider a scalar linear time- in variant system d x ( t ) = Ax ( t ) d t + B u ( t ) d t + σ B u ( t ) d v ( t ) + C d w ( t ) , (10) with quadratic running state cost and terminal state cost q x ( t ) = 1 2 Qx ( t ) 2 , φ x ( T ) = 1 2 Q T x ( t ) 2 . The dynamics and cost function parameters are set as A = 0 . 2 , B = 1 . 0 , C = 0 . 1 , σ = 0 . 5 , Q = 0 , Q T = 80 , R = 2 , x 0 = 1 . 0 . The task is to driv e the state to 0. Note that the problem is dif ferent than the one for LQG due to the presence of control multiplicative noise (i.e. v ( t ) 6 = 0 ). Let us assume that the value function ( (4) ) has the form V t, x ( t ) = 1 2 P ( t ) x 2 ( t ) + S ( t ) x ( t ) + c ( t ) , where S ( T ) = 0 , P ( T ) = Q T , c ( t ) = R T 0 1 2 c 2 P ( s ) d s . The values of P and Q are obtained by solving corresponding Riccatti equations, using ODE solv ers, that can be deri ved in a similar manner to the LQG case in Stengel [36 , Chapter 5 ] and are used to compute the optimal control ( (5) ) at ev ery timestep. The solution obtained from 2FBSDE is compared against the analytical solution in fig. 3. The resulting trajectories hav e matching mean and comparable variance, which v erifies the effecti veness of the controller on linear systems. High Dimensional Linear System: W e consider a linear time-in variant system gi ven by d x ( t ) = Ax ( t ) d t + Bu ( t ) d t + σ Bu ( t ) d v ( t ) + Σ d w ( t ) , x ∈ R 100 (11) with quadratic running state cost and terminal state cost q x ( t ) = φ x ( T ) = ( x − η ) T Q ( x − η ) . 6 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Figure 4: Cartpole Swing-up T ask: 2FBSDE is most aw are of the presence of control multiplicati ve noise and uses least control effort to perform the task. This is evident from the cart v elocity plot, a directly actuated state, which tries to stay as close to zero as possible. Figure 3: High dim Lin Sys The dynamics and cost function parameters are set as A = 0 , B = I , Σ = 0 . 5 I , σ = 0 . 1 , Q = 0 . 8 I , R = 0 . 02 I , x 0 = 1 . 0 I . The task is to drive all the states to η = 0 . Although these dynamics may seem tri vial comprising of 100 indepen- dent scalar systems, such dynamics arise in high-dimensional multi-agent systems wherein the independent agents are only coupled through the cost function. W e refer the reader to SM E and SM G.1 for deri v ation of the Riccati equations to com- pute the analytical solution and additional simulation details respectiv ely . Cartpole: W e applied the controllers to cartpole dynamics for a swing-up task with a time horizon of T = 2 . 0 seconds. The networks were trained using a batch size of 256 each for 2000 iterations. W e imposed a strict restriction on the controllers with control cost coefficient R = 0 . 5 and did not impose an y cost or target for the cart position state. W e would like to highlight in fig. 4 that both 2FBSDE and iLQG choose to pre-swing the pendulum and use the system’ s momentum to achieve the swing-up task. They thus respect the presence of control multiplicative noise entering the system as compared to FBSDE which tries to dri ve the pendulum to the desired vertical position as soon as possible by applying as much control as required. Additionally , we tested for a lower control cost R = 0 . 1 (see SM H for plots) and observ ed qualitativ ely different beha vior from the controllers. Quadcopter: The controller was also tested on a 12-state quadcopter dynamics model for a task of reaching and hov ering at a target position with a time horizon of 2.0 seconds. The network w as trained with a batch size of 256 for 5000 iterations. Only linear and angular states are included in fig. 5 since they most directly reflect the task performance (velocity plots included in SM H). The figure demonstrates superior performance of the 2FBSDE controller ov er the FBSDE and iLQG controller in reaching the target state faster and maintaining smaller state variance. Moreov er , these results also con vey the importance of taking into account multiplicativ e noise in the design of optimal controllers as the state dimensionality and system complexity increases. W e also tested the 2FBSDE controller for the same task (reach and hov er) for a longer horizon of 3.0 seconds (see SM H for plots) to verify its stabilizing capability in presence of control multiplicativ e noise. 2-link 6-muscle Human Arm: This is a 10-state bio-mechanical system wherein control multiplicative noise models hav e been found to closely mimic empirical observations [ 40 ]. The controllers were tasked with reaching a target position in 1 . 0 second. The networks were trained with a batch size of 256 for 2000 iterations. Additiv e noise in the joint-angle acceleration channels and multiplicati ve noise in muscle acti vations were considered. In fig. 6, we show the log of terminal state cost ( log φ ( x N ) ) v ersus dif ferent values of additiv e noise standard de viations (while holding multiplicativ e noise standard de viation fixed at 0.1) on the left and versus different values of multiplicati ve noise standard de viations (keeping additi ve noise standard de viation fixed at 0) on the right. As seen in the fig. 6, the 7 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Figure 5: Quadcopter Reach and Hover task: Abov e plots, from left to right, in the top row are x, y and z positions and botton ro w are roll, pitch and yaw angles. 2FBSDE clearly out-performs both FBSDE and iLQG, as indicated by the smaller variance in all states. Figure 6: Comparison of 2FBSDE and iLQG f or Human Arm system: Plots sho w terminal cost versus additive ( Σ ) and control multiplicativ e noise standard deviations ( σ ). The FBSDE results are omitted as failure (div ergence) occurred in all test trials. When additiv e noise is varied ( left ), 2FBSDE outperforms iLQG at lower Σ and performance deteriorates much slo wer than iLQG as Σ increases. When multiplicativ e noise is v aried ( right ), iLQG exhibits v ery erratic behaviour while the terminal cost gradually increases with σ for 2FBSDE. performance of iLQG is very erratic compared to 2FBSDE as σ is varied. The dif ference in behaviors can be attributed to the fact that iLQG is only aware of the first tw o moments of the uncertainty entering the system while the 2FBSDE , being a sampling based controller is exposed to the true uncertainty entering the system. Discussion: Although the performance of iLQG for the cartpole and human arm tasks seem competiti ve to 2FBSDE , we would like to highlight the fact that iLQG becomes brittle as σ of the control multiplicati ve noise is increased (or time horizon is increased) and requires very fine time discretizations, proper regularization scheduling and fine state cost coefficient tuning in order to be able to conv erge. Moreover , the control cost ( R ) had to be tuned to a high v alue in order to prev ent div ergence at higher noise standard deviations. This is in contrast to the results in Li and T odorov [27] , on account of two main reasons: firstly they do not consider the presence of additi ve noise in the angular acceleration channels in addition to multiplicati ve noise in the muscle acti vation channels and secondly the paper does not pro vide all details to fully reproduce the published results nor is code with muscle actuation made publicly available. Some of the crucial elements to fully implement the human arm model such as relationships between muscle lengths, muscle velocities, and the respecti ve joint angles had to be obtained by studying the work done by T eka et al. [37]. 8 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 6 Conclusions In this paper , we proposed the Deep 2 FBSDE Controller to solve the Stochastic Optimal Control problems for systems with additive, state dependent and control multiplicativ e noise. The algorithm relies on the 2FBSDE formulation with control in the forw ard process for sufficient exploration. The ef fectiv eness of the algorithm is demonstrated by comparing against analytical solution for a linear system, and against the first order FBSDE controller and the iLQG controller on systems of cartpole, quadcopter and 2-link human arm in simulation. Potential future directions of this work include application to financial models with intrinsic control multiplicativ e noise and theoretical analysis of error bounds on value function approximation as well as in vestigating ne wer architectures. References [1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Bre vdo, Zhifeng Chen, Craig Citro, Gre g S. Corrado, Andy Davis, Jef frey Dean, Matthieu Devin, Sanjay Ghemaw at, Ian Goodfellow , Andrew Harp, Geof frey Irving, Michael Isard, Y angqing Jia, Rafal Jozefowicz, Lukasz Kaiser , Manjunath Kudlur , Josh Lev enberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Murray , Chris Olah, Mike Schuster , Jonathon Shlens, Benoit Steiner , Ilya Sutske ver , Kunal T alwar , Paul T ucker , V incent V anhoucke, V ijay V asudev an, Fernanda V iégas, Oriol V inyals, Pete W arden, Martin W attenberg, Martin W icke, Y uan Y u, and Xiaoqiang Zheng. T ensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL http://tensorflow.org/ . Software av ailable from tensorflow .org. [2] Mario Annunziato and Alfio Borzi. Optimal control of probability density functions of stochastic processes. Mathematical Modelling and Analysis , 15(4):393–407, 2010. [3] Mario Annunziato and Alfio Borzì. A fokker–planck control framew ork for multidimensional stochastic processes. Journal of Computational and Applied Mathematics , 237(1):487–507, 2013. [4] K. S. Bakshi, D. D. F an, and E. A. Theodorou. Stochastic control of systems with control multiplicati ve noise using second order fbsdes. In 2017 American Control Confer ence (A CC) , pages 424–431, May 2017. doi: 10.23919/A CC.2017.7962990. [5] R. Bellman and R. Kalaba. Selected P apers On mathematical tr ends in Contr ol Theory . Dover Publications, 1964. [6] W . Brogan. Modern Contr ol Theory . Prentice-Hall, 1991. [7] Nicole El Karoui, Shige Peng, and Marie Claire Quenez. Backw ard stochastic differential equations in finance. Mathematical finance , 7(1):1–71, 1997. [8] Ht M ElKholy . Dynamic modeling and control of a quadrotor using linear and nonlinear approaches. Master of Science in Robotics, The American University in Cair o , 2014. [9] I. Exarchos and E. A. Theodorou. Learning optimal control via forward and backward stochastic dif ferential equations. In American Contr ol Confer ence (ACC), 2016 , pages 2155–2161. IEEE, 2016. [10] I. Exarchos and E. A. Theodorou. Stochastic optimal control via forward and backward stochastic differential equations and importance sampling. Automatica , 87:159–165, 2018. [11] I. Exarchos, E. A. Theodorou, and P . Tsiotras. Stochastic L 1 -optimal control via forward and backward sampling. Systems & Contr ol Letters , 118:101–108, 2018. [12] Ioannis Exarchos, Evangelos Theodorou, and Panagiotis Tsiotras. Stochastic dif ferential games: A sampling approach via fbsdes. Dynamic Games and Applications , 9(2):486–505, Jun 2019. ISSN 2153-0793. doi: 10.1007/s13235- 018- 0268- 4. URL https://doi.org/10.1007/s13235- 018- 0268- 4 . [13] W . H. Fleming and H. M. Soner . Contr olled Markov pr ocesses and viscosity solutions . Applications of mathematics. Springer, New Y ork, 2nd edition, 2006. [14] Xavier Glorot and Y oshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Pr oceedings of the thirteenth international confer ence on artificial intelligence and statistics , pages 249–256, 2010. [15] Alex Gorodetsk y , Sertac Karaman, and Y oussef Marzouk. Efficient high-dimensional stochastic optimal motion control using tensor-train decomposition. In Proceedings of Robotics: Science and Systems , Rome, Italy , July 2015. doi: 10.15607/RSS. 2015.XI.015. [16] Jiequn Han, Arnulf Jentzen, and W einan E. Solving high-dimensional partial dif ferential equations using deep learning. Pr oceedings of the National Academy of Sciences , 115(34):8505–8510, 2018. ISSN 0027-8424. doi: 10.1073/pnas.1718942115. URL https://www.pnas.org/content/115/34/8505 . [17] Jiequn Han et al. Deep Learning Approximation for Stochastic Control Problems. arXiv pr eprint arXiv:1611.07422 , 2016. [18] Sepp Hochreiter and Jürgen Schmidhuber . Long short-term memory . Neural Computation , 9(8):1735–1780, 1997. doi: 10.1162/neco.1997.9.8.1735. URL https://doi.org/10.1162/neco.1997.9.8.1735 . [19] V . A. Huynh, S. Karaman, and E. Frazzoli. An incremental sampling-based algorithm for stochastic optimal control. I. J . Robotic Res. , 35(4):305–333, 2016. doi: 10.1177/0278364915616866. URL http://dx.doi.org/10.1177/0278364915616866 . [20] Kiyosi Itô. 109. stochastic integral. Proceedings of the Imperial Academy , 20(8):519–524, 1944. 9 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 [21] H. J. Kappen. Linear theory for control of nonlinear stochastic systems. Phys Rev Lett , 95:200201, 2005. Journal Article United States. [22] I. Karatzas and S. E. Shreve. Br ownian Motion and Stoc hastic Calculus (Gr aduate T exts in Mathematics) . Springer , 2nd edition, August 1991. ISBN 0387976558. [23] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint , 2014. [24] Peter E Kloeden and Eckhard Platen. Numerical solution of stochastic differ ential equations , volume 23. Springer Science & Business Media, 2013. [25] H. J. Kushner and P . G. Dupuis. Numerical Methods for Stochastic Contr ol Problems in Continuous T ime . Springer-V erlag, London, UK, UK, 1992. ISBN 0-387-97834-8. [26] W eiwei Li and Emanuel T odorov . Iterative linear quadratic regulator design for nonlinear biological mov ement systems. In ICINCO (1) , pages 222–229, 2004. [27] W eiwei Li and Emanuel T odorov . Iterativ e linearization methods for approximately optimal control and estimation of non-linear stochastic system. International Journal of Contr ol , 80(9):1439–1453, 2007. [28] P . McLane. Optimal stochastic control of linear systems with state- and control-dependent disturbances. IEEE T ransactions on Automatic Contr ol , 16(6):793–798, December 1971. ISSN 0018-9286. doi: 10.1109/T AC.1971.1099828. [29] Djordje Mitrovic, Stefan Klanke, Rieko Osu, Mitsuo Kawato, and Sethu V ijayakumar . A computational model of limb impedance control based on principles of internal model uncertainty . PLOS ONE , 5(10):1–11, 10 2010. doi: 10.1371/journal. pone.0013601. URL https://doi.org/10.1371/journal.pone.0013601 . [30] Etienne Pardoux and Shige Peng. Adapted solution of a backward stochastic differential equation. Systems & Contr ol Letters , 14(1):55–61, 1990. [31] Etienne Pardoux and Aurel Rascanu. Stochastic Dif ferential Equations, Backwar d SDEs, P artial Differ ential Equations , volume 69. 07 2014. doi: 10.1007/978- 3- 319- 05714- 9. [32] Marcus A Pereira, Ziyi W ang, Ioannis Exarchos, and Ev angelos A Theodorou. Learning deep stochastic optimal control policies using forward-backward sdes. In Robotics: science and systems , 2019. [33] Y . Phillis. Controller design of systems with multiplicativ e noise. IEEE T ransactions on A utomatic Contr ol , 30(10):1017–1019, October 1985. ISSN 0018-9286. doi: 10.1109/T A C.1985.1103828. [34] J. A. Primbs. Portfolio optimization applications of stochastic receding horizon control. In 2007 American Contr ol Confer ence , pages 1811–1816, July 2007. doi: 10.1109/A CC.2007.4282251. [35] Stev en E Shrev e. Stochastic calculus for finance II: Continuous-time models , volume 11. Springer Science & Business Media, 2004. [36] R. F . Stengel. Optimal contr ol and estimation . Dover books on adv anced mathematics. Dov er Publications, New Y ork, 1994. [37] W ondimu W T eka, Khaldoun C Hamade, W illiam H Barnett, T aegyo Kim, Serge y N Markin, Ilya A Rybak, and Y aroslav I Molkov . From the motor cortex to the movement and back ag ain. PloS one , 12(6):e0179288, 2017. [38] E.A. Theodorou, J. Buchli, and S. Schaal. A generalized path integral approach to reinforcement learning. Journal of Machine Learning Resear ch , (11):3137–3181, 2010. [39] E.A. Theodorou, Y . T assa, and E. T odorov . Stochastic differential dynamic programming. In American Contr ol Confer ence , pages 1125–1132, 2010. [40] E. T odorov . Stochastic optimal control and estimation methods adapted to the noise characteristics of the sensorimotor system. Neural Computation , 17(5):1084, 2005. [41] E. T odorov . Linearly-solvable markov decision problems. In B. Scholkopf, J. Platt, and T . Hoffman, editors, Advances in Neural Information Pr ocessing Systems 19 , V ancouver , BC, 2007. Cambridge, MA: MIT Press. [42] E. T odorov . Efficient computation of optimal actions. Pr oceedings of the national academy of sciences , 106(28):11478–11483, 2009. [43] E. T odorov and W . Li. A generalized iterative lqg method for locally-optimal feedback control of constrained nonlinear stochastic systems. pages 300–306, 2005. [44] E. T odorov and W eiwei Li. A generalized iterativ e lqg method for locally-optimal feedback control of constrained nonlinear stochastic systems. In Pr oceedings of the 2005, American Contr ol Confer ence, 2005. , pages 300–306 v ol. 1, June 2005. doi: 10.1109/A CC.2005.1469949. [45] G. DeLa T orre and E.A. Theodorou. Stochastic variational integrators for system propag ation and linearization. Sept 2015. 10 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Supplementary Materials A Assumptions Assumption 1. Ther e exists a constant k > 0 suc h that | ( f + Gu )( t, x , u ) − ( f + Gu )( t, x 0 , u 0 ) | ≤ k ( | x − x 0 | + | u − u 0 | ) (12) | C ( t, x , u ) − C ( t, x 0 , u 0 ) | ≤ k ( | x − x 0 | + | u − u 0 | ) (13) | ( f + Gu )( t, x , u ) + C ( t, x ) | ≤ k (1 + | x | ) , (14) wher e C = [ σ Gu Σ ] , ∀ t ∈ [0 , T ] , ∀ x , x 0 ∈ R n x and ∀ u , u 0 ∈ R n u . B HJB PDE Derivation Applying the dynamic programming principle [5] to the value function we ha ve V ( t, x ( t )) = inf u ( s ) ∈U ([ t,t + d t ]) E Q t + d t Z t q ( x ( s )) + 1 2 u ( s ) T Ru ( s ) d s + V ( t + d t, x ( t + d t )) . (15) Then, we can approximate the running cost integral with a step function and apply Ito’ s lemma [20] to obtain V ( t, x ( t )) = inf u ∈U E Q q ( x ( t )) + 1 2 u ( t ) T Ru ( t ) d t + V ( t + d t, x ( t + d t )) Itô = inf u ∈U E Q q ( x ( t )) + 1 2 u ( t ) T Ru ( t ) d t + V ( t, x ( t )) + V t ( t, x ( t )) d t + V T x ( t, x ( t )) f ( t, x ( t )) d t + G ( t, x ( t ))( u d t + σ u ( t ) d v ( t )) + Σ ( t, x ( t )) d w ( t ) + 1 2 tr V xx ( t, x ( t )) C ( t, x ( t ) , u ( t )) C T ( t, x ( t ) , u ( t )) d t i = inf u ∈U q ( x ( t )) + 1 2 u ( t ) T Ru ( t ) d t + V ( t, x ( t )) + V t ( t, x ( t )) d t + V T x ( t, x ( t )) f ( t, x ( t )) d t + G ( t, x ( t )) u ( t ) d t + 1 2 tr V xx ( t, x ( t )) C ( t, x ( t ) , u ( t )) C T ( t, x ( t ) , u ( t )) d t i W e can cancel V ( t, x ( t )) on both sides and bring the terms not dependent on controls outside of the infimum to get V t + V T x f + q + inf u ∈U [0 ,T ] n 1 2 u T R u + V T x Gu + 1 2 tr( V xx CC T ) o = 0 (16) Note that the functional dependencies ha ve been dropped for bre vity . No w we can find the optimal control by taking the gradient of the terms inside the infimum with respect to u and setting it to zero. Before that we first substitute for C = σ Gu , Σ so that the term inside the trace operator becomes σ 2 V xx Guu T G T + V xx ΣΣ T . By using the property of trace operators, we can write, tr( V xx CC T ) = tr( σ 2 V xx Guu T G T + V xx ΣΣ T ) = tr( σ 2 u T G T V xx Gu ) + tr( V xx ΣΣ T ) . Note that the second term is not a function of u and therefore is zero when we take the gradient. Additionally , the first term is a scalar and taking its trace returns the same scalar . Now , taking the gradient w .r .t u , we get, Ru ∗ + ( V T x G ) T + σ 2 G T V xx Gu ∗ = 0 ⇒ ( R + σ 2 G T V xx G ) u ∗ = − ( G T V x ) ⇒ ˆ Ru ∗ = − ( G T V x ) ⇒ u ∗ = − ˆ R − 1 G T V x . where, ˆ R , ( R + σ 2 G T V xx G ) . 11 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 The optimal control abov e can be plugged back into (16) to obtain V t + V T x f + q + 1 2 V T x G ˆ R − T R ˆ R − 1 G T V x − V T x G ˆ R − 1 G T V x + 1 2 σ 2 V T x G ˆ R − T G T V xx G ˆ R − 1 G T V x + 1 2 tr( V xx ΣΣ T ) = 0 ⇒ V t + V T x f + q + 1 2 V T x G ˆ R − T R + σ 2 G T V xx G ˆ R − 1 G T V x − V T x G ˆ R − 1 G T V x + 1 2 tr( V xx ΣΣ T ) = 0 ⇒ V t + V T x f + q + 1 2 V T x G ˆ R − T ˆ R ˆ R − 1 G T V x − V T x G ˆ R − 1 G T V x + 1 2 tr( V xx ΣΣ T ) = 0 ⇒ V t + V T x f + q − 1 2 V T x G ˆ R − 1 G T V x + 1 2 tr( V xx ΣΣ T ) = 0 which giv es the HJB PDE as mentioned in (4). C Derivation of the 2FBSDEs Firstly we can apply Ito’ s dif ferentiation rule to V : d V Itô = V t d t + V T x d x + 1 2 tr V xx CC T d t. (17) Since V is the value function, we can substitute in the HJB PDE for V t and forward dynamics for d x to get: d V = − q + V T x f − 1 2 V T x G ˆ R − 1 G T V x + 1 2 tr V xx ΣΣ T d t + V T x f d t + G ( u ∗ d t + σ u ∗ d v ) + Σ d w + 1 2 tr V xx CC T d t = − q + V T x f − 1 2 V T x G ˆ R − 1 G T V x + 1 2 tr V xx ΣΣ T d t + V T x f d t + G ( u ∗ d t + σ u ∗ d v ) + Σ d w + 1 2 tr V xx ΣΣ T + σ 2 u ∗ T G T V xx Gu ∗ d t = − q + V T x f − 1 2 V T x G ˆ R − 1 G T V x − 1 2 σ 2 V T x G ˆ R − T G T V xx G ˆ R − 1 G T V x d t + V T x f d t + G ( u ∗ d t + σ u ∗ d v ) + Σ d w = − q + V T x f − 1 2 V T x G ˆ R − T ˆ R ˆ R − 1 G T V x − 1 2 σ 2 V T x G ˆ R − T G T V xx G ˆ R − 1 G T V x d t + V T x f d t + G ( u ∗ d t + σ u ∗ d v ) + Σ d w = − q + V T x f − 1 2 V T x G ˆ R − T ( R + 2 σ 2 G T V xx G ) ˆ R − 1 G T V x d t + V T x f d t + G ( u ∗ d t + σ u ∗ d v ) + Σ d w = − ( q − 1 2 V T x G ˆ R − T ( R + 2 σ 2 G T V xx G ) ˆ R − 1 G T V x d t + V T x G ( u ∗ d t + σ u ∗ d v ) + V T x Σ d w . (18) For V x , we can again apply Ito’ s differentiation rule: d V x Itô = V x t d t + V T xx d x + 1 2 tr V xxx CC T . (19) W e can again substitute in the forward dynamics for d x and get: d V x = ∂ t V x d t (20) + ∂ x V T x f d t + G ( u ∗ d t + σ u ∗ d v ) + Σ d w + 1 2 tr ∂ xx V x CC T d t = ( A + V xx f ) d t + V xx G ( u ∗ d t + σ u ∗ d v ) (21) + V xx Σ d w . (22) 12 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 W e hav e A = ∂ t V x + 1 2 tr( ∂ xx V x CC T ) . Note that the transpose on V xx is dropped since it is symmetric. D Loss Function The loss function used in this work builds on the loss functions used in [ 16 ] and [ 32 ]. Because the Deep 2FBSDE Controller propagates 2 BSDEs, in addition to using the propagated v alue function ( V t ) , the propagated gradient of the v alue function ( V x ,t ) can also be used in the loss function to enforce that the network meets both the terminal constraints i.e. φ ( x N ) and φ x ( x N ) respectiv ely . Moreov er, since the terminal cost function is kno wn, its Hessian can be computed and used to enforce that the output of the F C 1 layer at the terminal time index ( V xx ,N ) be equal to the target Hessian of the terminal cost function φ xx ( x N ) . Although this is enforced only at the terminal time index ( V xx ,N ) , because the weights of a recurrent neural network are shared across time, in order to be able to predict V xx ,N accurately all of the prior predictions V xx ,t will hav e to be adjusted accordingly , thereby representing some form of propagation of the Hessian of the v alue function. Additionally , applying the optimal control, which uses the network prediction, to the forward process introduces an additional gradient path through the system dynamics at every time step. Although this mak es training difficult (gradient vanishing problem) it allows the weights to now influence what the ne xt state (i.e. at the ne xt time index) will be. As a result, the weights can control the state at the end time index and hence the target V ∗ ( x N ) for the neural network prediction itself. This can be added to the loss function which can accelerate the minimization of the terminal cost to achiev e the task objectiv es. The final form of our loss function is L = c 1 || V ∗ − V N || 2 2 + c 2 || V ∗ x − V x ,N || 2 2 + c 3 || V ∗ xx − V xx ,N || 2 2 + c 4 || V ∗ || 2 2 + λ || θ || 2 2 , where V ∗ = φ ( x N ) , V ∗ x = φ x ( x N ) and V ∗ xx = φ xx ( x N ) . E Linear System - Analytical Solution W e provide the deriv ation of the Riccati equations for the Linear System inv olving multiplicative noise. Let’ s consider the time remaining t r = t f − t where t f is the terminal time and t is the current time. V ( t r , x ( t )) = inf u E [( q ( x ( t )) + 1 2 u ( t ) T Ru ( t )) dt + V ( t f − t − dt ) , x ( t + dt )] Itô = inf u E [( q ( x ( t )) + 1 2 u ( t ) T Ru ( t )) dt + V ( t r , x ( t )) − V t r ( t r , x ( t )) dt + V T x ( t r , x ( t )) d x + 1 2 T r ( V xx CC T ) dt ] = inf u E [ q dt + 1 2 u T Ru dt + V ( t r , x ) − V t r ( t r , x ) dt + V T x ( t r , x )( f dt + Gu dt + G σ u dv + Σ d w ) + 1 2 T r ( V xx CC T dt )] 0 = inf u E [ q dt + 1 2 u T Ru dt − V t r ( t r , x ) dt + V T x ( t r , x )( f dt + Gu dt + Gσ udv + Σ dw ) + 1 2 T r ( V xx CC T ) dt ] 0 = inf u q dt + 1 2 u T Ru dt + − V t r ( t r , x ) dt + V T x ( t r , x )( f dt + Gu dt ) + 1 2 T r ( V xx CC T ) dt 0 = inf u q + 1 2 u T Ru + − V t r ( t r , x ) + V T x ( t r , x )( f + Gu ) + 1 2 T r ( V xx CC T ) 0 = q − V t r ( t r , x ) + V T x ( t r , x ) f + inf u 1 2 u T Ru + V T x ( t r , x ) Gu + 1 2 T r ( V xx CC T ) V t r ( t r , x ) = q + V T x ( t r , x ) f + inf u 1 2 u T Ru + V T x ( t r , x ) Gu + 1 2 T r ( V xx CC T ) V t r ( t r , x ) = q + V T x ( t r , x ) f − 1 2 V T x G ˜ R − 1 G T V x + 1 2 T r ( V xx ΣΣ T ) (23) where ˆ R = ( R + σ 2 G T V xx G ) . In our specific example, f = Ax ( t ) , G = B , and q = ( x ( t ) − η ( t )) T Q ( x ( t ) − η ( t )) where η ( t ) is some desired trajectory . F or notational simplicity , we set x ( t ) = x and η ( t ) = η . Substituting these into the abov e equation giv es V t r = V T x ( Ax ) + x T Qx − 2 x T Q η + η T Q η − 1 2 V T x B ( R + σ 2 B T V xx B ) − 1 B T V x + 1 2 T r ( V xx ΣΣ T ) (24) Now as in [6], let’ s suppose that V ( x ( t ) , t r ) = x T P ( t r ) x + x T S ( t r ) + c ( t r ) . Then, V t r = x T d P ( t r ) dt r x + x T d S ( t r ) dt r + dc ( t r ) dt r (25) 13 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 V x = 2 P ( t r ) x + S ( t r ) (26) V xx = 2 P ( t r ) (27) Thus, plugging in these terms into (24) giv es V t r = (2 P ( t ) x + S ( t )) T ( Ax ) + x T Qx − 2 x T Q η + η T Q η (28) − 1 2 (2 P ( t ) x + S ( t )) T B ˆ R − 1 B T (2 P ( t ) x + S ( t )) + 1 2 T r (2 P ( t ) ΣΣ T ) (29) where ˆ R = ( R + σ 2 B T P ( t ) B ) . Expanding and simplifying gi ves V t r = 2 x T P ( t ) T Ax + S ( t ) T Ax + x T Qx − 2 x T Q η + η T Q η − 1 2 4 x T P ( t ) T B ˆ R − 1 B T P ( t ) x + 2 x T P ( t ) T B ˆ R − 1 B T S ( t )+ 2 S ( t ) T B ˆ R − 1 B T P ( t ) x + S ( t ) T B ˆ R − 1 B T S ( t ) + 1 2 T r (2 P ( t ) ΣΣ T ) (30) W e set P ( t ) = P and S ( t ) = S for notational simplicity . Since S T Ax is a scalar, then S T Ax = x T A T S . Also since 2 S T B ˆ R − 1 B T Px is a scalar , then 2 S T B ˆ R − 1 B T Px = (2 S T B ˆ R − 1 B T Px ) T = 2 x T P T B ˆ R − 1 B T S . Therefore, (30) can be written as V t r = x T (2 P T A + Q − 2 P T B ˆ R − 1 B T P ) x + x T ( A T S − 2 Q η − 2 P T B ˆ R − 1 B T S )+ ( η T Q η − 1 2 S T B ˆ R − 1 B T S + 1 2 tr ( PΣΣ T )) (31) Since x T 2 P Ax is not symmetric, it can be rewritten as x T ( P A + A T P ) x + x T ( P A − A T P ) x . The second term is alw ays zero since the matrix is ske w-symmetric. Then, equating the terms in (25) and (31) gi ves the Riccati equations d P ( t ) dt r = P A + A T P + Q − 2 PB ˆ R − 1 B T P (32) d S ( t ) dt r = A T S − 2 Q η − 2 P T B ˆ R − 1 B T S (33) dc ( t ) dt = η T Q η − 1 2 S T B ˆ R − 1 B T S + 1 2 T r (2 PΣΣ T ) (34) where the terminal conditions are P ( T ) = Q , S ( T ) = − 2 Q η , and c ( T ) = η T Q η . This is due to the fact that V ( x , T ) = φ ( T ) = ( x − η ) T Q ( x − η ) and since V is assumed to be quadratic then V ( x , T ) = x T P ( T ) x + x T S ( T ) + c ( T ) . Equating the same order terms giv es the terminal conditions. Since d {} /dt r = − d {} /dt , then − ˙ P = P A + A T P + Q − 2 P T B ˆ R − 1 B T P (35) − ˙ S = A T S − 2 Q η − 2 P T B ˆ R − 1 B T S (36) − ˙ c = η T Q η − 1 2 S T B ˆ R − 1 B T S + 1 2 T r (2 PΣΣ T ) (37) Since u ∗ = − ˆ R − 1 G T V x and ˆ R = ( R + σ 2 G T V xx G ) , then substituting for G = B , V x = P ( t ) x ( t ) + S ( t ) and V xx = P ( t ) giv es u ∗ = − ( R + σ 2 B T P ( t ) B ) − 1 B T ( P ( t ) x ( t ) + S ( t )) (38) F Non-linear System Dynamics and System Parameters For all simulation experiments, we used the same quadratic state cost of the form q ( x ) = 1 2 ( x − x target ) T Q ( x − x target ) for both the running and terminal state costs. 14 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 F .1 Cartpole The cartpole dynamics is giv en by d x θ ˙ x ˙ θ = ˙ x ˙ θ m p sin θ ( l ˙ θ 2 + g cos θ ) m c + m p sin 2 θ − m p l ˙ θ 2 cos θ sin θ − ( m c + m p ) g sin θ l ( m c + m p sin 2 θ ) d t + 0 0 1 m c + m p sin 2 θ − 1 l ( m c + m p sin 2 θ ) ( u d t + σ u d v ) + 0 2 × 2 0 2 × 2 0 2 × 2 I 2 × 2 d w . The model and dynamics parameters are set as m p = 0 . 01 kg , m c = 1 kg , l = 0 . 5 m , σ = 0 . 125 . The initial pole and cart position are 0 rad and 0 m with no velocity , and the target state is a pole angle of π rad and zeros for all other states. The control costs R are 0 . 5 and 0 . 1 for experiments in fig.4 and fig. 7 respectively . The state cost matrix is the same for both e xperiments at Q = diag [0 . 0 , 6 . 0 , 0 . 3 , 0 . 3] . F .2 Quadcopter The quadcopter dynamics used can be found in [8]. Its dynamics is gi ven by d x y z φ θ ψ ˙ x ˙ y ˙ z ˙ φ ˙ θ ˙ ψ = ˙ x ˙ y ˙ z ˙ φ ˙ θ ˙ ψ 0 0 g I yy I xx ˙ ψ ˙ θ − I zz I xx ˙ θ ˙ ψ I zz I yy ˙ φ ˙ ψ − I xx I yy ˙ ψ ˙ φ I xx I zz ˙ θ ˙ φ − I yy I zz ˙ φ ˙ θ d t + 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 − 1 m (sin φ sin ψ + cos φ cos ψ sin θ ) 0 0 0 − 1 m (cos φ sin ψ sin θ − cos ψ sin φ ) 0 0 0 − 1 m cos φ cos θ 0 0 0 0 l I xx 0 0 0 0 l I yy 0 0 0 0 1 I zz ( u 1 u 2 u 3 u 4 d t + σ u 1 u 2 u 3 u 4 d v ) + 0 6 × 6 0 6 × 6 0 6 × 6 I 6 × 6 d w , where u 1 u 2 u 3 u 4 = 1 1 1 1 0 − 1 0 1 1 0 − 1 0 d − d d − d τ 1 τ 2 τ 3 τ 4 . The states are positions, velocities, angles and angular rates, and the controls are the four rotor torques ( τ ). More specifically , u 1 is the thrust, u 2 is the roll acceleration, u 3 is the pitch acceleration, and u 4 is the yaw acceleration. The model and dynamics parameters are set as m = 0 . 47 kg , I xx = I yy = 4 . 86 × 10 − 3 kg m 2 , I zz = 8 . 8 × 10 − 3 kgm 2 , l = 0 . 225 m , d = 0 . 05 . The initial state conditions used are all zeros, and the tar get state is 1 meter each in the north-east-do wn directions and all other states zero. The control cost matrix is R = 2 I 4 × 4 . The state cost matrix is Q = diag [20 . 0 , 20 . 0 , 50 . 0 , 5 . 0 , 5 . 0 , 5 . 0 , 1 . 25 , 1 . 25 , 5 . 0 , 0 . 25 , 0 . 25 , 0 . 25] . F .3 2-link 6-muscle Human Arm The forward rigid-body dynamics of the 2-link human arm as stated in [26] is gi ven by: ¨ θ = M ( θ ) − 1 ( τ − C ( θ , ˙ θ ) − B ˙ θ ) where θ ∈ R 2 represents the joint angle vector consisting of θ 1 (shoulder joint angle) and θ 2 (elbow joint angle). M ( θ ) ∈ R 2 × 2 is the inertia matrix which is positiv e definite and symmetric. C ( θ , ˙ θ ) ∈ R 2 is the vector centripetal and Coriolis forces. B ∈ R 2 × 2 is the joint friction matrix. τ ∈ R 2 is the joint torque applied on the system. The torque is generated by activ ation of 6 muscle groups. Follo wing are equations for components of each of the above matrices and v ectors: 15 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 M = ˜ a 1 + 2˜ a 2 cosθ 2 ˜ a 3 + ˜ a 2 cosθ 2 ˜ a 3 + ˜ a 2 cosθ 2 ˜ a 3 C = − ˙ θ 2 (2 ˙ θ 1 + ˙ θ 2 ) ˙ θ 1 a 2 sinθ 2 B = b 11 b 12 b 21 b 22 ˜ a 1 = I 1 + I 2 + M 2 l 2 1 ˜ a 2 = m 2 L 1 s 2 ˜ a 3 = I 2 Where b 11 = b 22 = 0 . 05 , b 12 = b 21 = 0 . 025 , m i is the mass (1.4kg,1kg), l i is the length of link i (30cm, 33cm), s i is the distance between joint center and mass of link i (11cm, 16cm), I i represents for the moment of inertia ( 0 . 025 k g m 2 , 0 . 045 k g m 2 ). The activ ation dynamics for each muscle is gi ven by: ˙ a i = (1 + σ d v ) u i − a i ˜ t , ∀ i ∈ [1 , 6] ˜ t = t deact where t deact = 66 msec , a ∈ R 6 is a vector of muscle acti vations, u ∈ R 6 is a vector of instantaneous neural inputs. As a result of these dynamics, six ne w state variables ( a ) will be incorporated into the dynamical system. W ith the muscle acti vation dynamics proposed abov e, the joint torque vector can be computed as follows: τ = M ( θ ) T ( a, l ( θ ) , v ( θ , ˙ θ )) wherein T ( a, l, v ) ∈ R is the tensile force generated by each muscle, whose expression is giv en by: T ( a, l, v ) = A ( a, l )( F l ( l ) F V ( l, v ) + F P ( l )) A ( a, l ) = 1 − exp − a 0 . 56 N f ( l ) N f ( l ) ! N f ( l ) = 2 . 11 + 4 . 16 1 l − 1 F L ( l ) = exp − l 1 . 93 − 1 1 . 03 1 . 87 ! F V ( l, v ) = ( − 5 . 72 − v − 5 . 72+(1 . 38+2 . 09 l ) v , if v ≤ 0 0 . 62 − ( − 3 . 12+4 . 21 l − 2 . 67 l 2 ) v 0 . 62+ v , otherwise F p ( l ) = − 0 . 02 exp(13 . 8 − 18 . 7 l ) The equation for M ( θ ) is obtained from T eka et al. [37 , Equation 3 ] . The parameters used in the equa- tions abov e are mostly obtained by work in T eka et al. [37] , which we provide here in the following table: Muscle Maximal For ce, F max (N) Optimal Length, L opt (m) V elocity , v (m/sec) SF 420 0.185 − ˙ θ 1 R S F SE 570 0.170 − ˙ θ 1 R S E EF 1010 0.180 − ( ˙ θ 2 − ˙ θ 1 ) R E F EE 1880 0.055 − ( ˙ θ 2 − ˙ θ 1 ) R E E BF 460 0.130 − ˙ θ 1 R B F S − ( ˙ θ 2 − ˙ θ 1 ) R B F E BE 630 0.150 − ˙ θ 1 R B F S − ( ˙ θ 2 − ˙ θ 1 ) R B E E Where the last column consists of moment arms which are approximated according to [ 26 , figure B]. l ∈ R 6 × 1 is the length of each muscle, which is calculated by approximating the range of each muscle group in [ 26 ] using the data of joint angle ranges and linear relationships with corresponding joint angles as in [ 37 ]. Each of the fitted linear functions for muscle lengths and cosine functions for moment arms are av ailable in the provided MA TLAB code. 16 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 The above system is a deterministic model of the 2-link 6-muscle human arm. Ho wever , in the main paper we consider experiments with both additiv e and control multiplicativ e stochasticities. A state-space SDE model for the human arm is gi ven as follo ws, d θ 1 θ 2 ˙ θ 1 ˙ θ 2 a 1 a 2 a 3 a 4 a 5 a 6 = ˙ θ 1 ˙ θ 2 ¨ θ 1 ¨ θ 2 − a 1 t deact − a 2 t deact − a 3 t deact − a 4 t deact − a 5 t deact − a 6 t deact d t + 0 4 × 2 1 t deact I 6 × 6 ( u d t + σ u d v ) + 0 2 × 2 Σ 2 × 2 0 6 × 2 d w . where, ¨ θ = [ ¨ θ 1 , ¨ θ 2 ] T = M ( θ ) − 1 ( τ − C ( θ , ˙ θ ) − B ˙ θ ) and u = [ u 1 , u 2 , u 3 , u 4 , u 5 , u 6 ] T In this system, the control cost coefficient matrix is R = 2 . 0 ∗ I 6 × 6 . The state cost matrix is Q = diag [10 . 0 , 10 . 0 , 0 . 1 , 0 . 1 , 0 . 001 , 0 . 001 , 0 . 001 , 0 . 001 , 0 . 001 , 0 . 001] for running and terminal states. G Simulation Parameters G.1 High-dimensional linear system The networks for both the LSTM and Feed-forward Neural Networks ( FNN s) architecture designs were trained using a batch size of 256 each for 200 iterations. F or a time discretization of ∆ t = 0 . 01 , the resulting trajectories ha ve comparable mean and v ariance with the analytical solution which verifies the effecti veness of the controller on linear systems. Interestingly , for a time discretization of ∆ t = 0 . 02 , the analytical solution diver ges whereas 2FBSDE architectures con verge demonstrating that 2FBSDE is robust to time discretization errors. This is because we pick a simple Euler integration scheme for the analytical solution whose accuracy (and stability) can only be guaranteed for small time discretizations. The Deep Learning element of our algorithm is able to compensate for the time discretization errors. The comparison includes LSTM , analytical, and FNN s. LSTM -based architecture consists of 2 stacked layers of 8 LSTM cells each while FNN s-based architecture consists of 2 hidden-layer with 4 neurons each FNN s at ev ery time step. Both architectures have 2 linear FC output layers for V xx and A . In our simulation, the total number of trainable parameters were 50 , 515 and 3 , 926 , 201 for the LSTM-based and FNNs-based architectures respecti vely . The loss function coefficients used were c 1 = c 2 = c 3 = 1 , and c 4 = 0 . G.2 Nonlinear systems The precise training/network parameters are sho wn in the following table system batch size iterations c 1 c 2 c 3 c 4 λ d t (sec) T (sec) h CartPole 256 2000 1 1 1 1 0.0005 0.02 2 [8 , 8] QuadCopter 256 5000 1 1 1 1 0.0005 0.02 2 [8 , 8] HumanHand 256 2000 1 0 1 1 0.0005 0.02 2 [8 , 8] where iterations is the number of epochs. c 1 to c 4 represent of the weight of the components in the loss function in SM D. λ is the weights for L 2 regularization of neural network. d t is the time discretization. T is the time horizon for the task. h is the output size of each LSTM layer (cell state dimension is the same). 17 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Figure 7: Comparison of 2FBSDE, FBSDE and iLQG on Cartpole with control cost of R = 0 . 1 . Figure 8: Single control trajectory as well as mean and v ariance of 2FBSDE on Human Arm. The single trajectory demonstrates the feasibility of the resulting controls. H Additional Plots H.1 Cartpole Swing-up with Lower Control Cost The plots in fig. 7 show the comparison of the 2FBSDE, FBSDE and iLQG controllers when the restriction on the controls is lo wered as compared to that in the main paper . Here, the control cost is set to R = 0 . 1 as compared to R = 0 . 5 in the main paper . Clearly , the behavior is very different. Before the 2FBSDE and iLQG controllers used the momentum of the system to achie ve the the swing-up task ( R = 0 . 5 ). No w with a lower control cost, all three controllers try to reach the targets as soon as possible by applying the required control effort. The variance of the FBSDE controller , which does not take the control multiplicati ve noise into account in its deriv ation, has a higher v ariance around the target whereras the 2FBSDE and iLQG achiev e the target with v ery low v ariance. H.2 2-link 6-muscle Human Arm single control trajectory sample Fig. 8 includes a single control trajectory as well as the mean and variance for the human arm simulation to demonstrate the feasibility of control trajectories from 2FBSDE. H.3 QuadCopter V elocity States Fig. 9 sho ws the velocity trajectories of the quadcopter e xperiment in the main paper . H.4 Quadcopter longer time horizon Fig. 11 sho ws quadcopter state trajectories of 2FBSDE for longer time horizon (3 seconds). 18 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Figure 9: Comparison of 2FBSDE, FBSDE and iLQG on the quadcopter velocities and angular rates. Again the v ariance of 2FBSDE trajectories are smaller than FBSDE and iLQG. Figure 10: Phase plot at control multiplicative standard deviation σ = 0 . 1 and additiv e noise standard de viation Σ = 0 . 1 I . The yello w circle denotes the starting point, and yellow star denotes the tar get. H.5 Phase Plot for human arm simulation Fig. 10 is a phase plot of the human arm experiment experiment at σ = 0 . 1 and Σ = 0 . 1 I . It clearly sho ws that 2FBSDE can reach the target location and maintain small v ariance in the trajectory whereas iLQG div erges from the tar get. I Network Initialization Strategies For linear dynamics and cartpole used the Xa vier initialization strate gy [ 14 ]. This is considered to be standard method for recurrent networks that use tanh acti vations. This strategy was crucial to allo w using large learning rates and allo w con vergence in ∼ 2000 − 4000 iterations. W ithout this strategy , conv ergence is extremely slo w and prohibits the use for large learning rates. On the other hand, for high dimensional systems like the quadcopter and human arm, this strategy f ailed to work. The reason is partially explained in the loss function section of this supplementary text. Essentially , the F C layers having O ( n 2 x ) trainable parameters and random initialization v alues cause a sno wballing ef fect on the propag ation of V x ,t causing the loss function to di ver ge and make training impossible as the gradient step in ne ver reached. A simple solution to this problem was to use zero initialization for all weights and biases. This pre vents V x ,t from div erging as network predictions are zero and the state trajectory propagation is purely noise driv en. This allows computing the loss function without div erging and taking gradient steps to start making meaningful predictions at ev ery time step. Although this allows for training the network for high-dimensional systems, it slows do wn the process and conv ergence requires many more iterations. Therefore, further inv estigation into initialization strategies or other recurrent network architectures would allo w improving con ver gence speed. 19 A P R E P R I N T - D E C E M B E R 2 4 , 2 0 1 9 Figure 11: Quadcopter state trajectories of 2FBSDE for 3 seconds. The plots demonstrate the controller’ s capability to reach and hov er . J Machine inf ormation W e used T ensorflo w [ 1 ] extensiv ely for defining the computational graph in fig. 1 and model training. Because our current implementation in volves man y consecutiv e CPU-GPU transfers, we decided to implement the CPU version of T ensorflow as the data transfer ov erhead was very time consuming. The models were trained on multiple desktops computers / laptops to ev aluate diffent models and hyperparameters. An Alienware laptop was used with the following specs: Processor: Intel Core i9-8950HK CPU @ 2.90GHz × 12, Memory: 32GiB. The desktop computers used hav e the following specs: Processor: Intel Xeon(R) CPU E5-1607v3 @ 3.10GHz × 4 Memory: 32GiB 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment