Progressive transfer learning for low frequency data prediction in full waveform inversion
For the purpose of effective suppression of the cycle-skipping phenomenon in full waveform inversion (FWI), we developed a Deep Neural Network (DNN) approach to predict the absent low-frequency components by exploiting the implicit relation connectin…
Authors: Wenyi Hu, Yuchen Jin, Xuqing Wu
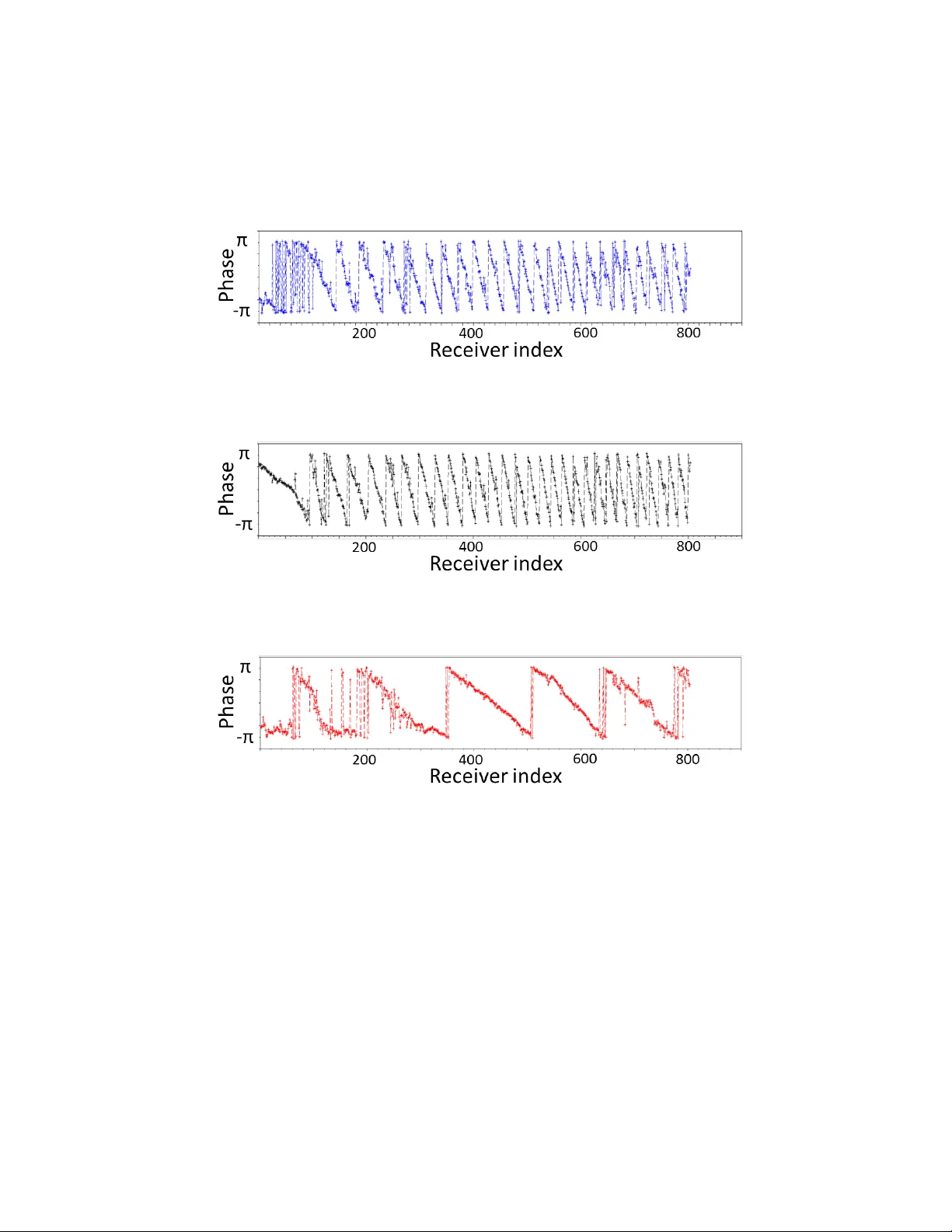
Progressiv e transfer learning for lo w frequency data prediction in full w a v eform in v ersion W en yi Hu ∗ , Y uc hen Jin † , Xuqing W u † ,and Jiefu Chen † ∗ A dvanc e d Ge ophysic al T e chnolo gy, Inc. 14100 Southwest F r e eway, Suite 110, Sugar L and, T exas 77478 Email:wenyi.hu@agtge o.c om † University of Houston, Houston, T exas 77204 (Decem b er 23, 2019) man uscript v1.1 Running head: Lo w frequency prediction by deep learning ABSTRA CT F or the purp ose of effectiv e suppression of the cycle-skipping phenomenon in full wa v eform in version (FWI), we developed a Deep Neural Net work (DNN) based approac h to predict the absen t lo w-frequency comp onen ts by exploiting the hidden relation connecting the lo w- frequency data and the high-frequency data implicitly through the subsurface geological and geoph ysical prop erties. In order to efficiently solve this c hallenging nonlinear regres- sion problem, tw o no vel strategies were proposed to design the DNN architecture and to optimize the learning pro cess: 1) Dual Data F eed structure; 2) Progressive T ransfer Learn- ing. With the Dual Data F eed structure, not only the high-frequency data, but also the corresp onding Beat T one data are fed in to the DNN to reliev e the burden of feature ex- traction, substantially reducing the netw ork complexity and the training cost. The second strategy , Progressiv e T ransfer Learning, enables us to unbiasedly train the DNN using a 1 single training dataset that is generated by an arbitrarily selected v elo cit y mo del. Unlik e other established deep learning approac hes where the training datasets are fixed, within the framework of the Progressive T ransfer Learning, the training velocity mo del and the asso ciated training dataset contin uously evolv e in an iterative manner b y gradually absorb- ing more and more reliable subsurface information retrieved b y the ph ysics-based inv ersion mo dule, progressively enhancing the prediction accuracy of the DNN and prop elling the v e- lo cit y mo del in version process out of the lo cal minima. The Progressiv e T ransfer Learning, alternatingly updating the training velocity mo del and the DNN parameters in a com- plemen tary fashion tow ard con vergence, sav es us from b eing ov erwhelmed b y the otherwise tremendous amoun t of training data, and a voids the underfitting and biased sampling issues. The numerical exp erimen ts v alidated that, without an y a priori geological information, the lo w-frequency data predicted by the Progressive T ransfer Learning are sufficiently accurate for an FWI engine to pro duce reliable subsurface velocity mo dels free of cycle-skipping- induced artifacts. 2 INTR ODUCTION F ull wa v eform inv ersion (FWI), mathematically built on nonlinear optimization algorithms, is an adv anced se ismic pro cessing tec hnology for high resolution subsurface velocity mo del building through a data-fitting pro cedure. Due to the extremely large n umber of unknowns in industrial-sized v elo city mo del building pro jects, most FWI metho ds emplo y the gradient- based lo cal optimization algorithms that often b ecome stagnant at a lo cal minimum if the in version pro cess is initiated at relatively high frequencies or the starting velocity mo del is not sufficien tly close to the true model. Because reliable low frequency (LF) comp onents b elo w 5 H z do not practically exist in most acquired seismic datasets and accurate starting v elo cit y models are usually not a v ailable, FWI often suffers from the lo cal minim um issue, or equiv alently the cycle-skipping phenomenon, observed as strong artifacts and wrong veloc- it y up date contaminating the reconstructed subsurface velocity mo dels. Sometimes, these cycle-skipping-induced artifacts are hard to iden tify from the real seismic reflection even ts and may even tually lead to improp er interpretation of the subsurface geological structures, prev enting FWI from b eing widely applied in subsurface h ydro carb on exploration. In recent years, there w as a surge of researc h efforts devoted to o vercome this challenge, i.e., eliminating or suppressing the cycle-skipping phenomenon without physically acquiring LF data. Man y of these researc h works can b e classified into the following categories (Hu et al., 2018): 1) scattering angle based filtering metho ds (Alkhalifah, 2014). This cate- gory of metho ds was dev elop ed based on the observ ation that the subsurface reconstruction resolution is highly dep enden t on the subsurface scattering angle. 2) FWI with extended v elo cit y mo del space (Symes, 2008; F u and Symes, 2015, 2017). These approaches in tro duce an additional dimension into the unknown velocity mo del and gradually enforce the shift 3 in this additional dimension tow ards zero. 3) FWI with time shift minimization (Xu et al., 2012; Ma and Hale, 2013), where a trav eltime difference minimization is implemented to correct the kinematic information for the cycle-skipping preven tion. 4) FWI with syn the- sized lo w frequency data (Shin and Cha, 2008; W u et al., 2014; Li and Demanet, 2016). These metho ds apply v arious nonlinear op erators to map the high frequency (HF) data to the low frequency (LF) domain. 5) FWI resolving phase am biguity (Hu, 2014; Choi and Alkhalifah, 2015). All of these research efforts help ed mitigating the cycle-skipping issue to some extent. How ever, till to day , this challenging problem has not b een completely solved. More recen tly , embracing the p o w er of machine learning and data analytics, some re- searc hers resort to the Deep Neural Netw ork (DNN) approac hes to predict the absent LF data by learning the underlying nonlinear relationship b et ween the HF comp onen ts and the LF comp onen ts (Jin et al., 2018; Sun and Demanet, 2018; Ov charenk o et al., 2018). While the early stage results of these pure data driven metho ds are encouraging, some ma- jor technical issues related to accuracy and efficiency need to b e addressed b efore w e hit a b ottlenec k in pro duction. Some of the main challenges are 1) How to design the training datasets to ensure an unbiased training pro cess? 2) Ho w to reduce the amoun t of training data to a more computationally manageable lev el without sacrificing the LF prediction ac- curacy? 3) Ho w to design qualit y control measures to monitor the training pro cess and to quan titatively ev aluate the reliability of the prediction results? In this work, after conducting a feasibility study of the LF comp onen ts synthesis from the HF data, we prop osed and developed a no vel DNN based approach to address these issues. There are t wo unique features differentiating our DNN approach from other existing metho ds: 1) the Dual Data F eed netw ork structure featuring tw o input branc hes receiving the HF data and the corresp onding Beat T one data sim ultaneously , thus partially reliev- 4 ing the netw ork from the heavy burden of feature extraction; 2) the Progressive T ransfer Learning strategy , a striking feature integrating the deep learning (DL) mo dule and the ph ysics-based mo dule seamlessly to iteratively enhance the LF data prediction accuracy . With this unique Progressive T ransfer Learning strategy , only a single set of training data is required to initiate and to complete the netw ork training pro cess. Unlike most con v entional DNN approaches where the training datasets are alw ays fixed during the netw ork training pro cess, we up date the training velocity mo del after eac h learning cycle to inject a progres- siv ely improving training dataset to the DL mo dule. Consequen tly , the netw ork training cost is substantially reduced and the LF data prediction accuracy is significantly improv ed, while the quality of the training pro cess is quantitativ ely monitored. This unique feature implies its great p otential in large industrial-sized pro jects while other machine learning metho ds tend to fail due to the limited av ailability of training data, the computational efficiency b ottlenec k, and the algorithm con vergence issue. R OLE OF LOW FREQUENCY COMPONENTS IN FWI Without losing generalit y , the cost function of a standard FWI can be p osed in the frequency domain as C ( v ) = N f X f =1 N s X s =1 N r X r =1 k S r,s,f ( v ) − M r,s,f k 2 , (1) where S are the sim ulation data, M are the measuremen t data, and v are the subsurface seismic v elo cities to b e reconstructed. The subscripts f , s , and r represen t the indices of the frequency , source, and receiv er. N s , N r , and N f are the n umber of sources, receiv ers, and fre- quencies, resp ectiv ely . The gradient of the cost function with resp ect to the seismic velocity can be computed by p erforming a residual bac k-propagation pro cedure (Pratt et al., 1998), whic h is used to up date the subsurface velocity mo del and minimize the discrepancy b e- 5 t ween the sim ulation data and the measuremen t data. The velocity model up date is carried out iteratively until the data misfit is within a predefined error tolerance (Hu et al., 2009). Unfortunately , as a nonlinear optimization problem, minimization of the cost function (1) is not alwa ys successful. The gradient-based algorithm often conv erges to a lo cal minimum and the data misfit may not b e contin uously reduced to the error tolerance, dep ending on the nonlinearity level of the problem. The important role pla yed by lo w frequency data can b e p erceived in Figure 1, a diagram showing a simple one-v ariable nonlinear optimization problem. As observed in Figure 1, at a high frequency (HF), a starting velocity mo del is often not in the basin of attraction of the global minim um; hence the algorithm tends to con verge to a local minimum V L instead of the global minimum V T . An effectiv e strategy for tackling this issue is to initiate the FWI inv ersion at a low er frequency (if the low e r frequency comp onent is a v ailable in the acquired seismic data), where the non-conv exit y nature of the cost function is alleviated and the global m inim um V A is obtained at the lo w frequency regime. After that, the FWI algorithm switches bac k to the high frequency regime with a b etter starting velocity mo del V A residing in the basin of attraction, securing the con vergence of the gradien t-based algorithm at the true solution V T . Based on these analyses, the notorious lo cal minimum issue, commonly referred to as the cycle-skipping phenomenon in FWI, can b e successfully preven ted if the optimization is p erformed at a sufficien tly low frequency b ecause the nonlinearit y of FWI reduces as the frequency de- creases. F rom this p ersp ectiv e, our task of cycle-skipping suppression can b e con verted to solving an equiv alent problem - the LF prediction from the recorded LF seismic data, whic h is a c hallenging nonlinear regression problem. 6 FEASIBILITY STUDY OF LOW FREQUENCY PREDICTION Before delving into a DNN to p erform this challenging task, the feasibility of the LF data prediction needs to b e inv estigated. Is it p ossible to recov er the absent LF seismic data from the acquired HF seismic data? A t first glance, this question app ears to b e a pure signal processing topic but, as a matter of fact, the answer not only lies in the data, but also relies on the sp ecific subsurface geological and geophysical en vironment where the data are acquired. F or a general random signal, prediction of the LF information from the HF comp onen ts is essen tially imp ossible because there is no meaningful relationship b et w een the different fre- quency bands. Ho wev er, an imp ortan t fact often neglected is: seismic data are not random signals. Instead, seismic data are the earth resp onses to the wideband excitation sources, recorded as the coherent bandlimited signals. This fact suggests an underlying nonlinear tunnel connecting the LF components and the HF comp onents of the seismic data. This nonlinear relationship, whose explicit mathematical form is often una v ailable, is unambigu- ously determined by the geological settings and the geophysical properties of the subsurface media. Here, as a feasibility study , w e aim to v alidate this statement empirically b y con- ducting a seismic bandwidth extension exp erimen t using the sparsity constrained inv ersion (Liang et al., 2017). The input seismic trace for this exp erimen t is plotted in Figure 2a and the corresp onding frequency sp ectrum is shown in Figure 2b, from which the components b elo w 5 H z are inten tionally remov ed. On the other hand, the information ab o v e 25 H z is also abandoned due to its relatively low signal-to-noise ratio (SNR). The energy spanning the frequency range b etw een 5 H z and 25 H z is then extracted to reconstruct the LF data b elo w 5 H z . F or this sp ecific example, based on the reflection characteristics observed in 7 Figure 2a, a reasonable assumption can b e made that the subsurface reflection even ts are predominan tly sparse, and thus the earth can b e depicted b y a limited num b er of discrete reflectors. Consequen tly , the rece iv ed seismogram after the deconv olution op eration con- sists of a series of impulses, whose sp ectrum is mainly contributed by the summation of the frequency domain harmonics corresp onding to these time domain impulses. This bandwidth extension task (or equiv alently , the LF and HF comp onent prediction) is cast as an inv erse problem in the frequency domain with the sparsity constrain ts defined in the time domain: ar g min k ˜ d − Ac k 2 2 + λ k c k 1 , (2) where ˜ d is the truncated length-M frequency spectrum (5 H z ≤ f ≤ 25 H z ) of the input seismic trace, c is the length- N coefficient sequence, with M < N , and the matrix A is defined as A m,n = exp ( j 2 π N mn ) , 0 ≤ n ≤ N − 1 . (3) Only when N = M , the co efficients c satisfying ˜ d = Ac are uniquely determined. Ho w- ev er, in scenarios where N > M , the non-uniqueness nature of the inv erse problem can b e ov ercome by the introduction of the L 1 regularization in (2). The sparsit y-constrained minimization problem (2) is solv ed b y the split v ariable augmented Lagrangian shrink age algorithm (SALSA) (Afonso et al., 2010, 2011) and an appro ximate solution of c can b e found to reconstruct the LF comp onen ts b elo w 5 H z . The phase of the predicted LF data is in go o d agreement with the input data as observed in Figure 3, strongly suggesting the feasibilit y of the LF prediction pro vided that the subsurface structural sparsity assump- tion can b e justified. W e are obliged to mention that, in this numerical exp erimen t, the amplitudes of the predicted LF signals deviate from the input data, partially due to the unkno wn densit y , attenuation prop erties, source w av elet estimation error, imp erfect im- pulse resp onses of the earth, noise contamination, and man y other unknown and uncertain 8 factors. F or this reason, the metho dology prop osed in this w ork is only intended for the LF phase information retriev al. DEEP LEARNING APPRO ACH TO LOW FREQUENCY PREDICTION Inspired by the con ven tional bandwidth extension technology that has b een widely applied to geological interpretation and reservoir c haracterization, w e aim to extend this trace-b y- trace approach to more general scenarios to b e suited for FWI. The subsurface reflector sparsit y is a critical element in the conv entional bandwidth extension algorithm b ecause it is the frequency domain harmonic feature emphasized b y the structural sparsity mak es the bandwidth extension p ossible and affordable (Zhang and Castagna, 2011). Although the subsurface structural sparsit y assumption is defensible for most qualitativ e geological in terpretation applications, it can b e hardly main tained for FWI applications unless the geological environmen t under inv estigation is ov ersimplified. As a direct result of non- sparse reflector structure, the single-trace approach emplo y ed in the previous example often giv es an unreliable or meaningless solution b ecause the optimization problem (2) b ecomes an underdetermined system. F or this reason, the adaption of the conv entional bandwidth extension approac h to the requirements of FWI is not trivial. Ev en if the sparsity condition of the subsurface structure does not hold for most FWI pro jects, the strong connection b et w een the LF and HF comp onen ts still exists but the difficult y level of LF prediction is dramatically increased. Theoretically , a natural and v alid strategy for generalizing the conv en tional bandwidth extension is to fully exploit this connection by bringing in the adjacent seismic traces to participate in the LF data re- 9 construction pro cess as the extra implicit constraints to the optimization problem. This strategy often leads to an extremely large-sized nonlinear inv erse problem b eyond the a v ail- able computation capability . Alternatively , a priori subsurface geological information can b e incorp orated into the inv ersion pro cess to alleviate the non-uniqueness of the in verse problem, but this strategy is not straightforw ard and often unmanageable with the concern o ver the a v ailabilit y and reliabilit y of the subsurface information. In this con text, we resort to the pure data-driv en approach - machine learning. Mac hine learning (ML) is an algorithm or a mathematical mo del that is used to analyze data, recognize the numerous patterns in the data that is imp ossible for a human b eing to identify exhaustively , learn the underlying nonlinear relationship b etw een the input and the output automatically , and then predict the v alue of new output data given the new input data p oin ts. Deep learning (DL) or DNN is a subset of machine learning metho ds established on the architecture featuring multiple lay ers of artificial neural net works to make predictions and decisions by automatically extracting the unique features buried in the data. Deep learning is esp ecially suitable for this w ork b ecause it is infeasible to manually extract the n umerous relev an t sets of features to accurately capture the underlying nonlinear relationship b et w een the LF and HF comp onen ts of the seismic data. Theoretically , a prop erly designed DNN for LF prediction is able to automatically and successfully p erform the feature extraction task as long as the connection b et ween the LF data and the HF data is solid and stable. Figure 4 is a diagram qualitativ ely sketc hing this connection, where we note that the HF data are dominan tly contributed from the subsurface high wa ven umber structures while only b eing v aguely connected to the low wa ven umber structures via far offset source/receiver geometry setting. This fact directly affects the feature extraction capability and the effectiv eness of the DNN for LF prediction. In order 10 to relieve the burden of feature extraction on the net work, w e need to someho w amplify the connection b etw een the lo w w av en umber structure and the HF data to build an unimpeded path linking the LF data, the low w av en umber comp onen ts of the subsurface structures, and the HF data. T o reac h that goal, we in tro duce the Beat T one data as the second input (Hu, 2014) in to the DNN. The Beat T one technique was dev elop ed to suppress the cycle-skipping phenomenon in FWI b y amplifying the lo w w av en umber information buried in the HF data, under the inspiration of the in terference Beat T one, an acoustic phenomenon commonly used b y m usicians for tuning c heck. The Beat T one metho d utilizes tw o seismic datasets extracted at t wo sligh tly differen t high frequencies to implicitly reduce the num b er of phase wrapping o ccurrences, generating a dataset showing a slow spatial phase v ariation pattern similar to a true low frequency dataset. A shot gather of 6 H z data (Figure 5a) and 7 H z data (Figure 5b) are compared with the corresp onding Beat T one data in Figure 5c to demonstrate that the Beat T one data is an approximation to 1 H z data in terms of phase wrapping b eha vior, although some remaining high wa v enum b er energy is observ ed in Figure 5c. The calculation of Beat T one data is straightforw ard Φ BT ( S 2 , S 1 ) = Φ ( S 2 ) − Φ ( S 1 ) (4) where Φ BT is the Beat T one phase and S 1 and S 2 represen t tw o frequency domain datasets extracted at the frequencies f 1 an f 2 with ∆ f = f 2 − f 1 f 1 and f 2 . With the in tro duction of Beat T one data in to the DNN as the second input, we establish a solid route connect- ing the LF comp onen ts and the HF comp onen ts through the subsurface lo w w a ven um b er structures, as sketc hed in Figure 6. Intuitiv ely , the similarity b et ween the Beat T one data and the true LF data ma y help us reduce the complexity of the netw ork architecture with- 11 out sacrificing the data prediction accuracy of the netw ork. Based on this hypothesis, we designed a DNN that features a Dual Data F eed structure to receiv e b oth HF data and Beat T one data simultaneously via t wo separate branc hes A and B sharing the same struc- ture as depicted in Figure 7. The outputs of the tw o branches merge at a stem netw ork to mix the learned features and even tually b e mapp ed to the LF phase prediction. Ba- sically , any con volutional neural netw ork (CNN) could b e employ ed to fill in the frame sho wn in Figure 7. After testing several candidate netw orks, the inception conv olutional net work (Szegedy et al., 2017) w as selected and mo dified to b e suited for this nonlinear regression problem b ecause of its high p erformance in b oth efficiency and accuracy . Unlike most traditional DNNs stac king deep er and deep er conv olution la y ers to tac kle more and more c hallenging tasks while ov erfitting and enormous computational cost b ecome the b ot- tlenec ks, the inception netw ork on the other hand, uses a v ariety of no vel strategies, suc h as con volution factorization metho ds, to enhance the o verall p erformance. Figure 8a sho ws the structure of our 1D inception blo c k adapted from the inceptV4 net work, which consists of multiple parallel branches with differen t con volution depths to capture b oth lo cal and global patterns in the input data. In Figure 8a, the conv olution blo c k with the total depth of D is composed of D + 2 parallel branc hes, while the depth d asso ciated with the individual branc h v aries from − 1 to D . When d = − 1, there are only a p o oling la yer and a 1 × 1 con volution lay er in the branch. If d = 0, the branc h only has a pro jection lay er to output a combination of the original features in the data. If d > 0, then there are d conv olution la yers after the pro jection, resulting in an output with the length of 2 x ( d − 1) x ( N / 2) + N . The other basic unit illustrated in Figure 8b is the deconv olution blo c k, which up-samples the input lay ers b y the size of the stride. The structure of the regressor is sho wn in Figure 9, where all the individual inception blo cks ha v e the same depth of 2 and the depth of the 12 en tire netw ork is 41. A tanh function is adopted as the nonlinear activ ation function, which maps the output to v alues in b et ween -1 and 1. The training pro cess of the netw ork can be set up as an optimization problem minimizing the follo wing loss function min Θ k f ( S HF , S BT , Θ ) − S LF ) k 2 2 , (5) where the netw ork output is represented b y the function f ( S HF , S BT , Θ ). S HF and S BT are the training datasets, HF data and the corresp onding Beat T one data, injected in to the t wo receiving branches of the net work. Given the ground truth S LF (LF training data), the parameters of the net work Θ can b e solv ed. F or a pro of of concept, a synthetic example is tested to demonstrate the p ow er of this data-driv en metho d for the LF seismic data prediction. The true velocity mo del to b e in verted for is shown in Figure 10a, where the strong reflector imp oses a main challenge if the FWI pro cess is initiated by a set of relatively high frequency measurement data and a simple starting velocity mo del shown in Figure 10b. Another v elo cit y mo del with the same dimension as the true v elo cit y mo del (Figure 10c) is arbitrarily selected to input in to a forward mo deling simulator to generate a set of synthetic training data. The training dataset contains the HF comp onen ts ranging from 10 H z to 18 H z in 0.5 H z increments, and an LF comp onen t (3 H z ), resulting in 18 discrete frequencies in total. After that, the Beat T one data with ∆ f = 3 H z are derived from the HF comp onen t pairs in the training dataset (i.e., 10 H z and 13 H z , 10.5 H z and 13.5 H z , etc.). Even tually , b oth the amplitude-normalized HF training data and the Beat T one training data are input in to the Dual Data F eed structured net work depicted in Figure 7 and Figure 9 for the sup ervised learning where the 3 H z training data serve as the ground truth. The fully trained DNN is able to predict the 3 H z data with sufficient accuracy from an FWI p ersp ectiv e. Similarly , 13 the 5 H z data are predicted by rep eating the netw ork training and the netw ork testing pro cedure. T o ev aluate the accuracy of the LF data predicted by the DNN, the predicted 3 H z and 5 H z data are fed into an FWI engine sequentially to p erform the velocity mo del inv ersion, follow ed b y a series of HF FWI on the 10 H z to 30 H z measurement data. The final FWI-reconstructed velocity mo del in Figure 11a is compared against the reference solution sho wn in Figure 11b. The reference solution is pro duced by the same FWI engine inv erting the measurement data cov ering the full bandwidth from 3 H z to 30 H z to av oid the cycle-skipping issue. According to the numerical exp erimen t results demonstrated in Figure 11a and Figure 11b, the velocity mo del reconstructed b y inv erting the predicted LF data is nearly iden tical to that pro duced by the true LF data. On the other hand, without LF comp onen ts, FWI completely fails to resolv e the strong reflector in the subsurface although the near surface top ograph y features are successfully reco vered, as observ ed in Figure 11c. TRAINING VELOCITY MODEL SELECTION AND SAMPLING BIAS The numerical exp erimen t result presen ted in Figure 11a demonstrates the capability of this pure data-driven metho d to accurately predict the absent LF phase information from the acquired HF data. The predicted LF data are subsequen tly exploited b y a standard FWI engine to successfully reconstruct the strong reflector in the subsurface v elo cit y mo del, a w ell-known challenging task. Ho wev er, one ma y argue that there is no solid conclusion should b e dra wn from this numerical experiment regarding the robustness and adaptiv eness of this approach, b ecause the training velocity mo del (Figure 10a) and the true v elo cit y mo del (Figure 10c) show similar patterns. Intuitiv ely , an arbitrarily selected training v elo c- it y mo del is non-represen tativ e to adequately quan tify the nonlinear relationship b etw een 14 the LF data and the HF data, and this arbitrary training data sampling strategy ma y sev erely bias the learning pro cess and degrade the prediction accuracy . Prompted by this concern, w e conducted another n umerical exp erimen t on more complex geological structures to in v estigate the impact of the training velocity mo del on the DNN p erformance. The true velocity mo del for this exp erimen t is sho wn in Figure 12a and the simple 1-D starting velocity mo del for FWI is display ed in Figure 12b. Again, we assume that only HF seismic data b ey ond 10 H z are acquired and the primary goal is to predict the phase of LF comp onents (3 H z , 5 H z , and 7 H z ). The prediction accuracy is to be ev aluated quan titatively in b oth the data domain (comparing the predicted LF data against the true LF data pro duced b y the forward sim ulation engine) and the mo del domain (comparing the v elo cit y mo del reconstructed b y inv erting the predicted LF data against the reference FWI solution). A similar training v elo cit y mo del is selected as shown in Figure 12c to initiate the netw ork training. In this experiment, as visually observ ed in Figure 12c, the training v elo cit y model is completely uncorrelated with the true velocity mo del. A full-bandwidth training dataset with the frequency con ten ts ranging from 3 H z to 30 H z is produced b y running a forw ard mo deling simulator on the training velocity mo del. The training curv e is plotted in Figure 13a, where the loss function reduces to 0.038 after 80 ep o c hs. The absen t LF comp onen ts in the testing dataset are then predicted b y the trained netw ork. The evolution of the cross-correlation b et ween the predicted LF data and the true data is plotted in Figure 13b as a quan titative measure of the net work prediction accuracy . The relativ ely large error in the predicted LF data, indicated by the cross-correlation v alue 0.60 of the fully trained net work, is presumably induced by the non-representativ e nature of the training velocity mo del. This large prediction error is exp ected to reflect a significant negativ e impact on the FWI velocity reconstruction. T o justify this surmise, the predicted 15 3 H z , 5 H z , and 7 H z comp onen ts are injected into an FWI engine to resolv e the large scale structures in the subsurface space. The obtained velocity mo del is further refined b y sequentially in verting the measured HF data ranging from 10 H z to 30 H z using the same FWI engine, rendering to the final result shown in Figure 14. The predicted LF data successfully help the FWI engine precisely delineate the water-bottom and roughly resolv e the top of salt, but fails to prop erly recov er most of the subsurface geophysical features. Strong cycle-skipping-induced artifacts con taminate the v elo cit y mo del, esp ecially in the sub-salt region at the center of the in version domain. This numerical exp eriment confirms our concerns of the non-representativ e training data and the inheren t sampling bias nature of this single-training-mo del approach, implying that accurate prediction of LF data is unlik ely , if not imp ossible, unless the geological settings are unrealistically simple. Another disadv antage of this DNN metho d worth men tioning is that there is no effective w ay to v alidate the prediction and ev aluate the accuracy; thus, applying this approac h to real field data pro jects tends to b e a risky practice. PR OGRESSIVE TRANSFER LEARNING METHOD Because the ro ot cause of the LF prediction failure in the previous n umerical exp erimen t is iden tified as the non-representativ e training v elo cit y mo del, an immediate but cum b ersome solution to this problem is a random velocity mo del generator to represen t as many differen t geological environmen ts as p ossible. Theoretically , a random velocity mo del generator is able to generalize the DNN to b e adaptiv e to all types of differen t scenarios. Unfortunately , there are at least t wo ma jor shortcomings of this strategy . First, it is unlik ely to b e suc- cessful or manageable to design and train a univ ersal gigan tic DNN to capture the global geological and geophysical features by exhaustiv ely learning numerous randomly generated 16 training velocity mo dels. Second, this approach often suffers from underfitting, prev enting the netw ork from absorbing the useful information carried b y the great amount of training data. Therefore, a more practical and effectiv e approach is desired. An imp ortan t phenomenon observ ed in the previous n umerical exp erimen t that could easily b e o verlooked is that the DNN trained b y the true v elo cit y mo del giv es nearly p erfect LF prediction. More sp ecifically , if we assign 80% of the true data as the training data and the remaining 20% as the testing data, then the trained net work is able to predict the 20% LF testing data with extremely high accuracy . At the first glance, this observ ation is by no means surprising or useful b ecause the true velocity mo del is alw a ys the unknowns w e in tend to seek. How ev er, this phenomenon offers us a v aluable guideline for the training v elo cit y mo del design: under the condition that only one training v elo cit y mo del is allo wed, the closer the training mo del is to the true mo del, the higher the netw ork prediction accuracy . Consequen tly , a straightforw ard strategy inspired by this guideline is to incorp orate the subsurface a priori information into the training velocity mo del. W e are again facing a dilemma here: on the one hand, accurate subsurface information is not av ailable until a prop er FWI pro cess is p erformed successfully , while on the other hand, an FWI is unlikely to b e successful unless the LF data are predicted accurately b y feeding the subsurface information in to the DNN training pro cess. In light of these thoughts, we prop ose the so- called Progressiv e T ransfer Learning metho d to get through this dilemma and even tually enhance the LF prediction accuracy without b eing o verwhelmed by tremendous amount of training v elo cit y mo dels and training data. Rather than throwing all the av ailable training datasets into a gigan tic netw ork to am- bitiously achiev e the adaptiveness to many differen t v arieties of geological and geophysical scenarios, the Progressive T ransfer Learning metho d conv erts the parallel training to an 17 iterativ e sequential training pro cess. This metho d alw ays trains the netw ork using a single training velocity mo del. Unlike other standard DL approaches, the training dataset in the Progressiv e T ransfer Learning workflo w is not fixed but evolv es and contin uously improv es b y gradually absorbing more and more reliable subsurface information pro vided b y the ph ysics-based mo dule as the learning pro cess proceeds. With this strategy , the DL net work is seamlessly integrated with the physics-based inv ersion to alternatingly b oost each other within ev ery learning cycle. The workflo w of the Progressive T ransfer Learning is shown in Figure 15, which con- sists of t wo main mo dules: 1) DL mo dule for LF prediction (red blo ck in Figure 15); 2) ph ysics-based module (FWI) for training data evolving (blue blo c k in Figure 15). The en tire learning pro cess is again initiated b y an arbitrarily selected training v elo cit y mo del. After the initial round of netw ork training, the predicted LF data are input into the FWI engine to obtain a lo w resolution v elo cit y model in the hop e of retrieving most of the subsurface lo w w av en umber structural information. Unfortunately , due to the arbitrarily selected training v elo cit y mo del, the accuracy of the first round LF data prediction by the netw ork is often insufficien t for a successful FWI, as noted in the previous section. Figure 16a to Figure 16c displa y three shot gathers (deploy ed at left, central, and right parts of the domain, resp ec- tiv ely) of the predicted 3 H z comp onen ts, along with the ground truth. As exp ected, the accuracy of the LF data prediction v aries from shot to shot, and from receiver to receiver. The predicted LF comp onents of the 30th shot (lo cated at the cen tral part of the domain) are in go o d agreement with the ground truth while the prediction of the 2nd shot (left part of the domain) and 53th shot (right part of the domain) deviate from the ground truth. This observ ation is coun terintuitiv e b ecause the righ t part of the true velocity mo del is relativ ely less complex b ecause of the lac k of salt dome. The FWI in version of the predicted 3 H z , 5 18 H z , and 7 H z data is able to delineate the water-bottom (Figure 17b) but fails to resolv e the large salt dome in the central region of the domain, whic h can be clearly identified in FWI result obtained inv erting the true LF data (3 H z , 5 H z , 7 H z )(Figure 17a). In spite of the large discrepancy b et w een the prediction and the true LF data, within the framew ork of Progressive T ransfer Learning, the FWI pro cess is contin ued on the measured HF data up to 30 H z to complete the first iteration of learning. In other words, the first iteration of the Progressiv e T ransfer Learning is exactly the same approach discussed in the previous section. Therefore, at this early stage of Progressive T ransfer Le arning, cycle- skipping is exp ected in the intermediate result shown in Figure 14. Within the scop e of Progressive T ransfer Learning, the velocity mo del obtained after the first round LF prediction is sent bac k into the DL mo dule, acting as an up dated train- ing velocity . This strategy is based on t wo fundamental hypotheses that we do not aim to test rigorously in this w ork: 1) the mac hine-learned relationship betw een the HF and LF comp onen ts on an y training velocity model is able to recov er a p ortion of the subsurface lo w w av en umber information, while the amoun t and the reliability of the recov ered infor- mation is highly dep endent on the represen tative lev el of the training v elo cit y mo del; 2) the subsequen t FWI op eration on the measured HF data is able to amplify and further correct these low wa v enum b er information b ecause HF data implicitly carry a great amount of suc h information. Under these t wo hypotheses, although the velocity mo del reconstructed after the first round of learning is contaminated b y strong artifacts (Figure 17b), it contains ric her and more accurate low wa ven um b er components, thus b eing a more represen tative and fa vorable training velocity mo del than the original one. A new training dataset is then pro duced b y p erforming a forw ard simulation on this up dated training v elo cit y mo del to re-train the netw ork, entering the second iteration of Progressiv e T ransfer Learning. The 19 second round LF prediction shows substantial improv ement ov er the previous iteration as plotted in Figure 18a to Figure 18c, establishing a solid base for the ph ysics-based mo dule to retriev e the subsurface low w av en umber information more reliably . In the every subsequen t learning iteration, the DL mo dule alwa ys feeds a set of enhanced LF prediction data in to the physics-based mo dule. On the other hand, the physics-based mo dule contin uously of- fers a more represen tative training velocity mo del and the corresp onding enhanced training dataset to the DL mo dule. Thus, the DL module and the physics-based module comple- men t each other alternatingly in an iterative manner, progressively prop elling the v elo cit y mo del inv ersion pro cess out of the lo cal minima. In this numerical exp erimen t, after three Progressiv e T ransfer Learning cycles, the predicted LF data are free of cycle-skipping and nearly conv erge to the true LF data, as demonstrated in Figure 19a to Figure 19c. Similar to the first learning cycle, after 80 ep o c hs of training, the loss function reduces to a small n umber 0.018, as plotted in Figure 20a. While the improv ement in the conv ergence rate of the learning pro cess is subtle, it is imp ortan t to note that the main b enefit brought b y the m ultiple transfer learning cycles is reflected in the LF prediction accuracy , which is quan- titativ ely measured by the cross-correlation v alidation result plotted in Figure 20b. The final cross-correlation v alue b etw een the predicted LF data and the true LF data is b o osted from 0.60 to 0.93 through the three Progressiv e T ransfer Learning cycles, which confirms our forecast that a more represen tativ e training v elo cit y mo del dramatically enhances the LF prediction accuracy . The final FWI result using the predicted LF data (3 H z , 5 H z , and 7 H z ) and the true measured HF data is shown in Figure 21a. F or an informativ e comparativ e study , the reference solution obtained b y inv erting the true full-bandwidth data (3 H z 30 H z ) and the one pro duced by in verting the HF data (10 H z 30 H z ) only are displa y ed in Figure 21b and Figure 21c, resp ectiv ely . This numerical exp erimen t 20 demonstrates that, giv en a 1-D starting v elo cit y mo del and an arbitrarily selected simple training v elo cit y mo del, the Progressive T ransfer Learning approach combined with a con- v entional FWI engine precisely resolves the shallow anomalies and successfully reconstructs the complex salt structures, as one would expect from the excellen t agreement betw een the predicted LF data and the true LF data. On the other hand, the direct in version of the HF data starting from 10 H z ends up with severe cycle-skipping-induced artifacts and the completely missing salt structure. The less fav orable v elo cit y reconstruction quality at the edges of the domain is probably due to the imbalanced illumination incurred by the offset limitation. CONCLUSION In this research work, w e developed a no vel deep learning based metho d, the so-called Pro- gressiv e T ransfer Learning, to reconstruct the absent lo w frequency comp onen ts in acquired seismic datasets by learning the implicit nonlinear relationship b etw een different frequency bands. This data-driven approac h do es not require an y a priori information of the subsur- face geological structures and geophysical prop erties. Instead, the subsurface information is gradually retriev ed from the data and pump ed in to the DNN within the learning process. This Progressive T ransfer Learning metho d contains t wo main mo dules: the deep learning mo dule and the ph ysics-based mo dule. After the initial netw ork training on an arbitrarily selected training velocity mo del, an inaccurate initial lo w frequency data prediction is p er- formed. In the every subsequent Progressive T ransfer Learning iteration, the physics-based mo dule provides an impro ved training v elo cit y mo del with richer subsurface information to the deep learning mo dule. On the other hand, the deep learning mo dule up dates the lo w frequency prediction with increased accuracy , and thus, in turn, enables the physics-based 21 mo dule to retriev e more and more reliable subsurface information. With this strategy , the deep learning mo dule and the ph ysics-based mo dule are integrated seamlessly , in teracting and complemen ting with eac h other to progressiv ely push the FWI pro cess off the lo cal min- ima. The Progressive T ransfer Learning pro cess can be quantitativ ely monitored b ecause the predicted low frequency data are exp ected to conv erge to the training data at the end of a successful transfer learning process, which also serves as a key reliability indicator of the final FWI results. The numerical exp eriments v alidate the effectiveness and robustness of the Progressiv e T ransfer Learning metho d b y successfully reconstructing the complex geological structures including multiple salt b o dies. The comparativ e study sho ws, without the Progressiv e T ransfer Learning Strategy , the same DNN fails to predict the lo w frequency comp onen ts with sufficien t accuracy in complex geological environmen t if it is trained by a single v elo cit y model, casting doubts on its practicalit y on field data pro jects. Instead of establishing a huge training v elo cit y mo del library to exhaustively capture the global geo- logical and geophysical characteristics, the Progressive T ransfer Learning metho d extracts lo cal subsurface features through a sequen tial learning pro cess aided by the physics-based in version. This unique self-learning feature sav es us from b eing ov erwhelmed with large amoun t of training data without sacrificing the prediction accuracy . A CKNO WLEDGEMENT This material is based up on work supp orted by the U.S. Department of Energy , Office of Science, SC-1, under Aw ard Number de-sc0019665. 22 DISCLAIMER This rep ort was prepared as an accoun t of w ork sponsored b y an agency of the United States Go vernmen t. Neither the United States Gov ernmen t nor an y agency thereof, nor any of their employ ees, makes any warran t y , express or implied, or assumes an y legal liabilit y or resp onsibilit y for the accuracy , completeness, or usefulness of an y information, apparatus, pro duct, or pro cess disclosed, or represents that its use would not infringe priv ately owned righ ts. Reference herein to an y sp ecific commercial pro duct, pro cess, or service by trade name, trademark, manufacturer, or otherwise do es not necessarily constitute or imply its endorsemen t, recommendation, or fav oring b y the United States Gov ernmen t or any agency thereof. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Go vernmen t or an y agency thereof. 23 REFERENCES Afonso, M., J. Bioucas-Dias, and M. Figueiredo, 2010, F ast image reco very using v ariable splitting and constrained optimization: IEEE T ransactions on Image Pro cessing, 19 , 2345–2356. ——–, 2011, An augmented lagrangian approach to the constrained optimization formula- tion of imaging in verse problems: IEEE T ransactions on Image Pro cessing, 20 , 681–695. Alkhalifah, T., 2014, Scattering-angle based filtering of the w av eform in v ersion gradients: Geoph ysical Journal International, 200 , 363–373. Choi, Y., and T. Alkhalifah, 2015, Un wrapp ed phase inv ersion with an exp onen tial damping: Geoph ysics, 80 , R251–R264. F u, L., and W. Symes, 2015, Reducing the cost of extended wa v eform inv ersion b y multiscale adaptiv e metho ds, in SEG T echnical Program Expanded Abstracts 2015: So ciet y of Exploration Geoph ysicists, 1127–1131. ——–, 2017, A discrepancy-based p enalt y method for extended w av eform inv ersion: Geo- ph ysics, 82 , R287–R298. Hu, W., 2014, FWI without low frequency data - b eat tone inv ersion, in SEG T echnical Program Expanded Abstracts 2014: So ciet y of Exploration Geoph ysicists, 1116–1120. Hu, W., A. Abubak ar, and T. M. Habashy , 2009, Simultaneous m ultifrequency in version of full-w av eform seismic data: Geoph ysics, 74 , R1–R14. Hu, W., J. Chen, J. Liu, and A. Abubak ar, 2018, Retrieving lo w w av en umber information in FWI: An ov erview of the cycle-skipping phenomenon and solutions: IEEE Signal Pro cessing Magazine, 35 , 132–141. Jin, Y., W. Hu, X. W u, and J. Chen, 2018, Learn low wa v enum b er information in FWI via deep inception based conv olutional netw orks, in SEG T echnical Program Expanded 24 Abstracts 2018: So ciet y of Exploration Geoph ysicists, 2091–2095. Li, Y., and Y. Demanet, 2016, F ull-w av eform in version with extrap olated low-frequency data: Geoph ysics, 81 , R339–R348. Liang, C., J. Castagna, and R. Za v ala T orres, 2017, T utorial: Sp ectral bandwidth exten- sionin ven tion v ersus harmonic extrap olation: Geoph ysics, 82 , W1–W16. Ma, Y., and D. Hale, 2013, W av e-equation reflection tra veltime inv ersion with dynamic w arping and full-wa v eform inv ersion: Geoph ysics, 78 , R223–R233. Ov charenk o, O., V. Kazei, D. P eter, X. Zhang, and T. Alkhalifah, 2018, Low-frequency data extrap olation using a feed-forward ANN: Presen ted at the 80th EAGE Conference and Exhibition 2018, EA GE. Pratt, R. G., C. Shin, and G. Hic k, 1998, Gauss-newton and full newton methods in frequency-space seismic w av eform in version: Geophysical Journal In ternational, 133 , 341–362. Shin, C., and Y. Cha, 2008, W a veform inv ersion in the Laplace domain: Geophysical Journal In ternational, 173 , 922–931. Sun, H., and L. Demanet, 2018, Low frequency extrap olation with deep learning, in SEG T echnical Program Expanded Abstracts 2018: So ciety of Exploration Geophysicists, 2011–2015. Symes, W. W., 2008, Migration v elo cit y analysis and w av eform inv ersion: Geoph ysical prosp ecting, 56 , 765–790. Szegedy , C., S. Ioffe, V. V anhouche, and A. Alemi, 2017, Inception-v4, inception-resnet and the impact of residual connections on learning: Presen ted at the . W u, R., J. Luo, and B. W u, 2014, Seismic en velope inv ersion and modulation signal mo del: Geoph ysics, 79 , W A13–W A24. 25 Xu, S., F. Chen, G. Lambar ´ e , Y. Zhang, and D. W ang, 2012, Inv ersion on reflected seis- mic wa v e, in SEG T echnical Program Expanded Abstracts 2012: So ciet y of Exploration Geoph ysicists, 1–7. Zhang, R., and J. Castagna, 2011, Seismic sparse-la yer reflectivity inv ersion using basis pursuit decomp osition: Geophysics, 76 , R147–R158. 26 LIST OF FIGURES 1 A diagram showing a one-v ariable nonlinear optimization problem. V L : lo cal min- im um; V I : starting v elo cit y mo del; V A : appro ximate solution obtained at low frequency; V T : true solution. 2 a) a seismic trace with sparse reflection even ts; b) sp ectrum of the trace with fre- quency comp onen ts b elo w 5 H z and ab ov e 25 H z abandoned. 3 Comparison b et w een phase sp ectra of input data (blue) and predicted LF data (red). 4 Diagram of relationship betw een seismic data and wa v enum ber comp onen ts of sub- surface structures. 5 Comparison b etw een high frequency data and the corresp onding Beat T one data. a) 6 H z ; b) 7 H z ; c) Beat T one data derived from 6 H z and 7 H z data. 6 Diagram of relationship b et ween high frequency data, low frequency data, Beat T one data, and wa v enum b er comp onen ts of subsurface structures. 7 Dual Data F eed structured netw ork. 8 Basic units of inception net work. a) conv olutional blo c k; b) deconv olutional blo c k. 9 Structure of the D-depth inception net work. 10 a) true v elocity mo del; b) initial velocity mo del for FWI; c) training velocity mo del. 11 a) v elo cit y model pro duced by FWI engine inv erting 3 H z and 5 H z data predicted b y the DNN, follow ed by FWI inv ersion of measurement data from 10 H z to 30 H z . The 3 H z and 5 H z data are predicted by learning 10 H z to 18 H z measurement data; b) reference solution pro duced b y FWI sequential in version of 3 H z to 30 H z measuremen t data; c) v elo cit y mo del pro duced by FWI sequentially inv erting 10 H z to 30 H z data. 12 a) true subsurface velocity mo del to reconstruct b y FWI; b) starting v elo cit y model 27 for FWI; c) training v elo cit y mo del arbitrarily selected. 13 The p erformance of first Progressiv e T ransfer Learning iteration. a) learning curv e using the training mo del in Figure 12c; b) correlation b et ween the predicted LF data and the true LF data as a measure of the prediction accuracy . 14 Reconstructed velocity mo del by FWI inv erting predicted 3 H z , 5 H z , and 7 H z data, follo wed by high frequency FWI p erformed sequentially from 10 H z to 30 H z . 15 W orkflow of Progress iv e T ransfer Learning for low frequency data reconstruction. LF — lo w frequency; HF — high frequency; LR — low resolution; HR — high resolution. 16 Comparison betw een the 1st round transfer learning prediction of 3 H z data (blue) and the true 3 H z data (red) for the BP2004 mo del. a) 2nd shot (deplo yed at left part of the domain); b) 30th shot (deploy ed at central part of the domain); c) 53rd shot (deploy ed at righ t part of the domain). 17 Comparison b etw een FWI result on LF data. 1) FWI result of true LF data in ver- sion (3 H z , 5 H z , and 7 H z ); 2) FWI result of inv erting the LF data (3 H z , 5 H z , and 7 H z ) predicted b y training on an arbitrarily selected velocity mo del sho wn in Figure 12c. 18 Comparison b et w een the 2nd round transfer learning prediction of 3 H z data (blue) and the true 3 H z data (red) for the BP2004 mo del. a) 2nd shot (deplo yed at left part of the domain); b) 30th shot (deploy ed at central part of the domain); c) 53rd shot (deploy ed at righ t part of the domain). 19 Comparison betw een the 3rd round transfer learning prediction of 3 H z data (blue) and the true 3 H z data (red) for the BP2004 mo del. a) 2nd shot (deplo yed at left part of the domain); b) 30th shot (deploy ed at central part of the domain); c) 53rd shot (deploy ed at righ t part of the domain). 20 a) learning curve of the 3rd iteration of Progressiv e T ransfer Learning; b) cross- 28 correlation b et ween the predicted LF data after the 3rd iteration of Progressive T ransfer Learning and the true LF data as a measure of prediction accuracy . 21 a) FWI result pro duced b y in verting the 3rd round transfer learning predicted 3 H z , 5 H z , 7 H z data, follow ed by measured HF data (10 H z to 30 H z ) in version; b) FWI result pro duced by sequen tially inv erting full-bandwidth measured data ( 3 H z to 30 H z ); c) FWI result pro duced by direct inv erting measured high frequency data sequen tially from 10 H z to 30 H z . 29 Figure 1: A diagram showing a one-v ariable nonlinear optimization problem. V L : lo cal minim um; V I : starting v elo cit y model; V A : approximate solution obtained at lo w frequency; V T : true solution. Hu, Jin, W u & Chen – manuscript v1.1 30 (a) (b) Figure 2: a) a seismic trace with sparse reflection ev ents; b) sp ectrum of the trace with frequency comp onen ts b elo w 5 H z and ab ov e 25 H z abandoned. Hu, Jin, W u & Chen – manuscript v1.1 31 Figure 3: Comparison b et ween phase sp ectra of input data (blue) and predicted LF data (red). Hu, Jin, W u & Chen – manuscript v1.1 32 Figure 4: Diagram of relationship b et ween seismic data and wa ven umber comp onen ts of subsurface structures. Hu, Jin, W u & Chen – manuscript v1.1 33 (a) (b) (c) Figure 5: Comparison betw een high frequency data and the corresp onding Beat T one data. a) 6 H z ; b) 7 H z ; c) Beat T one data derived from 6 H z and 7 H z data. Hu, Jin, W u & Chen – manuscript v1.1 34 Figure 6: Diagram of relationship b et ween high frequency data, lo w frequency data, Beat T one data, and wa v enum b er comp onen ts of subsurface structures. Hu, Jin, W u & Chen – manuscript v1.1 35 Figure 7: Dual Data F eed structured netw ork. Hu, Jin, W u & Chen – manuscript v1.1 36 (a) (b) Figure 8: Basic units of inception netw ork. a) con v olutional block; b) decon volutional blo c k. Hu, Jin, W u & Chen – manuscript v1.1 37 Figure 9: Structure of the D-depth inception net work. Hu, Jin, W u & Chen – manuscript v1.1 38 (a) (b) (c) Figure 10: a) true veloc it y mo del; b) initial velocity mo del for FWI; c) training velocity mo del. Hu, Jin, W u & Chen – manuscript v1.1 39 (a) (b) (c) Figure 11: a) velocity mo del pro duced b y FWI engine in verting 3 H z and 5 H z data predicted by the DNN, follow ed by FWI inv ersion of measuremen t data from 10 H z to 30 H z . The 3 H z and 5 H z data are predicted b y learning 10 H z to 18 H z measuremen t data; b) reference solution pro duced by FWI sequen tial inv ersion of 3 H z to 30 H z measurement data; c) v elo cit y mo del pro duced by FWI sequentially inv erting 10 H z to 30 H z data. Hu, Jin, W u & Chen – manuscript v1.1 40 (a) (b) (c) Figure 12: a) true subsurface velocity mo del to reconstruct by FWI; b) starting velocity mo del for FWI; c) training velocity mo del arbitrarily selected. Hu, Jin, W u & Chen – manuscript v1.1 41 (a) (b) Figure 13: The p erformance of first Progressive T ransfer Learning iteration. a) learning curv e using the training mo del in Figure 12c; b) correlation b et w een the predicted LF data and the true LF data as a measure of the prediction accuracy . Hu, Jin, W u & Chen – manuscript v1.1 42 Figure 14: Reconstructed velocity mo del by FWI inv erting predicted 3 H z , 5 H z , and 7 H z data, follow ed by high frequency FWI p erformed sequentially from 10 H z to 30 H z . Hu, Jin, W u & Chen – manuscript v1.1 43 Figure 15: W orkflo w of Progressive T ransfer Learning for lo w frequency data reconstruction. LF — lo w frequency; HF — high frequency; LR — low resolution; HR — high resolution. Hu, Jin, W u & Chen – manuscript v1.1 44 (a) (b) (c) Figure 16: Com parison b et w een the 1st round transfer learning prediction of 3 H z data (blue) and the true 3 H z data (red) for the BP2004 mo del. a) 2nd shot (deplo yed at left part of the domain); b) 30th shot (deploy ed at cen tral part of the domain); c) 53rd shot (deplo yed at right part of the domain). Hu, Jin, W u & Chen – manuscript v1.1 45 (a) (b) Figure 17: Comparison b et ween FWI result on LF data. 1) FWI result of true LF data in version (3 H z , 5 H z , and 7 H z ); 2) FWI result of inv erting the LF data (3 H z , 5 H z , and 7 H z ) predicted b y training on an arbitrarily selected velocity mo del sho wn in Figure 12c. Hu, Jin, W u & Chen – manuscript v1.1 46 (a) (b) (c) Figure 18: Comparison betw een the 2nd round transfer learning prediction of 3 H z data (blue) and the true 3 H z data (red) for the BP2004 mo del. a) 2nd shot (deplo yed at left part of the domain); b) 30th shot (deploy ed at cen tral part of the domain); c) 53rd shot (deplo yed at right part of the domain). Hu, Jin, W u & Chen – manuscript v1.1 47 (a) (b) (c) Figure 19: Comparison b et w een the 3rd round transfer learning prediction of 3 H z data (blue) and the true 3 H z data (red) for the BP2004 mo del. a) 2nd shot (deplo yed at left part of the domain); b) 30th shot (deploy ed at cen tral part of the domain); c) 53rd shot (deplo yed at right part of the domain). Hu, Jin, W u & Chen – manuscript v1.1 48 (a) (b) Figure 20: a) learning curve of the 3rd iteration of Progressiv e T ransfer Learning; b) cross- correlation b et ween the predicted LF data after the 3rd iteration of Progressive T ransfer Learning and the true LF data as a measure of prediction accuracy . Hu, Jin, W u & Chen – manuscript v1.1 49 (a) (b) (c) Figure 21: a) FWI result pro duced by inv erting the 3rd round transfer learning predicted 3 H z , 5 H z , 7 H z data, follow ed by measured HF data (10 H z to 30 H z ) in version; b) FWI result pro duced by sequen tially inv erting full-bandwidth measured data ( 3 H z to 30 H z ); c) FWI result pro duced by direct inv erting measured high frequency data sequen tially from 10 H z to 30 H z . Hu, Jin, W u & Chen – manuscript v1.1 50
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment