User Friendly Automatic Construction of Background Knowledge: Mode Construction from ER Diagrams
One of the key advantages of Inductive Logic Programming systems is the ability of the domain experts to provide background knowledge as modes that allow for efficient search through the space of hypotheses. However, there is an inherent assumption t…
Authors: Alex, er L. Hayes, Mayukh Das
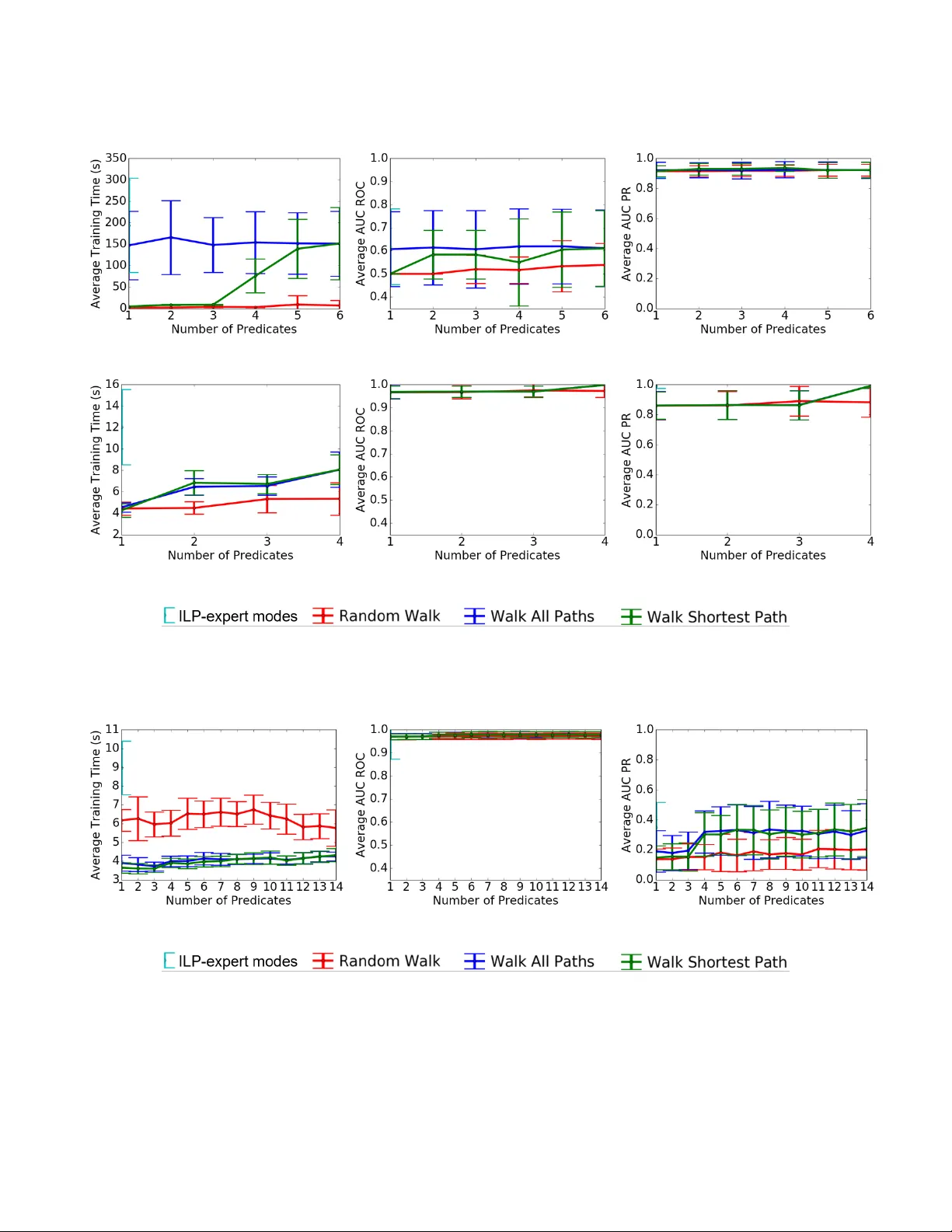
User Friendly A utomatic Construction of Background Knowledge: Mode Construction from ER Diagrams Alexander L. Hayes University of T exas at Dallas Alexander .Hayes@utdallas.edu Mayukh Das University of T exas at Dallas Mayukh.Das1@utdallas.edu Phillip Odom Indiana University , Bloomington phodom@indiana.edu Sriraam Natarajan University of T exas at Dallas Indiana University . Bloomington Sriraam.Natarajan@utdallas.edu ABSTRA CT One of the key advantages of Inductive Logic Programming systems is the ability of the domain experts to pro vide background knowl- edge as modes that allow for ecient search through the space of hypotheses. However , there is an inherent assumption that this expert should also be an ILP expert to provide eective modes . W e relax this assumption by designing a graphical user interface that allows the domain expert to interact with the system using Entity Relationship diagrams. These interactions are used to construct modes for the learning system. W e evaluate our algorithm on a probabilistic logic learning system where we demonstrate that the user is able to construct eective background knowledge on par with the expert-encoded knowledge on ve data sets. KEY W ORDS Feature selection, Logical and relational learning, Entity relation- ship models, Interaction paradigms 1 IN TRODUCTION Recently , there has b een an increase in the development of algo- rithms and models that combine the expressiv eness of rst-order logic with the ability of probability theory to model uncertainty . Collectively called Probabilistic Logic Models (PLMs) or Statistical Relational Learning models (SRL) [ 7 , 19 ], these methods have be- come popular for learning in the presence of multi-relational noisy data. While eective, learning these models remains a computation- ally intensive task. This is due to the fact that the learner should search for hypotheses at multiple levels of abstraction. Consequently , methods whose sear ch strategies are inspired from Inductive Logic Programming (ILP) hav e been introduced to make learning more ecient [ 13 , 15 ]. These methods have demon- strated arguably some of the best results in several benchmark and real data sets. While eective, the key issue with these methods is that they require the domain expert to also b e an expert in ILP— thus providing the right set of directives for learning the target concepts. These additional directives, typically called modes , restrict the search space such that the learning of these probabilistic clauses is ecient. Many real users of these systems, espe cially those who fail to learn good models with these algorithms, may not able to select the correct modes to guide the search. The consequence is that many of the learning procedures get stuck in a local minimum or get timed out resulting in sub-optimal models. One way that this pr oblem has been addressed in literature is by employing databases underneath the learner to improve the search speed [ 11 , 16 , 23 ]. While these systems have certainly improved the search, recent work by Male c et al. [ 11 ] clearly demonstrated the need for modes to achieve eective learning even when using databases. Their w ork show ed an or der of magnitude improvement over the standar d state-of-the-art PLM learning system. Howe ver , their w ork also required the modes to be specied for attaining this eciency . Inspired by their success, we propose a method for specifying modes fr om a database p erspective. Sp ecically , we propose to employ the use of Entity Relationship (ER) diagrams as the graphical tools based on which an user could spe cify modes. The key intuition is that the modes sp ecify how the search is conducted through the space of hypotheses. When viewed from a relational perspe ctive, this can be seen as specifying the parts of the relational graph that are relevant to the target concept. W e pro vide an interface that allows for an user to guide the PLM learners using ER diagrams. Our interface automatically converts the user inputs on ER diagrams to mode denitions that are then later employed to guide the search. Our work is also inspir ed by the work of W alker et al. [ 21 ] where a UI was designed to provide advice for a PLM learner . While their UI was domain-specic, our contribution is a generalized approach to utilize any ER diagram to automatically construct background knowledge for logic-based learners. Our work is also related to the other work of W alker et al. [ 22 ] where the mode construction was automated using a layered approach which relied on successiv ely broadening the search space until a relevant model was found. While their work was ee ctive, due to the layering, scaling their work to large tasks can be inecient. Ours is a more restricted approach which allows for a domain expert to specify the modes using an ER diagram. W e make the following contributions: (1) W e propose an ap- proach to make ILP and PLM systems more usable by domain ex- perts by creating a graphical user interface. (2) W e demonstrate how eective background knowledge can be encoded using an ER dia- gram and provide an algorithm for the translation from UI input to a mode spe cication le. (3) W e show empirically the eectiveness of our learning approach in standard PLM tasks. KCAP’17, Dec 2017, Austin, TX, USA Alexander L. Hayes, Mayukh Das, Phillip Odom, and Sriraam Natarajan Figure 1: An ER-Diagram illustrating 3 entities, Pr ofessors, Students, and Courses , their attributes (ovals) and the rela- tionships (diamonds) among them. W e rst provide the necessar y background knowledge of ER diagrams and ILP systems. Then we outline the procedure for con- verting the ER inputs to mode denitions. W e nally conclude the paper by demonstrating the eectiveness on standard PLM domains and outlining the directions for future research. 2 BA CKGROUND As our approach uses ER diagrams as a way of constructing back- ground knowledge through modes, we discuss both the diagram as well as how modes are typically used in ILP . 2.1 The Entity-Relational Model The entity-relationship model [ 3 ] allows for expressing the struc- ture and semantics of a database at an abstract level as objects and classes of objects (entities and entity classes), attributes of such entities, and relationships that exist b etween such entity classes. Entities are repr esented as rectangles, attributes as circles and re- lationships as diamonds. While relational logic ( as used in ILP) is equally expressive , ER models are repr esented as graphical struc- tures (ER diagrams) making them more intuitive and interpretable. ER modeling is insucient for expr essing operations on the data, but in our problem setting that has no impact. Figure 1 illustrates an ER diagram for an example domain. ER diagrams are commonly utilized by both database designers and domain experts to conceptualize the structural characteris- tics of a given domain [ 5 ]. A relational schema is an alternate abstract r epresentation of the structure of relational data consisting of structural denitions of relational tables, attributes, foreign key constraints, etc. Conceptually , the knowledge conveyed by a rela- tional schema can be used for abstracting background/modes for an ILP/PLM learning task. But, the limitation lies in the ambiguity it may introduce. For instance, the relation node “T As” (Figur e 1) can be expr essed in a relational schema either as a foreign key constraint from one entity to another or as a table with 2 columns having the unique identiers of the connected entities Course and Student . The choice typically depends on the design of the system that will use the database . ER diagrams avoid such ambiguity via consistent syntax. Our approach is motivate d from the intuitive connections b e- tween constrained logical clause search and SQL (Structured Quer y Language) query augmentation. Logical clauses are equivalent to relational queries since, fundamentally , SQL statements are man- ifestations of entity sets dened via r elational calculus. Several ILP/PLM learning frameworks have successfully utilize d this con- cept [ 11 , 16 ]. Similarly , modes for clause learning can be interpreted as constraints on relational quer y construction and query evalu- ation. “Hints, " in relational queries, are sp ecial symbolic tools to guide the query evaluation engine to prioritize some database op- eration over the others to enhance eciency [ 2 , 4 , 10 ]. Thus, they are akin to soft directives/constraints (modes) on the search space. 2.2 Background Knowledge for ILP Background knowledge serves two purposes in ILP systems: de- scribing the underlying structur e of data and constraining the space of models over which the algorithm explores. Thus, background knowledge (set via modes) is a key component for getting rela- tional learning algorithms to work eectively . A mode describ es a way of instantiating predicates in a clause that denes a hyp oth- esis. A mode for predicate pr ed with n arguments is dened as pr ed ( t y pe 1 , t y p e 2 , .. . , t y p e n ) . Each type describes the domain of ob- jects which can appear as that argument, as well as whether it can be instantiated with an input variable ( +), an output variable ( -), or a constant (#) [ 20 ]. Input variables must be previously dene d in the model. Output variables are free variables that have not been dened. ILP learners search through the space of models in dierent ways. Aleph [ 20 ] generates clauses bottom-up by constructing the most specic explanation of examples and then generalizing while TILDE [ 1 ] constructs clauses top-down. Our mode construction approach is capable of generating background knowledge for a variety of dierent ILP systems. T o validate our approach, we make use of a state-of-the-art ILP system called Relational Functional Gradient Boosting (RFGB) [ 14 ] that learns a set of boosted relational regression trees in a top-down manner . Relational regression trees contain relational logic in the inner nodes and regression values in the leaves. Each iteration of RFGB learns a tree ( ψ k ) that pushes the model in the direction of the current error . The error of the current model ( ∆ k − 1 ) is computed over each training example: ∆ k − 1 ( x i ) = I ( y i = 1 ) − P ( y i = 1 | P a ( x i )) where I is an indicator function for whether x i is a positive example and P represents the current predicted probability . The nal model is a sum over all of trees ( ψ M = ψ 0 + ψ 1 + . . . + ψ m ). For more details we refer to Natarajan et al. [14]. 3 H UMAN GUIDED MODE CONSTRUCTION Naive approaches for mode construction may allow for exhaustive search, enabling the ILP learner to nd the best solution at the cost of a time intensive search process. Other approaches allow for one free variable for each atom considered. This restricts the search space, but ignores the fact that not all areas of the search space are equally important for a given target. Alternatively , we consider guided construction of modes ( GMC ) for ILP where the human is assumed to be a domain expert and not an ILP expert. The expert is pro vided the structure of the domain User Friendly A utomatic Construction of Background Knowledge: Mode Construction from ER Diagrams KCAP’17, Dec 2017, Austin, TX, USA Algorithm 1 Guided Mode Construction ( GMC ) 1: procedure GMC (Expert E , max depth d ) 2: target t , related attributes or entities I = Interfa ce ( E ) 3: Modes M = ∅ 4: for i ∈ I do 5: Paths = FindP a ths ( t , i , d ) 6: for p ∈ Path do 7: M = M ∪ CreateMode ( p ) 8: end for 9: end for 10: return M 11: end procedure 12: procedure FindP a ths (target t , related attribute/entity u , nd shortest path i s S h or t e s t , max depth d ) 13: S olu t ions = ∅ , S ear che d = ∅ , T oE x p l or e = { t } 14: while | T o Ex pl or e | > 0 && l en ( T oE x plor e . pee k ()) < d do 15: n = { x 1 , r 1 , x 2 , r 2 , .. . , r k − 1 , x k } = T oE x plor e . de que ue () 16: for r ∈ R x k do 17: for Entity y , x k appearing in relation r do 18: if { n , r , y } ∈ S ear che d then 19: continue 20: end if 21: if y == u | | u ∈ A y then 22: S olu t ions . a ppe nd ({ n , r , y }) 23: if i s S h or t e s t then 24: return S ol u t ions 25: end if 26: end if 27: T o E x pl o r e . enq ue u e ( { n , r , y }) 28: end for 29: end for 30: end while 31: return S ol u t ions 32: end procedure 33: procedure Crea teMode (Path p ) 34: Modes M = ∅ 35: for { x i , r i , x i + 1 } ∈ p do 36: for T erm t j ∈ r i do 37: if t j == e i then 38: t j = + e j 39: else if t j ∈ A then 40: t j = # e j 41: else 42: t j = − e j 43: end if 44: end for 45: M . a ppe nd ( r i ( t 0 , t 1 , .. . , t n )) 46: end for 47: return M 48: end procedure in a graphical user interface that allows the expert to interact with the Entity-Relationship diagram. The target entity ab out which the model will be learned is marked and the expert is responsible for marking all of the attributes which are relevant to the target. Then, we nd paths through entities and r elations that are able to connect the target feature with all of the related entities 1 and their attributes. As we describe in more detail later , these paths are the basis for constructing the modes. 3.1 An Illustrative Example Consider a set of data involving professors, students, and courses, with some asso ciated attributes and relationships between each. Figure 2(a) sho ws such an ERD where Grade (marked in red) was identied by an expert as being an important attribute for predicting T enure (marked in blue). GMC rst connects the target concept to the related concepts by nding paths from one to another in the ER diagram. Figure 2(b) shows tw o paths that connect T enure to Grade . Once these paths are establishe d, variables can be set as being open (-), closed ( +), or grounded (#) based on the order in which entities (variables) appear . Since T enure is the target concept which everything should be learned with relation to, the conversion pro- cess begins with Tenure(+Professor) . Modes are added to allow the ILP learner to search along the path. W e show each step in one path and the corresponding modes that would be generated in T able 1. Note that the entities and attributes are highlighted in dierent colors to show which arguments have the same type . The rst time a type ( S t u d e nt , Cour s e ) is intr oduced along the path, the mode is set to − allowing a free variable to be introduced during the search. Subsequently , app earances of a type have modes that are set to + , forcing a pre vious variable to be used during search. As Gr ad e is an attribute (as opposed to an entity), it will be grounded using the # mode. Clause 1 in T able 1 gives an example of a clause that could be generated by an ILP system with the specied mo des. The English interpretation of this rule is that tenur e depends on the grades of students who are advised by a professor . 3.2 The Algorithm The goal of GMC (Algorithm 1) is to guide the learner by construct- ing background knowledge based on input from a human user . This background knowledge consists of a set of modes that denes the search space for an ILP learner , enabling it to nd a reasonable hy- pothesis eciently . W e have cr eated a user interface that allows for a human domain expert to provide relevant attributes or entities for a given target ( line 2 ). GMC constructs mo des that allow these rele- vant attributes or entities to appear in the model. Thus, the two key steps in GMC are 1) nding paths in the ER diagram ( FindP a ths ) and 2) generating modes fr om those paths ( Crea teMode ). W e now discuss each of these steps. 3.2.1 FindPaths. Given the target t and a relevant attribute or entity u , we nd paths between them in the ER diagram. A path includes the set of entities and relationships which together relate t to u . Each path p = ( t , r t , x 1 , r 1 , x 2 , r 2 , .. . , r k − 1 , x k ) consists of attributes or entities ( { x i } ) and relations ( { r j } ). W e explore the set of all paths in a breadth rst manner starting from t . At each step, we select from among the shortest paths to expand. Assume x k 1 Note that ERDs represent entity sets/classes/types and not actual instances or entities to be precise. However , since in the context of our approach we never deal with instances, we use the term "entity" to denote entity classes for br evity KCAP’17, Dec 2017, Austin, TX, USA Alexander L. Hayes, Mayukh Das, Phillip Odom, and Sriraam Natarajan (a) T arget : ‘T enure’ . Informative/important : ‘Grade’ , selected by user. (b) The e quidistant shortest paths between T enure and Grade. Figure 2: Illustrative example sho wing knowledge guided walks on the ERD, giv en in Figure 1, for mode construction. Step 1 Step 2 Step 3 Step 4 Step 5 Step 6 Path 1 T e nur e P r o f e s s or A d v i s e s S t u d e nt T ak e s G r ad e Modes 1 T e nur e ( + P r o f ) A d v i s e s ( + P r o f , − S t u d ) T ak e s ( + S t u d , − C our s e , # G r ad e ) Clause 1 T e nur e ( p ) ∧ A d v i s e s ( p , s ) ∧ T ak es ( s , c , A + ) T able 1: Each step of a path and corresponding modes generate d by GMC . is the current end of the selecte d path. W e denote R x k as the set of relations in which entity x k appears. Path p is then extended for each relation r ∈ R x k by creating a path for each entity that appears in r . GMC nds a path when it reaches u (if u is an entity) or when it reaches an entity y for which u is an attribute ( u ∈ A y ). There are two potential settings corresponding to the number of paths to be found. If i s Shor t e s t is set to t r ue , it will nd a shortest path. Other- wise, it will nd all paths up to a particular depth d . Our hypothesis is that nding all paths will yield background knowledge that en- compass the best model while nding the shortest path will yield the most ecient set of modes that still allow the learner to nd acceptable models. Note that the shortest path can be considered the most simple way to relate t and u and such simple knowledge is the basis for many learning algorithms. 3.2.2 CreateModes. Given a single path p found by FindP a ths , we now create a set of mo des that will guide the search. As describ ed previously , a mode is specie d for a particular pr edicate. Each argument of the mode species the attribute type (dened by the structure of the ER diagram) as well as how new variables/constants can be introduced. For each relationship in the path p , we dene a new mo de. As mentioned earlier , the number and typ es of the arguments are dened by the structure of the ER diagram. W e also assume that arguments corresponding to attribute values ( e.g. the value of blo od pressure or grade in a course) are considered as constants (#). Thus, we only need to describe selecting between input/output variables. For each pair of relations in the path connected through an entity ( ( r i , x i + 1 , r i + 1 ) ∈ p ), we generate a mode m r i + 1 for r i + 1 . W e denote r x j k to be the argument of relation r k that has asso ciated type x j . W e set the argument a = r x i + 1 i + 1 as an input variable. All other arguments are set as an output variable ( ∀ y ∈ Ar д s ( r i + 1 )\ a r y i + 1 ). Note that there could be multiple arguments with the same type ( | a | ≥ 0 ). If there are more than one, w e generate a mode for each argument in a as an input variable and treat all others as output variables. The set of modes generated by GMC ( M ) can be used directly for ILP search. As GMC allows for the domain expert to only provide input on the ER diagram, no expertise in mode construction is required. W e now describe our interface in more detail. 3.3 The Interface The primary objective of our approach is to facilitate a domain expert, having limited understanding of ILP, in creating suitable modes as per the given problem. This necessitates an intuitive and user-friendly interface. W e have developed a GUI (Figure 3) that provides a user , having basic understanding of entities and relations, with the tools to build ER diagrams fr om scratch or load existing ones and annotate them with kno wledge ab out targets and informa- tive attributes/entities. The interface is designed for allo wing the user to drag shapes and arrows to construct no des and edges of a ER diagram as well as to select any node by double clicking on it to set its properties from the drop-do wn menus in the left pane. The prop- erties include (1) whether the relation/attribute node is the target (2) whether the attribute/relation is important/informative/predictive and (3) if an attribute is multi-valued or binary . Note that if the data is stored in a relational database , an ER diagram can be constructed automatically to some degree of delity . But, in most cases, the sanity or the quality of the ER-Diagrams are subject to the database designer’s choice. User Friendly A utomatic Construction of Background Knowledge: Mode Construction from ER Diagrams KCAP’17, Dec 2017, Austin, TX, USA Figure 3: The Interface. It pr ovides a drag-and-drop console with drop downs for annotating the ERD. As mentione d ear- lier: rectangles, diamonds, and ellipses/circles represent en- tities, relations, and attributes respectively . Here , “Rating" is annotated as the target and the “Popularity" attribute is annotated as important . 4 EXPERIMEN TS W e pose the following questions to evaluate the eectiveness and eciency of our approach ( GMC ) in backgr ound knowledge con- struction. Q1 : Does GMC facilitate the learner to optimally explore the hypothesis space (performance)? Q2 : Can GMC enhance eciency via suciently constraining the search space? Q3 : Do simple ( Shortest Path ) modes generate robust models? Q4 : What is the importance of human guidance? W e discuss our results base d on two scenarios, (1) searching all paths from our target to our predicates, and (2) exploring the shortest paths. W e compare our appr oach against two baselines: (a) modes encoded by an ILP expert 2 , and (b) mode construction based on depth-restricted random paths. Note that a achieves similar performance to walking from the target to every feature in the domain at a lower average training time. b is inspired by the success of random walk algorithms that are capable of solving many challenging tasks [9]. The system has two components, (a) a platform-independent GUI component for creation and annotation of ER diagrams and (b) the mo de construction from the annotate d diagram which is designed to be compatible with any ER diagramming tool given a common intermediate representation. W e have used the state-of-the-art ILP structure/parameter learn- ing framework Relational Functional Gradient Boosting [ 15 ] as the test-bed for evaluating the quality of automatically constructed modes. 4.1 Domains W e use four standard ILP/PLM datasets, namely CiteSeer , W ebKB, Cora, and IMDB, for an empirical evaluation of our automatic mode construction system. “facts" refers to the evidence (all the relations 2 Discussion on manual mode construction is beyond the scope of this paper . between dierent objects that are true in the given domain) and “e xamples" refers the total number of positive and negative (true and false) target r elations/attributes/features across each cross- validation fold. CiteSeer [ 18 ] dataset was created for information extraction and citation matching. It has 121,891 facts and 116,679 e xamples split across four cross-validation folds, each corresponding to a dier ent topic. Our goal was to predict which eld the title of the paper cor- responded to ( infield_ftitle ), and the fourteen other pr edicates are based on tokens and their relative positions in a document. W ebKB [ 12 ] is a consolidated dataset of links among departmental web pages from four universities (Cornell University , University of T exas, University of W ashington, and University of Wisconsin) each grouped into one of four cross-validation folds. It has 1912 facts and 747 examples, where the target is to predict faculty based on several predicates ( courseProf , courseTA , project , and samePerson ). Cora [ 18 ], like CiteSeer , is about citation matching, with the key dierence being the type of relations that are captur ed. The dataset consists of 6,541 facts and 62,715 examples split into ve cr oss- validation folds. The target is to predict if 2 citations have the same author ( sameAuthor ). IMDB [ 12 ] represents relations between movies and the people who work on them, as well as several attributes of such movies and people. People can either b e an actor or a director (mutually exclusive), and the goal is to predict whether an actor w orked under a certain director ( workedUnder ). In total there are 664 facts and 5794 examples. UW-CSE is an anonymized representation of the sta and students of ve computer science departments distributed across ve cross- validation folds; consisting of 5121 facts and 94,000 examples. The goal is to predict who advises whom ( advisedby ). 4.2 Experimental Setup Our GMC algorithm has two settings, Walk All Paths for walking all paths on the graph from the user-specie d target to each selected feature, and Walk Shortest Path for nding only a shortest path from the target to each selected feature. Experiments w ere performe d on a ser ver with twenty Intel Xeon E5-2690 CP Us clocke d at 3.00GHz with no other processes on the server which might interfere with training time. T o compare perfor- mance for each method, we report the mean and standard deviation of the training time , AUC ROC , and AUC PR acr oss 5 cross-validation folds and 10 independent runs for every dataset and numb er of fea- tures. The settings (namely: negative:positive ratio and #literals at each tree-node) of the underlying PLM learner , ‘RFGB’ , were kept consistent across all the evaluated approaches and 10 trees were learned in each case. Features (attributes/relations) the expert annotates as impor- tant/informative ar e arranged in the order in which they were selected. In the experimental results (Figures 4, 5 & 6), the x-axis represents this or dering, and the respective values for each p oint represents the performance of a horizontal slice of all predicates up to and including that point. This shows how each additional predicate inuences performance/training time. KCAP’17, Dec 2017, Austin, TX, USA Alexander L. Hayes, Mayukh Das, Phillip Odom, and Sriraam Natarajan (a) CiteSeer A vg. Training Time (b) CiteSeer A vg. AUC ROC (c) CiteSeer A vg. AUC PR (d) W ebKB A vg. Training Time (e) W ekKB A vg. AUC ROC (f ) W ebKB Avg. AUC PR Figure 4: Results for CiteSeer and W ebKB Datasets; T op row: Citeseer , Bottom row: W ebKB. Left: Eciency - Training time (lower is better), Middle & Right: Performance - A verage AUC ROC and AUC PR respectively (higher is b etter). 4.3 Experimental Results From Figures 4, 5 and 6 we observe that both settings of our GMC algorithm outperforms Random W alk in 3 of the datasets ( Cite- Seer/W ebKB in AUC ROC and CiteSeer/W ebKB/U W -CSE in AUC PR). The dierence is more pronounced earlier in the learning curve when fewer paths are being found. As expected, when the number of paths increase, the performance of Random W alk often approaches GMC . Both of our GMC approaches are capable of matching the performance of ILP-expert modes , often with ver y few informative predicates marked (e xcept in the case of CiteSe er which requires additional marked predicates). Thus, our GMC methods generate modes that facilitate eective ILP search ( Q1 ). While our GMC approaches generate high performance, they also constrain the search space to allow for ecient models to be learned. The training time of Random W alk varies: it is lower than our approaches in three datasets (W ebKB/Cora/IMDB) and higher in CiteSeer and U W -CSE. Even though Random W alk is more ecient, it is less eective (W ebKB/Cora) than our approaches. When compared to the ILP-expert modes , our GMC approaches are signicantly more ecient in all domains except Cora, wher e W alk All Paths performs similarly to ILP-expert modes . O verall, both of our GMC approaches are capable of learning more ecient models than the baseline while also achieving high performance ( Q2 ). While both variants of our GMC algorithm ( W alk All Paths and W alk Shortest Path ) compare favorably to the other baselines, we now discuss their dierences. Intuitively , W alk Shortest Path should have an eciency advantage o ver W alk All Paths . This is demon- strated in two domains (W ebKB/Cora) where W alk Shortest Path achieves similar performance to W alk All Paths while having sig- nicantly lower training time. In all other domains, b oth variants perform similarly . This suggests that the shortest explanation is often sucient and allows for a robust and ecient search ( Q3 ). T o better comprehend the role of human guidance ( Q4 ), let us consider two—not necessarily distinct—aspects. Primarily , human guidance acts as search space constraints for the ILP learner to eciently search for models. Hence, careful encoding of modes is necessary to achieve comparable, at times better , performance than a super-exponential exhaustive search. Random W alks can manage to reduce the search space by w orking with randomly sampled regions. Howe ver , as the results illustrate (Figures 4( e), 4(f ), etc.), it may not result in robust models. The other aspect is knowledge about what the most important features/nodes are in automatic mode construction. The empirical results illustrate that, across all datasets and all empirical measurements, there exists a convergence User Friendly A utomatic Construction of Background Knowledge: Mode Construction from ER Diagrams KCAP’17, Dec 2017, Austin, TX, USA (a) Cora A vg. Training Time (b) Cora Avg. AUC ROC (c) Cora A vg. AUC PR (d) IMDB A vg. Training Time (e) IMDB A vg. AUC ROC (f ) IMDB A vg. AUC PR Figure 5: Results for Cora and IMDB Datasets; T op row: Cora, Bottom row: IMDB. Left: Eciency - Training time (lower is better), Middle & Right: Performance - A verage AUC ROC and AUC PR respectively (higher is b etter). (a) UW-CSE A vg. Training Time (b) U W-CSE A vg. AUC ROC (c) UW-CSE A vg. AUC PR Figure 6: UW -CSE results. Left: Eciency - T raining time (lower is better), Middle & Right: Performance - A verage AUC ROC and AUC PR respectively (higher is better). point where including additional guidance ( annotations of impor- tant features) no longer leads to better performance. IMDB requires all four predicates to be taken into account; but in CiteSeer , W ebKB , and Cora : performance no longer impr oves after predicates 9 , 3 , and KCAP’17, Dec 2017, Austin, TX, USA Alexander L. Hayes, Mayukh Das, Phillip Odom, and Sriraam Natarajan 1 , respectively . In all cases except Cora , training time continues to increase slightly while overall performance stabilizes. The domain expert is essential for pro viding the initial ER model as well as annotating what the most important features/nodes are. 5 CONCLUSION W e considered the problem of capturing domain expert knowledge in the context of learning rst-or der probabilistic models. W e dev el- oped a solution based on entity relationship diagrams that allows the domain expert to provide relevant knowledge ee ctively for making the search process ecient. Our solution is inspired by the obser vation that most probabilistic logic models can be se en as learning a probabilistic model over a relational graph in the lines of probabilistic relational models [ 6 ] and probabilistic entity- relational models [ 8 ]. Given this obser vation, the domain expert identies relevant nodes in the ER diagram which translates to providing appropriate modes for a clause learning system. Our ex- periments on standard PLM domains demonstrate the eectiveness of our proposed approach. Extending this system to actively solicit advice as neede d [ 17 ] is a possible future direction. Allowing for incomplete/noisy and even competing advice is another direction. Finally , extending the interface to allow for kno wledge capture in other learning frameworks such as se quential decision-making in relational models, relational de ep networks, and other relational models remain an interesting direction for future resear ch. A CKNO WLEDGEMEN TS Mayukh Das and Sriraam Natarajan gratefully acknowledge the support of the CwC Program Contract W911NF-15-1-0461 with the US Defense Advanced Research Projects Agency (D ARP A) and the Army Research Oce (ARO ). Phillip Odom and Sriraam Natarajan acknowledge the support of the Army Research Oce ( ARO) grant number W911NF-13-1-0432 under the Y oung Investigator Program. REFERENCES [1] H. Blockeel. Top-do wn induction of rst or der logical decision tr ees. AI Commun. , 12(1-2), 1999. [2] N. Bruno, R. Ramamurthy , and S. Chaudhuri. Flexible query hints in a relational database, May 29 2012. US Patent 8,190,595. [3] P. P .-S. Chen. The Entity-Relationship Model–Toward a Unied View of Data. ACM Transactions on Database Systems (TODS) , 1(1):9–36, 1976. [4] A. Diab , S. A. Gatz, S. Kapur , D . Ku, C. Kung, P. Hoang, Q . Lu, L. Pogue, Y. K. Shen, N. Shi, et al. Search system using search subdomain and hints to subdomains in search query statements and sponsored results on a subdomain-by-subdomain basis, Mar . 3 2009. US Patent 7,499,914. [5] H. Garcia-Molina, J. D. Ullman, and J. Widom. Database Systems, Second Edition . Pearson Education, Inc, 2009. [6] L. Getoor , N. Friedman, D. Koller , and A. Pfeer . Learning probabilistic r elational models. Relational Data Mining, S. Dzeroski and N. Lavrac, Eds. , 2001. [7] L. Getoor and B. T askar . Introduction to Statistical Relational Learning . MI T Press, 2007. [8] D. Heckerman, C. Meek, and D . Koller . Probabilistic models for relational data. T echnical Report MSR-TR-2004-30, March 2004. [9] N. Lao and W . W . Cohen. Relational retrieval using a combination of path- constrained random walks. Machine learning , 81(1):53–67, 2010. [10] G. M. Lohman, E. J. Shekita, D. E. Simmen, and M. S. Urata. Relational database query optimization to perform query evaluation plan, pruning based on the partition properties, July 18 2000. US Patent 6,092,062. [11] M. Malec, T . Khot, J. Nagy, E. Blasch, and S. Natarajan. Inductive logic program- ming meets relational databases: An application to statistical relational learning. In ILP , 2016. [12] L. Mihalkova and R. Mooney . Bottom-up learning of Markov logic network structure. In ICML , pages 625–632, 2007. [13] S. Natarajan, K. Kersting, T . Khot, and J. Shavlik. Boosted Statistical Relational Learners: From Benchmarks to Data-Driven Medicine . Springer, 2015. [14] S. Natarajan, T . Khot, K. Kersting, B. Gutmann, and J. Shavlik. Gradient-base d boosting for statistical relational learning: The Relational Dep endency Network case. MLJ , 2012. [15] S. Natarajan, T . Khot, K. Kersting, B. Guttmann, and J. Shavlik. Boosting Relational Dependency networks. In ILP , 2010. [16] F. Niu, C. Ré, A. Doan, and J. Shavlik. Tuy: Scaling up statistical inference in markov logic networks using an rdbms. CoRR , abs/1104.3216, 2011. [17] P. Odom and S. Natarajan. Actively interacting with experts: A probabilistic logic approach. In ECML , 2016. [18] H. Poon and P. Domingos. Joint inference in information extraction. In AAAI , pages 913–918, 2007. [19] L. D. Raedt, K. Kersting, S. Natarajan, and D. Poole. Statistical relational articial intelligence: Logic, probability , and computation . Morgan & Claypool Publishers, 2016. [20] A. Srinivasan. The Aleph Manual , 2004. [21] T . W alker, G. Kunapuli, N. Larsen, D. Page, and J. Shavlik. Integrating knowledge capture and supervised learning thr ough a human-computer interface. In KCAP , 2011. [22] T . W alker, C. O’Reilly , G. Kunapuli, S. Natarajan, R. Maclin, D. Page, and J. Shavlik. Automating the ILP Setup Task: Converting User Advice about Specic Examples into General Background Knowledge. In International Conference on Inductive Logic Programming , pages 253–268. Springer , 2010. [23] Q. Zeng, J. M. Patel, and D . Page. Quickfoil: scalable inductive logic programming. Proceedings of the VLDB Endowment , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment