Network of Evolvable Neural Units: Evolving to Learn at a Synaptic Level
Although Deep Neural Networks have seen great success in recent years through various changes in overall architectures and optimization strategies, their fundamental underlying design remains largely unchanged. Computational neuroscience on the other…
Authors: Paul Bertens, Seong-Whan Lee
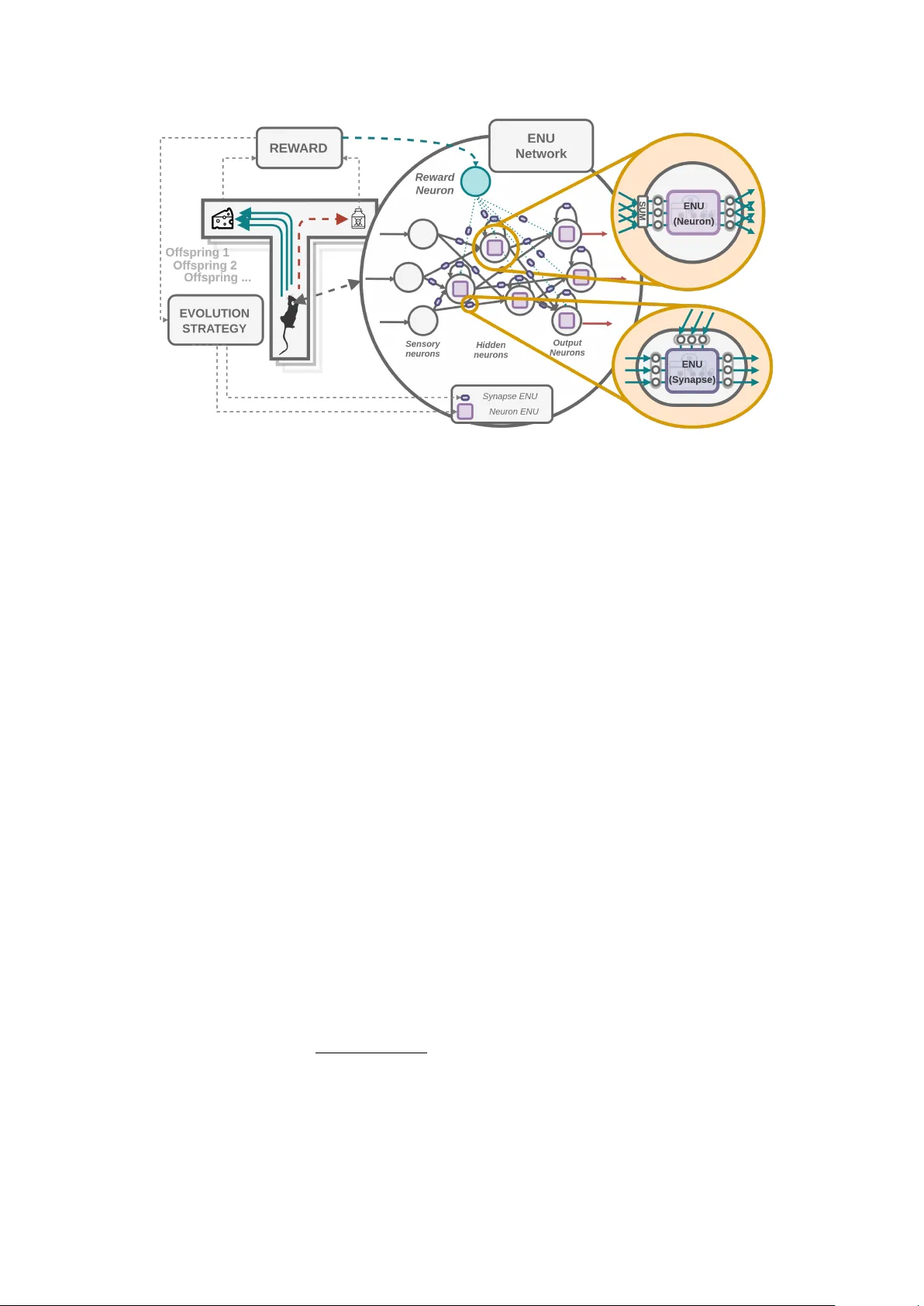
Net w ork of Ev olv able Neural Units: Ev olving to Learn at a Synaptic Lev el P aul Bertens ∗ , 1 , Seong-Whan Lee 1 , 2 1 Departmen t of Brain and Cognitiv e Engineering, 2 Departmen t of Artificial Intelligence, Korea Universit y , Seoul, South Korea Decem b er 17, 2019 Abstract Although Deep Neural Netw orks hav e seen great success in recent y ears through v arious c hanges in ov erall arc hitectures and optimization strategies, their fundamen tal underlying design remains largely unchanged. Computational neuroscience on the other hand provides more biologically realistic mo dels of neural pro cessing mechanisms, but they are still high level abstractions of the actual exp erimentally observed b eha viour. Here a mo del is prop osed that bridges Neuroscience, Machine Learning and Ev olutionary Algorithms to ev olve individual soma and synaptic compartmen t mo dels of neurons in a scalable manner. Instead of attempting to man ually derive mo dels for all the observed complexity and diversit y in neural pro cessing, we prop ose an Ev olv able Neural Unit (ENU) that can approximate the function of each individual neuron and synapse. W e demonstrate that this type of unit can b e evolv ed to mimic Integrate-And-Fire neurons and synaptic Spik e-Timing-Dep enden t Plasticity . Additionally , by constructing a new type of neural net work where each synapse and neuron is suc h an evolv able neural unit, we show it is p ossible to ev olve an agent capable of learning to solve a T-maze en vironment task. This net work indep enden tly discov ers spiking dynamics and reinforcement type learning rules, op ening up a new path tow ards biologically inspired artificial in telligence. 1 In tro duction Muc h research has b een done to understand how neural pro cessing works [ 1 , 2 , 3 ], including synaptic learning [ 4 ] and o verall net w ork dynamics [ 5 , 6 ]. Ho wev er these pro cesses are extremely complex and interact in a w ay that is currently still not w ell understo o d. Mathematical mo dels are commonly used to approximate neurons, synapses and learning mec hanisms [ 7 , 4 ]. How ev er, neurons can b eha ve in many differen t wa ys, and no single mo del can accurately capture all exp erimen tally observed b eha viour. The neural complexit y is mostly at the small scale, i.e. the cellular lo cal interactions that can lead to an intelligen t ov erall system. While information pro cessing at the net w ork level is generally well understo o d (and the basis for artificial neural net works [ 8 , 9 ]), its how individual neurons are actually capable of giving rise to the o verall net works b eha viour and learning capabilit y that is largely unknown. ∗ Gith ub: h ttps://github.com/paulbertens, e-mail: p.m.w.a.b ertens@gmail.com 1 Figure 1: Abstract o verview of a single neuron. F unctionally the dendrites receive information, the cell b o dy integrates and transforms that information and the axon transmits it to other neurons. Neurotransmitters allow for communication b etw een neurons, and the n umber of neurotransmitters released affect the s trength of the synaptic connection. Learning then o ccurs b y up dating this synaptic strength dep ending on the information received. Besides graded and action p oten tials (spik es), complex transp ort of mito c hondria, vesicles used to con tain neurotransmitters and other information that can c hange the b eha viour of the neuron also o ccur along the axon and dendrite. Biological Neural Net works When lo oking in more detail at the smaller scale of neurons and synapses, complexit y quickly arises. Differen t ion-c hannels in the neuron are responsible for generating action p oten tials (spikes) or graded p oten tials (real v alued), mainly so dium ( N a + ), p otassium ( K + ) and calcium ( C a 2+ ) channels [ 10 ]. These ion channels are also resp onsible for triggering the release of chemical neurotransmitters, the main metho d of communication b et w een neurons in biological neural netw orks. Man y t yp e of neurotransmitters exist that eac h hav e distinct roles, e.g. Dopamine [ 11 ] (related to learning), GABA B [ 12 ] (inhibitory), Acet ylcholine [ 13 ] (motor neurons) and Glutamate [ 14 ] (excitatory). Morphological differences across the brain are also common, where different type of neurons exist in different regions of the brain and across different cortical lay ers [15]. Axons and dendrites actively transp ort other information [ 16 ], for example vesicles [ 17 ] (whic h hold neurotransmitters) and mito c hondria [ 18 ] (required for mem brane excitabilit y and neuroplasticit y). Man y protein types are also common [ 16 ], which are resp onsible for a diver set of functions, including increasing or decreasing the num b er of neuroreceptors in the synapses [ 19 ], and aiding in the release of neurotransmitters [ 17 ]. F urthermore, neurons can exhibit b oth regular or bursting spiking b eha viour dep ending on their internal state and neuronal t yp e [ 20 , 21 ]. Deriving models capable of capturing all this b ehaviour is th us an activ e research area. These mec hanisms might how ev er simply b e the result of biological constrain ts and ev olutionary pro cesses, and it is still uncertain which structures exactly are required to exist for intelligen t b ehaviour to emerge. Generally mo dels in the computational neuroscience field fo cus on mo deling individual neurons and synaptic learning b eha viour. Simple Integrate and fire neurons [ 7 ] (IAF) assume input p otential is summated ov er time, and once this reaches some threshold a spike o ccurs. More adv anced mo dels also try to mo del the so dium and p otassium ion channels as done in the Ho dgkinHuxley (HH) mo del [ 22 ], which gives more realistic action p oten tials at the output. 2 Hebbian plasticity was one of the first prop osed mo dels describing synaptic learning [ 23 ], briefly it states that the synaptic weigh t increases if the pre-synaptic neuron fires b efore the p ost-synaptic neuron. This change in synaptic weigh t can then increase or decrease the firing rate of the p ost-synaptic neuron in the future when receiving a similar stimuli. A more extensiv e mo del that also tak es the spike timing into account is Spike Timing Dep enden t Plasticit y [ 4 ] (STDP), whic h up dates the weigh ts dep ending on the time b et ween the pre and p ost synaptic neuron. Artificial and Recurren t Neural Net w orks Deep Learning mo dels hav e b een very successful in man y practical applications [ 9 ], and although spiking neural net w orks (SNNs) ha v e b een developed [ 24 , 25 ], so far they hav e seen limited success due to their high computational demand and difficulty in training. Artificial Neural Net works, the foundation of deep learning mo dels, are esp ecially effective in p erforming function approximation, and are known to b e univ ersal function approximators [ 26 ]. Recurren t Neural Netw ork (RNNs) architectures hav e also b een inv estigated in order to pro cess sequen tial data and allow memory to b e stored b et w een successive time steps [ 9 ], most commonly Long-Short T erm Memory [ 27 ] (LSTMs) and Gated Recurrent Units [ 28 ] (GRUs). These add gating mechanisms to standard RNNs to allow for easier learning of long-range dep endencies and to av oid v anishing gradients in bac k-propagation. Deep learning based mo dels how ev er suffer from several limitations [ 1 ]. They require bac kpropagation of errors through the whole net work, ha ve difficult y p erforming one-shot learning (learning from a single example) and suffer from catastrophic forgetting of a previous task once trained on a new task. They are also extreme abstractions of biological neural net works, only considering a single weigh t v alue on the connections and ha ving a single real v alued num ber as their output. Ev olutionary Algorithms Ev olutionary algorithms hav e b een widely applied to a v ariety of domains [ 29 , 30 ], and man y related optimization algorithms exist that are based on the ev olutionary principles of m utation, repro duction and surviv al of the fittest. Recen tly Ev olution Strategies (ES) hav e b een successfully applied to train deep neural netw orks, despite the large amoun t of parameters of most neural netw ork architectures [ 31 ]. The adv an tage of ES is that it allows for non-differentiable ob jectiv e functions, and when training RNNs do es not require bac kpropagation through time. This means we can optimize and evolv e the parameters of a mo del to solve any desired ob jective w e w ant, and potentially learn ov er arbitrarily long sequences. 2 Ob jectiv e P ast attempts on mo deling biological neural netw orks ha ve mostly b een fo cused on manually deriving mathematical rules and abstractions based on exp erimen tal data, ho wev er in this paper a differen t approach is tak en. The functionality of differen t comp onen ts in neural net works are appro ximated using artificial Recurrent Neural Netw orks (RNNs), suc h that each synapse and neuron in the netw ork is a recurrent neural netw ork. T o make this computationally feasible the RNN w eight parameters across the global netw ork are shared, while each RNN keeps their own internal state. This w ay the num b er of parameters to b e learned are significantly reduced, and we can use evolutionary strategies to train such a netw ork. Due to the universal 3 function approximation prop erties of RNNs, there is essen tially no limitations on the neuronal b eha viour we can obtain. The RNN memory can store dynamic parameters that determine the b eha viour of our compartmen ts (e.g. synapse or neural cell b ody), while the shared weigh ts are ev olved. This is related to meta-learning approaches [ 32 , 33 , 34 , 35 , 36 ], where we are learning to learn. Since all RNN w eights are shared across all synaptic or neural compartments, learning different b eha viour can only o ccur b y learning (evolving) to store and up date dynamic parameters in the RNN memory state. Suc h an RNN can th us b e seen as mo deling a function that expresses the neuronal b eha viour. Ho wev er, instead of ha ving a fixed mathematical function deriv ed from exp erimen tal observ ation (lik e e.g. hebbian learning, integrate-and-fire neurons or STDP rules), we ev olve a function that could exhibit muc h more diverse b eha viour. In our case it is not required that the evolv ed b eha viour has to match exp erimen tal data or preexisting mo dels, as cells in the real world are b ound b y more physical constrain ts than in our sim ulated setting. Ultimately w e would lik e to evolv e a type of mini-agent that when duplicated and connected together in an ov erall neural net work exhibit intelligen t learning b eha viour. T o this end, netw ork agents containing these mini-agents are evolv ed using evolutionary algorithms, where their fitness is their ability to learn new tasks. 2.1 Con tributions T o summarize, we are thus attempting to evolv e a new type of Neural Netw ork where each individual neuron and synapse in the netw ork is by itself mo deled by an evolv able Recurrent Neural Netw ork. Our main contributions are as follows: • Prop ose an Ev olv able Neural Unit (ENU) that can be ev olved through Evolution Strategies (ES) which is able to learn to store relev an t information in its internal state memory and p erform complex pro cessing on the received input using that memory . • Demonstrate suc h an ENU can b e ev olved to approximate the neural dynamics of simple In tegrate and Fire neurons (IAF) and synaptic Spike-Timing-Dependent Plasticit y (STDP). • Com bine multiple ENUs in a larger netw ork, where the w eigh t parameters of the ENUs to b e evolv ed are shared across the neurons and synaptic compartments, but eac h internal state is unique and up dated based on the lo cal information they receive. • Efficien tly evolv e and compute suc h a net work of ENUs through large scale matrix m ultiplications on a single Graphical Pro cessing Unit (GPU). • Sho w it is p ossible to ev olve a netw ork of ENUs capable of reward based reinforcement learning purely through lo cal dynamics, i.e. evolving to learn. 3 Prop osed Mo del 3.1 Ev olv able Neural Units (ENUs) As the basis for an evolv able Recurren t Neural Net work (RNN) to approximate neural and synaptic b eha viour w e build up on previous work on mo deling long-term dep endencies through Gated Recurrent Units [ 28 ] (GRUs). W e extend up on this mo del and add an additional output 4 gate that applies a non-linear activ ation function and feeds this bac k to the input, which sim ultaneously also reduces the n umber of p ossible output channels (impro ving computational complexit y). Additionally they are implemented in suc h a w ay that allo ws them to be com bined and ev olved efficiently in a larger ov erall netw ork. W e term these units Evolv able Neural Units (ENUs). Figure 2: An Ev olv able Neural Unit . Differen t ev olv able gating mechanisms protect the internal memory of the neural unit (storing ”dynamic parameters”). This memory can p oten tially enco de and store the neuronal b ehaviour and determines ho w information is pro cessed (analogous to e.g. the membrane p oten tial, synaptic weigh ts, protein states etc.). The reset gate can forget past information, the up date gate determines how muc h w e change the memory state (our dynamic parameters) and the cell gate determines the new v alue of the dynamic parameters. An additional output gate is also used to reduce the num b er of output c hannels and to allow for spik e generation to p oten tially evolv e. In this diagram example we ha ve 4 dynamic parameters, 3 input channels and 3 output channels. Using a gating structure allo ws us to hav e fine grained control o ver how different input influences the internal memory state (storing ”dynamic parameters”), which in turn con trols ho w that input is pro cessed and how the dynamic parameters are up dated. The input and output of the ENU is a vector, where eac h v alue in the vector can b e considered a type of ”c hannel” used to transmit information b et ween different ENUs. The internal memory state is also a vector, that can store multiple v alues. It enables us to condition the received input on the dynamic parameters stored in the memory state, which control b oth the output and gating b eha viour of the ENU (see figure 2). Eac h gate in the mo del is a standard single la yer artificial neural netw ork with k output units and an evolv able w eight matrix w , where k is equal to the internal memory state size. These gates can pro cess information from the curren t input channels and previous memory state. This allows us for example to evolv e a function that adds some v alue to a dynamic parameter in the memory state, but only if there is a spike at a certain input channel. Evolving such units to p erform complex functions then b ecomes significan tly easier than in standard RNNs, whic h can suffer from v anishing v alues and undesired up dates to their internal memory state [ 27 ]. Protecting up dates to the memory state is esp ecially imp ortan t in our case, since they define the dynamic parameters that determine the b eha viour of our ENU, and should b e able to p ersist o ver their entire lifetime. 5 In tuitively this ENU t yp e arc hitecture allows us for example to ev olv e spik e based b eha viour through storing and summing received input into the memory state. Then once some threshold is reac hed the output gate can ev olv e to activ ate and output a v alue, a ”spik e”. This spike is then fed back into the input allowing the reset and up date gate to evolv e to reset the internal memory state. F or synaptic compartments the internal state could evolv e to memorize when a pre and p ost synaptic spike o ccurs , and also store and up date some dynamic ”weigh t” parameter that can c hange how the input is pro cessed and passed to the p ost-synaptic neuron. Additionally , m ultiple input and output c hannels allow flexibility in ev olving different type of information pro cessing mechanisms, e.g. using a type of neurotransmitter, or even functions analogous to dendritic and axonal transp ort. 3.2 Net w ork of ENUs By combining m ultiple ENUs in a single netw ork we can construct a ENU based Neural Net work (ENU-NN), this netw ork connects multiple neural and synaptic compartment ENU mo dels together as seen in figure 3. All soma and synaptic neuronal com partmen ts share the same ENU gate parameters, and we only ev olve the w eights of these shared gates. This means we hav e tw o ”chromosomes” to ev olve, one for the synapses and one for the neurons, shared across all synapses and neurons. How ev er, they eac h hav e unique internal memory state v ariables which allows for complex signal pro cessing and learning b eha viour to o ccur, as the compartments can evolv e to up date their in ternal states dep ending on the lo cal input they receiv e. Synaptic plasticity (the synaptic weigh ts) in such a mo del would thus no longer b e enco ded in the weigh ts of the net work directly , but could instead evolv e to b e stored and dynamically up dated in the in ternal states of the synapse ENUs as a function of the current and past input. T o ev olve reinforcement t yp e learning b ehaviour in suc h a net work we can construct a sparse recurrent net work with several input sensory neurons that detect e.g. differen t colors in fron t of the agen t (which has an ENU netw ork) in a given environmen t. W e can also designate some ENU neurons as output motor neurons that determine the action the agent should tak e. Additionally , to allo w reward feedback w e can hav e a rew ard neuron that uses different ENU input channels to indicate environmen tal rewards obtained (see Figure 3). The main comp onents of the ENU netw ork are as follows: • Neuron ENUs : Analogous to the biological cell b ody and axon. Resp onsible for transforming the summated input from its connected synapses. Can ev olve to use m ultiple channels to transmit information analogous to e.g. spik es or neurotransmitters. Also propogates it’s output bac kwards to all connected input synapses, this wa y the synapse ENU compartment can p oten tially learn STDP type learning rules based on p ost-synaptic neural b eha viour. • Synapse ENUs : Analogous to the biological dendrite and synapse. T ransforms in- formation from the pre-synaptic to p ost-synaptic ENU neuron, similar to weigh ts in artificial neural netw orks. Ho w ever, it is allow ed to use multiple channels to learn to transmit information analogous to e.g. spikes, graded p oten tial or other types of dendritic transp ort. • In tegration step : Sums up the output per c hannel of eac h incoming synapse connection, whic h is then pro cessed by the p ost-synaptic Neuron ENU. 6 Figure 3: Net w ork of ENUs . Example of evolving reinforcement based learning to solve a T-maze environmen t task. Rew ard from the en vironment determines the fitness of the agent. This reward is also passed to the reward neuron in the ENU Netw ork, whic h connects to the other ENU neurons, allowing them to ev olve to up date their incoming synapse ENUs according to the reward obtained. Several sensory input neurons are used to detect colors in fron t of the agent, and the output neurons determine the action the agen t has to take (forw ard, left or righ t). Eac h ENU is capable of up dating their unique internal dynamic parameters dep ending on the current and past input, which c hanges how information is pro cessed o ver m ultiple channels and compartmen ts within the ov erall ENU netw ork. 4 Metho d 4.1 Ev olution Strategies Since our desired goal is to solv e Reinforcemen t Learning (RL) based en vironmen ts and the task is not directly differentiable, w e cannot use standard Back-propagation through time (BPTT) to optimize our netw ork. W e w ould also like to b e able to learn ov er long time-spans, which mak es BPTT impractical due to v anishing gradient issues. This makes Evolution Strategies (ES) ideally suited [ 37 , 38 , 39 , 40 ], and we use a similar approach taken in previous work [ 31 ]. The gradien t is approximated through random Gaussian sampling across the parameter space, and the w eights are up dated following this approximate gradient direction (see Algorithm 1). W e can also use standard Sto c hastic Gradient Descen t (SGD) metho ds lik e momentum [ 41 ] on the resulting approximate gradients obtained. Due to weigh t sharing we only ha ve to ev olve the gate parameters of tw o ENUs, one for the synapse, and one for the neuron, giving us a relativ ely small parameter space. Fitness Ranking W e use fitness ranking in order to reduce the effect of outliers [ 31 ]. W e can sort and assign rank v alues to each offspring according to their fitness, whic h determines their relative w eight in calculating our appro ximate gradient. W e then get a transformed fitness function F r ( θ i ) = rank ( F ( θ i )) 5 P n i =0 rank ( F ( θ i )) 5 , where rank() assigns a linear ranking from 1.0 to 0.0. This results in around the top 20% b est p erforming agen ts to account for 80% of the gradien t estimate. 7 Algorithm 1 Evolution Strategies Input: base parameters θ k , learning rate α , standard deviation σ for k = 1 to N do Sample offspring mutations i , ..., n from N (0 , I ) Compute fitness F i = F ( θ k + σ i ) for i = 1 , ..., n Calculate approximate gradient G k = P n i =0 F i i Up date base parameters θ k +1 = θ k + αG k end for Batc hing Mini-batc hes were also used to b etter estimate the fitness of the same offspring across multiple en vironments, so the fitness of each offspring was determined b y the mean fitness across m mini-batch environmen ts. 4.2 Gating in an Evolv able Neural Unit The exact equations for the ENU gates and up dating of the memory state are as follo ws: z t = σ ( W z · [ h t − 1 , o t − 1 , x t ]) r t = σ ( W r · [ h t − 1 , o t − 1 , x t ]) e h t = tanh ( W c · [ r t h t − 1 , o t − 1 , x t ]) h t = (1 − z t ) h t − 1 + z t e h t o t = clip (( W o · h t ) , 0 , 1) (1) Where x t is the input, z t the up date gate, r t the reset gate, e h t the cell gate, h t the new memory state and o t the output gate. σ is the sigmoid function, ’ · ’ is matrix multiplication and is elemen t-wise m ultiplication. W ∗ are the weigh t matrices of eac h gate, and the parameters to b e ev olved. W e can also apply clipping (restricting output v alues to b e b et ween 0 and 1), since we use evolution strategies to optimize our parameters and do not require a strict differen tiable activ ation function. This clipping results in a thresholded output and preven ts explo ding v alues. 4.3 Implemen tation Figure 4 sho ws a detailed computation diagram, whic h relies heavily on large scale matrix m ultiplication. W e can reshap e eac h neuron and s ynaptic compartment output to batc hes and p erform standard matrix multiplication to compute the full ENU-NN net w ork in parallel (since our ENU parameters are shared). The connection matrix determines ho w neurons are connected, and in this case can b e either random or hav e a fixed sparse top ology . It determines ho w w e broadcast the output of a neuron to eac h synapse connected to it (Broadcasting ”copies” the output of neurons to different synapses as multiple synapses can b e connected to the same neuron). How ev er, the denser the connection matrix, the more synapses w e hav e and thus the higher our computational cost. ES can be p erformed efficien tly on a Graphical Pro cessing Unit (GPU) through multi- dimensional matrix multiplications, allowing us to ev aluate thousands of mutated net works in parallel. The weigh t matrix in this case is 3 dimensional, and the 3th dimension stores each offspring’s mutated weigh ts. 8 Normal matrix m ultiplication is of the form ( N , K ) x ( K, M ) → ( N , M ), where ( N is the batc h size, K the n umber of inputs units and M the n umber of output units), in the 3D case w e get ( P , N , K ) x ( P , K , M ) → ( P , N , M ), where P is the n umber of offspring. PyT orch [ 42 ] w as used for computing and evolving our ENU-NN, while the rest was implemented mainly in Nump y [43], including custom v ectorized exp erimen tal environmen ts. Figure 4: Computation flo w diagram . The sensory input neurons X are concatenated with all the ENU neurons H to get our input batc h. A connection matrix is then applied that broadcasts (copies) the neurons output to each connected synapse (1). On this resulting matrix we can then apply standard matrix m ultiplication and compute our synapse ENUs output in parallel (2). W e can reshap e this and sum along the first axis, as we hav e the same n umber of synapses for eac h neuron (3). This giv es us the integrated synaptic input to each neuron (4). Finally , w e apply the neuron ENUs on this summated batch and obtain the output for each neuron in the ENU netw ork (5). 4.4 Exp erimen ts First we evolv e an ENU to mimic the b eha viour of a simple Integrate and Fire (IAF) and Spik e Timing Dep enden t Plasticit y (STDP) mo del. W e then comb ine m ultiple neural and synaptic ENUs into a single netw ork, and evolv e reinforcement type learning b eha viour purely through lo cal dynamics. Figure 5: IAF and STDP exp erimen tal setup . F or ev olving the IAF ENU a single random graded p otential is giv en as input, with as goal to mimic the IAF spiking model (left). In case of evolving the STDP rule (right) multiple input channels are used. The graded input p oten tial, the input spik e, the neuromo dulation signal (A-NT1) and the backpr opagating spik e. The target is then to output the mo dified graded input p oten tial matching the STDP rule. 9 Ev olving In tegrate and Fire Neurons (IAF) The ENU receives random uniform noise as graded input p oten tial, and has to mimic the IAF mo del receiving the same input. Once the sum of the input p oten tials reaches a certain threshold, we reset the in ternal state of the IAF and output a spike (See also figure 5). The simplest IAF v arian t with linear summation is give b elo w: I AF ( x, t, h ) = ( 0; h t = h t − 1 + x, if h < th 1; h=0 , if h > = th (2) Where x is the input p oten tial, t the current time, h the membrane p oten tial and th the threshold. Learning spik e like b eha viour can ge nerally b e difficult since the task is not directly differen tiable. Optimizing the mean squared error b et w een the IAF mo del and ENU output directly is infeasible since even a small shift in spikes would cause a decremental effect on the error. How ev er, since we are using Ev olution Strategies we can ha v e more flexible loss functions and optimize the timing and intensit y of each spik e. Therefore, we optimize the Inter-Spik e In terv al (ISI) instead, which allows for incremental fitness improv emen ts and gradually gets eac h spike to b etter matc h the desired timing of the IAF mo del. W e also add an additional term that requires each spike to b e as close as 1 as p ossible (matching the IAF spik e). Ev olving Spik e-timing dep enden t plasticity (STDP) F or ev olving a STDP type learn- ing rule we require multiple input channels for the mo del. The basic equation for the STDP rule is as follows: W ( t ) = ( Ae ( − t τ ) , if t > 0 − Ae ( t τ ) , if t < 0 (3) where A and τ are constan ts that determine the shap e of the STDP function, t is the relative timing difference betw een the pre and p ost synaptic spik e and W is the resulting synaptic w eight v alue. First w e input random uniform noise as graded p otential, we then also generate a random input spik e from the pre-synaptic neuron at some time t i and a random backpropagating spike from the p ost-synaptic neuron at t b . W e also use a neuromo dulated v arian t of the standard STDP rule, whic h is known to play a role in synaptic learning [ 44 , 45 ], and only allows STDP t yp e up dates to o ccur if a given input neurotransmitter is present (See figure 5). In total w e th us hav e 4 input channels, and a single output channel that is the transformed graded input p oten tial m ultiplied by some weigh t v alue w . The weigh t v alue is up dated according to the standard STDP rule which is dep enden t on the timing b et w een the pre and p ost synaptic spike. The fitness is then the mean squared error b et ween the desired STDP mo del output and ENU output. Ev olving Reinforcement Learning in a net w ork of ENUs In order to evolv e reinforce- men t type learning behaviour, w e design an exp erimentally commonly used m aze task [ 46 ] (se e figure 3). The goal of the agent (i.e. the mouse), is to explore the maze and find fo od, once the agent eats the fo o d he will receive a p ositiv e reward and b e reset to the initial starting lo cation. On the other hand, if the fo o d was actually p oisonous he will receiv e a negativ e rew ard (and also b e reset). It is then up to the agent to remember where the fo o d w as and revisit the previous lo cation. After the agent has eaten the non-p oisonous fo o d several times 10 there is a random chance that the fo o d and p oison will b e switched. The agent th us has to ev olve to learn to detect from it’s sensory input whether the fo od is p oisonous or not, and can only kno w this by eating the fo od at least once to receive the asso ciated negativ e or p ositiv e rew ard. The fitness of the agen t is determined by the rew ard obtained in the en vironment, the b etter it is at remembering where fo od is and at av oiding eating p oison, the higher the fitness. W e also add an additional term that decays an agent’s ’energy’ every time step to encourage exploration. Eating fo od refreshes the energy again and gives the agent around 40 time steps to get new fo o d. Once the agent runs out of energy it dies and will no longer be able to mo v e or gather more rewards. T o this end w e provide several inputs to the agent, one that detects the wall of the maze, one that detects green and one that detects red. These inputs are passed to the first channel of the connected synapse ENU. W e also hav e a neuron that provides the resulting reward of eating the fo od or p oison. P ositive rew ards go to the second c hannel, while negative rewards to the third c hannel. F or the output the agent can either go forw ard, left or right or do nothing (if no output neuron activ ates). The ENU netw ork consists of 6 ENU neurons of which 3 are output neurons. Each neuron has 8 ENU synapses that sparsely connect to the other neurons (2 to the sensory neurons, 2 to the hidden neurons, 2 to the output neurons 1 to the reward neuron and 1 to itself ). The neuron that has the highest output activit y ov er 4 time steps determines the action of the agen t (this allows for sufficien t time of sensory input to propagate through the netw ork). The output is tak en from the first channel of the output neuron. W e also add noise to the output gate of the ENU, since all ENUs share the same parameters and we w ant each neuron and synapse to b ehav e slightly different up on initialization. It is imp ortan t to note that eac h generation the agents are reset and hav e no recollection of the past, each time they hav e to relearn whic h sensory neuron has what meaning and which output neuron p erforms what motor command. Also the netw ork input and output neurons get randomly sh uffled each generation, this av oids agents p oten tially exploiting the top ology to learn fixed b ehaviour. W e are thus evolving an ENU net work to perform reinforcemen t t yp e learning b eha viour (evolving to learn), instead of directly learning fixed b eha viour in the synaptic weigh ts. Exp erimen tal Details The exp erimen tal parameters were c hosen through initial exp eri- men tation such that we achiev ed a goo d balance b et ween computation time and p erformance. F or optimization w e used 1024 offspring and Gaussian m utations with standard deviation of 0.01, a learning rate of 1 and momentum of 0 . 9. F or b oth the synaptic and neuronal compartmen ts an ENU with a memory size of 32 units was used, with 16 output units (i.e. 16 output channels). The exp erimen ts were run on a single Titan V GPU with an i7 12-core CPU. In case of the T-maze exp eriment the m ean fitness w as taken across 8 random environmen ts for each offspring. F or evolving the IAF and STDP mo del the mean ov er 32 environmen ts was tak en (allowing us to plot a STDP type curve from multiple observ ations). 1 episo de in the en vironment is 1 generation and each episo de the ENU internal memory states are reset. In case of the IAF and STDP environmen t each episo de lasts for 100 time steps, while for the T-maze exp eriment the episo de lasted for 400 time steps. 11 5 Results Single ENU: Ev olving Integrate and Fire Neurons Results of evolving Integrate and Fire neurons for 3000 generations are shown in figure 6. It can b e seen that the ENU is able to accurately mimic the underlying IAF mo del, prop erly integrating the received graded input, and outputting a spike at the right time. This shows an ENU is capable of evolving to appro ximate spiking b eha viour. Figure 6: Result of ev olving In tegrate and Fire neurons , for a single input example (left) and of m ultiple inputs (right). The evolv ed ENU mo del closely matches the actual IAF mo del, prop erly integrating information and spiking at the right time once a threshold is reac hed. It is also able to correctly pro cess random graded input p oten tials that result in slo wer or faster spiking patterns. Figure 7: Results of evolving neuromo dulated Spik e-Timing-Dep enden t Plasticit y , for a single input example (left) and multiple input observ ations (right). It evolv ed to up date the synaptic weigh t only when the neurotransmitter signal is present in the input, it also ev olved to up date the w eights relative to the timing of the pre and p ost synaptic spik e, matc hing the original STDP function. Single ENU: Evolving Neuromo dulated STDP Figure 7 illustrates the results after ev olving an STDP t yp e learning rule for 10000 generations. If the pre-synaptic spike o ccurs after the p ost-synaptic spike the graded input p oten tial reduces in output intensit y as in the standard STDP rule (and vice versa). This demonstrates an ENU is capable of evolving 12 complex synaptic type learning through memorizing pre and p ost synaptic spik es in its internal memory and by storing and up dating some dynamic parameter that changes how the incoming input is pro cessed (analogous to a synaptic weigh t). It also had to ev olve the multiplication op eration of this dynamic parameter with the input, as initially the ENU has no suc h operation. Net w ork of ENUs: Ev olving Reinforcemen t Learning Results for ev olving Rein- forcemen t Learning b eha viour in a net work of ENUs after 30000 generations in a T-maze en vironment are sho wn in Figure 8. A single generation is one episo de in the en vironment (one sim ulation run) and last for 400 time steps. Each generation all the dynamic parameters of eac h synapse and neuron reset, meaning it alwa ys has to relearn which sensory neuron leads to a negative or p ositiv e rewards and which output neuron p erforms what action, as if it is reb orn (a blank slate). Figure 8: Results of ev olving Reinforcement learning in a net w ork of ENUs , sho wing b oth the output of the agent (top) and input (b ottom). Spik e lik e patterns on the output neuron evolv ed completely indep enden tly , ev en though we did not directly optimize for suc h b eha viour. F urthermore, it can b e seen that the agen t p erforms one-shot learning when eating the p oison, only eating it once and subsequently alwa ys av oiding it. In terestingly we obtain spike lik e patterns on the output neurons even though we nev er strictly enforced it. W e only optimize to maximize the reward in the environmen t. This could partially b e explained by the sensory input neurons outputting spikes as well. Ho wev er, the resulting output is not identical and it still had to evolv e to pro cess those input spikes and in tegrate them prop erly across the netw ork and at the output. An example of the steps taken by the agent are also giv en in figure 9. W e can see that the agen t at first detects red, eats the p oison, and subsequently receives a negative rew ard. After that the agen t learns to go the other wa y to get the fo od instead (detecting green). Once the fo od is switched it detects the p oison but do es not eat it (and so do es not receive a negative rew ard), since it has now learned to turn around and obtain fo o d on the other side instead. 13 Figure 9: Example of the ENU Net work evolv ed b eha viour . It evolv ed to learn to remem b er which fo o d gives a negativ e reward (1), av oid such reward in the future by taking a differen t route (2), and adapt to turn around once the fo o d and p oison are switched (3). The p erformance (and fitness) is measured by how go od the agent is at getting fo od and a voiding p oison. The ENU netw orks of the agen ts with random mutations b etter able to learn and store the right information in the internal memory of eac h individual ENU will th us hav e a higher fitness, able to learn quic ker from negative or p ositiv e rewards. Evolution Strategies then up dates the shared parameters of the ENU gates in that direction. This leads it to improv e its ability to pro cess information in the ENU netw ork and learn from reward feedbac k. It has to evolv e in a wa y such that all ENU compartmen ts with the shared gate parameters can co op erate and up date their unique internal state to achiev e an higher fitness. It th us ev olves a type of univ ersal function the same across all neurons and synapses that up dates their internal dynamic parameters dep ending on the input. The agent is able to learn through the evolv ed ENU net work that the sensory neuron that detects the color red and the activ ation of the output neuron that results in eating it lead to a negative reward. This means that it evolv ed a mec hanism for up dating the ENU synapse b etw een those neurons to hav e an inhibitory effect, suc h that next time it detects red, the previous action that led to eating the p oison is not chosen (it is inhibited), and instead another action is taken. Comparison to other mo dels Standard Deep Neural Netw orks (DNNs) use only a single v alue for the synaptic weigh t parameter (whic h is static) and neuron output. The same holds for spiking neural netw ork mo dels with STDP t yp e learning rules [ 24 ]. The activ ation function and up date rules of these mo dels are also fixed. Similarly , previous meta-learning approaches that learn to learn synaptic up date rules still use the same fundamental underlying design of DNN computations [ 35 , 36 ]. In our case, eac h dynamic parameter is a vector capable of storing multiple v alues that can influence the ”op eration” p erformed by the synaptic and neuronal ENU compartments. W e ev olve the ability of each ENU to up date those dynamic parameters based on the rew ard obtained and lo cal input receiv ed, unlike DNNs that use bac kpropagation ov er the entire netw ork given some learning signal. In order for learning to o ccur in our ENU net work, the synapse ENU has to evolv e the p erformed op eration on the input ov er multiple c hannels, which is not necessarily a multiplication as in standard DNNs. 14 Eac h generation our ”dynamic” parameters also get reset, while in DNNs the parameters of the w eights p ersist. DNNs are th us not learning-to-learn but learn fixed b eha viour instead, only applicable to the current en vironment. Additionally , to learn from reward signals using deep neural netw orks, reinforcement based learning metho ds lik e Deep Q-learning [ 47 ] or Actor-Critic mo dels [ 48 ] are required. In these metho ds how ever the agent requires millions of observ ations to up date the actions to take in that sp ecific environmen t. In our case the final evolv ed mo del is able to p erform one-shot learning from a single exp erience to mo dify it’s b eha viour. This is b ecause a learning rule evolv es that is able to up date the synaptic compartments given the rew ard, which consequen tly enables it to alter the w ay information flows through the synapses and neurons (ov er multiple c hannels). It also implicitly ev olved random exploration like b eha viour to seek out rewards, since this is required to achiev e a higher ov erall fitness. Having m ultiple c hannels allows for more flexibility in learning and information pro cessing b eha viour, and could also explain why biological net works migh t hav e evolv ed to use so many types of different neurotransmitters [49, 50]. 6 Discussion W e show ed that we were able to successfully train the prop osed Evolv able Neural Units (ENUs) to mimic In tegrate and Fire Neurons and Spike-Timing Dep enden t Plasticity . This demonstrated that in principle an ENU is flexible enough to evolv e neural like dynamics and complex pro cessing mec hanisms. W e then ev olve an interconnected net work where each synapse and neuron in the netw ork is such an ev olv able neural unit. This netw ork of ENUs can b e ev olved to solve a T-maze environmen t task, which results in an agent capable of reinforcemen t type learning b eha viour. This en vironment requires the agen t to ev olve the abilit y to learn to remember the color and lo cation of fo o d and p oison dep ending on the rew ard obtained, change its b eha viour to av oid such p oison, and dynamically adapt to c hanges in the environmen t. These neuronal and synaptic ENUs in the netw ork thus hav e to learn to work together co op erativ ely through lo cal dynamics to maximize their o verall fitness and surviv al, dynamically up dating the wa y they integrate and pro cess information. In teresting future directions include simulating and ev olving entire cortical columns by ev olving smaller net works that are robust to changes in net work size, allowing us to scale up the n umber of neurons and synaptic compartments after the evolutionary pro cess. F urthermore, w e could use separate ENUs to evolv e e.g. dendrites, axons or the b eha viour of different cell types seen across cortical lay ers. It is how ever still uncertain what asp ects of biological neural netw orks are actually necessary or just b ypro ducts of evolutionary pro cesses. It also remains an op en question what t yp e of en vironment w ould b e required in order for higher lev el intelligence to emerge, and researc h into op en-ended ev olution and artificial life might therefore b e critical to ac hieve such in telligence. The Evolv able Neural Units presen ted in this pap er offer a new direction for p oten tially more p ow erful and biologically realistic neural net works, and could ultimately not only lead to a greater understanding of neural pro cessing, but also to an artificially intelligen t system that can learn and act across a wide v ariet y of domains. 15 References [1] Demis Hassabis, Dharshan Kumaran, Christopher Summerfield, and Matthew Botvinick. Neuroscience-inspired artificial intelligence. Neur on , 95(2):245–258, 2017. [2] Nelson Spruston. Pyramidal neurons: dendritic structure and synaptic in tegration. Natur e R eviews Neur oscienc e , 9(3):206, 2008. [3] Jo˜ ao Sacramento, Rui P onte Costa, Y osh ua Bengio, and W alter Senn. Dendritic corti- cal microcircuits approximate the backpropagation algorithm. In A dvanc es in Neur al Information Pr o c essing Systems , pages 8721–8732, 2018. [4] Larry F Abb ott and Sac ha B Nelson. Synaptic plasticity: taming the b east. Natur e neur oscienc e , 3(11s):1178, 2000. [5] Christoph B¨ orgers and Nancy Kop ell. Synchronization in netw orks of excitatory and inhibitory neurons with sparse, random connectivit y . Neur al c omputation , 15(3):509–538, 2003. [6] Juergen F ell and Nikolai Axmacher. The role of phase synchronization in memory pro cesses. Natur e r eviews neur oscienc e , 12(2):105, 2011. [7] Larry F Abb ott. Lapicques introduction of the integrate-and-fire mo del neuron (1907). Br ain r ese ar ch bul letin , 50(5-6):303–304, 1999. [8] Anil K Jain, Jianchang Mao, and K Moidin Mohiuddin. Artificial neural netw orks: A tutorial. Computer , 29(3):31–44, 1996. [9] Y ann LeCun, Y osh ua Bengio, and Geoffrey Hin ton. Deep learning. natur e , 521(7553):436– 444, 2015. [10] William A Catterall. Structure and function of v oltage-gated ion channels. Annual r eview of bio chemistry , 64(1):493–531, 1995. [11] Shelly B Flagel, Jeremy J Clark, T erry E Robinson, Leah Ma yo, Ala yna Czuj, Ingo Willuhn, Christina A Ak ers, Sarah M Clinton, P aul EM Phillips, and Huda Akil. A selectiv e role for dopamine in stim ulus–reward learning. Natur e , 469(7328):53, 2011. [12] D A VID A McCormick. Gaba as an inhibitory neurotransmitter in human cerebral cortex. Journal of neur ophysiolo gy , 62(5):1018–1027, 1989. [13] Irwin B Levitan and Leonard K Kaczmarek. The neur on: c el l and mole cular biolo gy . Oxford Universit y Press, USA, 2015. [14] Maik en Nedergaard, T ak ahiro T ak ano, and Anker J Hansen. Beyond the role of glutamate as a neurotransmitter. Natur e R eviews Neur oscienc e , 3(9):748, 2002. [15] V ernon B Mountcastle. The columnar organization of the neo cortex. Br ain: a journal of neur olo gy , 120(4):701–722, 1997. [16] Ronald D V ale. The molecular motor to olb o x for intracellular transp ort. Cel l , 112(4):467– 480, 2003. 16 [17] Sabine Hilfiker, Vincent A Pierib one, Andrew J Czernik, Hung-T eh Kao, George J Augustine, and Paul Greengard. Synapsins as regulators of neurotransmitter release. Philosophic al T r ansactions of the R oyal So ciety of L ondon. Series B: Biolo gic al Scienc es , 354(1381):269–279, 1999. [18] P eter J Hollen b ec k and William M Saxton. The axonal transport of mito c hondria. Journal of c el l scienc e , 118(23):5411–5419, 2005. [19] Graham L Collingridge, John TR Isaac, and Y u Tian W ang. Receptor trafficking and synaptic plasticity . Natur e R eviews Neur oscienc e , 5(12):952, 2004. [20] Adam Kep ecs, Xiao-Jing W ang, and John Lisman. Bursting neurons signal input slop e. Journal of Neur oscienc e , 22(20):9053–9062, 2002. [21] Adam Kep ecs and John Lisman. Information encoding and computation with spik es and bursts. Network: Computation in neur al systems , 14(1):103–118, 2003. [22] Alan L Ho dgkin and Andrew F Huxley . A quantitativ e description of membrane current and its application to conduction and excitation in nerve. The Journal of physiolo gy , 117(4):500–544, 1952. [23] Donald Olding Hebb and DO Hebb. The or ganization of b ehavior , v olume 65. Wiley New Y ork, 1949. [24] W olfgang Maass. Net works of spiking neurons: the third generation of neural netw ork mo dels. Neur al networks , 10(9):1659–1671, 1997. [25] Guillaume Bellec, Darjan Sala j, Anand Subramoney , Rob ert Legenstein, and W olfgang Maass. Long short-term memory and learning-to-learn in netw orks of spiking neurons. In A dvanc es in Neur al Information Pr o c essing Systems , pages 787–797, 2018. [26] Kurt Hornik. Appro ximation capabilities of m ultilay er feedforward netw orks. Neur al networks , 4(2):251–257, 1991. [27] Sepp Ho c hreiter and J ¨ urgen Sc hmidhuber. Long short-term memory . Neur al c omputation , 9(8):1735–1780, 1997. [28] Kyungh yun Cho, Bart V an Merri ¨ en b o er, Caglar Gulcehre, Dzmitry Bahdanau, F ethi Bougares, Holger Sch w enk, and Y oshua Bengio. Learning phrase representations using rnn enco der-decoder for statistical machine translation. arXiv pr eprint arXiv:1406.1078 , 2014. [29] Thomas Bac k. Evolutionary algorithms in the ory and pr actic e: evolution str ate gies, evolutionary pr o gr amming, genetic algorithms . Oxford universit y press, 1996. [30] Kenneth O Stanley , Jeff Clune, Jo el Lehman, and Risto Miikkulainen. Designing neural net works through neuro ev olution. Natur e Machine Intel ligenc e , 1(1):24–35, 2019. [31] Tim Salimans, Jonathan Ho, Xi Chen, Szymon Sidor, and Ily a Sutsk ever. Evolution strate- gies as a scalable alternative to reinforcement learning. arXiv pr eprint arXiv:1703.03864 , 2017. 17 [32] J ¨ urgen Sc hmidhuber. Evolutionary principles in self-r efer ential le arning, or on le arning how to le arn: the meta-meta-... ho ok . PhD thesis, T ec hnische Universit¨ at M ¨ unc hen, 1987. [33] Sam y Bengio, Y oshua Bengio, Jo celyn Cloutier, and Jan Gecsei. On the optimization of a synaptic learning rule. In Pr eprints Conf. Optimality in A rtificial and Biolo gic al Neur al Networks , pages 6–8. Univ. of T exas, 1992. [34] J ¨ urgen Sc hmidhuber. Learning to con trol fast-w eigh t memories: An alternative to dynamic recurren t netw orks. Neur al Computation , 4(1):131–139, 1992. [35] Marcin Andrycho wicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, T om Sc haul, Brendan Shillingford, and Nando De F reitas. Learning to learn by gradient descen t b y gradient descen t. In A dvanc es in neur al information pr o c essing systems , pages 3981–3989, 2016. [36] Da vid Ha, Andrew Dai, and Quo c V Le. Hyp ernet works. arXiv pr eprint arXiv:1609.09106 , 2016. [37] Thomas Bac k, F rank Hoffmeister, and Hans-P aul Sc hw efel. A surv ey of ev olution strategies. In Pr o c e e dings of the fourth international c onfer enc e on genetic algorithms , volume 2. Morgan Kaufmann Publishers San Mateo, CA, 1991. [38] Hans-Georg Beyer and Hans-Paul Sch w efel. Ev olution strategies–a comprehensive in tro- duction. Natur al c omputing , 1(1):3–52, 2002. [39] Daan Wierstra, T om Schaul, T obias Glasmac hers, Yi Sun, Jan Peters, and J ¨ urgen Sc hmidhuber. Natural ev olution strategies. The Journal of Machine L e arning R ese ar ch , 15(1):949–980, 2014. [40] Jo el Lehman, Ja y Chen, Jeff Clune, and Kenneth O Stanley . Es is more than just a traditional finite-difference approximator. In Pr o c e e dings of the Genetic and Evolutionary Computation Confer enc e , pages 450–457. ACM, 2018. [41] Ily a Sutskev er, James Martens, George Dahl, and Geoffrey Hinton. On the imp ortance of initialization and momentum in deep learning. In International c onfer enc e on machine le arning , pages 1139–1147, 2013. [42] Adam Paszk e, Sam Gross, Soumith Chin tala, Gregory Chanan, Edw ard Y ang, Zac hary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differen tiation in pytorc h. 2017. [43] T ra vis E Oliphant. A guide to NumPy , volume 1. T relgol Publishing USA, 2006. [44] V erena P awlak, Jeffery R Wick ens, Alfredo Kirkw o o d, and Jason ND Kerr. Timing is not everything: neuromo dulation op ens the stdp gate. F r ontiers in synaptic neur oscienc e , 2:146, 2010. [45] Nicolas F r´ emaux and W ulfram Gerstner. Neuromo dulated spike-timing-dependent plas- ticit y , and theory of three-factor learning rules. F r ontiers in neur al cir cuits , 9:85, 2016. [46] Rob ert MJ Deacon and J Nicholas P Rawlins. T-maze alternation in the ro dent. Natur e pr oto c ols , 1(1):7, 2006. 18 [47] V olo dym yr Mnih, Koray Kavuk cuoglu, David Silver, Andrei A Rusu, Jo el V eness, Marc G Bellemare, Alex Gra ves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostro vski, et al. Human-lev el control through deep reinforcemen t learning. Natur e , 518(7540):529, 2015. [48] V olo dym yr Mnih, Adria Puigdomenec h Badia, Mehdi Mirza, Alex Gra ves, Timoth y Lillicrap, Tim Harley , Da vid Silv er, and Koray Ka vukcuoglu. Asynchronous metho ds for dee p reinforcemen t learning. In International c onfer enc e on machine le arning , pages 1928–1937, 2016. [49] Jean M Lauder. Neurotransmitters as gro wth regulatory signals: role of receptors and second messengers. T r ends in neur oscienc es , 16(6):233–240, 1993. [50] Kenji Doy a. Metalearning and neuromo dulation. Neur al Networks , 15(4-6):495–506, 2002. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment