Learned Video Compression via Joint Spatial-Temporal Correlation Exploration
Traditional video compression technologies have been developed over decades in pursuit of higher coding efficiency. Efficient temporal information representation plays a key role in video coding. Thus, in this paper, we propose to exploit the tempora…
Authors: Haojie Liu, Han shen, Lichao Huang
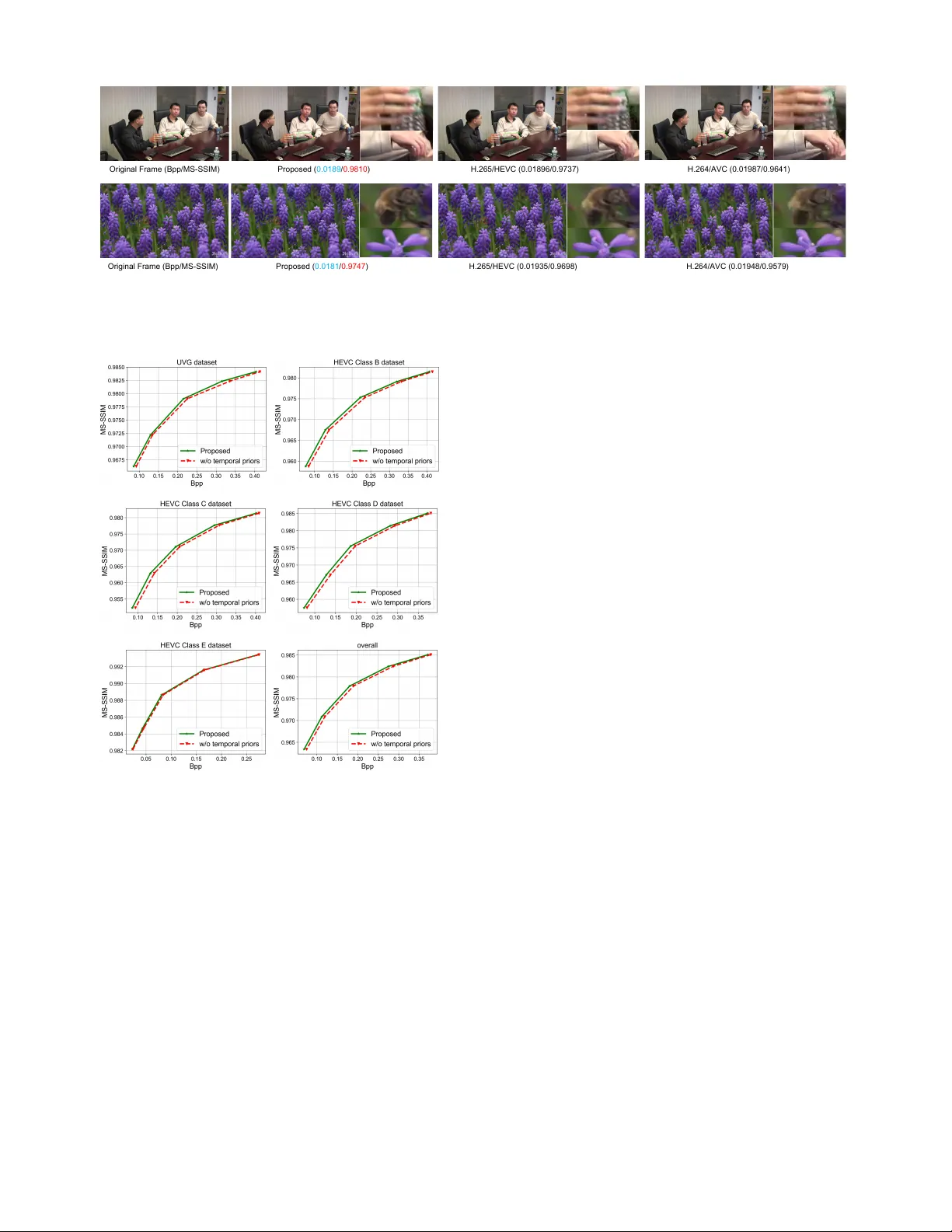
Learned V ideo Compr ession via Joint Spatial-T emporal Corr elation Exploration Haojie Liu 1 , Han Shen 2 , Lichao Huang 2 , Ming Lu 1 , T ong Chen 1 , Zhan Ma 1 ∗ 1 Nanjing Univ ersity , 2 Horizon Robotics { haojie, luming, tong } @smail.nju.edu.cn, { han.shen, lichao.huang } @horizon.ai, mazhan@nju.edu.cn Abstract T raditional video compression technologies ha ve been dev el- oped over decades in pursuit of higher coding ef ficienc y . Ef- ficient temporal information representation plays a key role in video coding. Thus, in this paper , we propose to exploit the temporal correlation using both first-order optical flow and second-order flow prediction. W e suggest an one-stage learning approach to encapsulate flow as quantized features from consecuti ve frames which is then entropy coded with adaptiv e contexts conditioned on joint spatial-temporal priors to exploit second-order correlations. Joint priors are embed- ded in autore gressiv e spatial neighbors, co-located hyper ele- ments and temporal neighbors using Con vLSTM recurrently . W e e v aluate our approach for the low-delay scenario with High-Efficienc y V ideo Coding (H.265/HEVC), H.264/A VC and another learned video compression method, following the common test settings. Our work offers the state-of-the- art performance, with consistent gains across all popular test sequences. Introduction V ideo content occupied more than 70% Internet traffic, and it became a big challenge for transmission and stor- age along its explosi v e growth. Researchers, engineers, etc, continuously pursue the (next-generation) high-ef ficienc y video compression for wider application enabling and larger market adoption. Con ventional video compression ap- proaches usually follo w the hybrid coding framew ork over decades (Sulli v an and Wie gand 2005) with hand-crafted tools for individual components. It is not efficient to jointly optimize the system in an end-to-end manner , especially for the inter tool efficiency exploration despite its great success of H.264/A VC (W ie gand et al. 2003) and H.265/HEVC (Sul- liv an et al. 2012). Recently , image compression algorithms (Ball ´ e, Laparra, and Simoncelli 2016; Li et al. 2017; Ball ´ e et al. 2018; Mentzer et al. 2018; Liu et al. 2019) based on machine learning have shown great superiority in coding efficiency for spatial r edundancy remov al, compared with con ven- ∗ Zhan Ma is the corresponding author . Copyright c 2020, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserved. Fir s t - orde r M ot i on Re pre s e nt a t i on Co ns e c ut i v e Fra m e s Co ns e c ut i v e Fra m e s S e c ond - orde r M ot i on Re pre s e nt a t i on Figure 1: T emporal correlation exploration using both first-order and second-order motion repr esentation. Frame-to-frame redundancies can be easily removed by ac- curate flow estimation and compensation (e.g., first-order); Then flow-to-flo w correlation can be further eliminated or reduced using predictions from joint spatial-temporal priors (e.g., second-order). tional codecs. These methods benefit from non-linear trans- forms, deep neural network (DNN) based conditional en- tropy model, and joint rate-distortion optimization (RDO), under an end-to-end learning strategy . Learned video com- pression can be extended from image compression by fur- ther exploiting the temporal redundancy or corr elation . W e proposed an end-to-end video compression framework using joint spatial-temporal priors to generate compact latent fea- ture representations for intra texture, inter motion and sparse inter residual signals. Intra textures are well represented by spatial priors for both reconstruction and entropy context modeling using a v ariational autoencoder (V AE) structure (Minnen, Ball ´ e, and T oderici 2018; Liu et al. 2019). W e directly use NLAIC method proposed in (Liu et al. 2019) for our intra te xture compression because of its state-of-the- art efficiency , and primarily in vestig ate learned inter coding with the focus on efficient temporal motion representation in this paper . W e represent temporal information or correlation using its both first-order and second-order statistics. The first-order temporal information is referred to as the motion fields (e.g., intensity , orientation) between consecutiv e frames. Motion fields can be described by either optical flo w or block-based motion vectors. Here, we suggest an one-stage unsupervised flow learning approach, where first-order motions are quan- tized temporal features learned from the consecutiv e frames directly . Our unsupervised flo w learning does not rely on a well pre-trained optical flow estimation network, such as FlowNet2 (Ilg et al. 2017; Sun et al. 2018), and can de- riv e the compressed optical flow from quantized features di- rectly . The second-order temporal information is flo w-to-flo w correlations, describing the object acceleration. Flo w can be further predicted for energy reduction. Thus, we fuse priors from spatial, temporal and h yper information to predict flow elements and compress the predictiv e difference. It turns out that this can be realized by entropy coding with adaptiv e contexts conditioned on fused priors. Inter residual is deriv ed between original frame and flow warped prediction. W e reuse the intra texture coding net- work here directly for residual coding. It is worth to point out that V AE structures are applied for all components (e.g., intra, inter , residual) in this paper . Contributions. 1) W e propose an end-to-end video compression method which offers the state-of-the-art performance against tradi- tional video codecs and recent learned approaches with con- sistent gains across a v ariety of common test sequences; 2) High-efficient inter coding is achieved by representing temporal correlation using both first-order optical flow and second-order flow predicti ve difference; 3) First-order flow is offered using an one-stage unsuper- vised learning and represented by quantized features deriv ed from consecutiv e frames; 4) Second-order flo w predicti v e dif ference compression is ef ficiently solved by entropy coding with adapti ve con- texts conditioned on fused priors (e.g., autoregressi v e spatial priors, hyperpriors, and temporal priors propagated using a Con vLSTM (Xingjian et al. 2015)). Related W ork Learned Image Compr ession DNN based image compression approaches generally rely on autoencoders. (T oderici et al. 2016) first proposed to use recurrent autoencoders to progressi vely encode bits for image compression. Recent years, con v olutional autoen- coders are studied extensiv ely , including non-linear trans- forms (e.g., generalized di visi ve normalization (Ball ´ e, La- parra, and Simoncelli 2016) and non-local attention trans- forms (NLAIC) (Liu et al. 2019)), differentiable quantiza- tion (e.g., soft-to-hard quantization (Mentzer et al. 2018) and uniform noise approximation (Ball ´ e, Laparra, and Simon- celli 2016)), and adapti ve entropy model using the Bayesian generativ e rules (e.g., PixelCNNs (Oord, Kalchbrenner , and Kavukcuoglu 2016) and variational autoencoders (Ball ´ e et al. 2018)). RDO (Sullivan and W ieg and 1998) is applied by minimizing Lagrangian cost J = R + λD , in end-to-end training. Here, R is referred to as entropy rate, and D is the distortion measured by either mean squared error (MSE) or multiscale structural similarity (MS-SSIM). These approaches demonstrated better coding efficienc y against traditional image coders, both objectively and sub- jectiv ely . In addition, extreme compression are under ex- ploration with adversarial training (e.g., conditional GANs (Agustsson et al. 2018), multi-scale discriminators (Rippel and Bourde v 2017) for satisfied subjecti v e quality at very low bit rates. Learned V ideo Compression Learned video compression (Djelouah et al. 2019; Habibian et al. 2019) is a relatively new area. (Chen et al. 2017) first proposed the DeepCoder where DNNs were used for intra texture and inter residual, and block motions were applied using traditional motion estimation for temporal informa- tion representation. Inspired by temporal interpolation and prediction (Niklaus, Mai, and Liu 2017; Niklaus and Liu 2018; Huang, W ang, and W ang 2015), (W u, Singhal, and Kr ¨ ahenb ¨ uhl 2018) introduced a RNN based video compres- sion framew ork through frame interpolation, of fering com- parable performance with H.264/A VC. Howe v er , interpola- tion typically brings structural delay . Recently , unsupervised flow estimation methods (Jason, Harle y , and Derpanis 2016; Meister , Hur , and Roth 2018) are introduced to utilize end- to-end learning for predicting optical flow between two frames without lev eraging groundtruth flow . The proposed brightness constancy , motion smoothness and bidirectional census loss are proven to be ef ficient for flow generation. Robust and reliable optical flo w deriv ation methods are emerged, such as FlowNet2 (Ilg et al. 2017) and PWC- Net (Sun et al. 2018). Flo wNet2 stacks multiple simple flownet and applies small displacements to correct flow . PWC-Net extends traditional p yramid flow reconstructed rules to learn and generate precise flow f aster . (Lu et al. 2019) replaced the block based motion estima- tion with a pre-trained FlowNet2 follo wed by a cascaded autoencoder for flow compression. U-Net alik e processing network was used to enhance the quality of predicted frame. In addition, the y directly used models in (Ball ´ e et al. 2018) for their intra and residual coding. The entire framework is so called D VC. D VC outperformed H.265/HEVC mainly at high bit rates b ut the coding ef ficiency dropped unexpectly at low bit rates as reported. All these attempts in learned video compression were try- ing to represent the temporal information more efficiently . Proposed Method Framework Over view Fig. 2 sk etches our learned video compression. Gi v en a group of pictures (GOP) X = { X 1 , X 2 , ..., X t } , we first encode X 1 using NLAIC-based intra coding in (Liu et al. 2019), having reconstructed frame as ˆ X 1 . For X 2 , we first learn the first-order flow for the predicted frame ˆ X p 2 using ˆ X 1 . Corresponding r 2 = X 2 − ˆ X p 2 is en- coded using residual coding sharing the same architecture as R e si d u a l Cod ing - + B it st r e a m t r I n t e r C o d i n g I n t r a Co d i n g Or ig i n a l F r a m e s R e co n st r u ct e d F r a m e s P r e d icte d F r a m e s Figure 2: Lear ned V ideo Compression. Intra & residual coding using NLAIC in (Liu et al. 2019), and inter coding by exploring one-stage unsupervised flo w learning, and quan- tized flow feature encoding using context adaptive entropy models. NLAIC-based intra coding, and reconstructed as ˆ r 2 . First- order flow is represented using quantized features that are entropy-coded with adaptive contexts conditioned on priors, by e xploiting the second-order temporal correlation. Final reconstruction ˆ X 2 is gi ven by ˆ X 2 = ˆ X p 2 + ˆ r 2 . Subsequent frames follow the same process as of X 2 . Adaptiv e entropy models for rate estimation and arith- metic encoding are embedded for intra, inter and residual components. Thanks to the V AE structures, intra and resid- ual coding use the joint autoregressi ve spatial and hyper pri- ors for the probability estimation; and inter coding applies priors from spatial, hyper and temporal information. Intra Coding W e directly apply the NLAIC approach in (Liu et al. 2019) for our intra coding. Its state-of-the-art coding efficienc y in image compression comes from the introduction of non- local attention transform that are embedded in both main and hyper encoder-decoder network in Fig. 3. Note that the main network is used to obtain the reconstructed frame and the hyperprior netw ork is used for conte xt modeling of adapti ve entropy coding. In NLAIC method, non-local attention modules (NLAM) are embedded to capture joint local and global correlations for both reconstruction and context probability modeling, by inheriting the advantages from both nonlocal processing and attention mechanism. NLAM applies joint spatial-channel attention masks for more compact feature representation. And, masked 3D con v olutions are used to fuse hyperpriors and autoregressiv e priors for accurate context estimation of adaptiv e entropy coding, ( µ i , σ i ) = F ( ˆ x 1 , ..., ˆ x i − 1 , ˆ z t ) . (1) F represents cascaded 3D 1 × 1 × 1 conv olutions to fuse the priors. ˆ x 1 , ˆ x 2 , ..., ˆ x i − 1 denote the causal (and possibly for- mer reconstructed) pixels prior to current pixel ˆ x i obtained by a 3D 5 × 5 × 5 masked con v olution and ˆ z t are the hyper- priors. Probability of each pix el symbol in ˆ x t can be simply N o n - l o ca l A t t e n t i o n T r a n sfo r m N o n - lo ca l A t t e n t io n T r a n sfo r m N o n - lo ca l A t t e n t io n T r a n sfo r m N o n - l o ca l A tt e n tio n T r a n sfo r m Q Q AD AE AE AD E n tr o p y M o d e l M a i n Ne t wo r k Hyp e r p r io r Ne t wo r k O u t p u t I n p u t Figure 3: NLAIC-based Intra Coding . A V AE architecture with non-local attention transforms embedded. “ AE” repre- sents the arithmetic encoding to encode the quantized fea- tures with corresponding probability distribution, “ AD” re- verts binary strings to feature elements and “Q” is for quan- tization. deriv ed using p ˆ x t | ˆ z t ( ˆ x t | ˆ z t ) = Y i ( N ( µ i , σ 2 i ) ∗ U ( − 1 2 , 1 2 ))( ˆ x i ) , (2) with a Gaussian distrib ution assumption with mean ( µ ) and variance ( σ ). Inter Coding V ideo coding performance heavily relies on the efficient temporal information representation. It has two folds. One needs to hav e the most accurate first-order flo w for compen- sation, and the other is to de vise second-order statistics for flow prediction. One-stage Unsupervised Flow Learning Previous work in (Lu et al. 2019) obtained decoded optical flo w using typi- cal two-stage methods sho wn in Fig. 4(a). It relied on a well pre-trained flow network to generate an uncompressed opti- cal flow that was then compressed using a cascaded autoen- coder . But, in our work, we lev erage the quantized features between consecutive frames as compact motion representa- tions and directly decode the compressed features for sub- sequent compensation. There is no need to e xplicitly derive raw and uncompressed flow in encoding process with su- pervised guidance as in Flo wNet2 and PWC-Net. Thus, it is an one-stage unsupervised flow learning and compensation approach in Fig. 4(b). W e concatenated two consecutiv e frames as the input for feature fusion, and the network is consisted of stacked NLAM 1 and downsampling (e.g., 5 × 5 con v olutions with stride 2), generating the fused features with ( H / 16) × 1 Nonlocal attention is used to capture local and global correla- tions. Ob ta i n e d F l o w P r e d i cte d F r a m e C o m p r e sse d F l o w S t a g e O n e S t a g e T wo F l o w N e t 2 F l o w C o d i n g W a r p i n g (a) D e co d e r Q C o m p r e sse d F lo w S t a g e O n e P r e d i cte d F r a m e W a r p i n g F e a t u re F u si o n Qu a n tize d F e a tu r e (b) Figure 4: Flow Learning and Compensation. (a) T wo-stage supervised approach using a pre-trained flow net (with explicit raw flow) and a cascaded flo w compression autoencoder; (b) One-stage unsupervised approach with implicit flow represented by quantized features that will be directly decoded for compensation. ( W / 16) × 64 dimension. Quantization is then applied to obtain the quantized features F for entropy coding. The decoder mirrors the stacked NLAM with upsampling (e.g., 5 × 5 decon v olutions with stride 2) in the feature fusion network, and derived the decoded flow ˆ f d t (at a size of H × W × 2 for separable horizontal and vertical orienta- tions) for compensation. Here, H, W denotes the height and width of the original frame, respectiv ely . T o avoid quantization induced motion noise,we first pre- train the network with uncompressed consecutiv e frames X t − 1 and X t . Then we replace X t − 1 using its decoded cor- respondence ˆ X t − 1 as described in Eq. (3) and (4). Note that we only hav e ˆ X t − 1 not X t − 1 for inter coding in practice. And we ha ve directly utilized the decoded flow ˆ f d t for end- to-end training and do not need a flow e xplicitly at encoding (i.e., implicitly represented by quantized features). A compressed flow representation of ˆ f d t , i.e., quantized features F , is encoded into the bitstream for deliv ery . ˆ f d t is then used for warping with reference frame to ha ve ˆ X p t for compensation, i.e., ˆ f d t = F d ( F e ( ˆ X t − 1 , X t )) , (3) ˆ X p t = warping ( ˆ X t − 1 , ˆ f d t ) , (4) Here F e and F d represent the feature fusion network with quantization and decoder network, respectively . Note that F = F e ( ˆ X t − 1 , X t ) . Context Adaptiv e Flow Compression Pre vious section introduced one-stage unsupervised flow learning targeting for the accurate first-order motion representation for com- pensation, where flow is represented implicitly using quan- tized features F . Ef ficient representation of F is highly de- sirable Generally , as shown in Fig. 1, there is not only the first- order correlation (frame-to-frame) that can be exploited by the flo w , but also the second-order correlation both spatially and temporally . A way to predict flow efficiently could lead to much better compression performance. Ideally , flow ele- ment can be estimated by its spatial neighbors, temporal co- located element, and hyper priors for energy compaction. A duality problem for such flo w prediction using neighbors, is flow element entrop y coding using adapti ve conte xts. Adaptiv e context modeling can lev erage priors from spa- tial autoregressiv e neighbors, temporal and hyper informa- tion, sho wn in Fig. 5. For spatial autoregressi v e prior , we propose to apply the 3D masked con volutions on quantized features F ; while for hyper priors, hyper decoder is used to decode corresponding information. Hyperpriors are widely used in V AE structured compression approaches. Note that, temporal correlations are exhibited in video sequence. In- stead of applying the only pixel domain frame b uffer in traditional video codecs, we propose to embed and propa- gate flo w representation at a frame recurrent way using the Con vLSTM, which is also referred to as the temporal prior buf fer . T emporal priors hav e the same dimension as the cur- rent quantized features F . These priors are fused together for context adaptive flow coding, i.e., ( µ F , σ F ) = F ( F 1 , ..., F i − 1 , ˆ z t , h t − 1 ) , (5) p F | ( F 1 ,..., F i − 1 , ˆ z t , h t − 1 ) ( F i | F 1 , ..., F i − 1 , ˆ z t , h t − 1 ) = Y i ( N ( µ F , σ 2 F ) ∗ U ( − 1 2 , 1 2 ))( F i ) . (6) Aut oreg res s iv e Priors T em poral Prio rs Qua nt iz ed F eat ures H y p er P riors F e a tu r e F u s i o n U pda t ed Priors 3 D M as k ed C on v C onv LST M H y p er D ec ode r Figure 5: Adaptive Contexts Using Fused Priors. Spatial autoregressi v e priors are applied using 3D masked con v olu- tions, temporal priors are propagated using con vLSTM, and hyperpriors are hyper decoder in a V AE setup. All priors are then fused together for probability modeling. Note that con- texts update at a frame recurrent fashion. F i , i = 0 , 1 , 2 , ... are elements of quantized features for im- plicit flow ˆ f d t representation, h t − 1 is aggregated temporal priors from pre vious flow representations, which is updated using standard Con vLSTM: ( h t , c t ) = ConvLSTM( F t , h t − 1 , c t − 1 ) , (7) where h t , c t are updated state at t and prepared for the next time step slot with c t − 1 as a memory gate. Residual Coding For the sake of simplicity , we encode the residual signals r t using the identical netw orks as the NLAIC-based intra coding. r t is obtained by r t = X t − X p t . Here, we do not calculate the loss between r t and ˆ r t but directly target for ov erall reconstruction loss D ( X t , X p t + ˆ r t ) for optimizing the residual coding. Experimental Studies W e proceed to the details about training strategy and e v alua- tion in this section. More ablation studies are gi v en to verify the effecti veness of our work. Implementation Details T raining & T esting Datasets. W e choose COCO (Lin et al. 2014) dataset to pre-train NLAIC-based intra coding net- work. And then we joint train video compression frame- work on V imeo 90k (Xue et al. 2019) which is a widely used dataset for lo w-le vel video processing tasks. All images from these the datasets are randomly cropped into 192 × 192 patches for training. W e gav e ev aluations on NLAIC using K odak dataset in ablation studies to understand the efficiency of nonlocal at- tention transforms. W e then e v aluated our video compres- sion approaches on standard HEVC dataset and ultra video Figure 6: Rate-Distortion P erf ormance Comparison. Ex- periments are performance for HEVC comment test classes and UVG videos for a v ariety of content distributions. Our method gains consistently across all test videos. group (UVG) dataset with different classes, resolution and frame rate. Loss Function & T raining Strategy . It is difficult to train multiple networks on-the-fly at one shot. Thus, we pre-train the intra coding and flo w learning and coding netw orks first, followed by the jointly training with pre-trained network models for an ov erall optimization, i.e., L = λ 1 n n X t =0 D 1 ( ˆ X t , X t ) + λ 2 n n X t =0 D 2 ( ˆ X p t , X t ) + R s + 1 n − 1 n X t =1 R t , (8) where D 1 is measured using MS-SSIM, and D 2 is the warp- ing loss e v aluated using L 1 norm and total variation loss. R s represents the bit rate of intra frame and R t is the bit rate of inter frames including bits for residual and flow respecti vely . Currently , λ 1 and λ 2 will be adapted according to the spec- ified ov erall bit rate and bit consumption percentage of flow information in inter coding. Besides, entrop y rate loss R is approximated by condi- tional probability p using Eq. (9), with main payload for context adaptiv e feature elements, and payload ov erhead for image height ( H ), width ( W ), number of frames ( N ) and GOP length ( n ), e.g., R = − X i log 2 ( p ) + ov erhead. (9) Note that bit consumption for “overhead” is less than 0.1% of the entire compressed bitstream, according to our exten- siv e simulations. T o well balance the efficiency of temporal information learning and training memory consumption, we have en- rolled 5 frames to train the video compression frame work and shared the weights for the subsequent frames. The ini- tial learning rate (LR) is set to 10e-4 and is clipped by half for e very 10 epochs. The final models are obtained using a LR of 10e-5. W e apply the distributed training on 4 GPUs (T itan Xp) for 5 days. Evaluation Criteria. For fair comparison, we have ap- plied the same setting as D VC in (Lu et al. 2019) for our method and traditional H.264/A VC, and HEVC codecs. W e use GOP of 10 and encode 100 frames on HEVC test se- quences and use GOP of 12 with 600 frames on UVG dataset. The reconstructed quality are measured in RGB do- main using MS-SSIM. Bits per pix el (Bpp) is used for bit rate measure which can be easily translated to the kbps by scaling it with H × W × n/τ . τ is the video duration in seconds. Perf ormance Comparison Rate distortion P erf ormance. Our approach outperforms all the existing methods as shown in Fig.6. Here, the distor- tion is measured by MS-SSIM which is prov en to be a more relev ant to human visual system, and used widely in learned compression methodologies (Minnen, Ball ´ e, and T oderici 2018). T o the best of our kno wledge, our work is the first end- to-end method that outperforms H.265/HEVC consistently across a v ariety of bit rates for all test sequences. In con- trast, algorithm in (W u, Singhal, and Kr ¨ ahenb ¨ uhl 2018) only presents a similar performance as H.264/A VC. D VC (Lu et al. 2019) impro ves (W u, Singhal, and Kr ¨ ahenb ¨ uhl 2018) with better coding efficienc y against HEVC at high bit rates. Howe ver , a clif f fall of performance is revealed for D VC at low bit rate (e.g., some rates ha ving performance ev en worse than H.264/A VC). W e have also observed that D VC’ s perfor - mance varies for different test sequences. But, our approach shows consistent gains, across contents and bit rates, leading to the conclusion that our model presents better generaliza- tion for practical applications. W e use H.264/A VC as the anchor for BD-Rate calcu- lation as sho wn in T able 1. Our approach reports 50.36% and 51.67% BD-rate reduction on HEVC test sequences and UVG dataset compared with H.264/A VC, respecti vely , offering a significant performance improvement margin in contrast to the HEVC or D VC o ver the H.264/A VC. V isual Comparison W e provide the visual quality com- parison with H.264/A VC and H.265/HEVC as sho wn in Fig. 8. T raditional codecs usually suf fer from blocky artif acts, es- pecially at lo w bit rate, because of its block based coding strategy . Our results eliminate this phenomenon and pro vide Figure 7: Efficiency of NLAM. NLAM is used in non- local attention transforms for intra & residual coding. Per- formance is reduced by removing NLAM, but still close to the work in (Minnen, Ball ´ e, and T oderici 2018). T able 1: BD-Rate Gain of Our Method, HEVC and D VC against the H.264/A VC Sequences H.265/HEVC D VC Ours ClassB -28.31% -29.09% -54.17% ClassC -20.50% -28.11% -39.17% ClassD -8.89% -27.35% -44.84% ClassE -29.52% -33.91% -63.28% A verage -21.73% -29.73% -50.36% UVG dataset -37.25% -28.28% -51.67% more visually satisfying quality of reconstructed frames. Meanwhile, we need less bits for similar visual quality . Ablation Study Non-local Attention T ransforms. Most e xisting image compressions apply Generalized Di visi v e Normalization (GDN) as non-linear transform to de-correlate spatial- channel redundancy (Minnen, Ball ´ e, and T oderici 2018; Ball ´ e 2018). Alternativ e non-local attention transform uti- lizes NLAM to capture both local and global correlations, leading to the state-of-the-art efficiency as reported in (Liu et al. 2019). Algorithms in (Minnen, Ball ´ e, and T oderici 2018) ranks the second place for coding ef ficiency . Both meth- ods in (Liu et al. 2019) and (Minnen, Ball ´ e, and T oderici 2018) apply the V AE structures. Fig. 7 experiments the ef fi- ciency of NLAM, re v ealing that performance can be retained closely to (Minnen, Ball ´ e, and T oderici 2018) even by re- moving all nonlocal operations. Second-order Flow Corr elations In Fig.1, we hav e shown that the second-order motion representations im- ply the further temporal redundancy between optical flows. Thus, we present a recurrent state (e.g., Con vLSTM) to ag- gregate temporal priors for inter coding which can effec- tiv ely reduce the bits for flo w compression. T emporal priors are fused with autoregressiv e and hyper priors to improve the context modeling of flo w element. Then we use ConvLSTM to combine temporal priors with current quantized features for the updated priors in a re- current way . Flow prediction provides an ef fecti ve means to exploit the redundancy between complex motion behaviors. Fig. 9 sho ws that efficienc y variations when removing the O ri gi na l F ra m e ( Bpp / MS - SS I M ) Prop os ed ( 0 . 0189 / 0 . 9810 ) H . 265 / HE VC ( 0 . 01896 / 0 . 9737 ) H . 264 / AV C ( 0 . 01987 / 0 . 9641 ) O ri g i n a l F ra m e ( Bpp / MS - SS I M ) Pro p o s e d ( 0 . 0181 / 0 . 9747 ) H . 265 / HE VC ( 0 . 01935 / 0 . 9698 ) H . 264 / AV C ( 0 . 01948 / 0 . 9579 ) Figure 8: V isual Comparison. Reconstructed frames of our method, H.265/HEVC and H.264/A VC. W e av oid blocky artifacts and provide better quality of reconstructed frame at lo w bit rate. Figure 9: Efficiency of T emporal Priors. 2% - 10% loss captured at similar bit rate when removing temporal priors for context modeling. Con vLSTM system from our entire framew ork without ex- ploiting the temporal correlations, where 2% to 10% quality loss is captured. Generally , bits consumed by motion information v aries across different content and bit rates, leading to a variety of percentages to the total bits. More bit saving is re vealed for low bit rates, and motion intensi v e content. For stationary content, such as HEVC Class E, spatial and hyper priors al- ready gi v e a good reference, thus temporal priors are less used. Conclusions & Future W ork In this paper , we present an end-to-end video compression framew ork and fully exploit the spatial and temporal redun- dancies. Ke y novelty laid on the accurate motion representa- tion for exploiting temporal correlation, via both first-order optical flow learning and second-order flo w predictive cod- ing. An one-stage unsupervised flow learning is applied with implicit flow representation using quantized features. These features are then compressed using joint spatial-temporal priors by which the probability model is conditioned adap- tiv ely . W e e v aluate our methods and report the state-of-the-art performances among all the existing video compression ap- proaches, including traditional H.264/A VC, H.265/HEVC, and learning-based D VC. Our approach offers the consis- tent gains o ver existing methods across a v ariety of contents and bit rates. As for the future study , an interesting topic is to devise implicit flow without actual bits consumption, such as the decoder-side flo w deriv ation, or frame interpolation and ex- trapolation. Currently , residual shares the same network with intra coding, which may be worth for deep inv estigation for network simplification. It is also significant to generalize the whole system to more comple x video data sets such as spec- tural video (Cao et al. 2016) and 3D video (M ¨ uller et al. 2013; Cao, Li, and Dai 2011). Acknowledgement This work was supported in part by the National Natural Sci- ence Foundation of China under Grant 61571215. References Agustsson, E.; Tschannen, M.; Mentzer, F .; T imofte, R.; and V an Gool, L. 2018. Generati ve adversarial networks for extreme learned image compression. arXiv pr eprint arXiv:1804.02958 . Ball ´ e, J.; Minnen, D.; Singh, S.; Hwang, S. J.; and Johnston, N. 2018. V ariational image compression with a scale hyper- prior . arXiv pr eprint arXiv:1802.01436 . Ball ´ e, J.; Laparra, V .; and Simoncelli, E. P . 2016. End- to-end optimized image compression. arXiv pr eprint arXiv:1611.01704 . Ball ´ e, J. 2018. Efficient nonlinear transforms for lossy im- age compression. arXiv preprint . Cao, X.; Y ue, T .; Lin, X.; Lin, S.; Y uan, X.; Dai, Q.; Carin, L.; and Brady , D. J. 2016. Computational snapshot mul- tispectral cameras: T o ward dynamic capture of the spectral world. IEEE Signal Pr ocessing Magazine 33(5):95–108. Cao, X.; Li, Z.; and Dai, Q. 2011. Semi-automatic 2d-to-3d con v ersion using disparity propagation. IEEE T r ansactions on Br oadcasting 57(2):491–499. Chen, T .; Liu, H.; Shen, Q.; Y ue, T .; Cao, X.; and Ma, Z. 2017. Deepcoder: A deep neural network based video com- pression. In V isual Communications and Image Pr ocessing (VCIP), 2017 IEEE , 1–4. IEEE. Djelouah, A.; Campos, J.; Schaub-Meyer , S.; and Schroers, C. 2019. Neural inter -frame compression for video cod- ing. In Proceedings of the IEEE International Conference on Computer V ision , 6421–6429. Habibian, A.; Rozendaal, T . v .; T omczak, J. M.; and Cohen, T . S. 2019. V ideo compression with rate-distortion autoen- coders. In Pr oceedings of the IEEE International Confer- ence on Computer V ision , 7033–7042. Huang, Y .; W ang, W .; and W ang, L. 2015. Bidirectional recurrent conv olutional networks for multi-frame super- resolution. In Cortes, C.; Lawrence, N. D.; Lee, D. D.; Sugiyama, M.; and Garnett, R., eds., Advances in Neural In- formation Pr ocessing Systems 28 . Curran Associates, Inc. 235–243. Ilg, E.; Mayer , N.; Saikia, T .; Keuper , M.; Dosovitskiy , A.; and Brox, T . 2017. Flownet 2.0: Evolution of optical flow estimation with deep networks. In 2017 IEEE confer ence on computer vision and pattern r ecognition (CVPR) , 1647– 1655. IEEE. Jason, J. Y .; Harley , A. W .; and Derpanis, K. G. 2016. Back to basics: Unsupervised learning of optical flo w via bright- ness constanc y and motion smoothness. In Eur opean Con- fer ence on Computer V ision , 3–10. Springer . Li, M.; Zuo, W .; Gu, S.; Zhao, D.; and Zhang, D. 2017. Learning con v olutional networks for content-weighted im- age compression. arXiv preprint . Lin, T .-Y .; Maire, M.; Belongie, S.; Hays, J.; Perona, P .; Ra- manan, D.; Doll ´ ar , P .; and Zitnick, C. L. 2014. Microsoft coco: Common objects in context. In Eur opean conference on computer vision , 740–755. Springer . Liu, H.; Chen, T .; Guo, P .; Shen, Q.; Cao, X.; W ang, Y .; and Ma, Z. 2019. Non-local attention optimized deep image compression. arXiv preprint . Lu, G.; Ouyang, W .; Xu, D.; Zhang, X.; Cai, C.; and Gao, Z. 2019. Dvc: An end-to-end deep video compression frame- work. In The IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) . Meister , S.; Hur , J.; and Roth, S. 2018. Unflow: Unsu- pervised learning of optical flow with a bidirectional census loss. In Thirty-Second AAAI Confer ence on Artificial Intel- ligence . Mentzer , F .; Agustsson, E.; Tschannen, M.; T imofte, R.; and V an Gool, L. 2018. Conditional probability models for deep image compression. In IEEE Confer ence on Computer V i- sion and P attern Recognition (CVPR) , v olume 1, 3. Minnen, D.; Ball ´ e, J.; and T oderici, G. D. 2018. Joint autore- gressiv e and hierarchical priors for learned image compres- sion. In Advances in Neural Information Pr ocessing Sys- tems , 10794–10803. M ¨ uller , K.; Schwarz, H.; Marpe, D.; Bartnik, C.; Bosse, S.; Brust, H.; Hinz, T .; Lakshman, H.; Merkle, P .; Rhee, F . H.; et al. 2013. 3d high-efficiency video coding for multi-view video and depth data. IEEE T ransactions on Image Pr ocess- ing 22(9):3366–3378. Niklaus, S., and Liu, F . 2018. Context-aw are synthesis for video frame interpolation. arXiv pr eprint arXiv:1803.10967 . Niklaus, S.; Mai, L.; and Liu, F . 2017. V ideo frame inter- polation via adapti ve con v olution. In IEEE Confer ence on Computer V ision and P attern Recognition , v olume 1, 3. Oord, A. v . d.; Kalchbrenner , N.; and Ka vukcuoglu, K. 2016. Pixel recurrent neural networks. arXiv preprint arXiv:1601.06759 . Rippel, O., and Bourdev , L. 2017. Real-time adaptive image compression. arXiv preprint . Sulliv an, G. J., and Wie gand, T . 1998. Rate-distortion op- timization for video compression. IEEE Signal Pr ocessing Magazine 15(6):74–90. Sulliv an, G. J., and W iegand, T . 2005. V ideo compression - from concepts to the h.264/a vc standard. Pr oceedings of the IEEE 93(1):18–31. Sulliv an, G. J.; Ohm, J.-R.; Han, W .-J.; and W ie gand, T . 2012. Overvie w of the high efficienc y video coding (he vc) standard. IEEE T r ansactions on cir cuits and systems for video technology 22(12):1649–1668. Sun, D.; Y ang, X.; Liu, M.-Y .; and Kautz, J. 2018. Pwc-net: Cnns for optical flow using pyramid, warping, and cost vol- ume. In Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition , 8934–8943. T oderici, G.; V incent, D.; Johnston, N.; Hwang, S.-J.; Min- nen, D.; Shor , J.; and Covell, M. 2016. Full resolution image compression with recurrent neural networks. CoRR abs/1608.05148. W ie gand, T .; Sulli v an, G. J.; Bjontegaard, G.; and Luthra, A. 2003. Overview of the h. 264/avc video coding stan- dard. IEEE T ransactions on circuits and systems for video technology 13(7):560–576. W u, C.-Y .; Singhal, N.; and Kr ¨ ahenb ¨ uhl, P . 2018. V ideo compression through image interpolation. In ECCV . Xingjian, S.; Chen, Z.; W ang, H.; Y eung, D.-Y .; W ong, W .- K.; and W oo, W .-c. 2015. Con v olutional lstm network: A machine learning approach for precipitation nowcasting. In Advances in neur al information pr ocessing systems , 802– 810. Xue, T .; Chen, B.; W u, J.; W ei, D.; and Freeman, W . T . 2019. V ideo enhancement with task-oriented flow . International Journal of Computer V ision 127(8):1106–1125.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment