A SOT-MRAM-based Processing-In-Memory Engine for Highly Compressed DNN Implementation
The computing wall and data movement challenges of deep neural networks (DNNs) have exposed the limitations of conventional CMOS-based DNN accelerators. Furthermore, the deep structure and large model size will make DNNs prohibitive to embedded syste…
Authors: Geng Yuan, Xiaolong Ma, Sheng Lin
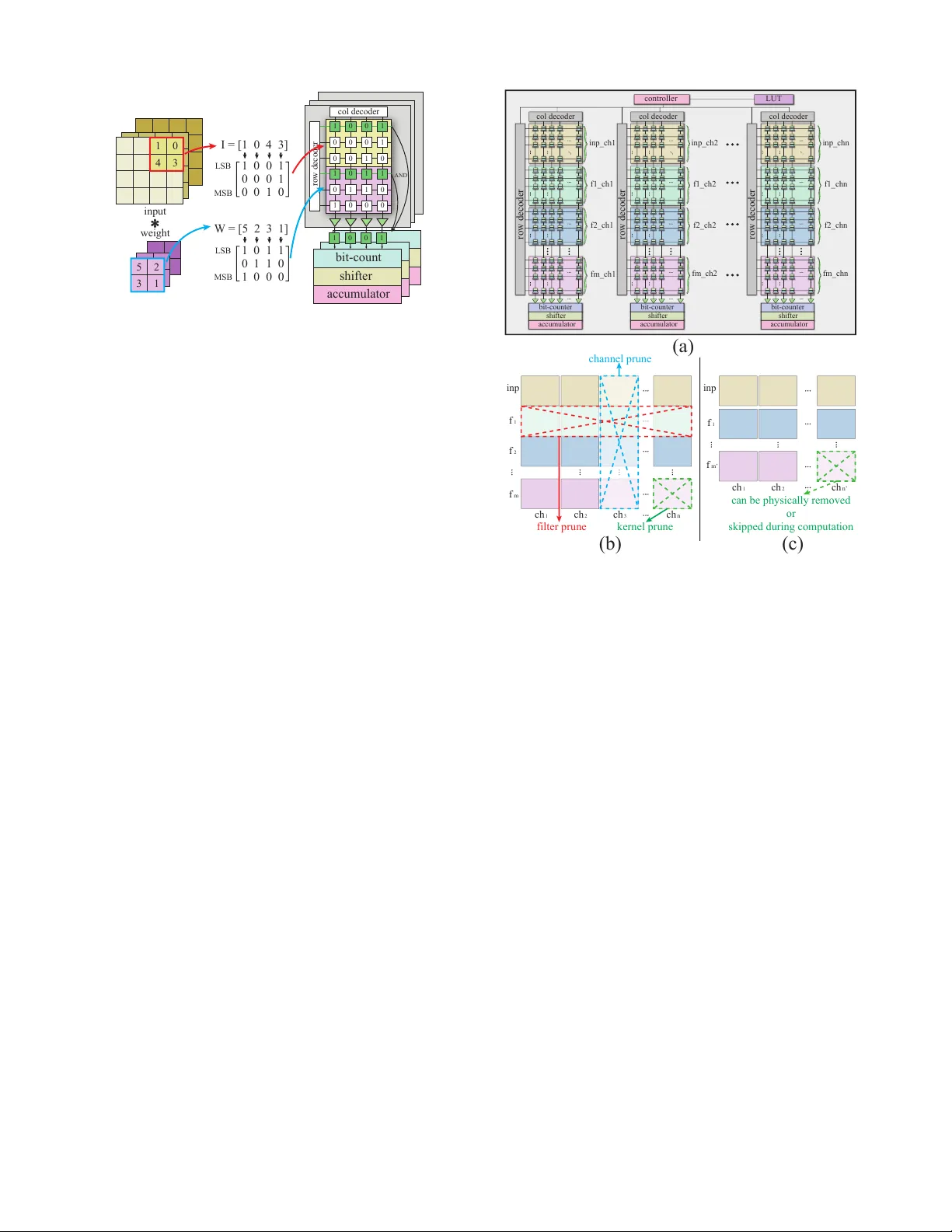
A SO T -MRAM-based Processing-In-Memory Engine for Highly Compressed DNN Implementation Geng Y uan † Northeastern University Boston, USA yuan.geng@husky .neu.edu Xiaolong Ma † Northeastern University Boston, USA ma.xiaol@husky .neu.edu Sheng Lin Northeastern University Boston, USA lin.sheng@husky .neu.edu Zhengang Li Northeastern University Boston, USA li.zhen@husky .neu.edu Caiwen Ding University of Connecticut Storrs, CT , USA caiwen.ding@uconn.edu Abstract —The computing wall and data mov ement challenges of deep neural networks (DNNs) ha ve exposed the limitations of conv entional CMOS-based DNN accelerators. Furthermore, the deep structure and lar ge model size will make DNNs prohibiti ve to embedded systems and IoT devices, wher e low power consumption are requir ed. T o address these challenges, spin orbit torque magnetic random-access memory (SO T -MRAM) and SOT -MRAM based Processing-In-Memory (PIM) engines hav e been used to reduce the power consumption of DNNs since SO T -MRAM has the characteristic of near -zero standby power , high density , none-volatile. Howe ver , the drawbacks of SO T -MRAM based PIM engines such as high writing latency and requiring low bit-width data decrease its popularity as a fav orable energy efficient DNN accelerator . T o mitigate these drawbacks, we pr opose an ultra energy efficient framework by using model compression techniques including weight pruning and quantization from the software le vel considering the archi- tecture of SO T -MRAM PIM. And we incorporate the alternating direction method of multipliers (ADMM) into the training phase to further guarantee the solution feasibility and satisfy SOT - MRAM hardwar e constraints. Thus, the f ootprint and power consumption of SO T -MRAM PIM can be reduced, while in- creasing the overall system throughput at the meantime, making our proposed ADMM-based SO T -MRAM PIM more energy efficiency and suitable f or embedded systems or IoT devices. Our experimental results show the accuracy and compr ession rate of our proposed framework is consistently outperf orming the reference works, while the efficiency (area & power) and throughput of SO T -MRAM PIM engine is significantly improved. I . I N T RO D U C T I O N Large-scale DNNs achieve significant improvement in many challenging problems, such as image classification [1], speech recognition [2] and natural language processing [3]. Howe ver , as the number of layers and the layer size are both expanding, the introduced intensive computation and storage hav e brought challenges to the traditional V on-Neumann architecture [4], such as computing wall, massi ve data mov ement and high power consumption [5], [6]. Furthermore, the deep structure and large model size will make DNNs prohibitiv e to embedded systems and IoT devices, where low power consumption are required. T o address these challenges, spin orbit torque magnetic random-access memory (SO T -MRAM) has been used to re- duce the power consumption of DNNs since it has the characteristic of near-zero standby power , high density , and none-volatile [7]. Combined with the in-memory comput- ing technique [8], [9], the SO T -MRAM based Processing-in- † These authors contributed equally . memory (PIM) engine could perform arithmetical and logic computations in parallel. Therefore, the most intensi ve oper- ation, matrix multiplication and accumulation (MAC) in both con v olutional layers (CONV) and fully-connected layers (FC), can be implemented using bit-wise parallel AND, bit-count, bit-shift, etc. Compared to SRAM and DRAM, SO T -MRAM has higher write latency and energy [7], [10], [11], which decrease its popularity as a fav orable ener gy ef ficient DNN accelerator . T o mitigate these drawbacks, from the software lev el, weight quantization has been introduced to SO T -MRAM PIM. By us- ing binarized weight representation, [10] efficiently processed data within SO T -MRAM to greatly reduce power -hungry and omit long distance data communication. Howe ver , weight binarization will cause accurac y degradation, especially for large-scale DNNs. In reality , many scenarios require as high accuracy as possible, e.g., self-driving cars. Thus, binarized weight representation is not fa v orable. In this work, we propose an ultra energy efficient frame work by using model compression techniques [12]–[16] including weight pruning and quantization from the software le v el considering the architecture of SOT -MRAM PIM. T o further guarantee the solution feasibility and satisfy SO T -MRAM hardware constraints while pro viding high solution quality (no obvious accurac y de gradation after model compression and after hardware mapping), we incorporate the alternating direction method of multipliers (ADMM) into the training phase. As a result, we can reduce the footprint and power consumption of SOT -MRAM PIM, and improve the overall system throughput, making our proposed ADMM-based SOT - MRAM PIM more ener gy ef ficienc y and suitable for embedded systems or IoT devices. In the follo wing paper , we first illustrate how to connect ADMM to our model compression techniques in order to achiev e deeply compressed models that are tailored to SO T - MRAM PIM designs. Then we introduce the architecture and mechanism of SOT -MRAM PIM and how to map our compressed model onto it. Finally , we e valuate our proposed framew ork on different networks. The experimental results show the accuracy and compression rate of our frame work is consistently outperforming the baseline works. And the efficienc y (area & power) and throughput of SO T -MRAM PIM engine can be significantly impro ved. I I . A U N I FI E D A N D S Y S T E M A T I C M O D E L C O M P R E S S I O N F R A M E W O R K F O R E FFI C I E N T S OT- M R A M B A S E D P I M E N G I N E D E S I G N In this section, we propose a unified and systematic frame- work for DNN model compression, which simultaneously and efficiently achiev es DNN weight pruning and quantization. By re-forming the pruning and quantization problems into optimization problems, the proposed framew ork can solve the structured pruning and lo w-bit quantization problems itera- tiv ely and analytically by extending the powerful ADMM [17] algorithm. In the meantime, our structured pruning model has a unique (i.e., tiny and regular) spatial property which naturally fits into the SO T -MRAM based processing-in-memory engine utilization, thereby successfully bridges the gap between the large-scale DNN inference and the computing ability limited platforms. After mapping the compressed DNN model on SO T - MRAM based processing-in-memory engine, bit-wise con v o- lution can be executed with very high efficiency consistently . A. DNN W eight Pruning using ADMM For an N -layer DNN of interest. The first M layers are CONV layers and the rest are FC layers. The weights and biases of the i -th layer are respectively denoted by W i and b i , and the loss function associated with the DNN is denoted by f { W i } N i =1 , { b i } N i =1 ; see [18]. In this paper , { W i } N i =1 and { b i } N i =1 respectiv ely characterize the collection of weights and biases from layer 1 to layer N . In this paper , our objecti ve is to implement structured pruning on the DNN. In the following discussion we focus on the CONV layers because they have the highest compu- tation requirements. More specifically , we minimize the loss function subject to specific structured sparsity constraints on the weights in the CONV layers, i.e., minimize { W i } , { b i } f { W i } N i =1 , { b i } N i =1 , subject to W i ∈ S i , i = 1 , . . . , M , (1) where S i is the set of W i with desired “structure”. Ne xt we introduce constraint sets corresponding to different types of structured sparsity to facilitate SO T -MRAM PIM engine implementation. The collection of weights in the i -th CONV layer is a four-dimensional tensor , i.e., W i ∈ R F i × C i × H i × W i , where F i , C i , H i , and W i are respecti vely the number of filters, the number of channels in a filter , the height of the filter , and the width of the filter, in layer i . F ilter-wise structured sparsity : When we train a DNN with sparsity at the filter le v el, the constraint on the weights in the i -th CONV layer is gi ven by W i ∈ S i := { X | the number of nonzero filters in X is less than or equal to α i } . Here, nonzero filter means that the filter contains some nonzero weight. Channel-wise structured sparsity : When we train a DNN with sparsity at the channel lev el, the constraint on the weights in the i -th CONV layer is giv en by W i ∈ S i := { X | the number of nonzero channels in X is less than or equal to β i } . Here, we call the c -th channel nonzero if ( X ) : ,c, : , : contains some nonzero element. Kernel-wise structured sparsity : When we train a DNN with sparsity at the Kernel le vel, the constraint on the weights in the i -th CONV layer is given by W i ∈ S i := { X | the number of nonzero vectors in { X f ,c, : , : } F i ,C i f ,c =1 is less than or equal to θ i } . T o solve the problem, we propose a systematic framework of dynamic ADMM regularization and masked mapping and retraining steps. W e can guarantee solution feasibility (satisfy- ing all constraints) and provide high solution quality through this integration. B. Solution to the DNN Pruning Pr oblem Corresponding to ev ery set S i , i = 1 , . . . , M we define the indicator function g i ( W i ) = ( 0 if W i ∈ S i , + ∞ otherwise. Furthermore, we incorporate auxiliary v ariables Z i , i = 1 , . . . , M . The original problem (1) is then equiv alent to minimize { W i } , { b i } f { W i } N i =1 , { b i } N i =1 + M X i =1 g i ( Z i ) , subject to W i = Z i , i = 1 , . . . , M . (2) By adopting augmented Lagrangian [19] on (2), the ADMM regularization decomposes problem (2) into two subproblems, and solves them iterati vely until con vergence. The first subproblem is minimize { W i } , { b i } f { W i } N i =1 , { b i } N i =1 + M X i =1 ρ i 2 k W i − Z k i + U k i k 2 F , (3) where U k i := U k − 1 i + W k i − Z k i . The first term in the objective function of (3) is the differentiable loss function of the DNN, and the second term is a quadratic re gularization term of the W i ’ s, which is differentiable and conv ex. As a result (3) can be solved by standard SGD. Although we cannot guarantee the global optimality , it is due to the non-con vexity of the DNN loss function rather than the quadratic term enrolled by our method. Please note that this subproblem and solution are the same for all types of structured sparsities. The Second subproblem is minimize { Z i } M X i =1 g i ( Z i ) + M X i =1 ρ i 2 k W k +1 i − Z i + U k i k 2 F . (4) Note that g i ( · ) is the indicator function of S i , thus this subproblem can be solved analytically and optimally [19]. For i = 1 , . . . , M , the optimal solution is the Euclidean projection of W k +1 i + U k i onto S i . The set S i is dif ferent when we apply different types of structured sparsity , and the Euclidean projections will be described ne xt. Solving the second subproblem for different structured spar- sities: For filter-wise structured sparsity constraints, we first calculate R f = k ( W k +1 i + U k i ) f , : , : , : k 2 F shifter accumulator shifter accumulator 1 input weight I = [1 0 4 3] W = [5 2 3 1] 1 1 0 0 0 0 0 0 0 0 1 0 1 0 1 1 1 0 0 1 AND bit-count shifter accumulator 1 0 0 0 1 0 1 1 1 LSB col decoder row decoder MSB 0 0 1 0 0 0 1 0 0 1 0 0 3 4 5 2 3 1 1 LSB MSB 0 1 1 0 1 1 0 1 0 0 0 * Fig. 1. Bit-wise conv olution using SOT -MRAM based PIM engine for f = 1 , . . . , F i , where k · k F denotes the Frobenius norm. W e then keep α i elements in ( W k +1 i + U k i ) f , : , : , : corresponding to the α i largest v alues in {R f } F i f =1 and set the rest to zero. For channel-wise structur ed sparsity , we first calculate R c = k ( W k +1 i + U k i ) : ,c, : , : k 2 F for c = 1 , . . . , C i . W e then keep β i elements in ( W k +1 i + U k i ) : ,c, : , : corresponding to the β i largest v alues in {R c } C i c =1 and set the rest to zero. For kernel-wise structured sparsity , we first calculate R f ,c = k ( W k +1 i + U k i ) f ,c, : , : k 2 F for f = 1 , . . . , F i , c = 1 . . . , C i . W e then keep θ i elements in ( W k +1 i + U k i ) f ,c, : , : corresponding to the θ i largest v alues in {R f ,c } F i ,C i f ,c =1 and set the rest to zero. C. SO T -MRAM Processing-In-Memory Engine for DNN The main purpose of SO T -MRAM PIM engine is to con vert and perform the MACs operations in con v olutional layers using bit-wise con volution format. There are four main steps included in bit-wise con volutions: par allel AND operation, bitcount, bitshift and accumulation . They can be formulated as Eqn.(5). And M and N stands for the bit-length of inputs and weights respectively . The c m ( I ) represents the m th -bit of all inputs in I , where the c n ( W ) contains the n th -bit of all weights in W . Consider a CONV layer with 2 × 2 kernel size, where W contains 4 weights on a kernel and I contains 4 current inputs cov ered by this kernel. W e assume both weights and inputs are using 3-bit representation. From Figure 1 we can see that inputs and weights are mapped to two different sub-arrays. During the computation, two ro ws are selected from two sub- arrays each time, and the parallel AND results can be obtained from sense amplifiers [20]. Each row in one sub-array will conduct parallel AND operation with all the ro ws from the other sub-array . And every AND results will go through bit- count and shifter unit, then accumulated with other results to get a bit-wise conv olution result [11]. I ∗ W = M − 1 X m =0 N − 1 X n =0 2 m + n bitcount ( and ( c m ( I ) , c n ( W ))) (5) col decoder bit-counter shifter accumulator controller bit-counter shifter accumulator bit-counter shifter accumulator LUT row decoder row decoder row decoder col decoder col decoder inp_ch1 f1_ch1 f2_ch1 inp f 1 f 2 f m inp f 1 f m’ ch 1 ch 2 ch 1 ch 2 ch 3 ch n ch n’ fm_ch1 inp_ch2 f1_ch2 f2_ch2 fm_ch2 } } } } } } } } inp_chn filter prune channel prune (a) (b) (c) can be physically removed or skipped during computation kernel prune f1_chn f2_chn fm_chn } } } } Fig. 2. Inputs and W eights mapping to the PIM Engine D. F ramework Mapping In our proposed framew ork, based on the architecture of SO T -MRAM-based PIM engine, we incorporate structured pruning and quantization using ADMM to ef fecti vely reduce the PIM engine’ s area and power . Quantization can be inte- grated in the same ADMM-based framew ork with dif ferent constraints. W e omit the details of ADMM quantization due to space limit. Please note that our ADMM-based framework can achiev e weight pruning and quantization simultaneously or separately . Moreo ver , the overall throughput of SO T -MRAM based DNN computing system can be impro ved as well. The SO T -MRAM-based PIM engine contains several processing elements (PEs). And each PE consists a column decoder , a row decoder, one computing set and multiple SO T -MRAM sub-arrays as shown in Figure 2(1). It also sho ws how we map the inputs and weights to the PIM engine. In each PE, the inputs will be mapped on one sub-array , and ev ery other sub-array will accommodate the different filters’ weights from the same input channel. For e xample, the P E 1 will compute the con v olution of the inputs in channel 1 and all the weights in channel 1 from f il ter 1 to f il ter m . And the number of columns and rows in each sub-array depends on the kernel size of the network and the bit-length of the inputs and weights respecti vely . All PEs are able to work parallelly and individually . In Figure 2(b), examples are giv en to show the correspond- ing structured pruning types that are used in our proposed framew ork and how it f acilitates the reduction of PIM engine size. For the filter pruning, all the sub-arrays on the same row (i.e., storing the weights from the same filter) can be removed. T ABLE I S T RU CT U R E D P R UN I N G R E SU LT S O N M N I S T , C I F A R -1 0 A ND I M AG E N E T U S IN G V G G -1 6 A N D R E S N ET - 18 / 5 0 ( R N T - 1 8 /5 0 I N TAB L E ) . A CC U R AC Y R E SU LT S F O R I M AG E N ET F O RM AT A S T O P -1 / T OP 5 A C CU R AC Y . Method Base Accuracy Prune Accuracy CONV Comp. Rate MNIST (LeNet-5) Group Scissor [21] 99.15% 99.14% 4.2 × Our’ s 99.16% 99.12% 81.3 × CIF AR-10 RNT -18 DCP [22] 88.9% 87.6% 2.0 × AMC [23] 90.5% 90.2% 2.0 × Our’ s 94.1% 93.2% 59.8 × VGG-16 Iterativ e Pruning [24], [25] 92.5% 92.2% 2.0 × 2PFPCE [26] 92.9% 92.8% 4.0 × Our’ s 93.7% 93.3% 44.8 × ImageNet AlexNet Deep compression [27] 57.2/82.2% 57.2/80.3% 2.7 × NeST [28] 57.2/82.2% 57.2/80.3% 4.2 × Our’ s 57.4/82.4% 57.3/82.2% 5.2 × RNT -18 Network Slimming [29] 68.9/88.7% 67.2/87.4% 1.4 × DCP [22] 69.6/88.9% 69.2/88.8% 3.3 × Our’ s 69.9/89.1% 69.1/88.4% 3.0 × RNT -50 Soft Filter Prune [30] 76.1/92.8% 74.6/92.1% 1.7 × ThiNet [31] 72.9/91.1% 68.4/88.3% 3.3 × Our’ s 76.0/92.8% 75.5/92.3% 2.7 × Thus, the number of sub-arrays that are contained by each PE will be reduced. For the channel prune, since the pruned channels are no longer needed, the number of required PEs can be reduced without decreasing the throughput. Since each sub-array stores the weights from one channel of one filter, which is also considered as the weights from one con volution kernel, the kernel pruning will remove all the weights on a sub-array . By applying filter pruning and channel pruning, all the pruned sub-arrays or PEs can be physically removed directly . Howe ver , removing the s ub-arrays by k ernel pruning may cause an unev en size between different PEs. But since all the sub-arrays have same size and a sub-array is considered as a basic computing unit in bit-wise con volutions, the control ov erheads for addressing une ven sub-array numbers in PEs is ignorable. An alternati ve w ay is to use a look-up-table (LUT) to mark those pruned sub-arrays and skip them during computation instead of removing them physically . Each pruning type has its o wn advantages. The filter pruning and channel pruning has propagation property . Because filter pruning (channel pruning) can not only remove the pruned weights b ut also remo ves the corresponding output channels (input channels) as well. By taking the adv antage of that, the corresponding channels (filters) in ne xt (previous) layer be- come redundant and can also be removed. The kernel pruning is especially tailored to the SO T -MRAM-based DNN comput- ing system. Compared to filter and channel pruning, kernel pruning provides higher pruning flexibility , which means it is easier to maintain network accuracy under the same pruning rate. And none of them will incur complicated control logic. The ADMM based quantization is also used in our proposed framew ork. In each weight sub-array , the number of rows equals to the bit-length that is used to represent the weights. The number of rows in each sub-array can be e venly reduced by quantizing the weights to fewer bits. Fig. 3. Power/area reduction and throughput improvement ov er uncompressed models using MNIST and CIF AR-10 dataset. I I I . E X P E R I M E N T A L R E S U LT S In our e xperiment, our generated compressed models are based on four widely used network structures, LeNet-5 [32], AlexNet [1], VGG-16 [33] and ResNet-18/50 [34], and are trained on an eight NVIDIA R TX-2080Ti GPUs serv er using PyT orch [35]. For hardware results, we choose 32nm CMOS technology for the peripheral circuits. Cacti 7 [36] is utilized to compute the energy and area of buf fers and on-chip inter- connects. NVSim platform [37] with modified SOT -MRAM configuration is used to model the SO T -MRAM sub-arrays. The power and area results of ADC are taken from [38]. Sev eral groups of experiments are performed, and we only show one result under each dataset and network, which achiev es highest compression rate with minor accuracy degra- dation. Our results are based on 8-bit quantization, and we use combined pruning scheme (which means all three pruning types are used simultaneously). T able I sho ws our result on MNIST dataset using LeNet-5 can achieve 81.3 × compression without accuracy degradation, which is 19.4 × higher than Group Scissor [21]. On CIF AR-10 dataset, our compression rates achiev e 59.8 × and 44.8 × on ResNet-18 and VGG-16 networks with minor accuracy degradation. And on ImageNet, our compression rates for AlexNet, ResNet-18 and VGG-16 is 5.2 × , 3.0 × and 2.7 × , respecti vely . By applying our framew ork, the power and area of SO T - MRAM PIM engine can be significantly reduced and the ov erall system throughput can also be improved comparing to uncompressed design, as shown in Figure 3. From our observation, channel pruning usually contrib utes more po wer and area saving than filter and kernel pruning, since it can remov e entire PE with its peripheral circuits. On the other hand, the filter and kernel pruning can reduce the computing iterations between sub-arrays, which can improve the o verall throughput. I V . C O N C L U S I O N In this paper , we propose an ultra ener gy ef ficient framework by using model compression techniques including weight pruning and quantization at the algorithm lev el considering the architecture of SOT -MRAM PIM. And we incorporate ADMM into the training phase to further guarantee the solu- tion feasibility and satisfy SOT -MRAM hardw are constraints. The experimental results show the accuracy and pruning rate of our framework is consistently outperforming the baseline works. Consequently , the area and power consumption of SO T - MRAM PIM can be significantly reduced, while the ov erall system throughput is also impro ved dramatically . R E F E R E N C E S [1] A. Krizhevsk y , I. Sutskever , and G. E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in NeurIPS , 2012, pp. 1097–1105. [2] D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen et al. , “Deep speech 2: End-to-end speech recognition in english and mandarin, ” in ICML , 2016, pp. 173–182. [3] R. Collobert and J. W eston, “ A unified architecture for natural language processing: Deep neural networks with multitask learning, ” in Proceed- ings of the 25th international conference on Machine learning . ACM, 2008, pp. 160–167. [4] G. Y uan, X. Ma, C. Ding, S. Lin, T . Zhang, Z. S. Jalali, Y . Zhao, L. Jiang, S. Soundarajan, and Y . W ang, “ An ultra-efficient memristor- based dnn framework with structured weight pruning and quantization using admm, ” in 2019 IEEE/ACM International Symposium on Low P ower Electr onics and Design (ISLPED) . IEEE, 2019, pp. 1–6. [5] G. Y uan, C. Ding, R. Cai, X. Ma, Z. Zhao, A. Ren, B. Y uan, and Y . W ang, “Memristor crossbar-based ultra-ef ficient next-generation base- band processors, ” in 2017 IEEE 60th International Midwest Symposium on Cir cuits and Systems (MWSCAS) . IEEE, 2017, pp. 1121–1124. [6] C. Ding, S. Liao, Y . W ang, Z. Li, N. Liu, Y . Zhuo, C. W ang, X. Qian, Y . Bai, G. Y uan et al. , “C ir cnn: accelerating and compressing deep neural networks using block-circulant weight matrices, ” in Proceedings of the 50th Annual IEEE/ACM International Symposium on Microar chi- tectur e . A CM, 2017, pp. 395–408. [7] S. Umesh and S. Mittal, “ A surve y of spintronic architectures for processing-in-memory and neural networks, ” Journal of Systems Archi- tectur e , 2018. [8] X. Ma, Y . Zhang, G. Y uan, A. Ren, Z. Li, J. Han, J. Hu, and Y . W ang, “ An area and energy efficient design of domain-wall memory-based deep con volutional neural networks using stochastic computing, ” in 2018 19th International Symposium on Quality Electronic Design (ISQED) . IEEE, 2018, pp. 314–321. [9] Y . W ang, C. Ding, G. Y uan, S. Liao, Z. Li, X. Ma, B. Y uan, X. Qian, J. T ang, Q. Qiu, and X. Lin, “T owards ultra-high performance and energy efficiency of deep learning systems: an algorithm-hardware co- optimization framew ork, ” in AAAI Conference on Artificial Intelligence, (AAAI-18) . AAAI, 2018. [10] S. Angizi, Z. He, F . Parveen, and D. F an, “Imce: ener gy-efficient bit-wise in-memory con volution engine for deep neural network, ” in Pr oceedings of the 23r d Asia and South P acific Design A utomation Confer ence . IEEE Press, 2018, pp. 111–116. [11] A. Roohi, S. Angizi, D. Fan, and R. F . DeMara, “Processing-in-memory acceleration of conv olutional neural networks for energy-ef fciency , and power -intermittency resilience, ” in 20th ISQED . IEEE, 2019. [12] S. Lin, X. Ma, S. Y e, G. Y uan, K. Ma, and Y . W ang, “T o ward extremely low bit and lossless accuracy in dnns with progressive admm, ” arXiv pr eprint arXiv:1905.00789 , 2019. [13] X. Ma, G. Y uan, S. Lin, Z. Li, H. Sun, and Y . W ang, “Resnet can be pruned 60x: Introducing network purification and unused path remov al (p-rm) after weight pruning, ” arXiv preprint , 2019. [14] C. Ding, A. Ren, G. Y uan, X. Ma, J. Li, N. Liu, B. Y uan, and Y . W ang, “Structured weight matrices-based hardware accelerators in deep neural networks: Fpgas and asics, ” in Pr oceedings of the 2018 on Great Lakes Symposium on VLSI . A CM, 2018, pp. 353–358. [15] X. Ma, F .-M. Guo, W . Niu, X. Lin, J. T ang, K. Ma, B. Ren, and Y . W ang, “Pconv: The missing but desirable sparsity in dnn weight pruning for real-time ex ecution on mobile devices, ” arXiv pr eprint arXiv:1909.05073 , 2019. [16] N. Liu, X. Ma, Z. Xu, Y . W ang, J. T ang, and J. Y e, “ Autoslim: An automatic dnn structured pruning framew ork for ultra-high compression rates, ” arXiv preprint , 2019. [17] S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein et al. , “Distributed optimization and statistical learning via the alternating direction method of multipliers, ” F oundations and Tr ends® in Machine learning , 2011. [18] T . Zhang, S. Y e, K. Zhang, J. T ang, W . W en, M. Fardad, and Y . W ang, “ A systematic dnn weight pruning framework using alternating direction method of multipliers, ” in Proceedings of ECCV , 2018, pp. 184–199. [19] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed optimization and statistical learning via the alternating direction method of multipliers, ” F oundations and T r ends® in Machine Learning , vol. 3, no. 1, pp. 1–122, 2011. [20] D. Fan and S. Angizi, “Energy efficient in-memory binary deep neural network accelerator with dual-mode SOT -MRAM, ” in Proceedings, ICCD 2017 , 2017. [21] Y . W ang, W . W en, B. Liu, D. Chiarulli, and H. Li, “Group scissor: Scaling neuromorphic computing design to large neural networks, ” in D AC . IEEE, 2017. [22] Z. Zhuang, M. T an, B. Zhuang, J. Liu, Y . Guo, Q. Wu, J. Huang, and J. Zhu, “Discrimination-aware channel pruning for deep neural networks, ” in Advances in NeurIPS , 2018, pp. 875–886. [23] Y . He, J. Lin, Z. Liu, H. W ang, L.-J. Li, and S. Han, “ Amc: Automl for model compression and acceleration on mobile devices, ” in ECCV . Springer , 2018, pp. 815–832. [24] S. Han, J. Pool, J. T ran, and W . Dally , “Learning both weights and connections for efficient neural network, ” in NeurIPS , 2015. [25] Z. Liu, M. Sun, T . Zhou, G. Huang, and T . Darrell, “Rethinking the value of network pruning, ” arXiv preprint , 2018. [26] C. Min, A. W ang, Y . Chen, W . Xu, and X. Chen, “2pfpce: T wo- phase filter pruning based on conditional entropy , ” arXiv preprint arXiv:1809.02220 , 2018. [27] S. Han, H. Mao, and W . J. Dally , “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding, ” arXiv pr eprint arXiv:1510.00149 , 2015. [28] X. Dai, H. Y in, and N. K. Jha, “Nest: a neural network synthesis tool based on a grow-and-prune paradigm, ” arXiv preprint , 2017. [29] Z. Liu, J. Li, Z. Shen, G. Huang, S. Y an, and C. Zhang, “Learning effi- cient con volutional netw orks through network slimming, ” in Pr oceedings of the IEEE International Confer ence on Computer V ision , 2017, pp. 2736–2744. [30] Y . He, G. Kang, X. Dong, Y . Fu, and Y . Y ang, “Soft filter pruning for accelerating deep convolutional neural networks, ” in International Joint Confer ence on Artificial Intelligence (IJCAI) , 2018, pp. 2234–2240. [31] J.-H. Luo, J. W u, and W . Lin, “Thinet: A filter level pruning method for deep neural network compression, ” in Pr oceedings of the IEEE international confer ence on computer vision , 2017, pp. 5058–5066. [32] Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner , “Gradient-based learning applied to document recognition, ” Proceedings of the IEEE , v ol. 86, no. 11, pp. 2278–2324, 1998. [33] K. Simonyan and A. Zisserman, “V ery deep conv olutional networks for large-scale image recognition, ” arXiv preprint , 2014. [34] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Proceedings of the IEEE confer ence on CVPR , 2016. [35] A. Paszke, S. Gross, S. Chintala, and G. Chanan, “Pytorch, ” 2017. [36] R. Balasubramonian, A. B. Kahng, and et al. , “Cacti 7: New tools for interconnect exploration in innovati ve off-chip memories, ” ACM T ACO , 2017. [37] X. Dong, C. Xu, S. Member , Y . Xie, S. Member , and N. P . Jouppi, “Nvsim: A circuit-level performance, energy , and area model for emerg- ing non volatile memory , ” IEEE TCAD , vol. 31, no. 7, 2012. [38] B. Murmann, “ Adc performance survey 1997-2019,[online]. a vailable: http://web .stanford.edu/ murmann/adcsurvey .html. ”
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment