Acoustic Impulse Responses for Wearable Audio Devices
We present an open-access dataset of over 8000 acoustic impulse from 160 microphones spread across the body and affixed to wearable accessories. The data can be used to evaluate audio capture and array processing systems using wearable devices such a…
Authors: Ryan M. Corey, Naoki Tsuda, Andrew C. Singer
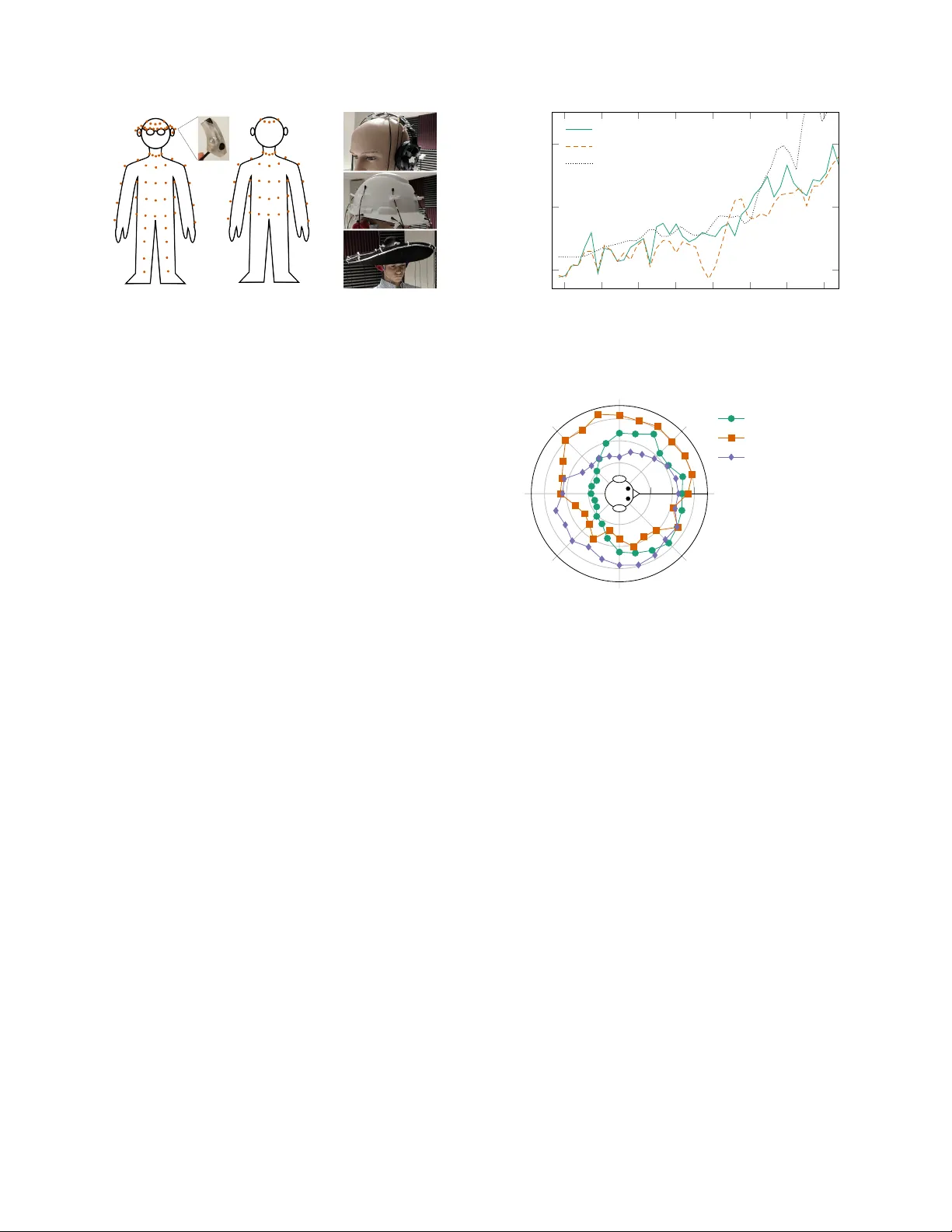
A COUSTIC IMPULSE RESPONSES FOR WEARABLE A UDIO DEVICES Ryan M. Cor ey , Naoki Tsuda, and Andr ew C. Singer Uni versity of Illinois at Urbana-Champaign ABSTRA CT W e present an open-access dataset of ov er 8000 acoustic impulse from 160 microphones spread across the body and affix ed to wear- able accessories. The data can be used to ev aluate audio capture and array processing systems using wearable de vices such as hearing aids, headphones, e yeglasses, jewelry , and clothing. W e analyze the acoustic transfer functions of dif ferent parts of the body , measure the effects of clothing worn o ver microphones, compare measurements from a li ve human subject to those from a mannequin, and simulate the noise-reduction performance of several beamformers. The re- sults suggest that arrays of microphones spread across the body are more effecti ve than those confined to a single device. Index T erms — Acoustic impulse response, microphone arrays, wearables, audio enhancement, hearing aids 1. INTR ODUCTION Thanks to advances in transducer technology , such as tin y digital MEMS microphones [1], multiple audio sensors can be embedded in wearable devices such as watches, headphon es, eye glasses, and other accessories. These microphones could be combined to perform array processing such as beamform- ing, localization, and source separation [2 – 4]. A wearable array with many microphones spread ov er a wide area would offer greater spatial resolution than the small arrays embed- ded in most hearing aids, headsets, and mobile phones today . W earable microphone arrays could dramatically improv e per - formance in assistiv e listening [5, 6], augmented reality [7], and machine perception applications. There hav e been se veral wearable array designs reported in the literature, including helmets [8 – 10], e yeglasses [11, 12], and vests [13, 14]. Howe ver , these designs ha ve been re- stricted to small areas of the body and the literature offers little guidance about how microphone placement affects per- formance. Furthermore, there is little publicly av ailable data, such as impulse response measurements, that can be used to design wearable arrays and test multimicrophone processing algorithms. Multimicrophone impulse response datasets, such as [15 – 17], are used to simulate sound propagation and e valuate rev erberant source separation and beamforming algorithms. This material is based upon work supported by the National Science Foundation Graduate Research Fellowship Program under Grant Number DGE-1144245. Fig. 1 : Impulse responses were measured using a studio monitor and 16 mi- crophones placed at 80 positions on the body and 80 positions on wearable accessories. T est signals were captured from 24 angles. There is abundant publicly av ailable data on head-related transfer functions (HR TF), which characterize directional filtering by the ears [18]. HR TF datasets, such as [19, 20], usually only include responses at the ear canals and some- times at hearing-aid earpieces [21]. T o simulate and ev aluate wearable audio systems, researchers could use impulse re- sponses measured with microphones placed all across the body . Note that whereas HR TFs are often used in human per- ceptual applications—for example, to create virtual sources in a listener’ s auditory en vironment [7]—these body-related transfer functions (BR TFs) are not directly related to human hearing. Rather , they help machines to localize, separate, and enhance real-world sound sources, and could be used alongside HR TFs in listening enhancement applications. Here we present a new dataset [22] of acoustic impulse responses measured at 160 sensor positions across the body and various wearable accessories. V ersion 1 of the wearable microphone dataset contains about 8000 measurements with one human subject, one mannequin, five head-mounted ac- cessories and six types of outerwear . The data and documen- tation is av ailable through the Illinois Data Bank 1 , an open- access data archiv al service maintained by the University of Illinois at Urbana-Champaign. The wearable microphone dataset can be used to char - acterize the acoustic effects of the body on wearable audio devices and to simulate microphone arrays for applications such as hearing aids, augmented reality , and human-computer interaction. In this paper, we analyze this data to describe 1 https://doi.org/10.13012/B2IDB- 1932389_V1 T o appear at ICASSP 2019 c 2019 IEEE Fig. 2 : Left: Impulse responses were measured at 80 positions on the body , including one microphone affixed to each ear and four in behind-the-ear shells. Right: W earable accessories with 16 microphones. the acoustic effects of different body parts, ev aluate the man- nequin as a human analogue, and compare the attenuation of different clothing w orn ov er microphones. Finally , we use the dataset to assess designs of wearable microphone arrays for a beamforming application. 2. IMPULSE RESPONSE MEASUREMENTS The measurement setup is shown in Fig. 1. The impulse responses were measured in an acoustically treated record- ing space in the Illinois Augmented Listening Laboratory . Each half-second impulse response was computed from a ten- second linear sweep repeated three times from a studio mon- itor , captured by 16 Countryman B3 omnidirectional lav alier microphones, and digitized at 24 bits and 48 kHz by a Focus- rite Scarlett audio interface. After each sequence of sweeps, the subject was rotated to capture impulse responses from a total of 24 source angles. The microphones were then moved to new positions and the measurements were repeated. The human subject is 181 cm tall with a head circumfer- ence of 61 cm. The hollow plastic mannequin, designed for displaying clothing, is 183 cm tall with a 56 cm head cir - cumference. Since the mannequin head has unnaturally small ears, a soft plastic replica ear was affixed to each side of the head. These replica ears are not intended to ha ve realistic HR TFs, since HR TF data from realistic head simulators and real humans is already readily av ailable. The BR TF data includes 80 microphone positions on the body , sho wn in Fig. 2. One microphone was placed just outside of each ear canal and af fixed using medical tape. These microphones capture approximate HR TFs and can be used to simulate binaural signal processing algorithms such as spatial-cue-preserving beamformers [23, 24]. Four micro- phones were mounted in a pair of custom-made behind-the- ear (BTE) shells similar to those used in many hearing aids. T en were attached to a pair of eyeglasses and the remaining 64 microphones were clipped onto the subject’ s clothing. Since a wearable microphone array might be covered by clothing, the torso measurements were repeated with different 125 250 500 1000 2000 4000 8000 16000 0 10 20 F requency (Hz) Atten uation (dB) Human Mannequin MIT-KEMAR Fig. 3 : Interaural level differences for sources to the left and right of the subject. The dotted curve is from the MIT KEMAR dataset [19]. 0 45 90 135 180 225 270 315 − 10 − 5 0 F ront Chest Left T emple Righ t Shoulder Fig. 4 : Overall power , in dB relati ve to a free-space microphone, recei ved by three microphones on the human subject. outerwear including a t-shirt, cotton dress shirt, heavy cotton sweatshirt, polyester pullov er , wool coat, and leather jack et. These BR TF measurements are supplemented by impulse responses from wearable accessories. Since many previously reported wearable arrays are mounted on the head, measure- ments were collected using over -the-ear headphones, a base- ball cap, a hard hat, a hat with a 40 cm flat brim, and a hat with a 60 cm curved brim, each with 16 microphones. 3. A COUSTIC TRANSFER FUNCTIONS 3.1. Effects of the body The acoustic effects of the head, which humans use to local- ize sound, have been well studied [18]. A microphone in the left ear will capture more energy from sources on the left than sources on the right, especially at high frequencies. This in- teraural level difference is shown in Fig. 3. The human head has a slightly stronger acoustic shadow effect than the plas- tic mannequin head. The head-shadow ef fect measured in the treated recording space is slightly weaker than fully-anechoic KEMAR data from [19]. The rest of the body has similar shadowing effects, which causes omnidirectional wearable microphones to have direc- 2 125 250 500 1000 2000 4000 8000 16000 0 5 10 15 F requency (Hz) Atten uation (dB) Human chest Mannequin chest Human forehead Mannequin forehead Fig. 5 : A verage attenuation by the body for sources on the opposite side of the body from each microphone. 125 250 500 1000 2000 4000 8000 16000 0 5 10 15 20 25 30 Dress shirt T-shirt Sweatshirt Pullov er W ool coat Leather jack et F requency (Hz) Atten uation (dB) Fig. 6 : A verage attenuation due to clothing for the 16 microphones on the mannequin torso. tional responses, as shown in Fig. 4. A microphone on the front of the chest receiv es about 8 dB less sound energy from sources behind the wearer . Microphones on the temple and shoulder are shadowed from the side b ut not from the front. The body-related shadow effect varies with frequency and body part. F or both the human and mannequin, the shado w effect was strongest for the the upper chest and weakest for the forehead, although the differences between body parts are small compared to variations across frequency . Fig. 5 shows the average difference in transfer function magnitude between the sources nearest to and farthest from each microphone on the upper chest and forehead. The transfer functions for the human and mannequin are similar in magnitude, suggesting that inexpensiv e plastic mannequins can be used as human analogues in wearable-microphone experiments. 3.2. Effects of clothing In many wearable-audio applications, microphones might be worn in, on, or under clothing. In the HR TF literature, i t has been shown that hair, e yeglasses, and hats hav e small but measurable effects on acoustic transfer functions to the ear [25 – 27] b ut do not significantly af fect human localization performance [26, 28]. The strongest effects are from curly hairstyles that cov er the pinna and wide-brimmed hats that reflect sounds from belo w into the ear and sounds from abov e away from the ear [26]. Clothing worn on the torso has little effect on HR TFs—at most, it changes the strength of mul- tipath reflections from sources below the listener [26]—but would of course ha ve a strong ef fect on BR TFs. The attenuation due to different clothing, av eraged over all microphones on the torso, is shown in Fig. 6. All garments attenuate higher frequencies, but the de gree of attenuation de- pends on the type of clothing. The t-shirt has the smallest ef- fect, up to 5 dB at 20 kHz. The light cotton dress shirt, heavy cotton sweatshirt, and polyester pullover have nearly identi- cal attenuation effects. The wool coat and leather jacket have strong high-frequency attenuation, suggesting that wearable audio devices might be less useful when covered by heavy outerwear . Note that the leather jacket appears to slightly am- plify sound around 200–600 Hz in this recording setup; the effect w as consistent across all microphones. 4. APPLICA TION TO BEAMFORMING Microphone arrays are often used for beamforming, that is, to isolate a desired source and remove unwanted noise [3, 5, 29]. A wearable array with many microphones spread across the body could perform stronger noise reduction than the small arrays included in many audio devices today . The wearable microphone dataset developed here can be used to study how performance scales with array size in a wearable application and how such arrays should be designed. 4.1. MVDR beamformer Let s [ n ] ∈ R be a sequence of speech samples emitted from a nonmoving source of interest. Let a [ n ] ∈ R M be an M - dimensional impulse response from the source to each of M microphones in an array . Let z [ n ] ∈ R M be an unwanted noise sequence. Assuming linear time-in v ariant propagation, the sampled recorded signal is x [ n ] = ∞ X k = −∞ a [ k ] s [ n − k ] + z [ n ] . (1) In the frequency domain, (1) can be written X ( ω ) = A ( ω ) S ( ω ) + Z ( ω ) , (2) where A ( ω ) is the discrete-time acoustic transfer function vector and X ( ω ) , S ( ω ) , and Z ( ω ) are discrete-time Fourier transforms of the corresponding sequences. If z [ n ] is a wide-sense stationary random process with power spectral density R ( ω ) , then the output y [ n ] of a minimum-variance distortionless-response (MVDR) beam- former is giv en in the frequency domain by Y ( ω ) = A 1 ( ω ) A H ( ω ) R − 1 ( ω ) A H ( ω ) R − 1 ( ω ) A ( ω ) X ( ω ) . (3) 3 0 10 20 Entire b o dy ( M = 80) Upper b o dy ( M = 64) Head and neck ( M = 32) T orso ( M = 18) Eyeglasses ( M = 16) BTE earpieces ( M = 6) Ears Only ( M = 2) SNR Improv emen t (dB) Fig. 7 : Experimental results for MVDR beamforming on the human subject with wearable arrays having different numbers of microphones. All arrays include the reference microphones near the ear canals. The box-and-whisk ers plot indicates the quartiles of the simulated SNR improvements. This beamformer minimizes noise power subject to the constraint that the output due to the target source has unity gain with respect to microphone 1, which is near the left ear . In a binaural system, there w ould be a second output with unity gain with respect to the right-ear microphone. This con- straint ensures that the target source sounds natural to the lis- tener , although any residual noise will be spatially and spec- trally distorted [23]. The performance metric used in these experiments is the improv ement in signal-to-noise ratio (SNR) between input and output: ∆ SNR = 10 log 10 P n ( d [ n ] − x 1 [ n ]) 2 P n ( d [ n ] − y [ n ]) 2 , (4) where d [ n ] is the noise-free desired sequence. 4.2. Beamforming simulation An MVDR beamformer was simulated using several wearable array configurations with different numbers of microphones. For each of 100 trials, a target source and fi ve interference sources were randomly placed at six of the 24 possible source locations. The source data was also randomly chosen from a set of ten-second anechoic speech clips from the VCTK cor- pus [30]. Since the source impulse responses are known, an MVDR beamformer with more than six inputs could achieve near-perfect performance by placing a null over each source. T o pre vent this overfitting, the beamformer was designed us- ing 32 ms windo wed impulse responses and diagonal loading about 10 dB below the a verage speech power . The results of the beamforming experiment for dif ferent numbers of microphones are shown in Fig. 7. Performance improv es rapidly with the first few sensors as each new in- put allows the beamformer to cancel an additional source. Larger arrays offer more marginal improvements, helping to reduce residual noise and compensate for transfer-function mismatch. The locations of the microphones also affect per- formance: notice that the 18 microphones on the ear canals 10 15 20 Brimmed hat (60 cm) Brimmed hat (40 cm) Hard hat Baseball cap Headphones F orehead and neck Shoulders and arms T orso W aist and legs SNR Improv emen t (dB) Fig. 8 : Experimental results for MVDR beamforming on the mannequin with different microphone configurations. Each array has M = 18 microphones, including the left and right reference microphones. and torso outperform 32 microphones on the head. The mi- crophones on the head are closely spaced, while those on the torso are widely separated and also more strongly shadowed by the body . Fig. 8 sho ws the performance of se veral arrays with M = 18 microphones, two of which are the left and right-ear ref- erence microphones. Comparing different head-mounted ac- cessories, the largest hat provides the best beamforming gain because of its spatial div ersity . The microphones attached to the o ver -the-ear headphones are too closely spaced to pro- vide much benefit at low frequencies and do not e xperience a strong shado wing effect at high frequencies. The 60 cm hat is about as ef fectiv e as the lower -body array , which cov ers the largest area among the clothing-based arrays. 5. CONCLUSIONS Many audio products, especially wearable devices such as hearing aids and headsets, use relatively fe w microphones that are closely spaced. The beamforming simulation sug- gests that performance could be improv ed by using man y mi- crophones spread across the body . For example, an array of 18 microphones across the torso reduced noise by an a ver - age of about 2 dB more than an array of 18 microphones spaced across headphones. It also outperformed an array of nearly twice as many microphones covering the head alone! The experiments with clothing suggest that wearable micro- phones remain useful ev en when covered by hea vy shirts and sweaters, though wind-blocking coats and jackets cause sig- nificant attenuation. Further work is required to understand how acoustic trans- fer functions vary between individuals. The wearable micro- phone dataset could be expanded in the future to include more human subjects and wearable de vices. This data will allow researchers to simulate and compare different wearable array designs and to dev elop ne w signal processing methods that take adv antage of larger arrays than are typically used today . 4 6. REFERENCES [1] E. P . Zwyssig, “Speech processing using digital MEMS mi- crophones, ” Ph.D. dissertation, The Univ ersity of Edinbur gh, 2013. [2] M. Brandstein and D. W ard, Micr ophone Arrays: Signal Pr o- cessing T echniques and Applications . Springer , 2013. [3] S. Gannot, E. V incent, S. Markovich-Golan, and A. Ozerov , “ A consolidated perspective on multimicrophone speech en- hancement and source separation, ” IEEE T ransactions on Au- dio, Speech, and Language Pr ocessing , v ol. 25, no. 4, pp. 692– 730, 2017. [4] E. V incent, T . V irtanen, and S. Gannot, Audio Sour ce Separa- tion and Speech Enhancement . Wile y , 2018. [5] S. Doclo, S. Gannot, M. Moonen, and A. Spriet, “ Acoustic beamforming for hearing aid applications, ” in Handbook on Array Pr ocessing and Sensor Networks , S. Haykin and K. R. Liu, Eds. Wiley , 2008, pp. 269–302. [6] S. Doclo, W . Kellermann, S. Makino, and S. E. Nordholm, “Multichannel signal enhancement algorithms for assisted lis- tening devices, ” IEEE Signal Processing Magazine , vol. 32, no. 2, pp. 18–30, 2015. [7] V . V alimaki, A. Franck, J. Ramo, H. Gamper, and L. Savioja, “ Assisted listening using a headset: Enhancing audio percep- tion in real, augmented, and virtual en vironments, ” IEEE Sig- nal Pr ocessing Magazine , vol. 32, no. 2, pp. 92–99, 2015. [8] M. V . Scanlon, “Helmet-mounted acousti c array for hostile fire detection and localization in an urban en vironment, ” in Unat- tended Gr ound, Sea, and Air Sensor T echnologies and Appli- cations , vol. 6963. International Society for Optics and Pho- tonics, 2008, p. 69630D. [9] P . W . Gillett, “Head mounted microphone arrays, ” Ph.D. dis- sertation, V irginia T ech, 2009. [10] P . Calamia, S. Davis, C. Smalt, and C. W eston, “ A confor- mal, helmet-mounted microphone array for auditory situational awareness and hearing protection, ” in IEEE W orksohp on Ap- plications of Signal Pr ocessing to Audio and Acoustics (W AS- P AA) , 2017. [11] W . Soede, F . A. Bilsen, and A. J. Berkhout, “ Assessment of a directional microphone array for hearing-impaired listeners, ” The J ournal of the Acoustical Society of America , vol. 94, no. 2, pp. 799–808, 1993. [12] D. Y . Levin, E. A. Habets, and S. Gannot, “Near-field signal ac- quisition for smartglasses using two acoustic vector-sensors, ” Speech Communication , vol. 83, pp. 42–53, 2016. [13] B. W idro w and F .-L. Luo, “Microphone arrays for hearing aids: An overvie w , ” Speech Communication , v ol. 39, no. 1-2, pp. 139–146, 2003. [14] A. Stupakov , E. Hanusa, J. Bilmes, and D. Fox, “COSINE - A corpus of multi-party conversational speech in noisy en- vironments, ” in IEEE International Conference on Acoustics, Speech, and Signal Pr ocessing (ICASSP) , 2009. [15] J. Y . C. W en, N. D. Gaubitch, E. A. P . Habets, T . Myatt, and P . A. Naylor , “Ev aluation of speech dere verberation algorithms using the MARD Y database, ” in International W orkshop on Acoustic Echo and Noise Contr ol (IW AENC) , 2006. [16] N. Ono, Z. K oldovsky , S. Miyabe, and N. Ito, “The 2013 signal separation ev aluation campaign, ” in IEEE W orkshop on Ma- chine Learning for Signal Pr ocessing (MLSP) , 2013. [17] E. Hadad, F . Heese, P . V ary , and S. Gannot, “Multichannel au- dio database in v arious acoustic en vironments, ” in Interntional W orkshop on Acoustic Signal Enhancement (IW AENC) . IEEE, 2014, pp. 313–317. [18] J. Blauert, Spatial hearing: The psychophysics of human sound localization . MIT press, 1997. [19] W . G. Gardner and K. D. Martin, “HR TF measurements of a KEMAR, ” The Journal of the Acoustical Society of America , vol. 97, no. 6, pp. 3907–3908, 1995. [20] V . R. Algazi, R. O. Duda, D. M. Thompson, and C. A vendano, “The CIPIC HR TF database, ” in IEEE W orkshop on Applica- tions of Signal Pr ocessing to Audio and Acoustics (W ASP AA) , 2001, pp. 99–102. [21] H. Kayser, S. D. Ewert, J. Anem ¨ uller , T . Rohdenburg, V . Hohmann, and B. Kollmeier , “Database of multichannel in- ear and behind-the-ear head-related and binaural room impulse responses, ” EURASIP Journal on Advances in Signal Pr ocess- ing , vol. 2009, p. 6, 2009. [22] R. M. Corey , N. Tsuda, and A. C. Singer, “W earable microphone impulse responses, ” 2018. [Online]. A vailable: https://doi.org/10.13012/B2IDB- 1932389 V1 [23] S. Doclo, T . J. Klasen, T . V an den Bogaert, J. W outers, and M. Moonen, “Theoretical analysis of binaural cue preserva- tion using multi-channel Wiener filtering and interaural trans- fer functions, ” in International W orkshop on Acoustic Echo and Noise Contr ol (IW AENC) , 2006. [24] D. Marquardt, “Development and ev aluation of psychoacous- tically moti vated binaural noise reduction and cue preservation techniques, ” Ph.D. dissertation, Carl von Ossietzky University of Oldenbur g, 2016. [25] G. W ers ´ enyi and A. Ill ´ enyi, “Differences in dummy-head HR TFs caused by the acoustical environment near the head, ” Electr onic Journal of T echnical Acoustics , vol. 1, pp. 1–15, 2005. [26] K. A. Riederer, “HR TF analysis: Objecti ve and subjectiv e ev al- uation of measured head-related transfer function, ” Ph.D. dis- sertation, Helsinki Univ ersity of T echnology , 2005. [27] B. E. Treeby , J. Pan, and R. M. Paurobally , “The effect of hair on auditory localization cues, ” The J ournal of the Acoustical Society of America , vol. 122, no. 6, pp. 3586–3597, 2007. [28] G. W ers ´ enyi and J. R ´ ep ´ as, “Comparison of HR TFs from a dummy-head equipped with hair, cap, and glasses in a virtual audio listening task over equalized headphones, ” in Audio En- gineering Society Con vention , 2017. [29] B. D. V an V een and K. M. Buckley , “Beamforming: A versa- tile appr oach to spatial filtering, ” IEEE AASP magazine , v ol. 5, no. 2, pp. 4–24, 1988. [30] C. V eaux, J. Y amagishi, and K. MacDonald, “CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit, ” 2017. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment