Survey on Deep Neural Networks in Speech and Vision Systems
This survey presents a review of state-of-the-art deep neural network architectures, algorithms, and systems in vision and speech applications. Recent advances in deep artificial neural network algorithms and architectures have spurred rapid innovati…
Authors: Mahbubul Alam, Manar D. Samad, Lasitha Vidyaratne
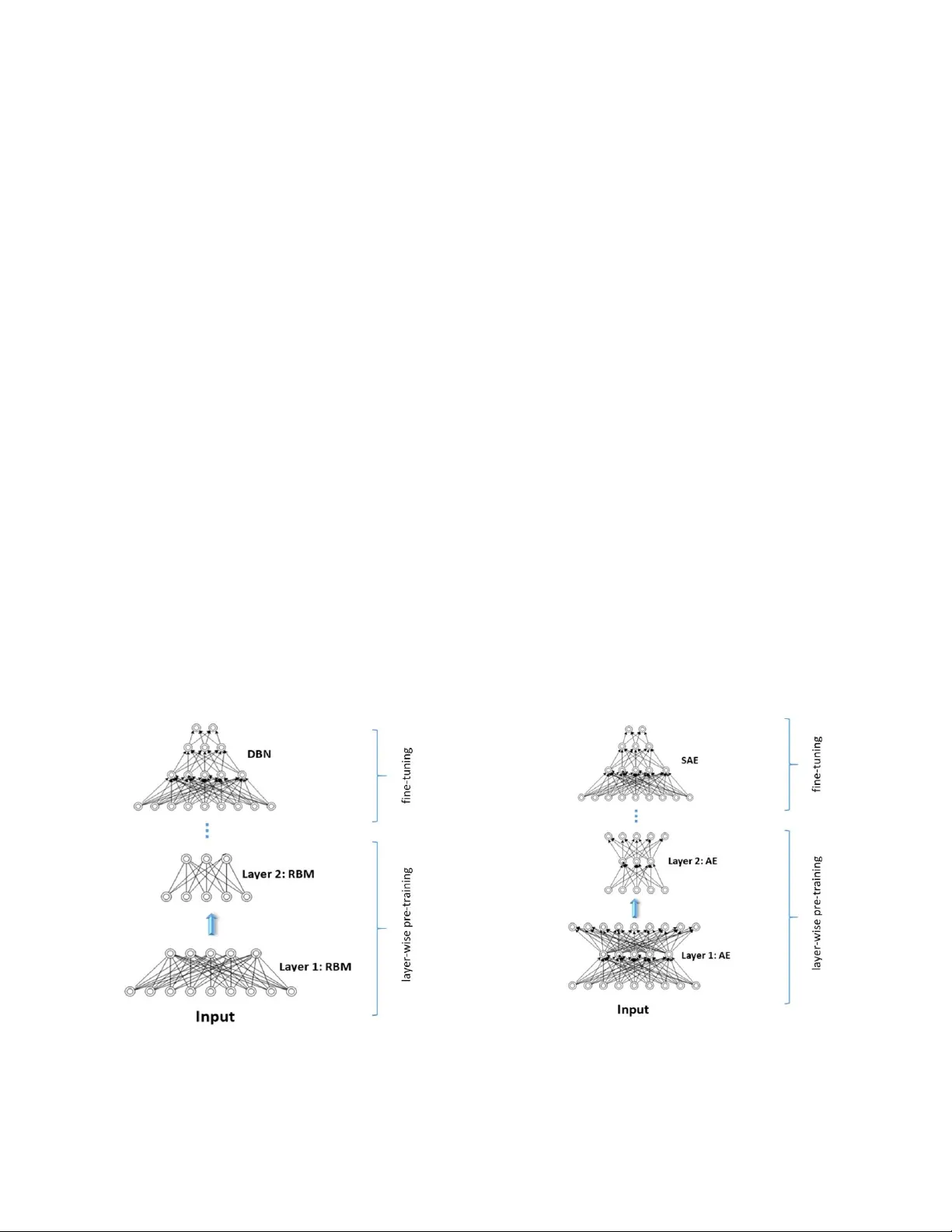
1 Abstract — This survey presents a review of sta te- of -t he-art deep neural network architectures, algorithms, and systems in vision and speech applications. Recent advance s in deep artificial neural net work algorithms and architectures ha ve spurred rapid innovation and development of intellig en t vision and speech syste m s. With availability of vast amounts of sen sor data an d cloud computing for processing and training of deep neural net works, and with increased sophistication in m obile and em bedded technology, the next-generation intelligent systems are poised to revolutionize personal and commercial computing. Th is survey begins by providing background an d evolution of some of the most successful deep learning mode ls for intelligent vision and speech systems to d ate. An overview of large- scale industrial research and development efforts is p rovided to empha si ze future trends and prospects of i ntelligent vision and speech systems. Ro bust and efficient intelligent system s demand low -la tency a nd high fidelity in resource-constrained h ardware platform s such as mobile devices, robots, and automobiles. Therefore, this survey also provides a s umm ary of key challenges and recent successes in running deep neural netw or ks on hardware-restricted platforms, i.e. w ithin limited me m ory, battery life, and processing capabilities. Finally, emerging app lications of vision and speech across disciplines such as affective computin g, intelligent transportation, and precision medicine are discussed. To our knowledge, this paper provides one of the most comprehensive surveys on the latest developments in intelligent vision and speech a pplications from the perspectives of both so ftw are and hardware systems. Many of th ese emerging technologies using deep n eura l netw orks show tr emendou s promise t o revolutionize research and development for future vision and speech systems. Index Ter ms — Vision and sp eech p roces si ng , computational intelligence, d eep learning, com puter v ision, na tural language p rocessing, hardware constraints, embedded system s, convolutional neural networks, d eep auto-encoders, recurrent neural networks. 1. INTRODUCTI ON HERE has been a massive accumulation of human -centric dat a to an un precedented scale over the last two dec ades. This data explotion coupled w it h rapid growth in co m puting po w er have rej uv enated the field of neural networks and sop histicated intelligent system (IS) . In the past, neural networks ha s mostly been limited to the applicatio n of i ndus trial control and r obotics. However, recent advancements in neural networks ha ve led to successful applications o f IS in al m ost every as pect o f human life with the introductio n of intelligent transportation [1 - 10] , intelligent diagnosis a nd health monitoring for precision medicine [11 - 14] , robotics and automation i n ho m e appliances [15 ], virtual onli ne assista nce [1 6], e-marketing [ 17] , and weather forecasting and natural d isasters monitoring [18] among others. Th e widespr ead success of I S tec hnology ha s red efin ed and aug m ented human ability to communicate and com prehend the w orld b y inn ovating on ‘smart’ p hysical syste ms . A ‘smart’ physical system is designed to interpret, act an d collaborate with complex multimodal human senses such as vision, touch, speech, smell, g estures, or hearing. A large body of smart physical systems have been d eveloped targeting two pr imary s enses u sed in human co mmunication: vision and speech. The advancement in speech and vision processing systems has enabled tremendous research and development in the areas of human-co m puter interactions [ 19] , biometric applications [ 20, 21] , security and su rveillance [22] , and m ost recently in computational behavioral anal ysis [23- 27] . While traditional machine learning an d evolutionar y computations ha ve enriched IS to solve complex pattern recognition problems over m any decades, th ese techniques have limitatio ns in their abilit y to p rocess nat ural data or images i n ra w data formats. A nu m ber of co m putational steps are us ed to extract representative features from raw data or images prior to ap ply ing machine learni ng models. This intermediate rep resentation of ra w data, known as ‘hand - engineered’ features, req uires domain e xpertise and human interpretation of physical patterns such as texture, shape, geo m etry , etc. T here are three major pro blem s with ‘hand - e ngin eered’ features t hat impede major pro gress in IS . First, the choice of ‘hand - engineered ’ features is application dependent and invol ves human interpretation and evaluation. S econd, ‘hand - e ngin eered’ features ar e extracted from each sample in a standalone manner without the knowledge of i nevitable n oise and variations in data. Third , ‘h and - engineer ed ’ features m ay perform excellent ly with some input but may co m pletely fail to extract quality features in ot her types of input data . This can lead to high variability in vision and spee ch recognition performance. M. Alam, M. D. Sa m ad 1 , L. Vid y aratne, A. Gla ndon and K. M. Iftekharuddin * Vision L ab in Department of Ele ctrical an d Computer E ngineer ing, Old Dominion U niversity , Norfol k, VA 23529 (email: malam001, l vidy001, agl an001, kiftekha@o du.edu *corr esponding author ). 1 Department of Com puter Scien ce , Tennesse e State University , N ashvill e, TN, 372 09 (email: msama d@tnstate.e du) Survey on Deep Neural Net works in S peech and Vision Systems T 2 A solution to the li mitations of ‘ha nd - engineered’ features has emerged through mimicking functions of biological neurons in artificial neural networks (ANN). The potential of ANNs is recently being exploited with access to large trainable datasets, efficient learning al gorithms, a nd p owerful co m putational resources. Fe w of these ad vancements in AN N over the last dec ade ha ve led to deep learning [28, 29] that, in turn, has r evolutionized several ap plication domains including co m puter vision, speech analysis, biomedical i mage processing, and o nlin e market analyses. The rapid success of deep learning over trad itional machine learning may be attributed to three factors. First, deep learning offers end- to -end trainable ar chitectures that in tegrate feature extraction , dimensionality reduction, and final classi fication . These steps are other w ise treated as standalone sub -systems i n conventio nal machine learnin g, which ma y result in subo ptimal pattern recognitio n performance. Second, target-specific a nd informative features may be learned from both input examples a nd classification targets without resorting to applicatio n-specific fea ture extractors. Third, deep learning m odels are highly f lexible in capturing complex n onlinear relationships between in puts and output targets at a level tha t is far beyond the capacity of ‘hand - engineered’ features. The remainder of this article is or gan ized as follows. Section 2 discusses dee p learning architect ures that have b een recentl y introduced to solve contemporary challenges in vision and speech domain. Section 3 provides a comprehensive discussion of real- world and co mm ercial ap plication cases for the tec hn ology. Section 4 discusses state- of -the-art results in i mplementing these sophisticated algorithms in r esource-co nstrained hard ware enviro nm ents. This section also highlights the p rospects o f ‘smart’ applications in mobile devices. Section 5 discusses several success ful and e m erging ap plications of ne ural networks in state- of - the-art IS . Section 6 elaborates potential develop m ents and challenges in the future for IS . Finally, Sectio n 7 conclud es with a summary of the ke y observations in thi s article. 2. D ESIG N AND A RCHITECTURE OF N EURAL N ETWORK S FOR D EEP L EA RNING An ANN consists of multiple levels of nonl inear m odules arranged hierarchica lly in la yers. This design is inspired by the hierarchical infor m ation pro cessing observed in the primate visual syste m [3 0, 31]. Such hierarchical arra ngements enable deep models to learn meaningful features at different levels o f abstraction. Several successful hierarchical ANNs kno wn as deep ne ural networks (DNNs ) are pr oposed in t he literature [32] . Fe w examples i nclude convolutional neural network s [33] , deep belief networks [1] , and stacked auto - encoders [3 4], generative ad versarial networks [35] , variational autoencoder s [ 36], flow models [37], recurrent neural networks [38 ], and attention bases models [3 9]. T hese models extract b oth simple and co mplex features similar to t he ones witnessed in the hierarchical regio ns of the p rimate vision sys tem. Consequentl y, the models show excellent performance in solving several computer vision tas ks , especially complex object reco gn ition [33]. C ichy et al. [30] s how that DNN models mimic biological brain function. The results f rom their object recognition experiment suggest a close relationship between the p rocessing stages in a DNN and the processing scheme obser ved in the human b rain. In the next few sections, w e discuss the most popular DNN m odels and their recent evolution s in var ious vision and speech applicatio ns. 2.1 Convolution al neural networks One of the first hierarchical model s, known as co nvolutional neural network s (CNNs/C onvNets) [33 , 40] , learns hier archical image patterns at multiple layers usin g a series o f 2D co nv olutional operatio ns . CNNs are designed to process multidimensional data structured in the form o f multiple arrays or tensors. For example, a 2D color image has three color channels represented b y three 2 D arra y s. T ypically, CNNs process input data using three basic ideas: local co nnectivity, s hared w eights, and po oling that are arranged in a series of connected lay ers. A si m plified CNN architecture is shown in Fig. 1. T he first few la yers are convolutional and pooling layers. The convolutional operation processes par ts of the input data in sm all localities to take advantage of local data dependency within a signal. The convolutional layers graduall y yield more high ly ab stract r epresentations o f the input data in deeper lay ers of the n etwork. An other aspect of the convolution operation is that filtering is repeated over the data. This maxi mizes the use of redundant p atterns in the data. While the convolutional layers detect local conjunctions of features fro m the previous la yer, the role of the p ooling la y er is to aggregate local features into a more global representatio n . Poo ling is p erformed b y s liding a no n-overlapping windo w o ver the Fig. 1. Gene ric architecture of Convolutional Ne ural Netw ork. 3 output of the convolutional layer to obtain a “pooled” value for each window . The pooled value is typically the maximum value over each windo w , ho wev er, averaging or other operations can be applied over the window . T his helps a netw ork become robust to sm all shifts and distortions in input data. The conv olutional layer en ds by vectorizing the multidimensional data prior to feeding them into fully connected neural networks that per f orm clas sif ication using highly ab stracted features fro m the pre vious la y ers. The training of all the w eights in t he CNN architect ure, includi ng the image filters and fully connected network weights, is performed by appl y ing a regul ar backpropagation algorithm commonly kno wn as gradient-descent opti m ization. 2.2 Deep gen erative models and auto -encoders The hierarchical model of CNN is designed to efficiently learn target-specific features from raw images and videos for vision related applications. However, the maj or breakthrough of hierarchical models is the introdu ction of the ‘greed y layer - wise’ training algorithm for deep belief net w orks (DBNs) proposed by Hinton et al. [28]. A DBN is built in a layer- by -layer fashion b y training each learning module known as the restricted Bo ltzmann machine (RBM) [41]. RBMs are composed of a visible and a hidden layer. T he visible layer repr esents raw data in a less abstract form, and the hidden la y er is trained to represent more ab stract features by capturing correlations in the visible la y er data [41] . Figure 2 (a) shows a standard architecture of a DBN. DBNs are considered hybrid networks that do not support direct end -to-end learning. Consequently, a more efficient ar chitecture, known as deep Boltzmann machines (DB Ms ) [4 2], has bee n introduced. Similar to DBNs, DBMs are str uctu red by stacking layers of RBMs. However, unlike DBNs, the inference procedure of DBMs is bidirectio nal, allowing them to learn in the presence of more ambiguous and challengi ng datasets. The introd uction o f DB Ms has led to the development o f the stacked auto -encoder (SAE) [34, 43], which is also formed by stacking multiple la y ers. Unlike DB Ns, SAEs utilize auto -encoders (AE) [44] as the basic learning module. An AE is t rained to learn a co py of the input at its output. In doing so, the hidden layer learns an abstract representation of inputs in a compressed form that is known as the encoding units. Figure 2 (b) sho ws the architect ure of an SAE as i t gradually lear ns lower dimensional encoding units at each layer. A greedy layer-wise training algorith m i s used to tr ain any of DBN, DBM, or SAE networks, where the parameters of each la y er are trained individually by keepi ng p aram eters in other layers fixed. After lay er-wise training of all layers, also known as pre-training, the hidden lay ers are stacked together. T he entire n etwork with all the stacked layers is th en fine-tuned against the target output units to adjust all the par ameters for a classification ta sk as ill ustrated in Fig. 2. DBNs a nd SAEs have achieved state- of -the-art performance in various vision-related app lications su ch as face verification [ 45], phone recognition [46] , and emotion recognition fro m i m age a nd speech [ 47, 4 8]. Mo reover, several studies [4 5, 49 ] have co m bined the advantages of different deep lear nin g models to further boost performance in these recognition tasks. For example, Lee et al. [49] have shown that combining convolution and weight sharing features of CNNs with the generative architecture of DBNs offer s better classification per f ormance on benchmark data sets such as MNI ST and Cal tech 101 [49]. T he hy brid of C NN and DBN models, also kno w n as the CDBN model, enables scalin g to pro blem s with large i mages without requiring an increase in the number of parameters of the network. (a) deep bel ief netw ork (DBN) (b) Stacked a uto-encoder (SAE) Fig. 2. A ty pical architecture i ncluding lay er-wise pre-training and f ine-tuning proced ure of (a) dee p belie f network (DBN) ; (b) Stacke d auto-encoder (SAE). 4 2.3 Variational A utoencoders Variational autoenco der (VAE) is a generative model that is designed to learn a meaningful latent repr esentation of the i nput data. The VAE architecture is analogous to an autoencoder, where the deter m inistic hidden layer is replaced w ith a p arameteri zable distribution formulated by variational Bayesian inference. VA E is, th erefore, represented by a directed graphical m odel cons isting of an i nput layer, a pro babilistic hidden la yer, and an o utput la y er to generate exa mples that are p robabilistically s imila r to the input cla ss. Kullback Leibler (KL) diverge nce is used as a constraint between the prior and posterior distribution to achieve a smooth tra nsition in t he hidden distrib utions bet w een different classes. Variatio n Ba y esian inference is used to co nstr uct a cost function for the neural net w ork that establishes a connection fro m the input to hidden la yer and then followed by t he output la y er [36]. T he parameterization o f hidden layers for several classes can be represented as p aram eter vector s. Linear co mbinations o f these class-specific vectors can be obtained and used to apply features from different input types into a new output example. VAE has succes sful applications i n image generation [50], motion prediction [51], text generation [5 2], and expressive speech g eneration [53] . 2.4 Generative Ad versarial Networks Generative ad versarial net w ork (G AN) i s another generative m odel, that is capable of cr eating realistic data (t y pically images) from a given class. A G A N is composed of t w o competing networks: th e generator and the discriminator. The generator aims to generate synt hetic i mages from ra w noise input that are as good as real images. The d iscriminator network has a bina ry target corresponding to ‘fake’ or ‘real’ inputs as it classi f ies r eal images aga inst the synthetically generated ones. The entire pipeline of two net works is trai ned with two alter nating goals. One goal is to upd ate the di scriminator t o improve its classificat ion per formance while keeping t he ge nerator parameters fixed. The discrimina tor network yields lo w cost values when co rrectly class ifying the generator examples a s ‘fake’ against ‘real’ images. The other goal is to update the generato r netw ork b y holding fixed par ame ters for the discriminator. Low co st values for the generator indicates generation of synthetic images that are so real that t he discriminator net work fails to classify it as ‘fake’ [35]. Thus, the t w o networks co m pete a gainst each other until an opti mal point has been rea ched, which ensur es that the fak e e xam ples are i ndistinguishable fro m real exa m ples. As a generative network, GAN has similar applicatio ns to VAE, inclu ding image generatio n [5 4] and super resolution [55 ] . The GAN model does not have control over modes of data to be generated. Conditional GAN (CGAN) m o del alleviate s th is by adding t he groun d truth lab el as an additional parameter to the generator to en force that the corresponding i mages are genera ted . By doing this modificatio n, CGAN allows the GAN model to generate new i mages from d iff erent classe s. Th e generator of the CGAN uses a n additional class input to identify th e new image ty pe to be g enerated. The di scriminator also has a n additional inp ut and onl y returns ‘real’ when the input looks r eal and matches the correspo ndin g input class pro vided in th e generator [56]. T he authors in [57] have e xtended the co nditional GAN architecture to construct images f rom semantic label maps. Bidirectional GAN is concerned w ith si multaneously learnin g to gen erate new images and lear ning to estimate the latent parameters of existing images [58]. For a given input exa mple, the hidden repr esentation can b e extracted. T hen the underlying representation ca n be used to generate a new image of s imilar semantic quality. The BigBiGan architecture [59] is an improved bidirectio nal GAN that achieves state- of - the-art results in e xtraction of image representation and also in image generation tasks. Despite the popularity a nd success of GANs, th ey ar e frequently p lagued b y instabil ity i n training [60] and subj ect to underfitting and overfitting [61 ]. Several studies aimed at improving training stabilit y and perfor m ance of GAN. T he auth ors in [62] a pproach these proble m s with a weight normalization tha t they call spectral nor m alization. Wasserstein G A N (WG A N) is anot her modification that i mproves the training of G AN for generating more realistic new exa m ple images. T he authors in [6 3] m otivate the improvement of GAN w ith significant theoretical underpinning. The m ain difference between GAN and WGAN is that instead of pro viding a binary decision about generated images b eing ‘fake’ or ‘real’, the di scriminator net w ork evaluates the generated images us ing a continuous quality sco re bet ween ‘fake’ a nd ‘real’. In [64], the aut hors co nsider weight clipping, which is part of WGAN training. Weight cl ipping is considered as a penalt y on the norm o f critic gradient, which has shown to improve training stability a nd image generatio n quality. In addition to W GA N there are additional works that attempt to i m prove GAN. For example, least squares generative adve rsarial net w orks improve stabilit y and perfor m ance [65]. They rep lace the standar d G AN cross- entropy loss with least squares loss to resolve the va nishing gradient problem. Recentl y , vec tor quantization is applied to VAE to generate synthetic image s of quality rivaling GAN while a voiding the aforementioned proble m s in training GAN [66] . 2.5 Flow-Based Models Flow models construct a decoder that is the exact inverse of the encoder module. This allo ws exact sampling fro m the in ferred data distribution. In VAE, a distribution parameter vector is extracted by the encoder to define a new d istribution t hat is sampled an d decoded to g enerate an image. In a f low m odel, given a latent variable, the en coder defines a deterministic transf ormatio n into an output i mage. An early flow model, known as No nlinear Independent Components Estimation (NI CE) [67], is used for generation of images with correctio ns to corrupt re gions of i nput images, which is known as i npainting . The authors in [37] have extend ed NICE w it h several more complex invertible operations , including various types of sampling and masked convo lution, to perform image generation . T heir proposed model is similar to conditional G AN as it can include add itional target class input to constrain the output image class. Another generati ve model called ‘GLOW’ uses ge nerative flow with invertible co nv olution s [68] and is sh own capable o f generating realistic high-resolution h um an face i mages. 5 2.6 Generative Mod els for Speech Several related gen erative models are applied in realistic speech synthesis. WaveNet [69] is an audio gen eration network based on deep autoregressive models that are used for image generatio n (e.g. PixelRNN [70 ]). WaveNet has no recurrent connections , which increases training spee d at the co st of increasing the depth o f the neural network . In W aveNet, a tec hnique called d ilated convolution has been found effective in expo nentially increasing the context region with the dep th of neural network. W aveNet also utilizes residual con nections as d escribed in Section 3. 1. Authors i n [69] have used c onditioning o n WaveNet to enable text- to -speech (TT S) generation that yields the state - of -th e-art performance when grad ed b y h uman liste ners. Waveglow [71] is another model t hat co m bines WaveNet and GLOW for frequency repr esentation of text seq uences as input to generate realistic speech. Another model, k nown as the Speech Enha ncement Generative Adversarial Net w ork (SEGAN) [72], use s deep learning and avoids preprocessing speech using spectral domain tec hniques. T he authors use a co nvolution aut oencoder model to input spe ech and output enhanced speech, and train in a generative adversarial setting. Another work [73] modifies the SEGAN autoencode r m odel in the context of Wassers tein GAN to perform noise-robust speech enhance m ent. 2.7 Recurrent neu ral networks Another variant of neural networks, known a s the recurr ent neural network ( RNN), captures useful te mporal p atterns in sequential data such as speech to augme nt recognition per form ance. An RNN arc hitecture includes hidden la y ers t hat retain the memory of past elements of an input seq uence. Despite effectiveness i n modeling seq uential data, RNNs have challenges using the traditional backpropagation technique for tr aining with a sequence o f data with large r degrees of separation [38]. T he long short-term memor y (LSTM) networks alle viate this shortcoming with special hidden units known as “gates” that can effectivel y control th e scale o f infor mation to remember or for get i n t he b ackpropagation [38]. Bidirectional RNNs [74] consider context from the past as well as t he future to process seque ntial data to im prove performance. T his, however, can hinder real-time operation as the entire sequence must be available for processing. A modification to LSTM, called Gated Recurrent Unit (GRU) [75] , has been introduced in the conte xt of machine translatio n. The GRU has shown to per form well on tra ns lation problems w ith short sentences . Several variations of LSTM including GRU are compared in [76]. The authors in [76] demonstrate experimentally that, in general, the original LSTM structure i s superior for various recog nition tasks. LST M is a p ow er ful model, however , recent ad vances in attention-based m odeling have shown to have better p erformance than RNN models for sequential a nd context based information processing [39] . 2.8 Attention in Neural Networks The process of attention is a n i m portant p roperty o f human perceptio n that greatl y impro ves the efficacy o f biological vision. The ‘attention pr ocess’ allows h umans to selecti vely focus on particular sections of the visual s pace to obtain relevant info rmation, avoiding the n eed to process the entire scene at once. Consequently, th e attention provides several advantages in v ision proc essing [77], such as dr astic reduction of computation al co m plexity due to the reduction of processing space and improved perfo rm ance as the objects of importa nce can always be central ized in the processing space . Additio nally, a ttention models provide noise reduction or filtering by avoiding the processing of irrelevant information in the visual scene and selective fixations over time that allow a contextual representatio n of t he scene w ithout ‘clutter’. He nce, the adoption o f such m ethodolog y for neural n etwork -based vision and speech processi ng is highly desirable. Early st udies have i ntroduced attentio n by mea ns of salie ncy ma ps (e.g., for mapping o f points that may conta in i m portant information in an image) . A more recent attempt has introduced attention to deep learning models. A seminal stud y by Laro chelle et al. [78] models attentio n in a third-order Boltzmann machine that is able to accumulat e information of an overall shape in an image over several f ixations. The m odel is only able to see a small ar ea of an input i mage, and it learns b y gathering inform ation through a sequence of fixatio ns over parts of the i m age. T o learn the sequence of fi xations and the overall classificatio n task, the authors in [78] have introduced a hybrid-cost for the Boltzmann machine. This model shows similar perfor mance to deep learning variants that use the whole input i mage for cla ssification. Another stud y [79 ] proposes a two-step s ys tem for an atten tion-based model. Fir st, the w hole input image is a ggressively downsampled and pro cessed to identify candidate locations that may contain important in formation. Next, ea ch location is visited by t he model in its original resolut ion. The information co llected at each location is aggregated to make the final decision. Similarly, Denil et al. [80] have proposed a two-pathway model fo r obj ect tracking, where one focuses on objec t recogn iti on and the other pathway works on re gulating the attention process. However, ‘ learning w here and w hen to attend’ is difficult as it is highly dependent o n the input and the ta sk . It is also ill -de fined in the sense that a particular sequence of fixations cannot be explicitly dictated as gro und truth. Due to this cha llenge, most recent studies o n deep learning with attentio n have e mployed rei nforcement learnin g (RL) for regulatin g the attention asp ect of the m o del. Accordingly, a seminal stud y b y Mnih et al . [ 77] builds a reinforcement lear ning policy on a two -path recurrent deep learning model to simultaneously learn the attention p rocess and the recognition task. Based on similar principles, Grego r et al . [81] propose a recurrent architect ure for i mag e generation. T he pro posed architecture uses a selecti ve attent ion proce ss to trace outli nes and generate d igits si milar to a human. Another study [82] utilizes the selecti ve attentio n process for image captioni ng. In this st udy , the RL based atte ntion p rocess lear ns t he sequence of g lim pses th rough the input image that best describes the scene repres entation. Conversely, Mansimov et al. [83] leverage the RL b ased selective attention on an image caption to ge nerate new images described in the caption. In this approach, the attention mechani sm learns to focus on each word in a sequential manner that is most relevant for image generation. Despite impressive performance in learning selecti ve attention using RL, deep RL still involves add itional 6 bu rdens in developing s uitable policy functions t hat are extre m ely task specific, and hence, are not generalizable. R L with dee p learning also frequentl y suffer s from instability in trai ning. A different set o f studies on designi ng neural network system s are analogous to the Turing machine architecture that suggests the use of an attention p rocess for in teracting with external memory of the overall system. In this ap proach, the p rocess of attentio n is implemented using a neural controller and a memory matrix [84] . The atten tional focusing allows selectivity of access, which is necessary for m emory control [84]. The neural Turing machine w ork is further explored in [85] considering attention-based global and loca l focus o n an input sequence for mac hine tra ns lation. In [86], an atte ntion mechanism i s combined with a bidir ectional LSTM network for speech re cognition. In [87], the authors, inspired by LST M for NLP, add a trust gate to augment LSTM for applications i n human s keleton-based action rec ognition. V aswani et al. [39] use a n attention module called ‘ T ransf or m er ’ to completely replace r ecurrency in language translation problems. T his model is able to achieve improved perfor m ance on English - to -German and English- to -French translation. Zhang et al. [88] propose self-attention generative adversarial networks (S AGAN) for i m age generation . A sta ndard convolutional layer can o nly cap ture loca l dependenci es in a fixed shape w indow. Attentio n mechanism allows the discriminator and gen erators of the GAN model to operate over lar ger and arbitrarily shaped context regions [88] . In order to sho w the growth in d eep learning models, Figure 3 summarizes the searc h results with model na m es found i n th e article abstracts as o f 2019. 2.9 Neural Architecture S earch Neural architect ure search (NAS) involves auto mated selection of t he arc hitectural parameters o f a neural network. In [89 ] architectural p arameters includ ing CNN filter size, stride, and the number o f filters in a given convol ution al la yer are selected using N AS. Additionall y , sk ip connections ( discussed in Section 3.1) are auto m atically selected to generate densely connected CNN. T he method in [ 89] uses reinforce m ent lear ning to train a n RNN to generate ar chitectur al para m eters of a CNN. A more recent method, called the Dif f erential Architecture Search (D ARTS) [90 ], avoid s the reinforcement learning parad igm a nd formulates the problem of par ameter selection a s a differentia ble function that i s amenable t o gradient descent. The gradient descent formulation improves perfor mance over rein f orcement learning and drastically reduces computational time to p erform the search. Another work, k nown as the p rogressive neural architecture search [9 1], performs a search o ver CNN architectures . They begin with a simple structure and progr ess through a parameter search space toward more co m plex CNN mod els. T hey are also able to reduce the search time a nd s pace for the optimal architecture when compared to reinforce m ent lear ning methods . The y have reported the state- of -th e-art p erformance on the CIFAR-10 i mag e classification dataset. Section 3 elaborates on t he contr ibutions of these deep lear ning m odels to vario us vision and speech r elated applications. 3 D EEP L EARNI NG IN V ISION AND S PEECH P RO CESSING This section discusses t he impact of neural net w orks that are driving the state- of -the-art intellige nt vision and speech syste m s. 3.1 Deep learn ing in computer vision Image classification and scene labeling: The CNN m o del is f irst introduced to perform recognition of ten hand- w ritten digits using im age exam ples from the MNIST database. T he proposed CNN m odel h as s hown significant performance improvement in hand-written digit recogniti on task compared to earlier state- of -the-art machine learning techniques. Since then CNNs have seen several evolutions and the current versions of CNN are trem endously successful in solving m ore complex and ch allenging image rec ognition tasks [21, 3 3, 92, 93]. For ex ample, Kr izhevsky et al. [33] utilize a deep CNN architecture n amed ‘A lexNet’ for so lving the I m ageNet classification c hallenge [94 ] to classif y 1000 obj ects from high - resolutio n natural image s. T heir Figure 3. Sear ch for article s showing incre asing prominen ce of dee p learning techniques 7 proposed CNN architecture has considerably outper formed previous state - of - the-art methods during the earliest attempt with the ImageNet classi fication challenge. The image reco gnition performance graduall y improved as reported in several publications s uch as GoogleNet [93 ], VGGNet [95 ] , ZFNet [96] and ResNet [9 7], following the i nitial succes s of AlexNet. More recently , He et al. [98] have ex tended A lexNet to demonstrate that a car efu lly trained deep CNN model is ab le to surpass human-level recognition perfo rman ce, reported in [94] on the I m ageNet dataset. AlexNet [ 33] and GoogLeNet [93] are two of the pio neering CNN ar chitectures that have si gnificantly improved image classificati on performance co mpared to the conventional hand-engineered co m puter vision m odels. However, a lim itation of these m odels is the vanishing grad ient problem when i ncreasing the number of la y ers to achieve more d epth in learning abstract features. Conseque ntly, a more sophisticated CNN architecture, such as ResNet [97], h as been proposed by incorporating “residual block” in the architecture. A residual block is essentia lly a block with a convolutional op eration and a skip connection that are combined into an out put. The skip connection directly passes the input with no trans f ormation. T his allo ws the mo del to achieve ver y deep structures providing a r emedy to the vanishing gradient problem. Densely connected n etworks are in troduced by Huang et al. [99]. They allow forward connections bet w een any two convolutional layers called ‘ skip ’ co nnections . Th ese con nections b etween further-separated layers further reduces vanishing gradient an d improves efficiency with reu se of features. Another architecture called squeeze-and-excitation [100] considers channel-wise dependencies i n convolutional feature maps. This is performed by calculating the mean stati stic for each channel and us ing this to infor m a rescaling of the feature m ap s. R ecently, a technique called EfficientNet [101] is used for scaling of the CNN m odel. The authors first ap ply Neural Architecture Search (described in Section 2.8 ), and then unifor mly scale network d epth, width, a nd resolution simultaneously. T his met hod has yielded the state- of -the-art performance in image rec ognition with an order of magnitude les s par am eters. The r eduction in parameters here also implies faster inference. I n Section 4 , we extend this disc ussion of efficient net w orks for app lications in limited resource environ ments. Scene labeling is another computer vision app lication that involves assi gn ing target classes to multiple portions of an image based o n the local con tent. Farabet et al. [92 ] have pro posed a scene labeling method using a multiscale CNN th at yields record accuracies on several scene lab eling prob lem datasets with up to 17 0 classes. CNNs have also de m onstrated the state- of -th e-art p erformance in o th er com puter vis ion applications, su ch as in human face, action, expression, and pose recognitions. Table I shows performance error rates of the neural networks d escribed above fo r image classification. Human face, actio n, and pose recognition: Hum an-centric recognitions ha ve long been an activ e area of r esearch in computer vision. A rec ent app roach in huma n face recognition is dedicated to improving the cost function of neural networks. T h e objective of su ch cost f unction f or face rec ognition is to maximize interclass variation (facial variations between human individuals) and minimize i ntraclass variation (facial variations within an individual due to facial expr ession s). W ang et a l . [102] have constructed a cost function called large margin cosine loss (LMCL) , which achieves the d esired variational properties . Using LMCL, thei r pr oposed model is able to achieve the state- of -the-art perfo rmance on several face reco gnition benchmarks. Following this work, Deng et al. [10 3] reformulated the cost function for face recognition. T heir cost function Additive An gular Margin Lo ss (ArcFace) is shown to further increase the margin b etween different face classes. ArcFace is shown to further improve face recognition p erformance on a large e xperimental stud y of 10 datasets. Several CNN-based models are propo sed in the lite rature to perform human acti on recognition. An architectur al feature called temporal p y ramid pooling is used in [104] to capture details from every fram e i n a video and is shown to perform actio n classification w ell with a s m all tr aining set. Another ar chitecture, called the t w o -stream CNN, an alyzes b oth spatial and temporal context i ndependently and gives co mpetitive result s on standar d video action benchmarks [95] . CNN architec tures that find pose features in an intermediate layer have been used for human actio n recognition. One of th e m ore successful architectu res f or action recognition is called R*CNN [105] . T his model uses co ntexts fro m the scene with human figure data to recognize actions. Action recognition has been performed using a skeletal representation of human individuals instead of RGB v ideo of the entire body posture. Kinect [10 6] has b een widely used to structure ill umination o f a n individ ual to ob tain a 3 D skeleton measure m ent. Kinect skeletons are mapp ed to co lor im ages representin g 3D data and used as inp ut i n [1 07] for a ResNet CNN. Tang et al. [108] apply reinforcement learning for a graph based CNN (GCNN) that captures s tructural and temporal inf ormat ion from 3D skeleton input. T he authors note th at future w ork may e xploit the graph str ucture in the w eight initialization process. Another T ABLE I S UMMARY OF THE SIGNIF I CANT STATE - OF - THE - ART CNN I MAGE CLASSIFICATION RESU LTS (* ACTUAL CLASS ERROR W ITHIN TOP 5 PREDICTIONS , ** PIXEL C LASS ERROR ) Architecture Dataset Error rate AlexNe t [33] - University o f Toronto 2012 Imagenet (natur al images) 17.0% * GoogLeN et [ 93 ] - Google 2014 Imagenet (natur al images) 6.67% * ResNet [71] - Micro soft 2015 Imagenet (natur al images) 4.70% * Squeeze & Excitation [ 100 ] – Oxford 2018 Imagenet (natur al images) 2.25% * Multiscale CNN [ 92 ] - Farabet et al. 2013 SIFT/Barcel ona (scene label ing) 32.20% ** 8 approach [109] uses r aw depth maps and intermediate 3D skeleton features i n a multiple channel CNN. A fusio n method is applied to the output of different CNN channels, to leverage b oth modalities. This work impro ves accuracy on a b enchmark with a large number of actio n classes. CNNs are used in hu m an pose estimation, for example, Deep Pose [20] is the first CNN ap plication to p ose estimation, which has o utperformed earlier methods [110] . Deep P ose is a cascad ed CNN based p ose estimation frame w ork. The cascad ing allows th e model to lear n a n initial pose esti mation based on the full image followed b y a CNN based regressor to r efine the joint predictions using h igher resolution sub -images. T om son et al. [21] propose a ‘Spatial Model’ which incorp orates a CNN architecture w ith Markov Random Field (MRF) a nd off ers impro ved results in human pose esti mation. Adversarial learn in g is applied to 2D im ages in [111] to extend the output pose prediction into 3 D space. Furthermore, new se nsing techniques allow efficient processing of 3D volumetric data using 3D convolutional networks. For example, in [ 112], h uman hand joint locations are estimated in real-time using a volumetric representat ion of input data and a 3D convolutional network . Another work extends po se estimation to dense pose estimation [113] where the goal is to generate a 3D m esh sur face of a n i ndiv idual from 2D images . Saliency detec tion and tracking: Saliency detection aims to identify regio ns of an inp ut image that represent an obj ect class of interest. Recent w ork in saliency detection has prop osed the integration of a C NN with a n RNN. Fo r exa mple, in [114] , RNN is used to refine CNN feature maps by iter atively leveraging deeper contextual information than pure CNN. T he work in [115] extends the idea of RNN feature map refinement b y introduci ng multi-path recurrency, whic h is esse ntially feedback connection from different depths of CNN. Deep learning has also been applied to detect salient objects in video. One of the recent studies has used 3D CNN [116] to capture the temporal in formation, while a noth er study [1 17] incorporates LSTM on top of CNN to capture the temporal i nformation . Recently, Sia m ese CNN has b een prop osed to track objec ts over time in video fram es. A Siamese CNN is a t w o branch CNN that takes t w o input images. The branches merge in t he deep layers to produce an inferenc e on the relation between t he two i m ages. In [118 , 119], Siamese CNN is used to generate information between adj acent imag es patches, which i s used in tracking obj ects . Reinforcement learning is a nother tech niqu e that is applied in [1 20] for tracking biological image features at s ubpixel level. Image gener ation and inpainting : Generative models including VAE, GAN and its variants, and flow -based models have applications in ima ge generation and i m age modification. As mentioned in Section 2.3 -2 .5 , these generative models p erform image generatio n and inpain ting including huma n face image ge neration. T hese models are ca pable of several othe r applications. In [121 ], a method called cycle GAN is used for the u npaired i m age- to -image tran slation pro blem. I mage- to - image translation would typically involve training on scenes where the input and output domai ns are given. For example , pairs of pictures o f day and ni gh t at a location co uld be a tr ainin g set. T hen given a new im age o f a location in the day, the net w ork may outpu t a night image. What cycle GAN accomplishes is even more impressive. T he training is done witho ut image pairs. So , th e day and night i m ages used in training are not fro m the sa m e locations. The network is then trained to convert day i mages into night images. Another important GAN application is photo inpainting. When a part of an image is re m oved or distorted , the network can make a guess of the missing part, for example, face inpainting [122] or n atural im a ge inpainting[123] . A rec ent study has considered partial convolution to p erform inpainting with irregular ly removed region s [124] . A r elated application of GAN is semantic image ge neration. P arts of an image have se m antic lab els and the goa l is to generate an image matchi ng t he labeling. The authors i n [57] use conditiona l GAN to generate high-resolution realistic i mages from semantic maps. A video prediction m odel based on flow networks ha s success co m parable to VAE in short-period pr ediction of future frames [1 25] . T ABLE II C OMPARISON OF C ONVOLUTIONAL N EURAL N ETWORK MODE L C ONTRIBUTIONS Architecture Application Contribution Limitations He et al. [ 98 ] AlexNe t Variant Image Classification First human le vel image classifica tion performance (incl uding fine grained tasks e .g. 100 dog bree ds differe ntiation). Used ReLu gene ralization and trai ning Misclassification o f image cases that require contex t Farabet et al. [ 92 ] Multiscale CNN Scene Label ing Weight sharing at multiple scale s to capture context without increasing number of trainable parameters. Gl obal application of graphical model to ge t consistent label s over the image Does not apply unsupervised pretraining Wang et al. [ 104 ] Tempor al Pyramid Pooling CNN Action Recognition Tempor al pooling for action class ification i n videos of arbitrary le ngth reduces the chance of overlooking import ant frames in decision Challenging sim ilar actions ofte n misclassifie d Tomson e t al. [21] Joint CNN / Graphical Mo del Human Pose Estimation Combining MRF with CNN al lows prior bel ief about joint config urations to imp act CNN body part detection This model w orks well fo r constrained set of human poses, gener al space of human poses re mains a challenge Ge et al. [112] 3D CNN Human Hand Pose Estimation Volumetric proce ssing of hum an depth m aps of human hands us ing 3D CNN. 3D reasoning impro ves occlude d finger estimation Inhere ntly constrained mode l. Require s clean and presegme nted hand regions fo r pose estimation. T he acceptable range of hand join t motion is lim ited. 9 Table II summarizes variants of CNN highlighting their contributions for various computer vision applications with pros and cons. A co mmon theme of CNN models is that these archit ectures can perform at human level or even better only for simpler tasks. In [98], the authors note that w hen images require context to explain in im age classification, there are more m is classified cases. A similar challen ge is observed in human action reco gn ition tasks using visual dat a or images. Authors in [104] have reported that similar hu man ac tions are m ore challe nging to classify using machine algorithms. In [21] , the mod el only works well for a constrained set of human poses. When the classifica tion proble m s become very difficult such as an arbitrary view or context dependent tas ks, the architectures of vision algorith ms still have roo m to improve. 3.2 Deep learn ing in speech recognition In addition to offering excellent performance in image recognition [21, 33, 92, 93], deep le arning m odels have also shown state- of -the-art performance in speech recog nition [126- 128] . A si gnificant milestone is ac hieved in acoustic m odeling research with the aid of DBNs at multiple institutions [127] . Follo w ing the wo rk in [28], DBNs are trained in layer- wise fashio n follo w ed by end - to -end fine-tu ning for speech app lications as sho wn in Fi g. 2 above. T his DBN architecture and tr aining process has b een extensively tested on a number of large -v ocabulary speech rec ognition datasets including T IMIT, B ing-Voice-Search speech, Switchboard speech, Google Vo ice Input speech, YouTu be speech, and the English -Broad cast-News speech datas et . DBNs significantly outperform state - of - the-art methods in speech reco gn ition when compared to highly tuned Gaussian mixture model (GMM)-HMM. S AEs likewise are shown to outperfor m (GMM) -HMM on Cantonese a nd other speech recognition tasks [43] . RNN has succeeded in improving speech recognition perfor m ance because of its ab ility t o learn seq uen tial patterns as seen in speech, lan guage, or time-ser ies data. RNNs have c hallenges in using trad itional backpro pagation technique for training suc h models. T his technique has difficulties in using memory to proce ss portions of a sequence with larger degrees of separation [39] . The problem i s addressed with the develop m ent of lo ng short-ter m m emory (LSTM) netw orks that use special hidden units known as “gates” to retain memory over longer portions of a sequence [40]. Sak et al. [129] first studied the L STM architecture in speech recognition over a large vocabulary set . Their d ouble-layer deep LSTM is found to be superio r to a baseline DBN model. LSTM has b een succe ssful in a n end- to -end speech learning m ethod, kn own as Deep -Speech-2 (DS2), for tw o large ly different languages: English and Mandari n Chinese. Other speech recognition studies using a n LST M network have s hown significa nt perfo rm ance improvement compared to previous state - of -the-art DBN based models. Furt herm ore, Chien et al. [ 130] performed an extensive experiment with various LSTM ar chitectures for speech rec ognition a nd co m pared the pe rformance w ith state- of -the-art models. The LSTM m odel is extended in Xiong et al . [131] to bidirectional LSTM. This BLSTM is stacked on top of convolutional layers to i m prove speech recognition performance. The inc lusion of at tention enables LSTM models to outper form purely recurrent architectures. An attention m echanism called Listen, Attend, and Spell (LAS) is used to encode, attend, and decode , respectively . This LAS module is used with L STM to improve speech recognition performance [132] . Using a pretraining technique [13 3] w ith attention and L STM model, speech recognition perfor m ance has been improved to a ne w state- of -the-art level . To summarize k ey results in speech recognition using DBNs, RNNs ( inclu ding LSTMs), and attention models , Another memory network based on RNN is proposed by Weston et al. [134] to recognize speech content. T his memory n etwork stores pieces of inf ormation to be able to retrieve the answer related to the inquiry, making it unique and distinctive fro m s tandard RNNs a nd LSTMs. RNN-based m odels have reac hed far be yon d sp eech recognition to support natural language p rocessing (NLP). NLP aims to interpret language a nd semantics from speec h or text to perform a variety of intelligent tasks, such as responding t o hum an speech, smart assista nts (Siri, Alexa, and Cortana), analyzin g sentiment to identify po sitive or negative attitude towards a situation, processing e vents o r news, and langua ge tra nslation in b oth sp eech a nd texts. Table III summerize s d ifferent architectures, d atasets used and perf orm ance error rates achieved b y the state - of - the-art speech reco gnition models. T ABLE III S UMM ARY OF THE SIGNIF I CANT STATE - OF - THE - ART DNN SPEECH RECOGNITION MODELS (* PERPEPLEXITY - SIZE OF MODEL NEEDED FOR OPT I MAL NEXT WO RD PREDICTION WITH 10K CLASSES , ** WORD ERROR RA TE ) Architecture Dataset Error rate RNN [126] - FIT, Cze ch Republic, Johns Hop kins University , 2011 Penn Corpus (natural language modeling) 123 * Autoencoder /DBN [ 128 ] - Collaboration, 201 2 English Broadcast Ne ws Spe ech Corpora (spoken wor d recognition) 15.5% ** LSTM [129 ] - Go ogle, 2014 Google Voice Search T ask (spoken word reco gnition) 10.7% ** Deep L STM [130 ] - National Chiao T ung Univer sity, 2016 CHiME 3 Chall enge (spoken wor d recognition) 8.1% ** CNN-BL STM [131] - Microsoft, 2017 Switchboard (spoken wor d recognition) 5.1% Attention (LA S) & LSTM [132] - Google , 2018 In -house google dictation (spoken wor d recognition) 4.1% Attention & L STM with pre training [133] - Collaboration, 2018 LibriSpee ch (spoken wor d recognition) 3.54% 10 Although R NNs/LSTMs ar e standard in sentiment analysis, authors i n [135] have proposed a novel no nlinear architecture of multiple LSTMs to capture sentiments from p hrases that constitute di ff erent order of the words in natural la nguage. Researchers from Goo gle machine lear ning [13 6] have developed a machine-based language trans lation s ys tem t hat runs Google’s pop ular online translation service. Although this system has been able to reduce average error by 60% compared to the previous system , it suffers fro m a few li mitations. A more efficient translator is used by neural machine translator (NMT) [136] where an entire sentence is i npu t at one time to capture better context and meaning instead of i nputting se ntences b y parts as i n traditional methods. More recentl y , a hybrid appr oach, combining sequential language patterns fro m LST Ms and hierarchical lear ning of images fro m CNNs, has emerged to describe im age co ntent and co ntexts using nat ural language descriptions. Karp athy et a l. [137] introduced this hybrid approach for i m age ca ptioning to incorpo rate both visual data a nd languag e d escriptions to ac hieve optimal per formance in image captioning across several datasets. Table IV summarizes variants of RNN , their pros and cons, and contributions to state- of -the-art speech recognitio n systems. Similar to vision tas ks, a common t heme e merges for RNN model s in sp eech recognitio n tasks as these architectures can per form at human level o r even better for si m pler tasks. For both CNNs and RNNs, the ar chitecture is inherently drive n by the problem domain. For example: multis cale CNN has been used to gather context for labeling across a scene [92], temporal pooling to understand actions across tim e [104] , MRF graphical modeling on top of CNN to form a prior belief of body poses [21 ], long term memory co m ponent for conte xt retrieval in stories, and CNN fused with RNN to inter pret images using la ngu age. In [99] , the authors note that the question and input stories are rather simple for the neural models to handle. In [10 1], the authors report that especially difficult translation prob lem s are yet to be successfully addressed in current studies. As tasks beco m e m ore complex or highly abstract , a m ore sophisticated intelligent system is required to reach human leve l performance. Speech e m otion and visua l speech reco gn ition are two important topics that have gained rec ent attention in deep learning literature. Mirsamadi et al. [138 ] have used a deep recurrent network with local attention to auto m atically learn speec h features from a udio signals. T heir proposed RNN captures a lar ge context region, while the atte ntion focuses on aspects of the speech relevant to e m otion d etection. This idea is later extended in Chen et al. [139] where o peration on frequency b ank repr esentation of spee ch signals ca n be used as inpu ts into a co nv olutional layer. T his convolutional layer is follo wed by LST M and attentio n layers. Mirsamadi et al. have further improved the work of Chen et al. to yield the stat e- of - the-art p erformance on Interactive Emotional D y adic Motio n Capture (IEMOC AP) e m otion reco gn ition ta sks. Another work in [140] applies adversarial auto-encoder for emotion recognition in speech . However, they use heuristic features as network input includin g spectral and ener gy features of speech in the IEMO CAP emotion recognition task. Visual speech rec ognition involves lip reading of human subjects in video data to generate text captions . Recentl y, two notable studies ha ve used attention-b ased networks for this pr oblem. Afouras et al. [141] use 3D CNN to capture spatio-t emporal information of the face, and a transformer self-attention m odule guides the network for speech extraction fro m the extracted convolutional featu res. Stafylakis et al. [142 ] consider zero -sh ot key w ord spotting, where the phrase is not seen in training and is search ed for in a visual spee ch video. T he input video is first fed to a 3D spatial -tem poral residual network to capture face information over time. This is followed by attention and LSTM layers to predict the presence of th e phrase in the video as well as the moment in time of the phrase. Bo th studies consider “in the wild” speech recognition or a large breadth of natural sentences in speech. 3.3 Datasets for vision a nd speech applica tio ns Several current datasets have been compiled for state - of - the-art benchmarking of compu ter vision. ImageNe t is a large -s cale dataset of annotated images including bounding boxes. T his dataset includes over 14 million labeled images spa n ning more than 20,000 categories [9 4] . CIFAR-10 is a dataset of smaller images that contain a recognizable object class in low resolution. Each image is o nly 32x32 pixels, and there are 10 classes with 60,000 im ages eac h[143 ] . Microsoft Common Obj ects in Co ntext (COCO) provides seg mentation of ob jects in i mages for b enchmarking pro blems i ncluding salienc y detection. This dataset includes 2.5 million instances o f objects in 328K images [144] . More complex image data sets are now b eing developed for UAV deployment . Here detection and tracking take place in a highly unconstrained environment. T his includes different w eather, obstacles, occlusions, and v aried camera orientation relative to the flight pat h. Recentl y, two large scale datasets were rele ased for benchmarking detection and tracking in U AV app lications. The Unmanned A erial Vehicle Benchmark [14 5] includes single and T ABLE IV C OMPARISON OF R ECURRENT N EURAL N ETWORK MODEL C ONTRI BUTIONS Architecture Application Contribution Limitations Amode i et al. [159] Gated Recurre nt Unit Network English or Chine se Speech Recogn ition Optimized Spee ch Recognitio n using G ated Recurrent Units fo r Spee d of Processing achieving near h uman le vel results Deploy ment requires G PU server Weston et al. [1 34] Memory Ne twork Answe ring questions about simple text stories Integr ation of long term memo ry (re adable and writable) component within neur al netw o rk architecture Questions and i nput stories are still rather simple Wu et al. [ 136 ] Deep L STM Language Translation (e.g. English- to -F rench) Multi-lay er LSTM with attentio n mechanism Especially difficult translatio n cases and multi-sentence in put ye t to be tested Karpathy e t al. [ 137 ] CNN/RNN Fusio n Labeling I mages and Image Reg ions Use of CNN and RNN together to gene rate natural languag e descriptions of image s Fixed image size / req uires traini ng CNN and RNN models se parately 11 multiple bounding boxes for detection and tracking in vari ous flig ht co nditions. An even more ambitious p roject called Vision Meets Drones [146] gathered a dataset with 2.5 million objec t annotations for detection and tracking in UAV urban and suburban flight environments. Speech recognition also has s everal current datasets for state - of -the-art benchmarking. DARPA commissio ned a co llaboration between Texas Instruments and MIT (T IMIT) to m ake a spee ch transcription dataset. TIMT includes 6 30 speakers from several American English dialects [147]. VoxCeleb is a m ore current spee ch dataset, with 1000 celebrities’ voice transcrip tions in a more unconstrained or “in t he wild ” setting [148] . In machine translatio n, Sta nford’s natural language pr ocessing gro up has released several public language transla tion datasets including W MT'15 English -Czech, W MT'14 English -German, and IWSLT'15 English- Vietnamese. The English to Czech and Engli sh to German d atasets have 15.8 and 4.5 million sentence pairs respectively [1 49] . CHiME 5 [150] is a speech recogn ition dataset that contains challenging speech recognition conditions including multiple speaker natural conversation s. A dataset called LRS3-TE D has been compiled for visual speech reco gn ition [151] . This dataset includes hundreds of hours of TED talk videos with subtitles aligned in time at the resolution of single word s . Ma ny other niche datasets can be foun d on the Kaggle Challenge w ebsite f ree to the p ublic. These datasets incl ude diverse com puter vision and spee ch relate d problems . 3.4 Deep learn ing in commercial vision and speech applications In r ecent years, giant co mpanies su ch as Google, Facebook, Apple, Micro soft, IBM, and others hav e adopted deep learning a s one of their core area s of research in artificial intelligence (AI). Goo gle Brain [15 2] focuses on en gineering the deep learning methods, such as tweaking CNN-based architecture s, to obtain competitive recognition performance in various challenging vision applications usin g a large number of cluster machines and high -end GPU-based computers. Facebook conducts extensive dee p learning resear ch in t heir Faceb ook AI Researc h (FAIR ) [153] lab for im age r ecognition and natural la nguage understanding. Many users aro und the globe ar e already ta king advanta ge of this recognition system i n the Facebook app lication. Their next milestone is to integrate the deep learning -based N LP approaches to the Facebook system to ac hieve near human-level per forman ce in understanding language. Recently, Face book ha s launc hed a beta AI assista nt syste m called ‘ M ’ [154] . ‘ M ’ utilizes NLP to s upport more co m plex tasks suc h as purchasin g items, arr ang ing delivery of gifts, booking restaurant reservation s, and making travel arrangements, o r appointments. Microsoft has investigated Cognitive toolkit [155] to show efficient ways to run learni ng deep models across distributed computers. They h ave also implemented an automatic speech recognition system achieving human level conversational speec h recognition [156] . More recently, they have i ntroduced a deep learning- based speech invoked assi stant called Cortana [15 7]. Baidu has studied d ee p learning to cr eate massive GP U systems with Infiniband [158] networks. T heir speech recognition s ystem named Deep Spee ch 2 (DS2) [1 59] has s hown remarkably improved perfor m ance o ver its co m petitors. Baidu is also one of the pioneering research groups to introduce deep lear ning-based self-driving cars with BMW. Nvidia has invested efforts in developing state - of -the-art GPUs to supp ort more efficient and real -time implementation of co m plex deep learning models [160] . Their high-end GPUs have led to one of the most po werful en d- to -end solutions for sel f-driving cars. IB M has recently i ntroduced their cognitive syste m known as Watson [161] . T his sy stem in corpo rates computer vis ion and speech recognition in a human friendly interface and NLP backend. While traditional computer m odels have relied on rigid mathematic principles, utilizing soft w are built upon rules and logic, Watso n ins tead relies on what IBM is callin g “cognitive co m puting” . T he Watson based co gnitive computin g system has already b een proven use fu l across a range of dif ferent applications suc h as healthcare, marketing, sales, customer service, operations, HR, and finance. Other major tech co mpanies that are actively involved in deep learning research include Ap ple [ 162], Amazon [163], Uber [164], and Intel [165 ] . Figure 4 summarizes publicatio n statistics over the past 10 years searching abstract for ‘ deep learning ’, ‘computer vision’, ‘ speech rec ogn ition’, and ‘natural language processing’ methods applied for computer vision and speech processi ng . Figure 4. Tr ends in Deep L earning ap plications in t he literature over the l ast decade 12 Although deep lear nin g ha s revolutionized to day’s i ntelligent sys tems with the aid of computational resources, its ap plications in more p ersonalized settings, such as in e mbedded and mobile hard w are systems , is anot her challenge that has led to an active area of research. T his challenge is due to the extensive req uirem ent of high -po wered and d edicated hard w are for executing the most robust a nd sophisticated deep learning algorithms. Co nsequently, there is a growing nee d for developing more efficient, yet robust deep models in reso urce restricted hardware environ ments. The next sections summarize some recent advances t o develop highly efficient deep m odels that are co mpatible w ith mobile hard w are systems. 4 V ISION A ND S PEECH ON R ESOURCE R ESTRI CTED H ARDWARE P LATF ORMS The success of future vision and speech systems depends on a ccessibility and adap tability to a variety of platfor ms that even tually drive the prospect of commercialization. While so me platforms are intended f or public and p ersonal usage, there are other commercial, industrial, and online -based platforms - all of which requ ire sea m less integration of I S. Ho w ever, s tate- of -the-art deep learning m odels have c hallenges in ad apting to e mbedded hard w are d ue to lar ge m emory fo otprint, high computational complexi ty, and high -power consumption. This has led to the research of improving system per formance in co m pact architectures to enable deployment in resource restricted platforms. T he following sections highlight so me of the major research efforts in integrating sophisticated algorithms i n resource restricted user platfor m s. 4.1 Speech recognition on mobile platforms Handheld devices such as smartphones a nd tablets are ubiquitous in modern life. Hence, a large effort in de velop ing intelligent systems is dedicate d to mobile platforms with a view to reaching out to billions o f mo bile users around t he world. Speech recognition has been a pioneering applicatio n in developi ng smart mobile a ssistants. The voice inp ut of a mobile user is first interpreted usin g a speech recognition al gorithm. T he answer is then retrieved b y an online searc h. The retrieved in formation is then spoken out b y the virt ual mobile as sistant. Major technolog y co m panies, such a s Go ogle [166 ], have enabled voi ce-based content search on Android d evices and a similar voice - base d virtual assistant, kno wn as Siri, is also available with Apple’s iO S devices. This intelli gent application provides mobile users with a fast and convenient hands - free feature to retrieve infor mation. However, m obile de vices, like other embedded syste ms , ha ve computational li mitations and iss ues related to po wer consumption and battery life. Therefore, mobile devices usually send input requests to a rem ote server to process an d send the infor m ation back to the device. T his further brings i n issues related to latency due to wireless network quality while connecting to the serve r. As an example, Key w o rd spotting (KWS) [167] d etects a set of previously de fin ed key w ords fro m speech data to en able hands-free features in mobile devices. The authors in [167] have proposed a low-latency keyw ord d etection method for mobile users using a deep learning-based technique and ter m ed it as ‘ deep KWS ’ . The deep KWS method has not only b een proven suitable for low- powered e m bedded systems but also has outperfor med the baseline Hidden Mar kov Models for b oth noisy and noise -free audio data. The deep KWS us es a f ully connected DNN w ith transfer learning [167] based on spe ech recognition. The netw ork is further optimized for KWS with end - to -end fine-tuning using stocha stic gradient descent. Sainath et al. [168] have introduced a similar ly small footprint KWS s y stem based on CNNs . T he ir proposed CNN uses fewer paramete rs than a standard DNN model, which makes the prop osed sy stem mor e attractive for platforms with resource constrai nts. Chen et al. [1 69] in another study propose the use of LSTM for the KWS task. The inherent recurrent c onn ections in LST M can make the KWS task suitable for reso urce restricted platforms by i m proving co mputational efficienc y. T o support this, the aut hors further show t hat the proposed LSTM outperforms a typical DNN -based KWS m ethod. A typical fr amework for deep learning based KWS system is shown in Fig . 5 . Similar to KWS systems, auto m atic speech recognition (ASR) [17 0] has become increasingly popular with mobile devices as it alleviates the need for tedious t y ping on small mobile devices. Google provides ASR -based search services [166] on Android, iOS, and Chro m e platforms, and Apple iO S devices, which ar e equipped with a conversational assista nt named Siri. Mo bile users can also type texts or emails b y speec h on both Android and iOS devices [171] . However, ASR ser vice is co ntingent on the availability of cellular m obile network since th e recognition task is performed on a rem ote server. This is a lim itation sinc e mobile network stre ngth can be low, inter mittent, or even ab sent at places. Therefore, developing an accurate spee ch recognitio n system in real-time, embedd ed on standalone modern mobile devic es, is still an active area of resear ch. Fig. 5 . Ge neralized frame work of a ke yword spotting (KW S) syste m that utilizes de ep learning. 13 Consequently, embedd ed speech recognition syste ms usin g DNNs have g ained attentio n. Lei et al. [17 0] have achieved substantial i mprovement in ASR p erformance over traditional gaussian mixture model ( GMM) ac oustic models eve n at a much lower footpr in t and memory r equirements. The authors sho w that a DNN model, with 1.4 8 million parameters, outperfor m s the generic G MM-based model while e xploiting only 17 % of the memory used by GM M. Furthermore, the authors use a langua ge model co m pression scheme LOUDS [17 2] to gain a further 60% improvement in the mem ory foo tprint for t he proposed method. Wang et al. [173] propose anoth er compressed DNN-based speech recognition system that is suitable for use in resource restricted platforms. The authors train a stan dard fully connected DNN m odel for speech recognition , compress the network using a sin gul ar value deco mposition m ethod, and then use sp lit vector quantization algorithms to enhance computational efficiency. T he a uthors have achieved a 75% to 80% reduction in memory footprint lowering the memory require ment to a mere 3.2 MB . A dditionally, they achieved a 10% to 50% reduction in co mputational cost with p erformance co m parable to that of the unco m pressed version. In [174] , the authors show lo w-rank r epresentation o f weight m atrices can increase r epresentational p ower per number of parameters. They also co m bine this lo w-rank tec hnique with ensembles of DNN to improv e performance on KWS tas k. T able V summarizes small footprint speech recognition and KWS systems, which are promising for app lication in resource restricted platforms. 4.2 Computer vision o n mobile platforms Real-time reco gn ition of obj ects or humans is an extre m ely desirable feat ure with handheld devices for convenient authentication, identification, navigational assistance, and wh en combined w ith speech recognition, it can even be used as a mobile teaching assistant. Though deep learnin g ha s advanced in spe ech recognition tasks on m obile platforms, i m age recognition sy stems are still challenging to deploy in mobile platfor m s due to the reso urce constraints. In a stud y , Sar kar et a l. [175] use a deep CNN for face recognition application in mobile platforms for the purpose of user authentication. The au thors first identify th e disparities in hardware an d software between m obile devices and typical workst ations in the context of deep learning, such as the unavailability of powerful GPUs and C UDA (an application programming interface by NVIDIA that enables general-purpose pro cessin g in GPU) capabilities. T he study subsequently proposes a pipeline that leverages AlexNet [33] th rough transfer learning [17 6] for feature extraction and then u ses a pool of SVM’s for scale-invariant classificatio n. The alg orithm is evaluated and compared in ter m s o f runtime and face reco gn ition accuracy on several m obile platforms embedde d with various Qualcomm Snapdragon CPUs and Adreo GPUs using t wo s tandard d atasets, UMD- AA [177] and MOB IO [ 178]. The algorithm ha s achieved 96% and 88% accuracies with MOBIO and UMD- AA d atasets, respectively, with a minimum r untime of 5.7 seconds on the Nexus 6 mobile phone (Qualco mm Snapdragon 805 CPU w ith Adreno 420 GPU). In another study, Howard et al. [179] have introduce d a class o f efficie nt CNN models termed ‘MobileNets ’ for m obile and e m bedded vision pro cessing applications. MobileNets models leverage the depthwise seper ability in convolution oper ation to obtain substantial improvements in efficiency o ver conventional CNNs. T he study also define s two global hyper -parameters that co nfigure the width and depth of the MobileNet architecture to represent a compromise between latency and accurac y in the m odel performance. C onducting experiments on multiple vision tasks, such as o bject detection, classification, face recognition, and geo -localization, the authors show approximately seven-fol d reduction in trainable par ameters using Mo bileNet at the cost of losing only 1 % accura cy when compared to conventional arc hitectures. Su et al. [180] have further improved MobileNet by reducing m odel- level and d ata-level redundancies that e xist i n the architecture. Specifically, the authors sugges t a n iterative pruning strategy [181 ] to address model- level red undancy, and a qua ntization strategy [182] to addr es s the data-level redundancy in the ir proposed ar chitecture. The authors show comparable accuracy of the proposed model with a conventional A lexNet on an I mag eNet classificatio n tas k with j us t 4% use of trainable para m eters and 31% of computational operations per i m age inference. Lane et al. [183] have also perf ormed an initial study using two p opular deep learning m odels: CNN and fully connected deep feed-forward networks, to analyze a udio and image d ata o n three hardware platforms : Qualcomm Snapdragon 8 00, Intel Edison, and Nvidia Tegra K1 as these are commonly used in w earable and mobile d evices. T he study includes extensive a nalyses o n energ y consumption, pr ocessing time, and memory footprint on these devices when running severa l state - of -the-art deep m odels for speech and image recognition applications such as the Deep KWS, DeepEar , ImageNet [33], and SVHN [184] (street-view house number recognition). T he study identifies a critica l need for o ptimization of t hese sop his ticated deep models in ter ms of comp utation al complexity and memor y usage for effective deployment in regular mobile platforms. T ABLE V KWS ARCHITECTURES WITH REDUCED COMPUTATIONAL AND MEMORY FOOTPR I NT (* RELATIVE IMPROVEMENT OVER COMPARISON NETWOR K FROM ROC CURVE , **WER ( WORD ERROR RATE ), *** RELATIVE FER ( FRAME E RROR R ATE ) OVER COMPARISON NETWOR K ) Compression te chnique Memory reducti on Error rate (vari ed datasets) DNN improve ment over HMM, 2014 [1 67] 2.1M parameter s 45.5% improve ment * CNN improve ment ove r DNN, 2015 [1 68 ] 65.5K paramete rs 41.1% improve ment * Fixed length vector LSTM, 2015 [1 69 ] 152 K paramete rs 86% improveme nt * Split vector quantiza tion, 2015 [1 73 ] 59.1 MB to 3.2M B 15.8% ** Low rank matri ces / ensem ble training, 2016 [1 74 ] 400 nodes per layer to 100 node s per l ayer -0.174 *** 14 In another stud y , Lane et al. [18 5] discuss the feasibility of incorporating deep learning algorithms in mobile se nsing for a number of signal and image processing applications. They highlight the limitations that deep models for mobile applicat ions a re still imple mented on clo ud-based systems rat her than o n standalo ne mobile d evices due to large computational overhead. However, the authors p oint o ut that mobile architectures have been ad vancing in recent years a nd m a y soon b e able to accomm odate complex deep learning methods i n devices. The authors subsequently implement a DNN architect ure on the Hexagon DSP o f a Qualcomm Snapdragon SoC (standard CPU used in mobile p hones) and co m pare its p erformance with classical machine learni ng algorithms such as decision tree, SVM, and GMM in processi ng activity recog nition , emotion recog nition, a nd speaker identification. They report increased ro bustn ess in perform ance with accep table l evels o f resource use for the p roposed DNN implementation in m obile hardware. 4.3 Compact, efficien t, low power deep lear ning for lightweight speech and vision processing As discussed in sections 4 .1 and 4. 2, hard w ar e constraints p ose a m ajor challenge in dep loying the most ro bust deep m odels in mobile hard w are platfor ms. This has led to a recent research trend that aims to develop compressed but efficient version s of deep models f or speech and vision processing. O ne seminal work in this area i s the development of the so ftware platfor m ‘DeepX’ b y Lane et al. [186] . ‘DeepX’ is based on t w o resource control algorithms. First, it d ecomposes large dee p architectures int o smaller blocks of sub-architectures and then assigns each block to the most ef ficient local p rocessing u nit (CPUs, GPUs, LPUs). Furthermore, the pr oposed software platfor m i s capable of dynamic dec omposition a nd r esource allocation using a resource prediction model [18 6]. Deploying o n two p opular mobile p latf orms, Qualcomm Snapd ragon 800 and Nvidia T egra K1, th e aut hors report impressive i m provements in r esource use by DeepX for four state - of -the-art dee p ar chitectures: AlexNet [33], SpeakerID [187], SVHN [188], and AudioScene in ob ject, face, character, and speaker r ecognition tasks , respectively [186] . Sindhwani et al. [18 9], on the other ha nd, propose a memory efficient method using a mathematical framework of struc tured matrices to represent large dense matrices such as neural network p arameters ( weight m atrices). Structured matrices, such as Toeplitz, Vandermonde, Couchy [190], essentially utilize various parameter sharing m ec hanisms to represent a 𝑚 × 𝑛 matrix with much less than 𝑚𝑛 parameters [1 89] . Authors also show that th e use of structured matrices re sults in substantial improve ments in computations, especial ly in the matrix multiplication o perations encountered in deep architect ures . The co m putation ti me complexity 𝑂 ( 𝑚𝑛 ) is reduced to 𝑂 (𝑚 𝑙𝑜𝑔 (𝑛 )) [189] . This makes both for ward computations a nd backpropagation faster and efficient while training neural netw orks . The authors test th e proposed fram ework on a de ep KWS architecture for mobile speech recognition and compare w it h other similar small footprint KWS models [168]. The results show that Toep litz based compression gives the best m odel com putatio n time, which is 80 times faster than the baseline, at the cost o f onl y 0.4% performance d egradation. They also conclude that the compressed model has achieve d a 3. 6 times red uction in memory footprint co m pared to the s mall footprint model prop osed in [168]. Han et a l. [181] propose a neural network-based three- stage compression scheme k nown as ‘deep compression’ f or reduction of memory f ootprint. The first sta ge called prun ing [191] essentially removes w eak connections in a DNN to obtain a sparse network. The second stage involves trained quantization and w eight sharing applied to the pruned network. The third stage uses Huffman coding for lossless data co m pression i n the net work. Autho rs repo rt reduced energ y co nsumption a nd a significant co m puting speedup in a co m parison bet ween various workstations and mobile hard w are platfor ms . An architecture called ShuffleNet [192] uses two architectural features. Gr oup convolu tion , introduced in [33], is used with channel shuffle architecture in a novel w ay to improve the efficiency o f co nvolutional net w orks . The group convolution improves the speed in proce ssin g i mages and offers comparable performance with red uced model co mplexity. T able VI summarizes res ults from dif f erent studies for compressed network energy consumption executing Ale xNet on a Tegra GPU. Fig ure 6 summarizes publication statistics over the past 5 years on small footprint analysis of dee p learnin g methods for com puter vision , speech processing, and natural language processing i n resource restricted hard w are platforms. T ABLE VI C OMPRESSED ARCHITECTURE ENERG Y AND POWER RUNNING A L EX N ET ON A T EGRA GPU Compression te chnique Execution tim e Energy consum ption Implied power consump tion Benchmark study , 2015 [1 85] 49.1msec 232.2mJ 4.7 W (all layers) Deep X sof tware acceler ator, 2016 [1 86 ] 866.7msec (av erage o f 3 trials) 234.1mJ 2.7 W (all layers) DNN various tech niques, 2016 [1 81 ] 4003.8msec 5.0mJ 0.0012W (o ne layer) 15 5 E MERGING A PPLICATIONS OF I NTELLI GENT V ISION AND S PEECH S YS TEMS We identify three f ields of research tha t ar e s hifting p aradigm through recent ad vances in visio n and speech-related frameworks. First, the q uan tification of human b ehavior and expressions from visual i mage and speech o ffers great poten tials in cyber netics, security and surveillance, for ensics, quantitati ve behavioral science, a nd psychology research [1 93]. Second, the field o f transportation resear ch is rapidl y incorporating intelligent visi on systems for smart traffic manage ment and self-drivi ng technology. Third, neural networks in medical i m age analysis show tre m endous p romise for ‘precision medicine’. This represen ts a vast opportunity to auto mate clinical measure m ents, op tim ize patient outco me predictions, and assist physicians in clinical p ractice. 5.1 Intelligence in behavioral science The field of behavioral science widely uses human annotatio ns and qualitative screening proto cols to study complex pa tterns in human beha vior. These traditional methods are prone to error d ue to high variabili ty i n human rati ng and qualitati ve n ature in behavioral information processing . Many computer vision studies o n h uman beha vior, e. g., f acial expression analyses [194] , can move across discipline s to revolutionize human beha vioral studies with a utomation and precision. In behavioral studies, f acial expressions a nd speech are t wo of the most common means to detect huma ns’ emotional states. Yang et al. use quantitative analysis of vocal idiosyncras y for screening depression severity [23]. Children with neurodevelopmental disorders such as auti sm are kno w n t o have distinctive characteristics i n speech and voice [24] . Hence, computational methods for detecting different ial speech features and d iscriminative models [25] can help in the develo pment of future applications to recognize emotion fro m the voice o f children with autism. Recentl y, deep learning frameworks have b een employed to recognize e m otion fro m speec h data promising more efficient and sop his ticated app lications in the future [26, 27 , 195] . On the other h and, visual images f rom videos are u sed to recognize human behavioral contents [196] such a s f acial expressions, head motion, human pose , and gestures to s upport a variety of applications for security, surveillance, and forensics [197- 199] and human-co m puter interactions [1 9]. The vision-based reco gn ition of facial action units defined by facial action coding system (FACS ) [200] has enab led m ore fin e- grain an alysis of emotional and p hysiological patterns beyond prototypical facial expressions such as happiness, fear, or anger. Several commercial applicatio ns f or rea l-time and ro bust facial expressio n and action unit level analysis have recentl y appea red in the market with co mpanies such as Noldus, Affectiva, and E m otient. W ith millions of facial images available for trainin g, state - of -the-art d eep learning m ethods have e nabled unprecedented accuracies in t hese co mmercially available facial expres sion reco gn ition app lications. T hese ap plications ar e d esig ned to serve a wide range of researc h studi es including classro om en gag ement anal ysis [2 01], consumer preference study in marketing [202 ], behavioral ec onomics [20 3], atypical facial expres sion anal y sis in neurological disord ers [204, 205], and other work in the fields of b ehav ioral science and psychology. The sophisticatio n in face and facial expression analyses may unravel use ful mark ers in diagnosi ng or differentiating individuals with behavioral or affective dysfunction such as those with auti sm sp ectrum d isorder [206] . Intelligent syste m s for human sentiment and expr ession recognition will play lead roles in developing interacti ve human-co m puter s ystems a nd smart virtual assistants in t he n ear future. 5.2 Intelligence in transportation Intelligent transportation systems (IT S) co ver a broad range of research i nterests i ncluding mon itoring driver’s inattention [1] , providing video -based lane tracking and smart assistance to driving [2 ], monitoring traffic for surveillance and traffic flow management [3], and more recently tre men dous intere sts in developing sel f-driving cars [4]. Boj arski et al. have recently used deep learning frameworks such as CNN to obtain steering commands from raw images captured by a f ront-faci ng camera [5]. The system is desi gn ed to operate o n highways, without lane markings, and in places with minimal visual g uidance. Lane change Fig . 6 . Publica tions on smal l footprint im pleme ntations of deep le arning in computer an d vision and spee ch pro cessing 16 detection [2, 6] and pedestrian detection [7] have been studied in computer vision and are rec ently being add ed as sa f ety features in rec ent p ersonal vehicles. Sim ilarly, co m puter vision a ssisted pr ediction of tra ffic character istics, auto matic parking, a nd congestion detection ma y significantl y ease our e f forts in traffic mana gem ent and sa fety. Sophisticated d eep lear ning methods , such as LST M, are be ing used to predict short term tr affic [6 ], and other deep learning frameworks are be ing u sed for predicting traffic speed and flow [8] and f or predicting driving behavior [9]. In [10], the authors suggest sev eral aspects of transportation that will be impacted by intellige nt s y stems. Considering m ultimodal data co llection from roadside sensors, RBM w ill be useful as they are pro ven to handle multimodal data proce ssin g. Considering systems o nboard vehicles, CNN can be combined with LSTM to take action in real-ti m e to avoid accidents and im prove v ehicle efficie ncy . In line with these research efforts, several car manufacturing companies, such as Audi [207] and Tesla [208] , are in active competition for developing next-ge neration self- driving vehicles with the aid of recent develop m ents in neural network based d eep learn ing tec hniques . Ride hailing and sharing is another growing domain in transportation. In ride hailing, there is a significa nt va lu e in predicting pickup demand at different locations to opti mize the transportation s ystem and service. C NN has bee n recently used fo r location-specific de mand of service prediction [209]. Travel tim e pred iction has been p erform ed us ing CNN and R NN to utiliz e road network topo logy and historical trip data [210] . Popular ride sharing services may be nefit fro m recent advances i n reinforce m ent learning. Alabbasi et al. have used deep Q-network (a model based on r einf orcement lear ning) along with CNN to develop an optimal vehicle dispatch p olicy that ultimately improves traffic congestion and emission [211] . 5.3 Intelligence in medicine Despite tre m endous develop ment in medical i maging techniques, the field of m edicine heavil y depends on manual an no tations and visual ass essment of a patient’s anatomy and physiology from medical images. C linicall y trained hum an eyes sometimes miss important and subtle markers in medical images resulting in mis diagnosis. Misdiag nosis or ev en failure to diagnose early c an lead to fatal conseque nces as misdiagnosis is known as the th ird most common cause of death i n t he United States [212] . T he sophisticated deep learnin g models with the availability o f m assive records of multi -institutional im aging databases m ay ultimately drive the future o f precision medicine. Deep learning methods have been successful in medical i m age seg mentation [11] , shape and functional measurements o f organs [14], disease diagnosis [12] , biom arker detection [13] , patients’ survival predictio n fro m images [213] , and many more. Authors in [21 4] have used a h y brid of LSTM and CNN model to predict p atient survival from echocardiographic videos of t he heart motion, which has s hown a prediction accuracy s uperior to that of trained ca rdiologists . Advances in deep neural networks have shown trem endous potential in almost all areas of medical imaging s uch as o phthalmology [215], dental radiography [ 216] , skin cancer im aging [ 217] , brain im aging [2 18], cardiac im aging [219, 220], urology [221], lung imaging [222], stroke imaging [223], and so on. In addition to acad em ic research, m a ny co mm ercial companies, in cluding pioneers in medical imaging such as Philips, Sie m ens, and IBM are investing on large initiatives to w ards incorporating deep lear nin g methods in intelli gent medical image analysis. However, a key chal lenge re mains with the req uirement of large ground truth medical imagin g d ata annotated b y clinical exp erts. W ith c ommercial initiatives, clinical and multi-instit utional collaborations, deep learning-based ap plications may soon be available in cl inical practice. 6 LI MITATIONS OF DEEP COMPUTATI ONAL MODELS Despite unpreced ented success es of neural network s in recent years , we identify a few sp ecific areas that may greatly i m pact the future progress of deep learning in intelligent syste ms. The first area is to develop a robust learning algorithm for deep models that requires a mi nim al amount o f training samples. 6.1 Effect of sample size The cu rrent deep learning m odels require a hu ge a m ount of training examples to achieve state- of -the-art performance. How ever, many app lication do mains may lack s uch a m assive volume of training examples such as in certain m edical imaging a nd behavioral analysis s tu dies. Moreover, prospective acquisition of data may also be expensive in ter ms of b oth human and com puting resources. The superior per f ormance o f deep models comes at the cost of network complexity , which is often hard to optim ize and prone to overfitting w ithout a large number of samples to train hun dre ds and thousands of paramete rs. Many research studies tend to present over-optimistic perfor m ance with deep m odels without proper validation o r p roof of ge neralization across datasets. Some of the solutions su ch as data augmentation [224, 225], transf er learning [226] , and introduction o f Bayesian co ncepts [ 227, 228] h ave laid the groundwork for using small data, w h ich we expect to pro gress over tim e. The second p otential fu ture direction in deep learnin g research may involve impro ving t he ar chitectures to efficiently handle high dimension al i m aging data. In medical i m aging, cardiovascular i m aging in volves time-sampled 3 D images of the heart as 4D d ata. Videos of 3 D models and 3D point cloud data involves processing of large v olumes of data. T he current deep CNN models are primarily designed to handle 2D images. Deep models are often extended to handle 3D volumes by either converting the information to 2D sequences or utilizing dimensionalit y reduction techniq ues in t he preprocessing sta ge. This, in tur n, results i n loss of important information in volume data that may be vital for the analysis. Therefore, a carefully designed deep learning architecture that is capable of efficiently handling raw 3D data similar to their 2 D co un terparts is highly desirab le. Finally, an emerging deep learning resear ch area involves achieving hig h efficiency for data intensive app lications. Ho w ever, the y requ ire careful selectio n of m odels, and m odel parameters to ensure model robustness. 17 6.2 Computation al burden on mobile platfo rms The com putational b urden of deep m odels is one of the m ajor constraints to overco m e in making deep m odels as ubiquitous as the internet of things or to embed in wearable or mobile devices w ithout the connectivity to a remote server . Current state- of -the- art deep lear nin g models utilize an enormous a m ount of hard w are resources, which p rohibit d eploying the m in most prac tical environments. As discussed in s ections 4.1 -4.3, w e believe that improvements in efficiency an d memory f ootprints may e nable the seamless utilizatio n of mobile and w earable d evices. An e m erging deep learning research area inv olves achievi ng r eal -time learning in mem ory-co nstrained applications. Such rea l-time operation will req uire careful selection of learning models, m odel parameterization and sophi sticated hardware- software co-design among other s. 6.3 Interpretability o f models The complexity in network architecture has been a critical factor in providing useful interpretation s of m odel outco m es . In m ost applications, deep models are us ed as ‘black - box’ and optimized using heuristic methods for di fferent tasks. For ex ample, dropout has been in troduced to combat m odel o verfitting [227, 229] which is es sentially deactivating a number of ne urons at random without lear ning whic h neurons and weights are truly imp ortant to optimize the network per formance. Mo re importantly, the importance of input features a nd the i nn er w orking principles are not well u nderstood in deep m odels. Though t here has b een some progress to understa nd the theoretical underpin ning of t hese networks, more w o rk needs to be d one . 6.4 Pitfalls of over- optimism In a few applicatio ns such as i n the game of GO, deep m odels hav e outperfor med huma n performance [2 30] and that has led to the notion that intellige nt systems may replace h uman experts in the future . However, t he vision -based intelligent algorithms may not be solely relied on for critical decision-making such as in clin ical diagnosis without the supervision of a radiologist, especiall y where human lives are at stake . While deep neural networks can perfor m many routine, repetitive, and pr edictive tasks better than human senses (such as vision) can offer , intelligent machines are unable to master many r eal-life inherently human level traits such as em pathy and many m ore. T herefore, neu ral networks are developing intelligent systems th at may be better vie w ed as complementary tools to op timize human performance and decision -making. 7 S UMMARY OF S URVEY This paper systematicall y r eviews the most recent pro gress in innovating sophisticated intellige nt algor ithms in vision and speech, their applicatio ns, an d their li mitations i n imple mentation on most popular m obile and e m bedded devices. The rapid evolution and success of deep learning al gorithms has pioneered many new applications and commercial initiatives per taining to intelligent vision and speech systems, which in t urn are i m proving our daily lives. Despite tremendous success and performanc e gain of deep learning algorithms, there remain substantial challenges in i mplementing standalone vision and speech applications on mobile and resource constrained devices. Fut ure research efforts will reach out to billio ns of mobile phone users with th e most sophisticated d eep learning -based intelligent s ystems. From sentiment and e m otion recognition to developing self -driving intelligent transportation systems, there is a long list of vi sion and speec h application s that will grad ually auto m ate and a ssist human’s vi su al and auditory per ception to a greater scale an d precision. With an overview of em erging applications acro ss many disciplines such a s behavioral science, psychology, transportation, and medicine, this paper serves as an excellent foundatio n for researchers, prac titioners, and applicatio n developers and users. The key observatio ns for this surve y paper are summarized below. First, we provide an o verview of different state - of -the-art DNN algorithms and architect ures in vision and speech applications. Severa l variants of CNN m odels [ 33, 92- 98] are proposed to address critical challenges related to vision-related reco gn ition. Currently, CNN is one of the s uccessful and d y namic areas of research and is dominating state- of -the-art vision systems both in the industr y and academia. In addition, w e briefly survey s everal other pioneering DNN archite ctures, such as DBN s, DBMs , VANs, GANs, V AEs and S A Es in vision and speech rec ognition applications. RNN models are lead ing the current speec h r ecognition systems, especi ally in the emerging app lications of NLP. Several revolutionary variants of RNN such as the n on -linear structure of L STM [130, 231] and the hy brid CNN-LSTM architecture [232] hav e made substantial improvements i n t he field o f i ntelligent speech recognition and automatic i m age captioning. Second, w e ad dress se veral ch allenges for state - of -the -art ne ural networks in adap ting to com pact and m obile platf orms. Despite tremendous success in performance, t he state - of -the-art i ntelligent algorit hms entail heavy computation, m emory usage, and power consumption. Studies on embedded intelligent systems, such as speech recognition and keyword spotting, are focused on adaptin g the most robust deep language models to resource restricted hardware available in mobile devic es. Se veral studies [167 -170, 173] have c ustomized DNN, CNN, and rec urrent LSTM architectures with compression and quantization sc hemes to achieve considerable reductions in memory and computational requirements. Similarly, recent studies o n embedded compu ter vision models suggest lightweight, e fficient deep architectures [17 5, 183, 185] that ar e ca pable o f real -time per f ormance on existing mobile CPU and GPU hardw are. We further identify several studies on developing co m putatio nal algorith m s and so f tware s y stems [181, 189, 233] that greatly augment the efficienc y of co ntemporary dee p models re gardless of the rec ognition task. In addition, we ident ify the need for further research in develop ing ro bust learning algorithms for deep models that can b e effective ly trained using a minimal a m ount of tr aining samples. Also, more co m putationall y efficient architecture is expected to emerge to fully 18 incorporate complex 3D/4D i maging data to trai n the deep models. Moreover, funda m ental r esearch i n hard w are -software co - design is needed to address real- time learning op eration for today’s memory -constrained cyber and p hysical systems. Third, w e identify three areas that are undergoing a paradig m shift largely d riven by vis ion and sp eech-based intelligent systems. The vision or speech-based recognition of hu man e motion and behavior is revolutionizin g a range of disciplines from b ehavioral science and psychology to consumer research and human-computer interactions. Intell igent applicatio ns for driver’s assistant and self-driving cars can greatly benefit from vision -based computational systems f or future traffic management and driverless autonomous services. Deep neural networks in vision-based intellige nt systems are rapidly transforming clinical research with th e promise o f futuristic precision d iagn ostic tools. Finally, we highlight three limitations of d eep models: pitfalls of using small datasets, hardware co nstraints in mobile devices, and the da nger o f o ver-optimism to r eplace human experts by intelligent systems . We hop e this co m prehensive surve y in deep neural networks for vision and speech processing will serve as a key tec hn ical resource for future i nnovations and evolutions in autono m ous systems. A CKNOWL EDGMENT The authors w ould like to ac knowledge partial fun ding of this work by the Natio nal Science Foundation (NSF) through a grant (Award# ECCS 1310353) and the National Institute of Health (NIH) through a grant (NIB IB/NIH grant# R01 EB020683) . Note the views and findings repo rted in this work completely belong to t he authors and not the NSF or NI H. R EFERENCES [1] Y. Dong, Z. Hu, K. Uchimura, and N. Muray ama, "Driver inattention monitoring system for intelligent vehicles: A rev iew," 2011 2010, vol. 12, 2 ed., pp. 596-614, doi: 10.1109/TITS.2010.2092770. [2] J. C. McCall and M. M. Trivedi, "Video-based lane estimation and tracking for driver assistance: Survey , system, and evaluation," vol. 7, ed, 2006, pp. 20-37. [3] N. Buch, S. a. Velastin, and J. Orw ell, "A Review of Computer Vision Techniques for the Analysis of Urban Traffic," IEEE Transactions on Intelligent Transportation Systems, vol. 12, no. 3, pp. 920-939, 2011, doi: 10.1109/TITS.2011.2119372. [4] E. Ohn-Bar and M. M. Trivedi, "Looking at Huma ns in the Age of Self-Drivin g a nd Highly Automated Vehicles," IEEE Transactions on Intelligent Vehicles, vol. 1, no. 1, pp. 90-104, 2016, doi: 10.1109/TIV.2016.2571067. [5] M. Bojarski et al. , "End to End Learning for Self-Driving Cars," arXiv:1604, pp. 1-9, 2016. [Online]. Available: [6] H. Woo et al. , "Lane-Change Detection Based on Vehicle-Trajectory Prediction," IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 1109-1116, 2017, doi: 10.1109/LRA .2017.2660543. [7] W. Ouyang, X. Zeng, and X. Wang, " Single -pedestrian detection aided by two-pedestrian d etec tion," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 9, pp. 1875-1889, 2015, doi: 10.1109/TPAMI.2014.2377734. [8] W. Huang, G. Song, H. Hong, and K. Xie, "Deep A rchitecture for Traffic Flow Prediction: Deep Belief Net works With Multitask Learning," IEEE Transactions on Intelligent Transportation Systems, vol. 15, no. 5, pp. 2191 - 2201, 2014, doi: 10.1109/TITS.2014.2311123. [9] X. Wang, R. Jiang, L. Li, Y. Lin, X. Zheng, an d F. -Y. Wang, " Capturing Car-Following Behaviors by Deep Learning," IEEE Transactions on Intelligent Transportation Systems, pp. 1-11, 2017, doi: 10.1109/TITS.2017.270696 3. [10] A. Ferdowsi, U. Challita, and W. Saad, "De ep Learning for Reliable Mobile Edge Analytics in Intelligent T ransportation Syste ms: An Overview," ieee vehicular technology magazine, vol. 14, no. 1, pp. 62-70, 2019. [11] M. Havaei et al. , "Brain tumor segmentation with Deep Neural Netw orks," Medical Imag e A nalysis, vol. 35, pp. 18-31, 2017, doi: 10.1016/j.media.2016.05.004. [12] S. Liu et al. , "Multimodal Neuroim aging Feature Learning for Multiclass Diag nosis of Alzheimer's Disease," IEEE Transactions on Biomedical Engineering, vol. 62, no. 4, pp. 1132-1140, 2015, doi: 10.1109/TBME.2014.2372011. [13] E. Putin et al. , "Deep biomarkers of human aging: Application of deep neural networks to biomarke r development," Aging, vol. 8, no. 5, pp. 1021-1033, 2016, doi: 10.18632/aging.100968. [14] R. C. Deo et al. , "An end- to -end computer vision pipeline for automated cardiac f unction assessment by echocardiography," CoRR, 2017. [15] M. R. Alam, M. B. I. Reaz, and M. A. M. Ali, "A review of smart homes — Past, present, and future," IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 42, no. 6, pp. 1190 - 1203, 2012. [16] R. S. Cooper, J. F. McElroy, W . Rolandi, D. Sanders, R. M. Ulmer, and E. Peebles, "Personal virtua l assistant," ed: Google Pa tents, 2011. [17] E. W. Ngai, L. Xiu, and D. C. Chau, "A pplication of data mining techniques in customer relationship m an agement: A literature review and classification," Expert systems with applications, vol. 36, no. 2, pp. 2592-2602, 2009. [18] S. Goswami, S. Chakraborty, S. G hosh, A. Chakrabarti, and B. Chakraborty, "A rev iew on application of data mining techniques to co mbat natural disasters," Ain Shams Engineering Journal, pp. 1-14, 2016. [19] S. S. Rautaray and A. Ag rawal, "Vision based hand gesture recognition for human computer interaction: a survey , " Artificial Intelligence Review, vol. 43, no. 1, pp. 1-54, 2015. [2 0] A. Toshev and C. Szegedy, "Deeppose: Human pose estimation via deep neural networks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2014, pp. 1653-1660. [21] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler, "Joint training of a convolutional network and a graphical model f or human pose estimation," in Advances in neural information processing systems , 2014, pp. 1799-1807. [22] S. Srivastava, A. Bisht, and N. Naray an, "Safety and security in smart cities using art ificia l intelligence — A review," in Cloud Computing, Data Science & Engineering-Confluence, 2017 7th International Conference on , 2017: IEEE, pp. 130-133. 19 [23] Y. Yang, C. Fairbairn, and J. F. Cohn, "Detecting depression sev erity from vocal prosody," IEEE Transactions on Affective Computing, vol. 4, no. 2, pp. 142-150, 2013, doi: 10.1109/T-AFFC.2012.38. [24] L. D. Shriberg, R. Paul, J. L. McSw eeny, A. Klin, D. J. Cohen, and F. R. Volkmar, "Speech and prosody characteristics of adol escents and adults with hi gh -functioning autism and Asperger syndrome," Journal of Speech, Language, and Hearing Research, vol. 44, n o. 5, pp. 1097-1115, 2001, doi: 10.1044/1092-4388(2001/087). [25] M. El Ayadi, M. S. Kame l, and F. Karray, "Survey on speech emotion recognition: Features, classification scheme s, and databas es," Pattern Recognition, vol. 44, no. 3, pp. 572-587, 2011, doi: 10.1016/j.patcog.2010.09.020. [26] H. M. Fayek, M. Lec h, and L. C ave don, "Evaluating deep learning architectures for Speech Emotion Recognition," Neu ral Networks, vol. 92, pp. 60-68, 2017, doi: 10.1016/j.neunet.2017.02.013. [27] Y. Kim, H. Lee, and E. M. Provost, "Deep learning for robust fea ture generation in audiovis ual emotion recognition," 2013, pp. 3687- 3691, doi: 10.1109/ICASSP.2013.6638346. [Online]. Av ailable: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=6638346 [28] G. E. Hinton, S. Osindero, and Y.-W. Teh, "A fast learning algorithm for deep belief nets," Neural computation, vol. 18, no. 7, pp. 1527-1554, 2006. [29] G. E. Hinton, "Learning m ultiple layers of representation," Trends in cognitive sciences, vol. 11, no. 10, pp. 428-434, 2007. [30] R. M. Cichy, A. Khosla, D. Pantazis, A . Torralba, and A . Oliva, "Comparison of deep neural networks to spatio -tem poral cortical dynamics of human visual object recognition reve als hierarchical correspondence," Scientific reports , vol. 6, pp. 1-13, 2016, Art no. 27755. [31] N. Kruger et al. , "Deep hierarchies in the primate visual cortex: What can w e learn for computer vision?," IEEE transactions on patter n analysis and machine intelligence, vol. 35, no. 8, pp. 1847-1871, 2013. [32] J. Schmidhuber, "Deep learning in neural networks: A n overview," Neural networks, vol. 61, pp. 85-117, 2015. [33] A. Krizhevsky, I. Sutskever, and G. E. Hinton, "Im agenet classification with deep convolutional neural networks," in Advances in neural information processing systems , 2012, pp. 1097-1105. [34] P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, and P.-A. Manzagol, "Stacked denoising autoencoders: Lea rning useful representations in a deep network with a local denoising criterion," Jo urnal of Mac hine Learning Research, vol. 11, no. Dec, pp. 3371 -3408, 20 10. [35] I. Goodfellow et al. , "Generative adversarial nets," in Advances in neural information processing systems , 2014, pp. 2672-2680. [36] D. P. Kingma and M. Welling, "A uto -encoding va riational bayes," 2 013. [37] L. Dinh, J. Sohl-Dickstein, and S. Bengio, "Density estimation using real nvp," 2 016. [38] Z. C. Lipton, J. Berkowitz, and C. Elkan, "A critical review of recurrent neural networks for sequence learning," arXiv preprint arXiv:1506.00019, pp. 1-38, 2015. [39] A. Vaswani et al. , "Attention is all you need," in Advances in neural information processing systems , 2017, pp. 5998 - 6008. [40] M. Alam, L. Vidyaratne, and K. M. Iftek haruddin, "Novel hierarchical Cellular Simultaneous Recurrent neural Netw ork for object detection," in Neural Networks (IJCNN), 2015 International Joint Conference on , 12-17 July 2015 2015, pp. 1-7, doi: 10.1109/IJCNN.2015.7280480. [41] R. Salakhutdinov, A. Mnih, and G . Hinton, "Restricted Boltzmann mach ines for collaborative filtering," in Proceedi ngs of the 24th international conference on Machine learning , 2007: ACM, pp. 791-798. [42] R. Salakhutdinov and G. Hinton, "De ep boltzmann machines," in Artificial Intelligence and Statistics , 2009, pp. 448-455. [43] J. Gehring, Y. Miao, F. Metze, and A. Waibel, "Extrac ting deep bottleneck features using stacke d auto -encoders," in Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on , 2013: IEEE, pp. 3377-3381. [44] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, "Extracting and composing robust features w ith denoising autoencoders," in Proceedings of the 25th international conference on Machine learning , 2008: ACM, pp. 1096-1103. [45] G. B. Huang, H. Lee, and E. Learned-Miller, "Learning hierarchical representations for face ve rification with convolutional deep belief networks," in Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on , 2012: IEEE, pp. 2518 -252 5. [46] Z. You, X. Wang, and B. Xu, "Investigation of deep boltzmann m achines for phone recognition," in 2 013 IEEE I nternational Conference on Acoustics, Speech and Signal Processing , 2013: IEEE, pp. 7600-7603. [47] G. Wen, H. Li, J. Huang, D. Li, and E. Xun, "Random Deep Belief Networks for Recognizing Em otion s from Speech Signals," Computational intelligence and neuroscience, vol. 2017, pp. 1-9, 2017. [48] C. Huang, W. Gong, W. Fu, and D. Feng, "A research of speech emotion recognition based on deep belief netw ork and SVM," Mathematical Problems in Engineering, vol. 2014, pp. 1-7, 2014. [49] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng, "Convolutional deep belief networks for scalable unsupervised learning of hier archical representations," in Proceedings of the 26th annual international conference on machine learning , 2009: ACM, pp. 609-616. [50] X. Yan, J. Yang, K. Sohn, and H. Le e, "Attribute2image: Conditional image generation from visual attributes," in Eu r opean Conference on Computer Vision , 2016: Springer, pp. 776-791. [51] J. Walker, C. Doersch, A. Gupta, and M. Hebert, "An uncertain f uture: Forecasting from static images using variational autoencod ers," in European Conference on Computer Vision , 2016: Springer, pp. 835-851. [52] S. Semeniuta, A. Severy n, and E. Barth, "A hyb rid convolutional variational autoencoder f or text generation," arXiv p repri nt arXiv:1702.02390, 2017. [53] K. Akuzawa, Y. Iwasawa, and Y. Matsuo, "Expressive speech synthesis via m odeling expressions with variational autoencoder," arXiv preprint arXiv:1804.02135, 2018. [54] S. Reed, Z. Akata, X. Yan, L. Logesw aran, B. Schiele, and H. Lee, "Generative adversarial text to image synthesis," arXiv preprin t arXiv:1605.05396, 2016. [55] C. Ledig et al. , "Photo-realistic single image super-resolution using a generative adversarial network," arXiv preprint, 2017. [56] M. Mirza and S. Osindero, "Conditional generativ e adversarial nets," 2014. [57] T. -C. Wang, M.-Y. L iu, J.-Y. Zhu, A. Tao, J. Kautz, and B. Catanzaro, "High-resolution image synthesis and semantic manipulation with conditional gans," in Proceedings of the IEEE conference on c omputer vision and pattern recognition , 2018, pp. 8798-8807. [58] J. Donahue, P. Krähenbühl, and T. Darrell, "A dversarial feature learning," 2016. 20 [59] J. Donahue and K. Simonyan, "Large scale adve rsarial representation learning," in Advances in Neural Information Processing Systems , 2019, pp. 10541-10551. [60] M. Arjovsky and L. Bottou, "Towards principled me thods for training g enerative adversarial networks," arXiv preprint arXiv:1701.04862, 2017. [61] I. Goodfellow, "NIPS 2016 tutorial: G enerative adversarial networks," arXiv preprin t arXiv:1701.00160, 2016. [62] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, "Spectral n ormalization for generative adversarial networks," arXiv preprint arXiv:1802.05957, 2018. [63] M. Arjovsky, S. Chintala, and L. Bottou, "Wa sserstein generative adversarial networks," in International conference on machine learning , 2017, pp. 214-223. [64] I. Gulrajani, F. Ahmed, M. Arjovsky , V. Dumoulin, and A. C. Courville, "Improved training of w asserstein gans," in Advances in neural information processing systems , 2017, pp. 5767-5777. [65] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. Paul Sm olley, "Least squares generative adversarial networks," in Pro cee dings of the IEEE International Conference on Computer Vision , 2017, pp. 2794-2802. [66] A. Razavi, A. v. d. Oord, and O. Viny als, "Generating Diverse High -Fidelity Images with VQ-V A E-2," arXiv preprint arXiv:1906.00446, 2019. [67] L. Dinh, D. Krueger, and Y. Bengio, "Nice: Non-linear independent components estimation," 2014. [68] D. P. Kingma and P. Dhariwal, "G low: Generative flow with invertible 1x1 convolutions," in Advanc es in Neural Information Processing Systems , 2018, pp. 10215-10224. [69] A. v. d. Oord et al. , "Wavenet: A generative model for raw audio," 2016. [70] A. v. d. Oord, N. Kalchbrenner, and K. Kavukc uoglu, "Pixel recurrent neural networks," 2016. [71] R. Prenger, R. Valle, and B. Catanzaro, "Waveg low: A flow -based generativ e network for speech synthesis," in ICAS SP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Process ing (ICASSP) , 2019: IEEE, pp. 3617-3621. [72] S. Pascual, A. Bonafonte, and J. Serra, " SEGAN: Speech enhancement generative adversarial n etwork," arXiv preprint arXiv:1703.09452, 2017. [73] N. Adiga, Y. Pantazis, V. Tsiaras, and Y. Stylianou, "Speech Enhancem ent for Noise -Robust Speech Sy nthesis Using Wasserstein GAN}}," Proc. Interspeech 2019, pp. 1821-1825, 2019. [74] X. Ma and E. Hovy , "En d- to -end sequence labeling via bi-directiona l lstm-cnns-crf," 2016. [75] K. Cho, B. Van Merriënboer, D. Bahdanau, and Y. Bengio, " On the properties of neural machine translation: Encoder -decoder approaches," 2014. [76] K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink, and J. Schm idhuber, "LSTM: A search space odyssey," IEEE tran sactions o n neural networks and learning systems, vol. 28, no. 10, pp. 2222-2232, 2016. [77] V. Mnih, N. Heess, and A. Graves, "Recurrent models of visual attention," in Advances in neural information processing systems , 2014, pp. 2204-2212. [78] H. Larochelle and G. E. Hinton, "Learning to combine fovea l glimpses with a third -order Boltzmann m achine," in Ad va nces in neural information processing systems , 2010, pp. 1243-1251. [79] M. A. Ranzato, "On learning where to look," 2014. [80] M. Denil, L. Bazzani, H. Larochelle, and N. de Freitas, " Learning where to attend with deep architectures f or image tracking," Neural computation, vol. 24, no. 8, pp. 2151-2184, 2012. [81] K. Gregor, I. Danihelka, A. Graves, D. J. Rezende, and D. Wierstra, " Draw: A recurrent neural network for image generation," arXiv preprint arXiv:1502.04623, 2015. [82] K. Fu, J. Jin, R. Cui, F. Sha, and C. Zhang, "A ligning Where to See and What to Tell: Im age Captioning with Region -Based Attention and Scene-Specific Contexts," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 12, pp. 2321-2334, 2017, doi: 10.1109/TPAMI.2016.2642953. [83] E. Mansimov, E. Parisotto, J. L. Ba, and R. Salakhutdinov, " Generating images from ca ptions with attention," a rXiv preprint arXiv:1511.02793, 2015. [84] A. Graves, G. Way ne, and I. Dan ihelka, "Ne ural t uring ma chines," arXiv p repri nt arXiv:1410.5401, pp. 1-26, 2014. [85] M. -T. Luong, H. Pham, and C. D. Manning, "Ef fective approaches to attention -based neural m achine translation," arXiv preprint arXiv:1508.04025, pp. 1-11, 2015. [86] W. Chan, N. Jaitly, Q. Le, and O. Vinyals, "Listen, attend and spell: A neural network for large vocabulary conversational speech recognition," in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Confere nce on , 2016: IEEE, pp. 4960- 4964. [87] J. Liu, A. Shahroudy, D. Xu, A. C. Kot, and G. Wa ng, "Skeleton -based action recognition using spa tio-temporal LSTM network with trust gates," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 3007-3021, 2018. [88] H. Zhang, I. Goodfellow, D. Metaxas, and A. Odena, "Self-attention generative adversarial networks," arXiv preprint arXiv:1805.08318, 2018. [89] B. Zoph and Q. V. Le, "Neural architecture searc h with reinforcement learning," 2016. [90] H. Liu, K. Simonyan, and Y. Yang, " Darts: Differentiable architecture search," a 2018. [91] C. Liu et al. , "Progressive neural architecture searc h," in Proceedings of the European Conference on Computer Vision (ECCV) , 2 018, pp. 19-34. [92] C. Farabet, C. Couprie, L. Najman, and Y. LeCun, "L earning hierarchical features for scene labeling," IEE E transactions on pattern analysis and machine intelligence, vol. 35, no. 8, pp. 1915-1929, 2013. [93] C. Szegedy et al. , "Going deeper with convolutions," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2015, pp. 1-9. [94] O. Russakovsky et al. , "Imagenet large sca le visual recognition challenge," Interna tional Jo urnal of Computer Vision, vol. 115, no. 3, pp. 211-252, 2015. 21 [95] K. Simonyan and A. Zisserma n, "Very deep convolutional networks for large-s cale image recognition," a rXiv preprint arXiv:1409.1556, pp. 1-14, 2014. [96] M. D. Zeiler and R. Fergus, "Visualizing and understanding co nvoluti onal netw orks," in European conference on computer vision , 2014: Springer, pp. 818-833. [97] Z. Wu, C. Shen, and A. v. d. Henge l, "Wider or deeper: Revisiting the resnet model for visual recognition," arXiv preprint arXiv:1611.10080, pp. 1-19, 2016. [98] K. He, X. Zhang, S. Ren, and J. Sun, "De lving deep into rectifiers: Surpassing human -level perf ormance on imagenet classification," in Proceedings of the IEEE international conference on computer vision , 2015, pp. 1026 - 1034. [99] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, "Densely connected convolutional netw orks," in Proceedings of the IEEE conference on computer vision and pattern recognition , 2017, pp. 4700-4708. [100] J. Hu, L. Shen, and G. Sun, "Squeeze-and-excitation networks," in Proceedings of the IEEE conference on computer vision and pattern recognition , 2018, pp. 7132-7141. [101] M. Tan and Q. V. Le, "Efficie ntNet: Rethin king M odel Scaling for Convolutional Neural Netw orks," 2019. [102] H. Wa ng et al. , "Cosface : Large margin cosine loss for deep face recognition," in Pr oceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 5265-5274. [103] J. Deng, J. Guo, N. Xue, and S. Zaf eiriou, "Arcface: Additive angular m arg in loss for deep face recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2019, pp. 4690-4699. [104] P. Wang, Y. Cao, C. Shen, L. Liu, and H. T . Shen, "Temporal py ramid pooling based convolutional neural networks for action recognition," IEEE Trans. Circuits and Systems for Video Technology, vol. 27, no. 12, pp. 2613 - 2622, 2017. [105] G. Gkioxari, R. Girshick, and J. Malik, "Contextual action recognition w ith r* cnn," in Proceedings of the IEEE international conference on computer vision , 2015, pp. 1080-1088. [106] J. Han, L. Shao, D. Xu, and J. Shotton, "Enhanced computer vision with microsoft kinect se nsor: A rev iew," IEEE transactions on cybernetics, vol. 43, no. 5, pp. 1318-1334, 2013. [107] H. -H. Pham, L. Khoudour, A. Crouzil, P. Zegers, and S. A. Velastin, "Exploiting deep residual netw orks for human action recognit ion from skeletal data," Computer Vision and Image Understanding, vol. 170, pp. 51-66, 2018. [108] Y. Tang, Y. Tian, J. Lu, P. Li, and J. Zhou, "Dee p progressive reinforcement learning for skeleton -based action recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 5323-5332. [109] A. Kamel, B. Sheng, P. Yang, P. L i, R. Shen, and D. D. Feng, "Deep convolutional neural netw orks for human action recognition u si ng depth maps and postures," IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2018. [110] P. F. Felzenszwalb and D. P. Huttenlocher, "Pictorial structures for object recognition," International jou r nal of computer vision, vol. 61, no. 1, pp. 55-79, 2005. [111] W. Yang, W. Ouyang, X. Wang, J. Ren, H. Li, and X. Wang, " 3d hu man pose estim ation in the wild by adversarial learning," in Proceedings of the IEEE Conference on Computer Vision and Pattern Rec ognition , 2018, pp. 5255-5264. [112] L. Ge, H. Liang, J. Yuan, and D. Thalma nn, "Real-ti me 3D hand pose estimation with 3D con vol utional neural networks," IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 4, pp. 956-970, 2019. [113] R. Alp Güler, N. Neverova, and I. Kokkinos, "Densepose: Dense human pose estim ation in the wild," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 7297-7306. [114] T. Wang et al. , "Detect globally, refine locally: A novel approach to saliency detection," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 3127-3135. [115] X. Zhang, T. Wang, J. Qi, H. Lu, and G. W ang, "Progressive attention guided recurrent netw ork for salient object detection," in Proceedings of the IEEE Conference on Computer Vision and Pattern Rec ognition , 2018, pp. 714-722. [116] Z. Wang, J. Ren, D. Zhang, M. Sun, and J. Jiang, "A deep -learning based feature hy brid framework for spatiotemporal saliency detection inside videos," Neurocomputing, vol. 287, pp. 68-83, 2018. [117] H. Song, W. Wang, S. Zhao, J. Shen, and K.-M. Lam, "Pyramid dilated deeper convlstm for video salient object detection," in Proceedings of the European Conference on Computer Vision (ECCV) , 2018, pp. 715-731. [118] L. Leal-Taixé, C. Canton-Ferrer, and K. Schindler, "Learning by tracking: Siamese CNN for robust target association," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recogniti on Workshops , 2016, pp. 33-40. [119] Q. Wang, L. Zhang, L. Bertinetto, W. Hu, and P. H. Torr, "Fast online object track ing and segmentation: A unifying approach," in Proceedings of the IEEE Conference on Computer Vision and Pattern Rec ognition , 2019, pp. 1328-1338. [120] T. Dai et al. , "Deep Reinforcement Learning for Subpixel Neural Tracking," in International Conference on Medical Imaging with Deep Learning , 2019, pp. 130-150. [121] J. -Y. Zhu, T. Park, P. Isola, and A. A. Efros, "Unpaired image- to -image translation using cycle-consistent adversarial networks," in Proceedings of the IEEE international conference on computer vision , 2017, pp. 2223 - 2232. [122] R. A. Yeh, C. Chen, T. Yian Lim, A. G . Schwing, M. Hasegawa-J ohnson, and M. N. Do, " Semantic image inpainting with deep generative models," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2017, pp. 5485-5493. [123] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A . A. Efros, "Context encoders: Feature learning by inpainting," in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 2536-2544. [124] G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, and B. Catanzaro, "Image inpainting for irregular holes using partial convolution s," in Proceedings of the European Conference on Computer Vision (ECCV) , 2018, pp. 85-100. [125] M. Kumar et al. , "VideoFlow: A flow-based generative model f or video," 2019. [126] T. Mikolov, A. Deoras, D. Povey, L. Burget, and J. Černocký , "Strategies for training larg e scale neural netw ork language models," in Automatic Speech Recognition and Understanding (ASRU), 2011 IEEE Workshop on , 2011: IEEE, pp. 196-201. [127] G. Hinton et al. , "Deep neural networks for acoustic modeling in speech recognition: The shared view s of four research groups," IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82-97, 2012. 22 [128] T. N. Sainath, A.-r. Mohamed, B. Kingsbury, and B. Ram abhadran, "Deep convolutional neural networks for LVCSR," in Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on , 2013: IEEE, pp. 8614-8618. [129] H. Sak, A. Senior, and F. Beaufays, "L ong short -term mem ory recurrent neural network architectures f or large scale acoustic modeling," in Fifteenth Annual Conference of the International Speech Communication Association , 2014, pp. 338-342. [130] J. -T. Chien and A. Misbullah, "Deep long short-term memory networks for speech recognition," in C hinese Spoken Language Processing (ISCSLP), 2016 10th International Symposium on , 2016: IEEE, pp. 1 - 5. [131] W. Xiong, L. Wu, F. Allev a, J. Droppo, X. Huang, and A. Stolcke, "The Microsoft 2017 conversational speech recognition sy stem ," in 2018 IEEE international conference on acoustics, speech and signa l processing (ICASSP) , 2018: IEEE, pp. 5934-5938. [132] C. -C. Chiu et al. , "State- of -the-art speech recognition with sequenc e- to -sequence models," in 2018 IEEE International Conference on Acoustics, Speech and Signal Process ing (ICASSP) , 2018: IEEE, pp. 4774-4778. [133] A. Zeyer, K. Irie, R. Schlüter, and H. Ney, "Improved training of end- to -end attention models for speech recognition," arXiv preprint arXiv:1805.03294, 2018. [134] J. Weston, S. Chopra, and A. Bordes, "Mem ory networks," pp. 1-15, 2014. [135] K. S. Tai, R. Socher, and C. D. Manning, "Improved sema ntic representations from tree -structured long short-term memory networks," arXiv preprint arXiv:1503.00075, pp. 1-11, 2015. [136] Y. Wu et al. , "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation," arXiv preprint arXiv:1609.08144, pp. 1-23, 2016. [137] A. Karpathy and L. Fei-Fei, "Deep visual-semantic alignments for generating imag e descriptions," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2015, pp. 3128-3137. [138] S. Mirsamadi, E. Barsoum, and C. Zhang, "A utomatic speech emotion recognition using recurrent neural networks w ith local attention," in 2017 IEEE International Conference on Acoustics, Spe ech and Sign al Processing (ICASSP) , 2017: IEEE, pp. 2227-2231. [139] M. Chen, X. He, J. Yang, and H. Zhang, "3-D convolutional recurrent neural networks w ith attention model for speech emotion recognition," IEEE Signal Processing Letters, vol. 25, no. 10, pp. 1440- 14 44, 2018. [140] S. Sahu, R. Gupta, G. Sivarama n, W. AbdAlmageed, and C. Espy- Wilson, "A dversarial auto-enco de rs for speech based emotion recognition," 2018. [141] T. Afouras, J. S. Chung, A. Senior, O. Viny als, and A. Zisse rma n, "Deep audio-visual speech recognition," IEEE transactions on pattern analysis and machine intelligence, 2018. [142] T. Stafylakis and G. Tzimiropoulos, "Zero-shot keyw ord spottin g f or visual speech recognition in-the-wild," in Proceeding s of the European Conference on Computer Vision (ECCV) , 2018, pp. 513-529. [143] A. Krizhevsky, V. Nair, and G. Hinton, "The CIFA R- 10 d atase t," online: http://www. cs. toronto. edu/kriz/cifar. html, vol. 55, 2014. [144] T. -Y. Lin et a l. , " Microsoft coco: Common objects in context," in European conference on computer vision , 2014: Springer, pp. 740- 755. [145] D. Du et al. , "The unmanned aerial vehicle benchmark: Object detection and tracking," in Proceedings of the European Conference on Computer Vision (ECCV) , 2018, pp. 370-386. [146] P. Zhu, L. Wen, X. Bian, H. Ling, and Q. Hu, " Vision meets drones: A challenge," a 2018. [147] C. Lopes and F. Perdigao, "Phone recognition on the T IMIT database," S peech Technologies/Book, vol. 1, pp. 285-302, 2011. [148] A. Na gra ni, J. S. Chung, and A. Zisserman, "Voxceleb: a large-scale speaker identification dataset," arXiv p repri 2017. [149] Stanford. "Neural Machine Translation." https://nlp.stanford.edu/pr ojects/nmt/ (accessed. [150] J. Barker, S. Watanabe, E. Vincent, and J. Trma l, "The fifth'CHiME'Speech Separation and Recognition Challenge: Dataset, task and baselines," 2018. [151] T. Afouras, J. S. Chung, and A. Zisse rman, "LRS3 -T ED: a large-scale dataset for visual speech recognition," arXiv p repri nt arXiv:1809.00496, 2018. [152] Google. "Google Brain Team's Mission." https://ai.google/research/team s/brain/ (accessed. [153] Facebook. "Facebook AI Research (FAIR)." https://research.fb.co m/category/facebook- ai -resea r ch -fair/ (accessed. [154] T. Simonite, "Facebook’s Perfect, Im possible Chatbot," MIT Technology Review . [Online]. Available: https://www.technologyreview.com/s/604117/facebooks-perfect-impossible-chatbot/ [155] Microsoft. "Cognitive Toolkit." https://docs.microsoft.com/en-us/cognitive-toolkit/ (accessed. [156] W. Xiong et al. , "Achieving human parity in conversational speech recognition," pp. 1-13, 2016. [157] Microsoft. "Cortana." https://www .microsoft.com/en-us/cortan a (acc essed. [158] I. T. Association, "Specification FAQ." [Onlin e ]. Available: http://www .infinibandta.org/content/pages.php?pg=technology_faq [159] D. Amodei et al. , "Deep speech 2: End- to -end speech recognition in english and mandarin," in International Conference on Machine Learning , 2016, pp. 173-182. [160] NVIDIA. "Deep Learning AI." https://www .nvidia.com/en -us/deep-learning-ai/ (acce ssed. [161] IBM. "Watson." https://www.ibm.com /watson/ (accessed. [162] A. Inc. "Apple Machine Learning Journal." https://machinelearning.apple.com/ (accessed. [163] A. W. Services. "Amazon Machine Learning." https://aws.am azon.com/sagemaker (accessed. [164] U. Engineering, "Engineering More Reliable Transportation with Mac hine Learning and AI at Uber." [Online]. Ava ilable: https://eng.uber.com/mac hine-learn ing/ [165] Intel, "Machine Learning Offers a Path to Deeper Insight." [Online]. A vailable: https://www.intel.com/content/www /us/en/analytics/machine-learnin g/overv iew.html [166] J. Schalkwyk et al. , "“Your Word is my Command”: Google Search by Voice: A Case Study," in Advances in Speech Recognition : Springer, 2010, pp. 61- 90. [167] G. Chen, C. Parada, and G. Heigold, "Sm all- footprint keyw ord spotting using deep neural networks," in Acoustics, Spee ch and Signal Processing (ICASSP), 2014 IEEE International Conference on , 2014: IEEE, pp. 4087-4091. 23 [168] T. N. Sainath and C. Parada, "Convolutional neural networks f or small -footprint keyword spotting," in Sixteenth Annual Conference of the International Speech Communication Association , 2015, pp. 1478-1482. [169] G. Chen, C. Parada, and T. N. Sainath, "Query- by -exa m ple keyword spotting using long short-term memory networks," in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Confere nce on , 2015: IEEE, pp. 5236-5240. [170] X. Lei, A. W. Senior, A. G ruenstein, and J. Sorensen, "Accurate and compact large vocabulary speech recognition on mobile dev ices," in Interspeech , 2013, vol. 1, pp. 662-665. [171] B. Ballinger, C. Allauzen, A. G ruenstein, and J . Schalkwy k, "On-demand language model interpolation for m obile speech input," in Interspeech , 2010, pp. 1812-1815. [172] J. Sorensen and C. Allauzen, "Unary data structures for language models," in Twelfth Annual Conference of the International S peech Communication Association , 2011, pp. 1425-1428. [173] Y. Wang, J. Li, and Y. Gong, "Small-footprint high-performance deep neural network-based speech recognition using split-VQ," in Acoustics, Speech and Signal Process ing (ICASSP), 2015 IEEE International Conference on , 2015: IEEE, pp. 4984-4988. [174] G. Tucker, M. Wu, M. Sun, S. Panchapagesa n, G. Fu, and S. Vitaladevuni, "Model Compression Applied to Sma ll -F ootprint Keyw ord Spotting," in INTERSPEECH , 2016, pp. 1878-1882. [175] S. Sarkar, V. M. Patel, and R. Chellappa, "Deep f eature-b ased face detection on mobile devices," in Identity, Security and Behavior Analysis (ISBA), 2016 IEEE International Conference on , 2016: IEEE, pp. 1-8. [176] Y. Bengio et al. , "Deep learners benefit m ore from out - of -distri bution examples," in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , 2011, pp. 164-172. [177] M. E. Fathy, V. M. Patel, and R. Chellappa, "Face-based active authentication on mobile devices," in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on , 2015: IEEE, pp. 1687-1691. [178] C. McCool and S. Marcel, "Mobio database f or the ICPR 2010 face and speech competition," Idiap, 2009. [179] A. G. Howard et al. , "Mobilenets: Efficient convolutional neural netw orks for mobil e v ision applications," arXiv preprint arXiv:1704.04861, 2017. [180] J. Su et al. , "Redundancy-Reduced MobileNet Acceleration on Reconfig urable Logic for ImageNet Classification," Cham, 2018: Springer International Publishing, in Applied Reconfigurable Computing. Architectures, Tools, and Applications, pp. 16 -28. [181] S. Han, H. Mao, and W. J. Dally , "Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding," pp. 1-14, 201 5. [182] S. Zhou, Y. Wu, Z. Ni, X. Zhou, H. Wen, and Y. Zou, "Doref a-n et: Tra ining low bitwidth convolutional neural networks with low bitwidth gradients," 2016. [183] N. D. Lane, S. Bhattacharya , P. Georgiev, C. Forlivesi , and F. Kaw sar, "An early resource characterization of deep learning on wearables, smartphones and internet- of -things devices," in Proceedings of the 2015 International Workshop on Internet of Things towards Applications , 2015: ACM, pp. 7-12. [184] I. J. Goodfellow, Y. Bulatov, J. Ibarz, S. Arnoud, and V. Shet, "Mul ti -digit number recognition from street view imagery using deep convolutional neural networks," pp. 1-13, 2013. [185] N. D. Lane and P. Georgiev, "Can deep learning revolutionize mobile sensing?," in Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications , 2015: ACM, pp. 117-122. [186] N. D. Lane et al. , "Deepx: A software accelerator for low-power deep learning inference on m obile devices," in Information Processing in Sensor Networks (IPSN), 2016 15th ACM/IEEE International Conference on , 2016: IEEE, pp. 1-12. [187] N. Evans, Z. Wu, J. Yamagishi, and T. Kinnunen, "A utomatic Speaker Verification Spoofing and Counterme asures Challenge (ASVspoof 2015) Database," 2015. [188] Y. Netzer, T. Wang, A. Coates, A . Bissacco, B. Wu, and A. Y. Ng, "Reading digits in natural images w ith unsup ervise d feature learning," in NIPS workshop on deep learning and unsupervised feature learning , 2011, vol. 2011, no. 2, p. 5. [189] V. Sindhwani, T. Sainath, and S. Kum ar, "Structured transforms for small -footprint deep learning," in Advances in Neural Informatio n Processing Systems , 2015, pp. 3088-3096. [190] V. Pan, Structured matrices and polynomials: unified superfast algorithms . Springer Science & Business Media, 2012. [191] S. Wang and J. Jiang, "Learning natural language inference with LSTM," pp. 1-10, 2015. [192] X. Zhang, X. Zhou, M. Lin, and J. Sun, "Shuff lenet: An extremely efficient convolutional neural netw ork for mobile devices," in Proceedings of the IEEE Conference on Computer Vision and Pattern Rec ognition , 2018, pp. 6848-6856. [193] R. A. Calvo and S. D'Mello, "Affect detection: An interdisciplinary review of models, methods, and their applications," IEEE Transactions on Affective Computing, vol. 1, no. 1, pp. 18-37, 2010, doi: 10.1109/T-AFFC.2010.1. [194] M. S. Bartlett, G. Littlewort, M. Frank, C. La i nscsek , I. Fasel, and J. Movellan, "Recognizing facial expression: ma chine learning and application to spontaneous behavior," in Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Comp uter Society Conference on , 2005, vol. 2: IEEE, pp. 568-573. [195] E. M. Albornoz, M. Sánchez-Gutiérrez, F. Martinez-Licona, H. L. Rufiner, and J. Goddard, "Spoken Emotion Recognition Using Deep Learning," Springer, Cham, 2014, pp. 104-111. [196] S. Wang and Q. Ji, "Video affectiv e content analysis: a survey of state of the art methods," IEEE Transactions on Affec tive Computing, vol. 6, no. 4, pp. 1-1, 2015, doi: 10.1109/TA FFC.2015.2432791. [197] M. G. Ball, B. Qela, and S. Wesolkow ski, "A review of the use of computational intelligence in the de sign of military su rveillance networks," in Recent Advances in Computational Intelligence in Defense and Security : Springer, 2016, pp. 663 - 693. [198] R. Olmos, S. Tabik, and F. Herrera, "Automa tic handgun detection alarm in videos using deep learning," Neurocomputing, vol. 275, pp. 66 -72, 2018. [199] X. Li et al. , "Towards reading hidden emotions: A comparativ e study of spontaneous micro -expression spotting and recognition methods," IEEE Transactions on Affective Computing, 2017. [200] P. Ekman, Friesen, W. V., & Hager, J. C. , "Facial Action Coding System - Manual and Investigator’s Guide. FACS," Research Nexus, 2002. [Online]. Available: https://doi.org/10.1016/j.msea.2004.04.064. 24 [201] J. Whitehill, Z. Serpell, Y. C. Lin, A . Foster, and J. R. Movellan, "The faces of engagem ent: Autom atic recognition of student engagement from facial expressions," IEEE Transactions on Affective Computing, vol. 5, no. 1, pp. 86-98, 2014, doi: 10.1109/TAFFC.2014.2316163. [202] K. A. Leitch, S. E. Duncan, S. O'Keefe , R. Rudd, and D. L. Gallagher, "Characterizing consumer em otional response to sweetene rs using an emotion terminology questionnaire and facial ex pression analysis," Food Research International, vol. 76, pp. 283-292, 2015, doi: 10.1016/j.foodres.2015.04.039. [203] C. F. Camerer, "Artificial intelligence and behavioral economics ," in Economics of Artificial Intelli gence : University of Chicago Press, 2017. [204] M. D. Samad, N. Diawara, J. L . Bobzien, J. W. Harrington, M. A. Witherow , and K. M. Iftekharuddin, "A Feasibility Study of Autism Behavioral Markers in Spontaneous Facial, Visual, and Hand Movem ent Response Data," IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 26, no. 2, pp. 353-361, 2018. [205] M. Leo et al. , "Computational Analysis of Deep Visual Data f or Quantifying Facial Expression Production," Applied Sciences, vol. 9, no. 21, p. 4542, 2019. [206] M. D. Samad, N. Diawara, J. L . Bobzien, C. M. Taylor, J. W. Harrington, and K. M. Iftekh aruddin, "A pilot study to identify autism related traits in spontaneous facial actions using computer vision," Research in Autism Spectrum Disorders, vol. 65, pp. 14 - 24, 2019. [207] Audi. "Autonomous Driving." https://www.audi.com/en/ex perience-aud i/m obil ity -and-trends/autonomous-driving.html (accessed. [208] Tesla. "All Tesla Cars Being Produced Now Hav e Full Self-Driving Hardw are." https://www.tesla.com/blog/all-tesla-cars-being- produced-now-have-full-self-driving-hardware (accessed. [209] C. Wang, Y. Hou, and M. Barth, "Data-Driven Multi-step Demand Prediction for Ride-Hailing Services Using Convolution al Neural Network," in Science and Information Conference , 2019: Springer, pp. 11-22. [210] S. Das et al. , "Map Enhanced Route Travel Time Prediction us ing Dee p Neural Networks," arXiv preprint arXiv:1911.02623, 2019. [211] A. Alabbasi, A. Ghosh, and V. Agga rwal, "Deeppool: Distributed model -f ree algorithm for ride-sharing usin g deep reinforcem ent learning," 2019. [212] M. Daniel and M. A. Makary , "Medical error — the third leading ca use of death in the US," Bmj, vol. 353, no. i2139, p. 476636183, 2016. [213] A. Ulloa et al. , "A deep neural network predicts survival af ter heart imaging better than cardiologists," arXiv p reprint arXiv:1811.10553, 2018. [214] A. Ulloa et al. , "A deep neural network to enhance prediction of 1-year mortality using echocardiographic videos of the heart," arXiv preprint arXiv:1811.10553, 2018. [215] E. Rahimy, "Deep learning applications in ophthalmology," Current opinion in ophthalmology, vol. 29, no. 3, pp. 254 - 260, 2018. [216] J. -H. Lee, D.-H. Kim, S.-N. Jeong, and S.-H. Choi, "De tection and diagnosis of dental caries using a deep learni ng -based convolutional neural network algorithm," Journal of dentistry, vol. 77, pp. 106-111, 2018. [217] A. Esteva et al. , "Dermatologist-level classification of skin cancer w ith deep neural networks," Na ture, vol. 542, no. 7639, p. 115, 2017. [218] E. Gong, J. M. Pauly, M. Winterma rk, and G. Zaharchuk, "Deep learn ing enables reduced ga dolinium dose for contrast‐enhanced brain MRI," Journal of Magnetic Resonance Imaging, vol. 48, no. 2, pp. 330-340, 2018. [219] G. A. Bello et al. , "Deep-learning cardiac motion analysis for human survival prediction," Natu re ma chine intelligence, vol. 1, no. 2, p. 95, 2019. [220] O. Bernard et al. , "Deep learning techniques for automatic MRI cardiac m ulti -structures segme ntation and diagnosis: Is the problem solved?," IEEE transactions on medical imaging, vol. 37, no. 11, pp. 2514- 252 5, 2018. [221] E. Arvaniti et al. , "Automated Gleason grading of prostate cancer tissue m icroarrays via deep learning," S cientific reports, vol. 8, 2018. [222] M. Anthimopoulos, S. Christodoulidis, L. Ebner, A. Christe, and S. Mougiakakou, "Lung pattern cl assif ication for interstitial lung diseases using a deep convolutional neural network," IEEE transactions on medical imaging, vol. 35, no. 5, pp. 1207 -1216, 2016. [223] M. R. Arbabshirani et al. , "Advanced machine learning in action: ide ntification of intr acranial hem orrhage on computed tomography scans of the head with clinical workf low integration," npj Digital M edicine, vol. 1, no. 1, p. 9, 2018. [224] C. C. Charalambous and A. A. Bharath, "A data augmentation methodology for training machine/deep learni ng gait recognition algorithms," pp. 1-12, 2016. [225] S. C. Wong, A. Gatt, V. Stam atescu, and M. D. McDonnell, "Understanding data augme ntation for classification: when to warp?," arXiv preprint arXiv:1609.08764, pp. 1-6, 2016. [226] J. Lu, V. Behbood, P. Hao, H. Zuo, S. Xue, and G. Zhang, "T ransfer learning using computational intelligence : a survey," Knowledge- Based Systems, vol. 80, pp. 14-23, 2015. [227] Y. Gal and Z. Ghahramani, "Dropout as a Bay esian approximation: R eprese nting model uncertainty in deep learning," in international conference on machine learning , 2016, pp. 1050-1059. [228] H. Wang and D.-Y. Yeung, "Towards bayesian deep learning: A survey ," pp. 1-17, 2016. [229] Y. LeCun, Y. Bengio, and G. Hinton, "Dee p learning," nature, vol. 521, no. 7553, p. 436, 2 015. [230] D. Silver et al. , "Mastering the game of Go with deep neural networks and tree searc h," nature, vol. 529, no. 7587, p. 484, 2016. [231] S. Hochreiter and J. Schmidhuber, "L ong short -term memory," Neural computation, vol. 9, no. 8, pp. 1735-1780, 1997. [232] J. Johnson, A. Karpathy, and L. Fei-Fei, "Densecap: Fully convolutional localization netw orks for dense captioning," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2016, pp. 4565 - 4574. [233] A. Rakotomamonjy and G. Gasso, "Histogram of gradients o f tim e – frequency representations for audio scene classification," IEEE/ACM Transactions on Audio, Speech, and Language Process ing, vol. 23, no. 1, pp. 142-153, 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment