Using Physics-Informed Super-Resolution Generative Adversarial Networks for Subgrid Modeling in Turbulent Reactive Flows
Turbulence is still one of the main challenges for accurately predicting reactive flows. Therefore, the development of new turbulence closures which can be applied to combustion problems is essential. Data-driven modeling has become very popular in m…
Authors: Mathis Bode, Michael Gauding, Zeyu Lian
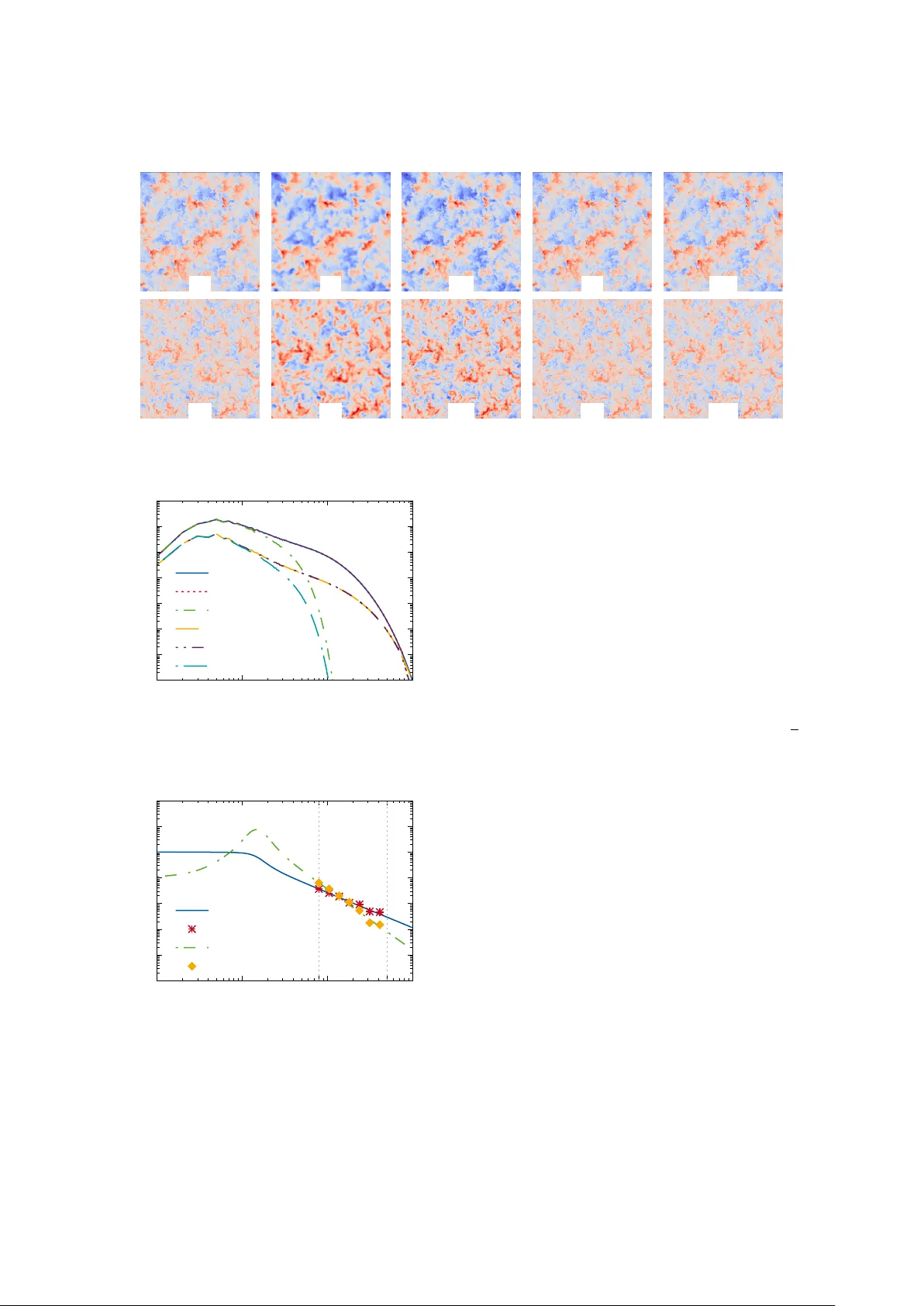
Using Physics-Informed Super -Resolution Generati ve Adv ersarial Networks for Subgrid Modeling in T urb ulent Reacti ve Flo ws Mathis Bode a, ∗∗ , Michael Gauding b , Zeyu Lian a , Dominik Denker a , Marco Davido vic a , K onstantin Kleinheinz a , Jenia Jitsev c, ∗ , Heinz Pitsch a, ∗ a Institute for Combustion T ec hnology (ITV), RWTH Aac hen University , T emplergr aben 64, 52056 Aachen, Germany b CORIA, CNRS UMR 6614, 76801 Saint Etienne du Rouvray , F rance c J ¨ ulich Super computing Centre (JSC), Institute for Advanced Simulation (IAS), F orschungszentrum J ¨ ulic h (FZJ), W ilhelm-Johnen-Straße, 52425 J ¨ ulich, Germany Abstract T urbulence is still one of the main challenges for accurately predicting reactive flo ws. Therefore, the development of new turbulence closures which can be applied to comb ustion problems is essential. Data-driv en modeling has become very popular in man y fields over the last years as large, often extensi vely labeled, datasets became av ailable and training of large neural networks became possible on GPUs speeding up the learning process tremendously . Howe ver , the successful application of deep neural netw orks in fluid dynamics, for example for subgrid modeling in the context of large-eddy simulations (LESs), is still challenging. Reasons for this are the large amount of degrees of freedom in realistic flo ws, the high requirements with respect to accuracy and error robustness, as well as open questions, such as the generalization capability of trained neural netw orks in such high-dimensional, physics-constrained scenarios. This work presents a no vel subgrid modeling approach based on a generativ e adversarial network (GAN), which is trained with unsupervised deep learning (DL) using adversarial and physics-informed losses. A two-step training method is used to impro ve the generalization capability , especially extrapolation, of the network. The novel approach giv es good results in a priori as well as a posteriori tests with decaying turbulence including turbulent mixing. The applicability of the network in complex combustion scenarios is furthermore discussed by employing it to a reactive LES of the Spray A case defined by the Engine Combustion Netw ork (ECN). K e ywor ds: Generativ e Adversarial Networks, Physics-Informed Neural Networks, Lar ge-Eddy Simulation, T urbulence, Spray ∗ Equal contribution ∗∗ Corresponding author: Email addr ess: m.bode@itv.rwth-aachen.de (Mathis Bode) Pr eprint submitted to Pr oceedings of the Combustion Institute November 27, 2019 1. Introduction Machine learning (ML) and deep learning (DL) have gained widespread use and impact in many research communities and industries. The av ailability of excep- tionally lar ge, often extensiv ely labeled datasets and the possibility to train large networks on GPUs, reducing the training time tremendously , are two reasons for this success. Prominent applications of DL include image processing [1 – 3], speech recognition [4], or learning of optimal complex control [5]. These data-driven ap- proaches have been also applied to fluid dynamic prob- lems [6 – 10] including works on subgrid modeling for large-eddy simulation (LES) [11, 12] based on direct numerical simulation (DNS) data. Recently , the idea of physics informed networks [13] rose, where archi- tecture or loss function are designed in order to support known properties of the underlying ph ysical problem. Neural networks hav e been also successfully applied to reactiv e flows. Examples are the adaptiv e reduc- tion scheme for modeling reactiv e flows by Banerjee et al. [14], artificial neural network (ANN)-based storage of flamelet solutions [15, 16], or direct mapping of LES resolved scales to filtered-flame generated manifolds us- ing customized conv olutional neural networks (CNNs) as shown by Seltz et al. [17]. Additionally , regularized decon volution methods, such as published by W ang and Ihme [18], are closely related ideas. Often the applications with respect to flow data are limited by either using only simple networks or small, artificial datasets. Thus, many open questions still re- main, such as determining proper network architectures for flow problems, searching for hyperparameters, or improving the generalization ability of networks. This work introduces the application of generativ e adversarial networks (GANs) [19] for subgrid model- ing in turbulent flows, as it seems to be a flexible tool, also promising for reactiv e turbulent flow simulations. GANs belong to a particular class of generativ e mod- els that aim to estimate the unkno wn probability density that underlies observed data. The special characteristic of this model class is the ability to perform such estima- tion without an explicitly provided data likelihood func- tion. The learning tak es place via an implicit generative model. Learning only requires access to data samples from the unknown distrib ution. GANs thus perform un- supervised learning of unknown data probability distri- bution and do not require any labels that are necessary in supervised learning scenarios. Simplified, the par- ticularly interesting feature of GANs is that beside the resulting generator network that is used for modeling, a second network, the discriminator, is used. While the generator creates new modeled data, the discriminator tries to assess, if it is real or generated data and provides that feedback for the training of the generator . Thereby , in each step, the discriminator learns better to identify model versus real data, which will help the generator to generate more realistic model data. More precisely , estimating an unknown data probability distribution by GAN learning can be understood as minimax zero-sum game carried out by two players, the generator and the discriminator , that are both deep networks constituting a full GAN. The game can be described as a gener- ator creating samples to present them to the discrim- inator , while the discriminator, being confronted with a mix of generated and real data samples, has the task to guess whether a presented input is generated or real data. So, the generator attempts to ’fool’ the discrim- inator , while the discriminator stri ves to become bet- ter in recognizing generated samples from real samples. It was shown that finding the equilibrium of this game corresponds to minimizing di ff erent distance measures between the generator model and the true data distri- bution, such as Kullback-Leibler (KL), Jensen-Shannon (JS) div ergence, or W asserstein distance, depending on a particular form of loss termed adversarial loss. Here, a physics-informed enhanced super-resolution GAN (PIESRGAN) is employed, built upon enhanced super-resolution GAN (ESRGAN) [2] architecture, which has been recently dev eloped in the context of super-resolving GANs (SRGANs) [20], to reconstruct fully-resolved turbulence fields from filtered data, such as from LES. T o this end, the ESRGAN is extended for three-dimensional (3-D) data handling and, most im- portantly , endowed with physics-informed loss. Once the fully-resolved data is reconstructed, a filter kernel is applied to close the filtered equations of the LES. Sec- tion 2 describes the PIESRGAN in detail and lies out key features of the network, which are required for an accurate reconstruction. It contains both, a priori and a posteriori tests with decaying turbulence data, including turbulent mixing of a passive scalare, which could be used as mixture fraction in any comb ustion model. Fur- thermore, an approach to improve the training and gen- eralization capability , especially for extrapolation, of the trained neural network by combining fully-resolved and under-resolv ed data is discussed. In Sec. 3, the potential of the novel method is demonstrated by us- ing PIESRGAN as subfilter model for the filtered mo- mentum and scalar equations in an LES of the Spray A case defined by the Engine Combustion Netw ork (ECN) [21], which is a complex reactive turbulent flo w featuring high Reynolds numbers and spray . The paper finishes with conclusions and future work. 2 2. Modeling A subgrid model needs to predict the subfilter statis- tics of fully-resolved data (e. g. DNS data denoted with ’H’), knowing only the corresponding filtered data with reduced information content (e. g. LES data de- noted with ’F’). Here, the fully-resolved data φ H and the filtered data φ F are connected by a filter operation φ F = F ( φ H ), for example with a Gaussian filter kernel. The filtered equations, which are solved in LES, could be also closed if the fully-resolved data is reconstructed with an inv erse filter operation φ H = F − 1 ( φ F ) that sta- tistically restores the original, fully-resolved data. The described challenges of subgrid models are sim- ilar to challenges faced in super-resolution imaging. Here, SRGANs were found to be a successful tool for approximating the inv erse decon volution operator φ R = ˜ F − 1 ( φ F ) ≈ F − 1 ( φ F ) [2, 20], where φ R denotes the re- constructed, high-resolution data. Thus, PIESRGAN is used as approximation ˜ F − 1 . For example, if φ k F de- notes a filtered solution at time k , the resulting simu- lation workflo w closing a chemical source term reads: 1. Use the PIESRGAN to reconstruct φ k R from φ k F . 2. Use φ k R to estimate the unclosed terms ˙ ω F in the fil- tered transport equation of φ by ev aluating the local source term with φ k R and applying a filter operator . 3. Use ˙ ω F and φ k F to advance the filtered transport equation of φ to φ k + 1 F . 4. Repeat 1.–3. 2.1. Network ar chitectur e The generator of the PIESRGAN is depicted in Fig. 1. It is fed with 3-D subboxes of the flow fields during training and heavily uses 3-D CNN lay- ers (Con v3D) [22] in combination with leaky rectified linear unit (LeakyReLU) layers for activ ation. The con volutional layers are capable of extraction increas- ingly complex multi-dimensional features with increas- ing network depth. The residual in residual dense block (RRDB), which is introduced in ESRGAN and replaces the residual block (RB) used in previous architectures, is impor- tant for the performance of state-of-the-art SRGANs. The RRDB contains fundamental architectural ele- ments, such as residual dense blocks (DBs) with skip- connections, where in turn each DB uses dense con- nections inside. The output from each layer within the DB is sent to all the following layers. For PIESRGAN, DBs are repeated three times, using residual skip con- nections as shown in Fig. 1 with the residual scaling factor β RSF = 0 . 2, which helps to avoid instabilities in the forward and backward propagation. The motiv a- tion behind the RRDB architecture is to enable genera- tion of super-resolv ed data through a very deep network that has enough capacity to learn and model all rele vant complex transformations that are necessary to specify the required reconstruction operation. As suggested by W ang et al. [2], all batch normal- ization (BN) layers of the ESRGAN architecture were remov ed for PIESRGAN. This reduces the computa- tional cost bound to BN and was shown to improve the performance with respect to former single image super - resolution (SISR) models that utilized BN [23]. More- ov er , using BN layers was shown to introduce distorting artifacts into generated images, which is absolutely un- desirable for modeling turbulence. Another di ff erence of PIESRGAN to traditional SISR applications lies in the input and output dimensions. In SISR, where the generated high resolution image contains an increased number of pixels, the fully- resolved data in turbulence contain finer structures that are enclosed in the flow . Therefore, turbulence super- resolution does not in volv e classical upsampling or downsampling. The input and output hence hold the same dimension, while the output flo w has more energy distributed in the high w av e number part. The discriminator inherits the basis CNN architecture as shown in Fig. 2. It consists of one Con v3d block without BN and sev en Conv3d blocks with BN, fol- lowed by a fully connected layer block with DropOut. LeakyReLu layers are used for activ ation. The blocks close to the input learn relativ e simple features extracted from turbulent flows, whereas the blocks close to the output learn more comple x, high-lev el features, like ed- dies / vorte xes. The number of filter maps increases with depth following conv entional design. The DB starts with a Dense(1024) hidden layer , which projects highly dimensional output from many filter maps of the fi- nal Con v3d block into a flat 1024 dimensional vector . The following Droupout layer with factor 0 . 4 serves as regularization, reducing the risk of overfitting. A relativistic adversarial loss as proposed by Jolicoeur- Martineau [24] is used. Using relativistic loss as ad- versarial loss was shown to stabilize GAN training in di ff erent scenarios [24]. It also presumably aids learn- ing of sharper edges and more detailed te xtures in SISR cases, which should also help to learn very high fre- quency details in the turb ulence context. The perceptual loss proposed for the ESRGAN based on the VGG-feature space pretrained with ImageNet dataset is less suitable for turbulence data, as the natu- ral image features from VGG19 may be not representa- tiv e for turbulent flows. Instead, physics-informed con- 3 Figure 1: Generator architecture of PIESRGAN. Figure 2: Discriminator architecture of PIESRGAN. straints are incorporated into the loss function, guided by laws governing the physics of turbulence flo w . More precisely , the loss function for PIESRGAN is chosen as L = β 1 L adv + β 2 L pixel + β 3 L gradient + β 4 L continuity , (1) where β 1 , β 2 , β 3 , and β 4 are coe ffi cients weighting the di ff erent loss term contributions. L adv is the discrim- inator / generator relativistic adversarial loss [2], which reflects both how well the generator is able to gener- ate high resolution turbulence samples that look like real, DNS-obtained full-resolved turbulence flows and how well the discriminator is still able to recognize real and generated flows apart. The pixel loss L pixel and the gradient loss L gradient are defined as mean-squared error (MSE) of the quantity itself and of the gradient of the quantity , respectiv ely [12]. If the MSE operator is ap- plied on tensors including vectors, such as the velocity , it is applied to all elements separately . Afterwards the resulting tensor is mapped into a scalar using the L 1 - norm. L continuity is the physics-informed continuity loss, which contrib utes to the total loss enforcing those phys- ically plausible solutions of the reconstructed flow field where div ergence of the velocity field should be zero for incompressible flo ws. If no reference solution exists, β 2 and β 3 are set to zero, reducing the loss to adversarial loss and potential continuity loss. 2.2. Implementation details All networks were trained using cropped sub-boxes with size 16 × 16 × 16 from the DNS and the correspond- ing filtered low-resolution flo w field. This box size was found to be a good compromise between memory re- quirement during the reconstruction step and the char- acteristic length scales of the flow and filter width. For mapping a passiv e scalar field combined with the veloc- ity fields, each batch with batch size 32, which is the number of samples processed before the model is up- dated, has the dimension 32 × 16 × 16 × 16 × 4, where four channels consist of one passive scalar channel and three velocity channels. The flow field at a given time step was divided into non-overlapping sub-boxes, which were all used for training in one epoch and accessed in random order . RMSProp, which relies on the stochas- tic gradient descent (SGD) approach, was used as opti- mizer . All fields were zero mean-centered and rescaled with the variance before using them for training. In order to increase the reproducibility of this work and clarify more technical details, the implemented PIESRGAN was uploaded to GIT (https: // git.rwth- aachen.de / Mathis.Bode / PIESRGAN.git). 2.3. T raining strate gy Many industrially relev ant applications are operated at very high Reynolds numbers that are not accessible by DNS. Thus training the netw ork only with DNS data of the relev ant Reynolds number range is not possible. This raises the question whether a network trained with DNS data of lo wer Re ynolds numbers is general enough to giv e also good results at higher Reynolds numbers, i. e. whether it has an extrapolation capability . It will be sho wn in the a priori test that training the network only with DNS data leads to bad accuracy for Reynolds numbers outside of the training range. There- fore, the training is extended by a second step in this work. After training generator and discriminator simul- taneously with DNS data (’H’) and corresponding fil- tered data (’F’), the generator is further trained and up- dated using filtered data (’ ˜ F’), which were generated for 4 a larger Reynolds number range with LES without sub- filter closing, which can be computed at low computa- tional cost. Corresponding ’H’ data do not e xist, and the discriminator is not further updated. Note that the loss function reduces for this second learning phase as al- ready mentioned before, as the ev aluation of loss terms related to DNS data is no longer possible. Thus, loss is driv en mainly by the part of adversarial loss that corre- sponds to correctly recognizing generated flow samples and by the physics-informed continuity constrain. 2.4. A priori testing One of the largest existing decaying turbulence DNS datasets [25] was used for training and testing the PIESRGAN. The dataset features periodic boxes of ho- mogeneous isotropic turbulence with Reynolds numbers based on the T aylor microscale of up to 88, which were simulated on 4096 3 mesh points. The first data time step is defined to lie in the self-similar range of the flow , as indicated with t start in Fig. 5. Before the training, the data was filtered to obtain combinations of ’H’ and ’F’. The PIESRGAN was able to reconstruct data within the trained Reynolds number range well. For testing the extrapolation capability of the network, the first time step of the DNS data was not used for training but only for testing. As the Reynolds number reduces over time for the decaying turbulence case, skipping the first time step of the data resulted in a highest Reynolds number for training of about 75, while testing was performed with a Reynolds number of 88. The results are shown in Fig. 3 as ’R 0 ’ for the fluctuation of a passive scalar z as well as the fluctuation of one velocity component, which is labeled as u . Obviously , the network adds in- su ffi cient small scale structures to the flow . Maybe be- cause it had nev er seen such a high Reynolds number before, i.e. nev er needed to add so small structures to the flo w . The column labeled with ’R’ sho ws the results of a network additionally trained with ’ ˜ F’ data, featur- ing Reynolds numbers based on the T aylor microscale of up to 250. The reconstruction results are much better and the visual agreement with the DNS data is almost perfect. One reason for this could be that the ’ ˜ F’ data just modifies all weights in the network, which results in more subfilter contributions for all Reynolds num- bers, randomly leading to the good reproduction for the target Reynolds number b ut w orse results for the others. That would contradict the idea that the neural network used the new data to really learn the target Reynolds number results by means of the adversarial loss. There- fore, the PIESRGAN was alternativ ely trained with the ’H’ / ’F’ dataset and additionally a dataset ’ ˜ F 0 ’, featuring only T aylor microscale-based Reynolds number of up to 200. These results are shown in Fig. 3 as ’R 00 ’, and the agreement is similarly good as before, which indi- cates that the network really learned to reproduce the higher Reynolds number data. W ithout showing the re- sults here, this was also emphasized by analyzing the results for ’R 0 ’ and ’R’ in the Reynolds number training range, which did not di ff er . The same result was also observed for the other two velocity components, which are not visualized in Fig. 3. In addition to the visual e valuation, Fig. 4 presents the spectrum denoted with S computed with ’H’, ’F’, and ’R’ data. It sho ws that also the statistical agreement between DNS and reconstructed data is very good. Only for v ery high wa venumbers, the reconstructed flo w field slightly di ff ers from the DNS data. Note that the spec- trum based on the velocity uses all three velocity com- ponents. Therefore, S ( u ) with bold notation for vectors is shown. The results presented in Fig. 3 and Fig. 4 indicate that the PIESRGAN is able to learn universal key features of turbulence with the adversarial loss, which enable the correct prediction of statistics of higher Reynolds num- ber flows, only seeing filtered data. This is a big ad- vantage to simpler networks fully relying on supervised learning. How the network is able to detect the target Reynolds number from the provided fluctuation is an open question and should be addressed in more detail in future work. 2.5. A posteriori testing Before using the trained network in a complex reac- tiv e turbulent flow , an a posteriori test is performed with respect to the decaying turbulence data. For that, fil- tered data of the early time step t start of the decaying turbulence DNS case are used as initial flow field and advanced over time according to the steps outlined at the beginning of this section. In order to keep the fil- ter width of the data consistent to the training data, the DNS data of size 4096 3 are filtered to a 64 3 mesh. The time step size of the LES was increased compared to the DNS. Figure 5 compares the decay of the ensemble- av eraged turbulent kinetic energy k and the ensemble- av eraged dissipation rate ε ev aluated during the DNS and the a posteriori test with PIESRGAN as LES model. The good agreement between DNS and PIESRGAN- LES is remarkable. During the decay , the Kolmogoro v length-scale and the integral length-scale increase with time following a power -law . This implies that the num- ber of wa venumbers that need closure decreases during the decay . The PIESRGAN accounts for this change of the relativ e rele vance of the subgrid closure, which un- derlines its ability to model small-scale turbulence. 5 z H z F z R 0 z R z R 00 u H u F u R 0 u R u R 00 Figure 3: V isualization of 2-D slices of the fluctuations of the passive scalar z and of the velocity component u for the time step with T aylor microscale-based Reynolds number of about 88. 10 − 8 10 − 6 10 − 4 10 − 2 10 0 10 1 10 2 10 3 W av en umber S ( u H ) S ( u R ) S ( u F ) S ( z H ) S ( z R ) S ( z F ) Figure 4: Spectra evaluated on DNS data, filtered data, and recon- structed data for the velocity vector u and the passive scalar z for the time step with Reynolds number of about 88. 10 − 3 10 − 2 10 − 1 10 0 10 1 10 2 t start t final Time k H k R ε H ε R Figure 5: T emporal ev olution of the ensemble-averaged turbulent ki- netic energy k and ensemble-av eraged dissipation rate ε . 3. Application One prominent example for turbulent reactive flows is the Spray A case (T aylor microscale-based Reynolds numbers of up to 235) defined by the ECN [21], which is chosen to demonstrate the usage of the trained PIESRGAN for combustion here. PIESRGAN is used as LES-subgrid model for the subfilter turbulent flux in the mixture fraction equation and for the subfilter Reynolds-stresses in the momentum equations. These quantities are known to be important for accurate re- sults [26]. More precisely , the same conditions and simulation setup as in Davidovic et al. [26] are com- puted, using the chemical mechanism of Y ao et al. [27] as well as a multiple representati ve interacti ve flamelets (MRIF) model. Details of the simulation setup and nu- merics can be found in former publications [26, 28 – 30]. Compared to the simulations performed by Davido vic et al. [26], a coarser mesh was used in this work to em- phasize e ff ects of the subgrid model, resulting in a min- imum grid spacing of 100 µ m close to the nozzle. The LES result with PIESRGAN as subgrid model for mix- ture fraction and velocity is visualized in Fig. 6. Note that the PIESRGAN was also used to ev aluate the mix- ture fraction v ariance on the reconstructed mixture frac- tion field. It could hav e also been used for computing the probability density function (PDF), used as part of the MRIF model, but instead a classical beta-PDF was used here. Furthermore, the ignition delay time, defined as the time, when the OH mass fraction reaches 2 % of its maximum value for the first time, was ev aluated as 0 . 379 ms (av eraged ov er four realizations), which is in reasonable agreement to about 0 . 4 ms measured in ex- periments [21]. In order to assess the e ff ect of the subgrid model- ing on the mixing, the fuel mass fraction is ev aluated 18 . 75 mm do wnstream from the nozzle. It is temporally and circumferentially averaged and plotted in Fig. 7 for 6 Figure 6: V isualization of the LES with PIESRGAN as subgrid model for the mixture fraction and v elocity applied to the Spray A case: Liq- uid droplets (dark blue), stoichiometric mixture fraction (light blue), and iso-temperature-surface 1100 K (red). A video of the injection can be found here: https: // youtu.be / 86gZEhRB5oY . the PIESRGAN-LES, an LES with dynamic Smagorin- sky model [26] (denoted with ’DS-LES’), and experi- mental data [31]. The mixing of the PIESRGAN-LES lies in between the experimental data and the DS-LES results. This indicates that the PIESRGAN is a ro- bust and accurate model, which is interesting consid- ering that it was trained with homogeneous isotropic turbulence data. Note that the PIESRGAN-LESs were run without any clipping, which weakens the hypothesis that data-driv en models are dangerous to use in real sim- ulations as extreme predictions might crash the simula- tion. Computationally , the PIESRGAN-LES was more expensi ve than the DS-LES. Howe ver , with the rapid improv ements in the field of DL on GPUs, this could change in the near future. 0.00 0.05 0.10 0.15 0.20 0 1 2 3 4 5 6 7 8 F uel mass fraction Distance from spray axis [mm] Exp erimen t PIESR GAN-LES DS-LES Figure 7: T emporally and circumferentially averaged fuel mass frac- tion ev aluated 18 . 75 mm do wnstream from the nozzle. 4. Conclusions This work presents a novel GAN-based subgrid modeling approach, which employs unsupervised DL with a combination of super-resolution adversarial and physics-informed losses for accurately predicting sub- filter statistics in a wide Reynolds number range. The PIESRGAN is trained with some of the largest exist- ing decaying turbulence data. A successive training with fully-resolved and under-resolv ed data increases the generalization capability of the network. It is shown that the trained network gi ves good results in a priori as well as a posteriori tests and ev en in a reactiv e LES with spray . Even though some aspects of the network are not fully understood yet and the data processing speed needs to be improved, this work emphasizes the large potential of data-driv en models for reactive flo ws. The GAN-method w as applied for modeling subfilter terms for momentum and scalar mixing in this work. Howe ver , the application to reactiv e scalar fields to close the chemical source term might be interesting. This is challenging for di ff erent reasons. For instance, for fast chemistry , the source term depends on the very smallest scales, which means that these need to be cor- rectly predicted for multi-scalar fields. Still, it will be interesting to assess the potential in future work. References [1] C. Dong, C. C. Loy , K. He, X. T ang, in: European conference on computer vision, Springer , pp. 184–199. [2] X. W ang, K. Y u, S. W u, J. Gu, Y . Liu, C. Dong, Y . Qiao, C. Lo y , ESRGAN: Enhanced Super-Resolution Generativ e Adversarial Networks, Lecture Notes in Computer Science 11133 (2019) 63–79. [3] H. Greenspan, B. V an Ginneken, R. M. Summers, Guest edi- torial deep learning in medical imaging: Overvie w and future promise of an exciting new technique, IEEE T ransactions on Medical Imaging 35 (2016) 1153–1159. [4] G. Hinton, L. Deng, D. Y u, et al., Deep neural networks for acoustic modeling in speech recognition, IEEE Signal process- ing magazine 29 (2012). [5] O. V inyals, I. Babuschkin, W . M. Czarnecki, et al., Grandmaster lev el in starcraft ii using multi-agent reinforcement learning., Nature (2019). [6] E. J. Parish, K. Duraisamy , A paradigm for data-driven predic- tiv e modeling using field inv ersion and machine learning, Jour- nal of Computational Physics 305 (2016) 758–774. [7] P . Srini vasan, L. Guastoni, H. Azizpour, P . Schlatter , R. V inuesa, Predictions of turbulent shear flows using deep neural networks, Physical Revie w Fluids 4 (2019) 054603. [8] R. Maulik, O. San, A neural network approach for the blind de- con volution of turbulent flows, Journal of Fluid Mechanics 831 (2017) 151–181. [9] M. Bode, M. Gauding, J. G ¨ obbert, B. Liao, J. Jitsev , H. Pitsch, T ow ards prediction of turbulent flows at high reynolds numbers using high performance computing data and deep learning, Lec- ture Notes in Computer Science 11203 (2018) 614–623. [10] J. Kutz, Deep learning in fluid dynamics, Journal of Fluid Me- chanics 814 (2017) 1–4. [11] C. J. Lape yre, A. Misdariis, N. Cazard, D. V eynante, T . Poinsot, T raining conv olutional neural networks to estimate turbulent sub-grid scale reaction rates, Combustion and Flame 203 (2019) 255–264. [12] M. Bode, M. Gauding, K. Kleinheinz, H. Pitsch, Deep learning at scale for subgrid modeling in turbulent flows: regression and reconstruction, arXiv preprint arXi v:1910.00928 (2019). 7 [13] M. Raissi, P . Perdikaris, G. Karniadakis, Physics-informed neu- ral networks: A deep learning framework for solving forward and in verse problems inv olving nonlinear partial di ff erential equations, Journal of Computational Physics 378 (2019) 686– 707. [14] I. Banerjee, M. G. Ierapetritou, An adaptive reduction scheme to model reacti ve flow , Combustion and Flame 144 (2006) 619– 633. [15] M. Ihme, C. Schmitt, H. Pitsch, Optimal artificial neural net- works and tabulation methods for chemistry representation in LES of a blu ff -body swirl-stabilized flame, Proceedings of the Combustion Institute 32 (2009) 1527–1535. [16] M. Bode, N. Collier, F . Bisetti, H. Pitsch, Adaptiv e chemistry lookup tables for combustion simulations using optimal b-spline interpolants, Combustion Theory and Modelling 23 (2019) 674– 699. [17] A. Seltz, P . Domingo, L. V ervisch, Z. M. Nikolaou, Direct map- ping from les resolved scales to filtered-flame generated man- ifolds using conv olutional neural networks, Combustion and Flame 210 (2019) 71–82. [18] Q. W ang, M. Ihme, A re gularized decon volution method for tur- bulent closure modeling in implicitly filtered lar ge-eddy simula- tion, Combustion and Flame 204 (2019) 341–355. [19] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farley , S. Ozair, A. Courville, Y . Bengio, in: Advances in neural information processing systems, pp. 2672–2680. [20] C. Ledig, L. Theis, F . Husz ´ ar , et al., in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4681–4690. [21] Engine combustion network: https: // ecn.sandia.gov , 2019. [22] A. Krizhevsk y , I. Sutskev er, G. E. Hinton, in: Advances in neu- ral information processing systems, pp. 1097–1105. [23] B. Lim, S. Son, H. Kim, S. Nah, K. Mu Lee, in: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 136–144. [24] A. Jolicoeur-Martineau, The relativistic discriminator: a key element missing from standard gan, arXiv preprint arXiv:1807.00734 (2018). [25] M. Gauding, L. W ang, J. H. Goebbert, M. Bode, L. Danaila, E. V area, On the self-similarity of line segments in decaying homogeneous isotropic turbulence, Computers & Fluids 180 (2019) 206–217. [26] M. Da vidovic, T . Falkenstein, M. Bode, L. Cai, S. Kang, J. Hin- richs, H. Pitsch, LES of n-dodecane spray combustion using a multiple representative interactive flamelets model, Oil & Gas Science and T echnology - Rev . IFP Energies nouvelles 72 (2017). [27] T . Y ao, Y . Pei, B.-J. Zhong, S. Som, T . Lu, K. Hong Luo, A com- pact skeletal mechanism for n-dodecane with optimized semi- global lo w-temperature chemistry for diesel engine simulations, Fuel 191 (2017) 339–349. [28] M. Bode, T . Falkenstein, V . Le Chenadec, S. Kang, H. Pitsch, T . Arima, H. T aniguchi, A new Euler / Lagrange approach for multiphase simulations of a multi-hole GDI injector , SAE T ech- nical Paper 2015-01-0949 (2015). [29] M. Bode, M. Davidovic, H.Pitsch, in: E. Di Napoli, M.-A. Hermanns, H. Iliev , A. Lintermann, A. Peyser (Eds.), High- Performance Scientific Computing, Springer International Pub- lishing, 2017, pp. 96–108. [30] M. Bode, M. Davidovic, H.Pitsch, in: W . E. Nagel (Ed.), High- Performance Computing in Science, Springer Nature, 2019, pp. 185–207. [31] L. M. Pickett, C. L. Genzale, J. Manin, Uncertainty quantifica- tion for liquid penetration of evaporating sprays at diesel-like conditions, Atomization and Sprays 25 (2015) 425–452. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment