Deep Convolutional Networks in System Identification
Recent developments within deep learning are relevant for nonlinear system identification problems. In this paper, we establish connections between the deep learning and the system identification communities. It has recently been shown that convoluti…
Authors: Carl Andersson, Ant^onio H. Ribeiro, Koen Tiels
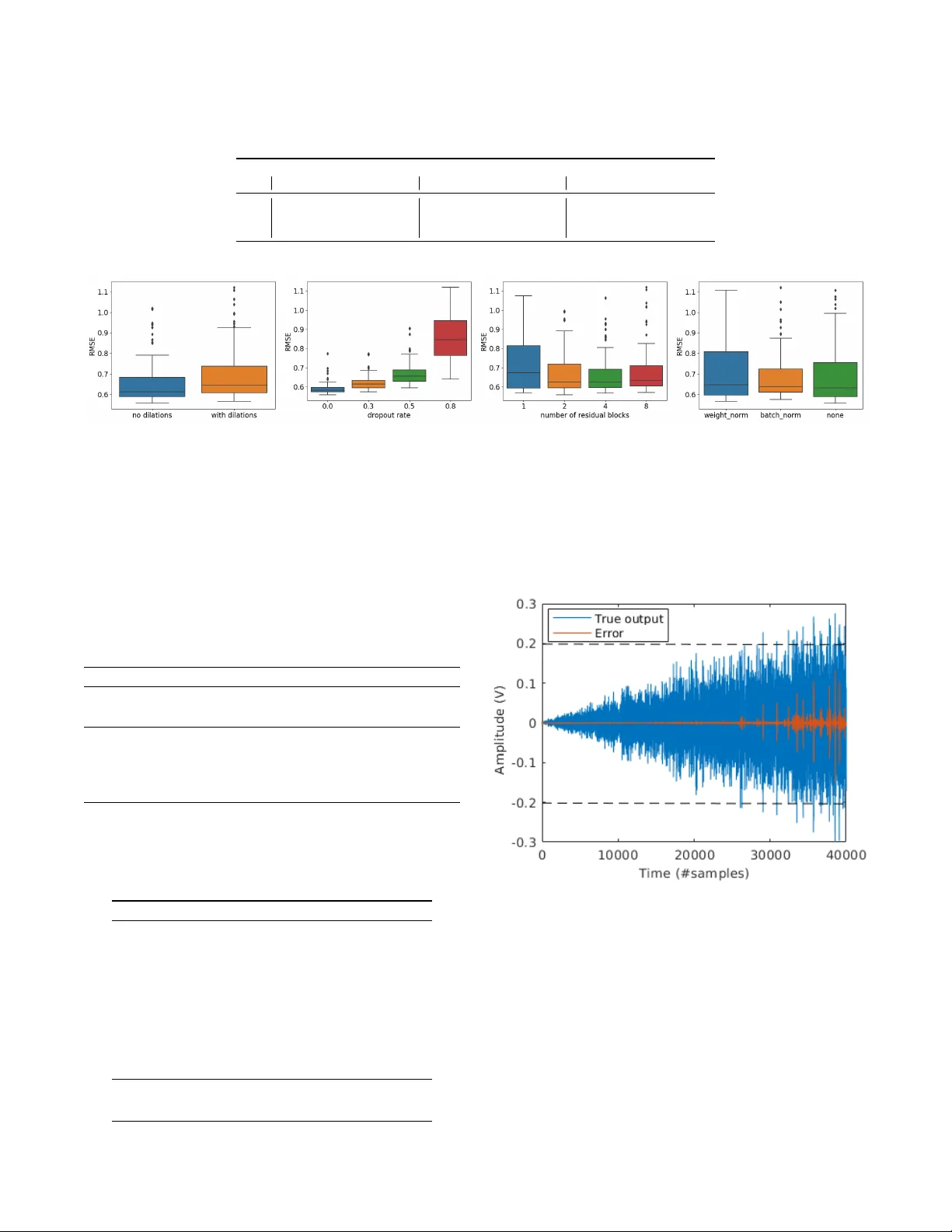
Deep Con volutional Netw orks in System Identification Carl Andersson ∗ , Ant ˆ onio H. Ribeiro ∗ , K oen T iels, Niklas W ahlstr ¨ om and Thomas B. Sch ¨ on Abstract — Recent developments within deep lear ning are rele vant for nonlinear system identification problems. In this paper , we establish connections between the deep learning and the system identification communities. It has recently been shown that con volutional architectures ar e at least as capable as r ecurrent architectur es when it comes to sequence modeling tasks. Inspired by these results we explore the explicit relationships between the recently proposed temporal con vo- lutional network (TCN) and two classic system identification model structures; V olterra series and block-oriented models. W e end the paper with an experimental study where we provide results on two real-w orld problems, the well-known Silverbox dataset and a newer dataset originating from ground vibration experiments on an F-16 fighter aircraft. I . I N T RO D U C T I O N Deep learning has, over the past decade, had a massiv e impact on sev eral branches of science and engineering, in- cluding for example computer vision [1], speech recognition [2] and natural language processing [3]. While the basic model class—neural networks—has been around for more than 70 years [4], there has been quite a few interesting and highly relev ant technical de velopments within the deep learning community that has, to the best of our kno wledge, not yet been fully exploited within the system identification community . Just to mention a few of these developments we hav e; new regularization methods [5], [6], [7], new architec- tures [8], [9], [10], improved optimization algorithms [11], [12], [13], ne w insights w .r .t. activ ation functions [14], [15], [16]. Moreover , the capability to significantly increase the depth [8], [9], [10] in the models has further improved the performance. Most of the existing model architectures hav e been made easily av ailable through high quality open source framew orks [17], [18], allowing deep learning to be easily implemented, trained, and deployed. The deep learning de velopments that are most relev ant for system identification are probably the ones that can be found under the name of sequence learning . Recurrent models, such as recurrent neural networks (RNN) and its extensions which include the long short-term memory (LSTM) [19] and the gated recurrent units (GR U) [20], hav e been the standard choice for sequence learning. In the neighbouring area of computer vision, the use of the so-called con volutional neural ∗ Equal contrib ution. This work has been supported by the Brazilian agencies CAPES, CNPq and F APEMIG, by the Swedish Research Council (VR) via the project NewLEADS – New Directions in Learning Dynamical Systems (contract number: 621-2016-06079), and by the Swedish Foundation for Strategic Research (SSF) via the project ASSEMBLE (contract number: RIT15- 0012). C. Andersson, A. H. Ribeiro, K. T iels, N. W ahlstr ¨ om and T . B. Sch ¨ on are with the Dept. of Information T echnology , Uppsala Uni- versity , 751 05 Uppsala, Sweden. A. Ribeiro is also with the Gradu- ate Program in Electrical Engineering at Universidade Federal de Mi- nas Gerais (UFMG) - A v . Ant ˆ onio Carlos 6627, 31270-901, Belo Hor- izonte, MG, Brazil E-mails: { carl.andersson, antonio.ribeiro, koen.tiels, niklas.wahlstrom, thomas.schon } @it.uu.se. networks (CNNs) [21] has had a very strong impact on tasks such as image classification [22], segmentation [23] and object detection [24]. Interestingly , it has recently [25] been shown that the CNN architecture is highly useful also for sequence learning tasks. More specifically , the so- called temporal CNN (TCN) can match or even outperform the older recurrent architectures in language and music modelling [25], [26], [27], text-to-speech conv ersion [26], machine translation [28], [29] and other sequential tasks [25]. W e will, for this reason, focus this paper on making use of TCNs for nonlinear system identification. Neural networks have enjoyed a long and fruitful history [30], [31], [32] also within the system identification commu- nity , where they remain a popular choice when it comes to modeling of nonlinear dynamical systems [33], [34], [35], [36], [37]. W e are writing this paper to reinforce the bridge between the system identification and the deep learning communities since we believ e that there is a lot to be gained from doing this. W e will describe the new TCN model from a system identification point of vie w (Section II). Additionally , we will show that there are indeed interesting connections between the deep TCN structure and the V olterra series and the block- oriented model structures commonly used within system identification (Section III). Perhaps most importantly , we will provide experimental results on two real-world problems (the Silverbox [38] and the F-16 [39] datasets) and on a toy problem (Section IV). I I . N E U R A L N E T W O R K S F O R T E M P O R A L M O D E L I N G The neural network is a uni versal function approxima- tor [40] with a sequential model structure of the form: ˆ y = g ( L ) ( z ( L − 1) ) , (1a) z ( l ) = g ( l ) ( z ( l − 1) ) , l = 1 , . . . , L − 1 , (1b) z (0) = x, (1c) where x, z ( l ) , ˆ y denotes the input, the hidden variables and the output, respecti vely . The transformation within each layer is of the form g ( l ) ( z ) = σ ( W ( l ) z + b ( l ) ) consisting of a linear transformation W ( l ) z + b ( l ) followed by a scalar nonlinear mapping, σ , that acts element-wise. In the final (output) layer the nonlinearity is usually omitted, i.e. g ( L ) ( z ) = W ( L ) z + b ( L ) . The neural network parameters { W ( l ) , b ( l ) } L l =1 are usu- ally referred to as the weights W ( l ) and the bias terms b ( l ) and they are estimated by minimizing the predic- tion error 1 N P N k =1 k ˆ y [ k ] − y [ k ] k 2 for some training dataset { x [ k ] , y [ k ] } N k =1 . T o train deep neural networks with many hidden layers (large L ) hav e been proved to be a notoriously hard opti- mization problem. The challenges includes the risk of getting stuck in bad local minimas, exploding and/or vanishing gra- dients, and dealing with large-scale datasets. It is only over the past decade that these challenges hav e been addressed, with improved hardware and algorithms, to the extent that training truly deep neural networks has become feasible. W e will very briefly re view some of these de velopments below . Additional information can be found in Appendix A. A. T emporal Con volutional Network As the name suggests, the temporal con volutional network (TCN) is based on con v olutions [25]. The use of TCNs within a system identification setting can in fact be inter- preted as using the nonlinear ARX model as the basic model component: ˆ y [ k + 1] = g ( x [ k ] , . . . x [ k − ( n − 1)]) , (2) with x [ k ] = ( u [ k ] , y [ k ]) . W e will proceed with this inter- pretation, where (2) would correspond to a one-layer TCN model. A full TCN can be understood as a sequential construction of sev eral nonlinear ARX models stacked on top of each other: ˆ y [ k + 1] = g ( L ) ( Z ( L − 1) [ k ]) , (3a) z ( l ) [ k ] = g ( l ) ( Z ( l − 1) [ k ]) , l = 1 , . . . , L − 1 , (3b) z (0) [ k ] = x [ k ] , (3c) where: Z ( l − 1) [ k ] = z ( l − 1) [ k ] , z ( l − 1) [ k − d l ] , . . . , z ( l − 1) [ k − ( n − 1) d l ] . The number of layers L , the size of each intermediate layer z ( l ) [ k ] , and the model order n , are all design choices determined by the user . This will also determine the number of parameters included in the model. For each layer , we optionally introduce a dilation factor d l . W ith d l = 1 we recov er the standard nonlinear ARX model in each layer . W ith d l > 1 the corresponding output of that layer can represent a wider range of past time instances. The effecti ve memory of that layer will be ( n − 1) d l . T ypically the dilation factor is chosen to increase exponentially with the number of layers, for example d l = 2 ( l − 1) , see Fig. 1a. If we assume that we hav e the same number of parameters in each layer, the memory will increase exponentially , not only with the number of layers, but also with the number of parameters in the model. This is a very attractiv e but yet uncommon property for system identification models present in the literature. Each layer in a TCN can also be seen as dilated causal con- volution where n would be the kernel size and dim ( z ( l ) [ k ]) the number of channels in layer l . These conv olutions can be efficiently implemented in a vectorized manner where many computations are reused across the different time steps k . Analogously to what is done in con volutional neural net- works we use zero-padding for z ( l ) [ k ] where k < 1 . W e refer to [25] for a presentation of TCN based on con volutions. B. Residual Blocks A residual block is a combination of possibly sev eral layers together with a skip connection z ( l + p ) = F ( z ( l ) ) + z ( l ) , (4) where the skip connection adds the value from the input of the block to its output. The purpose of the residual block is to let the layers learn deviations from the identity map rather than the whole transformation. This property is beneficial, especially in deep networks where we want the information to gradually change from the input to the output as we proceed through the layers. There is also some evidence that this makes it easier to train deeper neural networks [10]. W e employ residual blocks in our models by following the model structure in [25]. Each block consist of one skip connection and two linear mappings, each of them followed by batch normalization [13], activ ation function and dropout regularization [6]. See Fig. 1b for a visual description and Appendix A for a brief explanation of batch normalization and regularization methods. For both mappings a common dilation factor is used and hence the whole block can be seen as one of the layers g ( l ) ( z ) in the TCN model (3). Note that the skip connection only passes z ( l − 1) [ k ] to the next layer and not the whole Z ( l − 1) [ k ] for each time instance k . In cases where z ( l − 1) [ k ] and z ( l ) [ k ] are of different dimensions, a linear mapping is used between them. The coefficients of this linear mapping are also learned during training. I I I . C O N N E C T I O N S T O S Y S T E M I D E N T I FI C A T I O N This section describes equiv alences between the basic TCN architecture (i.e. without dilated con volutions and skip connections) and models in the system identification com- munity , namely V olterra series and block-oriented models. The discussion is limited to the nonlinear FIR case (where x = u ) instead of the more general NARX case ( x = ( u, y ) ) considered in (2), and to single input single output systems. A. Connection with V olterra series A V olterra series [41] can be considered as a T aylor series with memory . It is essentially a polynomial in (delayed) inputs u [ k ] , u [ k − 1] , . . . . Alternativ ely , a V olterra series can be considered as a nonlinear generalization of the impulse response h 1 [ τ ] . The output of a V olterra series is obtained using higher-order con volutions of the input with the V olterra kernels h d [ τ 1 , . . . , τ d ] for d = 0 , 1 , . . . , D . These kernels are the polynomial coefficients in the T aylor series. The basic TCN architecture is essentially the same as the time delay neural network (TDNN) in [42], except for the zero padding [25] and the use of ReLU activ ations instead of sigmoids. The TDNN has been shown to be equiv alent to an infinite-degree ( D → ∞ ) V olterra series in [43]. This connection is made explicit in [43] by showing how to compute the V olterra kernels from the estimated network weights W . The key ingredient is to use a T aylor series expansion of the acti vation functions σ either around zero (the bias term b is then considered part of the acti v ation function) or alternatively around the bias v alues if the T aylor series around zero does not conv erge for example. (a) (b) Fig. 1: Illustration of the temporal conv olution network (TCN) with residual blocks. (a) T emporal conv olutional network with dilated causal con v olutions with dilation factor d 1 = 1 , d 2 = 2 and d 3 = 4 and kernel size n = 3 . (b) A TCN residual block. Each block consists of two dense layers and an identity (or linear) map on the skip connection. As illustrated in (a) by connection with the same color , neural network weights are shared within the same layer and in variant to time translations. This reflects the hypothesis we are modeling a time in v ariant system. B. Connection with block-oriented models Block-oriented models [44], [45] combine linear time- in variant (L TI) subsystems (or blocks) and nonlinear static (i.e. memoryless) blocks. For example, a W iener model consists of the cascade of an L TI block and a nonlinear static block. For a Hammerstein model, the order is rev ersed: it is a nonlinear block followed by an L TI block. Generalizations of these simple structures are obtained by putting more blocks in series (as in [46] for Hammerstein systems) or in parallel branches (as in [47] for Wiener -Hammerstein systems) and/or to consider multiv ariate nonlinear blocks. A multi-layer basic TCN can be considered as cascading parallel Wiener models, one for each hidden layer, that have multiv ariate nonlinear blocks consisting of the activ ation functions (including the bias). The linear output layer cor- responds to adding FIR filters at the end of each parallel branch. The layers can be squeezed together to form less but larger layers (cf. squeezing together the sandwich model discussed in [48]). This is so since the dynamics consist of time delays and time delays can be placed before or after a static nonlinear function without changing the resulting output ( q − 1 σ ( z [ k ]) = σ ( q − 1 z [ k ]) = σ ( z [ k − 1]) ). The TCN model could be squeezed down to a parallel Wiener model. C. Conclusion The basic TCN architecture is equi valent to V olterra series and parallel W iener models. They are thus all univ ersal approximators for time-in variant systems with fading mem- ory [49]. This equiv alence does not mean that all these model structures can be trained with equal ease and will perform equally well in all identification tasks. For example, a V olterra series uses polynomial basis functions, whereas TDNNs use sigmoids and TCNs use ReLU acti vation func- tions. Depending on the system at hand, one basis function might be better suited than another to av oid bad local minima and/or to obtain both an accurate and sparse representation. I V . N U M E R I C A L R E S U LT S W e now present the performance of the TCN model on three system identification problems. W e compare this model with the classical NARX Multilayer Perceptron (MLP) network with two layers and with the Long Short-T erm Memory (LSTM) network. When av ailable, results from other papers on the same problem are also presented. W e make a distinction between training , validation and test datasets. The training dataset is used for estimating the parameters. The performance in the validation data is used as the early stopping criteria for the optimization algorithm and for choosing the best hyper-parameters (i.e. neural network number of layers, number of hidden nodes, optimization parameter , and so on). The test data allows us to assess the model performance on unseen data. Since the major goal of the first example is to compare dif ferent hyper-parameter choices we do not use a test set. In all the cases, the neural network parameters are esti- mated by minimizing the mean square error using the Adam optimizer [11] with default parameters and an initial learning rate of lr = 0 . 001 . The learning rate is reduced whenev er the validation loss does not improv e for 10 consecutiv e epochs. W e use the Root Mean Square Error (RMSE = q 1 N P N k =1 k ˆ y [ k ] − y [ k ] k 2 ) as metric for comparing the different methods in the validation and test data. Throughout the text we will make clear when the predicted output ˆ y is computed through the free-run simulation of the model and when it is computed through the one-step-ahead prediction. The code for reproducing the examples is av ailable at https://github .com/antonior92/sysid-neuralnet. Additional in- formation about the hyperparameters and training time can be found in Appendix B. A. Example 1: Nonlinear toy pr oblem The nonlinear system [31]: y ∗ [ k ] = (0 . 8 − 0 . 5 e − y ∗ [ k − 1] 2 ) y ∗ [ k − 1] − (0 . 3 + 0 . 9 e − y ∗ [ k − 1] 2 ) y ∗ [ k − 2] + u [ k − 1] + 0 . 2 u [ k − 2] + 0 . 1 u [ k − 1] u [ k − 2] + v [ k ] , y [ k ] = y ∗ [ k ] + w [ k ] , (5) was simulated and the generated dataset was used to build neural network models. Fig. 2 shows the validation results for a model obtained for a training and validation set gener- ated with white Gaussian process noise v and measurement noise w . In this section, we repeat this same experiment for different neural network architectures, with different noise lev els and different training set sizes N . Fig. 2: (Example 1) Displays 100 samples of the free-run simulation TCN model vs the simulation of the true system. The kernel size for the causal conv olutions is 2 , the dropout rate is 0 , it has 5 conv olutional layers and a dilation rate of 1 . The training set has 20 batches of 100 samples and was generated with (5) for v and w white Gaussian noise with standard deviations σ v = 0 . 3 and σ w = 0 . 3 . The v alidation set has 2 batches of 100 samples. For both, the input u is randomly generated with a standard Gaussian distribution, each randomly generated value held for 5 samples. The best results for each neural network architecture on the validation set are compared in T able I. It is interesting to see that when few samples ( N = 500 ) are av ailable for training, the TCN performs the best among the different architectures. On the other hand, when there is more data ( N = 8 000 ) the other architectures gives the best performance. Fig. 3 shows how different hyper-parameter choices im- pact the performance of the TCN. W e note that standard deep learning techniques such as dropout, batch normalization and weight normalization did not improve performance. The use of dropout actually hurts the model performance on the validation set. Furthermore, increasing the depth of the neural network does not actually improve its performance and the TCN yields better results in the training set without the use of dilations, which makes sense considering that this model does not require a long memory since the data were generated by a system of order 2. B. Example 2: Silverbox The Silverbox is an electronic circuit that mimics the input/output behavior of a mass-spring-damper with a cubic hardening spring. A benchmark dataset is av ailable through [38]. 1 The training and validation input consists of 10 realiza- tions of a random-phase multisine. Since the process noise and measurement noise is almost nonexistent in this system, 1 Data a vailable for do wnload at: http://www .nonlinearbenchmark.org/#Silverbox we use all the multisine realizations for training data, simply training until conv ergence. The test input consists of 40 400 samples of a Gaussian noise with a linearly increasing amplitude. This leads to the variance of the test output being lar ger than the variance seen in the training and validation dataset in the last third of the test data, hence the model needs to extrapolate in this region. Fig. 4 visualizes this extrapolation problem and T able II shows the RMSE only in the region where no extrapolation is needed. The corresponding RMSE for the full dataset is presented in T able III. Similarly to Section IV -A we found that the TCN did not benefit from the standard deep learning techniques such as dropout and batch normalization. W e also see that the LSTM outperforms the MLP and the TCN suggesting the Silverbox data is large enough to benefit of the increased complexity of the LSTM. C. Example 3: F-16 gr ound vibration test The F-16 vibration test was conducted on a real F-16 fighter equipped with dummy ordnances and accelerometers to measure the structural dynamics of the interface between the aircraft and the ordnance. A shaker mounted on the wing was used to generate multisine inputs to measure this dynamics. W e used the multisine realizations with random frequency grid with 49.0 N RMS amplitude [39] for training, validating and testing the model. 2 W e trained the TCN, MLP and LSTM networks for all the same configurations used in Example 1. The analysis of the different architecture choices for the TCN in the validation set again rev eals that common deep learning techniques such as dropout, batch normalization, weight normalization or the use of dilations do not improv e performance. The major difference here is that the use of a deeper neural network actually outperforms shallow neural networks (Fig. 5). The best results for each neural network architecture are compared in T able IV for free-run simulation and one-step- ahead prediction. The results are averaged ov er the 3 outputs. The TCN performs similar to the LSTM and the MLP . An earlier attempt on this dataset with a polynomial nonlinear state-space (PNLSS) model is reported in [63]. Due to the large amount of data and the large model order , the complexity of the PNLSS model had to be reduced and the optimization had to be focused in a limited frequency band (4.7 to 11 Hz). That PNLSS model only slightly improv ed on a linear model. Compared to that, the LSTM, MLP , and TCN perform better, also in the frequenc y band 4.7 to 11 Hz. This can be observed in Fig. 6, which compare the errors of these models with the noise floor and the total distortion le vel (= noise + nonlinear distortions), computed using the robust method [64]. Around the main resonance at 7.3 Hz (the wing- torsion mode [39]), the errors of the neural networks are significantly smaller than the total distortion lev el, indicating that the models do capture significant nonlinear behavior . Similar results are obtained in free-run simulation (not shown here). In contrast to the PNLSS models, the neural networks did not have to be reduced in complexity . Due to the mini- batch gradient descent, it is possible to train complex models on large amounts of data. 2 Data a vailable for do wnload at: http://www .nonlinearbenchmark.org/#F16 T ABLE I: (Example 1) One-step-ahead RMSE on the validation set for the models (MLP , LSTM and TCN) trained on datasets generated with: dif ferent noise lev els ( σ ) and lengths ( N ). The standard deviation of both the process noise v and the measurement noise w is denoted by σ . W e report only the best results among all hyper-parameters and architecture choices we have tried out for each entry . N=500 N=2 000 N=8 000 σ LSTM MLP TCN LSTM MLP TCN LSTM MLP TCN 0 . 0 0 . 362 0 . 270 0.254 0 . 245 0 . 204 0.196 0 . 165 0.154 0 . 159 0 . 3 0 . 712 0 . 645 0.607 0 . 602 0 . 586 0.558 0.549 0 . 561 0 . 551 0 . 6 1 . 183 1 . 160 1.094 1 . 105 1 . 070 1.066 1.038 1 . 052 1 . 043 (a) (b) (c) (d) Fig. 3: (Example 1) Box plots showing how different design choices affect the performance of the TCN for noise standard deviation σ = 0 . 3 and training data length N = 2 000 . On the y -axis the one-step-ahead RMSE on the validation set is displayed, and on the x -axis we have: in (a) the presence or absence of dilations; in (b) the dropout rate { 0.0, 0.3, 0.5, 0.8 } ; in (c) the number of residual blocks { 1, 2, 4, 8 } ; and, in (d) if batch norm , weight norm or nothing is used for normalizing the output of each con v olutional layer . The variation in performance for the box plot quartiles is achieved through the variation for all the other hyper-parameters not fixed by the hyper-parameter choice indicated on the x -axis. T ABLE II: (Example 2) Free-run simulation results for the Silverbox example on part of the test data (av oiding extrapolation). RMSE (mV) Which samples Approach Reference 0.7 first 25 000 Local Linear State Space [50] 0.24 first 30 000 NLSS with sigmoids [51] 1.9 400 to 30 000 W iener-Schetzen [52] 0.31 first 25 000 LSTM this paper 0.58 first 30 000 LSTM this paper 0.75 first 25 000 MLP this paper 0.95 first 30 000 MLP this paper 0.75 first 25 000 TCN this paper 1.16 first 30 000 TCN this paper T ABLE III: (Example 2) Free-run simulation results for the Silverbox example on the full test data. ( ∗ Computed from FIT=92.2886%). RMSE (mV) Approach Reference 0.96 Physical block-oriented [53] 0.38 Physical block-oriented [54] 0.30 Nonlinear ARX [55] 0.32 LSSVM with NARX [56] 1.3 Local Linear State Space [50] 0.26 PNLSS [57] 13.7 Best Linear Approximation [57] 0.35 Poly-LFR [58] 0.34 NLSS with sigmoids [51] 0.27 PWL-LSSVM with PWL-NARX [59] 7.8 MLP-ANN [60] 4.08 ∗ Piece-wise af fine LFR [61] 9.1 Extended fuzzy logic [62] 9.2 W iener-Schetzen [52] 3.98 LSTM this paper 4.08 MLP this paper 4.88 TCN this paper Fig. 4: (Example 2) The true output and the prediction error of the TCN model in free-run simulation for the Silverbox data. The model needs to extrapolate approximately outside the region ± 0 . 2 marked by the dashed lines. V . C O N C L U S I O N A N D F U T U R E W O R K In this paper we applied recent deep learning methods to standard system identification benchmarks. Our initial results indicate that these models have potential to provide good results in system identification problems, even if this requires us to rethink how to train and regularize these models. Indeed, methods which are used in traditional deep Fig. 5: (Example 3) Box plot showing how different depths of the neural network affects the performance of the TCN. Should be interpreted in the same way as Fig. 3. T ABLE IV: (Example 3) RMSE for free-run simulation and one-step-ahead prediction for the F16 example av eraged over the 3 outputs. The av erage RMS value of the 3 outputs is 1.0046. Mode LSTM MLP TCN Free-run simulation 0.74 0.48 0.63 One-step-ahead prediction 0.023 0.045 0.034 learning settings do not always improve the performance. For example, dropout did not yield better results in any of the problems. Neither did the long memory offered by the dilation factor in TCNs offer any improvement, which is most likely due to the fact that these problems have a relativ ely short and exponentially decaying memory , as most dynamical systems do. Other findings are that TCNs work well also for small datasets and that LSTMs did show a good ov erall performance despite being very rarely applied to system identification problems. Causal con volutions are effecti vely similar to NARX mod- els and share statistical properties with this class of models. Hence, they are also expected to be biased for settings where the noise is not white. This could justify the limitations Fig. 6: (Example 3) In one-step-ahead prediction mode, all tested model structures perform similar . The error is close to the noise floor around the main resonance at 7.3 Hz. (plot only at excited frequencies in [4 . 7 , 11] Hz; true output spectrum in black, noise distortion in grey dash-dotted line, total distortion (= noise + nonlinear distortions) in grey dotted line, error LSTM in green, error MLP in blue, and error TCN in red) of TCNs observed in our experiments. Extending TCNs to handle situations where the data is contaminated with non- white noise seems to be a promising direction in improving the performance of these models. Furthermore, both LSTMs and the dilated TCNs are designed to work well for data with long memory dependencies. Therefore it would be interesting to apply these models to system identification problems where such long term memory is actually needed, e.g. switched systems, or to study if the long-term memory can be translated into accurate long-term predictions, which could ha ve interesting applications in a model predictive control setting. R E F E R E N C E S [1] A. Krizhevsk y , I. Sutskever , and G. E. Hinton, “Imagenet classification with deep convolutional neural networks, ” in Advances in Neural Information Pr ocessing Systems NIPS , 2012. [2] G. Hinton, L. Deng, D. Y u, G. E. Dahl, A. Mohamed, N. Jaitly, A. Senior, V . V anhoucke, P . Nguyen, T . N. Sainath, and B. Kingsbury , “Deep neural networks for acoustic modeling in speech recognition: The shared vie ws of four research groups, ” IEEE Signal Pr ocess. Mag. , vol. 29, no. 6, pp. 82–97, 2012. [3] T . Mikolov , K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space, ” arXiv:1301.3781, T ech. Rep., 2013. [4] W . S. McCulloch and W . Pitts, “ A logical calculus of the ideas im- manent in nervous activity , ” The b ulletin of mathematical biophysics , vol. 5, no. 4, pp. 115–133, 1943. [5] I. Goodfellow , D. W arde-Farle y , M. Mirza, A. Courville, and Y . Ben- gio, “Maxout Networks, ” in Pr oceedings of the 30th International Confer ence on Machine Learning , S. Dasgupta and D. McAllester , Eds. PMLR, Feb . 2013, pp. 1319–1327. [6] N. Srivasta va, G. E. Hinton, A. Krizhevsky , I. Sutskev er , and R. Salakhutdinov , “Dropout: A simple way to prev ent neural networks from overfitting. ” Journal of Machine Learning Researc h , vol. 15, no. 1, pp. 1929–1958, 2014. [7] L. W an, M. Zeiler, S. Zhang, Y . Le Cun, and R. Fergus, “Regulariza- tion of Neural Networks using DropConnect, ” in Proceedings of the 30th International Conference on Machine Learning , S. Dasgupta and D. McAllester , Eds. PMLR, Feb . 2013, pp. 1058–1066. [8] K. Simonyan and A. Zisserman, “V ery Deep Conv olutional Networks for Large-Scale Image Recognition, ” arXiv:1409.1556 [cs] , Sep. 2014. [9] C. Szegedy , W . Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . V anhoucke, and A. Rabinovich, “Going deeper with con volutions, ” in Proc. IEEE Conf. Computer V ision and P attern Recognition , 2015, pp. 1–9. [10] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition, ” in Pr oc. IEEE Conf. Computer V ision and P attern Recognition (CVPR) , 2016, pp. 770–778. [11] D. P . Kingma and J. Ba, “ Adam: A Method for Stochastic Optimiza- tion, ” in Proceedings of the 3r d International Conference for Learning Repr esentations (ICLR) , Dec. 2014. [12] L. Bottou, F . E. Curtis, and J. Nocedal, “Optimization Methods for Large-Scale Machine Learning, ” SIAM Review , vol. 60, no. 2, pp. 223–311, Jan. 2018. [13] S. Ioffe and C. Szegedy , “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Cov ariate Shift, ” in Pr oceed- ings of the 32nd International Conference on Machine Learning . PMLR, Jun. 2015, pp. 448–456. [14] A. L. Maas, A. Y . Hannun, and A. Y . Ng, “Rectifier nonlinearities improve neural network acoustic models, ” in In ICML W orkshop on Deep Learning for Audio, Speech and Language Processing , 2013. [15] M. D. Zeiler, M. Ranzato, R. Monga, M. Mao, K. Y ang, Q. V . Le, P . Nguyen, A. Senior, V . V anhoucke, J. Dean, and G. E. Hinton, “On rectified linear units for speech processing, ” in 2013 IEEE Int. Conf. Acoustics, Speech and Signal Processing , May 2013, pp. 3517–3521. [16] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, ” in Pr oc. IEEE Int. Conf. Computer V ision , 2015, pp. 1026–1034. [17] M. Abadi, A. Agarwal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow , A. Harp, G. Irving, M. Isard, Y . Jia, R. Jozefowicz, L. Kaiser , M. Kudlur, J. Levenber g, D. Man ´ e, R. Monga, S. Moore, D. Murray , C. Olah, M. Schuster, J. Shlens, B. Steiner , I. Sutske ver , K. T alwar , P . Tucker , V . V anhoucke, V . V asudev an, F . V i ´ egas, O. V inyals, P . W ar- den, M. W attenberg, M. Wick e, Y . Y u, and X. Zheng, “T ensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, ” 2015, software available from tensorflo w .org. [18] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Y ang, Z. DeV ito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “ Automatic differen- tiation in PyT orch, ” 2017. [19] S. Hochreiter and J. Schmidhuber, “Long Short-T erm Memory , ” Neu- ral Computation , 1997. [20] C. Gulcehre, K. Cho, R. Pascanu, and Y . Bengio, “Learned-Norm Pooling for Deep Feedforward and Recurrent Neural Networks, ” 2014. [21] Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner, “Gradient-based learning applied to document recognition, ” Pr oc. IEEE , vol. 86, no. 11, pp. 2278–2324, Nov . 1998. [22] A. Krizhevsk y , I. Sutskever , and G. E. Hinton, “Imagenet classification with deep convolutional neural networks, ” in Advances in Neural Information Pr ocessing Systems , 2012, pp. 1097–1105. [23] J. Long, E. Shelhamer, and T . Darrell, “Fully conv olutional networks for semantic segmentation, ” in Pr oc. IEEE Conf. Computer V ision and P attern Recognition , 2015, pp. 3431–3440. [24] J. Redmon, S. Divv ala, R. Girshick, and A. Farhadi, “Y ou only look once: Unified, real-time object detection, ” in Proc. IEEE Conf. Computer V ision and P attern Recognition , 2016, pp. 779–788. [25] S. Bai, J. Z. Kolter , and V . Koltun, “An Empirical Evaluation of Generic Con volutional and Recurrent Networks for Sequence Mod- eling, ” 2018. [26] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “W av eNet: A Generativ e Model for Raw Audio, ” [cs] , Sep. 2016. [27] Y . N. Dauphin, A. Fan, M. Auli, and D. Grangier , “Language mod- eling with gated conv olutional networks, ” in Pr oceedings of the 34th International Conference on Machine Learning-V olume 70 . JMLR. org, 2017, pp. 933–941. [28] N. Kalchbrenner , L. Espeholt, K. Simonyan, A. van den Oord, A. Grav es, and K. Kavukcuoglu, “Neural Machine Translation in Linear T ime, ” arXiv:1610.10099 [cs] , Oct. 2016. [29] J. Gehring, M. Auli, D. Grangier, and Y . Dauphin, “ A Conv olutional Encoder Model for Neural Machine T ranslation, ” in Pr oceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , vol. 1, 2017, pp. 123–135. [30] K. S. Narendra and K. Parthasarathy , “Identification and control of dynamical systems using neural networks, ” IEEE T rans. Neural Netw . , vol. 1, no. 1, pp. 4–27, 1990. [31] S. Chen, S. A. Billings, and P . M. Grant, “Non-linear system identifica- tion using neural networks, ” International Journal of Contr ol , vol. 51, no. 6, pp. 1191–1214, 1990. [32] J. Sj ¨ oberg, Q. Zhang, L. Ljung, A. Benv eniste, B. Delyon, P .-Y . Glorennec, H. Hjalmarsson, and A. Juditsky , “Nonlinear black-box modeling in system identification: a unified overvie w, ” Automatica , 1995. [33] J. A. V argas, W . Pedrycz, and E. M. Hemerly , “Improved learning algorithm for two-layer neural networks for identification of nonlinear systems, ” Neur ocomputing , vol. 329, pp. 86–96, Feb. 2019. [34] D. Masti and A. Bemporad, “Learning Nonlinear State-Space Models Using Deep Autoencoders, ” in 2018 IEEE Conf. Decision and Contr ol (CDC) , 17, pp. 3862–3867. [35] J. de Jes ´ us Rubio, “Stable Kalman filter and neural network for the chaotic systems identification, ” Journal of the F ranklin Institute , vol. 354, no. 16, pp. 7444–7462, Nov . 2017. [36] R. Kumar , S. Sriv astava, J. R. P . Gupta, and A. Mohindru, “Com- parativ e study of neural networks for dynamic nonlinear systems identification, ” Soft Computing , vol. 23, no. 1, pp. 101–114, Jan. 2019. [37] X. Qian, H. Huang, X. Chen, and T . Huang, “Generalized Hybrid Constructiv e Learning Algorithm for Multioutput RBF Networks, ” IEEE T rans. Cybern. , vol. 47, no. 11, pp. 3634–3648, Nov . 2017. [38] T . Wigren and J. Schoukens, “Three free data sets for dev elopment and benchmarking in nonlinear system identification, ” in 2013 Eur opean Contr ol Conference (ECC) , 2013. [39] M. Schoukens and J.-P . No ¨ el, “F-16 aircraft benchmark based on ground vibration test data, ” in W orkshop on Nonlinear System Identi- fication Benc hmarks , Brussels, Belgium, 2017. [40] K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators, ” Neural Networks , vol. 2, no. 5, pp. 359–366, jan 1989. [41] M. Schetzen, The V olterra & W iener Theories of Nonlinear Systems . Malabar , Florida: Krieger Publishing Company , 2006. [42] A. W aibel, T . Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recognition using time-delay neural networks, ” IEEE T rans. Acoust., Speec h, Signal Process. , vol. 37, no. 3, pp. 328–339, 1989. [43] J. Wray and G. G. R. Green, “Calculation of the V olterra kernels of non-linear dynamic systems using an artificial neural network, ” Biological Cybernetics , vol. 71, no. 3, pp. 187–195, jul 1994. [44] F . Giri and E.-W . Bai, Eds., Block-oriented Nonlinear System Identi- fication . Springer London, 2010. [45] M. Schoukens and K. Tiels, “Identification of block-oriented nonlinear systems starting from linear approximations: A survey , ” Automatica , vol. 85, pp. 272–292, nov 2017. [46] A. W ills and B. Ninness, “Generalised Hammerstein–Wiener system estimation and a benchmark application, ” Control Engineering Prac- tice , v ol. 20, no. 11, pp. 1097–1108, nov 2012. [47] M. Schoukens, A. Marconato, R. Pintelon, G. V andersteen, and Y . Rolain, “Parametric identification of parallel Wiener-Hammerstein systems, ” Automatica , vol. 51, pp. 111–122, Jan. 2015. [48] G. Palm, “On representation and approximation of nonlinear systems, ” Biological Cybernetics , vol. 34, no. 1, pp. 49–52, 1979. [49] S. Boyd and L. O. Chua, “Fading memory and the problem of approx- imating nonlinear operators with V olterra series, ” IEEE T ransactions on Cir cuits and Systems , vol. CAS-32, no. 11, pp. 1150–1161, 1985. [50] V . V erdult, “Identification of local linear state-space models: The Silver-box case study , ” IF AC Proceedings V olumes , vol. 37, no. 13, pp. 393–398, sep 2004. [51] A. Marconato, J. Sj ¨ oberg, J. Suykens, and J. Schoukens, “Identification of the Silverbox benchmark using nonlinear state-space models, ” IF AC Pr oceedings V olumes , vol. 45, no. 16, pp. 632–637, jul 2012. [52] K. Tiels, “W iener system identification with generalized orthonormal basis functions, ” Ph.D. dissertation, Vrije Univ ersiteit Brussel, 2015. [53] H. Hjalmarsson and J. Schoukens, “On direct identification of physical parameters in non-linear models, ” IF AC Proceedings V olumes , vol. 37, no. 13, pp. 375–380, sep 2004. [54] J. Paduart, G. Horv ´ ath, and J. Schoukens, “Fast identification of systems with nonlinear feedback, ” IF AC Pr oceedings V olumes , vol. 37, no. 13, pp. 381–385, sep 2004. [55] L. Ljung, Q. Zhang, P . Lindskog, and A. Juditski, “Estimation of grey box and black box models for non-linear circuit data, ” IF AC Pr oceedings V olumes , vol. 37, no. 13, pp. 399–404, sep 2004. [56] M. Espinoza, K. Pelckmans, L. Hoegaerts, J. A. Suykens, and B. De Moor , “ A comparativ e study of LS-SVM’ s applied to the Silver Box identification problem, ” IF AC Proceedings V olumes , v ol. 37, no. 13, pp. 369–374, sep 2004. [57] J. Paduart, “Identification of nonlinear systems using polynomial nonlinear state space models, ” Ph.D. dissertation, Vrije Universiteit Brussel, 2008. [58] A. V an Mulders, J. Schoukens, and L. V anbeylen, “Identification of systems with localised nonlinearity: From state-space to block- structured models, ” Automatica , vol. 49, no. 5, pp. 1392–1396, 2013. [59] M. Espinoza, J. A. Suykens, and B. De Moor , “Kernel based par- tially linear models and nonlinear identification, ” IEEE T rans. Autom. Contr ol , vol. 50, no. 10, pp. 1602–1606, oct 2005. [60] L. Sragner , J. Schoukens, and G. Horv ´ ath, “Modelling of a slightly nonlinear system: a neural network approach, ” IF AC Pr oceedings V olumes , v ol. 37, no. 13, pp. 387–392, sep 2004. [61] E. Pepona, S. Paoletti, A. Garulli, and P . Date, “Identification of piecewise affine LFR models of interconnected systems, ” IEEE Tr ans. Contr ol Syst. T echnol. , vol. 19, no. 1, pp. 148–155, jan 2011. [62] F . Sabahi and M. R. Akbarzadeh-T , “Extended fuzzy logic: Sets and systems, ” IEEE T rans. Fuzzy Syst. , vol. 24, no. 3, pp. 530–543, 2016. [63] K. Tiels, “Polynomial nonlinear state-space modeling of the F-16 aircraft benchmark, ” in W orkshop on Nonlinear System Identification Benchmarks , Brussels, Belgium, 2017. [64] R. Pintelon and J. Schoukens, System identification: A frequency domain appr oach , 2nd ed. Wile y-IEEE Press, 2012. [65] T . Salimans and D. P . Kingma, “W eight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks, ” 2016. [66] N. Qian, “On the momentum term in gradient descent learning algorithms, ” Neural networks , vol. 12, no. 1, pp. 145–151, 1999. [67] T . T ieleman and G. Hinton, “Lecture 6.5—RmsProp: Divide the gradient by a running a verage of its recent magnitude, ” COURSERA: Neural Networks for Machine Learning, 2012. A P P E N D I X A. Neural networks common practices 1) Re gularization: Similar to other approaches within sys- tem identification, L2- and L1-regularization are commonly used to reduce the flexibility of a model and hence av oid ov erfitting. A number of other regularization techniques ha ve also appeared more specialized to neural networks. One of them is the dropout [6] which is a technique where a random subset of the hidden units in each layer is set to zero during training. New random subsets are drawn and set to zero in each optimization step which effecti vely means that a random subnetwork is trained during each iteration. Data augmentation is very common in classification prob- lems and it can also be interpreted as a regularization tech- nique. It is used to artificially increase the training dataset by utilizing the fact that the class is in variant under some transformation of the input (e.g. translation for image) or in the presence of some low intensity noise (e.g. salt pepper noise for images). Finally , early stopping is a pragmatic approach in which, as the name suggests, the optimization algorithm is inter- rupted before conv ergence. The stopping point is chosen as the point where a validation error is minimized. Hence, it av oids ov erfitting and can as such also be interpreted as a regularization technique. 2) Batch Normalization: Before training a neural net- work, the inputs are commonly normalized by subtracting the mean and di viding by the variance. The purpose of this is to av oid early saturation of the activ ation function and assuring that values in the proceeding layers are within the same dynamic range. In deep networks it is beneficial to not only normalize the input layer, but also the intermediate hidden layers. This idea is exploited in batch normalization [13] which, in addition to this normalization, introduces scaling parameters γ and a shift β to be learned during training. The output of the layer is then: ˜ z ( l ) [ k ] = γ ¯ z ( l ) [ k ] + β . (6) where ¯ z ( l ) [ k ] is normalized version of layer l output. The parameters γ and β will be trained jointly with all other parameters of the network. Batch normalization has become very popular in deep learning models. An alternativ e to batch normalization is weight normal- ization which is, essentially , a reparametrization of the weight matrix, decoupling the magnitude and direction of the weights [65]. 3) Optimization Algorithms: Neural networks are trained using gradient-based optimization methods. At each iteration only a random subset of the training data is used to com- pute the gradient and update the parameters. This is called mini-batch gradient descent and is a crucial component for efficient training of a neural network when the dataset is large. Multiple extensions to mini-batch gradient descent have been proposed to make the learning more efficient. Mo- mentum [66] applies a first order low-pass filter to the stochastic gradients to compensate for the noise introduced by the random sub-sampling. RMSprop [67] uses a lo w- passed version of the squared gradients to scale the learning rate in the different dimensions. One of the most popular optimization method today is referred to as Adam [11] which basically amounts to using RMSprop with momentum. B. Hyperparameter sear ch and training time All examples run with hardware acceleration provided by a single graphical processing unit (GPU). W e run different experiments in machines with different configurations so the times are not directly comparable. Some of these machines hav e a NVIDIA T itan V and others a NVIDIA GTX 1080TI. A in depth analysis of the training time is beyond the scope of this paper . The idea is to provide some basic notion of ho w much time is needed to run the neural network and the computational cost of doing hyperparameter search. For example 2, we provide the total time needed to do the hyperparameter search. It should be noticed, howe ver , that grid search is an inef ficient procedure. W e choose to use it in order to study the effect of hyperparameters, rather than because of its efficienc y . And, for example 3, we provide the total time for training the neural network with the best possible configuration. 1) Nonlinear toy pr oblem: W e used grid search for finding the hyperparameters. In each possible training configuration, we have trained the TCN for all possible combinations of: number of hidden layers in { 16, 32, 64, 128, 256 } ; dropout rate in { 0.0, 0.3, 0.5, 0.8 } ; number of residual blocks in { 1, 2, 4, 8 } ; for the kernel size in { 2, 4, 8, 16 } ; for the presence or absence of dilations; and, for the use of batch norm , weight norm or nothing after each con volutional layer . W e have trained the MLP for all combination of: number of hidden layers in { 16, 32, 64, 128, 256 } ; model order n in { 2, 4, 8, 16, 32, 64, 128 } ; activ ation function in { ReLU, sigmoid } . Finally , we trained the LSTM for all combinations of: number of hidden layers in { 16, 32, 64, 128 } ; number of stacked LSTM layers in { 1, 2, 3 } ; dropout rate in { 0.0, 0.3, 0.5, 0.8 } . The best hyperparameters for each configuration are described in T able V. For the TCN, it is better (in all configurations) to use no dilation, no normalization and kernel size equals to 2, hence these hyperparameters are omitted from the table. 2) Silverbox: Some hyperparameters were just experi- enced with manually to find good v alues and did not effect the results in any major fashion. For LSTM and MLP , dropout was disabled this way . For the TCN, the kernel size was set to 2 after initial experimentation. The number of layers (range { 2 , 3 } ), the number of hidden units (range { 4 , 8 , 16 , 32 } ) and dropout (range { 0 , 0 . 05 , 0 . 1 , 0 . 2 } ) were optimized using grid search. Similarly to the other experiments dropout yielded no gain and the best network had 2 layers with 8 units per layer . T otal time consumption for this optimization and hyper parameter search was 33 hours. The MLP was implemented as a single hidden layer neural network with ReLU as activ ation function. The model order (range { 1 , 2 , 4 , 8 , 16 , 32 , 64 } ) and the number of hidden units (range { 4 , 8 , 16 , 32 , 64 , 128 , 256 } ) were optimized using grid search and the best hyper parameters were 4 and 32 re- spectiv ely . T otal time consumption for this optimization and hyperparameter search was 7 hours. T ABLE V: (Example 1) Best model hyperparameters for: dif ferent noise lev els ( σ ) and lengths ( N ). The standard deviation of both the process noise v and the measurement noise w is denoted by σ . (a) TCN: The hyperparameters are the dropout rate (drop.), the number of layers (n. layers and the number of hidden layers (h. size). N=500 N=2 000 N=8 000 σ drop. n. layers h. size drop. n. layers h. size drop. n. layers h. size 0 . 0 0 . 0 2 256 0 . 0 2 64 0 . 0 4 32 0 . 3 0 . 3 8 128 0 . 0 2 128 0 . 0 8 16 0 . 6 0 . 0 8 256 0 . 0 1 64 0 . 0 8 16 (b) MLP: The hyperparameters are the activ ation function (activ . fun.), the number of hidden layers (h. size) and the model order n . N=500 N=2 000 N=8 000 σ activ . fun. h. size n activ . fun. h. size n activ . fun. h. size n 0 . 0 relu 128 2 relu 128 3 relu 256 3 0 . 3 relu 256 2 sigmoid 64 3 relu 128 3 0 . 6 relu 256 2 sigmoid 128 4 relu 128 3 (c) LSTM : The hyperparameters are the dropout rate (drop.), the number of hidden layers (h. size) and the number of stacked layers (n. layers). N=500 N=2 000 N=8 000 σ drop. h. size n. layers drop. h. size n. layers drop. h. size n. layers 0 . 0 0 . 0 128 2 0 . 0 32 1 0 . 0 32 2 0 . 3 0 . 3 128 2 0 . 0 64 3 0 . 0 64 2 0 . 6 0 . 0 128 3 0 . 0 128 3 0 . 3 64 2 In the LSTM case, the hyperparameters for batch size (range { 1 , 2 , 4 , 8 , 16 , 32 } ) and the number hidden units (range { 4 , 16 , 36 , 64 } ) were optimized using grid search and the best hyper parameters were 8 and 36 respectiv ely . T otal time consumption for this optimization and hyperparameter search was 40 hours. 3) F-16 gr ound vibration test: Again, we used grid search for finding the hyperparameters. In each possible training configuration, we have trained the TCN for all possible combinations of: number of hidden layers in { 16, 32, 64, 128 } ; dropout rate in { 0.0, 0.3, 0.5, 0.8 } ; number of residual blocks in { 1, 2, 4, 8 } ; for the kernel size in { 2, 4, 8, 16 } ; for the presence or absence of dilations; and, for the use of batch norm , weight norm or nothing after each con volutional layer . The best result in this case, is to use batch norm, no dilation, kernel size equals to 8 , dropout rate equals to 0 . 3 , and 8 layers. T raining the network with this configuration took approximately 40 minutes. W e have trained the MLP for all combination of: number of hidden layers in { 16, 32, 64, 128, 256 } ; model order n in { 2, 4, 8, 16, 32, 64, 128 } ; activ ation function in { ReLU, sigmoid } . Use sigmoid, model order equals to 64 and 256 hidden units yields the best results. T raining the netw ork with this configuration took 4 minutes. Training the network with this configuration took approximately 5 minutes. Finally , we trained the LSTM for all combinations of: number of hidden layers in { 16, 32, 64, 128 } ; number of stacked LSTM layers in { 1, 2 } ; dropout rate in { 0.0, 0.3, 0.5, 0.8 } . The best configuration is 2 stacked LSTM layers, dropout rate equals to 0 and hidden size equals to 128. Training the netw ork with this configuration took approximately 50 minutes.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment