Learning to Fix Build Errors with Graph2Diff Neural Networks
Professional software developers spend a significant amount of time fixing builds, but this has received little attention as a problem in automatic program repair. We present a new deep learning architecture, called Graph2Diff, for automatically loca…
Authors: Daniel Tarlow, Subhodeep Moitra, Andrew Rice
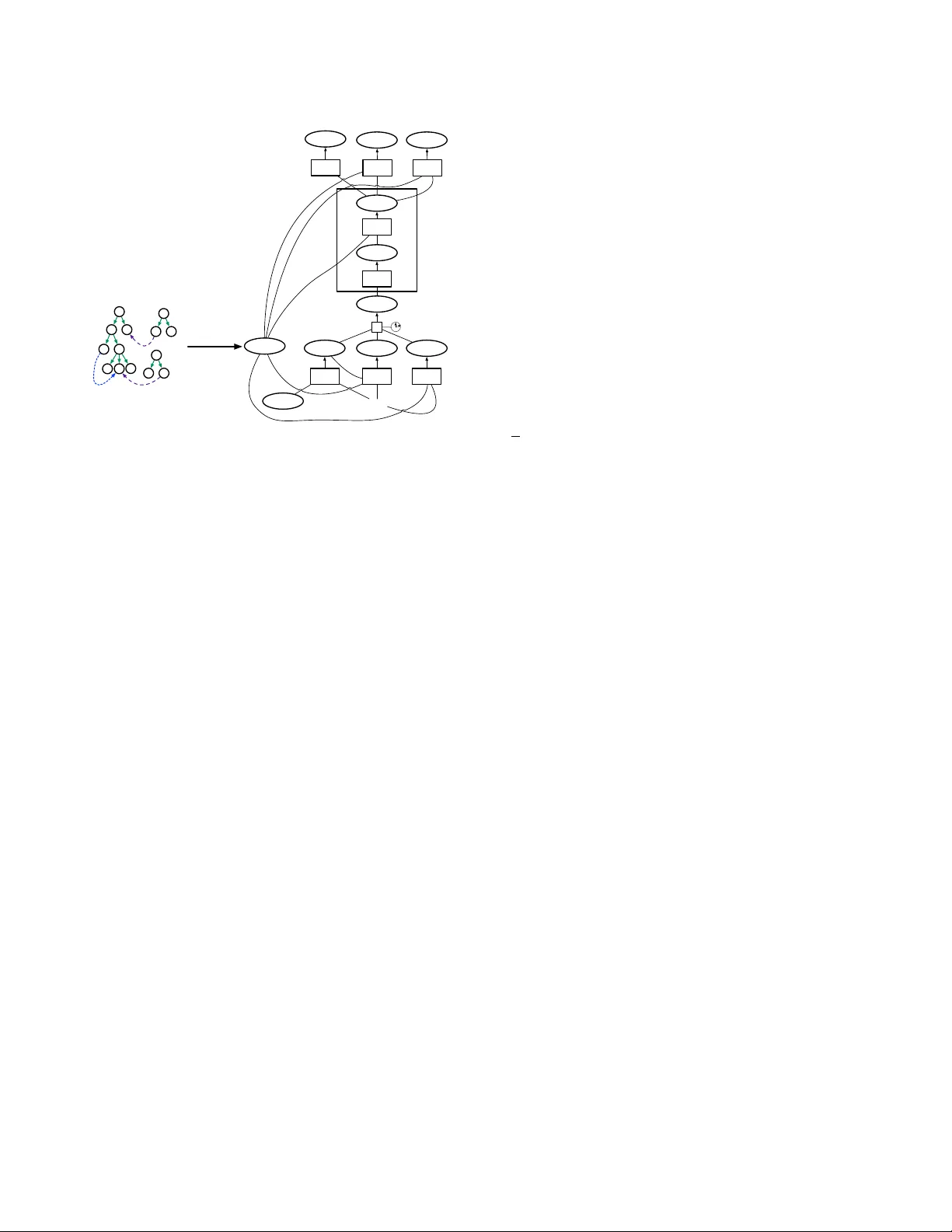
Learning to Fix Build Errors with Graph2Di Neural Netw orks Daniel T arlow Google Subhodeep Moitra Google Andrew Rice University of Cambridge & Google Zimin Chen ∗ KTH Royal Institute of T echnology Pierre- Antoine Manzagol Google Charles Sutton Google Edward Aftandilian Google ABSTRA CT Professional software developers spend a signicant amount of time xing builds, but this has received little attention as a prob- lem in automatic program repair . W e present a new deep learning architecture, calle d Graph2Di, for automatically localizing and xing build errors. W e represent sour ce code, build conguration les, and compiler diagnostic messages as a graph, and then use a Graph Neural Network model to predict a di. A di spe cies how to modify the code’s abstract syntax tree, represented in the neural network as a sequence of tokens and of pointers to code locations. Our network is an instance of a more general abstraction which w e call Graph2T ocopo, which is potentially useful in any development tool for predicting source code changes. W e evaluate the model on a dataset of over 500k r eal build errors and their r esolutions from professional developers. Compared to the approach of DeepDelta [ 23 ], our approach tackles the harder task of predicting a more precise di but still achieves ov er double the accuracy . A CM Reference Format: Daniel T arlow , Subho deep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Sutton, and Edward Aftandilian. 2019. Learning to Fix Build Errors with Graph2Di Neural Networks. In Preprint . A CM, New Y ork, NY, USA, 15 pages. 1 IN TRODUCTION Professional software developers spend a signicant amount of time xing builds; for example, one large-scale study found that developers build their code 7–10 times per day [ 31 ], with a signif- icant number of builds being unsuccessful. Build errors include simple errors such as syntax err ors, but for professional dev elopers these are a small minority of errors; instead, the majority are link- ing errors such as unresolv ed symbols, type errors, and incorrect build dependencies [ 31 ]. A recent paper by Google reports roughly 10 developer-months of eort are spent ev ery month xing small ∗ W ork done during internship at Google. Unpublished working draft. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specic permission and /or a fee. Request permissions from permissions@acm.org. Preprint, A ug 2019, not for distribution. © 2019 A ssociation for Computing Machinery. ACM ISBN 0000. . . $15.00 build errors [ 23 ]. Therefore, automatically repairing build errors is a research problem that has potential to ease a frequent pain point in the developer worko w . Happily , there are good reasons to think that automatic build repair is feasible: xes are often short (see Section 3), and we can test a proposed x before showing it to a developer simply by rebuilding the project. Build repair is thus a potential “sweet spot” for automatic program repair , hard enough to require new resear ch ideas, but still just within reach. Howev er , there is only a small literature on r epairing build errors. Previous work on syntax errors has been very successful generating repairs resolving missing delimiters and parentheses [ 10 , 15 ]. In contrast, in our corpus of professional build errors (T able 1), xes are more subtle, often requiring detailed information about the project APIs and dependencies. Re cently , the DeepDelt a system [ 23 ] aimed to repair build errors by applying neural machine translation (NMT), translating the text of the diagnostic message to a description of the repair in a custom domain-specic language (DSL). Although this work is very promising, the use of an o-the-shelf NMT system severely limits the types of build errors that it can x eectively . T o this end, we introduce a new deep learning architecture, called Graph2Di networks , specically for the problem of predicting e dits to source code, as a replacement for the celebrated sequence-to- sequence model used for machine translation. Graph2Di networks map a graph representation of the broken code to a di 1 in a domain- specic language that describ es the repair . The di can contain not only tokens, but also pointers into the input graph (such as “in- sert token HERE”) and copy instructions (i.e . “cop y a token from HERE in the input graph”). Thus, Graph2Di networks combine, ex- tend, and generalize a number of recent ideas from neural network models for source code [3, 4, 22, 44]. Graph2Di networks are based on three key architectural ideas from deep learning: graph neural networks, pointer models, and copy mechanisms. Each of these ideas addresses a key challenge in modelling source code and in program repair . First, graph neural networks [ 19 , 29 ] can e xplicitly encode syntactic structure, semantic information, and even information from program analysis in a form that neural netw orks can understand, allowing the network to learn to change one part of the code based on its relationship to another part of the code. Second, pointer models [ 38 ] can generate locations in the initial AST to b e edited, which leads to a compact way of generating changes to large les (as dis). Much work on program 1 W e slightly abuse terminology here and use “di ” to mean a sequence of edit opera- tions that can be applied to the broken AST to obtain the xed AST . 2019-11-05 02:46. Page 1 of 1–15. Preprint, A ug 2019, not for distribution. Daniel T arlow, Subhode ep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Suon, and Edward Aandilian repair divides the problem into two separate steps of fault local- ization and generating the repair; unfortunately , fault localization is a dicult problem [ 21 ]. Using p ointers, the machine learning component can pr edict both where and how to x. Finally , the copy mechanism addresses the w ell-known out-of-vocabulary problem of source code [ 5 , 16 , 17 ]: source code projects often include project- specic identiers that do not occur in the training set of a model. A copy mechanism can learn to copy any needed identiers from the broken source code, e ven if the model has nev er encountered the identier in the training set. Essentially , the copy mechanism is a way to encode into a neural network the insight fr om prior r esearch on program repair [ 6 , 18 ] that often code contains the seeds of its own repair . Copy mechanisms give the model a natural way to generate these xes. Graph2Di networks are an instantiation of a more general abstraction that we introduce, called Graph2T ocopo, which encapsulates the key ideas of graphs, copy mechanisms, and pointers into a simple conceptual framew ork that is agnostic to the machine learning approach, i.e., not just deep learning. Our contributions are: (1) W e study the challenges in repairing build errors seen in production code drawn from our collected dataset of 500 , 000 build repairs (Sec. 3). These observations motivate the requirements for a build repair tool: source code context is required, disjoint but correlated changes are often required, and r epairs do not always take place at diagnostic locations. (2) W e introduce the Graph2T ocopo abstraction (Sec. 4) and Graph2Di network for predicting source code edits (Sec. 6). They are particu- larly well-suited to code-to-e dit problems and have desirable prop- erties relative to Sequence-to-Sequence models and other Graph- to-Sequence models. In this paper we show the value of this archi- tecture for build repair , but in general this formulation is relevant to other tasks which require predicting changes to code. (3) Based on an extensive evaluation of our large historical data set of build errors, we nd that the Graph2Di networks have remarkable performance, achieving a precision of 61% at pr oducing the exact developer x when suggesting xes for 46% of the errors in our data set. They also achiev e over double the accuracy of the state- of-the-art DeepDelt a system. Finally , we show that in some cases where the propose d x does not match the developer’s x, the proposed x is actually preferable. Overall, our results suggest that incorp orating the syntactic and semantic structure of code has a signicant benet in conjunction with deep learning. In future work, we hope that our work provides a framework for enhancing deep learning with more sophisticated semantic information from pr ograms, ranging from types to pr o- gram analysis. 2 PROBLEM FORMULA TION Here we formulate the problem of resolving a set of build diag- nostics. The input is the state of the source tree at the time of a broken build and a list of diagnostics returned by the compiler . The target output is a di that can be applied to the code to re- solve all of the diagnostics. For our purposes, a di is a sequence of transformations to apply to the original source code to generate the repaired version. Compiler diagnostics do not always identify the source of the fault that needs to be repaired, so we require the models to predict the locations that need changing in addition to the repairs. This combines the well-studied problems of automate d fault localization and automated program repair . 2.1 Input data format W e represent source code les as Abstract Syntax T rees ( AST s) in order to capture the syntactic structure of the code (e.g., a state- ment is within a block that is within a for loop within a method declaration within a class, etc). Following DeepDelt a [ 23 ], we also parse build conguration les into a similar structure. Build errors are represented as a set of compiler diagnostics. A compiler diagnostic includes the kind of diagnostic (e.g., com- piler .err .cant.resolve), the text associated with the diagnostic (e.g., “Cannot resolve symbol WidgetMaker ”), and a location that is com- posed of a lename and line number . W e further assume that the diagnostic text can be decomposed into a text template and a list of arguments (e.g., template “Cannot r esolve symbol” and arguments list [“ WidgetMaker ”]). 2.2 Output data format The target output is a sequence of edits that can be applied to the AST s of the initial “broken” code in order to resolve all the diag- nostics (thus producing the “xed” AST s). In general, a resolution may require changing multiple les, but in this paper we restrict attention to xes that only require changing a single le. T o enable the use of AST s, we also discard broken code that cannot be parsed, not counting these cases in the results for this paper . W e use the GumTree code dierencing tool [ 14 ] to compute the dierence b etween the broken AST and the xed AST . W e convert the tree dierences into an edit script, which is a sequence of insertion, deletion, move, and update operations that can be applied to the broken AST to produce the xed AST . There is a question of how to represent edit scripts so that they can most easily be generated by machine learning models. In Sec. 4 we present a general abstraction for repr esenting edit scripts, and in Sec. 5 we present the specic instantiation that we use for xing build errors. 2.3 Problem Statement W e can now state the problem that we focus on. Given a set of build diagnostics, the AST of the le that ne eds to be change d, and the associated BUILD le AST , generate the e dit script that the developer applied to resolve the diagnostics. W e view the problem as the se cond, core stage of a two-stage prediction process. Stage 1 pr edicts the le that nee ds to be changed from the build diagnostics. Stage 2 uses the result of Stage 1 to construct the AST of the le that needs to b e changed and an AST of the associated BUILD le. The Stage 2 problem is then the problem statement above. Because Stage 2 is the core challenge that we are interested in, we use a heuristic for Stage 1 of choosing to edit the le with the most diagnostics associated with it, and we limit our experiments to examples where the Stage 1 prediction is correct ( ∼ 90% in our data). In practice if one were deploying such a system, the 10% of cases where the Stage 1 prediction is incorrect should be treated as errors. 2019-11-05 02:46. Page 2 of 1–15. Learning to Fix Build Errors with Graph2Di Neural Networks Preprint, A ug 2019, not for distribution. 3 D A T ASET Before describing our approach, we describe the data in more detail, as it motivates some of the modeling de cisions. T o collect data, we take advantage of the highly-instrumente d development process at Google [26], extending previous work by [23]. 3.1 Build Repair Dataset W e collecte d data by looking at one year of build logs and nding successive build attempts where the rst build produced compiler diagnostics and the second resulted in no diagnostics. W e then retrieved the associated “broken” and “xed” snapshots of the code. These are examples where a de veloper repaired one or more build errors. W e limit attention to examples with edit scripts of 7 or fewer edit operations, where the broken snapshot can be parsed successfully , and that x the build by changing the Java code of the le with the most number of diagnostics (i.e., discard xes that only change build conguration les, command line ags, and unexpected les). W e do not restrict the kinds of diagnostics, the vocabulary used in the edit scripts, or the sizes of input les. The result is a dataset of ∼ 500k xes. Figure 1 shows six examples from the dataset (with identiers renamed) and Figure 2 shows quantitative statistics. W e make the following observations: V ariable Misuse [3] errors o ccur . Row A shows one of 6% of the cases where the x replaces a single wrong usage of a variable. Source-code context is required since the same diagnostic kind has many dierent resolutions. Rows A -C are cant.resolve diagnostics, and rows D-F are incompatible.types diagnostics. Each requires a dierent replacement pattern. Figure 2(c) shows the frequency of diagnostic kinds in the dataset. A small number of diagnostic kinds dominate , but the graph has a heavy tail and there are numerous r esolution patterns per diagnostic, which means that a learning-based solution (as opp osed to attempting to build a hand crafted tool for these diagnostics) seems a go od option. Edit scripts can b e relatively long. Row E requires an edit script of length 4; by comparison, a V ariable Misuse bug such as in Row A can be xed with an edit script of length 1. Figure 2(a) shows the overall distribution of edit script lengths. Fixes do not always occur at the diagnostic location. Row A shows an example where the identier in the diagnostic is not the one that needs changing. Rows C and F show examples where the diagnostics indicate a dierent line to the one that ne eds changing. 36% of cases require changing a line not p ointed to by a diagnostic. There can b e multiple diagnostics. Row C shows an example where there ar e multiple diagnostics. Figure 2(b) shows the distri- bution of diagnostic frequency per build. Approximately 25% of failures had more than one diagnostic. Single xes can span multiple locations. In Ro w G, multiple code lo cations need to b e changed in order to x the error . The changes at the dierent locations ar e part of a single x but require dierent changes at the dierent locations. This shows that we need a exible model which do es not assume that xes at dierent locations are independent as in DeepFix [ 15 ], or that multi-hunk xes apply the same change at dierent locations as in [ 28 ]. 21% of the data requires editing more than one contiguous region. 4 GRAPH2TOCOPO ABSTRACTION Our aim is to develop a machine learning approach that can handle all of the complexities described in the previous section. These chal- lenges appear not only in xing build errors, but also in many other code editing tasks. T o match the generality of the challenges, w e start by developing an abstraction for code editing called Graph2T o copo . Graph2T ocopo aims to formalize the interface b etween the machine learning method and the code-editing problem — like program re- pair , auto-completion, refactoring, etc. Graph2T ocopo is a single abstraction that unies ideas fr om many recent works in modelling source co de [ 3 , 4 , 8 , 22 , 35 , 44 ]. Though we will take a deep learning approach in Sec. 6, Graph2T ocopo is not specic to deep learning. Graph2T ocopo aims to cr ystallize three key concepts that recur across co de e diting tasks: representing code as graphs, repr esenting pointers to code elements, and copying names from code. Represen- tation of code as a graph gives a convenient way of repr esenting code abstractly; of combining multiple sour ces of information, such as code, error messages, documentation, historical revision infor- mation, and so on; and for integrating statistical, syntactic, and semantic structure by constructing edges. Graphs are a natural choice because they are already a lingua franca for (non-learning based) syntactic and semantic analysis of code. At a high level, the goal of the Graph2T ocopo abstraction is to do for co de-editing tasks what the celebrated Seq2Seq abstraction [ 34 ] has done for natural language processing (NLP): Graph2T ocop o aims to serve as an interface between tool developers , that is, software engineering researchers who create new dev elopment tools based on predict- ing code edits, and mo del developers , machine learning researchers developing new model architectures and training methods. Part of our goal is to encourage modularity between these two research areas, so advances one on side can immediately benet the other . When designing a tool for a particular code-editing task, we envision that the tool developer will develop two formalisms, one for the input and one for the output. On the input side, the to ol developer designs a graph to represent the program to be edited, abstracting the code in a way that r eveals the most important infor- mation for the task (Sec. 4.1). On the output side, the tool developer develops an edit-domain specic language (eDSL) that formalizes the class of code edits that is necessary for the tool. Statements in the eDSL are T ocop o sequences (Sec. 4.2), that is, sequences that contain either tokens or two dierent types of location references, called copy operations and pointers. After wards, we envision that the tool developer could choose between many dierent learning methods for Graph2T ocop o (such as Sec. 6), without going into the details of how the models are implemented. 4.1 Code as Graphs W e represent code and related context as a directe d multi-graph with discrete labels on no des and edges. For dierent tasks, the graph can include dierent information such as abstract syntax trees, error messages, results of program analyses, and edges re- lating these components, e.g., a diagnostic line number refers to a location in the co de. Each node is sp ecied by an integer index i and is associated with a tuple of node features ( t i , v i ) , where t i is a member of a nite set of no de types T and v i is a string called the node value . E.g., to represent ASTs, T can b e the set of nonterminals 2019-11-05 02:46. Page 3 of 1–15. Preprint, A ug 2019, not for distribution. Daniel T arlow, Subhode ep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Suon, and Edward Aandilian Row Diagnostics Fix A cannot find symbol ‘widgetSet()’ - w i d g e t s F o r X . w i d g e t S e t ( ) . s t r e a m ( ) . f o r E a c h ( + w i d g e t C o u n t s . w i d g e t S e t ( ) . s t r e a m ( ) . f o r E a c h ( B cannot find symbol ‘of’ - F r a m e w o r k . c r e a t e W i d g e t ( n e w F o o M o d u l e . o f ( t h i s ) ) . a d d ( t h i s ) ; + F r a m e w o r k . c r e a t e W i d g e t ( F o o M o d u l e . o f ( t h i s ) ) . a d d ( t h i s ) ; C (line 10) cannot find symbol ‘longName’ (line 15) cannot find symbol ‘longName’ - S t r i n g l o n g n a m e = " r e a l l y l o n g s t r i n g a b c d e f g h i j k l m n o p q r s t u v w . . . " + S t r i n g l o n g N a m e = " r e a l l y l o n g s t r i n g a b c d e f g h i j k l m n o p q r s t u v w . . . " x = f ( l o n g N a m e ) / / ( l i n e 1 0 ) D i a g n o s t i c p o i n t e d h e r e / / . . . y = g ( a , b , c , l o n g N a m e ) / / ( l i n e 1 5 ) D i a g n o s t i c p o i n t e d h e r e D incompatible types: ParamsBuilder cannot be converted to Optional - r e t u r n n e w P a r a m s B u i l d e r ( a r g s ) ; + r e t u r n n e w P a r a m s B u i l d e r ( a r g s ) . b u i l d ( ) ; E incompatible types: RpcFuture cannot be converted to LongNameResponse - L o n g N a m e R e s p o n s e p r o d u c e L o n g N a m e R e s p o n s e F r o m X ( + L i s t e n a b l e F u t u r e < L o n g N a m e R e s p o n s e > p r o d u c e L o n g N a m e R e s p o n s e F r o m X ( F incompatible types: WidgetUnit cannot be converted to Long - p u b l i c W i d g e t s e t D e f a u l t W i d g e t U n i t ( W i d g e t U n i t d e f a u l t U n i t ) { + p u b l i c W i d g e t s e t D e f a u l t W i d g e t U n i t ( L o n g d e f a u l t U n i t ) { t h i s . d e f a u l t U n i t = d e f a u l t U n i t ; / / D i a g n o s t i c p o i n t e d h e r e G cannot find symbol ‘of(Widget,Widget)’ - i m p o r t c o m . g o o g l e . c o m m o n . c o l l e c t . I m m u t a b l e C o l l e c t i o n ; + i m p o r t c o m . g o o g l e . c o m m o n . c o l l e c t . I m m u t a b l e S e t ; / / . . . - I m m u t a b l e C o l l e c t i o n . o f ( + I m m u t a b l e S e t . o f ( Figure 1: Example diagnostics and xes from our dataset. (a) Fix length (b) # diagnostics (c) Diagnostic freq. Figure 2: Quantitative data statistics. used by Java, and node values v i could repr esent literals, keywords, and identiers. Edges are specied by a triple ( i , j , e ) , which means that there is an edge from i → j with typ e e . 4.2 Edits as T ocopo Sequences The second challenge is how to represent a code edit. W e propose to use a sequence of co de locations and tokens that we call a T ocop o sequence . In more detail, a T ocopo sequence is a sequence of T o- copo expressions, where a T ocop o expression is one of ( a) a token expression of the form TOKEN( t ) . These represent literal tokens, which could be commonly occurring identier names, or editing commands like INSERT and UPDATE , (b) a copy expression , which refers to a value in the input graph (c) an input pointer expression , which refers to a specic node in the input graph, and (d) an output pointer expression which refers to a previous element in the T ocopo sequence. This syntax is given in Figure 3. W e assume that a tool designer creates an eDSL to represent edits to source code in a way that is appropriate for the task at hand. The tool designer cho oses a set of key words for the edit DSL and how they ar e combined with code locations and code tokens to represent an edit. Just as a programming language is a subset of the set of all sequences of tokens, an edit DSL is as a subset of the s :: = s 1 , . . . , s M T ocopo sequence s :: = T ocopo expression TOKEN ( t ) T oken expression COPY ( n ) Copy expression INPUT_POINTER ( n ) Input pointer expression OUTPUT_POINTER ( m ) Output pointer expression Figure 3: Syntax of T o copo sequences. Here t denotes a to- ken, and n and m integers. set of all T ocopo se quences, that is, sequences of tokens, copy , and pointer operations. These three types of expressions are useful for constructing eDSLs for a variety of code editing tasks. The concept of T ocopo se quence is extremely generic, and does not say anything about what the edits do. What we can say about T ocopo sequences at this general level is what the r eferences mean, that is, the pointers and the copy operations. Given a graph G , a to- ken e xpression TOKEN ( t ) can be interpreted simply as referring to t . A copy expression COPY ( n ) refers to the value v n of no de n . An input pointer expression INPUT_POINTER ( n ) refers to node index n in G . Finally , given a T ocopo se quence s 1 . . . s M , OUTPUT_POINTER ( j ) for j < M refers to s j . This allows us to dene two T ocopo se quences s 1 . . . s M and s ′ 1 . . . s ′ M to b e referentially e quivalent, which we write s ⇔ G s ′ , if for all i ≤ M , the two e xpression s i and s ′ i refer to the same entity . In practice the equivalence arises when token t referred to in one expression is equivalent to the node value referred to by a copy operation in the other expression. A ke y constraint on the design of eDSLs, which we will leverage in the learning algorithm (Sec. 4) is that if s ′ ⇔ G s , then s and s ′ specify the same e dit to G . Remarks. First, it may be unclear why we need output pointers. These are useful for adding new larger subtrees to code, because using output pointers we can add multiple new nodes to the AST 2019-11-05 02:46. Page 4 of 1–15. Learning to Fix Build Errors with Graph2Di Neural Networks Preprint, A ug 2019, not for distribution. with a desired relationship among them. Second, the distinction between pointers and copy op erations is subtle, but important. Sometimes, it is important to sp ecify an exact code location , such as when specifying where a new AST no de should be inserte d. This is a pointer . Other times, it is useful to refer to the value of an input no de, such as when inserting a usage of a previously-dened variable, but any other location with the same node value will do just as w ell. This is a copy . Essentially , this is the co de-editing version of the classic distinction between pass-by-value and pass-by-reference in programming languages. 4.3 Program Repair as Graph2T ocop o T o be more concrete, w e give examples of several program repair methods from the literature, showing how they can be represented as Graph2T o copo problems. ( An example of a build repair specie d as a T ocopo sequence is shown in Figure 4.) First, Allamanis et al . [3] propose learning to repair variable misuse errors, such as the one in Figure 1A, using a graph neural network. They proposed using a graph called an augmented AST , that is, the AST of the program with additional edges to represent adjacent tokens, data ow , and control ow . Additionally , in each program, there is one identier expression for which we know a previously-declared variable should be used, but we do not know which one. This expression is represented by a sp ecial node in the graph of typ e HOLE , which has child no des of type CANDIDATE that represent all of the variables in scope. The goal is to predict which of the candidate nodes is the correct variable. This task can repr esented as a Graph2T ocopo problem in a very simple way . The input graph is simply the augmented AST , and the output T ocopo se quence has the form INPUT_POINTER( j ), where j is the node ID of one of the candidate nodes in the graph. V asic et al . [35] suggest a method for jointly localizing and repair- ing variable misuse errors, using two pointers: the rst is a reference to the variable usage that is an error (or to a spe cial sequence posi- tion that indicates no error), and the second pointer is a reference to another variable that should be used in place of the rst. This can be represented as a T o copo sequence of INPUT_POINTER(i) COPY(j) , where i is the node id of the incorrect variable usage, and j is the node id of any usage of the correct replacement. Note the dier ence between pointers and copy operations. A pointer is necessar y for the rst usage, while a copy provides more exibility for the second. 4.4 Learning for Graph2T ocopo Combining the graph-structured input with the T ocopo-structured output results in the Graph2T ocop o abstraction. A training set is collecte d of code snapshots represented as graphs, and target edits represented as T ocopo sequences in the eDSL in question. W e can then treat learning as a supervise d learning problem to map graphs to T ocopo sequences. A variety of learning algorithms can be applied to this task. Many learning metho ds, especially in deep learning, can dene a probability distribution p ( s | G , w ) over T o copo sequences s given graphs G and learnable weights w . (For now , we treat this distribution as a black box; se e Sec. 6 for how it is dene d in the build repair application.) Then, given a training set D = { ( G , s ) } of graphs and target T ocopo sequences, the learning algorithm chooses weights to maximize the probability of the data, that is, to maximize the objective function L ( w ) = Í ( G , s ) ∈ D log p ( s | G , w ) . For Graph2T o copo sequences, though, we can do better than this standard approach, in a way that eases the burden on the tool designer to choose which of potentially many reference-equivalent sequences should be provided as target output. Consider a single example ( G , s ) from the training set. The tool designer should not worry about which e quivalent sequence is desired when they all correspond to the same edit. Thus, we recommend training the model to maximize the probability assigned to the set of expressions equivalent to s . That is, let I G ( s ) = { s ′ | s ′ ⇔ G s } be the set of equivalent expressions, and train using the objective function L ( w ) = Õ ( G , s ) ∈ D log Õ s ′ ∈ I G ( s ) p ( s ′ | G , w ) . (1) This rewards a model for producing any T o copo sequence that is reference-equivalent to the provided target sequence, i.e., the mo del is free to use the copy mechanism as it sees t. It might seem that computing the objective function (1) is computationally intractable, as it may involve a sum over many sequences. Ho wever , it can often be computed eciently , and Graph2Di models are constrained so that it becomes inexpensive to compute. 5 BUILD REP AIR AS GRAPH2TOCOPO Now we cast build repair as a Graph2T ocopo problem. 5.1 Input Graph Representation The input graph is composed of several subgraphs: Code Subgraph. W e roughly follow [ 3 ] to represent source code as a graph, creating nodes for each node in the AST . For identiers and literals, the node value is the string r epresentation that appears in the source code text. For internal no des in the AST , the node value is a string rendering of the node kind. The node type is the kind of AST node as determined by the Java compiler . Diagnostic Subgraphs. There is one diagnostic subgraph for each compiler diagnostic. Nodes in this subgraph come from four sources. First, there is a node representing the diagnostic kind as reported by the compiler , for example, compiler.err.cant.resolve . Second, the text of the diagnostic message is tokenized into a sequence of tokens, each of which is added as a no de in the graph. Third, there is one node for each diagnostic argument (see Sec. 2.1) from the parsed diagnostic message. Finally , there is a diagnostic root node. The subgraph has a backbone tree structure where the root node is a parent of each other listed node, and the nodes are order ed as above. For purposes of creating edges, we treat this tree as an AST . BUILD File Subgraph. BUILD le are usually an XML-style doc- ument (e .g., BUILD le in Bazel, POM le in Maven, build.xml in Ant), which we encode as a tree. The subgraphs are connected by several typ es of edges, and we are planning to add more e dge typ es. An ablation study that removes all edges (Supplementary Materials) in the input graphs shows the importance of these edges. Currently , we have: • AST child: Connects all parents to their children. • Next node: Connects to the next node in a depth-rst traversal. 2019-11-05 02:46. Page 5 of 1–15. Preprint, A ug 2019, not for distribution. Daniel T arlow, Subhode ep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Suon, and Edward Aandilian • Next lexical use: Connects nodes with a given value in a chain structure, with neighbors in the chain being nearest uses when nodes are ordered by the depth-rst traversal. • Diagnostic location: Connects each diagnostic root node to all nodes in the code subgraph on the line where the error occurred. • Diagnostic argument: Connects diagnostic argument nodes to the corresponding nodes in the code subgraph where its string value is equivalent to the diagnostic argument. 5.2 Output eDSL Design Here we describe the eDSL that we use for representing repairs to build errors. A program in our eDSL, which we call an edit script , species how to transform the broken AST into the xed AST . Our goals in designing the eDSL are (a) given tw o AST s for a broken le and a manually r epaired le (which is what we have in our data), it is easy to generate a corresponding edit script, and (b) edit scripts should fully specify the change to the AST . 2 An edit script is a sequence of edit operations. Each e dit operation species one change to be made to the broken AST . As shorthand, we write TOKEN ( t ) as t and use POINTER to mean that either an INPUT_POINTER or OUTPUT_POINTER is valid: • INSERT POINTER() POINTER() . Inserts a new node of node type type and value value into the AST as a child of the node specie d by parentId. It is inserted into the children list after the referenced previousSibling node. If the new node should be the rst sibling, then the special FIRST_CHILD token is used in place of POINTER() . • DELETE INPUT_POINTER() deletes a node. • UPDATE INPUT_POINTER() sets the value of the referenced node to value . • MOVE INPUT_POINTER() POINTER() POINTER() moves the subtree rooted at source so that it is a child of newParent , occuring just after newSibling . • DONE indicates the end of the edit script. For example, Figure 4 sho ws an edit script that implements the x from Figure 1E. Each op eration in the edit script adds one no de of a three-node subtree in the AST that species a Java parameterized type to be inserte d, and then the old Java typ e is deleted. This uses input pointers, output pointers, and values. 6 GRAPH2DIFF ARCHI TECT URE Finally we are able to describ e our new de ep learning architec- ture for Graph2T ocopo problems. This architecture, which we call Graph2Di has two components. The rst is a graph encoder that converts the input graph into a N × H matrix called the node states , where N is the number of nodes in the input graph, and H is the dimension of the hidden states in the network. Each row of the node states matrix is a vector , which we call a node representation , that corresponds to one node in the input graph, and represents all the information about that node that the mo del has learned might be useful in predicting a x. The se cond component of Graph2Di is an edit-script decoder that predicts an e dit script one T ocopo ex- pression at a time, taking the node states and previous predictions as input. The decoder is based on modern deep learning ideas for sequences, namely the celebrated Transformer architecture [ 36 ] 2 As natural as requirement (b) sounds, it is not always respected in previous work. which is used in models like GPT -2 [ 27 ] and BERT [ 13 ], but r equires custom mo dications to handle the special T ocopo features of input pointers, output pointers, and copy operations. Due to space con- straints, we provide only a high-lev el description here. Full details are in the Supplementary Materials. 6.1 Graph Enco der Inspired by [ 3 ], we use a Gated Graph Neural Network (GGNN) to encode the graph into a matrix of node states. At a high level, a GGNN consists of a series of pr opagation steps. At each step , a new representation of each node is computed by passing the repre- sentations of the node’s neighbors at the last step through a neural network. T o initialize the node representations, we use a learnable continuous embedding for node’s type and value, summing them together with a positional embe dding [ 36 ] based on the or der in the depth-rst traversal. W e run GGNN propagation for a xed number of steps (see Sec. 7.1.1 for details), resulting in a representation for each node in the graph. 6.2 Edit-Script De coder The decoder is a neural network that predicts the e dit script one T ocopo expression at a time. If V is the size of the vocabular y , a T ocopo expression is either one of V token expressions, one of N input pointer expressions, or one of N copy expr essions. So we can treat predicting the next T ocopo expression as a classication prob- lem with V + 2 N outputs and predict this with a neural network. 3 The inputs to the decoder ar e (a) the node representations from the graph encoder , and ( b) a representation of the partial edit script generated so far . Our de coder then builds on the deco der from the Transformer model, which is based on a type of neural network called an attention operation . An attention operation is a network that updates the representation of a target sequence of length N 2 , represented as a N 2 × H matrix, based on information from a source sequence of length N 1 , represented as a N 1 × H matrix. The atten- tion operation produces an updated N 2 × H matrix representing the target. For mathematical details, see our Supplementary Material. Our edit-script decoder e xtends the T ransformer decoder to han- dle the pointer and copy op erations of T ocopo. Tw o main extensions are needed. First, the partial edit script contains T ocopo expressions, not just tokens as in Transformer , so w e need a way of representing T ocopo expressions as vectors that can be used within a deep net- work. T o do this, we start with an “output embedding” step, which produces a T × H matrix of hidden states, where T is the length of the partial edit script. Then several layers of attention operations alternate between (i) exchanging information amongst the outputs, via an attention operation where both the sour ce and target are the partial edit script (known as “causal self-attention”), and (ii) sending information from the sequence of nodes in the input graph to the output edit script, via an attention operation wher e the source is the input graph and the target is the partial edit script ( which we call “output-input attention”). This results nally in a T × H matrix representing the partial edit script, which is the input to an output layer , which predicts the next expr ession. 3 Our current implementation of the decoder handles output pointers in a simplied way , predicting only where output p ointers occur , but not predicting what they point to. Therefore , we treat OUTPUT_POINTER as a vocabulary item in this discussion. 2019-11-05 02:46. Page 6 of 1–15. Learning to Fix Build Errors with Graph2Di Neural Networks Preprint, A ug 2019, not for distribution. - L o n g N a m e R e s p o n s e p r o d u c e L o n g N a m e R e s p o n s e F r o m X ( + L i s t e n a b l e F u t u r e < L o n g N a m e R e s p o n s e > p r o d u c e L o n g N a m e R e s p o n s e F r o m X ( 0: MethodDef 1: Type 2: LongNameResponse 3: Id 4: produceLongNameResponseFormX 5: Args 0:INSERT 1:INPUT_POINTER(1) 2:INPUT_POINTER(2) 3:PARAMETERIZED_TYPE 4:TYPEAPPLY 5:INSERT 6:OUTPUT_POINTER(0) 7:FIRST_CHILD 8:IDENTIFIER 9:ListenableFuture 10:INSERT 11:OUTPUT_POINTER(0) 12:OUTPUT_POINTER(5) 13:IDENTIFIER 14:LongNameResponse 15:DELETE 16:INPUT_POINTER(2) 17:DONE Figure 4: An example edit script that makes the change sp ecied in Figure 1E. (T op) a textual di of the change, (Left) A subset of the original AST annotate d with input ids. (Right) An e dit script implementing the change, annotated with output ids. This leads to the second extension. The output layer must pro- duce a V + 2 N sized output of token, copy , and pointer predictions (whereas T ransformer outputs just tokens). T o do this, our output layer makes three separate predictions, which we call “heads” . The token head is an H × V matrix that maps the nal hidden state to a length V vector of token scores. The cop y head and the pointer heads are both attention operations with dierent parameters to produce length N vectors of copy scores and p ointer scores, re- spectively , as in [ 38 ]. The three output vectors are concatenated into the V + 2 N outputs, and a softmax is used to turn this into a distribution over predictions. A nal point is important but a bit te chnical. In order to be able to eciently train under the objective from (1) , we require that the representation of the T ocopo prex provided to the decoder is the same for all r eference-equivalent prexes; i.e., the network should make the same future predictions regardless of whether previous predictions used a token or an e quivalent copy operation. W e imp ose this constraint by representing the partial edit script as a list of sets of all T ocopo expressions that are reference-equivalent to each expression in the partial edit script. These sets can be used within our attention operations with only minor modications. For details, see the Supplementary Material. 7 EXPERIMEN TS W e have several goals and research questions (RQs) for the empiri- cal evaluation. First, we would like to evaluate our design choices in Graph2Di networks and better understand how they make use of available information. W e ask RQ1: How is Graph2Di p er- formance aected by (a) the amount of co de context in the input graph? (b) the model architectural choices? and (c) the amount of training data available? This question is important because the p erformance of deep learning metho ds can often b e sensitive to mo del architectural choices. T o understand how our results t in context with existing literature , we ask RQ2: How do Graph2Di networks compare to previous work on Seq2Seq for xing build errors? W e compare to the most closely related work, which is DeepDelta [ 23 ]. Even though DeepDelta can only b e evaluated on a less-stringent task than exact dev eloper x match, we nd that Graph2Di networks achieve over double the accuracy , which shows that Graph2Di networks are far more accurate than previous work. T urning attention to how the system would be used in practice, we ask RQ3: How often do incorrect predictions build successfully? , because xes that fail to build can be ltered out and not presented to developers. W e nd that 26% ± 13% of the incorrect predictions build successfully , leading to an estimated precision of 61% at producing the exact developer x when sug- gesting xes for 46% of the errors in our data set. Finally , we ask the qualitative RQ4: What kinds of xes does the model get correct? What kinds of predictions are incorrect but build successfully? There are some cases where the x is semantically incorrect and not desirable, but also cases where the predicted x is preferable over the one pr ovided by the developer . 7.1 RQ1: Graph2Di performance 7.1.1 Experimental details. W e follow standard machine learning experimental details, using train, validation and test splits and grid search for cho osing hyperparameters. Details app ear in the Sup- plementary Materials. Our main metric is se quence-level accuracy , which is how often the model predicts the full sequence correctly . This is a strict metric that only gives credit for exactly matching the developer’s change. In the future we plan to show proposals to developers and measure how often the y nd them useful. 7.1.2 Ee ct of context size and model depth. It is p ossible to reduce the size of the input graphs by pruning nodes that are far away from the sour ce of an error . Reducing graph sizes increases training throughput because less computation is needed for each example, and it may be p ossible for the learning problem to b ecome easier if the removed nodes are irrele vant to the x. Howev er , pruning nodes may also hurt p erformance of the model, for three reasons. First, if the error produced by the compiler is not near the source of the fault, then pruning can r emove the location of code that needs to be changed and make it impossible for the model to correctly output the pointer elements in the output DSL. Second, the x may require generating tokens that are out of vocabular y but present as the value of some input node. In this case , it is possible to generate the correct x by outputting a copy element. However , if pruning remov es all potential copy targets, then it will become impossible for the mo del to generate the correct answer . Third, there may be context in the distant nodes that are useful for the machine learning model in a less clear-cut way . Our rst experiment explores this question. Results app ear in Figure 5 (left), sho wing that including more context and p erforming more propagation steps helps performance. 7.1.3 Ee ct of dataset size. T o measure the ee ct of amount of data, we trained models using a random subsampling of the data. Figure 5 (right) shows the best resulting validation accuracy versus the number of training examples. The x-axis is on a log-scale but clearly shows that increasing data size leads to impro ved performance. 2019-11-05 02:46. Page 7 of 1–15. Preprint, A ug 2019, not for distribution. Daniel T arlow, Subhode ep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Suon, and Edward Aandilian Prune Distance Sequence-level V alidation Accuracy A vg. # Nodes # Possible 2 prop steps 4 prop steps 8 prop steps 1 25 125k 14.9% 15.5% 15.7% 2 41 145k 16.3% 16.9% 16.7% 4 192 240k 19.9% 22.4% 23.4% 8 1524 310k 23.8% 26.3% 28.0% 12 2385 315k 22.8% 25.6% 27.1% Figure 5: (Left) Best sequence-level validation accuracy achieved for various degrees of graph pruning. As the Prune Distance increases, more nodes are include d in the graph, it becomes possible to get more training examples correct (the neede d loca- tions and vocabulary appear in the input graph), and accuracy generally increases. More propagation steps leads to improved performance in most cases. (Right) Best validation accuracy vs training set size. 7.2 RQ2: Comparison to Sequence2Sequence DeepDelta [ 23 ] casts the problem of xing build errors in the Se- quence2Sequence framework. Here we compare Graph2Di to DeepDelta across the two axes that they var y: Graph versus Se- quence as input, and Di versus Sequence as output. Input: Graph vs Sequence. The main dierence in the input rep- resentation is the amount of information pro vided to the models about the source code surrounding the error . Within the context of Graph2Di models, w e can test ho w this choice aects performance while holding all else xed. T o use the same input information as DeepDelta, we prune all nodes in the input graph except for the nodes on a path from the lo cation of a diagnostic to the root of the AST . W e leave the diagnostic subgraph the same as in Graph2Di models. The result is a family of graph models that have a sequence input representation like that used in DeepDelta. W e call these models SeqGraph2X mo dels, because they have sequential co de in- put representations but are implemented within the Graph2T ocop o framework. A benet of the Graph2T ocopo framework is that they have a copy mechanism, unlike DeepDelta. Output: Di vs Sequence. Our di output is more precise than the sequence output of DeepDelta in three ways: (a) we refer to locations by pointing to nodes in the input graph, which resolves ambiguity when more than one input node has a given value (e.g., when changing a private modier to public it becomes clear which private to change); (b) we include a previous sibling pointer to sp ecify where we should insert into the list of children under the specied node, which resolves ambiguity about, e.g., or der in argument lists; (c) we generate AST types of new nodes to insert along with their value, which, e.g., resolves ambiguity b etween generating method invocations and metho d references. The ex- tra specicity in the di output is imp ortant, because it provides enough information to automatically apply a x generated by the model without additional heuristics or human judgement, which is crucial towards putting the system into practice. Further , evaluating correctness in terms of matching an imprecise target output gives an overestimate of ho w the system will perform in practice. The Graph2T ocopo framework makes it possible to run a se- ries of experiments that gradually change the specicity of the output DSL from our precise di output to the imprecise output from De epDelta. W e compar e four output DSLs: (1) ImpreciseDi (Imprec) : the output format fr om DeepDelta; (2) Imprecise With- Pointers (Imprec+P) : ImpreciseDi but representing locations more precisely with pointers; (3) Imprecise WithPointersAndSi- blings (Imprec+PS) : Imprecise WithPointers but adding previous sibling pointers; and (4) Di : the Graph2Di output DSL. Graph2Di vs DeepDelta. Finally , we compare to a more dir ect reimplementation of DeepDelta, which uses the same sequential in- put representation but uses the Google Neural Machine T ranslation model [ 40 ] for the Seq2Seq learning. There is no p ointer me cha- nism in this model, so it is not possible to evaluate on the more specic output DSLs and we compare just on ImpreciseDi. W e equivalently refer to the DeepDelta method as Seq2ImpreciseDi. Experiment details and results. W e used the same experimen- tal protocol as in the previous section to train the cross-product of options {Seq, SeqGraph, Graph} × {Di, Imprecise WithPointer- sAndSiblings, Imprecise WithPointers, ImpreciseDi }. Accuracy is measured based on whether the model predicte d the full sequence of its corresponding output correct ( so generally predicting more abstract outputs is expected to produce higher accuracy ). W e r eport dierences in absolute performance compared to the Graph2Di model on validation data. Results appear in Figure 6. Comparing the rst to the se cond row , we see that the Seq- Graph2T ocopo formulation improves over the pure Seq2Seq formu- lation, which we attribute primarily to the copy mechanism that comes with the T ocopo-base d output model. This is inline with other recent work that shows a benet of a copy mechanism in program repair [ 11 ]. Comparing the second row to the third, the graph-structured input improves performance regar dless of the out- put DSL, and the importance of the graph gr ows as the sp ecicity of the output DSL increases. Also , as expected, performance increases as the output DSL becomes more abstract (but recall that we ex- pect those other than Di to overestimate real-world performance). One other interesting comparison is Graph2Imprecise WithPointers versus Graph2ImpreciseDi. These output DSLs are the same ex- cept Imprecise WithPointers represents locations with p ointers and ImpreciseDi represents locations with the values of the nodes. By using the copy mechanism, it would be possible in principle for the ImpreciseDi model to mimic the Imprecise WithPointers model. W e suspect the dierence in performance comes from the stronger su- pervision in the Imprecise WithPointers model—super vision about locations points to exactly the region of the graph that ne eds to be 2019-11-05 02:46. Page 8 of 1–15. Learning to Fix Build Errors with Graph2Di Neural Networks Preprint, A ug 2019, not for distribution. Di Imprec+PS Imprec+P Imprec Seq2 — — — -12.9% (DeepDelta) SeqGraph2 -20.3% -13.5% -11.4% -4.8% Graph2 0.0% +3.3% +8.0% +4.7% Figure 6: Absolute sequence-level accuracy dierence ver- sus Graph2Di model. Rows correspond to input representa- tions and columns correspond to output DSLs with increas- ingly less precision. Only the Di column contains precise information needed to apply the change unambiguously . edited. In the ImpreciseDi mo del, the super vision about locations only narrows the location to a set of possible locations that could be copied from. W e also evaluated test accuracy for the De epDelta and Graph2Di mo dels that achieve best validation accuracy . Deep- Delta test accuracy is 10% and Graph2Di is 26%. In other wor ds, Graph2Di has more than double the accuracy of DeepDelta, even though Graph2Di predicts the change more precisely . 7.3 RQ3: How often do incorrect xes build? When deploying the system in practice, w e can increase precision by ltering out suggestions that do not actually result in a successful build. In this section we evaluate how eective this ltering step is. As a rst ltering step, w e remove all proposed test set xes from the best Graph2Di model that do not follow the grammar of our DSL (5%). From the remaining incorrect examples, we sample 50 examples and attempt to build the pr edicted change. Of these, 13 (26%) build successfully . If we extrapolate these results, this means that the model is able to make suggestions for 46% of the build errors in our data set. Of these, 61% of the time, the x exactly matches the one that was eventually suggested by the developer . 7.4 RQ4: Where is the model successful & not? 7.4.1 Example Correct and Incorrect Fixes. T o illustrate correct and incorrect predictions, we choose to zoom in on a single diagnostic kind (Incompatible typ es), be cause it gives a clearer sense of the variety of x patterns needed to resolve similar errors. It is also interesting because it is not the most common diagnostic kind (it is fth), so this allows exploration of what the mo del has learned about the long tail of potential repairs. Figur e 7 shows examples wher e the model predicted the full output se quence correctly (top) and incorrectly (bottom). Interestingly , in many of these cases the xes seem to depend on details of the relevant APIs. For example, in the rst and fourth correct examples, it generates an extra method call, presumably using the diagnostic message and surrounding context to determine the right method to call. The second example r eplaces the type in a declaration, which requir es generating a rare token via the copy me chanism. The third example is a relatively small change in terms of text but takes 17 tokens in the output se quence to generate (see Figure 4 (b)). The third example correctly converts an integer literal to a long literal. At the bottom, the rst example illustrates that one limitation of the approach is understanding the type signatures of rare methods ( getWidget ). The last example is simply hard to predict without knowing more de veloper intent. 7.4.2 A ccuracy by Diagnostic Kind. Figure 8 reports accuracy by the kind of the rst diagnostic message. W e show results for di- agnostic kinds that appear at least 10 times in the validation data. The model learns to x many kinds of errors, although ther e is a clear dierence in the diculty of dierent kinds. For example, the model never correctly xes a “missing return statement” error . W e suspect these xes are dicult be cause they are closer to program synthesis, where the model needs to generate a new line of co de that satises a variety of type constraints imposed by the context. 7.4.3 Incorrect Fixes that Build Successfully . Finally , we provide three examples from the sampled predictions wher e the x is not equivalent to the ground truth, but still builds. The ground truth x is marked by // Ground truth and the Graph2Di x is marked by // Graph2Diff fix . Listing 1 shows that Graph2Di is able to import from a dierent package with the same metho d name. In fact, in this case, the package imported by the developer is depre- cated and the model’s proposed x is preferred. Listing 2 renamed the method dierently compared to the ground truth x. It is one example of suggesting new method name, which has been explor ed by previous approach [ 2 ]. Listing 3 is one example where the pr e- dicted x is semantically dierent to the ground truth x, and it is unlikely that the predicted x is what the dev eloper intended to do. This is a example of false p ositive, and it is known as the overtting problem in the automated program repair community [32]. + import static junit.framework.Assert.assertFalse; // Ground truth + import static org.junit.Assert.assertFalse; // Graph2Di x Listing 1: Import dierent package − public void original_method_name() throws Exception + public void ground_truth_method_name() throws Exception // Ground truth + public void predicted_method_name() throws Exception // Graph2Di x Listing 2: Changed to a dierent method name − if (id.isEmpty() || Long.parseLong(id).equals(0L)) + if (id.isEmpty() || Long.valueOf(id).equals(0L)) // Ground truth + if (id.isEmpty() || Long.parseLong(id) != 0) // Graph2Di x Listing 3: Semantically dierent bug x 8 RELA TED W ORK Graph Neural Networks to Sequences. There has been much re- cent work on graph neural networks (GNNs) [ 41 ] but less work on using them to generate sequential outputs. Li et al . [19] map graphs to a sequence of outputs including tokens and pointers to graph nodes. The main dier ence is in the decoder model, which w e improve by adding a copy mechanism, feeding back previous out- puts (see Supplementary Materials for experiments demonstrating improved performance), and training under weak supervision. Xu et al . [42] present a Graph2Seq model for mapping from graphs to sequences using an attention-based decoder . Beck et al . [7] develop a graph-to-sequence model with GNNs and an attention-base d de- coder . In both cases, there is no copy or pointer mechanism. Song et al . [33] develop a model for generating text from Abstract Mean- ing Representation graphs, which maps from a graph structured input to a sequence output that also has a copy mechanism but not an equivalent of our p ointer mechanism. Finally , there are also some similarities between our model and generative models of graphs 2019-11-05 02:46. Page 9 of 1–15. Preprint, A ug 2019, not for distribution. Daniel T arlow, Subhode ep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Suon, and Edward Aandilian Diagnostics Fix incompatible types: Builder cannot be converted to WidgetGroup - W i d g e t G r o u p w i d g e t G r o u p = c o n v e r t e r . g e t W i d g e t G r o u p ( ) ; + W i d g e t G r o u p w i d g e t G r o u p = c o n v e r t e r . g e t W i d g e t G r o u p ( ) . b u i l d ( ) ; incompatible types: RpcFuture cannot be converted to LongNameResponse - L o n g N a m e R e s p o n s e p r o d u c e L o n g N a m e R e s p o n s e F r o m X ( + L i s t e n a b l e F u t u r e < L o n g N a m e R e s p o n s e > p r o d u c e L o n g N a m e R e s p o n s e F r o m X ( incompatible types: int cannot be converted to Long - L o n g j o b I d = 1 ; + L o n g j o b I d = 1 L ; incompatible types: ListenableFuture cannot be converted to FooResult - F o o R e s u l t x = c l i e n t . s e n d F o o ( r e q u e s t , p r o t o c o l ) ; + F o o R e s u l t x = c l i e n t . s e n d F o o ( r e q u e s t , p r o t o c o l ) . g e t ( ) ; incompatible types: GetWidgetResponse cannot be converted to Widget - r e t u r n w i d g e t . s t a r t ( ) . g e t ( ) ; + r e t u r n w i d g e t . s t a r t ( ) . g e t ( ) . g e t W i d g e t ( ) ; incompatible types: FooResponse cannot be converted to Optional - r e t u r n L O N G _ C O N S T A N T _ N A M E ; + r e t u r n O p t i o n a l . e m p t y ( ) ; Figure 7: Incompatible typ e error validation examples predicted (T op) correctly and (Bottom) incorrectly . Acc First diagnostic kind 86% compiler.err.unreachable.stmt 69% compiler.err.cant.assign.val.to.final.var 45% compiler.err.unreported.exception.need.to.catch.or.throw 42% compiler.err.non-static.cant.be.ref 33% compiler.err.cant.resolve 29% compiler.misc.inconvertible.types 29% compiler.err.var.might.not.have.been.initialized 20% compiler.err.except.never.thrown.in.try 17% compiler.err.doesnt.exist 13% compiler.err.class.public.should.be.in.file 12% compiler.err.cant.apply.symbols 10% compiler.err.cant.apply.symbol 9% compiler.misc.incompatible.upper.lower.bounds 9% compiler.err.abstract.cant.be.instantiated 9% compiler.err.cant.deref 6% compiler.err.does.not.override.abstract 3% compiler.err.already.defined 0% compiler.err.missing.ret.stmt Figure 8: Accuracy by kind of the rst diagnostic for those that appeared at least 10 times in validation data. [ 9 , 20 , 43 ], in that these mo dels map from a graph to a sequence of decisions that can include selecting no des (to determine edges), though it does not appear that either subsumes the other . Learning Program Repair . W e refer the reader to [ 24 ] for a com- prehensive re view of program repair . W e focus here on the most similar methods. SequenceR [ 11 ] addr esses the problem of program repair based on failing test cases and uses an external fault localiza- tion tool to propose buggy lines. A se quence-based neural network with copy mechanism is used to predict a xed line, using context around the buggy line including the method containing the buggy line and surrounding method signatures. The main dierences are that our approach can learn to edit anywhere in the input graph and the use of a graph-structured input representation. Allamanis et al . [3] introduce the V ariable Misuse problem and builds a GNN model to predict which variable should be used in a given location. It does not directly address the problem of deciding where to edit, instead relying on an external enumerative strategy . V asic et al . [35] uses a recurrent neural network with two output pointers to learn to localize and repair V ariable Misuse bugs. In our context, the rst pointer , which lo calizes the error , can be thought of as a T ocopo pointer , and the second pointer , which points to the variable that should replace the buggy one , can be thought of as a copy operation in T ocop o. Similar to [ 19 ], the rst predicted pointer is not fed back into the prediction of the second pointer . DeepFix is an early work that uses deep learning to x compila- tion errors [ 15 ]. They use a seq2seq neural network with attention mechanism to repair a single code line, and multi-line errors can be xed by multiple passes. The input is the whole pr ogram, and variables are renamed to r educe the vocabulary . Then, the model takes the input and predicts the line numb er along with the bug x. TRA CER [ 1 ] followed the same idea and improved upon Deep- Fix. The most signicant changes compared to De epFix are: 1) The fault localization and patch generation step are separate d. TRA CER relies on the line number reported by the compiler to localize the bug, while DeepFix outputs a line number and the corresponding bug x. 2) TRA CER’s input to the model is much smaller; only the lines surrounding the buggy line are used as input. W e have taken dierent design decisions compared to these two approaches. First, we use a copy mechanism to solve the out-of-vocabulary problem instead of renaming the variables, as we believe variable names contain valuable information for understanding the source code. Second, we take into account the whole program as well as the diagnostic information. Third, we do not assume that multi-line bugs ar e independent (e.g., row G in Figure 1) and x them in multi- ple passes. Instead, we use the pointer network to spe cify dierent locations and generate all bug xes simultaneously . The approach by [ 23 ] to x compilation errors is the closest related work, though we focus on all kinds of errors rather than a few common kinds. W e compared experimentally and discussed extensively in Sec. 7.2. Similarly , Getax also only focuses on a few kinds of errors [ 30 ]. They use a clustering algorithm to extract common edit patterns from past bug xes, and try to apply them on new unseen programs. W e have achieved similar results (Figure 8), but on more error types. Our post ltering steps also allow us to obtain a higher precision rate. 9 DISCUSSION W e have presented an end-to-end neural network-based approach for localizing and repairing build errors that more than doubles the accuracy of previous work. Evaluation on a large dataset of errors encountered by professional developers doing their day-to-day work shows that the model learns to x a wide variety of errors. 2019-11-05 02:46. Page 10 of 1–15. Learning to Fix Build Errors with Graph2Di Neural Networks Preprint, A ug 2019, not for distribution. W e hope that the Graph2T ocop o abstraction is particularly useful for developing new tools to pr edict code changes. Graph2T ocopo provides two ways for tool developers to incorporate their domain expertise into machine learning models. First, the input graphs can be expanded to include arbitrary information about the program, including type information and the results of static and dynamic analysis. Once these are adde d to the graph, the deep learning method can learn automatically when and how this information is statistically useful for predicting xes. Second, the edit DSLs can b e augmented with higher-level actions that perform more complex edits that are useful for a specic tool, such as inserting common idioms, applying common big xes, or even refactoring operations. Having designed these, the tool developer gains access to state of the art neural network approaches. The framework generalizes several recent works [ 3 , 11 , 35 ], and it would be straightforward to expr ess them as Graph2T o copo problems. W e are also looking forward to working with tool developers to develop new Graph2T ocopo problems. W e have already benete d from the generality of the Graph2T ocopo abstraction when running the experiments with dierent output DSLs in Sec. 7.2, where it was easy to use the same abstraction for a variety of input and output design choices. More broadly , we hope that xing build errors is a stepping stone to related code editing problems: there is a natural progression from xing build errors to other software maintenance tasks that require generating larger code changes. A CKNO WLEDGMEN TS W e thank Petros Maniatis for several valuable discussions and com- ments on earlier drafts. REFERENCES [1] Umair Z Ahmed, Pawan Kumar, Amey Karkare, Purushottam Kar , and Sumit Gulwani. 2018. Compilation error repair: for the student programs, from the student programs. In 2018 IEEE/ACM 40th International Conference on Software Engineering: Software Engineering Education and Training (ICSE-SEET) . IEEE, 78–87. [2] Miltiadis Allamanis, Earl T Barr , Christian Bird, and Charles Sutton. 2015. Sug- gesting accurate method and class names. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering . ACM, 38–49. [3] Miltiadis Allamanis, Mar c Brockschmidt, and Mahmoud Khademi. 2018. Learning to represent programs with graphs. In ICLR . [4] Miltiadis Allamanis, Hao Peng, and Charles Sutton. 2016. A convolutional at- tention network for extreme summarization of source co de. In International Conference on Machine Learning . 2091–2100. [5] Miltiadis Allamanis and Charles Sutton. 2013. Mining source code repositories at massive scale using language modeling. In Procee dings of the 10th W orking Conference on Mining Software Rep ositories . IEEE Press, 207–216. [6] Earl T Barr , Y uriy Brun, Premkumar Devanbu, Mark Harman, and Federica Sarro. 2014. The plastic surger y hypothesis. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering . ACM, 306–317. [7] Daniel Beck, Gholamreza Haari, and Tre vor Cohn. 2018. Graph-to-se quence learning using gated graph neural networks. arXiv preprint (2018). [8] A vishkar Bhoopchand, Tim Rocktäschel, Earl Barr , and Sebastian Riedel. 2016. Learning python code suggestion with a sparse pointer network. arXiv preprint arXiv:1611.08307 (2016). [9] Marc Brockschmidt, Miltiadis Allamanis, Alexander L Gaunt, and Oleksandr Polo- zov . 2018. Generative code modeling with graphs. arXiv preprint (2018). [10] Joshua Charles Campbell, Abram Hindle, and José Nelson Amaral. 2014. Syntax errors just aren’t natural: improving error reporting with language models. In W orking Conference on Mining Software Repositories (MSR) . 252–261. [11] Zimin Chen, Steve Kommrusch, Michele Tufano, Louis-Noël Pouchet, Denys Poshyvanyk, and Martin Monperrus. 2018. SequenceR: Sequence-to-Sequence Learning for End-to-End Program Repair . arXiv preprint arXiv:1901.01808 (2018). [12] K yunghyun Cho, Bart van Merrienboer , Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Y oshua Bengio. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In EMNLP . [13] Jacob Devlin, Ming- W ei Chang, Kenton Lee, and Kristina T outanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Conference of the North American Chapter of the Association for Computational Linguistics . 4171–4186. https://www .aclweb.org/anthology/N19- 1423 [14] Jean-Rémy Falleri, Floréal Morandat, Xavier Blanc, Matias Martinez, and Martin Monperrus. 2014. Fine-graine d and accurate source code dierencing. In Pro- ceedings of the 29th ACM/IEEE international conference on Automated software engineering . ACM, 313–324. [15] Rahul Gupta, Soham Pal, Aditya K anade, and Shirish Shevade. 2017. Deepx: Fix- ing common C language errors by deep learning. In Thirty-First AAAI Conference on A rticial Intelligence . [16] Vincent J. Hellendoorn and Premkumar Devanbu. 2017. Are Deep Neural Net- works the Best Choice for Modeling Source Code? . In Proceedings of the 2017 11th Joint Me eting on Foundations of Software Engineering (ESEC/FSE 2017) . A CM, New Y ork, N Y , USA, 763–773. https://doi.org/10.1145/3106237.3106290 [17] Rafael-Michael Karampatsis and Charles Sutton. 2019. Maybe Deep Neural Networks are the Best Choice for Modeling Source Code. CoRR abs/1903.05734 (2019). arXiv:1903.05734 [18] Claire Le Goues, ThanhV u Nguyen, Stephanie Forrest, and W estley W eimer . 2011. Genprog: A generic method for automatic software r epair . Ieee transactions on software engineering 38, 1 (2011), 54–72. [19] Y ujia Li, Daniel Tarlow , Marc Brockschmidt, and Richard Zemel. 2016. Gated graph sequence neural networks. In ICLR . [20] Y ujia Li, Oriol Vinyals, Chris Dyer , Razvan Pascanu, and Peter Battaglia. 2018. Learning deep generative models of graphs. arXiv preprint (2018). [21] Kui Liu, Anil Koyuncu, T egawendé F Bissyandé, Dongsun Kim, Jacques Klein, and Y ves Le Traon. 2019. Y ou cannot x what you cannot nd! an investigation of fault localization bias in benchmarking automated program repair systems. In 2019 12th IEEE Conference on Software Testing, V alidation and V erication (ICST) . IEEE, 102–113. [22] Chris Maddison and Daniel T arlow . 2014. Structured generative models of natural source code. In International Conference on Machine Learning . [23] Ali Mesbah, Andrew Rice, Emily Johnston, Nick Glorioso, and Edward Aftandilian. 2019. DeepDelta: Learning To Repair Compilation Errors. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2019) . ACM, New Y ork, NY, USA. [24] Martin Monperrus. 2018. The Living Review on Automated Program Repair . T e ch- nical Report hal-01956501. HAL/archives-ouvertes.fr . [25] Niki Parmar , Ashish Vaswani, Jakob Uszkoreit, Łukasz Kaiser , Noam Shazeer, Alexander Ku, and Dustin Tran. 2018. Image transformer. arXiv preprint arXiv:1802.05751 (2018). [26] Rachel Potvin and Josh Levenberg. 2016. Why Go ogle stores billions of lines of code in a single repository . Commun. ACM 59, 7 (2016), 78–87. [27] Alec Radford, Jerey W u, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever . 2019. Language Models are Unsuper vised Multitask Learners. (2019). [28] Seemanta Saha, Ripon K. Saha, and Mukul R. Prasad. 2019. Harnessing Evolution for Multi-hunk Program Repair . In Proceedings of the 41st International Conference on Software Engineering (ICSE ’19) . IEEE Press, Piscataway , NJ, USA, 13–24. https: //doi.org/10.1109/ICSE.2019.00020 [29] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner , and Gabriele Monfardini. 2009. The graph neural network model. IEEE Transactions on Neural Networks (2009). [30] Andrew Scott, Johannes Bader , and Satish Chandra. 2019. Getax: Learning to x bugs automatically . arXiv preprint arXiv:1902.06111 (2019). [31] Hyunmin Seo, Caitlin Sadowski, Sebastian Elbaum, Edward Aftandilian, and Robert Bowdidge. 2014. Programmers’ build errors: A case study (at Google). In International Conference on Software Engine ering . A CM, 724–734. [32] Edward K Smith, Earl T Barr , Claire Le Goues, and Yuriy Brun. 2015. Is the cure worse than the disease? overtting in automated program repair . In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering . ACM, 532–543. [33] Linfeng Song, Y ue Zhang, Zhiguo W ang, and Daniel Gildea. 2018. A graph-to- sequence model for AMR-to-text generation. arXiv preprint (2018). [34] Ilya Sutskever , Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems . [35] Marko V asic, Aditya Kanade, Petros Maniatis, David Bieber , and Rishabh Singh. 2019. Neural Program Repair by Jointly Learning to Localize and Repair . arXiv preprint arXiv:1904.01720 (2019). [36] Ashish Vaswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems . 5998–6008. 2019-11-05 02:46. Page 11 of 1–15. Preprint, A ug 2019, not for distribution. Daniel T arlow, Subhode ep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Suon, and Edward Aandilian 1 2 8 3 4 5 6 7 Diagnostic 1 Diagnostic 2 Java AST 9 10 11 12 13 14 Graph Neural Network T arget Output Sequence T oken Embeddings Input Node Hiddens Copy Embeddings Pointer Embeddings Output Embeddings Output Hiddens Embedding Lookup Sparse Attention Vocab Embeddings Embedding Lookup + Causal Self Attention Attention Output Hiddens Attention Weights Copy Logits Attention Weights Pointer Logits Dense Vocab Logits positional encoding N x Input Graph Figure 9: Graph2Di mo del. [37] Petar V eličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero , Pietro Lio, and Y oshua Bengio. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903 (2017). [38] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly . 2015. Pointer Networks. In Advances in Neural Information Processing Systems 28 , C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett (Eds.). Curran A ssociates, Inc., 2692–2700. http://papers.nips.cc/paper/5866- pointer- networks.pdf [39] Oriol Vinyals, Łukasz Kaiser , T err y K oo, Slav Petr ov , Ilya Sutskever , and Geore y Hinton. 2015. Grammar as a foreign language. In Advances in neural information processing systems . 2773–2781. [40] Y onghui Wu, Mike Schuster , Zhifeng Chen, Quo c V Le, Mohammad Norouzi, W olfgang Macherey , Maxim Krikun, Y uan Cao, Qin Gao, Klaus Macher ey , et al . 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144 (2016). [41] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. 2019. A comprehensive sur vey on graph neural networks. arXiv preprint arXiv:1901.00596 (2019). [42] Kun Xu, Lingfei Wu, Zhiguo W ang, Y ansong Feng, Michael Witbrock, and V adim Sheinin. 2018. Graph2seq: Graph to sequence learning with attention-based neural networks. arXiv preprint arXiv:1804.00823 (2018). [43] Jiaxuan Y ou, Rex Ying, Xiang Ren, William L Hamilton, and Jure Leskovec. 2018. GraphRNN: Generating realistic graphs with deep auto-regressive models. arXiv preprint arXiv:1802.08773 (2018). [44] Rui Zhao , David Bieber , K evin Swersky , and Daniel T arlow . 2019. Neural Networks for Modeling Source Code Edits. arXiv preprint arXiv:1904.02818 (2019). APPENDIX T ABLE OF CON TEN TS The appendix contains the following: • A detailed description of the Graph2Di neural network architec- ture and training objective. • Formal semantics of T ocopo sequences. • Additional experimental details and results. A DET AILED DESCRIPTION OF GRAPH2DIFF ARCHI TECT URE In this appendix we describe the Graph2Di architecture in mor e detail. A diagram of the architecture appears in Figure 9. A.1 Background Ops W e begin by reviewing two operations that we use repeatedly , sparse attention [36, 37] and graph propagation [19]. In a sparse attention op, we have M target entities, each attending to a subset of N source entities. Each target entity has a hidden state associated with it, and these hidden states are stacked into an M × H matrix denoted U , where H is the dimension of the hidden states. Similarly , there is a N × H matrix of hidden states associated with source entities, denoted V . Each sparse attention op has three dense layers associated with it: the query layer f Q transforms U into an M × H matrix of per-target queries; the key layer f K transforms V into an N × H matrix of per-source keys; and the value layer f V transforms V into an N × H matrix of p er-source values. Further , the op requires an M × N sparse binary tensor S , where S j i = 1 if target j is allowed to attend to source i and 0 otherwise. The attention weight from target j to source i is α j i = exp f Q ( U i ) , f K ( V j ) , and the result of sparse attention is a M × H matrix where row j is equal to 1 Z Í i : S j i = 1 α j i f V ( V i ) where Z = Í i : S j i = 1 α j i . A sp ecial case of sparse attention is causal self-attention [ 36 ], where U and V are both set to be the hidden states associated with output timesteps (i.e., M = N =#output steps) and S j i = 1 if i ≤ j and 0 other wise. In a GGNN graph propagation op [ 19 ], we have a hidden state for each of N nodes in a graph, stacke d into a N × H matrix U . There are E edge types, and each is asso ciated with a sparse tensor S ( e ) and an asso ciated dense layer f e . S ( e ) j i = 1 if there is an edge of type e from i to j and 0 other wise. The rst step is to send messages across all of the edges. For each no de j , the incoming messages are dened as m j = Í e Í i : S ( e ) j i = 1 f e ( U i ) . The second step is to update U by applying a GRU operation [ 12 ] to each node to get U ′ i = GRU ( U i , m i ) . The result of this update for each node is stacked into a N × H resulting matrix U ′ . A.2 Accommodating W eak Super vision As discussed in Sec. 4.4, we would like to train our mo dels to maxi- mize the log probability assigned to the set of T ocopo se quences that are r eference-equivalent to a given target s , which means summing over all valid T ocop o sequences s ′ ∈ I G ( s ) . Our decoder design is motivated by the observation that some architectural choices allow this summation to be computed eciently . Note that we can decomp ose I G ( s ) into a Cartesian product of per-timestep sets. Overloading notation, let I G ( s ) be the set of T ocopo expressions that evaluate to a target value s . Then I G ( s ) = I G ( s 1 ) × . . . × I G ( s M ) where × denotes Cartesian product. In other words, the set of equivalent T ocopo expressions at time m does not depend on which equivalent T ocop o expression is chosen at other time steps. As shorthand, let I m = I G ( s m ) . W e can leverage the above Cartesian pr oduct structure to sim- plify the training of our models with training objective of (1) , but we nee d to be careful about how the decoder is structured. Consider dening a model for pr edicting T o copo expression s m , and suppose the model has already predicted prex s 1 ∈ I 1 , . . . , s m − 1 ∈ I m − 1 . If we dene predictions in terms of p ( s m | s 1 , . . . , s m − 1 , G ) , where the predicted probability depends on the sequence of T ocopo expres- sions (i.e., how the prex was generated), then the summation in (1) requires summing over all valid pr ex sequences, which could 2019-11-05 02:46. Page 12 of 1–15. Learning to Fix Build Errors with Graph2Di Neural Networks Preprint, A ug 2019, not for distribution. be exponentially expensive: log Õ s ∈ I 1 × . . . × I m p ( s m | s 1 , . . . , s m − 1 , G ) . (2) Howev er , suppose we dene predictions in terms of p ( s m | I 1 , . . . , I m − 1 , G ) , where the pr edicted probability depends on the sequence of equivalence sets. Then we can write log p (I m | I 1 , . . . , I m − 1 , G ) = log Õ s m ∈ I m p ( s m | I 1 , . . . , I m − 1 , G ) . (3) In going from Eq. 2 to Eq. 3, we lose the ability to assign dierent probabilities to p ( s m | s 1 , . . . , s m − 1 , G ) and p ( s m | s ′ 1 , . . . , s ′ m − 1 , G ) for two dierent prexes s and s ′ that are reference-equivalent, but it allows us to perform the marginalization ne eded for training with weak supervision in linear rather than exponential time. Our full training objective is thus log p (I G ( s ) | G ) = Õ m log Õ s m ∈ I m p ( s m | I 1 , . . . , I m − 1 , G ) . (4) From the perspective of the de coder , this means that when fe eding back in predictions from previous time steps, we need to fe ed back the sets I 1 , . . . , I m − 1 and dene a neural network model that takes the sets as inputs to the deco der . This is accomplished via the Output Embedding model describ ed next. W e note that a simpler alternative that preser ves eciency is to not feed back denotation pr exes at all, and instead dene objective log p (I G ( s ) | G ) = Õ m log Õ s m ∈ I m p ( s m | m , G ) . (5) In this case, the predictions at the dierent time steps are condi- tionally independent of each other given the input graph. This is a good choice when there is no uncertainty in the outputs given the inputs, and it is a choice that has been made in pr evious related work [ 19 , 35 ]. However , it cannot represent certain important distri- butions over output sequences (e .g., .5 probability to make change A at position X and .5 probability to make change B at position Y). W e show in Se c. C.2.1 that this alternative leads to signicantly worse performance on our problem. A.3 T o copo De coder The de coder predicts the next element of the T ocopo sequence given the input graph and the previous predicted T ocop o elements. Output Embedding. When predicting the next token in the target output sequence, we condition on the pr eviously generated denota- tions. This section describes how to embed them into hidden states that can b e pr ocessed by later layers of the decoder . There are three stages of the output embedding. First, we embed the token associated with each output. For token outputs, this is a standard lo okup table into a learnable vector representation per output vocabulary element. Out of vocabulary tokens share a vector . There is no token associated with an input pointer , but we assume they have a special “POIN TER” token at this stage (i.e., all pointers share a “POINTER” emb edding). Second, we incorporate copy information. For each output token, we track which input nodes could have b een copied from to generate the token. This information can be r epresented as a sparse indicator matrix with rows corr esponding to output elements and columns corresponding to input nodes, with a 1 entry indicating that the output can be generated by copying from the node. W e then perform a sparse attention operation using embeddings fr om the rst output embedding stage as queries and the outputs of the graph encoder as keys and values. The result of this “ copy attention” is a weighted average of the nal node embeddings of nodes that could be copied from to generate each token, passed through a learnable dense lay er . For empty rows of the sparse matrix, the result is the zer o vector . Finally , we incorporate pointer information. This follows similar to the copy embeddings but is simpler be cause ther e can be at most one p ointer target per output se quence. In terms of the sparse matrix mentioned ab ove, each row has at most a single 1. Thus, we can apply the analogous operation by selecting the node embedding for the column with the 1 and passing it through a dierent learnable dense layer . For empty rows of the sparse matrix, the r esult is the zero vector . The output of each stage is an embedding vector per timestep (which may be the zer o vector). The total output embeddings are the sum of the embeddings from the three stages. Output Propagation. This stage propagates information fr om the input graph to the output sequence and between elements of the output sequence. W e repeatedly alternate steps of output-to-input attention and output-to-output causal self-attention. The result of each step of the deco der is an updated hidden state for each output step, which is fed as input for the next deco der step. It is initialized to the output of the embedding step ab ove. The result of the propagation stage is the nal hidden state for each output step. Output-to-input attention uses the current output hidden states as ke ys for a dense attention operation. The keys and values are the nal input graph node hidden states. As in [ 36 ], keys, queries, and values are passed through separate learnable dense layers before performing the attention. The result of attention is a vector for each output step. These ar e tr eated as messages and combined with the previous output hidden states using a GRU cell as in GGNNs [ 19 ]. The dense layers and GRU cell parameters ar e shared across propagation steps. Note that this step allows the output to depend on the entire input graph, even if the input graph has diameter greater than the number of input propagation steps. Output-to-output attention follows similarly to above but instead of input node hidden states as keys and values, it uses the current output hidden states and masks results so that it is imp ossible for information ab out future outputs to inuence predictions of previous outputs (i.e., it is causal self-attention [ 36 ]). The output hidden states are update d using a GRU cell as above. The dense layers and GRU cell parameters are shared across propagation steps, but there are separate parameter sets for output-to-input attention and output-to-output attention. Output Prediction. Given the result of output propagation, which is a hidden state per output timestep, the na l step is to predict a distribution over next outputs. At training time , we simultaneously make predictions for all outputs at once. The output-output propa- gation ensures that information only ows from previous to future timesteps, so the nal hidden state for output step t only includes information about the input graph and outputs up through time t . 2019-11-05 02:46. Page 13 of 1–15. Preprint, A ug 2019, not for distribution. Daniel T arlow, Subhode ep Moitra, Andrew Rice, Zimin Chen, Pierre- Antoine Manzagol, Charles Suon, and Edward Aandilian J s 1 . . . s M K G = concat ( J s 1 . . . s M − 1 K G , J s M K G ) J TOKEN ( t ) K G = ( T oken , t ) J COPY ( i ) K G = ( T oken , v i ) J INPUT_POINTER ( i ) K G = ( InputP ointer , i ) J OUTPUT_POINTER ( j ) K G = ( OutputP ointer , j ) T able 1: Dereferencing semantics of T o copo sequences. Here s 1 . . . s M are T o copo expressions, t ∈ L is a token, and i ∈ 1 . . . N indexes a no de in the input graph, and j ≥ 0 is an integer . W e can thus simply dene a mapping from output hidden state t to a distribution over the output t + 1 . Our approach is to dene three output heads. A token head, a copy head, and a pointer head. Letting H be the hidden size, V be the size of the output vocabulary , and N be the number of nodes in the input graph, the token head passes output hidden state t through a dense layer of size H × V . The result is a vector of length V of “vocab logits. ” The copy head passes output hidden state t through a dense layer of size H × H and then computes an inner product of the result with the nal repr esentation of each node in the input graph. This gives a size N vector of “copy logits. ” The pointer head performs the same operation but with a dierent dense layer , yielding a size N vector of “p ointer logits. ” The outputs of the three heads ar e concatenated together to yield a size V + 2 N vector of predictions. W e apply a log softmax over the combined vector to get log probabilities for a distribution over next outputs and take the log sum of probabilities asso ciated with correct outputs to compute the training objective. B FORMAL SEMAN TICS OF TOCOPO SEQUENCES W e give a formal semantics of what it means for two T ocop o se- quences to refer to the same nodes in the graph. See T able 1. Here ∅ represents an empty sequence, and concat (·) adds an element to the end of a sequence. T o interpret this, notice that many node values in G , for example, leaf nodes in the syntax tree, are tokens from L . Intuitively , for s and s ′ to be equivalent, this means that copy operations are matched either to copies on no des that have the same value, or an equal token from L . Intuitively , this semantics dereferences all of the pointers and copy op erations, but otherwise leaves the T ocopo sequence essentially unchanged. This is the maximum amount of semantic interpretation that we can do without specifying an eDSL. Now we can dene a notion of equivalence. Our notion of equiv- alence will be based on all of T wo T ocopo sequences s and s ′ are equivalent with respect to a graph G , which we write s ⇔ G s ′ , if the sequences have equal derferencing semantics J s K G = J s ′ K G . Because it is just checking the location refer ence, this notion e quiv- alence that is generic across eDSLs. If s ⇔ G s ′ , are equivalent T ocopo sequences, they should be equivalent semantically in any reasonable eDSL. C ADDI TIONAL EXPERIMEN T AL DET AILS AND RESULTS C.1 Experimental details For these experiments, we randomly split resolutions into 80% for training, 2500 examples for validation, and 10% for test. Unless otherwise specie d, all experiments use grid sear ches over learn- ing rates { 5 e − 3 , 1 e − 3 , 5 e − 4 , 1 e − 4 } , gradient clipping by max norm of { . 1 , 1 . 0 , 10 . 0 } , hidden dimension of { 64 , 128 } and number of propagation steps { 1 , 2 , 4 , 8 , 12 } . Batching follows that of [ 3 ], packing individual graphs into one large supergraph that contains the individual graphs as separate disconnecte d comp onents. W e add graphs to the supergraph as long as the current supergraph has fewer than 20 , 000 nodes. For some of the hyperparameter congu- rations w e exceeded GPU memory , in which case we discar ded that conguration. W e allowed training for up to 1M updates, which took on the order of 1 week p er run on a single GP U for the larger models. W e report results from the training step and hyperparame- ter conguration that achieved the best accuracy on the validation data. For Graph2T ocopo models, we use the following vocabulary sizes: 10000 for input graph node values, 1000 for input node typ es, and 1000 for output vocabulary . For DeepDelta, we use input and output vocab sizes of 30k, as that is the value used by [ 23 ] and we found it achieve better performance than the smaller vocab sizes used in Graph2T ocopo. C.2 Eect of autoregressive fee dback As discussed in Sec. A.2, there is a simpler decoder choice emplo yed by [ 19 ] in their latent hiddens model and [ 35 ] that do es not fee d back previous outputs when generating a sequence from a graph. W e evaluate an ablated form of our model that generates output se- quences in the same way , removing the autoregressive component of our method. In Figure 10, we see that feeding in previously pre- dicted outputs to the mo del is an important comp onent. Leaving it out costs 5-6% absolute performance (20-26% relative) degradation. C.2.1 Eect of graph structure . W e ran an experiment removing edge information from the model, preserving only a basic notion of ordering. W e rendered the diagnostic, build, and Java subgraphs in a linear order via a depth-rst pre-order trav ersal of nodes and removed all edges in the input graphs. W e added back edges con- necting each node to all no des within a distance of 10 in the linear ordering of nodes. This is meant to mimic a Transformer-style model with local attention [ 25 ], working on a linearization of tree structures as input [39]. No hyp erparameter setting was able to achieve more than 3% sequence-level validation accuracy , but the best p erforming edge- ablated model came from pruning at diameter 1 and doing 12 prop- agation steps. W e sp eculate that the edges contain critical infor- mation for localizing where the edit needs to take place, and this gets lost in the ablation. The diameter 1 problem suers the least because it has extracted the subgraph around the errors, which makes the localization problem easier (at the cost of not b eing able to solve as many problems by just looking at that local context). 2019-11-05 02:46. Page 14 of 1–15. Learning to Fix Build Errors with Graph2Di Neural Networks Preprint, A ug 2019, not for distribution. 2 prop steps 4 prop steps 8 prop steps Prune distance 8 (from above) 23.8% 26.3% 28.0% Prune distance 8, no feeding back previous outputs 17.5% 20.8% 22.3% Dierence (absolute) -6.3% -5.5% -5.7% Figure 10: Ee ct of removing autoregressive feedback in the decoder . 2019-11-05 02:46. Page 15 of 1–15.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment