TreeCaps: Tree-Structured Capsule Networks for Program Source Code Processing
Program comprehension is a fundamental task in software development and maintenance processes. Software developers often need to understand a large amount of existing code before they can develop new features or fix bugs in existing programs. Being a…
Authors: Vinoj Jayasundara, Nghi Duy Quoc Bui, Lingxiao Jiang
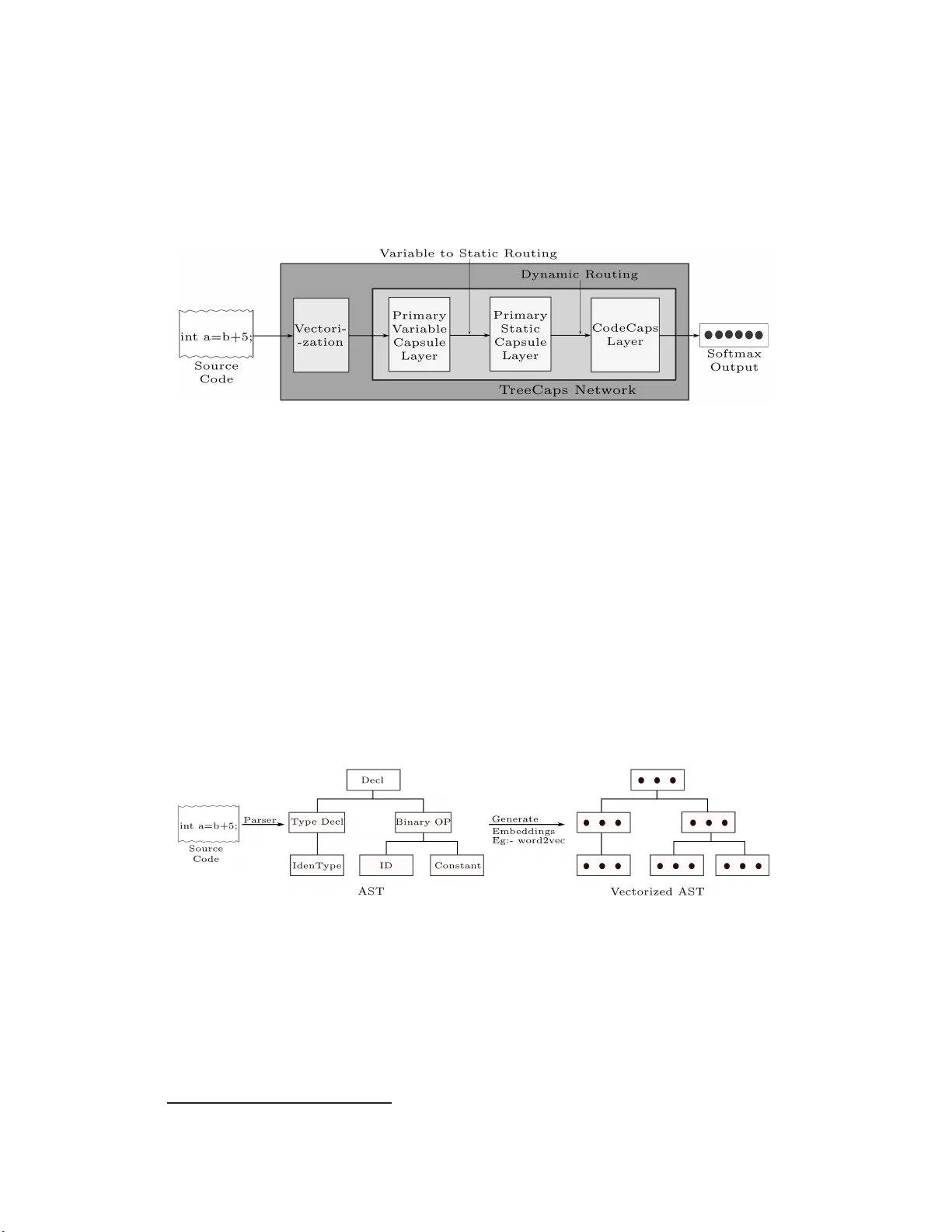
T r eeCaps:T ree-Structured Capsule Networks f or Pr ogram So u rce Code Processing V inoj Jayasundara 1 , 2 & Nghi Duy Quo c Bui 2 & Lingxiao Jiang 2 & David Lo 2 1 Artificial Intelligence Initiative (A*AI), A*ST AR, Singapore 2 School of Info rmation Sy stems, Singapore Managemen t University vinoj jayasu ndara@gmail.com, dqnbu i.2016 @phdis.smu.edu.sg lxjia ng@smu .edu.sg, davi dlo@s mu.ed u.sg Abstract Program com prehen sion is a fundamen tal task in sof tware development and main- tenance processes. Software dev elopers often need to understan d a large amount of existing cod e b efore they can develop new featu res or fix bugs in existing pro- grams. Being able to proce ss progr amming language code auto matically and pro- vide summaries of code fun ctionality acc u rately can sign ificantly help developers to redu ce time spen t in code navigation and un derstandin g, and th u s increase pro- ductivity . Different f rom n atural lan guage articles, sou rce cod e in pr ogramm ing languag e s often follows rigid syntactical structures an d there can exist dependen- cies among code elements that are located far away from each other thro ugh com- plex con trol flows and data flows. Existing studies on tree - based conv olution al neural n etworks (TBCNN) a nd gated graph neural network s (GGNN) are not able to cap ture essential seman tic depend encies among code elemen ts accur ately . In this pap er , we pr o pose novel tree-based capsule networks (T reeCaps) and relev ant technique s for p rocessing progra m c ode in an autom ated way that encodes co de syntactical struc tu res and captur es code dependen cies more accu rately . Based o n ev aluation on programs written in different programming languages, we show that our TreeCaps-based approach can outperfo rm o ther appr oaches in classify ing the function alities of many prog rams. 1 Intr oduction Understand ing prog ram co de is a fundam ental step for many software engin eering tasks. Software developers o ften spend more than 50% of their time in navigating thr o ugh existing code bases and un derstandin g the code bef ore they can implement n ew f e a tures or fix bugs (Xia et al. , 201 8; Evans Data Corp oration, 2 019; Britto n et al., 2012). I f suitable models for program s are built, they can be usefu l for many tasks, such as classifyin g the fun ctionality of programs (Nix a nd Zhang, 2017; Dahl et al., 2 013; Pascanu et al., 2015; Rastogi et al., 2 013), predicting bugs (Y ang et al., 2015; Li et al., 2017, 201 8), and p roviding bases for pr o gram tran slation (Ng u yen et al., 20 17; Gu et al., 201 7). Different from natural langua g e texts, progr a mming languages hav e clearly d efined gram mars and compilable sou rce cod e m ust follow rigid syntactical structures an d c an be unam biguo u sly par sed into syn ta x trees. There can be co mplex contro l flows and data flows amon g various c o de elem ents all over a prog ram that affect the semantic and fu nctionality o f the progr am. So me inter-dependent code elem ents can ap pear in an arbitrary o rder in the p rogra m ( e .g., a fu n ction A calls another function B while A an d B a re spatially far away from each othe r ); some code ele m ents, such as local variable nam e s, hav e n o significant impact on cod e function a lity . 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouv er , Canada. In the literature, tree-based con volutional neural networks (TBCNNs) have been p ropo sed (Peng et al., 2015; Mou et al., 2 016) to show promising results in p rogram ming lang uage p rocess- ing. TBCNNs accep t Abstract Syntax Trees (ASTs) of sou rce co de as the input, and capture ex- plicit, structural paren t-child-siblin g relations among cod e elements. Gated graph n eural networks (GGNNs) (Li et al., 2016) ar e also pr o posed as a way to learn grap h s, and ASTs ar e extende d to graphs with a v ariety of cod e depend encies added as ed ges amo n g tr ee nodes to m odel code seman- tics ( A llam anis et al., 2018b). W hile GGNNs cap ture mor e cod e semantics than T BCNNs, many additional edges amo ng tree nodes have to be added through pro g ram analysis techniques, and many of the edges may be noise, contributing longer t raining time and lower performanc e . A recen t model, known as ASTNN, based o n a seq u ence of small ASTs for statements (instead of one big AST for the whole pro gram) sh ows better per f ormanc e than TBCNNs and GGNNs (Zhan g et al., 2 019). In this paper, we pro pose a novel tree-based capsule network architecture, named T reeCaps , to capture bo th syntactical structure an d d epend e n cy informatio n in c o de, withou t the need of explic- itly adding depen dencies in the tree s or sp littin g a b ig tre e into smaller ones. Capsule Network s (CapsNet) (Sabou r et al., 2017) itself is a pro mising c oncept that has demon strated vast po tential in outp erform ing CNNs in various domain s in cluding comp u ter v ision and natural langu age pro- cessing, because it h a s the main advantage that it can d iscover and p reserve the relative spatial an d hierarchica l relation s amo ng objects within an inpu t (e.g., an image and a pie c e o f texts). T reeCaps adapts Cap sNet to ASTs f or progr ams, propo ses novel primary v ariable and prima ry static capsule layers, propo ses a novel variable-to-static routing algorithm to rou te a variable set of cap- sules to generate a static set of capsules (with the inten tion of p reserving code d ependen cies), and connects the tree cap sule lay e rs to a classification lay er to classify the function a lity of a p rogram . In ou r emp irical ev aluation, we take various sets of prog rams written in different prog ramming lan- guages (e.g. , Pyth on, Ja va, C) collected fr om GitHub and the litera ture, and train our TreeCaps models to classify p rogram s with dif ferent functio nalities. Results sho w that TreeCaps ou tperfor ms other ap p roache s in pr ogram classification b y significant margin s, while a study done on variants of the prop osed mo del r ev eals the effecti veness of the prop o sed variable-to-static ro uting algorithm , effect of the dimen sio n ality of the classification capsules on the mod el perf o rmance and the effec- ti veness of the use of add itio nal ca p sule layers. 2 Related W ork Capsule network s (Sabou r et al., 2 017; Hinton et al. , 201 8) use dynamic ro uting to model spatial and hierarch ical relations among o bjects in an image. The tech niques h av e been succ essfully applied to different tasks, such as computer vision, charac ter reco gnition, and text classification (Jayasunda r a et al., 20 19; Zh ao et al., 2018). None of the studies has considered complex tree data as inp ut. Capsule Grap h Neural Network (Xinyi and Ch e n, 2019) h as been r e cently prop osed to classify biolog ical an d social network gr a phs, yet, ha s n ot been a pplied to trees for prog ramming languag e s pro cessing y et. On the other hand, tree- and graph-b ased neural networks hav e been stu d ied for progr am languag e processing. TBCNNs (Peng et al., 2015; Mou et al., 20 16) have been used to mo d el code syntactical structures. GGNNs (Li et al., 201 6; Allaman is et al., 201 8 b ) build d ependen cy gr aphs fr om ASTs and use grap h n eural networks to encode the code d e penden cies. V arian ts of TBCNNs and GGNNs are also propo sed to represent prog rams differently and aim to ach ieve better tr aining accur acy and costs. For example, ASTNN ( Zhang et al., 2 019) splits an entire AST into a sequence of smaller ones and uses b idirectional gated r ecurren t units (Bi-GRU) to mo del the smaller ASTs th a t represent statements in progr ams. For ano th er example , bilateral dep endency tree- b ased CNNs (DTBCNNs) (BUI et al., 2019) are used to classify programs acr oss different p rogram ming la n guages. T ree- LSTM (W ei an d Li, 2017) has a lso been used to mo del tree structures in p rogra m cod e . Our work aims to mod e l tree stru ctures too , but designs special dynamic r o uting with the inten tion to capture code depe n dencies without the n eed of explicit program analysis technique s. More gener a lly , there is hug e interest in ap plying deep learnin g techniq ues for various so f tware engineer in g task s, such as pr o gram classification, b ug pr ediction, cod e clone detection, program refactoring, translation and even code synthesis (Allaman is et al., 2018a; Alon et al., 201 9; Hu et al., 2018; Ch e n et al., 2018; Pradel and Sen, 2018). W e are likely the first to adap t capsule networks for pr o gram source cod e proce ssing to capture bo th syntactical stru c tures and c o de depend encies, 2 especially fo r the pro blem of pro gram classification. In the fu ture, it can be an exciting area to combine more kind s o f semantic-aware cod e rep resentations (e.g., symbolic traces (He n kel et al. , 2018)) and tailored pro gram an alysis techniques with dee p learn ing to improve code learn in g task s. 3 Ap pr oach Overview Figure 1 : Approach Overview . The sour ce codes are parsed , vecto rized and fed into th e pr o posed T reeCaps network for the pro g ram classification task. The overview of our TreeCaps approa c h is sum marized in Fig. 1 . The so u rce co d e o f the trainin g sample pr ogram is parsed in to an AST and vectorized with the aid o f W ord2V ec (Mikolov et al., 2013) or a similar tech nique th at considers the AST node types, in stead of con crete tokens, as the vocabulary words (Peng et al., 201 5; BUI et al., 20 19). The AST an d the vectorized nod e s are then fed in to ou r TreeCaps n etwork, wh ich consists of a Primary V ariable Capsule (PVC) layer to accom modate th e varying nu mber o f nod es in the AST . Su bsequently , the capsules are r outed to the Primary Static Capsule ( PSC) layer using the pr oposed variable-to-static rou ting algorithm , followed by rou ting with th e dynamic ro uting algorithm to the Co d e Capsule (CC) layer . Actin g as the classification capsule layer, Code capsules capture and provid e embeddings for the en tire train ing sample, while d enoting th e pr obability of existence of the sour c e co de classes by the respective vector nor m s. Finally , a softmax layer is used on the vector no rms to outp ut th e pr obabilities for the input code sample to belo ng to various func tio nality classes. Section 4 and 5 explain more ab out the AST vector ization and other m ajor co mpon ents in T reeCaps. 4 Abstract Syntax T r ee V ectorization Figure 2: T ree V ecto r ization, wh ich generates the AST from the source co de a nd vectorizes it u sing an embedd ing gen eration tec hnique. Fig. 2 illustrates the vectorization of an AST . Every raw sou rce c o de is par sed with an approp ri- ate p arser correspon ding to the p rogram ming language to gen erate the AST . 1 The AST r e p resents the syntactic structure of the source co de with a set of gener a lized vocabulary words (i.e., node type n ames). W e use AST s to train the emb edding for node typ es by applying e m beddin g tech - niques, such as W ord2vec (M ikolov et al., 2013), in the context of ASTs using techniqu es similar to Peng et al. (20 15), which learns a vectorize d v ocabulary of nod e types, x node ∈ R V , wh ere V is the embedding size. The learned v ocabulary can subsequen tly be used to vectorize ea ch individual node of the ASTs, g enerating the vectorized ASTs. 1 W e use python AST parser for python programs, whereas we use srcML parser for C and Jav a programs. 3 5 T r ee-based Capsule Networks One of the main ch allenges in creating a tree-ba sed cap sule network is that the input of the n etwork is tree-stru ctured (ASTs in our ca se) . T ree-structured d a ta are inh erently different from ge n eric image data, X img ∈ R H × W × C , where H , W , C are the fixed height, width and the numb er of channels respectively , o r natural lan guage data, X nlp ∈ R L × E , where L, E ar e the fixed padd ed sentence len gth an d the word emb edding size respectively . Hence, the network arch itecture needs to be con structed to accommo date such tree-structure d d ata, X tree ∈ R T × V , wher e T , V are the variable tree size (th e number of nodes in the tree ) a nd the nod e emb edding size respectively . Figure 3 : V ariable-to-Static Routing: routes a variable set of capsules to gener ate a static set of capsules. 5.1 Primary V ariable T r eeCaps Layer A fu rther challenge with trees is that the tr e e size varies from p rogram to pro gram, and the number of child r en varies from nod e to no de. A nai ve solution to the prob lem can be to pad the sizes to r each a fixed, pre-d efined leng th , following a similar app roach in natural lang uage dom ain to preserve a fixed sentence length. Howe ver , zero -padd ing is n ot a p prop r iate in our case due to the degree o f variability . For in stance, the n umber of children per no de can vary fr om zero to hu ndred s, causing c h allenges in deciding the fixed pad ding length and intro ducing sparsity . Mo u et al. (2016) propo se a more effective app r oach ter m ed as co ntinuou s b in ary tree, where the conv olution wind ow is em ulated as a binary tr ee, wh ere the weight matrix cor respond ing to each n ode is repr esented as a weighted sum of three fixed matrices W t , W l , W r ∈ R V ′ × V and a bias term b ∈ R V ′ , where V ′ is the emb edding size after the c o n volution, and the weigh ting co efficients are calc u lated by taking the positional value in to account. Hence, for a co n volutional window of depth d in the original AST , and there are K + 1 n odes (includin g the parent n ode) which belo ng to that window with vector s [ x 1 , ..., x K + 1 ] , wher e x i ∈ R V , then the conv olutional outp ut y can be d efined as follows, y = tanh ( K + 1 X i =1 [ η t i W t + η l i W l + η r i W r ] x i + b ) (1) where η t i , η l i , η r i are weights defined with respect to the depth and the position o f th e ch ildren nodes: η t i = d i − 1 d − 1 η r i = (1 − η t i ) p i − 1 k − 1 η l i = (1 − η t i )(1 − η r i ) (2) where d i is the depth of th e no de i in the co n volutional windows, p i is the position of th e no de and k is th e total number of n ode’ s siblin gs. The o utput of tree-structured co n volution resembles the inp ut tree structure, Y conv ∈ R T × V ′ . In the Primary V aria b le Capsule lay er , y obtained from Equation 1 correspo n ds to the output of one conv olutional slice. W e use ε such slices with different random initialization s f or W , b , similar to CNNs for image data. Subsequen tly , as illustrated by Fig 3, we gr oup the conv olutional slices together to form N pvc = T × V ′ × ε D pvc sets of capsules with outputs u i ∈ R D pvc , i ∈ [1 , N pvc ] , where D pvc is th e dim ensions of the capsules (i.e., D pvc is the nu m ber of instantiation p arameters o f the capsules) in th e PVC layer . In o r der to vectorize each capsule outpu t u j as ˆ u j (to represen t the probab ility o f existence of an entity by the vector length), we subsequ e ntly apply a n on-linear squash func tio n as fo llows, ˆ u i = || u i || 2 || u i || 2 + 1 · u i || u i || 2 (3) where || ˆ u i || 2 ≤ 1 . Henc e , the output of the prim ary variable capsule layer is X pv c ∈ R N pvc × D pvc . 4 5.2 Primary Static T reeCaps Layer The key issue with passing the outp uts of the PVC layer, X pv c , to the Cod e Capsu le layer is that the numbe r o f c a psules, N pvc , is variable from one train ing example to another . Prior to ro uting the lower level capsules to a set of high er lev el ca p sules, the lower d imensional capsule outp uts need to b e pro jected to the h igher dimen sionality , with the aid of the tran sformation matrix which learn s the part-who le relationship between the lower and the higher level capsules (Sabou r et al., 2 017). Howe ver , a trainab le transfo r mation matrix cann ot b e defined in practice with variable dimen sions. Thus, the dynam ic routing in the literature (Sabour et al., 2017) cann ot be applied between a variable set of capsules and a static set of capsules. 5.2.1 V ariable-to-Stat ic Capsule Ro uting Therefo re, we pro pose a novel variable-to-static capsule routing algor ithm, summarized in Algo- rithm 1. Algorithm 1 V ariable-to-Static Capsule Routing 1: procedure R O U T I N G ( ˆ u i , r, a, b ) 2: ˆ U sorted ← sort ([ ˆ u 1 , ..., ˆ u N pvc ]) 3: Initialize v j : ∀ i, j ≤ a, v j ← ˆ U sorted [ i ] 4: Initialize α ij : ∀ j ∈ [1 , a ] , ∀ i ∈ [1 , b ] , α ij ← 0 5: for r iterations do 6: ∀ j ∈ [1 , a ] , ∀ i ∈ [1 , b ] , f ij ← ˆ u i · v j 7: ∀ j ∈ [1 , a ] , ∀ i ∈ [1 , b ] , α ij ← α ij + f ij 8: ∀ i ∈ [1 , b ] , β i ← S of tmax ( α i ) 9: ∀ j ∈ [1 , a ] , s j ← P i β ij ˆ u i 10: ∀ j ∈ [1 , a ] , v j ← S q u ash ( s j ) 11: return v j W e initialize the outputs of th e Primary Static Capsu le layer with the outpu ts of the a cap su les with th e high est L 2 norms in the PVC layer . Hen ce, th e outp uts of the PVC layer, [ ˆ u 1 , ..., ˆ u N pvc ] , are first sorted by their L 2 norms, to ob tain ˆ U sorted , and then the first a vectors of ˆ U sorted are assigned as v j , j ≤ a . T h e intuition is that, in practice, no t ev ery nod e of the AST c ontributes tow ards source code classification. Often, so urce code consists of n on-essential entities, and on ly a p ortion of all en tities deter mine the code class. Since the pr obability of existence of an entity is denoted by th e leng th of the capsule o u tput vector ( L 2 norm) , we only consider th e en tities with the h ig hest existence p robab ilities fo r in itializatio n. It should be n o ted that the ca p sules with the a -highest norms are used only for initialization , the actu al ou tputs o f the primar y static capsule s are determined by iteratively runn in g the variable-to-static routing algorithm . A well- known pr o perty of source co de is that d ependen cy relationships may exist am ong entities that are not sp atially co-lo c a ted. Theref o re, we route b nodes in the AST based on th e similarity be twe en them and the primary static cap sule layer o u tputs, wh ere a ≤ b ≤ N pvc . W e assign b = N pvc in ge n eral to route with all the node s in the AST . If co mputation al c o mplexity is c r itical, we can choose a smaller b and rou te with top - b n odes of the AST . a and b can be ch osen e mpirically , where computatio nal comp lexity also factors in when choo sing b . W e initialize the routing coefficients as α ij = 0 , equally to all the capsules in the p rimary variable capsule layer . Subsequen tly , as illustrated by Fig 3, they are iter ativ ely refined based on the ag r ee- ment between the curre n t prima ry static capsule layer o utputs v j and th e primary dy namic c a p sule layer outpu ts ˆ u i . Th e agreement in this case is measu r ed b y the d ot pro duct, f ij ← ˆ u i · v j , and the routing coefficients are adjusted with f ij accordin g ly . If a capsule γ in the primary dyn amic layer has a strong agree m ent with a capsule δ in the pr imary static layer , then f γ δ will be positively large, whereas if there is a strong disagre ement, th en f γ δ will be negati vely large. Subsequ ently , the sum of vectors ˆ u i is weighted by the up dated β ij to calculate s j , which is th en sq u ashed to upd ate v j . 5 Figure 4: Dy namic Routing between the Primar y Static Capsules and the Code Capsu les. 5.3 Code Capsule Layer Code Capsule lay er is the final layer o f the TreeCaps n etwork, which acts as the classification ca p sule layer, as illustrated by Fig ure 4. Sinc e the outputs o f the PSC layer X psc ∈ R N psc × D psc , where N psc = a and D psc = D pvc , consist of a fixed set o f c apsules, it ca n be ro u ted to the CC layer v ia the dyn amic routin g algorithm in the literature (Sabou r et al., 201 7) (summarized in A lg o. 2) . For each capsule j in the PSC layer, and for each capsule m in the CC lay er , we multiply the ou tput of the p rimary static c a psule v j by the tran sformation matrices W j m to p r oduce the predictio n vectors ˆ v m | j = W j m v j . The trainable transfor mation matrices learn the part-whole relationship s betwe e n the primary static capsules and the code cap sules, while effectiv ely transfo rming v j ’ s in to the same dimensiona lity as z m , where z m ’ s denote the outputs of the code capsule layer . Similar to the variable-to-static capsule routin g, we in itialize th e routin g coefficients γ j m equally , and itera ti vely refine them based on the agreements between the p rediction vectors ˆ v m | j and the code capsule outputs z m , where z m = sq uash ( P j γ j m ˆ v m | j ) . Algorithm 2 Dynam ic Rou tin g 1: procedure R O U T I N G ( ˆ v j , t, a, c ) 2: Initialize ∀ j ∈ [1 , a ] , ∀ m ∈ [1 , c ] , δ j m ← 0 3: for t iterations do 4: ∀ j ∈ [1 , a ] , γ j ← sof tmax ( δ j ) 5: ∀ m ∈ [1 , c ] , z m ← sq uash ( P j γ j m ˆ v m | j ) 6: ∀ j ∈ [1 , a ] , ∀ m ∈ [1 , c ] , δ j m ← δ j m + ˆ v m | j · z m 7: return ˆ z m The primar y static capsule o utputs a r e routed to the CC layer using the dynamic routing a lg orithm, as illustrated by Fig 4, to produ ce the fina l capsule ou tputs X cc ∈ R N cc × D cc , where N cc = κ is the number o f classes and D cc is the dimensionality of the code capsules. Ultimately , we calculate the probab ility of existence of each class by o btaining L 2 norm of each Code Cap s o utput vector . 5.4 Margin Loss for T reeCaps T raining W e u se th e Margin Loss pro posed by Sabour et al. (201 7) a s the loss fun ction for T reeCaps. For ev ery code capsule µ , the ma rgin loss L µ is defined as follows, L µ = T µ max(0 , m + − k v µ k ) 2 + λ (1 − T µ ) max(0 , k v µ k − m − ) 2 (4) where T µ is 1 if the correct class is µ and zero oth erwise. Follo wing Sabou r et al. (2017), λ is set to 0 . 5 to c o ntrol the initial lear n ing from sh r inking the len g th of the ou tput vectors of all the co de capsules, and m + , m − are set to 0 . 9 , 0 . 1 as the lower bo und fo r the correct class and the u p per bound for the inco r rect c la ss respecti vely . 6 Empirical Evaluation 6.1 Datasets and Implementation W e used th ree datasets in thre e pr ogramm ing lan g uages to ensu re cross-lan guage ro bustness. The first dataset ( A ) c o ntains 6 classes of sortin g algorithm s, with 34 6 training prog rams on average p er 6 class, written in Pytho n. 2 The secon d d ataset ( B ) is inherited fro m BUI et al. (20 1 9), which con tain s 10 classes of sortin g algorithms, with 64 trainin g progra ms on average per class, written in Jav a. The third d ataset ( C ) is inherited fro m Mou et al. (20 16), which contain s 1 04 classes of C p rogram s, with 375 training progr ams on average per class. For the dataset A, we used the publicly av ailable vectorizer ( see Footnote 2) to genera te em beddin gs for more than 9 0 AST node types in Python. For the datasets B & C, srcML 3 defines a u nified vocabulary fo r more than four hundr e d AST nod e types for C and Ja va (an d several other langu ages, but not Py thon), and w e ad apted the same vector izer to generate embed d ings for th e unified AST nod e typ es defined by srcML. W e used Keras and T en sorflow libr aries to im plement TreeCaps. T o tr ain the models, we used the RAdam optimizer (L iu et al., 2019) with an initial learning rate of 0 . 001 subjected to decay , on an Nvidia T esla P100 GPU. T o enhan ce the classification ac c uracies, a we ig hted average ensembling technique (Kro g h and V edelsby, 1995) was u sed. 6.2 Program Classificatio n Results T able 1: Comp arison o f TreeCaps with other app roaches. The me ans an d the standard deviations from 3 trials are shown. Model Dataset A Dataset B Dataset C GGNN Allamanis et al. (20 18b) - 85 . 00% 86 . 52% TBCNN (Mou et al., 20 16) 99 . 30% 75 . 00% 79 . 40% T reeCaps 100 . 00 ± 0 . 0 0% 92 . 11 ± 0 . 9 0% 87 . 95 ± 0 . 2 3% T reeCaps (3-ensem bles) 100.0 0% 94.08 % 89.41% T able 1 compares our results to o ther appr o aches for p rogra m classification. I t should be noted th at, Mou et al. ( 2016) have used cu stom-traine d initial em beddin g s for a small set of about 50 AST nod e types defined specifically for C languag e on ly (Peng et al., 20 1 5) a n d reported a higher result in their paper, while o ur appro ach gen erates the initial embed dings f or a mu ch larger vocabulary of mo re than th ree hundr ed u nified AST no de typ es f or b o th C and Jav a. For a fairer compar ison based on the same set of AST nod e vocabulary , especially for the datasets B & C, we used o ur emb edding s ba sed on srcML nod e vocabulary as the initial emb edding s across all mod els. W e followed th e technique s propo sed in Allam anis et al. (201 8a) and B UI et al. ( 2019) to re-g enerate th e results for GGNN an d the techniqu es pro posed in Mou et al. (2016) to re - generate the results for TBCNN. For the d ataset A, we achieved a perfect classification result, o utperfo rming TBCNN by a na rrow margin of less than 1% . Howe ver , the margin was more significant f or the datasets B an d C. An av erage accur acy of 9 2 . 11% was ach iev ed by o ur ap proach f o r the dataset B, outp erform ing oth er approa c h es at least by 7 . 1 1% . T reeCaps outp erform e d its conv olutional co unterpa r t (TBCNN) by a significant margin o f 17 . 11 % . The perfor mance was furth e r im proved by 1 . 97% with the use of 3 - model weighted average ensemblin g techniq ue. For the dataset C, our ap proach was able to surpass the other app roaches by 1 . 43 % , achieving a n accuracy o f 87 . 95 % . Howe ver , TreeCaps sur p assed TBCNN by a mo re significant margin of 8 . 55% . Three-mo del weighted a verage ensembling on the dataset C p rovided a further im provement of 2 . 89 % in comp arison to the oth er appro aches, achieving an accuracy of 89 . 41 % . 6.3 Model Analysis W e ev aluate th e effects o f various aspects of the T reeCaps model, includin g the effect o f the variable- to-static rou ting algorithm, variations in the num ber of instantiation pa r ameters in the Cod eCaps layer, and the addition of a secon dary capsule layer . W e evaluate these variations on the d ataset B. 6.3.1 Effect of the variable-to -static routing algorithm W e in vestigate the effect of the variable-to-static rou ting algor ithm by r e p lacing it w ith D y namic Max Pooling (DMP). Sinc e there is no alternative approa c h existing in the literature for routing a variable set o f capsules to a static set of cap sules, we co mpare the prop osed rou ting algorithm with dy namic po oling. The output of the PVC layer, X pv c ∈ R N pvc × D pvc consists of a variable 2 Collected from https://github .com/crestonb unch/tbcnn . 3 https://ww w.srcml.org/ 7 T able 2: Effect of d ifferent model variants Model V ariant Accuracy V ar iable-to-Static Rou ting Algorithm → Dyn a m ic Poo ling 83 . 43% Instantiation parameters → D cc = 4 90 . 90% D cc = 8 92 . 10% D cc = 12 90 . 33% D cc = 16 91 . 51% T reeCaps → T reeCaps + Second ary Capsule Lay er 92 . 31% T reeCaps with V a r iable-to-Static Ro u ting and D cc = 8 92 . 1 1% compon ent, N pvc . Using dynamic m ax p ooling across all the N pvc capsules w ill result in one output capsule, X dmp ∈ R 1 × D pvc . Since X dmp has no variable compon ents across the tra ining samples, it can now be routed to the code capsules using the dy namic r o uting algorithm. However , it shou ld be n oted that DMP is not su itable for capsule networks, as it d estroys the spatial and depend ency r elationships b etween the capsules. W e use DM P here o n ly for co mparison purpo ses. As summarized in T able 2, DMP yields a considerably lower accuracy of 83 . 43% than our routing algorithm by a significant margin of 8 . 68 % , establishing th e effecti veness of ou r propo sed algorithm. 6.3.2 Effect of the number of instantia tion parameters The instantiation param e ters D cc of the Code Capsule layer acts as the final emb edding s used for classification, in oth e r words, the dimen sionality o f the latent repr esentation of source code. If th e dimensiona lity of the latent represen tation is h igher than required , it can introduc e sparsity and/o r correlation s between the instantiation parameters, reducing the classification accu racy . On the con- trary , if the dimension ality of the late n t repr esentation is too low , it may not be sufficient to capture the variations in sou r ce cod e , lead in g to under-representatio n, red ucing the classification a ccuracy . Hence, in an attempt to identify a suitable value fo r D cc for sou rce code classification, w e in vesti- gate the effect of D cc in the accuracy . As summ arized in T able 2, we ob served that the mo st suitable value was D cc = 8 for the dataset B. 6.3.3 Effect of the addition of a seco ndary capsule layer W e ev aluate the ad dition of an extra capsu le layer fu n ctionally similar to a primary static ca p sule layer, which we call the second ary capsule (SC) layer . W ith resp ect to Fig 1, we stack the SC la y er in between the PSC lay er and the CC lay er . W e use dy namic rou ting to route b etween the PSC and SC layers and between th e SC and CC layers. E ven though we observed a minor imp rovement of the classification accur acy , the added com putation a l co mplexity increases the inf erence time by 16% , from 10 . 3 ms to 11 . 9 ms per sample. The usefulness of the addition of such a SC layer needs to be further inves tigated. 6.4 Discussion of Limitations & Future W ork Since TreeCaps is based on th e cap sule networks, it inher its the limitations o f cap sule networks such as the high co mputation al complexity in co mparison to CNNs, and perf ormance reduction with the increasing num ber o f classes. T reeCaps lack s a reco nstruction n e twork , similar to the recon struc- tion ne twork f or ima g e data pr esented by Sabour et al. (2017), which is u seful to in vestigate the interpretab ility of the cap sule ne twork, including the r elationship b etween th e lear n t instantiatio n parameters and the ph ysical attributes of data. W e intend to extend ou r work to furth er inv estigate the effects of d ifferent initial embeddin gs on the classification accuracy . Fur ther, we intend to com pare related pieces of code identified by TreeCaps to progr am d ependen cies identified by pro gram an alysis techniques, to ev aluate the effecti veness of T reeCaps as an em b edding gener ating techn ique, and to extend T reeCaps to other related tasks such as bug detection and localization. 8 7 Conclusion In this p aper, we prop osed a novel tree-ba sed capsule network ( T reeCaps ) to learn r ich syntactical structures and semantic dep endencies in p rogram sou rce code. The mode l pro posed n ovel tec hnical features that deal with variable sized trees ac r oss different pro grammin g languages, inclu ding pri- mary variable and pr imary static capsule layer s, an d the variable to static r outing algo r ithm. Ou r empirical evaluations show th a t these features sign ificantly co ntribute to the high classification ac- curacy of TreeCaps m odel for pr ogram classification tasks for various progr amming languages. T o the best of o ur knowledge, our work is the first to adap t capsule network s to trees a nd ap p ly them to progr a m so urce code learning . W e belie ve that T reeCaps can capture mo re code semantics than previous cod e lear n ing models and complem ent existing pro g ram ana lysis tec hniques well. 8 Acknowledgeme nt This research is suppo rted by the Nation al Research Foundatio n Singap ore under its AI Singapor e Programm e (A ward Number: AI SG-RP-2019 -010) . Refer ences Miltiadis Allam a nis, Earl T Barr, Premkumar Dev anbu, and Charles Sutton. A sur vey o f mach ine learning for big code an d n aturalness. AC M Computing Surveys , 51( 4 ):81, 2018a. Miltiadis Allamanis, M a rc Bro ckschmidt, and M a hmoud Kh a demi. Lear ning to repre sent prog rams with graphs. In International Co n fer ence on Learning Rep resentations , 201 8 b. Uri Alo n, Meital Zilbe r stein, Omer Levy , and E ran Y aha v . Code2vec: Lear ning distributed repre- sentations of cod e . Pr oc. ACM Pr ogr amming Langu ages , 3( POPL ) :40:1–4 0:29, Janu ary 2019. T om Britton, Lisa Jeng, Graham Carver , an d Paul Cheak. Quantify the time and cost sa ved using reversible debuggers. T echnical re p ort, Cambridge Judge Business Schoo l, 2 012. Nghi D. Q. BUI, Y ijun YU, and L ingxiao JIANG. Bilateral depend ency n eural n etworks for cross- languag e alg orithm classification. In IEEE/ACM I nternationa l Confe rence on Softwar e Ana lysis, Evolution and Reeng ineering , 2 019. Xinyun Chen, Chang Liu, an d Dawn So ng. Tree-to-tree neural n etworks f o r pro gram translation . In Advance s in Neural I nformation Pr ocessing Systems , pages 254 7–25 5 7, 2 018. George E Dahl, Jack W Stokes, Li Deng, an d Don g Y u. Large-scale malware classification using random p r ojections and n eural ne tworks. I n IEE E Internation al Conference on Acoustics, Speech and Signal Pr ocessing , pages 342 2–342 6. I EEE, 2013. Evans Data Corporatio n. Global d ev eloper pop ulation and demog raphic study . http: //evan sdata.com/reports/viewRelease.php?r eportID=9 , 2019. Xiaodong Gu, Hon gyu Z hang, D o ngmei Zhan g, and Sunghun Kim. DeepAM : Migrate apis with multi-mod al sequ ence to sequen c e learning. In I n ternationa l Joint Confer ence on Artificial Intel- ligence , p ages 3675– 3681 , 20 1 7. Jordan Hen kel, Shuven d u K Lahiri, Ben Lib lit, and Th omas Reps. Code vectors: Under standing progr ams th rough embe d ded abstracted sy m bolic traces. In Pr oceedings of th e 201 8 26th ACM Joint Meeting on Eur opean Software Enginee ring Confer ence and Symposiu m on the F oundatio ns of Softwar e Enginee rin g , pages 16 3–17 4 . A CM, 2 018. Geoffrey E Hinton , Sara Sabou r , and Nic h olas Fro sst. M atrix c apsules with E M rou ting. In Interna - tional Conference on Learning Rep resentations , May 201 8. Xing Hu , Ge Li, Xin Xia, David Lo , and Zh i Jin. Deep code comment generation . I n In te rn ational Confer ence on Pr ogr am Compr ehension , pages 20 0–210 . A CM, 2018 . 9 V in oj Jayasundara, Sandaru Jayaseka r a, Hirunim a Jay a sek ara, Jathusha n Rajasegaran, Suranga Seneviratne, and Rang a Rodrig o . T extCaps: Handwritten char a cter recogn ition with very small datasets. I n I EEE W inter Con fe rence o n A pplication s of Compu ter V ision , p ages 2 54–2 62, 20 19. Anders Krogh and Jesper V edelsby . Neural network ensembles, cross validation, and activ e learning. In Advan ces in neu ral informatio n pr ocessing systems , pag e s 2 31–2 38, 1995 . Jian Li, Pinjia He, Jieming Zh u, and Micha e l R L yu. So ftware defect prediction via conv olutional neural network. In IEEE Internationa l Con fe rence on S oftwar e Qu ality , Reliability a nd S ecurity , pages 318– 328. IEE E, 2 017. Y u jia Li, Dan iel T ar low , Marc Brock schmidt, and Richard Zem el. Gated graph sequen ce neural networks. In Intern a tional Con fer ence o n Learning Repres entation s , November 2016. Zhen Li, Deqing Zo u, Shouhuai Xu, Xinyu Ou , Hai Jin, Sujuan W ang, Zh ijun Deng, and Y uyi Zhong . V u ldeepecker: A deep learning-b ased system for vulnerab ility detection. arXiv pr eprint arXiv:180 1.016 81 , 20 1 8. Liyuan L iu, Ha oming Jian g, Pen gchen g He, W eizhu Chen, Xiao dong Liu, Jianfen g Gao, and Jiawei Han. O n the variance of the adaptive learning r a te an d beyond . arXiv pr eprint a rXiv: 1908 .0326 5 , 2019. T omas Mikolov , Ilya Sutskev er , Kai Che n , Greg S Corrado, and Jeff Dean. Distributed repr esenta- tions of word s an d phrases and their composition ality . In Advanc e s in neural info rmation pr ocess- ing systems , pages 31 11–3 1 19, 2013. Lili Mou, Ge Li, Lu Zhan g, T ao W ang, and Zhi Jin. Con volutional neur al ne twork s over tree structures for pr ogramm ing lan guage processing . In AA AI Confer ence on Artificial Inte lligence , 2016. T rong Duc Nguy en, Anh Tuan Nguye n, Hung Dang Ph an, and T ien N. Nguye n . Explor ing API em- bedding for API usages and applications. In Intern ational Confer ence o n Softwar e Engineering , pages 438– 449, 20 17. R. Nix a n d J. Zh ang. Classification o f an droid apps an d m alware using deep neural networks. In Internation al Joint Conference on Neural Networks , pag es 1871– 1878, May 201 7. Razvan Pascanu, Jack W Stokes, Hermine h Sanossian, Mady Marinescu, and Anil Thom as. Mal- ware classification w ith r ecurren t network s. In IEEE Internationa l Conference on Aco ustics, Speech and Signal Pr ocessing , pages 1 916– 1 920. IEEE, 20 15. Hao Peng, Lili Mou, Ge Li, Y uxuan Liu, Lu Zhan g, and Zhi Jin . Building progra m vector repre- sentations fo r deep learnin g. I n Pr oceedings of th e 8th Internation a l Conference on Knowledge Science, E ngineering and Management) , pages 5 47–5 53, Octo b er 2 8-30 2015. Michael Pradel and Koushik Sen . Deepbugs: A lear ning approa c h to n ame-based bug detectio n. Pr oceedings o f the ACM o n P r ogr amming Languages , 2(OOPSLA) :147, 2 018. V aib hav Rastog i, Y an Chen, and Xuxian Jiang. Catch me if you can: Evaluating android an ti- malware ag ainst transfo rmation attacks. IEEE T ransactions on Info rmation F o rensics and Secu- rity , 9(1) :99–10 8, 2 013. Sara Sabour , Nicholas Frosst, and Geoffrey E Hinton. Dynamic r o uting between capsu le s. In Con- fer ence on Neural Information Pr ocessing Sy stems , pages 385 6–38 66, Long Beach, CA, 2017. Huihui W ei and Min g Li. Supervised de ep featu res f o r software functio nal clone d etection b y ex- ploiting lexical and syntactical information in source code. In I nternation al J oint Confer ences o n Artificial Intelligence , pages 3034– 3040 , 2017 . X. Xia, L . Bao, D. Lo, Z. Xin g, A. E. Ha ssan, and S. Li. Measuring pro g ram comp rehension : A large-scale field study with profession als. I EEE T ransaction s on Software Engineerin g , 44( 10): 951–9 76, Oct 20 18. Zhang Xinyi and Lihu i Chen. Capsule graph n e u ral network. In Internation al Conference on Lea rn- ing Representations , 2019. 10 Xinli Y ang, David Lo, Xin Xia, Y un Zhang, and Jianling Sun. Deep learn ing for just-in-time defect prediction . In IEEE Interna tio nal Confer ence on S oftwar e Qu ality , Reliability and Security , page s 17–26 , 201 5. Jian Zhan g, Xu W ang , Ho ngyu Zhan g, Hailon g Su n, Kaixuan W ang, an d Xu d ong Liu. A novel neural source code r e p resentation based on abstract syntax tre e. In Interna tional Co n fer ence on Softwar e Engineerin g , page s 78 3–79 4 , 2019. W ei Zhao, Jianbo Y e, Min Y ang, Zeyang Lei, Suofei Zhang, and Zho u Zhao . In vestigating cap sule networks with dynamic routing for text classification. a rXiv p r eprint arXiv:1804 .0053 8 , 201 8. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment