Musical Instrument Playing Technique Detection Based on FCN: Using Chinese Bowed-Stringed Instrument as an Example
Unlike melody extraction and other aspects of music transcription, research on playing technique detection is still in its early stages. Compared to existing work mostly focused on playing technique detection for individual single notes, we propose a…
Authors: Zehao Wang, Jingru Li, Xiaoou Chen
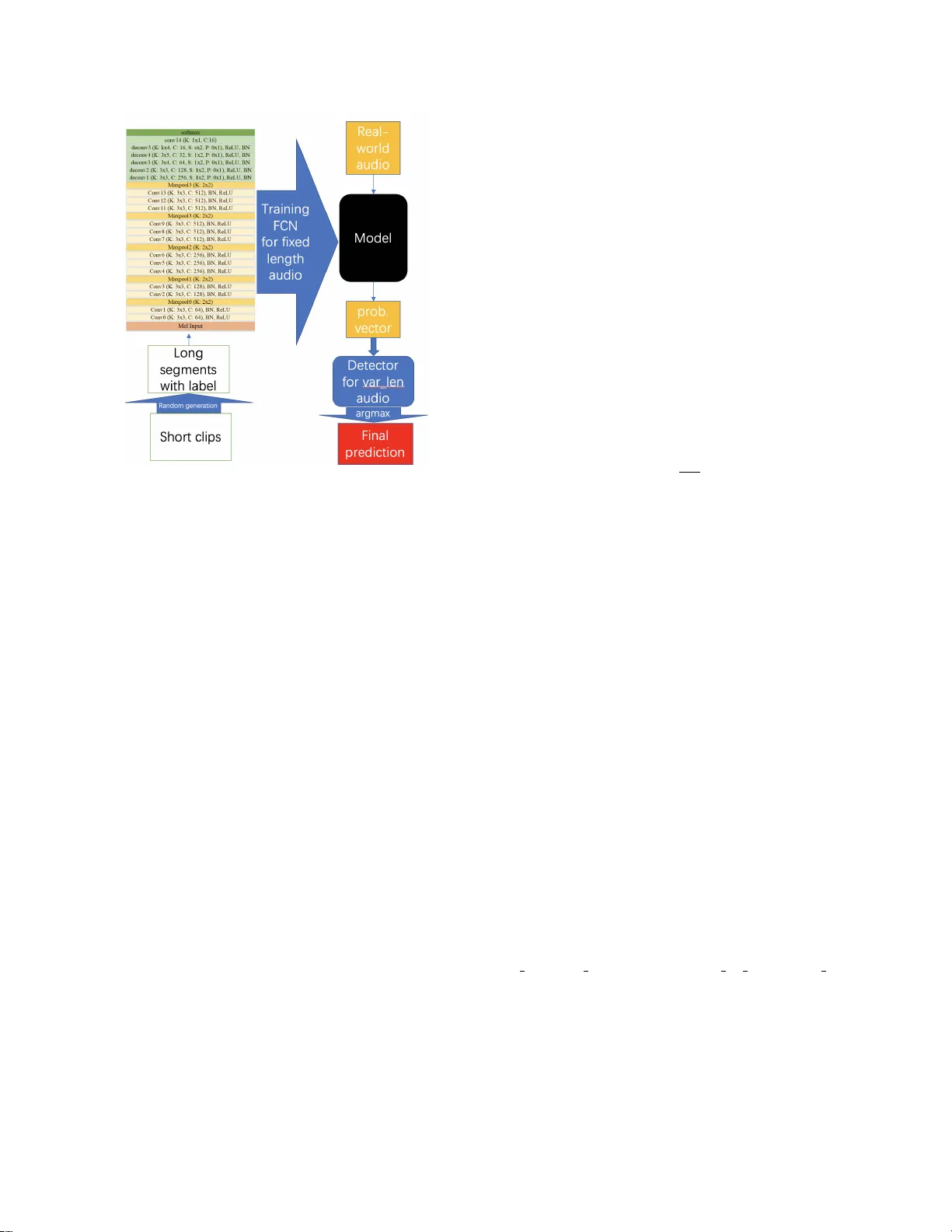
MUSICAL INSTR UMENT PLA YING TECHNIQUE DETECTION B ASED ON FCN: USING CHINESE BO WED-STRINGED INSTR UMENT AS AN EXAMPLE Zehao W ang ∗ 1 , Jingru Li ∗ 1 , Xiaoou Chen 2 , Zijin Li 3 , Shicheng Zhang 4 , Baoqiang Han 3 , Deshun Y ang 2 1 Peking Univ ersity , Beijing, China 2 W angxuan Institute of Computer T echnology , PKU, Beijing, China 3 China Conservatory of Music, Beijing, China 4 Univ ersity of Illinois at Urbana-Champaign, Illinois, USA { water45wzh, li jingru, chenxiaoou, yangdeshun } @pku.edu.cn, zijin.li@mcgill.ca, sz18@illinois.edu, hundel@126.com ABSTRA CT Unlike melody extraction and other aspects of music tran- scription, research on playing technique detection is still in its early stages. Compared to existing work mostly focused on playing technique detection for indi vidual single notes, we propose a general end-to-end method based on Sound Ev ent Detection by FCN for musical instrument playing technique detection. In our case, we choose Erhu, a well-kno wn Chinese bowed-stringed instrument, to experiment with our method. Because of the limitation of FCN, we present an algorithm to detect on v ariable length audio. The ef fectiv eness of the proposed frame work is tested on a ne w dataset, its cate go- rization of techniques is similar to our training dataset. The highest accuracy of our 3 experiments on the ne w test set is 87.31%. Furthermore, we also e v aluate the performance of the proposed framework on 10 real-world studio music (pro- duced by midi) and 7 real-world recording samples to address the ability of generalization on our model. Index T erms — Music Information Retrie v al, Playing T echnique Detection, Sound Event Detection 1. INTRODUCTION In addition to the recognition and extraction of music no- tions such as pitches and chords, the detection of musical instrument playing techniques also plays an important role in music transcription. In general, a note-by-note transcrip- tion of the pitches and the playing techniques associated with each note is demanded. In a sequence of melodic notes, play- ing techniques such as slide and vibrato determine how the notes are performed and sounded. Articulation on any form of representation of music, including western staff notation and Chinese numeric representation 1 , is highly instructiv e for performers. This can be illustrated in Fig . 1 through the ar- ticulation symbols on the guitar tab and Jianpu used by Erhu 2 and Guqin 3 . Playing technique detection from audio recording can help us to make automatic music transcription more accurate. ∗ Equal Contribution. 1 Called Jianpu in Chinese 2 A famous Chinese bo wed-stringed instrument like the violin 3 A famous Chinese stringed instrument like a harp lying flat Now adays there are useful methods for music transcription, such as through F0[ 1 ], CQT[ 2 ]...Perhaps it is more suitable to call them as melodic extraction. Currently , the mentioned methods are designed for solo music instrument note ex- traction, but if we w ant to expand it to all types of musical instruments, the notations for playing technique are neces- sary . W e can take the articulation, trill, as an example. Since it contains large number of different notes in a single oc- currence, the time value of each note is significantly short. The threshold of post-processing or other parameters in the melody extraction algorithm is not suitable for this technique, therefore some pitches may be ignored. Consequently it might lose some important information for accurate music transcription. The realization of playing technique detection from audio recording may also ex erts transformativ e force in industrial and educational applications. Applications, such as playing- technique-detection-based audio content analysis and music assisted teaching, including musical instrument playing or Or- chestration course in music composition, may be good exam- ples for illustration. Unlike melody e xtraction and other aspects of music tran- scription, research on playing technique detection is still in its early stages. The dif ficulties of this task are mainly about data acquisition and data labeling. Currently , the research on musical instrument playing technique detection in volv es guitar[ 3 ][ 4 ], piano[ 5 ][ 6 ], drum[ 7 ]...Among all the musical in- struments, the playing techniques of the bo wed-stringed are difficult to detect and manually label ev en for performers be- cause of its variety and uncertainty of onset, so the number of research in this field is not many . In this paper , we propose a general end-to-end method based on Sound Event Detection by FCN[ 8 ](Fully Con volu- tional Networks) through a deep learning method for our mu- sical instrument playing technique detection task. Consider- ing the data acquisition and variety of playing techniques, we choose Erhu, a well-known Chinese bo wed-stringed instru- ment, to e xperiment with our method. The contrib ution of this work is listed below . First, we compile an open dataset that contains about 30 Erhu playing techniques in 11 cate- gories, cov ering almost all the tones in the range of Erhu ( Section 3 ). W e have released experiment’ s Python code 4 and 4 https://github .com/water45wzh/MIPTD Erhu the full datasets with detailed information and demos 5 online. Second, we propose a method ha ving a lo w dependency on the sound characteristics of the tested instruments, ensuring its transferability to other audio clips recorded from different musical instruments. Third, we hav e conjectured several ways for its industrial application including boosting efficiency on the traditional music transcription task and realizing MIR- based music education pedagogy . 2. RELA TED WORK Currently , the research on Musical Instrument Playing T echnique Detection (MIPTD) mainly focuses on playing techniques classification of the single block of musical note. Through the ages, there are both traditional signal processing methods and statistical/deep learning methods for this task. Chen et al. [ 3 ] attempted to extend this research to guitar solo recordings, they considered the playing techniques as time sequence pattern recognition problem and dev eloped a two-stage framework for detecting fiv e fundamental playing techniques used by electric guitars. This work is v alidated on 42 electric guitar solo tracks without accompaniment, and also discussed ho w to apply the framew ork to the transcrip- tion of real-world electric guitar solo with accompaniment. W u et al. [ 7 ] studied the drum playing technique detec- tion in polyphonic mixtures. They focused on 4 rudimen- tary techniques: strike, b uzz roll, flam, and drag. This pa- per has discussed about the characteristic and challenge of this task, compared with dif ferent sets of features, like fea- tures extracted from NMF-based acti vation functions, as well as baseline spectral features. And the y also considered it’ s difficult to detect playing techniques from polyphonic music. Liang et al. [ 6 ] thought that detecting playing techniques from audio signal of musical performance is a special as- pect of automatic music transcription. They hav e studied deeply on piano sustain pedal detection, and giv en some use- ful datasets and frameworks to analyze the existence of pedal. The latest work of Liang[ 5 ] is about a joint model by CNN on detecting the pedal onset and segment with data fusion method to make piano sustain pedal detection more accurate. 3. D A T ASETS AND ERHU PLA YING TECHNIQUES T wo datasets are used in this paper . The first one is based on Chinese traditional musical instruments dataset DCMI [ 9 ]. This dataset contains solo instrument playing technique recordings on 82 different Chinese traditional musical in- struments with almost all types of playing techniques of the instruments. W e choose a subset of Erhu’ s playing techniques from DCMI and edit it to 927 audio clips of single playing techniques in 11 categories co vering almost all the tones in the range of Erhu, their time length ranges from about 0.2 5 https://water45wzh.github .io/MIPTD Erhu Fig. 1 . Playing techniques of Guitar , Erhu, Guqin to 2 seconds, in total 18.45 minutes. W e called these audio clips short clips . For the bre vity of this paper, details about the dataset and the in volv ed Erhu playing techniques can be found on the website. The second one is similar to the first, in total 7.36 minutes of 326 short clips, with changes of v ari- able on performer, instrument, and recording en vironment. This v ariation is considered for generalization performance on different data distrib ution. On both training and test, we randomly generate some 10 seconds long audio se gments from these two datasets men- tioned in last paragraph, we called these audio segments long se gments . There is a basic assumption that the techniques of Erhu are not o verlapped. The rationale of this assumption is due to the limitation of monophonic instruments. During the generation process, we e xecute a check operation to av oid the repetition of long segments sequence. T o av oid the uncer - tainty of the length of the generated long se gment, we directly trim the e xcess for more than 10 seconds. T o ensure the long segments sound more realistic, we make a 50 milliseconds cross-fade in each boundary of adjacent two short clips. Since the short clips are almost recorded in D major scale, the ran- dom generated long se gments sound closed to the real-world music. W e also label the timestamp of corresponding playing techniques during the long segments generation process. The format of the label consists of event tags recorded with a frame length of 0.05 second. Due to the impossibility of playing multiple techniques simultaneously on a solo instru- ment, the abov e operation is reasonable. Furthermore, we have 10 real-world music produced by one of the best digital instrument library , Silk from the f a- mous company EastW est 6 , and 7 real-world recorded sam- ples of Erhu solo by famous artists and corresponding manual ev ent based label. The detailed in volving audio’ s information and demo for their experiments can be found online 7 . The sample rate of all the audios in our datasets is 44.1kHz. 6 EastW est Sounds( http://www .soundsonline.com/ ) 7 https://water45wzh.github .io/MIPTD Erhu Fig. 2 . Frame work of our work. In deconv5, 4 classes: k = 3 , s = 1 , 7 classes: k = 3 , s = 2 , 11 classes: k = 4 , s = 3 . 4. PROPOSED METHOD 4.1. Overview Musical instrument playing technique detection (MIPTD) is essentially a task of sound event detection. W e can think of each technique as a sound event and recognize the event from the sound event stream. Currently CNN is widely used in the field of sound e vent detection[ 10 ] frequently using spectro- grams or mel-spectrograms as inputs. Because of the non- ov erlap feature of monophonic instrument, we can naturally treat it as the semantic segmentation in image segmentation tasks. Recent years, researchers proposed se veral approaches for the segmentation task. W e choose Fully Con volutional Networks[ 8 ][ 10 ], i.e. FCN for our task, which is a classical approach for image semantic se gmentation. This approach constructs an end-to-end Fully Connected Con volutional net- work, which is one of the state-of-the-art approaches for semantic segmentation task. In this paper, we ha ve adapted it to our musical instrument playing technique detection task. The main limitation of FCN is that it can only be used for fixed length audio. T o solv e this problem, we make a frame- work to detect variable length audio. Details are elaborated in 4.3 . The overvie w of the whole frame work for this task is shown in Fig . 2 . 4.2. Network Architectur e Our network architecture is also sho wn in Fig. 2. Its in- put is a mel-spectrogram and output is a k -dim probabilistic vector , k is the number of classes(4, 7, 11). 4.3. Detection on V ariable Length A udio Our trained model from abo ve neural network is specified for 10 seconds audio. For the detection on variable length audio, we use the fixed length(10s) of the model as the win- dow length and set a suitable hop length(we choose 2s) to slide sequentially from the start to the end on the entire au- dio recording. For a fixed 0.05 second frame of the audio, if there are more than two predictions on this frame due to over- lapped predictions, then we might compute the av erage of all the predicted probabilistic vectors of this frame as the final prediction for it, p f inal = 1 | P | X p ∈ P p (1) For an arbitrary frame, p f inal is the final prediction, P is a set of all the predictions for this frame. 5. EXPERIMENTS 5.1. Experimental Setup W e di vide each long segment in our generated datasets into some frames with a frame length of 0.05 second using mel-filters to e xtract 128bin mel-spectrogram with window length of 2048 points and hop length of 2205 samples. W e use PyT or ch for our implementations. W e initiate 3 experiments for dif ferent goals. Each exper - iment uses the first dataset or a subset of it to generate some 10s long se gments for training. The second is also using the dataset with its subset b ut to generate sev eral 10 seconds long segments for testing the generalization performance on high- quality midi music and recorded samples of our model. 4 classes: W e choose 3 common techniques (slide, stac- cato, trill) from 11 cate gories and 1 class for a subset of de- tache and other techniques. T raining set has 2000 long seg- ments, T est set has 1000. 7 classes: W e consider some subdivisions in all 11 cate- gories, then choose 6 common subdi visional techniques (trill, slide up, slide down, staccato, trill up short, slide legato) and 1 class for a subset of detache and other techniques. T raining: 4000, T est: 2000. 11 classes: This experiment uses the full version of the first dataset, all of which are identical to the 11 categories. T raining: 4000, T est: 2000. The reason of doing 3 experiments is because the 4 classes experiment is a simplified v ersion of 11 classes experiment, in order to pick out some common techniques for common Fig. 3 . V isualization for a studio music music. The purpose of the 7 classes experiments is to make a precise detection for the subdivisions of these techniques. A possible future work is to make a two-lev el system to realize the precise detection for the subdivisions. 5.2. Results on the test set The results of 3 e xperiments for our test set from the sec- ond dataset are shown in the follo wing table, 4 classes 7 classes 11 classes av erage accuracy 87.31% 67.94% 48.26% Because of short time value of some techniques (only 0.15- 0.20 second, 3-4 frames) and end-to-end feature in our pro- posed model, we decide not to implement post-process for the output prediction. The accuracy of one segment of these test data is calculated strictly by the following formula, accur acy of one segment = 1 n n X i =1 I ( p i = l i ) . (2) The input audio has n frames. Its ground-truth label is L = ( l 1 , l 2 , ..., l n ) and the output prediction by our model is P = ( p 1 , p 2 , ..., p n ) . I ( ∗ ) is an indicator function . 5.3. Results on real-world music For brevity of this paper , we will demonstrate several results on real-world music, both studio music and recorded samples. W e use sed vis 8 to visualize our results. As shown in Fig. 3 , here is an illustration for a studio music, which is called The Umbr ella of Cherbour g , there are 4 sentences in this piece, and the sequences of techniques used in the first three sentences are the same. And results of se veral recording samples are as follows. music time acc. of 4 classes acc. of 7 cl. acc. of 11 cl. The Moon’ s Reflection on the Sec- ond Spring 6m04s 40.90% 32.26% 17.06% Competing Horses-v 1 1m46s 28.84% 44.50% 12.39 % 8 V isualization toolbox for Sound Event Detec- tion( https://github .com/TUT -ARG/sed vis ) 6. CONCLUSION In this paper, we have proposed an approach for Musical Instrument Playing T echnique Detection using Erhu as an e x- ample. W e took adv antage of FCN to model a fixed length detector and then proposed an algorithm for v ariable length audio. W ithout any assumptions and requirements of data dis- tribution, we have successfully trained an end-to-end model using long segments randomly generated from 927 playing technique audio clips. Because of its end-to-end feature and slack dataset requirements, this method has high transferabil- ity on dataset of other musical instruments. The best e xperi- ment result on the test set is 87.31% . Our result on the real- world recording(44.50%) from famous artists is not as good as the other data, because of possible error of manual label- ing, the common issue of bowed-stringed instruments, and artistic expression from the different performers. One possi- ble future work is to make a combined system to implement the complete automatic music transcription, which means not only the pitch extraction for notes but also the techniques de- tection for notations on notes. Although the current research is preliminary compared to the ones in pitch extraction, we hope it will raise more awareness on the importance of the Musical Instrument Playing T echnique Detection(MIPTD). 7. A CKNO WLEDGEMENTS Thanks to Zihan Han of Xidian Uni versity , he provided a lot of help for us to record the test data set. 8. REFERENCES [1] FJ Ca ˜ nadas Quesada, N Ruiz Re yes, P V era Candeas, JJ Carabias, and S Maldonado, “ A multiple-f0 estima- tion approach based on gaussian spectral modelling for polyphonic music transcription, ” J ournal of New Music Resear ch , v ol. 39, no. 1, pp. 93–107, 2010. [2] Fabrizio Argenti, Paolo Nesi, and Gianni Pantaleo, “ Au- tomatic transcription of polyphonic music based on the constant-q bispectral analysis, ” IEEE T ransactions on Audio, Speech, and Languag e Pr ocessing , v ol. 19, no. 6, pp. 1610–1630, 2010. [3] Y uan-Ping Chen, Li Su, Y i-Hsuan Y ang, et al., “Electric guitar playing technique detection in real-w orld record- ing based on f0 sequence pattern recognition., ” in IS- MIR , 2015, pp. 708–714. [4] Li Su, Li-Fan Y u, and Y i-Hsuan Y ang, “Sparse cepstral, phase codes for guitar playing technique classification., ” in ISMIR , 2014, pp. 9–14. [5] Beici Liang, Gy ¨ orgy Fazekas, and Mark Sandler , “Pi- ano sustain-pedal detection using con volutional neural networks, ” in ICASSP 2019-2019 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2019, pp. 241–245. [6] Beici Liang, Gy ¨ orgy Fazekas, and Mark Sandler , “T o- wards the detection of piano pedalling techniques from audio signal, ” . [7] Chih-W ei W u and Alexander Lerch, “On drum playing technique detection in polyphonic mixtures., ” in ISMIR , 2016, pp. 218–224. [8] Jonathan Long, Evan Shelhamer , and Tre vor Darrell, “Fully conv olutional networks for semantic se gmenta- tion, ” in Pr oceedings of the IEEE confer ence on com- puter vision and pattern r ecognition , 2015, pp. 3431– 3440. [9] Zijin Li, Xiaojing Liang, Jingyu Liu, W ei Li, Jiaxing Zhu, and Baoqiang Han, “DCMI: A database of chinese musical instruments, ” . [10] T ing-W ei Su, Jen-Y u Liu, and Y i-Hsuan Y ang, “W eakly- supervised audio e vent detection using e vent-specific gaussian filters and fully con volutional netw orks, ” in 2017 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2017, pp. 791–795.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment