Efficient Computation of Probabilistic Dominance in Robust Multi-Objective Optimization
Real-world problems typically require the simultaneous optimization of several, often conflicting objectives. Many of these multi-objective optimization problems are characterized by wide ranges of uncertainties in their decision variables or objecti…
Authors: Faramarz Khosravi, Alex, er Ra{ss}
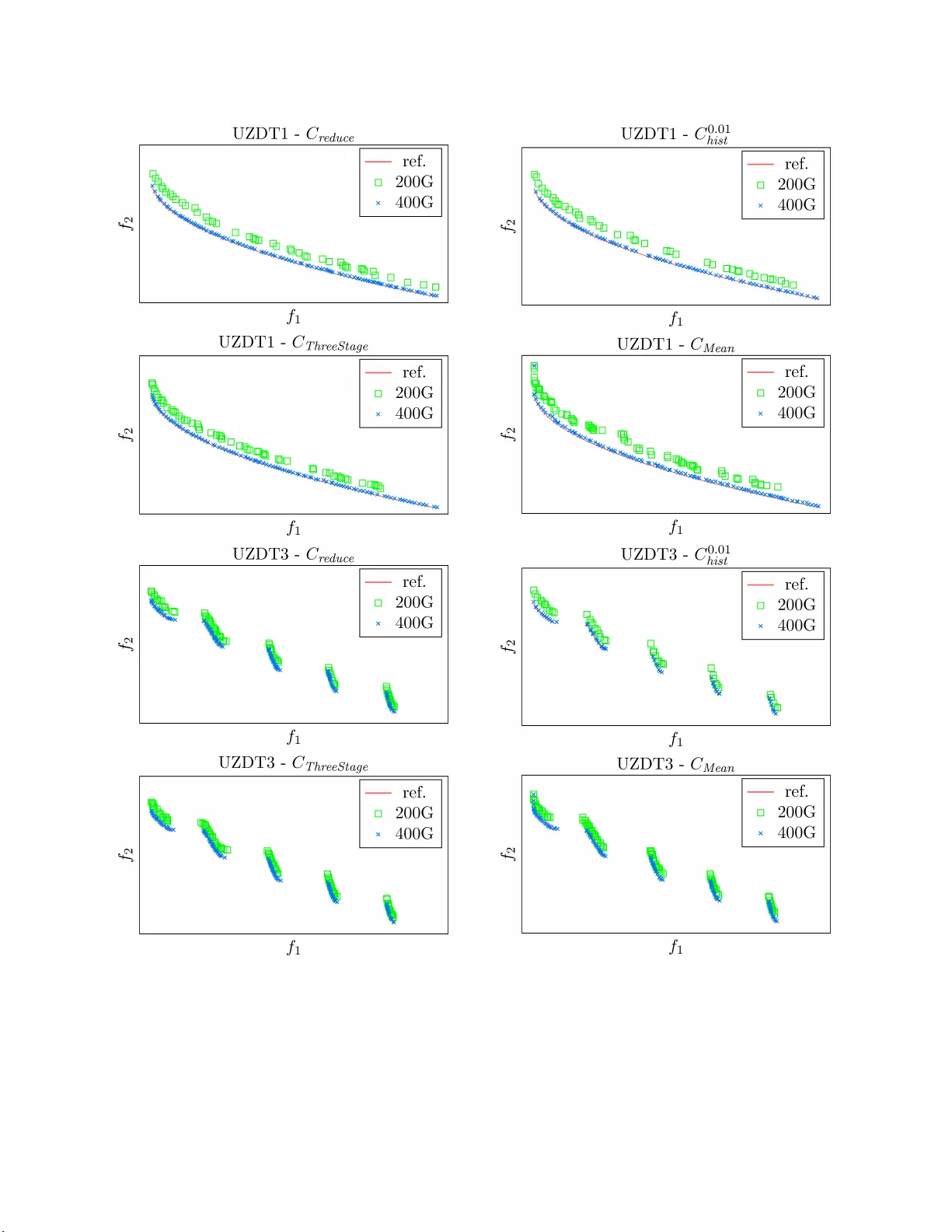
Efficien t Computation of Probabilis t ic Domina n c e in Robust Multi-Ob jectiv e Optimization ∗ F aram arz Khosravi, Alexander Raß, and J ¨ urgen T ei c h, Octob er 21, 201 9 Abstract Real-w orld problems t ypica lly require the sim ultaneous optimization of seve ral, of- ten conflicting ob jectiv es. Man y of these multi-obje ctive o ptimization pr oblems are c haracterized by wide range s of u ncertain ties in their decision v ariables or ob jectiv e functions, whic h furth er increases the complexit y of optimization. T o cop e with su c h uncertain ties, r obust op timization is wid ely studied aiming to distinguish candidate solutions with uncertain ob jectiv es sp ecified b y confidence interv als, probabilit y distri- butions or sampled data. Ho wev er, existing techniques mostly either fail to consider the actual distributions or assume uncertain t y as instances of unif orm or Gaussian distributions. This p ap er introdu ces an empirical app r oac h that enables an efficien t comparison of cand idate solutions with u ncertain ob jectiv es that can follo w arbitrary distributions. Giv en t w o candid ate solutions u nder comparison, this op erator calcu- lates the pr obabilit y that one solution domin ates the other in terms of eac h uncertain ob jectiv e. It can su bstitute for the standard comparison op erator of existing opti- mization tec hniqu es suc h as evo lutionary algorithms to enable disco v ering robus t so- lutions to problems with multiple un certain ob jectiv es. T h is pap er also p rop oses to incorp orate v arious un certain ties in w ell-kno wn m ulti-ob jectiv e problems to provide a b enchmark for ev aluating uncertain t y-a ware op timization tec h niques. The prop osed comparison op erator an d b enc hmark suite are in tegrated in to an existing optimization to ol that features a selection of multi-o b j ectiv e optimization problems and algorithms. Exp eriments sho w that in comparison with existing tec h niques, the prop osed approac h ac h iev es higher optimization qualit y at lo w er o verheads. Keyw ords: Multi- ob jectiv e optimization · uncertaint y · comparison op erator · proba- bilistic d ominance ∗ The autho rs are with the Department of C o mputer Science, F riedrich-Alexander-Universit¨ at Erla ng en- N¨ urnberg (F AU), Er langen 91058, German y . (e-mail: { faramar z.khosravi, alexander.r ass, juer- gen.teich } @fau.de). 1 Notation A a candidate solution B a candidate solution B b eta distribution C comparison o p erator c po sitiv e constant E expected v alue e appro ximation erro r f ob jectiv e function N G aussian distribution N n um b er of samples or quantile cuts n n umber of decision v ariables m n umber of ob jectiv e functions S seq uence of samples s sample from an uncertain ob jective ’s distribution U uniform distribution u uncertain ty added to an optimization problem V ar v ariance X random v ariable x dec ision v ar ia ble γ comparison threshold δ tolerance (b ound on an error) σ standard deviation ω in terv al width in a histogram 2 1 In t ro duction Real-w orld problems typically demand solutions that are optimized with resp ect to multiple criteria called ob jectiv es. In these so-called multi-obje c tive optimization pr o b lems , the ob jec- tiv es often conflict with eac h other suc h that no single solution can b e fo und to b e optimal in all ob jectiv es. Ins tead, one usually searc hes for a set o f non- do minated solutions kno wn as Par eto fr ont or Par eto set that prov ide decen t trade-offs a mong ob jectiv es. A solution is said t o dominate a no ther if it is a s go o d as the other in all ob jectiv es and is b etter with resp ect to at least one ob jectiv e. While exact optimization metho ds such as inte ge r line ar pr o gr amming ma y not b e applicable to complex optimization problems, p opula t io n-based meta-heuristics such as evolutionary algorithms enable a fast approxim ation to the P areto fron t of pro blems with sev eral ob jectiv es and large searc h spaces [1]. Ho w ev er, multi-ob jectiv e optimization problems are of t en c haracterized b y wide ranges of uncertainties including no ise, approximation error s or time-dep enden t v ariation in their ob jectiv e functions and p erturbatio ns in their decision v ariables [2]. Any optimization algo- rithm t hat neglects the effects of uncertain ty might prefer actually inferior solutio ns while tra v ersing the search space. As a remedy , r obust optim i z a tion tec hniques hav e b een prop osed to enable an accurate comparison of ob jectiv es in the presence of uncertain t y . Existing tec h- niques typically mo del uncertain ob jectiv es using instances o f unifor m [3] and Gaussian [4, 5] distributions, in terv als specified b y b est and worst cases [6, 7], or sampled data [8 , 9]. While the first t w o groups fail to deal with v arious, and p ossibly non-standard uncertain ty distri- butions, the third group of techniq ues enable t he comparison of candidate solutions with arbitrarily distributed uncertain ob jectiv es. Ho w ev er, these tec hniques rely on estimated statistics suc h as mean v alue and v ariance and do no t tak e t he a ctual uncertain t y distribu- tions into accoun t . This problem is addressed in a previous w ork of the a utho rs [10 ], whic h enables calculating the probabilit y that a n uncertain ob jectiv e of one solution is greater or smaller tha n t ha t of another solution, for an y arbitrary distribution give n as a closed-form function or sampled data. This probabilit y is calculated through partitioning the proba- bilit y distribution of ob jectiv es in to small interv als of the same size and applying rectangle in tegration, i. e., Riemann sum, while assuming a uniform distribution within each inte rv al. Therefore, the optimization algo r it hm can differen tiate instances of eac h uncertain ob jectiv es of tw o candidate solutions under comparison, a nd determine whether one solution dominates the ot her or not. This pap er extends the comparison op erator in [10 ] b y in tro ducing a new metho d for the calculation of the pr o babilit y that a n instance of uncertain o b jectiv e is greater than another instance o f the same o b jectiv e. Th is metho d is based on o bta ining the cum ulative distribution function (CDF) of eac h uncertain ob jectiv e, and partitioning the probability space into inte rv als o f the same size. It uses an iterative approach similar to [10], except that its accuracy is not impaired b y the assumption of uniform distribution within interv als. Moreo v er, this pap er extends the w ell-kno wn D TLZ m ulti-ob j ectiv e b enc hmark suite [11] to consider the effects of v a rious uncertain ties. It integrates the prop osed comparison op era- tor and the extended b enchm ark in to the m ulti-ob jectiv e optimization framew ork Opt4J [1 2 ] that incorp orat es sev eral optimization a lgorithms suc h a s evolutionary algorithms [13] and 3 particle sw ar m optimization [14]. Exp erimen ts show that compared to the existing tech - niques, t he prop osed approach enables comparing uncertain ob jectiv es more efficien t ly and ac hiev es higher optimization qualit y . The rest of this pap er is structured as follow s: Section 2 r eviews t he state-of-the- a rt tec hniques for robust m ulti-ob jective optimization. Sections 3 and 4 resp ective ly in tro duce the prop osed comparison op erator and uncertain multi-ob j ective optimization b enc hmar k. Section 5 presen t s the exp erimen tal setup and ev alua t ion results, a nd in the end, Section 6 concludes this work. 2 Related W ork The ob jectiv e f unctions and decision v ariables of m ulti-ob jectiv e opt imizatio n problems are often sub ject to v arious uncertainties . In t he context of probabilistic risk assessmen t, these uncertain ties are catego r ized with respect to their orig in as ale atory and epistem i c uncer- tain ties. Aleato ry uncertain t y refers to “the inheren t v ar ia tion asso ciated with the ph ysical system or the en vironmen t under consideration”, whereas epistemic uncertaint y describ es “an y lac k of kno wledge or informatio n in an y phase or activity of the mo deling pro cess” [15]. The probabilit y distribution of a decision v ariable or a n ob jectiv e function with aleator y uncertain t y can b e estimated through sampling or iterativ e function ev aluation, resp ectiv ely . Ho w ev er, obtaining the exact v alue or probability distribution of a v ariable o r function with epistemic uncertain t y is usually impracticable or unaffordable. In fact, only limited c haracteristics suc h as confidence inte rv als may b e a v ailable. T o deal with epistemic uncertain t y in the con text of m ulti-ob jectiv e optimization, t he w ork in [6] prop oses to represen t uncertain ob jectiv e v alues using low er and upp er b ounds rather than single p oint estimates. It also extends the we ak and strong dominance criteria of a m ulti-ob j ective ev olutionary algorithm. T o balance the a ccuracy and execution time of the pro cess of comparing candidate solutions, it in tegrates the w eak dominance criterion in to the pro cess of paren t selection and the strong dominance criterion into the pro cess of up dating the solution archiv e. The aut ho rs in [16] mo del uncertaint y as the lack of know l- edge ab out the exact effects of decision v ariables on ob jectiv e v alues using a triangular fuzzy represen ta tion. They incorp orate the p essimistic, an ticipated, and optimistic v alues of uncertain o b jectiv es in to the comparison of different solutions. Ho w ev er, the prop osed dom- inance criterion ma y fail to prop erly distinguish ob jectiv e v alues when the in terv als b et w een p essimistic a nd optimistic v alues do not o v erlap, whic h reduces the qualit y or robustness of o ptimization. Sinc e the distribution of uncertain t y in ob jectiv e functions and decision v ariables are not av ailable in the case of epistemic uncertain t y , the rest of this pap er fo cuses on dealing with aleatory uncertaint y , where there is a stronger demand fo r its effectiv e and efficien t handling. Another common classification of uncertainties can b e fo und in [2] where the uncertain- ties are categorized with resp ect to their manif estations in to four groups. The first group includes noise in o b jectiv e functions, i. e., v ariations in the results of differen t ev aluat ions of an ob j ective function with unc hanged input v ariables. The second group tak es p erturbations 4 in decision v a r iables, that are the input v ariables of ob jective functions, into consideration. The third gr oup describ es the error o f approximate ob jectiv e functions whic h is the case when the exact ev aluatio n of a n ob jectiv e function is costly or infeasible, and is therefore substituted by sim ulations. The last group mo dels time-v a r ying ob jectiv e functions where ev aluating a function with the same inputs and parameters at different p oin ts in time deliv ers differen t outputs, while the output is deterministic at any fixed p oint in time. An existing uncertain t y , regardless of what catego ry it b elongs to, results in ob jectiv e v alues that should b e represen ted b y probability distributions instead of single v alues. The resulting distribu- tion ma y b e an instance of a standard distribution suc h a s Gaussian, or migh t fo llow a n y arbitrary distribution g iven as a proba bilit y densit y function ( PD F) or sampled data. T o enable handling uncertain t y in m ulti-ob jectiv e optimization, a group of studies [3 – 5] prop ose tec hniques to determine pr ob abilistic dom i n anc e whic h describes the probability that one candidate solution dominates the other. This probabilit y is calculated as the in tersection of all probabilities tha t an uncertain ob jectiv e v alue fr o m the first solution is more fa v or- able than the same ob jectiv e of the other solution. The tec hniques in [3 – 5] are based on the simplistic assumption that differen t uncertain ob jectiv es are statistically indep enden t. Therefore, they calculate the join t pro babilit y as the pro duct of all individual proba bilities. T eich [3] provide s a mathematical approach for the calculation of probabilistic dominance giv en all ob jectiv es fo llow instances of con tin uous uniform distributions. This approac h can b e effortlessly extended to treat uncertain ob j ectiv e v alues with a n y discrete distribu- tions. The w ork in [4] assumes that eac h uncertain ob jectiv e is affected b y a Gaussian noise with known v ariance. The authors in [5] extend this techniq ue to enable the calculatio n of probabilistic dominance when instances of the same uncertain ob jectiv e hav e the same, but unkno wn v ariance. They prop ose a learning techniq ue to reduce the num b er of ob jectiv e function re-ev aluat ions needed to estimate this v ar ia nce. How ev er, the main dra wbac k of the tec hniques in [3 – 5] is that they require all uncertain ob jectiv es o f a solution to b e statistically indep enden t instances of sp ecific distribution types. In fact, an uncertain ob jectiv e v alue ma y follow a n arbitrary distribution tha t com bines the uncertain c haracteristics of differen t decision v ariables. Also, t w o differen t ob jectiv e functions sharing one or more uncertain decision v ariables would hav e statistically dep enden t uncertain ty distributions. The work in [17] compares candidate solutions with resp ect to the mean v alues of their uncertain ob jectiv es using a strict dominance criterion. It prop oses to deal with G aussian noise in ob jectiv e v alues while ranking the do minat ed solutions in the pro cess of paren t selection of a genetic algorit hm. F o r each dominated solution, a strength v alue is calculated whic h is the sum of the probabilities that this solution dominates an y other solution f r o m the p opulation. These pro babilities are calculated similar to the appro ac h in [4]. Each dominated solution is t hen ra nk ed with resp ect to the difference b et w een the sum of strength v alues of all solutions it dominates and that of all solutions dominating it. The calculation of this criterion is v ery time-consuming and the main dominance criterion do es not incorp o rate uncertain t y in the comparison of candidate solutions. Another group of studies in [8] a nd [1 8 ] prop oses to replace each uncertain o b jectiv e by one or more single-v alued ob jectiv es, eac h represen ting a unique statistic suc h as mean or 5 v ariance of the original ob j ective . This eliminates t he need fo r incorp orating t he effects of uncertain t y in the comparison op erator or do minance criteria of optimization a lgorithms. As an example, the w ork in [18] ado pt s the mean-v ariance mo del [19] t o replace the uncer- tain ob j ectiv e in a single-ob jectiv e optimization with tw o separate ob jectiv es represen ting its mean and v ar iance. It then uses in teger pro gramming for maximiz ing the mean and minimiz- ing the v ariance. The main disadv antage of this approac h is that it ma y recognize a solution with a significan tly inferior mean but a sligh tly b etter v a riance as non-dominated, whic h can cro wd the solution archiv e and slo w down the optimization. On the other hand, the tec hnique in [8] represen ts each uncertain ob jectiv e with a single statistic whic h is selected based on the criticalit y of the ob jective . F or example, it uses the fif t h p ercentile s for critical ob jectiv es whic h demand a high degree o f robustness a nd mean v alues f or the non-critical ones. How ev er, this tec hnique often fails to accurately compare uncertain ob jectiv es b ecause a single statistic cannot describ e all prop erties of the underlying probability distributions. The author s in [9 ] and [2 0 ] prop ose to extend the op erators used in existing multi- ob jectiv e optimizatio n tec hniques to enable coping with uncertain ob jectiv es. The w ork in [20] assumes that the uncertain ob jectiv es are sp ecified by mean v a lues and confidence in- terv als. It che c ks whether the confidence interv als of no ne of the uncertain ob jective s in t w o candidate solutions are o v erlapping. In this case, it can b e easily determined if one solution dominates the other or if the solutions are incomparable. How ev er, if the confidence interv als o v erlap fo r at least one ob jectiv e, it p erforms an it era t ive reduction of confidence interv als b y re-ev aluating the cor r esp o nding ob jectiv e functions. T his pro cess is con tinue d un til the in terv als a r e no longer o v erlapping o r no further reduction is p ossible. In the la tter case, the o v erlapping in terv als a re simply compared with resp ect to their mean v alues. The w o rk in [9] prop oses to compare instances of each uncertain ob jectiv e in a three-stage algorithm. T o compare tw o instances of an uncertain ob j ectiv e, this algorithm first c hec ks if the w orst-case of one is b etter than the b est-case of the other. If no preference can b e fo und, it prefers the ob jectiv e v alue whic h is significantly b etter with resp ect to the mean v alues. If the mean v al- ues are no t sufficien tly differen t , t he algorithm chec ks if one ob jectiv e v alue has a noticeably smaller deviation. Tw o ob jectiv e v alues that cannot b e differen tiated b y any o f these three comparisons a r e considered equal. T he comparison op erato rs in [9] a nd [20] enable com- paring arbitrarily distributed uncertain ob jectiv es. Moreo ve r, the optimization algorithms emplo ying these op erators compare instances of eac h o b jectiv e individually , whic h implic- itly tak es p ossible statistical dep endencies among ob jectiv es in to consideration. Nonetheless, these tec hniques dep end on estimated statistical prop erties and do no t reflect the pro babilit y that one candidate solution (or o b jectiv e v alue) do minates the other. A different approach is prop osed in [21] whic h prop oses to first solv e the optimization problem without the consideration of uncertain t y using the m ulti-ob jectiv e ev olutionar y algorithm presen ted in [1 3]. It p erforms the decomp osition prop osed in [22] to par tition the ob jectiv e space and represen t eac h sub-space by a weigh ted sum of o b jectiv es. Then, it maps eac h solution to a w eighte d sum suc h tha t the distance b etw een eac h solution and its corresp onding w eighted sum is minimized. T o deal with uncertaint y , it iterativ ely ev alua tes the optimal solution o f eac h we ighted sum and deriv es the mean and w orst-case ob jectiv e 6 v alues. In the end, it remo v es the non-optimal solutions that are dominated b y this w orst- case ob jectiv e v alue a nd lo o ks for robust solutio ns in the neighborho o d of the optimal solution of eac h we ighted sum. Although t his tec hnique helps iden tifying the robust regions [2 3] in the search space, it lacks efficiency and t r eats uncertaint y as w orst-case ob jectiv e v a lues. T o o v ercome the aforementioned limitations of existing uncertain t y-aw are optimization tec hniques, a histogr a m-based comparison o p erator has b een prop osed in [10]. It first pa r - titions the probability distribution of uncertain ob jectiv es into interv als o f iden tical width. Then, considering a uniform distribution within each interv al, it calculates the pro babilit y that an instance o f an uncertain ob jective is greater or smaller than another instance of the same ob jective , and enables to differen tiate the tw o solutions with resp ect to this uncertain ob jectiv e. Similar to the tec hniques in [9] and [20], it is capable of handling pro blems with statistically dep endent uncertain ob jectiv es b ecause it compares instances of eac h ob jectiv e separately . How ev er, at a reasonable p erfo rmance ov erhead, it a llo ws for considering the en tire probabilit y distribution rather than a certain n um b er of statistics. In this pap er, we prop ose an extension t o the approac h in [10 ], a iming a t improving its comparison accuracy and execution time. T o represen t the pro babilit y distribution of an uncertain o b jectiv e, it uses a CDF rather than a histogra m. Given a set o f samples obtained from iterativ e ev a luation of an uncertain ob jectiv e, it constructs the CDF o f the corresp onding uncertain ob j ective v alue by sorting the samples. F or a giv en v alue of the distribution, its cum ulativ e probabilit y equals the prop or t ion of samples smaller than this v alue to t he total n um b er of samples. W e then in tro duce a fast algo rithm to compare CDFs of tw o instances of an uncertain ob jectiv e in order to calculate the probability that one is greater than the other. Moreo v er, w e prop o se an approximate represen ta tion o f CDFs whic h helps t o significan tly reduce the time complexit y of this algorithm. 3 Prop osed Robust Mul ti-Ob jectiv e Opti mization A m ulti-ob jectiv e o ptimization problem includes a v ector o f n decision v ariables x = ( x 1 , x 2 , . . . , x n ) and a v ector of m o b jectiv e functions f ( x ) = f 1 ( x ) , f 2 ( x ) , . . . , f m ( x ) . The former describes a feasible solution in the constrained search space of the problem, and the latter ev aluates this solutio n with resp ect to different ob jectiv es, i. e., quality metrics, that a re to b e maximized or minimized. Finding a solution that is o pt imal in all o b jectiv es is often imp ossible due to the conflict b et w een differen t ob jective s. Therefore, m ulti-ob jectiv e opti- mization algor it hms typic ally searc h for a set of non- dominated solutions tha t offer decen t tradeoffs for the conflicting o b jectiv es. A solution A dominates another solution B , i. e., A ≻ B , if a nd only if A is a s go o d as B fo r all ob jectiv es and there is a t least one ob jectiv e for whic h A is b etter than B . In a maximization problem, a multi-ob jective dominance criterion can b e defined as f ollo ws: A ≻ B ⇐ ⇒ m ∀ i =1 f i ( A ) ≥ f i ( B ) ∧ m ∃ j =1 f j ( A ) > f j ( B ) (1) where ∧ denotes the log ical AND op eratio n. In the presence of uncertaint y , t he standard comparison op erator s cannot prop erly distinguish ob jectiv e v alues. Therefore, they should be 7 substituted by op erators that incorp orate the existing uncertaint y in to the comparison. This section in v estigates v a rious comparison op era t ors t ha t are based o n pr ob abilistic dom inanc e b et w een instances of uncertain o b jectiv es, with a sp ecial fo cus on tw o nov el op erators. Probabilistic dominance is originally defined to describ e the probabilit y that a solution A dominates another solution B , see [3] and [4]. This probabilit y is calculated as the pro duct of all pro ba bilities that an o b jectiv e from A is more fa v orable than the same ob jectiv e from B . F or a maximization problem, this probabilit y can b e calculated as follow s: Pr( A ≻ B ) = m Y i =1 Pr f i ( A ) > f i ( B ) . (2) A threshold v a lue can b e used to determine if the resulting proba bilit y is significan t enough to assume A dominates B . The main limitatio n of this approac h is that Equation (2) can o nly b e applied if all m ob jective functions are statistically indep enden t, whic h is most of t en no t true b ecause ob jective functions usually ha v e common decision v a riables in their inputs. T o o v ercome this limitation, we prop osed in [10] to calculate the pro babilit y Pr f i ( A ) > f i ( B ) for each ob jectiv e f i separately , to distinguish f i ( A ) and f i ( B ) using a threshold v alue, and then to determine dominance b et w een A and B according to Equation (1). F or a rbitrary distributions of f ( A ) and f ( B ), as closed-form PDFs o r sample data , the probabilit y that f ( A ) is greater than f ( B ) can b e calculated a s fo llows 1 (see a lso [2 4]): Pr f ( A ) > f ( B ) = Z f ( A ) f ( A ) Pr f ( A ) = a Pr f ( B ) < a d a . (3) where f ( A ) and f ( A ) denote the low er and upp er b ounds on f ( A ), resp ectiv ely . While Pr f ( A ) = a is obtained fro m the PD F of f ( A ), the second pro babilit y Pr f ( B ) < a can b e calculated as follow s: Pr f ( B ) < a = Z a f ( B ) Pr( f ( B ) = b )d b . (4) Figure 1 show s an example of PDFs for f ( A ) and f ( B ). The filled area under the curv e of f ( B ) in this figure amoun ts to t he probabilit y Pr f ( B ) < a for a giv en v alue of a . The exact calculation of these in tegrals is tedious if the PDFs of f ( A ) and f ( B ) are not av aila ble or if they do not follow instances of Uniform and Gaussian distributions. The fo llo wing subsections first describ e v arious approaches f o r the estimation of Pr f ( A ) > f ( B ) as w ell as other robust comparison op erators. Then, these are ev aluated with resp ect to estimation error and execution time. 3.1 Robust Comparison Op erators This subsection describ es v ar ious comparison op erators review ed in Section 2 along with t w o no v el approac hes to enable distinguishing instances of an uncertain ob jectiv e. These 1 Since the appro ach is applied to each ob jective function f i ( · ) separa tely , from here on this no tation is simply written as f ( · ) . 8 f ( A ) f ( B ) a f ( A ) f ( B ) ob jective v alue probability densit y f ( A ) f ( B ) Figure 1: Example of PDFs of one uncertain ob jectiv e of t w o candidate solutions A a nd B under comparison. op erators require the distribution of uncertain o b jectiv e v alues f ( A ) and f ( B ) giv en as PDFs or sample data . If t he PDFs are know n, differen t statistics of the distributions can b e obtained, including the exp ected v a lues ( E [ f ( · )]), v ariances ( V ar [ f ( · )]), standard deviations ( σ [ f ( · )]), p - th quan tiles ( q f ( · ) p ) and v alues of the CDFs ( F f ( · ) ( a ) = Pr f ( · ) ≤ a ). If the PDF of an uncertain ob jectiv e v alue is not a v ailable, it can b e represen ted by a p opulation of samples where eac h sample is an outcome of ev aluating the correspo nding ob jectiv e function. Giv en a sequence S of N independen t samples ( s 1 , s 2 , . . . , s N ), the sample mean and the (un biased) sample v ariance a nd standard deviation can b e estimated as follo ws: ˆ E [ S ] = 1 N N X i =1 s i , (5) ˆ V ar [ S ] = 1 N − 1 N X i =1 s i − ˆ E [ S ] 2 , (6) ˆ σ [ S ] = q ˆ V ar [ S ] . (7) Also, the p -th quan tile of a populat io n can b e calculated b y the in v erse empirical distribution function that t ra v erses the p opulation in the ascending order o f samples and returns the very first sample after the p · N smallest samples. More details on the afo remen tio ned statistics can b e fo und in [2 5]. 3.1.1 P airwise Comparison ( C pw ) The most straightforw ard appro a c h to estimate the probabilit y Pr f ( A ) > f ( B ) is t o gen- erate N samples ( a 1 , a 2 , . . . , a N ) from the distribution of f ( A ) and ( b 1 , b 2 , . . . , b N ) according 9 to the distribution of f ( B ), and to calculate the prop ortion of pairs ( a i , b i ) where a i > b i : Pr f ( A ) > f ( B ) ≈ 1 N { i | a i > b i } . (8) The absolute approximation error of this comparison op erator can b e determined as follows : e pw = Pr f ( A ) > f ( B ) − 1 N { i | a i > b i } . (9) The probabilit y that this error is larger than a constan t tolerance 0 < δ < 1 tends expo nen- tially t o zero for larg e v a lues of N according to Chernoff b ounds: Pr ( e pw > δ ) ≤ e − c · δ 2 · N , (10) where c is a p ositiv e constant. The time complexit y of the comparison is of the order O ( N ). Note that if the ev a lua t ion of ob jective functions is time-consuming, it is b etter to maintain a p o pulation of samples for eac h ob jectiv e o f each candidate solution thro ug hout the optimization. Otherwise, new samples can b e generated whenev er a comparison tak es place. 3.1.2 Uniform Appro ximation ( C uni ) [3] Another approach to estimate Pr f ( A ) > f ( B ) is based on the assumption that f ( A ) and f ( B ) can b e approx imated by unifo rm distributions U ( f ( A ) , f ( A )) and U ( f ( B ) , f ( B )), resp ectiv ely . This approac h is denoted b y C 1 uni . Assuming uniform distributions, Pr f ( A ) > f ( B ) can b e calculated as follo ws a ccording t o the la w of to tal probability 2 : Pr f ( A ) > f ( B ) = Pr f ( A ) > f ( B ) ∧ f ( A ) ≤ f ( B ) + Pr f ( A ) > f ( B ) , (11) where Pr f ( A ) > f ( B ) ∧ f ( A ) ≤ f ( B ) = max { f ( A ) , f ( B ) } 2 − min { f ( A ) , f ( B ) } 2 2 f ( A ) − f ( A ) f ( B ) − f ( B ) + max { f ( A ) , f ( B ) } − min { f ( A ) , f ( B ) } f ( B ) f ( A ) − f ( A ) f ( B ) − f ( B ) , ( 12) and Pr f ( A ) > f ( B ) = f ( B ) − min { f ( A ) , f ( B ) } f ( A ) − f ( A ) . (13) 2 F or cases f ( A ) ≤ f ( B ) a nd f ( B ) ≤ f ( A ) there is no need for applying E quation (11 ) as the pro bability Pr f ( A ) > f ( B ) amounts to 0 and 1, resp e ctively . 10 This comparison op erato r requires t he distribution of an uncertain ob jectiv e v a lue to ha v e finite b ounds. Alternativ ely , these low er and upp er b ounds can b e calculated as E [ f ( · )] − p 3 V ar [ f ( · )] and E [ f ( · )] + p 3 V ar [ f ( · )], resp ectiv ely , as the v ariance o f a uni- formly distributed random v a r ia ble f ( · ) ∼ U f ( · ) , f ( · ) equals f ( · ) − f ( · ) 2 / 12. This approac h is denoted as C 2 uni . Note that treating an ar bit r a ry distribution as a uniform dis- tribution can imp ose a significan t estimation error in the calculation of Pr f ( A ) > f ( B ) , but if the distributions are a ctually uniform then b oth v ersions accurately represen t the giv en distributions. If the lo w er a nd upp er b ounds or alternatively the exp ectation and v ariance ha v e to b e deriv ed fro m a p opulation of samples, the time needed for sample generation, i. e., ob jectiv e function ev a luation, whic h has the order O ( N ) can increase the execution time substan tia lly . Otherwise, the execution time is solely sp en t for p erforming the compar ison whic h is of order O (1). 3.1.3 Gaussian Appro ximation ( C gauss ) [4] This approac h assumes that the uncertain ob j ective v alues f ( A ) and f ( B ) follow instances of G aussian distributions, denoted as N ( E [ f ( A )] , V ar [ f ( A )]) and N ( E [ f ( B )] , V ar [ f ( B )]), resp ectiv ely . Th us, the probability of f ( A ) b eing greater than f ( B ) can b e estimated a s follo ws: Pr f ( A ) > f ( B ) = Pr( f ( B ) − f ( A ) < 0) = 1 2 1 + erf E [ f ( A )] − E [ f ( B )] p 2 ( V ar [ f ( A )] + V ar [ f ( B )] ) !! . (14) Here, f ( B ) − f ( A ) ∼ N E [ f ( A )] − E [ f ( B )] , V ar [ f ( A )] + V ar [ f ( B )] , and erf is the error function erf ( x ) = 2 √ π Z x 0 e − t 2 d t . (15) Differen t appro ximations of the error function can be used in this comparison op erat or. Some useful and fast appro ximations can b e fo und in [26]. If the distribution of an uncertain ob jective v alue is not av aila ble, its expected v alue and v ariance can b e deriv ed b y generating a p opulation of samples and applying t he resp ectiv e estimators t o this p opulat io n. This increases t he time complexit y from O ( 1) to O ( N ). Note that this comparison o p erator ma y b e sub ject to a noticeable appro ximation error since the actual distributions mig ht b e non-Ga ussian. 3.1.4 Histogram Appro ximation ( C ω hist ) [10 ] This approach is based on represen ting uncertain ob jectiv e v alues using histogra m-based distributions. Suc h a distribution partitio ns the actual PDF into interv als a nd considers a uniform distribution within eac h in terv al. A column is considered in each interv al suc h that the area co v ered b y t he column equals the probability o f the actual distribution within the 11 corresp onding in terv al. Giv en a uniform distribution within eac h interv al, histogram-based distributions are linear combinations — or more precisely affine com binations — of uniform distributions. Therefore, Pr f ( A ) > f ( B ) can b e calculated by an a ffine combination o f Equation (11). T o reduce computational o v erhead, w e prop osed in [10] to use histogr ams with a fixed in terv al width ω . Also, the columns ar e aligned to the in terv als I ω ,k := [ k · ω , ( k + 1) · ω [ for an y integer k suc h that the columns of differen t histograms either p erfectly ov erlap or are disjoin t . Giv en histogram-based distributions of uncertain ob jective v alues f ( A ) and f ( B ), Pr f ( A ) > f ( B ) = X k 1 2 Pr f ( A ) ∈ I ω ,k · Pr f ( B ) ∈ I ω ,k + Pr f ( A ) ∈ I ω ,k · Pr f ( B ) < k · ω , (16) where j f ( A ) /ω k ≤ k ≤ l f ( A ) /ω m . (17) The v alues for Pr f ( · ) ∈ I ω ,k can b e accurately ev alua ted if the a ctual PDF is a v ailable or they can b e estimated a s the prop ortion of samples that lie within I ω ,k . Therefore, a histogram-based distribution can b e constructed b y calculating f ( · ) /ω − f ( · ) /ω + 1 probabilities, one fo r eac h in terv al, or by generating N samples and calculating t his prop or- tion fo r eac h in terv al. Note that the n um b er o f in terv als can b e different when sampling is used, esp ecially f or small v alues o f N , b ecause not all p oten tial in terv als migh t b e filled with one o r more samples. The probabilities Pr f ( · ) ∈ I ω ,k and Pr f ( · ) < ω · k can b e pre-calculated without increasing the time complexity o f histogram preparation. The calculatio n o f Pr f ( A ) > f ( B ) according to the Equation (16) has then a time complexit y of O ( f ( A ) − f ( A )) /ω . The error of calculating this probability can b e b ounded b y the sum 1 2 · X k Pr ( f ( A ) ∈ I ω ,k ) · Pr ( f ( B ) ∈ I ω ,k ) , (18) where k rang es according to Equation (17). This error is due to the loss of information on the exact distribution within the interv als. Note that if a column from the histogram of f ( A ) p erfectly ov erlaps with a column from the histogram of f ( B ), then the v alues in eac h of the columns are assumed to b e greater tha n the v alues from t he other column ha lf the time — resulting in a pro ba bilit y of 0 . 5 . While dep ending on the distribution of uncertain ob jectiv e v alues within the shared in terv al, one distribution can alw ay s offer g reater v alues whic h yields a proba bilit y of 1 . This can b e the case esp ecially when ω is sufficien tly large. F urthermore, if the probabilities in Equation (16) ar e estimated b y samples, the comparison is sub j ect to an additional erro r t ha t is due to the difference b etw een the prop ortion of samples within an in terv al and the actual pro babilit y to ha v e a v a lue within that in terv al. The probability 12 that this additional error is equal to or gr eater than δ is b ounded b y e − c · δ 2 · N for large v alues of N and 0 < δ < 1, where c is a p ositiv e constan t and N is the num b er of used samples. This result can b e obtained b y application of the Dv oretzky-Kiefer-W olfowitz inequalit y [27] comparing the CDFs of the t w o histogra ms constructed according to the actual distribution and through sampling. The execution time and accuracy of this approa c h significan t ly dep end on the c hosen v alue of ω suc h that shrinking ω reduces the appro ximation error but increases ( f ( A ) − f ( A )) /ω whic h in turn prolongs the comparison, while expanding ω sp eeds up the comparison at the cost of increased approx imation error. In most cases, a rough idea on how the ob jectiv e v alues are distributed can b e established, and th us, a go o d c hoice for ω can b e made, at least af t er some prior exp eriments . 3.1.5 Prop osed Empirical Distribution-based Approac h ( C emp ) The distribution of uncertain ob jectiv e v a lues often cannot b e fitted to a closed-for m PDF, and therefore, m ust b e r epresen ted by a p opulation of samples. T o achiev e a go o d tradeoff b et w een the accuracy and execution time of the comparison, w e prop ose here a n a pproac h that is based on the empirical distribution of uncertain o b jectiv e v alues. Given the p opula- tion of samples S = ( s 1 , s 2 , . . . , s N ), a random v ariable X whic h is distributed according to the corresp o nding empirical distribution has a CDF F X ( y ) = Pr( X ≤ y ) = 1 N { i | s i ≤ y } , (19) whic h amoun ts to the prop o rtion of samples b eing smaller than or equal to y . Let f ( A ) and f ( B ) follow tw o empirical distributions that a re sp ecified by p opulations of samples ( a 1 , a 2 , . . . , a N ) and ( b 1 , b 2 , . . . , b M ), r esp ective ly . A naiv e a ppro ac h to compare these uncertain ob jectiv e v alues would then b e Pr( f ( A ) > f ( B )) = |{ ( i, j ) | a i > b j }| N · M . (20) Unlik e t he pairwise comparison C pw , eac h sample in the first p opulatio n is not only compared to the corresp onding sample but also to all other samples in the second p opulation. The desired probability is then estimated a s the prop ortion of pairs wherein the sample f rom the first p opulation is greater than the sample from the second p opulat io n. The time complexit y o f this approac h is of order O ( N · M ), or O ( N 2 ) if M = N , whic h is usually the case. T o reduce this complexit y , w e prop ose to first sort eac h p o pula t ion of samples in ascending order a nd then to a pply the function sho wn in Algo r it hm 1. This function receiv es sorted lists ( a 1 , . . . , a N ) and ( b 1 , . . . , b M ) that resp ectiv ely represen t the uncertain ob jectiv e v alues f ( A ) and f ( B ), and returns the probability Pr f ( A ) > f ( B ) . It uses tw o indices i a nd j to t r av erse these lists in ascending or der. It stores the pr o p ortion o f pairs wherein the sample a i is greater t ha n the sample b j in a v ariable named num pair s . F or eac h a i , it adds j − 1 to num pair s when b j is the first elemen t in its list that is not smaller than a i . Since eac h list is tr a v ersed only once, the comparison is p erformed in linear time 13 Algorithm 1: Comparing sorted lists o f samples Input: So r t ed lists ( a 1 , . . . , a N ) and ( b 1 , . . . , b M ) 1 j := 1; 2 num p airs := 0; 3 for i := 1 to N do 4 while j < = M and a i > b j do 5 j := j + 1; 6 num p airs := num p airs + j − 1; 7 return num p airs / ( N · M ); O ( N + M ), or simply O ( N ) if M = N . Also, the condition and the b o dy of the while lo op are ev aluated at most N + M a nd M times, resp ectiv ely . Note t ha t generating a nd sorting the samples hav e the time complexities of resp ectiv ely O ( N + M ) and O ( N log N + M log M ). If the PDFs of f ( A ) and f ( B ) are av ailable, the pro p osed approach can b e extended to deriv e N quan tiles tha t partition the actual distribution in to in terv als o f equal probabilities. This enables to construct empirical distributions that ac hiev e b etter appro ximations of the actual distributions. Figure 2 sho ws the exact CDFs of the distributions sho wn in Figure 1 as w ell a s a ppro ximations of these CDFs using 10 quan tiles. Using the quan tiles suc h that a i = q 2 i − 1 2 N , the difference b et w een the CDF s of the empirical and the a ctual distributions are restricted to 1 2 N . Considering this difference for b oth f ( A ) and f ( B ) results in a maxim um estimation error o f 1 / N fo r the calculation of Pr f ( A ) > f ( B ) . Let X A and X B b e random v ariables distributed according to the empirical distributions of f ( A ) and f ( B ), resp ectiv ely . Then Pr f ( A ) > f ( B ) = Z f ( A ) f ( A ) Pr f ( A ) = a Pr f ( B ) < a d a = Z f ( A ) f ( A ) Pr f ( A ) = a Pr( X B < a ) + ε ( a ) d a = ε + Z f ( A ) f ( A ) Pr( f ( A ) = a ) Pr( X B < a )d a = ε + Z f ( B ) f ( B ) Pr( f ( A ) ≥ b ) Pr( X B = b )d b = ε + Z f ( B ) f ( B ) (Pr( X A ≥ b ) + ε ′ ( b )) Pr( X B = b )d b = ε + ε ′ + Z f ( B ) f ( B ) Pr( X A ≥ b ) Pr( X B = b )d b = ε + ε ′ + Pr( X A > X B ) , (21) 14 Figure 2: Ex act and approxim ated CDFs fo r the distributions show n in Figure 1: t he ap- pro ximation uses 1 0 quan tiles. where ε ( x ) , ε, ε ′ ( x ) , ε ′ ∈ [ − 1 / ( 2 N ) , 1 / (2 N )] for all x ∈ [min { f ( A ) , f ( B ) } , max { f ( A ) , f ( B ) } ]. Note that the quan tiles are already sorted in the ascending order, and the time needed for deriving N quan tiles is of order O ( N ). Similar t o the pairwise comparison C pw , the erro r of the empirical distribution can b e b ounded. Let X b e a random v ariable t ha t follows the empirical distribution o f f ( · ) pro- duced from a p opulation of N samples. Then, according to the Dvoretzk y-Kiefer-W olfowitz inequalit y [27] Pr sup x ∈ R F f ( · ) ( x ) − F X ( x ) > δ ≤ e − c · δ 2 · N (22) for large v alues of N and 0 < δ < 1 , where c is a p ositiv e constant. The constants used here are w orse than t hose used for C pw as the result for the pairwise comparison of random v ariables f ( A ) and f ( B ) can b e seen as the v alue of the CDF of their difference at the p o in t zero F f ( B ) − f ( A ) (0). Here, instead, the maximal error among all input v alues is b o unded. The actual error of estimating Pr f ( A ) > f ( B ) is then b ounded b y the sum of t he tw o errors in tro duced b y the empirical distributions of f ( A ) a nd f ( B ). Nev ertheless, the exp erimen ts in Section 3.2 imply t hat this estimation is muc h more accurate. 3.1.6 Prop osed Reduced Empirical Dist ribution-based Approac h ( C r ed uc e ) The prop osed empirical distribution- based comparison op erato r can b e further improv ed for the case where the PDFs of the uncertain ob jectiv e v alues are unknow n and can only b e appro ximated through sampling. This approach is similar to the histogram approx imation ( C ω hist ) with the exception that the partitio ning is p erformed ev enly in the probabilit y do- main instead of the domain of the ob jectiv e v alues. It is used only if at least one of the uncertain ob jectiv e v alues is g iv en as a p opulation of samples rat her than a PD F. Other- wise, we use quan tiles as described f o r the empirical distribution ( C emp ) to pro vide a b etter 15 appro ximation. If w e hav e a sorted list of samples ( s 1 , . . . , s N ), then we will use o nly N ′ = Θ( √ N ) data p oin ts ( y 1 , . . . , y N ′ ), where y i = s ⌈ ( i − 1 / 2) · N/ N ′ ⌉ to pro duce the empirical distribution. In our experiments , w e will use exactly ⌈ √ N ⌉ data p oints . One could use pivot-based sorting algorithms like quic ksort for sorting the samples ( s 1 , . . . , s N ) and stop sorting if no ne of the needed indices are av ailable in a n in terv al which has to b e sorted curren tly , but as this do es not c hange the (exp ected) complexit y o f O ( N log N ) for sorting, w e do not elab orate on this impro v emen t. Therefore, for initialization, w e still hav e the same complexit y as for C emp with N sample generations plus O ( N log N ) f or sorting. The comparison of tw o uncertain ob jectiv e v alues is then muc h faster. Let ( a 1 , . . . , a N ′ ), ( b 1 , . . . , b M ′ ) b e the reduced list of sorted samples from uncertain ob jectiv e v alues f ( A ) and f ( B ), where N ′ = Θ( √ N ) and M ′ = Θ( √ M ), then w e can use again Algorithm 1 to obtain the complexit y O ( √ N + √ M ). The erro r caused b y appro ximation with an empirical distribution using only √ N samples is then automatically in O (1 / √ N ) whic h can b e obta ined b y an equation analogous to Equation (21). No w w e analyze the situation when w e pick a sp ecific p o sition z and query the probability of a random v a riable X to b e less than z . Let p b e the actual probability . F or N samples the relativ e num b er of samples less than z is exactly the v alue of the empirical distribution at z . This v alue multiplie d by N has a binomial distribution with par ameter p and its v ariance scales with N . C onsequen tly the v ar iance of the empirical distribution ev aluated o n any p osition scales with 1 / N and the standard deviation scales with 1 / √ N . Therefore, the order of t he error do es not ch ange if t he n um b er of data p oints is reduced to only the square ro ot o f the num b er of ev aluated samples as suggested. T a ble 1 summarizes the analyzed time complexities of the initialization, i. e., appro ximat- ing distributions, and comparison fo r all comparison op erators inv estigated in this section. It also rep orts if the r esult of the resp ectiv e comparison op erato r con v erges to the exact probabilit y Pr f ( A ) > f ( B ) . Note tha t the initia lizat io n is applicable o nly if the actual PDF of a t least one ob j ective function is not av ailable. Also, in the case of the prop osed empirical distribution- based approac h ( C emp ), N denotes either the num b er of quantiles or the num b er o f samples, dep ending on whether the actual PD F s ar e a v ailable or not. In the follow ing, w e ev aluate the inv estigated comparison op erato rs in t erms of ap- pro ximation error a nd execution time. F or the ev aluation, five scenarios of tw o ra ndom v ariables ( X 1 , X 2 ) with differen t distributions are selected, see the left column of Figure 3. These sc enarios combine instances of v arious distributions includin g unifo rm U ( X , X ), Gaus- sian N ( E [ X ] , V ar [ X ]) and b eta B ( α , β ) distributions. The first four scenarios are adopted from [10 ]. These scenarios v ary in their statistical prop erties and p ose differen t c hallenges to the comparison op erato r s. 3.2 Appro ximation Error Analysis of Comparison Op erators The r ig h t part of Figure 3 displa ys the quality of differen t compar ison op erators for eac h scenario. F or eac h scenario and eac h comparison op erat o r one can see the dev elopmen t of the absolute error - absolute difference of the ev alua ted v alue and the correct v a lue - while 16 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 2 4 6 random v ariable probability densi ty X 1 ∼ B (4 , 2) X 2 ∼ B (20 , 20) 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 − 3 10 − 2 10 − 1 10 0 N absolute error C 1 uni C 2 uni C 0 . 1 hist C gauss C 0 . 05 hist C pw C 0 . 01 hist C r educ e C emp 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 2 4 6 random v ariable probability densi ty X 1 ∼ U (0 . 3 , 0 . 8) X 2 ∼ U (0 . 4 , 0 . 6) 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 N absolute error C gauss C pw C 0 . 01 hist C r educ e C emp C 0 . 05 hist C 0 . 1 hist C 2 uni C 1 uni 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 2 4 6 random v ariable probability densi ty X 1 ∼ N ( 0 . 5 , 0 . 1 2 ) X 2 ∼ N ( 0 . 45 , 0 . 15 2 ) 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 − 3 10 − 2 10 − 1 10 0 N absolute error C 1 uni C 2 uni C 0 . 1 hist C 0 . 05 hist C pw C r educ e C emp C 0 . 01 hist C gauss 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 2 4 6 8 10 random v ariable probability densi ty X 1 ∼ B (0 . 3 , 0 . 3) X 2 ∼ N (0 . 3 , 0 . 05 2 ) 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 − 3 10 − 2 10 − 1 10 0 N absolute error C 1 uni C gauss C 2 uni C 0 . 1 hist C 0 . 05 hist C pw C r educ e C emp C 0 . 01 hist 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 5 10 15 20 random v ariable probability densi ty X 1 ∼ U ( 1 π , 1 e ) X 2 ∼ U ( 1 4 , 1 3 ) 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 N absolute error C 0 . 1 hist C 0 . 05 hist C gauss C 0 . 01 hist C pw C 2 uni C r educ e C emp C 1 uni Figure 3: Left: F iv e scenarios of tw o random v ariables with differen t distributions intro duced for ev aluating differen t comparison op erators. Righ t: The absolute error of comparison op- erators fo r eac h scenario and for differen t num b ers N of samples. The comparison op erator s in the legend are rank ed according to their absolute error b ound with the maximal num b er of samples N = 10 6 . 17 T a ble 1 : Time complexit y for initialization a nd comparison o f the inv estigated compar ison op erators, and the information whether their appro ximation error tends to zero if the n um b er of samples N is increased. initializat ion comparison error → 0 C pw — O ( N ) ✓ C 1 / 2 uni O ( N ) O (1) ✗ C gauss O ( N ) O (1) ✗ C ω hist O N + f ( · ) − f ( · ) ω O ( f ( · ) − f ( · ) ω ✗ C emp O ( N log N ) O ( N ) ✓ C r ed uc e O ( N log N ) O ( √ N ) ✓ the n um b er of samples is increased. T o b e more precise the presen ted graphs represen t an error b o und suc h that 99% of comparisons b y the resp ectiv e comparison op erator comply with that error b ound. This limitation is necessary b ecause ev en with lar ge nu mbers of samples all samples of one random v ariable can b e smaller than all samples of the other random v ar ia ble ev en if the first random v ariable dominates the second random v ariable with probabilit y greater tha n 50 %. In suc h cases all comparison op erators will fail ba dly but fortunately , suc h an ev en t will most lik ely not happ en. T o obtain additional information w e also provide in T able 2 the differences b et w een the a ctual do minance v alues a nd the ev aluated dominance v alues by eac h comparison o p erator if infinitely man y samples w ould ha v e b een used. C pw , C emp and C r ed uc e are omitted a s they alwa ys conv erge to the actual dominance v alues. These results visualize that the comparison op erators whic h assume uniform or Gaussian distributions ( C gauss , C uni ) outp erform other comparison op erators if the random v a riables actually follow instances of the assumed distribution but they can also ha v e quite large errors if this is not the case. Also the histogram ba sed comparison op erator ( C ω hist ) has this problem as it assumes piecewise constan t densities. Also if the p ositions where densities of t he histog r am can c hange do not match the p ositions where the actual distributions c hange, a significan t error can b e receiv ed. This is most explicitly track ed in the last scenario. But if the width ω of the columns in the histograms is suitably c hosen then it leads to similar results as f or the prop osed comparison op erators based on empirical distributions. The remaining comparison o p erators ( C pw , C emp and C r ed uc e ) finally conv erge to the actual dominance v alue if the num b er of samples is increased. The comparison op erat o r using empirical distributions ( C emp ) and it s reduced v ersion ( C r ed uc e ) con ve rge in all cases faster than the pairwise comparison ( C pw ). F or larg er sample sizes, there is almost no difference b et w een C emp and C r ed uc e . Only for v ery small sample sizes C r ed uc e has a la r g er error due to to o f ew data p oints in the reduced empirical distribution. Also for C pw , the 18 T a ble 2: F o r the scenarios in Figure 3, the actual v alues Pr( X 1 > X 2 ) a nd the v alues calculated by eac h comparison op erator ar e rep orted. Additionally , the resp ectiv e difference to the actual v alues if the n um b er o f samples tends to infinit y is sho wn. 1 2 3 4 5 Pr( X 1 > X 2 ) 0 . 7978 0 . 6000 0 . 6092 0 . 5 923 0 . 9727 C 1 uni 0 . 5000 − 0 . 2978 0 . 6000 ± 0 . 0000 0 . 5000 − 0 . 1092 0 . 5000 − 0 . 0923 0 . 9727 ± 0 . 0000 C 2 uni 0 . 7700 − 0 . 0278 0 . 6000 ± 0 . 0000 0 . 5962 − 0 . 0130 0 . 6461 +0 . 0538 0 . 9727 ± 0 . 0000 C gauss 0 . 8042 +0 . 0064 0 . 6261 +0 . 0261 0 . 6092 ± 0 . 0000 0 . 6922 +0 . 0999 0 . 9669 − 0 . 0058 C 0 . 1 hist 0 . 7902 − 0 . 0076 0 . 6000 ± 0 . 0000 0 . 6040 − 0 . 0052 0 . 5936 +0 . 0013 0 . 8000 − 0 . 1727 C 0 . 05 hist 0 . 7959 − 0 . 0019 0 . 6000 ± 0 . 0000 0 . 6079 − 0 . 0013 0 . 5926 +0 . 0003 0 . 8721 − 0 . 1006 C 0 . 01 hist 0 . 7977 − 0 . 0001 0 . 6000 ± 0 . 0000 0 . 6092 − 0 . 0000 5 0 . 5923 +0 . 0000 1 0 . 9683 − 0 . 0044 v ariance is quite large if the sample size is small. Here the presen ted exp erimen ts confirm the adv antages and disadv an tages predicted by theoretical ev a lua tion in the previous section. 3.3 Execution Time Analysis of Comparison Op erators In additio n t o the comparison op erators presen ted in Section 3.1, there exist other compar- ison op erators whic h leav e out the detour via probabilistic dominance. These comparison op erators do not calculate the dominance v a lue and ev a luate t he preference of an uncertain ob jectiv e v alue in comparison to another b y differen t ch aracteristics. Tw o w ell established comparison op erators of that kind are the mean-based approach [8] and the three-stage comparison o p erator [9 ] whic h are briefly intro duced in the follow ing: 3.3.1 Mean-ba sed Comparison Op erator ( C Me an ) [8] This comparison op erator simply decides whether f ( A ) or f ( B ) is b etter b y comparing their mean v alues. The initia lization takes linear time as t he mean has to b e estimated according to Equation (5) and the comparison tak es only constan t time. 19 10 − 3 10 − 2 10 − 1 10 0 10 1 10 2 C pw C 1 uni C 2 uni C gauss C emp C r educ e C 0 . 01 hist C 0 . 05 hist C 0 . 1 hist C Thr eeStage C Me an initialization time [ µs ] 10 − 3 10 − 2 10 − 1 10 0 10 1 C pw C 1 uni C 2 uni C gauss C emp C r educ e C 0 . 01 hist C 0 . 05 hist C 0 . 1 hist C Thr eeStage C Me an comparison time [ µ s ] 1 000 samples 100 samples 10 samples Figure 4: F or eac h comparison op era t o r, we displa y the execution times of the initialization of one ob j ect for comparison (once fo r eac h ob ject) and the execution times of the comparison of t w o already initialized ob jects in µs fo r 10 , 100 and 1 000 samples p er ob ject (Programming language: Ja v a, executed on a n Intel i7-479 0 with an Ubun tu op erating system). 3.3.2 Three-Stage Comparison Op erator ( C Thr e eStage ) [9] This comparison op erat or p erforms the compar ison in three stages. In the first stage, it c hec ks whether the domains, i. e., the interv al b et w een the lo w er and upp er b ound, of the t w o uncertain ob jectiv e v a lues o v erlap. If no t, then the v alue in the b etter region is decided to b e b etter. If the domains do o v erlap, the next stages apply . In the second stage, it c hec ks whether the mean of one uncertain ob jectiv e v alue is significan tly b etter than tha t of the o ther v alue. If this is true, then the means determine whether f ( A ) or f ( B ) is b etter. Otherwise the third stag e is applied where the uncertain ob jectiv e v alues a r e compared with resp ect to their 95 % quantile interv al, i. e., the in terv al b etw een the 0 . 025 -th and 0 . 975- th quan tile p oin ts. By comparison o f quan tiles it is c hec k ed whether f ( A ) or f ( B ) sho ws a considerably smaller deviation and deliv ers a more robust ob jectiv e v a lue. If the lengths of t hese quan tile interv als a re ve ry similar, it is decided that f ( A ) and f ( B ) ar e equally go o d. T o prepare quan tiles w e hav e the complexit y O ( N lo g N ) fo r sorting N samples during initialization time of eac h ob ject. The comparison is then ev aluated in constan t time. No w w e relate these tw o comparison op erators with the six probabilistic dominance- 20 based comparison op erators intro duced in Section 3.1. F or this purp ose, w e in terpret the dominance v a lues calculated b y a comparison op erator fro m Section 3.1 to obtain the a nswe r for t w o solutions A and B whether f ( A ) is greater/smaller than or as go o d as f ( B ). T o accomplish this for t w o uncertain ob jectiv e v alues f ( A ) and f ( B ), w e can define a threshold γ ≥ 0 . 5 to determine whether the probability that f ( A ) is greater/smaller than f ( B ) is significan t enough to reac h a conclusion. F or example, in case of a maximization problem w e sa y that f ( A ) is b etter than f ( B ) if Pr f ( A ) > f ( B ) > γ , f ( B ) is b etter than f ( A ) if Pr f ( B ) > f ( A ) > γ and otherwise they are equally go o d, see [1 0]. This probabilistic dominance criterion can incorp orate any of the previously in tro duced comparison o p erators in Section 3.1 to enable treating uncertain ty in m ulti-ob jectiv e o ptimization. All the previously in tro duced comparison o p erators (the six comparison op erators in- tro duced in Section 3.1 and t he tw o we ll established comparison op erators in tro duced in this section) hav e b een implemen ted in Ja v a and experimented on an In tel i7-4790 with an Ubun tu op erating system. The av erage execution times for the initializat io n and comparison of each comparison op erator for the scenarios in F ig ure 3 a r e visualized in Figure 4. The measured results comply with the presen ted complexities. The only surprise might b e tha t C gauss has suc h a slow comparison time which is mainly sp en t for the approxim ation of the error function in Equation (15). 4 Uncertain Multi- Ob jectiv e Optimizati on B enc hmark This section presen ts a num b er of uncertain m ulti-ob jectiv e optimization problems to ev al- uate t he prop osed comparison op erator along side the state-o f-the-art appro a c hes. These problems aim to incorp ora te v arious uncertain ties in six multi-ob jectiv e optimization pro b- lems of the DTLZ b enc hmark suite [1 1]. Eac h of these problems are sp ecified by a v ector of m ob jectiv e f unctions ( f 1 , f 2 , . . . , f m ), that receiv e a v ector o f n shared decision v ariables x = ( x 1 , x 2 , . . . , x n ) where ∀ i ∈ { 1 , 2 , . . . , n } : 0 ≤ x i ≤ 1 . T a ble 3 shows the prop osed uncertain DTLZ (UDTLZ) problems. The considered uncer- tain ties include p erturbation in decision v ariables as well as noise and appro ximation error in o b jectiv e functions 3 . The UDTLZ1 pro blem adds uncertainties sp ecified b y instances of Beta distribution B with different shap e parameters on to the decision v aria bles of the D TLZ1 problem. The b eta distribution generates samples u in the interv al [0 , 1] whic h are scaled to [0 , 0 . 001] and added t o the exp ected v alues x i . The resulting v alue x i is then b ounded to 1 whic h is the upp er b ound of x i . Similarly , UDTLZ6 incorp orates p erturbations fo llo wing instances of Gaussian distribution N in the decision v ariables of DTLZ6. The G aussian distributions in t his problem generate samples a r o und a n exp ected v alue of 0 with different standard deviations. Since the added v ariations may b e negative or p ositiv e, t he resulting v alue is then b ounded to [0 , 1 ]. 3 The uncertaint y due to time-v arying ob jective functions is not consider e d in the prop osed uncertain pro b- lems. How ever, the pro p osed comparison op era to r can deal with a ny uncertain ty that leads to probabilis tic representations of ob jective v alues. 21 T a ble 3: UDTLZ benchm ark suite incorpo rating uncertaint y in to DTLZ multi-ob jective opti- mization problems: N , B and U represen t G a ussian, Beta and discrete unifo r m distributions. Sho wn in b old a r e the pro p osed mo difications. problem ob jective functions UDTLZ1 f 1 ( x ) = 1 2 x 1 x 2 . . . x m − 1 1 + g ( x m , . . . , x n ) m ∀ i =2 f i ( x ) = 1 2 m − i Y j =1 x j (1 − x m − i +1 ) 1 + g ( x m , . . . , x n ) g ( x m , . . . , x n ) = 1 00( n − m + 1) n X i = m ( x i − 0 . 5) 2 − c o s 20 π ( x i − 0 . 5) where n ∀ i =1 x i = min( x i + 0 . 0 01 u i , 1) and u i ∼ B (10 + i, 2 + i ) UDTLZ2 f 1 ( x ) = 1 + g ( x m , . . . , x n ) cos( θ 1 ) . . . cos( θ m − 1 ) + u 1 m ∀ i =2 f i ( x ) = 1 + g ( x m , . . . , x n ) m − i Y j =1 cos( θ j ) sin( θ m − i +1 ) + u 1 θ i = π 2 x i , g ( x m , . . . , x n ) = n X i = m ( x i − 0 . 5) 2 where sin( θ ) = u 2 X X X j =1 ( − 1) j θ 2 j +1 (2 j + 1)! , cos( θ ) = u 2 X X X j =1 ( − 1) j θ 2 j (2 j )! , u 1 ∼ N 0 , 0 . 005 2 , u 2 ∼ U (3 , 12) UDTLZ3 Same a s in UDTLZ2 except that g ( x m , . . . , x n ) = 1 00( n − m + 1 ) n X i = m ( x i − 0 . 5) 2 − cos ( 20 π ( x i − 0 . 5) ) and u 2 ∼ U (12 , 19) UDTLZ4 Same a s in UDTLZ2 except that x is replaced b y x 100 in f i functions as sug gested in [11] UDTLZ5 Same a s in UDTLZ2 except that m − 1 ∀ i =2 θ i = π 1 + 2 g ( x m , . . . , x n ) x i 4 1 + g ( x m , . . . , x n ) and g ( x m , . . . , x n ) = n X i = m x i 0 . 1 UDTLZ6 m − 1 ∀ i =1 f i ( x i ) = x i , f m ( x ) = 1 + g ( x m , . . . , x n ) · h f 1 ( x 1 ) , . . . , f m − 1 ( x m − 1 ) , g ( x m , . . . , x n ) g ( x m , . . . , x n ) = 1 + 9 n − m + 1 n X i = m x i h f 1 ( x 1 ) , . . . , f m − 1 ( x m − 1 ) , g ( x m , . . . , x n )) = = m − m − 1 X i =1 f i ( x i ) 1 + g ( x m , . . . , x n ) 1 + sin 3 π f i ( x i ) where n ∀ i =1 x i = max (min ( x i + u, 1) , 0) and u ∼ N 0 , 10+ i 1000 22 UDTLZ2, UD TLZ3, UDTLZ 4 and UD TLZ5 use b oth f unction noise and approximation error to add uncertain ty to their correspo nding DTLZ problems. F unction noise u 1 describes samples fr o m a Gaussian distribution with an expected v alue of 0 and a standard deviation of 0 . 00 5 across all of these pr o blems. Also, function approximation error is added to this problems b y r eplacing eac h trigonometric or exp onential function with its corr esp o nding Maclaurin series where the n um b er of terms in series fo llows discrete uniform distributions U (3 , 12) fo r UDTLZ2 , UDTLZ4 and UDTLZ5, and U (12 , 19) in the case of UD TLZ3. 5 Exp erimen tal Set up and Ev aluations This section presen ts the results of ev a luating the prop o sed reduced empirical distribution- based comparison op erator as w ell as the tec hniques fro m [9], [10], and [8] in the contex t of m ulti-ob jectiv e o ptimization with uncertain ob jectiv es. All comparison op erators and the prop osed UDTLZ b enc hmark ha v e b een in tegrated in to the op en-source Opt4J optimization framew ork [12] and can b e paired with different optimizatio n tec hniques. The follow ing exp eriments use the w ell- kno wn Nond ominate d Sorting Gene tic Algorithm II (NSGA-II) [13] to optimize instances of UDTLZ as w ell as UZD T [1 0] b enc hmarks. NSGA-I I is configured with a p opulation size of λ = 2 5 and p erforms o ptimization runs for 400 generations in eac h case. The UZDT b ench mark extends the we ll-known ZDT b enc hmark suite [28] and incorp orates v arious uncertainties in the sp ecification of all six bi- ob jectiv e ZDT pro blems. Also, t he prop osed UD TLZ problems are configured with n = 7 decision v ariables and m = 3 ob jectiv e functions. A sample size N = 100 is used for all instances of the UZD T a nd UDTLZ problems a nd for all comparison op erator s. This r equires 100 itera t ive ev alua tions of eac h ob jectiv e f unction of each candidate solution, and allo ws a go o d balance b et w een the comparison accuracy and execution time. The prop osed comparison op erator uses a maxim um o f 20 steps in the appro ximated CDFs, while the histogram-based approach partitions eac h uncertain t y distribution in to interv als with a width of ω = 0 . 01. Both of these comparison op erators are ev aluat ed f or a compar ison threshold γ = 0 . 7 as suggested in [10]. Moreo v er, the three- stage approac h is configured to use mean v alue in the av erage criterion and the 95% quan tile in terv als in the spread criterio n, as suggested in [9]. Also, t he threshold v alues 0 . 1 and 0 . 3 are used for these criteria, resp ectiv ely . 5.1 Con v ergence and Div ersit y Figure 5 depicts the Pareto fro n t a ppro ximations for the UZDT1 and UZDT3 test prob- lems [10] obtained b y NSGA- I I incorp or ating the prop osed C r ed uc e , the histogram-ba sed C 0 . 01 hist [10], the three-stage C Thr e eStage [9] and the mean-based C Me an [8] comparison op erators. Sho wn are the reference P areto fro n t and t w o approximated fron ts ac hiev ed a fter 200 a nd 400 generations considering only the mean v alue of the uncertain ob j ective s f 1 and f 2 . T o obtain r eliable results, each optimization run is rep eated 10 times, the results are sorted with resp ect to the we ll-known ǫ -dominance criterion [29], and the run whic h pro vides the 23 Figure 5: Pareto fron t a ppro ximations for the UZDT1 and UZD T3 pro blems obtained a fter 200 and 400 generations o f NSGA-I I incorp orating differen t comparison op erato r s. Eac h case is run for 10 times and the median of the results is plotted. Sho wn are the mean v alues of the uncertain ob jectiv es f 1 and f 2 . 24 median ǫ -dominance is chos en. The results show that, t he first three comparison op erators outp erform the mean-based appro ac h in most of the cases. How ev er, the prop osed com- parison op erator p erforms slightly b etter in con v erging to the Pareto front, while co v ering div erse regions in the ob jectiv e space. Figure 6 depicts the ǫ -dominance [29] and dive rsity comparison indicator ( D CI) [30] calculated from the mean v alues of eac h uncertain ob jectiv e for v arious instances of UZDT and UDTLZ problems. Eac h result is calculated as the median of 10 optimization runs, calculated at each generation of NSGA-I I. ǫ -dominance is calculated using the approac h in [3 1] where the v alue of ǫ sp ecifies how m uc h the quality of candidate solutions found in an o pt imizatio n run should b e scaled so that these solutions w eakly dominate the true P areto front. I f the true P areto fro nt cannot b e accurately describ ed, whic h is the case for the UZDT and UDTLZ problems, it is replaced b y a reference set of solutions. This reference set con tains all solutions that turn out to b e non- dominated after com bining the appro ximated P areto fronts of all runs of ev ery optimization tec hnique in the exp eriments . T o calculate DCI, the ob jectiv e space is partit io ned into m -dimensional h yp ercub es of iden tical v olume. This a llows to define a new co ordinate system where solutions tha t lie within the same hy p ercub e are t r eat ed as equal. Giv en the co ordinates o f t w o sets of h y- p ercub es that enclose the reference and an appro ximated Pareto f ron t, the work in [30] first calculates the sum of the Euclidean distances b et w een eac h h yp ercub e of the approx imated fron t and the nearest h yp ercub e o f the r eference fro n t. Then it normalizes the result to a scale b et w een 0 and 1 t ha t respectiv ely indicate the minim um a nd maxim um p o ssible degrees of dive rsity . Figure 6 sho ws the deve lopmen t of ǫ -dominance and DCI through the optimization, whic h indicates that the prop osed comparison op erator allows for a fast con v ergence to the Pareto fron t. The fluctuations in the results are due to the fact that the solutions are ev olv ed with the help of elitism and cro wding distance approaches [13 ] whic h do not differen tiate candidate solutions in similar w ay s as in the p ost-optimization a lg orithms used t o calculate ǫ -dominance and DCI. Moreov er, while the former appro a c hes emplo y uncertain ty-a ware comparison op erato rs whic h consider v arious c haracteristics for the uncertain ty distribution of ob jectiv e v alues, the la tter algorithms alw a ys mak e decisions based on the mean v alues only . It should b e noted that the inten sity of these fluctuations a lso dep end on the exten t of uncertain t y in the ob j ectiv e functions suc h that for larg er uncertain ties, ob jectiv e v alues of man y candidate solutions w ould ov erlap. This ma y affect the dominance relation b et w een these candidate solutions and give rise to p ossible disagreemen ts among the a foremen tioned approac hes. 5.2 Robustness In the following, the prop osed comparison op erator C r ed uc e is compared with the tec hniques in [10], [9] a nd [8] in terms of robustness of the found solutions for the UZD T and UDTLZ problems. The robustness is measured in this pap er as the diagonal distance b et w een w orst- and b est-case ob jectiv e v alues such t hat a solution is said to b e more robust if it delive rs a smaller v alue for diago na l distance. Fig ur e 7 sho ws the results obtained f or all ev aluated 25 (a) UZDT1 (b) UZDT3 (c) UDTLZ2 (d) UDTLZ6 Figure 6: Resulting ǫ -dominance and DCI for the UZDT1, UZDT3, UDTLZ2 a nd UDTLZ6 problems. The results are obtained using o ptimizations that incorp orate differen t comparison op erators. F or a reliable interpretation of the results, eac h case is rep eated 10 times and at eac h g eneration, t he median ǫ -dominance and divers ity v alues of all 10 runs are calculated. comparison op erators and all UZDT and UDTLZ problem instances. In eac h case, the diagonal distance is calculated for all solutions in the P areto front appro ximations of 10 optimization runs, and av eraged. The results in Figure 7 sho w that none of the comparison o p erators performs considerably b etter in finding robust solutions. This can b e justified by the fact that the prop osed, the histogram-based and the mean-based comparison op erators do not consider the deviation of uncertain ob jectiv e v alues as a comparison criterion. The three-stage comparison o p erator tak es t his deviation into accoun t in its third stage. How ev er, w e ha v e observ ed that for all tested problems, in at least 94% of cases, ob jective v alues can b e distinguished in the first t w o stages, i. e., t he deviation criterion is used in less than 4% of a ll comparisons. Also, in more t ha n 9 2% of the extended comparisons, the compared uncertain ob jective v alues are 26 UZDT1 UZDT2 UZDT3 UZDT4 UZDT5 UZDT6 UDTLZ1 UDTLZ2 UDTLZ3 U DTLZ4 UDTLZ5 UDTLZ6 10 − 3 10 − 2 10 − 1 a verage diagonal distance C r e duc e C 0 . 01 hist [10] C Thr e eStage [9] C Me an [8] Figure 7: Av erage diag o nal distance of the solutions found for all UZ D T and UDTLZ prob- lems using optimizations that incorp orate differen t comparison op erator s. Each case is a v- eraged ov er the results of 10 indep enden t optimization runs. considered equal as their deviations are not no ticeably differen t. This indicates that although a deviation criterion is emplo y ed, it is not lik ely to find solutions with significantly smaller uncertain ties in their ob jectiv e v alues. Note that the diago na l distance do es not reflect the accuracy of the comparison o p erators in distinguishing differen tly distributed uncertain ob jectiv e v alues. 6 Conclus ion Multi-ob jectiv e o ptimization problems are oft en sub ject to v arious sources and forms of un- certain t y in their decision v ariables and ob j ectiv e functions. A wide range of approa ches has b een prop osed in the literature to distinguish candidate solutions with ob jectiv e v alues sp ecified by confidence interv als, probability distributions or sampled data . How ev er, these approac hes typic ally fail to t r eat uncertainties with non-standard distributions accurately and efficien tly . In this pap er, w e in v estigated a v ariety of tec hniques that offer the com- parison of uncertain ob jectiv e v a lues, and prop osed no v el techn iques f o r the calculation of the probabilit y that a n uncertain ob jectiv e of one solution is more fav orable than the same ob jectiv e of the other solution. T o enable disco v ering ro bust solutions to problems with m ultiple uncertain ob jectiv es, w e incorp orated the pro p osed comparison op erator into exist- ing optimization tec hniques suc h as ev olutionary algorithms. W e also extended w ell-kno wn m ulti-ob jectiv e problems with v arious unce rtainties and pro p osed a bench mark for ev aluating robust o ptimization tec hniques. The prop osed comparison op erators and b enc hmar k suite ha v e b een inte grat ed into an existing o ptimization f ramew ork that provides a selection of m ulti-ob jectiv e optimizatio n pro blems and algorithms. Exp erimen ts sho w that compared to existing tec hniques, our enhanced comparison op erator ac hiev es higher optimization quality and imp o ses low er o v erheads to the optimization pro cess. 27 References [1] L. Jourdan, M. Basseur, and E. T albi, “Hybridizing exact metho ds and metaheuristics: A ta xonom y ,” Eur op e an Journal of Op er ational R ese ar ch , v ol. 19 9, no. 3, pp. 620– 6 29, 2009. [2] Y. Jin and J. Brank e, “Ev olutionar y optimization in uncertain en vironmen t s- a surv ey ,” IEEE T r ansactions on Evolutionary Co m putation , v ol. 9, no. 3, pp. 3 03–317, 20 05. [3] J. T eic h, “ P areto-front exploration with uncertain ob jectiv es,” in International Confer- enc e on Evolutionary Multi-Criterion Optimization (EMO) , 2001, pp. 314–328. [4] E. J. Hughes, “Evolutionary m ulti-ob jectiv e ranking with uncertaint y and noise,” in International Conf e r enc e on Evolutionary Multi-Criterion Optimization (EMO) , 20 01, pp. 3 2 9–343. [5] J. E. Fieldsend and R. M. Eve rson, “ Multi- ob jectiv e optimisation in the presence of uncertain t y ,” in I EEE Congr ess on Evolutionary Computation (CEC) , v o l. 1, 200 5, pp. 243–250. [6] P . Lim b ourg , “Multi-ob jectiv e optimization of problems with epistemic uncertain t y ,” in Pr o c e e di n gs of the Evolutionary Multi-Criterion Optimization (EMO) , 2005, pp. 413– 427. [7] N. Esfahani and S. Malek, “Uncertaint y in self-ada ptiv e soft w are systems ,” in Sof twa r e Engine ering for Self-A da ptive Systems II , 2013 , pp. 214–238 . [8] I. Meedeniy a, A. Aleti, and L. Gr unske , “Arc hitecture-driv en reliability optimization with uncertain mo del parameters,” Journal of Systems and Softwar e , vol. 85, no. 10, pp. 2 3 40–2355, 2012 . [9] F. Khosravi, M. M ¨ uller, M. Glaß , and J. T eic h, “Uncertain t y-aw are reliabilit y analysis and optimization,” in Des i g n , Au tomation and T est i n Eur op e (DA TE) , 2015, pp. 97– 102. [10] F . Khosra vi, M. Borst, and J. T eic h, “Probabilistic dominance in robust m ulti-ob jectiv e optimization,” in IEEE Congr e s s on Evolutionary Computation (CEC) , 2018, pp. 1– 6 . [11] K . Deb, L. Thiele, M. La umanns, and E. Zitzler, “Scala ble m ulti-o b jectiv e optimization test pro blems,” in IEEE Cong r ess on Evolutionary Computation (CEC) , 2002, pp. 825– 830. [12] M. Luk asiewycz, M. Glaß, F. R eimann, and J. T eic h, “Opt4J - a mo dular framew ork for meta-heuristic o pt imizatio n,” in Pr o c e e dings of the Genetic & Evolutionary C ompu- tation Confer en c e (GECCO) , 2011, pp. 17 23–1730. 28 [13] K . Deb, S. Agraw al, A. Pratap, and T. Mey ariv a n, “A fast elitist non-dominat ed sorting genetic algorithm f or m ulti-ob jectiv e optimization: NSGA-I I,” in Pr o c e e dings of the Par al lel Pr oblem Sol v i ng fr om Natur e (PPSN) , 2000 , pp. 849–858 . [14] M. R eyes -Sierra and C. A. Co ello, “Multi-ob jectiv e pa rticle sw arm optimizers: A surve y of the state-o f -the-art,” I nternational journal of c omputational intel ligen c e r ese ar ch , v ol. 2, no. 3, pp. 287– 3 08, 2006. [15] W. L. Ob erk ampf, J. C. Helton, C. A. Joslyn, S. F. W o jtkiewicz, and S. F erson, “Chal- lenge problems: Uncertain ty in system response give n uncertain parameters,” R eliability Engine ering & System Safety , v ol. 85, no. 1- 3, pp. 11–19, 2 004. [16] N. Esfahani, K . R aza vi, and S. Malek, “Dealing with uncertain ty in early softw are arc hitecture,” in F oundations of Softwar e Engine eri n g (FSE) , 201 2, pp. 1–4. [17] H. Esk a ndar i, C. D. Geiger, and R. Bird, “Handling uncertain t y in ev o lutio nary m ulti- ob jectiv e optimization: Spga,” in I EEE Congr es s on Evolutionary Computation (CEC) , 2007, pp. 4130–41 37. [18] H. T ekiner-Mogulk o c and D. W. Coit, “System reliability optimization considering un- certain t y: Minimization of the co efficien t of v aria t ion for series-parallel systems ,” IEEE T r an s a ctions on R eliabi l i ty , v o l. 60, no . 3, pp. 6 6 7–674, 20 1 1. [19] H. Mark o witz, “P ortfolio selection,” The journal of financ e , v ol. 7, no. 1, pp. 77–91, 1952. [20] M. Mlak a r , T. T u ˇ sar, and B. F ilipiˇ c, “Comparing solutions under uncertaint y in multi- ob jectiv e optimization,” Mathematic al Pr oblems in Engine ering , v ol. 20 1 4, 2014. [21] Z . He, G. G. Y en, and Z . Yi, “Probust mu ltiob j ective optimization via ev olutionary algorithms,” IEEE T r ansactions on Evolutionary Computation , v ol. 23, no. 2, pp. 316– 330, 2018. [22] Q . Zhang and H. Li, “Mo ea/d: A m ultiob jectiv e ev olutiona r y algorithm based on decom- p osition,” IEEE T r ans a ctions on ev olutionary c omputation , v ol. 11, no. 6, pp. 712–73 1, 2007. [23] K . Deb and H. G upta, “ In tro ducing robustness in mu lti-o b jectiv e optimizatio n,” Evo- lutionary c o m putation , v ol. 14, no. 4, pp. 463–494, 20 0 6. [24] M. A. Soliman and I. F . Ily as, “ R anking with uncertain scores,” in IEEE International Confer enc e on Data Engine eri n g , 2009, pp. 31 7 –328. [25] R . Durrett, Pr ob ability: The ory and Examples , ser. Cam bridge Series in Statistical and Probabilistic Mathematics. Cam bridg e Univers ity Press, 2010. 29 [26] M. Abramow itz and I. A. Stegun, Handb o ok of Mathematic al F unctions, With F ormulas, Gr aphs, and Mathematic al T able s , 1964. [27] A. D v oretzky , J. Kiefer, a nd J. W olfo witz, “Asymptotic minimax c haracter of the sam- ple distribution function and of the classical multinomial estimator,” The Annals of Mathematic al Statistics , v ol. 27, no. 3, pp. 642–669, 19 5 6. [28] E. Zitzler, K . D eb, and L. Thiele, “ Comparison of Multiob jectiv e Ev olutionary Algo- rithms: Empirical Results,” Evolutionary C omputation , vol. 8, no. 2, pp. 1 7 3–195, 2 0 00. [29] E. Zitzler, L. Thiele, M. Laumanns, C. M. F onseca, and V. G. Da F o nseca, “P erfo rmance assessme nt of m ultiob jectiv e optimizers: An ana lysis a nd review,” IEEE T r ansactions on Evolutionary Computation , vol. 7, no. 2, pp. 117–132, 2 003. [30] M. Li, S. Y ang, and X. Liu, “D iversit y comparison of pa r eto front approximations in man y-ob jectiv e optimization,” IEEE T r ansactions o n Cyb ernetics , v ol. 44, no. 12, pp. 2568–258 4, 20 14. [31] M. Luk asiewycz, M. G laß, C. Haub elt, and J. T eich, “A feasibilit y-preserving lo cal searc h op erat o r for constrained discrete optimization pro blems,” in I EEE Congr ess on Evolutionary Computation (CEC) , 2 0 08, pp. 1968–197 5 . 30
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment