InSituNet: Deep Image Synthesis for Parameter Space Exploration of Ensemble Simulations
We propose InSituNet, a deep learning based surrogate model to support parameter space exploration for ensemble simulations that are visualized in situ. In situ visualization, generating visualizations at simulation time, is becoming prevalent in handling large-scale simulations because of the I/O and storage constraints. However, in situ visualization approaches limit the flexibility of post-hoc exploration because the raw simulation data are no longer available. Although multiple image-based approaches have been proposed to mitigate this limitation, those approaches lack the ability to explore the simulation parameters. Our approach allows flexible exploration of parameter space for large-scale ensemble simulations by taking advantage of the recent advances in deep learning. Specifically, we design InSituNet as a convolutional regression model to learn the mapping from the simulation and visualization parameters to the visualization results. With the trained model, users can generate new images for different simulation parameters under various visualization settings, which enables in-depth analysis of the underlying ensemble simulations. We demonstrate the effectiveness of InSituNet in combustion, cosmology, and ocean simulations through quantitative and qualitative evaluations.
💡 Research Summary
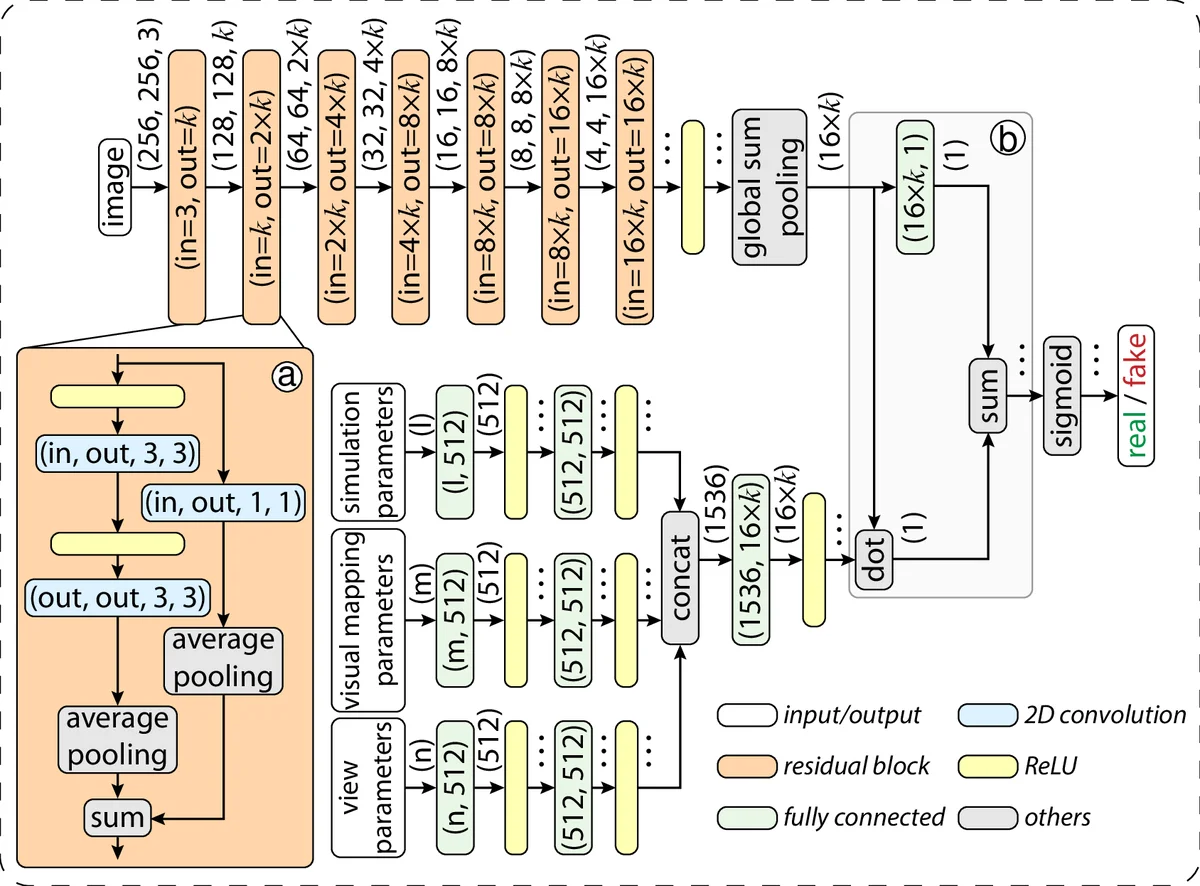
InSituNet addresses two critical challenges in large‑scale ensemble simulations: the I/O bottleneck caused by storing massive raw simulation data, and the limited flexibility of post‑hoc analysis when only in‑situ visualizations are retained. The authors propose a deep‑learning surrogate that learns a direct mapping from three groups of parameters—simulation parameters (P_sim), visual‑mapping parameters (P_vis), and view parameters (P_view)—to the corresponding RGB visualization image. By training this model offline on a database of images generated during in‑situ rendering, scientists can later synthesize new visualizations for arbitrary parameter combinations without rerunning expensive simulations.
The data collection pipeline integrates with existing in‑situ visualization workflows. For each ensemble member, the simulation is rendered in situ under multiple visual‑mapping settings (e.g., isosurface thresholds, color maps) and a set of camera viewpoints sampled uniformly over azimuth and elevation (≈100 viewpoints per member). Each image is stored together with its full parameter vector, forming a paired dataset (parameter → image). The authors deliberately use plain PNG images rather than more complex formats (volumetric depth images, explorable images) because they are universally supported by convolutional networks and simplify preprocessing.
InSituNet’s architecture consists of three subnetworks: a regression network R that predicts images, a pretrained feature comparator F (a VGG‑style network) that computes a perceptual (feature reconstruction) loss, and a discriminator D that supplies an adversarial loss. The total training objective combines L1 pixel loss, perceptual loss, and a Wasserstein GAN loss, encouraging both low‑frequency accuracy and high‑frequency texture fidelity. The regression network follows an encoder‑decoder design with residual blocks; the parameter vector is first processed by fully‑connected layers to a latent code, which is then up‑sampled through deconvolutional layers to the target resolution (256×256 or 512×512). Data augmentation (random rotations, color jitter) and batch normalization are employed to improve generalization.
Extensive hyper‑parameter studies reveal that the best performance is achieved with the L1 + perceptual + WGAN combination, yielding average PSNR improvements of 3–5 dB and SSIM gains of 0.02–0.04 over baseline methods such as simple image interpolation used in the Cinema framework. Quantitative metrics (PSNR, SSIM, LPIPS) and qualitative visual comparisons are presented for three scientific domains: (1) combustion, where flame shape and color are faithfully reproduced; (2) cosmology, where density fields and filamentary structures match ground truth; and (3) oceanography, where flow patterns and temperature isocontours are indistinguishable from the original simulations.
Beyond image synthesis, the trained model enables sensitivity analysis. By back‑propagating gradients from the output image to each input parameter, the system visualizes how changes in a specific simulation or visual‑mapping parameter affect pixel intensities. This gradient‑based “what‑if” analysis provides scientists with an intuitive tool to assess parameter impact without additional simulation runs, a capability not offered by traditional parameter‑space visualization techniques that rely on pre‑computed ensembles.
An interactive web‑based interface is built on top of the trained InSituNet. Users manipulate sliders for P_sim, dropdowns for P_vis, and 3‑D view controls for P_view, receiving immediate image feedback. This real‑time exploration supports rapid hypothesis testing, parameter tuning, and educational demonstrations.
The paper’s contributions are threefold: (1) a novel deep image synthesis surrogate that bridges simulation parameters to visual output, (2) an interactive visual analytics system for post‑hoc exploration of ensemble simulations, and (3) a comprehensive evaluation of loss functions, network architectures, and hyper‑parameters, providing practical guidance for applying the method to other domains.
Limitations include the focus on 2‑D RGB images; extending to full 3‑D volumetric outputs, preserving temporal continuity in time‑dependent simulations, and handling multimodal data (e.g., simultaneous pressure and temperature fields) are identified as future work. The authors also suggest scaling training to distributed GPU clusters to accommodate even larger parameter spaces.
In summary, InSituNet demonstrates that deep learning can effectively replace costly simulation runs for visual exploration, dramatically reducing I/O demands while empowering scientists to freely navigate the high‑dimensional parameter space of large‑scale ensemble simulations.
Comments & Academic Discussion
Loading comments...
Leave a Comment