Additive Margin SincNet for Speaker Recognition
Speaker Recognition is a challenging task with essential applications such as authentication, automation, and security. The SincNet is a new deep learning based model which has produced promising results to tackle the mentioned task. To train deep le…
Authors: Jo~ao Ant^onio Chagas Nunes, David Mac^edo, Cleber Zanchettin
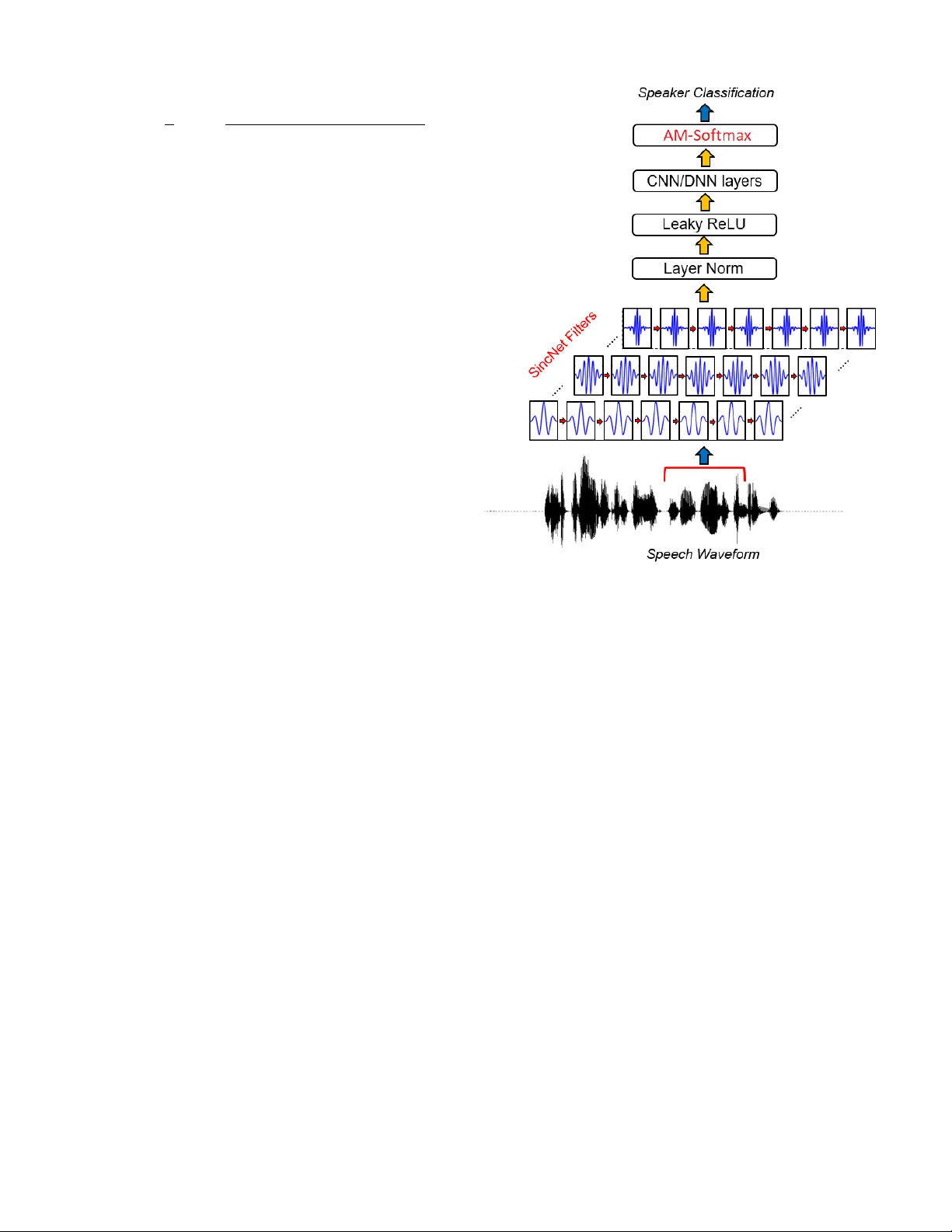
Additi v e Mar gin SincNet for Speaker Recognition Jo ˜ ao Ant ˆ onio Chagas Nunes Centr o de Inform ´ atica Universidade F ederal de P ernambuco 50.740-560, Recife, PE, Brazil jacn2@cin.ufpe.br David Mac ˆ edo Centr o de Inform ´ atica Universidade F ederal de P ernambuco 50.740-560, Recife, PE, Brazil dlm@cin.ufpe.br Cleber Zanchettin Centr o de Inform ´ atica Universidade F ederal de P ernambuco 50.740-560, Recife, PE, Brazil cz@cin.ufpe.br Abstract —Speaker Recognition is a challenging task with essential applications such as authentication, automation, and security . The SincNet is a new deep learning based model which has pr oduced pr omising r esults to tackle the mentioned task. T o train deep learning systems, the loss function is essential to the network performance. The Softmax loss function is a widely used function in deep learning methods, but it is not the best choice for all kind of problems. For distance-based problems, one new Softmax based loss function called Additive Margin Softmax (AM-Softmax) is proving to be a better choice than the traditional Softmax. The AM-Softmax introduces a margin of separation between the classes that f orces the samples from the same class to be closer to each other and also maximizes the distance between classes. In this paper , we propose a new approach for speaker recognition systems called AM-SincNet, which is based on the SincNet but uses an impr oved AM-Softmax layer . The proposed method is evaluated in the TIMIT dataset and obtained an improv ement of approximately 40% in the Frame Error Rate compared to SincNet. I . I N T R O D U C T I O N Speaker Recognition is an essential task with applications in biometric authentication, identification, and security among others [1]. The field is di vided into two main subtasks: Speak er Identification and Speaker V erification. In Speaker Identifica- tion, giv en an audio sample, the model tries to identify to which one in a list of predetermined speakers the locution belongs. In the Speaker V erification, the model verifies if a sampled audio belongs to a giv en speaker or not. Most of the literature techniques to tackle this problem are based on i -vectors methods [2], which extract features from the audio samples and classify the features using methods such as PLDA [3], heavy-tailed PLDA [4], and Gaussian PLD A [5]. Despite the advances in recent years [6], [7], [8], [9], [10], [11], [12], Speaker Recognition is still a challenging problem. In the past years, Deep Neural Netw orks (DNN) has been taking place on pattern recognition tasks and signal processing. Con volutional Neural Networks (CNN) hav e already show that they are the actual best choice to image classification, detection or recognition tasks. In the same way , DNN models are being used combined with the traditional approaches or in end-to- end approaches for Speaker Recognition tasks [13], [14], [15]. In hybrid approaches, it is common to use the DNN model to extract features from a raw audio sample and then encode it on embedding vectors with low-dimensionality which samples sharing common features with closer samples. Usually , the embedding vectors are classified using traditional approaches. The dif ficult behind the Speaker Recognition tasks is that audio signals are complex to model in low and high-le vel features that are discriminant enough to distinguish different speakers. Methods that use handcrafted features can extract more human-readable features and have a more appealing ap- proach because humans can see what the method is doing and which features are used to make the inference. Nev ertheless, handcrafted features lack in power . In fact, while we know what patterns they are looking for , we have no guarantee that these patterns are the best for the job . On the other hand, approaches based on Deep Learning have the po wer to learn patterns that humans may not be able to understand, but usually get better results than traditional methods, despite having more computational cost to training. A promising approach to Speak er Recognition based on Deep Learning is the SincNet model [17] that unifies the po wer of Deep Learning with the interpretability of the handcrafted features. SincNet uses a Deep Learning model to process raw audio samples and learn powerful features. Therefore, it replaces the first layer of the DNN model, which is responsible for the con volution with parametrized sinc functions. The parametrized sinc functions implement band-pass filters and are used to con volv e the w av eform audio signal to extract basic low-le vel features to be later processed by the deeper layers of the network. The use of the sinc functions helps the network to learn more relev ant features and also impro ves the con vergence time of the model as the sinc functions have significantly fewer parameters than the first layer of traditional DNN. At the top of the model, the SincNet uses a Softmax layer which is responsible for mapping the final features processed by the network into a multi-dimensional space corresponding to the different classes or speakers. The Softmax function is usually used as the last layer of DNN models. The function is used to delimit a linear surface that can be used as a decision boundary to separate samples from different classes. Although the Softmax function works well on optimizing a decision boundary that can be used to separate the classes, it is not appropriate to minimize the distance from samples of the same class. These character - istics may spoil the model ef ficiency on tasks like Speaker V erification that require to measure the distance between Fig. 1. Comparison between Softmax and AM-Softmax [16]. the samples to make a decision. T o deal with this problem, new approaches such as Additive Margin Softmax [16] (AM- Softmax) are being proposed. The AM-Softmax introduces an additiv e mar gin to the decision boundary which forces the samples to be closer to each other , maximizing the distance between the classes and at the same time minimizing the distance from samples of the same class. In this paper , we propose a new method for Speaker V er - ification called Additi ve Margin SincNet (AM-SincNet) that is highly inspirited on the SincNet architecture and the AM- Softmax loss function. In order to validate our hypothesis, the proposed method is ev aluated on the TIMIT [18] dataset based in the Frame Error Rate. The following sections are organized as: In Section II, we present the related works, the proposed method is introduced at Section III, Section IV explains how we built our experiments, the results are discussed at Section V, and finally at Section VI we made our conclusions. I I . R E L AT E D W O R K For some time, i -vectors [2] have been used as the state-of- the-art feature extraction method for speaker recognition tasks. Usually , the extracted features are classified using PLD A [3] or other similar techniques, such as heavy-tailed PLDA [4] and Gauss-PLD A [5]. The intuition behind these traditional methods and how they work can be better seem in [19]. Although they have been giving us some reasonable results, it is clear that there is still room for improv ements [19]. Recently , neural networks and deep learning techniques hav e shown to be a particularly attractiv e choice when dealing with feature extraction and patterns recognition in the most variety of data [20], [21]. For instance, CNNs are proving to produce a high performance on image classification tasks. Moreov er , deep learning architectures [22], [23] and hybrid systems [24], [25], [26], [27], [28] are higher quality results on processing audio signals than traditional approaches. As an example, [29] built a speaker verification framew ork based on the Inception-Resnet-v1 deep neural network architecture using the triplet loss function. SincNet [17] is one of these innov ativ e deep learning architecture for speaker recognition which uses parametrized sinc functions as a foundation to its first con volutional layer . Sinc functions are designed to process digital signals just like audio, and thus the use of them as the first conv olutional layer helps to capture more meaningful features to the network. Additionally , the extracted features are also more human- readable than the ones obtained from ordinary con volutions. Besides, the sinc functions reduce the number of parameters on the SincNet first layer because each sinc function of any size only hav e two parameters to learn against L from the con ventional conv olutional filter , where L is the size of the filter . As a result, the sinc functions enables the network to con verge faster . Another advantage of the sinc functions is the fact that they are symmetric, which means that we can reduce the computational effort to process it on 50% by simply calculating half of the filters and flipping it to the other side. The first layer of SincNet is made by 80 filters of size 251, and then it has two more con ventional conv olutional layers of size five with 60 filters each. Normalization is also applied to the input samples and the conv olutional layers, the traditional and the sinc one. After that, the result propagates to three more fully connected layers of size 2048, and it is normalized again. The hidden layers use the Leaky ReLU [30] as the activ ation function. The sinc conv olutional layer is initialized using mel- scale cutoff frequencies. On the other hand, the traditional con volutional layers together with the fully connected layers are initialized using Gl orot scheme. Finally , a Softmax layer provides the set of posterior probabilities for the classification. I I I . A D D I T I V E M A R G I N S I N C N E T The AM-SincNet is built by replacing the softmax layer of the SincNet with the Additive Margin Softmax [16]. The Additiv e Margin Softmax (AM-Softmax) is a loss function de- riv ed from the original Softmax which introduces an additiv e margin to its decision boundary . The additiv e margin works as a better class separator than the traditional decision boundary from Softmax. Furthermore, it also forces the samples from the same class to become closer to each other thus improving results for tasks such as classification and verification. The AM-Softmax equation is written as: Loss = − 1 n n X i =1 log φ i φ i + P c j =1 ,j 6 = y i exp ( s ( W T j f i )) (1) φ i = exp ( s ( W T y i f i − m )) (2) In the above equation, W is the weight matrix, and f i is the input from the i -th sample for the last fully connected layer . The W T y i f i is also known as the target logit for the i -th sample. The s and m are the parameters responsible for scaling and additiv e margin, respectiv ely . Although the network can learn s during the optimization process, this can mak e the con ver gence to be very slow . Thus, a smart choice is to follow [16] and set s to be a fixed value. On the other hand, the m parameter is fundamental and has to be chosen carefully . On our context, we assume that both W and f are normalized to one. Figure 1 shows a comparison between the traditional Softmax and the AM-Softmax. The SincNet approach has shown high-grade results on the speaker recognition task. Indeed, its architecture has been compared against ordinary CNNs and several other well- known methods for speaker recognition and verification such as MFCC and FB ANK, and, in every scenario, the SincNet has ov ercome alternati ve approaches. The SincNet most significant contribution was the usage of sinc functions as its first con- volutional layer . Nevertheless, to calculate the posterior prob- abilities ov er the target speaker , SincNet applies the Softmax loss function which, despite being a reasonable choice, is not particularly capable of producing a sharp distinction among the class in the final layer . Thus, we have decided to replace the last layer of SincNet from Softmax to AM-Softmax. Figure 2 is a minor modification of the original SincNet image that can be found in [17] which shows the archtecture of the proposed AM-SincNet. I V . E X P E R I M E N T S The proposed method AM-SincNet has been e valuated on the well known TIMIT dataset [18], which contains audio samples from 630 different speakers of the eight main Ameri- can dialects and where each speaker reads a few phonetically rich sentences. W e used the same pre-processing procedures as [17]. For example, the non-speech interval from the beginning and the end of the sentences were remov ed. Follo wing the same protocol of [17], we have used five utterances of each speaker for training the network and the remaining three for ev aluation. Moreov er, we also split the wav eform of each audio sample into 200ms chunks with 10ms ov erlap, and then these chunks were used to feed the network. For training, we configured the network to use the RMSprop as optimizer with mini-batches of size 128 along with a learning rate of lr = 0 . 001 , α = 0 . 95 , and = 10 − 7 . The AM- Softmax comes with two more parameters than the traditional Softmax, and the new parameters are the scaling factor s and the margin size m . As mentioned before, we set the scaling factor s to a fixed value of 30 in order to speed up the network training. On the other hand, for the margin parameter m we Fig. 2. Illustration of the proposed AM-SincNet architecture. Adapted from the original SincNet [17] carefully did several experiments to ev aluate the influence of it on the Frame Error Rate (FER). W e also hav e added an epsilon constant of value 10 − 11 to the AM-Softmax equation in order to avoid a di vision by zero on the required places. For each one of the experiments, we trained the models for exactly 352 epochs as it appeared enough to exploit adequately the different training speed presented by both competing models. T o run the experiments, we used an NVIDIA T itan XP GPU, and the training process lasts for about four days. The experiments performed by this paper may be reproduced by using the code that we made av ailable online at the GitHub 1 . V . R E S U LTS Sev eral experiments were made to ev aluate the proposed method against the traditional SincNet approach. In ev ery one of them, the proposed AM-SincNet has shown higher accurate results. The proposed AM-SincNet method requires two more parameters, the scaling parameter s and the margin parameter m . W e hav e decided to use s = 30 , and we have done experiments to ev aluate the influence of the margin parameter m on the Frame Error Rate. The T able I shows the Frame Error Rate (FER) in per - centage for the original SincNet and our proposed method 1 https://github .com/joaoantoniocn/AM-SincNet T ABLE I S I NC N E T A N D A M - S IN C N E T F R A ME E R RO R R ATE S ( % ) F O R T IM I T DAT A S E T . Epoch SincNet AM-SincNet m=0.35 m=0.40 m=0.45 m=0.50 m=0.55 m=0.60 m=0.65 m=0.70 m=0.75 m=0.80 0 97.25 98.77 98.76 98.71 99.06 98.08 99.13 98.14 97.65 98.21 98.78 16 55.32 56.70 57.93 57.29 58.37 54.09 56.44 54.69 57.23 60.98 55.65 32 50.29 44.20 46.37 44.57 43.46 44.23 45.56 49.98 44.84 44.32 48.68 48 46.67 41.99 39.88 45.43 40.54 40.49 39.17 41.25 38.87 37.95 42.45 64 45.40 41.51 38.05 42.05 38.02 38.13 37.45 36.83 38.86 37.36 37.34 80 43.49 36.30 36.37 36.57 34.89 36.34 36.99 34.47 34.11 34.72 34.51 96 44.83 34.37 34.11 33.50 33.68 36.82 33.41 33.07 33.13 34.00 34.14 ... ... ... ... ... ... ... ... ... ... ... ... 320 46.39 28.76 28.21 27.82 27.37 28.82 27.40 27.54 27.90 29.39 28.32 336 47.93 27.92 28.73 29.00 27.42 27.50 27.18 27.54 30.00 27.60 28.68 352 44.64 29.22 27.57 27.07 27.86 27.81 28.28 27.92 29.76 26.95 30.85 ov er 352 epochs on the test data. T o verify the influence of the margin parameter on the proposed method, we performed sev eral experiments using different values of m in the range 0 . 35 ≤ m ≤ 0 . 80 . The table sho ws the results from the first 96 and the last 32 epochs in steps of 16. The best result from each epoch is highlighted in bold. It is possible to see that traditional SincNet only gets better results than the proposed AM-SincNet on the first epochs when none of them ha ve gi ven proper training time yet. After that, on epoch 48, the original SincNet starts to con ver ge with an FER around 46% , while the proposed method keeps decreasing its error throughout training. In the epoch 96, the proposed method has already an FER more than 26% better than the original SincNet for almost ev ery value of m excluding m = 0 . 55 . The difference keeps increasing over the epochs, and at epoch 352 the proposed method has an FER of 26 . 95% ( m = 0 . 75 ) against 44 . 64% from SincNet, which means that at this epoch AM-SincNet has a Frame Error Rate approximately 40% better than traditional SincNet. The Figure 3 plots the Frame Error Rate on the test data for both methods along the training epochs. For the AM- SincNet, we used the margin parameter m = 0 . 50 . From T able I, we can also see the impact of the margin parameter m on our proposed method. It is possible to see that the FER calculated for m = 0 . 50 got the lowest (best) value at the epochs 32 and 320. In the same way , m = 0 . 55 and m = 0 . 60 got the lo west values at epochs 16 and 336, respectiv ely . The value m = 0 . 65 scores the lowest result for epochs 64 and 96, while m = 0 . 70 got the lowest score at epoch 80, and m = 0 . 75 reached the lowest value of epochs 48 and 352. The m = 0 . 35 , m = 0 . 40 , m = 0 . 45 , and m = 0 . 80 does not reach the lo west values of any epoch in this table. Although the results in T able I may indicate that there is a golden value of m which brings the best Frame Error Rate for the experiments, in fact, the difference of the FER calculated among the epochs 0 50 100 150 200 250 300 350 0 20 40 60 80 Epochs FER ( % ) SincNet AM-SincNet (m=0.50) Fig. 3. Comparison of Frame Error Rate ( % ) from SincNet and AM-SincNet (m=0.50) over the training epochs for TIMIT dataset. may not be so significant. Indeed, at the end of training, all of the experiments with the AM-SincNet seem to approximate the FER to a value around 27% . In any case, AM-SincNet ov ercomes the baseline approach. V I . C O N C L U S I O N This paper has proposed a new approach for directly processing wa veform audio that is highly inspirited in the neural network architecture SincNet and the Additive Margin Softmax loss function. The proposed method, AM-SincNet, has shown a Frame Error Rate about 40% smaller than the traditional SincNet. It shows that the loss function we use on a model can have a significant impact on the expected result. From Figure 3, it is possible to notice that the FER ( % ) from the proposed method may not hav e conv erged yet on the last epochs. Thus, if the training had last more, we may hav e noticed an ev en more significant difference between both methods. The proposed method comes with two more parameters for setting when compared with the traditional SincNet, although the experiments made here show that these extra parameters can be fixed values without compromising the performance of the model. For future work, we would like to test our method using different datasets such as V oxCeleb2 [22], which has ov er a million samples from over 6k speak ers. If we increase the amount of data, the model may show a more significant result. W e also intend to use more metrics such as the Classification Error Rate ( % ) (CER) and the Equal Error Rate ( % ) (EER) to compare the models. A C K N O W L E D G M E N T This work was supported in part by CNPq and CETENE (Brazilian research agencies). W e gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan XP GPU used for this research. R E F E R E N C E S [1] H. Beigi, Fundamentals of Speaker Recognition . Springer Publishing Company , Incorporated, 2011. [2] N. Dehak, P . J. Kenny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front end factor analysis for speaker verification, ” IEEE T ransactions on Audio, Speech and Language Pr ocessing , 2010. [3] S. Prince and J. H. Elder , “Probabilistic linear discriminant analysis for inferences about identity , ” 2007 IEEE 11th International Confer ence on Computer V ision , pp. 1–8, 2007. [4] P . Matejka, O. Glembek, F . Castaldo, M. J. Alam, O. Plchot, P . Kenn y , L. Burget, and J. Cernock, “Full-covariance ubm and heavy-tailed plda in i-vector speaker verification, ” 05 2011, pp. 4828–4831. [5] S. Cumani, O. Plchot, and P . Laface, “Probabilistic linear discriminant analysis of i-vector posterior distributions. ” in ICASSP . IEEE, 2013, pp. 7644–7648. [Online]. A vailable: http://dblp.uni- trier .de/db/conf/ icassp/icassp2013.html#CumaniPL13 [6] W . Campbell, D. Sturim, D. Reynolds, and A. Solomonof f, “Svm based speaker verification using a gmm supervector kernel and nap variability compensation, ” vol. 1, 06 2006, pp. I – I. [7] P . Kenny , G. Boulianne, P . Ouellet, and P . Dumouchel, “Joint factor analysis versus eigenchannels in speaker recognition, ” Audio, Speech, and Language Processing, IEEE T ransactions on , vol. 15, pp. 1435 – 1447, 06 2007. [8] S. Cumani, O. Plchot, and P . Laface, “Probabilistic linear discriminant analysis of i-vector posterior distributions, ” in 2013 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , May 2013, pp. 7644–7648. [9] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer , “End-to-end text- dependent speaker verification, ” 2016 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , Mar 2016. [Online]. A vailable: http://dx.doi.org/10.1109/ICASSP .2016.7472652 [10] D. Snyder , P . Ghahremani, D. Pove y , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur, “Deep neural network-based speaker embeddings for end-to-end speaker verification, ” in 2016 IEEE Spoken Language T ec hnology W orkshop (SLT) , Dec 2016, pp. 165–170. [11] M. McLaren, Y . Lei, and L. Ferrer, “ Advances in deep neural network approaches to speaker recognition, ” in 2015 IEEE International Confer- ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , April 2015, pp. 4814–4818. [12] F . Richardson, D. Reynolds, and N. Dehak, “Deep neural network ap- proaches to speaker and language recognition, ” IEEE Signal Processing Letters , vol. 22, pp. 1–1, 10 2015. [13] D. Snyder , P . Ghahremani, D. Pove y , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur, “Deep neural network-based speaker embeddings for end-to-end speaker verification, ” 12 2016, pp. 165–170. [14] G. Trigeor gis, F . Ringev al, R. Brueckner, E. Marchi, M. A. Nicolaou, B. Schuller, and S. Zafeiriou, “ Adieu features? end-to-end speech emotion recognition using a deep conv olutional recurrent network, ” in 2016 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , March 2016, pp. 5200–5204. [15] J.-W . Jung, H.-S. Heo, I.-H. Y ang, H.-j. Shim, and H.-J. Y u, “ A complete end-to-end speaker verification system using deep neural networks: From raw signals to verification result, ” 04 2018. [16] F . W ang, J. Cheng, W . Liu, and H. Liu, “ Additiv e margin softmax for face verification, ” IEEE Signal Processing Letters , vol. 25, no. 7, pp. 926–930, July 2018. [17] M. Rav anelli and Y . Bengio, “Speaker recognition from raw waveform with sincnet, ” 08 2018. [18] J. S. Garofolo, L. F . Lamel, W . M. Fisher, J. G. Fiscus, D. S. Pallett, and N. L. Dahlgren, “Darpa timit acoustic phonetic continuous speech corpus cdrom, ” 1993. [19] J. H. L. Hansen and T . Hasan, “Speaker recognition by machines and humans: A tutorial revie w , ” IEEE Signal Pr ocessing Magazine , vol. 32, no. 6, pp. 74–99, Nov 2015. [20] I. Goodfellow , Y . Bengio, and A. Courville, Deep Learning . MIT Press, 2016, http://www .deeplearningbook.org. [21] M. Rav anelli, P . Brakel, M. Omologo, and Y . Bengio, “ A network of deep neural networks for distant speech recognition, ” CoRR , vol. abs/1703.08002, 2017. [22] J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition, ” Interspeech 2018 , Sep 2018. [Online]. A vailable: http://dx.doi.org/10.21437/Interspeech.2018- 1929 [23] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kannan, and Z. Zhu, “Deep speaker: an end-to-end neural speaker embedding system, ” 2017. [24] E. V ariani, X. Lei, E. Mcdermott, I. L. Moreno, and J. Gonzalez- dominguez, “Deep neural networks for small footprint text-dependent speaker verification. ” [25] Y . Lei, N. Scheffer , L. Ferrer, and M. McLaren, “ A novel scheme for speaker recognition using a phonetically-aware deep neural network, ” 05 2014, pp. 1695–1699. [26] S. Hamidi Ghalehjegh and R. Rose, “Deep bottleneck features for i- vector based text-independent speaker verification, ” 12 2015, pp. 555– 560. [27] D. Snyder , D. Garcia-Romero, D. Povey , and S. Khudanpur , “Deep neural network embeddings for text-independent speaker verification. ” in INTERSPEECH , F . Lacerda, Ed. ISCA, 2017, pp. 999– 1003. [Online]. A vailable: http://dblp.uni- trier .de/db/conf/interspeech/ interspeech2017.html#SnyderGPK17 [28] D. Snyder , D. Garcia-Romero, G. Sell, D. Povey , and S. Khudanpur, “X- vectors: Robust dnn embeddings for speaker recognition, ” 2018 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 5329–5333, 2018. [29] C. Zhang, K. Koishida, and J. H. L. Hansen, “T ext-independent speaker verification based on triplet conv olutional neural network embeddings, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 26, no. 9, pp. 1633–1644, Sep. 2018. [30] A. L. Maas, A. Y . Hannun, and A. Y . Ng, “Rectifier nonlinearities improve neural network acoustic models, ” in in ICML W orkshop on Deep Learning for Audio, Speech and Language Pr ocessing , 2013.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment