A Test for Shared Patterns in Cross-modal Brain Activation Analysis
Determining the extent to which different cognitive modalities (understood here as the set of cognitive processes underlying the elaboration of a stimulus by the brain) rely on overlapping neural representations is a fundamental issue in cognitive ne…
Authors: Elena Kalinina, Fabian Pedregosa, Vittorio Iacovella
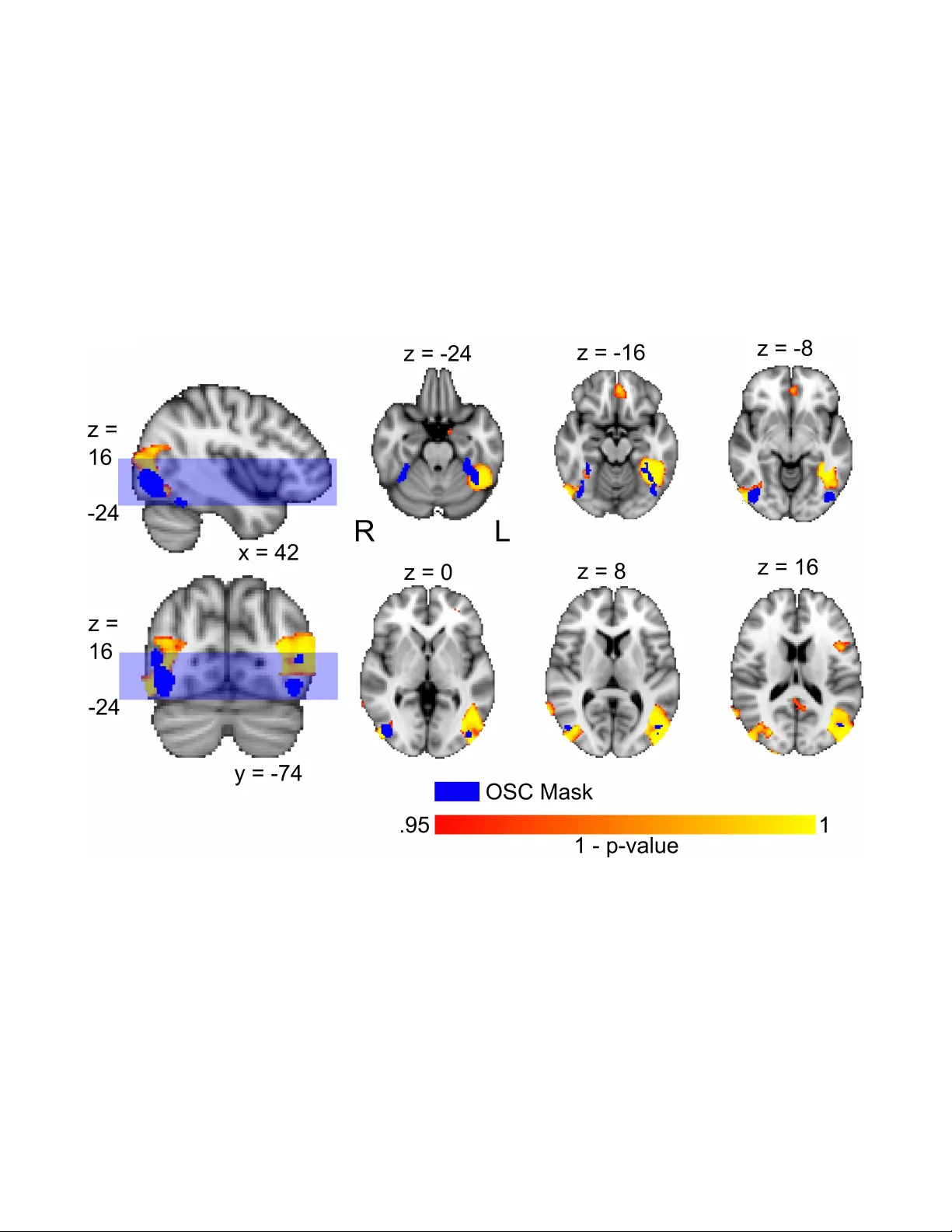
A T est f or Shared P atterns in Cr oss-modal Brain Activ ation Anal ysis Elena Kalinina 1,2,*, † , ‡ , Fabian P edregosa 3, † , ** , Vittorio Iacovella 2 , Emanuele Olivetti 1,2 , and P aolo A vesani 1,2 1 NeuroInf or matics Laboratory (NILab), Br uno K essler F oundation, T rento , Italy 2 Centro Interdipar timentale Mente e Cer vello (CIMeC), Univ ersity of T rento , Italy 3 Depar tment of Electrical Engineer ing, UC Berkeley , Calif or nia * e kalinina@outlook.it † These authors contributed equally to the paper . ‡ W ork done while PhD student at NeuroInformatics Laborator y (NILab) and Centro Interdipar timentale Mente e Cer v ello (CIMeC). ** W ork done while post-doctoral researcher at the Depar tment of Electr ical Engineering, UC Ber kele y . ABSTRA CT Determining the extent to which diff erent cognitiv e modalities (understood here as the set of cognitiv e processes underlying the elabor ation of a stimulus b y the brain) rely on ov erlapping neural representations is a fundamental issue in cognitiv e neuroscience. In the last decade, the identification of shared activity patter ns has been mostly framed as a super vised learning problem. F or instance, a classifier is trained to discriminate categories (e.g. faces vs . houses) in modality I (e.g. perception) and tested on the same categor ies in modality II (e.g. imager y). This type of analysis is often ref erred to as cross-modal decoding. In this paper we take a diff erent approach and instead f or mulate the prob lem of assessing shared patterns across modalities within the frame work of statistical hypothesis testing. We propose both an appropriate test statistic and a scheme based on per mutation testing to compute the significance of this test while making only minimal distr ibutional assumption. W e denote this test cross-modal per mutation test (C M P T ). We also provide empirical e vidence on synthetic datasets that our approach has greater statistical power than the cross-modal decoding method while maintaining low T ype I errors (rejecting a true null h ypothesis). W e compare both approaches on an fMRI data set with three different cognitive modalities (perception, imager y , visual search). Finally , we show ho w C M P T can be combined with Searchlight analysis to e xplore spatial distribution of shared activity patterns. Introduction Functional MRI recordings enable the inv estigation of activ ation patterns that characterize the working brain. The main goal is to detect whether the neural pattern of a re gion of interest correlates with a cogniti ve task, like, for e xample, object category identification. Such in vestigations are usually focused on a specific cogniti ve modality , i.e.: visual per ception , r eal auditory , visual imagery , auditory ima gery , etc. A qualitativ e discrimination task can be designed to extract rele vant information from patterns activ ated by two (or more) stimuli cate gories (like body and car ) in one of these cognitive modalities. Identification of activ ation patterns that are shared across modalities has been the subject of numerous neurocognitiv e studies, with such modalities as mental calculations 1 , sensory/motor stimulation 2 or words and picture-vie wing 3 , to name a few . The most common approach here is to cast the problem of identifying common activ ation patterns as a supervised learning, or brain decoding, problem 4 , 5 . Nastase and colleagues 9 point out that successful classification in this setting allo ws to conclude that neural patterns elicited by relev ant cognitiv e factors in one modality generalize accross to the patterns in the other modality . In other words, a lo w misclassification error on a modality which is different from the one used to train the classifier provides empirical e vidence that a giv en region of interest is in volv ed in the cognitiv e task encoded in both modalities. In the literature, such approach is referred to as cross-modal decoding analysis (C M DA ). Statistical significance of its result can be assessed using a t -test on the accurac y obtained by the classifier 1 , 6 , or by a permutation test based on computing the null distribution 2 , 7 , 8 of such statistic. Howe ver , C M D A suf fers from a number of practical issues. As we are going to discuss in section Methods, the accuracy of a decoding model is often lo w in a cross-modal setting, which most probably implies an exaggerated amount of T ype II errors (failure to reject the null hypothesis). Neuroscientific in vestigations into the acti vity patterns in the fMRI data studies can be formulated as “confirmatory” or “exploratory” analysis. Confirmatory analysis is centered on a pre-established re gion of interest (R OI). The C M D A method presented abov e is often used for the confirmatory approach, when it is run on the data coming from a predefined R OI (or a set of predefined R OIs). Exploratory analysis aims at localization of areas containing information about the presented stimuli. Here, C M D A is employed in conjunction with Searchlight technique to explore the spatial structure of cross-modal activ ations 9 . The outcome of the Searchlight procedure are maps, where each v oxel is assigned some quantitati ve measure of information that the voxel contains about the stimulus. The procedure of obtaining the maps consists in applying decoding sphere by sphere on time series extracted from the sphere voxels, and most commonly used information measure to produce Searchlight maps is classification accuracy . Maps are first calculated indi vidually for each subject and then pooled together to run group analysis, where the significance of the obtained v alues is typically established running t -tests vox elwise with respect to chance level. Classification accuracy and t -tests hav e been subject to numerous criticisms with regard to their role in Searchlight analysis 23 . Besides, use of Searchlight for cross-modal analysis faces interpretation challenges introduced by the asymmetries both in accuracies and p -v alues when training and testing on data coming from two dif ferent cognitiv e modalities 9 . In this work we dev elop a permutation test for the in vestigation of shared patterns across modalities that we denote cr oss-modal permutation test ( C M P T ). This test builds on a long tradition of randomization inference in the statistics literature, which can be traced back to the first half of the 20th century 10 – 12 . Permutation tests hav e recently seen renewed interest in neuroimaging 13 – 16 thanks to their minimal distrib utional assumptions and the a vailability of cheap computational resources. W e provide empirical e vidence on synthetic datasets that this method reduces T ype II errors (f ailure to reject a f alse null hypothesis) while maintaining T ype I errors comparable (incorrect rejection of the null hypothesis) with respect to C M DA . Our results highlight particular adv antages of C M P T in the small sample/high dimensional regime, a setting of practical importance in neuroimaging studies. Next, we compare C M P T and C M DA on an fMRI study of three cogniti ve modalities: visual attention, imagery and perception. W e conduct confirmatory analysis comparing the performance of C M P T and C M D A when identifying the presence of shared patterns within a functionally defined Region of Interest (R OI). Finally , we present the results of an exploratory analysis with Searchlight making use of the proposed C M P T test for the information based mapping to explore the presence of common patterns between dif ferent modalities at the whole brain le vel. The use of C M P T allo ws to o vercome major methodological drawbacks that had been pointed out for Searchlight in the literature 23 . Methods Cross-modal permutation test ( C M P T ) In this section we describe a statistical test for cross-modal activ ation pattern analysis that we denote C M P T . W e formulate the problem of assessing cross-modal acti vation as a hypothesis testing problem and propose an inference procedure for this test based on a permutation schema. Setting. W e assume that the experimental task consists of two modalities (e.g., auditory and visual perception) and each image in the dataset containing an activ ation pattern has an associated condition A or B (e.g., two stimuli categories like human body and car). In total, we observe n activ ation patterns for each modality , corresponding to the number of conditions in the experiment, where each acti v ation image is a mean image (av eraged by the number of trials in the experiment) representati ve of one condition, and the goal is to decide whether there is a common condition effect across the different modalities. Let us formalize this in the language of statistical hypothesis testing. Consider the set of pairs Z ( X , Y ) = { ( X 1 , Y 1 ) , . . . , ( X n , Y n ) } sampled iid from some unknown probability distrib ution P , where X = { X 1 , . . . , X n } (resp. Y = { Y 1 , . . . , Y n } ) are the activ ation patterns corresponding to the first (resp. second) modality , and where the experi mental paradigm is designed such that the X i and Y i are associated with the same condition (but dif ferent modality). Since the image pairs belong to the same condition, as long as there is a condition effect shared across modality , the sequences X and Y cannot be independent. W e hence formulate the null hypothesis (which we want to reject) that both sequences are independent and so their joint probability distrib ution P factorizes ov er their marginal: H 0 : P = P X × P Y , with P X , P Y the marginal distrib ution of P . (1) T est statistic. Giv en the set of image pairs X = { X 1 , . . . , X n } and Y = { Y 1 , . . . , Y n } described in the pre vious paragraph, let A (resp. B ) be the set of indices for the A (resp. B ) category . W e define X A = 1 | A | ∑ a ∈ A X a (resp. X B = 1 | B | ∑ b ∈ B X b ) as the average of activ ation patterns in X with index in A (resp. B ). Y A (resp. Y B ) are defined in similar way as the av erage of acti vation patterns in Y with index in A (resp. B ). Note that the index set is computed from images of X (and not Y ) on both cases. This asymmetry will be useful when designing the permutation scheme. Consider also that we have access to a similarity measure between images that we denote by ρ . For simplicity we will initially suppose that this measure is the Pearson correlation coefficient, although we will see later that this can be generalized to an y similarity measure between images. W e now ha ve all necessary ingredients to present the test statistic that we propose to distinguish the null hypothesis from 2/ 17 the alternativ e. This test statistic has values in [ − 1 , 1 ] and is defined as T ( X , Y ) = 1 4 ρ ( X A , Y A ) + ρ ( X B , Y B ) | {z } within-condition similarity − ( ρ ( X A , Y B ) + ρ ( X B , Y A )) | {z } between-condition similarity . (2) At first, its form might seem strange. Let us give tw o intuitions on the form of this test statistic: 1. As a differ ence of similarities . The test statistic can be split as a difference of two terms. The first term is the sum of similarities for images from the same condition (and different modalities), while the second term is a sum of similarities for images of dif ferent conditions (and dif ferent modalities). Hence, large v alues of the test statistic are achiev ed whenev er the within-condition similarity is larger than the between-condition similarity , bringing evidence for the e xistence of a condition-specific activ ation across modalities. 2. As a singularity test . If we compute all pairwise similarities between the images X A , X B , Y A and Y B , we obtain 4 scalars that can be arranged in a 2-by-2 matrix as follows: ρ ( X A , Y A ) ρ ( X A , Y B ) ρ ( X B , Y A ) ρ ( X B , Y B ) . (3) Under the null hypothesis, the samples X and Y are independent and so Y A ≈ Y B (recall that the indexing was deri ved from images in X ). Whenev er Y A = Y B the matrix abo ve becomes colinear . A standard way to test for colinearity is through its determinant. Computing the determinant of the above equation we obtain our test statistic (modulo the normalizing factor 1 4 ). Statistical inference . W e will estimate the distribution of this test statistic under the null hypothesis from the sample by repeatedly computing the test statistic over a permuted version of the initial sample, a technique often known as permutation or randomization test . For this to be v alid, it is necessary to identify the quantities that we wish to permute and verify that under the null hypothesis, all permutations yield the same sample distribution 17 . Consider the sequence X π which results from a random reordering of the activ ation images in X and the sequence of pairs Z ( X π , Y ) . Under the null hypothesis, since the probability distrib ution factorizes o ver its mar ginal, the permuted sequence is distributed as P 0 X × P Y , where P 0 X is the distribution of X π . No w , by the iid assumption made previously (which is commonplace in the context of permutation testing), this distribution is in v ariant to permutations, and so P 0 X = P X and the condition is verified. After computing the permuted test statistic for a large number of random permutations (typically around 10000), the significance of this test, i.e., the probability of observing a test statistic equal or as large as the one obtained, can be computed as p = number of times { T ( X π , Y ) ≥ T ( X , Y ) } number of permutations . (4) Extensions. This test extends naturally to the setting of group analysis. In this case, the test statistic ( 2 ) can be taken as the sum ov er all subjects of the subject-specific test statistic. Ideally , the same permutation should be used across subjects to obtain each v alue of the permuted test statistic 18 . It is theoretically possible to perform a two-tailed test using this test statistic. A large negati ve v alue of the test statistic would also bring e vidence to reject the null hypothesis of independence. Ho we ver , since the neuroscientific interpretation of such negati ve v alues is not useful for our practical purpose, we will only use the one tailed test in this paper . For simplicity , we hav e considered ρ the Pearson correlation coef ficient as similarity measure, b ut the method remains valid using any other similarity measures. The Pearson correlation, being a measure of the linear correlation, w orks best when the effect is (close to) linear , b ut other more complex similarities can be used such as a (negati ve) Malahanobis 19 or W asserstein 20 distance. Relationship with cross-modal decoding analysis (CMD A). C M DA can be regarded within the same hypothesis testing framew ork outlined before, but with a different test statistic. In C M DA , the test statistic is the accuracy of a classifier on images from one modality when it was trained on images from the other modality . Since both C M D A and C M P T follow the same permutation test approach to computing significance, both rely implicitly on a label exchangeability assumption behind the data-generating process. As we hav e seen in the previous subsection, a sufficient condition for this is to assume that the data we observe is sampled iid. Note that this iid assumption is on the pairs from different modalities ( X i , Y i ) and also on the experimental paradigm b ut not on the decoding train/test split, which divides the data by modality and is obviously not iid. This is a much weaker assumption than the distrib utional assumptions made by 3/ 17 traditional parametric methods, it is important to keep in mind that permutation tests are not fully assumption-free methods and at the bare minimum require exchangeability of the observ ations. A practical difference between both approaches is that the cross-modal permutation test is symmetric with respect to modalities while brain decoding is not. That is, C M P T would yield the same p -value regardless of the order in which the different modalities are labeled. This is not true for C M DA , where two possible tests can be performed (train on A and test on B or train on B and test on A ), and both can (and typically do) yield different p -values. Datasets Synthetic datasets W e construct a synthetic dataset according to a model in which the signal is a superposition of a modality-specific ef fect ( M X , X Y ), a condition-specific effect ( C i ) and a Gaussian noise ( ε i ): X i = α · C i + β · M X + ε i , Y i = α · C i + β · M Y + ε i where α , β are scalars that re gulate the amount of modality-specific and condition-specific signal in the image, respecti vely . W e then generated a total of 20 dif ferent images according to this model, considering two dif ferent modality-specific signals and two dif ferent condition-specific signals, all of them randomly generated from a Gaussian distribution. W e generate 3 versions of this dataset, one with 10 vox els, one with 100 and another one with 1000 vox els. fMRI dataset W e performed empirical analysis of the data coming from a neurocognitive study of visual attention. fMRI data were collected to in vestigate object cate gorization during preparatory acti vity in a visual search experiment, designed in a similar manner to the one illustrated in 21 . P ar ticipants. 24 participants (8 male, mean age 27.1, st.dev . 4.3 years) were recruited and accessed the research facility . All participantssubjects, before starting the e xperiment, signed a form confirming their informed consent to participate in the experimental study . After the experiment, they received monetary compensation. Each participant was instructed in advance about under going 2 experimental sessions (S1, S2) on two different days. The data on all three modalities in question (perception, imagery and visual search) were acquired in the same session, S1. Out of all 24, 22 completed a significant part (6/22) or the whole (16/22) of S1. During both S1 and S2, participants were also given other tasks, which we do not report here. Out of 16 participants that underwent the whole S1 only nine participants completed 4 runs of both perception/imagery task and visual search task (8 functional runs in total). Other participants failed to reach 4 runs at least in one of the task types. So, for the analysis we are using the data of the 9 participants that have the total of 8 functional runs each. The tasks are explained in the next section. Stimuli. T wo distinctive stimulus categories were presented to the participants throughout the tasks: people (whole body image) and cars. P articipants were instructed to deal with these categories in three different ways: in per ception modality , they had to attend to 8 presentations of 16 seconds long blocks of different instances of the same category (people, here depicted by whole body figures with no face, or cars), interspersed with 16 seconds long fixation periods. Participants were equipped with a two-b utton box. They were requested to perform a one-back task - i.e., to press a specific b utton whenever the y detected the same image repeated twice in a row . In imagery modality participants were instructed to close their eyes and mentally visualize instances of the category , indicated by the letter cue shown at the beginning of the trial. They had to press the response button whenev er they achie ved a mental image that w as sufficiently detailed, and then they had to switch to mental visualization of another instance of the same cate gory . At the end of the 16 seconds block, an auditory cue told the participants to open their eyes and go on with the e xperiment. Perception and Imagery blocks were randomly presented within the same functional run. In visual sear ch modality , participants were briefly (450 ms) shown images representing natural scenes (e.g.: crowded places, urban landscapes, etc ...). They were instructed through a visual cue (letter) to look for instances of one of the two categories within the scene. After scene presentation, they had 1.6 s to attend to the presentation of a mask and to giv e a positiv e or negati ve response by pressing a b utton. V isual search preparatory periods occurring between the presentation of the cue and the presentation of the scene had dif ferent lengths: 2, 4, 6, 8 or 10 seconds. Participants did not kno w in advance neither the lengths of preparatory period, nor their order of presentation throughout the task, which was random. Participants also had to perform a block-designed task, where we alternated presentation of images of intact and scrambled everyday objects, in order to functionally define an object selecti ve region of interest (R OI) localized in the temporal - occipital cortex (Fig. 1 ). So, for perception and imagery the overall number of trials was 32 per modality (8 trials per 4 runs). Each visual search run consisted of 40 trials, where for each particular type of delay duration there were 8 trials. The total number of visual search trials is 160 (40 per 4 runs), while for each duration there are 32 trials (8 per 4 runs) in the dataset. All experimental procedures had been 4/ 17 Figure 1 approv ed by the Ethical Committee of the Univ ersity of T rento and were carried out in accordance with applicable guidelines and regulations on safety and ethics. Data acquisition. Images were acquired with a 4T Bruker (https://www .bruker .com/) scanner . For each participant, we started both experimental sessions by acquiring a structural scan using a 3D T1-weighted Magnetization Prepared RApid Gradient Echo (MPRA GE) sequence (TR/TE = 2700/4.18 ms, flip angle = 7 ◦ , vox el size = 1 mm isotropic, matrix = 256 × 224 , 176 sagittal slices). Perception / Imagery and V isual Search tasks were performed while acquiring, respectively , 177 and 195 functional scans with the following parameters: (TR/TE = 2000 / 33 ms, flip angle = 73 ◦ , vox el size = 3x3x3 mm, 1 mm slice spacing, matrix = 64x64, 34 axial slices covering the entire brain), during session 1. Same acquisition parameters were used for 165 scans acquired during Functional Localizer task in session 2. Preprocessing. For data preprocessing FSL tools were used along with in-house b uilt Python code. In all functional runs 5 initial v olumes were discarded as dummy v olumes. The skull was remo ved from both functional and structural images to extract the brain. Functional images were subsequently corrected for slice timing and motion artifacts. Transformation of the functional images to standard space was carried out in the follo wing sequence. First structural scans were coregistered to the mean functional scan of each experimental run. Structural-in-functional-space images were then coregistered to standard (MNI) space to finally compute af fine parameters. T o extract task-related ef fects from functional localizer data, beta maps for both localizer conditions (Intact vs. Scrambled objects) were computed with linear re gression and next fed into contrast analysis (Intact vs. Scrambled). This analysis resulted in a R OI located in bilateral temporal occipital cortex. W e selected one cluster including 625 vox els from each hemisphere, ending up with a bilateral ROI with 1250 v oxels o verall. W e applied the R OI mask to functional data coming from Perception / Imagery and V isual Search tasks and we obtained matrices containing time-series of the R OI vox els. For CMPT analysis, 1250x16 matrices of Perception / Imagery data and 1250x40 matrices of V isual Search data were considered per run. Results For the rest of the paper we will refer to the rejection of the null hypothesis with the traditional significance of 0 . 05 without explicitly mentioning this number . Experiments on synthetic data In Figure 2 we plot the resulting p -value after performing both C M P T and C M D A on the synthetic dataset described in section Methods, for v arying magnitudes of the condition-specific ef fect ( α ) and dif ferent image sizes. In the case of decoding, this p -value w as computed as described in 27 . For α = 0 , the dataset has no condition-specific signal and so the test is not expected to produce a statistically significant result. Indeed, the p -value of CMPT is around 0 . 5 . Note that because of the discreteness of the test statistic (test set accuracy), the average p -value need not con verge to wards 0 . 5 as α goes to zero in the case for CMDA. As the magnitude of the effect ( α ) increases, the method that yields a lower p -value has greater statistical po wer, because it is able to reject the null hypothesis with a greater probability . W e can see in the figure, that in general C M DA p -values are higher , which translates into a lower probability of rejecting the null h ypothesis under this approach and hence higher T ype II error . In Figure 3 (top row) we can see that in the absence of signal ( α = 0 ), the distribution of p -va lues generated with C M P T (for 6000 repetitions) is relati vely flat, sho wing that the false positiv e rate (T ype I error) for a significance le vel of β is at the 5/ 17 0.0 0.2 0.4 0.6 0.8 1.0 M a g n i t u d e o f c o n d i t i o n e f f e c t ( ) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 p-value 10 voxels image 0.0 0.2 0.4 0.6 0.8 1.0 M a g n i t u d e o f c o n d i t i o n e f f e c t ( ) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 100 voxels image 0.0 0.2 0.4 0.6 0.8 1.0 M a g n i t u d e o f c o n d i t i o n e f f e c t ( ) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 1000 voxels image CMPT Decoding 0.05 significance level Figure 2 Figure 3 6/ 17 expected v alue of β . In the bottom row of that figure, we can see the same e xperiment for CMD A. In this case because of the discreteness of the test statistic, the distribution is not completely flat. From the simulation results (Figure 2 ) we see that the average p -values yielded by C M P T are always below those of C M D A . This implies that smaller effects can be detected, and hence, that C M P T has a higher sensitivity than C M D A . Furthermore, this effect is replicated across images with dif ferent number of vox els, highlighting the benefits of C M P T in the high-dimensional setting, which is of great practical importance in neuroimaging. Comparison of C M D A and C M P T on fMRI data In this section we assess the agreement or disagreement in detecting shared activ ation patterns between C M D A and C M P T . The similarity of acti vation maps for the the discrimination of body vs. car categories was computed for the following pairs of modalities: perception and imagery , imagery and visual search. The visual search modality was in vestigated more in detail by first considering all durations of preparation periods put together and then analysing separately different delays (2, 4, 6, 8 and 10s). This analysis was meant to emphasize the issue of small sample size typical for neuroscientific data. The comparison between C M DA and C M P T took into account additional elements such as the choice of ROI and the type of encoding of activ ation maps. The R OI chosen for the analysis was the Object Selectiv e Cortex (OSC) map sho wn in Fig. 1 . W e analysed separately the performance of methods for the left part of the ROI, right part of the ROI and the whole R OI. Encoding of the activ ation maps was of two types: raw BOLD and beta maps. For the raw BOLD encoding, the v olumes were selected that corresponded to the peak of the hemodynamic response function (HRF , as rendered by SPM software - www.fil.ion.ucl.ac.uk/spm/doc/ ) con volved with the boxcar function that represented the experimental manipulation. One volume was selected per trial, and for C M P T the v olumes were av eraged to produce a single representativ e volume per subject per condition per modality . For beta encoding, beta maps were calculated trial wise using linear regression; for C M P T the maps were a veraged ov er trials, too, to produce a single beta map per subject per condition per modality . C M DA was performed by training a logistic regression classifier with ` 2 regularization on the trials of one of the modalities. The regularization parameter w as selected according to a nested cross-validation scheme (lea ve-one-run out). The accuracy was then estimated on a test set from another modality . The training and test process was replicated for each subject. Then, the p -value w as computed for the group using the permutation scheme described in 2 . The resulting p -values are reported in T able 1. C M P T group analysis was carried out as described in section Cross-modal permutation test ( C M P T ). The similarity distance between activ ation maps that we used is the Pearson correlation measure, both for raw BOLD volume and beta maps encoding. The significance of the proposed test statistics was computed by a permutation scheme with 10 . 000 iterations to estimate the null distribution. The resulting p -v alues are reported in T able 1. In T able 1 we report only one result for the comparison between C M DA and C M P T related to raw BOLD volume encoding: the cross-modal analysis between Perception and Imagery . In this case none of the methods detect a meaningful shared activ ation pattern. Beta maps encoding on the other hand seems to be a more ef ficient representation. Chen and colleagues 22 demonstrate that using beta v alues is a way to get rid of intrinsic v ariabilities of BOLD signal throughout the brain and, specifically , within a single area. In our case, this means that beta v alues are more representative of the ef fect size than raw BOLD signal changes during task-on periods. For this reason in the presentation of results we only focus on results obtained with data encoded with beta maps. The results in T able 1 confirm our expectations about the presence of common patterns between modalities in Object Selectiv e Cortex. At the same time, C M P T appears to hav e higher statistical power and sensiti vity in rev ealing these patterns. The results reported in T able 1 illustrate two main scenarios: both C M DA and C M P T show significant p -v alues or only C M P T . In light of the simulation results we may argue, that since C M D A has a higher false error rate (Figure 2 ), in case of such disagreements the C M P T result is more reliable. This argument is further supported by the additional empirical evidence that the false positi ve rate or T ype I error is similar for the two tests, limiting the risk of the disagreement being biased by a more optimistic rejection of the null hypothesis. Cross-modal analysis results for perception vs. imagery with beta maps encoding are in agreement between C M DA and C M P T when the two hemispheres are considered individually , namely the left and right OSC respectively . When the analysis is extended to the joint R OI, the number of trials remains constant, while the number of v oxels double. In this case the classifier is affected by the higher dimensionality of data, and C M DA does not succeed in rejecting the null hypothesis. The empirical results also support the claim that C M P T is more rob ust not only in high-dimensional but also in small sample setting. Simulations show that the T ype II error of C M P T is below that of C M D A in the small sample regime (Fig. 2 ). W e may find analogous behaviour for the cross-modal analysis of visual search vs. imagery . If we consider the cumulative trials of visual search, irrespectiv e of the delays, C M DA rejects the null hypothesis. When we restrict the cross-modal analysis to single delays of preparation period for visual search, the number of trials drop from 160 to 32 . In this case C M DA fails to reject the 7/ 17 Figure 4 8/ 17 null hypothesis while C M P T does not. C M P T results are in line with the view that we should expect the presence of shared activity patterns between perceiv ed and imagined object cate gories. C M P T analysis also confirms that the presence of these patterns can be e xpected in high-le vel visual areas processing information about object categories. W e are going to further elaborate on this point in the discussion section. On the other hand, C M D A results appear to be affected by the data sample size relati ve to the high dimensionality of data. Exploratory data analysis with C M P T W e ran Searchlight analysis of the whole brain, using C M P T . First, we wanted to show if and how inserting C M P T as the elementary unit within the Searchlight frame work could identify v oxels that store information related to common acti vation patterns for two dif ferent cognitive modalities. Next, we intended to compare the spatial profiles of the exploratory analysis with the R OI individuated for the confirmatory analysis. T o construct group level maps, we referred to the procedure we illustrated in section Cross-modal Permutation T est ( C M P T ) at a R OI lev el. Here we consider the spheres centered on each voxel as R OIs: we first compute the ”true” statistic and then we proceeded by using permutations. W e started by computing single-participants’ C M P T - Searchlight maps, where each vox el was considered as the center of a sphere (r= 8), and calculated the T -statistic. Then, we summed up single-participants’ T -values and ended up with the true group-le vel statistic. Next, we created N=10000 permutations of the session labels, and we subsequently constructed 10000 a veraged beta maps for each of the conditions based on the permuted labels - that is, two maps per subject per modality per permutation. In this way , we made sure that the data coming from different participants were tested against the same permutations in a uniform way . W e then applied C M P T procedure on these permuted maps by first computing an individual T -statistic and then by summing up the group values - that is, we constructed an ad-hoc null distribution. Finally , we simply counted how many times the “true” group statistic was higher than the permuted group statistic, and we transformed the count in a fraction of the total number of permutations, obtaining a p-value. This value was assigned to the vox el in the center of the sphere. The procedure was repeated for each vox el within the gray matter mask. W e ended up with a C M P T Searchlight map of p-values coming from a combination of permutation-like tests. In Figures 4 and 5 we present results coming from the e xploratory analysis. Fig. 4 showcases the ov erlap between the whole OSC R OI and informative vox els identified by Searchlight in the occipital-temporal corte x for the cross-modal pair of perception vs. imagery only . In Fig. 5 , we put together fragments of maps for the pairs of cognitive processes where our confirmatory analysis yielded significant results, namely perception vs. imagery , visual search (delay 8s) vs. imagery , visual search (all delays) vs. imagery (see T able 1 ). F or merely illustrativ e purposes, the maps were thresholded at the con ventional significance lev el of 0.05 (as we are not aiming at significant cluster identification, no correction for multiple comparisons was carried out). In the left column of Fig. 5 we demonstrate the ov erlaps between the R OI identified in the course of the group analysis (Fig. 1 ) and the portions of the map that signal the presence of information about common patterns between two cognitiv e processes for a single slice (z=-16). The f act that the R OI identified contains a high portion of informative v oxels is further illustrated by the histograms in the right column of the same figure. These are histograms of the p-values of the v oxels within the R OI. W e can see that all three histograms hav e a ske wed shape, signalling the presence of a rather large number of vox els with p-values under 0.05 in the R OI. For comparison, we also ran C M D A Searchlight with the same sphere size (r=8) for the same modality pairs: perception vs. imagery , visual search (all delays) vs. imagery , visual search (delay 8) vs. imagery . The analysis was performed with Matlab 8.5.0, MathW orks, NatickMA, USA using in-house code and Libsvm library (https://www .csie.ntu.edu.tw/ cjlin/libsvm/). Classifier used for producing the maps was an SVM classifier with a linear kernel as implemented in the Libsvm library . For each subject, two Searchlight maps were obtained for each modality pair , one where the classifier was trained on the Imagery data and tested on the other modality data, and one where the assignment of train - test data w as rev ersed. Then, these two maps were av eraged as suggested in 9 yielding a single map per subject per modality pair . F or the group analysis, a one-sample t-test against chance lev el (50 %) was performed using SPM software. The resulting group maps were thresholded at the significance lev el of 0.05 and cluster size of 10 v oxels. Then we compared the group maps to the OSC R OI selected for the confirmatory analysis. The results are presented in T able 2. It sho ws percentages of vox els within the OSC R OI that were identified by the C M D A Searchlight as informative about shared patterns between two modalities. The numbers concerning the size of intersection between the Searchlight map and the R OI are gi ven both as an absolute number of v oxels within the R OI and in terms of percentages. The problem of asymmetry between classifier results when swapping train and test modalities in a cross-modal setting is well attested for the pair of perception vs. imagery . The accuracies obtained with the classifier trained on the imagery data have been sho wn to be consistently higher than after training on perception data ( 28 , 33 ). T o minimize the impact of this asymmetry in cross-modal inv estigations, it was suggested to average the maps resulting from different train-test combinations for a pair of modalities 9 . Howe ver , the authors of the paper showed that the diver gence in accuracy numbers obtained with different train-test combinations in their data was insignificant. 9/ 17 Figure 5 10/ 17 C M DA Searchlight results in our dataset seem to be rather seriously affected by the issues stemming from the accuracy asymmetries. First, for the pair of perception vs. imagery , C M D A Searchlight trained on imagery data identifies a high number of vox els within the OSC mask, both in right and left OSC. If trained on perception data, the Searchlight finds a much lo wer number of voxels within the same area, all of them in the right OSC. In the av eraged mask, the number of the voxels that survi ve is nearly 10 times lo wer than that identified by the Searchlight trained on imagery data (49 against 432). This same kind of asymmetry is ev en more prominent for the pair of imagery vs. visual search: Searchlight, trained on imagery data, identifies vox els within the OSC ROI, while it does not identify any in the same area if trained with visual search data (neither all delays, nor delay 8). This result makes us pose a question about the extent to which the voxels idenitified belong actually to really shared patterns between modalities, or we should rather talk about v oxels in one modality that are informati ve about the patterns in the other modality . Our overall conclusion about C M D A Searcchlight is that its use might be questionable in cases when notable asymmetry is expected, as is the case with perception vs. imagery . For some modality pairs asymmetry does not seem to be a big issue, as is the case with the data used in 9 , and the use of C M D A Searchlight could be more justified for these data. Discussion The patterns of brain activity that are shared between the cogniti ve processes of perception and imagery hav e been the subject of quite numerous studies. The question in vestigated was if we can arrive at abstract, top-do wn object representations 28 , 29 containing distinguishing features 30 , 31 that will hav e common neural substrate both for vie wed and imagined object categories 30 . T o test for the presence of shared patterns, many studies used cross-modal decoding - namely , multiv ariate pattern analysis with SVM classifiers 28 , 32 , 33 . Significant cross-modal classification accuracies were taken as the e vidence in fav our of the presence of shared acti vity patterns. In some studies, correlation-based analysis was also performed to visualize and estimate similarity between these patterns in terms of distance 28 , 32 . What emer ged from these studies was the view that, indeed, visual imagery acti vates the same areas that contain information about visually percei ved stimuli 30 , 34 , and shared patterns for stimulus categories in these tw o processes can be established 28 , 32 , 33 , 35 – 37 . The areas where these common representations were found include the v entral temporal pathway , lateral occipital cortex 28 , 32 , 33 , 36 and extrastriate cortex 29 , 32 , 35 , 36 . The question of shared patterns in early visual areas, such as V1, remains controversial 28 , 32 . Horikawa 31 showed that it depended on the feature type: lower visual features had similar representations for perception and imagery in lo wer visual areas, while the same was true for higher visual features in higher visual areas. Cichy 33 arriv ed at a similar conclusion about the subdivision of features: although they did not find significant accuracies for decoding object cate gories in lateral early visual cortex, the y could identify shared representations of object locations in these areas. T op-down attention patterns mediate attention biases during perception and af fect behavioural performance in attention related tasks. In case of visual attention, these patterns can be rev ealed in visual search experiments via activity in the category-related object selecti ve areas during preparatory delays 38 . Several studies attempted at demonstrating the high-le vel nature of the preparatory patterns through cross-modal analysis, mostly with visual perception as the other modality 21 , 38 , 39 . As object representations in the brain obtained during imagery tasks are thought to be closer to high-level top-do wn representations of objects in visual cortex 30 , 35 , the hypothesis naturally suggests itself that we can expect these patterns to sho w up also during visual search preparatory periods. W e tried to shed light on this hypothesis using both C M DA and C M P T on visual imagery and visual search data. Besides, we ran cross-modal analysis separately for preparatory periods of varying length (between 2 and 10 seconds) to get insights into preparatory dynamics. W e were expecting that only certain dealys would result significant, conforming different h ypotheses about this dynamics. For instance, if only shorter delays (2-4 s) had resulted significant, that could be evidence in fa vour of transitory and cue-related nature of the preparatory activity in the Object Selective Corte x. If, on the other hand, we had seen significant results in the longer delays, that could reveal the fact that it takes time for the activity to build up. First, we see that both methods confirm e xpectations about imagery patterns being more high lev el than perception. None of the methods yielded significant results in the pairs of visual search vs. perception. As for the presence of the shared patterns between visual imagery and visual search, we are faced again with limitations of C M DA as a method: its results can be significant and it can rev eal the presence of shared patterns between preparatory periods and imagery , but this type of analysis needs a lot of data. On the other hand, C M P T can reveal shared patterns ev en with fe wer data as is the case with 8 seconds delay . Further study is needed to uncov er the temporal dynamics of the preparatory top-do wn patterns. W e hypothesize that delays shorter that 8 s do not allo w the preparatory acti vity to build up, while in case of 10 s the delay it is too long, and the subject might be loosing concentration after a certain period of time. W e placed C M P T side by side with other standard data analysis techniques in order to examine whether this approach could be as informati ve as others. W e hav e shown that in confirmatory , top-do wn contexts C M P T can yield better results than C M DA . Howe ver , it is necessary to mention one limitation of the method. One of the overarching questions in the study of visual imagery is identifying neural representations of categorical features in the form of brain activ ation maps 30 , 35 . C M P T method cannot provide insights into the location of the discriminati ve patterns at a R OI lev el. Despite being a more robust test for cross-modal analysis, C M P T is not appropriate to in vestigate the shape of shared pattern within a gi ven R OI. In this case, 11/ 17 C M P T doesn’t support a sensiti vity analysis at the vox el le vel needed to compute granular brain maps of activ ations that are common between modalities. On the other hand, C M D A (at least when linear classifiers are used) contains a vector of weights that can gi ve some clues about the rele vance of the input features. Howe ver , C M P T combined with Searchlight technique can be a helpful method to locate brain regions that contain information about common patterns between modalities. W e took advantage of one strong point of the Searchlight analysis, its “modular” nature: Searchlight might be thought of as a generic framew ork of data examination that can subsume various analysis techniques as elementary units. Searchlight is widely used in neuroimaging, b ut it suffers from a number of issues. Conducting Searchlight analysis has se veral major adv antages: first, it can be run on the whole brain, no prior R OI selection is required. Next, it a voids the “curse of dimensionality” of full brain classification, by reducing the number of features used at each point by the classifier . Finally , it has prov en to be quite successful in identifying subject specific acti vation patterns 23 . The maps produced with Searchlight are of the same nature as the maps obtained with the uni variate GLM approach, b ut they are based on a more fine-grained pattern identification from multiple voxels and better reflect the spatial properties of the BOLD signal (that is, adjacent voxels ha ve similar activ ation patterns). Howe ver , major criticisms of the Searchlight approach regard the use of classification accurac y as the information measure and the t-test as the method to obtain group significances. As is pointed out in 23 , SVM classifiers can correctly classify ev en with a few number of highly informativ e voxels and when weakly informati ve vox els are numerous enough. Both of these behaviours can cause distortions in a map: in the first case, all searchlights o verlapping with one of a fe w informati ve v oxels will be significant. In this way , the number of informativ e vox els is ov erestimated. In the second case, the cause of distortions is “discontinuous information detection”: groups of weakly informative v oxels will be missed out if their size is belo w a certain threshold, b ut can be judged significant if you just add a single voxel. That leads to underestimation of the number of significant clusters just because the number of weakly significant voxels does not reach a certain mass. Ef ficiency of using classifiers with Searchlight depends strongly on the classifier parameters and sphere size 23 , 24 . In 24 , the point is raised against interpretability of classifier accuracy with neuroscientific data: unlike distance measures, its v alue depends on the properties of the dataset (amount of training data and what kind of data is used as test data) and not only on the presence of a particular ef fect in the data. Besides, the authors point out that capturing interactions of several f actors in a factorial experimental design cannot be cast as a classification task. So, addressing these methodological issues for Searchlight can significantly improve this v aluable tool and make its result more scientifically rigorous. Classification accuracy is not the only way to represent information content. In the original paper by Kriegesk orte 25 the metrics used was Mahalanobis distance between the distributions corresponding to stimulus categories. In 24 the authors build on the probabilistic model of the data proposing a cross-validated multiv ariate ANO V A (MANO V A) as the informational content measure. In 19 three v arious measures - classification accuracy , Euclidean/Mahalanobis distance, and Pearson correlation distance - are compared for reliability in the context of Searchlight analysis. In this paper, it was sho wn that “continuous crossvalidated distance estimators” such as Euclidean/Mahalanobis distance or Pearson correlation should be preferred for Searchlight because they are more interpretable from the neuroscientific vie wpoint. Another bunch of critical remarks concerns the use of t-tests for assessing significance at the group level. Certain properties of neuroscientific data make the use of t-tests questionable for this purpose, “particularly , the low number of observ ations and the non-gaussianity of the probability distribution of accuracy . As a consequence, several assumptions of the t-statistic are not met, rendering the procedure inv alid from a theoretical point of view” 26 . Howe ver , it is not the only option here. In 26 a non-parametric test for group significance and cluster inference was proposed based on permutations and bootstrapping procedure. Nastase and colleagues 9 also opt for permutation tests in Searchlight context. Methodologically , using C M P T in conjunction with the Searchlight technique for cross-modal pattern analysis has several advantages o ver the common Searchlight procedure because it does not rely neither on classification accuracy nor on the t-tests and hence av oids the common methodological pitfalls. At the same time, we are following the suggestions in the literature that are considered more appropriate for the Searchlight. First, the test statistic proposed in equation 2 that is used as the measure of information contained at each voxel is based on Pearson correlation and is interpretable in terms of similarity . Second, group significance is tested non-parametrically with permutation tests that do not make assumptions about the shape of the data distribution. W e found that C M P T integrated into Searchlight has proven ef fecti ve also to explore and, potentially , confirm what we observed using top-do wn, ROI-based analysis, which suggests both robustness and ef ficiency of the C M P T Searchlight in fMRI data analysis. Howe ver , it is important to note that confirmatory and e xploratory analyses report different p-v alues. While it is possible to qualitati vely compare the outcomes of these two analyses, plainly putting their p-v alues side by side might be misleading. CMPT -R OI p-values come from an extended, functionally well-defined area including 625 or 1250 vox els. CMPT -SL analysis spans ov er the whole brain sphere by sphere, extracting results from spheres including about 200 voxels each. This means that p-values coming from confirmatory and e xploratory analysis should not be compared on a purely quantitativ e lev el. The question of shared patterns between various cognitiv e modalities is relev ant not only for object categorization in visual processing. It is fundamental in the study of interactions between top-down and bottom-up processing streams in the human 12/ 17 brain in general. Further directions of study could include using the C M P T method and the C M P T Searchlight technique with a wider number of other cogniti ve modalities, such as auditory or linguistic 40 – 42 . Besides, we could inv estigate other areas that can share representations with imagery - for instance, working memory areas 35 . Finally , the C M P T method could be tried with other types of neuroimaging data - as, for e xample, EEG motor imagery data for Brain-Computer interfaces 43 or MEG data 44 , 45 . Ackno wledg ements The research was partially funded by the Autonomous Province of Trento, Call “Grandi Progetti 2012”, project “Characterizing and improving brain mechanisms of attention - A TTEND” and by Centro Internazionale per la Ricerca Matematica (CIRM). The authors gratefully ackno wledge the contribution of Marius Peelen to the disucssions of e xperiment design and data analysis and to V alentina Borghesani for v aluable feedback on the manuscript. A uthor contributions statement E.K., V .I. and P .A participated in designing the e xperiment. E.K. and V .I. implemented the design, conducted the experiment, acquired the data and preprocessed the data. All authors analysed the data. E.K., F .P . and E.O. implemented data analysis pipelines. F .P . designed, implemented and conducted experiments on simulated data. E.K., F .P ., V .I. and P .A. wrote the manuscript. Additional inf ormation The authors declare no competing interests. Data and code av ailability . Processed data (R OI beta-maps, BOLD volumes and Searchlight maps) are av ailable from a public repository on Github https://github.com/elena- kalinina/Code_CMPT_paper . The code used to generate and analyze synthetic data is a vailable from the same repository along with data analysis code and Searchlight implementation. Sharing the whole dataset in volves the consent of third-parties who participated in the experiment design. If the consensus is reached, the data could be made publicly av ailable. References 1. Knops, A., Thirion, B., Hubbard, E. M., Michel, V . & Dehaene, S. Recruitment of an area in volved in eye mo vements during mental arithmetic. Sci. 324 , 1583–1585 (2009). 2. Etzel, J. A., Gazzola, V . & Keysers, C. T esting simulation theory with cross-modal multivariate classification of fMRI data. PLoS ONE 3(11) , URL http://dx.doi.org/10.1371/journal.pone.0003690 . DOI 10.1371/jour- nal.pone.0003690. (2008). 3. Shinkarev a, S. V ., Malav e, V . L., Mason, R. A., Mitchell, T . M. & Just, M. A. Commonality of neural representations of words and pictures. Neur oImage 54 , 2418–2425 (2011). 4. Haynes, J.-D. & Rees, G. Decoding mental states from brain activity in humans. Nat. Rev. Neur osci. 7 , 523–534 (2006). 5. Kaplan, J. T ., Man, K. & Greening, S. G. Multiv ariate cross-classification: applying machine learning techniques to charac- terize abstraction in neural representations. F r ont. Hum. Neur osci. 9 , 151 URL http://journal.frontiersin. org/article/10.3389/fnhum.2015.00151 . DOI 10.3389/fnhum.2015.00151. (2015). 6. Majerus, S. et al. Cross-modal decoding of neural patterns associated with working memory: e vidence for attention-based accounts of working memory . Cereb. corte x 26 , 166–179 (2016). 7. V etter , P ., Smith, F . W . & Muckli, L. Decoding sound and imagery content in early visual corte x. Curr. Biol. 24 , 1256–1262 (2014). 8. Kaiser , D., Azzalini, D. C. & Peelen, M. V . Shape-independent object category responses re vealed by MEG and fMRI decoding. J. Neur ophysiol. 115(4) , 2246–50 (2016). 9. Nastase, S. A., Halchenko, Y . O., Da vis, B. & Hasson, U. Cross-modal searchlight classification: methodological challenges and recommended solutions. In P attern Recognition in Neur oImaging (PRNI), 2016 International W orkshop on , 1–4. IEEE. URL https://ieeexplore.ieee.org/document/7552355 . DOI 10.1109/PRNI.2016.7552355. (2016). 13/ 17 10. Fisher , R. A. The Design of Experiments. Oliv er Boyd, Edinb. (1935). 11. Pitman, E. J. Significance tests which may be applied to samples from any populations. Suppl. to J. Royal Stat. Soc. 4 , 119–130 (1937). 12. Lehmann, E. L. & Stein, C. On the theory of some non-parametric hypotheses. The Annals Math. Stat. 20(1) , 28–45 (1949). 13. Nichols, T . E. & Holmes, A. P . Nonparametric permutation tests for functional neuroimaging: a primer with e xamples. Hum. brain mapping 15 , 1–25 (2002). 14. Eklund, A., Nichols, T . E. & Knutsson, H. Cluster failure: why fmri inferences for spatial extent ha ve inflated false-positi ve rates. Pr oc. Natl. Acad. Sci. 113(28) , 7900–7905 (2016). 15. W oolrich, M. W ., Beckmann, C. F ., Nichols, T . E. & Smith, S. M. Statistical analysis of fMRI data. In fMRI T echniques and Pr otocols 41 , 183–239 Springer-V erlag, Ne w Y ork. (2009). 16. W inkler, A. M., Ridgway , G. R., Douaud, G., Nichols, T . E. & Smith, S. M. F aster permutation inference in brain imaging. Neur oImage 141 , 502 – 516 (2016). 17. Lehmann, E. L. & Romano, J. P . T esting Statistical Hypotheses . Springer-V erlag New Y ork. (2005). 18. Etzel, J. A. MVP A permutation schemes: permutation testing for the group level. In P attern Recognition in Neur oImaging (PRNI), 2015 International W orkshop on , 65–68. IEEE. URL https://ieeexplore.ieee.org/document/ 7270849 . DOI 10.1109/prni.2015.29. (2015) 19. W alther , A. et al. Reliability of dissimilarity measures for multi-voxel pattern analysis. Neur oImage 137 , 188–200 (2016). 20. Gramfort, A., Peyr ´ e, G. & Cuturi, M. Fast optimal transport averaging of neuroimaging data. Preprint at URL http: //arxiv.org/abs/1503.08596 . 1503.08596 . (2015). 21. Peelen, M. V ., Fei-Fei, L. & Kastner , S. Neural mechanisms of rapid natural scene categorization in human visual cortex. Nat. 460 , 94–97 (2009). 22. Chen, X., Pereira, F ., Lee, W ., Strother, S. & Mitchell, T . Exploring predicti ve and reproducible modeling with the single-subject FIA C dataset. Hum. brain mapping 27 , 452–461 (2006). 23. Etzel, J. A., Zacks, J. M. & Bra ver , T . S. Searchlight analysis: promise, pitfalls, and potential. Neur oImage 78 , 261–269 (2013). 24. Allefeld, C. & Haynes, J.-D. Searchlight-based multi-voxel pattern analysis of fMRI by cross-validated MANO V A. Neur oImage 89 , 345–357 (2014). 25. Kriegeskorte, N., Goebel, R. & Bandettini, P . Information-based functional brain mapping. Pr oc. Natl. Acad. Sci. United States Am. 103 , 3863–3868 (2006). 26. Stelzer , J., Chen, Y . & T urner , R. Statistical inference and multiple testing correction in classification-based multi-vox el pattern analysis (MVP A): Random permutations and cluster size control. Neur oImage 65 , 69–82 (2013). 27. Ojala, Markus, Garriga, Gemma C, Permutation tests for studying classifier performance. J. Mac h. Learn. Res. 11 , 1833–1863 (2010) 28. Reddy , L., Tsuchiya, N. & Serre, T . Reading the mind’ s eye: decoding cate gory information during mental imagery. Neur oImage 50 , 818–825 (2010). 29. Ishai, A. Seeing faces and objects with the ”mind’ s eye”. Arc h. italiennes de biologie 148 , 1–9 (2010). 30. Roldan, S. M. Object recognition in mental representations: directions for exploring diagnostic features through visual mental imagery . F r ont. Psychol. 8 URL http://dx.doi.org/10.3389/fpsyg.2017.00833 . DOI 10.3389/fp- syg.2017.00833. (2017). 31. Horikawa, T . & Kamitani, Y . Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 8 URL http://dx.doi.org/10.1038/ncomms15037 . DOI 10.1038/ncomms15037. (2017). 32. Lee, S.-H., Kravitz, D. J. & Baker , C. I. Disentangling visual imagery and perception of real-world objects. Neur oImage 59 , 4064–4073 (2012). 33. Cichy , R. M., Heinzle, J. & Haynes, J.-D. Imagery and perception share cortical representations of content and location. Cer eb. Cortex 22 , 372–380 (2012). 34. Farah, M. J. The neural basis of mental imagery . T r ends neur osciences 12 , 395–399 (1989). 14/ 17 35. Pearson, J., Naselaris, T ., Holmes, E. A. & Kosslyn, S. M. Mental imagery: functional mechanisms and clinical applications. T r ends cognitive sciences 19 , 590–602 (2015). 36. Stokes, M., Thompson, R., Cusack, R. & Duncan, J. T op-down acti vation of shape-specific population codes in visual cortex during mental imagery . The J. neur oscience : of ficial journal Soc. for Neur osci. 29 , 1565–1572 (2009). 37. Anderson, A. J. J., Bruni, E., Lopopolo, A., Poesio, M. & Baroni, M. Reading visually embodied meaning from the brain: V isually grounded computational models decode visual-object mental imagery induced by written text. Neur oImage 120 , 309–322 (2015). 38. Stokes, M., Thompson, R., Nobre, A. C. & Duncan, J. Shape-specific preparatory activity mediates attention to targets in human visual cortex. Pr oc. Natl. Acad. Sci. 106 , 19569–19574 (2009). 39. Peelen, M. V . & Kastner, S. A neural basis for real-world visual search in human occipitotemporal cortex. Proc. Natl. Acad. Sci. United States Am. 108 , 12125–12130 (2011). 40. Simanov a, I., Hagoort, P ., Oosten veld, R. & v an Gerven, M. A. Modality-independent decoding of semantic information from the human brain. Cer eb. cortex 24 , 426–434 (2014). 41. Simanov a, I., Francken, J. C., de Lange, F . P . & Bekkering, H. Linguistic priors shape categorical perception. Lang. Cogn. Neur osci. 31 , 159–165 (2016). 42. Borghesani, V ., Pedregosa, F ., Eger , E., Buiatti, M. & Piazza, M. A perceptual-to-conceptual gradient of word coding along the ventral path. In P attern Recognition in Neur oimaging, 2014 International W orkshop on , 1–4. IEEE. URL https://ieeexplore.ieee.org/document/6858512 . DOI 10.1109/prni.2014.6858512. (2014) 43. Choi, K. Electroencephalography (EEG)-based neurofeedback training for brain-computer interface (BCI). Exp. br ain r esear ch 231 , 351–365 (2013). 44. Dikker , S. & Pylkk ¨ anen, L. Predicting language: MEG evidence for lexical preactiv ation. Brain language 127 , 55–64 (2013). 45. Hirschfeld, G., Zwitserlood, P . & Dobel, C. Effects of language comprehension on visual processing - MEG dissociates early perceptual and late N400 effects. Brain languag e 116 , 91–96 (2011). Modalities R OI Encoding CMD A CMPT P vs I L+R Bold 0.12 0.75 P vs I L+R Beta 0.08 0.001 P vs I L Beta 0.001 0.001 P vs I R Beta 0.005 0.008 V vs I (delay 2 s) L+R Beta 0.272 0.589 V vs I (delay 4 s) L+R Beta 0.387 0.141 V vs I (delay 6 s) L+R Beta 0.165 0.303 V vs I (delay 8 s) L+R Beta 0.659 0.004 V vs I (delay 10 s) L+R Beta 0.249 0.461 V vs I (all delays) L+R Beta 0.012 0.001 T able 1. Comparison of cross-modal decoding analysis ( C M D A ) and cross-modal permutation test ( C M P T ). The values refer to p-value for the discrimination task of body vs. car in each pair of the cognitiv e modalities listed in the extreme left column, where P stands for per ception , I for imagery (I) and V for visual sear ch . 15/ 17 Modalities R OI Map T ype Intersection N V ox Intersection % P vs I L mean 4 0.64 P vs I L single P I 0 0 P vs I L single I P 239 38.24 V vs I L mean 5 0.8 V vs I L single V I 0 0 V vs I L single I V 12 1.92 V vs I (delay 8) L mean 0 0 V vs I (delay 8) L single I V 29 4.64 V vs I (delay 8) L single V I 0 0 P vs I R mean 45 7.2 P vs I R single P I 13 2.08 P vs I R single I P 193 30.88 V vs I R mean 0 0 V vs I R single V I 0 0 V vs I R single I V 1 0.16 V vs I (delay 8) R mean 0 0 V vs I (delay 8) R single I V 10 1.6 V vs I (delay 8) L single V I 0 0 P vs I L+R mean 49 3.92 P vs I L+R single P I 13 1.04 P vs I L+R single I P 432 34.56 V vs I L+R mean 5 0.4 V vs I L+R single V I 0 0 V vs I L+R single I V 13 1.04 V vs I (delay 8) L+R mean 0 0 V vs I (delay 8) L+R single I V 39 3.12 V vs I (delay 8) L+R single V I 0 0 . T able 2. Percentage of vox els within the OSC ROI identified by the C M D A Searchlight as informative about shared patterns between two modalities. The cognitiv e modalities are listed in the extreme left column. P stands for per ception , I for imagery and V for visual searc h . In the second column, it is shown which part of the OSC mask was used for calculations: left (L), right (R) or the whole mask (L+R). Number of voxels in L+R ROI is equal to 1250; each half of it (both L and R) has 650 vox els. The third column sho ws which type of map was used for calculations: an av eraged map (denoted as mean), or a single training - test pair map (denoted as single). In the names of the single maps, first comes the training modality , and second the test modality . In the last two columns you can find the numbers concerning the size of intersection between the map in column 3 and the R OI in column 2. In column 4, the intersection size is given as an absolute number of v oxels within the R OI. In the last, extreme right column, it is gi ven in terms of percentages. Figure 1. Object Selecti ve Cortex (OSC) group map in temporal-occipital cortex delineated based on the functional localizer (intact vs. scrambled objects). Its right (R) hemisphere part is shown in red, left (L) in blue. X, Y and Z locate the coordinates of the slices. Figure 2. Statistical po wer as a function of the effect size. W e compare the obtained p -value (y) for dif ferent magnitudes of the condition-specific effect (x) and dif ferent image sizes (10, 100 and 1000 voxels). Shaded areas correspond to the standard deviation. Across these dif ferent scenarios, C M P T yields a higher significance than the decoding-based approach. Figure 3. The distribution of p -values generated with C M P T (top) and C M D A (bottom) in the absense of condition-specific ef fect after 6000 repetitions of the experiment. p -values are on the x axis, while the frequencies are sho wn on the y axis. In case of C M P T (top) the distribution con ver ges to the uniform. The false positiv e rate (T ype I error) for a significance level of β is at the expected v alue of β . For C M D A (bottom), the distribution is not fully flat due to the discreteness of the scoring rule. Figure 4. Overlap between the whole OSC R OI and informative v oxels identified by Searchlight in the occipital-temporal cortex for the cross-modal pair of perception vs. imagery . The ROI (the same as in Figure fig:roi) is sho wn in blue. P-v alues in the Searchlight map are colorcoded. The maps were thresholded at the con ventional significance lev el of 0.05, and the color code shows values between 0.95 (corresponding to the p-value of 0.05) in red and 1 (corresponding to the p-v alue of 0.00) in yellow . The leftmost column of the figure shows sagitarial (top) and coronal (bottom) slices (at x= 42 and y = -74 correspondingly) where the rectangle shaded in blue delimits the axial slices further presented in columns 2 - 4. These are six 16/ 17 slices of the axial plane taken at steps of 8 between coordinates z = -24 and z = 16. W e can see that in all these six slices, there are ov erlaps between the OSC R OI and areas where Searchlight identified vox els informati ve about shared acti vity patterns between perception and imagery . Figure 5. C M P T - Searchlight analysis results. The rows represent results coming from the pairs of cognitive processes where our confirmatory analysis yielded significant p-v alues (T able 1): perception vs. imagery (top), visual search (delay of 8 s) vs. imagery (middle), visual search (all delays) vs. imagery (bottom). In each row , the left column shows the o verlap between the Object Selecti ve Cortex R OI previously defined for confirmatory analysis (Fig. 1 ) and the Searchlight maps obtained for this pair . In the right column, there is a histogram of p-values within the OSC R OI coming from the Searchlight map. The left column showcases axial slices of Searchlight maps for the corresponding pairs, focusing on posterior region. Slices are taken at z= -16, maps were thresholded at the significance level of 0.05, and the color code sho ws v alues between 0.95 (corresponding to the p-v alue of 0.05) in red and 1 (corresponding to the p-v alue of 0.00) in yello w . The OSC R OI is presented in green. Ov erlaps between the green area and colorcoded maps can be observ ed for all three pairs. The right column further illustrates the fact that the confirmatory OSC R OI identified contains a high portion of informati ve vox els. In each histogram, the x axis represents the p-v alues, while their frequencies (in % from the overall number of v oxels in the area) are ordered along the y-axis. All three histograms are ske wed to the right, signalling the presence of a rather large number of v oxels with p-v alues under 0.05 in the R OI. 17/ 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment