Verification of Neural Networks: Specifying Global Robustness using Generative Models
The success of neural networks across most machine learning tasks and the persistence of adversarial examples have made the verification of such models an important quest. Several techniques have been successfully developed to verify robustness, and …
Authors: Nathana"el Fijalkow, Mohit Kumar Gupta
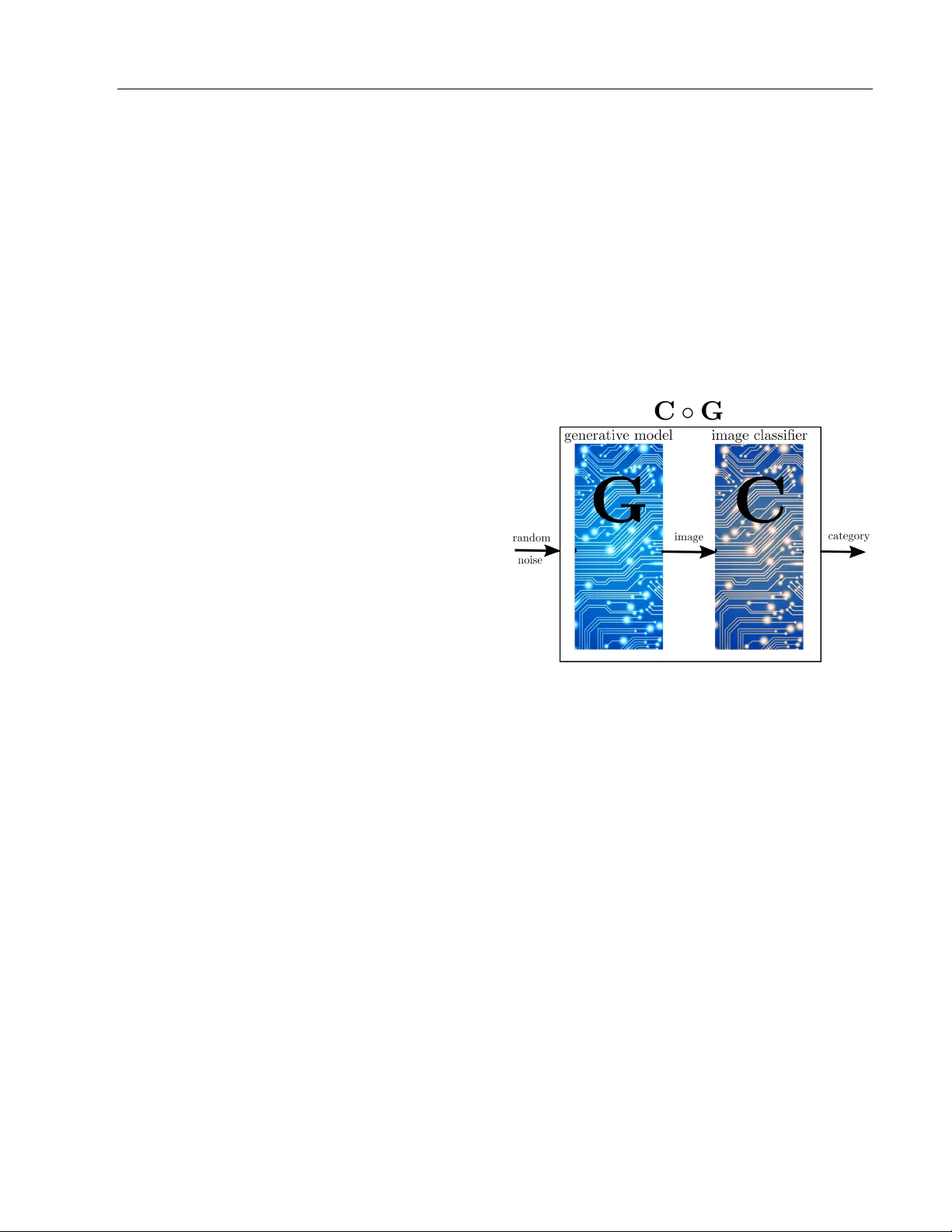
V erification of Neural Net w orks: Sp ecifying Global Robustness using Generativ e Mo dels Nathana¨ el Fijalk ow Mohit Kumar Gupta CNRS, LaBRI, Univ ersit´ e de Bordeaux, and The Alan T uring Institute, London Indian Institute of T ec hnology Bomba y Abstract The success of neural net works across most mac hine learning tasks and the persistence of adv ersarial examples hav e made the v erifica- tion of such models an imp ortan t quest. Sev- eral techniques hav e b een successfully devel- op ed to verify robustness, and are now able to ev aluate neural netw orks with thousands of no des. The main w eakness of this approach is in the specification: robustness is asserted on a v alidation set consisting of a finite set of examples, i.e. lo cally . W e prop ose a notion of global robustness based on generativ e mo dels, which asserts the robustness on a very large and represen tativ e set of examples. W e show ho w this can b e used for verifying neural netw orks. In this pap er w e exp erimen tally explore the merits of this approach, and sho w ho w it can be used to construct realistic adv ersarial examples. 1 In tro duction W e consider the task of certifying the correctness of an image classifier, i.e. a system taking as input an image and categorising it. As a main example we will consider the MNIST classification task, which consists in categorising hand-written digits. Our exp erimen- tal results are later repro duced for the drop-in dataset F ashion MNIST (Xiao et al. (2017)). The usual ev aluation pro cedure consists in setting aside from the dataset a v alidation set, and to rep ort on the success p ercentage of the image classifier on the v alidation set. With this pro cedure, it is com- monly accepted that the MNIST classification task T echnical report. is solved, with some conv olutional netw orks ac hieving ab o v e 99.7% accuracy (see e.g. Ciregan et al. (2012); W an et al. (2013)). F urther results suggest that even the b est conv olutional netw orks cannot be considered to b e robust, given the p ersistence of adversarial ex- amples: a small p erturbation – invisible to the h uman ey e – in images from the dataset is enough to induce misclassification (Szegedy et al. (2014)). This is a k ey motiv ation for the v erification of neural net works: can w e assert the robustness of a neural net- w ork, i.e. the absence of adversarial examples? This question has generated a gro wing in terest in the past y ears at the crossing of different researc h communities (see e.g. Huang et al. (2017); Katz et al. (2017); W eng et al. (2018); Gehr et al. (2018); Mirman et al. (2018); Gopinath et al. (2018); Katz et al. (2019)), with a range of protot yp e tools ac hieving impressive results. The robustness question is formulated as follows: giv en an image x and ε > 0, are all ε -p erturbations of x cor- rectly classified? W e point to a w eakness of the formalisation: it is lo c al , meaning it is asserted for a given image x (and then t ypically c hec ked against a finite set of images). In this pap er, we inv estigate a glob al approach for specifying the robustness of an image classifier. Let us start from the ultimate robustness ob jective, which reads: F or ev ery category , for ev ery r e al-life image of this category and for every p erturb ation of this image, the perturb ed image is correctly classified. F ormalising this raises three questions: 1. How do we quantify ov er al l real-life images? 2. What are p erturb e d images? 3. How do we effe ctively chec k robustness? In this work we prop ose a formalisation based on gen- erativ e mo dels. A generative mo del is a system taking T ec hnical report as input a random noise and generating images, in other words it represen ts a probabilistic distribution o ver images. Our sp ecification dep ends on t wo parameters ( ε, δ ). Informally , it reads: An image classifier is ( ε, δ )-robust with re- sp ect to a generative mo del if the probabil- it y that for a noise x , all ε -p erturbations of x generate correctly classified images is at least 1 − δ . The remainder of the pap er presents exp erimen ts sup- p orting the claims that the global robustness specifi- cation has the follo wing imp ortan t prop erties. Global. The first question stated ab o ve is ab out quan tifying ov er all images. The global robustness we prop ose addresses this p oin t b y (implicitly) quan tify- ing ov er a very large and representativ e set of images. Robust. The second question is about the notion of p erturbed images. The essence of generativ e mo dels is to pro duce images reminiscent of real images (from the dataset); hence testing against images given b y a generative mo del includes the very important per- turbation asp ect presen t in the intuitiv e definition of correctness. Effectiv e. The third question is ab out effectivit y . W e will explain that global robustness can be effectively ev aluated for image classifiers built using neural net- w orks. Related w ork Xiao et al. (2018) train generative mo dels for finding adv ersarial examples, and more specifically introduce a different training procedure (based on a new ob jec- tiv e function) whose goal is to pro duce adversarial ex- amples. Our approach is different in that w e use gen- erativ e models with the usual training pro cedure and ob jective, which is to pro duce a wide range of realistic images. 2 Global Correctness This section serv es as a tec hnical w arm-up for the next one: w e in tro duce the notion of glob al c orr e ctness , a step to wards our main definition of glob al r obustness . W e use R d for represen ting images with || · || the infinity norm ov er R d , and let C be the set of categories, so an image classifier represen ts a function C : R d → C . A generative mo del represents a distribution ov er im- ages, and in effect is a neural net work which takes as input a random noise in the form of a p -dimensional v ector x and pro duces an image G ( x ). Hence it rep- resen ts a function G : R p → R d . W e typ ically use a Gaussian distribution for the random noise, written x ∼ N (0 , 1). Our first definition is of glob al c orr e ctness , it relies on a first key but simple idea, whic h is to compose a genera- tiv e mo del G with an image classifier C : we construct a new neural net w ork C ◦ G by simply rewiring the output of G to the input of C , so C ◦ G represen ts a distribution o v er categories. Indeed, it tak es as input a random noise and outputs a category . Figure 1: Composition of a generativ e mo del with an image classifier Definition 1 (Global Correctness) . Given for e ach c ∈ C a gener ative mo del G c for images of c ate gory c , we say that the image classifier C is δ -c orr e ct with r esp e ct to the gener ative mo dels ( G c ) c ∈ C if for e ach c ∈ C , P x ∼N (0 , 1) ( C ◦ G c ( x ) = c ) ≥ 1 − δ. In wor ds, the pr ob ability that for a noise x the image gener ate d (using G c ) is c orr e ctly classifie d (by C ) is at le ast 1 − δ . Assumptions Our definition of global correctness hinges on tw o prop erties of generative mo dels: 1. generative mo dels pro duce a wide v ariet y of im- ages, 2. generative mo dels pro duce (almost only) realistic images. T ec hnical report The first assumption is the reason for the success of generativ e adversarial net works (GAN) (Goo d- fello w et al. (2014)). W e refer for instance to Karras et al. (2018) and to the attached web- site thispersondoesnotexist.com for a demo. In our exp erimen ts the generative mo dels we used are out of the shelf generativ e adv ersarial net works (GAN) (Go odfellow et al. (2014)), with 4 hidden lay ers of re- sp ectiv ely 256, 512 , 1024, and 784 no des, pro ducing images of single digits. T o test the second assumption we p erformed a first exp erimen t called the manual sc or e exp eriment . W e pic ked 100 digit images using a generative mo del and ask ed 5 individuals to tell for each of them whether they are “near-p erfect”, “p erturb ed but clearly iden- tifiable”, “hard to iden tify”, or “rubbish”, and whic h digit they represen t. The results are that 96 images w ere correctly identified; among them 63 images were declared “near-p erfect” b y all individuals, with an- other 26 including “p erturbed but clearly iden tifiable”, and 8 were considered “hard to identify” by at least one individual y et correctly identified. The remaining 4 w ere “rubbish” or incorrectly identified. It follows that against this generativ e model, w e should require an image classifier to b e at least . 89-correct, and even . 96-correct to matc h human p erception. Algorithm T o c heck whether a classifier is δ -correct, the Mon te Carlo integration metho d is a natural approach: w e sample n random noises x 1 , . . . , x n , and count for how man y x i ’s we hav e that C ◦ G c ( x ) = c . The central limit theorem states that the ratio of p ositiv es ov er n conv erges to P x ∼N (0 , 1) ( C ◦ G c ( x ) = c ) as 1 √ n . It follo ws that n = 10 4 samples gives a 10 − 2 precision on this n umber. In practice, rather than sampling the random noises indep enden tly , w e form (large) batches and leverage the tensor-based computation, enabling efficient GPU computation. 3 Global Robustness W e introduce the notion of global robustness, which giv es stronger guarantees than global correctness. In- deed, it includes the notion of p erturbations for im- ages. The usual notion of robustness, whic h we call here lo c al r obustness , can b e defined as follows. Definition 2 (Lo cal Robustness) . We say that the image classifier C is ε -r obust ar ound the image y ∈ R d of c ate gory c if ∀ y 0 , || y − y 0 || ≤ ε = ⇒ C ( y 0 ) = c. In wor ds, al l ε -p erturb ations of y ar e c orr e ctly classi- fie d (by C ). One important asp ect in this definition is the choice of the norm for the perturbations (here w e use the infinit y norm). W e ignore this as it will not play a role in our definition of robustness. A wealth of techniques ha ve b een dev elop ed for chec king lo cal robustness of neural netw orks, with state of the art to ols b eing able to handle nets with thousands of neurons. Assumptions Our definition of global robu stness is supp orted b y the t wo properties of generative models discussed ab o v e in the con text of global correctness, plus a third one: 3. generative models produce p erturbations of real- istic images. T o illustrate this w e designed a second exp erimen t called the r andom walk exp eriment : we perform a ran- dom walk on the space of random noises while observ- ing the ensued sequence of images pro duced by the generativ e mo del. More sp ecifically , w e pick a ran- dom noise x 0 , and define a sequence ( x i ) i ≥ 0 of ran- dom noises with x i +1 obtained from x i b y adding a small random noise to x i ; this induces the sequence of images ( G ( x i )) i ≥ 0 . The result is b est visualised in an animated GIF (see the Gith ub repository), see also the first 16 images in Figure 2. This supp orts the claim that images pro duced with similar random noises are (often) close to each other; in other words the genera- tiv e mo del is (almost ev erywhere) contin uous. Our definition of global robustness is reminiscent of the pr ovably appr oximately c orr e ct learning framew ork de- v elop ed b y V aliant (1984). It features tw o parameters. The first parameter, δ , quantifies the probabilit y that a generative mo del pro duces a realistic image. The second parameter, ε , measures the p erturbations on the noise, which by the con tin uity prop ert y discussed ab o v e transfers to p erturbations of the pro duced im- ages. Definition 3 (Global Robustness) . Given for e ach c ∈ C a gener ative mo del G c for images of c ate gory c , we say that the image classifier C is ( ε, δ ) -r obust with r esp e ct to the gener ative mo dels ( G c ) c ∈ C if for e ach c ∈ C , P x ∼N (0 , 1) ( ∀ x 0 , || x − x 0 || ≤ ε = ⇒ C ◦ G c ( x 0 ) = c ) ≥ 1 − δ. In wor ds, the pr ob ability that for a noise x , al l ε - p erturb ations of x gener ate (using G ) images c orr e ctly classifie d (by C ) is at le ast 1 − δ . T ec hnical report Figure 2: The random walk exp eriment Algorithm T o c heck whether a classifier is ( ε, δ )-robust, we extend the previous ideas using the Mon te Carlo integration: w e sample n random noises x 1 , . . . , x n , and coun t for ho w many x i ’s the follo wing prop ert y holds: ∀ x, || x i − x || ≤ ε = ⇒ C ◦ G c ( x ) = c. The central limit theorem states that the ratio of p os- itiv es ov er n conv erges to P x ∼N (0 , 1) ( ∀ x 0 , || x − x 0 || ≤ ε = ⇒ C ◦ G c ( x 0 ) = c ) as 1 √ n . As b efore, it follows that n = 10 4 samples giv es a 10 − 2 precision on this n umber. In other w ords, c hec king global robustness reduces to com bining Mon te Carlo in tegration with c hec king lo cal robustness. 4 Exp erimen ts The code for all exp erimen ts can b e found on the Gith ub rep ository https://github.com/mohitiitb/ NeuralNetworkVerification_GlobalRobustness . All experiments are presented in Jup yter noteb ook for- mat with pre-trained mo dels to be easily repro duced. Our exp erimen ts are all repro duced on the drop-in F ashion-MNIST dataset (Xiao et al. (2017)), obtaining similar results. W e report on exp erimen ts designed to assess the b en- efit of these tw o notions, whose common denominator is to go from a lo cal prop ert y to a global one by com- p osing with a generative mo del. W e first ev aluate the global correctness of sev eral im- age classifiers, sho wing that it provides a finer wa y of ev aluating them than the usual test set. W e then turn to global robustness and sho w ho w the negation of robustness can b e witnessed by realistic adversarial examples. The second set of exp erimen ts addresses the fact that b oth global correctness and robustness notions dep end on the choice of a generative mo del. W e show that this dep endence can b e made small, but that it can also b e used for refining the correctness and robustness notions. Choice of net works In all the exp erimen ts, our base case for image classifiers hav e 3 hidden lay ers of increasing capaci- ties: the first one, referred to as “small”, has la yers with (32 , 64 , 200) (n umber of no des), “medium” corre- sp onds to (64 , 128 , 256), and “large” to (64 , 128 , 512). The generative model are as described abov e, with 4 hidden la yers of respectively 256, 512 , 1024, and 784 no des. F or each of these three architectures w e either use the standard MNIST training set (6,000 images of each digit), or an augmen ted training set (24,000 images), obtained b y rotations, shear, and shifts. The same distinction applies to GANs: the “simple GAN” uses the standard training set, and the “augmented GAN” the augmen ted training set. Finally , we work with t w o netw orks obtained through robust training pro cedures. The first one w as prop osed b y M ¸ adry et al. (2018) for the MNIST Adversarial Example Challenge (the goal of the challenge w as to find adversarial examples, see b elo w), and the second one was defined by Papernot et al. (2016) through the pro cess of defense distillation. Ev aluating Global Correctness W e ev aluated the global correctness of all the image classifiers mentioned ab o ve against simple and aug- men ted GANs, and rep orted the results in the table b elo w. The last column is the usual v alidation pro- cedure, meaning the num ber of correct classification on the MNIST test set of 10,000 images. They all p erform very well, and close to p erfectly (ab ov e 99%), against this metric, hence cannot b e distinguished. Y et the composition with a generativ e model rev eals that their p erformance outside of the test set are actually differen t. It is instructiv e to study the outliers for each image classifier, i.e. the generated images which are incorrectly classified. W e refer to the Github reposi- tory for more exp erimen tal results along these lines. Finding Realistic Adv ersarial Examples Chec king the global robustness of an image classifier is out of reach for state of the art v erification to ols. Indeed, a single robustness chec k on a medium size net takes somewhere betw een dozens of seconds to a T ec hnical report Classifier simple GAN augmen ted GAN test set Standard training set small 98.89 92.82 99.79 medium 99.15 93.16 99.76 large 99.38 93.80 99.80 Augmen ted training set small 97.84 95.2 99.90 medium 99.11 96.53 99.86 large 99.25 97.66 99.84 Robust training pro cedures M ¸ adry et al. (2018) 98.87 93.17 99.6 P ap ernot et al. (2016) 99.64 94.78 99.17 few minutes, and to get a decent appro ximation we need to perform tens of thousands lo cal robustness c hecks. Hence with considerable computational efforts w e could analyse one image classifier, but could not p erform a wider comparison of differen t training pro- cedures and influence on differen t aspects. Thus our exp erimen ts fo cus on the negation of robustness, whic h is finding realistic adv ersarial examples, that w e define no w. Definition 4 (Realistic Adversarial Example) . An ε - r e alistic adversarial example for an image classifier C with r esp e ct to a gener ative mo del G is an image G ( x ) such that ther e exists another image G ( x 0 ) with || x − x 0 || ≤ ε and C ◦ G ( x ) 6 = C ◦ G ( x 0 ) In wor ds, x and x 0 ar e two ε -close r andom noises which gener ate images G ( x ) and G ( x 0 ) that ar e classifie d dif- fer ently by C . Note that a realistic adversarial example is not nec- essarily an adv ersarial example: the images G ( x ) and G ( x 0 ) may differ b y more than ε . Ho wev er, this is the assumption 3. discussed when defining global ro- bustness, if x and x 0 are close, then typic al ly G ( x ) and G ( x 0 ) are tw o very resemblan t images, so the tw o notions are indeed close. W e introduce t wo algorithms for finding realistic ad- v ersarial examples, which are directly inspired by al- gorithms developed for finding adversarial examples. The k ey difference is that realistic adversarial exam- ples are searc hed b y analysing the composed net work C ◦ G . Let us consider tw o digits, for the sake of explanation, 3 and 8. W e ha ve a generativ e mo del G 8 generating images of 8 and an image classifier C . The first algorithm is a black-b ox attack , meaning that it does not hav e access to the inner structure of the net works and it can only simulate them. It consists in sampling random noises, and performing a local searc h for a few steps. F rom a random noise x , w e inspect the random noise x + δ for a few small random noises δ , and choose the random noise x 0 maximising the score of 3 by the net C ◦ G 8 , written C ◦ G 8 ( x i )[3] in the pseudo code given in Algorithm 1. The algorithm is rep eatedly run un til a realistic adv ersarial example is found. Algorithm 1: The black-box attack for the digits 3 and 8. Data: A generativ e mo del G 8 and an image classifier C . A parameter ε > 0. N step ← 16 (n umber of steps) N dir ← 10 (n umber of directions) x 0 ∼ N (0 , 1) for i = 0 to N step − 1 do s max ← C ◦ G 8 ( x i )[3] (score of 3) x i +1 ← x i for j = 0 to N dir − 1 do δ j ∼ N (0 , ε N step ) s ← C ◦ G 8 ( x i + δ j )[3] if s > s max then s max ← s x i +1 ← x i + δ j if C ◦ G 8 ( x 0 ) 6 = C ◦ G 8 ( x i +1 ) then return x 0 ( ε -realistic adv ersarial example) The second algorithm is a white-b ox attack , meaning that it uses the inner structure of the netw orks. It is similar to the previous one, except that the lo cal searc h is replaced by a gradient ascent to maximise the score of 3 by the net C ◦ G 8 . In other words, instead of c ho osing a direction at random, it follo ws the gradien t to maximise the score. It is reminiscent of the pro jected gradien t descen t (PGD) attac k, but p erformed on the comp osed net work. The pseudo code is giv en in Algorithm 2. Both attacks successfully find realistic adversarial ex- amples within less than a min ute. The adjective “real- istic”, which is sub jective, is justified as follows: most attac ks constructing adversarial examples create un- T ec hnical report Algorithm 2: The white-b o x attack for the digits 3 and 8. Data: A generativ e mo del G 8 and an image classifier C . A parameter ε > 0. N step ← 16 (n umber of steps) α ← ε N step (step) x 0 ∼ N (0 , 1) for i = 0 to N step − 1 do x i +1 ← x i − α · Grad C ◦ G 8 ( x i )[3] if C ◦ G 8 ( x 0 ) 6 = C ◦ G 8 ( x i +1 ) then return x 0 ( ε -realistic adv ersarial example) realistic images b y adding noise or mo difying pixels, while with our definition the realistic adversarial ex- amples are images pro duced b y the generative mo del, hence p oten tially more realistic. See Figure 3 for some examples. On the Dep endence on the Generativ e Mo del Both global correctness and robustness notions are de- fined with respect to a generative model. This raises a question: how m uch do es it dep end on the choice of the generativ e mo del? T o answ er this question w e trained t wo GANs using the exact same training procedure but with t w o dis- join t training sets, and used the tw o GANs to ev aluate sev eral image classifiers. The outcome is that the tw o GANs yield sensibly the same results against all image classifiers. This suggests that the glob al correctness in- deed do es not depend dramatically on the c hoice of the generativ e model, provided that it is reasonably goo d and well-trained. W e refer to the Github rep ository for a complete exp osition of the results. Since the training set of the MNIST dataset contains 6,000 images of each digit, splitting it in t wo would not yield tw o large enough training sets. Hence we used the extended MNIST (EMNIST) dataset Cohen et al. (2017), which provided us with (roughly) 34,000 images of each digit, hence tw o disjoint datasets of ab out 17,000 images. On the Influence of Data Augmen tation Data augmentation is a classical tec hnique for increas- ing the size of a training set, it consists in creating new training data by applying a set of mild transformations to the existing training set. In the case of digit images, common transformations include rotations, shear, and shifts. Unsurprisingly , crossing the t wo training sets, e.g. us- ing the standard training set for the image classifier and an augmented one for the generative mo del yields w orse results than when using the same training set. More interestingly , the robust netw orks M ¸ adry et al. (2018); Papernot et al. (2016), which are trained us- ing an improv ed pro cedure but based on the standard training set, p erform well against generative mo dels trained on the augmen ted training set. In other w ords, one outcome of the improv ed training pro cedure is to b etter capture the natural image transformations, ev en if they were never used in training. 5 Conclusions W e defined t wo notions: global correctness and global robustness, based on generative mo dels, aiming at quan tifying the usability of an image classifier. W e p erformed some exp erimen ts on the MNIST dataset to understand the merits and limits of our definitions. An imp ortan t c hallenge lies ahead: to make the ver- ification of global robustness doable in a reasonable amoun t of time and computational effort. Bibliograph y Dan Ciregan, Ueli Meier, and Juergen Schmidh u- b er. Multi-column deep neural netw orks for im- age classification. In IEEE Confer enc e on Com- puter Vision and Pattern R e c o gnition (CCVPR) , pages 3642–3649, June 2012. doi: 10.1109/CVPR. 2012.6248110. URL https://ieeexplore.ieee. org/document/6248110 . Gregory Cohen, Saeed Afshar, Jonathan T apson, and Andr ´ e v an Schaik. EMNIST: an extension of MNIST to handwritten letters. CoRR , abs/1702.05373, 2017. URL . Timon Gehr, Matthew Mirman, Dana Drachsler- Cohen, P etar Tsanko v, Sw arat Chaudhuri, and Mar- tin T. V ec hev. AI2: safety and robustness certifica- tion of neural netw orks with abstract in terpretation. In IEEE Symp osium on Se curity and Privacy (SP) , pages 3–18, 2018. doi: 10.1109/SP .2018.00058. URL https://doi.org/10.1109/SP.2018.00058 . Ian J. Go odfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-F arley , Sherjil Ozair, Aaron C. Courville, and Y oshua Bengio. Genera- tiv e adv ersarial nets. In Confer enc e on Neur al In- formation Pr o c essing Systems (NIPS) , pages 2672– 2680, 2014. URL http://papers.nips.cc/paper/ 5423- generative- adversarial- nets . Divy a Gopinath, Guy Katz, Corina S. Pasarean u, and Clark Barrett. Deepsafe: A data-driv en ap- proac h for assessing robustness of neural net w orks. In Symp osium on A utomate d T e chnolo gy for V er- ific ation and Analysis (A TV A) , pages 3–19, 2018. T ec hnical report Figure 3: Examples of realistic adversarial examples. On the left hand side, against the smallest net, and on the righ t hand side, against M ¸ adry et al. (2018) doi: 10.1007/978- 3- 030- 01090- 4 \ 1. URL https: //doi.org/10.1007/978- 3- 030- 01090- 4_1 . Xiao wei Huang, Marta Kwiatko wsk a, Sen W ang, and Min W u. Safet y v erification of deep neural netw orks. In Computer-Aide d V erific a- tion (CA V) , pages 3–29, 2017. doi: 10.1007/ 978- 3- 319- 63387- 9 \ 1. URL https://doi.org/10. 1007/978- 3- 319- 63387- 9_1 . T ero Karras, Samuli Laine, and Timo Aila. A style- based generator architecture for generative adver- sarial netw orks. CoRR , abs/1812.04948, 2018. URL http://arxiv.org/abs/1812.04948 . Guy Katz, Clark W. Barrett, David L. Dill, Kyle Julian, and Myk el J. Ko chenderfer. Reluplex: An efficien t SMT solv er for v erifying deep neu- ral netw orks. In Computer-Aide d V erific ation (CA V) , pages 97–117, 2017. doi: 10.1007/ 978- 3- 319- 63387- 9 \ 5. URL https://doi.org/10. 1007/978- 3- 319- 63387- 9_5 . Guy Katz, Derek A. Huang, Duligur Ib eling, Kyle Ju- lian, Christopher Lazarus, Rachel Lim, Parth Shah, Shan tanu Thakoor, Haoze W u, Aleksandar Zeljic, Da vid L. Dill, Mykel J. Kochenderfer, and Clark W. Barrett. The marab ou framework for verification and analysis of deep neural netw orks. In Computer- A ide d V erific ation (CA V) , pages 443–452, 2019. doi: 10.1007/978- 3- 030- 25540- 4 \ 26. URL https: //doi.org/10.1007/978- 3- 030- 25540- 4_26 . Aleksander M ¸ adry , Aleksandar Mak elov, Ludwig Sc hmidt, Dimitris Tsipras, and Adrian Vladu. T o- w ards deep learning mo dels resistant to adversar- ial attacks. In International Confer enc e on L e arn- ing R epr esentations (ICLR) , 2018. URL https: //openreview.net/forum?id=rJzIBfZAb . Matthew Mirman, Timon Gehr, and Martin T. V ec hev. Differentiable abstract interpretation for pro v ably robust neural netw orks. In International Confer enc e on Machine L e arning (ICML) , pages 3575–3583, 2018. URL http://proceedings.mlr. press/v80/mirman18b.html . Nicolas Papernot, P atrick D. McDaniel, Xi W u, Somesh Jha, and Ananthram Swami. Distillation as a defense to adv ersarial p erturbations against deep neural net works. In IEEE Symp osium on Se- curity and Privacy (SP) , pages 582–597, 2016. doi: 10.1109/SP .2016.41. URL https://doi.org/10. 1109/SP.2016.41 . Christian Szegedy , W o jciec h Zaremba, Ilya Sutsk ever, Joan Bruna, Dumitru Erhan, Ian J. Go odfellow, and Rob F ergus. Intriguing prop erties of neural net works. In International Confer enc e on L e arn- ing R epr esentations (ICLR) , 2014. URL http: //arxiv.org/abs/1312.6199 . Leslie G. V aliant. A theory of the learnable. Com- munic ations of the ACM , 27(11):1134–1142, 1984. doi: 10.1145/1968.1972. URL https://doi.org/ 10.1145/1968.1972 . Li W an, Matthew Zeiler, Sixin Zhang, Y ann Le Cun, and Rob F ergus. Regularization of neural net w orks using dropconnect. In International Confer enc e on Machine L e arning (ICML) , v olume 28, pages 1058–1066, 2013. URL http://proceedings.mlr. press/v28/wan13.html . Tsui-W ei W eng, Huan Zhang, Hongge Chen, Zhao Song, Cho-Jui Hsieh, Luca Daniel, Duane S. Boning, and Inderjit S. Dhillon. T o wards fast computation of certified robustness for relu netw orks. In Inter- national Confer enc e on Machine L e arning (ICML) , pages 5273–5282, 2018. URL http://proceedings. mlr.press/v80/weng18a.html . Chao wei Xiao, Bo Li, Jun-Y an Zhu, W arren He, Mingy an Liu, and Da wn Song. Generating ad- v ersarial examples with adversarial net works. In Pr o c e e dings of the Twenty-Seventh International Joint Confer enc e on Artificial Intel ligenc e (IJCAI) , pages 3905–3911, 2018. doi: 10.24963/ijcai.2018/ 543. URL https://doi.org/10.24963/ijcai. 2018/543 . Han Xiao, Kashif Rasul, and Roland V ollgraf. F ashion-MNIST: a nov el image dataset for b enc h- marking mac hine learning algorithms. CoRR , T ec hnical report abs/1708.07747, 2017. URL abs/1708.07747 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment