Q-learning for POMDP: An application to learning locomotion gaits
This paper presents a Q-learning framework for learning optimal locomotion gaits in robotic systems modeled as coupled rigid bodies. Inspired by prevalence of periodic gaits in bio-locomotion, an open loop periodic input is assumed to (say) affect a …
Authors: Tixian Wang, Amirhossein Taghvaei, Prashant G. Mehta
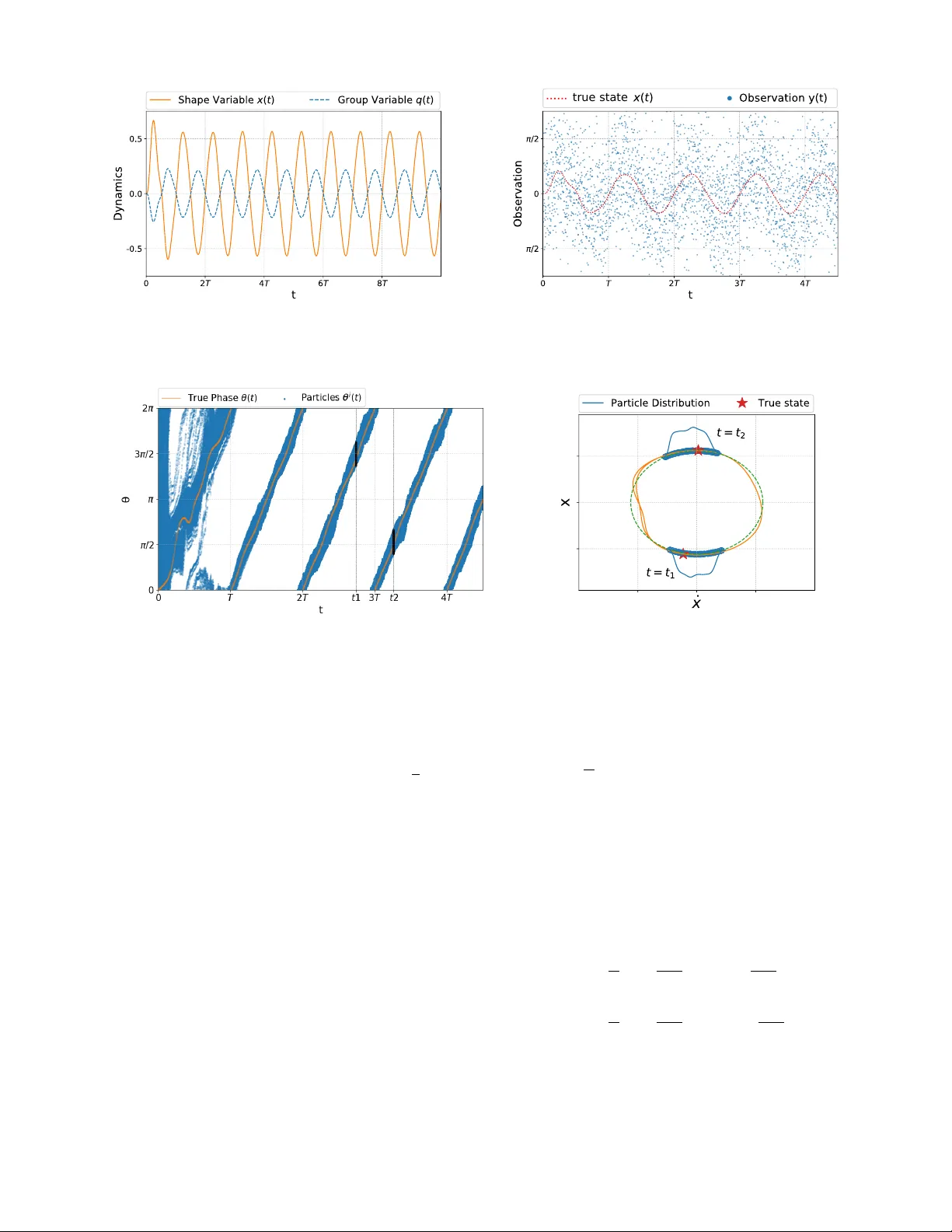
Q-learning f or POMDP: An application to learning locomotion gaits T ixian W ang, Amirhossein T aghv aei, and Prashant G. Mehta Abstract — This paper pr esents a Q-lear ning framework for learning optimal locomotion gaits in robotic systems modeled as coupled rigid bodies. Inspired by prevalence of periodic gaits in bio-locomotion, an open loop periodic input is assumed to (say) affect a nominal gait. The lear ning problem is to lear n a new (modified) gait by using only partial noisy measurements of the state. The objective of learning is to maximize a given reward modeled as an objective function in optimal contr ol settings. The proposed control architecture has three main components: (i) Phase modeling of dynamics by a single phase variable; (ii) A coupled oscillator feedback particle filter to represent the posterior distribution of the phase conditioned in the sensory measurements; and (iii) A Q-learning algorithm to learn the approximate optimal control law . The architecture is illustrated with the aid of a planar two-body system. The performance of the learning is demonstrated in a simulation envir onment. I . I N T RO D U C T I O N Biological locomotion is the mov ement of an animal from one location to another location, through periodic changes in the shape of the body , along with interaction with the en vironment [ 7 ]. The periodic motion of the shape, which constitutes the building block of locomotion, is called the locomotion gait . Examples of the locomotion gait are legged locomotion, flapping of the wings for flying, or wav elike motion of the fish for swimming. It is a wonderful example for learning because the dynamics are complicated but the goals (rew ard function) are easily modeled. In direct application of Q-learning to these problems, howe ver , a problem arises because the full state is not av ailable. The dynamics for such robotic systems are modeled using coupled rigid bodies. The configuration space is split into two sets of variables: (i) the shape v ariable that describes the robot’ s internal degrees of freedom; (ii) and the gr oup variable that describes the global position and orientation of the robot. The dynamics of the shape variable is given by a second-order dif ferential equation driven by control inputs. The dynamics of the group variable is giv en by a first-order dif ferential equation governed by non-holonomic constraints in the system (e.g conv ersation laws or no slipping conditions). A typical approach to design the locomotion gait is to search for a periodic orbit in the shape space that leads to a desired net change in the group variable. This idea of producing a net change through underlying periodic motion Financial support from the NSF grant CMMI-1462773 and ARO grant W911NF1810334 is gratefully acknowledged. T . W ang, A. T aghv aei and P . G. Mehta are with the Coordinated Science Laboratory and the Department of Mechanical Science and Engineering at the University of Illinois at Urbana-Champaign (UIUC). tixianw2@illinois.edu; taghvae2@illinois.edu; mehtapg@illinois.edu is kno wn as mechanical rectification [ 3 ], [ 11 ] and the net change in the group variable is called geometric phase [ 9 ], [10], [12]. The optimal gait is obtained by searching over a parameterized set of trajectories in the shape space to optimize a given optimization criteria [ 2 ], [ 17 ], [ 26 ], [ 15 ], [ 18 ], [ 6 ]. The resulting control la w is open-loop and can suffer from issues due to uncertainties in the en vironment, or disturbance which perturbs the trajectory aw ay from the orbit. The problem considered in this paper is to learn an approximate optimal gait giv en an open-loop periodic input. W e do not assume any control ov er this input: for example, it may correspond to the nominal gait or it may be exerted from the en vironment. The presence of the periodic input creates a limit cycle in the high-dimensional configuration space. The control problem is to actuate some of the system parameters to learn new types of gaits. For the purpose of learning, no knowledge of dynamic models is assumed. Furthermore, knowledge of full state is not assumed. At each time, one only has access to partial noisy measurements of the state. The proposed control architecture builds upon our prior work on phase estimation [ 22 ] and its use for optimal control of bio-locomotion [ 20 ]. As in [ 20 ], the control problem is modeled as an optimal control problem. Since full state feedback is not assumed, we are in the partially observed settings. The original contribution of this work is to extend our prior work to a reinforcement learning framework whereby ne w gaits can be learned by the robot only through the use of noisy measurements and observed re wards. The proposed control architecture has three parts: 1. Phase modeling: Under the assumed periodic input, the shape trajectory is a limit cycle in the high-dimensional phase space. The main complexity reduction technique is to introduce a phase v ariable θ ( t ) ∈ [ 0 , 2 π ] to parametrize the low-dimensional periodic orbit. The inspiration comes from neuroscience where phase reduction is a popular technique to obtain reduced order model of neuronal dynamics [ 8 ], [ 4 ]. 2. Coupled oscillator feedback particle filter: W e construct a nonlinear filtering algorithm to approximate the posterior distribution of the phase variable θ ( t ) , gi ven time history of sensory measurements. The coupled oscillator feedback particle filter (FPF) is comprised of a system of N coupled oscillators [ 23 ], [ 21 ]. The empirical distribution of the oscillators is used to approximate the posterior distribution. 3. Reinfor cement learning: The control problem is cast as a partially observed optimal control problem. The posterior distribution represents an information state for the problem. A Q-learning algorithm is proposed where the Q-function is approximated through a linear function approximation. The weights are learned by implementing a gradient descent algorithm to reduce the Bellman error [27], [25], [13]. The key component of the proposed architecture is the system of coupled oscillators that is used to both represent the posterior distribution (the belief state) and to learn the optimal control policy . This control system can be vie wed as a central pattern generator (CPG) which integrates sensory information to learn closed-loop optimal control policies for bio-locomotion. The proposed CPG control architecture is illustrated with the aid of a two-body planar system depicted in Fig. 1. An open-loop periodic torque is applied at the joint connecting the two links, which results in the body to oscillate in a periodic (b ut uncontrolled) manner . The control objectiv e is to turn the head clockwise by actuating the length of the tail body . Although only a two-body system is considered in this paper , the proposed architecture can easily be generalized to coupled body models of snake-robots and swimming fish robots. This is the subject of ongoing work. The remainder of this paper is organized as follows: The problem is formulated in Section II. The proposed solution is described in Section III. The numerical results appear in Section IV. I I . P RO B L E M F O R M U L AT I O N A. Modeling and dynamics Consider a system of two planar rigid bodies, the head body B 1 and the tail body B 2 , connected by a single degree of freedom pin joint as depicted in Figure 1. The configuration v ariables of the system are divided into two sets: i) the shape v ariable; ii) and the group variable. For the two-body system, the shape variable is the relativ e orientation between two bodies. It is denoted as the angle x . The group variable is the absolute orientation of the frame rigidly af fixed to head body . It is denoted as the angle q . There is no external force applied to the system, which means that the total angular momentum is conserved. The joint is assumed to be actuated by a motor with driv en torque τ . An open-loop periodic input is assumed for the torque actuation: τ ( t ) = τ 0 sin ( ω 0 t ) (1) where ω 0 is the frequency and τ 0 is the amplitude. There is no control objecti ve associated with this torque input, except to ha ve the shape variable x oscillate in a periodic manner . It is assumed that there exists a control actuation that changes the length of the tail body B 2 according to d ( t ) = ( 1 + u ( t )) ¯ d (2) where ¯ d is the nominal length and u represents the control input. The dynamics of the two-body system is described by a second-order ODE for the shape variable and a first-order ODE for the group v ariable: ¨ x ( t ) = ˜ g ( x ( t ) , ˙ x ( t ) , τ ( t ) , u ( t )) , ( x ( 0 ) , ˙ x ( 0 )) = ( x 0 , ˙ x 0 ) (3a) ˙ q ( t ) = ˜ f ( x ( t ) , ˙ x ( t ) , u ( t )) (3b) Fig. 1. Schematic of the two-body system. The e xplicit form of the functions ˜ f and ˜ g and their deri v ations appear in [ 20 ]. In this paper, the explicit form of ˜ f and ˜ g are assumed unknown. Rather , the dynamic model is treated as a simulator (black-box) that is used to simulate the dynamics (3a)-(3b). Remark 1: The modeling procedure is easily generalized to a chain of n planar rigid links, e.g used to model snake robots as in [ 9 ]. In such systems, the group variable is the position and orientation of the robot, and the configuration space of shape v ariable is n − 1 dimensional. With n links, the dimension of the system is 2 n + 1 . An interesting problem for the snake robot is to learn a turning maneuver by changing the friction coefficients with respect to the surface. B. Observation pr ocess For the purposes of learning and control design, the state ( x , ˙ x ) is assumed to be unknown. The follo wing continuous- time observ ation model is assumed for the sensor: d Z ( t ) = ˜ h ( x ( t ) , ˙ x ( t )) d t + σ W d W ( t ) (4) where Z ( t ) ∈ R denotes the observation at time t , W ( t ) is a standard W iener process, and σ W > 0 is the noise strength. The observation function ˜ h : R 2 → R is known and is assumed to be C 1 . C. Optimal contr ol pr oblem The control objectiv e is to turn the head body B 1 clockwise by actuating the control input u ( t ) . An uncontrolled periodic torque input (1) is assumed to be present. The control objecti ve is modeled as a discounted infinite-horizon optimal control problem: ˜ J ( x 0 , ˙ x 0 ) = min u ( · ) E Z ∞ 0 e − γ t ˜ c ( x ( t ) , ˙ x ( t ) , u ( t )) d t (5) subject to the dynamic constraints (3a) . Here, γ > 0 is the discount rate and the cost function ˜ c ( x , ˙ x , u ) = ˜ f ( x , ˙ x , u ) + 1 2 ε u 2 with ε > 0 as the control penalty parameter . The minimum is ov er all control inputs u ( · ) adapted to the filtration Z t : = σ ( Z ( s ) ; s ∈ [ 0 , t ]) generated by the observation process. Fig. 2. The limit c ycle solution for the shape dynamics ( x ( t ) , ˙ x ( t )) together with its limit cycle approximation (see (21)). The particular form of the cost function is assumed to maximize the rate of change, in the clockwise direction, in the group variable q . Indeed, by (3b) , ˜ f ( x , ˙ x , u ) = ˙ q . Therefore, minimizing the cost leads to net negati v e change in the head orientation q ( t ) . This corresponds to the clockwise rotation. I I I . S O L U T I O N A P P RO AC H Solving the optimal control problem (5) is challenging because of the following reasons: 1) The function ˜ g in the dynamic model (3a) is not known. For coupled rigid bodies, the model is nonlinear and complicated due to the details of the geometry , models of contact forces with the en vironment, uncertain parameters, etc. 2) The problem is partially observ ed, i.e., the state ( x , ˙ x ) is not known. As the number of links gro w , the state can be very high dimensional. 3) The e xplicit form of the function ˜ f which captures the relationship between shape and group dynamics is not known. These challenges are tackled by the following three-step procedure: A. Step 1. Phase modeling Consider the second-order equation (3a) for the shape variable x under the open-loop periodic input τ ( t ) giv en by (1) . The following assumption is made concerning its solution: Assumption A1 Under periodic forcing τ ( t ) as in (1) , the solution to (3a) is given by an isolated asymptotically stable periodic orbit (limit cycle) with period 2 π / ω 0 . Denote the set of points on limit cycle as P ⊂ R 2 . The limit cycle solution is parameterized by a phase coordinate θ ∈ [ 0 , 2 π ) in the sense that there exists an in vertible map X L C : [ 0 , 2 π ) → P such that X LC ( θ ( t )) = ( x ( t ) , ˙ x ( t )) , where θ ( t ) = ( ω 0 t + θ ( 0 )) mod 2 π (see Figure 2). The definition of the phase variable is extended locally in a small neighborhood of the limit cycle by using the notion of isochrons [8]. In terms of the phase variable, the first-order dynamics of the group variable (3b) is expressed as ˙ q ( t ) = ˜ f ( X L C ( θ ( t )) , u ( t )) = : f ( θ ( t ) , u ( t )) (6) and the observation model (4) is expressed as d Z ( t ) = h ( θ ( t )) d t + σ W d W ( t ) (7) where h ( θ ) : = ˜ h ( X L C ( θ )) . The optimal control problem (5) in terms of the phase variable is gi ven by J ( θ 0 ) = min u ( · ) E Z ∞ 0 e − γ t c ( θ ( t ) , u ( t )) d t (8) where c ( θ , u ) = f ( θ , u ) + 1 2 ε u 2 and the minimum is ov er all control inputs u ( · ) adapted to the filtration Z t . In contrast to the original problem, the ne w problem is described by a single phase v ariable. W ith u ( t ) ≡ 0 , the dynamics is described by the oscillator model θ ( t ) = ( ω 0 t + θ 0 ) mod 2 π . Now , in the presence of (small) control input, the dynamics need to be augmented by additional terms due to control: d θ ( t ) = ( ω 0 + ε g ( θ ( t )) , u ( t )) d t (9) B. Step 2. F eedback particle filter (FPF) A feedback particle filter is constructed to obtain the posterior distribution of the phase v ariable θ ( t ) giv en the noisy observations (7) . The filter is comprised of N stochastic processes { θ i ( t ) : 1 ≤ i ≤ N } , where the v alue θ i ( t ) ∈ [ 0 , 2 π ] is the state of the i -th particle (oscillator) at time t . The dynamics e volv es according to d θ i ( t ) = ω i d t + ε g ( θ i ( t )) , u ( t )) d t + K ( θ i ( t ) , t ) σ 2 W ◦ d Z ( t ) − h ( θ i ( t )) + ˆ h ( t ) 2 d t ! (10) where ω i ∼ Unif ([ ω 0 − δ , ω 0 + δ ]) is the frequency of the i -th oscillator , the initial condition θ i ( 0 ) = θ i 0 ∼ Unif ([ 0 , 2 π ]) , and ˆ h ( t ) : = E [ h ( θ i ( t )) | Z t ] . The notation ◦ denotes Stratonovich integration. In the numerical imple- mentation, ˆ h ( t ) ≈ N − 1 ∑ N i = 1 h ( θ i ( t )) . Based on the FPF theory , the gain function K ( θ , t ) is the solution of the Poisson equation, expressed in the weak-form as E [ K ( θ ( t ) , t ) ψ 0 ( θ t ) | Z t ] = E [( h ( θ t ) − ˆ h ) ψ ( θ ( t )) | Z t ] (11) for all test functions ψ where ψ 0 is the deri vati ve. In the nu- merical implementation, the gain function is approximated by choosing ψ from the Fourier basis functions { sin ( θ ) , cos ( θ ) } and approximating the expectations with empirical distrib ution of the oscillators { θ i ( t ) : 1 ≤ i ≤ N } . The detailed numerical algorithm to approximate the gain function appears in [ 23 ]. Remark 2: There are two manners in which control input u ( t ) af fects the dynamics of the filter state θ i ( t ) : 1) The O ( ε ) term ε g ( · , u ( t )) which models the ef fect of dynamics; 2) The FPF update term which models the effect of sensor measurements. This is because the control input u ( t ) affects the state x ( t ) (see (3a) ) which in turn affects the sensor measurements Z ( t ) (see (4)). C. Step 3. Q-learning Using the FPF , following the approach presented in [ 14 ], express the partially observed optimal control problem (8) as a fully observed optimal control problem in terms of oscillator states θ ( N ) ( t ) = ( θ 1 ( t ) , . . . , θ N ( t )) according to J ( N ) ( θ ( N ) 0 ) = min u ( · ) E Z ∞ 0 e − γ t c ( N ) ( θ ( N ) ( t ) , u ( t )) d t (12) subject to (10) , where the cost c ( N ) ( θ ( N ) , u ) : = 1 N ∑ N i = 1 c ( θ i , u ) and the minimization is over all control laws adapted to the filtration X t : = { θ i ( s ) ; s ≤ t , 1 ≤ i ≤ N } . The problem is now fully observed because the states of oscillators θ ( N ) ( t ) are known. The analogue of the Q-function for continuous-time sys- tems is the Hamiltonian function: H ( N ) ( θ ( N ) , u ) = c ( N ) ( θ ( N ) , u ) + D u J ( N ) ( θ ( N ) ) (13) where D u is the generator for (10) defined such that d d t E [ J ( N ) ( θ ( N ) ( t ))] = D u J ( N ) ( θ ( N ) ( t )) . The dynamic programming principle for the discounted problem implies: min u H ( N ) ( θ ( N ) , u ) = γ J ( N ) ( θ ( N ) ) (14) Substituting this into the definition of the Hamiltonian (13) yields the fixed-point equation: D u H ( N ) ( θ ( N ) ) = γ ( c ( N ) ( θ ( N ) , u ) − H ( N ) ( θ ( N ) , u )) (15) where H ( N ) ( θ ( N ) ) : = min u H ( N ) ( θ ( N ) , u ) . This is the fixed- point equation that appears in the Q-learning. Linear function approximation: Learning the exact Hamil- tonian (Q-function) is an infinite-dimensional problem. There- fore, we set the goal to learn an approximation. For this purpose, consider a fixed set of M real-valued functions { φ ( m ) ( θ , u ) } M m = 1 . The Hamiltonian is approximated as the linear combination of the basis functions as follows: ˆ H ( N ) ( θ ( N ) , u ; w ) = 1 N N ∑ i = 1 w T φ ( θ i , u ) (16) where w ∈ R M is a vector of parameters (or weights) and φ = ( φ ( 1 ) , φ ( 2 ) , . . . , φ ( M ) ) T is a vector of basis functions. Thus, the infinite-dimensional problem of learning the Hamiltonian function is con verted into the problem of learning the M - dimensional weight vector w . Define the point-wise Bellman error according to E ( θ ( N ) , u ; w ) : = D u ˆ H ( N ) ( θ ( N ) ; w ) + γ ( c ( N ) ( θ ( N ) , u ) − ˆ H ( N ) ( θ ( N ) , u ; w )) (17) where ˆ H ( N ) ( θ ( N ) ; w ) : = min u ˆ H ( N ) ( θ ( N ) , u ; w ) . The following learning algorithm is proposed to find the optimal parameters d d t w ( t ) = − 1 2 α ( t ) ∇ w E 2 ( θ ( N ) ( t ) , u ( t ) ; w ( t )) (18) where α ( t ) is the time-varying learning gain and u ( t ) is chosen to explore the state-action space. For con vergence analysis of the Q-learning algorithm see [ 24 ], [ 19 ], [ 5 ], [ 16 ]. Giv en a learned weight vector w ∗ , the learned optimal control policy is gi ven by: ˆ u ∗ ( θ ( N ) ; w ∗ ) = arg min v ˆ H ( N ) ( θ ( N ) , v ; w ∗ ) (19) D. Information structure In order to implement the algorithm, one requires knowl- edge of the following models: 1) A model for g ( θ , u ) which represents the reduced order model of dynamics as these af fect the phase variable; 2) A model for h ( θ ) which represents the reduced order model of the sensor . These models are needed to implement the coupled oscillator FPF (10) . It is noted that both the models are described with respect to the phase v ariable θ . In the simulation results presented next, we assume knowledge of h ( θ ) and ignore the term ε g ( θ i ( t ) , u ( t )) in the FPF . The formal reason for ignoring the term is that it is small ( O ( ε ) ) compared to other terms, O ( 1 ) frequency ω 0 and the update term. Although, we assume knowledge of the sensor model h ( θ ) for this paper , a learning algorithm could also be implemented to learn the sensor model in an online manner . This is the subject of future work. In numerical implementation, the generator D u is approxi- mated as D u ˆ H ( N ) ( θ ( N ) ( t )) ≈ ˆ H ( N ) ( θ ( N ) ( t + ∆ t )) − ˆ H ( N ) ( θ ( N ) ( t )) ∆ t where ∆ t is the discrete time step-size in the numerical algorithm and { θ i ( t ) } N i = 1 is the state of the oscillators at time t . The rew ard function f ( θ ( t ) , u ( t )) in the cost function is approximated as f ( θ ( t ) , u ( t )) = ˙ q ( t ) ≈ q ( t + ∆ t ) − q ( t ) ∆ t where q ( t ) is av ailable through the (black-box) simulator . The ov erall algorithm appears in T able 1. E. Appr oximate formula for optimal contr ol input Assuming the knowledge of the explicit form of the function f ( θ , u ) , a semi-analytic approach is presented in [ 20 ] to deriv e the follo wing approximate formula for optimal control: u ∗ ( t ) ≈ ε C N N ∑ i = 1 cos ( θ i ( t )) (20) where C is a constant that depends on the parameters of the model. The formula was shown to be valid in the asymptotic limit as ε → 0 . The control policy (20) is implemented in [ 20 ] Algorithm 1 Q-learning for Optimal Contol of T wo-body System Input: Parameters in T able I and a simulator for (3a) - (3b) - (4) Output: Optimal control policy ˆ u ∗ ( θ ( N ) ; w ) . 1: Initialize particles { θ i 0 } N i = 1 ∼ Unif ([ 0 , 2 π ]) ; 2: Initialize weight vector w 0 according to (22). 3: f or k = 0 to t T / ∆ t − 1 do 4: Choose control input u k according to (23); 5: Input u k to the simulator and output Z k and q k 6: Update particles in FPF θ i k + 1 = θ i k + ω i ∆ t + K ( θ i k ) σ 2 W ( Z k + 1 − Z k − h ( θ i k ) + ˆ h k 2 ∆ t ) 7: Compute the cost c k = 1 ∆ t ( q k + 1 − q k ) + 1 2 ε u 2 k 8: Compute D u ˆ H ( N ) k = 1 ∆ t ( ˆ H ( N ) ( θ ( N ) k + 1 ; w k ) − ˆ H ( N ) ( θ ( N ) k ; w k )) 9: Compute Bellman error E k = D u ˆ H ( N ) k + γ ( c k − ˆ H ( N ) ( θ ( N ) k , u k ; w k )) 10: Update weight vector w k + 1 = w k − ∆ t α k E k ∇ w E k 11: end for 12: Output the learned control policy ˆ u ∗ ( θ ( N ) ; w k ) from (19) . where it is numerically sho wn to lead to clockwise rotation of the head body . The formula (20) serves as a baseline for comparison with the results of the numerical implementation of the Q-learning algorithm. I V . N U M E R I C S In this section, we present the numerical results. These results illustrate the i) phase modeling; ii) the performance of coupled oscillator FPF; and iii) the performance of Q- learning algorithm. The numerical results are based on the use of Algorithm 1. The simulation parameters are tabulated in T able I. A. Simulator The simulator takes the control input u ( t ) and outputs the shape variable x ( t ) , the head orientation q ( t ) , and the observ ation Z ( t ) according to (3a) , (3b) , and (4) respecti vely . The explicit form of the simulated dynamics (3a) - (3b) are as follows: ¨ x = 1 ∆ − λ sin ( x ) A 1 A 2 A 1 + A 2 ˙ x 2 + ( A 1 + A 2 )( τ ( t ) − κ x − b ˙ x ) ˙ q = ˜ I 2 + λ cos ( x ) ˜ I 1 + ˜ I 2 + 2 λ cos ( x ) ˙ x where the parameters are defined in T able I; cf., [ 20 ] for additional details on modeling. The resulting state trajectory x ( t ) and head orientation q ( t ) , under periodic open-loop torque τ ( t ) (see (1) ), are depicted in Figure 3(a). It is observed that without control input, the head orientation oscillates, without any net change. T ABLE I P A R A ME T E R S F O R N U ME R I C AL S IM U L A T I ON Parameter Description Numerical value T w o-body system m i Mass of body B i m 1 = 1 m 2 = 1 2 I i Moment of inertia of body B i I 1 = 2 3 I 2 = 1 6 d i Span of body B i d 1 = 1 d 2 = 1 Some auxiliary parameters ˜ m = m 1 m 2 m 1 + m 2 , ˜ I i = I i + ˜ md 2 i , λ = ˜ md 1 d 2 A i ( x ) = ˜ I i + λ cos ( x ) , ∆ ( x ) = ˜ I 1 ˜ I 2 − λ 2 cos 2 ( x ) Dynamic model ω 0 Input torque frequency 1 . 0 τ 0 Input torque amplitude 1 . 0 κ T orsional spring coefficient 2 . 0 b V iscous friction coefficient 0 . 1 Sensor & FPF ∆ t Discrete time step-size 0 . 01 σ W Noise process std. dev . 0 . 1 N Number of particles 1000 δ Heterogeneous parameter 0 . 12 Q-learning t T simulation terminal time 1002 π / ω 0 γ Discount rate 1 . 0 ε Control penalty parameter 1 . 0 α k Learning gain 0 . 5 A Control exploration amplitude 0 . 25 The observ ation signal y ( t ) : = ( Z ( t + ∆ t ) − Z ( t )) / ∆ t , with the step-size ∆ t = 0 . 01 is depicted in Figure 3(b). The observ ation model is taken as ˜ h ( x , ˙ x ) = x . The noise strength σ w = 0 . 1. B. Phase modeling The limit cycle solution for the shape dynamics (3a) is depicted in Figure 2. The map ˜ X L C ( θ ( t )) = ( x ( t ) , ˙ x ( t )) is approximated as ˜ X L C ( θ ) ≈ ( r sin ( θ ) , r ω 0 cos ( θ )) (21) where r = 0 . 56 is numerically determined. C. Coupled oscillator feedback particle filter The trajectories of N = 1000 particles in the FPF algo- rithm (10) are depicted in Figure 4(a). The initial conditions θ i 0 are drawn from a uniform distribution in [ 0 , 2 π ] . The initial transients due to the initial condition con ver ge rapidly . The true phase variable θ ( t ) is also depicted as a solid line. It is observed that the ensemble of particles synchronize and track the true phase. The true state ( x ( t ) , ˙ x ( t )) , along with the empirical distri- bution of the particles, at two time instants, are shown in Figure 4(b). The particles are positioned on the approximate limit cycle map (21) . These results show that the filter is able to track the true state on the limit cycle accurately . D. Q-learning T o approximate the Hamiltonian function in (16) , the basis functions are selected to be the product of Fourier basis (a) true state (b) Fig. 3. Summary of numerical results for the two-body system simulator: (a) T rajectory for the shape variable x ( t ) and the the head orientation q ( t ) under no control input ( u ( t ) ≡ 0); (b) Observation process y ( t ) . (a) (b) Fig. 4. Summary of estimation results: (a) Time trace of N = 1000 particles in the FPF algorithm compared with the true phase θ ( t ) ; (b) Empirical distribution of the particles compared with the true state ( x , ˙ x ) at two time instants t 1 and t 2 . functions of θ and polynomial functions of u as follo ws: φ ( θ , u ) = cos ( θ ) , sin ( θ ) , cos ( 2 θ ) , sin ( 2 θ ) , u cos ( θ ) , u sin ( θ ) , u cos ( 2 θ ) , u sin ( 2 θ ) , 1 2 u 2 T The weight vector w 0 = w ( 1 ) 0 , ..., w ( 9 ) 0 T is initialized ran- domly as follows: w ( m ) 0 ∼ Unif ([ − 1 , 1 ]) for m = 1 , . . . , 8 w ( 9 ) 0 ∼ Unif ([ 0 . 9 , 1 . 1 ]) (22) The reason for choosing the particular initialization for w ( 9 ) 0 is to av oid numerical issues due to large control values whene ver w ( 9 ) 0 is small. The exploration control input u ( t ) to be used in (18) is chosen as a combination of sinusoidal functions with irrationally related frequencies as follo ws: u ( t ) = A sin ( ω 0 t ) + A sin ( π ω 0 t ) (23) The rationale for doing so is to explore the state-action space [1]. The L 2 -norm of the point-wise Bellman error (17) , over the j -th period is denoted as e j and defined to be: e j : = 1 T Z jT ( j − 1 ) T E ( θ ( N ) ( t ) , u ( t ) ; w ( t )) 2 d t (24) The average of the error e j and its v ariance over fifty Monte- Carlo runs are depicted in Figure 5(a). It is observed that the Bellman error drops by over three orders of magnitude. This suggests that the algorithm is able to learn the Hamiltonian function that solves the dynamic programming fixed-point equation (15). The learned optimal control policy (19) in terms of the selected basis functions is gi ven by: ˆ u ∗ ( θ ( N ) ; w ) = − 1 N N ∑ i = 1 w ( 5 ) w ( 9 ) cos ( θ i ) + w ( 6 ) w ( 9 ) sin ( θ i ) ! − 1 N N ∑ i = 1 w ( 7 ) w ( 9 ) cos ( 2 θ i ) + w ( 8 ) w ( 9 ) sin ( 2 θ i ) ! (25) The traces of the four components of the weight vector { w ( 5 ) ( t ) , w ( 6 ) ( t ) , w ( 7 ) ( t ) , w ( 8 ) ( t ) } are depicted in Figure 5(b). (a) , , (b) Fig. 5. Summary of Q-learning results: (a) The Bellman error as a function of time; (b) Conv ergence of the four weight components in the learned optimal control law (25). (a) (b) Fig. 6. Summary of control results: (a) Comparison of the control input learned from Q-learning (25) and the semi-analytical optimal control input (20) ; (b) Time trace of the orientation with no control input ( u ( t ) ≡ 0), semi-analytical control input, and the learned control input. It is observed that the components (weights) con verge quickly . Also, the component w ( 5 ) ( t ) , which corresponds to cos ( · ) , dominates while other components con ver ge to zero. Figure 6(a) depicts the learned optimal control policy as a function of time. Also depicted is a comparison with the semi-analytical solution (20) . It is observed that the learned optimal control coincides with the analytical formula in terms of both phase and amplitude. Figure 6(b) depicts the resulting head orientation with i) the learned optimal control policy (25) ; ii) the analytical control law (20) ; and iii) with no control input ( u ( t ) ≡ 0 ). It is observed that the learned optimal control input induces nearly the same net change in the head orientation as the analytical control law . That is, the Q-learning algorithm is able to learn the optimal control policy to rotate the head body clockwise. . V . C O N C L U S I O N S A N D F U T U R E W O R K W e introduced a coupled oscillator-based framework for learning the optimal control of periodic locomotory gaits. The frame work does not require kno wledge of the explicit form of the dynamic models or observation of the full state. The frame work was illustrated on the problem of turning the two-body planar system. One direction for future work, is to apply the framew ork to more complicated models such as coupled kinematic chains and continuum models. Another direction of future work is to consider more adv anced tasks such as turning to a certain angle or locating a target. R E F E R E N C E S [1] D. P . Bertsekas and J. N. Tsitsiklis. Neur o-dynamic pr ogramming , volume 5. Athena Scientific Belmont, MA, 1996. [2] J. Blair and T . Iwasaki. Optimal gaits for mechanical rectifier systems. IEEE T ransactions on Automatic Contr ol , 56(1):59–71, 2011. [3] R. W . Brockett. Pattern generation and the control of nonlinear systems. IEEE transactions on automatic contr ol , 48(10):1699–1711, 2003. [4] E. Brown, J. Moehlis, and P . Holmes. On the phase reduction and response dynamics of neural oscillator populations. Neural computation , 16(4):673–715, 2004. [5] E. Even-Dar and Y . Mansour . Learning rates for q-learning. Journal of Machine Learning Researc h , 5(Dec):1–25, 2003. [6] R. L. Hatton and H. Choset. Generating gaits for snake robots: annealed chain fitting and keyframe wav e extraction. Autonomous Robots , 28(3):271–281, 2010. [7] P . Holmes, R. J. Full, D. Koditschek, and J. Guckenheimer . The dynamics of legged locomotion: Models, analyses, and challenges. SIAM revie w , 48(2):207–304, 2006. [8] E. M Izhikevich. Dynamical systems in neur oscience . MIT press, 2007. [9] S. D. Kelly and R. M. Murray . Geometric phases and robotic locomotion. Journal of Robotic Systems , 12(6):417–431, 1995. [10] P . S. Krishnaprasad. Geometric phases, and optimal reconfiguration for multibody systems. In 1990 American Control Confer ence , pages 2440–2444. IEEE, 1990. [11] P . S. Krishnaprasad. Motion control and coupled oscillators. In Proc. Symposium on Motion, Control, and Geometry , 1997. [12] J. E. Marsden, R. Montgomery , and T . S. Ratiu. Reduction, symmetry , and phases in mechanics , volume 436. American Mathematical Soc., 1990. [13] P . G. Mehta and S. P . Meyn. Q-learning and pontryagin’ s minimum principle. In Pr oceedings of the 48h IEEE Confer ence on Decision and Contr ol (CDC) held jointly with 2009 28th Chinese Contr ol Conference , pages 3598–3605. IEEE, 2009. [14] P . G. Mehta and S. P . Meyn. A feedback particle filter-based approach to optimal control with partial observations. In 52nd IEEE conference on decision and control , pages 3121–3127. IEEE, 2013. [15] J. B Melli, C. W . Rowle y , and D. S. Rufat. Motion planning for an articulated body in a perfect planar fluid. SIAM Journal on applied dynamical systems , 5(4):650–669, 2006. [16] E. Moulines and F . R. Bach. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. In Advances in Neural Information Processing Systems , pages 451–459, 2011. [17] R. M. Murray and S. S. Sastry . Nonholonomic motion planning: Steering using sinusoids. IEEE transactions on Automatic Control , 38(5):700–716, 1993. [18] J. Ostrowski, A. Lewis, R. Murray , and J. Burdick. Nonholonomic mechanics and locomotion: the snakeboard example. In Pr oceedings of the 1994 IEEE International Confer ence on Robotics and Automation , pages 2391–2397. IEEE, 1994. [19] C. Szepesv ´ ari. The asymptotic con vergence-rate of q-learning. In Advances in Neural Information Pr ocessing Systems , pages 1064–1070, 1998. [20] A. T aghvaei, S. A. Hutchinson, and P . G. Mehta. A coupled oscillators- based control architecture for locomotory gaits. In Decision and Contr ol (CDC), 2014 IEEE 53rd Annual Conference on , pages 3487– 3492. IEEE, 2014. [21] A. K. T ilton, E. T . Hsiao-W ecksler, and P . G. Mehta. Filtering with rhythms: Application to estimation of gait cycle. In 2012 American Contr ol Conference (ACC) , pages 3433–3438. IEEE, 2012. [22] A. K. Tilton and P . G. Mehta. Control with rhythms: A cpg architecture for pumping a swing. In American Control Conference (A CC), 2014 , pages 584–589. IEEE, 2014. [23] A. K. T ilton, P . G. Mehta, and S. P . Meyn. Multi-dimensional feedback particle filter for coupled oscillators. In 2013 American Control Confer ence , pages 2415–2421. IEEE, 2013. [24] J. N. Tsitsiklis and B. V an Ro y . Optimal stopping of markov processes: Hilbert space theory , approximation algorithms, and an application to pricing high-dimensional financial derivati ves. IEEE T ransactions on Automatic Contr ol , 44(10):1840–1851, 1999. [25] D. Vrabie, M. Abu-Khalaf, F . L. Lewis, and Y . W ang. Continuous-time adp for linear systems with partially unkno wn dynamics. In 2007 IEEE International Symposium on Appr oximate Dynamic Pro gramming and Reinfor cement Learning , pages 247–253. IEEE, 2007. [26] G. C. W alsh and S. S. Sastry . On reorienting linked rigid bodies using internal motions. IEEE Tr ansactions on Robotics and Automation , 11(1):139–146, 1995. [27] C. J. C. H. W atkins. Learning fr om delayed re wards . PhD thesis, King’ s College, Cambridge, 1989.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment