A Video Recognition Method by using Adaptive Structural Learning of Long Short Term Memory based Deep Belief Network
Deep learning builds deep architectures such as multi-layered artificial neural networks to effectively represent multiple features of input patterns. The adaptive structural learning method of Deep Belief Network (DBN) can realize a high classificat…
Authors: Shin Kamada, Takumi Ichimura
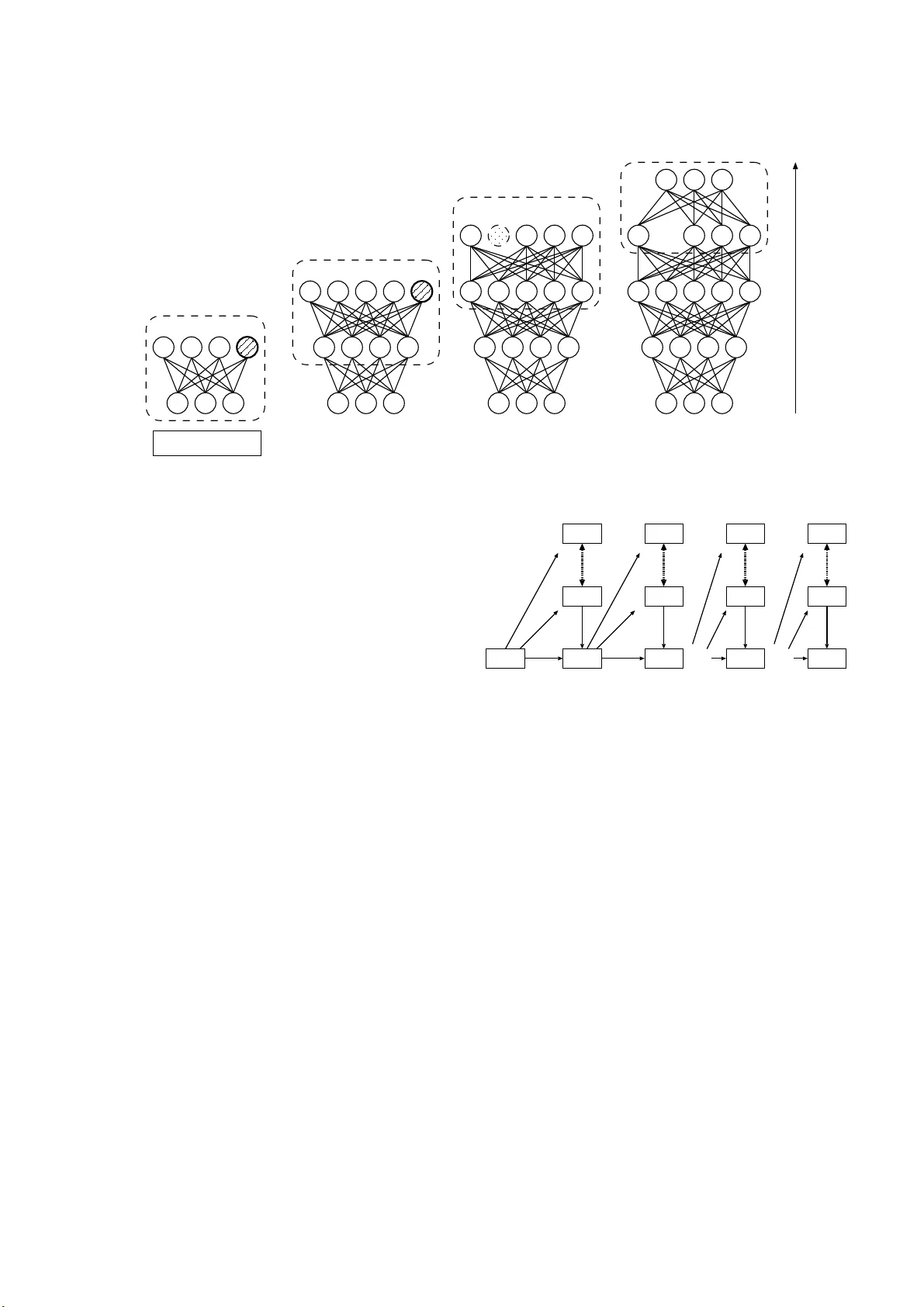
A V ideo Recognition Method by using Adapti v e Structural Learning of Long Short T erm Memory based Deep Belief Network Shin Kamada Advanced Artificial I n telligence Project Research Center, Research Organizatio n of Regional Oriente d Stu dies, Prefectural University of Hiroshima 1-1-7 1, Ujina-Higashi, Minami-k u, Hiroshima 7 34-85 58, Japan E-mail: skam ada@pu-hir o shima.ac.jp T akumi Ichimura Advanced Artificial I n telligence Project Research Center, Research Organizatio n of Regional Oriente d Stu dies, and Faculty of Man agement and Info rmation System, Prefectural University of Hir o shima 1-1-7 1, Ujina-Higashi, Minami-k u, Hiroshima 7 34-85 58, Japan E-mail: ichim ura@pu-h iroshima.ac.jp Abstract —Deep learning b uilds deep architectures such as multi-layere d artificial neural networks to effectively represent multiple features of input p atterns. The adaptive structural learning method of Deep Belief Network (DBN) can r ealize a high classification capability while sear ch ing the optimal network structure durin g the training. Th e method can find the op t imal number of hidden neurons of a Restricted Boltzmann Machine (RBM) by neuron generation-annihilation algorithm to train t h e giv en input data, and then it ca n make a new layer in DBN by the layer generation algorithm to actualize a deep data repre sentation. Mor eover , the learning algor ithm of Ad ap t iv e RBM and Adaptive DBN was extend ed to the time-series analysis by using th e idea of LSTM (Long Short T erm Memory). In this paper , our proposed prediction method w as appli ed to Moving MNIST , which is a bench mark data set for video recognition. W e challenge to rev eal the p ower of our proposed method in the video r ecognition resear ch field, si nce video in cludes rich source of visual i nfo rmation. Compared wi th the LSTM model, our method showed h igher prediction perfo rmance (more than 90% predication accuracy for test data). Index T erms —Deep learning, Deep Belief Network, Ad aptive structural learning method, Video r ecognition I . I N T RO D U C T I O N Recently , Artificial I ntelligence (AI) with sophisticated tech- nologies h as b ecome an essential techniq ue in our life. [1]. Es- pecially , the recent adv ances in d eep le a r ning methods enable higher per formanc e for sev eral big data com pared to traditional methods [2], [3]. For example, CNNs (Con volutional Neural Network) such as AlexNet [4], Goog LeNet [ 5], VGG16 [6], and ResNet [7], hig hly im proved classification o r de tection accuracy in image recognitio n [8]. As im provement of imag e recognitio n, deep learn ing is also applied to video recogn ition [9]. T he v ideo reco gnition is k ind o f fusion task wh ich n eeds both ima ge rec ognition and time-series pre d iction simultaneou sly . This is, re current c 2019 IEEE. Personal use of this materia l i s permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, includi ng repri nting/ republi shing this material for adverti sing or promotional purposes, creating new collect i ve works, for resale or redistributi on to servers or lists, or reuse of any cop yrighte d componen t of this work in other works. function tha t c la ssifies an given ima ge or detects an o bject while pred icting the f uture, is required . Und e rstanding of time series vide o is expected in various k inds indu strial fields, such as human detection, po se or facial estimation from video camera, autonom ous dri ving system, and so on [10]. LSTM ( L ong Sho rt T erm Memor y) is a well-known method for time-ser ies p rediction an d is a pplied to de e p learn ing methods[1 1 ]. The meth od en a bled the tradition al recu rrent neural network recog nizes no t o nly sh ort-term m emory but also long-term memor y for gi ven sequential data [12]. For video recognitio n of LSTM, the idea using co nvolutional filter instead of on e-dimension al neuron can be used since one frame of sequ ential video can b e seen as o ne imag e [13]. In our r esearch, we p roposed the adap ti ve structural lear ning method of DBN [14]. The adapti ve stru ctural learning can find a suitable size of network structure for giv en input space during its training. The neuro n genera tion and annihilation algorithm s [15], [16] wer e implemen te d o n Restricted Boltz- mann Machin e (RBM) [17], and laye r gen eration algor ithm [18] was implemen ted o n Deep Belief Network (DBN) [1 9]. The adap ti ve structural learning of DBN (Adaptive DBN) shows the highest classification capability in the r esearch field of imag e r ecognition by using som e benchm ark data sets su ch as MNIST [20], CIF AR-10, a nd CIF AR-100 [21]. Moreover , the learnin g alg orithm of Adap ti ve RBM a n d A d aptive DBN was extended to th e time-series prediction by using the ide a of LSTM [22]. LST M was often im plemented on a CNN structure, we implemen ted LSTM on ou r Adaptive RBM and DBN, and th e n the pro posed metho d showed highe r prediction accuracy than the other methods for several tim e- series ben chmark data sets, su c h as Notting ham (MIDI) and CMU (Mo tion Captur e). For further improvement of th e method , ou r proposed method was a p plied to Moving MNI ST [ 23] in th is paper , which is a benchm ark data set for vid eo r ecognition . W e challenge to reveal the power of ou r prop osed meth od in the video reco gnition research field, since video includes rich source of v isu a l in formation . Compared w ith the LSTM mo del [24], ou r metho d make a higher pe rforman ce of prediction . The remaind er of th is paper is organized as fo llows . In section II, basic idea of the adapti ve stru ctural learnin g of DBN is briefly explained. Section III gives th e description of the extension algorith m o f Ad aptiv e DBN f or time-series prediction . In section IV, the effecti veness of our propo sed method is verified on m oving MNIST . In section V, we give some discussions to con clude this pap er . I I . A DA P T I V E L E A R N I N G M E T H O D O F D E E P B E L I E F N E T W O R K This section explain s the tradition al RBM [17] and DBN [19] to describe th e basic behavior of our proposed adaptive learning meth od of DBN. A. Neur o n Gen eration and Annih ilation Algorithm of RBM While recent deep lear ning m o del has high e r classification capability , so me prob lems related to th e network structur e or the numbe r of some parameters still remains to become a difficult task as th e AI research . For the pro blem, we have developed th e adapti ve stru ctural learning meth od in RBM model ( Adaptive RBM) [14]. RBM as shown in Fig. 1 is an unsuper v ised g raphical and energy based model on two kinds of layer s; v isible laye r f o r inpu t and hidden laye r f or featur e vector , resp ecti vely . The n euron gen eration alg o rithm of th e Adaptive RBM can generate an optimal n umber o f hidd en neuron s and th e train ed RBM is suitable structur e for g i ven input spa ce. The neu ron gen eration is based on the ide a o f W alking Dis- tance (WD), which is inspired from the multi-layered neural network in the paper [25]. WD is th e difference between the prior variance and the cur rent on e of learning param e ters.RBM has 3 kin ds of parameters acco rding to visible neu rons, hid den neuron s, a nd the weigh ts a mong their con nections. The Adap - ti ve RBM can mo n itor their parameter s excludin g the visible one ( The p a per [14] describes the re a so n of the disregard) . The situation mea n s that o nly the existing h idden neur ons c a nnot represent an ambig uous pattern, because there is the lack of the number of hidden neur ons. In order to expr e ss the ambiguou s patterns, a new n e u ron is inserted to inherit the attributes o f the parent hidd en neuron as shown in Fig. 2(a). In add ition to the ne uron g eneration, the neu ron an n ihilation algorithm was applied to th e Adap ti ve RBM af ter n euron generation p rocess as shown in Fig. 2 ( b). W e may meet th at some unnecessary or redu ndant neur ons were generated due to the n e u ron ge neration pro c ess. Theref ore, such neurons will be r emoved the corresponding hidden neu ron according to the output activities. B. Layer Generation Alg o rithm of DBN A DBN is a hierarchical mo del of stacking th e se veral pre- trained RBMs. For building proce ss, o utput (hidd en neuron s activ ation ) of l -th RBM can be seen as th e next in put of ( l + 1) - th RBM. Generally , DBN with multiple RBMs has h igher data representatio n power than one RBM. Such hierarchical m odel visible neurons hidden neurons v 0 W ij h 0 ... ... v 1 v 2 v I h 1 h J Fig. 1. A network structur e of RB M visible neurons hidden neurons v 0 h 0 v 1 v 2 h new h 1 v 3 visible neurons hidden neurons v 0 h 0 v 1 v 2 h 1 v 3 generation (a) Neuron generat ion visible neurons hidden neurons v 0 h 0 v 1 v 2 h 1 h 2 v 3 visible neurons hidden neurons annihilation v 0 h 0 v 1 v 2 h 1 h 2 v 3 (b) Neuron annih ilati on Fig. 2. Adapti ve RBM can repr esent the specified features from an ab stract con cept to an concrete ob ject in the direction from input layer to o utput layer . Howe ver, the op timal n umber of RB Ms depen ds on the target data spa c e. W e developed Adaptive DBN which can automatically adjust an optimal network structure by the self-organizatio n in the similar way o f WD mon ito ring. If b oth WD and the energy function do not becom e small values, then a new RBM will be g enerated to keep the suitable n etwork classification p ower for th e data set, since th e RBM has lacked the power of d ata representatio n to draw an image of inpu t patter n s. Theref ore, the c o ndition for layer generatio n is defined b y using the total WD and the ene rgy fun c tion. Fig. 3 shows the overview of layer g e n eration in A d aptiv e DBN. I I I . A D A P T I V E R N N - D B N F O R T I M E - S E R I E S P R E D I C T I O N In time-series predictio n, some LSTM methods improve the prediction perfor m ance of the traditional r ecurrent neural net- work by using the several gates such as forget-g a te, peeph o le connectio n g ate, full an d grad ien t gate [1 1]. These gates can pre-training between 1st and 2nd layers pre-training between 4th and 5th layers, and fine-tuning for supervised learning Input Generation Generation Annihilation pre-training between 2nd and 3rd layers pre-training between 3rd and 4th layers Suitable number of hidden neurons and layers is automatically generated. Fig. 3. Overvie w of Adaptiv e DBN represent multiple patterns of time-series seq uence, th at is not only sh o rt-term memo ry but also lon g-term mem ory . Recurrent Neura l Network Restricted Boltzmann Machine (RNN-RBM) [26] is a RBM b a sed r ecurrent mo d el for time- series predictio n. The meth o d is a extension model of the traditional T empo ral RBM (TRBM) an d Recurren t TRBM (R TRBM) [27] and it also used a similar ide a o f LSTM f or better pe r forman c e. Fig. 4 shows the network stru cture of RNN-RBM. RNN- RBM had a recurrent stru cture on Ma r kov p rocess f o r g i ven time-series sequence, as well as RNN. Let an input seq uence with the le n gth T be V = { v (1) , · · · , v ( t ) , · · · , v ( T ) } . v ( t ) and h ( t ) are th e inpu t and hidden neu rons at t -th RBM, respectively . The time depen dency para m eters b ( t ) , c ( t ) , and u ( t ) are calculated by the p ast p arameters at t − 1 as fo llowing equations. b ( t ) = b + W uv u ( t − 1) , (1) c ( t ) = c + W uh u ( t − 1) , (2) u ( t ) = σ ( u + W uu u ( t − 1) + W vu v ( t ) ) , (3) where σ () is a acti vation func tion. For examp le, T anh func- tion was used in the p aper [2 6]. u ( t ) represents time-series context for g ive input. u (0) is the initial state an d the values are giv en ran domly . θ = { b , c , W , u , W uv , W uh , W vu , W uu } is a set o f lear ning p arameters, an d is n ot time- depende n cy . At each time t , the RBM learnin g can employ th e u pdate algorithm o f b ( t ) and c ( t ) at time t , and we ights W between them. After th e calcu lation of error contin u es till time T , the gradient for θ is updated to trace from time T b ack to time t to the contr ary b y BPTT[28], [29]. BPTT is Back Pro pagation u (0) W W uh W uv W uu W vu . . . . . . u (1) u (t) u (2) v (1) v (t) v (2) h (1) h (t) h (2) . . . . . . . . . u (T) v (T) h (T) . . . c (2) b (2) c (1) b (1) c (t) b (t) c (T) b (T) Fig. 4. Structure of RNN-RBM Throu g h Time metho d wh ich is often used in th e traditional recurren t neural network. W e d ev eloped Ad aptiv e RNN-RBM by a p plying the neu- ron g eneration and an nihilation algor ithm to RNN-RBM. An suitable number o f hid den neu rons is soug ht by the neur o n generation and an n ihilation algorithm for b etter representation power as same as usu al Adap ti ve RBM [2 2]. In additio n, the hierarchica l mode l with layer generatio n was de veloped as Adaptive RNN-DBN by u sing the same mon itoring function of Adapti ve DBN. In other words, the ou tput signal of hidden neuron h ( t ) at l -th Ada p ti ve RNN-RBM can be seen as the next input signal at ( l + 1) -th Ad aptiv e RNN-RBM as shown in Fig . 3 Th e prop osed A d aptiv e RNN-DBN was ap p lied to se veral time- series benchmark d ata sets, such as Notting ham (MIDI) a nd CMU (Motion Captur e). In [22], the pre diction accuracy of the pr oposed metho d is hig her than that of the traditional meth ods. I V . E X P E R I M E N T R E S U LT S In this pape r, the effecti ven e ss of ou r pro p osed method for moving MNIST b e nchmark data set [24] was verified. W e challenge to reveal the power of ou r prop osed meth od in the vide o reco gnition research field, since video includes rich source of visual in formation . When we want to detect and identify visual objec ts, faces, emo tio ns, actio ns or events in the r eal time, state-o f -the-art video r ecognition software for th e compreh ensiv e video content analysis can make th e adv anced solutions fo r AI-based visual con te n t search . Therefo re, the prediction p erforman ce is comp ared with the traditio nal LSTM in th is pap e r . A. Data set: Moving MNIST Moving MNIST [2 4] is a b e n chmark data set for video recogn itio n. There are 10 ,000 samples includ ing 8,000 fo r training an d 2 ,000 for test. Each sam p le consists of 20 sequen - tial gray scale images ( [0 , 255] ) of 64 × 64 patch , where two digits m ove in th e sequence s. Th e digits were cho sen randomly from the training set. Th e selected digits are placed initially at rand o m lo cations inside the patch. Each d igit was assigned a velocity which has directio n and magnitu de. The dir ection and the magnitu de also cho sen r a ndomly . Fig. 5 sh ows two samples o f 20 sequential images. Moving MNIST is u sed in various researches such as th e video decomp o sition [30] and the f u ture pr e dictor [2 4]. This paper aims to inv estigate the effecti ven ess of the o ur LSTM model in th e video reco gnition an d we compar e th e r ecognition capability as fu ture predicto r . Since any teacher signal for each samp le is not pr ovid ed in m oving MNIST , the LSTM in [24] inves tigated the cr oss entropy b e tween the given sequence (grou nd truth ) and th e predicted sequence. Fig. 6 shows th e com posite model o f LSTM in [24]. In the method , the first 10 fram es are u sed as an input sequence of the model, th e remaining 10 frames are used for evaluation of future pr e diction as shown in Fig. 5. Fig. 7 shows an ab stract procedure o f prediction in our method. As same as in our metho d , sam e ev alu ation method was used. Since our metho d can pre d ict next frame for g i ven frame, the p redicted fr ame is used for next inp ut, and then squared erro r and pred iction accuracy o f th e groun d truth images and th e predicted images were evaluated. B. Experimental Results T able I and T ab le II show the prediction result on moving MNIST for tr aining an d test. The value in T able I is the cross entropy between the gro und tru th images an d the predicted images at last sequence. Th e result of the L ST M is cited from the pap e r [24]. The left value of each colu mn in T able II is the sq uared erro r an d the value in brackets is the pr ediction accuracy . In the LSTM, the result f or trainin g and th e pr e diction accuracy for test are not rep orted. In the Adaptive RNN-DBN, three setting s of learning r atio (lr) were used for ev aluation. For trainin g of th e Adap ti ve RNN- D BN, the cross en tropy and the square d er ror reached almost 0 a n d pred iction accur acy reached almo st 100%. For test, th e three settings of Adap ti ve RNN-DBN showed smaller predictio n erro r than the LSTM. The best p erforman ce was acqu ired when the learn ing ratio was 0.05 0 in th e Adaptive RNN-DBN. W e also investigated the inter mediate result in the pre d icted images of the Adaptive RNN-DBN. T able III expresses the future prediction a ccuracy for ea ch pred icted sequen ce. Basi- cally , the p rediction accur acy was slo wly d ecreased from 11th to 2 0th frames. V . C O N C L U S I O N Deep learning is widely used in various kin ds of research fields, espe cially ima g e rec o gnition. In our research, Adapti ve DBN which can find the optimal n etwork stru cture for given data was developed. The method shows hig her classification accuracy than existing deep learn ing methods for several benchm a rk d ata sets. In this paper, our prop osed pre d iction method was ap p lied to Moving MNIST , wh ich is a benchm a rk data set f o r v ideo recogn ition. Comp ared with the LSTM model, our metho d showed high er pr ediction pe r forman c e (more than 90 % predication accuracy for test data) . Ou r propo sed method will b e further imp roved f or b etter p rediction capability b y evaluating the me th od on the o ther large video databases such as video streaming an d d efect detection in tim e- series vid eo data. A C K N OW L E D G M E N T This work was supported by JSPS KAKENHI Grant Num- ber 1 9K1214 2, 19K2 4365, and ob tained fro m the co mmis- sioned research by Natio n al Institute of Info rmation and Communica tio ns T echno logy (NICT , 214 05), J AP AN. R E F E R E N C E S [1] Mark ets and Mark ets, http:/ /www .marketsa ndmarke ts.com/Market- Reports/deep- learni n g - m a r k e t - 1 0 7 3 6 9 2 7 1 . h t m l (accesse d 28 Nov ember 2018) (2016) [2] Y . Bengio: Learnin g Deep A rchit ectur es for A I , F oundati ons and T rends in Machin e L earning archiv e, vo l.2, no.1, pp.1-127 (2009) [3] V . Le.Quoc, R.Marc’ s Aurelio, et.al.: Building high-leve l featur es using lar ge scale unsupervise d learning , Proc. of 2013 IEEE Internatio nal Conferen ce on Acoustics, Speech and Signal Processing, pp.8595-859 8 (2013) [4] A.Krizhe vsky , I.Sutske ver , G.E.Hinton, ImageNe t Classification with Deep Con volutional Neural Networks , Proc. of Adv ances in Neural Information Processing Systems 25 (NIPS 2012) (2012) T ABLE I P R E D I C T I O N R E S U LT ( C R O S S E N T RO P Y ) Model Tra ining T est LSTM [24] - 341.2 Adapti ve RNN-DBN (lr = 0.010) 18.5 165.3 Adapti ve RNN-DBN (lr = 0.050) 16.1 134.0 Adapti ve RNN-DBN (lr = 0.001) 17.0 140.6 T ABLE II P R E D I C T I O N R E S U LT ( S Q U A R E D L O S S A N D C O R R E C T R A T I O ) Model Tra ining T est Adapti ve RNN-DBN (lr = 0.010) 11.4 (9 9.0%) 119.9 (91.8%) Adapti ve RNN-DBN (lr = 0.050) 10.3 (9 9.4%) 100.5 (92.5%) Adapti ve RNN-DBN (lr = 0.001) 14.5 (9 8.9%) 140.2 (89.4%) Fig. 5. T wo samples of Moving MNIST T ABLE III P R E D I C T I O N A C C U R A C Y F O R E A C H F R A M E Sequence Model 11 12 13 14 15 16 17 18 19 20 Adapti ve RNN-DBN (lr = 0.010) 98.2% 97.9% 97.0% 95.2% 94.5% 93.9% 93.3% 92.8% 92.0% 91.8% Adapti ve RNN-DBN (lr = 0.050) 99.5% 98.0% 97.9% 96.5% 96.4% 94.5% 93.1% 92.9% 92.8% 92.5% Adapti ve RNN-DBN (lr = 0.001) 96.8% 96.8% 96.4% 94.8% 93.6% 92.9% 91.8% 91.0% 90.0% 89.4% v 1 v 2 W 1 v 3 W 1 v 4 W 3 v 5 W 3 v 3 W 2 v 2 W 2 v 4 ^ v 5 ^ v 6 ^ v 3 ^ v 2 ^ v 1 ^ Input Reconstruction Future Prediction copy copy Learned Representation Fig. 6. The Composite Model of LSTM [24] [5] C.Sze gedy , W . L iu, Y .Jia, P .Sermanet, S.Reed, D.Anguelov , D . Erhan, V .V anhouck e, A.Rabino vich, Going Deepe r with Con volutions , Proc. of CVPR2015 (2015) [6] K.Simony an, A.Zisserman, V ery deep con volutional networks for lar ge- scale ima ge r ecogniti on , Proc. of Interna tional Conference on Learni ng Represen tation s (ICLR 2015) (2015) [7] K.He, X.Zhang, S. Ren, J.Sun, J, Deep residual learning for imag e re cogn ition , Proc. of 2016 IEEE Conference on Computer V ision and Patt ern Recognition (CVPR), pp.770-778 (2016) [8] O.Russak ovsk y , J. Deng, H.Su, J.Krause, S.Satheesh, S.Ma, Z. Huang, A.Karpathy , A.Khosla, M.Bernstein , et al., Image net lar ge scale visual re cogn ition chall enge , Internationa l Journal of Computer V ision, vol.115, no.3. pp.211–252 (2015) [9] M.Mohammadi, A.Al-Fuqaha, S.Sorour , and M.Guiz ani, Deep Learning for IoT B ig Data and Streaming Analytics: A Surv e y , i n IEEE Commu- nicat ions Surveys & Tutori als (2018) [10] H.Zhang, Y .Zhang and B.Z hong, et.al., A Compr ehensiv e Survey of V ision-Based Human Action Reco gnitio n Methods , Sensors, vol .19, no.5, pp.1–20 (2019) [11] Y . Bengio , P .Simard, and P . Frasconi , Learning long-term dependencie s with gradie nt descent is difficu lt , IE EE Tra nsactio ns on Neural Networks, vol.5, no.2, pp.157–166 (1994) [12] Z.C.Lipton, D.C.Kale, C.Elkan, and R.W etzel l, Learning to Diagno se with LSTM Recurr ent Neur al Networks , in Internati onal Conferenc e on Learning Represe ntati ons (ICLR 2016), pp.1–18 (2016) [13] S.Xingji an, C.Zhourong, W . Hao, Y . Dit-Y an, W .W ai-kin, W .W ang-chun, Con volutional LSTM Network: A Mac hine Learning Appr oach for Pre cip- itatio n Nowcastin g , Adva nces in Neural Information Processing Systems 28 (NIPS 2015) pp.802–810 (2015) [14] S.Kamada, T . Ichimura, A.Hara, and K.J.Mackin, A daptive Structur e Learning Method of Deep Belief Network using Neuro n Generatio n- Annihilat ion and Layer Generat ion , Neural Computing and Applicatio ns, pp.1–15 (2018) [15] S.Kamada and T .Ichimura, An A daptiv e Learning Method of R estrict ed Boltzmann Ma chin e by Neuro n Gener ation and Annihilation Algorit hm . Proc. of 2016 IEEE Internatio nal Conferen ce on Systems, Man, and Cybernet ics (SMC20 16), pp.1273–1278 (2016) [16] S.Kamada, T . Ichimura, A Structural Learning Method of R estrict ed Boltzmann Ma chin e by Neuro n Gener ation and Annihilation Algorit hm , Neural Information Processing, Proc. of the 23rd Internation al Conferenc e on Neural Information Processing, Springer LNCS9950), pp.372–380 (2016) [17] G.E.Hinton, A Practica l Guide to T raining R estrict ed B oltzmann Ma- chi nes , Neural Networks, Trick s of the Tra de, Lecture Notes in Computer Science (LNCS, vol .7700), pp.599–619 (2012) [18] S.Kamada and T . Ichimura, An Adaptive Learning Method of Deep Belief Network by Layer Gener ation Algorithm , Proc. of IE EE TENCON2016, pp.2971–2974 (2016) [19] G.E.Hinton, S.Osindero and Y .T eh, A fast learning algori thm for deep belie f ne ts , Neural Computati on, vol.18, no.7, pp.1527–1554 (2006) [20] Y . LeCun, L.Bottou, Y .Bengio, and P .Haffne r , Gradient-base d learning applied to doc ument reco gnition , Proc. of the IEEE , vol.86, no.11, pp.2278–2324 (1998) [21] A.Krizhe vsky: Learning Multiple Layers of F eatur es from T iny Image s , Master of thesis, Univ ersity of T oronto (2009) [22] T .Ichimura, S.K amada, Adaptive L earning Method of Recurrent T em- poral Deep Belief Network to Analyze T ime Series Data , Proc. of the 2017 Inte rnatio nal Joint Confe rence on Neural Netw ork (IJCNN 2017), pp.2346–2353 (2017) [23] htt p://www .cs.toronto.edu/ ∼ nitish/ unsupervise d video/ (2019/7 /23) [24] N.Sri vasta va, E .Mansimov , R.S alakhutdino v , Unsupervised learning of video repr esentation s using LSTMs , Proc. of ICML ’15 Proceedi ngs of the Fig. 7. Abstrac t of predict ion 32nd Inte rnatio nal Conferenc e on Internat ional Conference on Machi ne Learning (ICML 15), vol.37, pp.843–852 (2015) [25] T .Ichimura, E.T azaki and K.Y oshida, Extraction of fuzzy rules using neural netw orks with structure le vel adaptation -verificat ion to the diag nosis of hepatobiliary disor ders , Internationa l Journal of Biomedical Computing, V ol.40, No.2, pp.139–146 (1995) [26] N.B.Lew ando wski, Y .Bengio and P .V incent, Modeling T emporal Depen- dencie s in High-Dimensional Sequences:Appli cation to P olyphonic Music Genera tion and T ranscript ion , Proc. of the 29th Internatio nal Confere nce on Machine Learning (ICML 2012), pp.1159–1166 (2012) [27] I.Sutske ver , G.E .Hinton, and G.W .T aylor , The Recurrent T emporal Re- stricted Boltzmann Machi ne , Proc. of Advance s in Neural Information Processing Systems 21 (NIPS-2008) (2008) [28] J.Elman, Fin ding structur e in time , Cogniti ve Science , V ol.14, No.2 (1990) [29] M.Jordan, Serial order: A parallel distributed pr ocessing appro ach , T ech. Rep . No. 8604. San Diego: Uni versity of Calif ornia, Institute for Cogniti ve S cienc e (1986) [30] J.Hsieh, B.Liu, D.Huang, L.Fei-Fei, J.C.Niebles, Learning to Decom- pose and Disentangle Repr esentati ons for V ideo Predict ion , Procs. of Adv ances in Neural Information Processing Systems 31 (NIPS 2018) (2018)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment