Uncertainty Quantification in Stochastic Economic Dispatch using Gaussian Process Emulation
The increasing penetration of renewable energy resources in power systems, represented as random processes, converts the traditional deterministic economic dispatch problem into a stochastic one. To solve this stochastic economic dispatch, the conven…
Authors: Zhixiong Hu, Yijun Xu, Mert Korkali
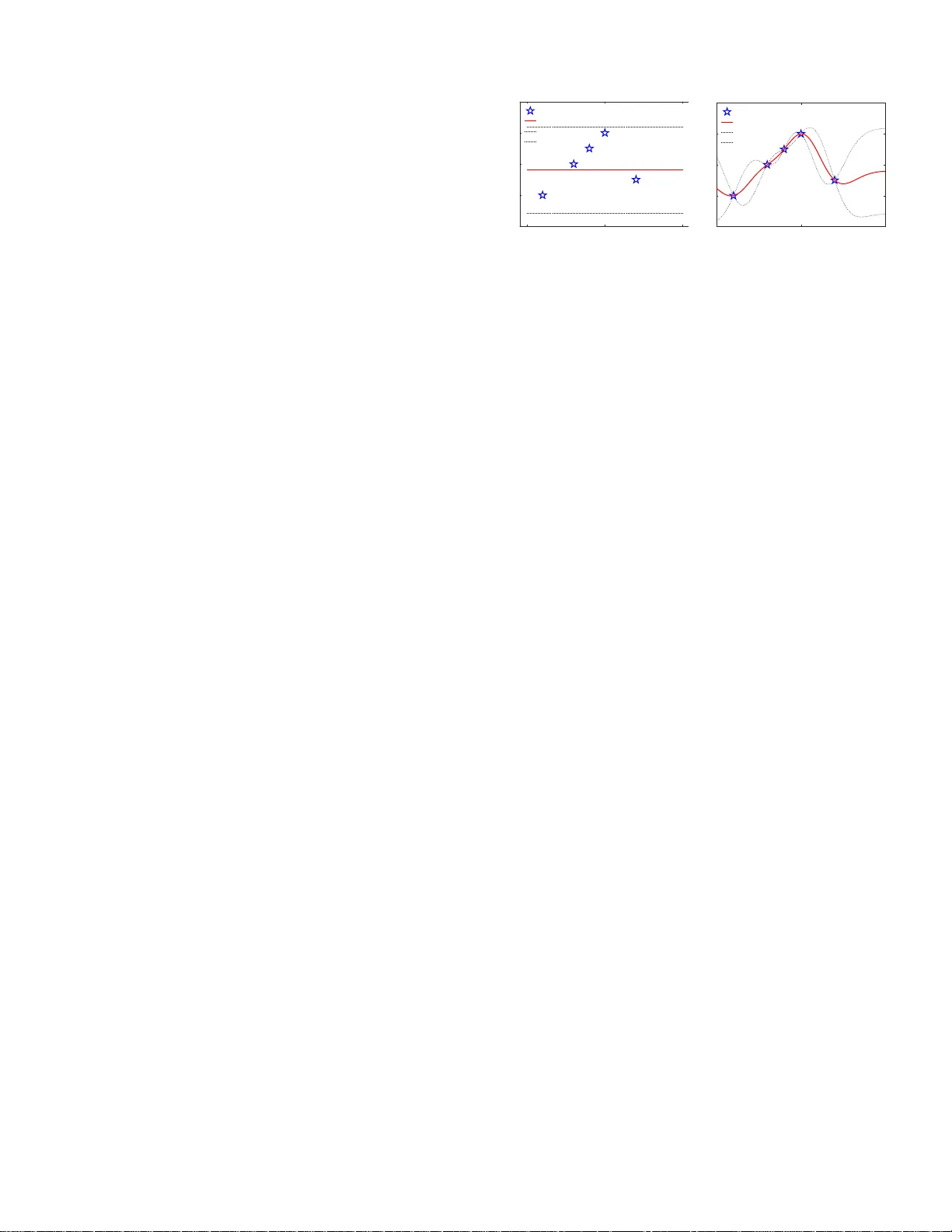
Uncertainty Quantification in Stochastic Econ omic Dispatch using Gauss ian Process Emulation Zhixiong Hu 1 , Y ijun Xu 2 , Mert K orkali 3 , Xiao Chen 4 , Lamine Mili 2 , and Charles H. T ong 4 1 Departmen t of Statist ics, Uni versi ty of Californi a-Santa Cruz, Santa Cruz, CA 95064 USA, e-mail: zhu95@ucsc.ed u 2 Departmen t of Electric al and Computer Engineering, V irgi nia T ech, North ern Vi rgini a Center , Fall s Church, V A 22043 USA, e-mail: { yijunxu,lmili } @vt.edu 3 Computati onal Engineeri ng Di vision, Lawrenc e Li vermore National Labora tory , Li vermore, CA 94550 USA, e-mail: korkali1@llnl.gov 4 Center for Applied Scientific Computing, Lawre nce Live rmore National Laborat ory , Li vermore, CA 94550 USA, e-mail: { chen7 3,tong10 } @lln l.gov Abstract —The increasing penetration of renewable ener gy resour ces in power systems, repre sented as random processes, con verts the traditional deterministic economic dispatch problem into a stochastic one. T o solve this stochastic economic dispatch, the conv ent i onal Monte Carlo method is p rohibitiv ely time con- suming f or medium- and large-scale power systems. T o over come this problem, we pro pose in this paper a n ov el Gaussian- process-emulator -based approach to quantify th e u n certainty in the stochastic economic d ispatch considerin g wind power penetration. Based on th e dimension-reduction results obtained by the Karhunen-Lo ` eve expansion, a Gaussian-process emulator is constructed. This surrogate allows us to e valuate the economic dispatch solv er at sampled values with a n egligible computational cost whi l e maintaining a d esirable accuracy . S imulation results conducted on the IEEE 118-bus system re veal that the proposed method has an excellent p erf ormance as compared to the tradi- tional Monte Carlo meth od. I . I N T RO D U C T I O N Power systems are in h erently stoc h astic. Sou rces of stochasticity inclu de time- varying lo ads, ren ew able energy intermittencies, and random outages o f generating units, lines, and transfo rmers, to cite a few . T hese stoch asticities tran slate into uncertainties in the power s ystem models. T o add ress this p roblem, r esearch activities have focused o n un certainty quantification in power sy stem plan ning, monitoring, and con- trol [ 1 ]–[ 6 ]. Among them, th e topic of stocha stic econom ic dispatch ( SED) has recently attracted considerable academic attention due to the increasing penetra tio n of renew able energy resources. T o acco u nt for the se u n certainties, some research e rs pro - pose to ad opt a scenario -based optimization appro ach. How- ev er , this ap proach only co nsiders a finite set o f samplin g realizations, which is obviously an oversimplification of the numero us cases that may occur in reality [ 7 ], [ 8 ]. By con tr ast, other resear chers propo se to make use of u ncertainty quan tifi- cation techn iques via Monte Carlo sampling. Howe ver , all the traditional Monte Carlo methods are proh ibitiv ely time con- suming when accurate estimation of uncertain model outputs are needed. This problem calls for the dev elopmen t o f new computatio nally efficient and accurate uncertainty modeling technique s for p ower system app lications [ 1 ], [ 9 ]. In this paper , we develop a new SED metho d based on a Gaussian process emulator (GPE) for power systems to which are connected wind power generatio n . The GPE allows us to ev aluate, with a negligible compu tational cost, the SED solver at sampled values through a nonparametric red uced- order representation [ 10 ]. T o further improve the computatio nal efficiency in the construction o f the surr ogate mode ls, a model reduction is achieved via the ap plication of the Karh unen- Lo ` eve expan sio n (KLE) to real-world data, collected from real-world wind farm s [ 11 ]. Th e simulation results conducted on a m odified IEEE 118-bus system reveal that the p roposed method can greatly improve the compu tational efficiency of the SED as compar ed to th e traditional Monte Carlo method while main taining a desirable estimatio n accuracy . I I . P R O B L E M F O R M U L A T I O N T raditionally , und er some ph ysical and econ o mic con- straints, the economic dispatch in power systems is kn own as a deterministic optimizatio n pr oblem. This problem aim s to iden tify an optimal set of power outputs of a fixed set of online thermal gen e r ating units that y ields a minimum cost, denoted by Q ( g ) . The cost Q is gener ally thoug ht to b e nonran dom sinc e the traditional thermal generatin g units u can be op timized and set eq ual to some determin istic optimal values. Howe ver, i n the face of the increasing pene tr ation of r enew- able energy resou rces, the abovementioned statemen t canno t hold true. Du e to the intrin sic rando mness of the renewable generation , represented (u sing random field s) as functions of a vector of rando m variables, ω , deno ted by p ( ω ) , the de termin- istic econo mic prob lem for find ing Q ( g ) = ar g min g { f ( g ) } is extended to an SE D problem described by Q ( g , p ( ω ) ) = ar g min g { f ( g , p ( ω )) } . (1) Here, f represents the objective fu nction. For this pr oblem, the random ness bro ught by p ( ω ) will lead to d ifferent optim iz e d values of g , which will inevitably change the deter ministic cost, Q ( g ) , into a random cost, Q ( g , p ( ω )) . In this paper , we consider the randomness b rough t by th e wind f arms as a spatiotem p oral random field, which is denoted by p i ( ω , t ) for the power generatio n of the i th wind farm. Her e, the tim e t ∈ T and T is a finite integer set repr esenting hours in a day , namely , T = { 1 , 2 , . . . , 24 } . Let us take an example. Suppo se that we cond uct a day-ahe ad SED pro blem over 24 hours of a power system w ith thre e farms. Th e n, we have an inpu t of th ree random fields, { p 1 ( ω , t ) , { p 2 ( ω , t ) , { p 3 ( ω , t ) } , consisting of 72 random v ariables in total. Our un certainty quantification goal is to quantify the statistical m o ments o f Q ( g , p ( ω )) , su c h as th e mean and v ar iance f o r a da y -ahead f orecast. Remark. Note that since we focu s on the qu antifica tio n of uncertainties in the SE D pr oblem instead o f th eir modelin g, the detailed description of “ f ” as well as all the equality and inequality c o nstraints of the SED topic dir ec tly follow fr om [ 1 ]. I I I . T H E O R E T I C A L B A C K G RO U N D In th is section , we briefly presen t the theo ry of the GPE and of th e KLE to assist u s in the SED p r oblem. A. Gaussian P r ocess Emu lator 1) Ba sic Theo ry: The GPE is k nown to be a powerful Bayesian-learnin g-based m ethod ba sed on a nonlinea r re gres- sion prob lem [ 10 ], [ 12 ]. T o describe this m ethod, let u s first denote the SED model by f ( · ) and its correspondin g vector- valued in put of p dimen sions by x . Due to the rand omness of x , we may observe n samples as a finite co llection of th e mo del input as { x 1 , x 2 , . . . , x n } . A c cording ly , its model o utput f ( x ) also becom es ra ndom and has its corr espondin g n realizations, denoted by { f ( x 1 ) , f ( x 2 ) , . . . , f ( x n ) } . If we assume that the m odel outp ut is a realiza- tion of a Gaussian process, then the finite co llection, { f ( x 1 ) , f ( x 2 ) , . . . , f ( x n ) } , of the r andom variables, f ( x ) , will follow a joint multivariate norm al p robab ility distribution, that is, we have f ( x 1 ) . . . f ( x n ) ∼ N m ( x 1 ) . . . m ( x n ) , k ( x 1 , x 1 ) · · · k ( x 1 , x n ) . . . . . . . . . k ( x n , x 1 ) · · · k ( x n , x n ) . (2) Here, m ( · ) is the m ean fun c tion and k ( · , · ) is a kernel fun ction that represents the co variance fun ction. Let us fu rther denote an n × p matrix , denoted by X = [ x 1 , x 2 , . . . , x n ] ⊺ . Then, ( 2 ) is simplified into f ( X ) | X ∼ N ( m ( X ) , k ( X , X )) , (3) where f ( X ) = ( f ( x 1 ) , f ( x 2 ) , . . . , f ( x n )) ⊺ and m ( X ) = ( m ( x 1 ) , m ( x 2 ) , . . . , m ( x n )) ⊺ . Now , if an observation noise ε is add ed to f ( X ) , we get Y = f ( X ) + ε . (4) For ind ependen t, identically and normally distributed noise ε ∼ N (0 , σ 2 I n ) (wher e I n and σ 2 are an n - d imensional identity matrix and the variance, resp e c ti vely), using no rmality proper ty , we o btain Y | X ∼ N m ( X ) , k ( X , X ) + σ 2 I n . (5) Note that ε is also called a “nu gget”. If σ 2 = 0 , then f ( x ) is observed without no ise. Howe ver, in p ractical implem entation, the nugg et is always added for the sake of num e rical stability . 2) Ba yesian Infer e n ce: Here , we present th e way to use the ab ovementioned finite collection o f n samples, { Y , X } , to infer the unknown system output, y ( x ) , on the s ample space of x ∈ R p in a Bayesian infer ence f ramework. W e assume that the read ers have th e basic kn owledge of Bayesian in ference. Here, th e finite collection o f samples { Y , X } provides us with the observations. T o infer a Bayesian posterio r distribution of the u nknown sy stem outp ut y ( x ) , we must assume a Bayesian prior d istribution of y ( x ) , e xpressed as y ( x ) | x ∼ N m ( x ) , k ( x , x ) + σ 2 I n x . (6) Then, we can f ormulate the joint distribution o f Y and y ( x ) using ( 5 ) and ( 6 ) as Y y ( x ) ∼ N m ( X ) m ( x ) , K 11 K 12 K 21 K 22 , (7) -5 0 5 x -4 -2 0 2 4 y(x) Data Prior Mean Lower 95% Upper 95% (a) -5 0 5 x -4 -2 0 2 4 y(x) Data Pred Mean Lower 95% Upper 95% (b) Fig. 1. (a) The prior and (b) updated posterior means as well as 95% confidenc e interv als (CIs) of a GP with const ant mean funct ion and squared expo nential kernel . T he posterior captures much more information of data than the prior does. where K 11 = k ( X , X ) + σ 2 I n , K 12 = k ( X , x ) , K 21 = k ( x , X ) and K 22 = k ( x , x ) + σ 2 I n x . No w , we can inf er y ( x ) based o n pr evious observations ( Y , X ) . Using the ru les of th e cond itio nal Gau ssian d istribution ( a.k.a. Gaussian co ndi- tioning or statistical linearization) [ 13 ], the Bayesian posterior distribution o f the system o utput y ( x ) conditioned upon the observations ( Y , X ) f ollows a Gaussian distribution given by y ( x ) | x , Y , X ∼ N ( µ ( x ) , Σ ( x )) , (8) where µ ( x ) = m ( x ) + K 21 K − 1 11 ( Y − m ( X )) , (9 ) Σ ( x ) = K 22 − K 21 K − 1 11 K 12 . (10) T o this po int, the form of th e GPE has been derived. No w , on one hand, we may d irectly use ( 9 ) as a surrogate mode l (a.k.a. the response surface or r e duced-o rder mo del) to capture very closely the beha vior of the co mplicated, origin a l simulatio n model of a p ower system while be ing co mputation ally inex- pensive to ev alu ate. On th e other han d, we may u se ( 10 ) to quantify the uncer tainty of the surrogate itself. In this paper, we only nee d to u se ( 9 ) as a surro gate mode l. Fig. 1 shows a simple examp le of how five 1- dimensiona l d ata points up d ate a Gaussian process p r ior to a posterior . 3) Mean and Covariance F unctions: T o further define the GPE, we nee d to select the f orms of the m ean fun ction m ( · ) and the covariance function represented via the kernel k ( · , · ) . The mean fu nction models the prior belief abo ut th e existence of a system a tic trend expressed as m ( x , β ) = H ( x ) β . (11) Here, H ( x ) can be any set of basis fu nctions. For example, let x i = ( x i 1 , . . . , x ip ) in dicate th e i th sample, i = 1 , 2 , . . . , n and x ik represents its k th element, k = 1 , 2 , . . . , p . For instance, H ( x i ) = 1 is a constant b asis; H ( x i ) = (1 , x i 1 , . . . , x ip ) is a linear basis; H ( x i ) = (1 , x i 1 , . . . , x ip , x 2 i 1 , . . . , x 2 ip ) is a pure quadra tic basis; an d β is a v ector of h yperpa r ameters. Since the covariance fun ction is repr esented b y a kernel function , cho osing th e latter is a must. T ab le I provides several popular covariance kernels. As for the parame te r s of a kernel fun ction, they are defined as fo llows: τ and ℓ k are the hyperp arameters defined in the po siti ve r e a l line; σ 2 and ℓ k correspo n d to th e ord er T ABLE I. C O M M O N LY U S E D C OV A R I A NC E K E R N E L S F O R G AU S S I A N P R O C E S S k SE ( x i , x j ) τ 2 exp − p P k =1 r 2 k 2 ℓ 2 k k E ( x i , x j ) τ 2 exp − p P k =1 | r k | ℓ k k RQ ( x i , x j ) τ 2 1 + p P k =1 r 2 k 2 αℓ 2 k − α k 3 / 2 ( x i , x j ) τ 2 1 + p P k =1 √ 3 r k ℓ k exp − p P k =1 √ 3 r k ℓ k ( r k = | x ik − x jk | ) Abbrv .: square exponential (SE), exponential (E), rational quadratic (RQ), and Martin 3/2 ( 3 / 2 ) kernels. of m agnitud e and the speed o f variation in th e k th in put dimension, respectively . Let θ = ( τ , ℓ 1 , . . . , ℓ p ) contain s the hyperp arameters of the cov ar ia n ce functio n, i.e., k ( x i , x j | θ ) = Cov( x i , x j | θ ) . (12) Until no w , the mode l structure of the GPE has b een fu lly defined. For simplicity , we write η = ( σ 2 , β , θ ) to r epresent all the hyperparameter s in the GPE model. 4) Hyp erparameter E stimation: Optimizing a GPE model is equivalent to estimating η g i ven the data ( Y , X ) . Alth ough different methods exist for estimating the hyp erparam eters η [ 12 ], we choose to adopt the Gaussian maximu m likelihood estimator (MLE) since it meets ou r d emand and is straig htfor- ward to compute. First, to ind icate the hyp e rparameter s, let us rewrite ( 5 ) as Y | X , η ∼ N m ( X ) , k ( X , X ) + σ 2 I n . (13) Then, using MLE , we ob tain b η = b β , b θ , b σ 2 = arg max β , θ ,σ 2 log P Y | X , β , θ , σ 2 . (14) Using ( 11 )–( 13 ) and simplify ing H ( x ) into H , the marginal log-likelihood can be expr e ssed a s log P Y | X , β , θ , σ 2 = − 1 2 ( Y − H β ) ⊺ k ( X , X | θ ) + σ 2 I n − 1 ( Y − H β ) − n 2 log 2 π − 1 2 log k ( X , X | θ ) + σ 2 I n , (15) which implies that the MLE of β condition e d upon θ and σ 2 is a weig hted least-squar es estimate g iv en by ˆ β ( θ ,σ 2 ) = h H ⊺ [ k ( X , X | θ )+ σ 2 I n ] − 1 H i − 1 H ⊺ [ k ( X , X | θ )+ σ 2 I n ] − 1 Y . (16) Plugging ( 16 ) into ( 15 ), we g e t the β -profile likelihood log P Y | X , ˆ β θ , σ 2 , θ , σ 2 . Then, ( 14 ) is r ewritten a s b θ , b σ 2 = arg max θ ,σ 2 log P Y | X , ˆ β θ , σ 2 , θ , σ 2 , (17) where b β = ˆ β b θ , b σ 2 . The next goal is to find b η from ( 15 )–( 17 ). Since b β can be straigh tf orwardly obtained fr om b θ , b σ 2 , on e only needs to find b θ , b σ 2 by m aximizing the β -pr ofile likelihood over θ , σ 2 . Here, we utilize a g r adient- based optimizer to achiev e this o p timization. T o overcome the presence of loc al optima in th e o bjective function, we initialize σ 2 somewhere close to 0 be c ause the glob al o ptimum is in this vicin ity . Once b η is o btained, the GPE mod el is fu lly constructed . 5) Sampling Strate gy: In order to obtain the ob servation sets con tained in ( Y , X ) , we n eed some samples th a t sat- isfy the sy stem function f ( X ) , i.e., the SED model. Here, a popu lar cho ic e to generate these samples is thro ugh the Latin hypercub e samp ling [ 14 ]. Unlike the Monte Car lo sampling, which ge nerates a set of indepen dent and iden tically distributed samples from the ta rget pr o bability distributions, the Latin hyp ercube samplin g gen erates n ear-random samples that follow a stan dard un iform distribution U (0 , 1 ) b a sed o n an equal-inter val segmentation. For a non unifor m distribution, th e in verse transfo r mation of the cu mulative distribution functio n is applied to m ap the u niform ly distributed samples into the targeted d istribution [ 15 ]. B. Karhu nen-Lo ` eve Expan sions As it is mentioned in Sectio n II, the dim ension fo r th e random fields representin g wind-farm generation may be so high th a t the GPE cannot be con structed e fficiently . There f ore, facing the ch allenge raised b y a high-dimensio nal raw data, an efficient dimen sion r e duction becom es a p rerequ isite. 1) Spectral Decomposition and T run cation: He re, we use the KL E to project the high-dimension al samples into low- dimensiona l latent variables. Let us consider a bo unded domain D ⊆ R an d a sample space Ω , and let X ( t ) be a zero-mean stochastic process with t ∈ D where X : D × Ω → R . Each X ( t ) is a r andom variable ind exed by t . Let us assume that X ( t ) fo r any time has a finite variance an d let us define the covariance fu nction C as C ( t, s ) = C ov( X ( t ) , X ( s )) , ∀ t, s ∈ D . Since C is positi ve definite, its spectral decomp osition is obtained as C ( t, s ) = ∞ X l =1 λ i u i ( t ) u i ( s ) . (18) Here, λ i denotes th e i th e igenv alue and u i denotes th e i th orthon ormal e igenfun ction of C . Then , we pu t X ( t ) into a KLE fr amew ork as follo ws: X ( t ) = ∞ X i =1 p λ i u i ( t ) ξ i , (19) where { ξ i , i = 1 , 2 , ... } are mutually uncorrelated univariate random variables with z e ro m ean an d unit variance. Here, we use an empir ical covariance matrix, C , calculated from the data. By applying the inner produ ct o f u i ( t ) to b oth sides o f ( 19 ) and making u i ( t ) or thonor mal, we obtain p λ i ξ i = h X ( t ) , u i ( t ) i ∀ i. (20) T ill now , the KLE m aps X ( t ) to la te n t variables ξ i by pro - jecting X ( t ) onto u i ( t ) . The in verse mapping can be achiev ed via ( 19 ) as well. Note that both transformation s are linear . In practice, X ( t ) is replaced b y a finite summation with p elements, yieldin g X ( t ) ≈ ˆ X ( t ) = p X i =1 p λ i u i ( t ) ξ i . (21) 2) Dimen sion Reduction: Her e, we pr esent the dimen sion reduction from the variance point of view . Con sid e r the tota l variance of X ( t ) over D . Using the ortho n ormality property of u i ( t ) , we ha ve Z D V ar[ X ( t )] d t = ∞ X i =1 λ i . (22) A finite series is used instead such that m ost of the v ariance is retained a f ter truncatio n, y ielding Z D V ar[ X ( t )] d t ≈ Z D V ar[ ˆ X ( t )] d t = p X i =1 λ i . (23) Specifically , we choose the first p largest eigen values as ( λ 1 , . . . , λ p ) , with the correspo nding eigenfu nctions as ( u 1 , . . . , u p ) such that the ob tained ξ contain over 95 % of the total variance calculated by ( P p i =1 λ i ) / ( P ∞ i =1 λ i ) . Since the calculated p is smaller than the original dimension of the raw data sequence, th e KLE has m apped the hig h - dimensiona l correlated X to the low-dimensional unc o rrelated ξ = ( ξ 1 , . . . , ξ p ) . It is worth poin ting out that the trun cated p dimensions will serve as the inp ut for the SED problem. I V . P RO P O S E D M E T H O D Using the th eory explained above, we prop ose a GPE- based method to solve the SED problem . W e first obtain ξ of th e p -tru ncated KLE for the SED in put. Then , to avoid the normality assump tion, w e estimate the closed-form solution of the joint p robab ility d ensity f unction (pdf ) of ξ via a kerne l density estima tio n [ 16 ]. Later, using th at den sity estimation, the input sam ples a r e regenerated. Finally , with th e training samples selected fr o m the Latin h y percub e sampling, the GPE surrogate is constructed to pro pagate the unce rtainty fro m the inp ut samples to th e ou tp ut. The details ar e describ ed in Algorithm 1. No te that since the input of the SED is spa- tiotempor a lly correlated, o u r appr o ach is n a turally com patible with the mo deling of a spa tiotempora l structure . T he local ξ is calculated by applyin g the KLE ind ividually to each locatio n. After estimatin g the joint pdfs of ξ at all loc ations, samples can be drawn at every location f o r each time step. Algorithm 1 The Prop osed GPE- based SED Metho d 1: Read the h isto r ical raw data of th e wind farm s; 2: Apply th e KL E on the pr eprocessed data to obtain p - dimensiona l trun c a ted da ta ; 3: Estimate the clo sed-form solution fo r the joint pdf o f ξ ; 4: Regenerate a large num ber of samples as the mod e l input through th e pdf ob tained f r om the kerne l density estimation; 5: Generate p -dimen sional n trainin g samp les X via the Latin hyperc u be sampling meth od; 6: Obtain realization s Y by ev aluating X thr ough the SED model; 7: Estimate the hy perparam eters η given the training set ( Y , X ) for th e GPE-b ased surr ogate model; 8: Propagate a large n umber of samples of the model input throug h the GPE-based sur rogate mo d els to obtain the SED system output realizatio ns; 9: Calculate the statistical moments of the SED output Q ( g , p ( ξ )) . V . C A S E S T U D I E S W e test our method on the IE EE 1 18-bus system [ 17 ] with the M A T P O W E R package using the MA TLAB R R 2019 a version and t he NREL ’ s W estern W in d Data Set [ 18 ]. In the expe riment, we pick one farm in Livermore, CA ( #L V ) an d two farms in Seattle, W A ( #SE1 , #SE2 ). For each farm, three turb ines are extrac te d from th e dataset: #9247 , #92 48 , #9249 for #L V ; #28914 , #28928 , #28959 for #SE 1 ; and #29138 , #29 153 , #291 54 for #SE2 . Th ese three wind farms are added at Buses 16, 58, and 78, re sp ec- ti vely . Assuming that the turbines in the same farm have the same wind speed and wind power all th e time, we calculate f or each time stamp the averaged wind speed and wind po wer over three selected wind turb ines and treat it as the p rev ailing wind speed and win d power o f that farm. For each farm, we take hourly averages on the co mmon wind speed and win d power to obtain the daily wind speed W and wind p ower P for each day in January between 20 04 a nd 200 6, which lead s to a total of 93 data p oints. The relationship between P an d W is mod e led by a decision tre e re gression model. T h e KLE is used to represen t the rando m ness of W . T o preserve 95% of the total variance of W , the first 8, 4, and 5 KL E modes are kept fo r #L V , #SE1 , and #SE 2 , respectively . T o test th e spatial depend ency of W among the three farms, we calcu late distance corr elation factors [ 19 ] between ξ o n different farms. The results are shown in Appendix, where a way to deal with th e d epende n cy b etween #SE1 and #SE2 is also provided. 0 5 10 15 20 W (m/s) 0 10 20 30 P (MW) (a) 40 100 150 200 250 300 350 400 450 GP training size (n) 0 1 2 3 4 5 d r 10 -3 (b) Fig. 2. (a) W ind po wer P versus wind speed W at Farm #L V in January ( Blue points denote real data points; whereas, red curve represent s predic tions by decision tree regression.). (b) T he relati ve dif ference betwe en E[ Q GP ] and E[ Q MC ] v arying by n . In order to ensure that the MC con ver ges, 8,000 realiz ations are used for Q MC . The GPE surrog a te with a pure quadr atic mean f unction and a squar e d expon ential kernel is constru cted for the SE D test system. L e t Q GP denote the estimatio n of th e m inimum produ ction cost Q from the GPE surro gate. Q MC is calcu lated by direct Mon te Carlo simulations perfo rmed on the test system. One of the most imp ortant r esults obtained from the SED is the expected minimum co st E[ Q ] . W e defin e the relative difference between E[ Q GP ] an d E[ Q MC ] as d r = | E[ Q GP ] − E[ Q MC ] | E[ Q MC ] · E[ Q MC ] is a fixed baseline wh ile E [ Q GP ] varies with the GPE trainin g size n . The smaller the d r is, the better the GPE surrogate fits its tar get. Figure 2(b) depicts the trace plot of d r over n . Notice that the appr o ach achieves less than 10 − 3 d r when n = 100 . T ABLE II. P R E D I C T I V E I N F ER E N C E S ( M E A N , 9 5 % C I A N D S TAN DA RD D E V I A T I O N ) O F M I N I M U M P RO D U C T I O N C OS T ( G P T R A I N I N G S I Z E n = 100 . ) Mean ( × 10 6 ) 95% CI ( × 10 6 ) Std. Dev . ( × 10 4 ) Q MC 2 . 955 (2 . 874 , 3 . 018) 3 . 908 Q GP 2 . 956 (2 . 869 , 3 . 020) 4 . 078 Numerical inf erences are listed in T able II . The G PE surrog ate, trained with 100 Latin hy percube simu lations, successfully calculates the SED values fo r the tested system und er 8,00 0 scenarios. T ABLE III. R E S U L T S F R O M R E P L I C AT I N G E M P I R I C A L M I N I M U M P R O D U C T I O N C OS T ( G P T R A I N I N G S I Z E n = 100 . ) Mean ( × 10 6 ) 95% CI ( × 10 6 ) Std. Dev . ( × 10 4 ) Q data 2 . 943 (2 . 849 , 3 . 017) 4 . 996 Q r GP 2 . 949 (2 . 858 , 3 . 025) 5 . 108 Ideally , a well- perfor ming surrogate is also expected to reasonably replicate th e empirical cost Q data for 9 3 d a ta poin ts. Correspon d ingly , we hav e th e rep lications Q GP from th e GPE- based surro gate estimation. The results in T ab le III indicate that the train ed GPE surrog ate is able to repro duce the empirical Q of th e test system . V I . C O N C L U S I O N S A N D F U T U R E W O R K In this paper, we propose a GPE-based framew ork in quantify ing uncer tainty for the SED problem. The pr o posed framework u tilizes the KLE to co nduct an effecti ve dimension reduction , which fu r ther accelerates the nonpar ametric GPE in the prop agation of uncertainties. The simulation results o n the modified IEEE 118 -bus system show that the proposed method is significan tly mo r e computation ally efficient than the traditional Monte Carlo method while achieving the desired simulation accu racy . A P P E N D I X M O D E L I N G S PA T I A L C O R R E L A T I O N S O F W I N D S P E E D S B E T W E E N W I N D F A RM S I N S E A T T L E T ABLE IV . D I S T A N C E C O RR E L AT I O N S F O R T H E F I R S T T H R E E O F ξ B E T W E E N W I N D F A R M S #L V – # SE1 #L V – # SE2 # SE1 – #SE2 ξ 1 0 . 141 0 . 123 0 . 592 ξ 2 0 . 221 0 . 166 0 . 289 ξ 3 0 . 131 0 . 231 0 . 319 T able IV sh ows that ξ 1 between #SE1 and #SE2 h av e a relativ ely high distance corre lation. One may still treat them indepen d ently since the value is not too close to 1 . In ad d ition, we pr ovid e a way to hand le the dep e ndency as described below . Considering that the Pea rson correlation of ξ 1 between #SE1 and #SE2 is calculated to be 0 .618, it is pro per to assume that th ey ar e linearly d ependen t, which can b e mod eled using a linear r egression. If we use ξ 11 and ξ 12 to disting uish ξ i in #SE1 and #SE2 , th e jo int samples of ξ 11 , ξ 12 can be obtained in tw o steps: 1) Sam ple ξ 11 from its d ensity func tion; 2) Sam ple ξ 12 ∼ N ( ˆ β 0 + ξ 11 ˆ β 1 , ˆ σ 2 ) , where ˆ β 0 , ˆ β 1 , ˆ σ 2 are the estimated in tercept, slope, a nd mean squared error from the results of the linear regression between ξ 12 and ξ 11 , respec tively . A C K N OW L E D G M E N T S This work was supported, in par t, b y the United States Departmen t of E nergy Of fice of Electricity Advanced Grid Modeling Pr o gram and per formed und er the auspices of the U.S. Department of Energy by Lawrence Livermore Nation al Laborato ry under Contract DE -A C52-07NA27344, and by the U.S. Nation al Science Foundation under EP AS Grant 191 7308 . Documen t released as LLNL-CONF-78851 8 . R E F E R E N C E S [1] C. Safta, R. L.-Y . Chen, H. N. Najm, A. Pinar , and J. P . W atson, “Ef ficient uncertaint y quanti fication in st ochastic economic dispatch, ” IEEE T rans. P ower Syst. , vol. 32, no. 4, pp. 2535–2546, Jul. 2017. [2] Y . Xu, L . Mili, A. Sandu, M. R. von Spakovsk y , and J. Zhao, “Propaga ting uncertainty in po wer system dynamic simulations using polynomia l chaos, ” IEE E T rans. P ower Syst. , vol. 34, no. 1, pp. 338– 348, Jan. 2019. [3] Y . Xu, L. Mili, and J. Zhao, “Probabi listic po wer flow calcul ation and v ariance analysis based on hierarchic al adapti ve polynomial chaos- ANO V A method, ” IEEE T rans. P ower Syst. , vol. 34, no. 5, pp. 3316– 3325, Sept. 2019. [4] Y . Xu e t al. , “Response -surfac e-based Bayesian inference for po wer system dynamic parameter estimation, ” IEEE T rans. Smart Grid , 2019. [Online]. A vai lable : https:/ /doi.org/ 10.1109/TSG.2019.289246 4 [5] X. Xu et al. , “Maximum loadabil ity of islanded microgrids with rene wable ene rgy generat ion, ” IEEE T rans. Smart Grid , vol. 10, no. 5, pp. 4696–4705, Sept. 2019. [6] H. Sheng and X. W ang, “ Applying polynomial chaos expa nsion to as- sess probabilist ic ava ilabl e del i very capab ility for distribut ion netw orks with rene wables, ” IEEE T rans. P ower Syst. , vol . 33, no. 6, pp. 6726– 6735, Nov . 2018. [7] P . A. Ruiz, C. R. Philbrick, E. Zak, K. W . Cheung, and P . W . Sauer , “Uncert ainty manage ment in the unit commitment problem, ” IEEE T rans. P ower Syst. , vol. 24, no. 2, pp. 642–651, May 2009. [8] S. T akriti, J. R. Birge, and E. Long, “ A stochastic model for the unit commitment probl em, ” IEEE T rans. P ower Sy st. , vol . 11, no . 3, pp. 1497–1508, Aug. 1996. [9] J. Li, N. Ou, G. Lin, and W . W ei, “Compressi ve sensing based stocha stic economic dispatch with high pen etrati on rene wables, ” IEEE T rans. P ower Syst. , vol. 34, no. 2, pp. 1438– 1449, Mar . 2019. [10] C. E. Ra smussen and C. K. I. W illiams, Gaussi an Pr ocesses for Mach ine Learnin g . Cambrid ge, MA, USA: MIT Press, 2006. [11] R. G. Ghanem and P . D. Spanos, Stochastic Fi nite Elements: A Spectr al Appr oach . Mi neola, NY , USA: Dover Publicati ons, Inc., 2003. [12] A. Gelman et al. , B ayesian Data Analysis , 3rd ed. Boca Raton, FL, USA: Chapman & Hall , 2014. [13] M. L. Eaton, Multivariate Stati stics: A V ector Space Appr oach . Ne w Y ork, NY , USA: John W iley & Sons, 1983. [14] T . J. Santner , B. J. W illia ms, and W . I. Notz, The Design and Analysis of Computer Experiments , 2nd ed. New Y ork, NY , USA: Springer , 2018. [15] L. De vroye , “Sample-based non-uniform random vari ate generati on, ” in Pr oc. 18th ACM Conf. W inter Simul. , 1986, pp. 260–265. [16] B. Silverman , Density Estimatio n for Statisti cs and Data Analy sis . Chapman & Hall/CRC, 1998. [17] Univ ersity of W ashingt on, Po wer Systems T est Case Archi ve. (accesse d on 8 /30/2019). [On line]. A vail able: http:/ /www .ee.washingt on.edu/research/pstca/ [18] NREL W estern W ind Data Set. (accessed on 8/30/ 2019). [Online]. A v ailabl e: https:/ /www .nrel.gov/gri d/western - wind- data.html [19] G. J. Sz ´ eke ly , M. L. Rizzo, and N. K. Bakirov , “Measuri ng and testing depende nce by correlat ion of distanc es, ” Ann. Statist. , vol. 35, no. 6, pp. 2769–2794, 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment