Emotion Filtering at the Edge
Voice controlled devices and services have become very popular in the consumer IoT. Cloud-based speech analysis services extract information from voice inputs using speech recognition techniques. Services providers can thus build very accurate profil…
Authors: Ranya Aloufi, Hamed Haddadi, David Boyle
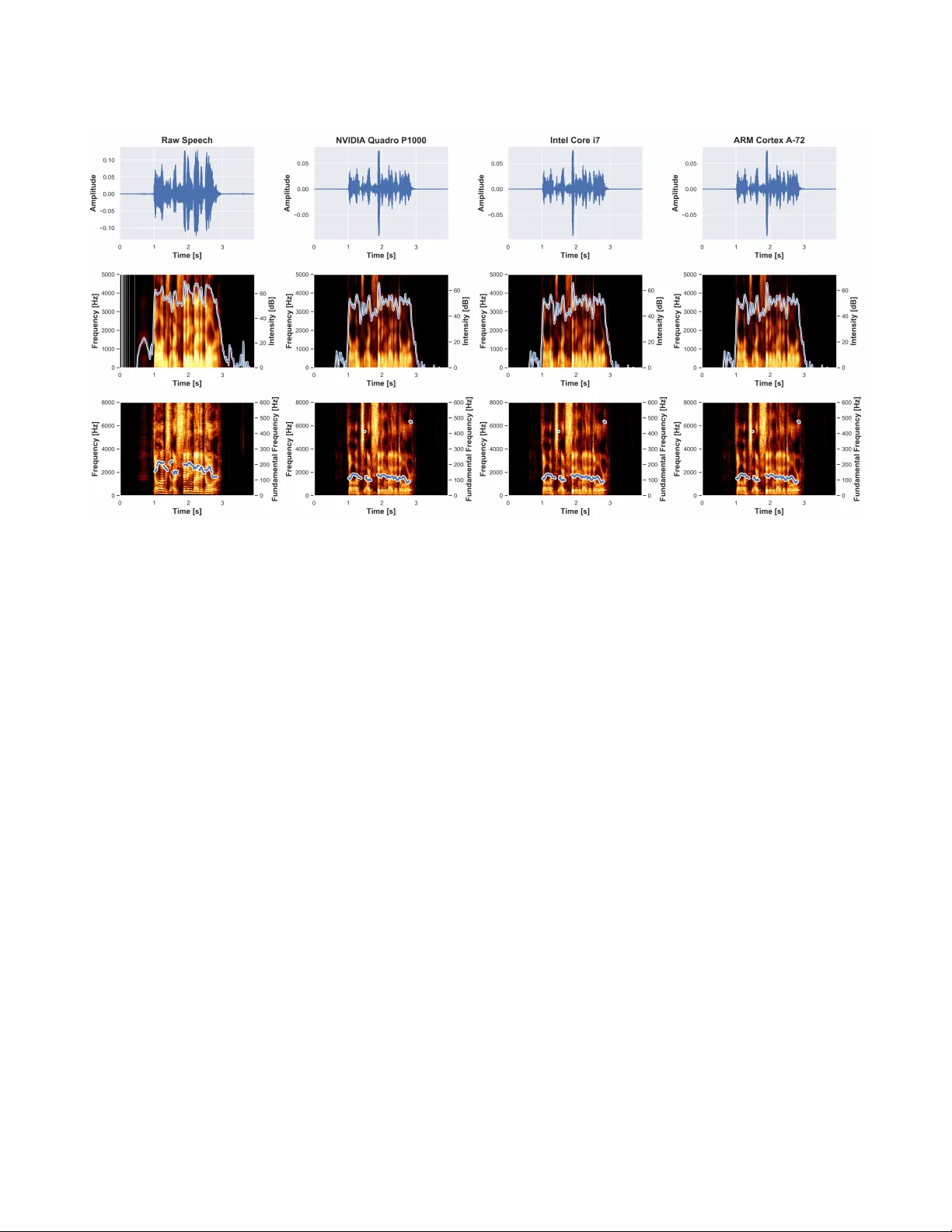
Emotion Filtering at the Edge Ranya Alou, Hamed Haddadi, David Boyle Systems and Algorithms Laborator y Imperial College London Abstract V oice controlled devices and services have become very popular in the consumer Io T . Cloud-based speech analysis services extract information from voice inputs using sp eech recognition techniques. Services providers can thus build very accurate proles of users’ demographic categories, per- sonal preferences, emotional states, etc., and may ther efore signicantly compromise their privacy . T o address this prob- lem, we have dev eloped a privacy-preserving interme diate layer between users and cloud services to sanitize voice in- put directly at edge de vices. W e use Cy cleGAN-based speech conversion to remov e sensitive information from raw voice input signals before regenerating neutralized signals for for- warding. W e implement and e valuate our emotion ltering approach using a relatively cheap Raspberry Pi 4, and show that performance accuracy is not compromised at the edge. In fact, signals generated at the edge dier only slightly ( ∼ 0.16%) from cloud-based approaches for spe ech recogni- tion. Experimental evaluation of generated signals show that identication of the emotional state of a speaker can be re- duced by ∼ 91%. CCS Concepts • Embedded systems ; • V oice-enabled ; • Security and Privacy ; • Performance and Utility ; Ke ywords Speech Analysis, V oice Synthesis, V oice Privacy , Internet of Things (Io T) 1 Introduction V oice-controlled Io T devices and smart home assistants have gained huge popularity . Seamless interaction between users and services are enabled by speech recognition. Many Io T devices such as home assistants, smartphones, and smart watches have built-in microphones that listen for user com- mands, and due to resource limitations on edge devices, speech analysis is usually outsourced to cloud ser vices. How- ever , services providers aim to e xpand their abilities to un- derstand the additional information about the speakers by developing models that process their voice input and de- tect their current conditions such as emotion classication and analysis of physical and mental wellbeing. They can collect sensitive behaviour patterns from voice input which include various embedded metadata such as "the who, when, where, what and ho w" that may violate user privacy in nu- merous ways. They may infer a user’s mental state, stress Figure 1: The data-ow of the proposed framework during the training and testing phases level, smoking habits, overall health conditions, indication of Parkinson’s disease, sleep patterns, and levels of exercise [ 18 ]. For instance, Amazon has patented technology that can ana- lyze users’ voice to identify emotions and/or mental health conditions. It allows understanding speaker commands and their emotion characterization to provide highly targeted content [ 7 ]. Similarly , Aectiva has developed a multimo dal articial emotional intelligence by combining the analysis of both face and sp eech as complementar y signals to under- stand the human emotion expression [ 1 ]. Therefor e, privacy- preserving spee ch analysis is playing an especially important role when it comes to adv ertising content r elated to physical or emotional states. Emotions are a universal aspect of human sp eech that convey their b ehaviour . As a consequence of listening to users’ voices and monitoring emotions, resulting critical decision-making may aect their life, ranging fr om tness trackers for well-being to suitability for recruitment and open many new privacy issues. In this paper , we propose a privacy-preserving architecture for speech analysis and evaluate it to mitigate the privacy risks of the cloud-based voice analysis services. It serves as a mask of the sensitive emotional patterns in the voice input to prevent ser vices providers from monitoring users’ emotions that associated with their voice. Our proposed solution is a feature learning and data recon- struction framework to bridge the communication between users edge devices and a service provider cloud. It performs emotion ltering in low cost edge de vices while still main- taining the usability of the voice input for the cloud-based ser- vices. It includes three components: pre-processor , emotion lter , and generator . Firstly , pre-processor extracts the sensi- tive features to be hidden and then used as a target to train the transformation mo del. Emotion lter is an embedde d- specic model that uses CycleGAN architecture [ 25 ] to trans- form the voice input style. Finally , the generator uses the output features to re-generate the voice les based on the state-of-the-art v ocoder: W ORLD [ 14 ]. T o evaluate the trade- o between data utility and privacy , the proposed method is tested on an emotion recognition task using the RA VDESS dataset [ 10 ]. The results show that the proposed solution can decrease the accuracy of the emotion recognition applica- tion, while aecting the accuracy of sp eech recognition and speaker identication techniques only minimally . Contribu- tions of this paper can be summarized as follows: • Privacy-preserving emotion lter using CycleGAN that learns ho w to replace sensitiv e emotional features of the voice input with corresponding neutral one. • Implementation and evaluation at the edge versus cloud to show how it can retain the similar perfor- mance accuracy in protecting sensitive information at edge and cloud-based approaches. Filtering the aect content of the voice signal is critical task to ensure appropriate protections for users of cloud- based voice analysis ser vices. The proposed framework is the rst privacy-pr eserving emotion lter for v oice inputs at edge devices to protect the private paralinguistic information of the speaker . It enables users to protect their sensitive emotional data, while beneting from sharing their non- sensitive data with cloud-based voice analysis services. In addition, we make our code and results available online. 1 2 Related W ork V oice versus Privacy V oice is considered to b e one of the unique biometric information that has been widely used in various Io T applications. It is a rich resource that dis- closes several possible states of a speaker , such as emo- tional state [ 20 ], condence and stress le vels, physical con- dition [ 15 , 20 , 21 ], age [ 9 ], gender , and personal traits. For example, Mairesse et al. [ 11 ] proposed classication, regres- sion and ranking models to learn the Big Five personality traits of a speaker . Previous studies on the voice input privacy have been fo cused on two main asp ects which are the voice- enabled systems breakthroughs and revealing the user’s pri- vacy by analyzing their communications. By spoong voice- based authentication systems, the attackers will have unau- thorized access to the private information of these systems users [ 23 ]. Alepis and Patsakis in [ 3 ] pr esented and analyzed 1 https://github.com/RanyaJumah/Embedded-PP-Speech-Analysis the potential risks of voice assistants in mobile devices, show- ing how urgent it is to develop privacy-preserving architec- tures for speech analysis by extracting the distinguishable features from the speech without compromising individual privacy . Edge Computing and Privacy-preserving Deep Learn- ing One of the primar y roles of the edge computing is to lter the data locally prior send it to the cloud which may be used to pr otect users privacy . In [ 17 ] a hybrid framew ork for privacy-preserving analytics is presented by splitting a deep neural network into a feature extractor module on user side, and a classier mo dule on cloud side. It protects the user privacy by removing the undesired sensitive information from the extracted featur es results. Generative adversarial networks (GANs) [ 5 ] are one of the deep learning mo dels that have been recently applied to lter the sensitive infor- mation from the raw data and regenerate the ltered data. For example, on-device transformation of sensor data was proposed by Malekzadeh et al. in [ 12 ]. They use convolu- tional auto-encoders (CAE) as a sensor data anonymizer to remove user identiable featur es locally and then share the ltered sensor data with specic applications such as daily activities monitoring apps. Privacy-preserving V oice Analysis on the Edge V oice conversion is one of privacy pr eser vation approaches that has b een use d in the context of speaker identity . For example, V oiceMask is proposed to mitigates the se curity and privacy risks of the voice input on mobile devices by concealing voiceprints and adding dierential privacy [ 19 ]. It sanitized the audio signal received from the microphone by hiding the speaker’s identity and then sending the p erturbed sp eech to the voice input apps or the cloud. Nautsch et al. in [ 16 ] investigate the gap in the development of privacy-preserving technologies to protect privacy in the case of spe ech signals and show the essential nee d to apply these technologies to protect sp eaker and speech characterisation in sp eech recordings. 3 System Framework Leveraging non-parallel voice conversion (VC) technol- ogy [ 8 ], our framework aims to protect the users’ privacy from v oice analysis service. The framework consists of three main components: (i) pre-processor , (ii) emotion lter , and (iii) generator . The description of the proposed framework is presented in Figure 1. Pre-processor The raw voice input is pre-processed to extract the distinguishing signal representation by perform- ing transformations functions to the voice input, and using the resulting outcomes as labels [ 4 ]. Prosody features such as spectral envelope (SPs) are the most eective features in emotion recognition tasks [ 22 ] which can b e computed directly from the signal by applying spe cic transformation Emotion Filtering at the Edge Figure 2: The emotion lter is traine d on the cloud, and then the pre-trained lter is used on the edge side for speaking style transformation functions to minimize the computational o verhead and ex- tract these specic features. W ORLD vocoder [ 14 ] is used to extract these specic features at frame-level ( a frame de- notes a number of samples with the same time-stamp, one per channel) from both the source and corresponding target signals. Emotion Filter T o learn the sensitive representations in the voice input, CycleGAN-based speaking style conversion is used to transform the raw voice emotional features to cor- responding normal one. Cy cleGAN [ 25 ] is a custom model of GANs that uses two generators and two discriminators. By considering X and Y as dierent domains that generators task to convert from X to Y and vice versa. Generator (G) maps from domain X to Y , and generator (F) maps from Y to X. In addition, two adv ersarial discriminators D (X) and D (Y), where D (X) aims to distinguish between objects in X domain and output objects fr om F (Y), and D (Y) aims to discriminate between (Y) and the output of G (X). It has intro- duced to overcome the diculty of preparing paired dataset in style conversion applications [ 25 ]. Therefore, changing emotion style by using CycleGAN will help to transfer be- tween emotions and neutral speaking style without paired training data. Consistent with TinyML [ 2 ]objectives to trade-o between the machine learning accuracy and resource eciency and optimize the performance cost of data analysis on constrained platforms such as Io T devices, we propose to implement the emotion lter on the edge to enable on-de vice privacy- preserving spee ch analysis. A pre-trained CycleGAN model is frozen by combining the model graph structure with its weight to create an emb edded version that can t on the edge devices for features transformation task. Generator The W ORLD synthesis algorithm is use d to re-generate a high-quality synthesized voice input by using the output features from the emotion ltering model. The generated voices are able to preser ve the content of the voice input and project away sensitive representations such as emotional patterns. T able 1: A comparison of the accuracy between raw and generate d voice across speech and speaker recog- nition tasks. Speech Recognition Speaker Recognition W ord Error Rate (WER %) Equal Error Rate (EER %) Raw V oice 5.27 0.06 NVIDIA Quadro P1000 20.36 0.120 Intel Core i7 20.66 0.121 ARM Cortex A -72 20.67 0.124 Figure 3: The emotion recognition accuracy of the raw and generated voices: similar performance accuracy by NVIDIA Quadro P1000, Intel Core i7, and ARM Cortex- A72 processor in hiding sensitiv e emotional patterns. In this way , the sensitive patterns in the voice input will not disclose to cloud-based voice input services providers and they will have only access to the synthesized voice. The output of the proposed framework will protect the speaker privacy by preserving the linguistic content and hiding the private non-linguistics content (emotional patterns). 4 Experimental Evaluation The sensitive information to be hidden is the sp eaker’s emotion. As our framework aims to de crease the emotion recognition accuracy while maintaining the speech and speaker recognition accuracy , the following subsections describ e the experimental setting, selected speech analysis tasks for eval- uation, and evolution results. 4.1 Experimental Setting W e conduct the experiment by running the proposed frame- work over NVIDIA Quadro P1000 with GP107 graphics pro- cessor and 4 GB memory , MacBook Pro with 2.7 GHz Intel Core i7 processor and 8 GB memory and Raspberry Pi4 with ARM Cortex- A72 and 4 GB memory . The experiment is exe- cuted over speech audio-only les in .wav format from the Figure 4: Spectrogram analysis of the raw ( happy) and generate d waveform (neutral) in term of (top)amplitude (the size of the oscillations of the vocal folds), (middle)intensity (acoustic intensity), and ( bottom)fundamental frequency (v ocal fold vibration property) Ryerson Audio- Visual Database of Emotional Spee ch and Song (RA VDESS) [ 10 ] with 48kHz/16-bit sampling rate. It contains recordings from 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent with seven spee ch emotions: 0 = neutral, 1 = calm, 2 = happ y , 3 = sad, 4 = angry , 5 = fearful, 6 = disgust, 7 = surprised. A subset of this dataset is use d to evaluate the eectiveness of the proposed framework. W e select 118 les where 96(training) and 22(testing) les with three emotions: neutral, happy , and angr y . It organised as follows (24 * 2) emotion les and (24 * 2) neutral les. T o overcome the model over-tting, dier ent texts have been choosing for training and testing sets. As depicted in Figure 2, the training phase begins at the cloud end (N VIDIA Quadro P1000 or MacBook Pro) by down- sampling the .wav les to 16 kHz to preserve the signal content information. Then, acoustic parameters spe ctral en- velopes (SEs) for each logarithmic fundamental frequency (log F0) are extracted as prosody featur es which are the most related feature to emotion recognition. These features are mapped from utterances spoken in an emotional style to cor- responding features of neutral utterances using CycleGAN with similar network architecture in [ 8 ]. The emotion lter is trained under 7500 iterations with learning rates of 0.0002 for the generator and 0.0001 for the discriminator . On the edge side (Raspberr y Pi 4), the pre-trained emotion lter is exported to apply on-device emotion ltering. Then, the raw voice signal is pre-processed to extract the prosody features. The emotionless speaking style is achieved by using the pretrained lter to convert these features in the raw signal. Finally , the outputs of the conversion phase are converted to neutral speech waveforms by using the WORLD synthesizer . 4.2 Spee ch Analysis T asks W e conducted objective evaluations of the generated voice for three spee ch analysis tasks. Firstly , the re-generated .wav le is evaluated by the trained emotion recognition model on RA VDESS dataset to identify the emotion state of the san- itized voices. Then, we perform speech and speaker recog- nition on the sanitized voices and evaluate the accuracy . The tools used in the three tasks evaluation is described as follows. Speech Recognition The IBM W atson sp eech-to-text ser- vice with speech recognition capabilities is use d to convert the generated speech into text [ 6 ]. The performance of the speech recognition on the sanitized voices is measured by the word error rate (WER), which is a common metric of the speech recognition p erformance to measures the dierence in the word lev el between two spoken sequences. Speaker Recognition T o ensure that the propose d sys- tem is highly condent that p erson is speaking and has been correctly identied, a V GG sp eaker recognition model on Emotion Filtering at the Edge V oxCeleb2 [ 24 ] has been used. All audio les are converted to 16-bit streams at a 16 kHz for consistency . The accuracy of speaker recognition is measured by the equal err or rate (EER), which is the rate at which b oth acceptance and rejec- tion errors are equal. Emotion Recognition T o automatically identify the emo- tional state of the users, an emotion classication model based on RA VDESS dataset has b een used to predict 7 emo- tion classes which are the following: 0 = neutral, 1 = calm, 2 = happy , 3 = sad, 4 = angry , 5 = fearful, 6 = disgust, 7 = sur- prised [ 13 ]. The accuracy of emotion recognition is dened as the success rate of correctly identied emotions. 4.3 Evaluation and Discussion From the experiments results, we can summaries the follow- ing: Results accuracy and privacy W e compare the accu- racy r esults from the speech and sp eaker r ecognition models on raw and transformed voices, and it shows that the utility of the signal r etains accepted, while the emotion recognition accuracy is sharply decreased, see Figure 3. The evaluation of the speech recognition p erformance is done using the aver- age of WER which is 20.36 %, 20.66 %, and 20.67 % in NVIDIA Quadro P1000, Intel Cor e i7, and ARM Cortex A -72 respe c- tively . In addition, the speaker recognition performance is measured by EER and the average of the error rate is ∼ 0.12 in all three platforms, as sho wn in T able 1. A s a result, the proposed framework has insignicant dierence in the per- formance accuracy across edge and cloud-based r esources. Howev er , the speech recognition accuracy will b e improved by increasing the dataset, rening the features set, and ma- nipulate the model architecture. Model optimization on the edge With relativ ely cheap ARM Cortex- A72 board device , we show that the proposed framework can be implemented with similar performance accuracy as on N VIDIA Quadro P1000 and Intel Core i7. Spectrogram analysis of the raw and transformed speech is illustrated in Figure 4, demonstrates that there are sim- ilar changes on the amplitude, intensity , and fundamental frequency of the transformed speech using cloud and edge resources which lead to alike accuracy performance over speech analysis tasks. However , optimizing the model will be considered by implementing dierent approaches such as weight pruning, compression, and quantization to enhance the model performance on the edge. Resource limitation and scalability Computational per- formance is limited by various resources constraint such as memory capacity . Figure 5 compares the execution time and memory usage of the emotion conversion model running on the NVIDIA Quadro P1000 and Intel Core i7 versus the ARM Cortex- A72. However , NVIDIA Quadro P1000 and Intel Core i7 outperforms ARM Cortex-A72 in the execution time. Figure 5: A comparison b etween the execution time and memory usage of running the mo del in N VIDIA Quadro P1000, Intel Core i7, and ARM Cortex- A72 Precisely , ARM Cortex- A72 implementation consumes twice as much time as that of the Intel Core i7. W e manage d to signicantly reduce the execution time and memory usage of running the proposed framework on edge devices. Privacy overhead on the edge W e performed a privacy overhead analysis for the emotion lter on the edge devices. W e use two type of speech analysis experiments: one inte- grated with the emotion lter and a baseline experiment without emotion lter , as described in T able 2. In the rst experiment, we disable the emotion lter and measure the overhead purely incurred by conguring the edge device (raspberr y pi), loading the .wav le, and uploading the le to the cloud. The second experiment type measures the over- head purely incurred by running the spe ech analysis with emotion lter . Precisely , we measure the overhead by: (1) conguring the e dge device, (2) loading .wav le, (3) pre- processing, ltering, and generating the .wav le, and (4) uploading the le to the cloud. Figure 6 shows the experi- ment results. Raspberry pi needs about 40 se cond for booting up. The ∆ average power consumption is 0.45 W att and ∆ average energy consumption is 31.2 Joule . The baseline la- tency is about 20 second, while the emotion lter latency is 41 second. 5 Discussion and Future W ork In this paper we pr esented a framework for privacy pr e- serving spe ech analytics which consists of a pre-processor , an emotion lter , and a generator . It will protect the user pri- vacy by hiding the undesired sensitive information from the extracted features by transforming the features correspond to emotional pattern while retaining the featur es correspond to spee ch content and speaker identity unchanged. There- fore, on the cloud side, only non-sensitive ltered features can be inferred such as linguistics content. Evaluating our framework by distribution the training and testing execution T able 2: Privacy O verhead Analysis Exp eriments Time Baseline Emotionless Filter T0 Pi on Pi on T1 Load .wav Load .wav T2 Cloud uploading Preprocessor (PP), emotion lter (EF), generator (G) T3 Cloud uploading Figure 6: Power and Energy Consumption between the edge and the cloud, we achieved high decrease in the emotion recognition task accuracy by ∼ 91%, while slightly de creasing for other tasks such as spe ech and speaker recognition. Protection the users’ privacy in sp eech analysis is a very challenging task. The challenge is how to sanitize the speech without decreasing the speech recognition accu- racy . W e will focus on extending the proposed framework by including spee ch content lter to prevent similar out- comes using other techniques, such as sentiment analysis to strengthen the user privacy . In addition, we will include speech analysis in-the-wild emotional dataset and further investigations of for privacy-preserving deep learning archi- tecture. References [1] [n. d.]. Emotion AI. https://www .aectiva.com/emotion- ai- overview/ [2] [n. d.]. TinyML. https://sites.google.com/site/rankmap/ [3] Efthimios Alepis and Constantinos Patsakis. 2017. Monkey says, mon- key does: security and privacy on voice assistants. (2017). [4] Carl Doersch and Andrew Zisserman. 2017. Multi-task self-supervised visual learning. [5] Ian Goodfellow , Jean Pouget-Abadie , Mehdi Mirza, Bing Xu, David W arde-Farley , Sherjil Ozair , Aaron Courville, and Y oshua Bengio. 2014. Generative adversarial nets. [6] IBM. 2019. IBM W atson Speech to T ext. https://speech- to- text- demo.ng.bluemix.net [7] Huafeng Jin and Shuo W ang. 2018. V oice-based determination of physical and emotional characteristics of users. [8] T akuhiro Kaneko, Hirokazu Kameoka, Kou T anaka, and Nobukatsu Hojo. 2019. CycleGAN- V C2: Improved CycleGAN-based Non-parallel V oice Conversion. [9] Robert M Krauss, Robin Freyberg, and Ezequiel Morsella. 2002. Infer- ring speakersâĂŹ physical attributes from their voices. (2002). [10] Steven R Livingstone and Frank A Russo. 2018. The Ryerson A udio- Visual Database of Emotional Speech and Song (RA VDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. (2018). [11] François Mairesse, Marilyn A W alker , Matthias R Mehl, and Roger K Moore. 2007. Using linguistic cues for the automatic recognition of personality in conversation and text. (2007). [12] Mohammad Malekzadeh, Richard G. Clegg, Andrea Cavallaro, and Hamed Haddadi. 2019. Mobile Sensor Data Anonymization. [13] Marcogdepinto. 2019. marcogdepinto/Emotion-Classication-Ravdess. https://github.com/marcogdepinto/Emotion- Classication- Ravdess [14] Masanori Morise, Fumiya Y okomori, and Kenji Ozawa. 2016. WORLD: a vocoder-based high-quality speech synthesis system for real-time applications. (2016). [15] Iosif Mporas and T odor Ganchev . 2009. Estimation of unknown speaker’s height from speech. (2009). [16] Andreas Nautsch, Abelino Jiménez, Amos Treiber , Jascha Kolberg, Catherine Jasserand, Els Kindt, Héctor Delgado, Massimiliano T odisco, Mohamed Amine Hmani, A ymen Mtibaa, et al . 2019. Preserving Pri- vacy in Speaker and Speech Characterisation. (2019). [17] Seyed Ali Osia, Ali Shahin Shamsabadi, Ali T aheri, Kleomenis K atevas, Sina Sajadmanesh, Hamid R Rabiee, Nicholas D Lane, and Hamed Had- dadi. 2017. A hybrid deep learning architecture for privacy-preserving mobile analytics. (2017). [18] Scott R Peppet. 2014. Regulating the internet of things: rst steps toward managing discrimination, privacy, security and consent. (2014). [19] Jianwei Qian, Haohua Du, Jiahui Hou, Linlin Chen, T aeho Jung, and Xiang- Y ang Li. 2018. Hideb ehind: Enjoy V oice Input with V oiceprint Unclonability and Anonymity . [20] Björn Schuller , Stefan Steidl, Anton Batliner , Alessandro Vinciarelli, Klaus Scherer , Fabien Ringeval, Mohamed Chetouani, Felix W eninger , Florian Eyben, Erik Marchi, et al . 2013. The IN TERSPEECH 2013 com- putational paralinguistics challenge: Social signals, conict, emotion, autism. [21] Aaron Sell, Gregory A Br yant, Leda Cosmides, John T ooby , Daniel Sznycer , Christopher V on Rueden, Andre Krauss, and Michael Gurven. 2010. Adaptations in humans for assessing physical strength from the voice. (2010). [22] George Trigeorgis, Fabien Ringeval, Raymond Brueckner , Erik Marchi, Mihalis A Nicolaou, Björn Schuller , and Stefanos Zafeiriou. 2016. Adieu features? end-to-end speech emotion recognition using a de ep convo- lutional recurrent network. [23] Zhizheng Wu, Nicholas Evans, T omi Kinnunen, Junichi Y amagishi, Federico Alegre, and Haizhou Li. 2015. Sp oong and countermeasures for speaker verication: A survey . (2015). [24] W eidi Xie, Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. 2019. Utterance-level Aggregation For Speaker Recognition In The Wild. (2019). [25] Jun- Y an Zhu, T aesung Park, Phillip Isola, and Alexei A Efr os. 2017. Un- paired image-to-image translation using cycle-consistent adversarial networks.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment