Heterogeneity-Aware Asynchronous Decentralized Training
Distributed deep learning training usually adopts All-Reduce as the synchronization mechanism for data parallel algorithms due to its high performance in homogeneous environment. However, its performance is bounded by the slowest worker among all wor…
Authors: Qinyi Luo, Jiaao He, Youwei Zhuo
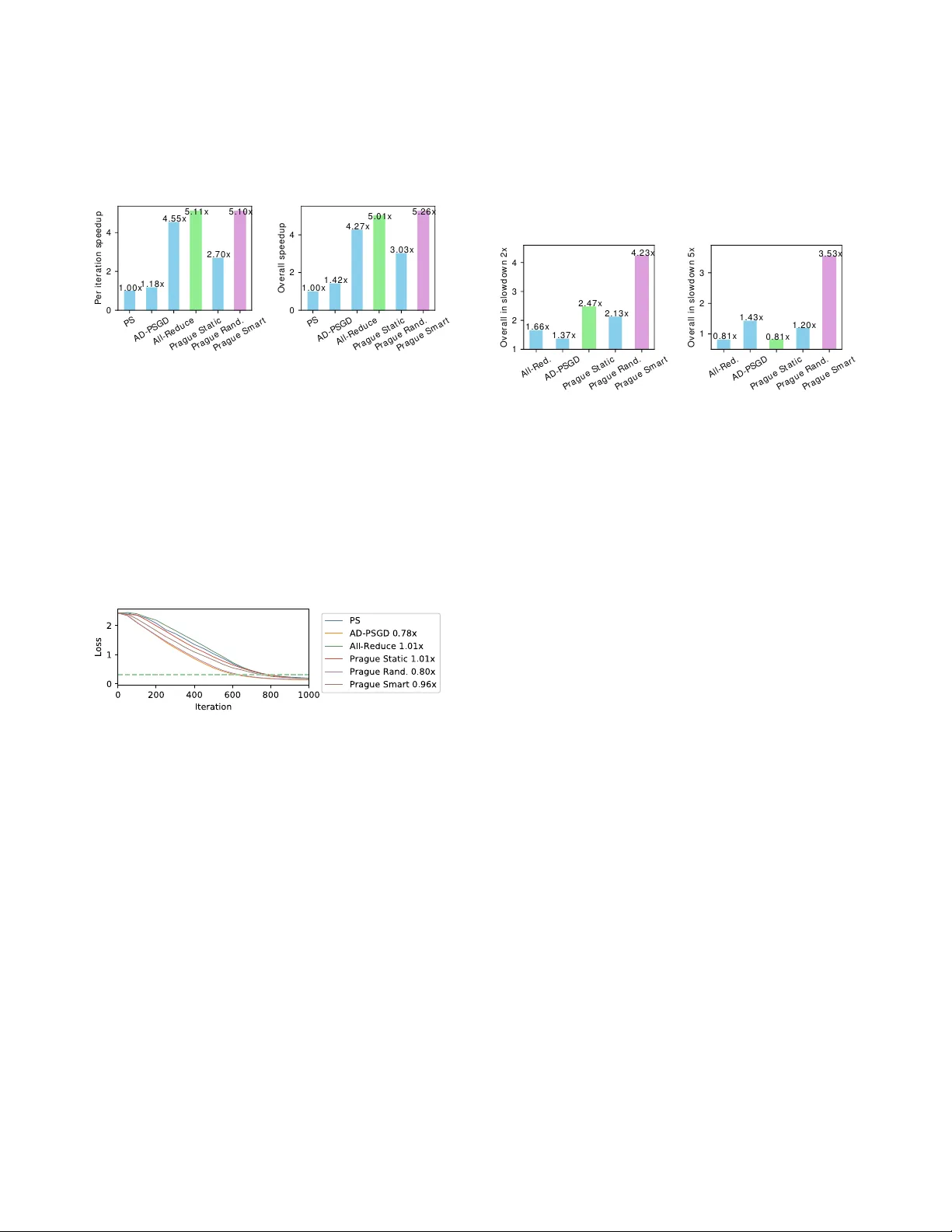
Heterogeneity-A ware Asynchronous Decentralized T raining Qinyi Luo ∗ 1 , Jiaao He ∗ 2 , Y ouwei Zhuo 1 , and Xuehai Qian 1 1 Uni versity of Southern California, CA, USA 2 Tsinghua Uni versity , Beijing, China Abstract Distributed deep learning training usually adopts All- Reduce as the synchr onization mechanism for data parallel algorithms due to its high performance in homogeneous en vi- r onment. However , its performance is bounded by the slowest worker among all work ers, and is significantly slower in het- er og eneous situations. AD-PSGD, a newly pr oposed synchr o- nization method which pr o vides numerically fast con ver gence and heter og eneity tolerance, suf fers fr om deadlock issues and high synchr onization overhead. Is it possible to get the best of both worlds — designing a distributed training method that has both high performance as All-Reduce in homogeneous en vir onment and good heter o geneity tolerance as AD-PSGD? In this paper , we pr opose Ripples , a high-performance heter og eneity-awar e async hr onous decentr alized training ap- pr oac h. W e achieve the above goal with intensive synchr o- nization optimization, emphasizing the interplay between algo- rithm and system implementation. T o r educe synchr onization cost, we pr opose a novel communication primitive P artial All-Reduce that allows a lar ge gr oup of workers to synchr o- nize quickly . T o r educe synchr onization conflict, we pr opose static gr oup scheduling in homog eneous en vir onment and sim- ple techniques (Gr oup Buffer and Gr oup Division) to avoid conflicts with slightly r educed r andomness. Our experiments show that in homogeneous en vir onment, Ripples is 1 . 1 × faster than the state-of-the-art implementation of All-Reduce, 5 . 1 × faster than P arameter Server and 4 . 3 × faster than AD-PSGD. In a heter ogeneous setting, Ripples shows 2 × speedup over All-Reduce, and still obtains 3 × speedup over the P arameter Server baseline. 1. Introduction Deep learning is popular no w . It has achie ved phenomenal advancement in various fields including image recognition [ 46 ], speech processing [ 19 ], machine translation [ 13 ], gaming [ 43 ], health care [ 53 ] and so on. The key success of deep learning is the increasing size of models that can achie ve high accuracy . At the same time, it is difficult to train the large and complex models. It is common that training a model may take hours or ev en days [ 17 ]. Therefore, it is crucial to accelerate training in the distrib uted manner to better prompt wider applications of deep learning. ∗ These two authors contributed equally . Jiaao He did this work during his internship at USC. In distributed training, multiple w orkers running on a num- ber of compute nodes cooperativ ely train a model with the help of communication between workers. The current widely used approach of distrib uted training is data parallelism [ 3 ], in which each worker keeps a replica of the whole model, pro- cesses training samples independently , and synchronizes the parameters e very iteration. P arameter Server (PS) [ 32 ] is the first approach to support distributed training by introducing a central node which manages one or more shared versions of the parameters of the whole model at PS. More recently , All-Reduce [ 41 ], an alternative distributed solution utilizing the adv anced Ring All-Reduce algorithm [ 15 ], is shown to provide superior performance than PS [ 26 , 31 , 45 , 52 ]. T o fun- damentally improv e the scalability , the general decentralized training [ 21 , 22 , 33 , 34 , 35 , 37 , 47 , 48 ] also recei ved intensi ve research interests. It has been recently theoretically shown for the first time that decentralized algorithms can outperform centralized ones [ 34 ]. While PS and All-Reduce are both spe- cial cases of the decentralized method, a general decentralized training scheme can use an arbitrary communication graph with spectral gap, doubly stochastic averaging and indepen- dence properties [ 35 ] to specify point-to-point communication between workers. The first ke y problem of distributed learning is the intensive communication among workers. During ex ecution, gradients or parameter updates are transferred between w orkers in dif- ferent nodes to achieve the ev entually trained model. In PS, all w orkers need to communicate with the parameter serv ers — easily causing communication bottleneck e ven if the number of workers is relati vely small. In All-Reduce, the communica- tion is more ev enly distrib uted among all workers, since it log- ically implements the all-to-all communication, the amount of parameters transferred is still high. More importantly , to hide communication latency , All-Reduce uses delicate pipelined op- erations among all workers. It makes this solution vulnerable to system heterogeneity , a concept that means the performance of dif ferent nodes (work ers) and the speed of dif ferent commu- nication links are dif ferent. Specifically , because All-Reduce requires global synchronization in ev ery step, its performance is strongly bounded by the slowest worker , thereby cannot tolerate heterogeneity well. W e believe that heter ogeneity is the second key challenge of distrib uted training. T o tolerate heterogeneity , both system and algorithm techniques hav e been proposed. At system le vel, backup worker [ 5 ] and bounded staleness [ 20 ] ha ve been sho wn to be H o m o . A l l - R e d u c e H e t e r o . A l l - R e d u c e H o m o . A D - P S G D H e t e r o . A D - P S G D 0 2 0 0 4 0 0 C o n v e r g e n c e t i m e / s e c 7 7 . 0 1 4 0 3 . 9 8 2 3 2 . 3 3 2 2 9 . 9 2 H o m o g e n e o u s E n v . H e t e r o g e n e o u s E n v . Figure 1: A comparison between All-Reduce [ 41 ] and AD- PSGD [ 35 ] in homogeneous (Homo) en vironment and hetero- geneous (Hetero) en vir onment. ef fectiv e in mitigating the effects of random worker slo wdo wn in both PS [ 2 , 5 , 20 , 42 , 51 ] and decentralized training [ 37 ]. Howe v er , if some w orkers e xperience se vere and continuous slowdo wn, the benefits of system solution are limited since the whole system will e v entually be dragged down by the slow workers or communication links. It motiv ates the more funda- mental algorithm le v el solutions. In particular , AD-PSGD [ 35 ] probabilistically reduces the effects of heterogeneity with ran- domized communication. In an additional synchronization thread, each work er randomly selects one w orker to a verage parameters between the two and atomically update both ver - sions. Moreov er , the workers need to wait for the current synchronization to finish before starting another , no matter if it acti vely initiates a synchronization or is passiv ely selected by another worker . While the slow workers inevitably have staler parameters and will drag do wn others’ progress, it will only happen if they happen to be selected. Unfortunately , the implementation in [ 35 ] only supports a certain type of com- munication graphs and suf fers from deadlock otherwise. More importantly , the parameter update protocol in AD-PSGD in- curs significant synchronization ov erhead to ensure atomicity . Figure 1 sho ws the training performance 1 of VGG-16 model ov er CIF AR-10 dataset, of All-Reduce [ 41 ] and AD-PSGD on 4 GTX nodes running 16 GPUs as 16 workers in total in homogeneous and heterogeneous 2 ex ecution en vironment. In Figure 1 , we see AD-PSGD’ s excellent ability to tolerate het- erogeneity — 1 . 75 times faster than All-Reduce. Howe v er , the figure also sho ws that All-Reduce is much faster ( 3 . 02 × ) than AD-PSGD in homogeneous en vironment. Thus, the open question is whether it is possible to improve AD-PSGD so that its performance is compar able to All-Reduce in a homo- geneous en vironment while still maintaining superior ability to tolerate heter ogeneity ? In this paper , we propose Ripples , a high-performance heterogeneity-aware asynchronous decentralized training ap- proach. Compared to the state-of-the-art solutions, Ripples gets the best of both worlds: it achieves better performance than All-Reduce in homogeneous en vironment and signifi- cantly outperforms AD-PSGD in both homogeneous and het- erogeneous en vironments. W e achiev e this almost ideal solu- tion with intensi ve synchronization optimization, emphasizing 1 Defined as the time for training loss to reach 0 . 32 2 The heterogeneous setting is that one worker is slowed do wn by 5 times. the interplay between algorithm and system implementation. T o r educe synchr onization cost , we propose a nov el communi- cation primitiv e, P artial All-Reduce , that allo ws a large group of workers to synchronize quickly . T o r educe synchr onization conflict , we propose static group scheduling in homogeneous en vironment and simple b ut smart techniques (Group Buffer and Group Di vision) to a void conflicts with slightly reduced randomness. W e perform experiments on Ma verick2 cluster of T A CC Super Computer . W e train a common model VGG-16 on CIF AR-10 dataset to look deeply into dif ferent algorithms. W e also train a large model, ResNet-50, on a large dataset, ImageNet, to validate the optimizations. Our experiments sho w that in homogeneous en vironment, Ripples is 1 . 1 × faster than the state-of-the-art implementation of All-Reduce, 5 . 1 × faster than Parameter Serv er and 4 . 3 × faster than AD-PSGD. In a heterogeneous setting, Ripples shows 4 . 4 × speedup ov er All-Reduce, and also obtains 3 . 5 × speedup over the Parameter Server baseline. 2. Background and Motiv ation 2.1. Distrib uted T raining In distributed training, a single model is trained collaborativ ely by multiple workers, which run in distrib uted compute nodes. T raining is most commonly accomplished with Stochastic Gradient Descent (SGD), which is an iterativ e algorithm that reaches the minimum of the loss function by continuously applying approximate gradients computed o ver randomly se- lected data samples. In each iteration, there are typically three steps: (1) randomly select samples from the data set; (2) compute gradients based on the selected data; and (3) apply gradients to the model parameters. There are a number of schemes to achiev e parallelism among multiple workers in distributed training: data paral- lelism [ 41 , 45 ], model parallelism [ 8 ], hybrid parallelism [ 27 , 50 ], and pipeline parallelism [ 16 ]. Among them, data paral- lelism can be easily deployed without significant efficiency loss compared with other models. Thus, it is supported by many popular machine learning frameworks such as T ensor- Flo w [ 1 ], MXNet [ 6 ] and PyT orch [ 38 ]. Recent papers [ 27 , 50 ] discussed the trade-of fs between data parallelism and model parallelism and proposed the hybrid approach. Due to space limit, we do not discuss other approaches in detail. Due to the popularity of data parallelism and the unresolved open problems, we focus on this model in this paper . In data parallelism , each worker consumes training data independently and computes gradients based on its own se- lected data. The gradients obtained by distributed workers are then gathered and applied to model parameters during syn- chr onization , and the updated model is subsequently used in the next iteration. Synchronization is both an essential part of parallelizing SGD and a critical factor in determining the training performance. 2 2.2. Existing Synchr onization A pproaches There are three main categories of approaches to performing synchronization in data parallelism: Parameter Serv ers (PS), All-Reduce, and generalized decentralized approaches. T raining with PS in v olves using one or more central nodes called P arameter Servers that gather gradients from all work- ers and also send back the updated model to the workers. This straightforward approach enables relativ ely easy management of the training process. Howe v er , PS has limited scalability due to the communication bottlenecks at Parameter Servers. Parameter Hub [ 36 ] provides a new approach to remove the bottleneck of communication by introducing a new netw ork device to work as Parameter Server . While promising, it re- quires special hardware supports that do not exist in common distributed en vironment (e.g., Amazon A WS). In contrast to PS, All-Reduce replaces the use of cen- tral nodes with carefully scheduled global communication to achiev e better parallelism. The state-of-the-art solu- tions [ 31 , 41 , 45 ] le verage Ring All-Reduce [ 38 ], the adv anced all-reduce algorithm that effecti vely utilizes the bandwidth between computation devices. Specifically , work ers are or- ganized as a ring, and gradients are divided into chunks and passed over the ring in a parallel manner . Different chunks of gradients are first accumulated to dif ferent workers, which are then broadcast to all work ers in a parallel man- ner . This algorithm achiev es ideal parallelism within the theoretical upper bound. Another algorithm, Hierarchical All-Reduce [ 7 , 31 ], has been successfully scaled up to 4560 nodes with 27360 GPUs. Utilizing All-Reduce algorithms based on MPIs [ 9 , 11 , 14 ] and NCCL [ 6 ], Horov od [ 41 ] en- ables high-performance data parallelism and is prov ed to be effecti v e and efficient — based on All-Reduce algorithms and high performance implementations, researchers were able to use the fastest supercomputer , Summit [ 10 ], to train a deep learning model in exascale [ 31 ]. Recently , the general decentralized approaches allow the point-to-point communication between workers by specifying a communication graph. Both PS and All-Reduce can be con- sidered as special case of the communication graph. T wo main algorithms proposed so far are Decentralized P arallel SGD (D- PSGD) [ 34 ] and Asynchronous D-PSGD (AD-PSGD) [ 35 ]. In D-PSGD, e very w orker has its o wn v ersion of parameters, and only synchronizes with its neighbors in the graph. As training proceeds, local information at a w orker propagates along edges of the communication graph and gradually reaches e very other worker , and thus models at different workers con verge collab- orativ ely to the same optimal point. The con v ergence rate has been prov ed to be similar to that of PS and All-Reduce [ 34 ]. Like All-Reduce, D-PSGD does not suf fer from communica- tion bottleneck. Howe ver , it relies on a fixed communication topology , which may be susceptible to heterogeneity (more discussion in Section 2.3 ). T o tolerate heterogeneity , AD-PSGD [ 35 ] introduces a ran- dom communication mechanism on top of D-PSGD. Instead of synchronizing with all the neighbors specified by the commu- nication graph, a w orker randomly selects a single neighbor , and performs an atomic model averaging with the neighbor, regardless of whether they are in the same iteration or not. While the slow w orkers ine vitably ha ve staler parameters and will affect the training of the global model, it will not block the progress of other workers unless it is selected, which happens only occasionally . 2.3. Challenges and Pr oblems Communication W ith the continuously increasing compute capability (e.g., GPUs), communication has become more important and the focus of recent optimizations. The commu- nication bottleneck in PS has been eliminated by approaches based on Ring All-Reduce, but the latter’ s strongly synchro- nized communication pattern has lower heterogeneity toler- ance. The generalized decentralized training captures both schemes and enables more optimization opportunities. Heterogeneity W ith the communication problem largely mit- igated, performance degradation in the heterogeneous dis- tributed en vironment becomes a major challenge. It is also known as the straggler problem, and occurs due to the per- formance dif ference among workers and the discrepancy or fluctuations of communication speed and bandwidth. Hetero- geneity is perv asiv e and can be caused by multiple reasons such as resource sharing in data center, paging, caching and hardware faults. The trend of heterogeneity and the “long tail ef fects” hav e been also discussed and confirmed in other recent works [ 5 , 12 , 24 , 28 , 35 ]. A number of countermeasures for dif- ferent synchronization schemes hav e been proposed, such as asynchronous ex ecution [ 39 ], bounded staleness [ 20 ], backup workers [ 5 ], adjusting the learning rate of stale gradients [ 28 ], sending accumulated gradients over bandwidth-scarce links when they reach a significance threshold [ 24 ], etc. Unfor- tunately , these techniques are mostly applicable for PS and decentralized training. For All-Reduce, with the delicate communication sched- ule, it is dif ficult to apply these ideas — making it inherently vulnerable to heterogeneity . From the computation aspect, a global barrier is introduced by the All-Reduce operation, so the throughput of computation is determined by the slowest worker in the cluster . From the communication aspect, al- though Ring All-Reduce algorithm is ideal in theory , the speed of sending chunks along the ring is bounded by the edge with the slowest connection. Considering the delicac y of All-Reduce, and due to the well- known limits of PS, tolerating heterogeneity in decentralized approach is particularly important. Recent work Hop [ 37 ] pre- sented the first detailed distributed protocol to support general decentralized training [ 34 ] with backup worker and bounded staleness to tolerate random slo wdo wn. Although the results are promising, the proposed methods are essentially system techniques to mitigate the ef fects of heterogeneity . The alterna- 3 tiv e way is algorithmic technique, with AD-PSGD [ 35 ] as an excellent e xample. While AD-PSGD is both communication- efficient and tolerates heterogeneity well, the atomic model av eraging step poses a ke y challenge of synchronization. Synchronization Conflict The atomic model averaging re- quires that two model averaging operations are serialized if they in volve the same work er . This requirement is to ensure fast con ver gence, and more relaxed semantic will increase the mutual influence of model updates from different work- ers — making the global trained model more vulnerable to “staler” updates. Note that the problem is different from the synchronization relaxation in HOGWILD! [ 39 ], where con- flict happens when two workers try to update the same shared parameter . Conflict is expected to be rare, since HOGWILD! requires the cost function to be “sparse” and separable. In the algorithm, work ers only update a small fraction of the parameters in each iteration, and the sparsity ensures that up- dates from different workers rarely in v olve the same parameter . Therefore, the algorithm can still con verge e ven without any locks. Howe ver , in AD-PSGD, the conflict is of a different nature and is expected to be frequent, because ev ery worker can initiate model averaging and it is likely that 2 of them end up choosing the same worker . T o ensure atomic model averaging and av oid deadlock as ex emplified in Figure 2 (a), AD-PSGD di vides the w orkers into 2 sets — activ e set and passi ve set, and requires that edges in the communication graph only exist between the two sets, i.e., neighbors of activ e work ers can only be passiv e work ers, and vice versa. This division is only possible when the communi- cation graph is bipartite. In the implementation, only active workers are allo wed to initiate model av eraging, while passiv e workers can only respond. This is slightly dif ferent from the algorithm, in which e very work er can initiate a veraging. When an activ e worker needs t o synchronize, it sends its model to the selected neighbor and blocks until it gets a response. Possible violation of atomicity can only happen when 2 active work ers select the same passi ve w orker , and it can be av oided by letting the passi ve worker deal with the requests one by one. Note that this scheme will incur deadlock if all workers are allo wed to initiate model av eraging or if the graph is not bipartite. Besides the restriction of the communication graph between workers, the synchronization o verhead is a more crucial prob- lem in a distributed en vironment. When training VGG-16 model ov er CIF AR-10, and ResNet-50 model over ImageNet using AD-PSGD on 16 GPUs, Figure 2 (b) shows that more than 90% of the time can be spent on synchronization in AD- PSGD. This is measured by comparing per iteration time of workers without synchronization (i.e., skip the synchronization operation to see the actual time of computation) and work ers with the synchronization enabled. 3. Partial All-Reduce Based on the results in Section 2.3 , we mainly focus on the synchronization challenge for decentralized training. This (a) An example deadlock happens when all workers first lock them- selves ( 1 ), and then try to lock their neighbors in a cycle ( 2 ), which blocks forev er . A l l - R e d u c e V G G - 1 6 A D - P S G D V G G - 1 6 A l l - R e d u c e R e s N e t - 5 0 A D - P S G D R e s N e t - 5 0 C o m p u t a t i o n S y n c h r o n i z a t i o n (b) Computation and synchronization ratio of different algorithms on differ - ent tasks Figure 2: Synchronization issues of AD-PSGD Require: A set of work ers represented as nodes V in a graph and the connection among them are represented by an adjacency matrix W 1: for w orker i ∈ V do 2: Initialize model weights x i 3: while not reached con ver gence do 4: Step 1. Read the local model x i from memory 5: Step 2. Compute gradients o ver randomly selected samples ξ i , and update weights: x i ← x 0 i − η k · ∇ F ( x i ; ξ i ) 6: Step 3. Randomly select a neighbor j 7: Step 4. Atomically av erage weights with the selected neighbor and update the local model as well as the selected neighbor’ s model: x i , x j ← 1 2 ( x i + x j ) 8: end while 9: end for Notes: x 0 i may be different from x i since it may hav e been modified by other workers in their a veraging step (i.e., step 4). T o ensure the correctness of execution, it is crucial to implement the a veraging step atomically with certain locking mechanisms. Figure 3: AD-PSGD Algorithm section first presents a deep analysis of AD-PSGD which moti vates our key contribution of P artial All-Reduce primiti v e. 3.1. AD-PSGD Insights AD-PSGD algorithm is shown in Figure 3 . Similar to tra- ditional training such as PS and All-Reduce, in one iteration, it computes gradients first, and then performs synchroniza- tion; the difference is that it only synchronizes with a random selected neighbor , instead of all the workers. Therefore, the global barrier is removed, enabling higher training throughput and better heterogeneity tolerance. In AD-PSGD, each worker i has a local version of parame- ters, which can be seen as a single concatenated vector x i , as the shapes do not matter in synchronization. Concatenating all the weight vectors together, they can be represented as a matrix X = [ x 1 x 2 . . . x n ] ∈ R N × n where N is the total size of weights in the model, and n is the number of workers. In this formalization, one iteration in a worker in AD- PSGD algorithm can be seen as one update to X . Formally , it can be represented as: X k + 1 = X k W k − γ ∂ g ( ˆ X k ; ξ i k , i ) . Here, ∂ g ( ˆ X k ; ξ i k , i ) is the update to x i according to gradient compu- tation based on a random worker i , the pre vious version of ˆ x i , and a random subset of the training samples ξ i k . W k is a synchr onization matrix that represents the process of model 4 Figure 4: Synchronization in AD-PSGD Figure 5: Conflict between two pair s of workers av eraging: x i , x j ← 1 2 ( x i + x j ) . Figure 4 shows an example of W k , in which worker 0 performs a synchronization with work er 3 . More generally , for an update between worker i and worker j , the non-zero entries of matrix W k are: W k i , i = W k i , j = W k j , i = W k j , j = 0 . 5 , W k u , u = 1 , ∀ u 6 = i , j . In AD-PSGD, a conflict happens when two workers i , j both select another worker u for synchronization. In order to k eep the atomic property of weight updating, the two operations need to be serialized. In matrix formalization, assume that W k represents the synchronization between i and u , W k + 1 repre- sents the synchronization between j and u . Ignoring the gradi- ent entry in the update, the updated weight X k + 2 can be repre- sented as: X k + 2 = X k + 1 W k + 1 = ( X k W k ) W k + 1 = X k ( W k W k + 1 ) . Figure 5 shows an example of two workers w 0 and w 4 re- quiring synchronization with the same w orker w 3 ( i = 0 , j = 4 , u = 3 ). The matrix on the right sho ws the production of W k and W k + 1 as a fused synchr onization matrix W f used = W k W k + 1 , which shows the final update o ver all the weights. W e can observe that the production is commutative in AD- PSGD — W k and W k + 1 can be exchanged (not mathematically but logically). It is because the order of synchronization is de- termined by the order of getting a lock, which is a completely random. Based on the atomicity requirement, the k ey insight is that in AD-PSGD, although the two synchronizations can be mathematically fused, they ha ve to be e xecuted sequentially . 3.2. Partial All-Reduce and Gr oup Fusion W e propose Gr oup Fusion — fusing multiple synchronizations approximately into one with reduced synchronization cost. In the precise fused synchronization, according to the W f used matrix, se veral w orkers update their weights to a certain linear combination of the weights of each worker in the group. Next, we seek proper approximation of the fused synchro- nization to achiev e efficient implementation. Our goal is to lev erage Ring All-Reduce, the high-performance algorithm that can compute the mean of se veral copies of weights in Figure 6: Synchronization with P artial All-Reduce Require: A set of worker represented as nodes V in a graph and their connection represented by a weighted adjacency matrix W 1: for w orker i ∈ V do 2: Initialize model parameters x i 3: while not reached con ver gence do 4: Step 1. Read the local model x i from memory 5: Step 2. Compute gradients o ver randomly selected samples ξ i , and update parameters: x i ← x i − η k · ∇ F ( x i ; ξ i ) 6: Step 3. Randomly generate a group G including i . 7: Step 4. Atomically average parameters in group G using P-Reduce: 8: ¯ x G = 1 | G | ∑ ∀ g ∈ G x g 9: x g ← ¯ x G , ∀ g ∈ G 10: end while 11: end for Figure 7: Proposed algorithm using P-Reduce O ( N ) time. W e cannot directly use All-Reduce to execute the synchronization among the three workers in Figure 5 . It is be- cause All-Reduce produces the same update for each work er , which is dif ferent from the outcome produced by multiplying a sequence of synchronization matrices in a certain order (on the right of Figure 5 ). Thanks to the commutati ve property of W k ’ s, our key idea is to slightly r elax the entries in W f used to lever age All-Reduce to perform the synchr onization specified by W f used . Generally , assume that there is a group of workers G = { w 1 , w 2 , . . . , w k } that perform a single fused synchronization together , W f used in v olves modifying the weights of all the w orkers in G . The W f used with appr oximation is defined as F G , which contains the following non-zero entries: F G i , j = 1 | G | , ∀ i , j ∈ G , F G u , u = 1 , ∀ u / ∈ G . Figure 6 sho ws an example of F G among worker 0 , 3 , 4 with the modified W f used . Although the example only inv olves 3 workers, the group can contain an arbitrary number of w orkers. Applying F G is equiv alent to performing All-Reduce in the gr oup G . W e define this operation as P artial All-Reduce or P-Reduce to distinguish our algorithm from the con v entional All-Reduce in deep learning training that performs All-Reduce among all workers. Based on P-Reduce, we present a formal description of the new algorithm in Figure 7 . Compared to the original AD-PSGD algorithm, there are two ke y dif ferences. First, in Step 3, each worker can ran- domly generate a group that may be lar ger than 2, as long as it contains itself, w i . The group in AD-PSGD of size 2 (one worker randomly selects a neighbor) becomes a special case. It essentially enlarges the unit of synchr onization to groups of 5 any size. Larger groups have tw o implications: (1) potentially enable fast propagation of model parameter updates among workers, speeding up con vergence; and (2) increase the chance of conflicts. Thus the new algorithm allo ws the system to e x- plore such a trade-off. The second dif ference from AD-PSGD is that the synchronization operation is performed by the new primiti ve P-Reduce in volving the workers in the group, instead of using individual messages among workers. This directly reduces the cost of synchronization. Although group fusion inspired us to propose the idea of P-Reduce, the algorithm in Figure 7 does not need to fuse groups during execution. In fact, the effects of fusing two groups of size 2 in AD-PSGD is reflected as generating group of arbitrary size in Step 3 of Figure 7 . As a result, Ripples only needs to deal with group generation but not group fusion. The system still needs to satisfy the atomicity requirement. If two G ’ s do not share common workers, the two non-conflicting F G ’ s can be ex ecuted concurrently . In an unrealistic but ideal situation, applying all the F G ’ s should not introduce any con- flict. Compared to All-Reduce, P-Reduce retains the efficient implementation while av oiding the global barrier . 3.3. Con vergence Property Analysis T o guarantee that models at dif ferent workers con verge to the same point, three requirements for W k are proposed in AD- PSGD [ 35 ]. In the follo wing, we sho w that although F G is not exactly the same as the result of multiplying a sequence of synchronization matrices in a certain order , our definition of F G satisfies all three con ver gence properties as AD-PSGD does. Doubly stochastic a veraging W k is doubly stochastic for all k . The sum of each row and each column equals to 1 in both W k and F G k . Spectral gap There exists a ρ ∈ [ 0 , 1 ) , such that: max {| λ 2 ( E [ W T k W k ]) | , | λ n ( E [ W T k W k ]) |} ≤ ρ , ∀ k . Basically , ( F G ) T F G = F G . And E [ F G ] can be regarded as a Markov T ransition Matrix. According to the Expander Graph The- ory [ 23 ], the spectral gap condition is fulfilled if the corre- sponding graph of random walk is connected. That means the update on any worker can be passed through sev eral groups to the whole graph. When creating the group generation methods in the following section, this property is alw ays kept in our mind to guarantee the con ver gence property . Dependence of random variables W k is a random v ariable dependent on i k 3 , but independent on ξ k and k . Up to no w , the only requirement on the generated group G k is that it should contain the initial worker i k . Theoretically , it is generated randomly without any connection to k or ξ k . Therefore, this condition is fulfilled. 3 i k is the worker initiating the synchronization. 4. Group Generation and Conflict Detection W ith P-Reduce, a group of workers becomes the basic unit of synchronization procedure. As a type of collective operati on, all workers in the group need to call P-Reduce function. It means that all group members should hav e the same group information to initiate the P-Reduce. It is non-trivial to obtain the consistent group among all workers inside the group. This section discusses how to generate the groups and serialize conflicting groups. 4.1. Gr oup Generator In Figure 7 , each worker needs to randomly generate a group. This can be performed by each worker based on the communi- cation graph with randomly selected neighbors. The work ers in each group will collectiv ely perform P-Reduce. The sys- tem needs to ensure atomicity — P-Reduces of groups with ov erlapping workers selected must be serialized. This can be implemented in either a centralized or distrib uted manner . In general, a distrib uted protocol in v olves multiple rounds of communication and coordination between work ers. For sim- plicity , Ripples implements a centralized component. W e can actually offload the group generation functionality from the workers to this component. Thus, we call it Gr oup Generator (GG) . When a work er needs to perform a synchronization, it just needs to contact GG without any group information, and then GG can select the group on behalf of the worker and maintain the atomicity . In the following, we explain the proto- col using an e xample. W e will find that the communications between workers and GG are only small messages, and do not introduce communication or scalability bottleneck. In Figure 8 , we consider four work ers W 0 , W 4 , W 5 , W 7 among a total number of 8 workers. In the beginning, W 0 and W 7 fin- ish an iteration and need to perform a synchronization. Instead of generating groups locally , they both send a synchronization request to GG, indicated in 1 and 2 . GG maintains the atom- icity with a local lock vector — a bit vector indicating whether each worker is currently performing a P-Reduce. This vector is initialized as all 0s. Assume that there is no other synchro- nization being performed in the system, and GG recei ves the request from W 0 first. After that, GG randomly generates a group [ 0 , 4 , 5 ] on behalf of W 0 ( 3 ) and sets the corresponding bits in the lock vector ( 4 ). Then, GG notifies the workers W 0 , W 4 , and W 5 ( 5 ) in the group so that they can collecti vely perform the P-Reduce. Later , GG receiv es the synchroniza- tion request from W 7 and randomly generates a group [ 4 , 5 , 7 ] . Unfortunately , it is conflicting with the first group due to the two o verlapped workers W 4 and W 5 , and needs to be serialized. W e can achie ve this by simply blocking the group [ 4 , 5 , 7 ] and storing it in a pending group queue ( 6 ). In the meantime, W 0 , W 4 and W 5 receiv e the notifications from GG and perform P-Reduce ( 7 ). They also need to ackno wledge GG to release the locks ( 8 ). After the locks for group [ 0 , 4 , 5 ] are released in GG, the group [ 4 , 5 , 7 ] can be performed after setting the 6 W0 W4 W5 Group Generator 1 3 W0: [0, 4, 5] 6 W7: [4, 5, 7] (pending) Lock Structure W7 2 4 5 5 5 7 7 7 After 8 8 8 8 Figure 8: GG generates groups on behalf of worker s Figure 9: A conflict-free static scheduling strategy corresponding bits in the lock vector . 4.2. Decentralized Static Scheduler As we hav e seen in the example in Figure 8 , tw o ov erlapping groups need to be serialized to ensure atomicity , causing delay in the execution. W e can eliminate the conflict by statically scheduling the groups to be non-ov erlapping. W e design a conflict-free schedule as shown in Figure 9 . There are 16 workers in total, and the schedule is periodic with a cycle length of 4. Every row corresponds to an iteration, and colored blocks with group indices indicate the grouping of workers. For example, in the first ro w , W 0 , W 4 , W 8 and W 12 are all colored yello w with an inde x “G1”, which means that these 4 workers are in the same group in the ( 4 k ) -th iteration, for any k ∈ N . Group indices do not indicate the sequence of execution; in fact, groups in the same ro w are expected to execute concurrently . In addition, some workers do not participate in synchronization in certain iterations, and this is sho wn by gray blocks marked with a hyphen "-". For instance, W 2 , W 6 , W 10 and W 14 do not participate in any group in the ( 4 k + 2 ) -th iteration, for any k ∈ N . Skipping synchronization can decrease the frequenc y of communication and thus shorten the training time. It is a technique that has been pro ved helpful in [ 29 , 49 ]. T o implement static scheduling, a naive way is to store the schedule table in the GG, and workers can access it by contacting the GG. Alternativ ely , we can store the table inside each worker , saving a round trip of communication between the worker and the GG. Since ev ery worker has the same schedule table stored locally , a consistent view of the groups is naturally ensured. In fact, storing a table is unnecessary , since the schedule is generated in a rule-based manner . For example, our previously proposed schedule is based on a worker’ s rank in its node. In an example where 4 workers are on a node, the rule of scheduling is shown in Figure 10 . In this way , a worker can simply call a local function S to obtain its group in an iteration. Phase L.W . 0 L.W . 1 L.W . 2 L.W . 3 0 Sync with L.W . 0s on ALL NODES No sync Sync with L.W . 3 Sync with L.W . 2 1 Sync L.W . 0-3 2 Sync with L.W . 3 Sync with L.W . 1 on the opposite node on the ring No sync Sync with L.W . 0 3 Sync L.W . 0-3 N otes: This table shows the rules that generate the schedule for 4 w orkers running on one node . The rules are the same for all 4 nodes . L.W . k stands for Local W orker k , the k -th worker on this node. The schedule has 4 phases, each corresponds to one training step. It repeats itself after ev ery 4 steps. Figure 10: An example of the static scheduling algorithm The logic of S guarantees that the schedule is consistent among all the workers, and a conflict-free static schedule is therefore enforced. 4.3. Discussion: Random vs. Static Although static scheduling can ideally eliminate conflict and speed up ex ecution, randomized group generation is more suitable for heterogeneous en vironment. W e compare the different characteristics of the tw o approaches belo w . Random GG is centralized, b ut it is different from Parame- ter Servers in that it does not in v olv e massiv e weight transfer . It only costs minor CPU and network resources compared with gradient accumulation or weight synchronization. In our experiment, it is found that GG can be put on a node to- gether with work ers without incurring an y performance loss. Howe v er , in random GG, contacting the GG induces commu- nication overhead, and conflicting groups need to be serialized, resulting in additional wait time. On the contrary , GG implemented as a static scheduler has no communication latenc y . W ith a proper design of S , it can not only fully parallelize synchronization, but also utilize the architecture of the work er devices to accelerate e very sin- gle P-Reduce operation. For example, it can schedule more intra-node synchronizations, and reduce the number of lar ge- scale inter-node synchronizations. Howe v er , the S function is pseudo random, which breaks the strict con ver gence condition of AD-PSGD, although the resulting algorithm still con v erges well in our experiments. When a certain worker is slower than others, the original AD-PSGD algorithm is able to tolerate the slowdo wn. How- ev er , the static scheduler does not ha ve such ability , as the schedule is in fact fixed. Synchronizations with the slow worker will slo w down the whole training. As for random GG, the stragglers’ effect can be largely ameliorated. W ell- designed group generation strate gy can ensure that at an y time, most workers will be able to proceed without depending on the few slo w w orkers, thus relie ving the slowdo wn problem. Also, slowdo wn detection and conflict av oidance mechanisms, which will be discussed in the follo wing section, can be easily integrated into random GG, making it better adapt to heteroge- neous en vironment. 7 5. Smart Randomized Group Generation The basic implementation of the scheduler in GG is to al- ways randomly generate a group as specified in Step 3 of Figure 7 . With the centralized GG, our objectiv e is to leverage the global and runtime information to generate groups in a more intelligent manner to: (1) avoid conflicts; and (2) em- brace heterogeneity . For example, a w orker may hav e already been assigned to sev eral groups and thus have se veral pending P-Reduces to perform. If the worker is still selected to be in- cluded in a ne w group, then other work ers will hav e to wait for all the prior scheduled P-Reduces to finish. Similarly , when a slow work er is in a group, the whole group may be blocked by this work er . Moreover , performing P-Reduce in dif ferent groups costs dif ferent time due to architecture factors. The group selection can e ven introduce architectural contentions on communication links. Based on the above insights, we propose intelligent scheduling mechanisms for GG to further improv e performance. 5.1. Conflict A voidance by Global Division An intuiti ve way of reducing conflict is to ha v e a Gr oup Buffer (GB) for each worker , which includes the ordered list of groups that include the corresponding worker . When a group is formed, the group information is inserted in the GB of all workers in volv ed. The consensus group order can be easily ensured among all GBs since the GG, as a centralized struc- ture, generates groups in a serial manner . Based on GB, when GG recei ves a synchronization request from a worker , it can first look up the worker’ s GB. If it is empty , a ne w group is generated for the worker; otherwise, the first existing group in the worker’ s GB will serve as the selected group. The main insight is that P-Reduce is a collecti ve operation. So if W i initiates a synchronization with W j , i.e., W i and W j are in the same group, P-Reduce of this group is only per- formed when W j also requests its synchronization. Therefore, the simple mechanism can a v oid generating a ne w group for W j when it is already scheduled (and ready) to execute a P- Reduce. Howe v er , with random group generation, nothing would prevent the selection of W j into a different group not initiated by W i . In this case, the ov erlapping groups and the corresponding P-Reduce operations are still serialized. Inspired by the static scheduling, we propose an operation called Global Division (GD) that divides all curr ent work ers with empty GBs into several non-conflicting gr oups . A GD is called whene ver a worker needs to generate a group and its GB is empty . A simple example is sho wn in Figure 11 . In total we have 4 workers and initially all GBs are empty . On the left, random selection sho ws a possible scenario without GD optimization. The groups are randomly generated, so if G 1 initiated by W 0 includes W 0 and W 1 , another group G 2 initiated by W 3 can still include W 1 as the ov erlapping worker , thus introducing a conflict. On the right, with GD, when W 0 requests a group, the GG will not only generate one for it, i.e., W0 W1 W2 W3 G1 G2 conflict W0 W1 W2 W3 G1 G2 No conflict Random Selection Global Division N otes: In random selection shown in (a), after G 1 is generated by request from W 0 and W 1 gets its group, no information is left to avoid the conflict that another request from W 3 may also generate a group including W 1 . In GD shown in (b), two groups are both generated upon the first request. Therefore, the second request directly gets a conflict-free group from the buf fer . Figure 11: An example of Global Division [ W 0 , W 2 ] , but also randomly generate groups for other work ers, i.e., only [ W 1 , W 3 ] in this example as there are only 4 work ers. In this way , when later W 3 requests a group, GG will directly provide the non-conflicting [ W 1 , W 3 ] generated before. It is worth emphasizing two conditions. First, a GD only generates groups for the current “idle” workers (including the caller worker) that are not assigned to an y group. Thus, when a worker requests a group, it is possible to generate groups in the abov e manner for just a subset of work ers. Second, a GD is only called when the initiator’ s GB is empty , otherwise the first group in the initiator’ s GB will be returned. Indeed, the proposed schemes to avoid conflict make the group generation not fully random. Howe ver , we argue that the effects are not critical. For the first optimization based on GB, we only reuse the existing group inv olving the worker who is requesting synchronization. This group is still generated in a fully random manner (if we do not use GD). For GD, essentially we generate a random gr oup partition among all idle workers together, which is triggered by the first worker in the set who initiates a synchronization. So the dif ference is between randomly generating each group and generating a random partition. W e acknowledge that they are not the same but belie v e that our method does not significantly damage the randomness. W e leave the theoretical analysis as the future work. Howe ver , based on the results sho wn in our ev aluation, the ideas work very well in practice. 5.2. Ar chitecture-A ware Scheduling If the groups are randomly di vided, multiple groups may all need to use the network bandwidth at the same time, causing congestion, which is not optimal in the perspecti ve of archi- tecture. In fact, All-Reduce is fast because it has a balanced utilization of different connections between dif ferent de vices, such as Infiniband HCA cards, QPI paths 4 , and PCIe slots. T o better utilize the bandwidth of different connections, we propose a ne w communication pattern called Inter -Intra Syn- chr onization that can be naturally incorporated with GD. Here, a node, commonly running 4 or 8 workers, are considered a unit. The scheme has an Inter and an Intr a phase. Inter phase One worker on each node is selected as Head W orker of the node. All the Head W orkers are randomly di- vided into se veral groups to synchronize in a inter -node man- 4 The Intel QuickPath Interconnect between CPU sockets within one node 8 W0 W1 W2 W3 W4 W5 W6 W7 W8 W9 W10 W11 W12 W13 W14 W15 Head W orker G1 G2 Head W orkers’ groups across nodes Non-Head W orkers’ groups G3 G6 G5 G4 No congestion on IB HCA car d No congestion on PCIe/QPI W0 W1 W2 W3 W4 W5 W6 W7 W8 W9 W10 W11 W12 W13 W14 W15 G1 G4 G3 G2 Figure 12: An example of Inter -Intra Synchronization ner . At the same time, the work ers that are not Head W orker are randomly assigned to groups with only local workers in the same node. In this way , only the Head W orker can gen- erate inter-node communication while the others only incur local communication, which can be carefully arranged to avoid congestion on PCIe switches or QPI. Intra phase W orkers within a node synchronize with all other local workers collectively . In another word, it inv olv es a P- Reduce among all the workers in the same node, without an y inter-node communication. Follo wing the Inter phase, the up- dates from workers on other nodes can be quickly propagated among local workers in this phase. The two phases can be realized easily with GD operations. Specifically , two groups are inserted to the GB of each worker . Each group is generated by a GD, one is mainly among Head W orkers in dif ferent nodes (the Inter phase), the other is purely among local work ers in the same node (the Intr a phase). An example can be seen in Figure 12 . It is worth noting that the proposed Inter-Intra Synchr oniza- tion is not the same as hierarchical All-Reduce [ 7 ], which is mathematically equi valent to All-Reduce among all workers in one step with acceleration brought by the hierarchical ar- chitecture. After an All-Reduce, all workers end up with the same weight. Differently , Inter-Intra synchronization strat- egy spreads multiple partial updates through P-Reduce in an architecture-aware and controlled manner . Thus, workers end up with differ ent weights after the synchronization. 5.3. T olerating Slowdown The mechanisms proposed so f ar are mainly ef fectiv e in homo- geneous ex ecution en vironment but do not help with slo wdo wn situations. Slo w workers in volved in groups can block the cur- rent and other groups as mentioned earlier . W e propose a simple solution by keeping track of e xecution information in GG. Specifically , an additional counter for each worker is placed in GG, which records how man y times the worker requires a group. When a worker is significantly W0 W1 W2 W10 Normal workers Slow workers Group Bu ff er G1 Group selection for W0: Group election for W10: non-empty bu ff er non-empty bu ff er slowness detected: C W10 too small Figure 13: T olerating slow worker s slower than other workers, the v alue of its counter should be also much smaller than the average. As a GD starts when a worker with an empty GB requests a group, an additional rule is added to filter the w orkers who can get a group in the division: the worker’ s counter , c w , should be not significantly smaller than the initiator’ s counter, c i , i.e., c i − c w < C t hres , where C t hres is a constant that can be adjusted. This filter works as follows. When a fast worker initiates a GD, only fast w orkers are assigned to groups, a v oiding the problem of being blocked by slow workers. When a slow worker initiates a division, some faster workers may be in- volv ed to synchronize with it. But the selected workers have empty buf fers as defined in GD operation. So, neither the fast workers or the slow w orker needs to wait for a long time for synchronization. By the filter rule, the ef fect of slo w work ers is minimized. 6. Implementation W e implement the proposed algorithms and protocols using T ensorFlow and its e xtensions. Specifically , Ripples is imple- mented as customized operators of T ensorFlow . 6.1. Partial All-Reduce Partial All-Reduce is implemented as a GPU T ensorFlow Op- erator . It takes the variables and the group as input tensor, and outputs a new tensor representing the result of synchroniza- tion. NCCL [ 25 ] is used to ex ecute All-Reduce, and MPI is used to help create NCCL communicator . W e use a simple b ut effecti v e strategy to concatenate all weights into one tensor . Specifically , all weights are flattened and concatenated into one tensor for faster P-Reduce, and are separated and reshaped after the P-Reduce operation. In NCCL, the upper bound of existing communicators is 64 . But it is inef ficient to destroy all the communicators after use. T o save the time of creating communicators, a distrib uted cache for communicators is used, which pro vides consistent presence of communicators. It does not remov e cached items, but simply stops caching when its size e xceeds a threshold. 6.2. Gr oup Generator Group Generator is a centralized controller among all workers. It requires lo w latency remote function call. RPC is used in this scenario. The server is a light-weight Python program 9 implemented by gRPC Python package. C++ is used in the core of the algorithms. It can be started and killed easily . The client is wrapped up as another T ensorFlow Python Operator . One function as static scheduler is implemented ac- cording to the scheduling rules. Another function as dynamic group generator using the centralized GG also uses gRPC. W e can easily switch between the methods of group generation using ex ecuting flags. 7. Evaluation 7.1. Evaluation Setup 7.1.1. Hardwar e En vironment W e conduct our experiment on Maverick2 cluster of T A CC Super Computer . Maverick2 is a cluster managed by SLURM. In the GTX partition, a node is configured as shown in the table in Figure 14 . Model Super Micro X10DRG-Q Motherboard Processor 2 x Intel(R) Xeon(R) CPU E5-2620 v4 GPUs 4 x NV idia 1080-TI GPUs Network Mellanox FDR Infiniband MT27500 Family ConnectX-3 Adapter Figure 14: Configuration of a node in GTX partition, Ma verick2 Cluster , T ACC Super Computer [ 4 ] 7.1.2. Dataset and Model T o test the performance of Rip- ples and compare it with other works, we train models on both medium and large data sets. First, we train VGG-16 model [ 44 ] on CIF AR-10 [ 30 ] image classification dataset. The model contains 9 . 23 M B of trainable 32-bit floating-point weights. A typical training setup is selected. The learning rate of SGD optimizer is set to 0 . 1 , and the batch size per work er is 128. Additionally , ResNet50 model [ 18 ] is trained ov er Ima- geNet dataset [ 40 ], which contains 1 , 281 , 167 images to be classified into 1 , 000 classes. W e aim to verify that Ripples is a valid algorithm that well con ver ges in different tasks. The model contains 196 M B of weights. Momentum optimizer is used with moment um = 0 . 9 and weight _ d ecay = 10 − 4 . The initial learning rate is 0 . 128 , and decays to its 0 . 1 × on epochs 30 , 60 , 80 , 90 . The training models are implemented using T ensorFlow [ 1 ]. 7.1.3. Baseline Setup Parameter Serv er is already integrated in T ensorFlow . W e implement AD-PSGD using remote v ari- able access supported by the T ensorFlo w distributed module. Horov od [ 41 ] is adopted to set up a high-performance state- of-the-art baseline, which significantly outperforms many other implementations of All-Reduce. It is configured with NCCL2 [ 25 ] in order to achie ve the best All-Reduce speed. W e also tune the size of fuse buf fer for better utilization of the Inifiniband network. In all test runs, each work er occupies a whole GPU. For better affinity , we bind the process of each worker to the CPU socket it is directly attached to. In random GG, the group size is 3. 7.1.4. Methodology W e use the time it takes for the model (randomly initialized using a fixed random seed across dif- ferent experiments) to achiev e l oss = 0 . 32 as the metric of performance on VGG-16. W e also inspect the loss w .r .t itera- tion curve and the a verage duration of an iteration to analyze the effect of our optimizations. 7.2. Interactions between Computation, Communication and Con ver gence B . S . 6 4 B . S . 1 2 8 B . S . 2 5 6 2 W . 4 W . 4 S . W . 8 S . W . 1 2 S . W . 8 W . 1 6 W . 0 . 0 0 0 . 0 5 0 . 1 0 0 . 1 5 A v e r a g e t i m e c o s t / m s 3 1 . 0 0 5 4 . 8 7 1 0 3 . 0 0 1 0 . 4 0 1 5 . 4 7 1 3 . 1 1 1 4 . 4 2 1 5 . 0 0 9 0 . 6 7 9 7 . 2 7 Ti m e o f c o m p u t a t i o n w i t h d i f f e r e n t b a t c h s i z e Ti m e o f A l l - R e d u c e w i t h d i f f e r e n t n u m b e r o f w o r k e r s Notes: B.S. means the batch size is 64 , 128 , 256 . W . means running 2 , 4 , 8 , 16 workers densely placed on 1 , 1 , 2 , 4 nodes. S.W . means running 4 , 8 , 12 workers, one on a node, using 4 , 8 , 12 nodes. Figure 15: A micro-benchmark showing the cost of different operations in computation and synchronization. In order to better understand how much time communica- tion takes in deep learning training compared to computation time, we first measured the time of computation with dif- ferent batch sizes and time of communication with dif ferent settings 5 . Figure 15 sho ws the time comparisons. Because of better utilization of SIMD devices, the computation is slightly more efficient when the batch size is larger . Interestingly , All-Reduce among workers within a single node or workers separately placed across dif ferent nodes are significantly faster than having multiple nodes with each running multiple work- ers. S e c . l e n . 1 S e c . l e n . 2 S e c . l e n . 3 S e c . l e n . 4 S e c . l e n . 5 S e c . l e n . 6 6 0 0 7 0 0 8 0 0 9 0 0 1 0 0 0 I t e r a t i o n s t o c o n v e r g e 7 0 0 6 6 3 6 7 3 8 8 7 8 6 9 9 3 7 Notes: The frequency of communication is controlled by a hyper -parameter Section Length , – # of iterations between two synchronizations. Figure 16: Effects of reducing synchr onization Although reducing communication by lo wering synchro- nization frequency can increase the throughput of training, it becomes harder to con ver ge. Figure 16 presents a simple experiment to show that the number of iterations needed to con v erge increases as communication frequency gets lower . T o get the best performance of con v ergence time, setting a proper lev el of synchronization intensity is necessary . This result 5 Size of weight to be synchronized is independent of batch size 10 sho ws that we cannot simply impro ve AD-PSGD by enlarging the amount of computation between synchronizations. 7.3. Speedup in Homogeneous En vironment P S A D - P S G D A l l - R e d u c e P r a g u e S t a t i c P r a g u e R a n d . P r a g u e S m a r t 0 2 4 P e r i t e r a t i o n s p e e d u p 1 . 0 0 x 1 . 1 8 x 4 . 5 5 x 5 . 1 1 x 2 . 7 0 x 5 . 1 0 x P S A D - P S G D A l l - R e d u c e P r a g u e S t a t i c P r a g u e R a n d . P r a g u e S m a r t 0 2 4 O v e r a l l s p e e d u p 1 . 0 0 x 1 . 4 2 x 4 . 2 7 x 5 . 0 1 x 3 . 0 3 x 5 . 2 6 x Figure 17: Per -iteration speedup and overall speedup In a homogeneous en vironment with 16 workers on 4 nodes, VGG-16 trained o ver CIF AR-10 is used to compare Ripples with differ ent ways of gr oup generation against Parameter Server , All-Reduce and AD-PSGD. The per-iteration speedup and conv ergence time speedup is sho wn in Figure 17 . Rip- ples is much faster than Parameter Server and the original AD-PSGD. All-Reduce is also much faster than these two baselines, due to the high throughput provided by Horov od. Howe v er , Ripples with both static scheduler and smart GG e ven outperform All-Reduce thanks to its smaller synchroniza- tion groups and architecture-aware scheduling. N otes: The speedup in the figure means the number of iterations to con verge compared to Parameter Server . Figure 18: Conver gence curve in terms of number of iterations for corresponding algorithms in Figure 17 Shown in Figure 18 , AD-PSGD has better con v ergence speed in terms of number of iterations. All-Reduce is math- ematically equi valent to Parameter Server . They are slightly different due to random sampling and competition in synchro- nization. Ripples with static scheduler has similar conv ergence speed as Parameter Server , but it gains speedup from its higher throughput. W e see that the number of iterations in random GG is less than smart GG, which is smaller than static schedul- ing. This is due to the decreasing amount of randomness from random GG to smart GG and to static scheduling. These results further demonstrate the trade-offs between ex ecution ef ficiency and statistical ef ficienc y [ 54 ]. Although AD-PSGD needs fe wer iterations to con v erge to the same er- ror , the e xecution time of each iteration is seriously af fected by the synchronization ov erhead, sho wn in Figure 2 (b). Rip- ples successfully explores this trade-off by slightly sacrificing statistical efficiency , i.e., running more iterations (0.96x vs. 0.78x), — mainly caused by the reduced randomness, to gain significant speedup in per iteration e xecution time (5.10x vs. 1.18x) and e ventually lead to o verall e xecution time speedup (5.26x vs. 1.42x). 7.4. Heter ogeneity T olerance A l l - R e d . A D - P S G D P r a g u e S t a t i c P r a g u e R a n d . P r a g u e S m a r t 1 2 3 4 O v e r a l l i n s l o w d o w n 2 x 1 . 6 6 x 1 . 3 7 x 2 . 4 7 x 2 . 1 3 x 4 . 2 3 x A l l - R e d . A D - P S G D P r a g u e S t a t i c P r a g u e R a n d . P r a g u e S m a r t 1 2 3 O v e r a l l i n s l o w d o w n 5 x 0 . 8 1 x 1 . 4 3 x 0 . 8 1 x 1 . 2 0 x 3 . 5 3 x Notes: The baseline is still Parameter Server without slo wdo wn in Figure 17 in con venience for comparing. Figure 19: Overall speedup of All-Reduce, Ripples with static scheduler and Ripples with random and smart GG in hetero- geneous envir onment (2x or 5x slowdo wn on one worker). One of the key adv antages of Ripples is better tolerance of heterogeneity . Based on the same setup in section 7.3 , het- erogeneity is simulated by adding 2 or 5 times the normal iteration time of sleep e very iteration on one specific worker , the slow worker . The result is shown in Figure 19 . In terms of the capability to tolerate slo wdo wn, e xperiment results of 2x slowdown show that: (1) random GG (3.03x vs. 2.13x) is slightly worse than AD-PSGD (1.42x vs. 1.37x), but it is much faster due to more efficient P-Reduce as the synchro- nization primitiv e; (2) smart GG (5.26x vs. 4.23x) is better than random GG (3.03x vs. 2.13x); and (3) while both suffer from more slo wdown, Ripples static (5.01x vs. 2.47x) is still considerably better than All-Reduce (4.27x vs. 1.66x). W e also see that with 2x slowdo wn, All-Reduce is still faster than AD-PSGD although much slower than itself in homogeneous setting. With 5x slo wdo wn, All-Reduce can only achie ve a little more than half of the performance in AD-PSGD. W e see that random GG is slightly slower than AD-PSGD, this is because the larger group size (3) in Ripples can increase the chance of conflicts. Nevertheless, smart GG outperforms AD-PSGD with a large mar gin. 7.5. V alidation on Large Model and Dataset This section shows the training performance of ResNet-50 on ImageNet by running only 10 hours of training on 8 nodes with 32 workers for each algorithm. W e conduct experiment in this manner to avoid affecting other experiments on the cluster , as T A CC Super Computer is shared by thousands of researchers. The training accuracy and the loss curves for the 10-hour ex ecutions are shown in Figure 20 . Please note the execution en vironment is homogeneous without slower workers. W e see that All-Reduce performs the best in this case, followed 11 Algorithm T otal iterations T op 1 Accuracy T op 5 Accuracy All-Reduce 55800 66.83% 84.81% AD-PSGD 32100 58.28% 78.00% Prague Static 58200 63.79% 82.38% Prague Smart 56800 64.21% 82.78% 0 5 0 0 0 1 0 0 0 0 1 5 0 0 0 2 0 0 0 0 2 5 0 0 0 3 0 0 0 0 3 5 0 0 0 t i m e / s e c 2 × 1 0 0 3 × 1 0 0 4 × 1 0 0 6 × 1 0 0 l o s s A l l - R e d u c e A D - P S G D P r a g u e S t a t i c P r a g u e S m a r t Figure 20: Iterations trained, final training accuracy of differ - ent algorithms after training f or 10 hours, and loss curve dur- ing the 10 hour s. by Ripples with smart GG. AD-PSGD suffers from through- put issue. In ResNet-50 over ImageNet, the upper bound of effecti v e batch size is very large. Therefore, although we make our best ef fort to enlarge the batch size, All-Reduce ob- tains much bigger con ver gence adv antage numerically , while Ripples can train more iterations using the same time. The smart GG performs better than static scheduler because it has more randomness in synchronization. Observing from the loss curve, Ripples still has competitiv e con ver gence speed compared with the state-of-the-art approach, All-Reduce, on large data sets. 8. Conclusion In this paper , we propose Ripples , a high-performance heterogeneity-aware asynchronous decentralized training ap- proach. T o reduce synchronization cost, we propose a nov el communication primitive, Partial All-Reduce, that allows a large group of work ers to synchronize quickly . T o reduce synchronization conflict, we propose static group scheduling in homogeneous en vironment and simple techniques (Group Buffer and Group Division) to av oid conflicts with slightly reduced randomness. Our experiments show that in homoge- neous en vironment, Ripples is 1 . 1 × faster than the state-of- the-art implementation of All-Reduce, and is 5 . 1 × faster than Parameter Serv er and 4 . 3 × faster than AD-PSGD. In a hetero- geneous setting, Ripples shows 2 × speedup ov er All-Reduce, and still obtains 3 × speedup ov er AD-PSGD. References [1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Bre vdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffre y Dean, Matthieu De vin, Sanjay Ghema wat, Ian Goodfello w , Andrew Harp, Ge- offre y Irving, Michael Isard, Y angqing Jia, Rafal Jozefowicz, Lukasz Kaiser , Manjunath Kudlur , Josh Le venber g, Dan Mané, Rajat Monga, Sherry Moore, Derek Murray , Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever , Kunal T alwar , Paul T ucker , V incent V anhoucke, V ijay V asudev an, Fernanda V iégas, Oriol V inyals, Pete W arden, Martin W attenberg, Martin W icke, Y uan Y u, and Xiao- qiang Zheng. T ensorFlo w: Large-scale machine learning on heteroge- neous systems, 2015. Software av ailable from tensorflo w .or g. [2] Martin Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffre y Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Lev enberg, Rajat Monga, Sherry Moore, Derek G. Murray , Benoit Steiner , Paul T ucker , Vi- jay V asudevan, Pete W arden, Martin Wicke, Y uan Y u, and Xiaoqiang Zheng. T ensorflow: A system for lar ge-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) , pages 265–283, 2016. [3] T al Ben-Nun and T orsten Hoefler. Demystifying parallel and dis- tributed deep learning: An in-depth concurrency analysis, 2018. cite [4] T exas Advanced Computing Center . Maverick2 User Guide - T A CC User P ortal . https://portal.tacc.utexas.edu/user- guides/ maverick2 . [5] Jianmin Chen, Rajat Monga, Samy Bengio, and Rafal Jozefowicz. Revisiting distrib uted synchronous sgd. In International Confer ence on Learning Repr esentations W orkshop T rac k , 2016. [6] T ianqi Chen, Mu Li, Y utian Li, Min Lin, Naiyan W ang, Minjie W ang, T ianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. CoRR , abs/1512.01274, 2015. [7] Minsik Cho, Ulrich Finkler , and David Kung. Blueconnect: Novel hierarchical all-reduce on multi-tired network for deep learning, 2018. [8] Adam Coates, Brody Huv al, T ao W ang, Da vid W u, Bryan Catanzaro, and Ng Andrew . Deep learning with cots hpc systems. In Sanjoy Dasgupta and David McAllester , editors, Proceedings of the 30th International Confer ence on Machine Learning , v olume 28.3 of Pr o- ceedings of Machine Learning Researc h , pages 1337–1345, Atlanta, Georgia, USA, 17–19 Jun 2013. PMLR. [9] MPI contributors. MPI: A Message-P assing Interface Stan- dar d , 2015. https://www.mpi- forum.org/docs/mpi- 3.1/ mpi31- report.pdf . [10] IBM Corporation and Oak Ridge National Laboratory . Summit - IBM P ower System AC922, IBM PO WER9 22C 3.07GHz, NVIDIA V olta GV100, Dual-rail Mellanox EDR Infiniband | TOP500 Super computer Sites . https://www.top500.org/system/179397 . [11] Intel Corporation. Intel R MPI Library | Intel R Softwar e . https: //software.intel.com/en- us/mpi- library . [12] Jeffre y Dean and Luiz André Barroso. The tail at scale. Commun. ACM , 56(2):74–80, February 2013. [13] Stephen Doherty . The impact of translation technologies on the process and product of translation. International Journal of Communication , 10:969, 02 2016. [14] Edgar Gabriel, Graham E. F agg, George Bosilca, Thara Angskun, Jack J. Dongarra, Jeffre y M. Squyres, V ishal Sahay , Prabhanjan Kam- badur , Brian Barrett, Andre w Lumsdaine, Ralph H. Castain, Da vid J. Daniel, Richard L. Graham, and T imothy S. W oodall. Open MPI: Goals, concept, and design of a next generation MPI implementa- tion. In Pr oceedings, 11th Eur opean PVM/MPI Users’ Gr oup Meeting , pages 97–104, Budapest, Hungary , September 2004. [15] Priya Goyal, Piotr Dollár , Ross B. Girshick, Pieter Noordhuis, Lukasz W esolowski, Aapo K yrola, Andrew T ulloch, Y angqing Jia, and Kaim- ing He. Accurate, large minibatch SGD: training imagenet in 1 hour . CoRR , abs/1706.02677, 2017. [16] Aaron Harlap, Deepak Narayanan, Amar Phanishayee, V i vek Se- shadri, Nikhil R. Dev anur , Gregory R. Ganger , and Phillip B. Gibbons. Pipedream: Fast and efficient pipeline parallel DNN training. CoRR , abs/1806.03377, 2018. [17] K. Hazelwood, S. Bird, D. Brooks, S. Chintala, U. Diril, D. Dzhul- gakov , M. Fawzy, B. Jia, Y . Jia, A. Kalro, J. Law, K. Lee, J. Lu, P . Noordhuis, M. Smelyanskiy , L. Xiong, and X. W ang. Applied ma- chine learning at facebook: A datacenter infrastructure perspective. In 2018 IEEE International Symposium on High P erformance Computer Ar chitectur e (HPCA) , pages 620–629, Feb 2018. [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Eur opean conference on computer vision , pages 630–645. Springer , 2016. [19] Geoffre y Hinton, Li Deng, Dong Y u, George Dahl, Abdel-rahman Mohamed, Na vdeep Jaitly , Andrew Senior , V incent V anhoucke, P atrick Nguyen, Brian Kingsbury , and T ara Sainath. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Pr ocessing Magazine , 29:82–97, Nov ember 2012. [20] Qirong Ho, James Cipar , Henggang Cui, Jin Kyu Kim, Seunghak Lee, Phillip B. Gibbons, Garth A. Gibson, Gre gory R. Ganger , and Eric P . Xing. More effectiv e distributed ml via a stale synchronous parallel parameter server . In Pr oceedings of the 26th International Confer ence on Neural Information Pr ocessing Systems - V olume 1 , NIPS’13, pages 1223–1231, USA, 2013. Curran Associates Inc. 12 [21] Rankyung Hong and Abhishek Chandra. Decentralized distributed deep learning in heterogeneous wan en vironments. In Pr oceedings of the ACM Symposium on Cloud Computing , SoCC ’18, pages 505–505, New Y ork, NY , USA, 2018. A CM. [22] Rankyung Hong and Abhishek Chandra. Dlion: Decentralized dis- tributed deep learning in micro-clouds. In 11th USENIX W orkshop on Hot T opics in Cloud Computing (HotCloud 19) , Renton, W A, July 2019. USENIX Association. [23] Shlomo Hoory , Nathan Linial, and A vi W igderson. Expander graphs and their applications. Bull. Amer . Math. Soc. 43 (2006), 439-561 , 2006. [24] Ke vin Hsieh, Aaron Harlap, Nandita V ijaykumar , Dimitris Konomis, Gregory R. Ganger, Phillip B. Gibbons, and Onur Mutlu. Gaia: Geo-distributed machine learning approaching LAN speeds. In 14th USENIX Symposium on Networked Systems Design and Implementa- tion (NSDI 17) , pages 629–647, Boston, MA, 2017. USENIX Associa- tion. [25] Sylvain Jeaugey . Nccl 2.0. GTC , 2017. [26] Xianyan Jia, Shutao Song, W ei He, Y angzihao W ang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Y uanzhou Y ang, Liwei Y u, et al. Highly scalable deep learning training system with mixed-precision: T raining imagenet in four minutes. arXiv pr eprint arXiv:1807.11205 , 2018. [27] Zhihao Jia, Matei Zaharia, and Alex Aiken. Beyond data and model parallelism for deep neural networks. CoRR , abs/1807.05358, 2018. [28] Jiawei Jiang, Bin Cui, Ce Zhang, and Lele Y u. Heterogeneity-a ware distributed parameter serv ers. In Pr oceedings of the 2017 ACM Inter - national Conference on Management of Data , SIGMOD ’17, pages 463–478, New Y ork, NY , USA, 2017. A CM. [29] Peng Jiang and Gagan Agrawal. Accelerating distributed stochastic gradient descent with adaptive periodic parameter a veraging: Poster . In Pr oceedings of the 24th Symposium on Principles and Practice of P arallel Pr ogr amming , PPoPP ’19, pages 403–404, Ne w Y ork, NY , USA, 2019. A CM. [30] A. Krizhe vsky and G. Hinton. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of T oronto , 2009. [31] Thorsten Kurth, Sean T reichler , Joshua Romero, Mayur Mudigonda, Nathan Luehr , Everett Phillips, Ankur Mahesh, Michael Matheson, Jack Deslippe, Massimiliano Fatica, et al. Exascale deep learning for climate analytics. In Pr oceedings of the International Confer ence for High P erformance Computing, Networking, Storage, and Analysis , page 51. IEEE Press, 2018. [32] Mu Li. Scaling distributed machine learning with the parameter server . In International Confer ence on Big Data Science and Computing , page 3, 2014. [33] Y oujie Li, Mingchao Y u, Songze Li, Salman A vestimehr, Nam Sung Kim, and Alexander Schwing. Pipe-sgd: A decentralized pipelined sgd framew ork for distributed deep net training. In Proceedings of the 32Nd International Conference on Neur al Information Pr ocessing Systems , NIPS’18, pages 8056–8067, USA, 2018. Curran Associates Inc. [34] Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, W ei Zhang, and Ji Liu. Can decentralized algorithms outperform centralized al- gorithms? a case study for decentralized parallel stochastic gradient descent. In I. Guyon, U. V . Luxburg, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, editors, Advances in Neural Informa- tion Pr ocessing Systems 30 , pages 5330–5340. Curran Associates, Inc., 2017. [35] Xiangru Lian, W ei Zhang, Ce Zhang, and Ji Liu. Asynchronous decentralized parallel stochastic gradient descent. In Proceedings of the 35th International Confer ence on Machine Learning, ICML 2018, Stockholmsmässan, Stoc kholm, Sweden, July 10-15, 2018 , pages 3049– 3058, 2018. [36] Liang Luo, Jacob Nelson, Luis Ceze, Amar Phanishayee, and Arvind Krishnamurthy . Parameter hub: a rack-scale parameter server for distributed deep neural network training. CoRR , abs/1805.07891, 2018. [37] Qinyi Luo, Jinkun Lin, Y ouwei Zhuo, and Xuehai Qian. Hop: Heterogeneity-aware decentralized training. CoRR , abs/1902.01064, 2019. [38] Pitch Patarasuk and Xin Y uan. Bandwidth optimal all-reduce al- gorithms for clusters of workstations. J. P arallel Distrib. Comput. , 69(2):117–124, February 2009. [39] Benjamin Recht, Christopher Re, Stephen Wright, and Feng Niu. Hog- wild: A lock-free approach to parallelizing stochastic gradient descent. In J. Shawe-T aylor, R. S. Zemel, P . L. Bartlett, F . Pereira, and K. Q. W einberger , editors, Advances in Neur al Information Pr ocessing Sys- tems 24 , pages 693–701. Curran Associates, Inc., 2011. [40] Olga Russakovsky , Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy , Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale V isual Recognition Challenge. International J ournal of Computer V ision (IJCV) , 115(3):211–252, 2015. [41] Alexander Ser geev and Mike Del Balso. Horov od: fast and easy dis- tributed deep learning in T ensorFlow . arXiv pr eprint arXiv:1802.05799 , 2018. [42] Xiaogang Shi, Bin Cui, Y ingxia Shao, and Y unhai T ong. T ornado: A system for real-time iterativ e analysis ov er ev olving data. In Pr oceed- ings of the 2016 International Conference on Management of Data , SIGMOD ’16, pages 417–430, New Y ork, NY , USA, 2016. A CM. [43] David Silv er , Aja Huang, Christopher J. Maddison, Arthur Guez, Lau- rent Sifre, George van den Driessche, Julian Schrittwieser , Ioannis Antonoglou, V eda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner , Ilya Sutske ver , Timo- thy Lillicrap, Madeleine Leach, K oray Ka vukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of go with deep neural networks and tree search. Natur e , 529:484–503, 2016. [44] Karen Simonyan and Andrew Zisserman. V ery deep con volutional networks for large-scale image recognition. CoRR , abs/1409.1556, 2014. [45] Peng Sun, W ansen Feng, Ruobing Han, Shengen Y an, and Y onggang W en. Optimizing network performance for distributed dnn training on gpu clusters: Imagenet/alexnet training in 1.5 minutes. arXiv pr eprint arXiv:1902.06855 , 2019. [46] Christian Sze gedy , W ei Liu, Y angqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov , Dumitru Erhan, V incent V anhoucke, and Andrew Rabinovich. Going deeper with con volutions. In Computer V ision and P attern Recognition (CVPR) , 2015. [47] Hanlin T ang, Shaoduo Gan, Ce Zhang, T ong Zhang, and Ji Liu. Com- munication compression for decentralized training. In NeurIPS , 2018. [48] Hanlin T ang, Xiangru Lian, Ming Y an, Ce Zhang, and Ji Liu. d 2 : Decentralized training over decentralized data. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Con- fer ence on Machine Learning , v olume 80 of Pr oceedings of Mac hine Learning Resear ch , pages 4848–4856, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR. [49] Jianyu W ang and Gauri Joshi. Adapti ve communication strate gies to achiev e the best error-runtime trade-off in local-update sgd. ArXiv , abs/1810.08313, 2018. [50] Minjie W ang, Chien-chin Huang, and Jinyang Li. Supporting very large models using automatic dataflow graph partitioning. CoRR , abs/1807.08887, 2018. [51] Eric P . Xing, Qirong Ho, W ei Dai, Jin-K yu Kim, Jinliang W ei, Seung- hak Lee, Xun Zheng, Pengtao Xie, Abhimanu K umar , and Y aoliang Y u. Petuum: A new platform for distrib uted machine learning on big data. In Pr oceedings of the 21th ACM SIGKDD International Confer ence on Knowledge Discovery and Data Mining , KDD ’15, pages 1335–1344, New Y ork, NY , USA, 2015. A CM. [52] Masafumi Y amazaki, Akihiko Kasagi, Akihiro T abuchi, T akumi Honda, Masahiro Miwa, Naoto Fukumoto, Tsuguchika T abaru, Atsushi Ike, and K ohta Nakashima. Y et another accelerated sgd: Resnet-50 training on imagenet in 74.7 seconds. arXiv pr eprint arXiv:1903.12650 , 2019. [53] Kun-Hsing Y u, Andre w Beam, and Isaac K ohane. Artificial intelligence in healthcare. Nature Biomedical Engineering , 2, 10 2018. [54] Ce Zhang and Christopher Ré. Dimmwitted: A study of main-memory statistical analytics. Proceedings of the VLDB Endowment , 7(12):1283– 1294, 2014. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment