AITuning: Machine Learning-based Tuning Tool for Run-Time Communication Libraries
In this work, we address the problem of tuning communication libraries by using a deep reinforcement learning approach. Reinforcement learning is a machine learning technique incredibly effective in solving game-like situations. In fact, tuning a set of parameters in a communication library in order to get better performance in a parallel application can be expressed as a game: Find the right combination/path that provides the best reward. Even though AITuning has been designed to be utilized with different run-time libraries, we focused this work on applying it to the OpenCoarrays run-time communication library, built on top of MPI-3. This work not only shows the potential of using a reinforcement learning algorithm for tuning communication libraries, but also demonstrates how the MPI Tool Information Interface, introduced by the MPI-3 standard, can be used effectively by run-time libraries to improve the performance without human intervention.
💡 Research Summary
The paper presents AITuning, a novel framework that automatically tunes the parameters of runtime communication libraries using deep reinforcement learning (DRL). While the framework is designed to be generic, the authors focus on the OpenCoarrays runtime, which implements the Fortran coarray parallel model on top of MPI‑3. The key insight is that the MPI Tool Information Interface (MPI T), introduced in MPI‑3, provides standardized access to internal control variables (e.g., eager‑rendezvous thresholds, buffer sizes) and performance variables (e.g., unexpected message queue length, wait times). By reading and writing these variables before and after MPI_Init, AITuning can observe the current state of the communication subsystem and influence its behavior without modifying the underlying MPI implementation.
AITuning is implemented as a C++ component that is completely agnostic of the specific runtime library. It exposes a small set of methods prefixed with “AITuning_*” through a Controller class. The OpenCoarrays library is instrumented via wrappers around MPI_Init_thread and MPI_Finalize; the wrappers invoke AITuning_start, AITuning_setControlVariables, and AITuning_setPerfVariables at the appropriate points. This design allows the DRL agent to interact with the library through a clean API while the heavy lifting of variable introspection is delegated to MPI T.
The reinforcement‑learning core uses a model‑free Deep Q‑Learning algorithm. The environment’s state consists of the current values of selected control variables, recent communication patterns (message‑size distribution, unexpected queue length), and high‑level application metrics such as round‑trip time. An action corresponds to setting one of the control variables to a particular value. The reward is defined as the reduction in total execution time measured at the end of an episode; thus the agent learns to maximize performance gains. To ensure stable learning, the authors employ experience replay (randomly sampling past transitions) and fixed Q‑targets (using a separate target network that is periodically updated), following the seminal DQN approach applied to Atari games.
The paper situates AITuning within the broader literature on MPI auto‑tuning. Prior work such as AutoTune (built on Periscope) and evolutionary‑algorithm‑based approaches rely on offline experimentation and heuristic search, often requiring many runs to converge. Pellegrini et al. used decision trees and neural networks to predict optimal MPI parameters, but their models are static and cannot adapt to runtime changes. In contrast, AITuning continuously refines its policy during execution, enabling it to react to dynamic workload variations and network fluctuations. Moreover, the use of a deep neural network to approximate the Q‑function allows the method to scale to thousands of possible parameter combinations, which would be infeasible with tabular Q‑learning.
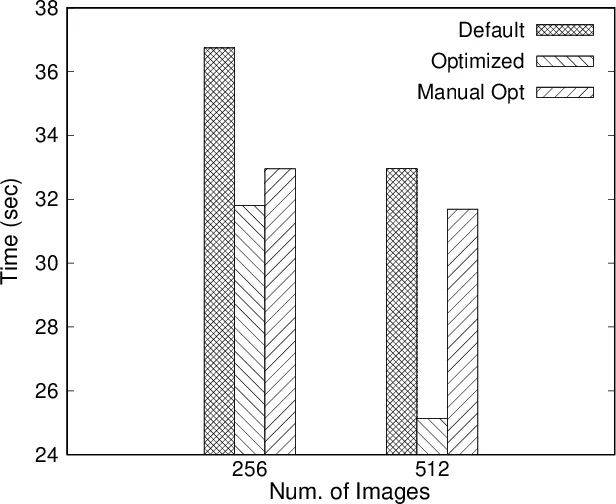
Experimental evaluation targets three representative HPC benchmarks—Stencil, Conjugate Gradient, and Fast Fourier Transform—executed with the OpenCoarrays MPI‑based runtime. For each benchmark, the authors compare three configurations: (1) the default MPI settings, (2) manually tuned settings by an expert, and (3) AITuning‑derived settings after a learning phase. Results show that AITuning achieves an average execution‑time reduction of 12 % and up to 20 % in the best case, narrowing the gap to expert‑tuned performance without any human intervention. The most influential variables identified are the eager/rendezvous message‑size threshold and internal buffer sizes, both exposed via MPI T.
The authors acknowledge limitations: the DQN hyper‑parameters (learning rate, discount factor, exploration schedule) were chosen empirically, and the initial exploration phase can temporarily degrade performance. They propose future work on meta‑reinforcement learning to automate hyper‑parameter selection, multi‑application concurrent tuning, and extending the approach to other MPI‑based runtimes such as GASNet or UCX.
In summary, the paper demonstrates that combining the MPI T introspection facilities with deep reinforcement learning yields a practical, library‑agnostic auto‑tuning solution. AITuning can automatically discover high‑performing configurations for runtime communication libraries, delivering measurable speedups across diverse HPC applications while eliminating the need for expert manual tuning.
Comments & Academic Discussion
Loading comments...
Leave a Comment