SegNAS3D: Network Architecture Search with Derivative-Free Global Optimization for 3D Image Segmentation
Deep learning has largely reduced the need for manual feature selection in image segmentation. Nevertheless, network architecture optimization and hyperparameter tuning are mostly manual and time consuming. Although there are increasing research effo…
Authors: Ken C. L. Wong, Mehdi Moradi
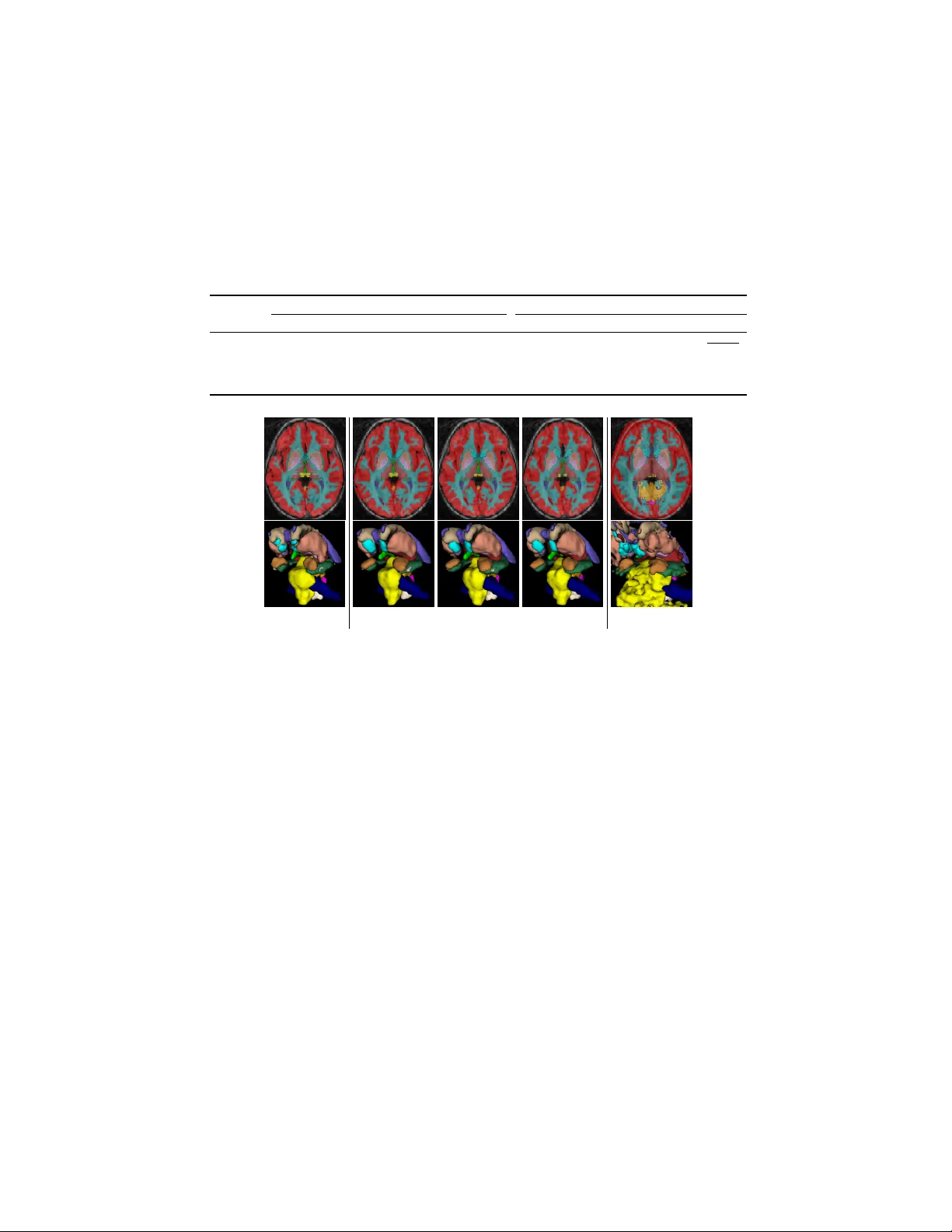
SegNAS3D: Net w ork Arc hitecture Searc h with Deriv ativ e-F ree Global Optimization for 3D Image Segmen tation ? Ken C. L. W ong, Mehdi Moradi IBM R esearch – Almaden Research Cen ter, San Jose, CA, USA { clwong, mmoradi } @us.ibm.com Abstract. Deep learning has largely reduced the need for man ual fea- ture selection in image segmentation. Nevertheless, net work architecture optimization and h yp erparameter tuning are mostly manual and time consuming. Although there are increasing researc h efforts on netw ork ar- c hitecture search in computer vision, most works concentrate on image classification but not segmentation, and there are very limited efforts on medical image segmentation esp ecially in 3D. T o remedy this, here w e propose a framework, SegNAS3D, for netw ork architecture searc h of 3D image segmentation. In this framework, a netw ork arc hitecture com- prises interconnected building blo c ks that consist of op erations such as con volution and skip connection. By represen ting the block structure as a learnable directed acyclic graph, h yp erparameters suc h as the num ber of feature channels and the option of using deep sup ervision can b e learned together through deriv ative-free global optimization. Exp erimen ts on 43 3D brain magnetic resonance images with 19 structures achiev ed an av- erage Dice coefficient of 82%. Eac h architecture searc h required less than three days on three GPUs and produced architectures that were muc h smaller than the state-of-the-art manually created architectures. 1 In tro duction Although deep learning has largely reduced the need for manual feature selection in image segmen tation [1,7], days to weeks are still required to manually search for the appropriate arc hitecture and hyperparameters. T o further reduce h u- man workloads, net w ork architecture searc h (NAS) has b een prop osed for image classification in the computer vision communit y to automatically generate net- w ork architectures. In [13], a recurrent netw ork was used to generate the mo del descriptions of neural netw orks, which was trained with reinforcement learning on 800 GPUs to learn architectures from scratch. In [12], a blo c k-wise netw ork generation pip eline w as introduced to automatically build netw orks using the Q-learning paradigm with tremendous increase of searc h efficiency . ? This pap er w as accepted by the International Conference on Medical Image Com- puting and Computer-Assisted Interv ention – MICCAI 2019. Ima g e ( sz =128 3 ) Op tional deep sup er vision Mg B l k ( ) Ga us sian noise ( s t d =1) Dr opout (0 . 5 ) … … … Con v (1 1 1) + sof tma x – nu mbe r of c han ne l s i n fir s t blo c k – nu mbe r of c han ne l s i n a b l oc k – nu mbe r of ma x pooli ng s – nu mbe r of labe l s Con v (1 1 1) + BN + R eL U Ma x pooli ng (2 2 2) Up samp l i ng (2 2 2) Cop y and c onc a t en a t e MgBlk( ) Spa t i al dr opout (0 . 1 ) Bloc k( ) O p tion al r es idu al c on necti on MgB l k ( ) MgB l k ( ) MgB l k ( ) MgB l k ( ) Fig. 1. Ov erall architecture. Blue and white boxes represen t op eration outputs and copied data, respectively . A MegaBlock (MgBlk) comprises a learnable blo c k in Section 2.1 with spatial drop out and an optional residual connection. n , p , and the options of using deep sup ervision and blo c k residual connections are learnable hyperparameters. Although these works are promising, efforts on NAS for medical image seg- men tation are very limited esp ecially in 3D. In [8], the policy gradient rein- forcemen t learning has b een used to learn the kernel size and the num b er of feature channels of each conv olutional lay er of a custom net work architecture for 2D medical image segmen tation. Without learnable lay er interconnections, this framew ork mainly p erforms h yperparameter tuning rather than arc hitecture searc h, and the computational complexit y is infeasible for 3D image segmenta- tion. In fact, the computational requirements for 3D images are muc h higher than 2D images. F urthermore, multiple lo cal optima can be exp ected in the ar- c hitecture searc h space but they are not handled b y most framew orks. Therefore, dev eloping an efficient NAS framework for 3D images is a very challenging task. In view of these issues, here w e propose a NAS framework, SegNAS3D, for 3D image segmentation with tw o key contributions. I) F or computational feasi- bilit y , inspired by [6], the o verall netw ork architecture is comp osed of rep etitiv e blo c k structures, with eac h blo ck structure represen ted as a learnable directed acyclic graph. Different from [6], the interconnections among block structures are also modeled as learnable h yp erparameters for a more complete netw ork arc hitecture search. I I) By constructing the hyperparameter search space with con tinuous relaxation and handling un trainable situations such as the out-of- memory (OOM) error, deriv ativ e-free global optimization is applied to searc h for the optimal architecture. T o the b est of our knowledge, this is the first w ork of netw ork architecture search for 3D image segmen tation with global optimiza- tion. Experiments on 43 3D brain magnetic resonance (MR) images with 19 anatomical structures ac hieved an a verage Dice co efficient of 82%. Each archi- tecture search required less than three days on three GPUs, and the resulted net works were muc h smaller than the V-Net [7] on the tested dataset. 2 Metho dology F or computational feasibilit y , inspired by [6,12], the segmen tation net work ar- c hitecture comprises tw o k ey comp onen ts: the building blo c ks and their in ter- 0 1 2 3 0 1 0 0 1 3 0 2 2 3 Output node Input node 0 1 2 3 1 3 2 0 1 2 3 0 1 5 0 1 0 4 2 2 3 0 1 2 3 1 2 5 4 0 1 2 3 0 1 0 0 1 0 4 2 2 3 0 1 2 3 1 2 4 0 1 2 3 0 1 5 0 1 0 0 2 2 3 0 1 2 3 1 2 5 (a) Output node Input node Output node Input node Output node Input node (b) (c) (d) ops : {1, 0 , 0, 3, 0, 2} ops : {1, 5 , 0, 0, 4 , 2 } ops : {1, 0 , 0, 0, 4 , 2 } ops : {1, 5 , 0, 0, 0, 2} Fig. 2. Examples of upp er triangular op eration matrices and the corresp onding blo c k structures for a directed acyclic graph with four no des. Each integer matrix element represen ts an op eration in T able 1 and ops represen ts the corresp onding set of op era- tions. (a) The simplest blo c k structure. (b) A more complicated blo ck structure with m ultiple nodal inputs and outputs. (c) and (d) Illegal blo ck structures with node 2 as a source and no de 1 as a sink, resp ectiv ely . T able 1. Block op erations and their corresp onding num b ers. Conv( k , d ) represents a k × k × k conv olution with dilation rate d . d = 1 means no dilation. Each con volution is follow ed by batc h normalization and ReLU activ ation. 0 1 2 3 4 5 6 None Conv(1, 1) Conv(3, 1) Conv(5, 1) Conv(3, 2) Conv(5, 2) Skip connection connections (Fig. 1). A building blo c k comprises v arious deep-learning lay ers suc h as conv olution and batch normalization, whose pattern is rep eatedly used in the ov erall netw ork. The residual units of the ResNet [3] are go od examples. The building blo c ks are connected together to form the netw ork architecture. F or classification netw orks, the blo cks are usually cascaded with p ooling lay ers in betw een [3,9]. F or segmen tation net works, there are more v ariations of ho w differen t blo c ks are connected [11,1,7]. 2.1 Blo c k Structure Inspired b y [6], a block is represen ted as a directed acyclic graph. Eac h node rep- resen ts a feature map (tensor) and eac h directed edge represents an op eration (e.g. conv olution). Here we represen t the graph as an upp er triangular opera- tion matrix which con tains all op erations among no des (Fig. 2). The rows and columns of the matrix represent the input and output no des, resp ectiv ely , with nonzero elemen ts represent op eration n umbers (T able 1). There are tw o t yp es of no des crucial for building trainable netw orks. 1) Source: a no de that does not ha ve paren ts in a block. 2) Sink: a no de that does not hav e c hildren in a blo c k. In a blo c k, only the first no de can b e the source and the last no de can b e the sink as they are connected to other blocks. A net w ork cannot b e built if there are sources or sinks as the in termediate no des. Therefore, the simplest blo c k structure can b e represen ted b y a “shifted” diagonal matrix (Fig. 2(a)), and more complicated structures can also b e achiev ed (Fig. 2(b)). With the ma- trix represen tation, a source and a sink can b e easily iden tified as the column and the ro w with all zeros, resp ectiv ely (Fig. 2(c) and (d)). The blo c k op erations and the corresp onding num bers are shown in T able 1. The op erations include conv olutions with differen t k ernel sizes ( k = 1 , 3 , 5) and dilation rates ( d = 1 , 2) for m ulti-scale features [11]. Eac h con v olution is follo wed b y batch normalization and ReLU activ ation. Skip connection which allows b et- ter conv ergence is also included. Outputs from different no des are combined by summation as concatenation mostly led to the OOM error in our experiments. The num b er of no des ( nodes ) in a blo c k is also a learnable hyperparameter. T o reduce the complexit y of arc hitecture searc h, all blo c ks in a netw ork share the same op eration matrix, with the n umbers of feature channels systematica lly assigned based on the n umber of feature channels of the first block (Section 2.2). 2.2 Net work Arc hitecture and Blo ck-Connecting Hyp erparameters Although there are multiple wa ys to connect the blo c ks together for image seg- men tation, we adopted an architecture similar to the U-Net [1] and V-Net [7] as they were prop osed for 3D medical image segmentation (Fig. 1). The arc hitecture con tains the enco ding and decoding paths with MegaBlo c ks. Eac h MegaBlo c k comprises a blo c k in Section 2.1 with spatial drop out and an optional resid- ual connection to reduce ov erfitting and enhance conv ergence. The num b er of c hannels is doubled after each max p ooling and is halved after each upsampling. Deep sup ervision whic h allows more direct backpropagation to the hidden la yers for faster conv ergence and b etter accuracy is also an option [5]. The num b er of feature channels of the first block ( n ), the num ber of max p oolings ( p ), and the options of using deep sup ervision ( sup ) and blo c k residual connections ( r es ) are learnable blo c k-connecting h yp erparameters. 2.3 Global Optimization with Con tin uous Relaxation As the num b er of hyperparameter combinations can b e huge ( > 141 millions in some of our experiments) and eac h corresp onds to a netw ork training, brute force search is prohibitiv e and nonlinear optimization is required. Compared with discrete optimization, there are many more contin uous optimization algo- rithms a v ailable esp ecially for deriv ativ e-free global optimization [2]. Therefore, similar to [6], con tinuous relaxation is used to remo ve the integralit y constraint of each parameter. This also allows us to introduce non-integral hyperparam- eters such as the learning rate if desired. Differen t from [6] which formulated the problem for lo cal gradient-based optimization, we use deriv ativ e-free global optimization. This is b ecause it is nonoptimal to compute gradien ts of the discon- tin uous ob jective function, and multiple local minima can b e expected. Handling of un trainable situations is also simpler without gradients. T able 2. V ariations of the prop osed framework with different learnable hyperparam- eters and their lo wer and upp er bounds. The effective set of integers of eac h half-op en in terv al [ a , b ) is { a , . . . , b − 1 } . F or bounds [0, 2), { 0, 1 } means { Disable, Enable } . The upp er bound of nodes determines the num b er of blo c k-op eration h yp erparameters ( ops ) required. F or example, nodes with bounds [2, 5) requires six ops to fill a 4 × 4 up- p er triangular matrix. Scalars in red are fixed. F or SegNAS 4 , ops of { 2, 0, 2 } represents t wo cascaded Conv(3, 1) in T able 1. Block-connecting hyperparameters Block structures n p sup res nodes ops SegNAS 11 [8, 33) [2, 6) [0, 2) [0, 2) [2, 5) [0, 7) (6 × ) SegNAS 4 [8, 33) [2, 6) [0, 2) [0, 2) 3 { 2, 0, 2 } SegNAS 7 16 4 0 1 [2, 5) [0, 7) (6 × ) Let x ∈ R n h b e a v ector of n h h yp erparameters after contin uous relaxation. W e use b x c (flo or of x ) to construct a net work architecture. Therefore, the ob- jectiv e function is a discon tin uous function in a b ounded con tinuous searc h space whic h can b e b etter handled by deriv ativ e-free global optimization. The ob jective function f = − ln( Dice ) is used, where D ice is the v alidation Dice coefficient. The deriv ativ e-free global optimization algorithm “con trolled random searc h” (CRS) [4] is used as it pro vides effectiv e search with go o d p erformance among tested algorithms. CRS starts with a p opulation of sample p oin ts (10 × ( n h + 1)) whic h are gradually ev olved b y an algorithm that resembles a randomized Nelder- Mead algorithm. Eac h search stops after 300 iterations. Sev eral issues need to b e handled for effective and efficient searc h. Firstly , to handle hyperparameters of illegal blo ck structures (Section 2.1) and OOM errors, w e assign them an ob jectiv e function v alue d max f e , which is 10 by clipping the minim um v alue of Dice as 10 − 4 . This tells the optimization algorithm that these situations are worse than having the worst segmentation. Secondly , as multiple x con tribute to the same b x c , w e sav e eac h b x c and the corresponding f to a void unnecessary training for b etter efficiency . 2.4 T raining Strategy In eac h netw ork training, image augmentation with rotation (axial, ± 30 ◦ ), shift- ing ( ± 20%), and scaling ([0.8, 1.2]) is used, and eac h image has an 80% chance to b e transformed. The optimizer Nadam is used for fast conv ergence with the learning rate as 10 − 3 . The exp onential logarithmic loss with Dice loss and cross- en tropy is used [10]. The IBM Po wer System A C922 equipp ed with NVLink for enhanced host to GPU comm unication w as used. This mac hine features NVIDIA T esla V100 GPUs with 16 GB memory , and three of these GPUs w ere used for m ulti-GPU training with a batch size of three and 100 ep o c hs. 0 50 100 150 200 250 Iteration 0.0 0.2 0.4 0.6 0.8 Validation Dice S e g N A S 1 1 S e g N A S 4 S e g N A S 7 Fig. 3. Evolutions of the v alidation Dice co efficients during search. Examples of a dataset split. Iterations with illegal blo ck structures and OOM errors are omitted. The effectiv e num b ers of v alidation Dice co efficien ts for SegNAS 11 , SegNAS 4 , and SegNAS 7 w ere 139, 272, and 189, resp ectiv ely , out of 300 iterations. 3 Exp erimen ts 3.1 Data and Exp erimen tal Setups W e v alidated our framework on 3D brain MR image segmentation. A dataset of 43 T1-weigh ted MP-RAGE images from different patients was neuroanatomi- cally lab eled to provide the training, v alidation, and testing samples. They were man ually segmen ted by highly trained experts, and each had 19 semantic lab els of brain structures. Eac h image was resampled to isotropic spacing using the minim um spacing, zero padded, and resized to 128 × 128 × 128. Three sets of dataset splits were generated by shuffling and splitting the dataset, with 50% for training, 20% for v alidation, and 30% for testing in each set. The training and v alidation data w ere used during arc hitecture searc h to pro- vide the training data and the v alidation Dice co efficien ts for the ob jective func- tion. The testing data were only used to test the optimal netw orks after search. Three v ariations of our prop osed framew ork w ere tested (T able 2). SegNAS 11 optimizes b oth blo c k structures and their interconnections. SegNAS 4 optimizes only the blo c k-connecting hyperparameters with fixed blo c k structures. SegNAS 7 optimizes only the blo c k structures with fixed blo c k-connecting h yp erparame- ters inferred from the V-Net. Note that the subscripts indicate the n um b ers of h yp erparameters to b e optimized. W e p erformed exp erimen ts on the 3D U-Net [1] and V-Net [7] for comparison. The same training strategy and dataset splits w ere used in all exp erimen ts. 3.2 Results and Discussion Examples of the evolutions of the v alidation Dice co efficien ts during search are sho wn in Fig. 3. In all tests, there w ere more fluctuations at the early iterations as the optimization algorithm searched for the global optim um, and the evo- lutions gradually conv erged. SegNAS 11 had the least effective n umber of Dice T able 3. Av erage results of all dataset splits and the optimal hyperparameters of a dataset split (same split as Fig. 3). The best results are in blue and the fixed h yp erpa- rameters are in red. The testing Dice coefficients are shown. GPU days are the num b er of searching da ys multiplied b y the num ber of GPUs (three) used. Strik ethrough ops of SegNAS 11 w ere not used to form the netw ork because of the num b er of nodes (three). Please refer to Section 2.1 and 2.2 for the definitions of hyperparameters. Average results (mean ± std) Optimal hyperparameters of a search Dice (%) Parameters (millions) GPU days n p sup r es nodes ops SegNAS 11 81.7 ± 0.3 9.7 ± 4.1 6.6 ± 0.6 26 3 0 1 3 { 2, 2, 3, 6, 3, 3 } SegNAS 4 81.0 ± 0.5 3.2 ± 0.6 3.6 ± 0.1 21 3 1 0 3 { 2, 0, 2 } SegNAS 7 77.7 ± 1.0 30.1 ± 5.4 8.2 ± 0.4 16 4 0 1 4 { 6, 2, 3, 0, 4, 3 } 3D U-Net OOM 19.1 ± 0.0 — — V-Net 47.9 ± 7.4 71.1 ± 0.0 — — Ground truth SegNAS 11 Dice = 83% SegNAS 4 Dice = 82% SegNAS 7 Dice = 78% V-Net Dice = 51% Fig. 4. Visualization of an example. T op: axial view. Bottom: 3D view with the cerebral grey , cerebral white, and cereb ellar grey matters hidden for b etter illustration. co efficien ts (139) as its larger num b er of hyperparameter combinations led to more illegal structures and OOM errors. In con trast, SegNAS 4 had the most effectiv e num b er (272). W e can also see that searching optimal blo c k structures (SegNAS 11 and SegNAS 7 ) led to larger fluctuations, and searching only blo c k- connecting h yp erparameters (SegNAS 4 ) ga ve faster conv ergence. T able 3 shows the av erage results from all three dataset splits and the opti- mal hyperparameters of a dataset split. The V-Net gav e the low est testing Dice co efficien ts and the largest mo del. SegNAS 11 had the b est segmentation p erfor- mance while SegNAS 4 pro duced the smallest mo dels with fewest GPU days for comparably go od p erformance. Among the v ariations, SegNAS 7 had the low est Dice co efficien ts, largest models, and most GPU days. The 3D U-Net gav e the OOM error and pro duced a larger netw ork than SegNAS 11 and SegNAS 4 . As three GPUs were used, each searc h required less than three da ys to complete. Fig. 4 sho ws the results of an example which are consistent with T able 3. Therefore, the block-connecting h yperparameters n , p , sup , and res are more effectiv e especially with simple blo c k structures such as that of SegNAS 4 . Searc h- ing also the blo c k structures can impro ve segmen tation accuracy with increased searc hing time and probably larger mo dels. Searching only the blo c k structures can lead to larger mo dels dep ending on the fixed n , p v alues and is not as effec- tiv e. The 3D U-Net ga ve the OOM error b ecause of its relatively large memory fo otprin t (e.g. tensors of 128 × 128 × 128 with 64 feature c hannels). The segmen- tations of the V-Net w ere inaccurate probably b ecause of insufficien t training data giv en the num b er of netw ork parameters. When we increased the amount of training data from 50% to 70%, the testing Dice co efficien ts of the V-Net in- creased to 68.1 ± 2.3%. These sho w the adv an tages of our framew ork as the OOM error is explicitly considered and the relation b et ween the netw ork size and the a v ailable data is automatically handled. 4 Conclusion W e presen t a netw ork arc hitecture search framework for 3D image segmen ta- tion. By represen ting the netw ork architecture with learnable connecting blo c k structures and iden tifying the hyperparameters to b e optimized, w e formulate the searc h as a global optimization problem with contin uous relaxation. With its flexibilit y , we studied three v ariations of the framework. The results show that the blo ck-connecting h yp erparameters are more effectiv e, and optimizing also the blo c k structures can further impro ve the segmentation performance. References 1. C ¸ i¸ cek, ¨ O., Ab dulk adir, A., Lienk amp, S.S., Bro x, T., Ronneb erger, O.: 3D U-Net: Learning dense volumetric segmen tation from sparse annotation. In: In ternational Conference on Medical Image Computing and Computer-Assisted In terven tion. LNCS, vol. 9901, pp. 424–432 (2016) 2. Conn, A.R., Sc heinberg, K., Vicente, L.N.: Introduction to Deriv ative-F ree Opti- mization. Siam (2009) 3. He, K., Zhang, X., Ren, S., Sun, J.: Identit y mappings in deep residual netw orks. In: European Conference on Computer Vision. LNCS, v ol. 9908, pp. 630–645 (2016) 4. Kaelo, P ., Ali, M.M.: Some v arian ts of the con trolled random search algorithm for global optimization. Journal of Optimization Theory and Applications 130(2), 253–264 (2006) 5. Lee, C.Y., Xie, S., Gallagher, P .W., Zhang, Z., T u, Z.: Deeply-sup ervised nets. In: International Conference on Artificial Intelligence and Statistics. pp. 562–570 (2015) 6. Liu, H., Simon yan, K., Y ang, Y.: DAR TS: Differen tiable architecture search. arXiv:1806.09055 [cs.LG] (2018) 7. Milletari, F., Na v ab, N., Ahmadi, S.A.: V-Net: F ully conv olutional neural net w orks for v olumetric medical image segmentation. In: IEEE International Conference on 3D Vision. pp. 565–571 (2016) 8. Mortazi, A., Bagci, U.: Automatically designing CNN arc hitectures for medical image segmentation. In: International W orkshop on Machine Learning in Medical Imaging. LNCS, vol. 11046, pp. 98–106 (2018) 9. Szegedy , C., Ioffe, S., V anhouck e, V., Alemi, A.A.: Inception-v4, Inception-ResNet and the impact of residual connections on learning. In: AAAI Conference on Arti- ficial Intelligence. pp. 4278–4284 (2017) 10. W ong, K.C.L., Moradi, M., T ang, H., Sy eda-Mahmo od, T.: 3D segmen tation with exp onen tial logarithmic loss for highly unbalanced ob ject sizes. In: In ternational Conference on Medical Image Computing and Computer-Assisted In terven tion. LNCS, vol. 11072, pp. 612–619 (2018) 11. Y u, F., Koltun, V.: Multi-scale con text aggregation b y dilated conv olutions. arXiv:1511.07122 [cs.CV] (2015) 12. Zhong, Z., Y an, J., W u, W., Shao, J., Liu, C.L.: Practical block-wise neural net work arc hitecture generation. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 2423–2432 (2018) 13. Zoph, B., Le, Q.V.: Neural architecture search with reinforcement learning. arXiv:1611.01578 [cs.LG] (2016)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment