Simultaneous reconstruction of the initial pressure and sound speed in photoacoustic tomography using a deep-learning approach
Photoacoustic tomography seeks to reconstruct an acoustic initial pressure distribution from the measurement of the ultrasound waveforms. Conventional methods assume a-prior knowledge of the sound speed distribution, which practically is unknown. One…
Authors: Hongming Shan, Christopher Wiedeman, Ge Wang
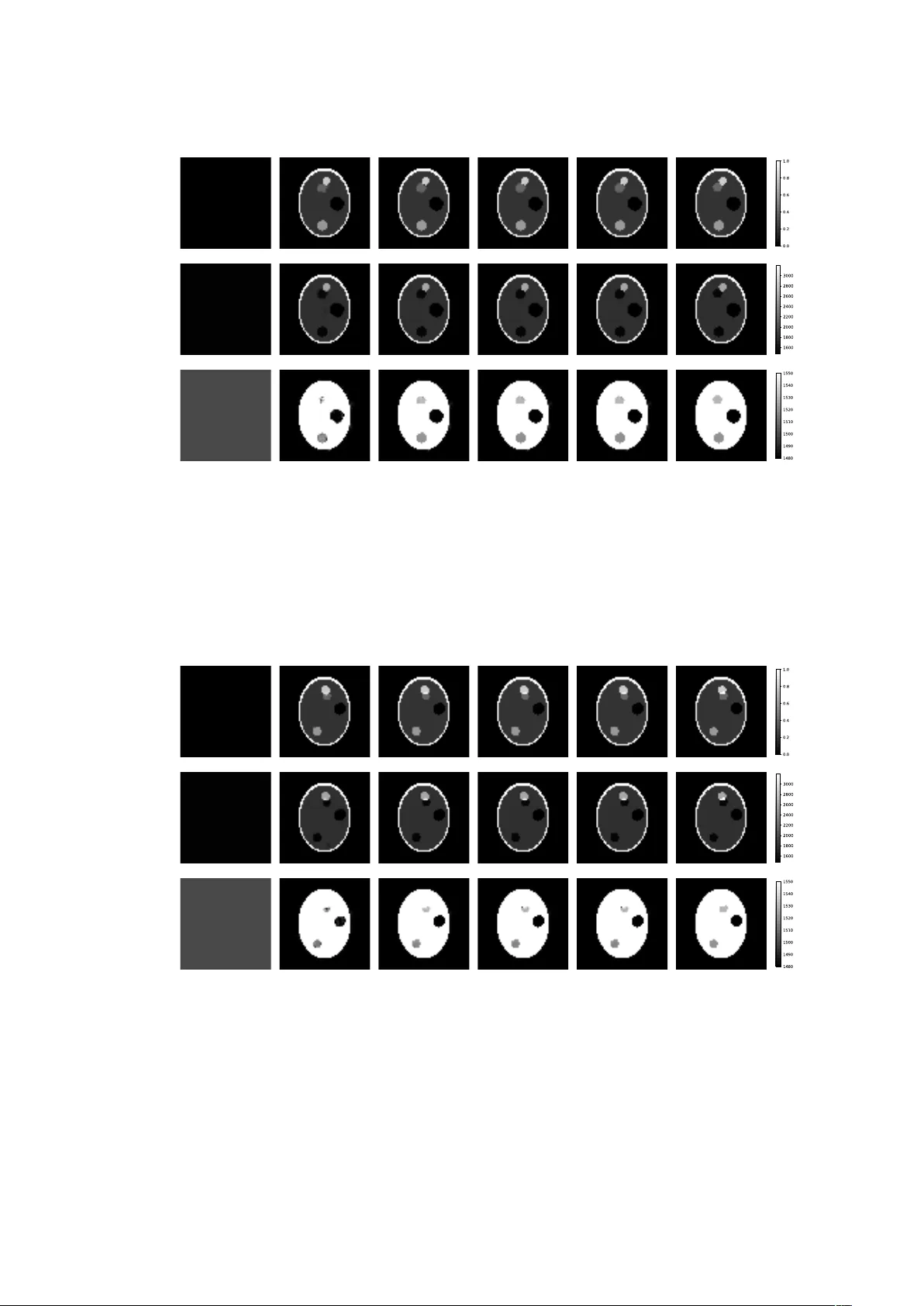
Simultaneous reconstruction of the initial pressure and sound speed in photoacoustic tomograph y using a deep-l earning approach Hongming Shan, Christopher Wiedeman, Ge W ang, Y ang Y ang Contact: shanh@rpi.edu, wiedec@rpi.edu, wangg6@rpi.edu, yangy5@msu.edu Rensselaer Pol ytechnic Institute Michigan State Univ ersity September 16, 2019 Abstract Photoacoustic tomography seeks to reconstruct an acoustic initial pressure distribution from the mea- surement of the ultrasound wa veforms. Conventional methods assume a-prior know ledge of the sound speed distribution, which practically is unkno wn. One way to circum vent the issue is to simultaneously reconstruct both the acoustic initial pressure and speed. In this article, we develop a novel data-driven method that integrates an advanced deep neural network through model-based iteration. The image of the initial pressure is significantly improved in our numerical simulation. 1 Introduction Photoacoustic tomography (P A T) is an emerging non-invasiv e modality that has manifested an enormous prospect for clinical practices [ 1 ]. In P A T , the tissue is illuminated with near- infrared light of wav elength 650-900nm. The absorbed optical energy is transformed into acoustic energy through the photoacoustic effect, and the generated ultrasound is measured by transducer arrays around the tissue in order to retrieve the optical internal proper- ties. The coupling mechanism of the optical and ultrasound waves gives multiple advantages ov er conv entional standalone modalities. For instance, the acoustic wave experiences less scattering in tissue compared to optical wav e, allowing P A T to break the optical diffusion limit and generate high-resolution images [2] while preserving intrinsic optical contrast [3]. T ypical photo-acoustic signal generation comprises three steps: (1) the tissue absorbs light; (2) the absorbed optical energy heats the tissue and raises the temperature; (3) thermo-elastic expansion occurs and generates ultrasound. The image formation in P A T is to recover the distribution of the deposited energy, known as the local optical fluence, from the ultrasound signals that are recorded by the sensors deploy ed around the tissue. As the initial ultrasound pressure is approximately proportional to the optical fluence, it is sufficient to reconstruct the initial pressure from the recorded ultrasound signals. Conventional reconstructive schemes, such as back -projection based methods [ 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 ] and time-rev ersal based methods [ 12 , 13 , 14 , 15 , 16 , 17 , 18 , 19 , 20 , 21 , 22 , 23 , 24 ], typically assume the sound speed is precisely known. This assumption howev er is not always fulfilled, and the precise sound speed distribution is often unknown. It is therefore of practical significance to study simultaneous reconstruction of both the sound speed distribution and the acoustic initial pressure. The purpose of this article is to address this issue using a data-driven approach. Data-driven approaches such as machine learning and deep learning have gained increasing attention recently in medical image reconstruction [ 25 , 26 ]. The powerful computational capacity of modern super computers has enabled these methods to enhance medical image reconstruction by extracting the hidden patterns in the data that would otherwise be lost. In P A T , data driven methods have achieved state-of -the-art results in P A T image reconstruction in the scenarios of sparse 1 data [ 27 , 28 , 29 ], limited view [ 30 , 31 , 32 ], artifacts removal [ 33 , 34 , 35 ], as well as other applications [ 36 , 37 , 38 ]. In addition to P A T , data-driven approaches hav e also found broad application in the image reconstruction of many other imaging modalities such as Computed T omograp hy (CT), Magnetic Resonance Imaging (MRI), as well as other related fields like radiomics and radiotheraphy , see [ 39 , 40 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 , 49 , 50 ] for some examples and applications along these directions. 2 Preliminary In this section, we formulate the mathematical model of the simultaneous reconstruction problem in P A T and review the recent advances based on model-driven approaches. Propagation of ultrasound in P A T is typically modeled as an initial value problem for the wav e equation. This can be written as ρ ( r ) ∂ u ∂ t ( r , t ) + ∇ p ( r , t ) = 0 , in (0 , T ) × R d 1 ρ ( r ) c ( r ) 2 ∂ p ∂ t ( r , t ) + ∇ · u ( r , t ) = 0 , in (0 , T ) × R d p ( r , 0) = p 0 ( r ) , u ( r , 0) = 0 , (1) where d = 2 , 3 is the dimension, u is the acoustic velocity, p is the acoustic pressure, T > 0 is the stoppage time of the measurement, ρ is the mass density, c is the sound speed, and p 0 is the initial pressure distribution. W e remark that another popular model in P A T is to deal with the second order acoustic equation rather than the abov e first order system. These models are more or less equivalent under suitable assumptions. Let Ω be a bounded domain in R d representing the tissue, with the boundary of Ω denoted by ∂ Ω . The measurement in P A T is the detected ultrasound signals, that is the temporal boundary data p | [0 ,T ] × ∂ Ω . W e further introduce a measurement map Λ which is defined as Λ : ( c, p 0 ) 7→ p | [0 ,T ] × ∂ Ω (2) where p is the solution of (1) . Assuming the mass density ρ is known, then the simultaneous reconstruction problem in PA T can be recast as the inverse problem to recover the pair ( c, p 0 ) from p | [0 ,T ] × ∂ Ω ; in other words, to invert the operator Λ . Note that Λ is linear in p 0 but non-linear in c . W e recall some known results regarding the simultaneous reconstruction in P A T . Linearization of the map (2) at sufficiently smooth pairs is studied in [ 51 ] and the linearized inversion is shown to be unstable in any scale of Sobolev spaces. Invertibility of Λ is established in [ 52 ] for radially symmetric sound speeds in any odd dimension higher than three; in [ 53 , 54 ] for sound speeds that satisfy certain orthogonality relation with harmonic functions. Numerical simulations have been implemented in [ 55 ] using the finite element model, and in [ 56 , 57 , 58 ] for parametrized sound speeds. Our data-driven approach is inspired by the work of Matthews et al. [ 56 ], where the authors proposed a direct optimization approach towards the simultaneous reconstruction, with the sound speed being confined in a parametrized lower -dimensional space. W e denote the measurement by g for simplicity . With slight abuse of notations, the discretized versions of p 0 and c are still denoted by themselves, which are two matrices. For a fixed sound speed c , the operator Λ( c, · ) is linear, hence its discretization is another matrix, say H ( c ) . The idea in Ref [56] is to minimize the objective function c p 0 , b c = arg min p 0 ≥ 0 , c ≥ 0 F ( p 0 , c ) + β R ( p 0 ) (3) where the data fidelity term is defined as F ( p 0 , c ) := 1 2 k g − H ( c ) p 0 k 2 and R denotes the regularization term for the initial pressure. This objective function can be solved using the proximal optimization method that allows constraints and nonsmooth regularization function for the initial pressure distribution. The initial pressure distribution and sound speed distribution are updated iteratively using gradient descent. The algorithm in Ref [ 56 ] is summarized in Algorithm 1 below . 3 Simultaneous Reconstruction via Deep Learning W e describe our data-driven method in this section. The motivation stems from some limitations of the iterative algorithm 1. For instance, repeated selection of step sizes to update the initial pressure and sound speed is time- 2 Algorithm 1 Simultaneous Reconstruction by iterative algorithm [56] Require: p (0) 0 , c (0) , β Ensure: b p 0 , b c 1: k ← 0 2: while stopping criterion is not satisfied do 3: Calculate gradients ∇ p 0 F and ∇ c F 4: Choose step length α p k and α c k 5: p ( k +1) 0 = pro x α p k β R p ( k ) 0 − α p k ∇ p 0 F 6: c ( k +1) = c ( k ) − α c k ∇ c F 7: k ← k + 1 8: end while 9: b p 0 ← p ( k +1) 0 10: b c ← c ( k +1) consuming; selection of the parameter β and the regularization term R is highly empirical; tuning β can be tedious. T o over come these limitations, we propose a simultaneous reconstruction network (SR-N et) to update the initial pressure and the sound speed for each iteration. 𝒑 𝟎 (𝒌) −𝜵 𝒑 𝟎 𝑭 𝒄 (𝒌) Conv ReLU Conv ReLU Conv ReLU Conv ReLU BN 𝒑 𝟎 (𝒌%𝟏) 𝒄 (𝒌%𝟏) Conv ReLU Conv ReLU Conv ReLU Conv ReLU ReLU Conv ReLU Conv BN ⊕ ReLU Conv ReLU Conv BN ⊕ Feature Ex traction Feature Fusi on Reconstruc tion Figure 1: The proposed simultaneous reconstruction network (SR-N et) for P A T . The proposed SR-Net is shown in Fig. 1. It contains three steps - feature extraction, feature fusion, and reconstruction. 1. F eature extraction: W e used two convolutional layers to extract features from the initial pressure dis- tribution, the negative gradient of data fidelity with respect to initial pressure, and current sound speed distribution. 2. F eature fusion: The feature maps extracted from above three branches are concatenated along the channel dimension, which are then fed into the batch normalization (BN) layer . Since the feature maps from the initial pressure and the sound speed are in different scale, this batch normalization layer can normalize feature maps into the same scale for subsequent feature fusion. The feature fusion part also contains two convolutional lay ers follow ed by ReL U. 3. Reconstruction: After the feature fusion, we use two convolutional layers to reconstruct the updated initial pressure and sound speed, respectively . A batch normalization lay er is used after first convolutional 3 layer to scale the fused feature back to the original scale. A skip connection after the second convolutional layer enables the network to learn the residual just like the traditional iterative algorithm (see step 5-6 in Algorithm 1). The last ReLU activation function guarantees the updated initial pressure and speed distribution are non-negative. T able 1: Network architectures of feature extraction, feature fusion, and reconstruction in SR-Net. Lay er F eature Extraction × 3 Featur e Fusion Reconstruction × 2 1 3 × 3 conv , 32, stride 1 Batch Normalization 3 × 3 con v , 16, stride 1 2 3 × 3 conv , 32, stride 1 3 × 3 conv , 64, stride 1 Batch Normalization 3 3 × 3 conv , 32, stride 1 3 × 3 conv , 1, stride 1 A detailed network structure is shown in T able 1. Note that zero-padding is used such that all feature maps have the same as the inputs. For each iteration, we trained SR- Net using the simulated dataset. At the k -th iteration, the loss function is chosen as follows: min θ SR E ( p ( k ) 0 , −∇ p 0 F,c ( k ) ,p 0 ,c ) p ( k +1) 0 − p 0 + 1 1000 c ( k +1) − c s.t. p ( k +1) 0 , c ( k +1) = SR-N et ( p ( k ) 0 , −∇ p 0 F , c ( k ) ) (4) where θ SR represents the parameters of the SR-N et. p 0 and c are the ground-truth labels. W e employ the Adam algorithm [ 59 ] to update the parameters in θ SR . The gradients of the parameters are computed using a back - propagation algorithm. The iterative reconstruction algorithm is summarized in Algorithm 2. Algorithm 2 Simultaneous reconstruction via Deep learning Require: p (0) 0 , c (0) , k max Ensure: b p 0 , b c 1: k ← 0 2: while k < k max do 3: Calculate gradient ∇ p 0 F 4: p ( k +1) 0 , c ( k +1) = SR-N et ( p ( k ) 0 , −∇ p 0 F , c ( k ) ) 5: k ← k + 1 6: end while 7: b p 0 ← p ( k +1) 0 8: b c ← c ( k +1) Note that our proposed network is different from the model in Ref [ 30 ] because 1) our network aims to reconstruct the initial pressure distribution and sound speed distribution simultaneously, while the model in Ref [ 30 ] assumes the sound speed is precisely known; 2) our network is a 2D network, while the model in Ref [ 30 ] is a 3D network; and 3) the proposed network used the batch normalization lay er to scale the feature maps, while the model in Ref [30] used an explicit coefficient to represent the step length. 4 RESUL TS 4.1 Data generation In this study , we used a simplified Shepp-logan phantom to train and test our network. Fig. 2 shows the phantom along with the initial pressure and the sound speed distribution. W e randomly changed the sizes and positions of the region 1, 3, 4, and 5 in order to increase the diversity of dataset. The corresponding initial pressure and sound speed are shown in T able 2. W e put the phantom into a 64 × 64 image, which is surrounded by 252 detectors in the rectangle form. For the training purpose, we randomly generated 5,120 images with acoustic signal of the size 252 × 652 . The mass density is assumed to be constant 1 throughout. Then we selected 1,024 images randomly to test the trained model. 4 1 2 3 4 5 6 (b) (a) (c) Figure 2: An example of phantom, initial pressure and sound speed. The phantom used in this study contains 6 regions (a ), which was filled with different initial pressure shown in (b). The corresponding sound speed distribution is shown in (c ). Note that the yellow background in ( a) denotes the outside of the phantom. T able 2: The initial pressure and sound speed for each region. Index Initial Pressure Sound Speed [m/ s] 1 0.0 1480 2 0.2 1800 3 0.4 1530 4 0.6 1520 5 0.8 2600 6 1.0 3198 4.2 Experimental results Throughout the experiments, the initial pressure was initialized uniformly as zero and the sound speed was initialized uniformly as 1,500 m/ s. The maximum number of iteration k max was set to 4. The gradient of the data fidelity with respect to the initial pressure is computed by the adjoint state method using the k -w ave package [ 60 ]. The proposed SR-N et was implemented by Pytorch and trained on four NVIDIA 1080Ti GPUs. W e show two testing images in Figs. 3 and 4, which were not used in training stage. It is observed that the proposed method can reconstruct the initial pressure and sound speed simultaneously with very high accuracy . Mean absolute error for sound speed and initial pressure were calculated for each reconstructed image at each iteration. The average value and standard deviations of these errors are contained in T able 3. T able 3: Mean absolute error of the initial pressure and sound speed distribution for each iteration in the form of MEAN ± STD . Mean Absolute Error Iter 1 Iter 2 Iter 3 I ter 4 p (1.43 ± 0.36) × 10 − 2 (0.86 ± 0.33) × 10 − 2 (0.85 ± 0.33) × 10 − 2 (0.85 ± 0.33) × 10 − 2 c [m/ s] 3.13 ± 0.64 1.33 ± 0.52 1.25 ± 0.52 1.24 ± 0.52 4.3 Generalization ability of the trained SR- Net on a new phantom All Shepp-Logan phantoms used to train the model featured all six regions listed in T able 2. T o test the generaliz- ability of the model, we reconstructed four phantoms with region 5 remov ed. Figures 5 and 6 illustrate two cases of this test. From these cases, it can be observed that the model still accurately reconstructs phantoms that contain less regions than the phantoms used to train the model. 5 p c c Initial Iter 1 Iter 2 Iter 3 Iter 4 GT Figure 3: The first case of the simultaneously reconstructed results by applying SR- Net to the same phantom. The first row shows the initial pressure. The second and third rows show the sound speed distribution in range of [1480, 3198] and of [1480, 1550 ], respectively . GT means the ground-truth. p c c Initial Iter 1 Iter 2 Iter 3 Iter 4 GT Figure 4: The second case of the simultaneously reconstructed results by applying the SR-N et to the same phantom. The first row shows the initial pressure. The second and third rows show the sound speed distribution in the range of [1480, 3198] and of [1480, 1550], respectively . GT means the ground-truth. 6 p c c Initial Iter 1 Iter 2 Iter 3 Iter 4 GT Figure 5: The first case of the simultaneously reconstructed results by applying the SR-N et to the new phantom. The first row shows the initial pressure. The second and third rows show the sound speed distribution in the range of [1480, 3198] and of [1480, 1550], respectively . GT means the ground-truth. p c c Initial Iter 1 Iter 2 Iter 3 Iter 4 GT Figure 6: The second case of the simultaneously reconstructed results by applying the SR-N et to the new phantom. The first row shows the initial pressure. The second and third rows show the sound speed distribution in the range of [1480, 3198] and of [1480, 1550], respectively . GT means the ground-truth. 7 5 Discussions and Conclusion The main weakness of this study is the numerical nature, which may not fully reflect all the physical factors in real clinical/pre-clinical applications. W e plan to perform physical phantom experiments as a next step. Also, we are interested in animal studies in vivo. Nev ertheless, the numerical results and the network trained with simulated data may serve a baseline for further improvements. Hopefully , this imaging modality may find practical use in some important tasks such as breast imaging. In conclusion, we have developed a simultaneous reconstruction network (SR- Net) to jointly recover the sound speed and initial pressure in photoacoustic tomography . The proposed SR-N et has several merits: automatically learning the step size, regularization term, and the trade-off between data fidelity and regularization in a data- driven manner, and not requiring the gradient of the data fidelity with respect to sound speed. In the future, we will further improve the structure of the network and also validate it on more complicated datasets. 6 Ackno wl edgment The research of Y . Y ang is partly supported by the NSF grant DMS-1715178, the AMS-Simons travel grant, and the startup fund from Michigan State University . The authors would like to thank NVIDIA Corporation for the donation of GPU used for this research. Ref erences [1] Jun Xia, J unjie Y ao, and Lihong V W ang. Photoacoustic tomograph y: principles and advances. Electromagnetic waves ( Cambridge, Mass.) , 147:1, 2014. [2] Lihong V W ang and Gene K Beare. Breaking the optical diffusion limit: Photoacoustic tomography . In Frontiers in Optics , page FWY2. Optical Society of America, 2010. [3] Junjie Y ao and Lihong V W ang. Photoacoustic tomograph y: fundamentals, advances and prospects. Contrast media & molecular imaging , 6(5):332–345, 2011. [4] David Finch, Rakesh, and Leonid Kun yansky. Recov ering a function from its spherical mean values in two and three dimensions. Photoacoustic Imaging and Spectroscopy , 2009. [5] David Finch, Markus Haltmeier , and Rak esh. Inversion of spherical means and the wa ve equation in even dimensions. SIAM Journal on Applied Mathematics , 68(2):392–412, 2007. [6] Markus Haltmeier, Thomas Schuster, and Otmar Scherzer. Filtered backprojection for thermoacoustic computed tomography in spherical geometry . Mathematical methods in the applied sciences , 28(16):1919–1937, 2005. [7] Robert A Kruger, Daniel R Reineck e, and Gabe A Kruger. Thermoacoustic computed tomography –technical considerations. Medical physics , 26(9):1832–1837, 1999. [8] Robert A Kruger, William L Kiser Jr, Daniel R Reineck e, and Gabe A Kruger. Thermoacoustic computed tomography using a conventional linear transducer array . Medical physics , 30(5):856–860, 2003. [9] Leonid A Kuny ansky. Explicit inversion formulae for the spherical mean Radon transform. Inverse problems , 23(1):373, 2007. [10] Minghua Xu and Lihong V W ang. Universal back -projection algorithm for photoacoustic computed tomog- raphy . Physical Review E , 71(1):016706, 2005. [11] Y uan Xu, Lihong V W ang, Gaik Ambartsoumian, and P eter Kuchment. R econstructions in limited-view thermoacoustic tomography . Medical physics , 31(4):724–733, 2004. [12] Eric Chung, Chi Y eung Lam, and Jianliang Qian. A Neumann series based method for photoacoustic tomography on irregular domains. Contemporary Mathematics , 615:89–104, 2014. 8 [13] Benjamín Palacios. Reconstruction for multi-wav e imaging in attenuating media with large damping coeffi- cient. Inverse Problems , 32(12):125008, 2016. [14] Andrew Homan. Multi-wa ve imaging in attenuating media. Inverse Problems & Imaging , 7(4):1235–1250, 2013. [15] Y ulia Hristova. Time reversal in thermoacoustic tomography—an error estimate. Inverse Problems , 25(5):055008, 2009. [16] Y ulia Hristova, P eter Kuchment, and Linh Nguyen. Reconstruction and time reversal in thermoacoustic tomography in acoustically homogeneous and inhomogeneous media. Inverse Problems , 24(5):055006, 2008. [17] Jianliang Qian, Plamen Stefano v, Gunther Uhlmann, and Hongkai Zhao. An efficient Neumann series–based algorithm for thermoacoustic and photoacoustic tomography with variable sound speed. SIAM Journal on Imaging Sciences , 4(3):850–883, 2011. [18] Plamen Stefanov and Gunther Uhlmann. Thermoacoustic tomography with variable sound speed. Inverse Problems , 25(7):075011, 2009. [19] Plamen Stefanov and Gunther Uhlmann. Thermoacoustic tomography arising in brain imaging. Inverse Problems , 27(4):045004, 2011. [20] Plamen Stefanov and Y ang Y ang. Multiwa ve tomography in a closed domain: averaged sharp time reversal. Inverse Problems , 31(6):065007, 2015. [21] Plamen Stefanov and Y ang Y ang. Thermo-and photoacoustic tomography with variable speed and planar detectors. SIAM Journal on Mathematical Analysis , 49(1):297–310, 2017. [22] Plamen Stefanov and Y ang Y ang. Multiwav e tomography with reflectors: Landweber’s iteration. Inverse Problems & Imaging , 11(2):373–401, 2017. [23] Zakaria Belhachmi, Thomas Glatz, and Otmar Scherzer. A direct method for photoacoustic tomography with inhomogeneous sound speed. Inverse Problems , 32(4):045005, mar 2016. [24] Ashkan Javaherian and Sean Holman. Direct quantitative photoacoustic tomography for realistic acoustic media. Inverse Problems , 2019. [25] Ge W ang. A perspective on deep imaging. IEEE Access , 4:8914–8924, 2016. [26] Ge W ang, Jong Chu Y e, Klaus Mueller, and J effrey A Fessler. Image reconstruction is a new frontier of machine learning. IEEE transactions on medical imaging , 37(6):1289–1296, 2018. [27] Stephan Antholzer, Markus Haltmeier, and Johannes Schwab. Deep learning for photoacoustic tomography from sparse data. Inverse Problems in Science and Engineering , 27(7):987–1005, 2019. [28] Stephan Antholzer, Markus Haltmeier , Robert Nuster, and Johannes Schwab. Photoacoustic image recon- struction via deep learning. In Photons Plus Ultrasound: Imaging and Sensing 2018 , volume 10494, 2018. [29] Stephan Antholzer, Johannes Schwab, and Markus Haltmeier . Deep learning versus ` 1 -minimization for compressed sensing photoacoustic tomograph y. In 2018 IEEE International Ultrasonics Symposium (IUS) , pages 206–212. IEEE, 2018. [30] Andreas Hauptmann, Felix Lucka, Marta M. Betck e, Nam Huynh, Jonas Adler, Ben T . Co x, Paul C. Beard, Sébastien Ourselin, and Simon R. Arridge. Model-based learning for accelerated, limited-view 3-D photoa- coustic tomography . IEEE T ransactions on Medical Imaging , 37(6):1382–1393, 2018. [31] Dominik W aibel, Janek Gröhl, F abian Isensee, Thomas Kirchner, Klaus Maier -Hein, and Lena Maier -Hein. Reconstruction of initial pressure from limited view photoacoustic images using deep learning. In Photons Plus Ultrasound: Imaging and Sensing 2018 , volume 10494, 2018. 9 [32] Johannes Schw ab, Stephan Antholzer, Robert Nuster, Günther Paltauf, and Markus Haltmeier. Deep learning of truncated singular values for limited view photoacoustic tomography . In Photons Plus Ultrasound: Imaging and Sensing 2019 , volume 10878, page 1087836. International Society for Optics and Photonics, 2019. [33] Steven Guan, Amir Khan, Siddhartha Sik dar, and Parag Chitnis. Fully dense UNet for 2D sparse photoacoustic tomography artifact removal. IEEE journal of biomedical and health informatics , 2019. [34] Derek Allman, Austin Reiter, and Muyinatu A Lediju Bell. Photoacoustic source detection and reflection artifact removal enabled by deep learning. IEEE transactions on medical imaging , 37(6):1464–1477, 2018. [35] Derek Allman, Austin Reiter, and Muyinatu Bell. Exploring the effects of transducer models when training convolutional neural networks to eliminate reflection artifacts in experimental photoacoustic images. In Photons Plus Ultrasound: Imaging and Sensing 2018 , volume 10494, page 104945H. International Society for Optics and Photonics, 2018. [36] Brendan Kell y, Thomas P Matthews, and Mark A Anastasio. Deep learning-guided image reconstruction from incomplete data. arXiv preprint , 2017. [37] Johannes Schwab, Stephan Antholzer, Robert Nuster, and Markus Haltmeier. Real-time photoacoustic projection imaging using deep learning. , 2018. [38] Hongming Shan, Ge W ang, and Y ang Y ang. A ccelerated correction of reflection artifacts by deep neural networks in photo-acoustic tomography . Applied Sciences , 9(13):2615, 2019. [39] Hu Chen, Yi Zhang, Y unjin Chen, Junfeng Zhang, W eihua Zhang, Huaiqiang Sun, Y ang L v , P eixi Liao, Jiliu Zhou, and Ge W ang. Learn: Learned experts’ assessment-based reconstruction network for sparse-data CT. IEEE transactions on medical imaging , 37(6):1333–1347, 2018. [40] Hongming Shan, Atul Padole, Fatemeh Homa younieh, Uwe Kruger, Ruhani Doda Khera, Chayanin Niti- warangkul, Mannudeep K Kalra, and Ge W ang. Competitive performance of a modularized deep neural network compared to commercial algorithms for low -dose CT image reconstruction. Nature Machine Intelli- gence , 1(6):269–276, 2019. [41] H Shan, Y Zhang, Q Y ang, U Kruger, MK Kalra, L Sun, W Cong, and G W ang. 3-D convolutional encoder - decoder network for low -dose CT via transfer learning from a 2-D trained network. IEEE T rans Med Imaging , 37(6):1522–1534, 2018. [42] Chenyu Y ou, Guang Li, Yi Zhang, Xiaoliu Zhang, Hongming Shan, Shenghong Ju, Zhen Zhao, Zhuiyang Zhang, W enxiang Cong, Michael W V annier, Punam K Saha, and Ge W ang. CT super-resolution GAN constrained by the identical, residual, and cycle learning ensemble (GAN-CIR CLE). IEEE T ransactions on Medical Imaging , 2019. [43] Huidong Xie, H ongming Shan, W enxiang Cong, Xiaohua Zhang, Shaohua Liu, Ruola Ning, and Ge W ang. Dual network architecture for few -view CT–trained on imagenet data and transferred for medical imaging. arXiv preprint arXiv:1907 .01262 , 2019. [44] Fenglei Fan, H ongming Shan, and Ge W ang. Quadratic autoencoder for low -dose CT denoising. In 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiolog y and Nuclear Medicine , volume 11072, page 110722Z. International Society for Optics and Photonics, 2019. [45] Hongming Shan, Uwe Kruger, and Ge W ang. A novel transfer learning framework for low-dose CT. In 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiolog y and Nuclear Medicine , volume 11072, page 110722Y. International Society for Optics and Photonics, 2019. [46] Qing Lyu, Hongming Shan, and Ge W ang. MRI super-resolution with ensemble learning and complementary priors. arXiv preprint arXiv:1907 .03063 , 2019. [47] Hongming Shan, Ge W ang, Mannudeep K Kalra, R de Souza, and Junping Zhang. Enhancing transferability of features from pretrained deep neural networks for lung nodule classification. In Proceedings of the 2017 International Conference on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine , 2017. 10 [48] Yiming Lei, Y ukun Tian, Hongming Shan, Junping Zhang, Ge W ang, and Mannudeep Kalra. Soft activation mapping of lung nodules in low -dose CT images. arXiv preprint , 2018. [49] Zhao Peng, Hongming Shan, Tianyu Liu, Xi Pei, Ge W ang, and X George Xu. MCDN et–a denoising convolu- tional neural network to accelerate Monte Carlo radiation transport simulations: A proof of principle with patient dose from x-ra y CT imaging. IEEE Access , 7:76680–76689, 2019. [50] Benjamin Q Huynh, Hui Li, and Maryellen L Giger. Digital mammographic tumor classification using transfer learning from deep convolutional neural networks. J ournal of Medical Imaging , 3(3):034501, 2016. [51] Plamen Stefanov and Gunther Uhlmann. Instability of the linearized problem in multiwave tomography of recov ery both the source and the speed. Inverse Problems & Imaging , 7(4):1367–1377, 2013. [52] David Finch and K yle S Hickmann. T ransmission eigenvalues and thermoacoustic tomography . Inverse Problems , 29(10):104016, 2013. [53] Hongyu Liu and Gunther Uhlmann. Determining both sound speed and internal source in thermo-and photo-acoustic tomography . Inverse Problems , 31(10):105005, 2015. [54] Christina Kno x and Amir Moradifam. Determining both the source of a wave and its speed in a medium from boundary measurements. arXiv preprint , 2018. [55] Zhen Y uan, Qizhi Zhang, and Huabei Jiang. Simultaneous reconstruction of acoustic and optical properties of heterogeneous media by quantitative photoacoustic tomography . Optics express , 14(15):6749–6754, 2006. [56] Thomas P Matthews, Joemini P oudel, Lei Li, Lihong V W ang, and Mark A Anastasio. Parameterized joint reconstruction of the initial pressure and sound speed distributions for photoacoustic computed tomography . SIAM journal on imaging sciences , 11(2):1560–1588, 2018. [57] Jin Zhang, Kun W ang, Y ongyi Y ang, and Mark A Anastasio. Simultaneous reconstruction of speed-of- sound and optical absorption properties in photoacoustic tomography via a time-domain iterative algorithm. In Photons Plus Ultrasound: Imaging and Sensing 2008: The Ninth Conference on Biomedical Thermoacoustics, Optoacoustics, and Acousto-optics , volume 6856, page 68561F . International Society for Optics and Photonics, 2008. [58] Thomas P Matthews and Mark A Anastasio. Joint reconstruction of the initial pressure and speed of sound distributions from combined photoacoustic and ultrasound tomography measurements. Inverse problems , 33(12):124002, 2017. [59] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint , 2014. [60] B. E. T reeby and B. T. Co x. k -wa ve: MA TLAB toolbo x for the simulation and reconstruction of photoacoustic wav e-fields. Journal of Biomedical Optics , 15(2):021314, 2010. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment