Proximal Recursion for the Wonham Filter
This paper contributes to the emerging viewpoint that governing equations for dynamic state estimation, conditioned on the history of noisy measurements, can be viewed as gradient flow on the manifold of joint probability density functions with respe…
Authors: Abhishek Halder, Tryphon T. Georgiou
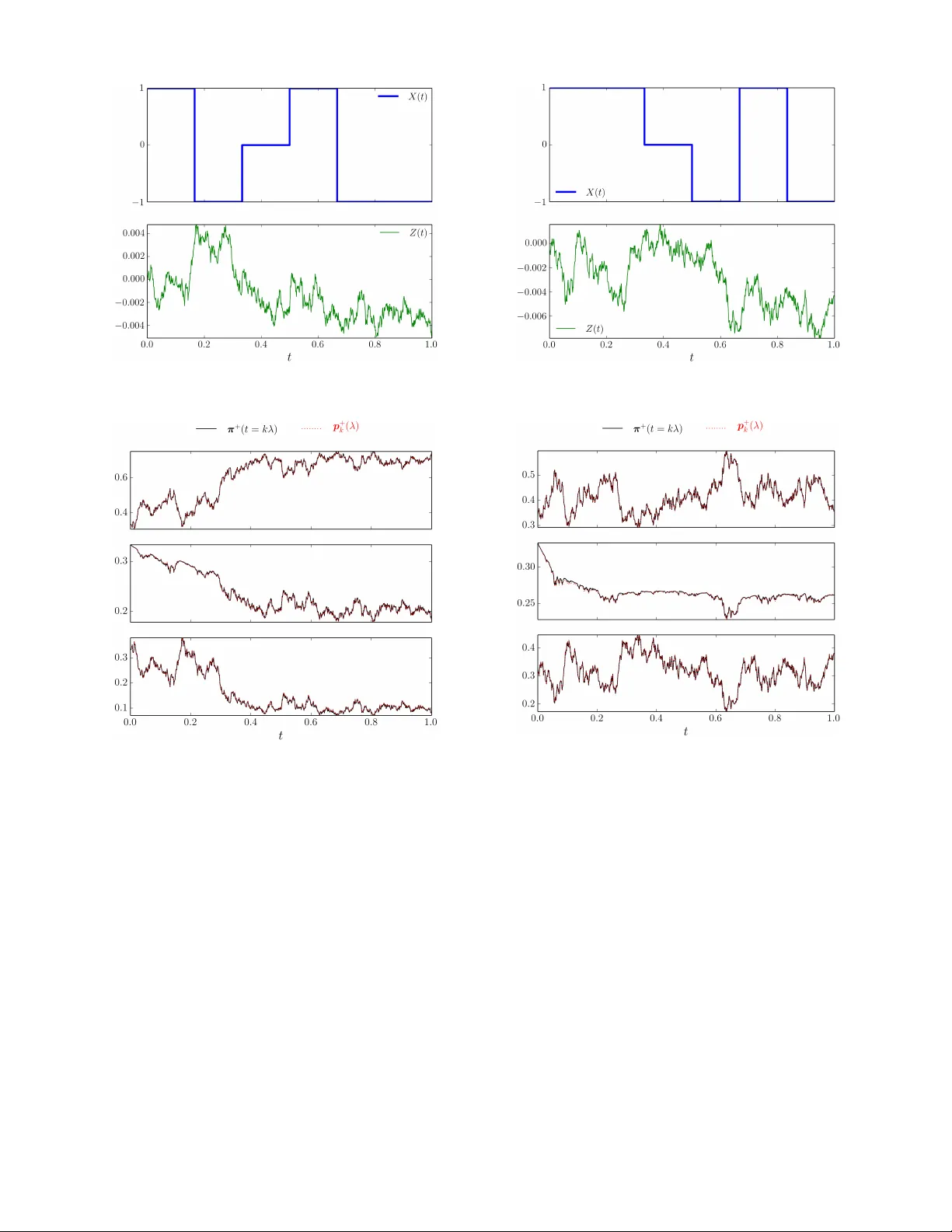
Proximal Recursion for the W onham Filter Abhishek Halder 1 , and T ryphon T . Georgiou 2 Abstract — This paper contributes to the emer ging viewpoint that gover ning equations f or dynamic state estimation, condi- tioned on the history of noisy measurements, can be viewed as gradient flow on the manifold of joint pr obability density functions with respect to suitable metrics. Her ein, we focus on the W onham filter where the prior dynamics is gi ven by a continuous time Mark ov chain on a finite state space; the measurement model includes noisy observation of the (possibly nonlinear function of) state. W e establish that the posterior flow given by the W onham filter can be viewed as the small time-step limit of proximal recursions of certain functionals on the probability simplex. The r esults of this paper extend our earlier work wher e similar pr oximal recursions wer e derived for the Kalman-Bucy filter . I . I N T RO D U C T I O N W e consider the problem of estimating the state of a continuous time Markov chain X ( t ) on finite state space Ω = { a 1 , . . . , a m } with m × m transition 1 rate matrix Q , with entries Q ij ≥ 0 , for i 6 = j , and Q ii = − P j 6 = i Q ij < 0 . T o ease notation, we hereafter write X ( t ) ∼ Markov ( Q ) . Suppose that one observes the process Z ( t ) gov erned by the It ˆ o stochastic differential equation (SDE) d Z ( t ) = h ( X ( t )) d t + σ V ( t ) d V ( t ) , (1) where h ( · ) is a deterministic injective function of the state, σ V ( t ) is continuously differentiable and bounded away from zero for all t ≥ 0 , and the standard W iener process V ( t ) is independent of the process X ( t ) . One typically refers to h ( · ) as the sensing or measurement model, and V ( t ) as the measurement noise. Gi ven the history of noisy observ ation { Z ( s ) , 0 ≤ s ≤ t } , the objectiv e of the estimation problem is to compute the conditional pr obability of the state X ( t ) , i.e., to compute the posterior pr obabilities π + i ( t ) := P X ( t ) = a i | Z ( s ) , 0 ≤ s ≤ t , i = 1 , . . . , m. (2) Let the initial occupation probability (ro w) vector be π 0 satisfying π 0 ≥ 0 element-wise, and π 0 1 = 1 , where 1 denotes a column vector of ones. The time e volution of the prior distribution π − ( t ) := { π − 1 ( t ) , . . . , π − m ( t ) } is governed by the ordinary differential equation (ODE) ˙ π − ( t ) = π − ( t ) Q , π − (0) = π 0 . (3) Supported in part by NSF under grants 1665031, 1807664 and 1839441, and by AFOSR under grant F A9550-17-1-0435. 1 Department of Applied Mathematics, University of California, Santa Cruz, CA 95064, USA, ahalder@ucsc.edu 2 Department of Mechanical and Aerospace Engineering, University of California, Irvine, CA 92617, USA, tryphon@uci.edu 1 W e suppose that the Markov chain is time-homogeneous, i.e., the associated transition probability matrix is exp( Q t ) for all t ≥ 0 . In other words, (3) gi ves the unconditional pr obabilities of the state X ( t ) , i.e., π − i ( t ) = P ( X ( t ) = a i ) , i = 1 , . . . , m . In [1], W onham showed that for the state-observation model giv en by X ( t ) ∼ Marko v ( Q ) , (4a) d Z ( t ) = h ( X ( t )) d t + σ V ( t ) d V ( t ) , (4b) the posterior probability π + ( t ) := { π + 1 ( t ) , . . . , π + m ( t ) } ev olves according to the It ˆ o SDE d π + ( t ) = π + ( t ) Q d t + 1 ( σ V ( t )) 2 π + ( t ) H − b h ( t ) I × d Z ( t ) − b h ( t )d t , (5) with initial condition π + (0) = π 0 , where H := diag ( h ( a 1 ) , . . . , h ( a m )) , b h ( t ) := m X i =1 h ( a i ) π + i ( t ) . The vector SDE (5) has since been kno wn as the W onham filtering equation that allo ws computing the conditional prob- abilities of the state. Reference [1, eqn. (21)] deriv ed (5) with h ( · ) as the identity map; the form (5) has appeared in the literature since then – for recent references see e.g., [2, eqn. (2)] and [3, eqn. (5)]. Having obtained π + from (5), assuming that the points in Ω are elements of a linear space, one can compute the optimal (in the minimum mean squared error sense) state estimate gi ven by the conditional expectation b X ( t ) := E [ X ( t ) | Z ( s ) , 0 ≤ s ≤ t ] = m X i =1 a i π + i ( t ) . (6) The purpose of this paper is to giv e ne w v ariational in- terpretation of the flow π + ( t ) governed by (5). Specifically , we seek a gradient flo w description for the ev olution of the posterior or conditional probability on the standard simplex ∆ m − 1 := { π ∈ R m ≥ 0 | π 1 = 1 } . (7) Such interpretations were uncovered in [6] for nonlinear filtering with zero prior dynamics and, more generally , in our recent works [4], [5] for the Kalman-Bucy filter . Results of such flavor are not only fundamental in systems-theoretic context, but may also be transformati ve in computation since they open up the possibility to solve the filtering equations via proximal algorithms [9], [10]. This is pursued in [11], [12] for fast computation of the prior joint probability density functions without spatial discretization. This paper is structured as follows. In Section II, we outline the main ideas for gradient flow formulation via Fig. 1: The block diagram showing the prior and posterior com- putation as sequential proximal updates giv en by (9) for k ∈ N . proximal recursion. The recursions for computing the pos- terior in the W onham filter are deri ved in Section III. In Section IV, proximal recursion for computing the prior is giv en for the case of re versible Markov chain. Numerical examples are gi ven in Section V for both rev ersible and non-rev ersible Mark ov chains to illustrate the scope of the proposed framew ork. Section VI concludes the paper . Notations: W e use ◦ to denote function composition, and h· , ·i to denote the standard Euclidean inner product. The no- tation ∇ x stands for standard Euclidean gradient w .r .t. vector x . Furthermore, denotes elementwise multiplication. The notation exp( · ) with vector ar gument means elementwise exponential, and the same with matrix ar gument denotes the exponential matrix. I I . M A I N I D E A W e adopt a metric viewpoint of gradient flow that approx- imates the flow of probability distribution π ( t ) starting from a giv en initial condition π 0 := π (0) , as the small time-step limit of a variational recursion in the form p k ( λ ) = arg inf p 1 2 d 2 ( p , p k − 1 ) + λ Φ( p ) , (8) where p 0 ≡ π 0 , k ∈ N , and λ is the step-size. Here, d ( · , · ) is a distance functional between tw o probability distributions, and the functional Φ( · ) depends on the generator of the flow π ( t ) . In particular , the functionals d ( · , · ) and Φ( · ) are to be chosen such that p k ( h ) → π ( t = kλ ) as λ ↓ 0 . The recursion (8) is reminiscent of the Euclidean setting, where the gradient flow for the ODE ˙ x = −∇ x Φ( x ) can be approximated via a recursion of the form (8) with d ( · , · ) as the Euclidean distance metric, and Φ( · , · ) as in the argument generating the vector field. In the optimization literature, the operators associated with such recursions are termed as Mor eau-Y osida pr oximal operator s [7]–[10], denoted as pro x d λ Φ , which reads, proximal operator for functional λ Φ w .r .t. d . Like wise, we use the same notation for the right-hand-side of (8) in our more general setting. This allows interpreting the discrete time-stepping as steepest descent of the functional Φ w .r .t. distance d . Proximal operators have also been used in general Hilbert spaces [13], and in the space of probability density functions [4], [5], [11], [12], [14]–[16]. The idea of applying proximal recursion in the space of probability measures appeared first in [14]; see also [15]. In the filtering context, we think of the computation of prior follo wed by that of posterior, as composition of re- spectiv e proximal operators. Denoting the approximate prior and posterior probability vectors for the proximal recursions associated with W onham filter as p − k and p + k , respectiv ely , we write p − k ( λ ) = pro x d − λ Φ − p + k − 1 = arg inf p ∈ ∆ m − 1 1 2 d − p , p + k − 1 2 + λ Φ − ( p ) , (9a) p + k ( λ ) = pro x d + λ Φ + p − k = arg inf p ∈ ∆ m − 1 1 2 d + p , p − k 2 + λ Φ + ( p ) , (9b) where k ∈ N , λ > 0 is the step-size, and ( d ± , Φ ± ) are to be determined functional pairs guaranteeing p + k ( λ ) → π + ( t = k λ ) as λ ↓ 0 , wherein π + ( t ) solv es (5). In other words, ( d ± , Φ ± ) are to be designed such that the composite map pro x d + λ Φ + ◦ pro x d − λ Φ − approximates the flo w of (5) in small time-step limit (see Fig. 1). Next, we focus on the problem of designing the pair ( d + , Φ + ) in (9b). I I I . P R OX I M A L R E C U R S I O N F O R T H E P O S T E R I O R W e first deri ve a proximal recursion of the form (9b) for the posterior update in the special case Q ≡ 0 (Section III- A). The proof for the same reco vers the explicit stochastic integral formula given in [1, eqn. (5)]. W e then show that the same proximal recursion applies for the general Q 6 = 0 case (Section III-B). A. The Case of Zer o Prior Dynamics As in [1, Section 2], we start with the simple case when the state X , instead of being a Mark ov chain, is a random variable taking values in Ω = { a 1 , . . . , a m } with a (known) prior probability distribution p 0 ∈ ∆ m − 1 at t = 0 . For k ∈ N , let t k − 1 := ( k − 1) λ where λ is the step size, and let { Z k − 1 } k ∈ N be the sequence of samples of the process Z ( t ) at { t k − 1 } k ∈ N . Introducing Y k − 1 := ( Z k − Z k − 1 ) /λ , we consider the functional Φ + ( p ) := 1 2 ( σ V ( t k − 1 )) 2 E h ( Y k − 1 − h ) 2 i , (10) where the expectation operator E [ · ] is taken w .r .t. the prob- ability v ector p ∈ ∆ m − 1 . The follo wing result shows that with Φ + as in (10), the functional 1 2 ( d + ) 2 in (9b) can be taken as the Kullback-Leibler di vergence D KL , giv en by D KL ( α k β ) := m X i =1 α i log( α i /β i ) , for α , β ∈ ∆ m − 1 . (11) In other words, (9b) can be viewed as an entropic proximal mapping [17], [18]. Theorem 1. Let Φ + ( p ) be as in (10), and consider the pr oximal r ecursion p + k ( λ ) = arg inf p ∈ ∆ m − 1 D KL p k p − k + Φ + ( p ) , k ∈ N , (12) with initial condition p 0 ∈ ∆ m − 1 . Let π + ( t ) be the flow generated by (5) with Q ≡ 0 and initial condition π + (0) ≡ p 0 . Then p + k ( λ ) → π + ( t = k λ ) as λ ↓ 0 . Pr oof. See Appendix A. B. The General Case In the following, we formally state and prov e that in the general case Q 6 = 0 , the recursion (12) still applies for the posterior computation. Compared to the proof of Theorem 1, the proof no w will differ since the map p + k − 1 7→ p − k is no longer identity , and one does not hav e an analytical solution for the SDE (5) for Q 6 = 0 , in general. Theorem 2. Let Φ + ( p ) be as in (10), and consider the pr oximal r ecursion p + k ( λ ) = arg inf p ∈ ∆ m − 1 D KL p k p − k + Φ + ( p ) , k ∈ N , (13) with initial condition p 0 ∈ ∆ m − 1 . Let π + ( t ) be the flow generated by (5) with initial condition π + (0) ≡ p 0 . Then p + k ( λ ) → π + ( t = k λ ) as λ ↓ 0 . Pr oof. See Appendix B. I V . P R OX I M A L R E C U R S I O N F O R T H E P R I O R W e no w deri ve a proximal recursion of the form (9a) for the prior update. W e assume that the Markov chain X ( t ) is irreducible. Then, X ( t ) has a unique stationary distribution vector π ∞ which is the limit lim t →∞ π − ( t ) and is elementwise positive. W e further assume that the Markov chain is rev ersible, i.e., that the detailed balance condition ( π ∞ ) i Q ( i, j ) = ( π ∞ ) j Q ( j, i ) (14) holds. Here ( · ) i denotes the i th entry of. Starting from a known probability distribution π − ( t k − 1 ) = p + k − 1 ( λ ) , for t k − 1 = ( k − 1) λ, the evolution of the prior π − ( t ) of X ( t ) is governed by the prior dynamics (3). Thus, π − ( t k − 1 + λ | {z } t k = kλ ) = p + k − 1 ( λ ) exp ( λ Q ) , equiv alently , p + k − 1 ( λ ) = π − ( t k ) exp ( − λ Q ) . Hence, p + k − 1 ( λ ) = π − ( t k )( I − λ Q ) + o ( λ ) , (15) where o ( λ ) signifies the “order of ”. As a consequence of (14), the transition rate matrix Q defines a symmetric operator when considered with respect to the inner product h p , q i π ∞ := X i ( p ) i ( q ) i ( π ∞ ) i . (16) Indeed, if D π ∞ denotes the diagonal matrix formed with the entries of π ∞ , then in matrix notation, (14) becomes D π ∞ Q = Q T D π ∞ , (17) and therefore h pQ , q i π ∞ = h p , q Q i π ∞ , where T denoting matrix/vector transposition. W e can now express p − k ( λ ) as a solution to a proximal recursion. Define the quadratic form Φ − ( p ) = − 1 2 h pQ , p i π ∞ , (18) and denote k p k 2 π ∞ = h p , p i π ∞ . (19) Theorem 3. Let Φ − ( p ) be as in (18). The λ -appr oximate prior satisfies the following proximal recur sion p − k ( λ ) = arg inf p ∈ ∆ m − 1 1 2 k p − p + k − 1 k 2 π ∞ + λ Φ − ( p ) . (20) Pr oof. The stationarity condition for (20) becomes 0 = ∂ ∂ p 1 2 k p − p + k − 1 k 2 π ∞ + λ Φ − ( p ) = ( p − p + k − 1 ) D − 1 π ∞ − λ p 1 2 QD − 1 π ∞ + D − 1 π ∞ Q T = ( p − p + k − 1 ) D − 1 π ∞ − λ pQD − 1 π ∞ , (21) since D − 1 π ∞ Q T = QD − 1 π ∞ from (17). Here, by 0 we denote the zero vector of compatible dimensions. Thus, p + k − 1 ( λ ) = p ( I − λ Q ) . For suf ficiently small λ , the matrix I − λ Q is in vertible and the unique minimizer p has positi ve entries. Moreov er , since Q 1 = 0 , p 1 = 1 and hence p ∈ ∆ m − 1 , thus, we set p − k ( λ ) = p + k − 1 ( λ )( I − λ Q ) − 1 . Comparing with (15) we see that p − k ( λ ) = π − ( k λ ) + o ( λ ) , which is our desired result. Remark 1. It is possible to use other (weighted) inner pr od- ucts instead of our specific c hoice (16). F or example , [19, Ch. 6.1.2] motivates the choice h p , q i π ∞ := P i ( p ) i ( q ) i ( π ∞ ) i , using which in (18) and (19), we again arrive at the state- ment in Theorem 3. The pr oof steps ar e as before , except now the common post-multiplication matrix term in (21) becomes D π ∞ instead of D − 1 π ∞ . V . N U M E R I C A L E X A M P L E S The e xamples belo w concern estimating the state of a 3-state continuous time Marko v chain, the first one being rev ersible while the second is not. A. Example 1 W e consider estimating the state of an irreducible Mark ov chain X ( t ) taking values in {− 1 , 0 , 1 } with rate matrix Q = − 1 1 / 2 1 / 2 2 − 2 0 3 0 − 3 . (22) It is easy to verify that the s tationary distribution π ∞ = (12 / 17 , 3 / 17 , 2 / 17) , and that the re versibility condition (14) holds. In (4b), we set h ( X ( t )) = 0 . 01 X ( t ) , and σ V = 0 . 01 . Fig. 2a sho ws a sample paths for X ( t ) and Z ( t ) . In Fig. 2b, we compare the time e v olution of the components (a) A sample path of the state X ( t ) ( top ) and of the observ ation process Z ( t ) ( bottom ) shown for Example 1 in Section V. (b) Starting from the initial occupation probability vector (1 / 3 , 1 / 3 , 1 / 3) , sho wn above are sample paths for the first ( in top ), the second ( in middle ), and the third ( in bottom ) component of the true ( black, solid ) and approximate ( red, dashed ) posterior probability vectors for Example 1 in Section V. Fig. 2: Simulation results for Example 1 in Section V. of the associated posterior probability v ector π + ( t ) from the W onham filter ( in blac k, solid ), with the same of the approximator p + k ( λ ) ( in r ed, dashed ) computed via the proposed proximal recursion framework (Fig. 1) with step- size λ = 10 − 3 and t ∈ [0 , 1] . W e only sho w here the result for a fixed initial condition π 0 = (1 / 3 , 1 / 3 , 1 / 3) ; the trends are similar for other initial conditions. Computing π + ( t ) in the W onham filter entails numerically solving the system of coupled nonlinear SDEs (5), done here via the Euler- Maruyama method. In contrast, computing p + k ( λ ) entails recursiv e ev aluation of (35) and (26). In our numerical experiments, the latter was observed to enjoy about an order of magnitude computational speed up. Fig. 2b shows that the respectiv e posterior sample paths match, as predicted. (a) A sample path of the state X ( t ) ( top ) and of the observ ation process Z ( t ) ( bottom ) shown for Example 2 in Section V. (b) Starting from the initial occupation probability vector (1 / 3 , 1 / 3 , 1 / 3) , sho wn above are sample paths for the first ( in top ), the second ( in middle ), and the third ( in bottom ) component of the true ( black, solid ) and approximate ( red, dashed ) posterior probability vectors for Example 2 in Section V. Fig. 3: Simulation results for Example 2 in Section V. B. Example 2 Next we consider a Marko v chain X ( t ) taking v alues in {− 1 , 0 , 1 } with rate matrix Q = − 5 3 2 4 − 10 6 3 4 − 7 , (23) and h ( · ) , σ V , λ as before. Here again, for t ∈ [0 , 1] , we compare the posterior sample paths computed from the W onham filter (5) with its approximator computed via the proposed proximal recursion approach. Notice that for prior computation, although one does not hav e a metric version of the variational formula (9a), the approximation (35) still applies for small λ . Thus, p + k ( λ ) can still be computed by recursiv e ev aluation of (35) and (26). Fig. 3a sho ws a sample path for X ( t ) , and the same for Z ( t ) . In Fig. 3b, we show the corresponding π + ( t ) from the W onham filter ( in black, solid ), and p + k ( λ ) ( in r ed, dashed ) from the proximal recursion for this case, starting from the initial condition π 0 = (1 / 3 , 1 / 3 , 1 / 3) . The respecti ve sample paths are in agreement, as e xpected. V I . C O N C L U S I O N S This purpose of this paper is to e xpand on the list of examples where the governing equations for state estimation, conditioned on the history of noisy measurements, can be expressed as gradient flo w on the space of probability density functions with respect to a suitable metric. This viewpoint promises a new class of estimation algorithms, taking advan- tage of implementation of flows via recursiv e application of proximal projections. Prior work elucidated the case of the Kalman-Bucy filter , and therefore, in the present w ork we sought to extend the paradigm to case of the W onham filter . The latter estimates the state of a continuous time Marko v chain on a finite state space based on noisy observations. In this paper we have established that the posterior flo w that is provided by the W onham filter can be expressed as the small time-step limit of proximal recursions of certain function- als on the probability simplex. Our preliminary numerical experiments reported here hint at possible computational advantages of the proposed approach, especially for large Markov chains. This will be systematically in vestigated in our future work. A P P E N D I X A. Pr oof of Theorem 1 W ith the stated choices for the pair ( d + , Φ + ) , we are led to the proximal map of the form arg inf p ∈ ∆ m − 1 D KL p k p − k + h c k − 1 , p i , k ∈ N , (24) where the i -th component of the ro w vector c k − 1 is c k − 1 ( i ) := λ 2 ( σ V ( t k − 1 )) 2 ( Y k − 1 − h ( a i )) 2 , i = 1 , . . . , m. (25) The objectiv e in (24) is strictly con ve x since D KL is strictly con ve x in p , and the other summand is linear in p . Therefore, the arg inf in (24), which we denote by p + k , is unique. By direct calculation (setting the gradient of Lagrangian w .r .t. p to zero, and enforcing the constraint p 1 = 1 ), we get p + k = p − k exp ( − c k − 1 ) / p − k exp( − c k − 1 ) 1 . (26) Since in this case, we have no prior dynamics, therefore p − k ≡ p + k − 1 for all k ∈ N . Hence, we can rewrite (26) in terms of the prior probability distrib ution p 0 as p + k = p 0 exp( − γ k − 1 ) / (( p 0 exp( − γ k − 1 )) 1 ) , (27) where the 1 × m vector γ k − 1 := k X r =1 c r − 1 . (28) Noting that (27) is simply normalization (i.e., Kullback- Leibler projection onto probability simplex) of the v ector p 0 exp( − γ k − 1 ) , we now unpack γ k − 1 as function of λ and the sampled process { Z k − 1 } k ∈ N . Because h ( · ) is injectiv e, the random variable e X := h ( X ) takes v alues in { e a 1 , . . . , e a m } , and e X = e a i := h ( a i ) with probability p 0 ( i ) . Combining (25) and (28), we then hav e γ k − 1 ( i ) = λ 2 k X r =1 ( Y r − 1 − e a i ) 2 ( σ V ( t r − 1 )) 2 , i = 1 , . . . , m. (29) Expanding the square in the numerator of each summand in (29), substituting Y r − 1 = ( Z r − Z r − 1 ) /λ for r = 1 , . . . , k , and rearranging yields γ k − 1 ( i ) = 1 2 k X r =1 ( Z r − Z r − 1 ) 2 λ ( σ V ( t r − 1 )) 2 | {z } term 1 − e a i k X r =1 Z r − Z r − 1 ( σ V ( t r − 1 )) 2 | {z } term 2 + 1 2 e a 2 i k X r =1 λ ( σ V ( t r − 1 )) 2 | {z } term 3 . (30) T o simplify the term 1 indicated in (30), we use the Euler- Maruyama update for (1) given by Z r = Z r − 1 + h ( a i ) λ + σ V ( t r − 1 ) ( V r − V r − 1 ) + O ( λ 2 ) , (31) where r = 1 , . . . , k , and the increments ( V r − V r − 1 ) are i.i.d. zero mean normal random v ariables with variance λ . From (31), we get ( Z r − Z r − 1 ) 2 = ( σ V ( t r − 1 )) 2 λ, (32) where we used 2 λ 2 = 0 , ( V r − V r − 1 ) 2 = λ , and ( V r − V r − 1 ) λ = 0 . Consequently , term 1 in (30) equals k / 2 . Combining (27), (30), and (32), we thus obtain p + k ( i ) = p 0 ( i ) exp( − k / 2 + term 2 − term 3 ) m X i =1 p 0 ( i ) exp( − k / 2 + term 2 − term 3 ) . (33) Passing (33) to the limit λ ↓ 0 , recalling that e a i = h ( a i ) , and that the time interval [0 , t ] was divided into sub-intervals with breakpoints t 0 ≡ 0 , t 1 , . . . , t k ≡ t , we arriv e at lim λ ↓ 0 p + k ( i ) = p 0 ( i ) exp h ( a i ) R t 0 d Z ( s ) ( σ V ( s )) 2 − 1 2 ( h ( a i )) 2 R t 0 d s ( σ V ( s )) 2 P m i =1 p 0 ( i ) exp h ( a i ) R t 0 d Z ( s ) ( σ V ( s )) 2 − 1 2 ( h ( a i )) 2 R t 0 d s ( σ V ( s )) 2 . (34) The right-hand-side of (34) is exactly the solution of the SDE (5) for Q ≡ 0 with initial condition π + (0) = p 0 ; see [1, Appendix 2] for a proof. Therefore, we conclude that lim λ ↓ 0 p + k = π + ( t = k λ ) , as desired. 2 These are equi valent to the well-kno wn relations in stochastic calculus: (d t ) 2 = 0 , (d V ) 2 = d t , and d V d t = 0 . B. Pr oof of Theorem 2 W e start by noting that the de velopment in Appendix A up to expression (26) still applies. Also, since h ( · ) is in- jectiv e, the process h ( X ( t )) ∼ Markov ( Q ) takes values in { h ( a 1 ) , . . . , h ( a m ) } . For X ( t ) ∼ Markov ( Q ) , the map p + k − 1 7→ p − k , k ∈ N , corresponding to the Euler discretization of (3) is p − k = p + k − 1 ( I + λ Q ) + O ( λ 2 ) . (35) Let ∆ Z k − 1 := Z k − Z k − 1 . Substituting Y k − 1 = ∆ Z k − 1 /λ in (25), expanding the square, and using (32), we ha ve exp( − c k − 1 ( i )) = exp( − 1 / 2) × exp h ( a i )∆ Z k − 1 ( σ V ( t k − 1 )) 2 ! × exp − λ ( h ( a i ) 2 2 ( σ V ( t k − 1 )) 2 ! , (36) for i = 1 , . . . , m . Up to first order, the second exponential f actor in (36) approximates as 1+ h ( a i )∆ Z k − 1 / ( σ V ( t k − 1 )) 2 . For the third exponential factor in (36), notice that since λ ≡ d t for λ ↓ 0 , therefore from (4b), we hav e h 2 ( a i ) = (d Z − σ V d V ) 2 /λ 2 = 0 , wherein we used (d Z ) 2 = σ 2 V λ , (d V ) 2 = λ , and λ d V = 0 . Putting these together, (36) yields exp( − c k − 1 ( i )) ≈ exp( − 1 / 2) 1 + h ( a i )∆ Z k − 1 ( σ V ( t k − 1 )) 2 ! . (37) Substituting for p − k and exp( − c k − 1 ) in (26) from (35) and (37), respectiv ely , we get p + k ( i ) = ν ( i ) /δ, i = 1 , . . . , m, (38) ν ( i ) := p + k − 1 ( i ) + λ m X j =1 p + k − 1 ( j ) Q ( i, j ) 1 + h ( a i )∆ Z k − 1 ( σ V ( t k − 1 )) 2 ! , (39a) δ := m X i =1 ν ( i ) . (39b) From (31), we observe that λ ∆ Z k − 1 = h ( a i ) λ 2 + σ V ( t k − 1 ) λ ( V k − V k − 1 ) = 0 , as both λ 2 and λ ( V k − V k − 1 ) are zero. This allows us to simplify (39a) as ν ( i ) = p + k − 1 ( i ) + ∆ Z k − 1 ( σ V ( t k − 1 )) 2 h ( a i ) p + k − 1 ( i ) + λ m X j =1 p + k − 1 ( j ) Q ( i, j ) + O ( λ 2 ) , (40) and consequently , (39b) reduces 3 to δ = m X i =1 ν ( i ) = 1 + ∆ Z k − 1 ( σ V ( t k − 1 )) 2 b h ( t k − 1 ) . (41) Combining (38), (40) and (41), we obtain p + k ( i ) − p + k − 1 ( i ) = ∆ Z k − 1 ( σ V ( t k − 1 )) 2 p + k − 1 h ( a i ) − b h ( t k − 1 ) 3 W e use here that P m i =1 Q ( i, j ) = 0 for all j = 1 , . . . , m . + λ m X j =1 p + k − 1 ( j ) Q ( i, j ) × 1 + ∆ Z k − 1 ( σ V ( t k − 1 )) 2 b h ( t k − 1 ) ! − 1 . (42) Up to first order , the second factor in (42) approximates as 1 − ∆ Z k − 1 b h ( t k − 1 ) / ( σ V ( t k − 1 )) 2 . Using this approximation together with (∆ Z k − 1 ) 2 = λ ( σ V ( t k − 1 )) 2 (from (32)), and that λ ∆ Z k − 1 = 0 (as before), (42) simplifies as p + k ( i ) − p + k − 1 ( i ) = λ m X j =1 p + k − 1 ( j ) Q ( i, j ) + p + k − 1 ( i ) ( σ V ( t k − 1 )) 2 × h ( a i ) − b h ( t k − 1 ) ∆ Z k − 1 − b h ( t k − 1 ) λ , (43) which is exactly the first order (Euler-Maruyama) discretiza- tion of the SDE (5). Specifically , in the limit λ ↓ 0 , (43) reduces to (5). Hence the statement. R E F E R E N C E S [1] W .M. W onham, “Some applications of stochastic differential equations to optimal nonlinear filtering”. Journal of the Society for Industrial and Applied Mathematics, Series A: Control , V ol. 2, No. 3, pp. 347–369, 1964. [2] Q. Zhang, Y .G. George, and J.B. Moore, “T wo-time-scale approxima- tion for W onham filters”. IEEE T ransactions on Information Theory , V ol. 53, No. 5, pp. 1706–1715, 2007. [3] T . Y ang, P .G. Mehta, and S.P . Meyn, “Feedback particle filter for a continuous-time Markov chain”. IEEE T ransactions on Automatic Contr ol , V ol. 61, No. 2, pp. 556–561, 2016. [4] A. Halder, and T .T . Georgiou, “Gradient flows in uncertainty propaga- tion and filtering of linear Gaussian systems”. 2017 IEEE 56th Annual Confer ence on Decision and Control (CDC) , pp. 3081–3088, 2017. [5] ——, “Gradient flows in filtering and Fisher-Rao geometry”. 2018 Annual American Contr ol Conference (A CC) , pp. 4281–4286, 2018. [6] R.S. Laugesen, P .G. Mehta, S.P . Meyn, and M. Raginsky , “Poisson’ s equation in nonlinear filtering”. SIAM J ournal on Control and Opti- mization , V ol. 53, No. 1, pp. 501–525, 2015. [7] J-J. Moreau, “Proximit ´ e et dualit ´ e dans un espace hilbertien”. Bulletin de la Soci ´ et ´ e math ´ ematique de F rance , V ol. 93, pp. 273–299, 1965. [8] K. Y osida, Functional Analysis , Spinger-V erlag, 1964. [9] R.T . Rockafeller , “Monotone operators and the proximal point algo- rithm”. SIAM Journal on Control and Optimization , V ol. 14, No. 5, pp. 877–898, 1976. [10] N. Parikh, and S. Boyd, “Proximal algorithms”. F oundations and T r ends R in Optimization , V ol. 1, No. 3, pp. 127–239, 2014. [11] K.F . Caluya, and A. Halder, “Proximal recursion for solving the Fokker -Planck equation”. 2019 Annual American Control Conference (ACC) , accepted, preprint arXi v:1809.10844, 2019. web: [12] ——, “Gradient flo w algorithms for density propagation in stochastic systems”. preprint, 2019. web: https://www.abhishekhalder.org/proxFPK.pdf [13] H.H. Bauschke, and P .L. Combettes, Conve x Analysis and Monotone Operator Theory in Hilbert Spaces . CMS Books in Mathematics, Springer; 2011. [14] R. Jordan, D. Kinderlehrer, and F . Otto, “The variational formulation of the Fokker–Planck equation”. SIAM Journal on Mathematical Analysis , V ol. 29, No. 1, pp. 1–17, 1998. [15] L. Ambrosio, N. Gigli, and G. Sav ar ´ e, Gradient flows: in metric spaces and in the space of pr obability measures . Springer Science & Business Media, 2008. [16] C. Zhang, A. T aghvaei, and P .G. Mehta, “ A mean-field optimal control formulation for global optimization”. IEEE T ransactions on Automatic Contr ol , V ol. 64, No. 1, pp. 282–289, 2018. [17] M. T eboulle, “Entropic proximal mappings with applications to non- linear programming”. Mathematics of Operations Researc h , V ol. 17, No. 3, pp. 670–690, 1992. [18] Y . Censor, and S.A. Zenios, “Proximal minimization algorithm with D-functions”. Journal of Optimization Theory and Applications , V ol. 73, No. 3, pp. 451–464, 1992. [19] D.W . Stroock, An intr oduction to Markov processes . Springer Science & Business Media, vol. 230, 2 nd ed.; 2013.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment