Faster and Accurate Classification for JPEG2000 Compressed Images in Networked Applications
JPEG2000 (j2k) is a highly popular format for image and video compression.With the rapidly growing applications of cloud based image classification, most existing j2k-compatible schemes would stream compressed color images from the source before reco…
Authors: Lahiru D. Chamain, Zhi Ding
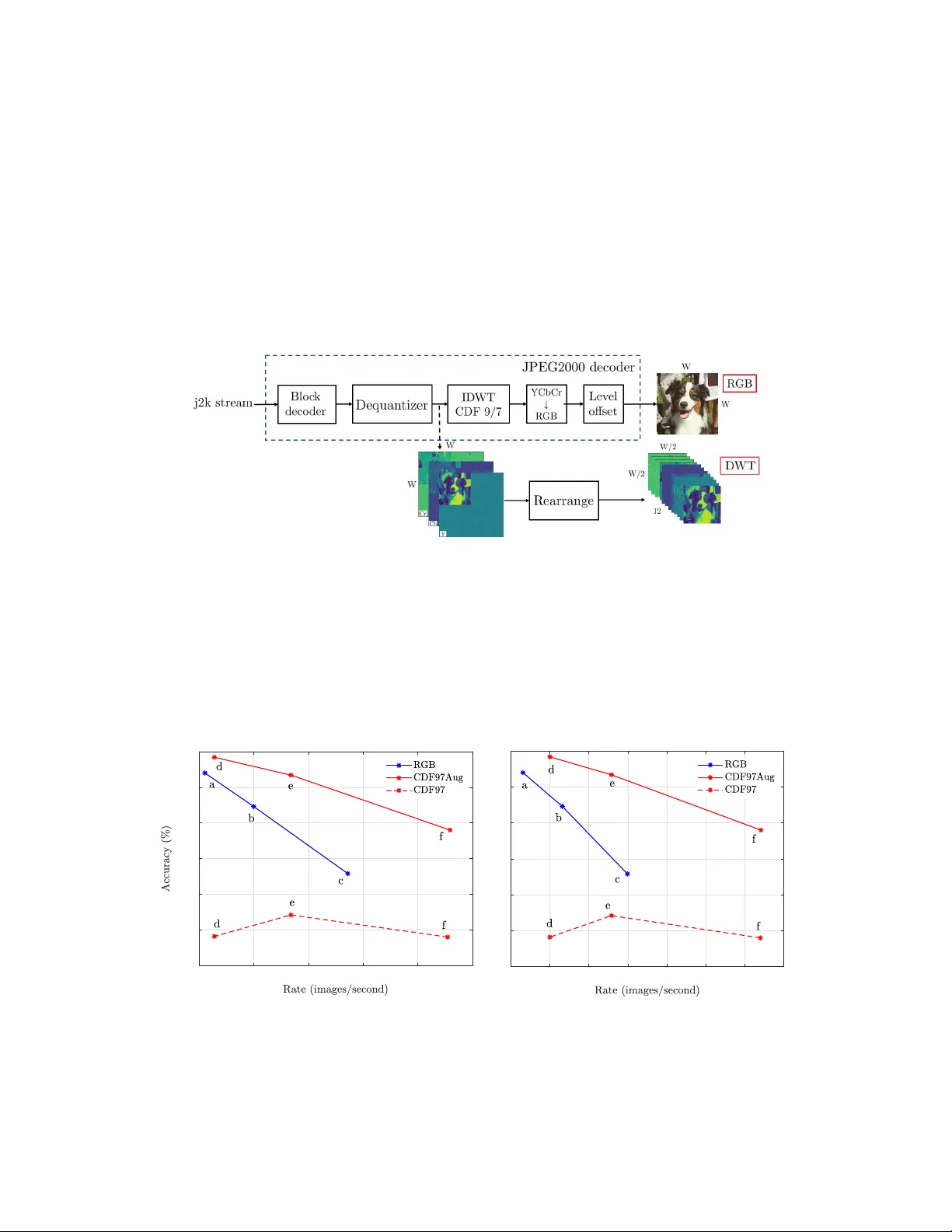
F aster and Accurate Classification f or JPEG2000 Compr essed Images in Networked A pplications Lahiru D. Chamain, Zhi Ding Department of Electrical & Computer Engineering Univ ersity of California Davis, CA 95616 {hdchamain, zding}@ucdavis.edu Abstract JPEG2000 (j2k) is a highly popular format for image and video compression. W ith the rapidly growing applications of cloud based image classification, most existing j2k-compatible schemes would stream compressed color images from the source before reconstruction at the processing center as inputs to deep CNNs. W e propose to remov e the computationally costly reconstruction step by training a deep CNN image classifier using the CDF 9/7 Discrete W av elet T ransformed (DWT) coef fi- cients directly extracted from j2k-compressed images. W e demonstrate additional computation savings by utilizing shallo wer CNN to achiev e classification of good accuracy in the D WT domain. Furthermore, we show that traditional augmentation transforms such as flipping/shifting are ineffecti ve in the D WT domain and present different augmentation transformations to achieve more accurate classification without any additional cost. This way , faster and more accurate classification is possible for j2k encoded images without image reconstruction. Through experi- ments on CIF AR-10 and Tin y ImageNet data sets, we sho w that the performance of the proposed solution is consistent for image transmission over limited channel bandwidth. 1 Introduction Artificial intelligence (AI), IoT and 5G are among the most exciting and game-changing technologies today , fueling new generations of technical solutions to some of the w orld’ s biggest problems. Image/video recognition in a network ed en vironment is among the top AI applications for years to come. Gi ven its rapidly growing popularity and usage for visual applications, JPEG2000 is playing an increasingly vital role in cyber intensi ve and autonomous systems. In this work, we explore ne w and better ways to exploit and optimize JPEG2000 (j2k) encoding in critical AI tasks such as image and video recognition. In a wide variety of application scenarios in volving lo w complexity IoT and networked sensors, traditional AI functionalities often rely on cloud computing to handle high comple xity processing tasks such as image recognition. There is clearly a trade-off among computation complexity , network payload, and performance in terms of accuracy . In cloud based AI image applications, neural networks are de veloped and trained in the cloud or on a server to which user images are sent o ver a channel. T o obtain classification labels, servers input the receiv ed images to its trained neural networks. In order to conserve limited channel bandwidth and storage capacity , source de vices often encode and compress the images before transmitting to the cloud by utilizing standardized compression techniques such as JPEG2000. Because most neural networks are designed to classify images in the spatial RBG domain, the cloud currently recei ves and decodes the compressed j2k images back into the RGB domain before forwarding them to trained neural networks for further processing, as illustrated in the top part of the Figure 1. Thus, a natural question arises is to ho w to achie ve faster training and inference with improv ed accuracy in a cloud based image classification under bandwidth, storage and computation constraints. Preprint. Under revie w . In this work, we study the trade-of f among computation complexity , accuracy and compression in a cyber -based image recognition system consisting of lo w complexity cameras, cloud servers, and band-limited communication links that connect them. W e claim that the con ventional use of image reconstruction is unnecessary for JPEG2000 encoded classification by constructing and training a deep CNN model with the DWT coef ficients transmitted in standard j2k stream. See the bottom part of the Figure 1. This result is consistent with the w ork of [ 1 ] for JPEG encoded images. Furthermore, we establish that more accurate classification is also possible by deploying shallower models to benefit from faster training and classification in comparison to models trained fo spatial RGB image inputs. Figure 2 describes our first set of results. T o achie ve these results, we introduce nov el augmentation transforms in the DWT domain instead of replicating conv entional spatial image transformations that lead to accuracy de gradation. Figure 1: W e adopt a standard JPEG2000 decoder . After dequantization, we harvest the CDF 9/7 coefficients by breaking into the JPEG2000 decoder . For illustration, we sho w a le vel-1 D WT compressed image. W e rearrange the CDF 9/7 coefficients as inputs to the deep CNN. W e explore the consistency of the proposed solution over band limited channels by changing the compression ratio of the JPEG2000 codec and observe that the accuracy improv ement of DWT domain is increasing compared to RGB domain. Finally we show that for the training of deep CNN models for band limited channels can use the pre-trained models for no compression case. This way we can cut do wn the training time of the models by 75% while leading to improv ed accuracy . This observation is consistent with using pre-trained models in RGB domain for band limited scenarios. 4000 5000 6000 7000 8000 9000 89 89.5 90 90.5 91 91.5 92 (a) inference 800 1000 1200 1400 1600 1800 2000 2200 89 89.5 90 90.5 91 91.5 92 (b) training Figure 2: (a). T est accuracy vs inference speed for the CIF AR-10 data set. The blue lines represent results using reconstructed RGB images. Red curves are results using D WT coef ficients extracted from JPEG2000 codec: dashed lines “CDF97” from regular augmentation and solid lines “CDF97Aug” from our proposed augmentation. (b). T est error vs training speed/epoch. Here rate is the number of images that go through the model in each epoch. The proposed model deli vers fast and accurate classification for both training and inference. 2 2 Related W orks Image classification in spectral domains has been studied by the machine learning (ML) community ov er the past few years. The compact representation of the images in spectral domains promises faster classification [ 1 – 4 ]. On the other hand, image compression for faster transmission or smaller storage has long been applied to spectral transformation to separate and remove information redundancy . These compact images require less bandwidth and storage in cloud based AI systems. A recent work [ 5 ] discusses how to learning can be applied to more ef ficiently quantize DB1 wavelet coef ficients to reduce image size without compromising classification accurac y . Another recent work [ 6 ] suggests an encoder decoder framew ork to learn compact representation before JPEG2000 compression. The authors of [ 1 ] applied existing JPEG codec to directly e xtract the Discrete Cosine transformed (DCT) coefficients for classifying imageNet [ 7 ] dataset. They claim faster classification by reducing some blocks of the ResNet stack, together with the time sav ed from not reconstructing RGB images before ResNet. Similar to this approach on JPEG, this paper uses the standard JPEG2000 codec to extract DWT coef ficients for classification. W e show not only faster but also more accurate classification results ev en before considering the reconstruction savings. Our results are from experiments on both CIF AR-10 [8] as well as T iny ImageNet (a subset of ImageNet [7]) datasets. T o the best of authors’ knowledge, this is the first reported work that successfully applies D WT coefficients e xtracted from within the JPEG2000 decoder for image classification. The authors of [ 9 ] demonstrated a similar concept of skipping reconstruction in ResNet classifier for a less common con volution encoder/decoder instead of the widely popular JPEG2000 encoder/decoder in multimedia applications. JPEG2000 uses CDF 9/7 wa velet as the mother wavelet in the discrete wav elet transformation (D WT). Despite the considerable volume of w orks on the use of DWT coef ficients for image compression (e.g., [ 3 , 5 , 10 – 12 ]), there are only a handful of published works that use CDF 9/7 wav elets for classification. For e xample, the authors of [ 3 , 5 , 11 ] uses DB1, mostly kno wn as ‘Harr’ wa velet for D WT calculation. Recent works [ 1 ],[ 5 ] and [ 9 ] hav e respectively shown that reconstruction of RGB images from DCT , DB1 and a custom compressed coefficients is unnecessary for classification purposes. The authors of [ 5 ] reported a classification accurac y of 88.9% for CIF AR-10 on a modified ResNet-20 by using unquantized CDF 9/7 D WT coefficients as CNN inputs. Furthermore they concluded that DB1 coefficients can achie ve better accuracy ov er CDF 9/7 wavelets using the same network. Howe ver , none of the pre vious works addressed the e xtension of regular augmentation techniques in transform domains such as DCT or DWT . In this work, we achie ved over 91.9% accuracy for CDF 9/7 coefficients e xtracted from JPEG2000 codec for the same dataset by applying our proposed augmentation techniques. In another recent work [ 5 ], the ef fect of the limited channel bandwidth in cloud based classification has been in vestigated for images in DB1 and RGB domains. In this paper, our work based on the CDF 9/7 coefficients of JPEG2000 obtains consistent results and similar conclusions. 3 Classification of JPEG2000 Compressed Images 3.1 JPEG2000 Compression Code JPEG2000 codec of fers two main compression paths, re versible and irre versible compression [ 13 ]. The rev ersible path uses CDF 5/3 wav elets for DWT calculation whereas the irrev ersible path is lossy and uses CDF 9/7 wa velets. This paper focuses on the lossy irre versible compression. In the JPEG2000 encoder , an RGB image with integer pixel values from 0 to 255 is first giv en a lev el offset of 128 to shift the intensity distribution center to 0. The of fset image is then conv erted to YCbCr color space by applying a linear mapping to f acilitate compression. From the YCbCr color space, CDF 9/7 wav elet coefficients are generated from a D WT transformation. The resulting DWT coefficients are then quantized with a deadzone quantizer as e xplained in [ 5 ] before sending to the block encoder . In the block encoder , the D WT coefficients are encoded using arithmetic code and efficiently arranged with EBCO T algorithm [14] to produce the e ventual j2k stream. 3 The decoder , as sho wn in Figure 1, e xtracts the CDF 9/7 coef ficients using the dequantizing block which multiplies the recei ved D WT oefficients with the same step size used by the encoder during quantization. In our experiments, we modified the open source ‘C’ codes of the OpenJPEG project 1 to extract D WT coef ficients and to generate RGB images. 3.2 ResNet Inputs The bottom part of the Figure 1 sho ws the process of adapting D WT coefficients e xtracted directly from the decoder to ResNet [ 15 ]. Similar to [ 5 ] three lev el-1 DWT channels corresponding to Y , Cb, and Cr are stacked in to a tensor of 12 sub bands each with the dimension of half of the RGB image. 3.3 Image A ugmentation Image augmentation is an essential step in deep CNN models to combat over fitting. By training with augmented images one can generalize the CNN model to classify unseen images during training. In each mini batch, augmentation can provide random transformations such as horizontal flipping, rotation, vertical and horizontal shifting. These transformations are meaningful in the spatial domain like RGB or YCbCr . Ho we ver , inputs in DWT or other transform domains, these con ventional transformations do not ha ve physical meaning and ha ve pro ven inef fective. Figure 3 shows a clear distortion in (c) as a result of incorrectly flipped high frequency sub-bands. (a) original (b) flipped in RGB (c) fillped in D WT (d) proposed Figure 3: (a) Original image. ‘Brownie’ of size 112 × 112 . (b) shows the horizontally flipped image in RGB domain. But at the training, mini batches are in DWT domain. (c) shows the result of using the same transformation in DWT domain and reconstructed in RGB for visualization. (d) horizontally flipped in D WT domain with proposed augmentation transform and reconstructed in RGB for visualization. (b) and (d) are exa ctly same proving the ef fectiv eness of the proposed method. (c) is distorted implying the ineffecti veness of the con v entional augmentation transforms. W e address this problem by proposing the follo wing augmentation transforms. Let n be the image dimension. Define X s ∈ R n × n and X w A ∈ R n × n where X w A is the D WT of X s and A is the D WT matrix of a wav elet a . Now we can write X w A as separable column and row transformations (See [16] for more details). X w A = A T X s A. (1) W e define the regular spatial domain transformation H as X s H = X s H (2) where X s H is the augmented X s in the spatial domain. W e suggest an alternative transformation ´ H defined as ´ H = A − 1 H A (3) which replaces H in augmentation in DWT domain. (See Section 3.7 for the formulation of A). 3.4 Computation Speed and Accuracy W e achiev e faster training and inference in three ways. First, we save computation cost by not reconstructing (Reconstruction g ain). Second, shallower models are suf ficient for image classification in spectral domain and lead to less computations and f aster training. Third, by applying specialized D WT augmentation, we improve classification accurac y . The first two methods are consistent with known results for JPEG as f aster classification can be achiev ed with fewer ResNet blocks [1]. 1 http://www .openjpe g.org/ 4 3.5 Reconstruction Gain Deep CNNs such as ResNet thriv e on RGB inputs and hav e been shown ef fectiv e with augmentation transforms like flipping, random cropping and rotations etc. In cloud based image classification, the receiv er node recei ves j2k stream of each inference image. W e demonstrate that the JPEG decoder steps after the dequantizer as sho wn in Figure 1 are unnecessary to achie ve the same le vel accurac y as reconstructed RGB images. Hence the computation required for IDWT , YCbCR to RGB con version, and the lev el offset can be omitted. W e call this computation/time saving “reconstruction gain’ which is dominated by the ID WT of CDF 9/7 wa velets in JPEG2000. The reconstruction gain amounts to ov er 80% decoding time of the OpenJPEG CPU implementation. See T able 1. 3.6 Shallow Models Deep CNN models with fe wer number of residual blocks ( B ( nf s ) ) are suf ficient to achiev e a giv en classification accuracy in D WT domain with CDF 9/7 wa velets in comparison to classification in the RGB domain. This can be seen by experimenting with 6 ResNet models parameterized as sho wn in T able 2. On the other hand, the width of the RGB inputs is 2 times larger than the CDF 9/7 inputs (for lev el 1 DWT), b ut DWT requires more con volution filters for each layer to compensate the larger input depth (12 channels) in CDF 9/7 compared to the 3 RGB channels. 3.7 Efficient A ugmentation The basis for the proposed augmentation transforms on D WT domain in Section 3.3 is the ability to represent D WT operation as an in vertible linear operation as sho wn in Eq. (1). W e formulated the matrix A ∈ R n × n for CDF 9/7 wa velets as follo ws. The lifting implementation of the 1-Dimensional DWT of CDF 9/7 w avelet consists of two predictions( P 1 , P 2 ), each follo wed by an update function ( U 1 and U 2 ). Then the resulting matrix is de-interleav ed ( S ) to form high and low frequency components. In OpenJPEG, this implementations consists of fiv e “for” loops for each operation. W e observed that this DWT matrix operation can be implemented as a matrix multiplication of three sub-functions: predictions, updates and de-interleaving. It can be denoted as A = P 1 U 1 P 2 U 2 S. (4) Matrix A and its in verse calculated this way 2 can be stored at the start of CNN training. W ith this implementation we could reduce the D WT con version time of 10,000 images of size 32 × 32 × 3 from 4 minutes to a mere 0.5 of a second on an INTEL 7 th GEN CORE i7-7700HQ CPU. 3.8 Bandwidth Constrained Cloud Image Classification In cloud based image classification, the av ailable bandwidth can critically affect the classification accuracy . The authors of [ 5 ] discussed this eff ect in more details. In JPEG2000 encoding, the precision of DWT coef ficients correspond to quality as higher quality layers offer more precision during encoding. When a compression parameter ‘ r ’ is used by the encoder , it changes the number of higher quality le vel bits proportionally . This is equiv alent to using larger step sizes in the dead zone quantizer . W e can test how rob ustly deep CNN image classifiers would respond to JPEG2000 encoded images ov er channels with different bandwidths. W e can easily observe such results by training a deep CNN model on the decoded DWT coefficients of images encoded at different compression ratio r . T o confirm that image reconstruction in deep CNN image classification of j2k is unnecessary , the testing accuracy of the DWT domain inputs should respond similarly to RGB image classifiers against a giv en bandwidth. 2 python code for this transformations is a vailable at https://driv e.google.com/open?id=16ZLKu107TSrnW uFi7Fw80MTT3Ck4008l 5 4 Experiments and Results 4.1 Pre-T raining and Fine-T uning In training a cloud based ML application for dif ferent av ailable bandwidths, one intuitiv e way is to train a base model for maximum allo wable bandwidth or using unquantized inputs. W e then fine-tune the model by using the base model as the pre-trained model. This approach can reduce time needed in training different models for dif ferent levels of a vailable bandwidths, as pre-training and fine-tuning can ease the con ver gence of the model to a higher accuracy le vel. 4.2 Results In the initial experiments, we used CIF AR-10 dataset which consists of 50,000 training images and 10000 testing images of size 32 × 32 belonging to 10 classes. W e then repeated the experiments on T iny ImageNet, as a subset of ImageNet dataset [ 7 ]. T iny ImageNet consists of RGB images of size 64 × 64 belonging to 200 classes, each class with 1300 training images and 50 validation images. For both CIF AR-10 and T iny ImageNet, we used ‘ Adam’ as the optimizer . T o compare the classification accuracy in RGB and DWT domains, we start by encoding original (source) images in the training set using JPEG2000 encoder at compression ratio r to generate j2k streams for each image. W e then decode the j2k streams into RGB images for RGB domain inputs and harvest their D WT v alues inside the codec for DWT domain) inputs as e xplained in Fig. 1. T able 1 summarizes the reconstruction gains for processing dif ferent size images in D WT domain. W e can see that the time sav ed by skipping RGB image reconstructing for inference accounts for ov er 80% of the total decoding time. The decoding time is based on an INTEL 7 th GEN CORE i7-7700HQ CPU. This gain impro ves with gro wing image size to allo w better inference speed compared to the RGB domain. T able 1: Reconstruction gain at different image sizes. Image size decoding time (ms) recon. gain (ms) recon. gain (%) 32 × 32 25 20 80.0 64 × 64 31 25 80.6 224 × 224 109 91 83.5 Figure 2 compares the classification accuracy and the speed of inference and training for uncom- pressed images (i.e., r = 0 ) of CIF AR-10 dataset. Each point in Fig 2 represents the test accuracy and the speed of a particular model. T o generate the results for a method, we changed the number of ResNet blocks to obtain better accuracy at the cost of training and inference time. T o calculate inference and training speed, we did not include the reconstruction gain as explained in Section 3.5. Inclusion of this extra gain would shift the DWT curves more fav orably to the right. W e gained approximately 2% improv ement in classification accuracy by applying our proposed augmentation techniques to the CIF AR-10 dataset. T able 2 and Fig. 4 describe the ResNet model settings corresponding to the result points a, b, c, d, e and f in Fig. 1 and Fig. 2 for the CIF AR-10 dataset. Note that the numbers of conv olution layers of the models used for DWT are lower than those used for RGB. Although D WT models used more kernels requiring more parameters, the RGB input width is 2 times lar ger and e vens out the time spent by D WT models on more kernels. W e used an initial learning rate of 0.001 which is reduced progressiv ely by 1 / 10 at 80, 120 and 160 o ver 200 epochs. For ImageNet e xperiments, we used a ResNet with 32 con volution layers with bottleneck architecture described in [ 15 ] for both RGB and D WT domains. This resulted in 3% accurac y gain ov er regular ResNet architecture for the D WT domain and 0.3% improv ement for the RGB domain. The initial learning rate is 0.001 which is reduced by 1 / 10 at 30, 60 and 90 ov er 95 epochs, respectiv ely . W e summarize the best classification models obtained for CIF AR-10 and T iny ImageNet datasets in T able 3 and T able 4, respectiv ely . W e repeated each experiment 3 times to compute the a verage and standard de viation of accuracy rates. Both data sets v alidate our claim of faster training and inference for JPEG2000 compressed images e ven without considering the reconstruction gain which is considerably large and gro ws with image size. Similarly , both datasets demonstrate the effecti veness 6 T able 2: Parameters for the ResNet models for RGB and CDF 9/7 inputs of CIF AR-10. Parameter/Domain RGB CDF 9/7 Model a b c d e f w 32 32 32 16 16 16 n c 3 3 3 12 12 12 n b 4 3 2 3 2 1 nf 0 16 16 16 64 64 64 nf 1 16 16 16 64 64 64 nf 2 32 32 32 96 96 96 nf 3 64 64 64 144 144 144 k 8 8 8 4 4 4 no of CONV layers 27 21 15 21 15 9 no of parameters (M) 0.37 0.27 0.18 1.79 1.17 0.55 Figure 4: ResNet(w , n c , n s ) represents a ResNet with n s = 3 stacks, each stack S ( n b , w ) consists of n b identical blocks for input image size w and n c channels. Each block B ( nf s ) consists of 2 con volution layers with nf s filters for the residual path and an identity connection followed by an activ ation function. After S 3 , the output is av erage-pooled (AP) with kernel size k and a dense layer is formed. S 2 and S 3 giv e additional con volution layer in the identity connection of the first block to match the down sampled input. T able 3: Results of CIF AR-10 based on models ‘a’ and ‘d’. parameter RGB CDF 9/7Aug (ours) CDF 9/7 T est Acc. ( % ) 91.70 ( ± 0.07 ) 91.92 ( ± 0.11) 89.41( ± 0.07) No of CONV layers 27 21 21 T raining rate/epoch (images/s) 862 1000 1000 Inference rate (images/s) 4108 4283 4259 of our proposed augmentation techniques for DWT domain images. CIF AR-10 shows ov er 2.5% and T iny ImageNet achie ves ov er 1% and 1.5% of top-5 and top-1 accuracy improv ement, respectiv ely . T able 4: Results of Tin y ImageNet. parameter RGB CDF 9/7Aug (ours) CDF 9/7 T op 5 test Acc. ( % ) 89.06( ± 0 . 03 ) 89.08 ( ± 0 . 02 ) 87.92( ± 0.07) T op 1 test Acc. ( % ) 67.35( ± 0.11 ) 67.56 ( ± 0.09) 65.78( ± 0.36) No of CONV layers 40 31 31 T raining rate/epoch (images/s) 670 694 694 Inference rate (images/s) 1865 1881 1881 Consider the accuracy of the proposed work in RGB domain. Both CIF AR-10 and T iny Imagenet results sho w top-1 accuracy improv ement of 0.2% on av erage. Overall, both e xperiments suggest that RGB image reconstruction from j2k stream is not necessary for CNN classification. Including the reconstruction gain, D WT domain models can perform more than × 2 times faster ov er RBG domain. Although faster decoders implemented on GPUs may reduce the gain, b ut as shown in T able 1, this gain gro ws with image size. 7 4.3 Experiments over Band width Constrained Channels Figure 5 shows how the classification accuracy beha ves under bandlimited channels. Results in Fig. 5(a) confirm faster and accurate classification for D WT domain models for channels with limited bandwidth. Results gi ven by Fig. 5(b) sho w the change of accuracy for a particular model for different bandwidth constraints. These results for JPEG2000 encoder that uses CDF 9/7 DWT coef ficients are consistent with the tests results from DB1 wa velets gi ven in [5]. 4000 5000 6000 7000 8000 9000 74 76 78 80 82 84 86 88 90 92 (a) 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 76 78 80 82 84 86 88 90 92 (b) Figure 5: (a). Models designed for CDF 9/7 DWT coefficients using the proposed augmentations are faster and more accurate under limited bandwidth. Parameter ‘r’ in JPEG2000 codec adjusts compression ratio and ‘BW’ is the bandwidth in terms of av erage image size. (b). Effect of channel bandwidth. RGB uses model ‘a’ and CDF 9/7 uses model ’ d’. This result is consistent with result from DB1 wa velets in [5] Fine tuning a base model for limited bandwidth can reduce training time. Figure 6 shows that the pre-training is feasible and achiev es a modest accuracy gain for both RGB and CDF 9/7 D WT . 0.2 0.3 0.4 0.5 0.6 0.7 76 78 80 82 84 86 88 90 92 Figure 6: Fine tuning for r = 5 , 10 , 15 using the pretrained D WT model for r = 0 reduces training time by 75% and improves accurac y . This observation is consistent with pre-training in RGB domain. CDF and RGB inputs use model ‘b’ and ‘e’ respectiv ely . 5 Conclusions This work in vestigates cloud-based deep CNN image classification in congested communication networks. W e proposed to directly train deep CNN classifier for JPEG2000 encoded images by using its D WT coefficients in j2k streams. W e achiev ed better accuracy and simpler computation by using shallo wer CNNs in the D WT domain. W e further introduced new augmentation transforms to de velop CNN models that are robust to common communication bandwidth constraints in cloud based AI applications. 8 References [1] L. Gueguen, A. Ser geev , B. Kadlec, R. Liu, and J. Y osinski, “Faster neural networks straight from jpe g, ” in Advances in Neural Information Pr ocessing Systems , 2018, pp. 3937–3948. [2] X. Zou, X. Xu, C. Qing, and X. Xing, “High speed deep networks based on discrete cosine transformation, ” in IEEE Int. Conf. on Image Processing (ICIP) , Oct 2014, pp. 5921–5925. [3] T . W illiams and R. Li, “ Advanced image classification using wav elets and conv olutional neural networks, ” in 15th IEEE Int. Conf. on Machine Learning and Applications (ICMLA) , Dec 2016, pp. 233–239. [4] D. Fu and G. Guimaraes, “Using compression to speed up image classification in artificial neural networks, ” 2016. [5] L.D. Chamain, Z. Ding, and S.S. Cheung, “Quannet: Joint image compression and classification over the channels with limited bandwidth, ” IEEE Inter . Conf. on Multimedia and Expo , 2019, in press. [6] F . Jiang, W . T ao, S. Liu, J. Ren, X. Guo, and D. Zhao, “ An end-to-end compression framework based on con volutional neural netw orks, ” IEEE T rans. on Circuits and Systems for V ideo T echnology , vol. 28, no. 10, pp. 3007–3018, 2018. [7] O. Russak ovsky , J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy , A. Khosla, M. Bern- stein, A. C. Ber g, and L. Fei-Fei, “ImageNet Large Scale V isual Recognition Challenge, ” International Journal of Computer V ision (IJCV) , vol. 115, no. 3, pp. 211–252, 2015. [8] A. Krizhevsky , I. Sutskev er, and G.E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neural information pr ocessing systems , 2012, pp. 1097–1105. [9] R. T orfason, F . Mentzer , E. Agustsson, M. Tschannen, R. Timofte, and L. V an Gool, “T owards image understanding from deep compression without decoding, ” arXiv preprint , 2018. [10] S. Fujieda, K. T akayama, and T . Hachisuka, “W avelet con volutional neural networks for texture classifica- tion, ” arXiv preprint , 2017. [11] A. Levinskis, “Conv olutional neural network feature reduction using wa velet transform, ” Elektr onika ir Elektr otechnika , v ol. 19, no. 3, pp. 61–64, 2013. [12] E. Kang, J. Min, and J.C. Y e, “ A deep con volutional neural network using directional wav elets for low-dose X-ray CT reconstruction, ” Medical Physics , vol. 44, no. 10, 2017. [13] D. T aubman and M. Marcellin, JPEG2000 Image Compression Fundamentals, Standards and Practice , vol. 642, Springer Science & Business Media, 2012. [14] D. T aubman, “High performance scalable image compression with ebcot, ” IEEE T ransactions on image pr ocessing , vol. 9, no. 7, pp. 1158–1170, 2000. [15] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Proceedings of the IEEE conf. on computer vision and pattern reco gnition , 2016, pp. 770–778. [16] R. C. Gonzalez, R. E. W oods, et al., “Digital image processing [m], ” Publishing house of electr onics industry , vol. 141, no. 7, 2002. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment