A View on Deep Reinforcement Learning in System Optimization
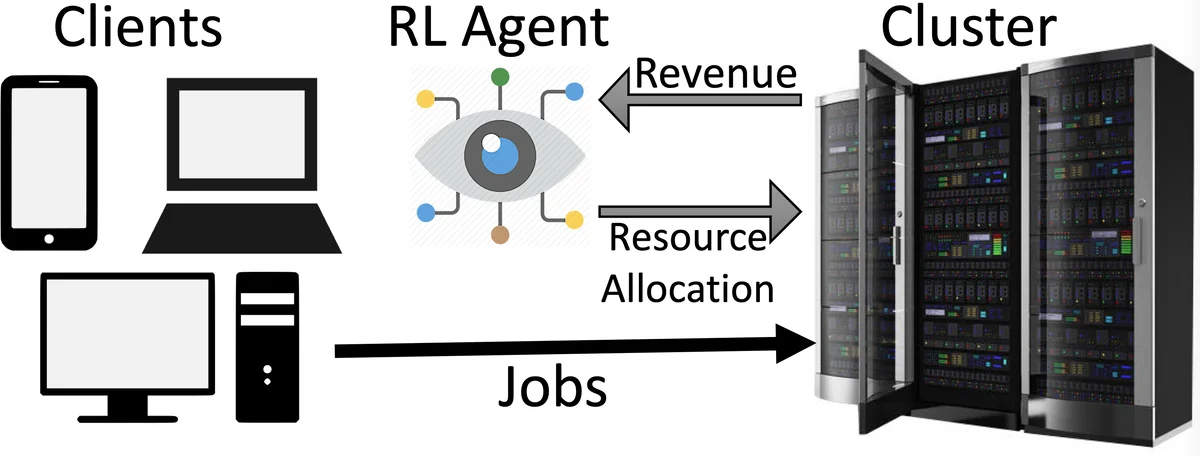
Many real-world systems problems require reasoning about the long term consequences of actions taken to configure and manage the system. These problems with delayed and often sequentially aggregated reward, are often inherently reinforcement learning problems and present the opportunity to leverage the recent substantial advances in deep reinforcement learning. However, in some cases, it is not clear why deep reinforcement learning is a good fit for the problem. Sometimes, it does not perform better than the state-of-the-art solutions. And in other cases, random search or greedy algorithms could outperform deep reinforcement learning. In this paper, we review, discuss, and evaluate the recent trends of using deep reinforcement learning in system optimization. We propose a set of essential metrics to guide future works in evaluating the efficacy of using deep reinforcement learning in system optimization. Our evaluation includes challenges, the types of problems, their formulation in the deep reinforcement learning setting, embedding, the model used, efficiency, and robustness. We conclude with a discussion on open challenges and potential directions for pushing further the integration of reinforcement learning in system optimization.
💡 Research Summary
**
The paper provides a comprehensive survey of recent efforts to apply deep reinforcement learning (DRL) to a wide range of system‑optimization problems, and it proposes a set of evaluation metrics to guide future research. It begins by arguing that many system management tasks—such as resource scheduling in data centers, edge‑caching, and energy‑aware provisioning—naturally involve delayed, sparse, and cumulative rewards, making them a good fit for reinforcement learning (RL). The authors contrast traditional tabular or linear approximations with modern deep‑neural‑network‑based policies and value functions, emphasizing the ability of DRL to generalize to unseen states.
The background section reviews the formalism of Markov Decision Processes (MDPs) and introduces the most common DRL algorithms: policy‑gradient methods (PG, PPO), value‑based methods (Q‑learning, SARSA, DDPG), and hybrid approaches. It clarifies the distinction between on‑policy vs. off‑policy, model‑free vs. model‑based, and notes that evolutionary or bandit‑style methods can also be combined with deep networks.
A central contribution is the taxonomy of system problems into continuing tasks (e.g., cloud job scheduling, where the environment never terminates) and episodic tasks (e.g., query‑plan generation, compiler phase ordering, where a clear episode ends after a finite number of decisions). The survey shows that continuing tasks are predominantly tackled with Q‑learning or SARSA because their temporal‑difference updates provide immediate, sample‑efficient policy refinement suitable for online adaptation. Episodic tasks, on the other hand, often employ policy‑gradient methods such as PPO, which can leverage batch updates and are well‑suited to problems where the reward is only known at the end of an episode. The paper lists representative works, the DRL algorithm used, and the specific optimization objective (latency, throughput, energy, etc.).
The authors then discuss practical challenges that frequently arise when deploying DRL in real systems: (1) Simulator fidelity – low‑quality simulators produce noisy reward signals that hinder learning; (2) Reward shaping – multi‑objective goals must be collapsed into a scalar, risking loss of important trade‑offs; (3) Exploration‑exploitation balance – aggressive exploration can incur prohibitive costs in production, while insufficient exploration leads to sub‑optimal policies; (4) State‑action space explosion – as system scale grows, the dimensionality of observations and actions can become intractable, reducing sample efficiency. To mitigate these issues, the paper highlights techniques such as learned embeddings for states and actions, hierarchical policies, meta‑learning for rapid adaptation, and model‑based planning to reduce environment interactions.
A key novelty is the proposal of seven essential evaluation metrics for DRL‑based system optimization: (i) Reward improvement (absolute and relative to baselines); (ii) Sample efficiency (number of environment interactions required); (iii) Computational and memory overhead (model size, inference latency); (iv) Stability and convergence speed (variance of returns, learning curves); (v) Generalizability/transferability (performance on unseen workloads or hardware); (vi) Robustness (sensitivity to noise, workload shifts); and (vii) Interpretability (ability to explain policy decisions). The authors argue that most existing papers focus solely on reward gains, neglecting these other dimensions that are critical for deployment in production environments.
In the final sections, the paper identifies open challenges and future research directions: the lack of standardized benchmarks and simulators hampers reproducibility; theoretical convergence guarantees for deep function approximators remain weak; multi‑objective reward design needs systematic approaches; and there is a pressing need for lightweight, energy‑aware DRL models that can run on edge devices. The authors call for community‑wide efforts to create shared datasets, develop theory‑driven algorithms, explore meta‑learning and transfer learning to improve sample efficiency, and design hardware‑friendly architectures.
Overall, the survey not only maps the current landscape of DRL applications in system optimization but also provides a concrete, multi‑dimensional framework for evaluating future work, highlighting both the promise and the practical hurdles that must be overcome for DRL to become a mainstream tool in systems engineering.
Comments & Academic Discussion
Loading comments...
Leave a Comment