Distance transform regression for spatially-aware deep semantic segmentation
Understanding visual scenes relies more and more on dense pixel-wise classification obtained via deep fully convolutional neural networks. However, due to the nature of the networks, predictions often suffer from blurry boundaries and ill-segmented s…
Authors: Nicolas Audebert (OBELIX), Alex, re Boulch
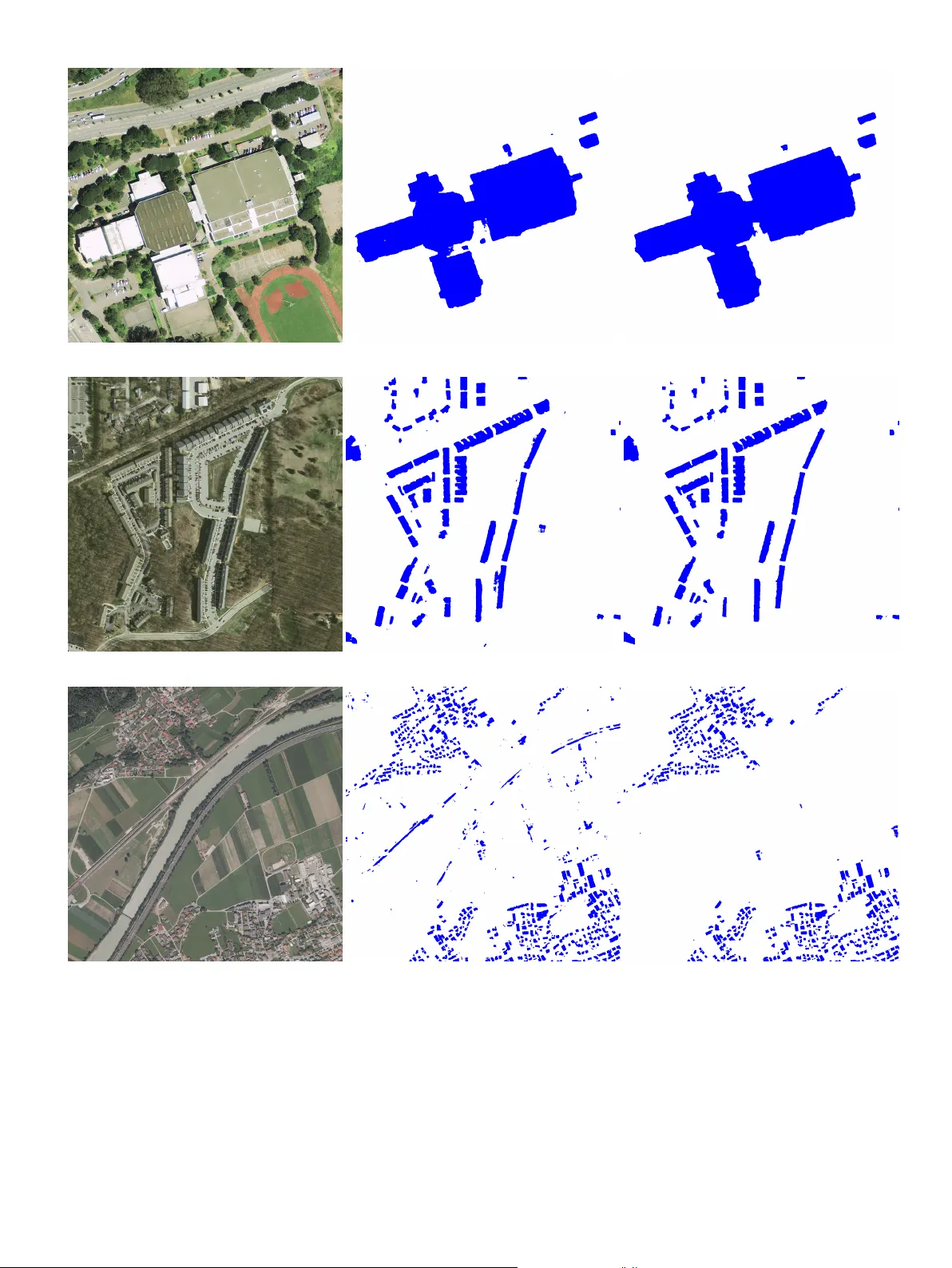
Distance transform regression for spatially-a w are deep seman tic segmen tation Nicolas Audeb ert a,b, ∗ , Alexandre Boulc h a , Bertrand Le Saux a , Sébastien Lefèvre b a DTIS, ONERA, Université Paris Saclay, F-91123 Palaise au - F r anc e b Univ. Br etagne-Sud, UMR 6074, IRISA, F-56000 V annes, F r anc e ABSTRA CT Understanding visual scenes relies more and more on dense pixel-wise classification obtained via deep fully conv olutional neural net works. Ho wev er, due to the nature of the net works, predictions often suffer from blurry b oundaries and ill-segmented shapes, fueling the need for p ost-pro cessing. This work in tro duces a new semantic segmentation regularization based on the regression of a distance transform. After computing the distance transform on the lab el masks, w e train a FCN in a multi-task setting in b oth discrete and contin uous spaces by learning jointly classification and distance regression. This requires almost no modification of the netw ork structure and adds a very low ov erhead to the training pro cess. Learning to appro ximate the distance transform back-propagates spatial cues that implicitly regularizes the segmentation. W e v alidate this technique with sev eral arc hitectures on v arious datasets, and w e show significant improv ements compared to comp etitive baselines. c 2019 Elsevier Ltd. All righ ts reserved. 1. Introduction Seman tic segmentation is a task that is of paramoun t imp ortance for visual scene understanding. It is often used as the first la yer to obtain represen tations of a scene with a high lev el of abstraction, such as listing ob jects and their shap es. F ully Con v olutional Net w orks (F CNs) ha ve prov ed themselv es to be very effective for semantic segmen tation of all kinds of images, from multimedia images Everingham et al. ( 2014 ) to remote sensing data Rottensteiner et al. ( 2012 ), medical imaging Ulman et al. ( 2017 ) and autonomous driving Cordts et al. ( 2016 ). Ho wev er, a recurren t issue often raised by the practitioners is the fact that FCN tend to produce blurry or noisy segmentations, in which spatial transitions b et ween classes are not as sharp as exp ected and ob jects sometimes lack connectivity or conv exity , and therefore the results need to b e regularized using some p ost-pro cessing Zheng et al. ( 2015 ); Chen et al. ( 2018 ). This has led the computer vision communit y to inv estigate many p ost-pro cessing an d regularization techniques to sharp en the visual b oundaries and enforce spatial smo othness in semantic maps inferred by F CN. Y et these metho ds are often either graphical mo dels ∗ Corresponding author: e-mail: nicolas.audebert@onera.fr (Nicolas Audebert) 2 added on top of deep neural netw orks Liu et al. ( 2018 ); Zheng et al. ( 2015 ) or based on sophisticated prior knowledge Le et al. ( 2018 ); Bertasius et al. ( 2016 ). In this work, w e propose a muc h straightforw ard approach b y introducing a simple implicit regularization embedded in the netw ork loss function. W e consider the distance transform of the segmen tation masks in a regression problem as a proxy for the semantic segmentation task. The distance transform is a contin uous represen tation of the lab el masks, where one pixel b ecomes represented not only by its belonging to a class, but b y its spatial proximit y to all classes. This means that the gradient back-propagated contains more information ab out the underlying spatial structure of the data compared to traditional classification. As suc h, the netw ork learns a smo other segmen tation with a v ery low complexity o v erhead. Moreov er, this is straigh tforw ard to implement and do es not rely on an y additional priors, but only on an alternative representation of the ground truth. Therefore any deep segmen tation arc hitecture can b e adapted in this fashion without any structural alteration. W e v alidate our metho d with sev eral arc hitectures on diverse application domains on which w e obtain significant impro vemen ts w.r.t strong baselines: urban scene understanding, R GB-D images and Earth Observ ation. 2. Related w ork Seman tic segmen tation is a longstanding task in the computer vision communit y . Sev eral benchmarks hav e been in tro duced on many application domains suc h as COCO Lin et al. ( 2014 ) and P ascal VOC Everingham et al. ( 2014 ) for multimedia images, Cam Vid Brostow et al. ( 2009 ) and Cityscapes Cordts et al. ( 2016 ) for autonomous driving, the ISPRS Seman tic Lab eling Rottensteiner et al. ( 2012 ) and INRIA Aerial Image Lab eling Maggiori et al. ( 2017 ) datasets for aerial image, and medical datasets Ulman et al. ( 2017 ), whic h are now dominated b y the deep fully conv olutional net works. Many applications rely on a pixel-wise semantic lab eling to p erform scene understanding, suc h as ob ject- instance detection and segmentation He et al. ( 2017 ); Arnab and T orr ( 2017 ) in m ultimedia images, segmen t-b efore- detect pipelines for remote sensing data processing Audeb ert et al. ( 2017 ); Sommer et al. ( 2017 ) and segmen tation of medical images for neural structure detection and gland segmentation Ronneb erger et al. ( 2015 ); Chen et al. ( 2016a ). State-of-the-art architectures are all derived from the F ully Con volutional Net work paradigm Long et al. ( 2015 ), whic h introduced the p ossibility to p erform pixel-wise classification using conv olutional netw orks that were previously restricted to image-wide classification. Many mo dels building up on this idea were then prop osed, e.g. DeepLab Chen et al. ( 2018 ), dilated con volutional netw orks Y u and Koltun ( 2015 ) or auto-enco der inspired architectures suc h as Seg- Net Badrinara yanan et al. ( 2017 ) and U-Net Ronneberger et al. ( 2015 ). The in tro duction of the residual learning framew ork He et al. ( 2016 ) also in tro duced man y new models for semantic segmentation, most notably the PSPNet Zhao et al. ( 2017 ) that incorp orates m ulti-scale context in the final classification using a pyramidal mo dule. 3 Ho wev er, one common deficiency of the F CNs is the lac k of spatial-aw areness that adversely affects the classification maps and makes spatial regularization a still activ e field of research Garcia-Garcia et al. ( 2017 ). Indeed, predictions often tend to b e blurry along the ob ject edges. As FCN p erform pixel-wise classification where all pixels are indep enden tly classified, spatial structure is fundamen tally implicit and relies only on the use of conv olutional filters. Although this has giv en excellent results on many datasets, this often leads to noisy segmen tations, where artifacts might arise in the form of a lac k of connectivity of ob jects and even salt-and-p epp er noise in the classifications. Those problems are especially critical in remote sensing applications, in which most ob jects are fundamentally groups of con vex structures and where connectivit y and inter-class transitions are a requirement for b etter mapping. T o address this issue, sev eral approaches for smo othing ha v e b een suggested. Graphical mo dels metho ds, such as dense Conditional Random Fields (CRF), hav e been used to spatially regularize the segmentation and sharpen the b oundaries as a p ost-pro cessing step Lin et al. ( 2016 ). Ho wev er, this broke the end-to-end learning paradigm, and led to several reformulations in order to couple more tightly the graphical models with deep net works. T o this end, Zheng et al. ( 2015 ); Liu et al. ( 2018 ) rewrote resp ectively the Conditional Random Field (CRF) and the Marko v Random Field (MRF) graphical mo dels as trainable neural net works. In a s imilar concept, Le et al. ( 2018 ) reform ulates the V ariational Lev el Set metho d to solve it using an FCN, while Chen et al. ( 2016b ) uses CNN to p erform domain transform filtering. Those methods all are revisiting traditional vision techniques adapted to fit into the deep learning framework. Ho wev er, they require hea vy netw ork mo dification and are computationally exp ensive. A more straigh tforward strategy consists in p erforming a data-driv en regularization b y enforcing new constraints on the mo del in the form a sp ecial loss p enalt y . Notably , this area has b een inv estigated in the literature for edge detection Y ang et al. ( 2016 ). F or instance, K okkinos ( 2015 ); Bertasius et al. ( 2016 ) introduce a carefully crafted loss esp ecially tailored for ob ject b oundary detection. CASENet Y u et al. ( 2017 ) tries to leverage semantics-related priors in to the edge prediction task b y learning the classes that are adjacent to eac h boundary , while the COB strategy Maninis et al. ( 2018 ) incorp orates geometric cues by predicting oriented b oundaries. Multi-scale approaches suc h as Liu et al. ( 2017 ) tune the net w ork arc hitecture to fuse activ ations from m ultiple la yers and improv e edge prediction by mixing lo w and high-lev el features. In the case of semantic segmentation, ob ject shapes b enefit from a b etter spatial regularit y as most shap es are often clean, closed sets. Therefore, better b oundaries often help by closing the contours and removing classification noise. T o this end, mo dels such as DeepContours Shen et al. ( 2015 ) explicitly learn b oth the segmentation and the region b oundaries using a m ulti-task hand-crafted loss. A similar approac h with an ensemble of models has b een suggested in Marmanis et al. ( 2017 ), esp ecially tailored for aerial images. Chen et al. ( 2016a ); Cheng et al. ( 2017 ) 4 (a) Car segmentation binary mask. (b) Signed distance transform (SDT). (c) T runcated and normalized SDT. Fig. 1: Differen t representations of a segmen tation label. still use a m ulti-task loss with explicit edge detection, but also fuse feature maps from several lay ers for more precise b oundaries, with applications in gland segmentation and aerial image lab eling, resp ectiv ely . The SharpMask Pinheiro et al. ( 2016 ) approac h uses a multi-stage netw ork to successively learn refinements of the segmented shap es. These methods all try to alleviate the classification noise b y incorp orating spatial-a w areness in the seman tic seg- men tation pip eline. How ev er, they share a common drawbac k as they introduce an explicit hand-crafted loss term to sharp en boundaries and spatially regularize the segmentation, either in the form of a regularization loss penalty , a hea vy net work modification or a graphical mo del p ost-pro cessing. This stems from the fact that segmentation labels are often an aggregation of binary masks that ha ve a low spatial-expressiv eness. In Ha yder et al. ( 2017 ), a distance transform was in tro duced to allow an instance segmen tation to infer shap es outside the original b ounding b o x of the ob ject. Indeed, the distance transform conv eys pro ximity meaning along the edges and even further. This allows the net work to learn more precise information than only “in” or “out” as w ould do one-hot enco ding and therefore feeds cues ab out the spatial structure to the net work. Inspired by this recent idea, w e introduce a distance transform regression loss in a m ulti-task learning framework, whic h acts as a natural regularizer for seman tic segmentation. This idea w as tested indep enden tly from us in Bisc hk e et al. ( 2017 ), although only for building fo otprin t extraction using a quantized distance transform that w as roughly equiv alen t to standard multi-class classification task. Our metho d is simpler as it directly works on the distance transform using a true regression. While previous metho ds brought additional complexit y , either in the form of a hand-crafted loss function or an alternative net work design, our approach remains straightforw ard and fully data-driven. It requires nearly almost no netw ork mo dification as it only adds a regression target, in the form of the distance transformed labels, to the original classification task. 5 3. Distance transform regression In this w ork, we suggest to use the signed distance transform (SDT) to improv e the learning pro cess of semantic segmen tation mo dels. The SDT transforms binary sparse masks in to equiv alent con tinuous representations. W e argue that this representation is more informativ e for training deep netw orks as one pixel now o wns a more precise representation of its spatial proximit y with v arious semantic classes. W e show that using a multi-task learning framework, w e can train a F CN to p erform b oth seman tic segmentation b y traditional classification and SDT regression, and this helps the netw ork infer b etter structured seman tic maps. 3.1. Signe d-distanc e tr ansform W e use the signed distance transform (SDT) Y e ( 1988 ), which assigns to each pixel of the foreground its distance to the closest bac kground p oint, and to each pixel of the background the opp osite of its distance to the closest foreground p oin t. If x i,j are the input image pixel v alues and M the foreground mask, then the pixels d i,j of the distance map are obtained with the follo wing equation: ∀ i, j, d i,j = ( + min z / ∈ M ( k x i,j − z k ) , if x i,j ∈ M , − min z ∈ M ( k x i,j − z k ) , if x i,j / ∈ M . (1) Considering that semantic segmen tation annotations can b e interpreted as binary masks, with one mask p er class, it is p ossible to conv ert the lab els into their signed-distance transform counterparts. In this work, we apply class-wise the signed Euclidean distance transform to the lab els using a linear time exact algorithm Maurer et al. ( 2003 ). In order to av oid issues where the nearest p oint is outside the receptive field of the netw ork, we clip the distance to a void long-range spatial dep endencies that would go out of the netw ork field-of-view. The clipping v alue is set globally for all classes. W e then normalize the SDT s of eac h class to constrain them in the [ − 1; 1] range. This can b e seen as feeding the SDT into a non-linear saturating activ ation function har dtanh . The visual representations are illustrated in Fig. 1 . The same pro cessing is applied to the distances estimated by the netw ork. 3.2. Multi-task le arning Signed distance transform maps are contin uous representations of the labels (classes). W e can train a deep netw ork to appro ximate these maps using a regression loss. Ho wev er, preliminary exp eriments sho w that training only for regression do es not bring any improv emen t compared to traditional classification and even degrades the results. Therefore, w e suggest to use a multi-task strategy , in which the net work learns both the classification on the usual one-hot lab els and the regression on all SDT s. More precisely , w e alter the net work to first predict the SDT s and w e then use an additional con volutional lay er to fuse the last la yer features 6 Source feature maps hardtanh Distances L dist = L 1 k concat dense predictions L seg = N LL softmax Segmen tation net w ork Segmen tation Fig. 2: Multi-task learning framew ork b y p erforming both distance regression and pixel-wise classification. Conv olutional la yers are in blue and non-linear activ ations are in green, while feature maps are in bro wn. and the inferred SDT s to p erform the final classification. In this wa y , the net work is trained in a cascaded multi-task fashion, where the distance transform regression is used as a proxy , i.e. an intermediate task, b efore classification. Therefore, the net work mo dification can b e summarized as follo ws. Instead of using the last lay er and feeding it in to a softmax, we now use the last lay er as a distance prediction. As distances are normalized b etw een -1 and 1, these distances pass through a har dtanh non-linearity . Then, we concatenate the previous lay er features maps and the distance predictions to feed b oth in to a conv olutional and a softmax lay er. The complete architecture is illustrated in Fig. 2 . In this work, we keep the traditional cross-entrop y loss for classification, in the form of the negative log-likelihoo d (NLL). As our regression results are constrained in [ − 1; 1] , we use the L1 loss to preserve relativ e errors. Assuming that Z seg , Z dist , Y seg , Y dist resp ectiv ely denote the output of the segmen tation softmax, the regressed dis- tance, the ground truth segmen tation lab els and the ground truth distances, the final loss to b e minimized is: L = N LLLoss ( Z seg , Y seg ) + λL 1( Z dist , Y dist ) (2) where λ is an h yp er-parameter that controls the strength of the regularization. 4. Exp eriments 4.1. Baselines W e first obtain baseline results on v arious datasets using SegNet or PSPNet for semantic segmentation, either using the cross entrop y for lab el classification or the L1 loss for distance regression. How ev er, note that our metho d is not arc hitecture-dep endent. It consists in a straigh tforw ard modification of the end of the net work that w ould fit an y arc hitecture designed for semantic segmentation. SegNet Badrinaray anan et al. ( 2017 ) is a p opular architecture for semantic segmen tation, originally designed for autonomous driving. It is designed around a symmetrical enco der-deco der architecture based on V GG-16 Simon yan and Zisserman ( 2015 ). The encoder results in do wnsampled feature maps at 1:32 resolution. These maps are then upsampled 7 and pro jected in the lab el space by the deco der using unp o oling lay er. The unp o oling op eration replaces the deco ded activ ations into the p ositions of the lo cal maxima computed in the enco der maxp o oling lay ers. PSPNet Zhao et al. ( 2017 ) is a recent model for semantic segmen tation that ac hieved new state-of-the-art results on sev eral datasets Cordts et al. ( 2016 ); Everingham et al. ( 2014 ). It is based on the popular ResNet He et al. ( 2016 ) mo del and uses a pyramidal mo dule at the end to incorp orate m ulti-scale contextual cues in the learning pro cess. In our case, w e use PSPNet, that enco des the input in to feature maps at 1:32 resolution, which are then upsampled using transp osed con volutions. 4.2. Datasets W e v alidate our metho d on several datasets in order to sho w its generalization capacity on multi and mono-class segmen tation of b oth ground and aerial images. ISPRS 2D Semantic L ab eling. The ISPRS 2D Seman tic Labeling Rottensteiner et al. ( 2012 ) datasets consist in t w o sets of aerial images. The V aihingen scene is comprised of 33 infrared-red-green (IRR G) tiles with a spatial resolution of 9cm/p x, with an av erage size of 2000 × 1500 px. Dense annotations are av ailable on 16 tiles for six classes: imp ervious surfaces, buildings, low vegetation, trees, cars and clutter, although the latter is not included in the ev aluation pro cess. The Potsdam scene is comprised of 38 infrared-red-green-blue (IRRGB) tiles with a spatial resolution of 5cm/px and size of 6000 × 6000 p x. Dense annotations for the same classes are av ailable on 24 tiles. Ev aluation is done by splitting the datasets with a 3-fold cross-v alidation. INRIA A erial Image L ab eling Benchmark. The INRIA A erial Image Lab eling dataset Maggiori et al. ( 2017 ) is comprised of 360 R GB tiles of 5000 × 5000 p x with a spatial resolution of 30cm/px on 10 cities across the glob e. Half of the cities are used for training and are asso ciated to a public ground truth of building fo otprints. The rest of the dataset is used only for ev aluation with a hidden ground truth. SUN RGB-D. The SUN R GB-D dataset Song et al. ( 2015 ) is comprised of 10,335 R GB-D images of indo or scenes acquired from v arious sensors, each capturing a color image and a depth map. These images hav e been annotated for 37 seman tic classes such as “chairs”, “flo or”, “wall” or “table”, with a few pixels unlab eled. Data F usion Contest 2015. The Data F usion Con test 2015 Camp os-T ab erner et al. ( 2016 ) is comprised of 7 aerial R GB images of 10 , 000 × 10 , 000 px with a spatial resolution of 5cm/px on the city of Zeebruges, Belgium. A dense set of annotations on 8 classes (6 from ISPRS dataset plus “water” and “boat”) is given. T wo images are reserved for testing, w e use one image for v alidation and the rest for training. 8 CamVid. The Cam Vid dataset Brostow et al. ( 2009 ) is comprised of 701 fully annotated still frames from urban driving videos, with a resolution of 360 × 480 px. W e use the same split as in Badrinara yanan et al. ( 2017 ), i.e. 367 training images, 101 v alidation images and 233 test images. The ground truth cov ers 11 classes relev an t to urban scene lab eling, suc h as “building”, “road”, “car”, “p edestrian” and “sidewalk”. A few pixels are assigned to a v oid class that is not ev aluated. 4.3. Exp erimental setup W e exp eriment with the SegNet and PSPNet mo dels. SegNet is trained for 50 ep o chs with a batch size of 10. Optimization is done using Sto chastic Gradien t Descen t (SGD) with a base learning rate of 0.01, divided by 10 after 25 and 45 ep o chs, and a weigh t decay set at 0.0005. Enco der w eights are initialized from V GG-16 Simon yan and Zisserman ( 2015 ) trained on ImageNet Deng et al. ( 2009 ), while deco der weigh ts are randomly initialized using the policy from He et al. ( 2015 ). F or SUN R GB-D, in order to v alidate our metho d in a m ulti-mo dal setting, w e use the F useNet Hazirbas et al. ( 2016 ) architecture. This mo del consists in a dual-stream SegNet that learns a joint representation of b oth the color image and the depth map. W e train it using SGD with a learning rate of 0.01 on resized 224 × 224 images. On aerial datasets, we randomly extract 256 × 256 crops ( 384 × 384 on the INRIA Lab eling dataset), augmented with flipping and mirroring. Inference is done using a sliding windo w of the same shap e with a 75% ov erlap. W e train a PSP-Net on Cam Vid for 750 ep o chs using SGD with a learning rate of 0.01, divided by 10 at ep o ch 500, a batc h size of 10 and a weigh t deca y set at 0.0005. W e extract random 224 × 224 crops from the original images and w e p erform random mirroring to augment the data. W e fine-tune on full scale images for 200 ep o c hs, following the practice from Jégou et al. ( 2017 ). Our implementation of PSPNet is based on ResNet-50 pre-trained on ImageNet and do es not use the auxiliary classification loss for deep sup ervision Zhao et al. ( 2017 ). Finally , we use median-frequency balancing to alleviate the class unbalance from SUN RGB-D and Cam Vid. F or a fair comparison, the same additional con volutional la yer required by our regression is added to the previous classification baselines, so that b oth mo dels ha ve the same num ber of parameters. All exp eriments are implemented using the PyT orch library noa ( 2016 ). SDT is computed on CPU using the Scip y library Jones et al. ( 2001 ) and cached on-memory or on-disk, whic h slows down training during the first ep o ch and uses system resources. Online SDT computation using a fast GPU implementation Zampirolli and Filip e ( 2017 ) would strongly alleviate those dra wbacks. 9 Metho d Dataset O A Roads Buildings Lo w veg. T rees Cars SegNet (SDT regression) V aihingen 89.49 91.03 95.60 81.23 88.31 0.00 SegNet (classification) 90.11 ± 0.11 91.31 ± 0.14 95.59 ± 0.14 78.43 ± 0.22 89.99 ± 0.14 82.37 ± 1.05 SegNet (+ SDT) 90.31 ± 0.12 91.55 ± 0.24 95.75 ± 0.21 78.80 ± 0.35 90.10 ± 0.11 81.59 ± 0.71 SegNet (classification) P otsdam 91.85 94.12 96.09 88.48 85.44 96.62 SegNet (+SDT) 92.22 94.33 96.52 88.55 86.55 96.79 T able 1: Results on the ISPRS datasets. F1 scores per class and ov erall accuracy (OA) are reported. (a) IRRG image (b) Ground truth (c) SegNet (classification) (d) SegNet (multi-task) Fig. 3: Excerpt of the results on the ISPRS V aihingen dataset. Legend: white: imp ervious surfaces, blue : buildings, cy an : low v egetation, green : trees, y ellow : vehicles, red : clutter, black: undefined. 4.4. R esults ISPRS dataset. The cross-v alidated results on the ISPRS V aihingen and Potsdam datasets are reported in T able 1 . F or V aihingen dataset, the v alidation set comprises 4 images out of 16 and 5 images out of 24 for Potsdam. All classes seem to b enefit from the distance transform regression. On Potsdam, the class “trees” is significantly impro ved as the distance transform regression forces the netw ork to b etter learn its closed shap e, despite the absence of leav es that mak e the underlying ground visible from the air. T wo example tiles are shown in Fig. 3 and Fig. 4 , where most buildings strongly benefit from the distance transform regression, with smo other shap es and less classification noise. Moreov er, w e also tested to p erform regression only on the V aihingen dataset, whic h sligh tly impro ved the results on several classes, although it missed all the cars and had a negative impact o v erall. It is also worth noting that our strategy succeeds while CRF did not impro ve classification results on this dataset as rep orted in Marmanis et al. ( 2017 ). INRIA A erial Image L ab eling Benchmark. The results on the test set of the INRIA Aerial Image Lab eling b enchmark are rep orted in T able 2 . Our results are comp etitive with those from other participan ts to the contest. Using the distance transform regression improv es the intersection o ver union (IoU) b y 0.47 and makes man y errors disapp ear. As shown 10 (a) RGB image (b) Ground truth (c) SegNet (classification) (d) SegNet (m ulti-task) Fig. 4: Excerpt of the results on the ISPRS Potsdam dataset. Legend: white: imp ervious surfaces, blue : buildings, cyan : low vegetation, green : trees, yello w : vehicles, red : clutter, black: undefined. Metho d Bellingham Blo omington Innsbruc k San F rancisco East T yrol IoU O A Inria1 52.91 46.08 58.12 57.84 59.03 55.82 93.54 Inria2 56.11 50.40 61.03 61.38 62.51 59.31 93.93 T eraDeep 58.08 53.38 59.47 64.34 62.00 60.95 94.41 RMIT 57.30 51.78 60.70 66.71 59.73 61.73 94.62 Raisa Energy 64.46 56.63 66.99 67.74 69.21 65.94 94.36 Duk eAMLL 66.90 58.48 69.92 75.54 72.34 70.91 95.70 NUS 65.36 58.50 68.45 71.17 71.58 68.36 95.18 SegNet* (classification) 63.42 62.74 63.77 66.53 65.90 65.04 94.74 SegNet* (+SDT) 68.92 68.12 71.87 71.17 74.75 71.02 95.63 T able 2: Results on the test set of the INRIA A erial Image Labeling Benchmark when our results w ere submitted (11/14/17). The multi-task framework consistently improv es the standard SegNet results. W e report the o verall accuracy (O A) and the in tersection ov er union (IoU) for each city . Best results are in b old , second b est are in italics . Metho d IoU (v al) O A (v al) SegNet Bisc hke et al. ( 2017 ) 72.57 95.66 SegNet (m ulti-task) Bischk e et al. ( 2017 ) 73.00 95.73 SegNet* (classification) 73.70 95.91 SegNet* (+SDT) 74.17 96.03 T able 3: Results on the validation set of the INRIA Aerial Image Lab eling Benchmark for comparison to Bischk e et al. ( 2017 ). W e report the ov erall accuracy (O A) and the intersection ov er union (IoU). (a) RGB image (b) Ground truth (c) SegNet (standard) (d) SegNet (multi-task) Fig. 5: Excerpt of the results on the INRIA Aerial Image Labeling dataset. Correctly classified pixels are in green , false positive are in pink and false negative are in blue . The m ulti-task framework allows the net work to better capture the spatial structure of the buildings. 11 (a) RGB image (b) SegNet (standard) (c) SegNet (multi-task) (d) RGB image (e) SegNet (standard) (f ) SegNet (multi-task) (g) RGB image (h) SegNet (standard) (i) SegNet (m ulti-task) Fig. 6: Excerpt of the results on the INRIA Aerial Image Lab eling test set. The multi-task framew ork filters out noisy predictions and cleans the predictions. Its effect is visible at multiple scales, b oth on a single building (more accurate shape) and on large areas (reduces the number of false positive buildings). in Fig. 5 , multi-task prediction yields more regular building shap es and no mis-classified "holes" within the building inner part. Although no additional buildings are detected, those that were already segmen ted b ecome cleaner. Note 12 Mo del O A AIoU AP DF CN-DCRF Jiang et al. ( 2017 ) 76.6 39.3 50.6 3D Graph CNN Qi et al. ( 2017 ) - 42.0 55.2 3D Graph CNN Qi et al. ( 2017 ) (MS) - 43.1 55.7 F useNet* Hazirbas et al. ( 2016 ) 76.8 39.0 55.3 F useNet* (+SDT) 77.0 38.9 56.5 T able 4: Results on the SUN R GB-D dataset on 224 × 224 images. W e report the ov erall accuracy , av erage intersection ov er union (AIoU) and average precision (AP). W e retrained our own reference F useNet. Best results are in b old , second b est are in italics . Metho d O A Roads Buildings Lo w veg. T rees Cars Clutter Boat W ater AlexNet (patc h) Camp os-T ab erner et al. ( 2016 ) 83.32 79.10 75.60 78.00 79.50 50.80 63.40 44.80 98.20 SegNet (classification) 86.67 84.05 82.21 82.24 69.10 79.27 65.78 56.80 98.93 SegNet (+SDT) 87.31 84.04 81.71 83.88 80.04 80.27 69.25 50.83 98.94 T able 5: Results on the Data F usion Con test 2015 dataset. W e report F1 scores per class and the ov erall accuracy (OA). that several missing buildings are actually false p ositive in the ground truth. W e also present a comparison to another m ulti-task approac h which uses a distance transform Bischk e et al. ( 2017 ) in table 3 , this time on their custom v alidation set. It shows that regression on SDT is b etter than SDT discretization follow ed by classification. SUN RGB-D. W e rep ort in T able 4 test results on the SUN RGB-D dataset. Switc hing to the m ulti-task setting improv es the ov erall accuracy and the av erage precision b y resp ectiv ely 0.33 and 1.06 p oints, while very sligh tly decreasing the a verage IoU. This sho ws that the distance transform regression also generalizes to a m ulti-mo dal setting on a dual-stream net work. Note that this result is comp etitive with the state-of-the-art 3D Graph CNN from Qi et al. ( 2017 ) that leverages 3D cues. Data F usion Contest 2015. T able 5 details the results on the Data F usion Contest 2015 dataset compared to the b est result from the original b enchmark Camp os-T ab erner et al. ( 2016 ). Most class es b enefit from the distance transform regression, with the exception of the “b oat” class. The o verall accuracy is improv ed b y 0.64% in the multi-task setting. Similarly to the Potsdam dataset, trees and low vegetation strongly b enefit from the distance transform regression. Indeed, vegetation is often annotated as closed shap es ev en if it is p ossible to see what lies underneath. Therefore, filter resp onses to the pixel sp ectrometry can b e deceptiv e. Learning distances forces the classifier to integrate spatial features in to the decision pro cess. CamVid. The test results on the Cam Vid dataset are rep orted in T able 6 that also includes a comparison with other metho ds from the state-of-the-art, notably Jégou et al. ( 2017 ). W e rep ort here the results obtained b y training tw o archi- tectures: a deep er PSPNet Zhao et al. ( 2017 ) based on ResNet-101 He et al. ( 2016 ) and a fully conv olutional DenseNet 13 Mo del mIoU OA Building T ree Sky Car Sign Road P edest. F ence P ole Sidewalk Cyclist SegNet Badrinara yanan et al. ( 2017 ) 46.4 62.5 68.7 52.0 87.0 58.5 13.4 86.2 25.3 17.9 16.0 60.5 24.8 DeepLab Chen et al. ( 2018 ) 61.6 – 81.5 74.6 89.0 82.2 42.3 92.2 48.4 27.2 14.3 75.4 50.1 Tiramisu Jégou et al. ( 2017 ) 58.9 88.9 77.6 72.0 92.4 73.2 31.8 92.8 37.9 26.2 32.6 79.9 31.1 Tiramisu Jégou et al. ( 2017 ) 66.9 91.5 83.0 77.3 93.0 77.3 43.9 94.5 59.6 37.1 37.8 82.2 50.5 PSPNet-50* (classif.) 60.2 89.9 76.3 67.7 89.2 71.0 37.8 91.5 44.0 33.7 26.9 76.6 47.4 PSPNet-50* (+ SDT) 60.7 90.1 76.9 69.7 88.7 72.7 38.1 90.6 44.0 36.6 27.1 75.6 47.7 PSPNet-50* (+ mask) 60.0 89.8 75.6 67.1 89.6 71.4 37.3 92.8 44.4 36.1 27.6 75.7 42.6 PSPNet101* (classif.) 60.3 89.3 74.7 64.1 89.0 71.8 36.6 90.8 44.5 38.5 25.4 77.4 50.3 PSPNet101* (+ SDT) 62.2 90.0 76.2 66.4 88.8 78.0 37.6 90.7 47.2 40.1 28.6 78.9 51.2 DenseUNet* (classif.) 59.5 89.6 75.8 68.6 90.9 75.3 37.3 90.0 42.1 26.5 30.1 74.1 43.7 DenseUNet* (+ SDT) 61.6 90.6 77.5 69.7 91.1 78.9 44.0 90.7 46.9 23.7 31.6 77.4 46.2 T able 6: Results on Cam Vid rep orting Intersection ov er Union (IoU) per class, the mean IoU (mIoU) and the ov erall accuracy (OA). Mo dels with an “*” are ours. The top part of the table shows several state-of-the-art metho ds, while the b ottom part shows how the distance transform regression consistently improv ed the metrics on several mo dels. Best results are in b old , second b est are in italics . Fig. 7: Example of segmen tation results on Cam Vid using PSPNet. F rom left to righ t: RGB image, PSPNet (classification), PSPNet (multi- task), ground truth. The distance transform regression helps improv e the consistency and smo othness of the sidewalks, trees, p oles and traffic signs. using skip connections from DenseNet Huang et al. ( 2017 ) with a UNet-inspired encoder-deco der structure Ronneb erger et al. ( 2015 ). W e use median frequency balancing for b oth the classification and the regression losses. On the DenseUNet architecture, em b edding the distance transform regression in the netw ork improv es the mean IoU by 2.1% and the ov erall accuracy by 1.0%, with consistent mo derate impro v ements on all classes and significan t impro vemen ts on cyclists, p edestrians and traffic signs thanks to the class balancing. On the PSPNet-101, our metho d impro ves the IoU by 1.9% and the ov erall accuracy by 0.7%, with p er class metrics consistent with the other mo dels, 14 Fig. 8: Exploration of several v alues for the trade-off factor of the distance transform regularization on the ISPRS V aihingen dataset and influence on the relative improv ement . Results are obtained using a 3-fold cross-v alidation. i.e. significant impro v ements on all classes except roads and sky . Some examples are sho wn in Fig. 7 where the distance transform regression once again pro duces smo other segmen tations. The PSPNet baseline is comp etitiv e with those other metho ds and its mean IoU is impro ved by 0.5 by switching to the multi-task setting including the distance transform regression. Most classes b enefit from the distance transform regression, with the exception of the “road” and “sky” classes. This is due to the void pixels, that are concen trated on those classes and that result in noisy distance lab els. Ov erall, our results are comp etitive with other state-of-the-art metho ds, with oly Jégou et al. ( 2017 ) obtaining a b etter segmentation. How ever we were not able to reproduce their results and therefore unable to test the effect of the distance regression on their mo del, although it is exp ected to b ehav e similarly to our DenseUNet reference. 4.5. Discussion Hyp erp ar ameter tuning. In order to b etter understand how the weigh t of each loss impacts the learning pro cess, we train several mo dels on the ISPRS V aihingen dataset using different v alues for λ . This adjusts the relative influence of the distance transform regression compared to the cross-en trop y classification loss. As reported in T able 1 , we compared the regression + classification framework to b oth individual regression and classification. It is worth noting that SDT regression alone performs worse than the classification. This justifies the need to concatenate the inferred SDT with the last lay ers features in order to actually improv e the p erformances. Classification alone can b e interpreted as λ = 0 . As can be seen in the results, incorporating the SDT regression b y increasing λ helps the netw ork significan tly . Impro vemen ts obtained with several v alues of λ are detailed in Fig. 8 . There are tw o visible p eaks: one around 0.5 and one around 2. Ho wev er, these tw o are not equiv alent. The 0.5 peak is unstable and presents a high standard deviation in o verall accuracy , while the λ = 2 p eak is even more robust than the traditional classification. Interestingly , this v alue is equiv alent to rescaling the gradient from the distance regression so that its norm is approximately equal to the gradient 15 coming from the classification. Indeed, exp erimen ts sho w that there is a ratio of 2 b etw een b oth gradients and that they decrease roughly at the same sp eed during training. Therefore, it seems that b etter results are obtained when b oth tasks are given similar weigh ts in the optimization pro cess. Nonetheless, all v alues of λ in the test range impro ved the accuracy and reduced its standard deviation, making it a fairly easy hyperparameter to choose. Finally , we also inv estigate the impact of using the distance transform regression compared to p erforming the re- gression on the lab el binary masks, which can b e seen as a clipp ed-SDT with a threshold of 1. W e exp erimented this on Cam Vid, as rep orted in T able 6 , on lines PSPNet-50* (classification, +mask, +SDT). Using the L1 regression on the masks do es not improv e the segmentation and even worsens it on many classes. This is not surprising, as the regularization brough t by the SDT regression relies on spatial cues that are absent from the binary masks. Effe ct of the multi-task le arning. The multi-task learning incorp orating the distance transform regression in the semantic segmen tation mo del helps the netw ork to learn spatial structures. More precisely , it constrains the netw ork not only to learn if a pixel is in or out a class mask, but also the Euclidean distance of this pixel w.r.t the mask. This information can b e critical when the filter responses are am biguous. F or example, trees from birdview might reveal the ground underneath during the winter, as there are no leav es, although annotations still consider the tree to hav e a shap e similar to a disk. Spatial proximit y helps in taking these cases into accoun t and removing some of the salt-and-p epp er classification noise that it induces, as sho wn on the ISPRS V aihingen and Potsdam and DFC2015 datasets. Moreov er, as the netw ork has to assign spatial distances to each pixel w.r.t the differen t classes, it also learns helpful cues regarding the spatial structure underlying the semantic maps. As illustrated in Figs. 5 and 6 , the predictions b ecome more coherent with the original structure, with sharp er b oundaries and less holes when shap es are supp osed to b e closed. It can be noted that m ulti-task is pro cessed by concatenation of SDT s and feature maps. Indeed, concatenation with con volution generalizes the weigh ted sum operator. It ensures some balance in the influence of SDT and feature maps. Ho wev er, other mechanisms could ha ve b een considered. F or example, m ultiplication would intricate SDT s and feature maps. This is relev ant when SDT s are w ell-estimated but can degrade dramatically results otherwise. F or instance, in T able 1, regression fails to estimate the car SDT (which yields a n ull F1-score for this class) so m ulti-task with m ultiplication would also fail. 5. Conclusion In this work, w e lo oked into semantic segmentation using F ully Con volutional Netw orks. Semantic segmentation is the first blo ck of man y computer vision pip elines for scene understanding and therefore is a critical vision task. Despite their 16 excellen t results, F CNs often lack spatial-aw areness without sp ecific regularization tec hniques. This can b e done using v arious metho ds ranging from graphical mo dels to ad ho c loss p enalties. W e in vestigated an alternative ground truth represen tation for semantic segmen tation tasks, in the form of the signed distance transform. W e show how using b oth lab el classification and distance transform regression in a multi-task setting helps state-of-the-art net works to improv e the segmentation. Esp ecially , constraining the net w ork to learn distance cues helps the segmentation b y including spatial information. This implicit method for segmen tation smo othing is fully data-driv en and relies on no prior, while adding only a very lo w ov erhead to the training pro cess. Using the distance transform regression as a regularizer, we obtained consisten t quantitativ e and qualitative impro v ements in sev eral applications of semantic segmentation for urban scene understanding, RGB-D semantic segmentation and aerial image labeling. W e argue that this metho d can b e used straigh tforwardly for many use cases and could help practitioners to qualitatively impro v e segmentation results without using CRF or other ad ho c graphical mo dels. References PyT orch: T en sors and Dynamic neural net works in Python with strong GPU acceleration, 2016. http://p ytorch.org/. 8 Anurag Arnab and Philip H. S. T orr. Pixelwise Instance Segmentation With a Dynamically Instantiated Net w ork. In IEEE Confer enc e on Computer Vision and Pattern R e co gnition (CVPR) , pages 441–450, 2017. 2 Nicolas Audebert, Bertrand Le Saux, and Sébastien Lefèvre. Segment-before-Detect: V ehicle Detection and Classification through Semantic Segmentation of Aerial Images. R emote Sensing , 9(4):368, April 2017. doi: 10.3390/rs9040368. 2 Vijay Badrinaray anan, Alex Kendall, and Rob erto Cipolla. SegNet: A Deep Convolutional Enco der-Deco der Architecture for Scene Seg- mentation. IEEE T ransactions on Pattern Analysis and Machine Intel ligence , 39(12):2481–2495, December 2017. ISSN 0162-8828. doi: 10.1109/TP AMI.2016.2644615. 2 , 6 , 8 , 13 Gedas Bertasius, Jian bo Shi, and Lorenzo T orresani. Semantic Segmentation With Boundary Neural Fields. In IEEE Confer enc e on Computer Vision and Pattern R e co gnition (CVPR) , pages 3602–3610, 2016. 2 , 3 Benjamin Bischk e, Patric k Helb er, Joac him F olz, Damian Borth, and Andreas Dengel. Multi-T ask Learning for Segmen tation of Building F o otprin ts with Deep Neural Netw orks. arXiv:1709.05932 [cs] , Septem ber 2017. 4 , 10 , 12 Gabriel J. Brostow, Julien F auqueur, and Rob erto Cip olla. Seman tic ob ject classes in video: A high-definition ground truth database. Pattern R e co gnition L etters , 30(2):88–97, January 2009. ISSN 0167-8655. doi: 10.1016/j.patrec.2008.04.005. 2 , 8 Manuel Camp os-T ab erner, A driana Romero-Soriano, Carlo Gatta, Gustau Camps-V alls, Adrien Lagrange, Bertrand Le Saux, Anne Beaup ère, Alexandre Boulch, Adrien Chan-Hon-T ong, Stéphane Herbin, Hic ham Randrianarivo, Marin F erecatu, Michal Shimoni, Gabriele Moser, and Devis T uia. Pro cessing of Extremely High-Resolution LiDAR and RGB Data: Outcome of the 2015 IEEE GRSS Data F usion Contest Part A: 2-D Contest. IEEE Journal of Selecte d T opics in Applie d Earth Observations and Remote Sensing , 9(12):5547–5559, December 2016. ISSN 1939-1404. doi: 10.1109/JST ARS.2016.2569162. 7 , 12 Hao Chen, X iao juan Qi, Lequan Y u, and Pheng-Ann Heng. DCAN: Deep Contour-A ware Netw orks for Accurate Gland Segmentation. In Pr o ce e dings of the IEEE Confer enc e on Computer Vision and Pattern Re c o gnition , pages 2487–2496, 2016a. 2 , 3 L. C. Chen, J. T. Barron, G. Papandreou, K. Murphy , and A. L. Y uille. Semantic Image Segmentation with T ask-Sp ecific Edge Detection Using CNNs and a Discriminatively T rained Domain T ransform. In Pr o c e edings of the IEEE Confer enc e on Computer Vision and Pattern R e co gnition , pages 4545–4554, June 2016b. doi: 10.1109/CVPR.2016.492. 3 Liang-Chieh Chen, Georges Papandreou, Murphy , Kevin, and Y uille, Alan. DeepLab: Semantic Image Segmen tation with Deep Conv olutional Nets, Atrous Conv olution, and F ully Connected CRF s. IEEE T ransactions on Pattern Analysis and Machine Intel ligence , 40(4):834–848, April 2018. ISSN 0162-8828. doi: 10.1109/TP AMI.2017.2699184. 1 , 2 , 13 D. Cheng, G. Meng, S. Xiang, and C P an. F usionNet: Edge A w are Deep Conv olutional Netw orks for Semantic Segmentation of Remote Sensing Harb or Images. IEEE Journal of Sele cte d T opics in Applie d Earth Observations and R emote Sensing , 10(12):5769–5783, Decem b er 2017. ISSN 1939-1404. doi: 10.1109/JST ARS.2017.2747599. 3 Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Ro drigo Benenson, Uwe F ranke, Stefan Roth, and Bernt Schiele. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Pr o ce e dings of the 2016 IEEE Conferenc e on Computer Vision and Pattern R e co gnition (CVPR) , pages 3213–3223, Las V egas, United States, June 2016. doi: 10.1109/CVPR.2016.350. 1 , 2 , 7 Jia Deng, W ei Dong, Richard So cher, Li-Jia Li, Kai Li, and Li F ei-F ei. ImageNet: A large-scale hierarchical image database. In Pro c e e dings of the IEEE Confer ence on Computer Vision and Pattern R e c o gnition (CVPR) , pages 248–255, June 2009. doi: 10.1109/CVPR.2009.5206848. 8 Mark Everingham, S. M. Ali Eslami, Luc V an Go ol, Christopher K. I. Williams, John Winn, and Andrew Zisserman. The Pascal Visual Ob ject Classes Challenge: A Retrosp ective. International Journal of Computer Vision , 111(1):98–136, June 2014. ISSN 0920-5691, 1573-1405. doi: 10.1007/s11263- 014- 0733- 5. 1 , 2 , 7 Alberto Garcia-Garcia, Sergio Orts-Escolano, Sergiu Oprea, Victor Villena-Martinez, and Jose Garcia-Ro driguez. A Review on Deep Learning T echniques Applied to Semantic Segmen tation. arXiv:1704.06857 [cs] , April 2017. 3 Zeeshan Hayder, Xuming He, and Mathieu Salzmann. Boundary-aw are Instance Segmentation. In Pr o c ee dings of the IEEE Confer enc e on Computer Vision and Pattern R e co gnition , 2017. 4 17 Caner Hazirbas, Lingni Ma, Csaba Domokos, and Daniel Cremers. F useNet: Incorp orating Depth into Semantic Segmentation via F usion-Based CNN Arc hitecture. In Computer Vision – ACCV 2016 , pages 213–228. Springer, Cham, Nov ember 2016. doi: 10.1007/978- 3- 319- 54181- 5_14. 8 , 12 Kaiming He, Xiangyu Zhang, Shao qing Ren, and Jian Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Pr o c ee dings of the IEEE International Confer ence on Computer Vision , pages 1026–1034, December 2015. doi: 10.1109/ ICCV.2015.123. 8 Kaiming He, Xiangyu Zhang, Shao qing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In Pr o ce e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c ognition (CVPR) , pages 770–778, Las V egas, United States, June 2016. doi: 10.1109/ CVPR.2016.90. 2 , 7 , 12 Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. In Pro c e e dings of the International Confer enc e on Computer Vision , March 2017. 2 Gao Huang, Zhuang Liu, Kilian Q. W ein b erger, and Laurens v an der Maaten. Densely connected con v olutional net works. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern Re c o gnition , volume 1, page 3, 2017. 13 Simon Jégou, Michael Drozdzal, David V azquez, Adriana Romero, and Y oshua Bengio. The One Hundred Lay ers Tiramisu: F ully Conv o- lutional DenseNets for Semantic Segmentation. In Pr o ce e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition W orkshops (CVPR W) , pages 1175–1183, Honolulu, United States, July 2017. doi: 10.1109/CVPR W.2017.156. 8 , 12 , 13 , 14 Jindong Jiang, Zhijun Zhang, Y ongqian Huang, and Lunan Zheng. Incorp orating Depth in to b oth CNN and CRF for Indo or Semantic Segmentation. arXiv:1705.07383 [cs] , Ma y 2017. 12 Eric Jones, T ravis Oliphant, P earu P eterson, and others. SciPy: Op en source scientific to ols for Python. http://www.scip y .org/, 2001. 8 Iasonas Kokkinos. Pushing the Boundaries of Boundary Detection using Deep Learning. arXiv:1511.07386 [cs] , No vem ber 2015. 3 TT. Hoang Ngan Le, Kha Gia Quach, Khoa Luu, Chi Nhan Duong, and Marios Savvides. Reform ulating Lev el Sets as Deep Recurrent Neural Netw ork Approach to Semantic Segmentation. IEEE T r ansactions on Image Pro c essing , 27(5):2393–2407, May 2018. ISSN 1057-7149. doi: 10.1109/TIP .2018.2794205. 2 , 3 Guosheng Lin, Ch unhua Shen, Anton V an Den Hengel, and Ian Reid. Efficient piecewise training of deep structured mo dels for seman tic segmentation. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , pages 3194–3203, Las V egas, United States, 2016. doi: 10.1109/CVPR.2016.348. 3 T sung-Yi Lin, Mic hael Maire, Serge Belongie, James Hays, Pietro P erona, Dev a Ramanan, Piotr Dollár, and C. La wrence Zitnick. Microsoft COCO: Common Ob jects in Context. In David Fleet, T omas Pa jdla, Bernt Schiele, and Tinne T uytelaars, editors, Computer Vision – ECCV 2014 , num b er 8693 in Lecture Notes in Computer Science, pages 740–755. Springer International Publishing, Septem b er 2014. ISBN 978-3-319-10601-4 978-3-319-10602-1. doi: 10.1007/978- 3- 319- 10602- 1_48. 2 Y un Liu, Ming-Ming Cheng, Xiaow ei Hu, Kai W ang, and Xiang Bai. Richer Con volutional F eatures for Edge Detection. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern Re c o gnition , pages 3000–3009, 2017. 3 Ziwei Liu, Xiaoxiao Li, Ping Luo, Chen Change Loy , and Xiao ou T ang. Deep Learning Marko v Random Field for Semantic Segmen tation. IEEE T r ansactions on Pattern A nalysis and Machine Intel ligenc e , 40(8):1814–1828, August 2018. ISSN 0162-8828. doi: 10.1109/TP AMI. 2017.2737535. 2 , 3 Jonathan Long, Ev an Shelhamer, and T revor Darrell. F ully convolutional networks for semantic segmentation. In Pr o c ee dings of the IEEE Confer enc e on Computer Vision and Pattern Re c o gnition (CVPR) , pages 3431–3440, June 2015. doi: 10.1109/CVPR.2015.7298965. 2 Emmanuel Maggiori, Y uliya T arabalk a, Guillaume Charpiat, and Pierre Alliez. Can Semantic Lab eling Metho ds Generalize to An y City? The Inria Aerial Image Lab eling Benchmark. In Pr o c e e dings of the IEEE International Symposium on Ge oscienc e and R emote Sensing (IGARSS) , July 2017. doi: 10.1109/IGARSS.2017.8127684. 2 , 7 K. K. Maninis, J. Pon t-T uset, P . Arbelaez, and L. V an Go ol. Conv olutional Orien ted Boundaries: F rom Image Segmen tation to High-Level T asks. IEEE T r ansactions on Pattern Analysis and Machine Intel ligenc e , 40(4):819–833, April 2018. ISSN 0162-8828. doi: 10.1109/ TP AMI.2017.2700300. 3 Dimitrios Marmanis, K onrad Schindler, Jan Dirk W egner, Silv ano Galliani, Mihai Datcu, and Uwe Stilla. Classification With an Edge: Improving Semantic Image Segmentation with Boundary Detection. ISPRS Journal of Photo gr ammetry and R emote Sensing , 2017. doi: 10.1016/j.isprsjprs.2017.11.009. 3 , 9 Calvin R. Maurer, Rensheng Qi, and Vijay Ragha v an. A linear time algorithm for computing exact Euclidean distance transforms of binary images in arbitrary dimensions. IEEE T r ansactions on Pattern Analysis and Machine Intel ligenc e , 25(2):265–270, F ebruary 2003. ISSN 0162-8828. doi: 10.1109/TP AMI.2003.1177156. 5 Pedro O. Pinheiro, T sung-Yi Lin, Ronan Collob ert, and Piotr Dollár. Learning to Refine Ob ject Segments. In Computer Vision – ECCV 2016 , Lecture Notes in Computer Science, pages 75–91. Springer, Cham, October 2016. ISBN 978-3-319-46447-3 978-3-319-46448-0. doi: 10.1007/978- 3- 319- 46448- 0_5. 4 Xiao juan Qi, Renjie Liao, Jiay a Jia, Sanja Fidler, and Raquel Urtasun. 3D Graph Neural Netw orks for RGBD Seman tic Segmentation. In Pr o ce e dings of the International Confer enc e on Computer Vision , 2017. 12 Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Con volutional Netw orks for Biomedical Image Segmentation. In Nassir Nav ab, Joachim Hornegger, William M. W ells, and Alejandro F. F rangi, editors, Me dic al Image Computing and Computer-Assiste d Intervention – MICCAI 2015: 18th International Confer enc e, Munich, Germany, October 5-9, 2015, Pr o c e e dings, Part III , pages 234–241. Springer International Publishing, Cham, 2015. ISBN 978-3-319-24574-4. doi: 10.1007/978- 3- 319- 24574- 4_28. 2 , 13 F ranz Rottensteiner, Gunho Sohn, Jaewook Jung, Markus Gerke, Caroline Baillard, Sebastien Benitez, and Uw e Breitkopf. The ISPRS benchmark on urban ob ject classification and 3D building reconstruction. ISPRS Annals of the Photo gr ammetry, Remote Sensing and Sp atial Information Scienc es , 1:3, 2012. 1 , 2 , 7 W ei Shen, Xinggang W ang, Y an W ang, Xiang Bai, and Z. Zhang. DeepContour: A deep conv olutional feature learned by p ositive-sharing loss for con tour detection. In Pr oc e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e co gnition , pages 3982–3991, June 2015. doi: 10.1109/CVPR.2015.7299024. 3 Karen Simony an and Andrew Zisserman. V ery Deep Con volutional Net works for Large-Scale Image Recognition. In Pr o c e e dings of the International Confer enc e on Le arning R epr esentations (ICLR) , May 2015. 6 , 8 L. Sommer, K. Nie, A. Sc h umann, T. Sch uchert, and J. Beyerer. Semantic labeling for improved vehicle detection in aerial imagery . In IEEE International Confer enc e on A dvanc e d Vide o and Signal Based Surveil lance (A VSS) , pages 1–6, August 2017. doi: 10.1109/A VSS.2017. 8078510. 2 S. Song, S. P . Lich tenberg, and J. Xiao. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Pr o c ee dings of the IEEE Confer enc e on Computer Vision and Pattern R e co gnition , pages 567–576, June 2015. doi: 10.1109/CVPR.2015.7298655. 7 Vladimír Ulman, Martin Mask a, Klas E. G. Magn usson, Olaf Ronneberger, Carsten Haub old, Nathalie Harder, Pa v el Matula, Petr Matula, 18 David Sv ob o da, Mirosla v Rado jevic, Ihor Smal, Karl Rohr, Joakim Jaldén, Helen M. Blau, Oleh Dzyubac hyk, Boudewijn Lelieveldt, Pengdong Xiao, Y uexiang Li, Siu-Y eung Cho, Alexandre C. Dufour, Jean-Christophe Oliv o-Marin, Constan tino C. Rey es-Aldasoro, Jose A. Solis-Lemus, Rob ert Bensch, Thomas Brox, Johannes Stegmaier, Ralf Mikut, Steffen W olf, F red A. Hamprech t, Tiago Esteves, Pedro Quelhas, Ömer Demirel, Lars Malmström, Florian Jug, Pa vel T omancak, Erik Meijering, Arrate Muñoz-Barrutia, Michal Kozubek, and Carlos Ortiz-de-Solorzano. An ob jective comparison of cell-tracking algorithms. Nature Metho ds , adv ance online publication, Octob er 2017. ISSN 1548-7091. doi: 10.1038/nmeth.4473. 1 , 2 J. Y ang, B. Price, S. Cohen, H. Lee, and M. Y ang. Ob ject Contour Detection with a F ully Conv olutional Enco der-Deco der Netw ork. In Pr o ce e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , pages 193–202, June 2016. doi: 10.1109/ CVPR.2016.28. 3 Q. Z. Y e. The signed Euclidean distance transform and its applications. In [1988 Pr o c e edings] 9th International Confer enc e on Pattern R e co gnition , pages 495–499 v ol.1, Nov ember 1988. doi: 10.1109/ICPR.1988.28276. 5 Fisher Y u and Vladlen Koltun. Multi-Scale Context Aggregation by Dilated Conv olutions. In Pr o ce e dings of the International Confer ence on L e arning Repr esentations (ICLR) , No v ember 2015. 2 Zhiding Y u, Chen F eng, Ming-Y u Liu, and Srikumar Ramalingam. CASENet: Deep Category-A ware Semantic Edge Detection. In Pr o c e edings of the IEEE Confer enc e on Computer Vision and Pattern Re c o gnition , pages 5964–5973, 2017. 3 F. d A. Zampirolli and L. Filip e. A F ast CUDA-Based Implemen tation for the Euclidean Distance T ransform. In International Confer enc e on High Performanc e Computing Simulation , pages 815–818, July 2017. doi: 10.1109/HPCS.2017.123. 8 Hengshuang Zhao, Jianping Shi, Xiao juan Qi, Xiaogang W ang, and Jiay a Jia. Pyramid Scene Parsing Netw ork. In Pr o ce e dings of the IEEE Conferenc e on Computer Vision and Pattern R e co gnition (CVPR) , pages 2881–2890, Honolulu, United States, July 2017. doi: 10.1109/CVPR.2017.660. 2 , 7 , 8 , 12 Shuai Zheng, Sadeep Jay asumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang, and Philip H. S. T orr. Conditional Random Fields as Recurrent Neural Netw orks. In Pr o c e e dings of the IEEE International Confer enc e on Computer Vision , pages 1529–1537, December 2015. doi: 10.1109/ICCV.2015.179. 1 , 2 , 3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment