An efficient and perceptually motivated auditory neural encoding and decoding algorithm for spiking neural networks
Auditory front-end is an integral part of a spiking neural network (SNN) when performing auditory cognitive tasks. It encodes the temporal dynamic stimulus, such as speech and audio, into an efficient, effective and reconstructable spike pattern to f…
Authors: Zihan Pan, Yansong Chua, Jibin Wu
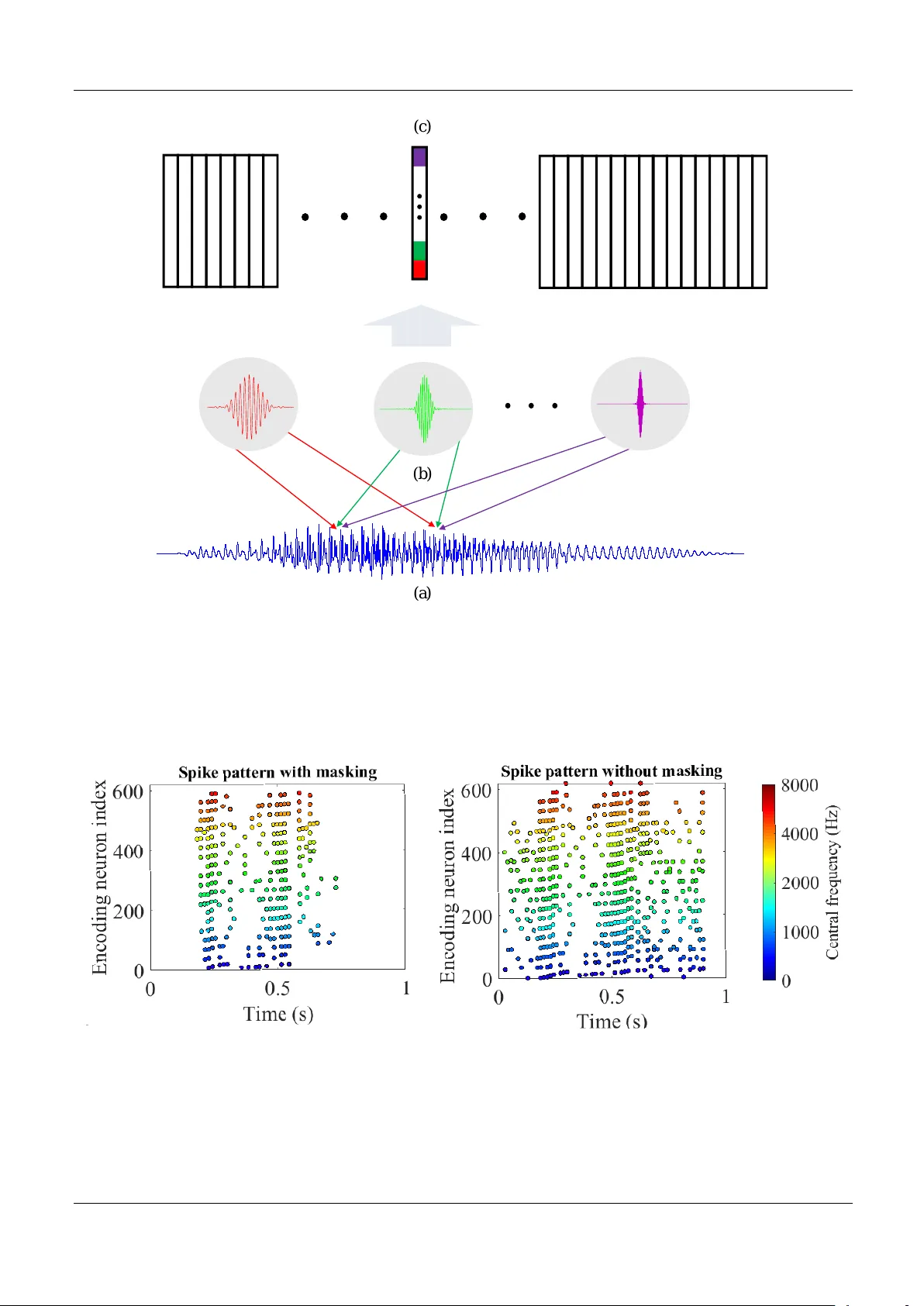
An efficient and per ceptuall y motiv ated auditory neural encoding and decoding algorithm f or spiking neural netw orks P an Zihan 1 , Chua Y ansong 2 ∗ , W u Jibin 1 , Zhang Malu 1 , Li Haizhou 1 , and Eliathamby Ambikairajah 3 1 Depar tment of Electrical and Computer Engineer ing, National Univ ersity of Singapore, Singapore , 117583 2 Institute f or Inf ocomm Research Agency f or Science, T echnology and Research, Singapore, 138632 3 School of Electrical Engineer ing and T elecommunications , University of New South W ales , Austr alia Correspondence*: Corresponding A uthor James4424@gmail.com ABSTRA CT A uditor y front-end is an integr al par t of a spiking neural networ k (SNN) when perf or ming auditor y cognitiv e tasks. It encodes the temporal dynamic stimulus, such as speech and audio , into an efficient, eff ective and reconstructable spike patter n to f acilitate the subsequent processing. How e ver , most of the auditor y front-ends in current studies hav e not made use of recent findings in psychoacoustics and ph ysiology concerning human listening. In this paper , we propose a neural encoding and decoding scheme that is optimized for speech processing. The neural encoding scheme, that we call Biologically plausib le Auditory Encoding (BAE), emulates the functions of the perceptual components of the human auditor y system, that include the cochlear filter bank, the inner hair cells, auditor y masking eff ects from psychoacoustic models, and the spike neural encoding by the auditor y ner v e . We e v aluate the perceptual quality of the BAE scheme using PESQ; the perf or mance of the BAE based on speech recognition experiments. Finally , we also b uilt and pub lished two spik e-version of speech datasets: the Spik e-TIDIGITS and the Spike-TIMIT , f or researchers to use and benchmar king of future SNN research. Keyw ords: Spiking neural netw ork, neural encoding, auditory perception, spike database 1 INTR ODUCTION The temporal or rate based Spiking Neural Netw orks (SNN), supported by stronger biological e vidence than the con ventional artificial neural networks (ANN), represents a promising research direction. Neurons in a SNN communicate using spiking trains that are temporal signals in nature, therefore, making SNN a natural choice for dealing with dynamic signals such as audio, speech, and music. In the domain of rate-coding, we studied the computational ef ficiency of SNN (Pan et al., 2019). Recently , further e vidence has supported the theory of temporal coding with spike times. T o learn a temporal spike pattern, a number of learning rules hav e been proposed, which include the single-spike T empotron (G ¨ utig and Sompolinsky, 2006), conductance-based T empotron (G ¨ utig and Sompolinsky, 2009), the multi-spike learning rule ReSuMe (Ponulak and Kasi ´ nski, 2010) (T aherkhani et al., 2015), the multi-layer spike learning rule SpikeProp (Bohte et al., 2002), and the Multi-spike T empotron (G ¨ utig, 2016), etc. The more recent studies are aggregate-label learning (G ¨ utig, 2016), and a novel probability-based multi-layer SNN learning rule (SLA YER) (Shrestha and Orchard, 2018). In our research, we are constantly addressing the question: what are the advantages of SNN o ver ANN? From the viewpoint of neural encoding, we expect to encode a dynamic stimulus into spike patterns, which was sho wn to be possible (Maass, 1997) (Ghosh-Dastidar and Adeli, 2009). Deep ANNs ha ve benefited 1 P an Zihan et al. An efficient auditory neural encoding from the datasets created in recent years. In the field of image classification, there is ImageNet (Deng et al., 2012) (Russako vsky et al., 2015); in the field of image detection, there is COCO dataset (V eit et al., 2016); while in the field of Automated Speech Recognition (ASR), there is TIMIT for phonemically and lexically transcribed speech of American English speakers (Garofolo, 1993). W ith the advent of these datasets, better and faster deep ANNs ine vitably follo w (Simonyan and Zisserman, 2014)(Hochreiter and Schmidhuber, 1997)(Redmon et al., 2016). The publicly a vailable datasets become the common platform for technology benchmarking. In the study of neuromorphic computing, there are some datasets such as N-MNIST (Orchard et al., 2015), D VS Gestures (Amir et al., 2017) and N-TIDIGITS (Anumula et al., 2018). They are designed for SNN benchmarking. Ho wev er , these datasets are relati vely small compared to the deep learning datasets. One may ar gue that the benchmarking datasets for deep learning may not be suitable for SNN studies. Let us consider image classification as an example. Humans process static images in a similar way as they would process liv e visual inputs. W e note that live visual inputs contain much richer information than 2-D images. When we map (Rueckauer et al., 2017) or quantize (Zhou et al., 2016) static images into spike trains, and compare the performance of an ANN on static images, and a SNN on spik e trains, we observe an accurac y drop. One should howe ver not hastily conclude that SNNs are inherently poor in image classification as a consequence of e vent-based acti vations in SNNs. Rather , the question seems to be: how can one better encode images into spikes that are useful for SNNs, and how can one better use these spikes in an image classification task? F or some of the recent image-based neuromorphic datasets, Laxmi et al (Iyer et al., 2018) has argued that no additional information is encoded in the time domain that is useful for pattern classification. This prompts us to look into the de velopment of e vent-based datasets that inherently contain spatio-temporal information. On the other hand, a dataset has to be complex enough such that it simulates a real-world problem. There are some datasets that support the learning of temporal patterns (W u et al., 2018a)(Zhang et al., 2018) (Zhang et al., 2017) (Malu et al., 2019), whereby each pattern contains only a single label, such as a sound ev ent or an isolated word. Such datasets are much simpler than those in deep learning studies (Gra ves et al., 2006) Gra ves (2012), whereby a temporal pattern in v olves a sequence of labels, such as continuous speech. F or SNN study to progress from isolated w ord recognition to wards continuous speech recognition, a continuous speech database is required. In this paper , we would describe ho w we con v ert the TIMIT dataset to its ev ent-based equi valent: Spik e-TIMIT . A typical pattern classification task consists of three stages: encoding, feature representation, and classification. The boundaries between each stage are getting less clear in an end-to-end classification neural network. Even then, a good encoding scheme can significantly ease the workload of the subsequent stages in a classification task, for instance, the Mel-Frequenc y Cepstral Coef ficients (MFCC) (Mermelstein, 1976) is still v ery much in use for automatic speech recognition (ASR). Hence the design of a spiking dataset should consider ho w the encoding scheme could help reduce the workload of the SNN in a classification task. This cannot be misconstrued as gi ving the SNN an unfair adv antage so long as all SNNs are measured using the same benchmark. The human cochlea performs frequenc y filtering (T obias, 2012) while human vision performs orientation discrimination (Appelle, 1972). These all in volv e encoding schemes to help us better understand our en vironment. In our earlier work (P an et al., 2019), on a simple dataset TIDIGITS (Leonard and Doddington, 1993) that contains only single spoken digits, we used a population threshold coding scheme to encode the dataset into e vents, which we refer to as Spike-TIDIGITS. Using such an encoding scheme, we go on to show that the dataset becomes linearly separable, i.e., the input can be classified based on spike counts alone. This demonstrates that when information is encoded in both the temporal (spike timing) and spatial (which neuron to spike) domain, the encoding scheme is able to project the inputs to a higher dimension, that takes some of the workload off the subsequent feature extraction and classification stages. In the case of Spike-TIDIGITS, the spikes encoded can be directly counted and then classified using a Support V ector Machine (SVM). Using this neural encoding scheme, W e further enhance it and then apply it to the TIMIT dataset in this work. The moti vation of this paper is tw o-fold. Firstly , we belie ve that we need well-designed spike-encoded datasets that represent the state-of-the-art encoding methodology . W ith these datasets, one can focus the research on SNN feature representation and classification tasks. Secondly , the datasets should present a challenge in pattern classification, that become the reference benchmark in future SNN studies. As speech is the most common way of human communication, we are looking into the neural encoding of speech signals in this work. The first question is how best possible to con vert speech signals into spikes. As it is, there hav e been many related works in speech and audio encoding, each of which is optimized for 2 P an Zihan et al. An efficient auditory neural encoding a specific objecti ve, for example, minimum signal reconstruction error (Xiao et al., 2016) (Dennis et al., 2013) (Loiselle et al., 2005). Ho we ver , none of them is optimized for neuromorphic implementation, that considers the psycho-acoustics, computational ef ficiency , and ef fectiv eness for pattern classification. In the SNN applications for speech recognition (Xiao et al., 2016) (Darabkh et al., 2018), Mel-Frequency Cepstral Coef ficients (MFCC) (Mermelstein, 1976) are commonly used as the spectral representation in speech recognition. Others hav e tried to use the biologically plausible cochlear filter bank, but they are either analog filters which are prone to changes in the external en vironment (Liu and Delbruck, 2010), or yet to be studied in a spike-dri ven SNN system (Loiselle et al., 2005). Considering spectral representation, an important step in neural encoding is to then con vert the spectral energy in a perceptual frequency band into a spike train. The most common way is to treat the two- dimensional time-frequency spectrogram as a static image, then con verting each ’pix el’ value into a spike latency time within the framing window size (W u et al., 2018a), or into the phase of the sub-threshold membrane potential oscillation (Nadasdy, 2009). Such methods do not represent the spatio-temporal dynamics of the auditory signals in a way that can be directly learned in a SNN (W u et al., 2018b). Furthermore, these prior studies mostly encode all the frequenc y components in the frames, and all of these frames into spike trains, introducing a lot of redundancy and hence unnecessary computational load for the subsequent SNN processing, such as speech recognition. Finally , little research has been studied on how to reconstruct a neural encoded speech signal back into its auditory signals for perceptual ev aluation. Speech signal reconstruction is a critical task in speech information processing, such as speech synthesis, singing synthesis, and dialogue technology . T o address the need of neuromorphic computing for speech information processing, we propose three criteria for a biologically plausible auditory encoding (B AE) front-end: 1. Biologically plausible spectral features. 2. Sparse and energy-ef ficient spike neural coding scheme. 3. Friendly for temporal learning algorithms on cogniti ve tasks. The fundamental research problem in neural encoding is how to encode the dynamic and continuous speech signals into discrete spike patterns. Spike rate code is thought to be less likely in an auditory system since much evidence suggest otherwise, such as the example of ho w bats rely highly on the precise spike timing of their auditory system to locate sound sources by detecting a time difference as short as 5 µs . Latency code and phase code are well supported by neuro-biological observ ations. Ho we ver , on its o wn, they cannot pro vide an in v ariant representation of the patterns for a classification task. T o facilitate the processing of a SNN in a cognitiv e task, neural temporal encoding should not only consider how to encode the stimulus into spik es, but also care about ho w to represent the in variant features. Just like the auditory and visual sensory representations in the human prefrontal cortex, such representations in the proposed B AE front-end are required in a SNN framework, that can then be implemented with a lo w cost neuromorphic solution, that can ef fecti vely reduce the processing workload in the subsequent SNN pipeline. A large number of observ ations in neuroscience support the observation that our auditory sensory neurons encode the input stimulus using threshold crossing e vents in a population of sensory neurons (Ehret, 1997) (Hopfield, 2004). Inspired by these observ ations, a simple v ersion of threshold coding has been proposed (G ¨ utig and Sompolinsk y, 2009), in which a population of encoding neurons with a set of uniformly distributed thresholds encode the spectral energy of different frequenc y channels into spikes. Such a cross-and-fire mechanism is reminiscent of quantization from the point of view of information coding. In our proposed B AE encoding front-end, such a neural coding scheme is also being incorporated. Further in v estigation is presented in the experiment section. Besides ef fectiv e neural coding representation, an ef ficient auditory front-end aims to encode acoustic signals into sparse spike patterns, while maintaining suf ficient perceptual information. T o achie ve such a goal, our biological auditory system has provided us a solution best understood as masking ef fects(Harris and Dallos, 1979)(Shinn-Cunningham, 2008). Masking is a complex and yet to be fully understood psychoacoustic phenomenon as some components of the acoustic ev ents are not perceptible in both frequency and time domain (Ambikairajah et al., 1997). From the vie wpoint of perceptual coding, these components are regarded as redundancies since they are inaudible. Implementing the masking effects, those inaudible components will be coded with larger quantization noise or not coded at all. Although the mechanism and function of masking is not yet fully understood, its effects ha ve already been successfully Frontier s 3 P an Zihan et al. An efficient auditory neural encoding exploited in auditory signal compression and coding (Ambikairajah et al., 2001), for efficient information storage, communication, and retrie val. In this paper , we propose a nov el idea to apply the auditory masking ef fects in both frequency and time domain, which we refer to as simultaneous masking and temporal masking, respecti vely , in our auditory neural encoding front-end so as to reduce the number of encoding spikes. This impro ves the the sparsity and ef ficiency of our encoding scheme. Gi ven ho w we address the three optimization criteria of neural encoding, we refer to it as biologically plausible auditory encoding scheme or B AE. Such an auditory encoding front-end also provides an engineering platform to bridge the study of masking ef fects between psycho-acoustics and speech processing. Our main contributions in this paper are: 1) we emphasize the importance of spike acoustic datasets for SNN research. 2) we propose an integrated auditory neural encoding front-end to further research in SNN-based learning algorithms. W ith the proposed B AE encoding front-end, the speech datasets can be con verted into an ener gy-efficient, information-compact, and well-representati ve spike patterns for subsequent SNN tasks. The rest of this paper is org anized as follows: in Section 2 we discuss the auditory masking ef fects, and ho w simultaneous masking in the frequency domain, and temporal masking in the time domain for neural encoding of acoustic stimulus is being implemented; the B AE encoding scheme is applied in conjunction with masking to TIDIGITS and TIMIT datasets. In Section 3, we describe the details of the resulting spike datasets and e valuate them in comparison with their original datasets in a recognition task. In Section 4, we discuss our findings and conclude in Section 5. 2 MA TERIALS AND METHODS 2.1 A uditory masking effects Most of our speech processing front-ends employ a fixed feature extraction mechanism, such as MFCC, to encode the input signals, whereas the human auditory sensory system ignores some while strongly emphasizes others, commonly referred to as attention mechanism in psycho-acoustics. The auditory masking ef fects closely emulate this phenomenon (Shinn-Cunningham, 2008). Auditory masking is a kno wn perceptual property of the human auditory system that occurs whene v er the presence of a strong audio signal makes its neighborhood of weaker signals inaudible, both in the frequency and time domain. One of the most notable application of auditory masking is the MPEG/audio international standard for audio signal compression (F ogg et al., 2007) (Ambikairajah et al., 2001). It compresses the audio data in lar ge part by remo ving the acoustically irrele vant parts of the audio signal, or by encoding those parts with less number of bits, due to more tolerance to quantization noise (Ambikairajah et al., 1997). T o achiev e such a goal, this algorithm designs two dif ferent kinds of maskings from the psycho-acoustic model (Lagerstrom, 2001): 1. In the frequency domain, two kinds of masking ef fects are used. Firstly , by allocating the quantization noise in the least sensitiv e regions of the spectrum, the perceptual distortion caused by quantization is minimized. Secondly , an absolute hearing threshold is exploited, belo w which the spectral components are entirely remov ed. 2. In the time domain, the masking ef fect is applied such that the local peaks of the temporal signals in each frequency band will mak e their ensuing audio signals inaudible. Moti vated by the abov e signal compression theory , we propose an auditory masking approach to spike neural encoding, which greatly increases the coding ef ficiency of the spik e patterns, by eliminating those perceptually insignificant spike e vents. The approach is conceptually consistent with the MPEG-1 layer III signal compression standard (Fogg et al., 2007), with modifications according to the characteristics of spiking neurons. 2.1.1 Simultaneous masking The masking ef fect present in the frequenc y domain is referred to as simultaneous masking. According to the MPEG-1 standards, there are two sorts of masking strategies in the frequency domain: the absolute hearing threshold and the frequency mask ers. The simultaneous masking effects are common in our daily life. For instance, the sensible sound lev els of our auditory systems vary in dif ferent frequencies, therefore, 4 P an Zihan et al. An efficient auditory neural encoding we can be more sensiti ve to the sounds in our li ving en vironment. This is an e volutionary adv antage for survi val, in both human beings and animals. Besides the absolute hearing threshold, e very acoustic e vent in the spectrum will also influence the perception of the neighboring frequency components, that is, different le vels of tones could contrib ute to masking ef fects of other frequency tones. F or instance, in a symphony sho w , the sounds from different musical instruments can be fully or partially masked by each other . As a result, we can enjoy the compositions of various frequency components with rich div ersities. Such a psycho-acoustic phenomenon is called frequency masking. Figure 1 illustrates the absolute hearing threshold, T a , as a function of frequency in Hz. The function is deri ved from psycho-acoustic e xperiments, in which pure tones continuous in the frequency domain are presented to the test subjects and the minimal audible sound pressure lev els (SPL) in dB are recorded. The commonly used function to approximate the threshold is (Ambikairajah et al., 1997): T a ( f ) = 3 . 64 × ( f 1000 ) − 0 . 8 − 6 . 5 × e − 0 . 6( f 1000 − 3 . 3) 2 + 0 . 001 × ( f 1000 ) 4 (1) For the frequency maskers, in the MPEG-1 standard, some sample pulses under masking thresholds might be partially masked, thus they are encoded by less number of bits. Howe ver , in the event-based scenario, spike patterns carry no amplitude information, similar to on-of f binary values, which means that partial masking can hardly be realized. As such, we hav e modified the approach such that all components under the frequency mask ers are fully masked (discarded). Further reconstruction and pattern recognition experiments are necessary to e v aluate such an approach. Figure 2 sho ws the o verall masking thresholds with both masking strategies in the frequency domain. This figure illustrates the simultaneous masking thresholds added to the acoustic e vents in a spectrogram. The sound signals with dif ferent spectral po wer in dif ferent cochlear filter channels will suffer from v arious masking thresholds. Figure 3 provides a real-world example of the simultaneous masking. The spectrogram of a speech utterance of “one” from TIDIGITS dataset is demonstrated in a 3-D plot. The gre y surface illustrates the simultaneous masking threshold acting on the spectrogram (colorful surface). By the masking strategy , the acoustic ev ents with spectral energy lower than the threshold surface will be removed. Section 2.3 will introduce ho w to con vert the mask ed spectrogram into a sparse and well-represented spike pattern. 2.1.2 T emporal masking Another auditory masking ef fect is temporal masking in the time domain. Conceptually similar to the frequency mask ers, a louder sound will mask the perception of the other acoustic components in the time domain. As illustrated in Figure 4, the vertical bars represent the signal intensity of short-time frames, that is called acoustic e vents, along the time axis. A local peak (the first red bar) forms a mask er that makes the follo wing ev ents inaudible until the next local peak (the second red bar) exceeds the masker curve. According to the psycho-acoustic studies, the temporal mask er threshold is modeled as an exponentially decaying curve (Ambikairajah et al., 2001): y ( n ) = c n × p 1 (2) where y ( n ) denotes the masking threshold le vel on the n th follo wing an acoustic e vent; c is the e xponential index and p 1 represents the sound level of the local peak as the beginning of the masker . The decaying parameter c is tuned according to the hearing quality . 2.1.3 A uditor y masking eff ects in both domains By applying both the simultaneous masking and temporal masking illustrated above, we can remov e those imperceptible acoustic e vents (frames) from the o verall spectrogram. Since our goal is to apply the masking ef fects in the precise timing neural code, we propose the strategy as follo ws: 1. The spike pattern P K × N ( p ij ) is generated from the raw spectrogram S K × N ( s ij ) without masking ef fects, by some temporal neural coding methods, which will be discussed in Section 2.2.2. Here the index i, j refers to the time-frequency bin in the spectrogram, with i referring to the frequency bin, and Frontier s 5 P an Zihan et al. An efficient auditory neural encoding j referring to the time frame index. The spike pattern P K × N is defined as a matrix that: p ij = t f , if a spike is emitted within the duration of the time-frequenc y bin i, j 0 , otherwise (3) where t f is the encoded precise spike timing. As such the spike pattern P K × N ( p ij ) is a sparse matrix that records the spike timing. 2. According to the spectrogram S K × N ( s ij ) and the auditory perceptual model, the simultaneous masking le vel matrix M simultaneous ( m simultaneous ij ) and the temporal masking le vel matrix M temporal ( m temporal ij ) are obtained. The o verall masking le vel matrix M K × N ( m ij ) is defined as follo ws. It provides a 2-D masking threshold surface that has the same dimensions as the spectrogram. m ij = min n m simultaneous ij , m temporal ij o (4) 3. A masker map Φ K × N ( φ ij ) is generated, whose dimensions are the same as the spectrogram. The element of the matrix Φ K × N ( φ ij ) is defined as: φ ij = 1 , if s ij ≥ m ij 0 , if s ij < m ij (5) where the time-frequency bin i, j is masked with φ i,j = 0 when the frame energy s ij is less than the masking threshold m ij , otherwise, φ i,j = 1 . 4. Apply the masker map matrix Φ K × N ( φ ij ) to the encoded pattern P K × N ( p ij ) to generate a masked spike pattern P mask ( p mask ij ) : P mask = P K × N ◦ Φ K × N (6) where ◦ denotes the Hadamard product. By doing so, those perceptually insignificant spikes are eliminated, thus forming a more compact and sparse spike pattern. Figure 5 demonstrates the auditory masking effects acting in both the frequenc y and time domains, on a speech utterance of “one” in TIDIGITS dataset. The colored surf ace represents the original spectrogram while the gre y areas represent the spectral ener gy v alues that are being mask ed. For TIDIGITS datasets, nearly half of the acoustic e vents (frames) are remov ed according to our auditory masking strategy , which corresponds to the 55% removal of PCM pulses in speech coding (Ambikairajah et al., 2001). 2.2 Cochlear filter s and spike coding The human auditory system is primarily a frequency analyzer (T obias, 2012). Many studies have confirmed the e xistence of the perceptual centre frequencies and equi v alent bandwidths. T o emulate the working of the human cochlea, sev eral artificial cochlear filter banks have been well studied: GammaT one filter bank (Patterson et al., 1987)(Hohmann, 2002), Constant Q T ransform-based filter bank (CQT) (Brown, 1991)(Bro wn and Puckette, 1992), Bark-scale filter bank (Smith and Abel, 1999), etc. The y share the same idea of logarithm distributed centre frequencies and constant Q factors b ut slightly differ in the exact parameters. T o build the auditory encoding system, we adopt an e vent-based CQT -based filter bank in the time domain, follo wing our previous w ork (Pan et al., 2018). 2.2.1 Time-domain cochlear filter bank Adopting an ev ent-based approach to emulate the human auditory system, we propose a neuronal implementation of the e vent-dri ven cochlear fil ter bank, of which the computation can be parallelized as follo ws, • As illustrated in Figure 6, a speech wav eform (a) is filtered by K neurons (b) where each neuron represents one cochlear filter from a particular frequency bin. • The weights of each neuron in (b) are set as the time-domain impulse response of the corresponding cochlear filter . The computing of a neuron with its input is inherently a time-domain con volution process. 6 P an Zihan et al. An efficient auditory neural encoding • The output of the filter bank neurons is a K -length vector (c), where K is the number of filters, for each time step. Since the signal (a) shifts sample by sample, the width of the output matrix is the same as the length of the input signal. As such, the auditory signal is decomposed into multiple channels in parallel, forming a spectrogram. Suppose a speech signal x with M samples x = [ x 1 , x 2 , ..., x M ] sampled at 16kHz. For the k th cochlear filter , the impulse response (wa velet) is a M k -length vector F k = [ F k (1) , F k (2) , ..., F k ( M k )] . W e note the impulse response F k has an infinite windo w size, ho we ver , numerically its amplitude decreases to small v alues outside an effecti v e window , thus having little influence on the con volution results. As in v estigated in (Pan et al., 2018), we empirically set M k to an optimal v alue. So the m th output of the k th cochlear filter neuron is modeled as y k ( m ) : y k ( m ) = M k X i =1 φ m ( i ) F k ( i ) , k = 1 , 2 , ..., K , m = 1 , 2 , ..., M (7) φ m = [ x m , x m +1 , x m +2 , ..., x m + M k − 1 ] , m ∈ 1 , ..., M (8) φ m is a subset of the input samples within the m th windo w , whose length is the same as that of the M k -length wa velet, indicated as the samples between the two arro ws in Figure 6 (a) and (b). The windo w φ m will mov e sample by sample, naturally along with the flo w of the input signal samples. At each time step, a vector of length K , which is the number of filters, is generated as shown in (c). After M such samples, the final output time-frequency map of the filter bank is a K × M matrix Y K × M . After time-domain cochlear filtering, the K × M time-frequency map Y K × M should be framed, which emulates the signal processing of hair cells in the auditory pathway . For the output w av eform from each channel, we apply a framing window of length l (samples) with a step size of l / 2 and calculate the logarithmic frame ener gy e of one framing window: e = 10 log( l X q =1 x 2 q ) (9) where x q denotes the samples within the l -length window; e is the spectral energy of one frame, hence obtaining the time-frequency spectrum S K × N ( s ij ) as indicated in Section 2.1.3 which will be further encoded into spikes. 2.2.2 Neural spik e encoding In the inner ear , the motion of the stereocilia in the inner hair cells is con verted into a chemical signal that excites adjacent nerv e fibers, generating neural impulses that are then transmitted along the auditory pathway . Similarly , we would like to con vert the sub-band framing energy into electrical impulses, or so-called spikes, for the purpose of information encoding and transmission. In prior w ork, the temporal dynamic sequences are encoded using se veral dif ferent methods: latency coding (W u et al., 2018a), phase coding (Arnal and Giraud, 2012)(Giraud and Poeppel, 2012), latenc y population coding (Dean et al., 2005), that are adopted for specific applications. These encoding schemes are not optimized for SNN computation. W e would like to propose a biologically plausible neural encoding scheme taking into account the three criteria as defined in Section 1. In this section, the particular neural temporal coding scheme, which con v erts perceptual spectral po wer to precise spike times, is designed to meet the need of synaptic learning rules in SNNs (G ¨ utig and Sompolinsky, 2006)(Ponulak and Kasi ´ nski, 2010). As such, the resulting temporal spike patterns are supposed to be friendly to wards temporal learning rules. In our previous work (Pan et al., 2019), two mainstream neural coding schemes, the single neuron temporal codes and (latency coding, phase coding) and the population codes (population latency/phase coding, threshold coding) are compared. It is found that the threshold coding outperforms the other coding schemes in SNN-based pattern recognition tasks. Next are some observations made whilst comparing threshold coding, and the single neuron temporal coding. Frontier s 7 P an Zihan et al. An efficient auditory neural encoding First of all, the single temporal coding scheme, such as latency or phase coding, encodes the spectral po wer using spike delaying time, or phase-locking time. Suppose a frame of normalized spectral power is e , the n th latency spik e timing t f n = is defined as: t f n = (1 − e ) ∗ T + ( n − 1) ∗ T = ( n − e ) ∗ T (10) where T denotes the time duration of the encoding windo w . For the phase coding, t f n is phase-locked to the nearest peak of the sub-threshold membrane oscillation. The spectral power , that represents the amplitude information, e is represented as the relati ve spike timing (1 − e ) ∗ T within each windo w and the number of spikes embedded are in the order n . Unfortunately , the SNN can hardly decode such an encoding scheme without the kno wledge of the encoding windo w boundaries, implicitly provided by the spike order n and windo w length T . The spatio-temporal spike patterns could not provide such knowledge explicitly to the SNN. On the other hand, in the population code, such as threshold coding, the multiple encoding neurons naturally represent the amplitudes of the spectral power frames, and we only need to represent the temporal information in the spike timing. For example, the spike timing of the n th onset encoding neuron of the threshold code t n f is: t n f = t crossing (11) t crossing records the time when the spectral tuning curve from one sub-band crosses the onset threshold θ n of the n th encoding neuron. In this way , both the temporal and amplitude information is encoded and made kno wn to the SNN, which meets the third criterion mentioned abov e. Secondly , coding efficienc y , which refers to the average encoding spike rates (number of spikes per second), is also studied in (Pan et al., 2019). The threshold code has the least average spik e rates among all in v estigated neural codes. As the threshold code encodes only threshold-crossing ev ents, it is supposed to be the most ef ficient coding method. Thirdly , the threshold code promises to be more rob ust against noise, such as spike jitter . As it encodes the trajectory of the dynamics of the sub-band spectral power , the perturbation of precise spike timing will hav e less impact on the sequence of encoding neurons. As such, the threshold code is a promising encoding scheme for temporal sequence recognition tasks (Pan et al., 2019). Further e v aluation will be provided later in the e xperiments. While we note that each neural coding scheme has its own adv antages, we focus on how the encoding scheme may help subsequent SNN learning algorithms in a cognitiv e task in this paper . As such, we adopt the threshold code for all experiments in this paper . 2.3 Biologically plausib le auditory encoding (BAE) with masking eff ects W e propose a B AE front-end with masking effects as illustrated in Figure 8. Firstly the auditory stimuli are sensed and amplified by the microphone and some peripheral circuits, leading to a digital signal (a). This process corresponds to the pathway of the pinna, e xternal auditory meatus, tympanic membrane and auditory tube. Then the physically sensed stimuli are filtered by the cochlear filter bank (b), that emulates the cochlear function of frequency analysis. The outputs of the cochlear filter bank are parallel streams of time-domain sub-band (or so-called critical band) signals with psycho-acoustic centre frequencies and bandwidths. For the purpose of further neural coding and cognitiv e tasks, the sub-band signals should be framed as the logarithm-scale energy as per equation 9. The output of (c), the raw spectrogram, is then con verted into a precise spike pattern. The spectrogram is also being used to calculate the simultaneous and temporal masking lev els, as in (d) and (e), under which the spikes will be omitted. Finally a sparse, perceptually related, and learnable temporal spike pattern for a learning SNN is generated as sho wn in (g). Figure 9 giv es an example of the intermediate results at different stages in Figure 8 for a speech data wa veform. Figure 9(a) and (b) sho w the raw w av eform and the spectrogram of a speech utterance “three” spoken by a male speaker . The spectrogram is further encoded into a raw spike pattern by threshold neural coding. Figure 9(d) is the mask as formulated in Section 2.1, according to which the raw spike pattern 8 P an Zihan et al. An efficient auditory neural encoding 9(c) is masked and results in a masked spike pattern (e). According to T able 4, 50 . 48% of all spikes are discarded. 3 EXPERIMENT AND RESUL TS 3.1 Spike-TIDIGITS and Spike-TIMIT databases The TIDIGITS (Leonard and Doddington, 1993) (LDC Catalog No. LDC93S10) is a speech corpus of spoken digits for speaker independent speech recognition (Cook e et al., 2001) (T amazin et al., 2019). The speakers are from different genders (male and female), age ranges (adults and children), dialect districts (Boston, Richmond, Lubbock, etc.). As such, the corpus pro vides suf ficiently speaker di versity and becomes one of the common benchmarking datasets. TIDIGITS has a vocab ulary of 11 spoken words of digits. The original database contains both isolated digits and digit sequences. In this work, we only use the isolated digits: each utterance contains one individual spok en digit. In this first attempt, we would like to b uild a spike-v ersion speech dataset that contains suf ficient di versity and can be immediately used to train a SNN classifier (W u et al., 2018a) (Pan et al., 2018). As each digit is repeated 224 and 226 times, the Spike-TIDIGITS has 224 × 11 = 2464 and 226 × 11 = 2486 isolated digit utterances for the training and testing set, respecti vely . The B AE encoder proposed in Section 2.3 and Figure 8 is applied as the standard encoding scheme to generate this spike dataset. T able 1 and T able 2 describe the parameters in the encoding process of Spike-TIDIGITS. Next, we encode one of the most popular speech dataset TIMIT (Garofolo, 1993) into a spik e-version, Spike-TIMIT . TIMIT dataset consists of richer acoustic-phonetic content than TIDIGITS (Messaoud and Hamida, 2011). It consists of continuous speech utterances, that are useful for the e valuation of speech coding schemes (Besacier et al., 2000), speech enhancement El-Solh et al. (2007) or automatic speech recognition systems (Mohamed et al., 2011) (Gra ves et al., 2013). Similar to TIDIGITS, the speak ers of TIMIT corpus are from 8 dif ferent dialect regions in the United States, 438 males and 192 females. There are 4621 and 1679 speech sequences in the training and testing sets. This corpus has a vocab ulary of 6224 words, which is lar ger than that of TIDIGITS. Our proposed BAE scheme is next ev aluated in the following sections, using both reconstruction and speech pattern recognition experiments. 3.2 A udio reconstruction from masked patterns According to equation 5, we adopt the binary auditory mask Φ K × N ( φ ij ) which either fully encodes or ignores an acoustic e vent. It is suggested in auditory theory (Ambikairajah et al., 1997) that partial masking may exist in the frequenc y domain, especially in the presence of rich frequenc y tones. W e would lik e to e valuate the masking ef fect in the B AE front-end through both objecti vely and subjecti v ely . W e be gin by reconstructing the spike trains into speech signals, and then ev aluate the speech quality using se veral objecti ve speech quality measures: Perceptual Ev aluation of Speech Quality (PESQ), Root Mean Square Error (RMSE) and Signal to Distortion Ratio (SDR). The PESQ, defined in (Beerends et al., 2002) (Rix et al., 2002), is standardized as ITU-T recommendation P .862 for speech quality test methodology (Recommendation, 2001). The core principle of PESQ is the use of human auditory perception model (Rix et al., 2001) for speech quality assessment. For speech coding, especially the perceptual masking proposed in this paper , the PESQ measure could correctly distinguish between audible and inaudible distortions and thus assess the impact of perceptually masked coding noise. Besides, the PESQ is also used in the assessment of MPEG audio coding where auditory masking is in volv ed. In this paper , the PESQ scores are further con v erted to MOS-LQO (Mean Opinion Score-Listening Quality Objecti ve) scores ranging 1 to 5, which are more intuitive for assessing speech quality . The mapping function is obtained from ITU-T Recommendation P .862.1(ITU-T, 2003). T able 3 defines the MOS scales and their corresponding speech quality subjecti ve descriptions (Rec, 1996). Besides PESQ, the RMSE (equation 12) and Expand SDR (equation 13) measures are also reported, where x i and ˆ x i denote the i th time-domain sample of the original and reconstructed speech signals x 1 × M and ˆ x 1 × M , respecti vely . Frontier s 9 P an Zihan et al. An efficient auditory neural encoding RMSE = v u u t 1 M M X i =1 ( x i − ˆ x i ) 2 (12) SDR = 10 log 10 ( P M i =1 ( x i ) 2 P M i =1 ( x i − ˆ x i ) 2 ) (13) For comparison, we compare three groups of reconstructed speech signals: (1) the reconstructed signal ˆ s mask from spike trains with auditory masking; (2) the reconstructed signal ˆ s raw from raw spike trains without auditory masking; (3) the reconstructed signal ˆ s random from randomly masked spike trains. Figure 10 depicts the flo wchart of the reconstruction process. The left and right panels represent the spike encoding and decoding processes. The raw speech signals are first decomposed by a series of cochlear analysis filters, generating parallel streams of sub-band signals as in Figure 8(b). The 20 sub-band wa veforms are encoded into spike times with masking strategies and then decoded back to sub-band speech signals. The reproduced sub-band wa veforms 1 to K (20 in this work) are gain-weighted and summed to form the reconstructed speech signal for perceptual quality e valuation. Since the cochlear filters decompose the input signal by various weighting gains in dif ferent frequency bands, the weighting gains in the decoding part represent the in v erse processing of the cochlear filters. The speech quality of the three groups of reconstructed signals is measured, as reported in T able 4 and 5. For a f air comparison, we also simulate a random masking effect by dropping the same amount of spik es as that of the auditory masking. The ra w spike patterns without any masking are used as a reference. The perceptual quality scores of the ˆ s mask and ˆ s raw are rather close at a high le vel of around 4.5, which suggests satisfying subjective quality between “Excellent” and “Good” according to T able 3. It is noted that the speech signals with random masking are percei ved as “Poor” in quality . Besides the PESQ, the other two measures also lead to the same conclusion. The RMSE of ˆ s raw and ˆ s mask are approximately two orders of magnitude larger than that of the ˆ s random ; the SDRs also sho w a great gap. 3.3 Speech recognition b y SNN for TIDIGITS dataset In this section, we ev aluate the B AE scheme in an SNN-based pattern recognition task, which also aims to e valuate the coding fidelity of our proposed methodology . The spike patterns encoded from TIDIGITS speech dataset are fed into an SNN, and the outputs correspond to the labels of which spoken digits the patterns are encoded from. The synapse efficac y updating rule is the MPD-AL, which is an efficient membrane potential driv en aggregate-label learning algorithm for leak y integrate-and-fire spiking neurons (Malu et al., 2019). The network structure is gi ven in T able 6. T o ev aluate the ef fectiv eness of the B AE front-end, we compare the classification performances between spike patterns with and without auditory masking. Gaussian noise, measured by Signal-to-Noise Ratio (SNR) in dB, is added to the original speech wa v eforms before the encoding process. T able 7 sho ws the classification accuracies under noisy conditions and in the clean condition. The results show that the pattern classification accuracies of masked patterns are slightly higher than those of the original patterns, under dif ferent test conditions. Above all, referring to T able 4, our proposed B AE scheme helps to reduce nearly half of the spikes, which is a dramatic impro vement in coding ef ficiency . 3.4 Large v ocab ular y speec h recognition for TIMIT dataset In Section 2.3, we present ho w the TIMIT dataset has been encoded into spik e trains, which we henceforth refer to as Spike-TIMIT . W e next train a recurrent neural network, the LSTM (Hochreiter and Schmidhuber, 1997) on both the original TIMIT and Spike-TIMIT datasets, with the CTC loss function (Gra ves et al., 2006). For the v alidation datasets, the normalized Le venshtein distance (by the labels) or the label error rate (LER) is reported (Graves et al., 2006). W e obtained an LER of 0.27 and 0.28 respectiv ely for the TIMIT and Spike-TIMIT datasets. The network architecture of the LSTM used for both datasets is illustrated in T able 8. The LSTM networks are adapted from T ensorpack (Zhou et al., 2016). W e notice some improv ement in accurac y when dropout is introduced for Spike-TIMIT b ut not for TIMIT . W e further 10 P an Zihan et al. An efficient auditory neural encoding note that the Spike-TIMIT system in v olves many more input neurons than the TIMIT system (620 vs 39). Ho wev er , because the TIMIT system emplo ys more LSTM neurons, the Spike-TIMIT systems ha ve much fe wer parameters than the TIMIT system (4.5M vs 13M). This is also a desired outcome of the BAE front-end, that is, more neurons are used for neural encoding so that f ar less neurons and parameters are needed in the feature representation and classification pipeline, leading to overall saving in number of neurons and parameters. 4 DISCUSSION In this paper , we propose a biologically plausible auditory encoding (BAE) scheme, especially for speech signals. The encoding scheme is inspired by the modeling of human auditory sensory system, which is composed of spectral analysis, neural spike coding, as well as the psycho-acoustic perception model. W e adopt three criteria for formulating the auditory encoding scheme. For the spectral analysis part, a time-domain e vent-based cochlear filter bank is applied, with the perceptual scale of centre frequencies and bandwidths. The key feature of the spectral analysis is the parallel implementation of time-domain con volution. One of the most important properties of SNN is its asynchronous processing. The parallel implementation makes the neural encoding scheme a friendly front- end for an y SNN processing. The neural encoding scheme, the threshold code in our case, helps to generate a sparse and representativ e spike patterns for efficient computing in the SNN classifier . The threshold code helps in two aspects: firstly it tracks the trajectory of the spectral po wer tuning curv es, which represents the features in the acoustic dynamics; secondly , the threshold code, as a form of population neural code, is able to project the dynamics in the time domain onto the spatial domain, which facilitates the parallel processing of spiking neurons on cogniti ve tasks (P an et al., 2019). Another ke y component of the B AE front-end is the implementation of auditory masking that benefits from findings in human psycho-acoustic experiments. The integrated auditory encoding scheme fulfills the three proposed design criteria. W e hav e ev aluated our B AE scheme through signal reconstruction and speech recognition experiments giving very promising results. T o share our study with the research community , the spike-v ersion of TIDIGITS and TIMIT speech corpus, namely , Spike-TIDIGITS and Spike-TIMIT , will be be made a vailable as benchmarking datasets. Figure 11 illustrates some interesting findings in our proposed auditory masking strategy . The upper , middle and lo wer panels of Figure 11 represent three speech utterances from the TIDIGITS dataset. The first and second column illustrates the encoded spike patterns with and without auditory masking effects. It is apparent that a large number of spikes are remov ed. The graphs in the third column demonstrate the membrane potential of the output neuron in the trained SNN classifier after being fed with both patterns during the testing phase. For example, the LIF neuron in (c) responds to the speech utterance of “six”. As such, the encoded pattern of spoken “six”, as in (a) and (b) will trigger the corresponding neuron to fire a spike in the testing phase. The sub-figure (c) demonstrates that though the sub-threshold membrane potentials of masking/unmasking patterns ha ve dif ferent trajectories, the two membrane potential curves will exceed the firing threshold (which is 1 in this e xample) at close timing. Similar results are observed in (f) and (i). The spike patterns with or without auditory masking lead to similar neuronal responses, either in spiking acti vities (firing or not) or in membrane potential dynamics, as observed in (c), (f), (i). It is interesting to observe that auditory masking has little impact on the neuronal dynamics. As a psycho-acoustic experiment, the auditory mask is al ways studied using listening tests. It remains unclear ho w the human auditory system responds to auditory masking. Figure 11 provides an answer to the same question from a SNN perspecti ve. The parameters of auditory masking ef fects in this work, such as the exponential decaying parameter c in equation 2, or the cross-channel simultaneous masking thresholds in Figure 2, are all deri v ed in the acoustic model of MPEG-1 Layer III standard (Fogg et al., 2007) and tuned according to the particular tasks. Ho wev er , from a neuroscience point of vie w , our brain is adapti ve to dif ferent en vironments. This suggests that the parameters could be optimized by machine learning methodology , for different tasks and datasets. Also, the threshold neural code, which encodes the dynamics of the spectrum using threshold- crossing e vents, relies heavily on the choice of thresholds. W e use 15 uniformly distributed thresholds for simplicity . W e note that the recording of threshold-crossing events is analogous to quantization in digital coding, that the maximal coding ef ficiency (maximal information being con veyed constrained by the numbers of neurons or spik es) maybe deri ved using an information-theoretic approach. The Ef ficient Coding Hypothesis (ECH) (Barlo w et al., 1961) (Srini v asan et al., 1982) that describes the link between Frontier s 11 P an Zihan et al. An efficient auditory neural encoding neural encoding and information theory could provide us the theoretical framew ork to determine the optimal threshold distribution in the neural threshold code. It may also otherwise be learned using machine learning techniques. 5 CONCLUSION Our proposed B AE scheme, moti v ated by the human auditory sensory system, could encode temporal speech data into spike patterns that are sparse, ef ficient, and friendly to SNN learning rules. It is both ef ficient and effecti ve. W e use the B AE scheme to encode popular speech datasets, namely , TIDIGITS and TIMIT into their spike v ersions: Spike-TIDIGITS and Spike-TIMIT . The two spike datasets are to be published as benchmarking datasets, in the hope of improving SNN-based classifiers. CONFLICT OF INTEREST ST A TEMENT The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest A UTHOR CONTRIBUTION Zihan Pan performed the experiments and wrote the paper . All authors contributed to the experiments design, result interpretation and writing. FUNDING This work was supported by in part by the Programmatic Grant No. A1687b0033 from the Singapore Gov ernment’ s Research, Innov ation and Enterprise 2020 plan (Advanced Manuf acturing and Engineering domain). REFERENCES Ambikairajah, E., Davis, A., and W ong, W . (1997). Auditory masking and mpeg-1 audio compression. Electr onics & communication engineering journal 9, 165–175 Ambikairajah, E., Epps, J., and Lin, L. (2001). W ideband speech and audio coding using gammatone filter banks. In 2001 IEEE International Confer ence on Acoustics, Speech, and Signal Pr ocessing . Pr oceedings (Cat. No. 01CH37221) (IEEE), vol. 2, 773–776 Amir , A., T aba, B., Berg, D., Melano, T ., McKinstry , J., Di Nolfo, C., et al. (2017). A lo w power , fully e vent-based gesture recognition system. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition . 7243–7252 Anumula, J., Neil, D., Delbruck, T ., and Liu, S.-C. (2018). Feature representations for neuromorphic audio spike streams. F r ontiers in neur oscience 12, 23 Appelle, S. (1972). Perception and discrimination as a function of stimulus orientation: the” oblique ef fect” in man and animals. Psycholo gical bulletin 78, 266 Arnal, L. H. and Giraud, A.-L. (2012). Cortical oscillations and sensory predictions. T r ends in cognitive sciences 16, 390–398 Barlo w , H. B. et al. (1961). Possible principles underlying the transformation of sensory messages. Sensory communication 1, 217–234 Beerends, J. G., Hekstra, A. P ., Rix, A. W ., and Hollier , M. P . (2002). Perceptual ev aluation of speech quality (pesq) the new itu standard for end-to-end speech quality assessment part ii: psychoacoustic model. J ournal of the Audio Engineering Society 50, 765–778 Besacier , L., Grassi, S., Dufaux, A., Ansorge, M., and Pellandini, F . (2000). Gsm speech coding and speaker recognition. In 2000 IEEE International Confer ence on Acoustics, Speech, and Signal Pr ocessing. Pr oceedings (Cat. No. 00CH37100) (IEEE), v ol. 2, II1085–II1088 Bohte, S. M., K ok, J. N., and La Poutre, H. (2002). Error-backpropag ation in temporally encoded networks of spiking neurons. Neur ocomputing 48, 17–37 Bro wn, J. C. (1991). Calculation of a constant q spectral transform. The Journal of the Acoustical Society of America 89, 425–434 12 P an Zihan et al. An efficient auditory neural encoding Bro wn, J. C. and Puckette, M. S. (1992). An ef ficient algorithm for the calculation of a constant q transform. The J ournal of the Acoustical Society of America 92, 2698–2701 Cooke, M., Green, P ., Josifovski, L., and V izinho, A. (2001). Robust automatic speech recognition with missing and unreliable acoustic data. Speech communication 34, 267–285 Darabkh, K. A., Haddad, L., Sweidan, S. Z., Haw a, M., Saif an, R., and Alnabelsi, S. H. (2018). An ef ficient speech recognition system for arm-disabled students based on isolated words. Computer Applications in Engineering Education 26, 285–301 Dean, I., Harper , N. S., and McAlpine, D. (2005). Neural population coding of sound lev el adapts to stimulus statistics. Natur e neur oscience 8, 1684 Deng, J., Ber g, A., Satheesh, S., Su, H., Khosla, A., and Fei-Fei, L. (2012). Imagenet large scale visual recognition competition 2012 (ilsvrc2012). Google Sc holar Dennis, J., Y u, Q., T ang, H., T ran, H. D., and Li, H. (2013). T emporal coding of local spectrogram features for robust sound recognition. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer ence on (IEEE), 803–807 Ehret, G. (1997). The auditory cortex. Journal of Compar ative Physiology A 181, 547–557 El-Solh, A., Cuhadar , A., and Goubran, R. A. (2007). Evaluation of speech enhancement techniques for speaker identification in noisy en vironments. In Ninth IEEE International Symposium on Multimedia W orkshops (ISMW 2007) (IEEE), 235–239 Fogg, C., LeGall, D. J., Mitchell, J. L., and Pennebaker , W . B. (2007). MPEG video compression standar d (Springer Science & Business Media) Garofolo, J. S. (1993). T imit acoustic phonetic continuous speech corpus. Linguistic Data Consortium, 1993 Ghosh-Dastidar , S. and Adeli, H. (2009). Spiking neural networks. International journal of neural systems 19, 295–308 Giraud, A.-L. and Poeppel, D. (2012). Cortical oscillations and speech processing: emer ging computational principles and operations. Natur e neur oscience 15, 511 Grav es, A. (2012). Sequence transduction with recurrent neural netw orks. arXiv pr eprint Grav es, A., Fern ´ andez, S., Gomez, F ., and Schmidhuber , J. (2006). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Pr oceedings of the 23r d international confer ence on Machine learning (A CM), 369–376 Grav es, A., Mohamed, A.-r ., and Hinton, G. (2013). Speech recognition with deep recurrent neural networks. In 2013 IEEE international confer ence on acoustics, speec h and signal pr ocessing (IEEE), 6645–6649 G ¨ utig, R. (2016). Spiking neurons can discover predicti ve features by aggre gate-label learning. Science 351, aab4113 G ¨ utig, R. and Sompolinsky , H. (2006). The tempotron: a neuron that learns spike timing–based decisions. Natur e neur oscience 9, 420 G ¨ utig, R. and Sompolinsky , H. (2009). T ime-warp–in variant neuronal processing. PLoS biology 7, e1000141 Harris, D. M. and Dallos, P . (1979). Forw ard masking of auditory nerve fiber responses. J ournal of Neur ophysiology 42, 1083–1107 Hochreiter , S. and Schmidhuber , J. (1997). Long short-term memory . Neural computation 9, 1735–1780 Hohmann, V . (2002). Frequency analysis and synthesis using a gammatone filterbank. Acta Acustica united with Acustica 88, 433–442 Hopfield, J. (2004). Encoding for computation: recognizing brief dynamical patterns by exploiting ef fects of weak rhythms on action-potential timing. Pr oceedings of the National Academy of Sciences 101, 6255–6260 ITU-T , R. P . (2003). 862.1: Mapping function for transforming p. 862 raw result scores to mos-lqo. International T elecommunication Union, Geneva, Switzerland (2003 No v .) Iyer , L. R., Chua, Y ., and Li, H. (2018). Is neuromorphic mnist neuromorphic? analyzing the discriminati ve po wer of neuromorphic datasets in the time domain. arXiv pr eprint Lagerstrom, K. (2001). Design and implementation of an mpeg-1 layer iii audio decoder . Chalmers University of T ec hnology , Department of Computer Engineering Gothenbur g, Sweden Leonard, R. G. and Doddington, G. (1993). Tidigits ldc93s10. W eb Download. Philadelphia: Linguistic Data Consortium Liu, S.-C. and Delbruck, T . (2010). Neuromorphic sensory systems. Current opinion in neur obiology 20, 288–295 Frontier s 13 P an Zihan et al. An efficient auditory neural encoding Loiselle, S., Rouat, J., Pressnitzer , D., and Thorpe, S. (2005). Exploration of rank order coding with spiking neural networks for speech recognition. In Neural Networks, 2005. IJCNN’05. Pr oceedings. 2005 IEEE International J oint Confer ence on (IEEE), vol. 4, 2076–2080 Maass, W . (1997). Networks of spiking neurons: the third generation of neural netw ork models. Neural networks 10, 1659–1671 Malu, Z., Jibin, W ., Chua, Y ., Xiaoling, L., Pan, Z., and Li, H. (2019). Mpd-al: An efficient membrane potential dri ven aggre gate-label learning algorithm for spiking neurons Mermelstein, P . (1976). Distance measures for speech recognition, psychological and instrumental. P attern r ecognition and artificial intellig ence 116, 374–388 Messaoud, Z. B. and Hamida, A. B. (2011). Combining formant frequency based on variable order lpc coding with acoustic features for timit phone recognition. International J ournal of Speech T echnology 14, 393 Mohamed, A.-r ., Dahl, G. E., and Hinton, G. (2011). Acoustic modeling using deep belief networks. IEEE transactions on audio, speec h, and language pr ocessing 20, 14–22 Nadasdy , Z. (2009). Information encoding and reconstruction from the phase of action potentials. F r ontiers in systems neur oscience 3, 6 Orchard, G., Jayawant, A., Cohen, G. K., and Thakor , N. (2015). Con v erting static image datasets to spiking neuromorphic datasets using saccades. F r ontiers in neur oscience 9, 437 Pan, Z., Li, H., W u, J., and Chua, Y . (2018). An ev ent-based cochlear filter temporal encoding scheme for speech signals. In 2018 International J oint Confer ence on Neural Networks (IJCNN) (IEEE), 1–8 Pan, Z., W u, J., Chua, Y ., Zhang, M., and Li, H. (2019). Neural population coding for ef fectiv e temporal classification. In 2019 International J oint Confer ence on Neural Networks (IJCNN) (IEEE), 1–8 Patterson, R., Nimmo-Smith, I., Holdsworth, J., and Rice, P . (1987). An efficient auditory filterbank based on the gammatone function. In a meeting of the IOC Speech Gr oup on Auditory Modelling at RSRE . vol. 2 Ponulak, F . and Kasi ´ nski, A. (2010). Supervised learning in spiking neural networks with resume: sequence learning, classification, and spike shifting. Neural computation 22, 467–510 Rec, I. (1996). P . 800: Methods for subjectiv e determination of transmission quality . International T elecommunication Union, Geneva , 22 Recommendation, I.-T . (2001). Perceptual e v aluation of speech quality (pesq): An objecti v e method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs. Rec. ITU-T P . 862 Redmon, J., Divv ala, S., Girshick, R., and Farhadi, A. (2016). Y ou only look once: Unified, real-time object detection. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition . 779–788 Rix, A. W ., Beerends, J. G., Hollier , M. P ., and Hekstra, A. P . (2001). Perceptual ev aluation of speech quality (pesq)-a ne w method for speech quality assessment of telephone networks and codecs. In 2001 IEEE International Confer ence on Acoustics, Speech, and Signal Pr ocessing. Pr oceedings (Cat. No. 01CH37221) (IEEE), vol. 2, 749–752 Rix, A. W ., Hollier , M. P ., Hekstra, A. P ., and Beerends, J. G. (2002). Perceptual e v aluation of speech quality (pesq) the ne w itu standard for end-to-end speech quality assessment part i–time-delay compensation. J ournal of the Audio Engineering Society 50, 755–764 Rueckauer , B., Lungu, I.-A., Hu, Y ., Pfeif fer , M., and Liu, S.-C. (2017). Conv ersion of continuous-v alued deep networks to ef ficient ev ent-dri ven networks for image classification. F r ontiers in neur oscience 11, 682 Russako vsky , O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet Large Scale V isual Recognition Challenge. International J ournal of Computer V ision (IJCV) 115, 211–252. doi:10.1007/s11263- 015- 0816- y Shinn-Cunningham, B. G. (2008). Object-based auditory and visual attention. T r ends in cognitive sciences 12, 182–186 Shrestha, S. B. and Orchard, G. (2018). Slayer: Spike layer error reassignment in time. In Advances in Neural Information Pr ocessing Systems . 1412–1421 Simonyan, K. and Zisserman, A. (2014). V ery deep con volutional networks for lar ge-scale image recognition. arXiv pr eprint Smith, J. O. and Abel, J. S. (1999). Bark and erb bilinear transforms. IEEE T ransactions on speec h and Audio Pr ocessing 7, 697–708 14 P an Zihan et al. An efficient auditory neural encoding Srini vasan, M. V ., Laughlin, S. B., and Dubs, A. (1982). Predictiv e coding: a fresh vie w of inhibition in the retina. Pr oceedings of the Royal Society of London. Series B. Biological Sciences 216, 427–459 T aherkhani, A., Belatreche, A., Li, Y ., and Maguire, L. P . (2015). Dl-resume: A delay learning-based remote supervised method for spiking neurons. IEEE transactions on neural networks and learning systems 26, 3137–3149 T amazin, M., Gouda, A., and Khedr , M. (2019). Enhanced automatic speech recognition system based on enhancing po wer-normalized cepstral coef ficients. Applied Sciences 9, 2166 T obias, J. (2012). F oundations of modern auditory theory (Else vier) V eit, A., Matera, T ., Neumann, L., Matas, J., and Belongie, S. (2016). Coco-text: Dataset and benchmark for text detection and recognition in natural images. arXiv pr eprint W u, J., Chua, Y ., and Li, H. (2018a). A biologically plausible speech recognition framew ork based on spiking neural networks. In 2018 International Joint Confer ence on Neur al Networks (IJCNN) (IEEE), 1–8 W u, J., Chua, Y ., Zhang, M., Li, H., and T an, K. C. (2018b). A spiking neural network frame work for robust sound classification. F r ontiers in neur oscience 12 Xiao, R., Y an, R., T ang, H., and T an, K. C. (2016). A spiking neural network model for sound recognition. In International Confer ence on Cognitive Systems and Signal Pr ocessing (Springer), 584–594 Zhang, M., Qu, H., Belatreche, A., Chen, Y ., and Y i, Z. (2018). A highly effecti ve and rob ust membrane potential-dri ven supervised learning method for spiking neurons. IEEE transactions on neural networks and learning systems , 1–15 Zhang, M., Qu, H., Belatreche, A., and Xie, X. (2017). Empd: An efficient membrane potential dri ven supervised learning algorithm for spiking neurons. IEEE T r ansactions on Cognitive and Developmental Systems 10, 151–162 Zhou, S., W u, Y ., Ni, Z., Zhou, X., W en, H., and Zou, Y . (2016). Dorefa-net: T raining low bitwidth con v olutional neural networks with lo w bitwidth gradients. arXiv pr eprint FIGURES 10 2 10 3 10 4 Frequency (Hz) -20 0 20 40 60 80 Threshold value (dB) Absolute hearing threshold Figure 1. Absolute hearing threshold T a for the simultaneous masking. Our hearing is more sensiti v e to the acoustic stimulus around se veral thousand Hz, that co vers the majority of the sounds in our daily life. The sounds belo w the thresholds are completely inaudible. Frontier s 15 P an Zihan et al. An efficient auditory neural encoding Figure 2. The frequenc y masking thresholds acting on a maskee (the acoustic ev ents being masked), generated by the acoustic e vents from the neighboring critical bands, are sho wn as a surface in a 3-D plot. The acoustic events are referred to as the spectral po wer of the frames in a spectrogram. The spectral ener gy axis is the sound le v el of a mask ee; the critical band axis is the frequenc y bins of the cochlear filter bank, as introduced in Section 3.1; the masking thresholds axis indicates the overall masking le vels on the maskees of dif ferent sound lev els from v arious critical bands. For e xample, an acoustic e vent of 20 dB le vel on the 10 th critical band is masked off by the masking threshold of nearly 23 dB, which is introduced by the other auditory components of its neighboring frequency channels. Figure 3. The ov erall simultaneous masking effects on a speech utterance of “one”, in a 3D spectrogram. Combining the two kinds of masking ef fects in the frequency domain (refer to Figure 1 and Figure 2), the grey surface shows the ov erall masking thresholds on a speech utterance (the colorful surface). All the spectral energy under the thresholds will be imperceptible. 16 P an Zihan et al. An efficient auditory neural encoding T im e Sign al intensit y Figure 4. The illustration of temporal masking: each bar represents the acoustic e vent receiv ed by the auditory system. In this paper , acoustic e vents generally referred to framing spectral po wer , which are the elements to be parsed to an auditory neural encoding scheme. A local peak e vent (red bar) forms a masking shado w represented by an exponentially decaying curv e. The subsequent e vents that are weak er than the leading local peak will not be audible until another local peak e vent e xceeds the masker curve. Figure 5. Both the simultaneous and temporal masking ef fects acting on the 3-D plot spectrogram of a speech utterance of “one”. The grey-color shaded parts of the spectrogram are mask ed. Frontier s 17 P an Zihan et al. An efficient auditory neural encoding (a) (b) (c) Figure 6. (a) A speech signal of M samples; (b) Time-domain filter bank with K neurons that act as filters; (c) The output spectrogram that has K × M dimension Figure 7. Encoded spike patterns by threshold coding with/without masking. The tw o spike patterns are encoded from a speech utterance of “fi ve” in TIDIGITS dataset. The x-axis and y-axis represent the time and encoding neuron inde x. The position of colorful dots indicate the spik e timing of the corresponding encoding neurons. The colors distinguish the centre frequencies of the cochlear filter bank. W ith auditory masking, the number of spikes reduces by nearly 50% , which are close to the 55% reducing rate of coding pulses as reported in (Ambikairajah et al., 1997). 18 P an Zihan et al. An efficient auditory neural encoding Au d ito ry sig n als Co ch lear f ilter b an k Fr am ing l o g ener g y Thre sh o ld co d in g (a ) (e) (c) (d) Sim u ltan eo u s m ask in g T em p o ral m ask in g (b) Sp ik e p attern (f ) (g) Figure 8. The B AE scheme for temporal learning algorithms in auditory cognitive tasks. The ra w auditory signals (a) are filtered by the CQT -based ev ent-driv en cochlear filter bank, resulting in a parallel stream of sub-band signals. For each sub-band, the signal is logarithmically framed, which corresponds to the processing in auditory hair cells. The framed spectral signals are then further masked in simultaneous and temporal masking. (a) ( b ) (c) (d) (e) Figure 9. An illustration of the intermediate results in a B AE process. Raw speech signal (a) of a speech utterance “three” is filtered and framed into a spectrogram (b), corresponding to the process in Figure 8(b) and (c). By applying the neural threshold code, a precise spike pattern (c) is generated from the spectrogram. The masker map as described in Equation (4) is illustrated in (d), where yellow and dark blue color blocks represent v alue 1 and 0, respecti vely . The masker (d) is applied on the spike pattern (c) and the auditory masked spike pattern is obtained in (e). Frontier s 19 P an Zihan et al. An efficient auditory neural encoding sub-band waveformK Decoded sub-bandwaveformK Spike decoder spiketrainK Spike encoder speechsignal × × 1 sub-band waveform1 Decoded sub-bandwaveform1 spiketrain1 Cochlear filter1 Cochlear filterK Reconstructed speechsignal Encoding Decoding Figure 10. The reconstruction from a spike pattern into a speech signal. Parallel streams of threshold- encoded spike trains that represent the dynamics of multiple frequency channels are first decoded into sub-band digital signals. The sub-band signals are further fed into a series of synthesis filters, which are built in versely from the corresponding analysis cochlear filters as in Figure 6. The synthesis filters compensate the gains from the analysis filters for each frequency bin. Finally , the outputs from the synthesis filter banks sum up to generate the reconstructed speech signal. 20 P an Zihan et al. An efficient auditory neural encoding (a) ( b ) (c) (d) (e) (f ) (g) (h) ( i ) Figure 11. Free membrane potential of trained Leaky-Integrate and Fire neurons, by feeding patterns with and without masking. The upper , middle, and lo wer panels are for three dif ferent speech utterances “six”, “se ven”, and “eight”. The spik e patterns with or without masking are apparently dif ferent, b ut the output neuron follo ws similar membrane potential trajectories. T ABLES parameters windo w size 30 ms stride size 15 ms frequency range [200 Hz , 8000 Hz ] sampling rate 20 kHz T able 1. Parameters of neural threshold encoding for TIDIGITS. Frontier s 21 P an Zihan et al. An efficient auditory neural encoding Cochlear filter index centre frequency (Hz) bandwidth (Hz) 1 200.2 69.3 2 238.3 83.0 3 283.2 98.6 4 336.4 117.2 5 400.4 139.6 6 476.1 166.0 7 565.9 197.3 8 672.3 234.4 9 800.8 278.3 10 952.1 331.1 11 1131.3 394.5 12 1345.2 468.8 13 1600.6 557.6 14 1903.3 663.1 15 2263.7 788.1 16 2690.9 937.5 17 3200.2 1114.3 18 3805.7 1325.2 19 4525.9 1576.2 20 8000.5 6949.2 T able 2. Cochlear filter parameters: we use a total of 20 cochlear filters in the B AE front-end. The centre frequency and bandwidth of each filter are listed. MSO scores 5 4 3 2 1 Speech quality Excellent Good Fair Poor Bad T able 3. MOS scales and their corresponding speech quality subjectiv e assessments Reconstucted signals PESQ RMSE SDR (dB) Reduced rates ( % ) ˆ s raw 4 . 54 4 . 78 × 10 − 4 34 . 60 0 ˆ s mask 4 . 43 7 . 49 × 10 − 4 29 . 94 50 . 48 ˆ s random 2 . 92 1 . 05 × 10 − 2 4 . 76 49 . 91 T able 4. The objecti ve speech quality meansures of the reconstructed speech signals for spoken digits TIDIGITS dataset. The reduced rates refer to the ratio of masked spikes. Reconstructed signals PESQ RMSE SDR (dB) Reduced rates ( % ) ˆ s raw 4 . 54 1 . 23 × 10 − 4 42 . 28 0 ˆ s mask 4 . 44 3 . 10 × 10 − 4 34 . 02 29 . 33 ˆ s random 2 . 35 9 . 20 × 10 − 3 4 . 83 30 . 8 T able 5. The objectiv e speech quality measures of the reconstructed speech signals for continuous and large v ocab ulary speech dataset TIMIT . The reduced rates refer to the ratio of masked spikes. 22 P an Zihan et al. An efficient auditory neural encoding Dataset Input layer Output layer Spike-TIDIGITS 1 × 620 encoding neurons 1 × 11 Leak y Integrate-and-Fire neurons T able 6. SNN architectures for Spike-TIDIGITS classification SNR -10 0 10 20 30 clean W ith masking 59.5 78.2 87.5 91.9 93.5 97.4 W/o masking 61.2 76.5 87.1 90.8 93.4 96.9 T able 7. TIDIGITS classification accuracies under Gaussian noise Dataset Input layer Hidden layer Output layer TIMIT 1 × 39 1 × 1024 LSTM- 1 × 1024 LSTM 1 × 620 Spike-TIMIT 1 × 620 Dropout ( 0 . 2 )- 1 × 512 LSTM- 1 × 512 LSTM 1 × 620 T able 8. LSTM architectures for TIMIT and Spike-TIMIT classification Frontier s 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment